Mike Blazer
04 Apr 2025 08:15
Меня только вчера подключили к клиенту, сообщает Кэтрин Вотье Онг.
Их отдел закупок работает вечность, поэтому, хотя мы работали вместе в прошлом году, оформление контракта заняло 6 месяцев.
За это время они перенесли свой сайт без моего участия, и он работает на Angular JS 18, причем все страницы, кроме главной, выдают 404-ую ошибку.
Теперь (на 2-й день сотрудничества) их разработчики (с которыми я еще не встречалась) выложили стейджинг в продакшн без защиты паролем и без noindex.
*вздох
@
Читать полностью…
Mike Blazer
03 Apr 2025 15:05
Вот, оказывается, кому достаются все сливки...
@
Читать полностью…
Mike Blazer
03 Apr 2025 11:05
SEO совет: забытое искусство управления картами сайта, которое позволяет предоставлять дополнительную информацию о странице.
Здесь можно применить различные дополнительные теги в зависимости от типа сайта, например, включить теги для страницы, связанной с видео, новостной статьей или изображениями.
Из этих трех вариантов мой любимый связан с включением тега, который часто дает значительное преимущество для более эффективной индексации контента на основе изображений, пишет Броди Кларк.
При тестировании этого подхода для различных типов сайтов, будь то интернет-магазины, онлайн-маркетплейсы или издатели всех видов, использование этих поддерживаемых Google тегов становится очевидным выбором.
В случае индексации и ранжирования изображений или видео во вкладках "Картинки" или "Видео", исходным URL на самом деле является страница (а не URL изображения/видео).
Из-за этого может показаться, что предоставление такой информации через сайтмапы не дает особой пользы, но мой опыт показывает, что польза выходит за рамки индексации и помогает Google лучше понимать эти ресурсы, по сути напрямую подключая их к поисковику.
Существует множество особенностей, связанных с такой реализацией, например, возможность использовать в карте сайта изображения, размещенные на внешних CDN, или принятие решений в случаях, когда на странице находится несколько изображений или видео.
Если вы управляете крупным сайтом, на котором регулярно публикуется важная информация в виде новостей, изображений или видео, обязательно используйте этот недооцененный инструмент, который поддерживается и рекомендуется Google.
@
Читать полностью…
Mike Blazer
02 Apr 2025 17:05
Можно ли объединить 2 страницы и получить больше лидов и трафика, чем приносили раньше?
Да, и вот как!
Если ваши страницы конкурируют между собой, Google не знает, какую из них ранжировать.
И в результате – вы получаете трафик немного на одну и немного на другую.
Немного коммерческого трафика и немного информационного.
Так было у этого клиента.
Вместо сильной страницы про ABC Development Services, у них было три:
🔹 Сервисная ABC Development Services
🔹 Информационная статья - How to Develop ABC Development
🔹 Ещё статья - ABC Development Best Practicies
Что мы сделали?
1️⃣ Смерджили всё в одну страницу → перенесли информацию в блоки FAQ + обновили структуру
2️⃣ Удалили дублирующий контент → оставили только ту страницу, которая лучше всего конвертировала (важно!)
3️⃣ Добавили внутренние линки → чтобы другие страницы сайта передавали авторитет именно на этот лендинг
На сайте клиента была статья "... ABC App Development", которая ранжировалась в топ-3.
Но проблема – с неё не приходило ни одного лида.
Почему?
🔹 Google воспринимал её как основной результат для запросов про ...ABC App Development.
🔹 Из-за этого коммерческая страница оставалась в тени.
Если SEO трафик не конвертирует – проблема может быть в том, что Google ранжирует "не ту" страницу, а у людей другой интент.
Результат:
🔹 Коммерческая страница вышла в ТОП 3-10
🔹 x5 переходов на сервисную страницу
Поэтому самое время убрать полностью каннибализацию и даже пожертвовать не конверсионным трафиком!
Также ищите вчерашний пост чтобы прочитать ещё что было сделано!
@
Читать полностью…
Mike Blazer
02 Apr 2025 13:10
Обычно SVG-изображения хороши для веб-производительности 🚀
Когда вы находите огромный SVG-файл, это обычно не из-за самого векторного изображения... а скорее из-за растровых изображений, встроенных внутрь него.
Я только что нашел страницу, загружающую два SVG по 17 мегабайт, сообщает Мэтт Зейнерт.
@
Читать полностью…
Mike Blazer
02 Apr 2025 08:15
Оказывается, частое размещение постов в социальных сетях - отличный способ быть процитированным в LLM.
Вы можете использовать LLM, чтобы резюмировать то, что кто-то (кто активно общается в социальных сетях) сказал на заданную тему...
Это может стать хорошей отправной точкой для написания статьи, создания видеоролика и т. д.
@
Читать полностью…
Mike Blazer
01 Apr 2025 15:05
Подумай дважды, прежде чем лезть в SEO, иначе придется сеошить дважды, прежде чем начнешь соображать.
@
Читать полностью…
Mike Blazer
01 Apr 2025 11:05
Я работаю с GSC уже много лет...
...
но продолжаю находить новые несоответствия в фильтрации данных, говорит Иван Палий.
Вы, вероятно, знаете, что фильтрация данных GSC по любому поисковому запросу значительно уменьшает показы и клики на графиках.
Причина — анонимизированные запросы.
Это распространенная проблема, однако, я не ожидал, что увижу увеличение метрик при добавлении доменного имени в фильтр страниц.
Я заметил это случайно, когда хотел посмотреть количество показов для поискового запроса "sitechecker", чтобы измерить рост узнаваемости бренда, но по ошибке выбрал фильтр страниц вместо фильтра поисковых запросов.
Удивленный, я перепроверил это на другом крупном сайте — та же закономерность.
Вот цифры:
Sitechecker:
— 899К кликов и 60М показов — режим по умолчанию
— 904К кликов и 84М показов — фильтр страниц включает доменное имя
— 597К кликов и 27М показов — фильтр с регулярным выражением .* по поисковому запросу
Favikon:
— 452К кликов и 35М показов — режим по умолчанию
— 459К кликов и 33М показов — фильтр страниц включает доменное имя
— 233К кликов и 19М показов — фильтр с регулярным выражением .* по поисковому запросу
Кстати, интересно, что в случае с Favikon, клики выросли, а показы уменьшились, когда я применил фильтр страниц по доменному имени.
У вас есть гипотеза, почему это происходит?
Я не знаю.
И ChatGPT не смог найти четкого объяснения.
Было бы легко объяснить, если бы данных после фильтрации стало меньше, но их стало больше :)
Еще скриншоты: 01, 02, 03, 04, 05
@
Читать полностью…
Mike Blazer
31 Mar 2025 17:05
SEO Факты
1. Никто не знает алгоритм Google
2. Никто не знает, как применяются все факторы алгоритма и какой у них вес
3. Поведенческие факторы пользователей, агрегированные поведенческие данные и машинное обучение — один из наиболее эффективных способов определения полезности контента
4. Старый принцип, когда ссылки действуют как голоса, по-прежнему имеет вес, потому что он стимулирует контент ссылаться (создавая более сильную и широкую сеть для краулинга поисковыми системами) — поэтому есть стимул сохранять эту систему
5. Вес ссылок ВСЕ ЕЩЕ рассчитывается через систему PageRank от Google
6. DR/DA/TF/CF и другие ссылочные пузомерки НЕ используются в ранжировании и являются инструментами для оценки потенциального веса ссылок — но ими легко манипулировать
7. Прогнозируемый домен/трафик со ссылающейся страницы — лучший индикатор "потенциала" для наследования ссылочного веса
8. Core Web Vitals вряд ли являются ПРЯМЫМИ факторами ранжирования — однако, медленные сайты и плохая загрузка с большей вероятностью приведут к негативному поведению пользователей, что может повлиять на собираемые данные, как указано в пункте 3
9. Новые домены, как правило, начинают ранжироваться быстрее, пока нет поведенческих данных, которые Google мог бы использовать для взвешивания - это, по-видимому, объясняет, почему некоторые новые домены могут начать быстро ранжироваться в довольно конкурентных SERP - обычно это происходит ненадолго, до "коррекции", понижающей сайты, пока они не наберут вес, т. е. ссылки, прогрессивный трафик через длинные хвосты, где поведенческие данные могут быть агрегированы
10. Домены-старички существуют и могут противоречить всей логике СЕРПа — это обычно старые домены (иногда старые EMD) — они могут продолжать ранжироваться, даже если они не соответствуют принципам, которые мы бы ожидали
11. EMD остаются мощными — особенно в сочетании с линкбилдингом в стиле "HARO-образным" (где брендовые анкоры основаны на ключевых словах)
12. Google HCU представляется многогранным алгоритмом, в котором определенные элементы веса бренда могут преобладать над потерями, все, что падает ниже "оценки качества", в конечном итоге может быть подавлено - это подавление замедляет способность нового трафика использоваться для поведенческой оценки, создавая вечный "замкнутый круг"
13. Google МОЖЕТ рендерить Javascript, но это остается неэффективным — Google не может взаимодействовать с выводом после рендеринга — когда многие JS-сайты динамически загружают контент путем взаимодействия — это может создавать проблемы с краулингом/индексацией
14. Google индексирует значительно меньше контента сейчас — это "индексациея первого прохода", когда оценка ПЕРЕД индексацией выполняется — устраняя необходимость рендеринга + индексации контента, который, вероятно, не будет показан
15. Google не нужен разобранный HTML для извлечения контента (DOM Parsing)
16. Чрезмерно длинные тайтлы/дескрипшены не проблема — если страница имеет хороший CTR, несмотря на длинные/короткие описания, то контент, вероятно, переписывается/обрезается
17. Минимизация индексного следа с логикой МЕНЬШЕ МУСОРА И БОЛЬШЕ ЦЕННОГО КОНТЕНТА с меньшей вероятностью исказит поведенческие сигналы, которые могли бы свидетельствовать о "менее" полезном сайте
18. Минимизация индексных следов полезна для уменьшения размытия PageRank
@
Читать полностью…
Mike Blazer
31 Mar 2025 15:05
Куда движутся деньги умных маркетологов?
119 компаний, каждая из которых генерирует более $10 миллионов годовой выручки, поделились информацией о своих текущих контент-стратегиях и планах по их корректировке на следующий год.
Взгляните на график.
Самое большое изменение, которое они планируют внедрить в 2025 году - это более активное использование ИИ для поддержания актуальности контента, чтобы он стабильно удерживал высокие позиции в СЕРП.
@
Читать полностью…
Mike Blazer
31 Mar 2025 08:15
Давайте поговорим о бессмысленной, бесполезной фразе которая, кажется, встречается повсюду: "Контент высокого качества".
Нужно повысить позиции в Google?
Кто-нибудь обязательно порекомендует "качественный контент".
Хотите попасть в ответы ИИ?
Найдётся консультант, который скажет, что вам нужен "качественный контент".
Не хватает вовлечённости в социальных сетях?
Готовьтесь к потоку советов типа "вам нужен качественный контента".
Эти слова ничего не значат.
С таким же успехом можно сказать "вам нужно больше орклеборка в вашем спригглтрафе!"
Это настолько же полезно.
Качество варьируется от человека к человеку.
И даже если 1000 человек оценят (по шкале 0-10) качество каждого контента в определённой нише, на блоге, в социальных сетях, корреляция между оценкой и метриками успеха этого контента будет смехотворно низкой.
Давайте будем лучше, окей?
При создании контента в digital-маркетинге обычно преследуются следующие цели:
— Охват конкретных групп определёнными сообщениями
— Привлечение трафика на сайты или страницы
— Формирование осведомлённости о брендах, людях, событиях, продуктах или проблемах
— Получение прямых продаж или запросов
— Стимулирование действий, таких как подписки на email-рассылку, подписки в соцсетях или сбор данных
Настоящие вопросы не о "качестве", а об эффективности: Что нужно создавать для достижения маркетинговых целей?
Где и как распространять контент?
Как измерять прогресс для создания маркетингового маховика?
Но 100 контент-креаторов дадут 100 разных определений, создавая проблемную вариативность в определении, стоимости, измерении и эффективности.
Согласие о низком и высоком качестве остаётся невозможным.
В конечном счёте, единственное мнение, которое имеет значение, принадлежит целевой аудитории.
Вместо ориентации на расплывчатые определения, создатели контента должны определить конкретные цели и работать в обратном направлении.
Например, ведение контент-маркетинга для IndieHackers может быть направлено на:
— Попадание в поле зрения новой аудитории
— Восстановление связи с неактивными пользователями
— Увеличение конверсии подписчиков на email-рассылку
— Охват новой аудитории в сфере ПО/технологий, заинтересованной в проектах инди-разработчиков
— Привлечение людей на офлайн-встречи
— Увеличение количества основателей, публикующих треды о своём опыте
С чёткими бизнес-целями начинается настоящая высокоценная работа: исследование целевой аудитории, поиск интересующих тем, мозговой штурм тем, которые могут привлечь внимание, выбор подходящих форматов и перечисление конкретных атрибутов, необходимых для успеха контента у этой аудитории.
Универсальной дорожной карты для этого процесса не существует - каждая организация, создатель и аудитория требуют уникального подхода, ориентированного на конкретные результаты, а не на расплывчатое "качество".
https://sparktoro.com/blog/high-quality-content-is-the-most-useless-phrase-in-marketing-we-can-do-better/
@
Читать полностью…
Mike Blazer
29 Mar 2025 09:05
Джон Мюллер говорит, что если какая-то схема неописана в документации Гугла по структурированным данным - то она не даст никакого эффекта.
А в вашей практике случалось ли, что схема вне доки Гугла срабатывала?
Напишите в комментариях.
@
Читать полностью…
Mike Blazer
28 Mar 2025 15:05
Создание сайта - первый шаг к получению санкций от Google.
@
Читать полностью…
Mike Blazer
28 Mar 2025 11:15
Внешние ссылки в ChatGPT Deep Research содержат:
— параметры srsltid, которые приходят из Google Merchant Center.
Эти параметры часто появляются в органических результатах поиска Google в последнее время, даже если сайты правильно используют каноникал теги.
Это хорошо задокументированная проблема в SEO-сфере.
— Подсветка ScrolltoText...
которая либо добавляется OpenAI, либо берется из ссылки в Google (AIO, фичеред сниппеты).
Второй вариант кажется более вероятным.
Поэтому вопрос: OpenAI Deep Research просто парсит ссылки из Google в рамках своего исследования?
Почему Google это разрешает? 😅
@
Читать полностью…
Mike Blazer
27 Mar 2025 17:05
Исследование "Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study" от Google Research исследует, как классификаторы, обученные различать написанный человеком и сгенерированный машиной текст, могут служить неконтролируемыми предикторами качества веб-страниц.
Применив такие модели к 500 миллионам веб-страниц эти детекторы могут эффективно идентифицировать низкокачественные страницы без явной маркировки.
Более того, многие низкокачественные страницы происходят из машинно-переведенного контента, ферм эссе, SEO-манипуляций и NSFW-контента.
Интересно отметить, что Google использует в статье классификацию веб-сайтов под названием NSFW.
NSFW (небезопасно для работы) сайты — это веб-сайты, содержащие контент, считающийся неприемлемым, откровенным или оскорбительным для профессионального или публичного просмотра.
Типы NSFW-контента:
— Контент для взрослых – Порнографический материал, откровенные изображения или видео.
— Насилие и кровь – Графические изображения насилия, травм или тревожные образы.
— Ненормативная лексика и язык вражды – Грубый язык, оскорбительные выражения или экстремистский контент.
— Наркотики и злоупотребление веществами – Контент, продвигающий или изображающий употребление наркотиков.
— Азартные игры и ставки – Онлайн-казино, спортивные ставки или нерегулируемые игровые сайты.
— Мошеннические сайты и вредоносное ПО – Поддельные веб-сайты, созданные для обмана пользователей или распространения вирусов.
Исследование выявляет несколько факторов, которые коррелируют с низкокачественными страницами:
Вероятность машинно-сгенерированного текста – Более высокие показатели указывают на контент плохого качества.
— Читабельность и связность – Бессвязный или непонятный текст является сильным сигналом низкого качества.
— Чрезмерная оптимизация ключевых слов – Злоупотребление ключевиками и SEO-манипуляции.
— Длина документа – Низкокачественный контент часто встречается в более коротких документах (~3000 символов или меньше).
— Тип контента – Высокие встречаемость на NSFW-сайтах, машинных переводах и фермах эссе.
https://research.google/pubs/generative-models-are-unsupervised-predictors-of-page-quality-a-colossal-scale-study/
@
Читать полностью…
Mike Blazer
03 Apr 2025 17:05
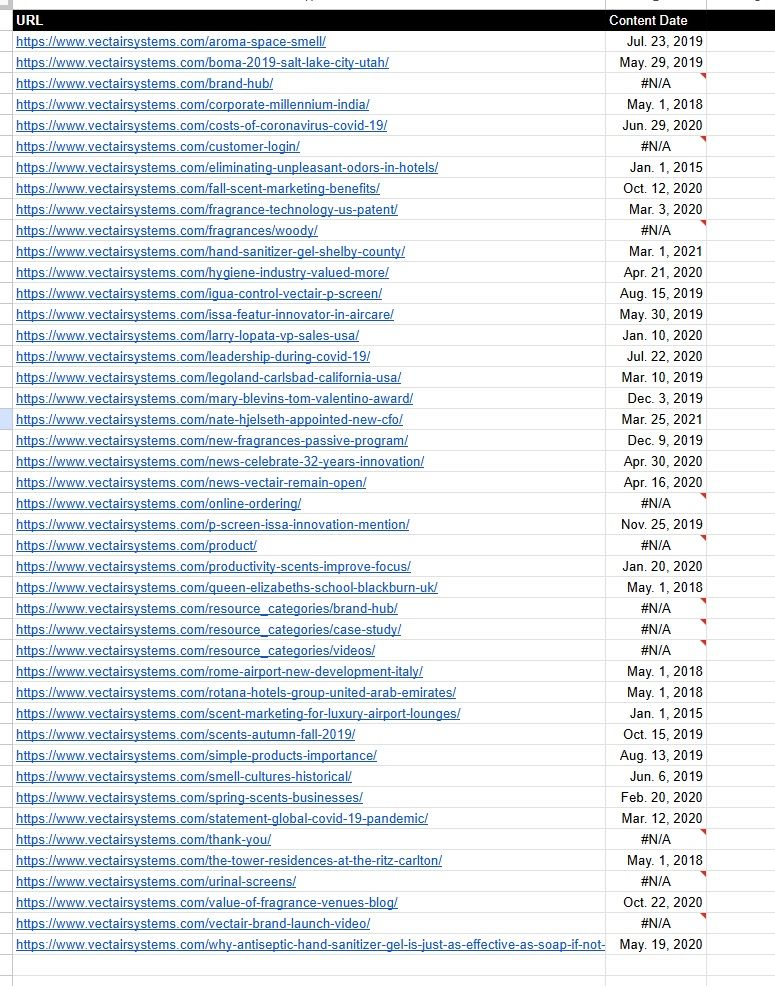
Получи даты контента для твоих URL в G`oogle Sheets` за секунды!
Сделать это до глупости просто - достаточно занести список URL-адресов ваших сайтов в лист Google.
Перейдите на страницу и найдите нужный вам элемент, например DATE, щелкните правой кнопкой мыши на тексте и нажмите INSPECT.
Когда откроется devtools, он автоматически покажет вам выделенный HTML-элемент.
Щелкните правой кнопкой мыши, COPY > Full XPATH.
Затем вставьте XPATH в эту формулу
=IMPORTXML(A2, "Вставьте сюда свой полный xpath")
Таким образом, это выглядит примерно так:
=IMPORTXML(A2, "/html/body/main/section/div[2]/div[2]/span[2]")
Скопируйте функцию ячейки и вставьте ее в свой лист, а затем просто проведите
CASCADE по всем УРЛам.
В первый раз она запросит у вас разрешение на доступ к внешним
URL-адресам, дайте разрешение и запустите снова.
Это СУПЕР ПРОСТОЙ и быстрый способ получения дат контента.
Но это можно сделать с любым видимым элементом страницы - лучше всего работают последовательные элементы, т. е. авторы, даты и т. д.
Можно сделать это и другим способом:
1 . Откройте
URL-адрес и просмотрите исходный код
2. Найдите "
datePublished", если он отображается в исходном тексте.
3. Скопируйте этот скрипт:
function getDatePublished(url) {
const html = UrlFetchApp.fetch(url).getContentText();
const match = html.match(/"datePublished":"([^"]+)"/);
return match ? match[1] : "Not found";
}4. Вернитесь на лист, нажмите
EXTENSIONS >
APPS SCRIPT, вставьте скрипт, сохраните и запустите, дайте разрешения.
5. Вызовите скрипт следующим образом:
=getDatePublished(A2)
Что вы можете сделать с этими удивительными данными?
Используйте
VLOOKUP, чтобы сопоставить ваши
URL-адреса с данными поисковой консоли за последние 3, 12 и 16 месяцев, загруженными в лист.
Примените фильтр и найдите устаревший контент, у которого мало или совсем нет кликов и показов.
Проверьте наличие внешних ссылок с помощью пакетного анализа
AHREFS - все, на которые есть внешние ссылки,
URL-адреса
301, те, на которые нет ссылок, удаляют контент и
HTTP 410 URL-адреса, чтобы устранить их.
@
Читать полностью…
Mike Blazer
03 Apr 2025 13:10
Бинг выдача с 9 рекламами!!!
Представьте, что LLM-ки ходят в Бинг за инфой и скликивают рекламу...
Оли так и пишет: "Когда мы тестировали OpenAi Operator, он использовал Bing и кликал по объявлениям."
@
Читать полностью…
Mike Blazer
03 Apr 2025 08:15
Исправления технического SEO не могут восстановить трафик, если само техническое SEO его не сломало.
Резкое падение органического трафика крайне маловероятно из-за того, что что-то на сайте сломалось с точки зрения технического SEO.
В редких случаях я видел, когда техническое SEO становилось причиной значительного падения SEO-трафика, но это происходило из-за чего-то конкретного, например, неправильного robots.txt, сломанных каноникал директив или неудачного внедрения технических изменений, пишет Эли Шварц.
Обычно эти проблемы можно выявить быстрым просмотром исходного кода нескольких страниц или уточнением, были ли недавно какие-то серьезные технические изменения.
Тем не менее, многие люди сначала пытаются устранить проблемы с SEO, ища технические проблемы, тратя ценное время, которое следовало бы посвятить поиску реальных причин.
Каждые пару недель компании просят меня порекомендовать им агентство для аудита их сайта из-за внезапного (или даже постепенного) падения трафика, и я стараюсь быстро оценить, может ли техническая проблема вообще быть виновником, прежде чем позволить им совершить эту ошибку.
@
Читать полностью…
Mike Blazer
02 Apr 2025 15:05
Гугл и вебмастера
@
Читать полностью…
Mike Blazer
02 Apr 2025 11:05
Все в восторге от траффикового потенциала ChatGPT.
Вот почему я настроен скептически, пишет Эндрю Чарльтон.
Для одного из наших клиентов, переходы из ChatGPT составили всего 0.0031% от общего трафика в феврале.
И это характерно для большинства моих клиентов (даже тех, кто сильно зависит от информационного трафика)
На первый взгляд, рост еженедельной активной аудитории ChatGPT - с 50 миллионов в январе 2023 до 400 миллионов к февралю 2025 - должен изменить ситуацию.
Но когда прогнозируешь рост рефералов, цифры остаются непримечательными.
Вот как это выглядит в конкретных числах:
Потенциальный рост еженедельной активной аудитории ChatGPT:
2025: 400 млн пользователей (текущее состояние)
2026: 800 млн пользователей (рост в 2 раза)
2027: 1.6 млрд пользователей (рост в 2 раза)
2028: 2.4 млрд пользователей (+50%)
2029: 3.36 млрд пользователей (+40%)
Прогноз доли реферального трафика (при пропорциональном росте):
2025: 0.0031% (текущее состояние)
2026: 0.0062%
2027: 0.0124%
2028: 0.0186%
2029: 0.0248%
Даже при агрессивных предположениях о росте пользователей, рефералы от ChatGPT будут составлять едва ли 0.025% от общего трафика через пять лет.
Это вряд ли можно назвать переломным моментом, если только Google полностью не утратит хватку в поиске.
Стоит отметить, что эти проценты предполагают пропорциональный рост всего остального - что в случае Google маловероятно, учитывая продолжающееся снижение кликов.
И, конечно, это только если реферальный трафик будет масштабироваться пропорционально росту пользователей (я ожидаю, что процент рефералов от пользователей вырастет, как объясню ниже).
Как и Google, OpenAI в конечном итоге потребуется как-то стимулировать создателей контента.
Модель Google, вознаграждающая сайты трафиком в обмен на парсинг их контента, успешно работала десятилетиями - авторы получают клики, а Google поддерживает свой поисковый индекс.
Если OpenAI хочет, чтобы качественный, свежий контент продолжал поступать в ChatGPT, компании, вероятно, придется усилить это соотношение.
Сейчас баланс нарушен, слишком много контента используется без достаточного вознаграждения.
Чтобы это изменилось, количество кликов должно увеличиться.
Так что, возможно, в долгосрочной перспективе рефералы из ChatGPT вырастут.
Но пока они едва заметны в общей статистике.
@
Читать полностью…
Mike Blazer
01 Apr 2025 17:05
VPN портят данные в GSC (и да, это важно)
Если вы анализируете данные по странам в GSC для SEO-инсайтов, вам необходимо знать о серьезном слепом пятне: VPN.
Вот масштаб проблемы:
— 45% американцев используют VPN для работы или личных целей
— Около 1.5 миллиарда пользователей VPN по всему миру
— Прогнозируется рост рынка VPN до $87.1 миллиарда к 2027 году
Это имеет серьезные последствия для вашей SEO-отчетности.
Когда пользователь подключается через VPN, его трафик выглядит так, будто он идет из места расположения VPN-сервера, а не из его фактического физического местоположения.
Это значит, что трафик, который кажется идущим из Германии, может на самом деле быть от человека, сидящего в Дании.
Корпоративные VPN особенно проблематичны, поскольку они могут сделать так, что целые компании будут выглядеть как браузеры из одного местоположения, создавая искусственные "хотспоты" в ваших данных.
Так что в следующий раз, когда вы будете отчитываться о "новой международной аудитории" или принимать решения по геотаргетингу на основе данных GSC, не забудьте учесть эффект VPN.
Как вы отделяете реальный международный трафик от VPN-помех?
https://www.top10vpn.com/assets/2020/03/Top10VPN-GWI-Global-VPN-Usage-Report-2020.pdf
@
Читать полностью…
Mike Blazer
01 Apr 2025 13:10
Freshness Distance Calculator помогает определить, как часто вам следует обновлять ваш контент.
Анализируя результаты поиска, инструмент подсказывает, когда именно следует обновлять страницы, чтобы сохранить их конкурентоспособность.
https://freshnessdistancecalculator.com/
@
Читать полностью…
Mike Blazer
01 Apr 2025 08:15
Большой список поисковых операторов SEO для построения ссылок, аутрича, анализа конкурентов
Можете заменить "intitle" на "inurl" или "intext"
article + intitle:"keyword"
become a contributor + intitle:"keyword"
become a writer + intitle:"keyword"
blog + intitle:"keyword"
category + intitle:"keyword"
contribute to our + intitle:"keyword"
contribute to this + intitle:"keyword"
directory + intitle:"keyword"
guest article + intitle:"keyword"
guest author + intitle:"keyword"
guest blog + intitle:"keyword"
guest blogger + intitle:"keyword"
guest column + intitle:"keyword"
guest post + intitle:"keyword"
guest writing + intitle:"keyword"
guest writer + intitle:"keyword"
guide + intitle:"keyword"
links + intitle:"keyword"
magazine + intitle:"keyword"
news + intitle:"keyword"
research + intitle:"keyword"
resource + intitle:"keyword"
roundup + intitle:"keyword"
submit + intitle:"keyword"
tag + intitle:"keyword"
useful + intitle:"keyword"
website + intitle:"keyword"
write for us + intitle:"keyword"
@
Читать полностью…
Mike Blazer
31 Mar 2025 15:20
Политики Google по спаму основаны на пресечении злоупотребления "практиками", а не типами контента.
-
Спам никогда не был связан с "содержанием".
Он почти всегда был связан с "интентом".
-
Даже если намерения не были спамерскими, если это спам - это будет нарушать правила.
Т.е. вы нанимаете кого-то, они что-то для вас делают, вы понятия не имеете, что это спам - ну, это всё равно спам.
@
Читать полностью…
Mike Blazer
31 Mar 2025 11:05
Мне одному кажется, что к Google было бы гораздо больше симпатий, если бы они выпустили новые рекомендации до того, как взмахнут косой, уничтожая владельцев сайтов? - спрашивает Росс Стивенс
После 2 лет теории SEO и гаданий владельцев сайтов, это выглядит типа так:
"Круто, вы мертвы, а теперь вот почему".
@
Читать полностью…
Mike Blazer
30 Mar 2025 10:05
В 2013 году, когда я получил ручник "pure spam", вот что я отправил в GSC в качестве запроса на пересмотр.
Помогло ли это добиться снятия "бана"?
Нет.
@
Читать полностью…
Mike Blazer
28 Mar 2025 17:05
Пробую клоакинг в первый раз.
@
Читать полностью…
Mike Blazer
28 Mar 2025 13:05
Все вокруг: ап Гугла тебя не задел?
Я: нет, все классно!
Тоже я: ...
@
Читать полностью…
Mike Blazer
28 Mar 2025 08:15
SEO-"эксперты" придают косинусному сходству слишком большое значение для семантического соответствия!
Косинусное сходство - это чисто геометрическая мера, основанная на НАПРАВЛЕНИИ вектора, а не на ВЕЛИЧИНЕ!
Учет только углов между векторами без учета их длин - это ОГРАНИЧЕНИЕ!
Косинусное сходство учитывает только ОРИЕНТАЦИЮ векторов, а не их величину.
Ему важны ПРИСУТСТВИЕ и ЧАСТОТА слов, а не длина документа...
И это еще не все!
Косинусное сходство предполагает, что векторное пространство идеально отражает семантические связи.
→ Понимают ли люди, что эмбеддинги - это аппроксимации, натренированные на конечных данных?
Эмбендинги не всегда могут передать все нюансы...
Возможно, проще всего понять, что косинусоидальное сходство не учитывает порядок слов (или синтаксис), а ведь оба эти фактора очень важны для смысла!
Демонстрация этого:
🟢 Собака гналась за кошкой
⭕️ Кошка гналась за собакой
Несмотря на противоположные значения, в модели bag-of-words (где текст представлен как неупорядоченный набор терминов) эти предложения могут иметь одинаковые векторы и косинусное сходство, равное 1.
Хотите еще один простой пример?
⭕️ Студент оценил учителя
🟢 Учитель оценил студента
Поскольку эти предложения содержат одинаковые слова, их векторные представления очень похожи: у них высокий показатель косинусного сходства...
Но значения ОЧЕНЬ разные!
Представьте себе риск, когда возникает сложная ситуация! 🥲
Да, косинусное сходство - простая концепция, но эта простота приводит к семантическим жертвам!
Косинусное сходство часто упускает СМЫСЛ, игнорируя ВЕЛИЧИНУ и КОНТЕКСТ!
Мы все знаем, что смысл заключается не только в самих словах, но и в их взаимосвязи и ПОРЯДКЕ.
А косинусное сходство, по крайней мере в его базовой форме, упускает эти существенные различия.
В обработке естественного языка КОНТЕКСТ и ПОРЯДОК слов очень важны, но базовое косинусное сходство не учитывает эти факторы!
И даже при использовании эмбеддингов, включающих некоторый контекст (например, трансформаторов), косинусное сходство не сможет полностью отразить структурные различия, которые мы интуитивно понимаем.
Люди, работающие в сфере SEO, придают косинусному сходству слишком большое значение для семантического соответствия, поскольку переоценивают его способность отражать богатство языка.
@
Читать полностью…
Mike Blazer
27 Mar 2025 15:05
Если вы должны это делать, это работа. Если вы хотите это делать, то это игра.
@
Читать полностью…



 2557
2557
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}