Mike Blazer
10 Apr 2025 15:05
Восприятие Google как рефералa, а не просто поисковой системы, полностью меняет подход к SEO.
Когда Google показывает сайт в поисковой выдаче, он фактически дает рекомендацию, аналогично тому, как работают академические цитаты.
Эта экономика цитирования в поиске работает по тем же принципам, что и академические ссылки — чем больше авторитетных источников цитируют работу, тем больше авторитета она получает.
Традиционное понимание реферального трафика подразумевает, что сайты ссылаются на другие сайты на основе заработанного доверия, отношений или авторитета.
Однако SEO-специалисты часто воспринимают позиции в Google как должное, а не как заработанную цитату.
Такая смена мышления предполагает, что вместо пассивной оптимизации в надежде на трафик, сайты должны активно зарабатывать свое место в поисковой выдаче.
Линкбилдинг обычно включает создание убедительных историй, выстраивание отношений и наращивание авторитета.
Применение такого же подхода к поисковой видимости означает, что к Google нужно относиться как к журналистам, отраслевым блогам или академическим коллегам — субъектам, которых нужно убедить в ценности контента.
Фокус смещается с простого ранжирования по ключевым словам на то, чтобы стать наиболее цитируемым источником по теме, демонстрируя экспертность, надежность и влияние.
В академическом мире часто цитируемые работы становятся фундаментальными источниками.
Аналогично в SEO, часто цитируемые источники обычно доминируют в поисковой выдаче.
По мере развития поиска с внедрением ИИ, zero-click выдачи и обновлений алгоритмов, одних только традиционных SEO-тактик будет недостаточно.
Успех в этой среде требует получения рекомендаций через авторитетность, а не только через техническую оптимизацию.
Отказ от термина "органический" поиск признает, что поисковая видимость зарабатывается активным участием в конкурентной экономике цитирования, основанной на доверии, а не является пассивным, естественным явлением.
https://notes.recollect.fyi/9RwdaTDB
@
Читать полностью…
Mike Blazer
10 Apr 2025 11:05
Можно ли обойти IT компании с бюджетом 10 000+/мес на SEO и занять ТОП?
Да, если повторить эту стратегию!
Кейс:
— Игроки в нише – крупные компании по разработке (150-250 человек), страницы существуют годами и накопили минимум 40-60 бэклинков
— Клиент – молодая компания до 50 человек (ограниченный бюджет на маркетинг и почти без линкбилдинга)
— Задача – выйти в ТОП по конкурентным коммерческим запросам
ЧТО СДЕЛАЛИ
Контент:
— Убрали канибализацию контента
— Вместо нескольких страниц (лендинг, статья, FAQ) оставили одну сильную
— Добавили FAQ для удержания информационного трафика на коммерческой странице
— Оптимизировали CTA
— Оптимизировали страницу под реальные запросы из США
Перелинковка:
— Перестроили логику перелинковки
— Перенаправили внутренний вес страниц на нужный лендинг
— Изменили анкор-листы, чтобы улучшить релевантность и кликабельность
Линкбилдинг:
— Для топа (еще не все запросы в ТОПе) хватило менее 20 новых линков (у конкурентов 40-60)
— Линк-инсерты
— Листиклы для получения реферального и AI трафика
Результаты:
— ТОП-3 по конкурентным запросам за 5 месяцев
— х5 органического трафика по коммерческим запросам при сравнении 90 дней до и 90 после
Бонус: Google начал ранжировать обновленный лендинг даже по информационным запросам.
Бонус 2: Удалось повторить это на еще одном кластере запросов.
@
Читать полностью…
Mike Blazer
09 Apr 2025 17:05
Простой прием - перенос локации в начало title-тегов - привел к впечатляющему росту органического трафика, несмотря на то, что позиции в выдаче немного снизились.
https://www.searchpilot.com/resources/case-studies/adding-location-to-start-of-title-tags-ctr
@
Читать полностью…
Mike Blazer
09 Apr 2025 13:10
Nofollow - это подсказка, а не директива!
Do-follow также является подсказкой, поскольку ссылки могут быть легко обесценены.
-
В доказательство этого, гляньте что пишет Чарльз Флоат:
У нас есть ссылка на главную страницу с Ahrefs.
Ссылка является NoFollow.
Мы уже ранжируемся по нескольким ключевым словам, связанным с Ahrefs.
На сайте есть 1 упоминание о Ahrefs.
(За скриншотами следуйте сюда)
@
Читать полностью…
Mike Blazer
09 Apr 2025 08:15
CuriousSEO:
Мы заметили странную проблему после редиректа домена приобретенной компании.
Корпорацию Б поглотила Корпорация А, и corporationb.com теперь редиректит на corporationa.com.
Однако, тайтлы Корпорации А в СЕРПах изменились и теперь отображают название бренда Корпорации Б.
Это произошло в двух разных случаях поглощения у разных клиентов.
На сайте Корпорации А нет упоминаний названия Корпорации Б.
Схема полностью корректна.
Может, старые бэклинки вызывают это, хотя на все них тоже настроены редиректы?
-
Джон Мюллер:
Вам нужно использовать доменное имя как запасной вариант в разметке schema.org.
Гугл почти всегда использует именно это.
Через некоторое время (год? не знаю) попробуйте снова использовать название компании.
-
CuriousSEO:
То есть вы предлагаете что-то вроде этого на данный момент?
{
"@": "https://schema.org",
"@": "Organization",
"url": "https://www.corporationa.com",
"name": "corporationa.com",
// ... другие свойства
}-
Джон Мюллер:
Да, как описано в
https://developers.google.com/search/docs/appearance/site-names#troubleshooting ("Укажите имя домена или поддомена в качестве запасного варианта") или даже в качестве следующего варианта, если замечаете, что система не подхватывает ни один из них.
Использование доменного имени должно сработать, конечно, оно не так красиво как "настоящее" название, но лучше, чем неправильное имя.
@
Читать полностью…
Mike Blazer
08 Apr 2025 15:05
Стив Джобс был одержим наймом "лучших людей".
Но как на самом деле распознать исключительный талант?
Вот 10 неочевидных сигналов для поиска высокоэффективных сотрудников:
1. Им не нужен менеджмент.
Стив говорил: "Лучшим людям не нужно управление".
Как только они знают цель, они сразу берутся за дело.
Спросите:
"Какое крутое достижение вы реализовали без указаний сверху?"
Слушайте про самостоятельность и находчивость.
2. У них загораются глаза, когда вы говорите о вашей миссии.
Джобс показывал кандидатам прототип Мака.
Если они не загорались энтузиазмом, он их не брал.
3. Они самоучки.
Стив нанимал людей, одержимых обучением.
Дипломы переоценены.
Спросите: "Какому навыку вы недавно научились сами — и почему?"
Исключительные люди никогда не перестают учиться.
4. Они терпели неудачи.
Серьёзные неудачи.
Настоящие таланты не боятся рисковать — и с треском проваливаться.
Стив ценил людей, способных подняться и стать сильнее.
5. Они вызывают полярные мнения.
Лучшие люди имеют твёрдую позицию.
Они яростно спорят — но меняют мнение, когда их переубеждают.
Стив обожал хорошие дискуссии.
6. Они художники, а не профессионалы.
Джобс хотел видеть людей, которые относились к своему делу как к искусству.
Именно они доводят, улучшают и совершенствуют до состояния "безумно крутого".
7. Они упрощают хаос.
Стив говорил: "Простое может быть сложнее сложного".
Исключительные люди превращают хаос в ясность.
Это их суперсила.
8. Они притягивают таланты.
А-игроки нанимают А-игроков.
Они как магниты для других исключительных людей.
9. Они одержимы деталями.
Детали имеют значение.
Джобс мог зациклиться на внутренностях продуктов — даже если их никто не видел.
Великие люди глубоко заботятся о мелочах.
10. Они стремятся к величию.
Высокоэффективные люди отказываются довольствоваться "достаточно хорошим".
@
Читать полностью…
Mike Blazer
08 Apr 2025 11:05
Google внезапно решил неправильно интерпретировать локализованные страницы веб-сайта — выбирая французскую версию как каноникал для немецкой, немецкую для испанской и так далее.
Естественно, неканонические версии выпали из индекса Google, что вызвало болезненное падение трафика.
Все эти страницы оказались в категории "Дубликат, Google выбрал другой каноникал, чем пользователь".
Поэтому я сделала то, что сделал бы любой сеошник: тройную проверку каноникал и hreflang тегов, пишет Ксения Демченко.
Они были абсолютно в порядке.
Так... что же на самом деле помогло?
Мы продублировали каноникал теги в HTTP-хидере (хотя они уже были правильно реализованы в HTML-коде и остались там).
Это вроде как противоречит рекомендациям, поскольку Google рекомендует использовать только один вариант.
Но в моём случае это сработало, и проблема исчезла навсегда.
@
Читать полностью…
Mike Blazer
07 Apr 2025 17:10
Как быть заметным одновременно в поисковиках и LLM (часть 2/2)?
LLM не видят слова, а видят эмбеддинги, причем сущности с похожими значениями располагаются ближе друг к другу.
Это помогает в обработке неоднозначности и сохраняет контекст в длительных разговорах.
Для видимости в LLM нам следует:
— Использовать язык, богатый сущностями
— Строить семантические связи через линкбилдинг
— Оптимизировать структурированные данные на основе сущностей
— Фокусироваться на семантическом поиске, а не только на ключевых словах
Косинусная близость
Когда LLM получает запрос, она вычисляет косинусную близость между эмбеддингом запроса и эмбеддингами сохраненного контента.
Более высокая косинусная близость означает более близкие эмбеддинги и более высокую вероятность выбора для генерации ответа.
Косинусная близость действует как показатель релевантности и помогает с устранением неоднозначности сущностей.
Она позволяет LLM понимать связанные сущности, даже если они не упоминаются напрямую.
Для увеличения косинусной близости:
— Укрепляйте кластеры сущностей, пиша о связанных концепциях
— Используйте естественный язык со структурированными данными
— Создавайте контент, отражающий кластеры с высокой близостью
— Включайте семантические вариации
Значимость сущностей
Значимость сущности указывает, какие сущности наиболее важны в контенте.
Когда ключевые сущности последовательно появляются в важных структурных элементах и поддерживаются семантически связанными терминами, они становятся высоко значимыми, улучшая косинусную близость с релевантными запросами.
Чтобы повысить значимость, стратегически структурируйте контент с сильными вступлениями, которые подчеркивают ключевые сущности, включайте детальные описания и усиливайте сущности, используя связанные термины везде с внутренними ссылками на релевантный контент.
Моносемантичность
Моносемантичность относится к словам или концепциям, имеющим единственное, однозначное значение в контексте.
Эта ясность облегчает обработку для LLM и увеличивает косинусную близость между эмбеддингами.
Для оптимизации моносемантичности:
— Укрепляйте кластеры эмбеддингов сущностей, упоминая связанные термины вместе
— Используйте разметку Schema для устранения неоднозначности
— Увеличивайте "плотность" контекста с более конкретной информацией
— Усиливайте внутреннюю перелинковку для закрепления взаимоотношений
Мультимодальная оптимизация
Семантическая структура применима и к мультимодальной видимости.
Косинусная близость работает для разных типов эмбеддингов (текст, изображения, видео).
Мультимодальный контент улучшает моносемантичность, увеличивает косинусную близость через усиление контекста, улучшает пользовательский опыт и соответствует тому, как люди обрабатывают информацию.
Оптимизируйте с помощью:
— SEO для изображений и визуального поиска
— Использования Schema разметки для мультимедийного контента
— Обогащения контента различными форматами медиа
Упоминания бренда и структурированные данные
Упоминания бренда важны не потому, что они напрямую повышают "авторитет", а потому что укрепляют позицию бренда как сущности в более широкой семантической сети.
Ценные упоминания контекстуально релевантны, появляются вместе со связанными сущностями и появляются в авторитетном, тематически релевантном контенте.
Структурированные данные остаются критически важными, даже если LLM не обрабатывают их напрямую.
Поисковые системы используют структурированные данные для понимания сущностей и отношений для Графов Знаний, которые влияют на обучающие данные LLM.
Структурированные данные помогают разрешить полисемию, улучшают семантическую близость для RAG-систем и питают AI Overviews.
В итоге, наличие сайта, оптимизированного для всего поискового пути и нескольких поисковых функций, создает основу для видимости в LLM, потому что такой подход соответствует тому, как LLM структурируют свои знания.
https://www.iloveseo.net/a-guide-to-semantics-or-how-to-be-visible-both-in-search-and-llms/
@
Читать полностью…
Mike Blazer
07 Apr 2025 15:05
Учебник для основателей бутстрап-проектов в $1 млн
Делай:
— провиди исследование рынка. Проверь, есть ли достаточный спрос (соцсети, отзывы или поисковый трафик)
— создавай MVP с помощью ноукода, бойлерплейтов, ИИ, форков или вайтлейблов
— когда накопишь достаточно знаний, перепиши с нуля используя код
— расти через соцсети, SEO и листинги
— когда получишь 100 платящих пользователей, забудь про рост
— сфокусируйся на том, чтобы сделать этих пользователей супер-счастливыми для запуска сарафанного радио
— когда сарафан заработает, переключись на масштабирование маркетинговых каналов
— найми людей, чтобы всё работало на автопилоте
— запусти новый продукт для той же аудитории
— делай перелинковку и бандлы продуктов
— улучшай маржинальность, используя одних и тех же людей (дизайн, поддержка, разработка) для обоих продуктов
— запускай директории как преимущество для привлечения дополнительного трафика
— направляй весь трафик на свои продукты, увеличивай продажи
— автоматизируй всё что можно, чтобы убрать людей из процесса
Не надо:
— не создавай второй продукт, пока первый не стал успешным
— не трать деньги на рекламу до PMF
— не двигайся медленно, потому что скорость инноваций - это 90% успеха
— не отдавай на аутсорс до получения тракшена (подтверждения жизнеспособности продукта на рынке)
— не думай, что количество фич важнее качества
— не рассчитывай на легкую прогулку
— не увольняйся с работы ради полного погружения, если у тебя нет сбережений на 5 лет
— не нанимай людей до получения тракшена
— не ищи читкоды и короткие пути
— не копируй других без существенных улучшений
— не делай B2C
— не делай одно и то же снова и снова, надеясь на лучший результат
Я делал то, о чём проповедую, говорит Джон Раш.
Жаль, что я не знал этого раньше и потратил десятилетие, делая неправильные вещи.
Это работает.
Я не знаю, сработает ли это у вас.
Не следуйте слепо; лучше используйте это, чтобы отточить свою мудрость и найти свой путь.
P.S. PMF, это Product-Market Fit - состояние, когда продукт полностью соответствует потребностям рынка и имеет стабильный спрос среди целевой аудитории.
@
Читать полностью…
Mike Blazer
07 Apr 2025 11:05
GeeksforGeeks получил ручник ...
Этот сайт имел почти 70 миллионов ежемесячного трафика по данным Semrush.
-
GeeksforGeeks: Статьи GeeksforGeeks пропали из поиска Google! 🚨
Недавно мы заметили, что статьи GeeksforGeeks не появляются в результатах поиска Google, из-за чего пользователям сложно получить доступ к нашему ценному контенту.
Мы хотим связаться с представителями Google, чтобы понять проблему и найти решение.
-
Geeks For Geeks следует придерживаться своего програмного контента - похоже, они решили, что могут писать обо всем на свете, и Google будет их ранжировать.
Скриншот 1, Скриншот 2
Они буквально штампуют контент типа - "Имя известного человека + все об их жизни, браке или детях".
Что случилось с обучающими програмными материалами?
Скриншот 3
-
Злоупотребление масштабированным контентом.
Намеренное или непреднамеренное.
Как запрос "how many kids does rihanna have" относится к сайту GeeksforGeeks?
Скриншот 4
-
Сейчас в индексе всего 10 их страниц.
-
Пострадали не только GeeksforGeeks, несколько других также получили ручные санкции 1 апреля.
@
Читать полностью…
Mike Blazer
06 Apr 2025 09:15
Субдомен субдомена субдомена субдомена
@
Читать полностью…
Mike Blazer
04 Apr 2025 15:05
Как ссылочный "сок" дает буст
@
Читать полностью…
Mike Blazer
04 Apr 2025 11:05
Как контент выглядит для владельца сайта и как он выглядит для посетителя сайта
@
Читать полностью…
Mike Blazer
03 Apr 2025 17:05
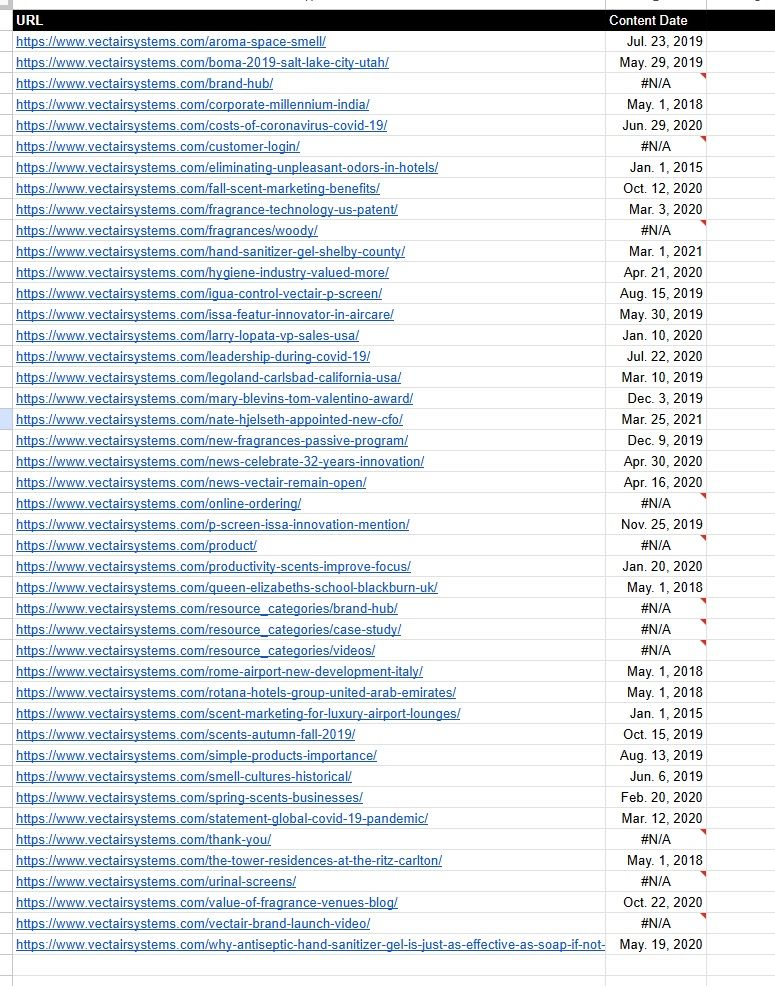
Получи даты контента для твоих URL в G`oogle Sheets` за секунды!
Сделать это до глупости просто - достаточно занести список URL-адресов ваших сайтов в лист Google.
Перейдите на страницу и найдите нужный вам элемент, например DATE, щелкните правой кнопкой мыши на тексте и нажмите INSPECT.
Когда откроется devtools, он автоматически покажет вам выделенный HTML-элемент.
Щелкните правой кнопкой мыши, COPY > Full XPATH.
Затем вставьте XPATH в эту формулу
=IMPORTXML(A2, "Вставьте сюда свой полный xpath")
Таким образом, это выглядит примерно так:
=IMPORTXML(A2, "/html/body/main/section/div[2]/div[2]/span[2]")
Скопируйте функцию ячейки и вставьте ее в свой лист, а затем просто проведите
CASCADE по всем УРЛам.
В первый раз она запросит у вас разрешение на доступ к внешним
URL-адресам, дайте разрешение и запустите снова.
Это СУПЕР ПРОСТОЙ и быстрый способ получения дат контента.
Но это можно сделать с любым видимым элементом страницы - лучше всего работают последовательные элементы, т. е. авторы, даты и т. д.
Можно сделать это и другим способом:
1 . Откройте
URL-адрес и просмотрите исходный код
2. Найдите "
datePublished", если он отображается в исходном тексте.
3. Скопируйте этот скрипт:
function getDatePublished(url) {
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/"datePublished":"([^"]+)"/);
return match ? match[1] : "Not found";
}4. Вернитесь на лист, нажмите
EXTENSIONS >
APPS SCRIPT, вставьте скрипт, сохраните и запустите, дайте разрешения.
5. Вызовите скрипт следующим образом:
=getDatePublished(A2)
Что вы можете сделать с этими удивительными данными?
Используйте
VLOOKUP, чтобы сопоставить ваши
URL-адреса с данными поисковой консоли за последние 3, 12 и 16 месяцев, загруженными в лист.
Примените фильтр и найдите устаревший контент, у которого мало или совсем нет кликов и показов.
Проверьте наличие внешних ссылок с помощью пакетного анализа
AHREFS - все, на которые есть внешние ссылки,
URL-адреса
301, те, на которые нет ссылок, удаляют контент и
HTTP 410 URL-адреса, чтобы устранить их.
@
Читать полностью…
Mike Blazer
03 Apr 2025 13:10
Бинг выдача с 9 рекламами!!!
Представьте, что LLM-ки ходят в Бинг за инфой и скликивают рекламу...
Оли так и пишет: "Когда мы тестировали OpenAi Operator, он использовал Bing и кликал по объявлениям."
@
Читать полностью…
Mike Blazer
10 Apr 2025 13:10
Что изменилось и не изменилось в линкбилдинге?
Я бы сказал, что изменилось очень мало - но разговоры и нарратив меняются, иногда в лучшую сторону, иногда в худшую, с множеством безумных теорий заговора о релевантности, низком качестве и т.д.
Попробую быстро разобрать по пунктам, основываясь на моем 21-летнем опыте, пишет WebLinkr:
1. Ссылки и органический трафик (как валидация) остаются единственными факторами ранжирования в SEO
2. Да, релевантность - это контрольные ворота для передачи авторитета - релевантность должна быть только в контексте контента, а не "всего сайта".
Когда люди говорят "с релевантных сайтов или доменов" - это сильное преувеличение
3. Авторитет PageRank кумулятивен - другими словами, 1000 низкокачественных сайтов = много PageRank.
4. PageRank однонаправлен и ВСЕГДА положителен - не существует "низкокачественного" PageRank
5. PBN - технически они не для продаж ссылок
6. Штрафы за ссылочный спам бинарны - они либо передают авторитет (от 1 до X, где X >=1000 миллиардов, например)
7. Не существует такого понятия как хороший ссылочный профиль или % или соотношение - это личные ограничения, придуманные для успокоения людей (чтобы они чувствовали себя безопасно) относительно того, сколько ссылок действительно органические, а сколько созданы искусственно
8. Любые самостоятельно построенные ссылки обычно не имеют ценности - профили в соцсетях, site-wide и т.д.
9. Бэклинки из социальных сетей практически бесполезны
10. Страница со ссылкой ДОЛЖНА ТАКЖЕ РАНЖИРОВАТЬСЯ и ПОЛУЧАТЬ органический трафик, чтобы передавать авторитет - так что если страница, ссылающаяся на вас, не ранжируется, она бесполезна
11. Технически говоря, любые гостевые посты для SEO, платные или нет = ссылочный спам
12. Спамные на вид ссылки <> ссылочный спам
13. Токсичные ссылки, они же спамные на вид, НЕ НАНОСЯТ ВРЕДА
tl;dr Мой совет, как делать правильно для SEO
14. Нормально и даже рекомендуется получать ссылки от локальных бизнесов, которые вы знаете, с которыми ведете дела или имеете отношения, и строить совместную стратегию выхода на рынок или кампанию.
Не беспокойтесь об их авторитете домена или PageRank, беспокойтесь о том, чтобы помочь им получить трафик.
@
Читать полностью…
Mike Blazer
10 Apr 2025 08:15
Рик:
GSC показывает мне кучу неканонических URL с добавленными хэшбэнгами.
Я передал это инженерам, и они сказали, что нашли и исправили проблему.
Это было 2-3 недели назад, а неканонические URL с хэшбэнгами до сих пор появляются в GSC.
Я пытался провести валидацию фикса дважды за прошедшие 3 недели, но фикс не валидируется.
Инспектор URL не показывает реферер.
Если запретить Google краулить URL с хэшбэнгами, это уменьшит количество краулящихся URL примерно на 33%.
Поскольку инженеры не могут найти никаких рефереров на эти страницы, я рассматриваю два сценария:
1. Данные в GSC устарели, и эти URL будут отображаться еще какое-то время
2. Эти URL где-то есть на сайте, и мы можем решить проблему с помощью постоянного редиректа, пока инженеры не найдут баг.
-
Дэйв Смарт:
#! — это неудобная штука, пережиток старых дней краулинга JavaScript,
robots.txt не может их заблокировать,
Disallow: /*#!
фактически то же самое, что и
Disallow: /
Это первый раз, когда я заметил, что там написано, что индексация разрешена, хотя страница неканоническая.
Это вполне стандартно, любая страница "
не индексируется: альтернативная страница с правильным каноникал-тегом" будет отображаться таким образом, так это выглядит в
GSC.
Учитывая, что каноникалы, похоже, уважаются, я бы особо не беспокоился об этом, учитывая отсутствие реального контроля, и то, что каноникалы, похоже, делают свою работу.
Я бы предположил, как и ты, что это что-то историческое, всплывшее для проверки того, что происходит в наши дни с этими
URL, или, возможно, с внешних сайтов, но отсутствие рефереров на любом из них указывает на первую версию.
-
Рик:
Вот что я пытаюсь решить.
Эти
URL с хэшбэнгами составляют около 1/3 неиндексируемых страниц, которые краулятся.
Я хочу сократить порог от серого до зеленого.
Кроме того, общее количество запросов краулинга падает с такой же скоростью.
-
Дэйв Смарт:
Я тебя понимаю, но здесь мало что можно сделать, ИМХО.
Ты не можешь заблокировать или средиректить эти
URL на стороне сервера, так как # и !
не передаются как часть сетевого запроса
Ты не можешь использовать
robots.txt, во-первых, из-за того, как он парсится, но опять же, запрос будет на
URL без #!
Так что есть две реалистичные опции:
1. Полагаться на каноникалы, как ты сейчас делаешь, и жить с тем, что показывает отчет
2. В крайнем случае, ты мог бы использовать клиентские
JavaScript-редиректы, но я думаю, что будет хуже с точки зрения расхода краулингового бюджета (ему придется краулить это, рендерить И ЗАТЕМ редиректить), и всё это для того, чтобы в конечном итоге просто переместить их из одной причины, по которой они не индексируются, в другую причину в отчете.
@
Читать полностью…
Mike Blazer
09 Apr 2025 15:05
Как работает определение AI-контента
Системы определения AI-контента анализируют текстовые паттерны и аномалии в текстах, написанных машиной.
Статистические методы детекции из 2000-х изучают частотность слов, n-граммные паттерны, синтаксические структуры вроде последовательностей Субъект-Глагол-Объект и стилистические элементы.
Простой пример: "Кошка сидела" показывает базовые паттерны, такие как частотность слов и биграммы.
Эти методы становятся более сложными благодаря обучающим алгоритмам, таким как Naive Bayes, Logistic Regression, Decision Trees и методам подсчета вероятности слов, известным как логиты.
Нейронки служат основным методом детекции, требуя как минимум нескольких тысяч текстовых сэмплов и меток для обучения паттернам, оставаясь при этом экономически эффективными.
LLM вроде ChatGPT не могут распознать собственный выход без файнтюна - тесты показывают, как ChatGPT генерирует текст и затем не может определить его как AI-сгенерированный в отдельных беседах.
Вотермаркинг встраивает скрытые сигналы в AI-сгенерированный текст, подобно УФ-чернилам на бумажных деньгах.
Исследования описывают три подхода: добавление меток в релизные датасеты, внедрение вотермарок во время генерации LLM и добавление их после генерации.
Модели, обученные на текстах с вотермарками, становятся "радиоактивными", улучшая определяемость их выдачи.
Методы детекции достигают 80% точности в контролируемых условиях, но сталкиваются со значительными ограничениями.
Модели, обученные на определенных типах контента, плохо работают с другими стилями письма, как показано при тестировании контента на Singlish против моделей, обученных на стандартных новостных статьях.
Системы также испытывают трудности со смешанным AI-человеческим контентом и сталкиваются с проблемами из-за инструментов "очеловечивания", которые нарушают AI-паттерны через опечатки, грамматические ошибки или сложные техники файнтюна.
Хотя "очеловечиватели" могут обойти известные детекторы, они часто проваливаются против новых, неизвестных.
Подобно тому, как сталь ядерной эры содержит следы радиоактивных осадков, делая доядерную "низкофоновую" сталь редкой и ценной для чувствительного оборудования, поиск чисто человеческого контента становится все сложнее по мере интеграции AI в создание контента, потенциально делая традиционные методы детекции устаревшими.
https://ahrefs.com/blog/how-do-ai-content-detectors-work/
@
Читать полностью…
Mike Blazer
09 Apr 2025 11:05
Техническое SEO не имеет значения для маленьких сайтов?
Мы сделали всего одно (1) изменение в загрузке контента, пишет Бет Вудкок.
Страницы, которые застряли в лимбо "Обнаружено - в настоящее время не проиндексировано", наконец проиндексировались и начали приносить как клики, так и показы.
Никакого обширного аудита, полного пустых слов.
Никакого 200-страничного отчета, набитого бесполезными оптимизациями.
Только одно целевое исправление.
Дело не всегда в бесконечных чек-листах или техническом жаргоне.
Иногда достаточно просто знать, за какой рычаг нужно потянуть.
На данный момент мы наблюдаем увеличение сеансов на сайте на 30% — это все данные, которые я могу видеть прямо сейчас.
В чем заключалось изменение?
Удаление эффекта постепенного появления текста (fade-in) на новых шаблонных страницах.
Весь контент был в исходном коде, но Гугл явно не оценил, что не мог видеть контент с переходом от "белого к черному" без скроллинга!
Как я пришла к выводу, что проблема в fade-in текста?
При проверке через GSC текст отображался очень светлым белым, а на "скриншоте" его не было.
Также я сравнила исходный и рендеренный код, чтобы увидеть, какие конкретно теги были добавлены для эффектов - весь контент присутствовал в HTML.
Взяла пару страниц, с индексацией которых были проблемы, отключила эффект появления текста, попросила Google проиндексировать их, и бум!
Практически мгновенная индексация!
@
Читать полностью…
Mike Blazer
08 Apr 2025 17:05
Ян Шимечик:
Ребята, безопасно ли запускать редизайн сайта (полностью переработанный код, обновленный контент, но те же URL) в середине обновления ядра?
Или лучше подождать, пока оно завершится?
-
Джон Мюллер:
Просто запустите, когда/если он будет готов. Обновление ядра основано на данных за более длительный период времени.
В нем нет ничего, что могло бы повлиять на новый сайт, поскольку для нового сайта нет данных.
-
Джереми Старк:
В прошлом году мы запустили 2 сайта в середине обновления ядра, на одном сайте было много изменений URL... никаких проблем не возникло ни с одним из них.
@
Читать полностью…
Mike Blazer
08 Apr 2025 13:10
Я перенес страницу с сайта, который пострадал от Google HCU, на другой домен и видимость выросла на 216% по сравнению с пиком до HCU, пишет Джеймс Брокбэнк.
Как и многие другие, я давно подозревал, что HCU на самом деле не связан с качеством самого контента страницы.
Полгода назад у меня появилась возможность самому провести тест: взять страницу с контент-сайта, пострадавшего от HCU, и опубликовать ее в блоге "реального бизнеса" (то есть не контент-сайта) в той же нише.
На самом деле я хотел создать тот же материал для бренда, с которым работаю, и вспомнил, что именно эта тема уже освещалась на контент-сайте, с которым я работал в 21/22 годах.
С согласия и понимания владельцев обоих сайтов я перенес пост с домена А на домен Б.
Оригинальный сайт до сих пор работает.
Это был отличный контент, написанный человеком, разбирающимся в теме.
Он заслуживал высоких позиций.
В контент были внесены небольшие изменения (внутренние ссылки изменены, упоминания бренда и экспертов заменены, добавлен СТА для бизнеса), но ничего существенного.
Я даже использовал те же изображения.
Я НЕ делал 301 редирект со старого URL на новый.
Это был на 99% тот же самый контент, просто на другом домене.
На оригинальном домене (на пике): 538 ежемесячных органических сессий.
На новом домене: 1700 ежемесячных органических сессий.
Это увеличение на 216%.
Это не призвано доказать, что изменение домена для контента, пострадавшего от HCU, заставит его снова ранжироваться.
Это был просто изолированный тест, который я провел из любопытства; у меня была идеальная возможность перенести контент на тематически релевантный домен (принадлежащий "реальному" бизнесу).
Но это, безусловно, интересно.
Если HCU "не понравился" контент (он исчез из топ-100), теоретически он не должен снова ранжироваться.
Сегодня он ранжируется по 400+ ключевым словам, включая множество позиций на первом месте и много featured сниппетов.
Фактически, он занимает первую позицию по основному целевому запросу.
Если верить каждому слову Google, этот контент не является полезным и не должен ранжироваться 🤷♂️
@
Читать полностью…
Mike Blazer
08 Apr 2025 08:15
Корай Тугберк Гюбюр говорит, что просто потому, что Google краулит URL, не значит, что он сразу полностью обрабатывает или понимает контент.
Он ссылается на заявления Панду Найака, главного по ранжированию в Google, упоминая два важных момента:
1. Google не запускает RankBrain (свой продвинутый алгоритм ранжирования) для страницы, если она еще не попала в первые 20 результатов поиска.
2. Google не применяет свой алгоритм NavBoost к страницам, которые не получают кликов.
@
Читать полностью…
Mike Blazer
07 Apr 2025 17:05
Как быть заметным одновременно в поисковиках и LLM (часть 1/2)?
Вам нужны семантика и SEO.
Позвольте представить вам Tratos, моего клиента из индустрии промышленных кабелей, пишет Джанлука Фиорелли.
Моя SEO-стратегия обычно следует таким тактическим шагам:
1. Определение онтологии домена клиента (промышленные кабели).
2. Определение связанных сущностей (обслуживаемые отрасли, такие как горнодобывающая промышленность, телеком, поставщики энергии, продукты и компоненты).
3. Использование Google как инструмента для получения запросов, связанных с нашими сидами сущностей, из таких функций как фильтры по темам, People Also Ask, People Also Search for и т.д.
4. Проведение анализа распознавания именованных сущностей (Named Entity Recognition) для запросов из СЕРПов Google.
5. Определение таксономии на основе поиска по сущностям.
6. Анализ путей поиска целевой аудитории (обнаружение, оценка и принятие решений)
7. Кластеризация фаз поискового пути через внутреннюю перелинковку, усиление тематического авторитета.
8. Проведение анализа эмбеддингов и косинусной близости для выявления контентных пробелов.
9. Использование этих инсайтов для обновления существующего контента и создания нового, с фокусом на значимость сущностей и ясность языка.
Дополнительный пункт включает анализ СЕРПов для понимания паттернов отображения Google для наших важных сущностей и запросов, что влияет на форматирование контента с изображениями, видео или специфическим форматированием текста.
Благодаря этой методологии, сфокусированной на семантике, видимость Tratos стабильно и значительно увеличилась.
Они начали конкурировать за запросы типа "[тип кабеля]" и "[тип кабеля] + manufacturer", а также за более общие информационные запросы, связанные с промышленными кабелями, например "What is voltage rating".
Их видимость расширилась в избранных сниппетах, People Also Ask, Things to Know, блоках изображений в поиске и даже в брендированных People Also Search For.
Что важно, их семантически оптимизированный контент, сгруппированный в тематические хабы, стал видимым для многих вариаций запросов, которые не были явно таргетированы.
Затем мы заметили, что контент сайта постоянно цитировался и на него ссылались как на источники для ответов `LLM, связанных с темами промышленных кабелей, в ChatGPT, Perplexity, Gemini и AI Overview.
`
Так как же это произошло без специальных действий по оптимизации для LLM?
Ответ — семантика.
Понимание причин видимости сайта в LLM
Большая языковая модель (LLM) похожа на суперзаряженную функцию автозаполнения, прогнозирующую и генерирующую текст на основе паттернов, изученных из огромных объемов текста.
Она выбирает слова на основе вероятности, разбивая предложения на более мелкие части, анализируя контекст и вычисляя вероятность следующего слова.
Поиск по сущностям
Поиск по сущностям — ключевой фактор того, как LLM понимают контекст.
Сущность — это любой конкретный человек, место, вещь или концепция, которая даёт контекст языку.
Когда задается вопрос, LLM идентифицируют ключевые сущности и их взаимоотношения, используя контекст для устранения неоднозначности.
Классическое SEO фокусировалось на ключевых словах, но LLM и современные поисковые системы выходят за рамки совпадения ключевых слов, чтобы понять значение через сущности и взаимоотношения.
SEO на основе сущностей оптимизирует контент, чтобы поисковые системы и LLM понимали:
— Форматирование контента (формат обзора, формат списка и т.д.)
— Значимость сущностей (обсуждение связанных концепций)
— Чёткие контекстуальные сигналы (например, геолокализация)
Эмбеддинги
Эмбеддинги позволяют LLM "понимать" язык и контекст в масштабе.
Они преобразуют слова, фразы и сущности в математические представления (векторы), которые отражают их значение и взаимоотношения.
Похожие значения группируются близко друг к другу в этом многомерном пространстве.
Конец 1-ой части.
Продолжение следует...
@
Читать полностью…
Mike Blazer
07 Apr 2025 13:10
Дэнни Салливан недавно пояснил, что у них нет "системы ранжирования брендов".
Он также сказал:
Это означает, что если вы создали бренд (любого размера - моя местная пиццерия как локальный бренд, который я узнаю), что-то узнаваемое, что-то, что люди целенаправленно ищут и которому доверяют до такой степени, что, возможно, ищут вас напрямую или приходят к вам напрямую, вы, вероятно, хорошо справляетесь с удовлетворением потребностей людей в целом.
И наши системы ранжирования пытаются вознаграждать сайты, анализируя множество сигналов, которые, по нашему мнению, согласуются с этим.
Так что если вы сайт, который хочет выделиться среди других сайтов, которые могут предлагать похожие вещи, стандартную информацию или что-то ещё — вы один в море вариантов, понимание того, как выделиться и построить свой бренд (любого размера, большого, маленького и т.д.) — это в целом хорошая идея... полностью независимо от поиска...
И делая это, вы, вероятно, соответствуете тому, что поисковые системы хотят вознаграждать.
Некоторым сеошникам
нужно понять, что "не напрямую" может означать одно из двух:
а) непрямое влияние (у них есть 1+ прокси-метрик/факторов)
б) ничего (они не используют это или что-то подобное, точка)
Так что да, у Google нет прямого фактора ранжирования "бренд".
Но если вы собираетесь заниматься SEO, "бренд" имеет несколько достойных преимуществ.
1. Снижение конкуренции:
Должно быть гораздо меньше конкуренции за запросы, которые включают название вашей "компании".
2. Большая релевантность:
По праву, вы должны не только ранжироваться, но и ранжироваться легче по запросам с названием "компании".
3. Увеличение кликов/трафика:
Какую бы позицию вы ни занимали, ваша кликабельность должна превосходить норму для этой позиции.
4. Удовлетворенность пользователей:
Если вы делаете поиск по запросу [{компания} {продукт/услуга}] и кликаете на релевантный листинг "компании", скорее всего, вы не вернетесь в СЕРП и не кликнете на конкурирующий листинг (вас, вероятно, будут считать "удовлетворенным").
Всё это - победы!
Ещё лучше - ничто из этого не должно требовать ничего, кроме минимальной дополнительной работы... вы должны быть релевантны для "бренда" и т.д.
С самого начала.
Так что действительно нет оправданий.
@
Читать полностью…
Mike Blazer
07 Apr 2025 08:15
Если в интернете доступно 155 000 рецептов жареной курицы, очень сложно понять, какие из них действительно лучшие. Но если ваш бренд узнаваем, это становится сильным сигналом в поиске.
— Дэнни Салливан
-
Гугл говорит, что не
отдает предпочтение крупным брендам, а потом заявляет такое — это гигантское противоречие.
И что действительно несправедливо, так это то, что не имеет значения, ЗА ЧТО узнаваем ваш бренд.
Вам не нужно быть известным
как эксперт по жареной курице — это просто чистый конкурс узнаваемости имени.
Почти как будто качество контента и экспертность на самом деле не имеют к этому никакого отношения.
И снова — вот так мы получаем консолидированный веб, открытый только для 16 медиа-компаний с венчурным финансированием.
Потому что 10 (а в наши дни 8) самых узнаваемых имен всегда побеждают.
-
Это популярность...
То, что Гугл
любит называть "авторитетом", и удовлетворенность.
Так что всё сводится к ссылкам и тому, чтобы пользователи не избегали вас или не уходили к конкурентам и т.д.
Так (почти) всегда и было.
Качество должно быть способом "заработать" ссылки и удовлетворить пользователей.
Реальность такова: поскольку Гугл отдает предпочтение сайтам с большим количеством ссылок, "качество" часто отходит на второй план.
Вместо этого, это игра популярности с "достаточно хорошим" контентом.
Что подкрепляется такими вещами, как "брендовые запросы".
Они не имеют прямого влияния на ранжирование.
Но когда люди ищут "X + термин", они вряд ли уйдут к Y для этого термина.
И Гугл более чем осведомлен об этих предубеждениях.
Это было отмечено для них более 12 лет назад.
Проблема в том... как они ясно дали понять на мероприятии
Create Event...
Если бы они перевернули систему и взвесили факторы по-другому, они бы расстроили множество крупных сайтов.
-
Гугл: "у нас нет
системы ранжирования брендов. У нас просто есть система, которая измеряет предпочтение названия компании, осведомленность, симпатию и лояльность"...
👀
@
Читать полностью…
Mike Blazer
04 Apr 2025 17:05
Контент креаторы vs Google
@
Читать полностью…
Mike Blazer
04 Apr 2025 13:10
Карты сайта передают PageRank 🔥
Согласно формуле PageRank, каждая страница изначально имеет базовое значение PageRank.
Это означает, что даже без входящих ссылок страница имеет минимальное значение PageRank, которое она может передавать другим страницам.
В патенте PR не говорится явно, что какие-то типы страниц будут передавать PR, а какие-то нет.
Это значит, что не исключено, что XML-страницы (например, карты сайта) тоже могут передавать PageRank 🙂.
И именно поэтому сеошники сообщают, что карты сайта с 10к или даже 1к страниц работают лучше, чем те, в которых 50к страниц... 😄
@
Читать полностью…
Mike Blazer
04 Apr 2025 08:15
Меня только вчера подключили к клиенту, сообщает Кэтрин Вотье Онг.
Их отдел закупок работает вечность, поэтому, хотя мы работали вместе в прошлом году, оформление контракта заняло 6 месяцев.
За это время они перенесли свой сайт без моего участия, и он работает на Angular JS 18, причем все страницы, кроме главной, выдают 404-ую ошибку.
Теперь (на 2-й день сотрудничества) их разработчики (с которыми я еще не встречалась) выложили стейджинг в продакшн без защиты паролем и без noindex.
*вздох
@
Читать полностью…
Mike Blazer
03 Apr 2025 15:05
Вот, оказывается, кому достаются все сливки...
@
Читать полностью…
Mike Blazer
03 Apr 2025 11:05
SEO совет: забытое искусство управления картами сайта, которое позволяет предоставлять дополнительную информацию о странице.
Здесь можно применить различные дополнительные теги в зависимости от типа сайта, например, включить теги для страницы, связанной с видео, новостной статьей или изображениями.
Из этих трех вариантов мой любимый связан с включением тега, который часто дает значительное преимущество для более эффективной индексации контента на основе изображений, пишет Броди Кларк.
При тестировании этого подхода для различных типов сайтов, будь то интернет-магазины, онлайн-маркетплейсы или издатели всех видов, использование этих поддерживаемых Google тегов становится очевидным выбором.
В случае индексации и ранжирования изображений или видео во вкладках "Картинки" или "Видео", исходным URL на самом деле является страница (а не URL изображения/видео).
Из-за этого может показаться, что предоставление такой информации через сайтмапы не дает особой пользы, но мой опыт показывает, что польза выходит за рамки индексации и помогает Google лучше понимать эти ресурсы, по сути напрямую подключая их к поисковику.
Существует множество особенностей, связанных с такой реализацией, например, возможность использовать в карте сайта изображения, размещенные на внешних CDN, или принятие решений в случаях, когда на странице находится несколько изображений или видео.
Если вы управляете крупным сайтом, на котором регулярно публикуется важная информация в виде новостей, изображений или видео, обязательно используйте этот недооцененный инструмент, который поддерживается и рекомендуется Google.
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}