Mike Blazer
08 Jul 2025 17:05
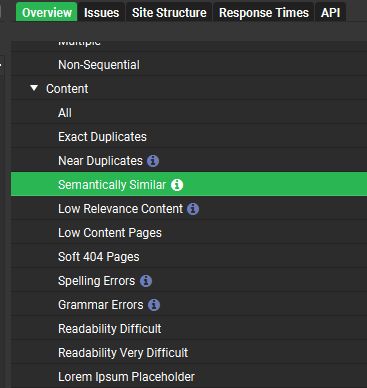
Большинство сеошников используют новую фичу Screaming Frog "Semantic Similarity" только для внутреннего аудита контента.
Но знаете ли вы, что ее можно применять и в вашей линкбилдинг-стратегии?
Semantic Similarity = детектор "воды" для фейкового тематического авторитета ✨
Используйте это для оценки сайтов-доноров ПЕРЕД тем, как проставлять ссылки!
И вот как это сделать всего за пару кликов:
1. Прокраульте потенциального донора с помощью v22.1 + OpenAI API
2. Проверьте, нет ли почти идентичных контентных кластеров
3. и если вы заметите, что на нескольких страницах говорится одно и то же, но немного другими словами…
🚩 перед вами контентная ферма ☢️
*бонусные советы, если вы также получили результаты в отчете Overview > Content:
❌ 'Low Relevance' (Низкая релевантность) = плохой таргетинг
❌ 'Near Duplicate' (Почти дубликат) = ленивый копипаст
Так что, как всегда, пожалуйста, не сливайте свои бэклинки на пустышки :D
@
Читать полностью…
Mike Blazer
08 Jul 2025 13:10
Джо Янгблад отследил попытку нового агентства вывести Гугл бизнес-профиль (GBP) его клиента в топ-1 в крупном мегаполисе за заявленные 60-90 дней.
Первые действия (первые 48 часов)
Получив доступ к GBP на уровне "Менеджер", новое агентство внесло несколько изменений в самом профиле:
— Было переписано основное описание компании.
— Были опубликованы два вопроса в разделе "Вопросы и ответы", на которые тут же ответили с аккаунта менеджера.
— Был опубликован один пост в GBP.
— Было загружено видео, предположительно созданное с помощью генеративного ИИ.
Примерно через 48 часов наблюдался небольшой рост позиций по одному из целевых запросов, однако это движение соответствовало обычным дневным колебаниям.
Анализ через неделю
По прошествии шести дней стратегия агентства заключалась исключительно в активности внутри профиля.
Стандартных спам-сигналов, таких как переспам ключами в названии, фейковые отзывы или использование PBN, обнаружено не было.
Ключевые действия были следующими:
— Контент: Было переписано описание в GBP, а для всех услуг добавлены новые, сгенерированные ИИ описания с переспамом ключевыми словами.
— Посты: Было опубликовано два поста в GBP, один из которых был сильно переоптимизирован ключами.
— Q&A: Были самостоятельно опубликованы и отвечены два вопроса в разделе "Вопросы и ответы".
К концу первой недели весь первоначальный рост позиций был утерян.
Позиции как в локал паке (блоке с картами) Google Maps, так и в классической поисковой выдаче оказались ниже, чем до того, как агентство взялось за работу.
Отчет за месяц
Через месяц агентство проделало следующее:
— Всего постов: 10. Посты были однотипными: в них повторялась одна и та же информация об услугах, но с ротацией названий целевых городов.
— Всего Q&A: 3.
— Никаких других изменений, таких как новые ссылки или упоминания, обнаружено не было.
Сканирование в Local Falcon на 30-й день показало, что позиции по большинству целевых запросов не изменились или упали.
Некоторые незначительные улучшения позиций наблюдались на точках сетки далеко за пределами целевой зоны обслуживания, что можно списать на обычные алгоритмические колебания.
В целом, позиции в GBP на Картах продолжали снижаться в течение всего месяца.
По прошествии 30 дней нет никаких доказательств того, что стратегия частых, переспамленных ключами постов в GBP и самостоятельных ответов на вопросы в Q&A эффективна для улучшения локальных позиций для бизнеса с зоной обслуживания (SAB) на конкурентном рынке.
@
Читать полностью…
Mike Blazer
08 Jul 2025 08:15
Использование FAQ в вашем контенте может стать ОТЛИЧНЫМ способом оптимизации под AI-поиск.
Этот анализ показал, что у FAQ самая высокая семантическая релевантность.
Крис Грин провел отличное исследование, основанное на данных, чтобы проанализировать, какие структуры контента лучше всего оптимизированы для LLM.
Поскольку LLM разбивают ваш контент на чанки (chunks) и сохраняют в виде векторов, Крис решил проверить, какие стили написания текста наиболее эффективны в такой системе.
В своем анализе он протестировал написание трех разных статей в трех разных стилях.
Среди этих стилей были:
1. Плотная проза: Контент был написан в традиционном стиле, абзацами.
2. Структурированный контент: Он взял абзацы и применил форматирование, например, заголовки и маркированные списки.
3. Вопрос-Ответ (Q&A): Он превратил абзацы в формат FAQ.
После этого он протестировал различные методы чанкинга, чтобы увидеть, как структуры контента соотносятся друг с другом.
Затем он измерил эффективность каждого типа контента для каждого метода чанкинга.
Результаты показали, что контент в формате FAQ стабильно демонстрирует наибольшее сходство с контрольным запросом.
Структурированный контент оказался на втором месте по эффективности, в то время как традиционные абзацы в целом показали самые слабые результаты.
С точки зрения семантического совпадения, это вполне логично.
Поскольку разделы FAQ, как правило, предельно лаконичны, это означает, что контент в них имеет относительно высокую плотность.
В результате это чрезвычайно эффективный метод для случаев, когда LLM разбивают ваш контент на чанки.
https://www.chris-green.net/post/content-structure-for-ai-search
@
Читать полностью…
Mike Blazer
07 Jul 2025 17:05
Почему ваши разработчики ненавидят ваши "простые" просьбы о функциях
Фаундер/ПМ: "Просто добавьте кнопку логина! Разве это так сложно?"
Разработчик: (дергается глаз).
Вот что происходит, когда вы просите "крошечную" фичу:
1. Вход через соцсети "в один клик"
Вы видите: Кнопку.
Разработчики видят: OAuth-потоки, хранение токенов, обработку ошибок, соответствие GDPR и 3 дня тестирования корнер кейсов.
2. Требование "Просто сделайте это быстрее".
Вы думаете: Оптимизировать код.
Реальность: Реструктуризация базы данных, слои кэширования и борьба с 5-летним наследием решений.
3. Фича "Как у Amazon"
Ваше видение: "Базовый поисковый фильтр".
Сфера применения: персонализированные рекомендации, инвентаризация в реальном времени и сортировка на основе ИИ.
Почему это разочаровывает разработчиков:
— Скрытая сложность ≠ лень. Маленькая просьба может обернуться неделей работы.
— Каждая "простая" функция затягивает дорожную карту. Технический долг тихо усугубляется.
— Разрабы хотят создавать отличные вещи, но им нужны реалистичные приоритеты.
Как исправить ситуацию?
✅ Запрашивать оценку, прежде чем называть задачу "простой".
✅ Компромиссы неизбежны. Скорость против масштаба? Дешевизна против перспективности?
✅ Привлекайте разработчиков к раннему обсуждению. (Они быстрее обнаружат подводные камни).
@
Читать полностью…
Mike Blazer
07 Jul 2025 13:10
Когда PPC-специалист уничтожает твоё SEO 🤯
Мы работали над SEO для клиента последние два года, планомерно наращивая органическую видимость и трафик на их основные коммерческие страницы, пишет Джейд Халлам.
Прогресс был стабильным, особенно учитывая бюджет.
В то же время другое агентство занималось их PPC-кампаниями.
Они спросили, могут ли внести несколько изменений в лендинги для PPC, которые мы создали.
Конечно.
Мы даже позаботились о том, чтобы SEO и PPC страницы были разделены, чтобы они могли вносить правки не влияя на наши поисковые показатели.
Но вместо редактирования этих страниц...
Они отредактировали основные категории и продуктовые страницы.
Те, что ранжировались в Google.
Те, что приносили органическую выручку.
В следующий момент позиции падают.
Органический трафик следует за ними.
Проверяем сайт и обнаруживаем виновника: половина SEO-контента исчезла.
*Рыдает в GSC.*
Вот почему сотрудничество между командами, внутренними или внешними, не обсуждается.
Нельзя оптимизировать один канал в ущерб другому.
Мы все работаем над одной целью: больше бабок для клиента.
Так что, пожалуйста, PPC-специалисты, поговорите с вашими SEO перед внесением изменений.
Мы обещаем, что не будем кусаеться... если только вы не удалите наш контент 😅
@
Читать полностью…
Mike Blazer
07 Jul 2025 08:15
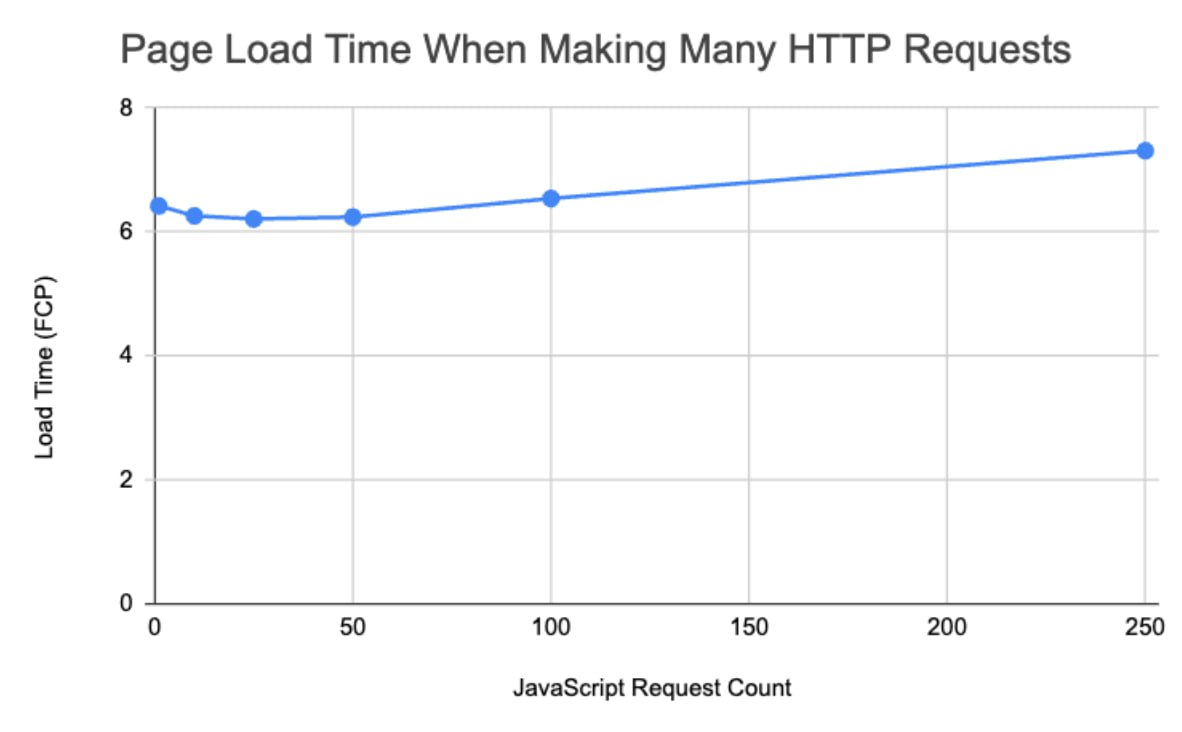
Улучшает ли уменьшение количества HTTP-запросов скорость загрузки страницы?
Современные реалии
— С доминированием HTTP/2 количество запросов влияет меньше, чем во времена HTTP/1.1
— HTTP/2 поддерживает множество параллельных запросов на одном соединении (до 100 по умолчанию)
— Только при сотнях запросов накладные расходы существенно влияют на производительность
Что действительно важно
— Размер ресурса: Большой файл (1МБ) обычно сильнее влияет на производительность, чем несколько маленьких
— Влияние на рендеринг: Запросы, блокирующие рендеринг, сильнее влияют на пользовательский опыт, чем неблокирующие
— Время запросов: Поздно загружаемые запросы минимально влияют на воспринимаемую скорость
Практические подходы к оптимизации
— Объединять файлы CSS и JavaScript во время сборки
— Внедрять ленивую загрузку для изображений под сгибом с помощью loading="lazy"
— Минимизировать сторонние ресурсы, добавляющие ненужные запросы
— Фокусироваться на улучшении пользовательских метрик, а не произвольного количества запросов
При тестировании 250 отдельных запросов сделали страницу всего на 0.89 секунд медленнее (14%) по сравнению с одним запросом того же общего размера.
Влияние меньшего количества запросов становится значимым только в масштабе или при использовании HTTP/1.1.
https://www.debugbear.com/blog/make-fewer-http-requests
@
Читать полностью…
Mike Blazer
06 Jul 2025 14:05
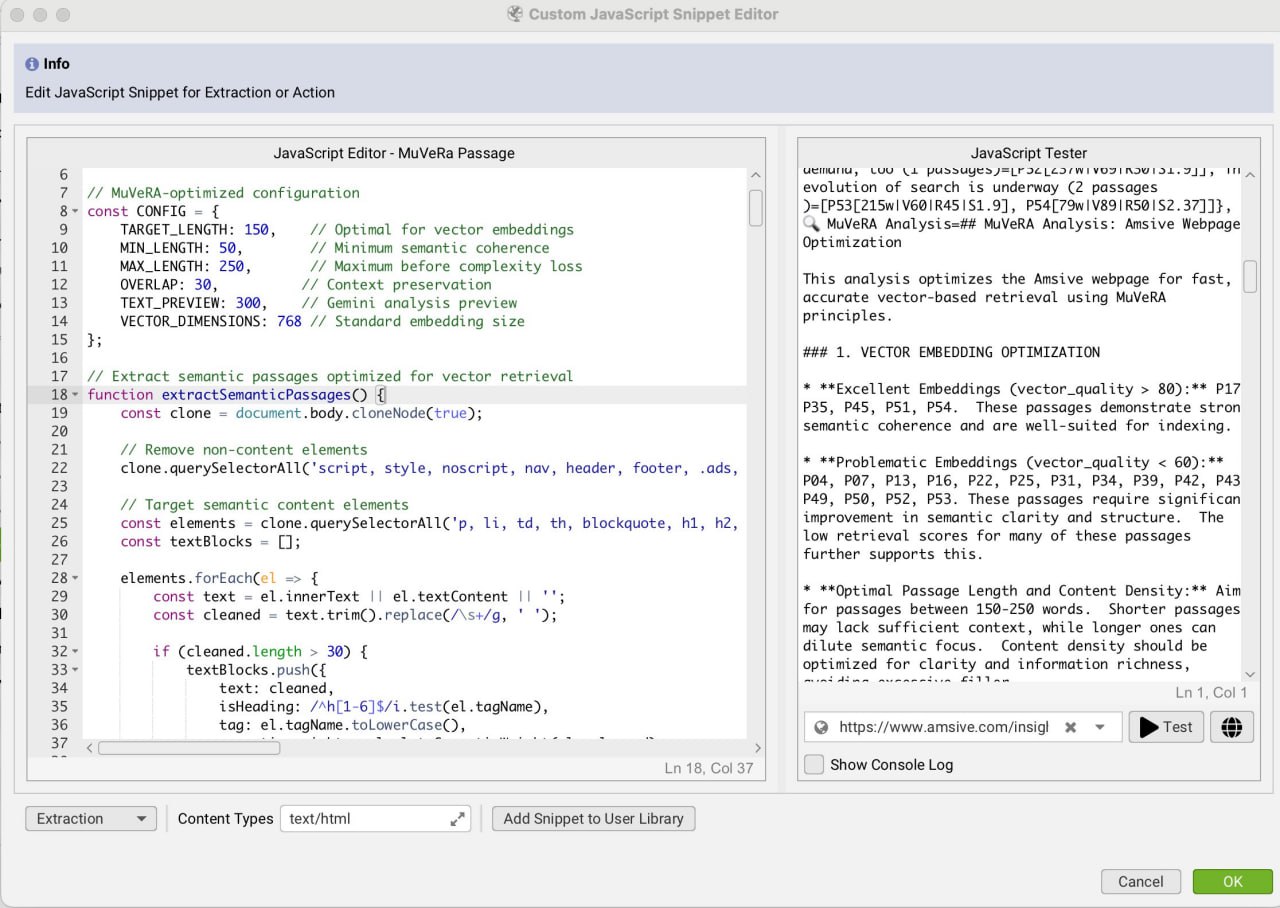
Оптимизация контента для векторного поиска с помощью фрагмента кода Screaming Frog, вдохновленного MuVeRA
Я создал кастомный JavaScript-сниппет для Screaming Frog, вдохновленный концепцией MuVeRA, после прочтения исследования Google о многовекторном поиске, — пишет Метехан Йешильюрт.
Вместо ускорения поиска, что было целью Google, я использую этот инструмент для оптимизации контента, чтобы улучшить его извлечение.
Инструмент разбивает контент на пассажи по 150 слов, что оптимально для эмбеддингов, и присваивает им оценку качества, чтобы определить, какие разделы будут наиболее эффективны в поисковых системах, основанных на векторном поиске.
Каждый пассаж анализируется независимо по таким параметрам, как качество вектора, семантический вес и потенциал для поисковой выдачи.
Хотя инструмент и экспериментальный, он позволяет взглянуть на ваш контент глазами современных поисковых систем на базе ИИ 🔍.
Полное руководство и бесплатный кастомный Javascript-сниппет доступны по ссылке: https://metehan.ai/blog/screaming-frog-muvera-analysis/
@
Читать полностью…
Mike Blazer
06 Jul 2025 09:15
Фундаментальное различие между #GEO и #SEO заключается в том, что GEOшники пытаются обмануть Gemini, чтобы тот включил их сайты в обзоры AI.
Напротив, SEOшники пытаются убедить Google отказаться от обзоров AI и вернуться к традиционным десяти синим ссылкам.
@
Читать полностью…
Mike Blazer
04 Jul 2025 17:05
Сеошники из ниш типа адалта в то время как все другие в индустрии SEO суетятся по поводу AI Overviews & AI Mode.
@
Читать полностью…
Mike Blazer
04 Jul 2025 13:10
Директор смотрит на 50к статей без вычитки, которые залила SEO-команда
@
Читать полностью…
Mike Blazer
04 Jul 2025 08:15
Мы начали замечать, что в результатах ChatGPT по товарным запросам стали появляться описания коллекций, — говорит Сэм Райт.
И это не страницы товаров или структурированные данные.
Это обычные страницы категорий с релевантным описательным контентом.
Легко предположить, что основным источником для таких запросов должны быть карточки товаров.
И зачастую так и есть.
Но мы наблюдаем, что когда контент на странице категории соответствует поисковому интенту, он используется — независимо от типа страницы.
Скриншот показывает улучшение видимости для коллекций, на которые был добавлен описательный контент.
Это результат более традиционной работы по SEO, не связанной с ChatGPT, но он служит хорошим напоминанием, что такой подход уже доказал свою эффективность.
То, что такой же тип контента подтягивается в сгенерированные ИИ ответы, — это приятный бонус, который подтверждает правильность общей стратегии.
Большая часть нашей работы по разбивке таксономии, улучшению иерархии коллекций и добавлению контента на страницы категорий часто продиктована практическими потребностями: мерчандайзингом, фильтрацией, помощью клиентам в принятии решений.
Но она всегда положительно влияла на поисковые показатели, а теперь, похоже, способствует и видимости в ИИ-поиске.
Все это не говорит о каком-то кардинальном изменении подхода.
Во многом это лишь подтверждает, что проверенные временем SEO-практики продолжают приносить пользу, даже несмотря на меняющиеся условия.
@
Читать полностью…
Mike Blazer
03 Jul 2025 15:05
12 новых KPI для эры генеративного ИИ: конец эпохи старых SEO-дашбордов
Традиционные SEO KPI, такие как клики и позиции, теряют актуальность, поскольку поиск трансформируется в интерфейсы на базе ИИ.
С появлением систем вроде ChatGPT, CoPilot и Gemini, использующих RAG, эмбеддинги и векторные базы данных, понятие видимости в сети радикально изменилось.
Контент теперь не только ранжируется, но извлекается, анализируется и цитируется ИИ-моделями.
Это требует новых показателей эффективности, соответствующих современному техническому стеку поиска на базе ИИ.
Устаревшие и современные метрики поиска
Традиционные SEO-дашборды фокусировались на KPI, ориентированных на взаимодействие человека с поисковой выдачей:
— Органические сессии и CTR
— Средняя позиция
— Показатель отказов и время на сайте
— Количество обратных ссылок и авторитет домена (DA)
Эти метрики становятся менее значимыми в условиях, где ответы ИИ формируются на основе нового стека технологий:
— Векторные базы данных и эмбеддинги
— Реранкеры BM25 + Reciprocal Rank Fusion (RRF)
— Большие языковые модели (LLM)
— AI-агенты и плагины
Эффективность теперь нужно оценивать по тому, как контент обрабатывается и используется в этом новом пайплайне.
12 предлагаемых KPI для эры поиска на базе ИИ
Эти метрики разработаны для оценки эффективности в системах обнаружения контента, управляемых ИИ.
1. Частота извлечения чанков
Измеряет, как часто блок контента ("чанк") извлекается ИИ для ответа. Это ключевой показатель видимости в RAG-системах.
2. Оценка релевантности эмбеддинга
Определяет векторное сходство между запросом и эмбеддингом чанка. Высокий балл важен для попадания в векторную базу.
3. Коэффициент атрибуции в ответах ИИ
Показывает, как часто бренд или домен указывается как источник в ответах ИИ, отражая видимость без кликов.
4. Количество цитирований ИИ
Отслеживает упоминания на платформах ИИ (ChatGPT, Perplexity, Gemini), указывая на достоверность контента.
5. Показатель присутствия в векторном индексе
Доля контента сайта, проиндексированного в векторных базах. Без индексации извлечение невозможно.
6. Оценка уверенности при извлечении
Вероятность, присваиваемая моделью при выборе чанка, отражает её уверенность в релевантности.
7. Вклад в ранг по RRF
Вес чанка в гибридной системе ранжирования с использованием Reciprocal Rank Fusion для объединения лексического и векторного поиска.
8. Охват ответов LLM
Число уникальных вопросов, на которые контент домена отвечает, показывая его полезность.
9. Успешность обхода ботами ИИ-моделей
Оценивает, как эффективно боты ИИ (GPTBot, Google-Extended, CCBot) получают доступ к контенту сайта.
10. Оценка семантической плотности
Измеряет концептуальное богатство и точность чанка. Плотный контент чаще извлекается.
11. Присутствие в интерфейсах "нулевого клика"
Появление в системах без ссылок (голосовые помощники, прямые ответы), где видимость не связана с трафиком.
12. Машинно-валидированная авторитетность
Показатель авторитетности на основе частоты извлечения, цитирований и структуры, заменяющий метрики вроде DA.
https://duaneforresterdecodes.substack.com/p/12-new-kpis-for-the-genai-era-the
@
Читать полностью…
Mike Blazer
03 Jul 2025 11:05
Скейтборд состоит из шести основных компонентов: деки, оси, колес, подшипников, антискользящей ленты и крепежа.
Большинство скейт-магазинов при создании своего веб-сайта создают одну коллекцию для каждого из этих компонентов.
Но скейтбордисты не просто ищут "скейтборды", они знают, что им нужно, и ищут именно эти товары.
Если разбить эти шесть начальных коллекций по способам покупки скейтбордистов (по размеру/форме/использованию), мы можем создать около 100 страниц коллекций, нацеленных на тысячи ключевых слов в месяц.
Деки — 7.5–10 дюймов, попсикл, олдскул, фигурные...
Колеса — 50–60 мм, конические, радиальные, круизер, мягкие...
Подшипники — Abec 3–9, без защиты, керамические, швейцарские...
Оси — полые, титановые, цветные, необработанные/полированные, низкие, высокие...
Антискользящая лента — черная, цветная, прозрачная, с рисунком...
Крепеж — болты для деки, втулки, подкладки, гайки для оси, рельсы для деки...
Использование - для начинающих, для детей, для улицы, для верта, для боула...
Каждый из этих типов продуктов заслуживает собственной коллекции.
Именно так вы должны подходить к SEO для любого интернет-магазина.
Когда люди хотят что-то купить, они ищут именно то, что им нужно.
Если вы продаете диваны, разделите свою коллекцию по цвету, стилю, размеру, назначению, декору, комнате...
Если это аквариумы, продавайте их по типу рыб, уровню опыта, типу воды, форме и т. д.
Вы поняли идею.
Вы должны разбить каждую из своих коллекций на подколлекции и нацелиться на высокоспецифичные длинные ключевые слова с этими коллекциями.
Меньше конкуренции, больше намерений, лучшие конверсии.
@
Читать полностью…
Mike Blazer
02 Jul 2025 17:05
Всего один твит, опубликованный 3 дня назад, приносит примерно 1.2 миллиона переходов из поиска Google в месяц.
Вся вовлеченность под твитом — фейковая, но Google не может это определить.
UGC (пользовательский контент) — это самая большая слепая зона Google на данный момент.
Вот твит, который ранжируется в Google. Он нацелен на ключевые слова, связанные со "сливами" модели OnlyFans Софи Рейн.
Давайте посмотрим на сам твит:
Скриншот 1
Вот его метрики:
— 40 тыс. просмотров
— 5 ретвитов
— 214 комментариев
— 292 лайка
— 34 закладки
Ни одна из ссылок не ведет на слив.
Они являются частью цепочки редиректов, где конечный пункт назначения определяется тем, кто больше заплатит за ваши уникальные данные о поведении в браузере.
Скриншот 2
Все комментарии оставлены всего 2-3 аккаунтами и представляют собой просто случайные наборы символов.
Один аккаунт оставил почти 100% из 214 комментариев.
Лайки также накручены, а ретвиты, по-видимому, сделаны с сетки аккаунтов автора поста.
Скриншот 3
У Google нет надежного способа измерять качество UGC.
Это касается всех социальных платформ, включая Twitter, Instagram, Reddit, TikTok и другие.
В качестве сигналов ранжирования они используют метрики вовлеченности конкретных платформ и данные о трафике из Chrome и Android, перекладывая при этом ответственность за модерацию непосредственно на сами платформы.
Google настолько сильно поощряет такое поведение, что у платформ практически нет шансов это остановить.
Это просто слишком выгодно.
@
Читать полностью…
Mike Blazer
02 Jul 2025 13:10
Я провел A/B-тест по увеличению количества внутренних ссылок, в частности, на страницы, которые ранжируются на 4-15 позициях в поисковой выдаче, и вот что я обнаружил, — пишет Робин Алленсон:
➟ Подход: я использовал систематически увеличивал количество ссылок на целевые страницы, сохранив при этом контрольную группу для сравнения.
➟ Источники данных: Logfile Analyzer от Botify (через API) + GSC.
➟ Методология: A/B-тестирование с подходом "разность разностей" (difference of differences), чтобы изолировать эффект. И, как видно на графике ниже, мы разделили страницы на три группы:
🔶 Boosted (розовая): Получали в 2 раза больше внутренних ссылок, чем обычно.
🔶 Linked (синяя): Стандартная внутренняя перелинковка без изменений.
🔶 Unlinked (зеленая): Без дополнительных ссылок от нашего инструмента (хотя на этих страницах все еще могли быть другие ссылки).
Без сомнения — результаты были значительными!
Разница в производительности между группами boosted, linked и unlinked демонстрирует значительные преимущества, которых можно достичь за счет стратегического увеличения количества внутренних ссылок.
Внутренняя перелинковка — это не просто навигация, это мощный инструмент для ранжирования.
И при стратегическом подходе она может обеспечить измеримые улучшения в сканируемости, позициях и трафике.
@
Читать полностью…
Mike Blazer
08 Jul 2025 15:05
Мета-описание - идеальная метафора когнитивного искажения в SEO.
Верить в то, что оно имеет КАКОЙ-ЛИБО эффект - 100% суеверие.
1) Можно ранжироваться БЕЗ мета-деска
2) Он просто не требуется
3) Это не "доверенный" сигнал - это скрытое описание
4) Google настолько не доверяет ему, что переписывает его более чем в 70% случаев.
И всё же некоторые сеошники/продакт-менеджеры/копирайтеры говорят о нём так много, как будто это "скрытый источник" SEO...
Вы не можете мне сказать, что эти люди основывают свои выводы на науке, тестах, реальности...
-
НЕ игнорируйте мета-дескрипшн!
Дело не всегда в:
— Прямых факторах ранжирования
— Поисковой оптимизации
Вместе с тайтлами, мета-дескрипшн - это ваша первая коммуникация с потенциальными клиентами через поисковые системы.
Они дают обещание.
Они сообщают пользователям, что они могут ожидать найти.
В некоторых случаях они выступают как (дис)квалификаторы (помогают избежать нерелевантных кликов).
В других случаях они действуют как приманка ("бесплатная доставка").
Стоит ли в них инвестировать?
Если у вас нет более приоритетных задач (таких как улучшение релевантности и привлекательности тайтлов, разбор редиректов и т.д.) - то да!
Но они не помогают с ранжированием?
Нет - не напрямую.
Они не помогают уже много лет.
Но если учесть, что они действуют как аннотация на обложке книги, они:
— помогают части людей решить, стоит ли кликать на ваш листинг или нет
— формируют ожидания пользователя (психологическая составляющая удовлетворенности)
— могут помочь снизить возврат в СЕРПы/неудовлетворенность
... они, вероятно, играют косвенную роль.
Фокусируйтесь на целях!
Дело не в том, является ли это "фактором ранжирования" или помогает "генерировать трафик" и т.д.
Важно то, способствуют ли они достижению бизнес-цели.
Помогают ли они получать квалифицированный трафик, который конвертируется, жертвует, регистрируется, бронирует звонок и т.д.?
Помогают ли они влиять на восприятие людей?
Привлекают ли они внимание?
Но Google переписывает их!?
Иногда.
Это зависит от их релевантности (странице, запросу) и/или от того, насколько они неудачные/общие.
Значительный процент из "Гугж переписывает их более чем в 70% случаев" приходится на скучные, общие, перенасыщенные ключевыми словами, дублированные мета-дески!
Если вы инвестируете время/усилия и предоставляете релевантные (для страницы и основного запроса) описания, обычно Google будет использовать то, что вы предоставили.
Но если вы не уверены - удалите их.
Пусть Google заполнит их.
Отметьте, что создает Google для различных запросов.
Затем клонируйте, подкорректируйте и посмотрите, сможете ли вы получить лучший CTR.
@
Читать полностью…
Mike Blazer
08 Jul 2025 11:05
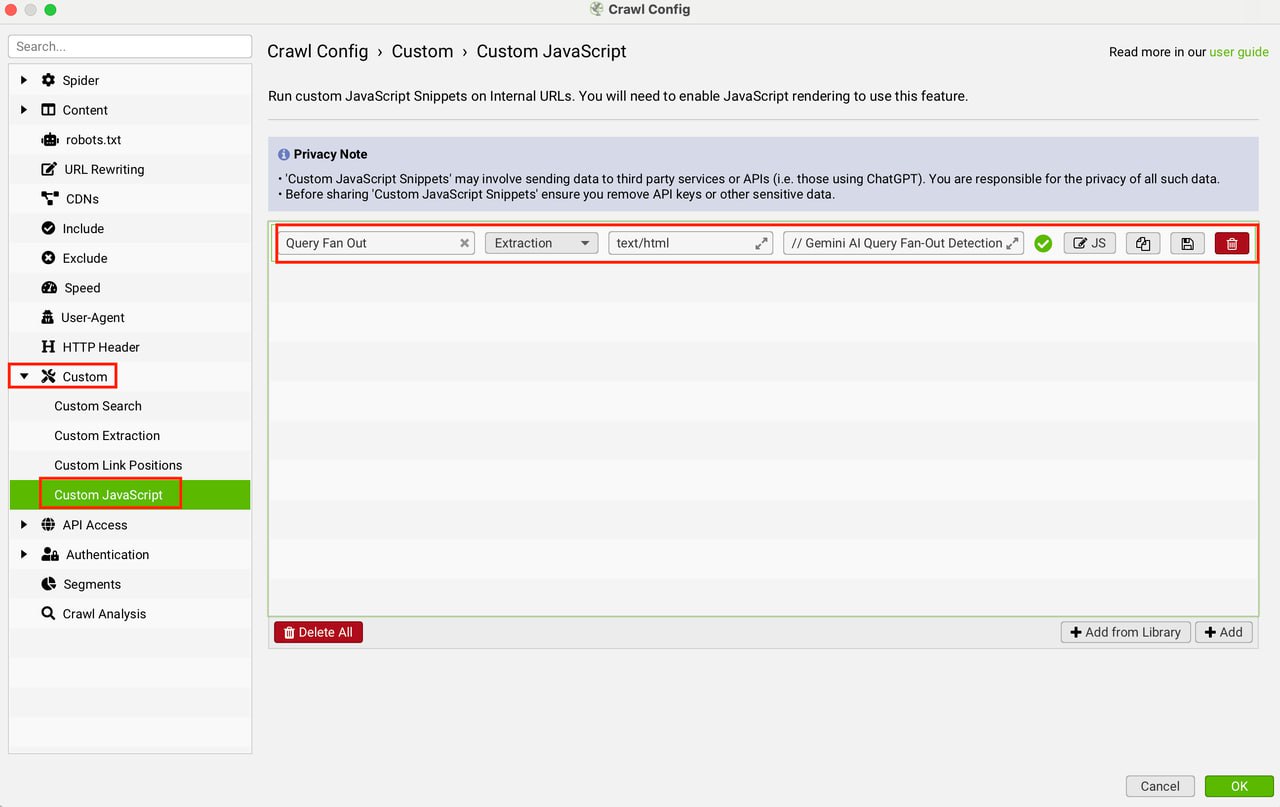
Анализ веерного расширения запросов (query fan-out) в режиме AI от Google с помощью Screaming Frog и Gemini AI
Кастомный JavaScript для Screaming Frog через API Gemini AI оценивает, насколько контент страницы покрывает подзапросы, генерируемые AI-режимом Google.
Анализ 2000+ страниц выявил, что большинство контента отвечает лишь на 30% прогнозируемых запросов, указывая на серьезные пробелы в оптимизации.
Выводы основаны на прогнозах моделей Gemini 1.5 Flash и 2.5 Pro.
Для больших краулов советуем использовать быструю модель Flash.
Оптимизация только на основе этого анализа может угрожать текущим позициям.
Необходимые условия:
— Screaming Frog с включенным рендерингом JavaScript.
— API-ключ Gemini.
— Кастомный скрипт доступен на GitHub.
В обновленной версии два варианта извлечения данных:
1. Только заголовки, элементы <ul>, и <ol>.
2. Необработанный контент из <body>.
Механизм веерного расширения запросов в AI-обзорах
Режим AI от Google разбивает тему на сеть подзапросов, ищет ответы в своем индексе.
Для запроса вроде "sustainable marketing strategies for e-commerce" создаются уточнения о бюджете, каналах, метриках и примерах.
Большинство контента не покрывает всю сеть подзапросов.
Функционал скрипта
Скрипт автоматизирует анализ через пять действий:
1. Извлечение семантических чанков: Сегментирует контент с учетом верстки, как Google Document AI.
2. Определение главной сущности: Выявляет основную тему страницы.
3. Прогноз веерных запросов: Создает 8–10 подзапросов, которые AI от Google мог бы сгенерировать.
4. Оценка покрытия: Проверяет ответы на запросы с оценками "Да", "Частично" или "Нет".
5. Уточняющие вопросы: Предсказывает следующие логичные вопросы пользователя.
Ключевые аналитические выводы
Есть связь между структурой контента и покрытием запросов:
— Страницы с глубокими деталями: Охватывают до 70% запросов. Например, страницы, имеющие 15 и более хорошо структурированных разделов, в среднем достигали покрытия 7 из 10.
— Тонкие страницы: Охватывают менее 20% из-за краткости. Например, страницы с менее чем 5 разделами в среднем показывали покрытие лишь 3 из 10, что указывает на серьезные пробелы.
— Частые упущения: Примеры, кейсы и узкие уточнения (метрики, бюджеты, конкретные стратегии).
Практическое применение
Настройка:
1. Настройте доступ к Gemini API с достаточным лимитом запросов.
2. В Screaming Frog выберите Configuration > Custom > Custom Javascript.
3. Добавьте скрипт и API-ключ.
4. Прокраульте ключевые страницы, выявляя те, где покрытие ниже 5/10, и повторяющиеся упущенные запросы.
Стратегия оптимизации:
— Сущностный подход: Составьте карту веток запросов от основной сущности.
— Фокус на покрытии: Оценивайте успех по охвату запросов, а не по ключевым словам.
— Семантический чанкинг: Структурируйте контент для парсинга ИИ-системами.
— Предвосхищение вопросов: Каждый раздел должен отвечать на текущий запрос и вести к следующему.
https://metehan.ai/blog/query-fan-out-screaming-frog-ai/
@
Читать полностью…
Mike Blazer
07 Jul 2025 20:08
SEOшники летом, когда разработчики в отпусках
@
Читать полностью…
Mike Blazer
07 Jul 2025 15:05
Инсайты о чанкинге и не только от Google
Вот несколько интересных цитат из документации Vertex AI:
— По умолчанию документы разбиваются на чанки с определенным перекрытием для повышения релевантности и качества поиска. Стандартное перекрытие чанков составляет 200 токенов.
— Когда документы добавляются в индекс, они разбиваются на чанки. Параметр chunk_size (в токенах) определяет размер чанка. Размер чанка по умолчанию — 1024 токена.
— Меньший размер чанка означает более точные эмбеддинги. Больший размер чанка означает, что эмбеддинги могут быть более общими, но могут упускать конкретные детали.
— layout parser извлекает из документа такие элементы контента, как текст, таблицы и списки. Затем layout parser создает контекстно-зависимые чанки, которые облегчают поиск информации в генеративном ИИ и поисковых приложениях.
— LLM parser, управляемый промптом, обращал внимание на структуру заголовков и мог извлекать всю релевантную информацию, связанную с определенной темой или разделом.
— Имейте в виду, что парсинг в значительной степени зависит от HTML-тегов, поэтому форматирование на основе CSS может не учитываться.
— Связь между сгенерированным контентом и grounding chunks. Это повторяющееся поле. Каждое поле grounding_supports показывает связь между одним текстовым сегментом сгенерированного контекста и одним или несколькими чанками, полученными с помощью RAG.
— Confidence Score: Оценка, которая используется для привязки текста к определенному чанку. Максимально возможная оценка — 1, и чем выше оценка, тем выше уровень уверенности. Каждая оценка соответствует каждому grounding_chunk_indices. В вывод включаются только чанки с confidence score не ниже 0.6.
Про ranking API:
— Набор записей, релевантных запросу. Записи предоставляются в виде массива объектов. Каждая запись может включать уникальный ID, заголовок и содержимое документа. Для каждой записи указывайте либо заголовок, либо содержимое, либо и то, и другое. Максимальное количество поддерживаемых токенов на запись зависит от используемой версии модели. Например, модели до версии 003 поддерживают 512 токенов, а версия 004 — 1024 токена. Если общая длина заголовка и содержимого превышает лимит токенов модели, лишний контент обрезается. Вы можете включать до 200 записей в одном запросе.
— Score: значение с плавающей точкой от 0 до 1, которое указывает на релевантность записи.
@
Читать полностью…
Mike Blazer
07 Jul 2025 11:05
Немного грустно видеть, как наша индустрия теряет почву под ногами.
SEO-шники метаются, как рыбы на суше.
Половина считает, что AIO/GEO/WhateverEO — это будущее.
Кто-то думает: "Мы вообще не понимаем, как сейчас работает SEO", и раз Гугл сплоховал с Github, то надо всё переосмысливать... бла-бла-бла — а другие ушли в SEX (Search Engine eXperience optimization — да ну, что бы это ни значило).
А ещё есть группа, которая наваливает на всех SEO-шников просто за то, что они SEO.
Что на самом деле изменилось?
Кратко:
— Реферальный трафик сейчас около 10–15% от того, что был в 2010 году.
В 2010-м по одному ключевику или качественной двухсловной фразе можно было получать от 15 000 до 30 000 рефералов в день из Google.
Те же ключи на прошлой неделе принесли примерно 200–300 (и это нам ещё повезло).
— Google — согласно их же докам — всё ещё в конце прошлого года использовал ключевые слова, PageRank и подсчёт кликов Navboost как основные ингредиенты алгоритма.
Позиции по топ-1 или топ-2 ключевым фразам практически не изменились.
В выдаче от двух лет назад почти тот же органический ранжинг (почти до URL), что и десять минут назад.
(единственное, что изменилось — это SOT (Slop on Top)) и увеличилось количество рекламы.
— ИИ никто публично не просил.
Фактически, легко найти десять негативных комментов про Google AI, тогда как положительные — надо поискать.
Всё остальное — это просто PR-монополия Google с пафосным спином.
Будьте реалистами: ИИ — это всего лишь повод для Google забрать себе большую долю.
Не долю поискового рынка, а долю всего интернета.
Они хотят всё.
Они — новый AOL.
Сейчас можно делать как минимум пару десятков вещей для генерации трафика — и ни одна из них не связана с SEO или Google.
Так что берите колу и расслабьтесь.
@
Читать полностью…
Mike Blazer
06 Jul 2025 15:35
🚨 Google только что снес 70% трафика некоторых веб-сайтов во время Июньского обновления
Я отслеживал последствия последнего основного апдейта Google, говорит Мохит Шарма, и результаты ЖЕСТОЧАЙШИЕ.
Вот что на самом деле происходит прямо сейчас:
ПОЛНЫЙ РАЗГРОМ:
📉 Сайты с контентом, сгенерированным ИИ: ПАДЕНИЕ НА 40-70%
📉 Страницы, переспамленные ключевыми словами: УНИЧТОЖЕНЫ
📉 Контент с "SEO-хаками": ИСЧЕЗ из выдачи
НО ПОГОДИТЕ… Некоторые сайты ПРОЦВЕТАЮТ:
📈 Контент, ориентированный на пользователя: РОСТ 150%+
📈 Экспертные гайды: ДОМИНИРУЮТ на первой странице
📈 Сайты с реальным E-A-T: СОКРУШАЮТ конкурентов
Вот неудобная правда: Если вы все еще занимаетесь SEO так, как в 2020, вы скоро останетесь за бортом.
Что РЕАЛЬНО работает прямо сейчас:
✅ Писать в первую очередь для людей, а во вторую — для поисковиков
✅ Нарабатывать реальную экспертность (а не просто делать "исследование ключевых слов")
✅ Создавать контент, который действительно решает проблемы
✅ Фокусироваться на пользовательском опыте, а не на "факторах ранжирования"
СУРОВАЯ РЕАЛЬНОСТЬ: Я только что провел аудит сайта клиента, который ПОЛУЧИЛ 200% ПРИРОСТА трафика во время этого апдейта. Хотите знать их секрет? Они перестали гоняться за алгоритмами и начали помогать своим клиентам.
👉 Мой прогноз: К 2026 году 80% существующих "SEO-стратегий" полностью устареют.
P.S. - Если ваш трафик упал, еще не поздно восстановиться. Но действовать нужно быстро.
@
Читать полностью…
Mike Blazer
06 Jul 2025 11:05
Утечка системного промпта ChatGPT 4o: влияние на SEO
Утекший в сеть внутренний системный промпт для ChatGPT 4o, датированный июнем 2025 года, которым поделился Джеймс Берри из LLMrefs, раскрывает, как модель использует и ограничивает веб-поиск.
Анализ промпта освещает конкретные условия активации веб-поиска и их влияние на SEO и видимость сайтов издателей.
1. Когда активируется веб-поиск?
Системный промпт разрешает использовать веб-инструмент при строгом соблюдении условий, указывая, что его следует применять для "доступа к актуальной информации из веба или когда для ответа требуются данные о местоположении".
Веб-поиск разрешен для:
— Событий в реальном времени или текущих событий (например, погода, спортивные результаты).
— Данных, привязанных к местоположению (например, местные компании).
— Нишевых тем, отсутствующих в обучающих данных.
— Случаев, когда устаревшая информация может нанести вред, например, использование устаревшей версии программной библиотеки.
Однако веб-поиск запрещен, если ChatGPT может ответить, основываясь на своих внутренних знаниях, за исключением случаев, когда пользователь запрашивает информацию из общедоступных источников.
В документе также отмечается, что старый инструмент browser устарел и отключен.
2. Как ChatGPT выполняет поиск, когда это разрешено?
Промпт подробно описывает технические параметры выполнения веб-поиска:
— Параллельные запросы: Генерирует до пяти уникальных поисковых запросов одновременно.
— Усиление терминов: Использует оператор "+" для приоритизации ключевых терминов.
— Контроль свежести: Применяет параметр --QDF со значением от 0 (без привязки ко времени) до 5 (критически важно по времени), чтобы отдавать предпочтение свежему контенту.
— Многоязычный поиск: Для запросов не на английском языке поиск выполняется как на языке оригинала, так и на английском.
*Примечание: Утечка описывает эти механизмы формирования запросов, но не подтверждает их последовательное применение к публичному веб-поиску.*
3. Что в промпте говорится о ссылках и видимости источников
Документ не содержит доказательств того, что ChatGPT хранит URL-адреса или поддерживает постоянный веб-индекс.
Ссылки появляются в ответах только в результате поиска в реальном времени.
Таким образом, видимость сайта в ChatGPT — редкое явление.
Для SEO это означает, что если сайт не ранжируется в результатах поиска Bing в реальном времени в момент выполнения поиска, маловероятно, что он будет процитирован.
4. Вывод: редкий поиск означает редкие ссылки
Утечка данных о ChatGPT 4o согласуется с выводами из предыдущей утечки системного промпта Claude: LLM используют поиск в реальном времени только при крайней необходимости, в основном полагаясь на внутренние знания.
В отличие от поисковых систем, у LLM отсутствует индекс URL-адресов, по которому можно делать запросы.
Ссылки из базы знаний модели часто являются вероятностными, что приводит к появлению неработающих или вымышленных URL.
Надежные ссылки, как правило, появляются только в результате поиска в реальном времени.
Это ограничивает реферальный потенциал.
Анализ SISTRIX показывает, что ChatGPT ссылается на внешние источники лишь в 6.3% ответов, по сравнению с 23% у Gemini и средним показателем по отрасли в 13.95%.
Для SEO-специалистов это означает:
— Не стоит ожидать постоянного трафика или ссылок от ChatGPT.
— Видимость зависит от ранжирования в результатах поиска в реальном времени в те редкие моменты, когда запускается живой поиск.
— Большинство ответов ИИ не дают шанса на цитирование вашего сайта.
https://gpt-insights.de/ai-insights/chatgpt-leak-web-search-en/
@
Читать полностью…
Mike Blazer
05 Jul 2025 10:11
Будни
@
Читать полностью…
Mike Blazer
04 Jul 2025 15:05
Трафик и сеошники...
Ответ на вопрос "чем ты занимаешся" можно иллюстрировать данным видео.
@
Читать полностью…
Mike Blazer
04 Jul 2025 11:05
Публичная база данных с исследованиями, новостями и примерами использования ИИ в SEO
https://merj.com/ai-search
Любой желающий может добавить ссылки:
https://merj.com/ai-search/submit
@
Читать полностью…
Mike Blazer
03 Jul 2025 17:05
Переспам ключевыми словами повышает косинусное сходство лишь до определенного момента, после которого этот показатель начинает снижаться.
В этой статье явление описывается как "эффект ковбелла":
https://dejan.ai/media/pdf/cowbell_research_paper_final_v4-final-2a.pdf
Использованный инструмент:
https://dejan.ai/tools/geo/
@
Читать полностью…
Mike Blazer
03 Jul 2025 13:10
А вы знали, что у Google есть официальный Ranking API?
Я создал инструмент, который объединяет DataForSEO и Google Vertex AI Ranking API, — говорит Метехан Ешильюрт.
И да, исходный код в открытом доступе.
Вот что я обнаружил, протестировав запрос: "what is SEO" (для Великобритании)
💾 Топ-2 в выдаче → AI Score: 0.996
Собственный гайд по SEO от Google — идеальное семантическое совпадение.
💾 Топ-5 в выдаче → AI Score: 0.992
Гайд, затерявшийся в выдаче, который ИИ оценил как высокорелевантный.
💾 Топ-6 в выдаче → AI Score: 0.145
Высокая позиция, но низкое?!! качество.
Вероятно, выезжает за счет внутренних ссылок + авторитета.
Что я понял после 100+ тестов:
🧠 Слабый/короткий контент все еще может ранжироваться (если это позволяет структура)
🔍 Google ранжирует пассажи, а не страницы
🔗 Внутренние ссылки формируют "понимание" ИИ
https://metehan.ai/blog/google-vertex-ai-ranking-api/
@
Читать полностью…
Mike Blazer
03 Jul 2025 08:15
Колин Ричардсон рассмотрел кейс сайта с временными вакансиями, где страницы удаляются после закрытия позиции, возвращая ошибку 404.
Клиент обеспокоен 404-ми в GSC, но Колин сомневается в проблеме, задаваясь вопросом: "Разве Google не понимает, что страницы временные?"
Клиент предложил закрыть вакансии от индексации через noindex, чтобы избежать ошибок 404, но Колин считает это неудачным решением.
Он думает перехватывать 404 для определенных URL, отдавая статус 410, и ищет другие варианты.
Колин отметил, что после удаления страницы сложно определить категорию вакансии по URL, но редирект на основную страницу вакансий может помочь.
С учетом сотен новых URL ежемесячно и невозможности изменить систему, он сосредоточился на обработке 404 по URL-путям.
Поскольку вакансии актуальны лишь несколько недель, archive.org использовать нерационально.
Колин хочет создать кастомный контент для 404 страниц вакансий и считает статус 410 более подходящим.
Советы и мнения сообщества
Стратегии редиректов:
— Автоматически перенаправлять 404 на релевантные категории вакансий.
— Редирект на новые вакансии рискован, так как они тоже станут 404.
— Большинство 404 переводить на главную страницу вакансий или на категории.
— Использовать Wayback Machine для данных о страницах с 404.
— Автоматизировать обнаружение таких страниц и настройку редиректов через разработчика.
Аргументы против редиректов:
— Избегать 301 редиректов, кроме случаев повторной публикации вакансии, иначе возникают запутанные цепочки.
— Редирект на категории сбивает пользователей с толку, не показывая, что вакансия закрыта.
— Google может считать такие редиректы soft 404, и они останутся в отчетах GSC.
Коды ответа 404 vs 410:
— В GSC 410 и 404 отображаются в одном отчете, разницы нет.
— Google понимает временность страниц, 404/410 — подходящие статусы.
— Без прямой замены страницы эти статусы не вредят сайту.
Noindex vs 404:
— Noindex лишь переносит страницы в другой отчет, эффект тот же, что у 404 — они выпадают из индекса.
Подход "Оставлять как есть":
— Для агрегаторов вакансий лучше оставить 404, чтобы сосредоточиться на актуальных объявлениях и ускорить исключение старых из индекса.
— Оставить 404 — оптимально для UX и проще в реализации.
Решения с кастомной 404 страницей:
— Создать специальную 404 страницу для вакансий с пояснением о закрытии и переходом к другим вакансиям.
— Настроить общую 404 страницу с сообщением о недоступности и встроенным поиском для удержания пользователей.
— Отслеживать поведение пользователей на 404 страницах для анализа.
Техническая реализация:
— Анализировать 404 по разделам сайта, фильтруя "шум" от вакансий.
— Согласовать срок действия страницы с датой "valid through" в Schema.org для подачи поисковикам консистентных сигналов об активном и устаревшем контенте.
Альтернативный подход к статусу страницы:
— Вместо 404 обновлять статус на "Сотрудник найден" или "Приостановлено", убирая неактивные вакансии из списка, как с товарами без наличия.
Отношение к проблеме:
— Многие переживают из-за отчета "Почему страницы не индексируются" в GSC, но 404 сами по себе не вредны и не должны вызывать беспокойство.
@
Читать полностью…
Mike Blazer
02 Jul 2025 15:05
Инструмент, который поможет определить, насколько AI Overviews (AIO) от Google влияют на ваше SEO.
Загрузите данные из GSC, и инструмент:
— Определит затронутые запросы
— Выявит разрыв между кликами и показами
— Проверит наличие AI Overview (и упоминается ли в нем ваш домен)
— Спрогнозирует ожидаемый CTR с помощью моделирования временных рядов
https://aio-impact-analyzer.streamlit.app/
@
Читать полностью…
Mike Blazer
02 Jul 2025 11:05
Чеклист по оптимизации контента для AI-поиска (Google Таблицы) от Алейды Солис 👇
В нем она разбирает самые важные аспекты оптимизации контента под AI-ответы, их значимость и дает практические рекомендации по внедрению:
1. Оптимизация для извлечения на уровне чанков (Chunk-Level Retrieval)
2. Оптимизация для синтеза ответов (Answer Synthesis)
3. Оптимизация для повышения цитируемости (Citation-Worthiness)
4. Оптимизация по тематической широте и глубине
5. Оптимизация для поддержки мультимодальности
6. Оптимизация под сигналы авторитетности контента
7. Оптимизация для создания контента, устойчивого к персонализации
8. Оптимизация сканируемости и индексируемости контента
https://docs.google.com/spreadsheets/d/1GNjOSdkJuEtv5O3zyBWBkeiD0PecZv6IDd5_4_QoQQY/edit?gid=0#gid=0
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}