Mike Blazer
17 Feb 2025 13:05
Есть гораздо более эффективный способ изучения ссылочного профиля домена, чем проверка DR/DA/TD/CF!
1. Сделайте копию этой Google таблицы.
Откройте ее, FILE > MAKE A COPY, убедитесь, что скрипты тоже копируются.
2. Зайдите в Ahrefs и введите домен
3. В левом меню кликните на REFERRING DOMAINS
4. Измените SHOW HISTORY на "Don't Show"
5. Экспортируйте все внешние ссылки в Google таблицу
6. Удалите колонку A, затем скопируйте все данные в скопированную выше таблицу во вкладку REFERRING DOMAINS (там оставлена 1 строка для примера)
7. Кликните EXTENSIONS > APPS SCRIPTS
8. В редакторе скриптов убедитесь, что в выпадающем списке выбран "populateReferringDomainsInsights" и нажмите RUN - он запросит разрешения, предоставьте разрешения для запуска
9. Когда выполнение завершится, вернитесь в таблицу и перейдите на вкладку REFERRING DOMAIN INSIGHTS
Теперь у вас будет обзор того, сколько бэклинков попадает в каждую группу по трафику.
Это дает два представления:
1. Внешние ссылки по показателям трафика
2. Внешние ссылки по показателям трафика + группировка по DR
Таким образом, вы получаете наглядное представление о распределении трафика с внешних ссылок.
Это очень общий взгляд, НО это отличный способ увидеть, какая часть ссылочного профиля домена реально обеспечивается доменами с трафиком.
DR сам по себе бесполезен - потому что его легко накрутить.
НО прогнозируемый трафик - гораздо лучший индикатор здоровья домена.
Поэтому если у вас ОГРОМНОЕ количество бэклинков в группах с низким трафиком, то есть:
0-100, 101-1k, 1k-5k, возможно, стоит внимательнее присмотреться к вашей стратегии линкбилдинга.
Есть также другие факторы, такие как спам от внешних ссылок без вашего влияния (с которым сталкиваются некоторые сайты).
ВАЖНО: НИ В КОЕМ СЛУЧАЕ НЕ НУЖНО ДЕЛАТЬ ДЕЗАВУИРОВАНИЕ, если только у вас нет ручных санкций ИЛИ если нет явного спама от внешних ссылок, где есть корреляция между началом/происхождением спама и видимым влиянием на сайт.
@
Читать полностью…
Mike Blazer
17 Feb 2025 08:15
Почему многие SEO-специалисты останутся без работы через 24 месяца (если не изменятся)
Предложение в SEO превышает спрос.
В результате рынок снизил цены.
Большинство агентств берут столько же, сколько 5-7 лет назад, что фактически означает сокращение выручки более чем на 20%.
Вдобавок к этому, затраты на персонал выше, инфляция кусается, и это тоже влияет на доходы.
Входит AI.
SEO-специалисты делают 1 из 4 вещей.
1. Херачат AI-контент (нажмите сюда, чтобы сгенерить 200 статей).
2. "Усилия первого результата": когда люди просто используют первое, что выдает AI.
3. "Смотрите, какой я умный": множество бесплатных и платных инструментов ИИ, которые не обеспечивают эффективности.
Они просто плохо делают то, что вы уже умеете делать.
4. Продуктивный AI-пользователь.
Именно последний способ имеет значение.
Видите ли, AI — это инструмент, который поставляется без инструкции.
Значит, вам самим нужно во всем разобраться.
И именно этот пробел ставит ваши рабочие места под огромный риск.
Потому что высокопродуктивные SEO-специалисты, вооруженные AI, заберут ваши рабочие места и клиентов.
Но НЕ по тем причинам, о которых вы думаете.
Да, они будут более продуктивными.
Однако дело не в количестве... а в том, куда направлена эта продуктивность.
Некоторые используют её для достижения более быстрых результатов для клиентов, что ведет к росту эффективности и улучшению репутации.
Другие используют её для снижения затрат и, следовательно, получат больший маркетинговый бюджет для роста.
А для некоторых высвобожденное время будет использовано для увеличения собственной маркетинговой активности.
И вы не увидите, как это увеличение происходит поэтапно.
Это будет происходить через удержание клиентов и маркетинговую активность в течение следующих 24 месяцев.
Проблема для вас заключается в том, что на смену вам придут SEO-специалисты, которые используют ИИ для выполнения превосходной работы с большей скоростью.
— Именно эти SEO-специалисты получат работу.
— Именно эти сеошники выиграют больше клиентов.
— Именно этих сеошников будут искать работодатели.
Примите AI или будьте заменены.
Но... это не задача ваших работодателей — учить вас этому.
Вы не можете быть пассажиром в своем AI-путешествии.
Вам нужно научиться улучшать свою роль с помощью AI.
Конечно, агентства должны лидировать в этом.
Но ежедневное использование AI "в окопах" зависит от вас.
— Нет оправданий плохим тайтл-тегам.
— Нет оправданий слабому контенту.
— Нет оправданий небрежной SEO-стратегии.
Жесткая реальность для SEO-специалистов не в том, "использовали ли вы AI?"
А в том, что вы должны уметь рассказать своему руководству, "как вы использовали AI" для улучшения работы.
AI помогает вам делать больше, оставаясь собой.
И рынок будет требовать AI-грамотности.
Не проспите это.
Погружайтесь прямо сейчас.
@
Читать полностью…
Mike Blazer
16 Feb 2025 09:05
Гуглер 1: Было бы здорово занять первое место по запросу "AI"?
Гуглер 2: Кажется, у меня есть идея...
@
Читать полностью…
Mike Blazer
14 Feb 2025 15:05
Каково это - слушать подкасты
@
Читать полностью…
Mike Blazer
14 Feb 2025 11:15
Вот почему нельзя полагаться только на ИИ
Мы создали 1000 статей с помощью ИИ, пишет Ниль Патель.
Половина из них была создана исключительно ИИ, а другая половина - с помощью человека.
Посмотрите на разницу, если оценивать каждую статью по оригинальности, читабельности, SEO, вовлеченности и тону голоса.
ИИ останется здесь, но не забывайте о человеке... по крайней мере, при создании контента.
@
Читать полностью…
Mike Blazer
13 Feb 2025 17:05
У клиента на сайте был выложен пример файла Microsoft Excel, который их пользователи могли скачать и использовать для загрузки данных на FTP, рассказывает Билл Хартцер.
Этот пример Excel-файла содержал тестовые данные, что-то вроде: "Джон Доу, 123 Main St., 555-555-1212" и т.п.
Google отметил этот файл и наложил санкции на сайт, посчитав его ресурсом, который "распространяет персональные данные".
Это сопровождалось предупреждением в Google Search Console.
🤦🤦🤦
Билл буквально удалил файл через WordPress и отправил запрос на пересмотр в GSC.
Спустя несколько дней предупреждение было снято, и GSC прислала письмо, что проблема устранена.
Оказывается, "Джон Доу с 123 Main St." — это персональная информация.
Извините, Джон Доу, что раскрыли ваши персональные данные!
@
Читать полностью…
Mike Blazer
13 Feb 2025 13:05
Старый домен до сих пор индексируется и получает трафик (несмотря на 301-редиректы)
Прошло уже более 100 дней с момента миграции домена, и после настройки всех 301-редиректов старый домен всё ещё индексируется и получает трафик.
Я перепроверил процесс миграции и редиректы уже миллион раз, но основная проблема в том, что Гугл неэффективно индексирует наш новый домен и страницы, пишет Энес Кайнар.
Вот что мы сделали в процессе миграции, если вам интересно:
- Настроили 301-редиректы со всех URL и страниц на соответствующие страницы нового домена.
- Обновили настройки GSC для нового домена и отправили запрос на миграцию в консоль.
- Создали новые сайтмапы для домена.
- Обновили все бэклинки, чтобы они вели на новый домен и страницы.
И мы продолжаем работать над проектом, чтобы улучшить показатели нового домена.
Однако старый домен до сих пор появляется в результатах поиска Google по многим запросам и получает значительный трафик, в то время как клики и показы для нового домена оставляют желать лучшего.
Кроме того, когда мы общаемся с кем-то, кто также проходит через процесс миграции домена, все говорят, что это нормально, мол, Google в последнее время усложнил процесс миграции.
Но нормально ли получать такие результаты спустя более 100 дней?
Может быть, мы что-то упустили?
Как бы вы ускорили этот процесс?
@
Читать полностью…
Mike Blazer
13 Feb 2025 08:15
Если вы получаете трафик с изображений, сгенерированных ИИ, вас может скоро накрыть (если уже не накрыло), пишет Зак Ноутс
График ниже показывает соотношение веб-трафика и трафика с картинок для нашей видеоигры Animal Matchup, и трафик с изображений (который приходит с наших AI-изображений) резко просел.
Мы не вносили никаких изменений на уровне сайта в изображения, у нас нет новых технических проблем, а веб-трафик остается относительно стабильным.
Это наводит на мысль, что Гугл объявил охоту на AI-генеренку.
Если это так, у меня двоякие чувства по этому поводу...
Для некоторых наших СЕРПов это, считаю, хорошо.
Например, если кто-то ищет в Google Images "nile croc vs saltwater croc size", то мы не заслуживаем ранжироваться с нашими AI-картинками.
Есть более качественные, не-AI изображения, показывающие графики сравнения размеров с реальными данными.
Это обеспечивает лучший пользовательский опыт для информационного интента.
Однако, если кто-то ищет "Gorilla vs Grizzly Bear", наши AI-картинки (и наша AI-игра) более уместны, так как такой пользователь скорее хочет развлечься, представляя гипотетическую схватку между двумя видами.
Так что, если Гугл действительно ударил по AI-генеренке, то да, это, вероятно, улучшает UX для некоторых СЕРПов, но в других случаях качественные AI-изображения просто попали под раздачу.
АПДЕЙТ:
Мне написали в личку другие владельцы сайтов с AI-картинками.
У них были падения трафика в то же время.
На Animal Matchup трафик с картинок не восстановился, а веб-трафик немного просел, но так сильно, как картиночный.
Скриншот
@
Читать полностью…
Mike Blazer
12 Feb 2025 15:05
Токийский университет использовал ключевое слово "Площадь Тяньаньмэнь" для блокировки поступления китайских абитуриентов
В документе, подготовленном студентами Токийского университета, говорится о том, что на одной из магистерских программ использовался HTML-хак, чтобы помешать студентам из материкового Китая подавать документы:
в HTML-код было вставлена фраза "Площадь Тяньаньмэнь", чтобы страница не загружалась в материковом Китае.
(Китай блочит страницы с вхождениями подобных "ключей".)
https://unseen-japan.com/tokyo-university-chinese-students-tiananmen/
@
Читать полностью…
Mike Blazer
12 Feb 2025 11:15
Декабрьское обновление ядра Google обрушило 44% наших ключей, рассказывает Эндрю Чарльтон.
Вот почему мы не паникуем...
Алгоритмические апдейты — это известные неизвестные в SEO.
Знаешь, что они придут.
Знаешь, что всё перевернут.
Но никогда точно не знаешь как — и просел ли твой сайт из-за твоих действий или просто попал под раздачу в процессе эволюции поисковой выдачи.
Декабрьский апдейт?
Он обрушил 44% информационных запросов наших клиентов по определённым группам страниц.
Что мы сделали?
Не паниковали.
Провели аудит.
Разбив все типы страниц по категориям в нашем дашборде отчётности, мы моментально определили, где сконцентрировались потери — и соответствовали ли они нашим прогнозам год к году (или сильно отклонялись от них).
Дальше мы разобрали каждый потерянный ключ, чтобы найти закономерности:
Вот что бросилось в глаза:
1️⃣ Многие потерянные ключи были низкокачественными запросами, по которым мы вообще не должны были ранжироваться — типа околотематических тем (или даже спама), которые размывали наш основной фокус.
Апдейт сделал нам одолжение.
2️⃣ В 2024 году мы видели, как категории и карточки товаров ранжировались бок о бок по одним и тем же запросам — Google постепенно избавлялся от этих дублей, но декабрьский апдейт захлопнул дверь окончательно.
Вот что важно:
- Помимо потерянных ключей, более 70% запросов показали улучшение позиций.
- Лидов больше, чем за тот же период прошлого года.
Это не история успеха.
Это напоминание о том, что данные важнее шума.
Когда падает трафик, спроси себя:
- Что конкретно теряется?
- Соответствует ли это бизнес-целям?
- Где надо восстанавливать позиции, а где отпустить?
Не весь трафик — хороший трафик.
Не все потери — провал.
А иногда алгоритмы заставляют сфокусироваться на том, что действительно влияет на результат.
Когда вы в последний раз анализировали свои потери трафика — не только чтобы их исправить, но и чтобы понять, стоило ли их вообще сохранять?
@
Читать полностью…
Mike Blazer
11 Feb 2025 17:05
Я покупаю и продаю кучу ссылок, и мне плевать, если это кого-то смущает, пишет Grind Stone.
Пока вы жалуетесь на то, что Google сломан, я активно пытаюсь сломать его еще быстрее.
Давайте начистоту - если ты энтерпрайз-сеошник, тебе лучше прекратить читать прямо сейчас.
После того как потратишь безумные суммы на тысячи ссылок и бесконечные часы на анализ таблиц, точно понимаешь, что работает, а что нет.
Мы еженедельно анализируем сотни доменов, намного больше, чем следовало бы здравомыслящему человеку, отслеживая позиции и паттерны трафика, которые невозможно отфильтровать алгоритмически.
Вот что происходит в траншеях: владельцы сайтов уже не просто фейкят авторитетность - они производят целые профили трафика.
Они используют CTR-боты из методички по ранжированию GMB, чтобы накручивать брендовые запросы, создавать фейковый объем хвостовых запросов и даже запускают PPC-кампании для накрутки CPC по бессмысленным ключам.
Мы делаем аутрич на десятки тысяч сайтов еженедельно и получаем еще тысячи предложений.
Каждый сайт тщательно проверяется, потому что никогда не знаешь, где может скрываться золотая жила.
Но вот вам суровая правда - те сайты с якобы идеальными метриками (хороший авторитет, стабильный трафик, низкий AR) часто оказываются совершенно бесполезными.
Можно залить на каждый по 100 ссылок и не увидеть никакого движения в позициях, потому что они не ранжируются по запросам, которые имеют значение в уравнении Волюм х CPC х Интент.
Эта троица - Волюм х CPC х Интент - ваш путь к стабильным победам.
Работает со всеми типами ссылок - PR, гостевые посты, PBN, нич-эдиты, что бы вы ни выбрали.
Применяйте это к прямым закупкам ссылок, дропам с существующими бэклинками и даже через три рукопожатия...
Единственный способ заметить эти паттерны - самому испачкать руки, потратить серьезные деньги на тысячи ссылок и протестировать все самостоятельно.
Не верьте мне - или кому-либо еще.
Убиваться над таблицами - это жесть, но это единственный способ не слить бюджет на бесполезные ссылки в этой игре фейковых метрик и искусственной авторитетности.
@
Читать полностью…
Mike Blazer
11 Feb 2025 13:05
Хотите поспорить, сколько разных сайтов Gambling.com Group нужно, чтобы заспамить Google локализованным контентом от сторонних контент-маркетинг/SEO-компаний?
Похоже, у них есть отдельный домен для каждого штата США.
Почему?
Потому что весь контент создан исключительно для поиска Гугла.
Ведь зачем "Bet Missouri" писать о шоколаде?:
https://www.betmissouri.com/info/hot-chocolate
@
Читать полностью…
Mike Blazer
11 Feb 2025 08:15
Как одно техническое исправление принесло блогу 7000 кликов за 30 дней
В прошлом году мы начали работать с B2B SAAS-клиентом, у которого контент постепенно терял позиции, пишет Билл Гаул.
Причина?
Их было несколько, но одна из них — глубина краулинга и неоптимальная архитектура сайта.
На многих сайтах настройка страницы блога такова, что лучшие посты со временем "уплывают" всё глубже и глубже в архитектуру сайта по мере добавления новых статей.
(всё дальше и дальше от главной страницы)
Для нашего клиента это было серьёзной проблемой.
Некоторые ценные статьи в блоге находились на расстоянии аж 7, 8, 9 кликов от главной страницы.
Наше решение?
Увеличить количество постов, отображаемых на странице блога.
В течение 30 дней это принесло дополнительные 7000 кликов (рост трафика блога на 23%), причём даже без изменения самого контента.
@
Читать полностью…
Mike Blazer
10 Feb 2025 15:05
AI-обзоры Google уничтожают показатели кликабельности
Трейси Макдональд проанализировала 10 000 информационных запросов в топ-20 позиций, отсортированных по потенциальному трафику.
Методология исследования включала данные из трех источников (Google Ads, GSC и ZipTie) за период январь 2024 - январь 2025.
Ключевые находки:
1. Запросы с AIO изначально имели низкий CTR (подтверждено исследованием SparkToro по zero-click запросам)
2. Влияние AIO аналогично фичерд сниппетов: они появляются на запросах, изначально имеющих низкую кликабельность
3. Органический CTR для запросов с AIO упал с 1.41% до 0.64%
4. Запросы без AIO показали рост органической кликабельности
5. Платный CTR снижается по всем запросам независимо от присутствия AIO
6. Бренды в AIO получают двойной буст благодаря социальному доказательству и высокому базовому CTR брендовых запросов:
— органический CTR растет с 0.74% до 1.02%
— платный CTR увеличивается с 7.89% до 11%
https://www.seerinteractive.com/insights/ctr-aio
@
Читать полностью…
Mike Blazer
10 Feb 2025 11:15
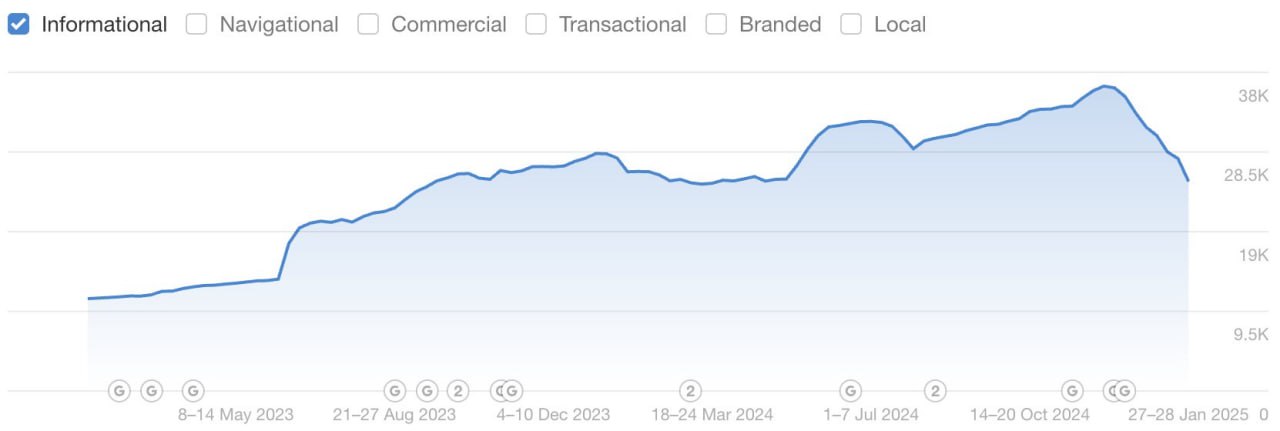
Обновления ядра Google влияют на индексацию, а не только на видимость
Апдейты ядра, выпускаемые несколько раз в год, активно удаляют проиндексированные страницы и понижают приоритет краулинга неиндексированных страниц.
Данные показывают две четкие закономерности во время апдейтов ядра.
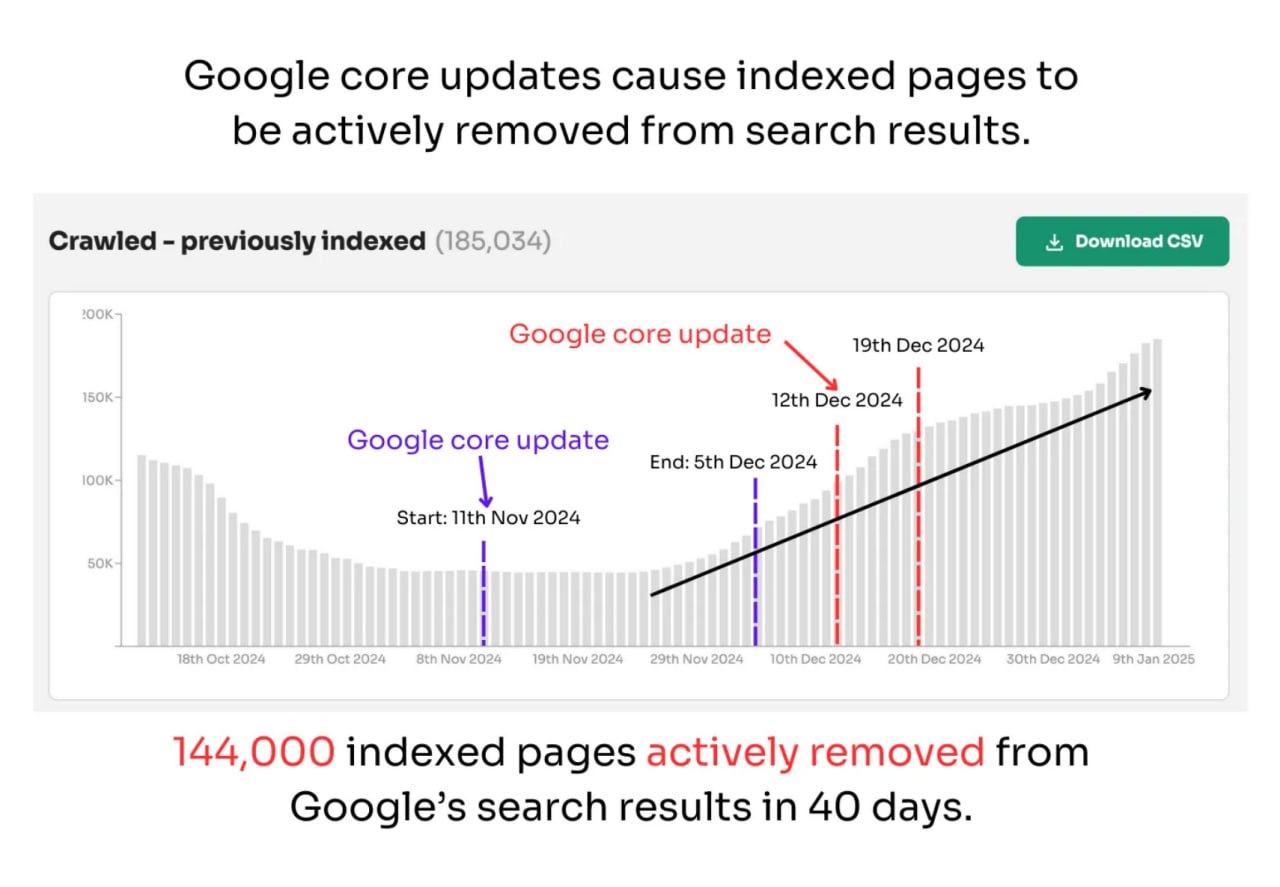
Крупный многоязычный сайт с более чем 1 миллионом страниц потерял 144 000 страниц из индекса за 30-40 дней.
Небольшой издательский сайт с менее чем 10 000 страниц потерял 500 проиндексированных страниц, которые были активно удалены из индекса Google после декабрьского корного апдейта 2024 года.
Кор-апдейты могут привести к тому, что система индексации Google полностью "забывает" урлы.
Сайт с программным SEO показал, что неиндексированные страницы перешли из статуса "отсканировано — в настоящее время не проиндексировано" в статус "URL неизвестен Google", увеличившись с 5 000 до 10 000 страниц в течение 30 дней после декабрьского апдейта 2024 года.
Гари Иллиес подтвердил, что "неизвестные" URLs получают нулевой приоритет от гуглобота.
Три ключевых доказательства подтверждают это влияние на индексацию.
9-летнее исследование Scientometrics, опубликованное в феврале 2016 года, показало, что размер индекса Google существенно варьируется из-за системных апдейтов, а не показывает рост.
Патент Google под названием "Managing URLs" описывает использование порогов важности для управления проиндексированными страницами, объясняя, как Google удаляет старые страницы, когда новым страницам с более высокими показателями важности требуется место в индексе.
Гари Иллиес на конференции SERP в мае 2024 года прямо подтвердил массовую деиндексацию URLs с февраля из-за изменения восприятия качества сайтов.
Это заявление согласуется с неподтвержденным апдейтом Google от 14 февраля 2024 года.
Отчет по индексации страниц в GSC показывает эти влияния через конкретные метрики.
Чтобы проанализировать эффекты корного апдейта, проверьте "Все отправленные страницы" в разделе XML Sitemaps, изучите "Почему страницы не индексируются" и отсортируйте по количеству страниц.
Увеличение количества страниц со статусом "Отсканировано - сейчас не индексируется" или "Обнаружено - сейчас не индексируется" после апдейтов указывает на то, что Google активно удаляет страницы или снижает приоритет краулинга.
Декабрьский и ноябрьский апдейты 2024 года продемонстрировали это поведение через систематическое удаление проиндексированных страниц и корректировку приоритетов краулинга на основе пороговых значений качества Google.
Когда Google обновляет свои системы, как количество проиндексированных страниц, так и их приоритеты краулинга меняются в соответствии с этими перекалиброванными пороговыми значениями важности.
https://indexinginsight.substack.com/p/google-core-updates-impact-indexing
@
Читать полностью…
Mike Blazer
17 Feb 2025 11:15
Теперь, когда все SEO-отчеты за год уже подведены, хочу поделиться выводами по моей клиентской базе, пишет Мэтью Браун.
СРАБОТАЛО:
— Переработка внутренней перелинковки с фокусом на контентные "солнечные системы" в рамках связанных тематик.
Сокращение общего количества ссылок по сайту в пользу перелинковки внутри этих тематических групп.
— Переработка юзабилити, особенно та, что снижает сложность доступа к основному контенту.
Уменьшение необходимых кликов, скроллинга и всего, что мешает восприятию.
— Скорость выхода контента.
Это всегда работало в новостях, но теперь похоже стало серьезным фактором и в органической выдаче.
Тут надо идти гораздо дальше, чем просто поставить "обновлено в январе 2025" в теге.
Команды по соцсетям и контенту, которые следят за изменениями в первых рядах, очень важны для этого.
— Постоянное улучшение самого эффективного контента.
Сложно убедить команды работать над страницами, которые уже хорошо ранжируются, но опережение конкурентского контента реально приносит дивиденды как в органике, так и в AI-поисковиках.
Никогда не забывайте про ваши лучшие страницы!
— Переработка ALT-текстов и подписей к изображениям.
Это дало более сильный положительный эффект, чем в прошлые годы.
Теория — усилилось внимание к этому для подготовки результатов по картинкам к включению в генеративные движки.
НЕ СРАБОТАЛО:
— Фокус на Core Web Vitals.
Уже который год подряд я экономлю время и деньги клиентов, используя их только как диагностический инструмент для выявления потенциальных проблем с юзабилити, а НЕ как метрики для улучшения.
— Расширение типового контента.
Похоже, времена, когда можно было запускать страницы, которые по сути дублируют уже существующий контент, прошли, даже на очень авторитетных доменах.
Я очень скептически отношусь к заявлениям типа "давайте сделаем свои рецепты/тексты песен/спортивные обзоры".
— Переработка SEO-тегов (с использованием AI-решений или без).
Если теги не в совсем плохом состоянии, небольшие улучшения тайтлов/дескрипшенов/схем и т.д. уже не меняют результат так, как раньше.
БОЛЬШОЕ исключение: Когда нужно добавить локальные сигналы, игнорируйте предыдущие предложения.
— Доработка Schema.org разметки.
Как и с тегами выше — разметка полезна для поддерживаемых поисковых фич, но её улучшение, похоже, ничего не даёт.
НА ЧТО ОБРАТИТЬ ВНИМАНИЕ В 2025:
— Исправьте недружелюбный к пользователям UX, особенно рекламу.
Плохие поведенческие сигналы сейчас важнее практически всего остального в SEO.
У меня есть целая презентация про рекламу, за которую меня, наверное, захотят распять все команды по монетизации в интернете.
— Прекратите пытаться подстроиться под AI-ответы и генеративный поиск.
К тому моменту, как вы создадите контент, копирующий формат того, что показывается сейчас, пользователи и поисковики могут уйти дальше.
Делайте максимально качественно и пусть будет, что будет.
— Не позволяйте техническому SEO выпадать из ключевых компетенций.
Оно уже не даёт такого сильного эффекта, как раньше, поэтому я вижу, как сайты забрасывают его.
Это создаст возможности, если вы не будете одним из них.
@
Читать полностью…
Mike Blazer
16 Feb 2025 13:05
На Flippa продали аккаунт в TikTok.
Как думаете, за сколько продали тикток-аккаунт с 519 000 подписчиков?
За $2500 ☠️ ☠️ ☠️
Аккаунты в TikTok сейчас продаются за гроши.
Немного статистики:
519к подписчиков
457к среднее количество просмотров на пост!
$6к заработано за все время
Ниша: юмор и лайфстайл
Финальная цена продажи - $2.5к
@
Читать полностью…
Mike Blazer
14 Feb 2025 17:05
Работа сеошника в двух словах
@
Читать полностью…
Mike Blazer
14 Feb 2025 13:05
Когда в идеале овладел сеошкой по чеклистам
@
Читать полностью…
Mike Blazer
14 Feb 2025 08:15
Как погоня за данными чуть не уничтожила бренд Nike
Nike пережила историческое падение рыночной стоимости на $25 млрд 28 июня 2024 года, потеряв 32% капитализации за один день.
Эта катастрофа произошла не из-за политических скандалов, а из-за чрезмерной зависимости от управления на основе данных.
Трансформация началась, когда Джон Донахо, проработавший 23 года в Bain & Company, в 2020 году стал "CEO" второго по стоимости бренда одежды в мире.
Бывший маркетинговый директор Nike Массимо Джунко выделил три на первый взгляд разумных, но в итоге катастрофических решения.
Во-первых, компания провела реструктуризацию, уволив сотни экспертов и отказавшись от традиционных продуктовых категорий (бег, баскетбол, футбол) в пользу упрощенной сегментации на мужскую, женскую и детскую линейки.
Это серьезно ударило по продуктовым инновациям и внутренней экспертизе.
Во-вторых, Nike перешла на модель прямых продаж (DTC), разорвав партнерства с крупными ритейлерами вроде Macy's и Foot Locker.
Хотя изначально это сработало во время бума e-commerce в пандемию, позже это обернулось провалом, когда покупатели стали выбирать другие бренды из-за снизившейся доступности Nike.
В-третьих, Nike заменила эмоциональные брендовые кампании на диджитал-маркетинг, основанный на данных.
Это создало возможности для конкурентов вроде Tracksmith лучше установить связь с увлеченными спортсменами.
Постоянные скидки и растущие складские запасы подорвали ценность бренда, из-за чего стало сложнее оправдывать цену в $200 за кроссовки.
Креативный брендинг строится на ассоциациях и эмпатии — нематериальных активах, которые создают огромную ценность, но с трудом поддаются измерению.
Новое руководство Nike, сфокусированное на краткосрочной прибыли и оптимизации затрат, не смогло это осознать.
Разработка продуктов пострадала от чрезмерной опоры на данные вместо инноваций.
Отсутствие вдохновляющих кампаний вроде Dream Crazy в течение шести лет привело к тому, что бренд стал восприниматься как устаревший и дешевый.
Видимость бренда и его значимость в сознании потребителей являются критическими факторами успеха.
Отсутствие у Донахо глубокого понимания культуры кроссовок и ритейла привело к катастрофе.
Его консалтинговый бэкграунд привел к приоритету сокращения расходов, что только усугубило проблемы Nike.
Ситуация начала меняться, когда Эллиот Хилл, ветеран Nike с 1988 года, стал CEO в октябре.
Его понимание организации сразу дало результаты с влиятельной кампанией Олимпиады-2024 в Париже "Winning Isn't for Everyone / Am I a Bad Person" ("Победа не для всех / Я плохой человек?").
Эта история дает четкий урок: будьте осторожны с чрезмерной зависимостью от консультантов.
Их аналитические процессы часто не способны понять важность брендинга, пока это не отражается на продажах.
То, что что-то нельзя точно измерить, не значит, что этого не существует — возможно, это и есть самый важный драйвер роста.
https://www.linkedin.com/pulse/how-consultants-almost-destroyed-nikes-brand-erik-mashkilleyson-eywwf/
@
Читать полностью…
Mike Blazer
13 Feb 2025 15:05
Посторонись - сайт с тонким аффилиатным контентом, бесполезный сервис сравнения и спамный агрегатор товаров...
Google теперь публикует пережёванные характеристики производителей прямо из маркетинговых материалов.
-
Ещё один пример экспериментального AI-обзора от Google, который фактически занимает весь СЕРП по ecomm запросу со словом "vs", сравнивающему две модели детских велосипедов.
Обратите внимание на выпадающие меню под каждым из этих пунктов сравнения с длинными списками характеристик.
Хз добавляют ли они какую-то дополнительную ценность при клике.
Такой перебор с характеристиками напоминает переоптимизированную продуктовую страницу.
Конечно, эти элементы нужны для того, чтобы удерживать людей в СЕРПе.
Источники указаны, но там столько сопутствующей информации, что мало кто переходит на сайты издателей.
@
Читать полностью…
Mike Blazer
13 Feb 2025 11:15
Использование @ в Schema.org для связей между сущностями
Атрибут @ создает уникальные идентификаторы для узлов в структурированных данных JSON-LD, работая иначе, чем свойства url и identifier в Schema.org.
В то время как url и identifier передают информацию поисковикам, @ служит внутренней системой референсов.
URL-форматирование следует шаблону {url для сущности @} + #{schema-type}.
Фрагменты страниц вроде #organization резолвятся только относительно URL текущей страницы, ограничивая ссылки этой страницей.
Для связей сущностей между страницами нужны оба свойства - @ и url работающие вместе: @ обеспечивает уникальную идентификацию, а url указывает расположение домашней страницы сущности.
Инструменты тестирования анализируют структурированные данные постранично и пропускают ошибки @.
Валидатор Schema.org проверяет больше типов, чем только подходящие для обогащенных результатов, превосходя функционал Google Rich Results Test.
Google Rich Results Test и краулы Screaming Frog не отловят проблемы с имплементацией @ даже с включенными настройками структурированных данных.
Для устранения неоднозначности сущностей требуются связи sameAs с авторитетными источниками: Wikipedia, Wikidata, профили в соцсетях, официальные справочники, отраслевые базы данных.
Техника @ организует множественные сущности и @ на сложных страницах.
Для имплементации нужны осмысленные фрагменты (#organization, #author-jane-doe), стабильные идентификаторы без динамических компонентов, полная схема на странице несмотря на референсы, и традиционные HTML-ссылки в дополнение к связям в структурированных данных.
Свойство sameAs связывает внутренние сущности с внешними авторитетными источниками для консолидации графа знаний.
Использование JSON-LD достигает 41% страниц, преимущественно в имплементациях для ecommerce и локального бизнеса.
Свойства @ и url устанавливают связи между сущностями для текущей обработки поисковыми системами и будущих разработок в области обработки связанных данных.
https://momenticmarketing.com/blog/id-schema-for-seo-llms-knowledge-graphs
@
Читать полностью…
Mike Blazer
12 Feb 2025 17:05
Поисковые системы отдают приоритет сайтам, которые демонстрируют ответственность, надёжность и реальное существование бизнеса, а также на основе его бизнес-модели и связей с реальным миром.
Например, если сайт ранжируется по запросам об оформлении кредитных карт, но не может их выпускать, пользователям приходится переходить на другой сайт для достижения своей цели.
Это увеличивает "дистанцию до удовлетворения запроса" (distance to satisfaction), которую поисковики стремятся минимизировать.
Сайты, способные напрямую удовлетворять потребности пользователей (например, банки или интернет-магазины), получают приоритет над агрегаторами и партнерскими сайтами.
Именно поэтому нишевые бренды с реальной ответственностью перед клиентами показывают лучшие результаты, чем нишевые сайты, заточенные только под трафик.
Партнерские сайты сталкиваются с особыми сложностями в текущих реалиях.
Поисковики часто отдают предпочтение прямым бизнесам или авторитетным брендам, а не партнерским сайтам, особенно когда у последних нет четкого УТП.
Контекст источника и релевантность на основе сущностей (entity-based relevance) важны для ранжирования.
Чтобы конкурировать, партнерским сайтам необходимо выделяться за счет уникальных инсайтов, партнерских отношений или позиционирования себя как экспертов.
Например, если вы пишете о фотоаппаратах, релевантность вашего сайта зависит от того, кто вы — производитель, фотограф, аффилиат или инженер-оптик.
Поисковики оценивают вашу связь с темой, и эта релевантность на основе сущностей определяет ваши шансы на ранжирование.
Корректировки поискового алгоритма Google, такие как HCU, существенно повлияли на сайты без чёткой тематической направленности.
Многие новые сайты пытаются ранжироваться по всему, что приносит доход, часто без логической связи между темами.
Такое отсутствие фокуса может привести к санкциям, поскольку поисковики отдают предпочтение сайтам, которые предоставляют явную ценность и экспертизу в конкретной области.
Проблемы партнёрского маркетинга
Одна из ключевых проблем аффилиатов - отсутствие прочной связи с продвигаемыми товарами или услугами.
Чтобы добиться успеха, аффилиатам нужно позиционировать себя как экспертов или обзорщиков, а не просто промоутеров.
Например, вместо того чтобы представляться аффилиатом, вы можете позиционировать себя как тестировщика продуктов или обзорщика, подчёркивая свою экспертизу в предметной области.
Построение крепких отношений с партнёрами также критически важно.
Получение обратной ссылки от партнёра на странице "О нас" или в другом релевантном разделе может усилить вашу авторитетность.
Информационное фуражирование
Поисковые системы постоянно тестируют различные конфигурации поисковой выдачи, чтобы определить, какая схема обеспечивает максимальную удовлетворённость пользователей.
Этот процесс, известный как "Информационное фуражирование", включает эксперименты с размещением агрегаторов, прямых интернет-магазинов и других типов сайтов.
Например, изначально в выдаче могут присутствовать несколько партнёрских сайтов, но если поисковики обнаружат, что пользователи предпочитают прямые интернет-магазины, они могут соответственно скорректировать ранжирование.
В такой конкурентной среде партнёрские сайты соревнуются не только с прямыми продавцами или банками — они конкурируют с самым репрезентативным и полным источником в своей нише.
Если поисковик определяет один партнёрский сайт как наиболее авторитетный и всеобъемлющий, он может снизить видимость других аффилиатов в том же кластере.
Поэтому важно освещать каждый аспект темы лучше конкурентов, если вы хотите заменить текущий репрезентативный источник.
@
Читать полностью…
Mike Blazer
12 Feb 2025 13:05
Недавно у меня был созвон с одним eCommerce-брендом, который тратил приличные деньги на SEO с помощью цифрового агентства полного цикла, но в итоге получил падение органического трафика на 80%, пишет Джеймс Норки.
Первое, что бросилось мне в глаза - агентство изменило мега-меню с примерно 100 пунктов до более чем 800+ позиций, что было полным бардаком с точки зрения SEO и юзабилити.
Многие из перечисленных товаров были суперхвостовыми запросами, по которым продавалось не больше 1 товара в месяц, а то и меньше.
Сайт отметил значительное падение - это подтвердилось при отслеживании изменений через Wayback Archive и сопоставлении падения видимости в Ahrefs, владелец также подтвердил существенные потери.
При разработке меню нужно думать о пользователе и включать в список топовые продукты с точки зрения генерации выручки.
Нет смысла включать в список то, что вообще не продается.
Отличный пример меню можно увидеть на сайте Koala (скрин).
Органическая видимость у Koala выглядит хорошо, и они внесли изменения с учетом пользовательских потребностей, что привело к сильным SEO-результатам.
@
Читать полностью…
Mike Blazer
12 Feb 2025 08:15
Насколько точны оценки трафика в Ahrefs, Semrush или Similarweb?
Спойлер: не очень😅 Но насколько именно?
Владислав Тришкин подсчитал цифры, сравнив реальный трафик из GSC со значениями, которые показывали эти инструменты для 184 (!) сайтов.
Результаты:
📉 Ahrefs недооценивает на 49%
📈 Similarweb переоценивает на 57%
📈 Semrush переоценивает на 62%
Мораль сей басни?
Относитесь к этим показателям трафика с долей скептицизма, когда делаете прогнозы.
https://www.slideshare.net/slideshow/seo-b3c1/272436520
@
Читать полностью…
Mike Blazer
11 Feb 2025 15:05
Как проводить исследование аудитории в 2025 году
Исследование аудитории включает сбор и анализ данных о поведении, мотивации, болевых точках и языке целевой аудитории для формирования стратегий, кампаний и месседжей.
В отличие от маркетинговых исследований, изучающих макроэкономические тренды и конкурентоспособность, исследование аудитории работает на микроуровне, показывая, как люди взаимодействуют с контентом.
Традиционные методы вроде опросов часто не соответствуют реальному поведению (например, люди утверждают, что читают "The Wall Street Journal", хотя на самом деле читают "Morning Brew").
Современные сложности включают достоверность реферальных данных (100% визитов с TikTok/Slack маскируются как "директ", 75% переходов из Facebook Messenger не имеют реферальных данных) и zero-click поиски в Google.
5 устойчивых мифов тормозят прогресс:
1. Опора исключительно на данные опросов.
2. Отождествление существующих клиентов с общей аудиторией (упуская криэйторов, венчурных инвесторов).
3. Приоритет источников трафика над центрами принятия решений (40% поисков в Google заканчиваются кликом, половина из которых брендовые/навигационные запросы).
4. Переоценка интервью/фокус-групп для поведенческих данных.
5. Восприятие исследований как разовой задачи.
Согласно "State of (Dis)Content Report 2024", 41% маркетологов недостаточно используют исследования аудитории, что коррелирует с неудовлетворенностью карьерой.
12 эффективных методов исследования:
1. Социальное прослушивание: Отслеживание упоминаний бренда/конкурентов через инструменты типа Google Alerts. Масштабируемо, но требует определенной известности.
2. Анализ соцсетей: Курирование фидов через LinkedIn Saved Searches или Instagram-финсты. Анализ хештегов/вовлеченности. Требует предварительного знания аудитории.
3. Анализ конкурентов: Аудит прямых, аудиторных (например, платформы вебинаров vs CRM) и желаемых конкурентов с помощью SEO-инструментов. Выявляет SEO-пробелы.
4. Комьюнити-менеджмент: Мониторинг сабреддитов (без самопиара) или ведение Slack-групп. Трудоемко, но дает честную обратную связь.
5. Опросы/голосования: Сбор предпочтений в масштабе (например, опросы в Instagram Stories). Подвержены искажениям самоотчетности.
6. Интервью с клиентами: Выявление болевых точек через нишевые платформы. Риск несоответствия поведенческой отчетности.
7. Анализ поискового интента: Классификация ключевых слов (информационные, навигационные и т.д.). Отслеживание трендов в таблицах. Сложности с неоднозначными запросами.
8. Веб-аналитика: Показывает эффективность контента, показатели отказов. Переизбыток метрик усложняет приоритизацию.
9. Кросс-платформенное отслеживание: Построение мультиканальных путей. Требует интеграционных усилий.
10. Данные первого лица: Сегментация метрик CRM/email. Ограничено для новых брендов.
11. Сторонние исследования: Цитирование демографических трендов. Недостаточно релевантно для ниш.
12. AI-аналитика: Прогнозирование трендов, но риск изоляции данных/проблем с GDPR.
Для защиты от будущих изменений диверсифицируйте источники данных и следите за изменениями платформ (например, изменения API в X, Threads/Bluesky).
Фокусируйтесь на базовых принципах, а не на тактиках типа "Ссылка в комментариях!".
Гибкость зависит от комбинации анализа поискового интента с отслеживанием комьюнити.
https://sparktoro.com/blog/audience-research-the-complete-guide-for-marketers/
@
Читать полностью…
Mike Blazer
11 Feb 2025 11:15
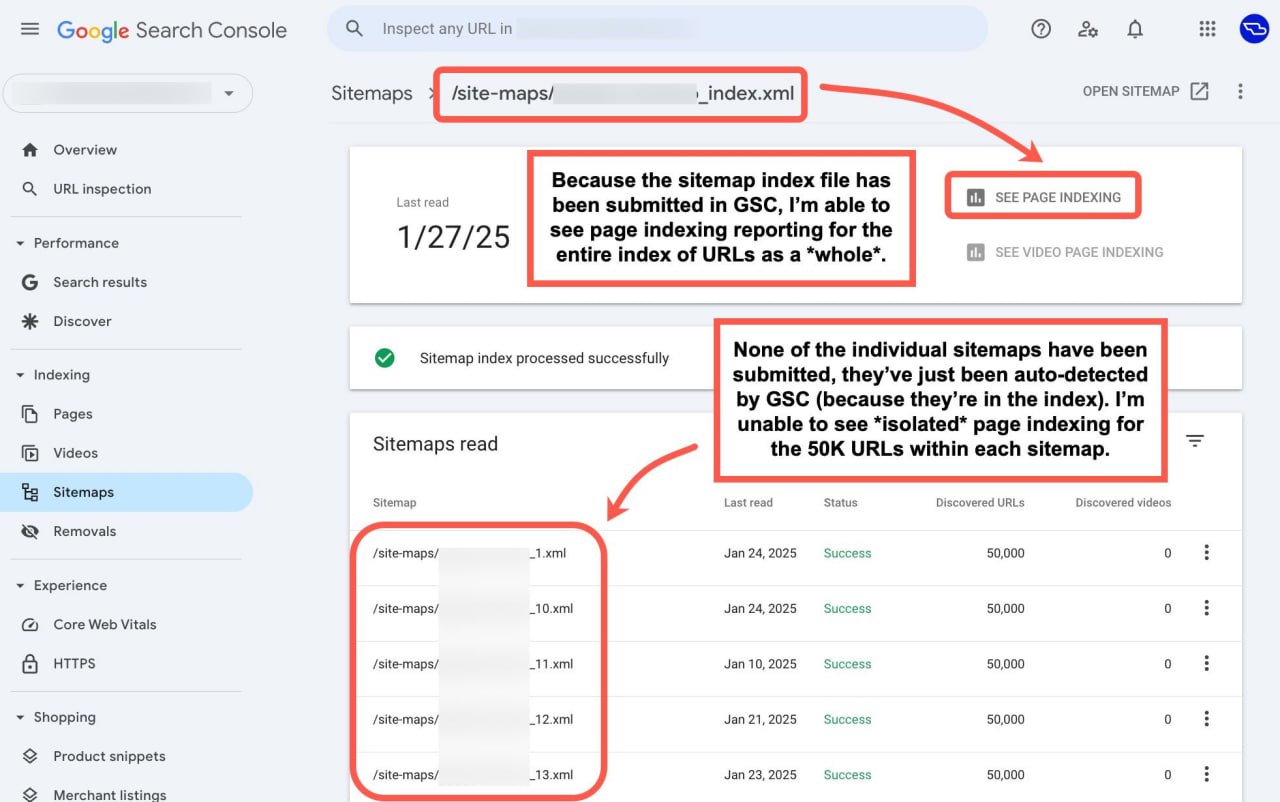
Техническое SEO: недостаточно просто добавить файл сайтмап индекса в GSC, нужно также отдельно сабмитить и все отдельные сайтмапы.
Когда я получаю доступ к GSC клиента, особенно для крупных сайтов, к сожалению, часто сталкиваюсь с тем, что не имею доступа к необходимым данным об индексации с самого начала, пишет Броди Кларк.
Основная причина в том, что был добавлен только сайтмап индекс, а отдельные сайтмапы для ключевых разделов не были сабмитнуты, например, для: товаров, категорий, статей, гайдов и т.д.
Когда речь идет о крупных сайтах, которые максимально заполняют сайтмапы (лимит - 50К страниц), вы теряете массу полезных инсайтов, особенно если можете отслеживать индексацию только для миллионов URL-ов одновременно.
Если вы еще не добавили свои сайтмапы в GSC таким образом, не откладывайте и сделайте это прямо сейчас.
@
Читать полностью…
Mike Blazer
10 Feb 2025 17:05
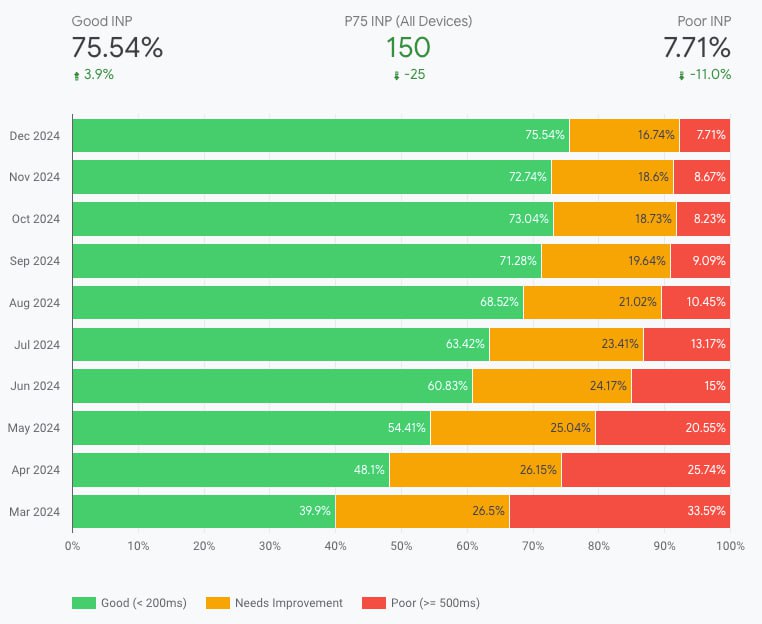
Снижение INP на 80% увеличило рост конверсий на 36% у QuintoAndar
Изначально платформа недвижимости демонстрировала худший INP среди конкурентов: только 42% страниц соответствовали порогу "хорошо" в 200 миллисекунд. Для решения проблемы была введена инициатива "Code Yellow" — концепция, вдохновлённая Google, которая позволяла привлекать любых сотрудников для работ по улучшению производительности.
Анализ RUM (Real User Monitoring) показал, что у 25% пользователей взаимодействие с платформой занимало до 4 секунд во время поиска недвижимости.
Основные стратегии оптимизации
1. Работа с длинными задачами:
- Использование async/await для управления точками приостановки выполнения кода.
- Реализация React-переходов для предотвращения блокировки UI при обновлении состояния.
2. Дополнительные оптимизации:
- Мемоизация данных.
- Дебаунсинг событий.
- Использование аборт-контроллеров.
- Применение React Suspense.
3. Структурные изменения:
- Удаление сторонних пикселей.
- Отказ от CSS-in-JS.
- Оптимизация рендеринга для снижения задержек ввода, вызванных перегрузкой главного потока.
Метрики и управление процессами
Для оценки влияния изменений использовалась метрика Total Blocking Time (TBT) в качестве прокси-показателя.
Система управления производительностью включала:
- Фиксированные и переменные пороговые значения, разделённые по типу приложений и пользовательскому опыту.
- Хранение данных RUM в базе данных с временными рядами для мониторинга и выявления аномальных шаблонов.
- Регулярный анализ порогов тревог на заседаниях раз в две недели.
- Подробные "руководства по действиям" для управления инцидентами.
Внедрение изменений
Для развёртывания изменений использовалась система Canary Release:
- Постепенное масштабирование внедрения: на 1%, 10%, 65% и 100%.
- Автоматический откат изменений в случае ухудшения производительности.
Результаты
Комплексный подход позволил достичь значительных улучшений:
- INP на мобильных устройствах снизился с 1 006 мс до 216 мс.
- Доля страниц с хорошими показателями INP увеличилась с 42% до 78%.
- Число пользователей с плохим опытом сократилось с 32% до 6.9%.
Улучшение пользовательского опыта привело к 36%-му росту конверсий записи на просмотр недвижимости в годовом выражении.
https://web.dev/case-studies/quintoandar-inp
@
Читать полностью…
Mike Blazer
10 Feb 2025 13:05
Поиск потерянных URL после миграции CMS с помощью командной строки и Internet Archive
После миграции CMS всякое может таинственным образом пропасть.
Вместо полноценного сайта у вас может остаться только раздел с гитарами — очевидно, что никто не стал бы делать такое специально, верно?
Вот быстрый и грязный хак для проверки важных потерянных URL.
Internet Archive (IA) предоставляет способ извлечения известных URL.
Поскольку постоянно дергать archive.org немного некрасиво (и иногда не срабатывает — в таком случае закиньте донат в $5 и попробуйте снова), давайте сохраним вывод в текстовый файл:
curl "http://web.archive.org/cdx/search/cdx?url=colored.house.com*&output=txt&from=20241201&to=20241231" --output - > archive-wh-urls.txt
Архив включает нерабочие и не-
HTML URL, поэтому фильтруем их с помощью
grep " text/html 200 ".
Это также отфильтрует
http URL, потому что, будем надеяться, вы настроили редирект на
https.
Затем оставляем
URL из каждой строки (3-й элемент):
awk '{print $3}'.
Теперь каноникализация — у нас есть
URL с параметрами запроса, которые нужно почистить.
Обрежем всё после знака вопроса с помощью
sed 's/\?.*//'.
Не нужно беспокоиться о фрагментах ("#"), так как в
IA их нет (хэштеги же для
JavaScript, верно, а кому он нужен?).
Это отражает базовую каноникализацию, которую делают поисковики.
Oтсортируем по частоте встречаемости
URL:
sort | uniq -c | sort -nr | awk '{print $2}'.
Теперь мы практически Гугл (только без
GPU).
Вот промежуточный шаг:
cat archive-wh-urls.txt | grep " text/html 200 " | awk '{print $3}' | sed 's/\?.*//' | sort | uniq -c | sort -nr | awk '{print $2}' > archive-wh-urls-clean.txtТеперь самая забавная часть — проверка работоспособности
URL.
Разумный человек создал бы простой, читаемый скрипт.
Но мы здесь не для этого.
Возьмем топовые
URL (
head -n 50) и используем
xargs для передачи их в
curl.
Кто-то реально делает так в жизни?
Это дичь.
Но опять же, если бы ракетные инженеры занимались чистыми миграциями
CMS, нас бы здесь не было.
Финальная проверка:
cat archive-wh-urls-clean.txt | head -n 50 | xargs -I {} curl -s -o /dev/null -w "%{http_code} %{url_effective}\\n" {} | grep -v "^[23]"Это показывает топовые "важные"
URL, которые работали в декабре, но теперь не работают или редиректят.
Серьезные владельцы сайтов могут затем решить, какой исторический контент сохранить, что нуждается в новых
URL, а что может остаться
404.
https://johnmu.com/2025-trust-issues/@
Читать полностью…
Mike Blazer
10 Feb 2025 08:15
Массовая скупка Австралийских дропов
Drop.com.au перехватил 271 797 освобожденных и удаленных австралийских доменов с 1 июля по 31 декабря 2024 года, что составляет 99.8% всех дропнутых .au доменов.
SEO Web Recovery выкупили 263 727 из этих доменов через платформу Daily Domain Name Drop Auction от Drop.com.au, что составляет 97% всех доступных освободившихся австралийских доменных имен.
Drop.com.au является частью Above.com, компании, специализирующейся на парковке доменов.
SEO Web Recovery является их крупнейшим VIP-клиентом.
1. Кто такие SEO Web Recovery и какая у них связь с Drop.com.au и Above.com?
2. Сколько денег SEO Web Recovery заплатил Drop.com.au за 263 727 доменных имен?
https://assets.com.au/seo-web-recovery-registered-97-of-every-expired-domain-name-for-the-last-half-of-2024/
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}