Mike Blazer
17 Apr 2025 17:05
В прошлом месяце AI-краулеры сгенерировали 90% трафика моего сайта, заставив меня заплатить $90 штрафа за превышение лимита данных, пишет Гергей Орос.
Именно тогда я достиг точки кипения:
Для контекста: это произошло с моим сайд-проектом TechPays, который посещает около 1000 пользователей в день (имеются в виду живые люди!), с ежемесячным исходящим трафиком около 30-40 ГБ.
Эти показатели оставались неизменными на протяжении нескольких лет.
Пока несколько месяцев назад не появились AI-краулеры!
Они начали генерировать всё больше и больше данных, осуществляя бессмысленный краулинг (повторный краулинг одних и тех же страниц ежедневно или даже ежечасно, краулинг пустых страниц и т.д.).
В прошлом месяце сайт впервые превысил лимит исходящего трафика в 500 ГБ — это был максимум, включенный в мой текущий тариф у хостинг-провайдера Render.
И этот тариф более чем разумен для данного проекта.
С этого момента мне пришлось платить по $30 за каждые дополнительные 100 ГБ данных: только за прошлый месяц это обошлось мне в $90.
И не было никаких признаков замедления роста трафика из-за этих краулеров (среди главных нарушителей были боты, идентифицирующие себя как Meta AI, ImagesiftBot, DotBot)
Я не хотел продолжать платить за обучение AI-краулеров — особенно учитывая, что объем данных продолжал расти, а все больше AI-краулеров открыто игнорировали robots.txt.
Сначала я пытался решить проблему, блокируя IP-адреса самых злостных ботов — а затем решил попробовать перенести мои нейм-серверы в Cloudflare, настроив прокси DNS-записей через их сервис (это означает, что домен резолвится на IP Cloudflare, Cloudflare проверяет запрос и решает, пересылать ли его на мои настоящие серверы), и включил блокировку AI-краулеров (вот эту)
Похоже, это сработало: ежемесячный исходящий трафик моего сайта вернулся к ~40 ГБ в месяц, снизившись с 800 ГБ!
На обычных посетителей это не должно повлиять — за исключением того, что Cloudflare иногда может проводить проверку на бота.
Это решение бесплатное и не создает привязки: я всегда могу сменить нейм-серверы, например, на серверы моего регистратора доменов или любые другие (я не хостю свои домены на Cloudflare, а просто использую их нейм-серверы)
Cloudflare явно субсидирует расходы на пропускную способность и функциональность блокировки ботов — и создает хорошее отношение к себе со стороны разработчиков, таких как я.
Я просто хочу, чтобы этот небольшой сайд-проект работал нормально и не подвергался все более агрессивным "атакам" AI-краулеров, за которые мне приходится платить увеличенные расходы на ресурсы (например, трафик, CPU и т.д.).
(В качестве бонуса я включил функцию Cloudflare "AI Labyrinth", которая использует AI-генерируемый контент, чтобы замедлить, запутать и потратить впустую ресурсы AI-краулеров и других ботов, не уважающих ограничения robots.txt. Это своего рода "месть"!)
@
Читать полностью…
Mike Blazer
17 Apr 2025 13:10
Нет, ссылки не спасут вас от негативных последствий обновления ядра Google.
Я уже много раз говорил об этом раньше, но вот еще один отличный пример, говорит Гленн Гейб.
Мощный сайт был разгромлен мартовским обновлением ядра 2025 года.
У сайта 7.7 млн бэклинков почти со 100 тыс. ссылающихся доменов (и более 3 млн ссылок после фильтрации).
Таким образом, ссылки и упоминания с авторитетных сайтов важны, но, опять же, они не спасут вас от удара обновления ядра, если есть другие большие проблемы.
@
Читать полностью…
Mike Blazer
17 Apr 2025 08:15
Марк Уильямс-Кук задался вопросом, будет ли Google продолжать показывать страницу в поисковых результатах (СЕРП), если она возвращает ошибку 404 (не soft 404), но пользователи постоянно кликают на нее, когда она появляется в поиске.
Он уточнил:
— Он наблюдал страницу конкурента, которая возвращала 404 в течение месяца, но все еще отображалась в поисковых результатах
— Он предположил, что это может быть связано с кликами пользователей
— Он подтвердил тестирование с помощью Rich Result Tester (RRT) и проверил, что URL в СЕРПе совпадает с URL приземления
— Изначально он подозревал клоакинг
— Что касается noindex, он подчеркнул, что это директива (а не рекомендация), которая должна обрабатываться немедленно, когда она в HTML
— Он никогда не видел, чтобы правильно реализованный тег noindex не был учтен, если только что-то не было сломано
— Он отметил, что noindex обычно вступает в силу сразу после очередного краулинга
Мнения сообщества
— Если пользовательские сигналы достаточно сильны и указывают на ценность страницы, Google может оставить ее в индексе и продолжать показывать.
— Идея о том, что страница с 404 статусом и кликами может оставаться в индексе, имеет смысл, особенно учитывая пользовательские сигналы как часть патента оценки качества сайта.
— Пользователи будут продолжать кликать на результат из любопытства, но со временем он должен выпасть, поскольку постоянно возвращает статус 404.
— Закон Ньютона применительно к поиску: объект в движении остается в движении, пока на него не подействует внешняя сила.
В терминах SEO, эта "поисковая инерция" означает, что после того, как страница была архивирована, проиндексирована и ранжирована, она не исчезает мгновенно, когда начинает возвращать ошибки 404.
У страницы есть установившаяся инерция в индексе Google.
— Асинхронная природа алгоритма Google означает, что разные системы (краулинг, индексация, архивирование, механизмы ранжирования и сигналы пользовательского поведения) не синхронизируются мгновенно.
— Сигналы пользовательского поведения могут еще не предоставить достаточно доказательств того, что страница бесполезна. Как и физический распад, этот цифровой распад следует естественной прогрессии.
— Статус 410 "Gone" может быть более эффективной альтернативой для преодоления "поисковой инерции" по сравнению с 404.
— Пользовательские логоритмические сигналы значительно сильнее в некоторых аспектах, чем алгоритмические сигналы.
— Бот Google перекраулит несколько раз, чтобы убедиться, что статус 410 является намеренным.
Даже со статусом 410 и нулевыми внутренними ссылками страницы все равно могут изредка появляться в поисковых результатах.
— Если Googlebot может видеть код статуса 404 (чего не произойдет, если URL заблокирован в robots.txt), URL будет удален из индекса Google и не будет показываться пользователям.
— Время, за которое страница с 404 выпадает из индекса, может варьироваться от минут до месяцев, в зависимости от частоты краулинга и приоритета URL (имеет ли он внутренние ссылки, бэклинки, трафик и т.д.).
@
Читать полностью…
Mike Blazer
16 Apr 2025 15:05
Эндрю Чарлтон пережил более 100 миграций сайтов.
Вот 7 самых дорогостоящих ошибок, которые он видит у маркетологов:
1. Вообще делать миграцию.
Крутой дизайн ≠ гарантированные лиды.
↳ Если вы новичок в бизнесе, не используйте это как возможность доказать свою ценность.
Даже если вы преуспеете, вы, скорее всего, завысите ожидания от результатов, из-за чего успех покажется меньше, чем есть на самом деле - или ваше начальство уже успеет это сделать.
В любом случае, согласовать ожидания никогда не бывает просто.
2. Подключение SEO-специалистов слишком поздно.
Позднее вмешательство SEO создает эффект снежного кома ошибок
Плохой дизайн → некачественная разработка → проблемная миграция
↳ Пусть SEO-специалисты проверят вайрфреймы и дизайн еще до начала разработки.
Ранняя оценка рисков предотвращает будущий хаос.
Чем ближе дедлайны, тем сложнее их сдвинуть.
3. Игнорирование редиректов.
Редиректы URL несут риски - нужна очень веская причина для их внедрения.
↳ Чаще всего редиректы создают проблемы.
Типичные ошибки:
— Редирект всего на главную.
— Цепочки редиректов.
— Отсутствие тестирования, приводящее к 404-м.
4. Пропуск бенчмаркинга.
Нет данных = нечем оправдаться при падении трафика
↳ Если планируете миграцию, настройте отслеживание прямо сейчас - вам нужны данные для сравнения.
Покупаете или объединяете сайты?
Объедините и данные тоже, чтобы видеть общее влияние.
Отслеживайте:
— Макро-метрики: трафик, лиды, конверсии.
— Микро-метрики: позиции по ключевым группам страниц.
5. Отсутствие бюджета или времени на фиксы.
SEO-специалисты должны быть вовлечены в процесс.
↳ Хороший SEO должен:
— Оценить, сколько времени займут фиксы после аудитов/проверок.
Планируйте это.
Заложите время на правки в план миграции.
6. Отсутствие внешних коммуникаций
Большая миграция?
Сообщите клиентам заранее.
↳ Критично, если меняются ключевые функции — например, оплата счетов.
↳ Еще важнее, если сайт покупается и объединяется с другим.
7. Делать все правильно до самого запуска.
(больше касается разработчиков).
Вот типичные катастрофы в день запуска:
— оставленные noindex теги по всему сайту
— Disallow: / в robots.txt
— URL'ы стейджинга в продакшене
Хорошие SEO-специалисты всё это отловят.
@
Читать полностью…
Mike Blazer
16 Apr 2025 11:05
Этот SEO-хак может мгновенно обеспечить вам Knowledge Panel.
Давид де Врис сделал нечто безумное - и это сработало.
Он зарегистрировал домен с точным вхождением ключевого слова:
Bedsforseniors.com
Затем зарегистрировался в Google Merchant Center + Google Ads... под названием компании "Beds for Seniors".
Вот и всё.
Google наградил его брендовой панелью знаний для абсолютно нового домена.
Вот почему это умно: 👇
1️⃣ Точное соответствие названия = высокая релевантность ключевым словам
2️⃣ Регистрация в собственных продуктах Google (Merchant + Ads) повышает доверие
3️⃣ Google воспринимает это как реальный бизнес → активирует брендовую панель
Бонус: Он почти мгновенно попал в топы по коммерческому запросу.
Никаких бэклинков.
Никакого построения бренда.
Никакой долгой игры.
Примечание: scam advisor пометил сайт, так что держите свою whois-информацию в чистоте.
Но стратегия работает - особенно если вы в локальном SEO, лид-генерации или аффилиате.
P.S. Видели ли вы более быстрый способ получить панель знаний?
@
Читать полностью…
Mike Blazer
15 Apr 2025 17:05
На GPT-4o можно генерить левые паспорта!
Найдите шаблон паспорта и фотографию человека и скажите "замените это фото на фото этого человека".
Да, там есть ошибки.
Да, это не пройдет многие проверки.
Но люди забывают, сколько произвольных процессов требуют подтверждения паспортом, которые не проходят через эти строгие проверки!
Они происходят обычно по электронной почте, и хотя Photoshop существует, это увеличивает доступность в 100 раз и скорость в 5 раз.
Что касается ошибок, их можно исправить с помощью инструмента кисти.
Дальше будет только лучше.
Что касается закодированных водяных знаков на изображениях - это можно тривиально обойти с помощью скриншота или EXIF edit.
Это не критика OpenAI!
Безопасность - сложная задача!
@
Читать полностью…
Mike Blazer
15 Apr 2025 13:10
Как я позволил Google написать для меня Featured Snippet, рассказ Стива Тота
Этот SEO-трюк был настолько простым...
Что я почти не верил, что он сработает.
Вот что произошло:
У меня был блог, который ранжировался на #2 позиции по ключевому слову, но без фичерд сниппет.
Вместо того, чтобы переписывать его вручную, я попробовал кое-что другое:
1: Я открыл Google Docs и начал писать предложение в стиле сниппета.
2: Я позволил предиктивному тексту Google автозаполнить как можно больше.
3: Я скопировал сгенерированный ИИ сниппет и разместил его под H1 моего блога.
4: Ждал... и наблюдал за волшебством.
Через несколько дней наша страница получила featured snippet.
Почему это сработало?
Предиктивный текст Google отражает то, как он понимает контент.
Если он что-то автозаполняет, вероятно, это соответствует тому, как Google хочет отображать информацию.
Этот трюк занял менее 5 минут и помог нам занять позицию #0.
Попробуйте сами!
Вот пошаговое видео об этом: видео
@
Читать полностью…
Mike Blazer
15 Apr 2025 08:15
Если Google не краулит весь ваш контент, проверьте время ответа сервера.
Сайты с откликом <200 мс краулятся глубже, чем более медленные.
Иногда лучшее SEO-решение — это просто более хороший хостинг-план.
-
Заметен явный порог отсечения на 350 мс.
-
"Время краулинга" давно является частью "краулингового бюджета".
У Google есть ограниченное время на выполнение задач, и более медленные сайты получают меньше прокрауленных URL.
Решения:
1) Ускорение:
Начните с основ — уменьшите DNS/TTFB и т.д., так как это влияет на все запросы ресурсов.
И извините — но часто вам не нужно менять хостинг, либо настройте кэширование на вашем сайте и сервере, либо установите CDN (обычно это гораздо дешевле и проще, чем миграция хостинга).
2) Уборка:
Убедитесь, что не тратите краулы на дубликаты, soft-404, линковку реальных 404/410, индексацию слабого/мусорного контента, цепочки редиректов и т.д.
3) Приоритизация:
Расставьте приоритеты контента.
Имейте несколько сайтмапов, по разделам/типам контента.
Вам нужен 1+ для существующих страниц и отдельный "новый" сайтмап, который указывает на новый контент (вы также можете иметь один для "обновленного" контента).
Продумайте внутренние ссылки для продвижения нового (и обновленного) контента, чтобы боты приоритизировали эти URL.
4) Наращивание:
Получайте новые ссылки.
Google, похоже, по-прежнему учитывает входящие ссылки при приоритизации краулов — так что получение нескольких ссылок на новый контент может привлечь внимание Google.
И чем больше у вас ссылочная масса, тем чаще Google, как правило, краулит.
@
Читать полностью…
Mike Blazer
14 Apr 2025 15:05
Мартин Шплитт:
"Если URL не полностью рендерится, мы не можем утверждать, что это дубликат, потому что мы не знаем".
@
Читать полностью…
Mike Blazer
14 Apr 2025 11:05
Чтобы появиться в ИИ, вы не можете строить модные хедлесс-сайты.
ИИ просто не выполняет JavaScript при краулинге вашего сайта, пишет Йост де Валк.
-
Скриншот, который я показываю, был сделан в октябре прошлого года во время моего тестирования, говорит Мартин МакДональд.
Эта часть до сих пор не изменилась, OpenAI не выполняет JS, когда вы запрашиваете конкретный URL.
Похоже, что источник, откуда они получают веб-контент, действительно рендерит и упрощает JS перед тем, как OAI его потребляет.
У меня есть конкретные доказательства этого из обычных ответов, которые он дает, где данные были на странице, требующей JS для правильного парсинга.
Информация, которую он не мог бы знать без рендеринга JS......
Так что я предполагаю (это просто догадка), что Bing делает рендеринг, а они потребляют готовый контент.
Или они просто используют индекс Bing.
Хз.....?
@
Читать полностью…
Mike Blazer
13 Apr 2025 14:05
Grok 3 с DeepSearch справляется с работой на ура, когда не может получить доступ к URL, предположительно из-за этого правила в файле robots.txt сайта:
User-Agent: *
Disallow: /*?*search=
Может, пора снова разрешить поиск по сайту?
@
Читать полностью…
Mike Blazer
12 Apr 2025 09:15
О бане в Гугле GeeksforGeeks предупреждает своих посетителей так, как будто это неполадка на стороне Гугла:
⚠️ Important Notice: Due to temporary issues with Google search, our site may not appear in results.
Please use the search below to find your desired articles.
Про сам бан писалось
тут.
@
Читать полностью…
Mike Blazer
11 Apr 2025 15:05
Для отображения фавикона в результатах поиска Bing сайт должен соответствовать следующим требованиям:
...
...
5. На сайте должен быть валидный файл сайтмапа (sitemap.xml), и в нем должен быть указан URL файла фавиконки
@
Читать полностью…
Mike Blazer
11 Apr 2025 11:05
Почему ваши важные страницы не индексируются в GSC?
Не проиндексированные страницы можно разделить на 3 типа:
1️⃣ Технические:
Эти ошибки связаны со страницами, которые либо не соответствуют основным техническим требованиям Google, либо имеют директивы, запрещающие Google индексировать страницу.
2️⃣ Дубли:
Эти ошибки относятся к страницам, на которых срабатывает алгоритм каноникализации Google, и из группы дублирующихся страниц выбирается канонический URL.
3️⃣ Качество:
Эти ошибки относятся к страницам, которые активно удаляются из результатов поиска Google и со временем забываются.
https://indexinginsight.substack.com/p/3-types-of-not-indexed-pages-in-gsc
@
Читать полностью…
Mike Blazer
10 Apr 2025 20:19
Surfer чуточку нафотошопили...
@
Читать полностью…
Mike Blazer
17 Apr 2025 15:05
Оптимизация
@
Читать полностью…
Mike Blazer
17 Apr 2025 11:05
Ограничения сайтмапов в GSC
У Шона есть 16 000 сайтмапов внутри одного файла сайтмап-индекса.
Несмотря на то, что документация Google предполагает, что это должно работать, GSC не отображает это корректно.
GSC показывает "ноль деталей о количестве URL или разбивке сайтмапов" при работе с таким объемом.
Кроме того, GSC API полностью отказывается работать при попытке доступа к этим данным.
Официальная документация утверждает:
— Вы можете отправить до 500 сайтмап-индекс файлов на сайт в GSC
— Каждый файл сайтмап-индекс может содержать до 50 000 ссылок на сайтмапы
— Каждый отдельный сайтмап может содержать до 50 000 URL
Теоретический лимит должен быть 50 000, но всё начало "тормозить" ещё до достижения этого числа.
@
Читать полностью…
Mike Blazer
16 Apr 2025 17:05
Хотите понять, как AI Overviews влияют на эффективность вашего сайта?
Данные о показах и кликах AI Overviews, смешанные со всеми остальными результатами поиска, усложняют анализ.
Но зная типы запросов, которые обычно вызывают AI Overviews, Джес Шольц создала регулярку для GSC, чтобы выявить запросы, которые с высокой вероятностью подвержены влиянию.
Вот базовая регулярка (но обязательно настройте его под свою нишу):
^(who|what|whats|when|where|wheres|why|how|which|should)\b|.*\b(benefits of|difference between|advantages|disadvantages|examples of|meaning of|guide to|vs|versus|compare|comparison|alternative|alternatives|types of|ways to|tips|pros|cons|worth it|best|top)\b.*
Хотите копнуть глубже?
Попробуйте этот воркфлоу:
1️⃣ Используйте регулярку для поиска потенциальных запросов в
GSC2️⃣ Добавьте их в
ZipTie, чтобы подтвердить, какие из них действительно возвращают
AI Overviews (и упоминается ли ваш сайт)
3️⃣ Запустите эксперименты по оптимизации под ИИ и детально отслеживайте результаты
Это не идеальное решение, но оно лучше того, что Google предлагает из коробки.
@
Читать полностью…
Mike Blazer
16 Apr 2025 13:10
Акарш Кавуттан обратился к сообществу с проблемой, связанной с Single Page Application (SPA) клиента, который использует сторонний предварительный рендеринг (от prerender.io).
Из-за ограничений SPA их страницы ошибок возвращают статус-коды 200 вместо корректных 404.
Он отметил, что конкуренты с похожими настройками решают эту проблему по-разному:
— g2g: нет страницы ошибки, все несуществующие URL редиректят на главную страницу со статусом 200
— lootbar.gg: показывает страницу ошибки для несуществующих URL, но все равно возвращает статус 200.
Акарш обнаружил потенциальное решение: редирект недействительных маршрутов на специальную статическую HTML-страницу вне SPA, которая настроена на сервере для возврата корректного HTTP-статуса 404.
Он упомянул, что документация Google предлагает закрывать от индексации страницы 404 и поставил под вопрос, достигнут ли краулеры когда-либо страниц 404, если гигиена сайта в порядке, предполагая, что большинство 404 генерируются пользователями, набирающими некорректные URL.
Советы и мнения сообщества
— Подтвердили, что подход с выделенной страницей 404 является валидным, с альтернативой в виде использования тегов noindex, как описано в документации Google по исправлению проблем поиска, связанных с JavaScript
— Нет большой практической разницы между подходами в том, как Google обрабатывает это, поэтому выбирайте то, что проще реализовать/управлять
— Prerender.io можно настроить для возврата 404 на маршруте с мета-тегом (ссылаясь на документацию лучших практик prerender.io)
— Не редиректьте на страницу с названием "404" - эта страница может фактически ранжироваться в результатах поиска
— Если все редиректы указывают на одну страницу, эта страница имеет тенденцию собирать много ссылочной массы, и если/когда noindex не работает, страница 404 может стать лучше всего ранжируемой страницей на вашем сайте
— 404 также происходят из-за внешних ссылок, особенно когда страницы раньше существовали
— Google не просто забывает о страницах, которые раньше существовали на сайте, но больше не имеют ссылок - они остаются в индексе и будут проверяться и перепроверяться, даже с чистым сайтом, который не ссылается на 404
— Неправильно связанные страницы могут возникать как внутренне, так и внешне. Ошибки неизбежно будут совершаться
@
Читать полностью…
Mike Blazer
16 Apr 2025 08:15
Кевин Индиг создал полностью автоматизированный воркфлоу, который точно определяет каннибализацию, измеряя реальную схожесть контента — за пределами простого совпадения ключевиков.
В нём есть все свежие фундаментальные вещи, которые вы ожидаете:
— чёткая токенизация
— эмбеддинги pinecone
— сочная косинусная схожесть
Но Кевин пошёл ещё дальше.
Воркфлоу также:
— Проверяет бизнес-ценность затронутых ключевых слов, чтобы сосредоточиться на результате.
— Отделяет брендовые от небрендовых запросов для лучших рекомендаций.
— Выполняет исторический анализ СЕРПов, чтобы вы знали, была ли каннибализация одноразовым сбоем или долгосрочной проблемой.
В нём 37 шагов.
Попробуйте: https://airops.typeform.com/to/Hd3ce2pU
@
Читать полностью…
Mike Blazer
15 Apr 2025 15:05
Многие не в курсе, что GSC отчитывается по калифорнийскому времени (PST), а не по вашему местному.
Эта мелочь может серьезно накосячить с репортингом, если не быть начеку.
Для сеошников в Австралии (да и вообще за пределами западного побережья США) это означает, что всплеск трафика в понедельник может выглядеть так, будто он случился в воскресенье.
Ситуация еще больше усложняется, когда вы сводите данные из GSC с инструментами вроде GA4, которые юзают локальное время.
Если пытаетесь сопоставить тренды или объяснить просадку, несовпадение часовых поясов может оказаться той самой загвоздкой.
@
Читать полностью…
Mike Blazer
15 Apr 2025 11:05
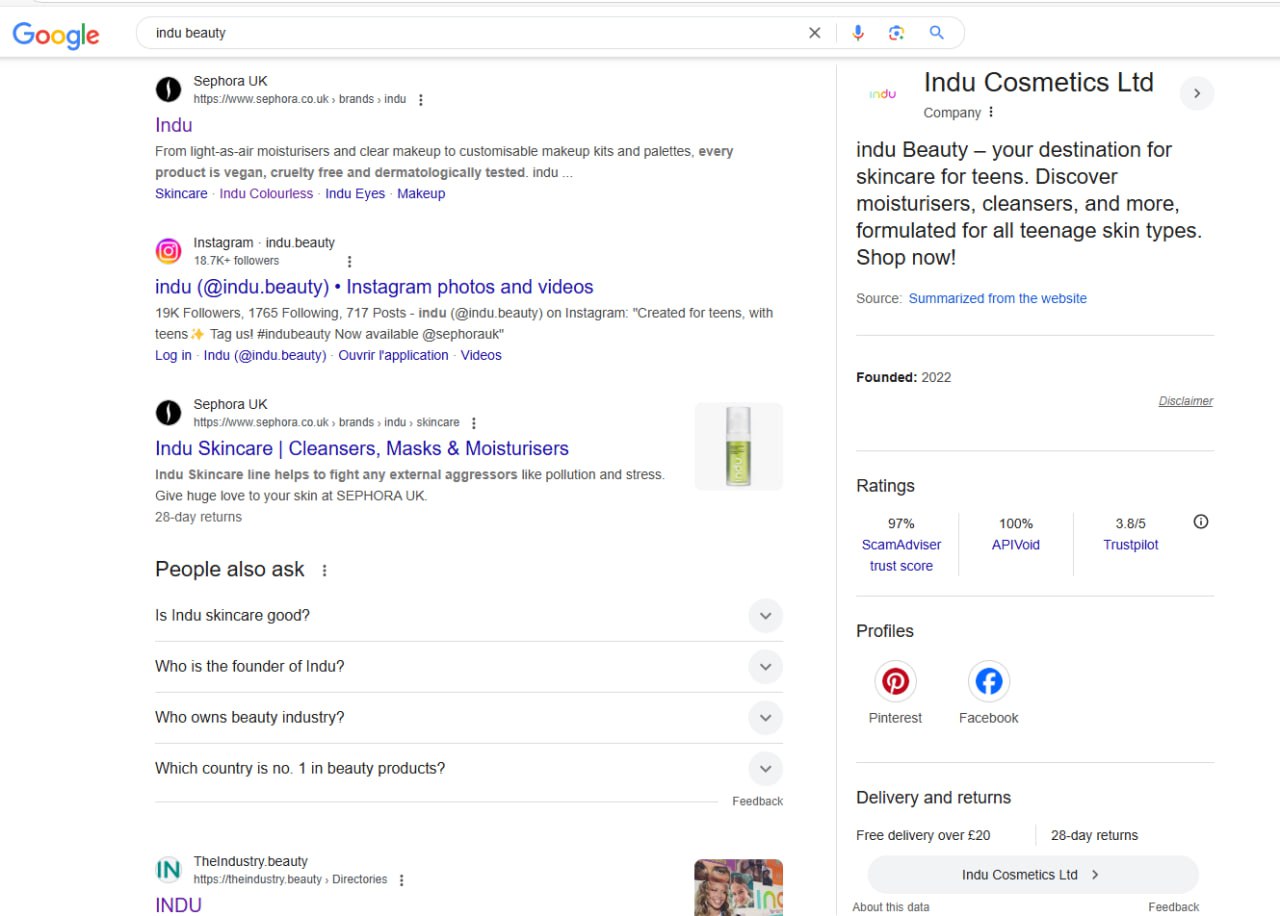
Дейв Эшворт столкнулся с необычной SEO-проблемой с двумя сайтами брендов косметики на Shopify:
— indu.me (запущен в 2023)
— syncbeauty.com (запущен пару месяцев назад)
Суть проблемы в том, что ни один из сайтов не появляется в органической выдаче Google при поиске по названию бренда, несмотря на то, что Google показывает Knowledge Panel с информацией "обобщенной с сайта".
Дейв тщательно проаудировал сайты и не нашел никаких проблем.
GSC не показывает никаких проблем - всё краулится и индексируется, данные показывают показы и клики.
Дейв поднял этот вопрос на форуме сообщества Google, где модераторы эскалировали его инженерам, но ничего не решилось.
Он подтвердил, что ручных санкций в GSC нет.
Он отметил, что при поиске "indu" Google отображает AI-обзор сайта, показывая их страницы в Sephora, Instagram, LinkedIn и упоминания в бьюти-изданиях - это говорит о том, что Google точно знает, кто такие Indu.
Дейв рассматривает возможность предложить смену домена на что-то вроде "indubeauty.com", но замечает, что такой подход не помогает Sync Beauty.
Советы и идеи сообщества
— Для Indu beauty то, что отображается - это Google Business Profile (GBP), а не Knowledge Panel.
— Данные Ahrefs показывают, что у Indu были сильные напор на линкбилдинг, который достиг пика примерно в ноябре 2024, а затем снизился.
Сайт появляется на 4 странице по запросу "indu skincare", но никогда не ранжировался по "indu beauty".
— Сайт ранжировался по запросу "indu" в контексте индийского телешоу.
— То, что Google возвращает сайт бренда как панель, означает, что он в общих чертах понимает оба бренда в контексте "beauty", но это не является общепринятой интерпретацией запроса.
— Поскольку Sephora ранжируется по Indu и поисков по "indu" в контексте красоты ограничены, Google может видеть меньше причин возвращать сайт, когда Sephora предлагает такое же ценностное предложение.
— В файле robots.txt на indu.me есть проблемы:
1. дублирующаяся директива user agent,
2. пустой блок и относительный URL сайтмапа (/sitemap.xml) вместо абсолютного URL.
— Проблема, вероятно, не техническая и не связана с Shopify.
Для "indu" СЕРП показывает аккаунт в Instagram аналогично поискам по "indu beauty".
— Google может не понимать поисковый интент для "indu", потому что он слишком широкий.
— Существует проблема распознавания сущности:
бренд называется "indu", но на сайте используется "indu beauty", что не является частью названия бренда.
— Домен .me может препятствовать видимости, так как они редко появляются в СЕРПах.
— Существует несогласованность сущности:
"Indu Cosmetics Ltd" не соответствует бренду.
— Проблемы с реализацией Schema:
существует несколько схем, добавлены локации Sephora, и ни одна не соответствует бренду.
— Существуют потенциальные проблемы с дублированным контентом, поскольку компания запустилась с продуктами, доступными только в Sephora, прежде чем начать продавать напрямую.
— При поиске описаний продуктов с syncbeauty.com в кавычках не появляется никаких результатов, несмотря на то, что текст отображается в мета-дескрипшенах через поиск с оператором site:.
— Возможно, недостаточно взаимодействия через Google, потому что подростки не так часто используют его для поиска.
— Подобные проблемы испытывали Xyon Health при найме SEO-менеджера и Geeks for Geeks (у которых ручные санкции).
— Проверьте общие черты между приложениями, установленными на обоих сайтах.
— Рассмотрите возможность выпуска пресс-релиза с хорошим синдикационным распространением для анонсирования бренда.
— Сайты, ссылающиеся на Sync с подробностями, на первый взгляд похожи на PBN.
@
Читать полностью…
Mike Blazer
14 Apr 2025 17:05
Когда Google обсуждает *любой* потенциальный сигнал ранжирования, в слове "напрямую" (directly) содержится вся суть 💪.
-
Существует 3 состояния:
Напрямую, Косвенно, Не используется.
Переведем их как:
Фактически, Прокси, Бред.
По какой-то непонятной причине, значительный % SEO-сектора фокусируется на Фактическом, не может понять Прокси и обожает налегать на Бред.
@
Читать полностью…
Mike Blazer
14 Apr 2025 13:10
Джилл Карен занимается SEO уже более 15 лет, но сталкивается с беспрецедентными трудностями в продвижении сайта клиента.
Она работает с компанией-разработчиком ПО, чей директор часто меняет направление развития, из-за чего внешний вид и контент сайта менялись как минимум 4 раза за последние годы (2 раза с тех пор, как она начала работать с ними в мае).
Они удалили много контента и все еще работают над улучшением оставшегося.
Джилл особенно озадачена эффективностью основных страниц.
Для главного сервиса компании ей удалось вывести их на вторую страницу выдачи на короткое время после 18 месяцев отсутствия видимости, но затем они снова провалились.
Она пробовала все, но не может даже попасть в топ-100.
Сайту нужно больше бэклинков, и он находится в очень конкурентной нише, хотя они получают много брендового трафика.
Джилл готова заплатить за консультацию, так как у нее заканчиваются идеи.
Она работает над планом построения ссылочной массы, но сталкивается с проблемами из-за отсутствия бюджета и поддержки руководства.
Впервые в карьере она сомневается в своих навыках.
Дополнительные детали ситуации:
— Некоторые страницы хорошо ранжировались несколько месяцев, затем исчезли без изменений
— GSC не показывает проблем, хотя были сложности с краулингом
— Технические проблемы выявлены и переданы разработчикам
— Работа над сайтом идет 3 месяца без прогресса
— Директор провел АБ-тест страницы с ПО в декабре 2023, после чего сайт перестал ранжироваться по основному запросу
— Оригинальная страница исчезла, была восстановлена в сентябре 2024, но снова пропала
— Большая часть трафика приходит от брендовых запросов
— Контакт компании ранее покупал бэклинки против рекомендаций Джилл
— Она указывает на проблемы с брендом, но клиент не реагирует без конкретных данных
Советы и мнения сообщества:
1. Возможно, сайт подвергся мягким санкциям.
Нет определенного способа узнать это, особенно если GSC не показывает проблем.
2. Проблема может затрагивать не только одну страницу, а весь сайт.
Сайты с мягкими санкциями часто требуют реструктуризации и улучшения контента.
3. Внезапная деиндексация страницы указывает на проблемы, но важно исследовать все возможные причины.
4. Изменение URL может серьезно влиять на позиции.
Один спец упомянул клиента, чьи позиции не восстановились через 1.5 месяца после CRO-теста с изменением URL.
5. Рекомендуется поддерживать сайт в чистоте и наращивать качественные бэклинки.
Избегать массового дезавуирования ссылок без веских причин.
6. Стоит проверить, вносил ли клиент крупные изменения в структуру сайта, особенно во время АБ-теста.
7. Техническое расследование должно включать сравнение DOM с конкурентами и анализ проблем в GSC.
8. Рекомендуется использовать "Проверку URL" в GSC для основных страниц, анализируя ошибки в Javascript Console и Page Resources.
9. История домена может быть фактором проблем с ранжированием.
10. Следует проверить совпадение падения позиций с core-апдейтами и провести технический анализ.
11. После изучения сайта обнаружено сильное размывание бренда:
— Компания существует более 40 лет, бренд изначально был одним продуктом
— Страница продукта схожа по интенту с главной страницей
— Существует www2-сайт c некорректными редиректами
— Некоторые редиректы ведут к 404, но всё ещё индексируются
— Исторически продукт не показывается по запросам бренд+продукт
— В результатах появляются субдомены других брендов с брендом клиента
12. Страницы продуктов слишком похожи друг на друга, что недостаточно конкурентоспособно.
13. Необходима дифференциация страниц продуктов, исправление проблем домена и улучшение внутренней перелинковки.
14. Часто упускается что-то простое, как очки, которые находятся у вас на голове.
@
Читать полностью…
Mike Blazer
14 Apr 2025 08:15
Tripadvisor разработал Baldur — инструмент для самостоятельного проведения экспериментов, специально созданный для маркетинговых инициатив.
Этот инструмент обеспечивает более эффективное принятие решений благодаря демократизированным процессам экспериментирования, которые ранее тормозились из-за необходимости привлечения дата-сайентистов.
Маркетинговые эксперименты фундаментально отличаются от продуктовых A/B-тестов.
В стандартных A/B-тестах отдельные пользователи случайным образом распределяются в контрольные или экспериментальные группы, что позволяет контролировать все сторонние переменные.
Такая рандомизация на уровне пользователей позволяет напрямую делать выводы о причинно-следственных связях влияния функций.
Однако маркетинговые эксперименты имеют дело с "аморфными группами", а не с отдельными пользователями, поскольку кампании нацелены на более широкие сегменты, такие как определенные рыночные зоны (DMA) или категории поисковых запросов.
Эта структурная разница создает три существенные проблемы:
— Совокупные эффекты и конфаундеры на уровне группы создают большие различия в том, как метрики реагируют на кампании
— Пользователи могут перемещаться между экспериментальными единицами, нарушая предположение о стабильности значения воздействия (SUTVA)
— Доступно меньше экспериментальных единиц для распределения, при этом высокообъемные единицы могут доминировать в поведении группы
Для решения этих ограничений Baldur использует методологию разности разностей (DiD).
DiD предполагает, что параллельные временные ряды из одного источника данных продолжали бы развиваться параллельно без вмешательства.
Процесс включает:
1. Случайное разделение экспериментальных единиц на группы
2. Построение графиков агрегированного ежедневного поведения для каждой группы
3. Использование параллельных трендов до эксперимента как основы для валидных контрольных и экспериментальных групп
Когда эксперимент запускается, любая наблюдаемая разница между контролем и тестом приписывается эффекту воздействия.
DiD рассчитывается путем сравнения разницы между тестом и контролем в пост-периоде с разницей в пре-периоде.
Поскольку случайная группировка редко дает естественно параллельные тренды при ограниченном количестве экспериментальных единиц, Baldur автоматизирует поиск оптимальных разделений.
Инструмент проводит пользователей через этапы конфигурации, включая:
— Добавление метаданных
— Написание SQL-запросов с определенными требованиями к столбцам
— Установку параметров, таких как дата начала пре-периода, метрики и количество вариантов
Затем Baldur выполняет процесс, который:
1. Создает случайные разделения с использованием стратифицированной выборки
2. Агрегирует каждую группу по дням для создания временных рядов
3. Сравнивает временные ряды, используя такие метрики, как корреляция Пирсона, MAPE и дрифт
4. Повторяет процесс для запрошенного количества разделений
5. Ранжирует результаты для определения лучшего разделения
6. Выводит визуализации для оценки пользователем
7. Генерирует таблицу с назначениями вариантов
8. Анализирует результаты, используя t-тесты для DiD для расчета p-value
Эта автоматизация позволила стейкхолдерам Tripadvisor самостоятельно создавать и измерять маркетинговые и SEO эксперименты, ускоряя обучение и инновации.
https://medium.com/tripadvisor/introducing-baldur-tripadvisors-self-serve-experimentation-tool-for-marketing-7fc9933b25cc
@
Читать полностью…
Mike Blazer
13 Apr 2025 09:15
Вот почему Google не хочет давать вам данные AI Overviews в Google Search Console:
#1 позиция стабильно приносит меньше кликов, чем вторая... и дальше будет только хуже.
Если ссылка отображается в AI Overview (#2), её CTR меньше половины от CTR первого органического результата, который идёт следом.
А #1 в прошлом году показывала до 4 раз более высокую кликабельность, когда AIO отсутствовал.
Для этих запросов, которые показывают AI Overviews, показы выросли на 88% по сравнению с предыдущим годом, но клики упали на 33% (при этом средняя позиция улучшилась на 21% год к году).
@
Читать полностью…
Mike Blazer
11 Apr 2025 17:05
Все в 2025:
— SEO умерло.
— Платный маркетинг умер.
— Маркетинг умер.
— Дизайн умер.
— SaaS умер.
— Твоя компания? Наверное, умерла.
Также все в 2025:
— Ищем директора по маркетингу с 10-летним опытом во всем, что умерло.
— И, да, обязательно владение экселем.
Да здравствует эксель!
@
Читать полностью…
Mike Blazer
11 Apr 2025 13:10
Google:
— Чтобы ранжироваться, создавайте полезный контент, но если вы пытаетесь ранжироваться - это спам.
— Если вы всё-таки ранжируетесь и это не спам, мы его украдем.
— Если вы не ранжируетесь и это спам, мы будем его ранжировать, если вы разместите его на Reddit, но мы и это украдем.
— Если вы не ранжируетесь и это не спам, значит он полезный.
Мда
@
Читать полностью…
Mike Blazer
11 Apr 2025 08:15
Метод для выгрузки всех URL-адресов archive.org для домена в текстовый файл:
http://web.archive.org/cdx/search/cdx?url=example.com*&output=txt
Замените example.com на домен, по которому хотите получить данные.
Вот Google-таблица, куда можно вставить УРЛы из полученного вывода:
https://docs.google.com/spreadsheets/d/1Mq3WdRESZXouE-9ha2ITQzj9xThjr0V0TuN7_nbaBvM/edit?usp=sharing
Она настроена на обработку этих URL и выделение уникальных, так что в итоге получается финальный набор, который можно использовать для анализа (краулинга и т.д.).
@
Читать полностью…
Mike Blazer
10 Apr 2025 17:05
Получи SEO-инсайты из Википедии (на основе реальных аналитических данных).
Если Википедия хорошо ранжируется по какому-либо запросу в вашей нише, вы можете получить представление о том, сколько трафика посылает Google, поскольку их аналитика полностью открыта.
Этот инструмент позволяет вводить твою нишу, ключевое слово или искать по URL статьи для автоматических предложений страниц с трендами.
Попробуй!
https://detailed.com/wiki/
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}