Mike Blazer
04 Apr 2025 15:05
Как ссылочный "сок" дает буст
@
Читать полностью…
Mike Blazer
04 Apr 2025 11:05
Как контент выглядит для владельца сайта и как он выглядит для посетителя сайта
@
Читать полностью…
Mike Blazer
03 Apr 2025 17:05
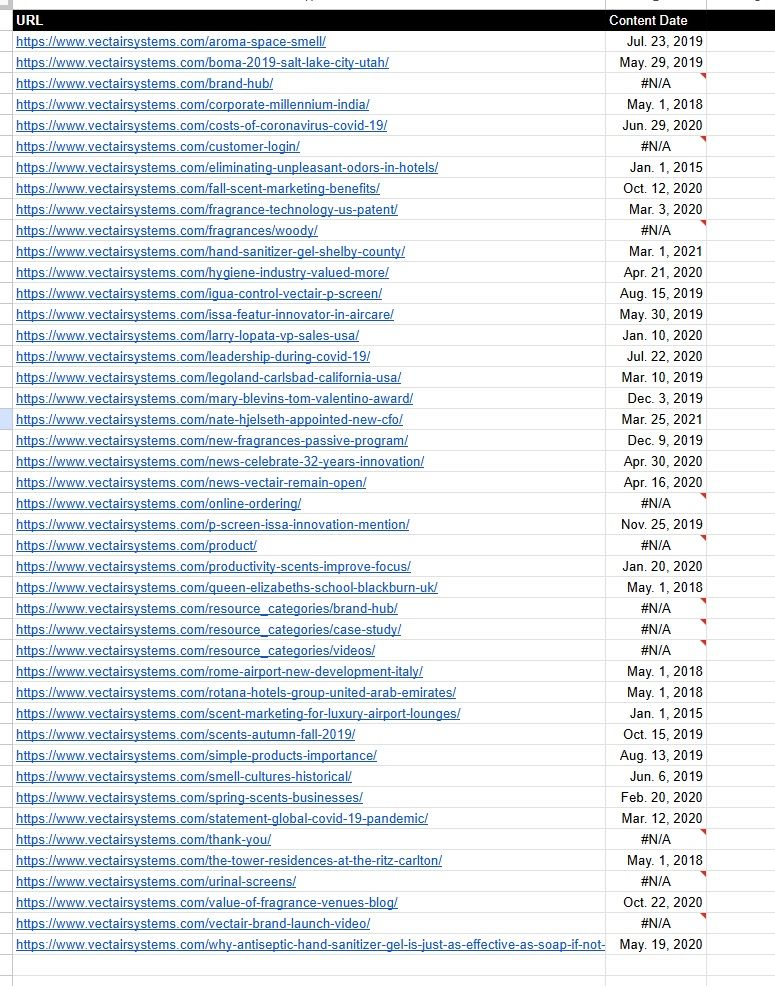
Получи даты контента для твоих URL в G`oogle Sheets` за секунды!
Сделать это до глупости просто - достаточно занести список URL-адресов ваших сайтов в лист Google.
Перейдите на страницу и найдите нужный вам элемент, например DATE, щелкните правой кнопкой мыши на тексте и нажмите INSPECT.
Когда откроется devtools, он автоматически покажет вам выделенный HTML-элемент.
Щелкните правой кнопкой мыши, COPY > Full XPATH.
Затем вставьте XPATH в эту формулу
=IMPORTXML(A2, "Вставьте сюда свой полный xpath")
Таким образом, это выглядит примерно так:
=IMPORTXML(A2, "/html/body/main/section/div[2]/div[2]/span[2]")
Скопируйте функцию ячейки и вставьте ее в свой лист, а затем просто проведите
CASCADE по всем УРЛам.
В первый раз она запросит у вас разрешение на доступ к внешним
URL-адресам, дайте разрешение и запустите снова.
Это СУПЕР ПРОСТОЙ и быстрый способ получения дат контента.
Но это можно сделать с любым видимым элементом страницы - лучше всего работают последовательные элементы, т. е. авторы, даты и т. д.
Можно сделать это и другим способом:
1 . Откройте
URL-адрес и просмотрите исходный код
2. Найдите "
datePublished", если он отображается в исходном тексте.
3. Скопируйте этот скрипт:
function getDatePublished(url) {
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/"datePublished":"([^"]+)"/);
return match ? match[1] : "Not found";
}4. Вернитесь на лист, нажмите
EXTENSIONS >
APPS SCRIPT, вставьте скрипт, сохраните и запустите, дайте разрешения.
5. Вызовите скрипт следующим образом:
=getDatePublished(A2)
Что вы можете сделать с этими удивительными данными?
Используйте
VLOOKUP, чтобы сопоставить ваши
URL-адреса с данными поисковой консоли за последние 3, 12 и 16 месяцев, загруженными в лист.
Примените фильтр и найдите устаревший контент, у которого мало или совсем нет кликов и показов.
Проверьте наличие внешних ссылок с помощью пакетного анализа
AHREFS - все, на которые есть внешние ссылки,
URL-адреса
301, те, на которые нет ссылок, удаляют контент и
HTTP 410 URL-адреса, чтобы устранить их.
@
Читать полностью…
Mike Blazer
03 Apr 2025 13:10
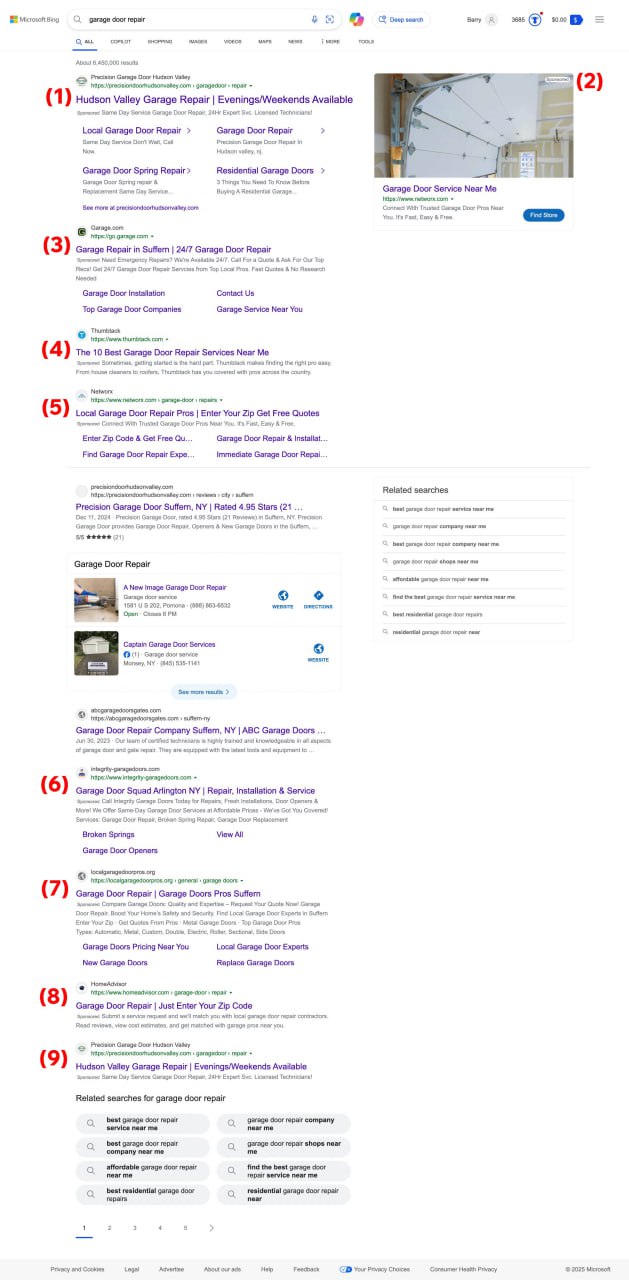
Бинг выдача с 9 рекламами!!!
Представьте, что LLM-ки ходят в Бинг за инфой и скликивают рекламу...
Оли так и пишет: "Когда мы тестировали OpenAi Operator, он использовал Bing и кликал по объявлениям."
@
Читать полностью…
Mike Blazer
03 Apr 2025 08:15
Исправления технического SEO не могут восстановить трафик, если само техническое SEO его не сломало.
Резкое падение органического трафика крайне маловероятно из-за того, что что-то на сайте сломалось с точки зрения технического SEO.
В редких случаях я видел, когда техническое SEO становилось причиной значительного падения SEO-трафика, но это происходило из-за чего-то конкретного, например, неправильного robots.txt, сломанных каноникал директив или неудачного внедрения технических изменений, пишет Эли Шварц.
Обычно эти проблемы можно выявить быстрым просмотром исходного кода нескольких страниц или уточнением, были ли недавно какие-то серьезные технические изменения.
Тем не менее, многие люди сначала пытаются устранить проблемы с SEO, ища технические проблемы, тратя ценное время, которое следовало бы посвятить поиску реальных причин.
Каждые пару недель компании просят меня порекомендовать им агентство для аудита их сайта из-за внезапного (или даже постепенного) падения трафика, и я стараюсь быстро оценить, может ли техническая проблема вообще быть виновником, прежде чем позволить им совершить эту ошибку.
@
Читать полностью…
Mike Blazer
02 Apr 2025 11:05
Все в восторге от траффикового потенциала ChatGPT.
Вот почему я настроен скептически, пишет Эндрю Чарльтон.
Для одного из наших клиентов, переходы из ChatGPT составили всего 0.0031% от общего трафика в феврале.
И это характерно для большинства моих клиентов (даже тех, кто сильно зависит от информационного трафика)
На первый взгляд, рост еженедельной активной аудитории ChatGPT - с 50 миллионов в январе 2023 до 400 миллионов к февралю 2025 - должен изменить ситуацию.
Но когда прогнозируешь рост рефералов, цифры остаются непримечательными.
Вот как это выглядит в конкретных числах:
Потенциальный рост еженедельной активной аудитории ChatGPT:
2025: 400 млн пользователей (текущее состояние)
2026: 800 млн пользователей (рост в 2 раза)
2027: 1.6 млрд пользователей (рост в 2 раза)
2028: 2.4 млрд пользователей (+50%)
2029: 3.36 млрд пользователей (+40%)
Прогноз доли реферального трафика (при пропорциональном росте):
2025: 0.0031% (текущее состояние)
2026: 0.0062%
2027: 0.0124%
2028: 0.0186%
2029: 0.0248%
Даже при агрессивных предположениях о росте пользователей, рефералы от ChatGPT будут составлять едва ли 0.025% от общего трафика через пять лет.
Это вряд ли можно назвать переломным моментом, если только Google полностью не утратит хватку в поиске.
Стоит отметить, что эти проценты предполагают пропорциональный рост всего остального - что в случае Google маловероятно, учитывая продолжающееся снижение кликов.
И, конечно, это только если реферальный трафик будет масштабироваться пропорционально росту пользователей (я ожидаю, что процент рефералов от пользователей вырастет, как объясню ниже).
Как и Google, OpenAI в конечном итоге потребуется как-то стимулировать создателей контента.
Модель Google, вознаграждающая сайты трафиком в обмен на парсинг их контента, успешно работала десятилетиями - авторы получают клики, а Google поддерживает свой поисковый индекс.
Если OpenAI хочет, чтобы качественный, свежий контент продолжал поступать в ChatGPT, компании, вероятно, придется усилить это соотношение.
Сейчас баланс нарушен, слишком много контента используется без достаточного вознаграждения.
Чтобы это изменилось, количество кликов должно увеличиться.
Так что, возможно, в долгосрочной перспективе рефералы из ChatGPT вырастут.
Но пока они едва заметны в общей статистике.
@
Читать полностью…
Mike Blazer
01 Apr 2025 17:05
VPN портят данные в GSC (и да, это важно)
Если вы анализируете данные по странам в GSC для SEO-инсайтов, вам необходимо знать о серьезном слепом пятне: VPN.
Вот масштаб проблемы:
— 45% американцев используют VPN для работы или личных целей
— Около 1.5 миллиарда пользователей VPN по всему миру
— Прогнозируется рост рынка VPN до $87.1 миллиарда к 2027 году
Это имеет серьезные последствия для вашей SEO-отчетности.
Когда пользователь подключается через VPN, его трафик выглядит так, будто он идет из места расположения VPN-сервера, а не из его фактического физического местоположения.
Это значит, что трафик, который кажется идущим из Германии, может на самом деле быть от человека, сидящего в Дании.
Корпоративные VPN особенно проблематичны, поскольку они могут сделать так, что целые компании будут выглядеть как браузеры из одного местоположения, создавая искусственные "хотспоты" в ваших данных.
Так что в следующий раз, когда вы будете отчитываться о "новой международной аудитории" или принимать решения по геотаргетингу на основе данных GSC, не забудьте учесть эффект VPN.
Как вы отделяете реальный международный трафик от VPN-помех?
https://www.top10vpn.com/assets/2020/03/Top10VPN-GWI-Global-VPN-Usage-Report-2020.pdf
@
Читать полностью…
Mike Blazer
01 Apr 2025 13:10
Freshness Distance Calculator помогает определить, как часто вам следует обновлять ваш контент.
Анализируя результаты поиска, инструмент подсказывает, когда именно следует обновлять страницы, чтобы сохранить их конкурентоспособность.
https://freshnessdistancecalculator.com/
@
Читать полностью…
Mike Blazer
01 Apr 2025 08:15
Большой список поисковых операторов SEO для построения ссылок, аутрича, анализа конкурентов
Можете заменить "intitle" на "inurl" или "intext"
article + intitle:"keyword"
become a contributor + intitle:"keyword"
become a writer + intitle:"keyword"
blog + intitle:"keyword"
category + intitle:"keyword"
contribute to our + intitle:"keyword"
contribute to this + intitle:"keyword"
directory + intitle:"keyword"
guest article + intitle:"keyword"
guest author + intitle:"keyword"
guest blog + intitle:"keyword"
guest blogger + intitle:"keyword"
guest column + intitle:"keyword"
guest post + intitle:"keyword"
guest writing + intitle:"keyword"
guest writer + intitle:"keyword"
guide + intitle:"keyword"
links + intitle:"keyword"
magazine + intitle:"keyword"
news + intitle:"keyword"
research + intitle:"keyword"
resource + intitle:"keyword"
roundup + intitle:"keyword"
submit + intitle:"keyword"
tag + intitle:"keyword"
useful + intitle:"keyword"
website + intitle:"keyword"
write for us + intitle:"keyword"
@
Читать полностью…
Mike Blazer
31 Mar 2025 15:20
Политики Google по спаму основаны на пресечении злоупотребления "практиками", а не типами контента.
-
Спам никогда не был связан с "содержанием".
Он почти всегда был связан с "интентом".
-
Даже если намерения не были спамерскими, если это спам - это будет нарушать правила.
Т.е. вы нанимаете кого-то, они что-то для вас делают, вы понятия не имеете, что это спам - ну, это всё равно спам.
@
Читать полностью…
Mike Blazer
31 Mar 2025 11:05
Мне одному кажется, что к Google было бы гораздо больше симпатий, если бы они выпустили новые рекомендации до того, как взмахнут косой, уничтожая владельцев сайтов? - спрашивает Росс Стивенс
После 2 лет теории SEO и гаданий владельцев сайтов, это выглядит типа так:
"Круто, вы мертвы, а теперь вот почему".
@
Читать полностью…
Mike Blazer
30 Mar 2025 10:05
В 2013 году, когда я получил ручник "pure spam", вот что я отправил в GSC в качестве запроса на пересмотр.
Помогло ли это добиться снятия "бана"?
Нет.
@
Читать полностью…
Mike Blazer
28 Mar 2025 13:05
Все вокруг: ап Гугла тебя не задел?
Я: нет, все классно!
Тоже я: ...
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}