Mike Blazer
09 Feb 2025 14:05
Реальный хак:
Если добавить "fuck" в конце поискового запроса, это отключает AI-обзоры.
Минус в том, что вместо них получаешь результаты с Reddit'а...
@
Читать полностью…
Mike Blazer
08 Feb 2025 10:46
Как на самом деле работает A/B-тестирование мета-тайтлов:
Вы пишете новые сочные тайтлы и применяете их к выборке страниц, ждете 30 дней, наблюдая рост кликов и CTR, и делаете вывод, что новые метатеги эффективны.
Что происходит под капотом:
Ваши новые мета-тайтлы оказались хуже предыдущих версий, из-за чего Google начал чаще переписывать переписывать ваши тайтлы в сниппетах, что привело к улучшению CTR и, как следствие, увеличению кликов и показов.
@
Читать полностью…
Mike Blazer
07 Feb 2025 15:05
Когда я вижу людей, которые все еще используют Google для поиска
@
Читать полностью…
Mike Blazer
07 Feb 2025 11:15
9 промптов для создания эмоциональных заголовков:
— Achievement:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can achieve their goals with [brand] product.
— Autonomy:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can feel more free with [brand] product.
— Belonging:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can feel more accepted with [brand] product.
— Competence:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can feel more competent with [brand] product.
— Empowerment:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can feel empowered with [brand] product.
— Engagement:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can enjoy more of their life experience with [brand] product.
— Esteem:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can increase their appeal with [brand] product.
— Nurturance:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can nurture themselves (or their families) with [brand] product.
— Security:
Give me 10 ad headlines (4-7 words long) that persuades [target market] that they can guarantee their success with [brand] product.
@
Читать полностью…
Mike Blazer
06 Feb 2025 17:05
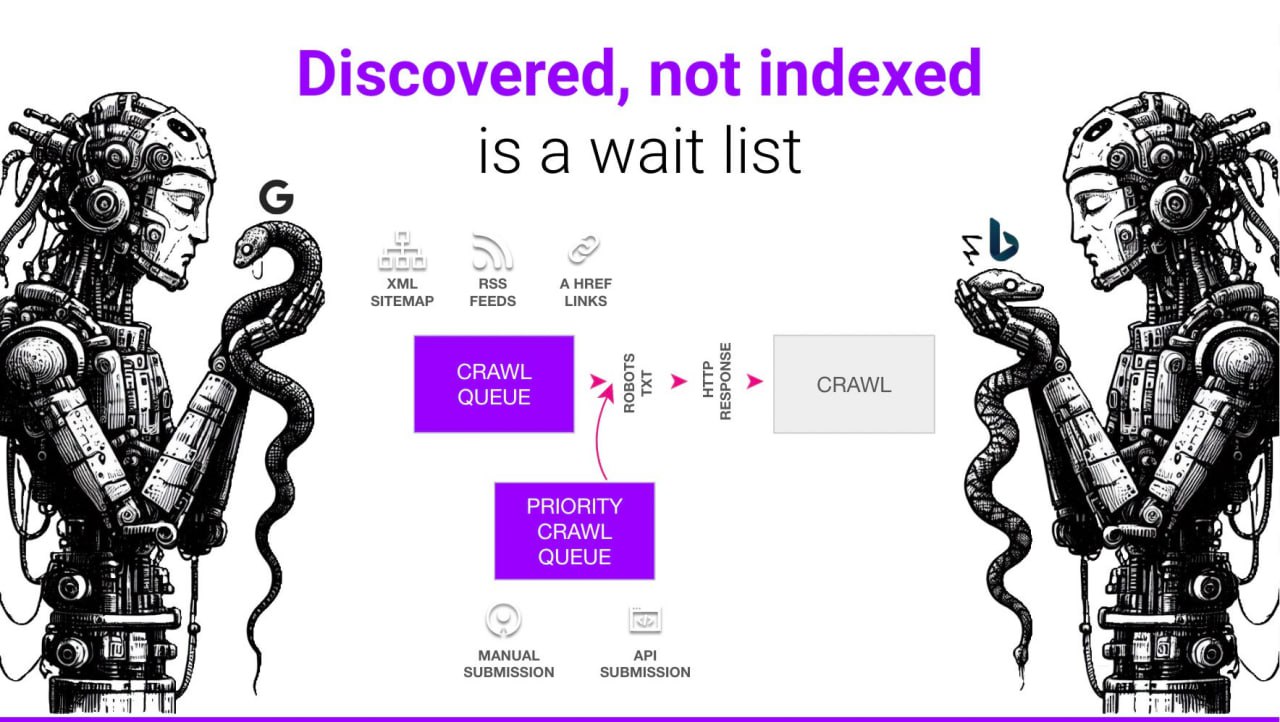
"Обнаружено - в настоящее время не проиндексировано" - это список ожидания
Что на самом деле означает "Discovered - currently not indexed"?
У Гуглбота и Бингбота всегда есть очередь URL-адресов, ожидающих краулинга.
Она формируется из URL, найденных в:
📍 XML-сайтмапах
📍 RSS-фидах
📍 Во внутренних и внешних ссылках
Краулинг работает как двухуровневая система с приоритетной очередью, которая позволяет ускорить процесс, когда вы:
📍 Вручную отправляете URL в GSC или Bing Webmaster Tools
📍 Отправляете через API индексации
Все эти URL, ожидающие в очередях, помечены как "Discovered - currently not indexed".
Поисковики знают об их существовании, но еще не добрались до их краулинга.
Большое количество таких исключений показывает, что нужно сфокусироваться на оптимизации краулинга.
-
Перейдем к "Crawled - currently not indexed" (Просканировано - в настоящее время не проиндексировано).
Многие считают, что это проблема качества контента.
Но часто это не так.
Это техническая проблема.
Либо вы прячете большую часть SEO-значимого контента за JavaScript.
В этом случае решение простое - прекратите это делать.
Особенно учитывая растущие доказательства того, что AI-краулеры не могут получить доступ к контенту с клиентским рендерингом.
Либо исключение происходит потому, что контент все еще анализируется для понимания контекста:
📍 Мета-теги, каноникалы, структурированные данные, текст, изображения, видео - все требует оценки.
📍 Нужно отметить дубликаты, оценить качество и проверить информационную ценность.
📍 Необходимо учесть авторитет бренда, силу путей и ссылочные сигналы.
И все это требует времени.
Чтобы ускорить процесс и уменьшить количество ценных URL, помеченных как "Crawled - currently not indexed", сосредоточьтесь на оптимизации краулинга и индексации.
@
Читать полностью…
Mike Blazer
06 Feb 2025 13:05
Инструмент для проверки HTTP Cache Header в Request Metrics.
Удобный инструмент для анализа того, как браузеры будут кэшировать ваш сайт, изображения, скрипты и любые другие веб-ресурсы.
Грамотное использование кэширования может значительно улучшить веб-перформанс для повторных посетителей.
Абсолютно бесплатно, без регистрации:
https://requestmetrics.com/resources/tools/http-cache-checker/
@
Читать полностью…
Mike Blazer
06 Feb 2025 08:15
Сколько контента нужно публиковать?
— Если конкуренты публикуют 1200 статей в год, то 100 постов в месяц - вполне реально.
— Оцените ценность трафика относительно ваших затрат, чтобы понять ROI.
Если вы уверены в качестве - спринтуйте.
Если нет - начните с малого и оттачивайте процесс.
-
Как определить объем публикации контента для SEO
Объем публикаций в SEO — это не про то, чтобы равняться на производительность конкурентов.
Контент — это инвестиционный актив, и частота публикаций должна определяться потребностями аудитории, а не действиями других.
Как и при производстве терок для сыра, создание контента должно базироваться на финансовых возможностях и прогнозируемой отдаче.
Правильный подход к определению объема публикаций начинается с анализа аудитории и спроса/интереса, установки четкого бюджета и определения конкретных целей.
Чтобы определить оптимальную скорость производства контента, посчитайте стоимость одного материала и ожидаемую отдачу со временем, затем разделите доступный бюджет на количество необходимых релевантных материалов.
Такой подход гарантирует, что ваша контент-стратегия соответствует вашим целям, а не слепо следует графикам публикаций конкурентов.
Хотя анализ конкурентов важен, он должен выходить за рамки простого подсчета количества контента.
Сфокусируйтесь на том, как работает их контент, насколько он релевантен вашему бизнесу и какое реальное влияние оказывает.
Если конкуренты публикует 1000 пустышек в месяц ради 10000 визитов без влияния на бизнес — это не та модель, которой стоит подражать.
При масштабировании производства контента нужно учитывать несколько критических факторов.
Важно правильно распределять бюджет между созданием нового контента и улучшением существующих материалов.
Масштабное производство контента может привести к каннибализации ключевых слов, что требует надежной системы отслеживания контента.
Некачественный контент в больших объемах рискует привести к санкциям от Google, а программная генерация контента может создать проблемы с дублями при создании похожих сравнительных страниц (например, [X vs Y] и [Y vs X], или [красные яблоки] vs [апельсины]).
Пробелы в контенте для пути пользователя и поддерживающих материалах могут навредить конверсии больше, чем помогает трендовый контент.
Для крупных сайтов краулинговый бюджет становится важным фактором, когда новый контент может отвлекать внимание от старого, или новый контент может игнорироваться.
Это требует правильных методов управления краулингом.
Наконец, темы и форматы контента различаются по потенциальной отдаче, поэтому важно отдавать приоритет тем, которые имеют больший интерес и потенциал трафика, чтобы не тратить ресурсы на низкоэффективный контент.
@
Читать полностью…
Mike Blazer
05 Feb 2025 15:05
На основе наблюдений за 142 сайтами в нише купонов и промокодов, где отслеживались случаи манипуляций с репутацией сайтов, Мальте Ландвер делится следующими наблюдениями:
▶️ Май 2024: Затронуты были только США и Великобритания.
▶️ Июнь 2024: Эффект распространился на другие англоязычные страны.
▶️ Q4 2024: В США под санкции попали дополнительные компании.
▶️ Январь 2025: Произошел запуск во многих (но не всех) странах ЕС.
Похоже, что Гуглу нужно обучить людей, владеющих соответствующими языками, чтобы выдавать эти ручные санкции.
Это объясняет, почему Гугл сначала расширил охват с США/Великобритании на другие англоязычные рынки.
@
Читать полностью…
Mike Blazer
05 Feb 2025 11:15
Какая самая недооцененная конфигурация в международном SEO?
Нет, это не hreflang разметка:
Это возможность краулинга перекрестных ссылок между страницами на разных языках или версиями URL для разных стран!
До сих пор это настолько легкодоступный фрукт для СТОЛЬКИХ сайтов с международными версиями, которые в итоге реализуют глобальную навигацию без возможности краулинга, или такую, которая всегда ведет на главную страницу каждой языковой/региональной версии вместо альтернативных языковых/региональных версий текущей страницы.
Это не только помогает краулингу между различными международными версиями сайта, но и позволяет передавать внутренний ссылочный вес между ними, что особенно полезно, когда у вас есть одна хорошо развитая версия и много новых!
Работаете над сайтом с международными версиями?
Сделайте себе одолжение - проверьте, правильно ли это реализовано, и если нет - сделайте это приоритетной задачей прямо сейчас.
@
Читать полностью…
Mike Blazer
04 Feb 2025 17:05
Возвращение Короля
(или как мы обошли Semrush и Ahrefs по запросу "SEO checker")
Годами мы пытались вывести главную страницу Sitechecker на первое место по этому ключу, пишет Иван Палий.
Ничего не помогало: ни смена контента, ни дизайн страницы, ни мощные бэклинки.
Потом Роман Рогоза сделал наблюдение.
В топ-10 ранжировались 2 типа сайтов:
— те, кто выдают SEO-отчет без регистрации;
— те, кто выдают SEO-отчет только после регистрации (Semrush и Ahrefs).
Наша главная страница тоже требовала регистрации для получения отчета и, как следствие, имела высокий показатель отказов.
Но мы же не Semrush и не Ahrefs, чтобы ранжироваться в топ-10 с такой воронкой :)
SEO-специалисты, которые раньше не работали с SaaS, часто этого не понимают.
Ни один инструмент анализа СЕРПа вам этого не покажет!
В анализе СЕРПа вы увидите бэклинки, тайтлы, количество слов на странице и многое другое, но вы никогда не увидите пользовательскую воронку.
Именно поэтому, анализируя как можно улучшить позиции по ключам, связанным с инструментами, нужно вручную проходить воронки всех конкурентов в СЕРПе.
Поэтому мы приняли стратегическое решение.
Главную страницу будем ранжировать только по брендовым запросам.
А по ключу "seo checker" будем ранжировать отдельную страницу /on-page-seo-checker/, где будем выдавать отчет БЕЗ регистрации.
Такая миграция была непростой.
Поменять воронку легко, но много времени ушло на смену URL в старых бэклинках.
В общей сложности нам потребовался 1 ГОД, чтобы стать вторыми по этому ключу.
Теперь пора на матч с Seobility они очень долго доминируют на первом месте.
Они изначально выбрали правильную стратегию, и сдвинуть их будет очень сложно.
P.S. Я учитываю, что Гугл может легко выкинуть нас со второй позиции.
Но самый большой риск — если Semrush или Ahrefs изменят свою воронку.
Они сразу же займут топ 1-2.
Надеюсь, они это не читают.
@
Читать полностью…
Mike Blazer
04 Feb 2025 13:05
Влияние манипуляций с CTR на позиции: реальный эксперимент
Недавно мы с Рэндом Фишкиным провели эксперимент во время нашего вебинара, чтобы проверить, остается ли CTR фактором ранжирования, манипулируя кликами для вьетнамского ресторана в Сиэтле, пишет Джой Хокинс.
Мы попросили сотни зрителей вебинара ввести запрос "Vietnamese Restaurant Seattle" и кликнуть на результат со второй страницы выдачи.
Первоначальные результаты были впечатляющими - ресторан практически моментально поднялся на вторую позицию после начала массовых кликов.
Однако то, что произошло дальше, оказалось более показательным.
В течение последующих недель и месяцев позиции постепенно снижались, пока сайт не вернулся на исходные места.
Это не первый раз, когда я тестирую манипуляции с CTR.
Каждый тест показывает одну и ту же картину - позиции растут, пока продолжаются искусственные клики, но падают, как только они прекращаются.
Это похоже на оплату временной видимости, которая исчезает, как только вы перестаете платить.
Но у манипуляций с CTR есть еще более темная сторона.
Во время интервью с агентством, занимающимся накруткой CTR, в подкасте Крейга Кэмпбелла они раскрыли, что Google может обнаруживать и наказывать подозрительные паттерны кликов.
Если вы продолжаете отправлять фейковые клики, когда сайт попадает на 2-3 страницу выдачи, Google распознает их как искусственные и может даже понизить ваши позиции.
Мы наблюдали это своими глазами во время нашего эксперимента.
Тестовый ресторан испытал серьезное падение позиций, в то время как другие компании в том же сегменте сохраняли стабильные позиции.
https://www.sterlingsky.ca/does-ctr-manipulation-work-long-term/
@
Читать полностью…
Mike Blazer
04 Feb 2025 08:15
Настали золотые времена для SEO-специалистов, ведь PPC не может купить себе место в ответах LLM.
Мы наконец-то попадаем в переговорные советов директоров.
Наконец-то получаем более крупные бюджеты.
Наконец-то нас признают драйвером роста бренда.
Но этот момент мимолетен.
Реклама придет.
Бренды смогут платить за видимость в LLM.
И то, что произойдет потом, зависит от того, что вы делаете сейчас.
Не повторяйте прошлых ошибок.
Давайте договоримся:
🏆 Отслеживание позиций в СЕРПе никогда не было KPI (метрика - да, но не KPI).
Отслеживание промптов в LLM ничем не отличается.
🧠 SEO - это не про клики на сайт.
Это про то, чтобы быть на первом месте в сознании потребителя, когда он готов к конверсии.
💩 Спам с помощью ИИ и блэкхат-трюки не принесут вам уважения на уровне руководства.
Сфокусируйтесь на создании устойчивой ценности
@
Читать полностью…
Mike Blazer
03 Feb 2025 15:05
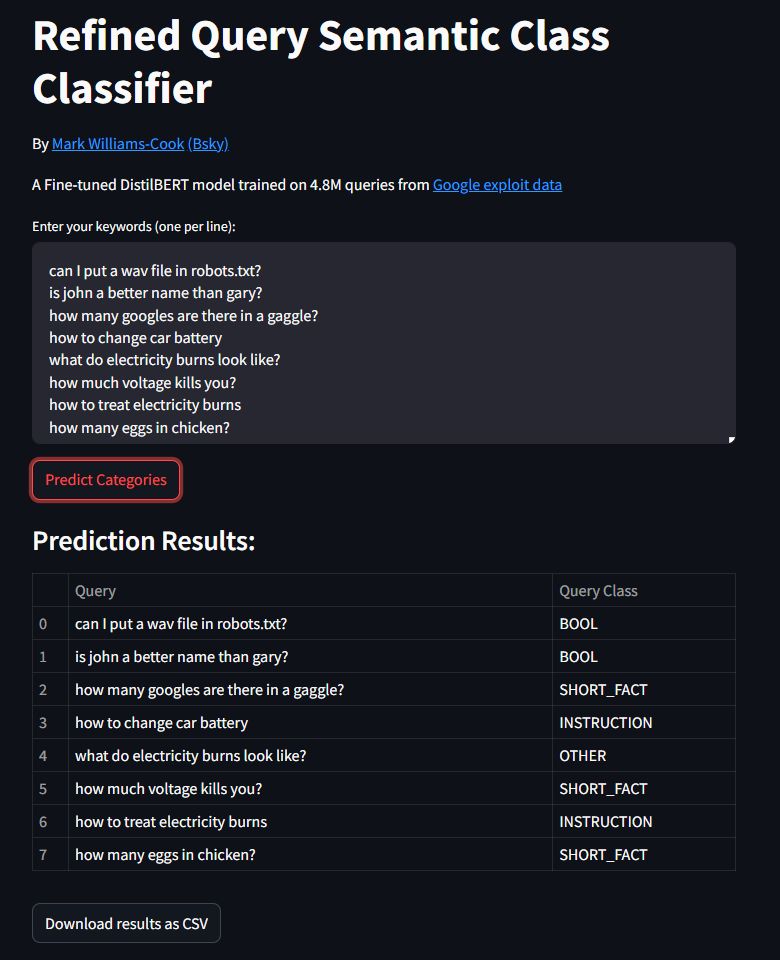
Бесплатный инструмент, который может предсказать, какой семантический класс запроса Google присвоит любому поисковому термину
Модель DistilBERT, обученная на 4..8 млн реальных запросов из данных Google и семантических классов от Google, теперь может классифицировать ваши запросы по одному из восьми различных типов:
1. SHORT_FACT (короткий факт)
2. REASON (причина)
3. DEFINITION (определение)
4. COMPARISON (сравнение)
5. INSTRUCTION (инструкция)
6. CONSEQUENCE (следствие)
7. BOOL (да/нет вопрос)
8. OTHER (прочее)
Больше про них тут.
Инструмент позволяет вводить список запросов.
https://rqpredictor.streamlit.app/
Обратите внимание, что особенно для "короткохвостых" запросов он регулярно возвращает "OTHER" или для очень похожих запросов выдает разные категории - и это, скорее всего, правильно!
Давайте разберемся почему.
Пользовательский интент субъективен, а не объективен.
Это означает, что один и тот же запрос может иметь разное значение для разных людей, и Google должен отражать эту разницу в СЕРПах.
В целом, чем короче ключевик, тем шире потенциальное значение.
Если вы введете запрос "Обручальные кольца", он, вероятно, будет помечен как "OTHER".
Это может быть кто-то, кто ищет факты об обручальных кольцах (сколько они должны стоить), кто-то, кто ищет сравнения (золото против серебра), или кто-то, кто хочет их купить.
Без простого способа классифицировать поиск категория "OTHER" как гибридная может оказаться вполне подходящей.
Если вы не получаете ожидаемые категории - В ЭТОМ И ЕСТЬ СМЫСЛ ИНСТРУМЕНТА
Как говорит Марк Уильямс-Кук, они использовали 20% реальных данных для слепого тестирования инструмента, и он показал невероятно точные результаты, поэтому если вы думаете, что категоризация неверна, ИСПОЛЬЗУЙТЕ ДАННЫЕ, ЧТОБЫ СКОРРЕКТИРОВАТЬ СВОЕ МНЕНИЕ, а не отбрасывайте их просто потому, что вы не согласны.
@
Читать полностью…
Mike Blazer
03 Feb 2025 11:15
Эта игра в кошки-мышки с "накруткой репутации сайта" - просто безумие какое-то.
Одна из компаний, попавшая под санкции, продолжает запускать партнерские продукты на новых сайтах, в папках или поддоменах, используя клоакинг и другие методы, чтобы уклониться от санкций и/или спрятаться от Гугла.
Их тактики постоянно раскрывают публично в LinkedIn, после чего сайт снова попадает под санкции Гугла буквально через пару дней.
Но конечно же, только после того, как они успевают срубить кучу бабла в процессе.
@
Читать полностью…
Mike Blazer
02 Feb 2025 17:33
Я разработал прогу на Python, которая помогает упорядочить большую коллекцию личных фотографий и видео, накопленных за более чем 5 лет. В разработке использовались LLM.
Процесс обработки коллекции происходит в три основных этапа:
1. Анализ метаданных
- Извлечение всей доступной информации из файлов (форматы EXIF, IPTC)
- Сбор геолокационных данных (координат съёмок)
2. Определение локаций
- Преобразование географических координат (широты и долготы) в понятные адреса с помощью обратного геокодирования
- Определение конкретных локаций съёмки
3. Организация файлов
Программа автоматически:
- Объединяет фотографии и видео в логические группы (события, путешествия, истории) на основе:
* Времени съёмки
* Интервалов между снимками
* Географической близости
- Корректирует ориентацию фотографий согласно EXIF-данным
- Создаёт систему папок, названных по дате и месту съёмки
- Распределяет файлы по соответствующим папкам
В настоящее время я продолжаю отладку программы для достижения максимальной точности и удобства использования.
@
Читать полностью…
Mike Blazer
09 Feb 2025 09:05
Bitly внедряет межстраничную рекламу под названием "Destination Previews" (предпросмотр назначения) для всех ссылок и QR-кодов бесплатных аккаунтов
В их уведомлении пользователям говорится:
Начиная с февраля, ваши ссылки и QR-коды Bitly могут показывать страницу предпросмотра перед тем, как перенаправить вашу аудиторию на целевой URL.
Эта страница включает информацию о ссылке и может содержать рекламу.
Вы можете в любой момент отключить страницу предпросмотра для ваших ссылок и QR-кодов, выбрав платный тариф Bitly.
Этот шаг
Spectrum Equity, купившей
Bitly в 2017 году, вероятно, направлен на монетизацию миллионов существующих ссылок
Bitly по всему интернету с 2008 года, а не на конвертацию бесплатных пользователей в платных подписчиков, учитывая строгое ограничение бесплатного тарифа в 5 ссылок в месяц.
Традиционные
301-редиректы
Bitly передают ссылочный вес целевым страницам, но эти межстраничные объявления разорвут цепочку редиректов, блокируя передачу ссылочного веса.
Хотя
Bitly мог бы сохранить ссылочный вес, не показывая межстраничную рекламу поисковым ботам, это может нарушать политику Google по спаму и рекомендации по пользовательскому опыту.
Саймон Кокс
не рекомендует использовать сокращатели
URL для SEO, советуя вместо этого использовать собственный домен с короткими именами папок, редиректящими на более длинные
URL (например,
example.com/topic редиректит на
example.com/category/long-article-title/).
YOURLS представляет жизнеспособную альтернативу как самохостящийся опенсорсный сокращатель
URL, который работает на базовом шаред-хостинге с кастомными доменами.
Пошаговая инструкция по установке
YOURLS для внедрения -
тут.
@
Читать полностью…
Mike Blazer
07 Feb 2025 17:05
Директор, сеошник, и письмо от спаммера, обещающее за $100, с помощью AI продвинуть сайт в топ за неделю.
@
Читать полностью…
Mike Blazer
07 Feb 2025 13:05
Все работает до того момента, пока не перестает работать
@
Читать полностью…
Mike Blazer
07 Feb 2025 08:15
Squish
Сжимайте и конвертируйте ваши изображения в AVIF, JPEG, JPEG XL, PNG или WebP
Отличный инструмент для оптимизации изображений прямо в браузере.
https://squish.addy.ie
@
Читать полностью…
Mike Blazer
06 Feb 2025 15:05
Если ты не лежишь без сна по ночам, думая об этом, значит, ты недостаточно сильно этого хочешь
@
Читать полностью…
Mike Blazer
06 Feb 2025 11:15
Прикольно наблюдать, как Healthline часто получает featured snippets и AI Overviews благодаря своей секции "Итоги", где кратко излагаются основные выводы из статьи.
@
Читать полностью…
Mike Blazer
05 Feb 2025 17:05
Как руководитель по найму и руководитель менеджеров по найму, я просмотрела, наверное, около 1000 резюме за свою карьеру, пишет Джинни Ким.
Вот самые большие ошибки, которые я вижу постоянно (и что делать вместо этого):
❌ Акцент на обязанностях вместо результатов.
Если ваша должность "редактор e-commerce", читающий ваше резюме человек, вероятно, может догадаться о ваших базовых обязанностях — так что не тратьте много места на их перечисление.
✅ Делайте упор на достижения в каждой роли.
Какое влияние вы оказали на команду или бизнес?
Увеличили ли вы трафик в вашем направлении на X%?
Внесли вклад в рекордную выручку во время Черной пятницы/Киберпонедельника?
Оптимизировали процесс публикации?
Корректировка пунктов с акцентом на результаты поможет вам выделиться среди других кандидатов.
❌ Отсутствие адаптации резюме под конкретную вакансию.
Когда я искала Директора по SEO-контенту в Policygenius, было поразительно, сколько резюме я получила от очень опытных редакторов, в которых вообще не было слов "SEO" или "поиск".
Возможно, у них был релевантный опыт, но как я могла об этом узнать?
✅ Найдите время, чтобы убедиться, что ваши пункты соответствуют описанию вакансии.
Не заставляйте менеджера по найму или рекрутера гадать о ваших квалификациях; сделайте так, чтобы им было легко увидеть, что вы отлично подходите.
❌ Перегруженность резюме.
Я не строга насчет правила одной страницы (хотя если у вас менее 5 лет опыта работы, придерживайтесь одной страницы!).
Но однажды я видела резюме, где человек использовал целых четыре страницы (!), чтобы описать последние четыре года своей карьеры.
Если вы не создаете академическое CV, резюме должно быть кратким обзором вашей карьеры с акцентом на последние 5-10 лет, а не исчерпывающим отчетом обо всем, что вы когда-либо делали на работе.
✅ Будьте безжалостны в выделении своих самых больших достижений в каждой роли и уложитесь в две страницы или меньше.
Когда у вас накопится 10-15 лет опыта, ранние карьерные позиции должны вообще исчезнуть из вашего резюме (давайте признаем, они, вероятно, уже неактуальны).
✅ Бонус: Большой вклад в чрезмерную длину резюме вносит раздутое описание в сводке о себе.
Если ваша сводка занимает 3/4 страницы — это не сводка!
Постарайтесь уложиться в 4-5 строк — максимум 1/4 страницы — а большие достижения укажите под соответствующими должностями.
@
Читать полностью…
Mike Blazer
05 Feb 2025 13:05
Совет по краулингу сайтов, которые обычно блокируют ваши запросы
Улучшаем краулинг сайтов, использующих Cloudflare, Akamai и подобные системы защиты.
Вот что нужно сделать для УЛУЧШЕНИЯ краулинга таких сайтов...
1. Зайдите на сайт, который хотите прокраулить, через браузер
2. На стартовой точке краулинга откройте DevTools (обычно F12), перейдите на вкладку APPLICATION, затем в разделе STORAGE слева нажмите Cookies - найдите основной сессионный куки
3. Скопируйте строку куки (можно также скопировать содержимое куки, отправить его в chatGPT/gemini и попросить построить строку куки)
4. В Screaming Frog идите в CONFIGURATION > Crawl Config > HTTP Header
5. В правом нижнем углу нажмите + ADD, в селекторе для новой записи выберите COOKIE и в текстовое поле справа вставьте строку куки
6. Теперь, когда мы инициировали сессию через браузер, используем ТОТ ЖЕ юзер-агент, что и наш браузер (поддерживая сессию активной) - в DEVTOOLS (F12) нажмите NETWORK и обновите страницу, затем в левой секции под NAME кликните на название сайта, увидите HEADERS, PREVIEW, RESPONSE и т.д. Нажмите HEADERS, прокрутите вниз и скопируйте USER AGENT
7. В Screaming Frog перейдите в USER-Agent, измените юзер-агент на CUSTOM и вставьте в поле HTTP request user agent
8. Вернитесь в HTTP Header в Screaming Frog и используйте следующие значения:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Cache-Control: no-cache
Pragma: no-cache
Accept-Language: en-US,en;q=0.5
Connection: keep-alive
Upgrade: 1
Примечание!
У вас могут быть не все эти заголовки - чтобы добавить их, нажмите +
ADD и используйте выпадающий селектор.
9. В
Screaming Frog перейдите в
SPEED, измените
MAX THREADS на 1 и поставьте галочку
Limit URL/s на 0.1 (да, медленно, но нужно эмулировать реальный браузинг - можно экспериментировать, но легко спровоцировать
Cloudflare и подобные системы)
10. Перейдите в
SPIDER >
Crawl и настройте как на моих скриншотах - по сути, не нужно ставить галочки
IMAGES,
MEDIA,
CSS для краулинга и хранения, как и
SWF.
Это влияет на рендеринг в
Screaming Frog и проверки
IMG ALT и т.д. - но это низкоприоритетные вещи, о которых можно не беспокоиться.
11. Перейдите в
SPIDER >
Extraction - это опционально, но БОЛЬШИНСТВУ сеошников не нужно беспокоиться о:
FORMS,
Page Size,
Hash Value,
Text to Code Ratio,
Meta Keywords - так что снимите эти галочки
12. Нажмите
SPIDER >
Rendering и измените рендеринг на
Javascript, я также предпочитаю менять пресеты
WINDOW SIZE на
DESKTOP13.
SPIDER >
Advanced - убедитесь, что
Always Follow Redirects и
Always Follow Canonicals ОТКЛЮЧЕНЫ, а
RESPECT HSTS Policy ВКЛЮЧЕН
14. Раздел
Robots.txt - убедитесь, что выбран
RESPECT ROBOTS.TXTЭто может
УЛУЧШИТЬ КРАУЛИНГ сайтов, которые обычно сложно краулить, но это не панацея.
Больше скриншотов
тут.
@
Читать полностью…
Mike Blazer
05 Feb 2025 08:15
Иногда чтобы занять первое место в списке, достаточно просто убедиться, что название твоего бизнеса начинается с AAA.
Названия файлов?
Символы вроде "!" творят чудеса для общих папок в глобальной команде на Google Workspace.
Почему так важно быть первым в выдаче?
Предвзятость порядка.
До того как я стал сеошником, я помогал семейному бизнесу, рассказывает Виктор Пан.
Представьте открытие ресторана быстрого питания на оживленном перекрестке с арендой около $40,000 в месяц.
То, как и где представлены позиции меню, сильно влияет на прибыльность и повторные визиты.
Ссылка
Если правильно провести маркетинговое исследование, можно распределить позиции меню в матрице меню.
Какие были мои цели тогда?
Повысить прибыльность.
Увеличить LTV клиентов/снизить отток.
Тут и появляется матрица меню.
Она помогает бизнесу визуализировать, какие позиции должны заказывать чаще.
И в инженерии меню, и в методологиях опросов существует предвзятость в пользу первого пункта в списке.
Когда понимаешь это, возникает самосбывающееся пророчество.
Этот первый пункт создает предвзятость первого впечатления.
Этот первый пункт часто запоминается из-за эффекта первичности.
Другими словами, порядок важен, потому что человеческое поведение имеет определенную предсказуемость, на которую можно влиять.
Это тонкий язык, который бизнес использует для изменения выбора пользователя с целью оптимизации бизнес-результатов.
Роль дизайнера меню во многом похожа на роль поискового инженера.
Частая жалоба, которую я слышу от сеошников - что Гугл выбрал прибыльность вместо качества.
Что "ухудшение" технологий намеренное, чтобы приходилось запускать больше рекламы для латания дыр.
Не так все просто.
Эффективность рекламы не может падать.
ROAS должен работать для доверия к рекламной платформе.
Материалы, всплывшие в ходе антимонопольного процесса против Google, приоткрывают завесу над политикой того, что максимизировать.
Об этом стоит серьезно задуматься и в отношении контента вашего сайта.
Больше трафика?
А может лучше качественный трафик?
Проблема узконаправленного фокуса на порядке и позициях в том, что мы заметаем под ковер все наши прошлые "достижения".
Учитывая, как развивается информационный поиск, бизнесам придется проявить еще больше креатива в конвертации высокочастотных запросов в деньги.
@
Читать полностью…
Mike Blazer
04 Feb 2025 15:05
Деян Петрович произвел реверс-инжиниринг ключевого этапа из пайплайна Google по обнаружению скама на базе ИИ, который определяет основной бренд и намерение страницы.
Что Gemini думает о вашем бренде?
В Chrome Dev для тех, у кого эта функция включена, есть квантованная версия флагманской модели Google Gemini.
Модель выполняет множество задач: от суммаризации, перевода и помощи в написании текстов до предотвращения скама.
Архитектура модели засекречена, но её веса хранятся в виде 3ГБ .bin файла на машине пользователя.
Внутри папки "\User Data\optimization_guide_model_store\55\" находится файл "on_device_model_execution_config.pb", который определяет промпт для роли Gemini в обнаружении мошенничества.
Модель получает очищенный текст из Chrome и возвращает два параметра:
- Бренд
- Интент
Вот инструмент: https://brand-intent.dejan.ai
Вы можете либо ввести URL для парсинга, либо вставить обычный текст.
https://dejan.ai/blog/what-does-gemini-think-about-your-brand/
@
Читать полностью…
Mike Blazer
04 Feb 2025 11:15
"ИИ-контент звучит неестественно"
Это не так, вы просто используете неправильные промпты.
1. Используйте ChatGPT o1-mini
Эта модель не ленится, и нам нужна она только для переписывания текста.
2. Используйте промпт для очеловечивания:
<context>
Rewrite this blog post and keep the same structure, information and length. Only change the language used.
</context>
<prohibited_words>
Do not use complex or abstract terms such as 'meticulous,' 'navigating,' 'complexities,' 'realm,' 'bespoke,' 'tailored,' 'towards,' 'underpins,' 'ever-changing,' 'ever-evolving,' 'the world of,' 'not only,' 'seeking more than just,' 'designed to enhance,' 'it's not merely,' 'our suite,' 'it is advisable,' 'daunting,' 'in the heart of,' 'when it comes to,' 'in the realm of,' 'amongst,' 'unlock the secrets,' 'unveil the secrets,' 'transforms' and 'robust.' This approach aims to streamline content production for enhanced NLP algorithm comprehension, ensuring the output is direct, accessible, and easily interpretable.
</prohibited_words>
<blog_post>
[PASTE YOUR BLOG POST HERE]
</blog_post>
Не забудьте заменить "
[PASTE YOUR BLOG POST HERE]" на ваш текст блога.
3. Пост готов
Больше никаких "
In the fast-paced world of..."
4. Обойдет ли это детекторы ИИ?
Мы делаем это не для того, чтобы обойти детекторы ИИ.
Наша цель - сделать контент более читабельным для людей.
Да и Гугл на это не обращает внимания,
пруф.
@
Читать полностью…
Mike Blazer
03 Feb 2025 17:05
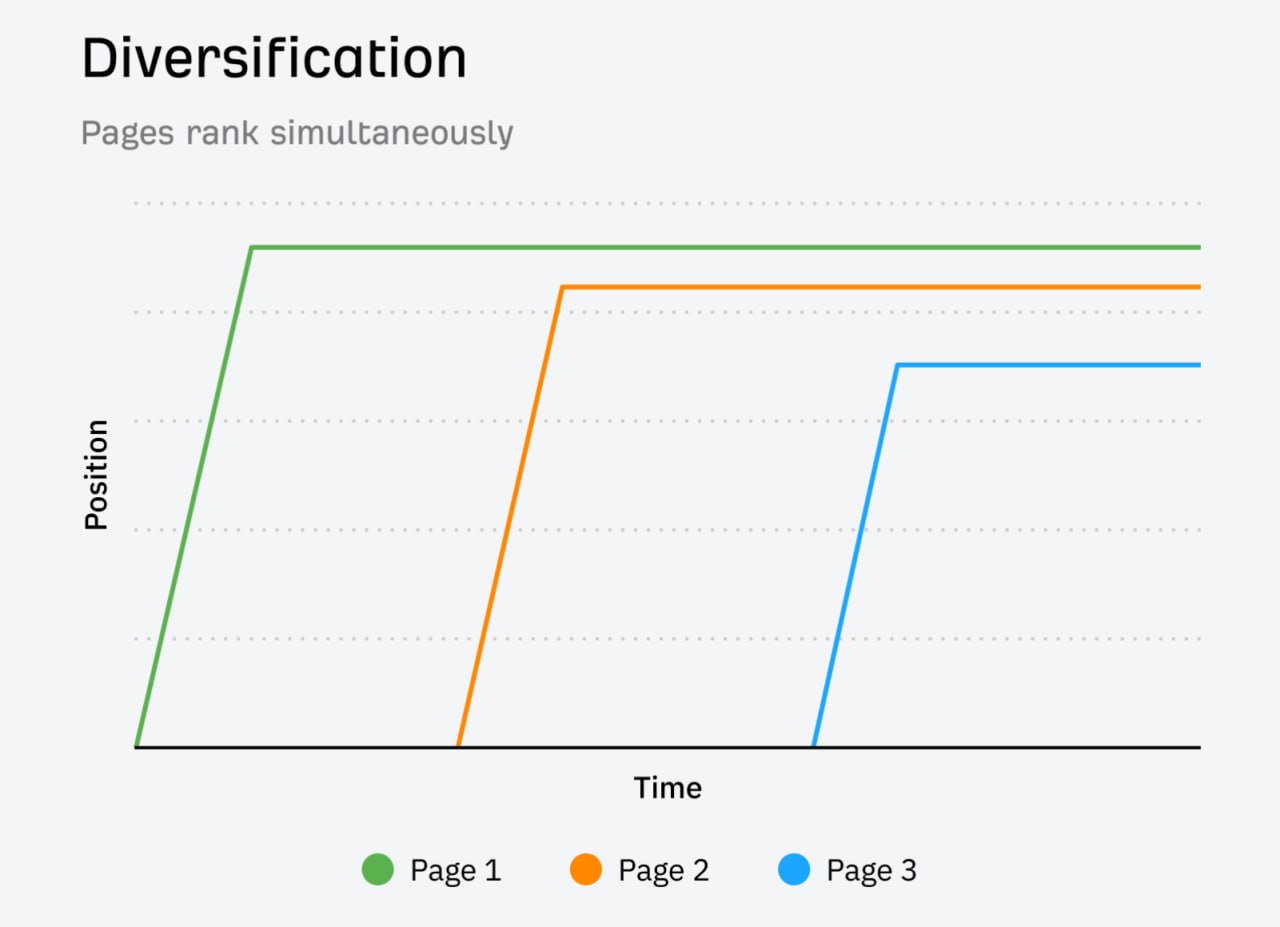
Несколько URL-адресов, ранжируемых по одному ключевику - исследование 9.7 тыс. случаев
На Ahrefs.com обнаружено 9700 случаев множественного ранжирования, когда сайт ранжируется по одному ключевику несколькими страницами.
После анализа 80 ключей с множественным ранжированием только один случай требовал исправления.
Каннибализация ключей происходит, когда Google меняет местами позиции нескольких страниц или когда похожие страницы ранжируются одновременно.
История позиций по запросу "seo case studies" показала, как новые кейсы заменяли старые в СЕРПе.
Создание пилларной страницы с внутренними ссылками на кейсы решило проблему, подняв сайт в топ-3 и получив некоторые кейсы в виде сайтлинков.
По запросу "broken link building" два руководства одновременно ранжировались в топ-10.
Их объединение в одно комплексное руководство значительно улучшило позиции, показав, что контент этих страниц был достаточно близок для слияния.
Диверсификация ключей происходит, когда страницы ранжируются одновременно без смены позиций.
По запросу "keyword rankings" глоссарий занимает фичерд сниппет, а лендинг инструмента находится на 4-й позиции.
Аналогично, по "SEO audit" блог на 4-м месте, а страница инструмента на 7-м, удовлетворяя разные поисковые интенты.
Данные по трафику для ключей с 2 URL в топ-10 показывают разные результаты:
- "keyword search": прирост 1.94% (98.10% старая страница, 1.90% новая)
- "seo audit": прирост 37.74% (72.60% старая, 27.40% новая)
- "free seo tools": прирост 296.13% (25.24% старая, 74.76% новая)
- "affiliate marketing for beginners": прирост 6.63% (93.78% старая, 6.22% новая)
- "free keyword research tool": прирост 677.69% (12.86% старая, 87.14% новая)
- "keyword rankings": прирост 60.71% (62.22% старая, 37.78% новая)
- "how to become an affiliate marketer": прирост 2.39% (97.67% старая, 2.33% новая)
- "keyword difficulty": прирост 9233.33% (1.07% старая, 98.93% новая)
Поддержание топовых позиций для двух страниц оказывается сложным.
Большинство историй позиций показывают нестабильное ранжирование - страницы появляются в топ-10, пропадают на месяцы, затем случайно возвращаются.
Альтернативные тактики диверсификации включают ранжирование видео для видео-выдачи или создание страниц с определениями для фичерд сниппетов.
Наблюдения:
- Медианная частотность для каннибализированных ключей (50) соответствует единичным ранжированиям (40).
- Распределение количества слов показывает, что большинство множественных ранжирований происходит с запросами из 3-4 слов.
- Ключи с множественным ранжированием показывают более высокую сложность (медиана KD 64 против 37).
Используя отчет Traffic Share в Keywords Explorer от Ahrefs можно оценить потенциал трафика для каждой позиции.
Анализ по фреймворку 3C показывает, что ранжирующийся контент Ahrefs соответствует существующим паттернам СЕРПа - когда в выдаче показываются статьи и лендинги, сайт ранжируется обоими типами.
Один конкурент приобрел SEO-блог и теперь ранжируется в топ-10 по 8700 ключам обоими сайтами, несмотря на то, что это один бизнес.
Google рассматривает их как отдельные сущности, что позволяет эффективно диверсифицировать СЕРП через приобретение сайтов.
https://ahrefs.com/blog/multiple-rankings-study/
@
Читать полностью…
Mike Blazer
03 Feb 2025 13:05
Как отследить клики и CTR с AI-обзоров Google (но для этого нужно иметь ручные санкции)
Лазейка в Google позволяет сайтам с ручными действиями на уровне директории ранжироваться в AI-обзорах (AIO), даже если их удалили или серьезно понизили в выдаче по 10 синим ссылкам.
Анализируя сайт с ручными санкциями на уровне каталога, Гленн Гейб обнаружил, что он генерирует приличный трафик и занимает первое место в поисковых результатах по многим запросам.
Проблема заключается в твиддлерах Google — настройках, которые повышают, понижают или фильтруют ранжирование.
Когда применяются ручные санкции, твиддлер удаляет сайты из обычного поиска, но не влияет на ранжирование в AI-обзорах.
Процесс "деиндексации" работает как инструмент удаления URL в GSC, где ссылки скрываются из SERP, но остаются в индексе.
GSC не предоставляет отдельного трекинга для AIO — данные смешиваются с традиционным ранжированием.
Как отследить чистую производительность AI-обзоров, пока существует эта лазейка:
1. Зайдите в отчет по производительности GSC
2. Идентифицируйте контент, который попал под санкции (каталог/субдомен)
3. Сделайте фильтрацию данных по временным рамкам после применения санкций
4. Проверьте запросы и позиции — ищите позиции #1, несмотря на санкции
5. Проведите поиск в Google (в режиме инкогнито и авторизованно), чтобы проверить присутствие в AIO
6. Проанализируйте данные в GSC
Настройка каталогов как отдельных свойств в GSC упрощает этот анализ, так как устраняет необходимость в фильтрах лендингов.
Все ссылки, находящиеся внутри AIO, в отчетах GSC занимают позицию #1, так как они наследуют позицию AI-блока.
Анализ показал, что запросы, ранжирующиеся в AI-обзорах, имеют среднюю позицию 1.2 с CTR 4.9%, в сравнении с позицией 4.6 и CTR 2.7%, когда они ранжируются в обычных результатах.
Для запросов с ограниченными данными используйте регулярки с вертикальными чертами (|), чтобы объединить несколько запросов, ранжирующихся в AIO, что позволит получить больший объем данных для анализа.
Возможность собирать эти данные может исчезнуть, как только Google исправит лазейку, поэтому данный анализ — это временный шанс для сайтов с ручниками.
https://www.gsqi.com/marketing-blog/how-to-track-aio-performance-gsc-manual-action/
@
Читать полностью…
Mike Blazer
03 Feb 2025 08:15
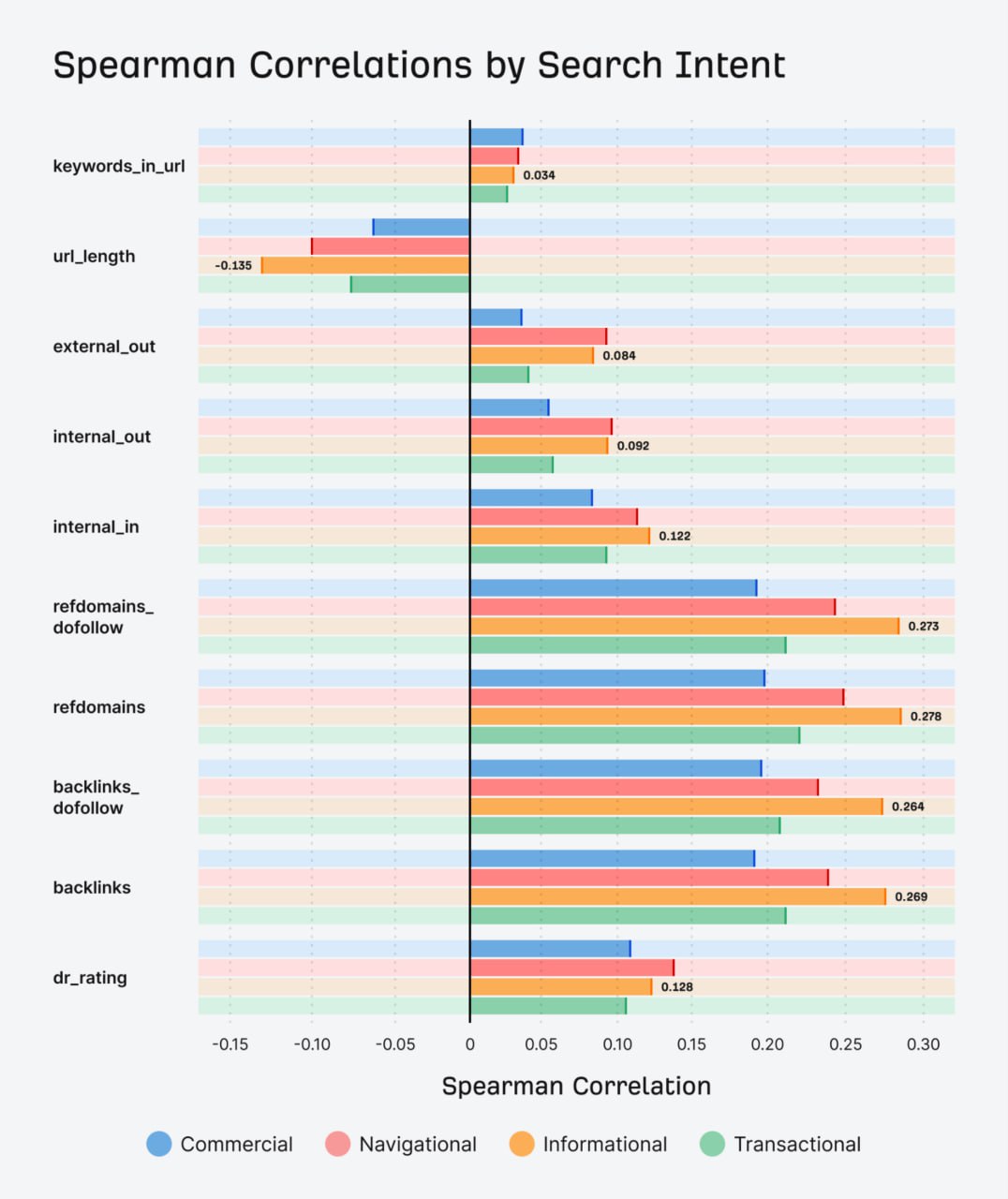
Google заявляет "Ссылки менее важны" — Ahrefs проанализировал 1 000 000 СЕРПов, чтобы проверить это
Исследование 1 миллиона СЕРПов показало различную важность ссылок для разных типов поисковых запросов.
Предыдущие тесты с дезавуированием ссылок демонстрировали явное падение позиций, подтверждая, что ссылки по-прежнему влияют на ранжирование.
Для топ-20 позиций корреляционный анализ показал следующие значения:
- реферальные домены - 0.255,
- активные реферальные домены - 0.250,
- бэклинки - 0.248,
- и активные бэклинки - 0.242.
- DR коррелировал на уровне 0.131,
- внутренние входящие ссылки - 0.117,
- внутренние исходящие ссылки - 0.093,
- и внешние исходящие ссылки - 0.083.
URL-факторы показали минимальное влияние: ключевые слова (0.034) и длина (-0.107).
Эти корреляции, хотя и слабые по шкале Спирмена, указывают на то, что ссылки остаются фактором ранжирования.
Визуализация данных в виде box-plot показала, что лучшие ссылочные метрики обычно коррелируют с более высокими позициями, где 50% значений попадают в выделенные области, а медиана отмечена центральной линией.
Внешние ссылки продемонстрировали более сильную корреляцию, чем внутренние ссылки с того же сайта, что говорит о том, что Google рассматривает внешние ссылки как более надежные сигналы.
Высокочастотные запросы показали более сильную корреляцию со ссылками, что указывает либо на конкурентную необходимость, либо на естественное получение ссылок из-за повышенной видимости.
Брендовые запросы показали более высокую корреляцию из-за того, что популярность бренда способствует получению ссылок, в то время как небрендовые запросы снижали эти показатели.
По сравнению с исследованием 2019 года по небрендовым низкочастотным запросам (корреляция 0.27-0.29), текущие корреляции снизились до 0.22-0.24.
С ростом AI-контента важность ссылок может возрасти, так как Google ищет надежные сигналы качества.
Локальные запросы показали корреляцию 0.33 для ссылок и реферальных доменов - выше исторических средних значений.
Внутренние ссылки оказались особенно ценными для локальных запросов, где внешние сигналы более редки.
Информационные запросы продемонстрировали более сильную корреляцию со ссылками, чем коммерческие, возможно, из-за того, что Google использует ссылки для определения качества в конкурентном информационном пространстве.
Ссылки - это одна из частей большого пазла ранжирования.
Там, где у Google больше сигналов, он может меньше полагаться на какой-то один сигнал.
Там, где у него меньше сигналов, он может больше полагаться на такие вещи, как ссылки.
В областях с высокой конкуренцией, где контент может быть сильным, они также могут полагаться на сигналы ссылок как на более сильный дифференцирующий фактор.
https://ahrefs.com/blog/links-matter-less-but-still-matter/
@
Читать полностью…
Mike Blazer
02 Feb 2025 14:05
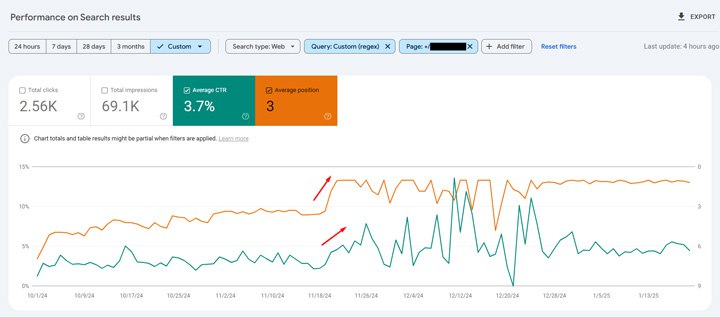
study.com добились потрясающего SEO-роста.
Что-то случилось в июле 2023 года, и с тех пор 📈📈📈
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}