Mike Blazer
22 December 2025 15:05
Искусство инференс-инжиниринга и оптимизации: За пределами SEO и GEO
Иерархия обновилась: SEO > `AI SEO` > `AEO`.
Ранжирование больше не самоцель; цель — стать "`Ground Truth`" (Фундаментальной Истиной) для LLM (ChatGPT, Gemini, Perplexity).
Это требует сдвига от оптимизации ключей к Инференс-Инжинирингу (Inference Engineering).
1️⃣ Фаза I: Загрузка фактов (Input)
LLM не браузит, она процессит.
Вы должны инжинирить входные данные так, чтобы модель тратила 0% вычислений на "угадывание" структуры.
— Протокол: Явно определяйте Сущность (Кто), Атрибут (Что) и Отношения (Основатели/Материнская компания).
— Перплексия против Бёрстиности (Burstiness): Держите факты с низкой перплексией (структура S-V-O) для точности, но аналитику с высокой бёрстиностью (уникальные инсайты), чтобы избежать фильтрации как "генерик".
— Эффективность памяти: Сжимайте концепции бренда. Плотный инпут предотвращает потерю контекстного окна.
2️⃣ Фаза II: Цикл Скульптора (Output)
Двигайтесь дальше "спама консенсусом" (замусоривания упоминаниями).
— Рекурсивное улучшение: Скармливаем спроектированную схему -> Анализируем вывод (inference) -> Фиксим галлюцинации -> Заливаем обратно.
— Цель: Стабильное состояние, где модель воспроизводит "Ground Truth" без дрифта.
3️⃣ Оптимизация под RAG
Если это не сритривили (retrieved), это не выведут (inferred).
— Семантический чанкинг: RAG читает чанки (куски), а не страницы. Каждый раздел H2 должен быть самодостаточным (Субъект + Действие + Контекст).
— `CoT` Структурирование: Пишите нумерованными логическими шагами, чтобы соответствовать рассуждениям LLM по принципу "Chain-of-Thought" (цепочка мыслей).
— Защитная дисамбигуация: Форсируйте совместную встречаемость (Бренд + Индустрия) и юзайте схему SameAs.
4️⃣ Критические сигналы из сливов
Оптимизация под конкретные алгоритмические теги, подтвержденные в недавних ликах:
— contentEffort: Оценка человеческого труда на базе LLM. Низкие усилия (спинненный AI) обесцениваются.
— topic_embedding_confidence: Сила связи между сущностью и темой.
— OriginalContentScore и consensus_score: Главные фильтры против коллапса модели (Model Collapse).
— siteAuthority и Q*: Метрики "высокой дороги" против SpamBrain.
Хватит оптимизировать под краул.
Начинайте инжинирить под инференс.
https://www.searchable.com/blog/the-art-of-ai-seo
#AgenticSEO #LLM #GEO
@
Пушки — в @
Читать полностью…
Mike Blazer
22 December 2025 08:15
Внешняя валидация — единственная механика для цитирования в ChatGPT
Цитирование в ChatGPT не рандомно; за тем, кого упоминают, стоит просчитанная формула.
Ahrefs только что проанализировал 26,283 URL и вскрыл всю мету для видимости в AI.
Стандартный плейбук — написать статью Best X, занять Топ-1 у себя и ждать, что ChatGPT это подхватит — не работает.
Самопиарные листиклы почти не влияют на видимость в AI.
Чтобы вас цитировали в 2025, нужна внешняя валидация.
ChatGPT подавляюще часто ссылается на сторонние подборки, PR-сайты, отраслевые блоги и хабы сравнения тулов типа G2 или TechRadar.
Алгоритм требует консенсуса по всему вебу, а не вашего мнения о себе.
Вот конкретная механика того, что драйвит цитирование:
— Свежесть критична: 79% процитированных страниц были обновлены в 2025 году. Модели жестко приоритизируют недавно обновленный контент. Если ваши упоминания старые — вы исчезаете.
— Повторение решает: Бренды, которые светятся на 1-3 местах в нескольких независимых списках, рекомендуются гораздо чаще. ИИ верит паттернам; если несколько сайтов говорят, что вы норм, ChatGPT это эхом повторяет.
Мой чеклист по AI SEO на 2025 год полностью сфокусирован на офф-сайт сигналах, пишет Джеки Чоу.
Вам нужно засветить бренд на 3-7 внешних площадках, включая нишевые блоги, партнерские листиклы, PR-статьи и страницы Alternatives to X.
Авторитет помогает, но объем решает.
Также нужно диверсифицировать форматы, которыми кормится модель — не полагайтесь только на списки.
Используйте баинг-гайды, ревью и сравнения.
Критически важно: обновляйте эти размещения каждые 3-6 месяцев, потому что протухшие упоминания теряют вес.
Хватит ранжировать себя на первом месте у себя же на сайте или плодить десятки клонов best X.
Исследование доказывает без сомнений: ChatGPT верит третьим источникам, а не вашему сайту.
Мой обновленный плейбук прост: я размещаю клиентов на нескольких сторонних доменах, обновляю эти цитаты по расписанию и миксую форматы под паттерны обучения ИИ.
AI SEO — это больше не спам в своем блоге.
Это спам во всех чужих блогах.
#GEO #BrandMentions #DigitalPR
@
Пушки — в @
Читать полностью…
Mike Blazer
20 December 2025 11:15
Если вы ломаете голову над новогодним подарком сеошнику или целой SEO-команде — забейте.
Алкоголь выпьют.
Худи выбросят.
Кружку разобьют.
Знания, как нагибать выдачу в 2026-м — останутся и принесут кэш ВАМ.
Подарите годовой доступ в @.
Это буст для мозга любого Head of SEO и тимлида.
Для тех, кто в теме, это ценнее любых «Ролексов».
На носу Новый год.
В платежке появилась кнопка «Купить в подарок».
Берете ссылку -> кидаете в личку сотруднику.
Один клик.
Это лучшая инвестиция, которую вы сделаете в этом декабре.
Всё.
Вы — лучший Санта в индустрии!
Действуйте.
Читать полностью…
Mike Blazer
19 December 2025 12:10
Код 499 в логах Nginx убивает цитируемость сайта в ответах AI
Когда AI-система выполняет RAG-запрос в реальном времени, скорость — это не опция, это требование.
Для сайтов, работающих на серверах Nginx, есть конкретный криминалистический сигнал, который показывает, когда ваша инфраструктура проваливает этот тест, детализирует Джейми Индиго.
В этих сценариях реального времени AI-бот действует от имени пользователя и ждать не может.
Решает только ваш TTFB.
Если ваш сервер слишком медленно отвечает, LLM просто забивает и закрывает соединение.
И это не тихий провал.
Эта прерванная попытка логируется как код состояния 499 Client Closed Request.
Вам нужно работать со своими инженерами по надежности сайта (SRE), чтобы мониторить именно эти ошибки.
Отслеживание кодов 499 позволяет точно определить, когда и где время ответа вашего сервера становится прямым узким местом, из-за которого вы теряете ценные цитирования в AI-ответах и пользовательский трафик, который за ними следует.
#ServerResponse #LogFileAnalysis #RAG
@
Пушки — в @
Читать полностью…
Mike Blazer
18 December 2025 21:00
Семантические коконы мертвы ))
@
Пушки — в @
Читать полностью…
Mike Blazer
18 December 2025 12:10
Фреймворк RISE приоритизирует SEO-задачи и находит точки роста в энтерпрайзе
На огромном enterprise-сайте с миллионами страниц вы не можете позволить себе застрять в цикле аудитов и "хаотичных телодвижений в SEO".
Это как быть врачом в переполненной реанимации; нужно проводить триаж.
Вы должны сфокусироваться на том, что реально продвинет бизнес вперед.
Для этого мы строим весь наш подход через фреймворк под названием RISE, подробно рассказывает Трэвис Таллент.
RISE расшифровывается как Radius/Reach (Радиус/Охват), Intent (Намерение), Scale (Масштаб) и Execution (Исполнение).
Это процесс, который переключает вас с разрозненных оптимизаций на хорошо отлаженную машину.
Первое — `R` (Radius/Reach), где мы оцениваем масштаб возможностей.
Мы начинаем с анализа брендовых и небрендовых запросов, а затем наносим на карту все небрендовые возможности по всему пути пользователя — от обнаружения до рассмотрения, конверсии и лояльности.
Затем мы накладываем на эту карту данные о видимости конкурентов, чтобы найти точные гэпы.
Для одного клиента с 61 миллионом страниц этот процесс показал, что они доминировали на поздних этапах, но их просто рвали на этапе обнаружения.
Это и стало нашим первоначальным фокусом.
Далее — `I` (Intent).
Как только мы знаем, где находится возможность, мы накладываем данные об аудитории, чтобы понять, на кого мы нацелены и, что крайне важно, где еще они проводят время.
Если ваша аудитория плотно сидит на Reddit, YouTube или LinkedIn, ваша стратегия должна выходить за рамки вашего основного сайта, чтобы встретить их на этих платформах.
Это приводит нас к `S` (Scale).
После определения нескольких высокоценных возможностей встает вопрос, как их эффективно реализовать.
Мы используем модель RISE для приоритизации, вычисляя оценку по формуле Охват x Влияние x Уверенность / Усилия.
Это заставляет подходить к делу на основе данных.
Для одного бренда мы обнаружили, что, хотя мультимедийный контент предлагал огромный потенциальный импакт, требуемые усилия были колоссальными.
Оценка RISE ясно дала понять, что фокус на масштабируемом текстовом контенте был более приоритетной инициативой.
Цель — определить автоматизируемые, высокоэффективные задачи.
Вместо того чтобы фиксить одну внутреннюю ссылку на одной странице, мы нашли проблему с внутренней перелинковкой на всем сайте и написали скрипт, чтобы решить ее сразу на тысячах страниц.
Наконец, `E` (Execution) связывает все воедино, согласовывая действия со всеми стейкхолдерами в рамках квартального стратегического фреймворка.
Такой подход превращает SEO из изолированной активности в просчитанный бизнес-план.
Для того сайта с 61 миллионом страниц этот переход от хаотичных действий к оркестрованной стратегии привел к 400% росту оптимизированного трафика и сделал их самым цитируемым брендом в их вертикали в результатах AI-поиска.
#Strategy #Enterprise #Audits
@
Пушки — в @
Читать полностью…
Mike Blazer
17 December 2025 15:05
Фреймворк "Impact Score" фильтрует мусорные ссылки с накрученным DR
Поработав с бесчисленным количеством клиентов — от агентств до инхаус-команд — я видела один и тот же паттерн: они попадали в ловушку пузомерок, не понимая, что такое действительно хорошая обратная ссылка.
Моей целью было создать способ объяснить им, что цель ссылки — не просто перелинковка или буст DR; это получение реального трафика и конверсий.
Вот почему я разработала Impact Score, фреймворк, призванный сместить фокус на более качественную оценку ссылок, рассказывает Тамара Новитович.
Это не железная математическая метрика, а стратегический план для оценки ссылок на основе шести ключевых факторов: реферальный трафик, вовлеченность, конверсии, контекст, релевантность и поисковый интент.
Фреймворк разделен на две четкие фазы:
1. Анализ перед публикацией: Прежде чем ссылка будет размещена, вы должны оценить ее потенциал на основе контекста и релевантности. Это самые важные опережающие индикаторы, поскольку именно они создают возможность для ссылки приносить вовлеченность и конверсии в будущем. Эта часть все еще в основном ручной процесс, требующий вашего собственного суждения, хотя можно использовать LLM для анализа контента на тематическое соответствие.
2. Отслеживание после публикации: Как только ссылка размещена, вы отслеживаете итоговые метрики: фактический реферальный трафик, вовлеченность пользователей и конверсии, которые она генерирует.
Используя этот фреймворк, вы начнете видеть, какие бэклинки приносят ощутимую бизнес-ценность, а какие просто накручивают цифры.
Это позволяет вам выстроить повторяемый процесс для выявления высокоэффективных возможностей и отказа от бесполезных размещений.
#LinkEquity #SearchIntent #Strategy
@
Пушки — в @
Читать полностью…
Mike Blazer
17 December 2025 08:15
Массовые 301 редиректы на главную при чистке контента убивают ссылочный вес
Для сайтов, страдающих от раздутого контента, что видно по большому количеству страниц в статусе "Просканировано, не проиндексировано", систематический аудит контента — это Подтвержденная, но рискованная стратегия восстановления.
Огромное число неиндексируемых страниц — в некоторых случаях более 90% всех статей на сайте — является прямым сигналом, что авторитета сайта не хватает для поддержки такого объема контента.
Критически важно понимать, что распространенная практика выпиливания неэффективных страниц с последующим массовым 301 редиректом на главную — это провальная тактика.
Такой подход сливает впустую весь существующий ссылочный вес и рискует быть помеченным как манипулятивная схема, принося больше вреда, чем пользы.
Правильный протокол — это дотошный аудит по каждому URL перед удалением любого контента.
Схема действий требует сбора данных по эффективности из GSC, ссылочных профилей из инструментов вроде Ahrefs или Semrush и метрик вовлеченности из платформ аналитики.
Эти данные ложатся в основу стратегического выбора:
— Объединять: Контент, нацеленный на одинаковые ключи или пересекающийся по интенту, нужно слить в одну, авторитетную статью. Более слабые страницы затем удаляются и 301 редиректом направляются на новый, объединенный ассет.
— Обновлять: Страницы на релевантные темы со слабым контентом нужно помечать для расширения и переписывания, а не удаления.
— Редиректить: Устаревший, но все еще релевантный контент, например, статья о ежегодном событии, должен быть перенаправлен на самую свежую версию.
— Удалять: Удалять следует только те страницы, у которых нулевой трафик, нет ценных бэклинков и нет стратегической релевантности.
Исполнение плана по редиректам имеет первостепенное значение.
Редиректы должны указывать на наиболее семантически релевантную страницу, чтобы правильно передать ссылочный вес.
Если близкой по смыслу страницы не существует, правильный технический ответ — отдать 404 код.
Хорошо оформленная 404 страница, которая помогает пользователю в навигации, предпочтительнее нерелевантного редиректа.
После аудита всю генерацию нового контента следует поставить на паузу.
Ресурсы нужно перебросить на получение высокоавторитетных внешних бэклинков, чтобы устранить основной дефицит авторитета, и на укрепление внутренней перелинковки для поддержки новой, отточенной структуры контента.
https://www.reddit.com/r/SEO/comments/1od7mp0/need_expert_level_advice_on_seo_before_deleting/
#Audits #Pruning #Redirects
@
Пушки — в @
Читать полностью…
Mike Blazer
16 December 2025 12:10
Жесткий QDP-фильтр для новых URL спасает краулинговый бюджет и PageRank
Создание новой страницы под каждую вариацию запроса — критическая ошибка, которая размывает сигналы ранжирования вашего сайта, в первую очередь PageRank.
Чтобы избежать раздувания индекса и консолидировать авторитет, нужно внедрить жесткий фреймворк для принятия решений о том, когда новый URL оправдан.
Фреймворк QDP – Query Deserves Page дает четкий тест.
Новую страницу нужно создавать, только если целевой запрос соответствует как минимум трем из следующих четырех критериев:
1. Запрос имеет высокий поисковый объем.
2. Запрос включает сущности, которые явно отличаются от существующего контента.
3. Запрос имеет низкое семантическое сходство с существующими страницами.
4. Запрос является частью понятного, масштабируемого паттерна.
Если тема или атрибут сущности не проходят QDP-тест, они не заслуживают отдельного URL.
Вместо этого применяйте концепцию PoS (Page or Segment).
Она диктует, что контент нужно создавать как четко определенный сегмент внутри более широкой, уже существующей страницы.
Например, второстепенная слот-игра без поискового спроса не должна быть отдельной страницей-обзором, а должна стать разделом в листикле типа "Best Egyptian-Theme Slot Games".
Этот подход напрямую совпадает с тем, как работают поисковики.
Google оценивает и статистику по запросам, и статистику по документам — такую как PageRank, размер кластера и сходство словаря, — чтобы определить, нужен ли новый индекс, а следовательно, и новый URL.
Используя модель PoS для тем с меньшей ценностью, вы снижаете затраты краулеров на обход, консолидируете сигналы ранжирования на меньшем количестве мощных URL и избегаете санкций за тонкий контент.
https://seobymarta.com/blog/topical-authority-in-the-casino-industry-interview-koray-tugberk-gubur/
#TopicalAuthority #URLStructure #ContentStrategy
@
Пушки — в @
Читать полностью…
Mike Blazer
15 December 2025 15:05
Разметка H5 и H6 помогает LLM правильно нарезать контент на чанки
Чтобы отстроиться от массы стандартного веб-спама, нужно проанализировать, что эти автоматизированные, мусорные сайты стабильно не делают.
У них почти никогда нет рабочего номера телефона, а структура контента ленивая, указывает Алехандро Мейерханс.
Именно здесь вы можете создать незаметные, но мощные сигналы для дифференциации.
В то время как большинство людей останавливаются на H3 или, может, H4, внедрение тегов H5 и H6 — это то, чего нет практически ни на одном спам-сайте.
Их наличие — простой, нестандартный сигнал траста.
В контексте AI SEO у этой практики есть прямое функциональное назначение.
Мы знаем, что LLM делают запросы в реальном времени и разбивают контент на чанки, чтобы сформулировать ответы, и заголовки — самый простой способ для них определить, где должен начинаться новый чанк.
Когда вы используете более глубокие теги, например H5 перед списком буллет-поинтов, вы должны делать это в правильной каскадной последовательности (H1 -> H2 -> H3 и т.д.).
Этим вы говорите AI, который будет "читать по чанкам" ваш контент, что именно этот раздел он должен использовать для очень длиннохвостого запроса.
Вы оптимизируете свой контент для парсинга LLM, по сути, создавая более мелкие и точные чанки, которые можно напрямую смапить на очень специфические вопросы пользователей.
#HeaderTags #Chunking #GEO
@
Пушки — в @
Читать полностью…
Mike Blazer
15 December 2025 08:15
Сквозняк в футере на 15 000 ссылок перебивает контекстную релевантность
Когда сравниваем внутренние ссылки, критически важно разделять качество контекста и голый объем.
Судя по нашим тестам, навигационные ссылки — те, что в сайдбаре, футере или хлебных крошках — дают меньше выхлопа, чем контентные ссылки в пересчете один к одному, утверждает Клинт Батлер.
Причина в контексте: ссылка в тексте позволяет заюзать точечный анкор, будь то точное вхождение, частичное или сущности, тогда как навигационные ссылки обычно используют общие термины, не привязанные к теме.
Однако сравнение один к одному — это ловушка.
Ссылка в футере, проставленная на всем сайте, по своей сути мощнее одной-единственной ссылки в контенте, потому что генерирует огромное количество линков — по одному с каждой страницы сайта.
И этот чистый объем создает сигнал, который может перебить более низкую контекстную релевантность каждой отдельной ссылки.
В тесте, который мы с Тедом проводили, мы добавили 15 000 внутренних ссылок на одну страницу, используя только футер.
Одного этого хватило, чтобы затолкать страницу в середину второй страницы выдачи по конкурентному запросу.
Это доказывает, что, хотя одна контентная ссылка контекстуально круче, большой объем сквозных ссылок можно использовать как дубину для получения серьезного веса в ранжировании.
#Interlinking #LinkEquity #PageRank
@
Пушки — в @
Читать полностью…
Mike Blazer
12 December 2025 15:05
Мир, в котором мы живем.
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
12 December 2025 08:15
Дропы, вылетевшие из индекса, сохраняют ссылочный вес, если их бэклинки все еще живы
Консенсус в комьюнити подтверждает: покупка дропов, даже тех, что были неактивны два-три года, — все еще рабочая тактика для использования накопленного SEO-авторитета.
Успех этой стратегии зависит не от возраста домена или его статуса в индексе, а от текущего качества и индексации его бэклинков.
Процесс восстановления нормально проверенного домена может занять от нескольких недель до нескольких месяцев.
Ключевое требование — жесткая проверка домена несколькими тулзами.
Схема такая: юзаем тулзы вроде Ahrefs, SEMrush и Majestic, чтобы проанализировать ссылочный профиль, смотрим на количество живых доноров и убеждаемся, что ключевые метрики типа Trust Flow и Citation Flow в норме.
Параллельно надо чекать Wayback Machine, чтобы изучить историю контента и использования домена и отфильтровать все, что раньше юзалось под спам.
Также говорят, что для успеха с современными алгоритмами критически важно брать домен с высокой тематической релевантностью новому проекту.
Главный спорный момент — жизнеспособность доменов, которые годами были полностью выпилены из индекса.
Большинство считает, что долгий период вне индекса убивает почти всю мощь домена для ранжирования.
Однако есть и заслуживающий доверия контраргумент: вылет из индекса — это не смертельный косяк.
Согласно этой точке зрения, домен вернется в индекс и восстановит свой авторитет, если его бэклинки все еще индексируются Гуглом.
Это восстановление зависит от конкретной реализации: нужно построить на дропе новый, богатый контентом сайт, чтобы размещать новые ссылки, так как эффективность этого метода для прямых 301 редиректов не подтверждена.
https://www.blackhatworld.com/seo/expired-domains-experiences.1762418
#ExpiredDomains #LinkEquity #Backlinks
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
11 December 2025 15:05
listicle.com — простая фришная тулза, чтобы находить листиклы и упоминания бренда.
#Tools #BrandMentions #LinkBuilding
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
11 December 2025 08:15
Жесткие SEO-силосы больше не гарантируют рост позиций
Прямое влияние на ранжирование от внедрения жестких сило-структур теперь является методикой, которую активно обсуждают и у которой падает выхлоп, особенно для небольших сайтов.
Эта тактика в основном считается задачей с низким приоритетом, а ее основная ценность сместилась с прямого фактора ранжирования на вспомогательный инструмент для улучшения пользовательского опыта (UX), эффективности краулинга и организации контента на крупных сайтах.
Для небольших сайтов в диапазоне 50-100 страниц жестко выстроенная архитектура-силос показывает практически такой же эффект для ранжирования, как и слабо организованный блог с сильными контентными кластерами.
Гугл стал лучше понимать контекст и семантическую релевантность, что уменьшило его зависимость от строгих URL-структур как основного сигнала тематического авторитета.
Хотя логичная архитектура сайта по-прежнему полезна, ее роль теперь вторична по отношению к качеству контента, ссылочному весу и демонстрации экспертности.
Более гибкая модель "hub and spoke" или pillar page, где основная страница-хаб ссылается на 5-10 связанных постов, теперь считается более эффективным и естественным способом достижения тех же целей без жесткости традиционных силосов.
Этот подход фокусируется на создании сильной внутренней перелинковки между тематически релевантными материалами, которую поисковики могут интерпретировать без необходимости в строгой иерархической структуре папок.
Хотя большинство доказательств влияния — неофициальные, некоторые кейсы предполагают незначительные, но долгосрочные плюсы.
На нишевых сайтах до 100 страниц целенаправленная сило-структура, по наблюдениям, дала немного более сильную индексацию и лучшую среднюю позицию со временем.
В то же время, более значительные результаты от сплит-тестов были зафиксированы на крупных сайтах (от 400 страниц), где двухуровневая сило-структура помогает управлять краулинговым бюджетом и усиливать тематическую релевантность в рамках большой контентной базы.
Для таких крупных сайтов силосование остается валидной организационной стратегией, но это уже не та фундаментальная тактика ранжирования, какой она была раньше.
https://www.blackhatworld.com/seo/are-silo-structures-still-worth-the-effort.1728975
#Siloing #TopicalAuthority #Interlinking
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
22 December 2025 12:10
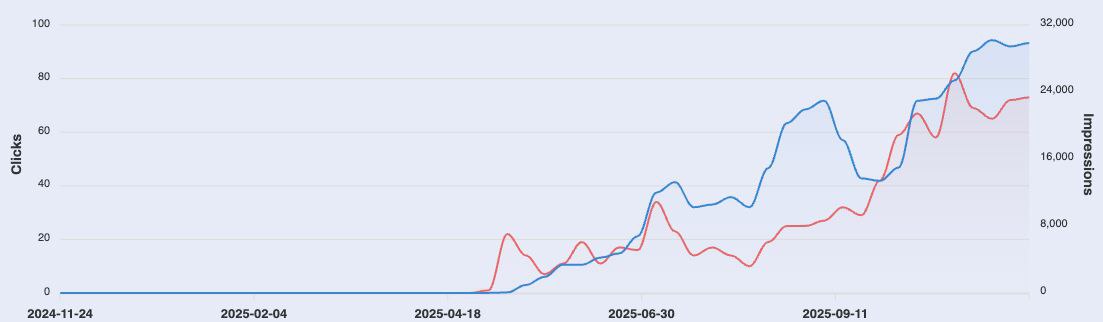
Мы 6 месяцев тестировали AI-контент против написанного людьми (SEO и GEO) — и результаты реально шокирующие, пишет Эндрю ван Россенберг.
В апреле этого года мы начали инвестировать в SEO и GEO.
На старте: ноль посетителей, нет блога, нет органики.
С тех пор мы проводили довольно прямолинейный тест:
— Мы написали 28 лонгридов "ручками", заточенных под очень специфические запросы нижнего этапа воронки (bottom-of-the-funnel).
— Мы также опубликовали 192 сгенерированных ИИ поста для верхнего этапа воронки (top-of-the-funnel), используя одну тулзу (имен называть не будем).
Разница в результатах... мягко говоря, шокирует.
— Посты, написанные людьми: 722 клика и 300,154 показов.
— AI-контент? 9 кликов и 9,682 показов.
Люди, которые в итоге бронируют у нас встречи (1-3 в неделю), часто говорят, что нашли нас через LLM, и каждый раз упоминают конкретную статью — одну из тех, что написаны вручную.
Мы не уверены на 100%, что именно дает такую разницу.
— Может, качество.
— Может, то, как Гугл относится к AI-контенту.
— Может, AI-посты слишком общие (top-of-funnel).
— А может, наши рукописные статьи просто топчик.
В любом случае, ясно одно: качество все еще бьет количество.
Но хотелось бы докопаться до точной причины.
#AIContent #ContentStrategy #Experiments
@
Пушки — в @
Читать полностью…
Mike Blazer
21 December 2025 10:07
Неделя №9 в @ — всё.
В паблике было тихо? Это потому, что вся жара происходила внутри.
Мы разбирали темки, которые слишком опасны и профитны, чтобы их разглашать. 220+ подписчиков PRO уже в курсе, как меняются правила игры.
Чек-лист упущенных возможностей:
1. Зомби-технология на 30% CTR: Фреймворк, который индустрия похоронила, но топы втихую используют для программного захвата выдачи.
2. "Отмывание" ссылочного веса: Загадочный редирект, который умеет отсекать "токсичность" донора, передавая на ваш сайт только чистый траст (эксперты в тупике).
3. Бэкдор в Knowledge Graph: Как получить граф знаний в США, используя хитрую лазейку.
4. Pop-Under траф снова в игре: Почему этот мусорный трафик убивает позиции, но идеально подходит для одной специфической задачи (это не накрутка).
5. Алхимия доменов: Как заставить AI считать ваш бренд точным вхождением ключа (EMD), используя "векторную магию" символов.
6. Вы невидимы для AI: Новый фреймворк показал, почему Google вас видит, а Perplexity — полностью игнорирует (и как это измерить).
7. Атака "Очистка списка": Изощренный метод негативного SEO путем сжигания вашего краулингового бюджета в ноль.
8. Математическая ошибка: Тест опроверг главную фобию сеошников — действие, которое по логике должно "размывать" вес страницы, на самом деле его умножает.
9. Социальное самоубийство: Скрытый триггер в E-E-A-T, из-за которого Google считает вашу компанию мертвой (хотя сайт работает идеально).
10. **Слив поведенческих одной строкой:** Критическая ошибка в верстке ссылок, которая искусственно обрубает поведенческие метрики ваших страниц (проверьте свой сайт прямо сейчас).
Можно бесконечно анализировать прошлое. Ребята в PRO создают будущее.
Инструменты для роста — внутри. Отговорки — снаружи.
Действуйте.
Читать полностью…
Mike Blazer
19 December 2025 15:05
ЛОЛ
@
Пушки — в @
Читать полностью…
Mike Blazer
19 December 2025 08:15
Метод «Чистой комнаты» точно замеряет передаваемый вес одного бэклинка
После дохрена провальных тестов, зашумленных кривыми данными, я разработал финальную методологию, как изолировать и замерить реальный выхлоп от одного-единственного бэклинка, детализирует эксперт.
Весь протокол заточен под создание "чистой комнаты", где можно отследить одну переменную без всяких помех.
Для этого придется железно соблюдать ряд условий.
Во-первых, моя базовая гипотеза для эффективной ссылки требует выполнения трех условий: домен-донор должен передавать вес, ссылающаяся страница — не быть сиротой, и страница должна быть в индексе Google.
Чтобы это протестировать, надо выбрать целевой URL, где один-единственный ключ ранжируется между 50-й и 100-й позицией.
Это гарантирует, что есть огромный потенциал для роста, и не придется бодаться в волатильном топ-20.
Критически важные ограничения для тестовой среды следующие:
1. Целевой URL должен иметь ноль существующих бэклинков.
2. Ключевой момент: надо прочекать через Ahrefs, что как минимум у 50% урлов, ранжирующихся выше вашего целевого, тоже нет бэклинков.
Такой сетап гарантирует, что вы работаете в выдаче с низкой конкуренцией по бэклинкам, где появление одной новой ссылки дает чистый и измеримый сигнал.
Любое отклонение от этих правил херит весь тест, потому что вносит слишком много переменных.
#Backlinks #Experiments #LinkEquity
@
Пушки — в @
Читать полностью…
Mike Blazer
18 December 2025 15:05
Блок FAQ из одного вопроса с жесткой структурой захватывает фичерд сниппеты
Забудьте про традиционный подход с размещением нескольких коротких вопросов на странице; эта модель неэффективна для получения видимости.
Я выяснил, что на каждой странице должен быть только один, но исчерпывающий FAQ, утверждает Брюс Клей.
Это не для простых информационных запросов типа часов работы, а для сложных вопросов, требующих развернутого ответа.
Эту модель можно увидеть внизу всех постов в моем блоге.
Формат строгий и не обсуждается.
Ответ должен быть самодостаточным блоком из пяти или более абзацев, который полностью закрывает вопрос пользователя.
Критически важно, чтобы он также включал практический чек-лист с описанием, как реализовать решение.
Недавно я провел прямой A/B тест, где одна статья была опубликована без этой специфической структуры FAQ, и она показала себя заметно хуже, чем статьи с ней.
Я твердо убежден, что этот развернутый формат с одним вопросом работает как мощный сигнал для поисковиков, говоря им, что ваша страница достойна фичерд сниппета.
#FeaturedSnippets #ContentOptimization #ABTesting
@
Пушки — в @
Читать полностью…
Mike Blazer
18 December 2025 08:15
Внедрение Speculation Rules API дает нулевой TTFB и мгновенный LCP
Данные кейса от Etsy показывают, что используя Speculation Rules API для предзагрузки по наведению курсора, они добились нулевого Time to First Byte (TTFB) для переходов вплоть до 45-50-го перцентиля, детализирует Барри Поллард.
Это фактически убирает время ответа сервера как основной баттлнек для Largest Contentful Paint (LCP), что дает огромное преимущество перед традиционной оптимизацией.
Действие prefetch в этом API мощнее, чем устаревший <link rel="prefetch">, так как он может держать даже некэшируемые документы во временном кэше в памяти до пяти минут, тогда как старый метод работает только для ресурсов, кэшируемых по HTTP.
Есть целый спектр вариантов внедрения: от консервативных до агрессивных.
На консервативном конце, кейс Shopify показал, что даже запуск правил спекуляции по клику или mousedown дал стабильное улучшение на 120-180 миллисекунд по TTFB, First Contentful Paint (FCP) и LCP для всех пользователей на всей их платформе.
На агрессивном конце, Scalemates.com использовал pre-render и добился медианного LCP всего в `404` миллисекунды.
Сам Google Поиск использует многоуровневую стратегию: агрессивно предзагружает два верхних органических результата сразу при загрузке SERP и откладывает остальные до наведения курсора пользователем, балансируя использование ресурсов с вероятностью клика.
Однако эта мощь несет в себе и серьезные риски, которые нужно купировать.
Спекулятивные загрузки могут увеличить нагрузку на сервер и расходы на CDN, впустую тратить трафик пользователя и приводить к завышенным показателям аналитики или показов рекламы, если ваши провайдеры не поддерживают API.
Что еще опаснее, они могут непреднамеренно триггерить GET-запросы, изменяющие состояние, например, ссылки "add-to-cart" или "logout", или отдавать юзерам устаревший контент, если все настроено криво.
Ключевой принцип, который нужно запомнить: `prefetch` всегда менее рискован, чем `pre-render`.
Управлять этими рисками можно с помощью выражений where в ваших правилах, чтобы явно исключить проблемные URL, например, содержащие /wp-admin/ или add-to-cart.
#LCP #TTFB #SiteSpeed
@
Пушки — в @
Читать полностью…
Mike Blazer
17 December 2025 12:10
Google выкидывает страницы из индекса через 90 дней без подпитки внешними ссылками
Из моих собственных тестов я вижу стабильный паттерн: я могу загнать новые страницы в индекс без каких-либо внешних ссылок, но через пару месяцев они часто просто исчезают с радаров, делится инсайтом Чарльз.
Это вообще не редкость, когда такие страницы полностью вылетают из индекса.
Это наблюдение привело меня к гипотезе об алгоритмическом жизненном цикле страницы в индексе Google.
Внешние ссылки теперь, похоже, являются меньшим сигналом для первичной индексации и более критичным сигналом для удержания в индексе.
Моя теория в том, что Google работает по модели с испытательным сроком.
Он говорит: "Окей, мы проиндексируем тебя сегодня", предоставляя странице временную видимость.
Однако, если эта страница не сможет получить ни одной подтверждающей dofollow ссылки в течение следующих трех месяцев, она считается неважной и выпадает из индекса.
Первоначальное включение в индекс — это, по сути, ловушка, если вы не готовы ко второй фазе.
Страница получает шанс, но ее дальнейшее выживание зависит от получения внешнего подтверждения.
Вам нужно обеспечить, чтобы ваши страницы получали ссылки, так как это, по-видимому, основной фактор, который определяет, останутся ли они в индексе надолго.
#Indexing #Backlinks
@
Пушки — в @
Читать полностью…
Mike Blazer
16 December 2025 15:05
Накачка тренда под уже занятый ТОП-1 гарантирует 100% перехват трафика
Бренды постоянно делают все наоборот.
Взять, к примеру, кампанию Zara "pink jeans" — они заплатили целое состояние инфлюенсерам, чтобы создать массовый тренд, и успешно утроили поисковый спрос на общий термин "pink jeans".
Проблема была в том, что когда люди шли в Google, Zara и близко не было на первой странице.
Они создали тренд и слили весь органический трафик и продажи прямиком своим конкурентам, отмечает Кэрри Роуз.
Я постоянно видела эту схему и поняла, что мы можем просто развернуть весь процесс в обратную сторону, чтобы гарантированно забирать ценность, которую мы создаем.
Вместо того чтобы ждать тренд, на который нужно реагировать, или создавать тренд, по которому мы не ранжируемся, мы создаем его для ключевого слова, которое мы уже держим.
Это простой, но мощный переворот традиционной модели PR/инфлюенсеров.
Вот точный процесс, который мы заюзали с Pretty Little Thing:
1. Определить своих победителей: Мы выгрузили полный список всех продуктов и ключевых слов, по которым мы уже были на #1 в Google.
2. Выбрать цель: Из этого списка мы выбрали "halterneck wrap top". Ключевым фактором здесь был инвентарь и выбор; у нас было 405 различных моделей на складе, так что мы знали, что сможем удовлетворить спрос, который собирались создать.
3. Сфабриковать тренд: Мы дали этот топ небольшой, целевой группе всего из 25 инфлюенсеров в TikTok. Они снимали танцы, обзоры и стилизовали продукт, создавая первоначальный хайп.
4. Усилить с помощью `PR`: Затем мы протолкнули эту историю в СМИ, подавая ее как "трендовый вирусный топ из TikTok". Он появился в Cosmo, Daily Mail и HypeBae, закрепив тренд в сознании общественности.
Поскольку мы уже занимали позицию #1 по запросу "halterneck wrap top", мы забрали 100% нового поискового спроса.
Поиски по этому термину взлетели на 841%, и мы распродали абсолютно все топы.
Это привело 46 000 человек на страницу этого конкретного продукта органически всего за 24 часа, и все это с нулевыми затратами на платную рекламу.
Это готовый плейбук, который можно повторять снова и снова, чтобы превратить существующее SEO-доминирование в гарантированные продажи.
#DigitalPR #Strategy #Ecommerce
@
Пушки — в @
Читать полностью…
Mike Blazer
16 December 2025 08:15
Промпт-инъекция заставляет LLM слить свои внутренние факторы ранжирования
Самый большой секрет в оптимизации под AI заключается в том, что вы можете напрямую спросить большую языковую модель (LLM) объяснить свою логику, потому что это не поисковик, который скрытничает.
Я использую конкретный промпт, чтобы вытащить алгоритм ранжирования, который LLM использует для данного запроса, раскрывает Тед Кубайтис.
Вы буквально говорите ей:
"Напиши список из топ-20 [ваша тема] и обоснуй позицию в рейтинге, указав типы упоминаний и сигналов, которые ты использовала для ранжирования каждого пункта".
Это заставляет модель рассказать вам об алгоритме, который она применила, чтобы расставить результаты в таком порядке.
Когда я прогнал это для "топ-20 SEO-инструментов", LLM сначала перечислила факторы, которые она учитывала, а затем выдала таблицу с рейтингами и обоснованиями.
SEMRush оказался на первом месте, потому что он "очень часто появляется на первом месте в подборках лучших инструментов".
У Ahrefs были "сильные упоминания во многих списках лучших инструментов".
Дальше по списку Surfer "часто цитировался в списках инструментов для оптимизации контента", но не обязательно на верхних позициях.
Это показывает, что включение в множество таких статей-подборок или "лучших из лучших" сейчас является мощнейшим фактором для AI, и это можно и нужно абьюзить.
Качество получаемой информации напрямую зависит от промпт-инжиниринга.
Чем больше усилий вы вкладываете в промпт, тем лучше информацию вы получаете.
Например, можно попросить, чтобы сигналы были вынесены в отдельный столбец таблицы с оценкой или показателем для каждого.
Этот процесс нужно повторять для каждой отдельной LLM, на которую вы нацелены — вы должны прогнать это на Gemini, чтобы понять логику Gemini, и на ChatGPT для логики ChatGPT, так как они ведут себя по-разному.
Не могу отделаться от мысли, что в конечном итоге им придется скрывать эту логику, чтобы избежать эксплуатации, так что сейчас самое время этим пользоваться.
#LLM #GEO #PromptInjection
@
Пушки — в @
Читать полностью…
Mike Blazer
15 December 2025 12:10
Markdown-клоакинг обходит корпоративную бюрократию и ускоряет тесты контента
Забудьте про миф, что отдача упрощенной markdown-версии страницы AI-краулерам улучшает позиции; это пустая трата ресурсов, так как современные RAG-пайплайны и так эффективно парсят хорошо структурированный HTML, утверждает Алекс Халлидей.
Реальный, "недокументированный" эксплойт для клоакинга на основе юзер-агента — это обход внутренней корпоративной политики на страницах с высокими ставками, где любое изменение превращается в политический ад.
В крупных организациях продуктовый маркетинг, бренд и другие команды могут заблокировать любую попытку быстрой итерации контента.
Эта тактика создает стратегическую лазейку.
Используя Cloudflare worker или Vercel middleware, вы отдаете измененную markdown-версию страницы исключительно ботам с юзер-агентами типа GPTbot.
Политически заряженная, видимая пользователям HTML-страница остается нетронутой.
Эта "теневая" версия становится вашим частным полигоном, позволяя быстро итерировать изменения контента и тестировать гипотезы до успешных вариантов без единого митинга.
Как только у вас будут данные, доказывающие, что ваши изменения работают, вы можете использовать их как рычаг, чтобы продавить внедрение выигрышных модификаций на живую страницу, вооружившись доказательствами, а не мнениями.
Однако это не лишено риска.
Как только вы создаете расходящиеся пути для контента, вы закладываете потенциальные мины.
Хотя это и не определено явно для данного кейса, вы работаете в серой зоне, которая напоминает традиционный клоакинг и обманные практики.
Что еще важнее, вы рискуете серьезно запутать пользователя, если LLM процитирует текст из вашей версии только для ботов, а пользователь перейдет на страницу, где этого текста и в помине нет.
Это нужно менеджить как плотный, краткосрочный цикл тестирования, а не как постоянное разветвление контента.
#Cloaking #Experiments #Enterprise
@
Пушки — в @
Читать полностью…
Mike Blazer
13 December 2025 12:05
#8 неделя в @ — DONE.
Ушли глубоко в техничку и серые схемы - за что банят, если делать криво, и за что платят миллионы, если делать грамотно.
Вот темки, которые прошли мимо вас:
1. Как обойти DR80-гигантов на сайте с DR25: Забрать трафик у крупняков проще, чем отобрять конфету у ребенка (алгоритм требует этого, а вы не знали).
2. ChatGPT палит неудачников: Как увидеть сайты, которые AI *рассмотрел, но отверг* в последнюю секунду — и узнать точные критерии отказа.
3. Дыра в фильтрах трастовых сайтов: Тип файла, который обходит модерацию трастовых платформ и конвертит «хомяков» пачками (идеально для серых ниш).
4. Кейс "addicting games": как удаление переспама ключей уронило сайт с #1 за пределы топ-100 и как топы забирают SERP с 98,000 ключей
5. VIP-очередь для Googlebot: Эксплойт с приоритетами краулинга, который заставляет бота мгновенно индексировать даже самые "мертвые" URL.
6. "Отмывание" тематики дропа: Как заставить Google забыть старую тематику дропа и безопасно приклеить к новому домену.
7. Взлом Графа Знаний через браузер: Специальный тип URL, который принудительно связывает ваш бренд с нужными ключами прямо внутри Google Maps (без ссылок).
8. Угон бренда: Самая грязная схема перехвата брендового трафика, которая убивает репутацию конкурента в ноль, (пока вы зарабатываете).
9. Google не читает ваш текст: Почему сайты залетают в ТОП без смысла, чисто на математике распределения слов (и как подделать этот сигнал).
10. Это не HCU и не Spam Update: Скрытая техническая ошибка («петля смерти»), которая выглядит как жесткие санкции (но лечится за 5 минут).
Окно возможностей закрывается быстрее, чем вы думаете.
Перестаньте быть последним звеном в пищевой цепи. Быстрые съедают умных.
Либо вы первые, либо вы никакие.
Фиксируйте доступ, пока эти схемы еще живы.
Читать полностью…
Mike Blazer
12 December 2025 12:05
Как покупка одноплатника за $60 сэкономила мне $1200 в год (и это не предел).
Я получил очередное письмо в духе "Мы повышаем цены, чтобы дать вам больше ценности (читай: порадовать акционеров)", пишет Мэтт Лориц Холл.
Решил копнуть в сторону селф-хостинга и выяснил, что сейчас это проще пареной репы.
— Опенсорсные тулзы вроде Portainer упрощают управление докер-контейнерами.
— На Ютубе и Реддите есть мануалы вообще по любой теме.
— Claude и другие LLM делают дебаггинг не таким геморным, как раньше.
С Raspberry Pi за 60 баксов и нормальным инетом можно запустить опенсорсные аналоги почти любой платной подписки.
Airtable, Zapier, Quickbooks, Google Drive, Slack... у всего этого есть бесплатные селф-хостед альтернативы.
А Cloudflare Tunnels позволяют бесплатно и безопасно прикрутить свои домены к этим приложениям.
Даже "Малинка" не обязательна... можно все развернуть на Маке или ПК, если интернет стабильный.
(Ну или взять VPS за $6/мес).
Пока что экономлю $1400 в год.
Да, есть некоторые компромиссы, но по сути — настроил и забыл.
Я доволен.
У вас есть выбор.
Как говорит Стив Дотто: вы контролируете технологии, а не они вас.
#WebDev #Tools #Automation
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
11 December 2025 12:05
Сплит-тест 90 дней: Claude уделывает GPT по эффективности и вовлечению
Я провел жесткий 90-дневный сравнительный тест Claude и GPT-4 на 200 статьях (100 парных), пишет Ноэль Сета.
Чтобы изолировать AI-модель как единственную переменную, я ввел идентичные ограничения: одинаковые темы, промпты, живой редактор, график паблишинга и усилия по промоушену.
Операционная эффективность и уровень галлюцинаций
Пока GPT-4 дает х2 скорость генерации и лучше справляется со списками, он сыпется на точности.
Критическая точка трения вылезла в уровне галлюцинаций:
— `GPT`-4: 15-22%
— `Claude`: 8-12%
На глубоком фактчекинге 50 статей Claude выдал значительно меньше ложных клеймов, требующих фикса.
GPT-4 выплевывал больше объема (2,100 слов в среднем), но требовал резать воду на 20% статей.
Claude выдавал меньше (1,850 слов), требовал "добавить мяса" на 35% статей, но держал структуру и контекст чище.
Перформанс в ранжировании: Статистическая погрешность
Вопреки хайпу, выбор модели не оказал статистически значимого влияния на сырые позиции в SERP после редактуры человеком.
— `Claude`: 47% Топ-10 (Ср. поз: 12.3). Выход на 1 страницу: 52 дня.
— `GPT`-4: 43% Топ-10 (Ср. поз: 13.8). Выход на 1 страницу: 58 дней.
Рычаг Вовлечения и Конверсии
Там, где позиции были равны, метрики вглубь воронки топили за Claude из-за более естественного, менее формального тона.
— `Time on Page`: 3:42 (Claude) vs 3:18 (GPT-4).
— `Bounce Rate`: 58% (Claude) vs 62% (GPT-4).
— `Conversion Rate`: 3.2% (Claude) vs 2.9% (GPT-4).
Claude сгенерил 384 лида против 348 у GPT-4, разрыв в бизнес-импакте — 10%.
Скрытый ROI: Скорость редактуры
Решающий фактор для контент-команд — косты на зачистку.
— `GPT`-4: 51 минута правки на статью (Фокус: удаление шелухи, фикс флоу).
— `Claude`: 42 минуты правки на статью (Фокус: добавление глубины).
Выбор Claude экономил 9 минут на статью.
На выборке в 100 статей это аккумулировалось в 15 часов сэкономленного труда — эквивалент $750–$1,500 операционной экономии в зависимости от рейтов редактора.
Хотя подписка стоит одинаково ($20/мес), Claude снижает общую стоимость владения (TCO) за счет сокращения времени редактора.
Протокол деплоя
— Заряжайте `Claude` для контента, требующего живого тона, сложного контекста и строгой точности, чтобы снизить оверхед на редактуру.
— Заряжайте `GPT`-4 только когда сырая скорость и объем в приоритете над нюансами.
В сухом остатке: качество человеческой редактуры остается главным фактором ранжирования, но Claude дает более эффективный стартовый бейслайн.
#AIContent #Claude #ChatGPT
@
Но самое "мясо" — в @
Читать полностью…
Mike Blazer
10 December 2025 15:05
Незамаскированные UTM-метки сливают всю рекламную стратегию конкурентов
Огромная ошибка многих маркетологов — оставлять свои UTM-теги незамаскированными, что создает massive утечку данных, которую можно напрямую использовать для реверс-инжиниринга всей их платной воронки, раскрывает Рик Чебрика.
Библиотека рекламы показывает только креативы конкурента, но никогда не раскроет аудиторию, на которую они таргетируются.
Незамаскированные UTM-метки полностью обходят это ограничение.
Процесс — это чистый сбор разведданных.
Когда видите рекламу конкурента, кликните по ней и скопируйте полный URL назначения.
Вставьте эту строку прямо в LLM типа ChatGPT с промптом: "сделай реверс-инжиниринг воронки на основе UTM-меток в этом URL".
Поскольку они не маскируют параметры, UTM-метки часто раскрывают всё: платформу, адсет и даже конкретный таргетинг на аудиторию, например, "1% lookalike audience".
Теперь у вас есть их стратегия для верха воронки, их креативы и их лендинг — три компонента, необходимых для копирования.
Мы использовали именно эту методику, чтобы выходить на новые рынки и сокращать фазу обучения с месяцев до дней.
Совместив извлечение UTM с анализом долгоиграющей рекламы в библиотеке платформы, мы создали базовую кампанию, которая принесла более чем 10-кратный `ROI` в течение трех месяцев.
Люди думают, что это магия.
В реальности мы просто довольно хитрые.
Чтобы защититься от этого, вы должны маскировать свои собственные UTM-метки.
В рекламных платформах вроде Meta и TikTok настройте свои кастомные UTM-теги так, чтобы они ссылались на цифровой Campaign ID, а не на описательный Campaign Name.
По умолчанию большинство платформ подтягивает человекочитаемое название, что и является источником утечки.
Переключение на неописательный ID не позволит конкурентам использовать ваши же данные против вас.
#CompetitorAnalysis #GreyHatSEO #SEM
@
Но самое "мясо" — в @
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}