Mike Blazer
15 May 2025 15:05
Жизнь в налоговом раю: переезд из Германии на Кипр
Переезд из Германии на Кипр, чтобы уйти от налоговой ставки в 50% в пользу более привлекательных 12.5%, на бумаге казался идеальной оптимизацией в Excel-табличке, пишет Оле Леманн.
Будучи "табличным гуру" в Берлине, это казалось взломом секретного кода, но реальность показала, что я решал совершенно не то уравнение.
Жизнь в налоговой гавани оказалась гораздо сложнее и затратнее, чем ожидалось, фактически разделяя тебя как личность, когда вся жизнь организована вокруг налоговой оптимизации.
Требование о 60-дневном резидентстве на Кипре, которое изначально казалось выполнимым, в итоге стало контролировать каждый аспект жизни.
Визиты к семье, командировки и спонтанные возможности превратились в сложные расчеты риск-менеджмента резидентства.
По сути, одно ограничение (высокие налоги) сменилось другим (постоянный подсчет дней).
Физическая удаленность от основных инновационных хабов вроде SF, NYC и Сингапура оказалась губительной для развития бизнеса.
Находиться вдали от реальных инновационных центров стоит дороже любой налоговой экономии – энергетику и возможности, циркулирующие в этих локациях, невозможно воспроизвести в налоговом раю.
Бизнес растет медленнее в налогово-эффективных зонах, независимо от экономии на бумаге, при этом теряется доступ к критически важным драйверам роста бизнеса.
Проблемы с инфраструктурой и логистикой создавали постоянное трение, превращая простые задачи в многоступенчатые челленджи.
Обычная стойка для приседаний ехала три недели из-за особенностей логистики ЕС и островного положения.
Базовые бизнес-потребности сталкивались с повышенными расходами на доставку, а содержание нескольких жилищ плюс частые экстренные перелеты быстро съели обещанную налоговую экономию.
Профессиональная сеть контактов деградировала несмотря на Zoom-коллы, поскольку ничто не могло заменить случайные знакомства в реальных инновационных хабах.
Среда налоговой гавани привлекала людей с мышлением защиты капитала, а не его создания, где разговоры крутились вокруг налоговых схем вместо создания значимых венчуров.
Окружение не стимулирует создавать что-то значимое, потому что все здесь временно.
Психологическое влияние оказалось существенным.
Идентичность сместилась от гордого местного предпринимателя, создающего что-то значимое, до очередного экспата в погоне за налоговыми льготами.
Настоящая проблема Германии была не только в налоговой ставке, но в фундаментальном анти-предпринимательском настрое – однако обмен этого на место, ценящее только низкие налоги, не стал улучшением.
Жизнь с временным мышлением создала странное лимбо-состояние с вечной 70%-ной вовлеченностью во все – никаких инвестиций в правильное обустройство дома или офиса.
Построение длительных отношений стало практически невозможным из-за постоянной текучки людей, поддерживающих минимальные требования резидентства.
Комьюнити никогда не укреплялось, так как люди исчезали на месяцы, ненадолго возвращаясь, чтобы снова исчезнуть.
Налоговая оптимизация обошлась ценой реальной оптимизации жизни.
Урок очевиден - если вы не стали бы жить в месте, где нет налоговых преимуществ, не живите там ради налоговых преимуществ.
Истинная цена налоговой оптимизации оплачивается более ценными валютами: временем, энергией, комьюнити и душевным спокойствием.
@
Читать полностью…
Mike Blazer
14 May 2025 17:05
Недавно опубликованные документы по антимонопольному делу Министерства юстиции США против Google раскрывают интересную инфу:
Поисковый индекс состоит из фактического контента, который прокраулен (заголовки и текст), и ничего больше, т. е. это инвертированный индекс.
Существуют также другие отдельные специализированные инвертированные индексы для других целей, таких как фиды из Twitter, Macy's и т. д.
Они хранятся отдельно от индекса для органических результатов.
Это касается только 10 синих ссылок, но некоторые сигналы хранятся для удобства в индексе поиска.
Сигналы на основе запросов не хранятся, а вычисляются во время запроса.
https://www.justice.gov/atr/media/1398871/dlMacy's это e-commerce ритейлер.
Это наводит на мысль, что для каждого крупного сайта у Гугла может быть отдельный индекс.
Обмозгуйте это перед сном...
@
Читать полностью…
Mike Blazer
14 May 2025 13:10
Исследование ключевиков с помощью только Google Search Console?
Без Ahrefs.
Без Semrush.
Только данные, которые Google уже предоставляет вам. 👇
Мы использовали именно этот метод, чтобы извлечь 390 172 ключевых слова с одного сайта и создать контент-план, построенный исключительно на реальном поисковом поведении, пишет Стив Тот.
Результат?
Революционный.
— Тысячи низкоконкурентных ключей с высоким интентом
— Напрямую связаны с вашими существующими страницами
— Отфильтрованы, обогащены и готовы к использованию
Мы использовали это для планирования SEO-контента на 6+ месяцев.
Все подкреплено данными.
Никаких догадок.
Каждый месяц (начиная с 16 месяцев назад) мы выполняли 4 отдельных выгрузки ключевых слов:
1) "обычная выгрузка" без параметров регулярных выражений
2) регулярное выражение для ключей с 3+ словами
3) регулярное выражение для 6+ слов
4) регулярное выражение для вопросительных запросов
Вот регулярное выражение:
1) нормальное извлечение, не требуется.
2) ([^" "]*\s){2,}? (3+ слова)
3) ([^" "]*\s){5,}? (6+ слов)
4)
^(who|what|where|when|why|how|was|wasn't|wasnt|did|didn't|didnt|do|is|isn't|isnt|are|aren't|arent|will|won't|wont|does|doesn't|doesnt|should|shouldn't|shouldnt|were|weren't|werent|would|wouldn't|wouldnt|can|can't|cant|could|couldn't|couldnt)[" "]
Даже если вы не попробуете весь метод, можете использовать регулярку прямо в
GSC, чтобы получить отличные результаты.
@
Читать полностью…
Mike Blazer
14 May 2025 08:15
Метод Link Lazarus использует битые ссылки из Википедии
Йесилюрт обнаружил, что дроп-домены с бэклинками из Википедии сохраняют ценные сигналы авторитетности, которые часто не замечаются популярными SEO-инструментами.
Его метод улучшает традиционные подходы работы с битыми ссылками через:
— Глубокий анализ контента: Изучение архивного контента для выявления связей между сущностями
— Стратегическое маппирование: Сопоставление просроченных доменов с релевантным контентом
— Редиректы на основе интента: Сохранение тематической целостности
— Улучшенное воссоздание контента: Повышение ценности контента, когда это выгодно
Популярные инструменты вроде Ahrefs и Semrush часто не показывают обратные ссылки из Википедии на просроченные домены.
Python-инструмент Йесилюрта на базе Streamlit систематически находит эти возможности путем краулинга Википедии, извлечения внешних ссылок, определения мертвых и проверки доступности доменов.
https://huggingface.co/spaces/metehan777/link-lazarus
(Ограничен 20 результатами/страницами вики.)
Рабочий процесс включает:
1. Сканирование Википедии через поиск по ключевым словам и краулинг категорий
2. Анализ контента через Archive.org
3. Проверку домена через WHOIS и DNS-чеки
4. Маппинг контента с помощью ИИ и эмбеддингов
5. Редиректы на основе топиков, сохраняющие релевантность
Результаты демонстрируют эффективность метода:
— AppSamurai доминировал на первой странице выдачи по целевым запросам
— Сайт в конкурентной нише поднялся с позиции #23 на #2
— Выявлено 1 862 просроченных домена на страницах Википедии на разных языках
— Новый домен в конкурентной нише показал значительное улучшение за 3 недели
— Обнаружены домены с цитированием из Гарварда, MIT и правительственных источников
Метод Link Lazarus работает не только с Википедией, но и с другими авторитетными платформами.
https://metehan.ai/blog/link-lazarus-method/
@
Читать полностью…
Mike Blazer
13 May 2025 15:05
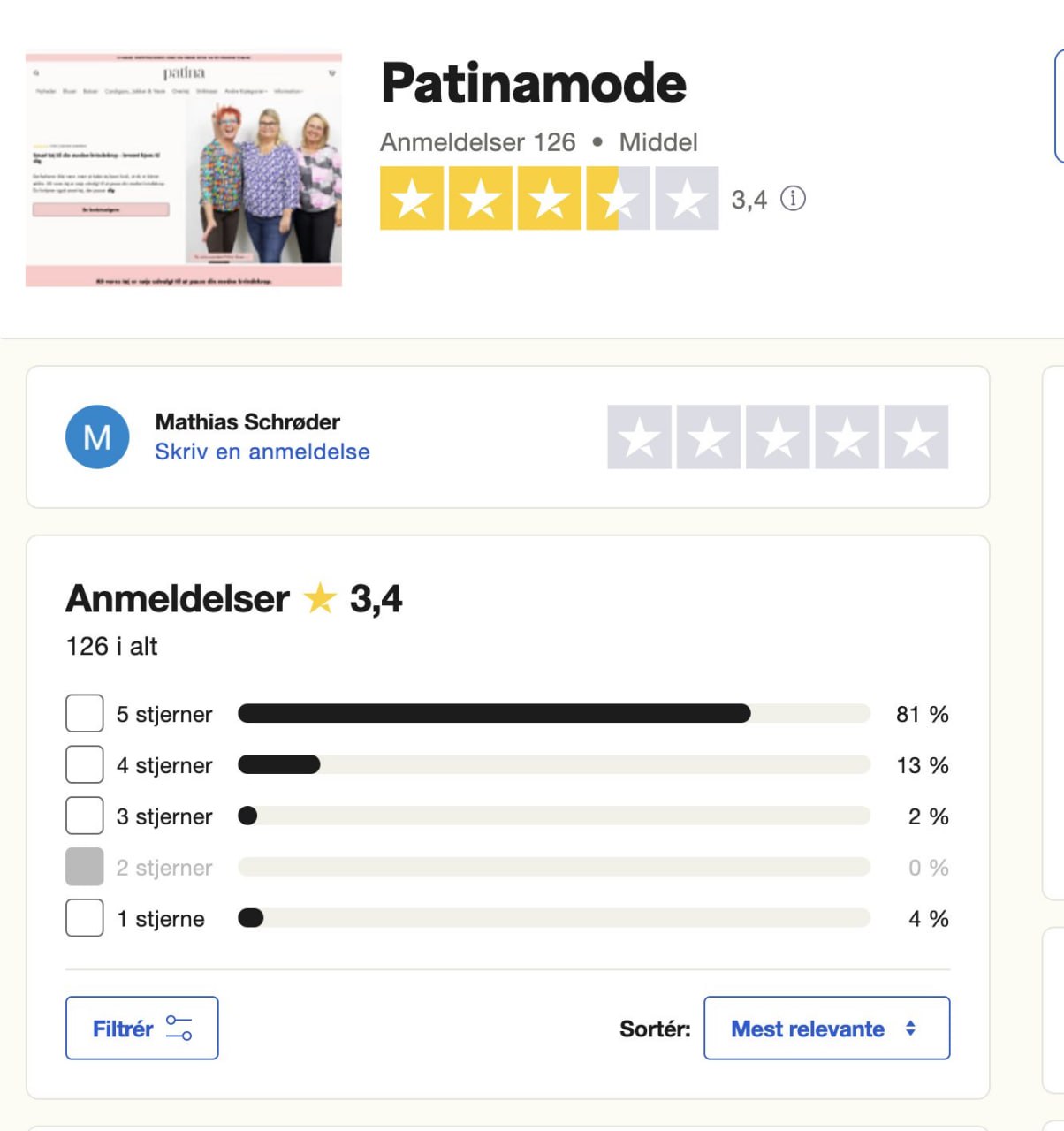
Вау, TrustPilot - это просто развод, мошенничество и все прочие подобные слова, которые только можно придумать.
Я случайно заметил, что у нас средний рейтинг 3.4 по отзывам на Trustpilot, говорит Матиас Шрёдер.
Что казалось странным, учитывая, что у нас средний балл 4.9 по 7660 отзывам через Judge Me Reviews.
Так что я посчитал.
У нас 126 отзывов на Trustpilot:
1 звезда: 5
2 звезды: 0
3 звезды: 2
4 звезды: 16
5 звезд: 103
Среднее арифметическое: 4.68
Средний балл по версии Trustpilot, то есть их TrustScore: 3.4 🙃
Какого хрена?
Их объяснение:
"Расчет основан на различных параметрах, таких как общее количество отзывов компании и дата создания отзывов.
На TrustScore также влияет то, активно ли компания приглашает своих клиентов оставлять отзывы или нет."
Позвольте мне перевести это для вас:
Trustpilot намеренно занижает средние рейтинги продавцов, использующих другие платформы для отзывов, и маскирует это под собственный "алгоритм TrustScore".
На самом деле, единственный способ получить много отзывов, свежие отзывы и активно приглашать клиентов оставлять отзывы на Trustpilot - те самые "различные параметры" в их объяснении - это... использовать Trustpilot.
Последнее предложение, которое я получил от Trustpilot, было $400 в месяц.
И это было более 5 лет назад, когда мы были лишь частью того бизнеса, которым являемся сегодня.
Так что, поскольку я не готов платить эту сумму, которая, я не удивлюсь, сейчас уже превышает $1000 в месяц, они просто портят нашу репутацию, выдавая нам низкий рейтинг.
РАЗВОД.
@
Читать полностью…
Mike Blazer
13 May 2025 11:05
Хотите увеличить свои шансы появиться в Google Discover? 👀
Тогда перестаньте использовать один и тот же заголовок везде.
Многие люди по-прежнему используют один и тот же текст для <title>, <h1> и og:title.
Но данные, представленные Джоном Шехата, показывают, что это может быть стратегической ошибкой, потому что Google выбирает, какой заголовок показывать, и не всегда выбирает тот, который вы предполагаете.
В США заголовок Open Graph (og:title) используется в 34% случаев в Discover.
В Германии этот показатель достигает 61%.
Другими словами, если вы не тестируете разные версии заголовков, вы можете упустить отличную возможность повысить свою видимость.
Практический совет:
Создайте три разных версии заголовка для каждой статьи:
— Оптимизированный для SEO заголовок (<title>)
— Привлекательный для читателей заголовок (<h1>)
— Заголовок, рассчитанный на вовлечение в социальные сети (og:title)
Google любит возможность выбора.
Дайте ему его 🤓
@
Читать полностью…
Mike Blazer
12 May 2025 18:56
⚠️ Гайз, остерегайтесь мошенников косящих под меня‼️
Я никому не пишу, ничего не предлагаю и не прошу денег.
Будьте бдительны!
@
Читать полностью…
Mike Blazer
12 May 2025 15:05
В чёрном SEO атаки каноникализации - реальность.
Вы можете использовать кросс-доменные каноникалы чтобы:
— Повысить авторитет своего сайта, или
— Перенаправить алгоритмические санкции на конкурента.
Это работает.
Если у вашего бренда нет исторических данных или сильного распознавания сущности, они даже могут заставить ваш сайт ранжироваться по запросам малайзийских мыльных опер всего с несколькими низкокачественными сигналами.
Та же тактика применима к Web Answers.
Джеймс Дули создаёт блестящие модели "искусственного консенсуса" - формируя понимание LLM с помощью семантического слоения.
Убедить LLM - все равно что сформировать массовое сознание.
Нельзя сказать это один раз.
Вы говорите это:
— С другой страницы
— На другом сайте
— В другое время
— Через другую призму
Это многомерное повторение создаёт новые определения.
@
Читать полностью…
Mike Blazer
12 May 2025 11:05
В то время как 301-редиректы отлично работают для поисковых систем, они недостаточны для моделей искусственного интеллекта (LLMs) типа GPT, Gemini и Claude. Вот почему это важно:
Ключевая проблема
LLM не краулят веб в реальном времени и не следуют техническим редиректам.
Они обучаются через лингвистические ассоциации.
Когда вы мигрируете домены без должного лингвистического контекста:
— Ваш бренд разделяется на две отдельные сущности в понимании ИИ
— Обе версии становятся слабее, так как сигналы разделяются
— Вероятность рекомендации в системах ИИ снижается
Примеры из реального мира
— Neckermann.de → Otto.de:
Несмотря на миграцию, LLM все еще воспринимают Neckermann как отдельный бренд, не связывая его с Otto
— Amiando.com → events.xing.com:
Частичное разделение сохраняется, с ассоциациями стартапа, все еще привязанными к оригинальному домену
Как предотвратить разделение сущностей
— Создавайте поясняющий контент, связывающий старый и новый домены
— Обеспечьте со-цитирование в медиа ("X теперь известен как Y")
— Обновите ссылки в вики и директориях
— Включите упоминания на новом сайте ("ранее известный как...")
Это относится не только к доменам, но и к важным субдоменам и стратегическим URL.
Без лингвистического подкрепления присутствие вашего бренда в ИИ-экосистеме останется фрагментированным и ослабленным.
https://gpt-insights.de/ai-insights/domainumzug-llms-redirects/
@
Читать полностью…
Mike Blazer
11 May 2025 19:12
Похоже, Google больше не ограничивает количество слов при поиске.
Раньше максимальное количество слов составляло 32, но теперь поиск прерывается только при достижении максимального предела URL-адресов.
Это изменение, вызванное ИИ.
@
Читать полностью…
Mike Blazer
09 May 2025 15:05
Вот как выглядит деиндексация
@
Читать полностью…
Mike Blazer
09 May 2025 11:05
Как заработать $300 за 3 часа, используя только свой ноутбук:
— Открой ноутбук
— Купи домен
— Создай сайт
— Открой ChatGPT
— Сгенерируй 50 статей
— Наставь ссылок
— Размести посты в соцсетях
Когда всё это сделаешь:
Продай ноутбук за $300.
@
Читать полностью…
Mike Blazer
08 May 2025 17:05
Загадка Googlebot
Мы разгадали загадку краулинга Googlebot'ом неожиданных 404-ых ошибок и развернули автоматическую систему смягчения для клиентов Vercel, сообщает Мальте Убл.
Анализируя логи нашей платформы, мы заметили более высокий, чем ожидалось, процент 404-ых ошибок для Googlebot, которому не было очевидного объяснения.
Копнув глубже, мы заметили еще кое-что: многие URL-адреса, возвращавшие 404, были для вспомогательных ресурсов (JS и CSS, а не документов), и они раньше существовали.
Однако ко времени запроса Googlebot они уже были заменены новым релизом клиента.
Но почему Googlebot запрашивал такие старые URL?
Оказывается, происходит следующее: Googlebot скачивает HTML-документ и потом иногда хранит его у себя неделями!
А затем в какой-то момент рендерит скачанный HTML в хедлесс Chromium браузере.
Этот браузер потом скачивает все вспомогательные ресурсы, на которые были ссылки несколько недель назад.
Естественно, вспомогательные ресурсы к этому времени могут быть уже недоступны, и поэтому мы видим 404 в наших логах.
404-ые ошибки для JS и CSS файлов могут быть крайне проблематичными, так как рендеринг страницы может не сработать.
Google индексирует только отрендеренный DOM (а не исходный HTML), и соответственно неудачные рендеры плохо влияют на SEO.
Так что же можно сделать?
Два года назад Vercel запустил штуку под названием Skew Protection.
Он позволяет автоматически перенаправлять подзапросы на тот же деплой, что и основная страница.
Skew Protection помог бы здесь, но стандартная конфигурация покрывает только минуты и до нескольких дней - а Googlebot ждал неделями.
Это натолкнуло нас на идею: что если мы расширим Skew Protection до 60 дней специально для Googlebot?
Он рендерит действительно старые документы.
Если мы позволим ему запрашивать файлы, которые он запросил бы во время первоначального краулинга, тогда результаты рендеринга будут гораздо ближе к ожиданиям.
И это сработало.
Общий объем 404-ых ошибок снизился на 80%.
Некоторый базовый уровень 404-ых ошибок ожидаем, так как наши клиенты иногда действительно запрашивают файлы, которых легитимно не существует.
Какое влияние это оказывает: намного, намного меньше неудачных краулов для клиентов Vercel.
Skew Protection изначально был разработан, чтобы помочь с краткосрочными ошибками во время деплоя, но оказалось, что это мощный примитив для SEO.
Насколько нам известно, Vercel - единственная платформа, поддерживающая Skew Protection, но мы бы хотели увидеть более широкое принятие этой технологии в индустрии.
https://vercel.com/changelog/automatic-mitigation-of-crawler-delay-via-skew-protection
@
Читать полностью…
Mike Blazer
08 May 2025 13:10
Марк Уильямс-Кук обнаружил эксплойт в Google...
Он раскрыл более 2000 параметров и метрик, которые использует Google.
Один из них был "site_quality"!
Знали ли вы, что у Google есть оценка "site_quality" для каждого сайта (поддомена)?
Эта оценка определяет такие вещи, как право вашего сайта на отображение в рич сниппетах!
Конкретные сайты набирают гораздо больше баллов, чем популярные.
Оценка выставляется на основе сайта (поддомена).
Существует патент Google "Site quality score", который примерно описывает его как поисковый интерес к веб-сайту.
"site_quality" не коррелирует с ссылками.
Похоже, что "site_quality" - это оценка, основанная на том, сколько людей целенаправленно ищут именно этот конкретный веб-сайт.
@
Читать полностью…
Mike Blazer
08 May 2025 08:15
SearchPilot провели SEO-тест для клиента из туристической индустрии, чтобы определить, улучшит ли добавление кодов городов назначения (например, LOND) или IATA-кодов аэропортов (например, LHR) в тайтлы и H1-заголовки органический трафик на страницах авиарейсов их итальянского домена.
Они реализовали эти коды в скобках после названий направлений на тестовых страницах и измерили влияние на органический трафик по сравнению с контрольными страницами без кодов.
Результаты оказались отрицательными: страницы с добавленными кодами показали падение органического трафика на 16% (с уровнем достоверности 95%).
Анализ показал, что коды, вероятно, сделали тайтлы менее естественными, не предоставили дополнительной ценности пользователям и выглядели как переоптимизация для Google.
Негативное влияние было сильнее на страницах городов, чем на страницах аэропортов, что предполагает, что пользователи обычно не ищут с использованием кодов городов.
На основе этих результатов SearchPilot рекомендовал отказаться от внедрения данного изменения.
https://www.searchpilot.com/resources/case-studies/adding-destination-city-or-airport-iata-codes-to-title-and-h1
@
Читать полностью…
Mike Blazer
14 May 2025 18:05
Кое-что еще из этого же документа
Сигналы ABC (основные сигналы):
(Разработаны инженерами, считаются «сырыми».)
— Якоря (A -anchors): ссылки с исходной страницы на целевую страницу.
— Текст (B - body): термины в документе.
— Клики (C - clicks): исторически, время, которое пользователь провел на странице по ссылке, прежде чем вернуться к SERP.
Эти сигналы, наряду с такими факторами, как Navboost, являются ключевыми компонентами тематичности (T - topicality).
Тематичность (T):
— Оценка релевантности документа запросу (базовый балл).
— Эффективно сочетает (по крайней мере) сигналы ABC относительно ручным способом.
— Оценивает релевантность документа на основе терминов запроса.
— Находился в постоянном развитии до примерно 5 лет назад; сейчас изменения менее значительны.
@
Читать полностью…
Mike Blazer
14 May 2025 15:05
Букмарклет, который извлекает схему из страниц и сохраняет ее в текстовый файл с разделением между JSON и Microdata:
javascript:(function(){javascript:(function(){function e(){return Array.from(document.querySelectorAll('script[type="application/ld+json"]')).map(e=>e.textContent).join("\n\n")}function t(){return Array.from(document.querySelectorAll("[itemscope]")).map(e=>Array.from(e.querySelectorAll("[itemprop]")).map(e=>`${e.getAttribute("itemprop")}: ${e.textContent.trim()}`).join("\n")).join("\n\n")}function n(e){return e.replace(/^(https?:\/\/)?(www\.)?/,"").replace(/[^a-z0-9]/gi,"_").toLowerCase()}const o=e(),r=t(),c=`JSON-LD:\n${o}\n\nMicrodata:\n${r}`,a=n(window.location.hostname+window.location.pathname),i=new Date().toISOString().split("T")[0],l=`${a}_${i}.txt`,s=new Blob([c],{type:"text/plain"}),p=document.createElement("a");p.href=URL.createObjectURL(s),p.download=l,p.click(),URL.revokeObjectURL(p.href)})();})();@
Читать полностью…
Mike Blazer
14 May 2025 11:05
Я восстановил трафик 3 сайтов, удалив страницы, на которые владелец купил сотни платных ссылок, говорит Шейн Дутка.
Найти сайты, продающие ссылки, чрезвычайно просто, и мы знаем (благодаря утечке API), что Google встроил в свой алгоритм функции, которые выявляют "BadBackLinks".
Я только что запустил бесплатный инструмент getseoshield.com, который индексирует все сайты, активно продающие ссылки (на данный момент 157,411) по всему интернету.
Мы находим эти ссылки, агрегируя их с различных маркетплейсов, гигов на Fiverr и тех самых нежелательных писем, которые мы все так любим.
Этот сайт позволяет проверить, насколько "токсичен" ваш ссылочный профиль, и увидеть, какие страницы пострадали больше всего.
Если мы находим несколько источников для одной и той же ссылки, мы помечаем сайт как "высокорисковый", то есть получить ссылку с такого сайта хуже, чем с сайта, найденного только из одного источника.
Чем больше платных ссылок относительно неоплачиваемых = более токсичный ссылочный профиль.
Для спасения сайта я обычно перепубликую страницы по новым URL без 301 редиректа (то есть разрывая ссылку).
Разрывая ссылки с сайтов, которые активно продают ссылки, вы потенциально можете восстановить сайт (я делал это 3 разных раза).
Если вы активно покупаете ссылки на линкбилдинговых маркетплейсах, и ваш трафик растет - отлично, но если трафик падает, я бы рекомендовал удалить страницы со слишком большим количеством токсичных ссылок.
Проблема возникает всегда, когда вы перебарщиваете.
Несколько стратегических ссылок с оптимизированным анкором - отлично.
Сотни покупных ссылок с маркетплейсов - не очень.
Больше информации в видео.
@
Читать полностью…
Mike Blazer
13 May 2025 17:05
Гуглу не важно, лучше ли ваша статья.
Ему важно, уходят ли пользователи с сайта или остаются.
Вот как Чарльз Флоут заманивает по CTR, а затем удерживает на странице:
— Тайтл = кликбейт → Используйте сильные слова + вопросительные модификаторы
— Первые 150 слов = резюме + интригующий CTA → Не давайте ответ сразу
— Добавьте якорные ссылки в оглавление → Манипулируйте метриками глубины просмотра страницы
— Встройте мультимедиа (видео, GIF, слайдеры) в первый экран
— Загружайте похожие статьи в середине контента через AJAX → Держит время на сайте завышенным
Вам не нужен более качественный контент или информация.
Вам нужна лучшая психология кликов.
@
Читать полностью…
Mike Blazer
13 May 2025 13:10
Вы можете предсказать, будет ли страница деиндексирована!
На основе комплексного исследования 1.4 миллиона страниц на 18 сайтах, проведенного Indexing Insight, выявлена чёткая корреляция между частотой краулинга и статусом индексации.
Ключевые выводы:
1. Порог в 130 дней: Страницы, не краулившиеся более 130 дней, имеют 99% шанс быть деиндексированными.
После 151 дня деиндексация становится практически гарантированной (100%).
2. Корреляция между краулингом и индексацией: Чем дольше страница не краулится, тем выше риск её деиндексации:
— Страницы, краулившиеся в течение 30 дней: 97% остаются в индексе
— Страницы, краулившиеся в течение 100-130 дней: 85-94% остаются в индексе
— Страницы, краулившиеся после 131 дня: Резкое снижение индексации (падает до 0% после 151 дня)
3. Практическое применение: Мониторинг "Дней с последнего краула" через URL Inspection API предоставляет надёжный индикатор страниц, находящихся под угрозой деиндексации.
"CrawlRank" (КраулРанк) - страницы, которые краулятся реже, получают меньше видимости в поиске.
Отметка в 130 дней служит системой раннего предупреждения, позволяющей вебмастерам предпринять превентивные меры до того, как важные приносящие доход страницы исчезнут из индекса.
https://indexinginsight.substack.com/p/new-study-the-130-day-indexing-rule
@
Читать полностью…
Mike Blazer
13 May 2025 08:15
Я изучил более 15 исследований по AI Overviews, чтобы вам не пришлось, пишет Мальте Ландвер.
Влияние на CTR: от +19% до -85%.
Средний показатель: -40%.
Медианный: -37%.
Почему такие разные цифры?
Некоторые исследования сегментируют данные по тематике, брендовым vs не брендовым запросам, позиции или месяцу.
Так мы получаем 32 значения из 8 разных источников.
Эти +19% относились к брендовым запросам в исследовании Amsive.
Ни одно другое исследование не содержало среза данных с положительным влиянием на кликабельность.
Я не стал учитывать исследования от SEMrush, Botify, Siege Media, Advanced Web Ranking и других.
Они не использовали показатель кликабельности, а скорее смотрели, как часто появляются ИИ-обзоры.
Или же они учитывали общее число кликов, на которое могут влиять позиции сайта и поисковый объем.
@
Читать полностью…
Mike Blazer
12 May 2025 17:05
SEO в эпоху агентов: итоги NYC SEO Week
Джеймс Кэдуолладер представил концепцию "Agentic Internet", где агенты на базе LLM выступают посредниками во взаимодействии с вебом, смещая фокус SEO с UX на Agent Experience (AX, опыт агента).
Агенты отдают предпочтение структурированным данным, семантическим URL, метаданным и сравнительным листиклам, часто игнорируя JavaScript и традиционные бэклинки.
Это ведет к потенциальному "будущему без кликов" и риску потери прямых отношений с пользователями.
-
Майк Кинг подробно описал механики AI-поиска: векторные эмбеддинги, обеспечивающие семантическое понимание за рамками устаревших лексических моделей.
Он выступил за "инженерию релевантности" (информационный поиск + UX + digital PR) и бросил вызов таким нормам, как короткие теги title, ссылаясь на тесты, показывающие, что когда Google дописывает ключевые слова к коротким тайтлам (что видно по данным GSC), это увеличивает клики.
Кинг описал гибридные системы извлечения (лексические + векторные) и расширение запросов.
-
AI Overviews (AIOs), встречающиеся примерно в 20% запросов в Google (и эта цифра, вероятно, будет расти), используют Retrieval-Augmented Generation (RAG) — семантический чанкинг и индексацию для извлечения данных LLM.
Кристал Картер отметила, что структурированные данные помогают усвоению информации Deepseek LLM, а Кришна Мадхаван подчеркнул важность фактологичного и ясного стиля письма для включения в LLM.
Примечательно, что Рикардо Баэза-Йейтс назвал RAG "костылём" для недостатков LLM, предупредив, что он усиливает посредственность и предвзятость.
Джефф Койл заявил, что AI отдает приоритет результатам (полезности, доверию), а не кликам.
Маник Бхан подтвердил, что тематическая релевантность важнее авторитета домена, рекомендуя визуализацию тематических векторов и отсечение нетематического контента.
Бьянка Андерсон призвала к "коперниканскому перевороту" в SEO KPI: отходить от трафика/позиций к оценке контента по его конверсионному потенциалу, поскольку AIOs могут снизить трафик.
-
Чтобы появляться в ответах LLM, Маник Бхан посоветовал включать контент в обучающие корпуса, такие как Common Crawl, через гостевые посты или PR Newswire, а также оптимизировать страницы "О нас".
Дэн Петровик обсудил отслеживание восприятия бренда/сущности в LLM и двунаправленные запросы.
Джори Форд предложила создавать "ответные активы" для LLM и анализировать поведение ботов (логи Cloudflare, показывающие высокую активность ботов при низком количестве кликов, указывают на упущенную оптимизацию).
Автор оригинального обзора отметил риск манипулирования LLM посредством повторяющейся обратной связи.
-
Кэрри Роуз подчеркнула важность digital PR для заметности бренда путем простановки ссылок на *страницы категорий* для закрепления лидерства в категории, используя модель "7/11/4" для запоминаемости бренда.
Рикардо Баэза-Йейтс также указал на языковое неравенство, предвзятость и недостаток прозрачности генеративного ИИ.
Роберт Хансен подтвердил существование негативного SEO, упомянув DMCA-спам, записи в RBL и манипулирование LLM.
-
Гарретт Сассман посоветовал создавать отдельные страницы под каждый интент и диверсифицировать трафик.
Он отметил рост длиннохвостых, диалоговых запросов, что совпадает с доминированием LLM, но предостерег от заискивания перед LLM.
Лили Рей осветила повторяющийся цикл в SEO (тактики -> их копирование -> апдейты Google -> ухудшение UX), что наблюдается с AI-контентом и ведет к санкциям, таким как Helpful Content Update 2023 года и Core & Spam Updates 2024 года.
Будущее требует аутентичного, ориентированного на пользователя и понятного для LLM контента, с фокусом на бренд, оригинальные исследования, мультимедиа и доверие сообщества, при этом сеошникам необходимо отслеживать видимость в AI-саммари и сентимент LLM.
https://lilyray.nyc/seo-in-the-age-of-agents-takeaways-from-nyc-seo-week/
@
Читать полностью…
Mike Blazer
12 May 2025 13:10
Google недавно провел второй "Саммит Создателей" в Вашингтоне, для независимых издателей, которые потеряли трафик 🔍 🏛
Только семь человек были приглашены на 3 дня встреч с сотрудниками Google.
Одна из издательниц опубликовала свой опыт.
Интересная цитата о крупных сайтах против независимых издателей 🗣
...вот что Google признал сразу на саммите: они знают, что их система отдавала предпочтение крупным сайтам.
Они не намеревались этого делать, но именно так эволюционировал алгоритм.
Они прямо сказали нам, что больше трафика уходило к крупным изданиям, и они активно пытаются это исправить.
Это не решается за одну ночь.
Они даже сказали, что хотели бы просто щелкнуть переключателем, чтобы сбалансировать ситуацию, но требуются месяцы, чтобы исправить их чрезмерную коррекцию.
Увидим ли мы возвращение независимых сайтов?
Также, Google сообщил, что некоторые виджеты Оглавления (
TOC) могут запутать их краулеров и даже снизить показатели ясности контента.
Они предположили, что если контент хорошо написан, организован с заголовками и имеет естественный поток, оглавление, вероятно, не требуется, и в некоторых случаях его удаление может помочь.
Вывод заключался в том, чтобы не полагаться на инструменты (такие как виджеты оглавления) для исправления того, что должна обеспечивать сильная структура написания.
https://tomikoharvey.com/google-creator-summit-review/@
Читать полностью…
Mike Blazer
12 May 2025 08:15
Мы будем оглядываться на эту эпоху и думать:
"Удивительно, как все SaaS-компании имели на своих сайтах библиотеки переработанного контента из Википедии".
Мы настолько привыкли к образовательным блогам и ресурсным центрам, что считаем их неотъемлемой частью пользовательского опыта и цифрового маркетинга в целом.
Но это не так: они являются результатом очень специфических стимулов, созданных одной компанией (Google).
И эти стимулы исчезают.
Мы создавали эти псевдоблоги, потому что это было невероятно прибыльно.
Несколько страниц текста из Википедии и несколько стоковых изображений с Unsplash исторически было достаточно, чтобы заработать тысячи и тысячи посещений.
Было глупо игнорировать создание контента в больших объемах.
Это был самый предсказуемый, самый надежный и самый прибыльный канал маркетинга.
Но стимулы меняются.
Вознаграждения меняются.
И если нынешняя тенденция сохранится, мы будем так же глупы, продолжая заниматься созданием контента того же типа.
Google не нравится "необходимое зло" в виде перенаправления трафика на сайты издателей.
В их идеальном мире пользователи бесконечно циркулируют между ресурсами Google и рекламой Google.
Перенаправление трафика на сторонний веб-сайт — это провал, потому что это выводит людей из их экосистемы.
Трафик был необходимым стимулом для поощрения создания контента, который питал машину Google.
Вы создаете контент, Google ранжирует его и вознаграждает вас частью своего поискового спроса.
Но благодаря Google LLM теперь обладает невероятным богатством информации.
Он достиг точки, когда ему не нужно стимулировать создание контента.
Как мы видим по замедлению индексации и мерам против программного контента, он хочет СОКРАТИТЬ создание контента.
Создание контента теперь является угрозой для поиска, а не преимуществом.
Благодаря поисковым функциям и рекламе Google, трафик на протяжении многих лет подвергался тысяче мелких ударов.
Но на этот раз все по-другому.
Социальный договор, который Google заключил с такими издателями, как вы и я, нарушен.
LLM нанесли смертельный удар.
Контент по-прежнему будет иметь несомненную ценность для потенциальных клиентов.
Некоторые темы заслуживают того, чтобы о них писали, даже если они не приносят трафика из поисковых систем.
Объясните, почему ваша компания существует.
Осветите основную информацию, необходимую для понимания особенностей вашего продукта.
Помогите клиентам использовать ваш продукт для достижения полезных результатов.
Но даже если это сделано хорошо, это относительно небольшая библиотека контента.
А сегодня контент-маркетинг вышел далеко за эти рамки и затронул темы, которые имеют очень малое отношение к продуктам и убеждениям компании.
Это просто арбитраж информации — и LLM гораздо лучше нас в арбитраже.
Каким бы ни было будущее контент-маркетинга, оно НЕ будет похоже на корпоративные википедии, охватывающие все возможные темы "как сделать" и "что такое".
Контент останется ядром маркетинга, но тех, кто думает, что сможет прожить следующие несколько лет без серьезных изменений в своей стратегии, ждет шок.
Нам нужно мыслить шире.
@
Читать полностью…
Mike Blazer
09 May 2025 17:05
Я показываю коллегам как надо попасть под интент
@
Читать полностью…
Mike Blazer
09 May 2025 13:10
Когда ты, испробовав все методы спама с помощью ИИ, возвращаешься к старой доброй SEOшке
@
Читать полностью…
Mike Blazer
09 May 2025 08:15
Каждый SEO-специалист проходит одну и ту же кривую обучения.
1. Начальный восторг
Добавляешь ключи.
Подкручиваешь тайтлы.
Работает.
Кажется простым.
Ты подсел.
2. Беспорядок
Краулинговый бюджет.
Хрефленги.
Схема.
Знаешь больше, но чувствуешь себя в тупике.
Уверенный и перегруженный одновременно.
3. Тихая ясность
Перестаешь гнаться за всем.
Фокусируешься на том, что важно:
Хороший контент.
Релевантные ссылки.
Четкие приоритеты.
Опасность?
Застрять посередине.
Это называется "запутаться в паутине".
Исправлять сложные проблемы, когда можно делать простые действия с большим эффектом, не изобретая велосипед.
Вот правда:
— Не каждая SEO-задача заслуживает твоего времени.
— Не каждое исправление приносит результаты.
— Иногда ты делаешь всё "правильно"...
А это всё равно требует времени.
В чем же секрет?
Фокус + терпение.
Продолжай.
Не парься по мелочам.
Даже когда кажется, что не работает.
@
Читать полностью…
Mike Blazer
08 May 2025 15:05
Как отзывы влияют на органический трафик из Google и на рекомендации ваших компании через ChatGPT?
В идеале, ваш продукт или услуга должны иметь рейтинг не менее 4.5 из 5 звезд и более 200 отзывов.
@
Читать полностью…
Mike Blazer
08 May 2025 11:05
Большинство SEO-спецов гадают, сколько контента нужно публиковать.
Google сам подскажет - если знаешь этот трюк.
Используй этот поисковый оператор:
site:comeptitor.com before:2025-04-21 after:2025-04-01
Это покажет все страницы, которые конкурент проиндексировал за этот период.
Теперь у тебя есть реальные данные.
Вот что можно с этим сделать:
✅ Ставить контент-цели, подкрепленные доказательствами
✅ Показывать клиентам, как быстро публикуются конкуренты
✅ Замечать тренды в контенте ниши за считанные секунды
Никаких догадок. Никакой воды.
Вот
ссылка на это
@
Читать полностью…
Mike Blazer
07 May 2025 17:05
Теперь с расширением Advanced GSC Visualizer вы можете визуализировать данные о краулинге из GSC и быстро выявлять полезные инсайты.
Устанавливайте здесь:👇
https://chromewebstore.google.com/detail/advanced-gsc-visualizer/cdiccpnglfpnclonhpchpaaoigfpieel
Advanced GSC Visualizer теперь включает:
— детальные отчеты по краулингу,
— оценки здоровья краулинга,
— сводки по успешным ответам сервера,
— выгружаемые разбивки запросов краулера,
— и рекомендации.
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}