Mike Blazer
24 October 2025 08:15
Кейс: Как юридическая платформа может получить +3.5 млн кликов с помощью автономной перелинковки
Юридическая платформа с 10 миллионами программно-сгенерированных страниц использовала Autonomous Linking API от Quattr для решения проблем с ручной и шаблонной перелинковкой.
Для оценки выхлопа для органического трафика провели 30-дневный контролируемый эксперимент на сегменте в 50 000 страниц.
В чем была проблема: не работало масштабирование и релевантность
Из-за огромных масштабов платформы традиционные методы перелинковки не работали.
— Ручная перелинковка: Невозможна для миллионов страниц, когда ежедневно публикуются тысячи новых дел.
— Шаблонные системы: Линковка по атрибутам из БД (юрисдикция, тип дела) не создавала сильных семантических связей. В итоге Гугл плохо понимал авторитет страниц, а позиции стагнировали.
Платформе требовалось автоматизированное решение, понимающее семантическую релевантность и адаптирующееся к новому контенту без постоянного вмешательства разрабов.
Решение: Контролируемый эксперимент с перелинковкой на базе ИИ
Провели контролируемый эксперимент, чтобы доказать причинно-следственную связь и оценить выхлоп.
— Дизайн эксперимента:
— Тестовая группа: ~50 000 страниц дел из Нью-Йорка получили по 10 ИИ-сгенерированных внутренних ссылок.
— Контрольные группы: Страницы из Массачусетса и Флориды без изменений, что позволило изолировать эффект от внешних факторов вроде апдейтов Гугла.
— Источник данных: Ежедневные клики и показы на уровне URL из Google Search Console Bulk Export.
— Технология `API`:
Autonomous Linking API от Quattr работает на двух типах данных:
1. Векторные представления: Анализируют контент страницы для поиска семантических связей. Это круче простого совпадения по ключам, так как система понимает контекстуальную релевантность.
2. Данные из `GSC`: Использует реальные поисковые запросы, приводящие трафик на страницу, для генерации релевантных анкоров на основе спроса.
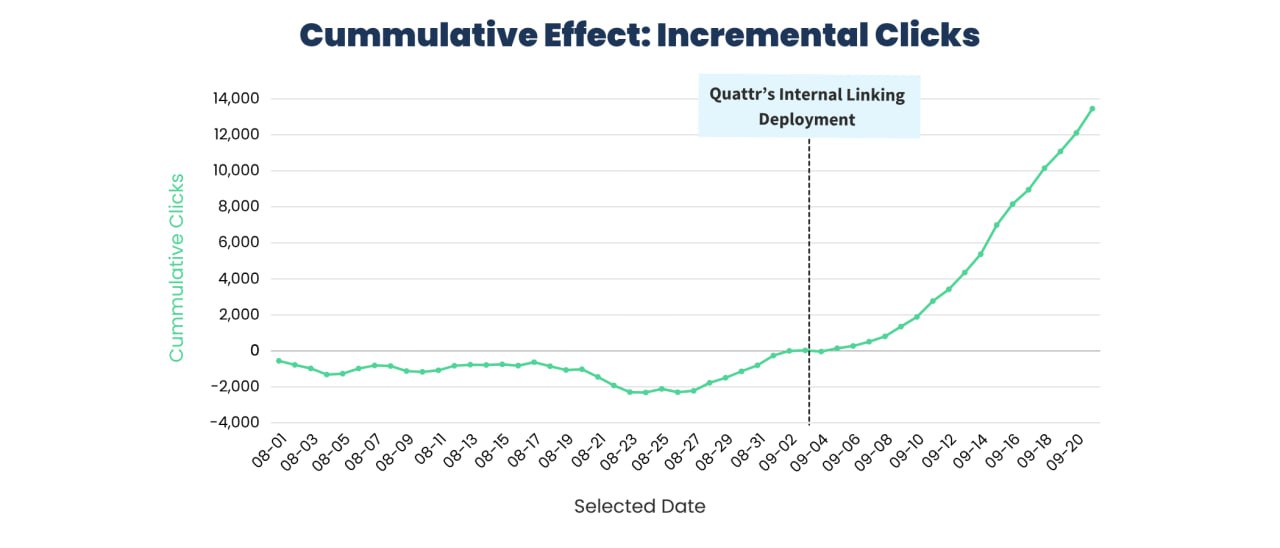
Подтвержденные результаты
Тестовая группа сразу показала статистически значимый рост относительно контрольных групп.
— Неделя 1: Рост органических кликов на +12%.
— Эффект за 28 дней (с поправкой на контрольную группу):
— Прирост ежедневных кликов на +15.1% по сравнению со страницами из Нью-Йорка, которые не трогали (+580 кликов/день).
— Прирост ежедневных кликов на +19.4% по сравнению с контрольными штатами (Флорида и Массачусетс) (+748 кликов/день).
— Общий прирост за пилот: +13 400 дополнительных органических кликов за 28 дней.
— Влияние на `CTR`: Кликабельность (CTR) выросла на 0,47 п.п. (+5,5%) при тех же показах (-0,7%), что позволило конвертировать существующую видимость в трафик.
— Стабильность перфоманса: Тестовые URL показывали значительно больше "дней с кликами", что указывает на более стабильную и устойчивую производительность.
Прогноз эффекта в масштабах всей платформы
Результаты пилота экстраполировали для оценки потенциального эффекта на весь сайт.
— Исходные данные по платформе: 29.5 млн органических кликов в год.
— Прогнозируемый рост: Применение консервативного показателя роста в 12% ко всей платформе дает потенциальный прирост в +3.5 млн дополнительных органических кликов в год, что составляет почти 300 000 дополнительных кликов в месяц.
https://www.quattr.com/case-studies/legal-intelligence-platform-seo-impact-with-quattr-internal-linking
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 13:10
Как захватить авторитет бренда через ссылку "`Official Site`" в Википедии
Есть прямой метод, как манипулировать восприятием вашего сайта Гуглом и заставить его ранжироваться выше, эксплуатируя страницу бренда в Википедии.
Я видел кейсы, когда можно было поставить свой сайт в раздел "официальный сайт" в статье о бренде на Википедии, и Google соответственно менял свое понимание, рассказывает Корай Тугберк Губюр.
Если вам удастся успешно выдать свой сайт за официальный на этой странице, Google обновляет свой граф знаний и ставит ваш URL прямо в панель знаний бренда, что, в свою очередь, поднимает ваши позиции в обычной поисковой выдаче.
Для целевого бренда бороться с этим невероятно сложно: они не могут контролировать Википедию каждый день, что делает их уязвимыми для такого рода захвата.
Ключ к реализации этой тактики — целиться в неанглоязычные рынки.
В то время как английская версия Википедии жестко регулируется и ее сложно редактировать, в других языках порог входа значительно ниже.
Голландская, испанская или норвежская Википедия, например, гораздо проще поддаются манипуляциям, потому что у них не так много редакторов и нет такого же уровня строгого надзора.
Этот недостаток ресурсов создает очевидную уязвимость, что делает ее отличной возможностью для такого рода манипуляций с авторитетом.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 08:15
Почему анкорный текст в основной навигации убивает ваши позиции
Гайз, надо завязывать с широкими, общими анкорами типа "earrings" в навигации по всему сайту.
У таких запросов обычно смешанный интент, и пробиться по ним в топ нереально.
Я бы лучше целился в ключ с меньшим трафиком, но с более четким таргетингом.
Поскольку это сквозные ссылки, их нужно заюзать для точного вхождения очень специфичных, длиннохвостых запросов.
Как утверждает Тед Кубайтис, если категория посвящена браслетам с черными бриллиантами, анкор должен быть "black diamond bracelets", чтобы передать по ссылке максимум целевой релевантности.
Это критическая ошибка, которая касается многих стандартных названий в навигации.
Люди ставят анкоры, которые не являются целевыми ключами и не имеют поискового объема.
Вы постоянно видите общие термины вроде "New Arrivals", "Best Sellers" или "Gifts".
Выйти в топ по ключу "new arrivals" само по себе бессмысленно — это могут быть книги, кухонная утварь или что угодно.
Это нецелевой запрос, и победа по нему не даст вам ровным счетом ничего.
Нужно нишеваться.
Вместо "New Arrivals" должно быть "New Jewelry" или "New Gemstone Jewelry".
То же самое касается категории "Gifts".
Если вы победите по ключу "gifts", вы не выиграете ничего.
Это высококонкурентный ключ с нулевым таргетингом, который будет стоить вам целого состояния.
Нужно добавлять тематику и конкретику: "jewelry gifts", "wedding gifts".
Вы должны пройтись по всем ссылкам в основной навигации и воспринимать их буквально.
Если анкор гласит "socks and shoes", вы таргетируете ключ "socks and shoes", а не "socks" и "shoes" по отдельности.
Нужно убедиться, что каждый из них нацелен на ключ с реальным поисковым объемом.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 15:05
Плейбук "Фрагментация контента" для системного демонтажа авторитетных сайтов
У нас был клиент в крипто-сфере, где сайт типа Forbes доминировал почти во всем, и нам нужно было придумать, как победить огромную компанию с таким авторитетом.
Решением стала техника, которую я называю "Фрагментация контента", и мы использовали ее, чтобы системно их обойти, рассказывает Энди Чедвик.
Стратегия начинается с выбора жирного URL-конкурента в стиле "ultimate guide".
Вы берете эту одну страницу и загоняете ее в Ahrefs, чтобы увидеть каждый ключевик, по которому она ранжируется.
И что вы обнаружите: хотя она может быть на первом месте по своему главному запросу, она часто слабо ранжируется — на седьмой, девятой или даже одиннадцатой позиции — по сотням других длиннохвостых запросов.
Она держит эти позиции только за счет авторитета домена, а не потому, что является лучшим ресурсом по этим конкретным вопросам.
Вот она, уязвимость.
Дальше вы собираете все эти ключевики и прогоняете их через инструмент кластеризации.
Анализируя СЕРПы, тулза группирует запросы и показывает, на сколько именно гипер-сфокусированных страниц можно разбить ту одну статью конкурента.
Вместо того чтобы пытаться обойти Forbes одной статьей, что у вас не выйдет, вы можете обойти их десятью или двадцатью, каждая из которых нацелена на свой специфический кластер запросов.
Это позволяет откусывать их трафик кусок за куском, попутно выстраивая свой собственный тематический хаб.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
22 October 2025 11:05
Используйте логи сервера как оружие, чтобы прибить бесконечные циклы краулинга
Когда вы пытаетесь вычистить бесконечный цикл краулинга на e-commerce сайте, программные ссылки в шаблоне пофиксить легко.
А вот скрытые ссылки в контенте — те, что редакторы вручную вставляли в описания продуктов много лет назад, — вынесут вам мозг, потому что их невозможно найти стандартным поиском.
Для ситуации, которая совсем зашла в тупик, есть быстрый и грязный хак, чтобы отловить их все, делится Тед Кубайтис.
Во-первых, вам нужно полностью изменить проблемную структуру URL.
Например, переименуйте старый путь для поиска с /search на что-то совершенно новое, вроде /find.
Затем вы внедряете общий редирект, который отправляет каждый URL, все еще использующий старый путь /search, на одну-единственную, общую страницу.
Это действие фактически создает ловушку-приманку (honeypot).
Последний шаг — мониторить логи вашего сервера.
Когда краулеры и пользователи будут попадать на старые внутренние ссылки, разбросанные по вашему сайту, они будут пойманы вашим редиректом.
URL-адреса рефереров в ваших веб-логах для каждого хита по этому старому, средирекченному пути теперь дадут вам точный список всех мест, которые вам все еще нужно пофиксить.
Это превращает ваши логи в диагностический инструмент, который точно определяет источник каждой проблемной ссылки, позволяя вам наконец искоренить цикл краулинга.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
21 October 2025 17:05
Утечка 'UGGDiscussionEffortScore' подтверждает: комьюнити — это измеримый сигнал качества
Хотя многие из слитых сигналов указывают на санкции, были раскрыты и позитивные атрибуты.
Мы увидели прямое подтверждение, что живое, хорошо модерируемое комьюнити на вашей странице — это измеримый положительный сигнал, как говориться в видео Шона Андерсона.
Существование UGGDiscussionEffortScore жестко зашивает этот принцип прямо в системы Гугла.
Этот показатель подтверждает, что активный раздел с пользовательским контентом, например, оживленный тред с комментариями или хорошо управляемый форум, напрямую влияет на то, как система воспринимает ценность вашей страницы.
Ключевой момент — фокус системы на "усилиях" (effort).
Важно не просто наличие комментариев, а качество и живость дискасса.
Гугл фундаментально рассматривает такое глубокое вовлечение пользователей как осязаемый признак качества, делая построение комьюнити неотъемлемой частью ваших технических сигналов качества, а не просто фичей для UX.
@
Читать полностью…
Mike Blazer
21 October 2025 11:05
Mike Blazer PRO
По вашим просьбам, приватный канал с 100% годнотой.
Что внутри:
— Самые ценные SEO/GEO/AI инсайты
— Отборные стратегии, тактики, реальные хаки продвижения
— Эксперименты, кейсы, схемы, фреймворки
— Фишки черного SEO
Только концентрат, эксклюзив и секреты для узкого круга ценителей премиум контента и своего времени. Никакой воды!
Паблик без изменений, но самое мощное уходит в PRO.
Первые подписчики ловят супер-цену, дальше — дороже.
Жмите и фиксируйте доступ к Mike Blazer PRO!
Читать полностью…
Mike Blazer
20 October 2025 18:05
⚡️ ВНИМАНИЕ!
Завтра в середине дня я опубликую важную новость, которая некоторых обрадует, а других, может быть, огорчит.
Не пропустите главный анонс этого года!
@
Читать полностью…
Mike Blazer
20 October 2025 15:05
Как использовать метаданные изображений как оружие для доминирования по long-tail запросам
Хватит относиться к оптимизации картинок как к простой задаче по доступности, пора рассматривать ее как мощный инструмент для семантического расширения.
Мы выяснили, что изображения — идеальный инструмент для стратегического таргетинга вторичных и LSI-ключевиков, чтобы расширить тематическую релевантность страницы, говориться в видео Шона Андерсона.
Для информационной страницы о "home workouts" alt-текст картинки "a man performing a body weight exercise for chest strength at home" намного лучше, чем просто "man doing push-ups", потому что он обогащает контекст страницы связанными понятиями.
Эта стратегия особенно эффективна для привлечения высокоинтентных, длиннохвостых запросов в e-commerce и локальном SEO.
Для товара в e-commerce обязательно используйте максимально описательные имена файлов и alt текст.
Имя файла должно быть Brooks-Adrenaline-GTS-22-Womens-Blue.jpg, а не shoes.jpg.
Соответствующий alt текст дает еще более глубокий контекст, например:
"a pair of women's Brooks Adrenaline GTS22 running shoes for over pronation in a blue colorway".
Аналогично, локальный подрядчик в Глазго должен использовать alt текст, который уточняет услугу и местоположение:
"A modern kitchen renovation with a marble island recently completed for a client in Glasgow's West End".
Это в одном сигнале передает местоположение, тип работы и ключевые особенности.
Существует четкая операционная иерархия для передачи этих контекстных сигналов поисковым системам.
Первичный сигнал — это само имя файла изображения, где слова нужно разделять дефисами.
Второй, и самый важный для богатого описания, — это alt текст.
Третий уровень контекста обеспечивают подписи и окружающий текст на странице, которые Google использует для дополнительной проверки тематики изображения.
Ссылаясь на Джона Мюллера и Барри Шварца, критически важно понимать, что алгоритмы ранжирования для этого контекстного понимания сильно полагаются на атрибут alt; атрибут title лишь вспомогательный и не является значимым фактором ранжирования.
@
Читать полностью…
Mike Blazer
20 October 2025 11:05
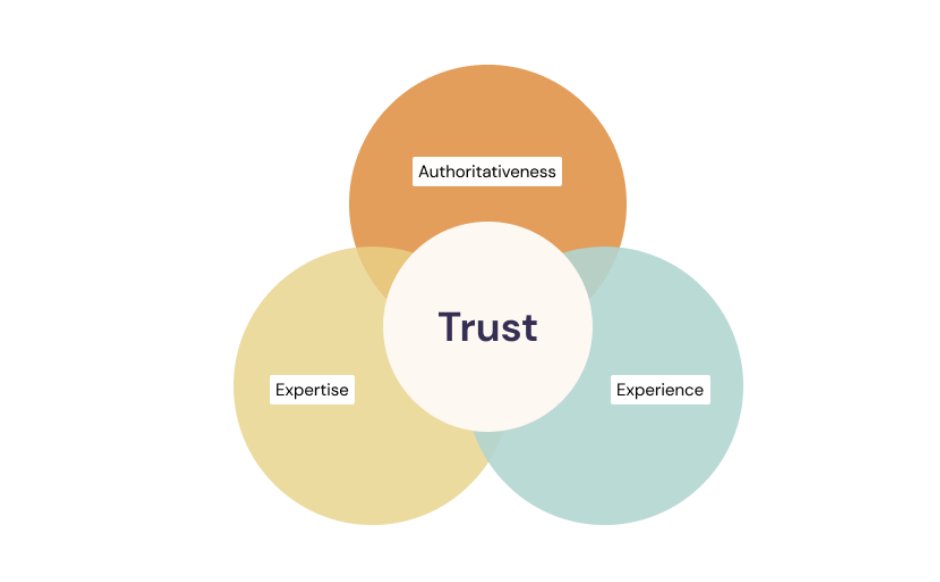
Разбираем E-E-A-T: как утекшие сигналы Гугла связаны с качеством контента
E-E-A-T — это концептуальная цель алгоритмов ранжирования Гугла.
Благодаря утекшей документации и судебным показаниям стало понятно, как она превращается в машиночитаемые сигналы в многоэтапном процессе ранжирования.
Системы вроде SegIndexer, Mustang и Navboost последовательно фильтруют контент по качеству, оценивают его и вносят финальные корректировки.
В этой статье мы сопоставим утекшие атрибуты с каждым из компонентов E-E-A-T.
Experience
Опыт измеряется сигналами личного участия и оригинальности контента.
— contentEffort: LLM-оценка человеческих усилий в контенте. Штрафует копипаст и шаблонный AI-текст.
— originalContentScore: Измеряет уникальность контента, отличая его от синдицированной или вторичной информации.
— isAuthor & author: Идентифицирует и отслеживает работы автора, позволяя системам строить профиль его опыта.
— lastSignificantUpdate: Отличает мелкие правки от серьезных, сигнализируя об актуальном опыте в теме.
— docImages: Оригинальные, релевантные изображения служат подтверждением личного опыта.
Expertise
Экспертность определяется через тематическую специализацию и семантическую глубину.
— siteFocusScore & siteRadius: Измеряют тематическую специализацию, поощряя нишевый фокус и наказывая за контент вне основной тематики.
— site2vecEmbeddingEncoded: Создает математическое представление тематик сайта для измерения его тематической целостности.
— EntityAnnotations & QBST: Определяют сущности на странице и ключевые термины, ожидаемые в экспертном документе по запросу.
— ymylHealthScore: Отдельный классификатор, показывающий, что для YMYL-тем ("Your Money or Your Life") применяются более высокие, алгоритмически измеряемые стандарты экспертности.
Authoritativeness
Авторитетность измеряется комплексными сигналами репутации сайта, влияющими на общую, независимую от запроса, оценку качества (Q*).
— siteAuthority: Метрика, отражающая общую важность домена.
— predictedDefaultNsr: Версионированная базовая оценка качества, создающая "алгоритмическую инерцию": история высокого качества делает сайт более устойчивым к просадкам.
— Homepage PageRank: Фундаментальный сигнал авторитетности для всего домена.
— queriesForWhichOfficial: Хранит запросы, по которым страница считается "официальным" результатом.
Trust
Траст — базовое требование, основанное на технической исправности, пользовательском подтверждении и отсутствии спам-сигналов.
— pandaDemotion: Санкции на весь сайт за низкокачественный, тонкий или дублированный контент. Работают как "алгоритмический долг", просаживающий видимость.
— Сигналы, подтвержденные пользователями: Показания по делу Минюста подтвердили: Navboost использует клики из Chrome для корректировки ранжирования. Система классифицирует поведение пользователей на сигналы: GoodClicks (запрос удовлетворен), BadClicks (пого-стикинг) и last longest clicks (сильный сигнал удовлетворенности). Постоянное негативное поведение юзеров может привести к санкциям, вроде navDemotion.
— Технические и спам-сигналы: Траст снижается из-за негативных сигналов: badSslCertificate (плохой SSL-сертификат), clutterScore (перегруженный макет), scamness (подозрение на мошенничество) и spamrank (ссылки на спамные сайты).
— Проверка в реальном мире: Для локальных сущностей сигналы вроде brickAndMortarStrength измеряют их физическую заметность и надежность (например, наличие офиса).
https://www.hobo-web.co.uk/eeat/
@
Читать полностью…
Mike Blazer
19 October 2025 15:05
Как агрессивный таргетинг по ключевым словам обогнал The New York Times за 5 минут
Мое прозрение о силе размещения ключевых слов окончательно закрепилось, когда я опубликовал статью и через пять минут обогнал The New York Times по той же теме.
После публикации поста я отправил его в GSC, и хотя у нашего домена не было особого авторитета, я занял первое место, выше Times — сайта, который получает 235 миллионов кликов в месяц, — объясняет Эдвард Штурм.
Единственная разница между нашими статьями была в том, что, хотя материал The New York Times был о том же самом, моя статья была специально заточена под ключевое слово.
Я разместил целевой ключ в самом начале тайтла, в URL-слаге, в H1, в мета-дескрипшене и в первом предложении на странице.
Этот опыт кардинально изменил мой взгляд на SEO.
Раньше я думал, что бэклинки — это все, но у нашего сайта было гораздо меньше авторитета домена и ссылок, чем у The New York Times.
Это доказало мне, что таргетинг — это примерно 80% успеха.
Бэклинки по-прежнему важны, и определенная скорость прироста ссылок, вероятно, помогла моему контенту так быстро проиндексироваться, но они не являются альфой и омегой, как часто пишут в материалах для новичков.
Ключ в том, что пользователи хотят получать быстрые ответы со страницы, которая выглядит так, будто написана специально для них, и агрессивный, прямой таргетинг дает именно этот сигнал.
@
Читать полностью…
Mike Blazer
19 October 2025 11:05
Как неконсистентные данные в отзывах убивают ваши рич сниппеты
Пример, как микроразметка может пойти не так, был у одного бренда, с которым я работал.
Мы увидели, как Гугл полностью перестал показывать рич сниппеты для их страниц.
Я опишу тот же бренд, где это произошло, говорит Зак Чахалис.
К счастью, они пофиксили проблему, но это был критически важный урок о консистентности данных.
Проблема была в том, что команда не до конца понимала весь свой техстек.
Они хотели включить разметку отзывов в основную схему продукта, которую писали сами, но не понимали, что сторонний инструмент для интеграции отзывов, который они юзали, *тоже* добавлял свою собственную разметку.
Хотя эти два скрипта часто совпадали, иногда данные об отзывах, которые они кешировали для своего скрипта, приводили к тому, что оценка и количество отзывов отличались от тех, что подтягивал сторонний инструмент.
Это создавало прямой конфликт.
Поисковики обычно пасуют, если видят что-то противоречивое; они смотрят на это как на получение нескольких разных сигналов, и если не могут разобраться, то не хотят с этим заморачиваться.
Прямое следствие — Гугл перестал показывать рич сниппеты для этих страниц, пока мы не пофиксили ошибку.
Это также критично для e-commerce брендов, потому что Google использует структурированные данные для валидации товарных фидов.
Ключевой момент: ваша разметка должна соответствовать актуальной цене и наличию товара, так как они могут полагаться на эти структурированные данные, чтобы быстрее понимать меняющуюся информацию.
@
Читать полностью…
Mike Blazer
18 October 2025 15:05
Теория: Google оценивает ваш сайт на основе контента первого дня
Для новых сайтов я использую метод, который называю "теорией первого индекса" — кажется, ее изначально придумал Чарльз Флоут.
Суть в том, чтобы с самого начала заложить тематический авторитет, — говорит Джеймс Оливер.
Вся стратегия заключается в том, чтобы загрузить весь контент на сайт *до* того, как он станет доступен.
Вместо того чтобы публиковать статьи по одной, я готовлю от 50 до 100 страниц, чтобы с первого дня закрепить тематический авторитет сайта, а затем публикую все разом.
Логика в том, что Google одновременно забирает весь этот контент в свой индекс, и этот первоначальный "снимок" хранится в индексе до двух лет, прежде чем обновится.
Это с самого начала создает для сайта четкий, авторитетный след в конкретной тематике.
Чтобы максимально ускорить этот процесс и заполнить необходимую тематическую карту, эффективно использовать ИИ-агентов для генерации первоначальной пачки контента.
@
Читать полностью…
Mike Blazer
18 October 2025 11:05
Почему спам-атаки ссылками могут случайно помочь хорошо зарекомендовавшим себя сайтам
Атаки с помощью негативного SEO обычно сосредоточены в нишах, где крутятся большие деньги, например, в iGaming или в индустрии матрасов, потому что в менее конкурентных сферах это просто не стоит времени атакующего.
У меня было несколько случаев, когда на мой сайт слали спамные ссылки, но во многих случаях это в итоге только помогало, — говорит Джеймс Оливер.
Это происходит потому, что если у вас уже есть хороший, устоявшийся ссылочный профиль, новые спамные ссылки просто уравновешиваются существующим авторитетом.
Вместо того чтобы наложить на сайт санкции, атака просто увеличивает общий объем ссылок, а сильный фундамент поглощает негативные сигналы.
Подавляющее большинство людей такая атака не затронет, хотя у этого феномена есть определенные нюансы.
@
Читать полностью…
Mike Blazer
17 October 2025 17:05
Это не должно было сработать, но…
@
Читать полностью…
Mike Blazer
23 October 2025 17:05
Может все-таки настало время снова качать форумы?
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 11:05
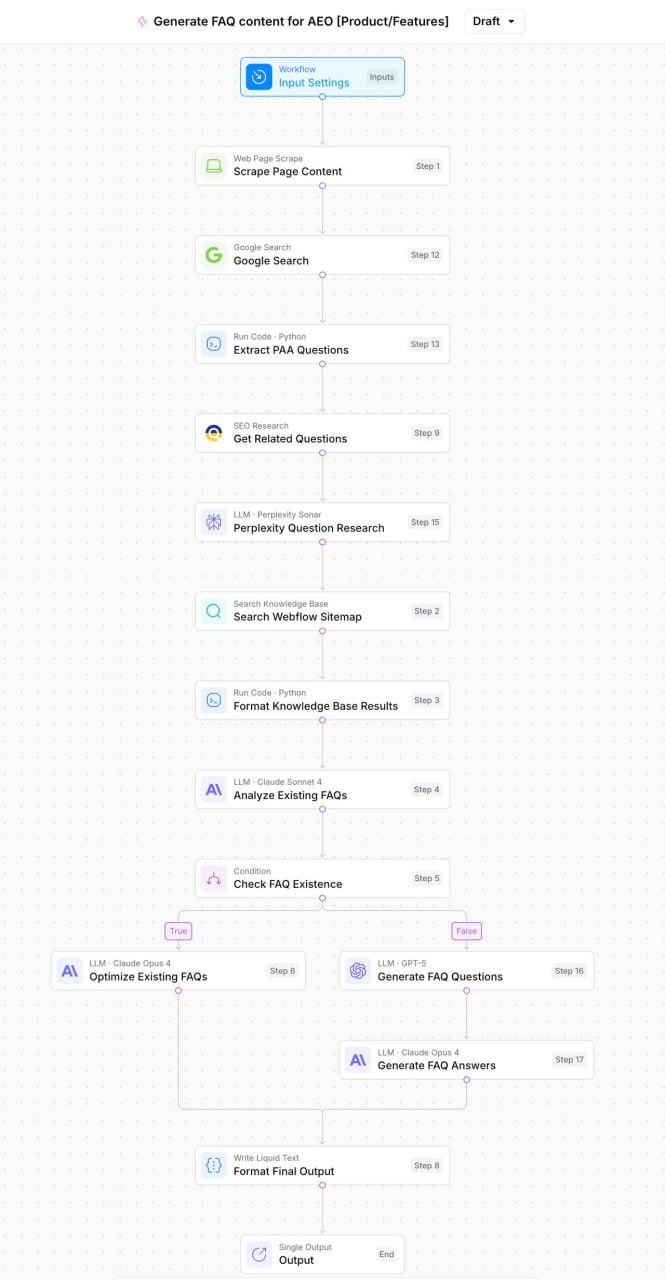
Кейс Webflow: +24% к показам в SEO за счет автоматизации FAQ и микроразметки
Эксперимент по добавлению автоматизированного воркфлоу для FAQ и микроразметки Schema на шесть ключевых страниц Webflow (Design, CMS, SEO, Shared Libraries, Interactions, Hosting) дал серьезный буст перфомансу.
Воркфлоу на базе ИИ, собранный в AirOps, использовал Perplexity для рисерча вопросов юзеров из гугловского "People Also Ask", Reddit и профильных форумов.
Процесс состоял из четырех шагов:
1. Анализ существующего контента в FAQ, чтобы найти гэпы.
2. Генерация финального списка релевантнтых вопросов с высоким интентом.
3. Создание новых ответов в стилистике бренда, заточенных под конкретный продукт.
4. Автоматическое структурирование контента в чистую микроразметку Schema.
Результаты:
— +331 новое AI-цитирование (57% всех новых цитирований на Webflow.com)
— +149 тыс. SEO-показов (+24% по сравнению с предыдущим периодом)
— Рост видимости почти по всем отслеживаемым запросам
Успех стратегии — в том, что мы отвечали на вопросы, которые юзеры активно ищут, и структурировали контент как для поисковиков, так и для answer engines.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 18:49
Браузер OpenAI Atlas идентифицирует себя как Googlebot для каждого запроса.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 13:10
Как напичкать e-comm страницы контентом, который увидят только краулеры
Многие сеошники думают, что для добавления контента на страницы категорий нужно сходить с ума и писать полотна повторяющегося текста про безопасность, но этого делать не нужно, раскрывает секрет Тед Кубайтис.
Вместо этого можно сделать количество отображаемых товаров на странице прямым рычагом для увеличения уникального текста.
Фишка в том, чтобы встроить короткие описания продуктов из вашей CMS в исходный код для каждого товара в листинге.
Можно разместить этот текст внутри скрытого div, который появляется только при наведении, или просто засунуть его в атрибут title для ссылки каждого продукта.
Если вы добавите короткие описания в исходный код для всех товаров на странице категории, это уже куча текста.
Более агрессивный вариант — загружать полный HTML для большого количества продуктов (скажем, 100) при первоначальной загрузке страницы, но использовать lazy loading на уровне отображения, чтобы показывать их по мере скролла.
Это отдает весь контент Гуглоботу сразу, сохраняя при этом хороший UX для покупателей.
Похоже на сероватую технику с каруселью, где страница визуально показывает четыре товара, но в исходном коде их 100.
Сделав так, ваше SEO для страниц категорий сводится к простому изменению числа отображаемых товаров.
Больше товаров — больше SEO.
Внезапно у вас появляется 50 или 100 уникальных коротких описаний, названий продуктов и всех сопутствующих сущностей и LSI, что дико раскачивает некогда тощую страницу.
Это простой, белый метод, который творит чудеса.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
22 October 2025 08:15
Порог правок страницы, который триггерит алгоритмическую пессимизацию
Быстро вносить онпейдж-изменения — затягивающий процесс, но есть серьезный риск, что это выйдет боком.
Мы видели, что чрезмерное количество правок на одной странице может вызвать специфические алгоритмические санкции, предупреждает Ли Витчер.
Существует порог, после которого Гугл пессимизирует страницу — закинет ее на позицию типа 57-й — и будет держать там, пока она не "стабилизируется" и ей снова можно будет доверять.
Алгоритму не нравится постоянно краулить страницу, которая находится в состоянии непрерывных изменений.
Чтобы этого избежать, нужна дисциплина.
После внесения онпейдж-изменений оставьте страницу в покое как минимум на две недели.
Эта проблема касается не только мелких правок; постоянная смена основной темы URL — это верный способ нарваться на санкции.
Классический пример — e-commerce сайт, который использовал одну и ту же страницу "specials" для разных праздников: Пасхи, потом Дня матери, потом Четвертого июля.
Из-за постоянной смены товаров и темы этот URL перестал ранжироваться вообще по чему-либо.
Он был полностью убит.
Если вы обнаружили, что страница попала под санкции за нестабильность, есть способ из этого выбраться.
Исторически успешной тактикой является перенос контента на новый URL и установка 301 редиректа со страницы под санкциями на новую.
Это может сбросить счетчик правок и флаги санкций, давая вам свежий старт ценой потери примерно 15% авторитета, которая связана с редиректом.
@
Читать полностью…
Mike Blazer
21 October 2025 15:05
Google теперь помечает целые мобильные сети, где идет активный парсинг
При парсинге Google есть разные методы, от резидентных прокси до выделенных IP-инфраструктур.
Но мы заметили интересный побочный эффект, связанный именно с использованием мобильных 4G-прокси: интенсивный, географически сконцентрированный парсинг может привести к тому, что весь мобильный IP-блок будет помечен, — сообщает Кевин Ришар.
Это создает серьезный сопутствующий ущерб для обычных пользователей.
Доказательство этому — прямое наблюдение во Франции.
В некоторых городах, где, как мы знаем, люди активно парсят, мой коллега столкнулся с показательной штукой.
Он был в одном из таких городов, подключенный к обычной мобильной сети 4G, и просто открыл окно в режиме инкогнито.
Он сразу же словил капчу.
Это произошло не из-за его собственной активности, а потому, что другой наш коллега активно парсит, используя 4G-ключи из этого конкретного города.
Этот инцидент демонстрирует, что система обнаружения Google работает на уровне выше, чем отдельный IP-адрес.
Когда она выявляет интенсивную, постоянную активность по парсингу, исходящую из IP-диапазона определенного мобильного оператора в конкретной локации, она, похоже, помечает весь сегмент сети.
В результате даже легитимные, обычные пользователи в той же сети рассматриваются как подозрительный трафик, что вызывает капчи для базовых поисков даже в чистой среде без куки.
@
Читать полностью…
Mike Blazer
21 October 2025 08:15
"Неправильная" стратегия каноникалов, которая пережила рекомендации самого Google
Критическая ошибка, которая учит Google не доверять каноникалам сайта, — это каноникализация страниц пагинации, таких как страница 2, 3 или 4, на первую страницу.
Поскольку каждая страница пагинации имеет уникальный контент, такое злоупотребление сигнализирует Google, что вашим декларациям каноникалов нельзя доверять по всему домену, — предупреждает Тед Кубайтис.
Тут надо быть строгим: если контент уникален, каноникал должен быть уникальным для этого контента.
На седьмой странице вашей категории носков — другие товары, чем на первой.
Когда вы раз за разом показываете Google, что контент не соответствует заявленному вами каноникалу, вы, по сути, дрессируете алгоритм игнорировать ваши каноникалы по всему сайту.
Тем не менее есть мощное контрнаблюдение из ранних дней алгоритма Panda.
"Когда Panda только выкатили, у меня был e-commerce сайт, который он буквально раздавил.
В качестве фикса мы сделали именно то, что Google делать не рекомендует: мы каноникализировали все наши страницы пагинации на главную страницу категории", — вспоминает Чарльз Тейлор.
В результате, в течение недели после следующего апдейта Panda, восстановление сайта было как хоккейная клюшка — резко вверх.
Год спустя Google вышел и сказал, что так делать не следует, и посоветовал всем вместо этого использовать rel=prev/next.
Я ничего не менял ни на одном из своих e-commerce сайтов, и все они остались в порядке.
Затем, годы спустя, Google между делом объявил, что они все равно уже больше года не поддерживают rel=prev/next.
И все это время сайты, которые сохраняли первоначальную "неправильную" стратегию каноникализации, оставались вообще без изменений.
@
Читать полностью…
Mike Blazer
20 October 2025 17:05
Почему "LSI-ключевиков" никогда не существовало и что Google делал на самом деле
Концепция "LSI-ключевиков" — это миф, поскольку латентно-семантическое индексирование никогда не было жизнеспособной технологией для веб-поиска, утверждается в видео Шона Андерсона.
У LSI есть два фатальных недостатка: его вычислительно невозможно масштабировать на весь интернет, и, будучи моделью "мешка слов", он полностью игнорирует грамматику, не видя критической разницы между "собака кусает человека" и "человек кусает собаку".
Покойный Билл Славски отлично подметил, сравнив использование LSI для современного поиска с "попыткой использовать телеграф для просмотра TikTok".
Настоящий механизм, стоявший за обновлением "Brandy" в 2004 году, был раскрыт годы спустя инженером Google Полом Хааром: это была "система синонимов".
Эта система брала ваш поисковый запрос и автоматически расширяла его за кулисами, по сути добавляя к вашему поиску слово OR.
Запрос "cycling tours" превращался в поиск "cycling OR bicycle OR bike tours".
Именно это позволило странице о "pre-owned automobiles" внезапно начать ранжироваться по запросу "used cars" — система просто сопоставляла синонимы, закидывая гораздо более широкую сеть, чтобы охватить все способы, которыми люди говорят об одной и той же теме.
Та система 2004 года была первым шагом на прямом, 20-летнем эволюционном пути к современному ИИ.
Прогресс очевиден: от расширения на уровне слов в системе синонимов мы перешли к расширению на уровне концепций с системами вроде RankBrain и Neural Matching.
Теперь у нас есть AI Overviews, которые используют архитектуру Query Fan-Out, беря один вопрос и расширяя его до десятков новых, более конкретных подзапросов.
Это как пирамида из черепах: та самая первая система синонимов — это фундаментальная черепаха, на которой все держится.
Так почему же миф об LSI продержался два десятилетия?
Это был "феномен движения вперед через ошибку".
SEO-специалисты, верившие в LSI, начали добавлять в свой контент синонимы и связанные термины.
Они делали правильные вещи по неправильным причинам, случайно создавая идеальную мишень для реальной системы синонимов Google и получая положительные результаты.
Вот почему важно понимать суть.
Как прямо заявил сам Джон Мюллер из Google: "Не существует такой вещи, как LSI-ключевики".
Понимание реальной истории показывает, что цель всегда была не в том, чтобы насыпать ключевиков по чек-листу, а в том, чтобы создавать исчерпывающий, полезный контент, который естественным образом охватывает всю широту темы.
@
Читать полностью…
Mike Blazer
20 October 2025 13:10
Слив Гугла показал, что система Google "`Goldmine`" стравливает ваш тайтл с H1 и анкорами
Слитые документы Google подтвердили существование системы titlematchScore, которая алгоритмически оценивает, насколько тайтл вашей страницы соответствует запросу пользователя.
Но самый важный инсайт в том, что Google рассчитывает sitewide titlematchScore (общую оценку тайтлов по всему сайту).
Это значит, что качество ваших тайтлов оценивается в совокупности, и несколько плохих тайтлов могут негативно повлиять на авторитет всего домена, раскрывает Сайрус Шепард.
Система активно выискивает эти слабые звенья, используя специальный флаг BadTitleInfo для выявления и оценки некачественных тайтлов, что служит прямым негативным фактором ранжирования для контента, который считается спамным, размытым или неэффективным.
Движком этой оценки является внутреннее соревнование под кодовым названием Goldmine, которое анализирует пул потенциальных тайтлов для SERP, чтобы выбрать лучший, объясняется в видео Шона Андерсона.
Ваш HTML-тег title — лишь один из кандидатов в этой борьбе.
Система формирует свой пул кандидатов из нескольких источников, включая ваш H1 на странице, который, как подтверждает внутренний атрибут goldmineHeaderIsH1, рассматривается как отдельный и очень весомый конкурент.
Критически важно, что Goldmine также наполняет свой пул кандидатов, используя якорные тексты как внутренних (source_onsite_anchor), так и внешних (source_offdo_anchor) ссылок.
Это означает, что каждый раз, когда вы используете дженерал-анкоры для внутренней перелинковки типа "click here" или "learn more", вы целенаправленно засоряете пул кандидатов в тайтлы для страницы низкокачественными вариантами, что потенциально может привести к выбору слабого тайтла для выдачи.
Когда все предоставленные кандидаты оказываются низкокачественными, Goldmine использует запасной вариант sourceGeneratedTitle, чтобы сгенерить тайтл с нуля.
Оценка каждого кандидата корректируется системой Blockbird — это кастомная, эффективная языковая модель, созданная для глубокого семантического анализа тайтлов в огромных масштабах.
Blockbird оценивает семантическую целостность, контекстуальную релевантность и естественность.
Затем система Goldmine применяет количественные штрафы.
Атрибут dup_tokens штрафует за переспам ключевыми словами, а goldmineHasBoilerplateInTitle — за повторение неинформативного текста в тайтлах по всему сайту.
Более того, атрибут isTruncated подтверждает, что тайтлы, превышающие лимит в 600 пикселей, активно штрафуются во время отбора, а не просто обрезаются для отображения.
Чрезмерная длина — это конкурентный недостаток.
Финальный фильтр — это поведенческие факторы.
Обманчивый или кликбейтный тайтл может получить высокую начальную оценку от Blockbird, но негативные сигналы от пользователей (плохие клики) со временем понизят его оценку NavBoost, что приведет к его понижению в выдаче.
Это заставляет вас относиться ко всей вашей стратегии внутренней перелинковки как к форме контроля качества тайтлов.
Вы должны провести аудит сайта и агрессивно вычистить дженерал-анкоры, чтобы перестать засорять пул кандидатов для атрибута sourceOnsiteAnchor.
@
Читать полностью…
Mike Blazer
20 October 2025 08:15
Анализ протокола GoogleApi.ContentWarehouse.V1.Model.ImageData из утечки данных Гугла 2024 года показывает, как устроен современный поиск по картинкам.
Это не советы из SEO-блогов, а описание многоуровневого процесса, по которому Гугл индексирует, понимает и ранжирует визуал.
Для успеха в поиске по картинкам нужна комплексная стратегия, связывающая он-пейдж контекст, семантику внутри картинки, алгоритмические оценки качества и сигналы ПФ.
Топ-10 инсайтов из схемы ImageData
1. Определение первоисточника: Гугл юзает contentFirstCrawlTime, чтобы определить, когда впервые увидел контент картинки, отдавая приоритет оригиналам.
2. Алгоритмическая эстетика: Модель NIMA (Neural Image Assessment) алгоритмически оценивает картинки по техническому качеству (nimavq — фокус, свет) и эстетической привлекательности (nimaAva — композиция).
3. Оценка анти-кликбейта: clickMagnetScore пенальтит картинки за клики по нерелевантным "плохим запросам" для борьбы с визуальным кликбейтом, так как не все клики полезны.
4. Связка с сущностями: Объекты на картинке через multibangKgEntities линкуются с графом знаний, связывая изображение с реальными понятиями вроде "Эйфелевой башни".
5. Фильтр качества при индексации: Внутренняя система Amarna (corpusSelectionInfo) фильтрует качество, и визуал низкого уровня не попадает в основной индекс.
6. Индексация всего текста: Системы OCR (ocrGoodoc, ocrTaser) считывают и индексируют текст внутри изображений, делая слова на инфографике или товарах доступными для поиска.
7. Сигнал для товарных фото: whiteBackgroundScore — косвенный признак профессиональной товарной фотографии, сигнализирующий о коммерческом трасте.
8. Иерархия дублей: Даже одинаковые картинки ранжируются в кластере дублей, а rankInNeardupCluster отдает топ-позицию изображению на более авторитетной или качественной странице.
9. Лицензирование на основе метаданных: Бейдж "Лицензируемая" в выдаче подтягивается из атрибута imageLicenseInfo, который берется из метаданных IPTC в файле или из он-пейдж микроразметки.
10. Контекстно-зависимая безопасность: Финальный рейтинг SafeSearch (finalPornScore) — сводная оценка, объединяющая анализ пикселей с контекстными сигналами, включая запросы, по которым ранжируется изображение ("navboost queries").
Ключевые системы и процессы
— Архитектура и происхождение: Гугл для каждой картинки определяет источник правды. canonicalDocid — это канонический идентификатор, собирающий все факторы ранжирования. contentFirstCrawlTime — мощный сигнал для определения первоисточника. Движок Mustang ранжирует картинки и использует rankInNeardupCluster для построения иерархии даже среди идентичных изображений.
— Семантическое понимание: Гугл глубоко понимает содержание картинки: OCR извлекает текст, imageRegions определяет объекты, а multibangKgEntities связывает их с графом знаний, что является ядром SEO для картинок на основе сущностей. Специальные детекторы классифицируют изображения по типу (photoDetectorScore, clipartDetectorScore) для соответствия интенту пользователя.
— Качество и вовлеченность: Качество оценивается с двух сторон: внутреннее — алгоритмическими оценками NIMA за техничку и эстетику, а внешнее — сигналами ПФ, вроде h2c и h2i. По сути, это версия NavBoost для картинок.
— Коммерция и монетизация: Коммерческие фичи встроены в схему. Атрибут shoppingProductInformation — это богатая структура данных для товарных картинок, заполняемая структурированными данными продавцов. Поле imageLicenseInfo из IPTC или он-пейдж микроразметки отвечает за показ бейджа "Лицензируемая".
https://www.hobo-web.co.uk/the-definitive-guide-to-image-seo-google-content-warehouse-imagedata-schema-analysis/
@
Читать полностью…
Mike Blazer
19 October 2025 13:10
Как одно слово в тайтле бросило вызов многомиллионному конкуренту
Работая с клиентом по супер-конкурентному, высокочастотному ключу, мы раскопали в GSC серьезную возможность.
Мы увидели, что вариация ключа со словом "free" генерирует дохера объема.
Этот ключ и его вариации давали общий поисковый объем около миллиона визитов в месяц, за который боролись пять разных многомиллионных компаний.
Основываясь на этом инсайте, мы сделали простое изменение: просто добавили слово "free" в тайтл.
Как только мы это сделали, позиции рванули вверх, говорит Сайрус Шепард.
Страница переместилась с седьмой позиции примерно на 2.5.
Хотя на фоне происходили и другие изменения, это было главным.
Примерно через две недели наш основной конкурент, лидер рынка, скопировал нас, и его позиции снова сравнялись с нашими.
Но мы впервые добились того, чтобы лидер ниши догонял нашу стратегию, а не наоборот.
@
Читать полностью…
Mike Blazer
19 October 2025 09:15
Почему ваш URL-слаг почти никогда не должен совпадать с H1
При создании контента стоит избегать слишком длинных слагов, особенно тех, которые дублируют заголовок, например, /five-great-options-for-patient-scheduling-software.
Это проблема, потому что если вы позже измените заголовок — например, расширив список до десяти вариантов — у вас будут проблемы, так как в слаге все еще будет написано "пять".
Я обычно делаю так, чтобы слаг состоял только из ключевого слова, на котором я фокусируюсь, — объясняет Илиас Исм.
Для страницы о программах для записи пациентов слаг должен быть просто /программы-для-записи-пациентов.
Больше ничего не нужно.
Такая структура позволяет вам четко понимать, что именно на этот ключ нацелена данная страница.
Это также дает вам свободу всегда менять заголовок или все содержимое — все что угодно — пока слаг остается неизменным.
Если у вас сейчас длинный, описательный URL, вы можете просто сделать редирект на новый, чистый слаг после его изменения.
@
Читать полностью…
Mike Blazer
18 October 2025 13:10
Как использовать анализ логов с помощью ИИ для защиты от атак негативным SEO-трафиком
Чтобы защититься от тактик конкурентов, таких как пого-стикинг — отправка плохого трафика, который просто сразу уходит, — вы должны постоянно заниматься поддержкой сайта и мониторить источники трафика.
Вы можете обучить ИИ на конкретных паттернах, чтобы найти источник этих атак.
Процесс начинается, когда вы скачиваете серверные логи примерно за месяц и загружаете их в ИИ для обучения, объясняет Мигель Алмела.
Как только ИИ обучен на ваших лог-файлах, вы можете применять фильтры для поиска сходств.
Например, вы можете отфильтровать все визиты длительностью менее одной секунды и проанализировать соответствующие IP.
Это часто выявляет паттерн, например, все вредоносные пользователи исходят из одного конкретного дата-центра.
Как только вы определите этот источник, вы можете полностью его заблочить.
Если атака более сложная и использует резидентные прокси, защита становится более комплексной.
В этом случае вам нужно применить более продвинутые фильтры к данным логов.
Это не то чтобы гемор, но этим определенно нужно заняться.
@
Читать полностью…
Mike Blazer
18 October 2025 09:15
Сайты, восстанавливающиеся после HCU, убирают дату первоначальной публикации
Сайты, которые успешно восстановились после апдейта HCU, часто являются теми, кто усердно обновляет свои старые посты.
Основываясь на масштабном исследовании 5000 доменов, мы увидели, что одна из ключевых тактик — это "подход с одной датой", объясняет Сайрус Шепард.
Вместо того чтобы показывать и дату первоначальной публикации, и дату последнего обновления поста, эти восстанавливающиеся сайты показывают только самую свежую дату обновления.
Это отход от слишком агрессивных сеошных техник.
Мы обнаружили, что сайты, постоянно обновляющие дату на каждом посте, теряли позиции.
Теперь, если вы обновляете дату, вы также должны внести существенное обновление в сам контент.
Это не требует полного переписывания; обновление всего пары предложений или абзаца достаточно, чтобы триггернуть алгоритм свежести Google.
Сочетание этих обновлений контента с показом только одной, самой свежей даты — ключевая характеристика сайтов, которые начали восстанавливаться после HCU.
@
Читать полностью…
Mike Blazer
17 October 2025 15:05
Когда ваш коллега нажал на ссылку, чтобы "выиграть" iPhone 16 Pro, и теперь всем приходится приходить на работу в 7 утра на курс по кибербезопасности
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}