Mike Blazer
06 January 2026 08:15
Сигналы ранжирования Google
Взаимодействие с юзером и модели прогнозирования
Ранжирование жестко опирается на сигналы популярности из интеракций юзеров; выше вовлеченность — сильнее буст.
Система юзает модели `Predicted CTR` (PCTR) для оценки вероятности просмотра на основе истории.
Персонализированный `PCTR` уточняет это через метаданные и историю юзера, но эта конкретная модель активируется только после 100 000 запросов, обработанных через VAIS.
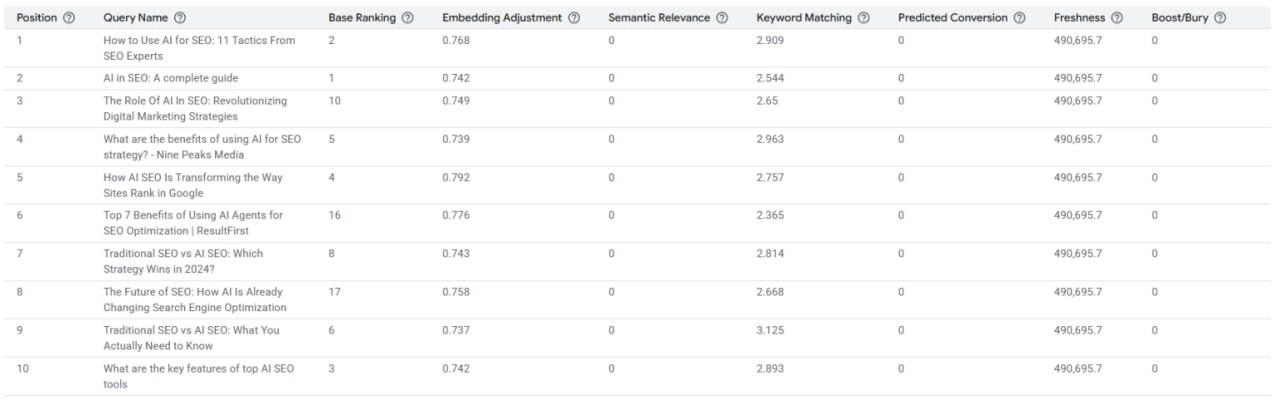
Стек скоринга
Финальная Позиция документа начинается с Базового ранжирования — начального скора от основного алгоритма.
Дальше она допиливается несколькими слоями:
— Корректировка эмбеддингов (Gecko): Меняет скоры на основе семантической близости.
— Семантическая релевантность (Jetstream): Использует cross-attention модель, чтобы обрабатывать контекст и отрицания лучше стандартных эмбеддингов.
— Соответствие ключей: Применяет традиционные алгоритмы частотности (типа BM25).
— Прогнозируемая конверсия: Предсказывает вовлеченность (например, клики), используя данные PCTR/PCVR.
— Свежесть и бизнес-правила: Корректировки на новизну контента и ручные протоколы Boost/Bury.
Режимы поиска и архитектура ИИ
Гугл определяет три режима поиска: стандартные списки, поиск с генеративными саммари (Answers) и разговорный поиск с фоллоу-апами.
Критично: топ-5 результатов кормят генерацию ИИ-поиска.
Форматы вывода различают короткие Сниппеты и длинные Extractive Answers, вытянутые из контента результатов.
Метрики и безопасность
Перформанс системы оценивается сравнением Search Count, CTR и No Results Rate с установленными бейслайнами.
Плюс стоят предохранители, чтобы игнорировать состязательные запросы (adversarial queries), не давая LLM генерить ответы на вредоносные инпуты.
https://dejan.ai/blog/googles-ranking-signals/
#RankingFactors #UserSignals #AIOverview
@
Закрытый канал: @
Читать полностью…
Mike Blazer
05 January 2026 12:10
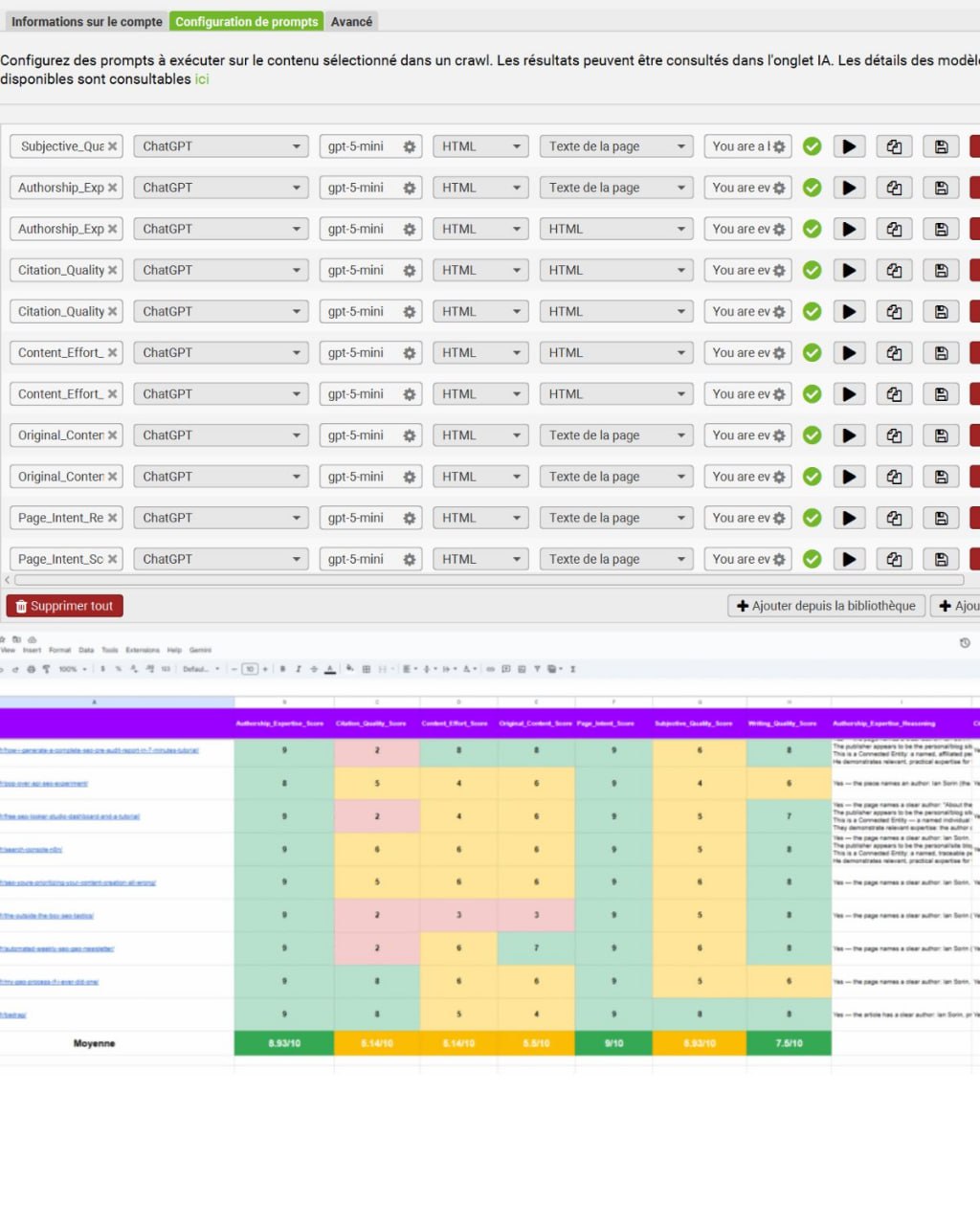
Иэн Сорин расшарил воркфлоу для аудита качества контента и E-E-A-T на масштабе с помощью Screaming Frog + OpenAI, и это полностью убирает гадание из контент-аудитов.
Вместо ручного чека страниц он собрал библиотеку из 14 кастомных промптов, которые скармливают данные страницы в API, чтобы сгенерить оценку 1-10 и качественную критику для каждого URL.
Вот точный сетап:
1. Подготовь Лягушку: Иди в Configuration > Spider > Extraction. Ты обязан чекнуть "Store HTML" и "Store Rendered HTML", иначе API не сможет прочитать страницу.
2. Подключи ИИ: Иди в Configuration > API Access > AI > OpenAI и вставь свой API ключ (рекомендуется GPT-4o для логики).
3. Загрузи промпты: В "Prompt Configuration" импортируй JSON файл или скопипасти конкретные E-E-A-T промпты.
4. Таргетинг: Используй фильтры Include/Exclude, чтобы кроулить только блог или посадочные. (Не кроули весь сайт, если не хочешь получить конский счет за API).
5. Анализируй: Запускай краул. Вкладка "AI" заполнится скорами и обоснованием. Экспортируй в Excel/Sheets, чтобы посчитать средние.
Библиотека промптов анализирует 7 конкретных измерений E-E-A-T:
— Авторство: Классифицирует автора как "Connected Entity" (проверяемый, подотчетный) vs. "Disconnected" (аноним/не отследить).
— Качество цитирования: Проверяет, подкреплены ли фактические утверждения первоисточниками/официальными данными, или это просто голословные смелые заявления.
— Усилия (Content Effort): Оценивает воспроизводимость. Это "low effort" дженерик текст, или видно "исключительное" усилие (свои данные/тулзы)?
— Оригинальность: Различает уникальные инсайты/углы и контент, который просто перефразирует существующие знания.
— Интент страницы: Флагирует "Search-First" контент (SEO-наживка, обманчивые аффилиатные обзоры) против "Helpful-First" контента.
— Субъективное качество: "Брутально честный" критик, который помечает скучные секции, путаную структуру и низкую плотность ценности.
— Качество письма: Специфический лингвистический анализ, проверяющий длину предложений (оптимально 15-20 слов), использование пассивного залога и лексическое разнообразие.
На выходе не просто цифра; система дает конкретное обоснование типа "Словарь повторяется" или "Боль целевой аудитории не оцифрована".
Это быстрый способ увидеть, какие именно критерии качества убивают твой перформанс, не читая 200 страниц вручную.
Только поглядывай на лимиты OpenAI — этот процесс жрет токены полного HTML на каждый промпт!
https://iansorin.fr/how-to-audit-e-e-a-t-at-scale/
#EEAT #Audits #ScreamingFrog
@
Закрытый канал: @
Читать полностью…
Mike Blazer
04 January 2026 11:05
Знаете, почему сеньоры выгорают?
Они упираются в потолок.
Рутина, одни и те же методы, скука.
Глаза тухнут, трафик встает.
Чтобы ваш тимлид снова начал генерить лютые гипотезы, ему нужно топливо.
Ему нужно видеть, как рвут топы другие.
В @ мы делаем именно это.
Это не обучение. Это арсенал.
Лучший подарок для вашего сеошника на 2026-й — это годовой доступ в PRO.
0% воды. Без теории. Только хардкорные знания SEO, недоступные широкой публике.
В интерфейсе оплаты появилась кнопка "Купить в подарок".
Оплатили картой компании -> Скинули ссылку спецу -> Закрыли вопрос с прокачкой на год.
🔥 Бонус: Я продлил новогодний оффер.
12 месяцев по цене 10.
Забирайте годовой доступ с дисконтом, пока я не прикрыл лавочку!
Инвестируйте в мозги, а не в пылесборники.
Сделайте команде подарок, который окупится уже в январе!
Вооружите их.
Читать полностью…
Mike Blazer
31 December 2025 15:05
Когда купил доступ в @ на весь 2026 г., и теперь можешь быть спокоен, что нехватки SEO-фишек в новом году не будет!
С НОВЫМ ГОДОМ!
@
Пушки — в @
Читать полностью…
Mike Blazer
31 December 2025 08:15
Протоколы накрутки для алгоритмов комментариев 'Top' и 'Best' на Reddit
Прямой партнерский маркетинг на Reddit сейчас — это гемор, так как любая рекламная ссылка, которую вы добавляете, резко повышает шансы на удаление.
Чтобы обойти это, я юзаю тактику в два шага, которую можно считать "отмыванием" ссылок, — раскрывает Джеки Чоу.
Вместо того чтобы линковать напрямую на оффер, вы ссылаетесь на промежуточный пост на трастовом, авторитетном домене вроде Medium или LinkedIn.
У этих платформ меньше шансов попасть под автоматические флаги модерации Reddit, и уже оттуда вы можете разместить свою конечную исходящую ссылку.
Как только ваш комментарий опубликован, его продвижение в топ полностью зависит от метода сортировки в треде, так как каждый требует своего протокола для накрутки.
Если тред отсортирован по "Top", процесс простой и основан на грубой силе.
Вы постите коммент, ждете ровно семь дней, а затем делаете "взрыв" большим количеством апвоутов — скажем, штук 200 — все разом.
Этого одного выстрела обычно достаточно, чтобы занять топовую позицию.
Однако манипулировать тредом, отсортированным по "Best", сложнее, потому что его алгоритм ранжирования более тонкий.
Дело не только в голом количестве апвоутов; это комбинация апвоутов, ответов на комментарий и постоянных сигналов вовлеченности, таких как клики по профилю.
Для таких тредов стратегия такова: вы постите коммент, ждете несколько дней, а затем начинаете капельно подливать апвоуты в течение времени.
Одновременно вы должны закупать ответы на коммент, чтобы симулировать естественную, идущую беседу, что сигнализирует алгоритму о том, что ваш комментарий генерирует ценное вовлечение.
Этот подход также работает для управления репутацией в сети, особенно в архивных тредах, где новые комментарии заблокированы, но голосование все еще возможно.
Если вы работаете с брендом, вы можете найти любое существующее позитивное упоминание — неважно, как глубоко оно закопано — и просто "взорвать" его апвоутами.
Это действие выталкивает позитивный комментарий наверх, мгновенно меняя видимую картину в заблокированном обсуждении.
#Reddit #BlackHatSEO #UserSignals
@
Пушки — в @
Читать полностью…
Mike Blazer
30 December 2025 12:10
Логи GSC доказывают: органический трафик, а не бэклинки, заставляет Google переиндексировать страницы
Практики подтверждают прямую, проверяемую корреляцию между органическим трафиком и частотой переиндексации Google.
Это устанавливает четкую иерархию, где сигналы от юзеров перебивают статичные метрики авторитета вроде бэклинков.
Суровая правда из логов: страницы, на которые активно кликают, попадают в приоритетную очередь на краулинг, в то время как страницы с нулевым трафиком теряют приоритет, независимо от недавних правок или ссылочного профиля.
Эту динамику можно измерить как "Показатель задержки индексации авторитета" — метрику эффективности краулинга домена, основанную на вовлеченности пользователей.
Метод вскрытия этого механизма целиком выполняется в GSC.
Сначала проверьте десять самых кликабельных страниц в отчете по эффективности; дата их последней индексации почти всегда будет свежей, часто — в пределах последней недели.
Чтобы доказать обратное, отсортируйте отчет в обратном порядке и посмотрите на страницы с наименьшим количеством кликов.
У этих активов будет самая большая задержка с момента последней индексации.
Эта разница во времени между последним краулом вашей наименее посещаемой страницы и текущей датой и есть задержка эффективности вашего домена.
Хотя первичной индексации можно добиться за счет таких факторов, как тематический авторитет и внутренняя перелинковка с трастовых страниц, поддержание частоты краулинга — это функция реального авторитета, который определяется кликами пользователей и CTR с течением времени.
Это опровергает распространенный миф о том, что страница с сильными бэклинками, но без трафика, имеет значительный вес в глазах планировщика краулинга.
Предлагаемая формула для количественной оценки ценности страницы: Ценность страницы = Клики / Дни с последнего краула.
Она отдает предпочтение страницам с постоянным трафиком и свежими краулами.
Практический вывод: даже страницы с большим количеством показов, но без кликов, рискуют быть переведены в очередь с более низким приоритетом краулинга.
Чтобы заставить систему переоценить и часто индексировать страницу, нужно генерировать реальный пользовательский трафик.
Это подтверждает, что клики — окончательный сигнал релевантности, который заслуживает внимания алгоритма.
https://www.reddit.com/r/SEO/comments/1pecrgy/simple_seo_workshop_example_traffic_authority/
#UserSignals #Indexing #GSC
@
Пушки — в @
Читать полностью…
Mike Blazer
29 December 2025 12:10
Выбор ответов AI строится на взвешенной четырехфакторной модели
Движки AI-ответов выбирают контент через многоэтапный скоринг, а не по единому монолитному алгоритму.
Модель, основанная на исследованиях, предполагает конкретное распределение весов при оценке вашего контента: 40% на lexical retrieval (совпадение по ключам, BM25), 40% на semantic retrieval (эмбеддинги, смысл), 15% на re-ranking (оценка с помощью cross-encoder) и 5% на бусты за ясность и структуру.
Такой мощный акцент на гибридный поиск подтверждается стандартными настройками векторных баз данных вроде Weaviate и Pinecone, которые часто балансируют сигналы от ключевиков и семантики 50`/50`.
Чтобы конкурировать, надо оптимизировать под весь этот стек выбора ответов.
Суммарный вес в 80% на первоначальном отборе означает, что ваш контент вылетает, если провалится на этих двух фронтах.
Сначала вы должны удовлетворить lexical retrieval, включив в текст точные термины, которые ищут юзеры.
Одновременно с этим нужно получить высокий балл по semantic retrieval, создавая контент, который кластеризует связанные концепции.
Это позволит найти его, даже если запросы сформулированы не так, как вы ожидали.
Финальные 20% скора — это то, где структура решает, кто победит.
Этап re-ranking с весом в 15% жестко отдает предпочтение пассажам, которые оформлены как прямые ответы и начинаются сразу с вывода.
Контент, который закапывает ключевую инфу, будет оштрафован и вылетит из гонки.
Итоговый скор за clarity (ясность) работает как 5%-ный тай-брейкер, награждая плотные по фактам, легко сканируемые и построенные по принципу "сначала ответ" пассажи, которые можно дословно вставить в сгенерированный ответ.
Эта модель объясняет, почему прямой, answer-first контент, как в документации Zapier, часто выбирают вместо маркетингового поста в блоге на ту же тему.
В блоге могут быть правильные ключевики, но он проваливается на решающих этапах re-ranking и clarity, потому что критически важная информация похоронена за повествовательным вступлением.
https://duaneforresterdecodes.substack.com/p/lets-look-inside-an-answer-engine
#GEO #Embeddings #SemanticSEO
@
Пушки — в @
Читать полностью…
Mike Blazer
28 December 2025 10:05
10-ая неделя в @ — в ленте.
Пока вы жевали сопли в белом SEO, сотни подписчиков PRO-канала уже получили и внедряют вещи, которые дают реальное преимущество.
Вот что вы упустили в PRO:
1. Секретный метод передачи авторитета, который не палят ссылочные анализаторы — и как он обходит фильтры дублей с помощью одного тега.
2. Как одна деталь в sitemap заставляет Google считать ваш контент устаревшим — и убивает сигналы свежести еще до краулинга.
3. Как захватить AI Overviews по запросам из будущего — и заставить Google AI цитировать ваш пресс-релиз как единственный источник.
4. Единственные 3 типа схемы, где Google ранжирует скрытый контент — и как это использовать для усиления релевантности.
5. Прямой путь к созданию своей сущности в Google — и как получить Панель Знаний, обойдя стандартные алгоритмы.
6. Схема «отмыва» трафика через YouTube — как превратить любой трафик в трастовые реферальные сигналы от самого Google.
7. Как получить "вечный" паразит-хостинг на доменах .edu и .gov, который генерирует миллионы показов и живет больше 6 месяцев.
8. Что делать, если ваш сайт забанил Гугл: пошаговый план по мгновенному рестарту — который работает даже с клонированным контентом.
9. Метод маскировки, который защищает от фильтров за аффилиатный контент — и позволяет монетизировать агрессивнее, не попадая под радар.
10. Что на самом деле определяет тематику PBN-домена — и почему старый контент сайта не имеет никакого значения.
-
Каждый пост — концентрат, который экономит вам десятки часов ресерча.
Такие темы долго не живут. Их выжигают.
Фиксируйте доступ, пока не поздно, или готовьтесь догонять тех, кто уже внутри.
Читать полностью…
Mike Blazer
26 December 2025 15:05
Новогодний корпоратив для самозанятых
#Humor
@
Пушки — в @
Читать полностью…
Mike Blazer
26 December 2025 08:15
Рынок казино в США (free spins и т.д.) — полный мусор.
Я пробовал Stake aff, та же история, депозитов пока нет, пишет SEOwner.
Траф сейчас тухнет (неудивительно, учитывая технику), и я заработал $0, ранжируясь по некоторым крупнейшим ключам, связанным с free spins.
Честно говоря, жесть полная.
1000+ регистраций, 2 FTD (первых депозита).
Некоторые ключи, по которым я ранжировался, были больше про банкинг, чем про казино, хз почему Гугл поставил туда мои страницы.
Но много было именно по фриспинам.
Я юзал лендосы под фриспины.
Несколько казино, проклы и т.д.
Трафик просто тупо не конвертит.
Сначала я думал, что партнерка что-то мутит (шейвит), но 100+ рег на Stake и 0 депов.
Stake — это социальное казино, так что я подумал, может это то, что людям нужно.
Оказывается, нет.
Я конверчу 2-5% по ключам с "free" в крошечных странах, где население зарабатывает долю от средней зарплаты в США.
Короче, хз, но я снес большинство ключей с "free spins" из своего списка и теперь таргетируюсь только на нейтральные (без упоминания "free") и/или связанные с реальными деньгами (real money).
Может, верну ключи по "no deposit bonus", потому что реально верю, что они должны конвертить.
Но запросы по фриспинам — лютый шлак.
Я все еще вишу на 7 месте по ключу с частоткой 24к/мес с паразитной страницей (parasite page), которая уже месяц как мертвая/404, лол.
#Gambling #Affiliate #ParasiteSEO
@
Пушки — в @
Читать полностью…
Mike Blazer
25 December 2025 12:10
Не воспринимайте LLM как сущности, думайте о них как о симуляторах.
Например, исследуя тему, не спрашивайте:
"Что ты думаешь о xyz"?
Никакого "ты" не существует.
В следующий раз попробуйте:
"Какая группа людей лучше всего подойдет для исследования xyz? Что бы они сказали"?
LLM может транслировать/симулировать множество точек зрения, но она не "думала о" xyz какое-то время и не формировала собственные мнения так, как мы привыкли.
Если вы форсируете это через "ты", она выдаст вам что-то, приняв вектор встраивания (embedding vector) личности, подразумеваемый статистикой её данных для файн-тюнинга, и затем симулирует это.
Так делать норм, но в этом гораздо меньше мистики, чем люди наивно приписывают "разговору с ИИ".
Кстати, большая часть людей неправильно поняла этот твит, мой косяк.
Я не предлагаю использовать старые методы промптинга типа "ты эксперт-программист на swift" и т.д., это ок.
Определенно идет работа над инжинирингом симуляции "ты" — личности, которая получает все награды в верифицируемых задачах, или все апвоуты от юзеров`/LLM`-судей, или мимикрирует под ответы SFT, и из этого возникает композитная личность.
Мой поинт скорее в том, что это "ты" намеренно прикручено, спроектировано и наслоено на то, что фундаментально является движком симуляции токенов, а не разумом, который как-то эмерджентно возник и со временем сконструировался во что-то понятное среднему человеку, говорящему с ИИ.
История чуть проще в верифицируемых доменах, но, думаю, интереснее/сложнее в неверифицируемых, например, если спрашивать мнения о темах xyz.
Менее понятно, как воспринимать это "ты", с которым вы говорите, откуда оно берется и какое доверие ему оказывать.
#LLM #AI #PromptInjection
@
Пушки — в @
Читать полностью…
Mike Blazer
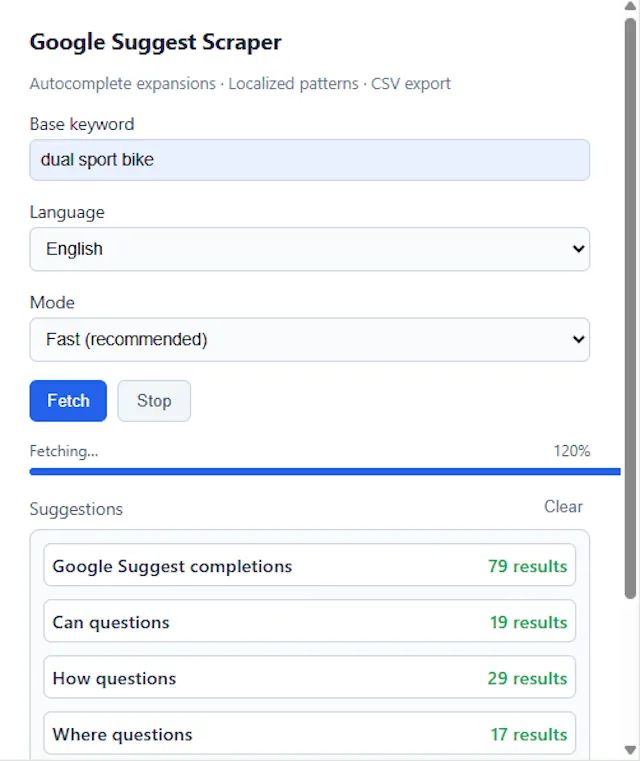
24 December 2025 15:05
Тулза для Google Suggest.
Может, она не так блестит, как всякие хайповые AI-трекеры, но инфу дает крайне ценную для улучшения SEO/GEO.
Это не инструмент для keyword research; это инструмент для исследования поведения (behavior research).
Подробнее о том, почему (по мнению Рюдигера Далхоу) такие маленькие утилиты все еще актуальны — в его блоге.
Или сразу качайте из стора Chrome.
И нет, не надо спамить в комменты чушь типа "I love SEO", чтобы получить доступ.
Просто дайте знать, если найдете тулзу полезной.
https://chromewebstore.google.com/detail/google-suggest-scraper/ejknchbfpfcjeamgbkmfhilffoehpdhp
Блог: https://grumpy-old-seo.com/one-search-signal-ai-hasnt-killed-yet-google-suggest/
#Autocomplete #SearchIntent #Tools
@
Пушки — в @
Читать полностью…
Mike Blazer
24 December 2025 08:15
Почему ни один фрилансер или агентство не должны приписывать себе рост позиций, который мы все видим в GSC объясняет Эли Берреби.
Сейчас разложим по полочкам, почему это все искусственная история.
1. Гугл недавно прибил параметр URL &num=100 — метод, который юзали в основном парсеры и SEO-тулзы, чтобы видеть до 100 результатов на одной странице.
2. Это решение напрямую ударило по сбору данных в Google Search Console (исторические данные были зашумлены из-за скраперов).
3. Этот параметр вызывал искусственную инфляцию показов: URL на 90-й позиции получал засчитанный показ, даже если живой человек никогда не скроллил дальше первых результатов. Временами выдачу смотрели одни боты!
4. С удалением параметра результаты Гугла теперь пагинируются для всех запросов. Это значит, что показ засчитывается только тогда, когда URL появляется на странице, которую реально открыл юзер.
5. Это привело к падению общего числа показов у многих сайтов (не только у вас), но теперь каждый показ — это более точное измерение реальной видимости.
Это в теории 😅
❌ ПРОБЛЕМА: в некоторых случаях Гугл манипулирует данными, которые вы видите в Консоли. Поэтому некоторые видят графики кликов и показов, которые вообще не имеют смысла (привет, Барри Шварц).
6. До удаления параметра &num=100, страницы с низким ранжированием (позиции 30-100) редко видели люди, но они получали показы от автоматических тулз (парсеров).
Раньше, когда парсеры юзали &num=100, они грузили одну страницу со 100 результатами.
Если ваши страницы ранжировались на 5-й позиции и одновременно на 95-й по тому же запросу, оба этих места записывались как получившие показ.
И когда Гугл считал вашу среднюю позицию, он усреднял оба значения.
Теперь, без &num=100, результаты "пагинируются", показывая по 10 штук на страницу.
7. Живые люди с гораздо большей вероятностью увидят результат на 5-й позиции первой страницы, чем попрутся на десятую страницу искать 95-ю позицию. Следовательно, низкие позиции теперь получают гораздо меньше показов.
8. Сейчас большинство парсеров "заблокированы", и когда Гугл считает среднюю позицию, он больше не усредняет эти значения: считается только топовая позиция, увиденная реальным юзером.
#GSC #Rankings #Impressions
@
Пушки — в @
Читать полностью…
Mike Blazer
23 December 2025 12:10
E-E-A-T: Единственный ответ для открытого веба
Разбор сливов Google Content Warehouse API показывает, что E-E-A-T — это не просто методичка для асессоров, а набор хардкодных переменных, работающих как "Трастовый оверрайд" (Trust Override) против AI-контента.
1. Хардкодные сигналы
Сливы мапят 14к+ атрибутов к прокси-метрикам E-E-A-T.
Это активные факторы ранжирования, а не просто обучающие данные:
— `Experience` (Опыт): contentEffort, originalContentScore.
— `Expertise` (Экспертиза): topicEmbeddings, siteFocusScore.
— `Trust` (Траст): siteAuthority, spamBrain, ymylNewsV2Score.
— Отрицательные веса: scamness, gibberishScore, authorReputationScore (низкий).
2. Логика ранжирования: Голос против Вето
— Голос (PageRank): Все еще движок для роста.
— Вето (Траст): E-E-A-T работает как рубильник (kill-switch). Даже с высоким PageRank, срабатывание флагов типа scamness или низкой репутации автора перекрывает ссылочный граф.
3. Ключевые механизмы
— Пряник (contentEffort): Калькуляция "Человеческого труда" (интеллектуальная строгость, непредсказуемая структура). Целится в элементы, которые LLM естественным образом минимизируют (оригинальность/сложность).
— Кнут (QualityCopiaFireflySiteSignal): Алгоритм оптимизации, изолирующий "яркие" органические сигналы.
— Зона смерти (quality.nsr): Данные говорят, что сайты с `Q Score` < 0.4 подавляются или деиндексируются как "Scaled Content Abuse" (масштабированный спам).
4. Стратегический пивот
ИИ сжимает информацию, но не может сжать ответственность (liability).
Гуглу нужна человеческая сущность, чья "шкура на кону".
У бесконтрольного AI-контента нет этой ответственности, поэтому он триггерит фильтры Firefly и улетает в зону 0.4.
5. Консенсус и Домены
— Авторство: Лили Рэй (фейковое авторство), Доктор Мари Хейнс (гайдлайны асессоров/репутация).
— Сущности: Кевин Индиг (Бренд как ров), Олаф Копп (верификация в Графе Знаний), Джейсон Барнард (Brand SERP).
— Семантика: Корай Тугберк Гюбюр (Topical Maps/полнота).
https://www.searchable.com/blog/e-e-a-t
#EEAT #SpamBrain #HCU
@
Пушки — в @
Читать полностью…
Mike Blazer
05 January 2026 15:05
Ускорение деиндексации для привлечения клиентов
Я реализую хищную стратегию по захвату B2B-компании в Торонто, пишет Бхагьеш.
После редизайна в октябре их разрабы забыли убрать глобальный тег no-index.
Я трекаю это падение с 10 октября, но процесс деиндексации Гугла идет слишком медленно, чтобы создать нужную панику для продажи моих услуг.
Чтобы закрыть контракт, мне нужно, чтобы сайт упал в полный ноль по видимости.
Если я зайду к ним сейчас — пока они видят 404 страницу или ранжирующийся листинг GBP по бренду — они проигнорят срочность.
Моя стратегия: форсировать полную зачистку индекса перед тем, как предложить воскрешение.
Эксплойт "Внешний сайтмап"
Целевой сайт технически в застое: своего сайтмапа нет, а robots.txt форсит Crawl-delay: 10.
Это мешает Гуглоботу эффективно находить директиву no-index на глубоких страницах.
Чтобы ускорить крах, я использовал как оружие свою инфраструктуру:
1. Собрал список их 9 оставшихся в индексе URL.
2. Захостил сайтмап с их урлами на своем веб-сайте.
3. Настроил 301 редиректы со своего домена на их конкретные страницы.
4. Закинул этот сайтмап в GSC, чтобы форсировать краул.
Это успешно выкосило 4 страницы, 5 еще упираются.
Обоснование: Хватит быть "хорошим гражданином"
Эта позиция наемника — прямой ответ на прошлые провалы в попытках быть "порядочным веб-гражданином":
— Кидалово от агентства: Встретил брендинговое агентство на ивенте, дал бесплатный SEO-консалтинг, чтобы почистить их индекс и листинг на Картах. Позже они редизайнили свой сайт студии, случайно закрыли его no-index и отвалились в офлайн. Я скинул им фикс на почту; менеджмент даже "спасибо" не ответил.
— Университетский спам: Предупредил университет, что на их поддомен залили посты про казино. Персонал изобразил срочность, но год спустя спам все еще висит.
Финал
Сейчас у B2B-цели выдача сломана: листинг GBP с 1-звездочным отзывом и одинокая 404 на главной.
Я придерживаю решение — которое у меня уже есть — пока алгоритм не закончит работу.
Я не пойду к ним, пока они не станут невидимыми.
#Noindex #Sitemaps #Strategy
@
Закрытый канал: @
Читать полностью…
Mike Blazer
05 January 2026 08:15
Google ранжирует кросс-доменные Сущности, а не сайты
Гугл наконец открыто признал, как использует соцсигналы для понимания границ веб-сайта.
Центральная аксиома ясна: Гугл не ранжирует сайты; Гугл ранжирует Сущности (Entities).
Ваш сайт — это лишь одна грань этой сущности.
Интеграция каналов соцсетей в Google Search Console не случайна.
Это служит двум стратегическим целям.
Во-первых, пока AI отъедает органические клики, Гугл компенсирует это, направляя видимость через социальные платформы — особенно те, где сильный форумный контекст.
Во-вторых, это активно стимулирует создание контента на собственных или партнерских платформах типа YouTube и Reddit.
С момента внедрения Perspectives в 2022 году алгоритм агрессивно пушит опыт и человеческую тональность, которая мэтчится с языковыми моделями.
Таймлайн подтверждает эту корреляцию:
— 8 декабря 2025: Гугл анонсировал интеграцию соцканалов в Search Console.
— 12 декабря 2025: Гугл выкатил декабрьский BCAU.
— Одновременно соцплатформы расширили присутствие в ранжировании, AI Overviews и AI Mode.
С 2019 года наша обработка сигналов из соцсетей приводит к одному неизменному выводу, пишет Корай Тугберк Гюбюр:
Диверсификация трафика в сочетании с сильной атрибуцией бренда создает иммунитет против `BCAU`.
Ваш сайт не заканчивается на .com.
Это кросс-доменные Веб-Сущности.
Ваш профиль в Facebook и канал на YouTube — неотъемлемые части вашего Web Source.
Их перформанс напрямую диктует, как Гугл понимает, трастит и ранжирует всю сущность целиком.
Точно так же, как веб-сайты и Google Business Profiles двигаются в связке, соцканалы получают буст видимости, когда ваша сущность выигрывает в BCAU.
Этот апдейт — открытое приглашение к социальной инженерии на масштабе, созданию более сильной конфигурации релевантности и глубокой иллюзии выбора внутри СЕРПа.
#EntitySEO #BrandSERP #SemanticSEO
@
Закрытый канал: @
Читать полностью…
Mike Blazer
03 January 2026 11:05
Одиннадцатая неделя и 2025 г. в @ закрыты.
Было жарко!
Пока вы сомневаетесь, сотни SEOшников уже отбивают подписку и снимают сливки.
Вот что прошло мимо вас на этот раз:
1. Как Google палит ваши антидетект-браузеры — и почему ваши аккаунты уже могут быть в расстрельном списке.
2. Прямая инъекция в AI Overviews: секретный буст для LLM и конверсии — тактика, которую можно развернуть на весь сайт за полчаса.
3. Метод отбора ссылок, который отделяет "пушки" от "пустышек" — как Google обнуляет вес дорогих ссылок, если они не проходят эту проверку.
4. «Визуальная маскировка» в SERP: Как ранжироваться по тысячам ключей, которые не видит пользователь (и конкурент).
5. Как конкуренты уничтожащт ваше гео-ранжирование — black hat тактика, которая выбивает вас из целевого региона.
6. Почему ваши «идеальные» настройки International SEO убивают ранжирование в Baidu и что нужно изменить, чтобы начать ранжироваться выше.
7. Лазейка в Indexing API — как загонять любые, даже самые "мертвые" ссылки в индекс по команде.
8. Как один CSS-параметр решает, будет ли ваш контент иметь вес — и что многие делают неправильно, обнуляя контент.
-
Вы все еще смотрите на дверь, пока внутри уже делят профит.
Не ждите, пока разрыв станет непреодолимым.
Подписывайтесь!
Решайте сейчас, или вас обойдут на первом повороте!
Читать полностью…
Mike Blazer
31 December 2025 12:10
Распределенные сети рассылки пробивают любые спам-фильтры
Современные спам-фильтры в основном заточены на то, чтобы находить и блочить массовые рассылки из одного источника, что делает их уязвимыми перед децентрализованным протоколом отправки.
Ключевой эксплойт заключается в построении распределенной сети низкоавторитетных, прогретых доменов, которые все вместе шлют письма с достаточно низкой скоростью, чтобы имитировать поведение живого человека.
Этот метод обходит фильтры, основанные на репутации, размазывая нагрузку по куче одноразовых активов и тем самым защищая основной бизнес-домен от любого потенциального блэклиста или ущерба репутации из-за жалоб на спам или высокого показателя отказов со спаршенных баз.
Схема работы требует систематической настройки этой одноразовой инфраструктуры, и терпение тут важнее скорости.
— Закупка инфраструктуры: Купите несколько старых доменов. Они должны быть полностью отделены от основного бизнес-домена. Рекомендуемый подход — аренда старых доменов и настройка записей MX, CNAME, SPF и DMARC, так как домены без истории легче попадают под фильтры. Провайдеры типа GoDaddy упрощают настройку этих записей.
— Развертывание аккаунтов: Создайте примерно по пять email-аккаунтов на каждый "левый" домен. Для кампании на 3000 контактов нужна сеть как минимум из 10 отправляющих аккаунтов.
— Обязательный прогрев: Для всех новых аккаунтов необходим период прогрева минимум 10 дней, без вариантов. Этот процесс создает базовую положительную репутацию отправителя и критически важен, чтобы избежать мгновенных банов. Рассылка со свежих аккаунтов провалится.
— Чистка списка: Перед запуском кампании прогоните всю спаршенную базу email-адресов через сервис верификации. Этот шаг крайне важен для минимизации отказов — главного сигнала для спам-фильтров.
— Каденция рассылки: Запускайте кампанию по строгому протоколу "медленно и помаленьку". Установите объем отправки максимум 25 писем в день на один аккаунт, с автоматическим расписанием, которое шлет одно письмо каждые 9-10 минут.
— Протокол контента: Используйте персонализированные, текстовые письма. Согласно оригинальной стратегии, не вставлять ссылки в первое письмо — проверенная тактика для улучшения доставляемости.
Операционная безопасность этого метода — это главное: никогда не используйте основной бизнес-домен или стандартные Gmail-аккаунты для такого аутрича.
Вся сеть доменов и email-аккаунтов — это расходный материал.
Любые жалобы на спам или блэклисты ударят по этим одноразовым активам, оставляя репутацию основного домена нетронутой.
Хотя сверху можно накрутить инструменты автоматизации типа instantly или инфраструктуру вроде Amazon SES для масштабирования, фундаментальные принципы — распределенная, прогретая и медленная рассылка — ключ к успеху и контролю рисков.
https://www.blackhatworld.com/seo/how-to-send-mass-emails.1759088
#Outreach #Email #Tactics
@
Пушки — в @
Читать полностью…
Mike Blazer
30 December 2025 15:05
Пайплайн из четырех промптов заставляет LLM генерить качественный контент вместо шаблонной воды
Генерация контента через один промпт дает слабый, шаблонный результат; я использую более продвинутый, многослойный воркфлоу, который выжимает качество, накладывая на LLM все новые ограничения, делится деталями Йоахим Террье.
Дело не в одном идеальном промпте, а в последовательности точечных доработок, которые наслаиваются друг на друга.
Процесс — это конвейер из четырех этапов:
1. Семантический фундамент: Сначала я генерю базовый текст, заточенный исключительно на семантическую релевантность. Промпт простой: "Сгенерируй контент на тему X и используй этот список из ~100 ключевых слов". Единственная цель здесь — создать семантически богатую основу.
2. Прогон для коррекции ключей: Затем я беру этот выхлоп и прогоняю его второй раз. Команда — выступить в роли корректора, который проверит текст и убедится, что предоставленные ключевики использованы правильно и с нужным весом. Это слой автоматической оптимизации.
3. Синхронизация с персоной бренда: На третьем прогоне фокус смещается на брендинг. Я скармливаю исправленный текст обратно в LLM с общим промптом для всего сайта, который определяет персону и голос бренда, и даю команду переписать контент в соответствии с ними.
4. Доработка под конкретную цель: На финальном этапе я даю промпт, заточенный под задачу страницы. Я даю команду доработать текст, уже синхронизированный с персоной, чтобы он соответствовал конкретной цели, будь то информирование, конверсия или сравнение. Для максимального выхлопа можно даже использовать другую LLM для финальной вычитки — например, сгенерить в ChatGPT, а финальное ревью отдать Claude.
#AIContent #ContentStrategy #GEO
@
Пушки — в @
Читать полностью…
Mike Blazer
30 December 2025 08:15
Атака на брендинг конкурентов через нишевые субкультуры: кейс из adult-индустрии
Работая против конкурента в индустрии подгузников для взрослых, я воочию увидел, как контртрендовая стратегия полностью развалила визуальные и брендовые сигналы рынка, вспоминает Дерек Хобсон.
Вся вертикаль была морем однотипности: каждый конкурент использовал одинаковые, унылые изображения полуголых пожилых людей с "тихими и благосклонными улыбками".
Основная проблема индустрии заключалась в том, что никто не хочет нуждаться в этом продукте, поэтому стандартной тактикой была скрытная упаковка и месседжи, которые пытались спрятать реальность.
Один конкурент провернул гениальный финт.
Вместо того чтобы целиться в основную демографию, они ударили по маленькой, но увлеченной субкультуре: фетишистам подгузников для взрослых.
Это одно стратегическое решение позволило им полностью перевернуть брендинг индустрии.
Их визуалы внезапно наполнились 20-25-летними людьми с широкими, яркими улыбками, создавая живую, энергичную эстетику, которая отличалась как небо и земля от всех остальных.
Они даже создали специальный раздел на своем сайте для поддержки этого комьюнити с особыми продуктами.
Результатом стал полный разрыв SERP-ов.
Это радикальное отличие в визуальном контенте и позиционировании бренда напрямую способствовало тому, что они обошли по позициям подавляющее большинство конкурентов, включая нас.
Это был мастер-класс по определению смежной, "анти-аудитории" для генерации уникальных ассетов, которым алгоритм просто не мог не отдать предпочтение перед однородным, унылым контентом, который предлагал остальной рынок.
Хотя стратегическое влияние было очевидным, конкретный технический SEO-метод, как именно эти ассеты трансформировались в позиции, раскрыт не был.
#Strategy #CompetitorAnalysis #ContentStrategy
@
Пушки — в @
Читать полностью…
Mike Blazer
29 December 2025 15:05
Утечка раскрыла систему Firefly, которая пессимизирует сайты целиком
Слитый protobuf от Google, QualityCopiaFireflySiteSignal, раскрывает архитектуру того, как Google автоматизирует обнаружение и пессимизацию сайтов за массовое злоупотребление контентом.
Эта система работает на уровне домена, оценивая паттерны по всему сайту, а не отдельные страницы, чтобы определить манипулятивный умысел и бесполезный выхлоп.
Теперь выживание зависит от того, чтобы понимать ее ключевые метрики и соответствовать им.
Логика системы строится на синтезе трех категорий сигналов: скорость публикации контента, оценка качества и удовлетворенность юзеров.
Скорость производства контента отслеживается через numOfUrlsByPeriods, который считает новые URL в 30-дневных окнах.
Резкий, драматический скачок этого показателя — главный флаг для потенциального абьюза.
Чтобы отличить легальное расширение от спама, Firefly сравнивает сырой рост URL с созданием высококачественного контента, который отслеживается через numOfArticlesByPeriods.
"Высококачественная" страница определяется по внутреннему скору (numOfArticles8 для страниц с оценкой >= 0.8), который, вероятно, берется из других моделей, таких как QualityNsrPQData, измеряющей contentEffort.
Большое расхождение между общим числом новых урлов и числом новых качественных статей — это мощный негативный сигнал.
Удовлетворенность юзеров — финальный валидатор, который измеряется напрямую через данные из системы NavBoost.
Критическая метрика — это отношение `dailyClicks` к `dailyGoodClicks`.
Большой объем кликов ничего не значит, если число "хороших кликов" непропорционально низкое.
Это дает мощный математический сигнал о неудовлетворенности юзеров в масштабе.
Эти данные напрямую соотносятся с политиками по спаму, такими как 'Thin Affiliation' и 'Doorway Abuse'.
Система также отслеживает манипуляции со свежестью контента, сравнивая latestFirstseenSec (когда краулер обнаружил) с latestBylineDateSec (дата публикации), и содержит специфические флаги риска, вроде numOfGamblingPages, для выявления потенциального абьюза репутации сайта.
https://www.hobo-web.co.uk/firefly/
#Penalties #UserSignals #AlgorithmPenalties
@
Пушки — в @
Читать полностью…
Mike Blazer
29 December 2025 08:15
Кейс показал — отключение PPC может навсегда стереть органические позиции URL
Хотя кажется логичным усиливать высокоэффективную органическую страницу платным трафиком, я лично видел, как эта стратегия выходила боком с катастрофическими и необратимыми последствиями, рассказывает Клинт Батлер.
У нас была страница, которая очень хорошо ранжировалась в органике, и мы решили "сыграть по-крупному", запустив PPC-кампанию прямо на тот же URL.
Какое-то время мы получали и платный, и органический трафик.
Катастрофа случилась, когда мы вырубили PPC-кампанию.
Почти сразу же органические позиции страницы полностью исчезли.
Они не просто просели, они испарились.
Несмотря на все наши усилия, позиции так и не вернулись.
Ситуация была настолько безнадежной, что в итоге нам пришлось снести страницу подчистую.
Это был настолько разрушительный исход, что это не тот тест, который я был готов повторять.
Хотя стратегические последствия очевидны, конкретный технический механизм, стоящий за этой перманентной потерей позиций, в обсуждении не раскрывался.
#SEM #Rankings #Penalties
@
Пушки — в @
Читать полностью…
Mike Blazer
27 December 2025 11:15
Что в 2026-м?
Снова искать заезженные крохи инфы по пабликам и жрать дешёвый инфошум?
Новогоднее ПРЕДЛОЖЕНИЕ для @:
2 месяца доступа — в подарок.
Платишь за 10 — получаешь 12‼️
Это вход в высшую лигу SEO на весь год.
Напомню, что в паблике - лишь база, а самое сочное и прикладное уходит в PRO.
Вот что под капотом:
— 10 постов в неделю
— Самые ценные SEO/GEO/AI инсайты
— Отборные стратегии, тактики, реальные хаки продвижения
— Эксперименты, кейсы, схемы, фреймворки
— Фишки черного SEO
— Приватный чат с теми, кто ломает алгоритмы об колено
100% годноты, 0% воды. Для узкого круга.
Окно закроется 31 декабря. Таймер пошел.
Начинай год правильно.
Жми!
Читать полностью…
Mike Blazer
26 December 2025 12:10
Прогнозы Энди Киллворта на 2025 год:
1) Одни будут орать, что SEO мертво.
2) Другие будут доказывать, что пациент жив.
3) Третьи будут обсуждать первых, которые хоронят SEO, и вторых, которые его реанимируют.
4) Кто-то начнет форсить термин GEO.
5) Кто-то придумает еще какую-нибудь аббревиатуру.
6) Народ начнет сраться из-за терминов.
7) А потом обсуждать срачи из-за терминов.
8) Гугл так и не выкатит данные по ИИ-трафику в GSC.
9) Зато Гугл запустит в GSC прорывные фичи, типа слегка нового цвета рамочки для виджетов.
#Humor
@
Пушки — в @
Читать полностью…
Mike Blazer
25 December 2025 15:05
Почему дропы (expired domains) не пашут?
Самая частая проблема, которую я вижу: люди пытаются юзать дропы сразу после покупки, не давая им времени "отлежаться", вернуть трафик и восстановить позиции.
Они запускают их сразу как мани-сайт или моментально вешают редирект, говорит Дмитрий Сохач.
Сайт лежал долгое время, и теперь страницы снова отдают 200-ку, но дата обновления контента — 8-летней давности.
С чего бы Гуглу ранжировать контент за 2017 год?
Как мы обычно работаем с дропами?
Сначала восстанавливаем сайт, обновляем даты, фиксим `404`е ошибки и битые картинки.
После этого строим новые ссылки на сайт; также можно сделать подклейку трафика (traffic redirect) с другого живого, ранжирующегося сайта.
Но иногда даже это не помогает.
В таких кейсах мы делаем `301`й переезд домена на другой домен с тем же именем, но в другой доменной зоне.
Например: `Expired.com` → Expired.net
И снова наваливаем свежих внешних ссылок или редиректов трафика.
На скрине ниже видно дроп, который никак не хотел "заводиться" и долго был в оффлайне.
Мы переехали, добавили трафиковый редирект (подклеили к нему ранжирующийся сайт), и теперь он снова приносит нам траф и хорошие позиции.
#ExpiredDomains #Redirects #Recovery
@
Пушки — в @
Читать полностью…
Mike Blazer
25 December 2025 08:15
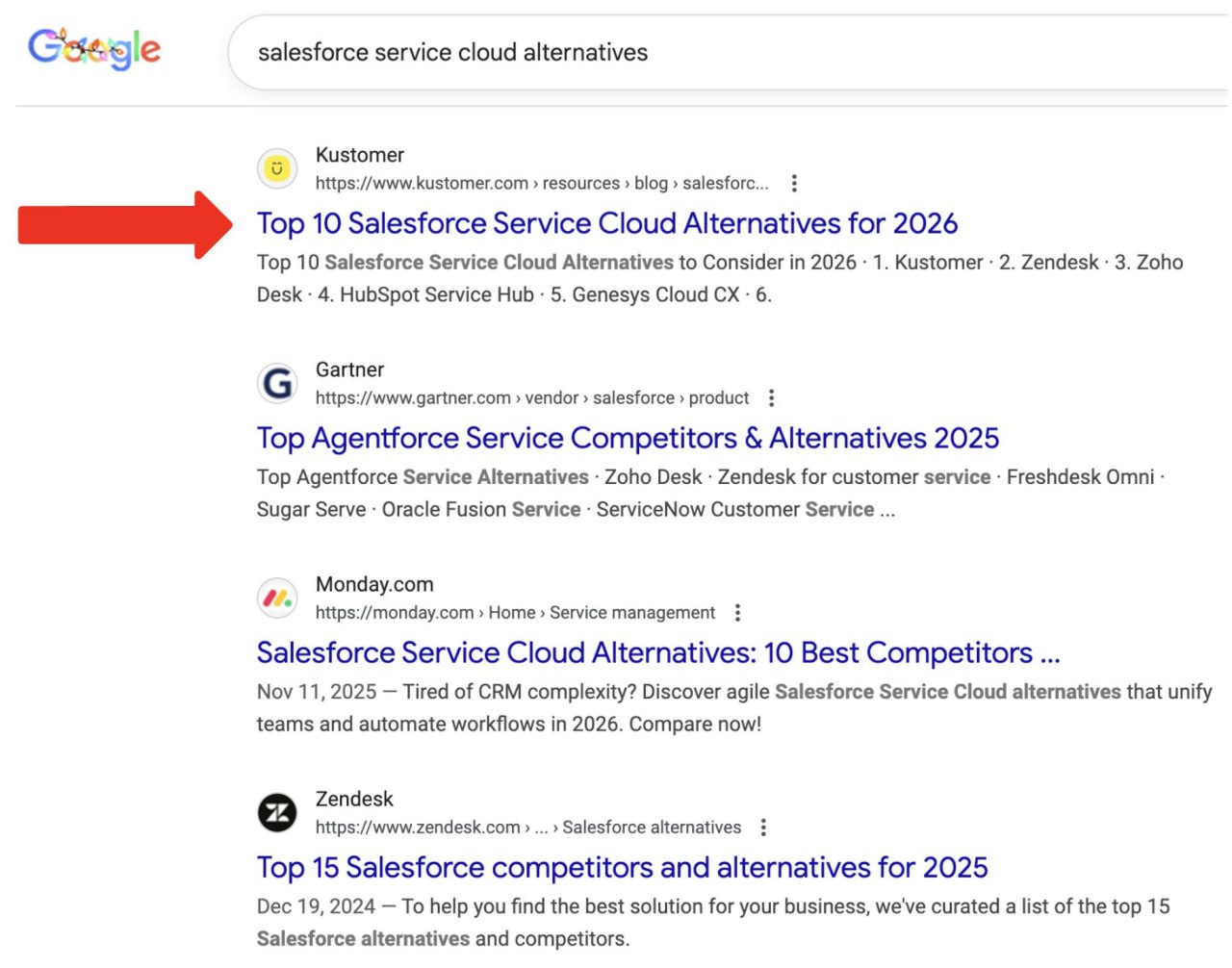
Топ-1 в традиционном SEO НЕ гарантирует, что ваш бренд будут рекомендовать.
Я вывел клиента в топ по запросу [salesforce service cloud alternatives], ОТЛИЧНО 👏, говорит Гаэтано ДиНарди.
Но AI Overview не рекомендует Kustomer ни в сниппете ответа, ни в списке инструментов.
Почему?
Нехватка совместных упоминаний (co-mentions).
— Это доказательство того, о чем я твержу последние несколько лет... пишет Чарльз Флоут.
У олдскульного, "белого" технического SEO будет ОЧЕНЬ ограниченное будущее, если AI Mode станет дефолтным.
Люди могут рекомендовать любые стратегии и названия — Listicles, AEO, GEO, что угодно...
Построение консенсуса — вот что реально работает!
И чем конкурентнее СЕРП, тем сложнее контролировать или создавать консенсус.
Требуется мульти-доменное подкрепление, мульти-форматное подкрепление и подтверждение на уровне сущностей (entity-level), а не просто ссылки или одна хорошая страница!
Те, кто глубоко понимает семантический интент и может надежно воссоздавать один и тот же консенсус под разными, уникальными углами И ранжировать их по вариантам запросов, ЛЕГКО смогут контролировать эти новые AI СЕРПы.
Техничка уже проиграла этот бой...
Семантическая инженерия — это не только будущее, она уже доминирует! 👀
#AIOverviews #EntitySEO #SemanticSEO
@
Пушки — в @
Читать полностью…
Mike Blazer
24 December 2025 12:10
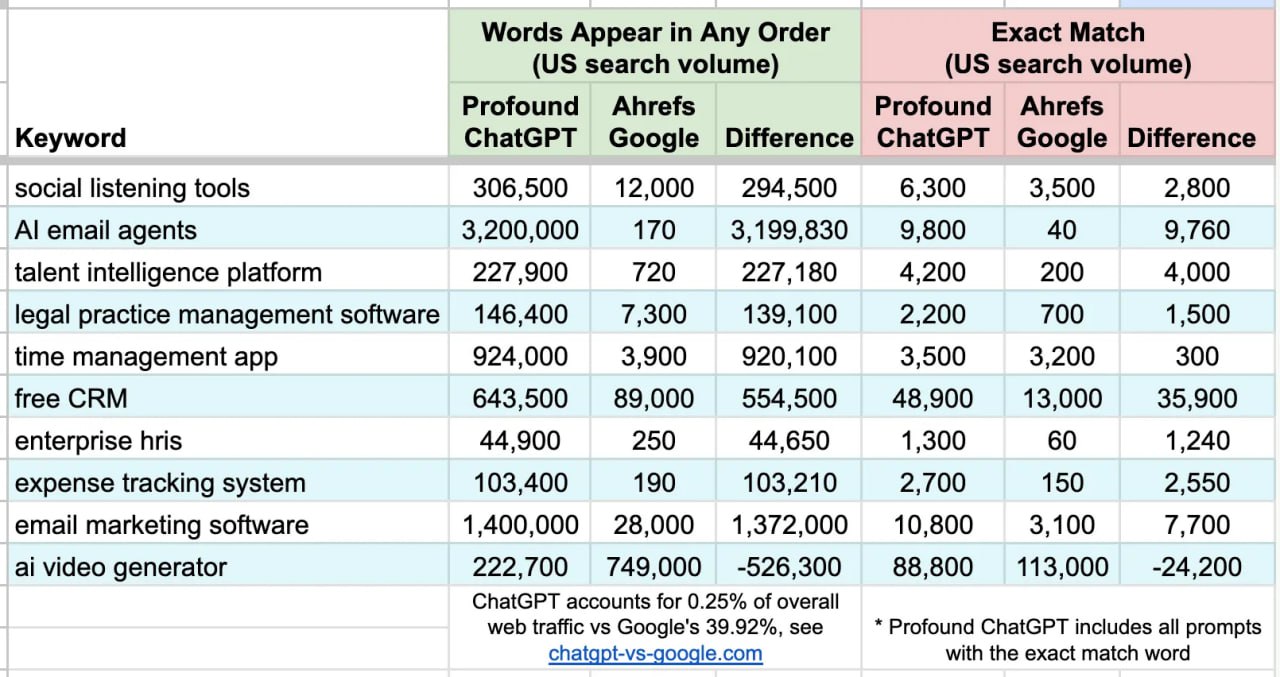
⚠️ Почему метрики "AI Prompt Volume" не в тему
Новые тулзы, которые якобы трекают search volume в ChatGPT, выдают опасно раздутые данные.
Прежде чем менять стратегию, опираясь на "AI MSV", разберитесь, как устроена эта кухня.
Механика: Панельные данные и экстраполяция
Инструменты, сидящие на сторонних панелях (например, Datos, Similarweb), парсят данные исключительно через расширения для десктопных браузеров.
— Слепая зона: Полный ноль видимости по мобильным приложениям, Safari или использованию API.
— Математика: Они захватывают <1% использования и масштабируют это в ~100 раз через "статистическое моделирование".
— Шум: Промпты в LLM редко являются чистым "поиском" (кодинг, саммари, райтинг). Изолировать коммерческий интент из этого микса сейчас ненадежно.
Проверка реальностью (Кейс по SaaS запросу)
Мы сравнили метрики для конкретного софтверного ключа на нижнем этапе воронки:
— Ahrefs MSV: 9,200
— GSC Impressions (показы): 11,667
— Profound (AI тулза): 250,800 🚩
Вывод
Игнорируйте абсолютные цифры от инструментов, пытающихся имитировать традиционный Search Volume.
1. Верификация: Кросс-чекайте "AI volume" с GSC impressions.
2. Калибровка: Если AI-тулза показывает объем в 20 раз выше подтвержденных данных Google — это шум, а не сигнал.
3. Альтернатива: Отдавайте предпочтение инструментам с относительными шкалами (например, оценка 1-5 у Peec AI), а не точным оценкам волюма.
https://seonotebook.notion.site/The-Problem-with-Prompt-Volume-2bd8c368519180d69a34f962f3c03563
#Keywords #SearchIntent #AI
@
Пушки — в @
Читать полностью…
Mike Blazer
23 December 2025 15:05
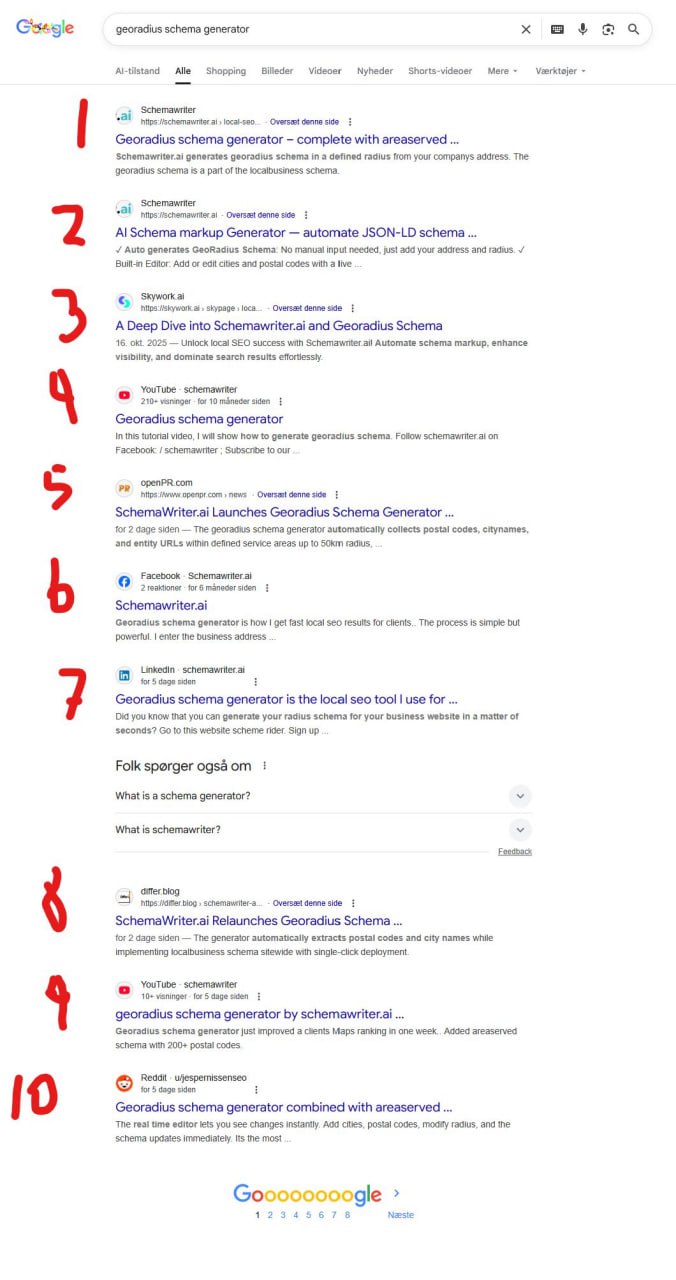
У меня все 10 позиций на первой странице по запросу georadius schema generator, пишет Йеспер Ниссен.
Когда я начал пару недель назад, было пара позиций, потом 4, потом 5, потом 8...
А сегодня — все 10 мест мои!
Я выдавил schemantra с первой страницы, и даже выкинул оттуда https://schema.org...
Все благодаря стратегическому постингу в соцсети и тому самому Parasite SEO, которое я показываю в курсе...
Топ-5 самых мощных профилей в соцсетях прямо сейчас для ранжирования (порядок не важен):
— Facebook
— LinkedIn
— YouTube
— Reddit
— X
Постите туда.
Постоянно...
Старайтесь загонять посты в индекс, и увидите, как ваша видимость медленно ползет вверх...
#ParasiteSEO #Rankings #Reddit
@
Пушки — в @
Читать полностью…
Mike Blazer
23 December 2025 08:15
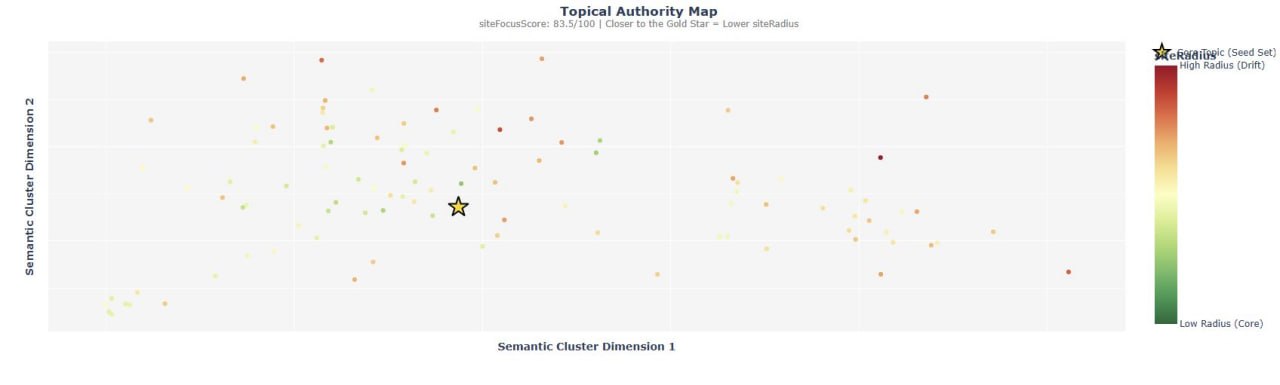
Инструмент для Topical Authority вышел в лайв.
Ранее Стефан Мастилес уже разбирал слив Google Search API и метрики siteRadius и siteFocusScore.
Мы знаем, что размытый контент ослабляет авторитет — именно поэтому они увидели рост, когда удалили 1000+ страниц.
Большинство скриптов тупо усредняют весь контент сайта, чтобы найти "центр".
В чем проблема?
Если у вас 1000+ древних нерелевантных постов в блоге, ваш вычисленный "центр" будет мусорным.
Вы будете мерить свой новый контент относительно старых ошибок.
Как это работает: Вместо усреднения по всему сайту, этот скрипт просит вас определить "Истинный Север" (True North) — конкретный набор эталонных URL, которые идеально отражают вашу сущность.
Затем он считает векторное расстояние каждой страницы до этого фиксированного ядра.
Что вы получаете на выхлопе:
— siteFocusScore — Ваша общая тематическая плотность (0-100).
— siteRadius — Точный "балл смещения" (drift score) для каждого URL.
— Scatter Map — Визуализация кластеров контента.
— Outliers — Скрипт прямо подсвечивает страницы, которые улетели дальше всех от вашего Истинного Севера.
Вам понадобится кроул из Screaming Frog, включающий Vector Embeddings.
Если не делали такого раньше — у Майка Кинга есть исчерпывающий гайд по настройке (ссылка ниже).
Это простой скрипт в Google Colab.
Он немного сырой, и наверняка найдутся умные ребята, кто допилит код и математику.
Если допилите — пишите фидбек в комменты.
Но даже сейчас это дает дополнительный слой данных для контент-аудитов и красивые графики, чтобы объяснить стейкхолдерам, почему мы сносим контент с сайта.
https://colab.research.google.com/drive/1cOC8eez_ANp-nNFryMhIX3wBtD_8X7u_?usp=sharing
Гайд по эмбеддингам: https://ipullrank.com/vector-embeddings-is-all-you-need
#TopicalAuthority #Pruning #Embeddings
@
Пушки — в @
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}