Mike Blazer
11 Jul 2025 17:05
Когда ляпнул про эмбеддинги и веерные расширения запроса кому не надо
@
Читать полностью…
Mike Blazer
11 Jul 2025 13:10
Съезд инфобарыг SEO
@
Читать полностью…
Mike Blazer
11 Jul 2025 08:15
Патенты Google указывают на то, что поисковые запросы интерпретируются в трех основных измерениях: Query Aspect (аспект запроса), Query Theme (тема запроса) и Query Phrasification (фразификация запроса).
Например, запрос "hotel" может иметь тему "holiday" и аспект "best", в результате чего формируется сформулированный запрос, такой как:
"Find the best hotel price for holiday."
Эти концепции постоянно используются в технической документации Google.
Патент Search with Stateful Chat описывает, как pre-trigger классификаторы используют заранее определенные шаблоны для интерпретации определенных типов запросов.
Эти триггеры активируются контекстным движком, который определяет интент пользователя на основе поисковой сессии, поведения пользователя и окружения запроса.
Другие патенты описывают похожие системы поисковика, основанные на пользовательском контексте, в которых модели оценки и аспекты запроса изменяются в зависимости от выводимого контекста.
Этот фреймворк не нов; он является результатом двух десятилетий развития семантического поиска, который теперь лежит в основе интерфейса Google AI Mode.
Эволюция системы во многом опирается на использование синтетических запросов и пользовательских сессий, что позволяет Google симулировать поисковое поведение в обучающих целях, не полагаясь исключительно на реальные данные пользователей.
Система также использует обучение с подкреплением, и это предполагает, что обновления выкатываются батчами и улучшаются за счет обратной связи от машинного обучения.
Соответственно, интерпретация терминов может меняться; такие слова, как "download" и "upload", со временем могут активировать различные аспекты, темы или фразификации на основе изученного контекста.
Когда страница ранжируется по разговорному запросу, она ранжируется по машинно-интерпретированной, сформулированной версии этого запроса, а не по исходному тексту, введенному пользователем.
@
Читать полностью…
Mike Blazer
10 Jul 2025 15:05
Экспертность, Опыт, Авторитетность, Достоверность
Экспертность - как ты объясняешь то, что делаешь в своем контенте.
Опыт - то, что ты описываешь как уже сделанное в своем контенте.
Авторитетность - ты заработал видимую репутацию за то, что делаешь.
Достоверность - ты говоришь по существу, предоставляешь четкую информацию лаконично, и подтверждаешь свои утверждения надежными ссылками или цитатами.
@
Читать полностью…
Mike Blazer
10 Jul 2025 11:05
Noindex больше не означает "нерендерится"
Вопреки официальной документации, похоже, теперь Google пропускает страницы с директивой noindex через свой Web Rendering Service (WRS).
Раньше директива noindex препятствовала рендерингу, а это означало, что никакой JavaScript на странице не выполнялся.
Недавние тесты показывают, что это поведение изменилось.
И хотя инструменты для проверки в реальном времени, такие как Инструмент проверки URL, уже некоторое время рендерят страницы с noindex, теперь это, по-видимому, происходит и в основном конвейере индексации.
Методология тестирования и результаты
Была проведена серия тестов с использованием страниц с директивой noindex, которые также содержали JavaScript fetch()-запрос к эндпоинту, логирующему детали запроса.
— Тест 1: мета-тег `noindex`
Тестировалась страница с мета-тегом noindex для роботов. JavaScript на странице также удалял этот тег.
- Результат: Гуглобот выполнил fetch()-запрос методом POST, подтвердив, что страница была отрендерена. Страница была корректно обработана как noindex и не попала в индекс (статус в GSC: "Исключено тегом noindex").
— Тест 2: HTTP-хидер `noindex`
Тестировалась страница, которая отдавалась с HTTP-хидером X-Robots-Tag: noindex.
- Результат: Как и в первом тесте, Гуглобот отрендерил страницу и выполнил fetch()-запрос методом POST. Страница не была проиндексирована (статус в GSC: "Исключено тегом noindex").
— Тест 3: код ответа HTTP 404
Тестировалась страница, которая возвращала код ответа HTTP 404.
- Результат: fetch()-запрос не был выполнен. По-видимому, Гуглобот не рендерит страницы, которые отдают код ответа 404.
— Тест 4: `noindex` с JavaScript-редиректом
Страница с мета-тегом noindex содержала JavaScript-редирект на другой URL.
- Результат: Страница была отрендерена, и fetch()-запрос был выполнен. Однако в GSC страница получила статус "Исключено тегом noindex", а не "Страница с переадресацией". Это указывает на то, что директива noindex получила приоритет, а редирект не был обработан.
Результаты тестов подтверждают, что теперь Google рендерит страницы с директивой noindex, выполняя JavaScript и даже отправляя POST-запросы.
Использование метода POST указывает на то, что это часть формального процесса рендеринга, а не спекулятивная выборка.
https://tamethebots.com/blog-n-bits/noindex-does-not-mean-not-rendered
@
Читать полностью…
Mike Blazer
09 Jul 2025 17:05
⚠️ Если вы изучаете или начинаете использовать векторные эмбеддинги, остерегайтесь эффекта плотности.
Один из способов применения векторных эмбеддингов и косинусного сходства — это измерение и поиск наиболее релевантной страницы из группы по конкретному запросу.
Screaming Frog упрощает эту задачу благодаря правильным настройкам и встроенной функции.
Суперполезно, но будьте осторожны.
На этот показатель сходства влияет множество факторов.
Один из них — плотность.
Например, я прогнал несколько страниц одного маркетингового агентства по запросу "boston seo agency", — говорит Брайан Горман.
Самой похожей оказалась страница, на которой не было ничего, кроме карточки одного поста из блога.
Одна из тех страниц-агрегаторов, которые собирают подходящие статьи по датам.
Не главная?
Не страница с SEO-услугами?
Почему?
Это и есть эффект плотности.
Поскольку на странице не было другого контента, информация о местоположении в футере была интерпретирована с более высокой плотностью, чем на главной странице, где был тот же футер, но гораздо больше основного контента, который его "разбавлял".
С точки зрения данных о местоположении, страница с тонким контентом была как эспрессо, а главная — как разбавленный кофе.
И поскольку запрос содержал "boston", сходство оказалось высоким.
Очевидно, мы не должны слепо доверять этим показателям, но также очень важно понимать, что на них влияет, чтобы вы могли здраво рассуждать и приходить к верным выводам.
ИМХО, это показывает, что новых тактик, которые мы осваиваем, часто недостаточно самих по себе — всегда копайте глубже и формируйте более полный контекст, прежде чем принимать решение.
@
Читать полностью…
Mike Blazer
09 Jul 2025 13:10
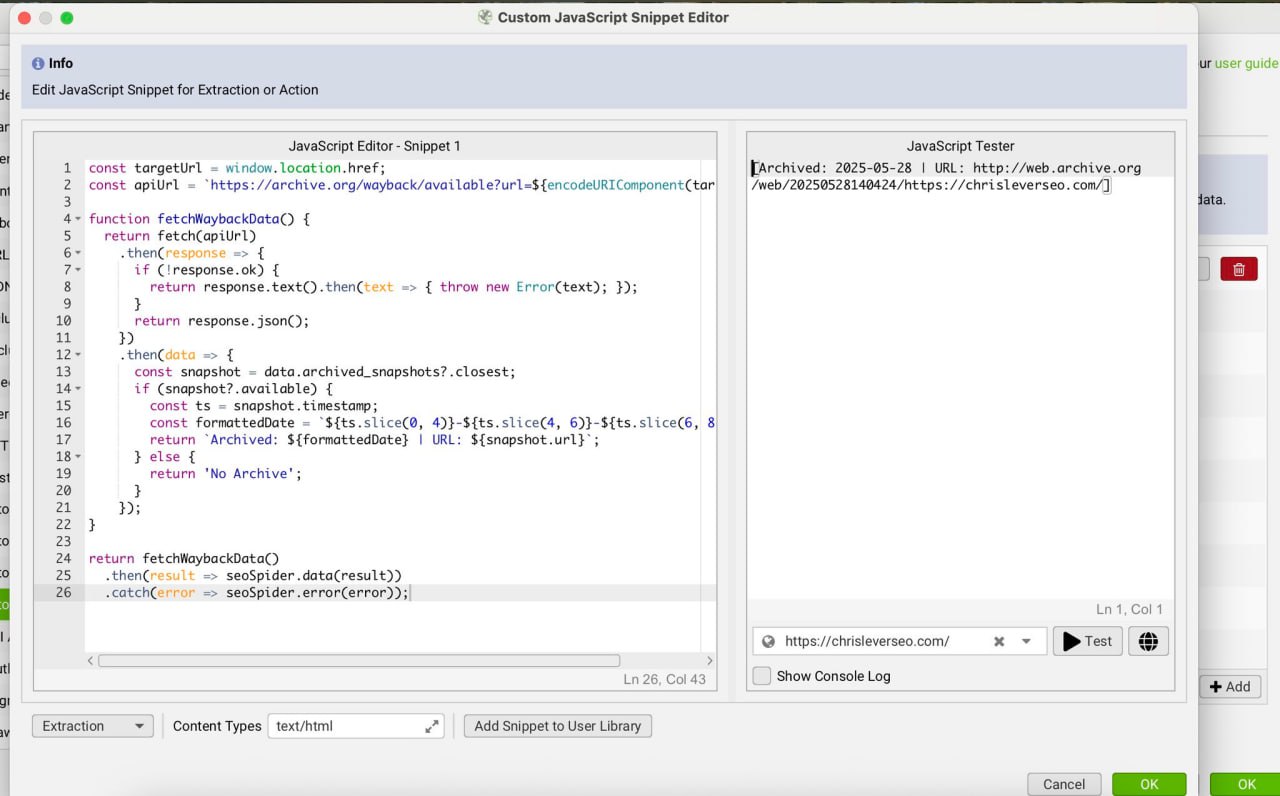
Вы можете напрямую обращаться к бесплатному Wayback Machine API из Screaming Frog с помощью кастомного JavaScript-сниппета.
Это позволит обогатить данные краула архивной информацией, такой как:
— Когда страница была заархивирована в последний раз
— Была ли она вообще когда-либо заархивирована
— Прямая ссылка на снапшот
Зачем это может пригодиться?
— Находить удаленный контент: страницы, которые раньше существовали, а теперь отдают 404-ю ошибку, можно проверить на предмет их исторической ценности.
— Оценивать деградацию сайта: можно увидеть, какие разделы сайта существовали ранее, но со временем незаметно исчезли.
— Восстановление: находить страницы с историческими ссылками или упоминаниями, которые стоит восстановить или с которых нужно настроить редирект.
Используемый JS-сниппет:
const targetUrl = window.location.href;
const apiUrl = `https://archive.org/wayback/available?url=${encodeURIComponent(targetUrl)}`;
function fetchWaybackData() {
return fetch(apiUrl)
.then((response) => {
if (!response.ok) {
return response.text().then((text) => {
throw new Error(text);
});
}
return response.json();
})
.then((data) => {
const snapshot = data.archived_snapshots?.closest;
if (snapshot?.available) {
const ts = snapshot.timestamp;
const formattedDate = `${ts.slice(0, 4)}-${ts.slice(4, 6)}-${ts.slice(6, 8)}`;
return `Archived: ${formattedDate} | URL: ${snapshot.url}`;
} else {
return "No Archive";
}
});
}
return fetchWaybackData()
.then((result) => seoSpider.data(result))
.catch((error) => seoSpider.error(error));
@
Читать полностью…
Mike Blazer
09 Jul 2025 08:15
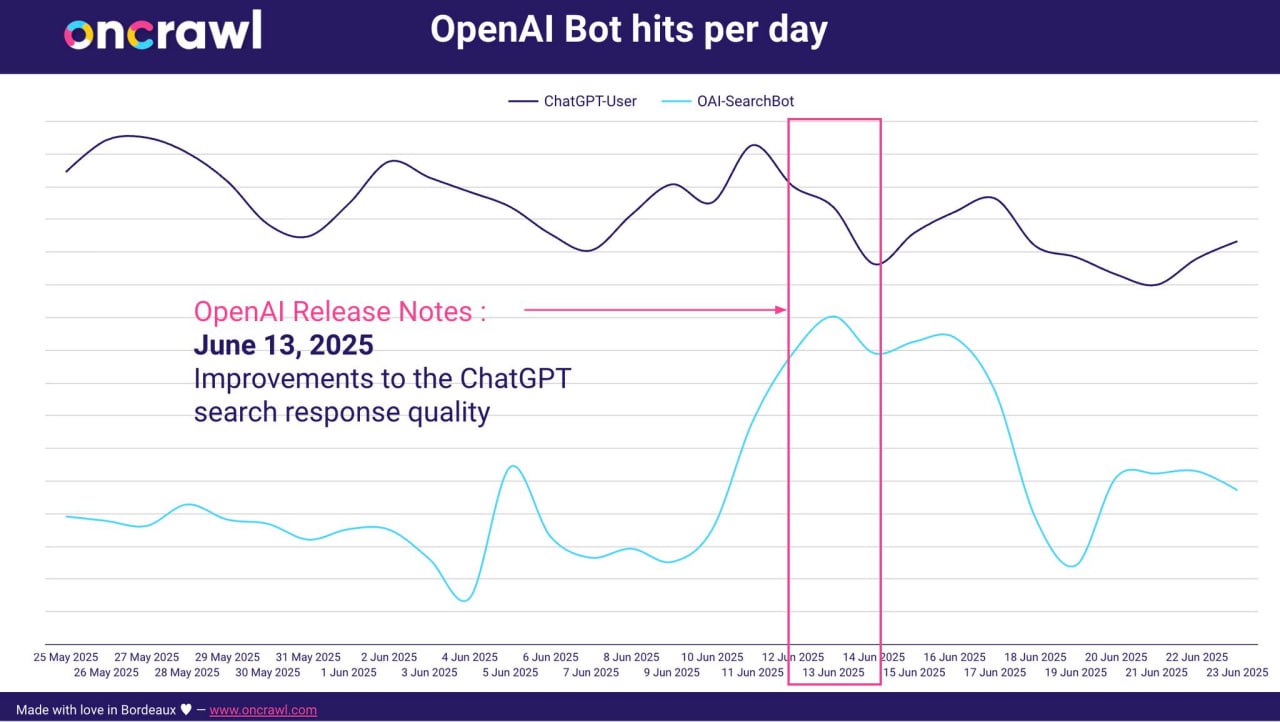
OAI-SearchBot от OpenAI ведет себя подобно Гуглоботу: его активность резко возрастает в периоды крупных апдейтов.
Мониторинг с помощью Oncrawl зафиксировал пик трафика OAI-SearchBot примерно 13 июня.
Это совпало с опубликованным апдейтом OpenAI, направленным на улучшение качества поисковых ответов ChatGPT (Источник: Жером Саломон).
Хотя в официальной документации говорится, что OAI-SearchBot используется для отображения сайтов в поисковой выдаче ChatGPT, важно понимать конкретный механизм его работы.
Поиск ChatGPT не имеет собственного индекса и в основном полагается на Bing's Search API.
Согласно разъяснениям службы поддержки OpenAI, функция бота заключается в следующем:
1. OAI-SearchBot сканирует общедоступный веб-контент в фоновом режиме, используя поисковую выдачу Bing в качестве отправной точки.
2. Он не извлекает контент в реальном времени непосредственно в ответ на запрос пользователя; эту функцию выполняет ChatGPT-User.
3. Основная цель бота — поддерживать и улучшать качество поисковой выдачи. Сканируемый им контент может использоваться для настройки или обучения поисковых моделей OpenAI.
И ChatGPT-User, и OAI-SearchBot являются ключевыми ботами, влияющими на видимость в ChatGPT.
Рост их совокупной активности на сайте — это индикатор того, что его контент получает больше видимости в ответах ChatGPT.
@
Читать полностью…
Mike Blazer
08 Jul 2025 17:05
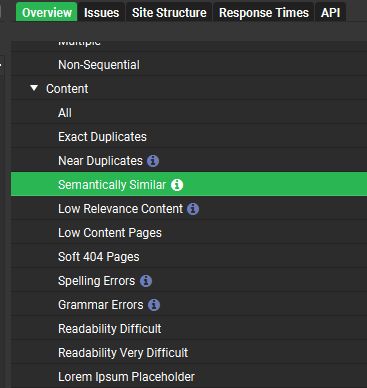
Большинство сеошников используют новую фичу Screaming Frog "Semantic Similarity" только для внутреннего аудита контента.
Но знаете ли вы, что ее можно применять и в вашей линкбилдинг-стратегии?
Semantic Similarity = детектор "воды" для фейкового тематического авторитета ✨
Используйте это для оценки сайтов-доноров ПЕРЕД тем, как проставлять ссылки!
И вот как это сделать всего за пару кликов:
1. Прокраульте потенциального донора с помощью v22.1 + OpenAI API
2. Проверьте, нет ли почти идентичных контентных кластеров
3. и если вы заметите, что на нескольких страницах говорится одно и то же, но немного другими словами…
🚩 перед вами контентная ферма ☢️
*бонусные советы, если вы также получили результаты в отчете Overview > Content:
❌ 'Low Relevance' (Низкая релевантность) = плохой таргетинг
❌ 'Near Duplicate' (Почти дубликат) = ленивый копипаст
Так что, как всегда, пожалуйста, не сливайте свои бэклинки на пустышки :D
@
Читать полностью…
Mike Blazer
08 Jul 2025 13:10
Джо Янгблад отследил попытку нового агентства вывести Гугл бизнес-профиль (GBP) его клиента в топ-1 в крупном мегаполисе за заявленные 60-90 дней.
Первые действия (первые 48 часов)
Получив доступ к GBP на уровне "Менеджер", новое агентство внесло несколько изменений в самом профиле:
— Было переписано основное описание компании.
— Были опубликованы два вопроса в разделе "Вопросы и ответы", на которые тут же ответили с аккаунта менеджера.
— Был опубликован один пост в GBP.
— Было загружено видео, предположительно созданное с помощью генеративного ИИ.
Примерно через 48 часов наблюдался небольшой рост позиций по одному из целевых запросов, однако это движение соответствовало обычным дневным колебаниям.
Анализ через неделю
По прошествии шести дней стратегия агентства заключалась исключительно в активности внутри профиля.
Стандартных спам-сигналов, таких как переспам ключами в названии, фейковые отзывы или использование PBN, обнаружено не было.
Ключевые действия были следующими:
— Контент: Было переписано описание в GBP, а для всех услуг добавлены новые, сгенерированные ИИ описания с переспамом ключевыми словами.
— Посты: Было опубликовано два поста в GBP, один из которых был сильно переоптимизирован ключами.
— Q&A: Были самостоятельно опубликованы и отвечены два вопроса в разделе "Вопросы и ответы".
К концу первой недели весь первоначальный рост позиций был утерян.
Позиции как в локал паке (блоке с картами) Google Maps, так и в классической поисковой выдаче оказались ниже, чем до того, как агентство взялось за работу.
Отчет за месяц
Через месяц агентство проделало следующее:
— Всего постов: 10. Посты были однотипными: в них повторялась одна и та же информация об услугах, но с ротацией названий целевых городов.
— Всего Q&A: 3.
— Никаких других изменений, таких как новые ссылки или упоминания, обнаружено не было.
Сканирование в Local Falcon на 30-й день показало, что позиции по большинству целевых запросов не изменились или упали.
Некоторые незначительные улучшения позиций наблюдались на точках сетки далеко за пределами целевой зоны обслуживания, что можно списать на обычные алгоритмические колебания.
В целом, позиции в GBP на Картах продолжали снижаться в течение всего месяца.
По прошествии 30 дней нет никаких доказательств того, что стратегия частых, переспамленных ключами постов в GBP и самостоятельных ответов на вопросы в Q&A эффективна для улучшения локальных позиций для бизнеса с зоной обслуживания (SAB) на конкурентном рынке.
@
Читать полностью…
Mike Blazer
08 Jul 2025 08:15
Использование FAQ в вашем контенте может стать ОТЛИЧНЫМ способом оптимизации под AI-поиск.
Этот анализ показал, что у FAQ самая высокая семантическая релевантность.
Крис Грин провел отличное исследование, основанное на данных, чтобы проанализировать, какие структуры контента лучше всего оптимизированы для LLM.
Поскольку LLM разбивают ваш контент на чанки (chunks) и сохраняют в виде векторов, Крис решил проверить, какие стили написания текста наиболее эффективны в такой системе.
В своем анализе он протестировал написание трех разных статей в трех разных стилях.
Среди этих стилей были:
1. Плотная проза: Контент был написан в традиционном стиле, абзацами.
2. Структурированный контент: Он взял абзацы и применил форматирование, например, заголовки и маркированные списки.
3. Вопрос-Ответ (Q&A): Он превратил абзацы в формат FAQ.
После этого он протестировал различные методы чанкинга, чтобы увидеть, как структуры контента соотносятся друг с другом.
Затем он измерил эффективность каждого типа контента для каждого метода чанкинга.
Результаты показали, что контент в формате FAQ стабильно демонстрирует наибольшее сходство с контрольным запросом.
Структурированный контент оказался на втором месте по эффективности, в то время как традиционные абзацы в целом показали самые слабые результаты.
С точки зрения семантического совпадения, это вполне логично.
Поскольку разделы FAQ, как правило, предельно лаконичны, это означает, что контент в них имеет относительно высокую плотность.
В результате это чрезвычайно эффективный метод для случаев, когда LLM разбивают ваш контент на чанки.
https://www.chris-green.net/post/content-structure-for-ai-search
@
Читать полностью…
Mike Blazer
07 Jul 2025 17:05
Почему ваши разработчики ненавидят ваши "простые" просьбы о функциях
Фаундер/ПМ: "Просто добавьте кнопку логина! Разве это так сложно?"
Разработчик: (дергается глаз).
Вот что происходит, когда вы просите "крошечную" фичу:
1. Вход через соцсети "в один клик"
Вы видите: Кнопку.
Разработчики видят: OAuth-потоки, хранение токенов, обработку ошибок, соответствие GDPR и 3 дня тестирования корнер кейсов.
2. Требование "Просто сделайте это быстрее".
Вы думаете: Оптимизировать код.
Реальность: Реструктуризация базы данных, слои кэширования и борьба с 5-летним наследием решений.
3. Фича "Как у Amazon"
Ваше видение: "Базовый поисковый фильтр".
Сфера применения: персонализированные рекомендации, инвентаризация в реальном времени и сортировка на основе ИИ.
Почему это разочаровывает разработчиков:
— Скрытая сложность ≠ лень. Маленькая просьба может обернуться неделей работы.
— Каждая "простая" функция затягивает дорожную карту. Технический долг тихо усугубляется.
— Разрабы хотят создавать отличные вещи, но им нужны реалистичные приоритеты.
Как исправить ситуацию?
✅ Запрашивать оценку, прежде чем называть задачу "простой".
✅ Компромиссы неизбежны. Скорость против масштаба? Дешевизна против перспективности?
✅ Привлекайте разработчиков к раннему обсуждению. (Они быстрее обнаружат подводные камни).
@
Читать полностью…
Mike Blazer
07 Jul 2025 13:10
Когда PPC-специалист уничтожает твоё SEO 🤯
Мы работали над SEO для клиента последние два года, планомерно наращивая органическую видимость и трафик на их основные коммерческие страницы, пишет Джейд Халлам.
Прогресс был стабильным, особенно учитывая бюджет.
В то же время другое агентство занималось их PPC-кампаниями.
Они спросили, могут ли внести несколько изменений в лендинги для PPC, которые мы создали.
Конечно.
Мы даже позаботились о том, чтобы SEO и PPC страницы были разделены, чтобы они могли вносить правки не влияя на наши поисковые показатели.
Но вместо редактирования этих страниц...
Они отредактировали основные категории и продуктовые страницы.
Те, что ранжировались в Google.
Те, что приносили органическую выручку.
В следующий момент позиции падают.
Органический трафик следует за ними.
Проверяем сайт и обнаруживаем виновника: половина SEO-контента исчезла.
*Рыдает в GSC.*
Вот почему сотрудничество между командами, внутренними или внешними, не обсуждается.
Нельзя оптимизировать один канал в ущерб другому.
Мы все работаем над одной целью: больше бабок для клиента.
Так что, пожалуйста, PPC-специалисты, поговорите с вашими SEO перед внесением изменений.
Мы обещаем, что не будем кусаеться... если только вы не удалите наш контент 😅
@
Читать полностью…
Mike Blazer
07 Jul 2025 08:15
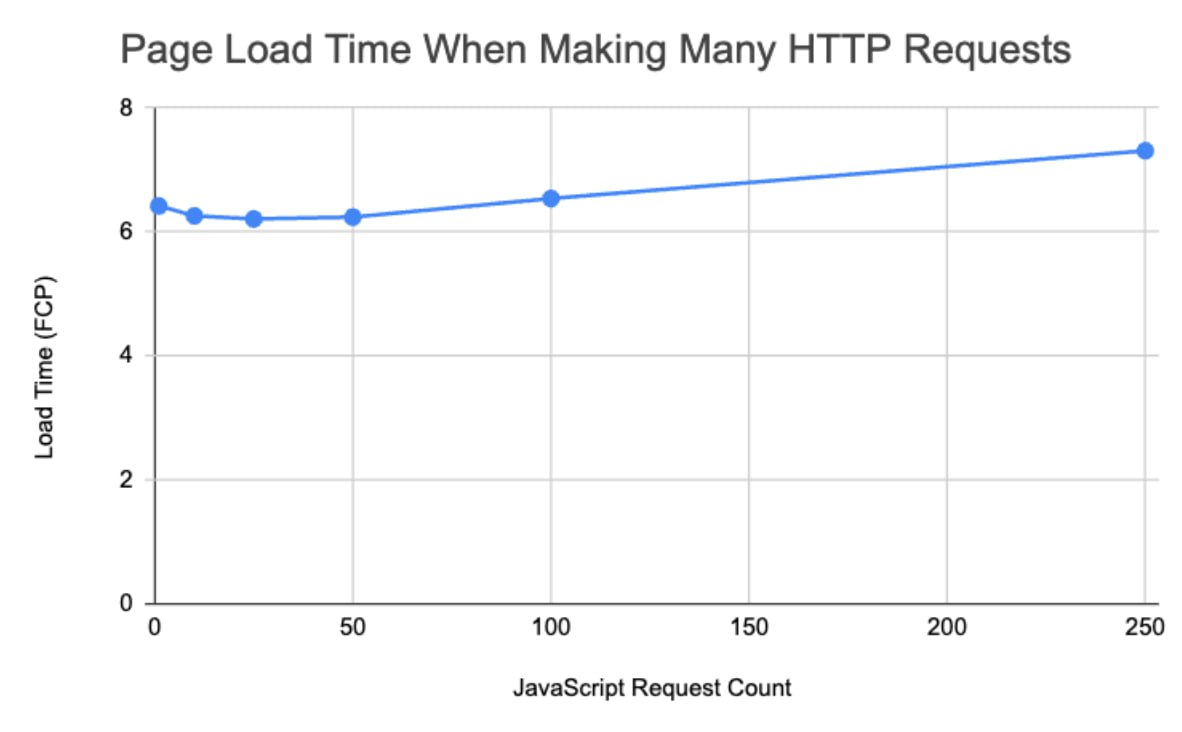
Улучшает ли уменьшение количества HTTP-запросов скорость загрузки страницы?
Современные реалии
— С доминированием HTTP/2 количество запросов влияет меньше, чем во времена HTTP/1.1
— HTTP/2 поддерживает множество параллельных запросов на одном соединении (до 100 по умолчанию)
— Только при сотнях запросов накладные расходы существенно влияют на производительность
Что действительно важно
— Размер ресурса: Большой файл (1МБ) обычно сильнее влияет на производительность, чем несколько маленьких
— Влияние на рендеринг: Запросы, блокирующие рендеринг, сильнее влияют на пользовательский опыт, чем неблокирующие
— Время запросов: Поздно загружаемые запросы минимально влияют на воспринимаемую скорость
Практические подходы к оптимизации
— Объединять файлы CSS и JavaScript во время сборки
— Внедрять ленивую загрузку для изображений под сгибом с помощью loading="lazy"
— Минимизировать сторонние ресурсы, добавляющие ненужные запросы
— Фокусироваться на улучшении пользовательских метрик, а не произвольного количества запросов
При тестировании 250 отдельных запросов сделали страницу всего на 0.89 секунд медленнее (14%) по сравнению с одним запросом того же общего размера.
Влияние меньшего количества запросов становится значимым только в масштабе или при использовании HTTP/1.1.
https://www.debugbear.com/blog/make-fewer-http-requests
@
Читать полностью…
Mike Blazer
06 Jul 2025 14:05
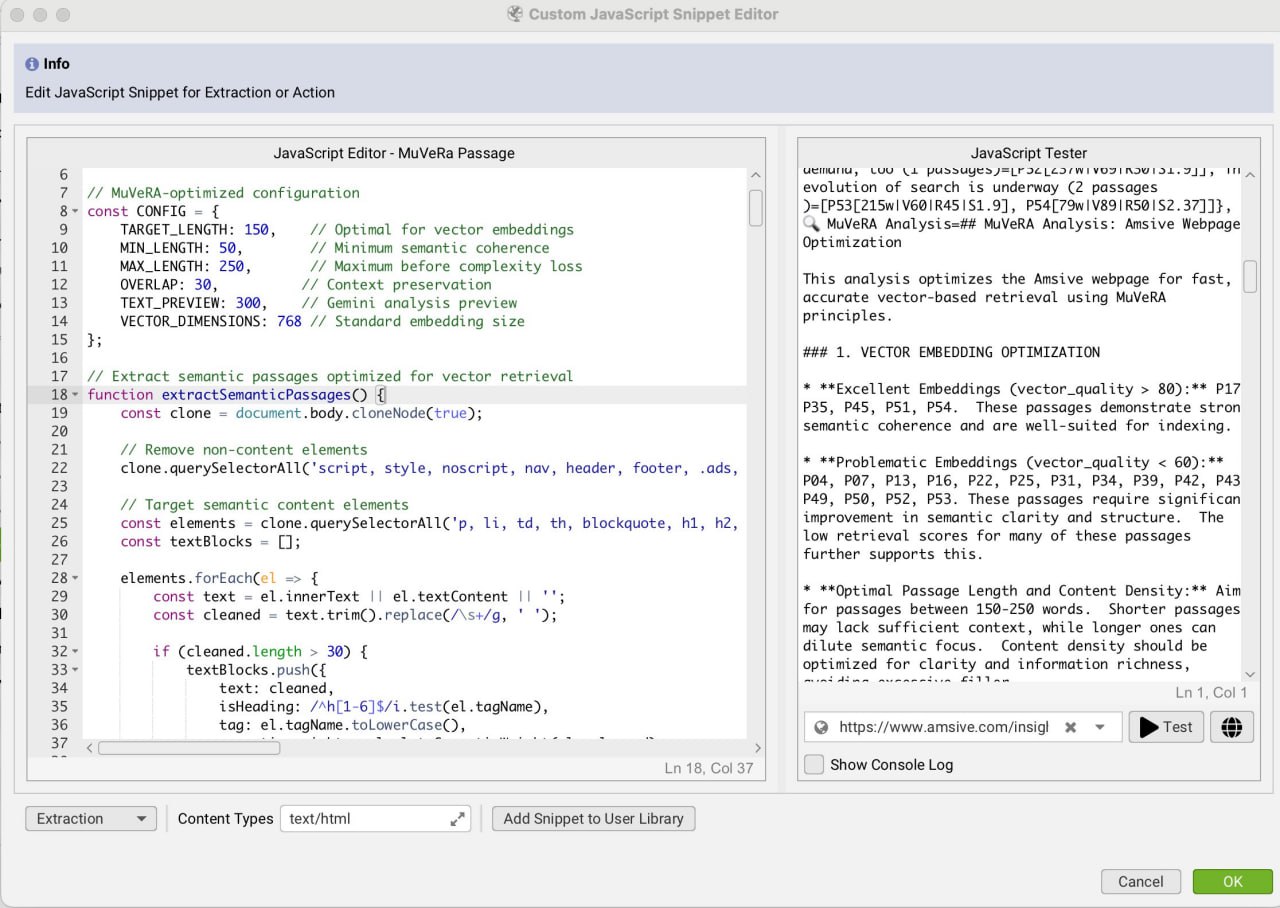
Оптимизация контента для векторного поиска с помощью фрагмента кода Screaming Frog, вдохновленного MuVeRA
Я создал кастомный JavaScript-сниппет для Screaming Frog, вдохновленный концепцией MuVeRA, после прочтения исследования Google о многовекторном поиске, — пишет Метехан Йешильюрт.
Вместо ускорения поиска, что было целью Google, я использую этот инструмент для оптимизации контента, чтобы улучшить его извлечение.
Инструмент разбивает контент на пассажи по 150 слов, что оптимально для эмбеддингов, и присваивает им оценку качества, чтобы определить, какие разделы будут наиболее эффективны в поисковых системах, основанных на векторном поиске.
Каждый пассаж анализируется независимо по таким параметрам, как качество вектора, семантический вес и потенциал для поисковой выдачи.
Хотя инструмент и экспериментальный, он позволяет взглянуть на ваш контент глазами современных поисковых систем на базе ИИ 🔍.
Полное руководство и бесплатный кастомный Javascript-сниппет доступны по ссылке: https://metehan.ai/blog/screaming-frog-muvera-analysis/
@
Читать полностью…
Mike Blazer
11 Jul 2025 15:05
Для увеличения прибыли Google объявляет о планах убрать все оставшиеся результаты поиска из поисковой выдачи
@
Читать полностью…
Mike Blazer
11 Jul 2025 11:05
Помогает ли удаление контента для SEO?
Стратегическое удаление страниц блога может дать ценные результаты для SEO.
Анализ двух кейсов — в сфере SaaS и туризме — показывает, что удаление неэффективного контента улучшает тематическую ясность, перераспределяет бюджет и усиливает фокус бренда.
В обоих случаях удалялся устаревший или малоценный контент, а пересекающиеся статьи консолидировались без повторной оптимизации.
Кейс 1: SaaS-компания
— Ниша: SaaS (крупная компания)
— Цель: Улучшить тематическую ясность, органическую видимость и траст.
— Стратегия: Удаление и консолидация неэффективного контента блога.
— Результаты:
- Вырос органический трафик.
- Тематическая принадлежность домена стала четче.
- Увеличилось число упоминаний бренда.
- Возросло количество ИИ-цитирований, что говорит о росте авторитета.
— Вывод: Сокращение контента улучшило ключевые показатели. Стратегия масштабируется на локализованные версии сайта.
Кейс 2: Туристический сервис
— Ниша: Туристические услуги (средняя/крупная компания)
— Цель: Усилить фокус и убрать контент с низким ROI.
— Стратегия: Удаление и консолидация общего контента блога, созданного ранее другим агентством.
— Результаты:
- Органический трафик остался без значительных изменений.
- Главный итог — финансовая ясность: блог не приносил ROI, трафика и конверсий.
— Вывод: Бюджет и ресурсы перераспределили на другой SEO-проект с положительными результатами. Блог под наблюдением для возможного полного удаления.
7 ключевых уроков по чистке контента
1. Ценность контента зависит от ниши: Влияние контента варьируется по отраслям. Где-то он эффективен, а где-то создает лишь информационный шум без стратегии.
2. Лишний контент увеличивает затраты: Неэффективный контент тратит бюджет. Его удаление уточняет ROI и перенаправляет средства на успешные проекты.
3. Технический контроль необходим: Удаление требует знаний в техническом SEO, чтобы избежать проблем на сайте. Нужен опытный специалист для планирования.
4. Модель "контент-хаба" часто устарела: Большие объемы контента без стратегии и уникальности становятся шумом в текущей поисковой среде.
5. SEO нуждается в автономии: Если SEO подчинено отделу контента, эффективность падает. Специалистам нужна свобода для экспериментов и стратегий.
6. Ясность важнее объема для ИИ-поиска: Видимость в LLM и ИИ-поиске достигается качественным, фокусным контентом, а не количеством нерелевантных материалов.
7. Просчитанный риск приносит результат: Смелые шаги, как удаление контента, могут дать значительный эффект, даже если он отличается от ожиданий. Успех требует сотрудничества и готовности к адаптации.
https://www.linkedin.com/pulse/does-deleting-content-help-seo-7-lessons-from-two-bold-anconitano-ivb0f/
@
Читать полностью…
Mike Blazer
10 Jul 2025 17:05
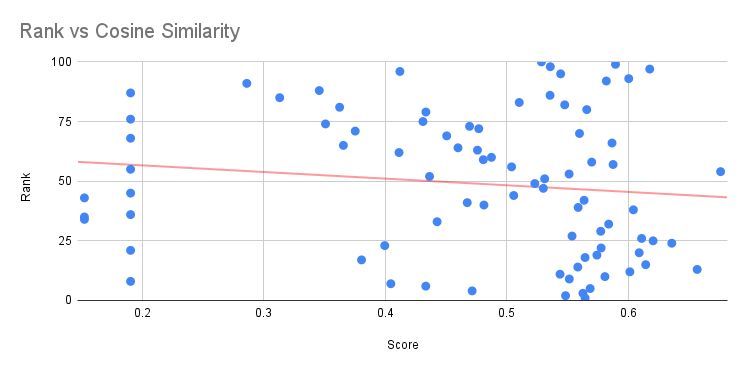
Чем больше я экспериментирую с векторными эмбеддингами и семантическим поиском, тем меньше я верю, что это продвинутый фактор ранжирования Google 📈, — говорит Сайрус Шепард.
Скорее, это больше похоже на базовое условие для участия в игре.
Тот минимум, который нужен, чтобы просто быть в игре ♦️
Возьмите любой конкурентный запрос, и у всех топ-100 результатов в выдаче будут достаточно схожие векторные эмбеддинги относительно этого поискового запроса.
И при этом часто нет никакой корреляции с позицией.
Так в чем же дело?
Мы знаем, что поиск "релевантных" документов — это один из первых шагов, которые Google предпринимает при ответе на запрос.
Сокращение числа возможных документов с миллиардов до нескольких тысяч.
После этого такие сигналы, как ссылки, клики, качество и все остальные факторы ранжирования, вероятно, играют гораздо более важную роль.
Так что же, векторные эмбеддинги бесполезны?
Нет, отнюдь нет.
Особенно для понимания контента в больших масштабах, определения релевантности, поиска аномалий и целого ряда других задач.
(И, как отметил в комментариях Кай Шпристерсбах, очень сложные запросы / развернутые поисковые фразы с гораздо большей вероятностью выигрывают от такого типа анализа!)
Но подняться с 10-й на 5-ю позицию по конкурентному запросу за счет улучшения показателей косинусного сходства?
Я пока не вижу тому доказательств.
Буду рад, если кто-то докажет, что я неправ!
Если у вас есть доказательства обратного или вы считаете, что я упускаю что-то важное, пожалуйста, поделитесь...
@
Читать полностью…
Mike Blazer
10 Jul 2025 13:10
"Rocketship SEO" — новый плагин для WordPress, разработанный, чтобы быть супербыстрым и совместимым с вашим текущим стеком.
Он предоставляет мощные SEO-инструменты без раздутого функционала и платной подписки.
👉 Рекомендации тайтлов с помощью ИИ
👉 Рекомендации мета-дескрипшенов с помощью ИИ
👉 Генерация атрибутов Alt и Title для изображений с помощью ИИ
👉 SEO-рекомендации по контенту с помощью ИИ
👉 Автоматическое оглавление
👉 XML-карты сайта (если они вам нужны)
👉 Микроразметка Schema (если она вам нужна)
👉 Теги Open Graph (если они вам нужны)
👉 Карточки Twitter (если они вам нужны)
👉 Массовые рекомендации для мета-тегов с помощью ИИ
👉 Совместимость с блочным и классическим редакторами
👉 Возможность легко исключать отдельные посты из XML-карты сайта (при использовании нашего генератора)
👉 Простое закрытие контента от индексации через noindex
👉 Протестирована (и продолжает тестироваться) совместимость с Yoast и RankMath. На очереди — Slim SEO и SEOPress.
В разработке еще масса новых функций.
https://wordpress.org/plugins/rocketship-seo/
@
Читать полностью…
Mike Blazer
10 Jul 2025 08:15
Может ли оптимизация под векторный поиск принести больше вреда, чем пользы?
Векторный поиск используется в Google Поиске.
Если вы понимаете, как под него оптимизироваться, вы можете очень понравиться машинам.
Но, вполне возможно, что если при этом вы не будете выглядеть так же хорошо для пользователей, то рискуете научить системы Google отдавать вашему сайту меньше предпочтения.
Подробнее:
Риски оптимизации под векторный поиск
Оптимизация под векторный поиск может временно повысить позиции, но становится вредной, если сигналы ПФ не подтверждают релевантность, определенную алгоритмом.
Это может со временем привести к пессимизации контента в системах Google.
Использование векторного поиска в Google
Векторный поиск превращает текст в числовые эмбеддинги, где семантическая близость отражается близостью в многомерном пространстве.
Системы Google, включая RankBrain, применяют этот метод и, как подтверждено, переранжируют топовые результаты выдачи.
Однако полагаться только на этот механизм — ошибка.
Джон Мюллер из Google отметил: "Оптимизация под эмбеддинги — это, по сути, переспам ключевыми словами".
Решающая роль сигналов ПФ
Модели ранжирования Google улучшаются благодаря поведенческим сигналам, таким как клики, внимание и удовлетворенность пользователей.
Системы, включая helpful content system и обновление марта 2024 года, строятся на обучении через взаимодействия с пользователями.
Конфликт возникает, если контент кажется релевантным для векторного поиска, но не удовлетворяет аудиторию.
При постоянных негативных сигналах ПФ Google считает контент бесполезным и снижает его позиции.
Долгосрочная стратегия: приоритет на ценности для человека
Эффективное решение — создавать контент с явной ценностью для пользователей.
Это требует оригинального, экспертного анализа с глубокими инсайтами, а не пересказа существующих данных.
Такой подход приносит позитивные поведенческие сигналы, необходимые для устойчивой видимости в системах ранжирования Google.
https://mariehaynes.com/could-optimizing-for-vector-search-do-more-harm-than-good/
@
Читать полностью…
Mike Blazer
09 Jul 2025 15:05
Чем старше ваш сайт, тем больше страниц нужно почистить, обрезать или объединить.
Посмотрите, сколько нерелевантных страниц накапливается на сайте в зависимости от его возраста.
В рамках этого исследования нерелевантной считалась проиндексированная страница, которая получает мало SEO-трафика или вообще его не получает.
Просто не забывайте проводить стандартную уборку сайта.
Нерелевантные страницы будут всегда, но они не должны составлять значительный процент вашего сайта.
@
Читать полностью…
Mike Blazer
09 Jul 2025 11:05
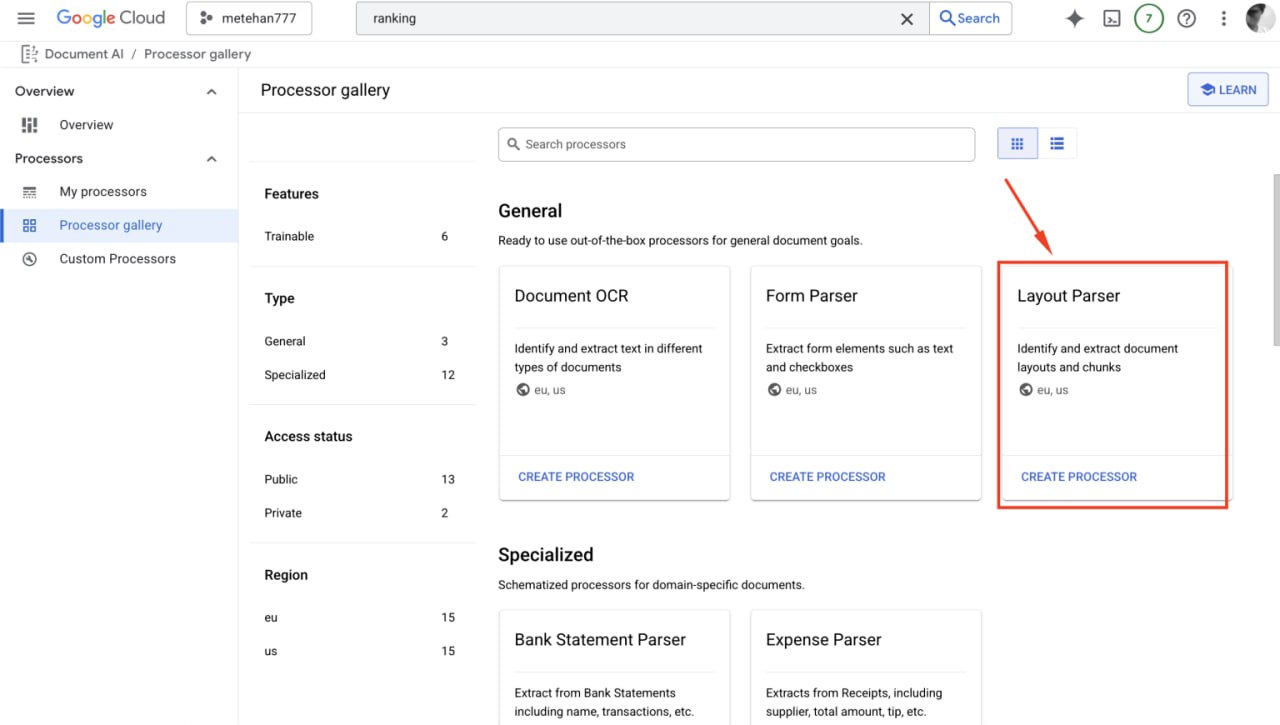
А вы знали, что у Google есть продукт для парсинга HTML-структуры?
Метехан Ешилюрт провел эксперимент с Google Document AI Layout Parser на трех веб-страницах: статье по техническому SEO, лендинге приложения и руководстве по привлечению пользователей.
Цель — изучить, как модель машинного обучения анализирует структуру HTML.
Хотя Document AI отличается от парсера Google Поиска, результаты показывают важность чистого и логичного HTML для обработки контента.
Инструмент преобразует HTML в структурированный JSON, классифицируя блоки контента и их связи.
Ключевые выводы
1. Навигационный "мусор" может скрыть контент
Анализ выявил, что излишние навигационные элементы затрудняют доступ к основному контенту.
На одной странице парсер добрался до контента лишь на 122-м блоке, пройдя 121 навигационный блок.
SEO-статья:
— Первый блок контента: Блок 3
— Навигационные блоки: 2
Лендинг приложения:
— Первый блок контента: Блок 122
— Навигационные блоки: 121
Руководство пользователя:
— Первый блок контента: Блок 1
— Навигационные блоки: 0
2. Учитываются все DOM-элементы
Парсер присваивает ID каждому DOM-элементу, даже пустым оберткам, что указывает на лишнюю нагрузку от избыточного HTML.
3. Иерархия элементов сохраняется
Парсер поддерживает связи "родитель-потомок".
Контент, вложенный в заголовок, связывается с ним в JSON, подчеркивая важность структуры заголовков (H1 → H2 → H3).
4. Классификация контента
Инструмент определяет типы контента: от heading-1 до heading-6, paragraph, header, footer и списки.
Различие между header и heading может указывать на разный вес элементов.
5. Структурированные данные неизменны
Таблицы и списки парсятся с сохранением структуры, включая объединенные ячейки и типы списков, что облегчает извлечение данных.
На основе работы парсера рекомендуются следующие практики технического SEO:
— Сокращайте HTML-раздутость: Уменьшайте пустые или лишние обертки (div) для оптимизации DOM.
— Приоритизируйте контент: Размещайте ключевой контент выше в DOM, минимизируя предшествующие навигационные элементы.
— Соблюдайте иерархию заголовков: Используйте заголовки последовательно для семантической структуры.
— Структурируйте данные: Применяйте списки и таблицы для упрощения извлечения. Пишите контент в виде независимых фрагментов для парсинга и ранжирования.
Важно понимать, что эксперимент проводился с Google Cloud Document AI, а не с краулером Google Поиска.
Влияние на ранжирование не подтверждено и требует дополнительных тестов.
Выводы поддерживают проверенные методы создания чистого, семантического и доступного HTML.
https://metehan.ai/blog/google-document-ai-layout-parser/
@
Читать полностью…
Mike Blazer
08 Jul 2025 20:15
LOL
@
Читать полностью…
Mike Blazer
08 Jul 2025 15:05
Мета-описание - идеальная метафора когнитивного искажения в SEO.
Верить в то, что оно имеет КАКОЙ-ЛИБО эффект - 100% суеверие.
1) Можно ранжироваться БЕЗ мета-деска
2) Он просто не требуется
3) Это не "доверенный" сигнал - это скрытое описание
4) Google настолько не доверяет ему, что переписывает его более чем в 70% случаев.
И всё же некоторые сеошники/продакт-менеджеры/копирайтеры говорят о нём так много, как будто это "скрытый источник" SEO...
Вы не можете мне сказать, что эти люди основывают свои выводы на науке, тестах, реальности...
-
НЕ игнорируйте мета-дескрипшн!
Дело не всегда в:
— Прямых факторах ранжирования
— Поисковой оптимизации
Вместе с тайтлами, мета-дескрипшн - это ваша первая коммуникация с потенциальными клиентами через поисковые системы.
Они дают обещание.
Они сообщают пользователям, что они могут ожидать найти.
В некоторых случаях они выступают как (дис)квалификаторы (помогают избежать нерелевантных кликов).
В других случаях они действуют как приманка ("бесплатная доставка").
Стоит ли в них инвестировать?
Если у вас нет более приоритетных задач (таких как улучшение релевантности и привлекательности тайтлов, разбор редиректов и т.д.) - то да!
Но они не помогают с ранжированием?
Нет - не напрямую.
Они не помогают уже много лет.
Но если учесть, что они действуют как аннотация на обложке книги, они:
— помогают части людей решить, стоит ли кликать на ваш листинг или нет
— формируют ожидания пользователя (психологическая составляющая удовлетворенности)
— могут помочь снизить возврат в СЕРПы/неудовлетворенность
... они, вероятно, играют косвенную роль.
Фокусируйтесь на целях!
Дело не в том, является ли это "фактором ранжирования" или помогает "генерировать трафик" и т.д.
Важно то, способствуют ли они достижению бизнес-цели.
Помогают ли они получать квалифицированный трафик, который конвертируется, жертвует, регистрируется, бронирует звонок и т.д.?
Помогают ли они влиять на восприятие людей?
Привлекают ли они внимание?
Но Google переписывает их!?
Иногда.
Это зависит от их релевантности (странице, запросу) и/или от того, насколько они неудачные/общие.
Значительный процент из "Гугж переписывает их более чем в 70% случаев" приходится на скучные, общие, перенасыщенные ключевыми словами, дублированные мета-дески!
Если вы инвестируете время/усилия и предоставляете релевантные (для страницы и основного запроса) описания, обычно Google будет использовать то, что вы предоставили.
Но если вы не уверены - удалите их.
Пусть Google заполнит их.
Отметьте, что создает Google для различных запросов.
Затем клонируйте, подкорректируйте и посмотрите, сможете ли вы получить лучший CTR.
@
Читать полностью…
Mike Blazer
08 Jul 2025 11:05
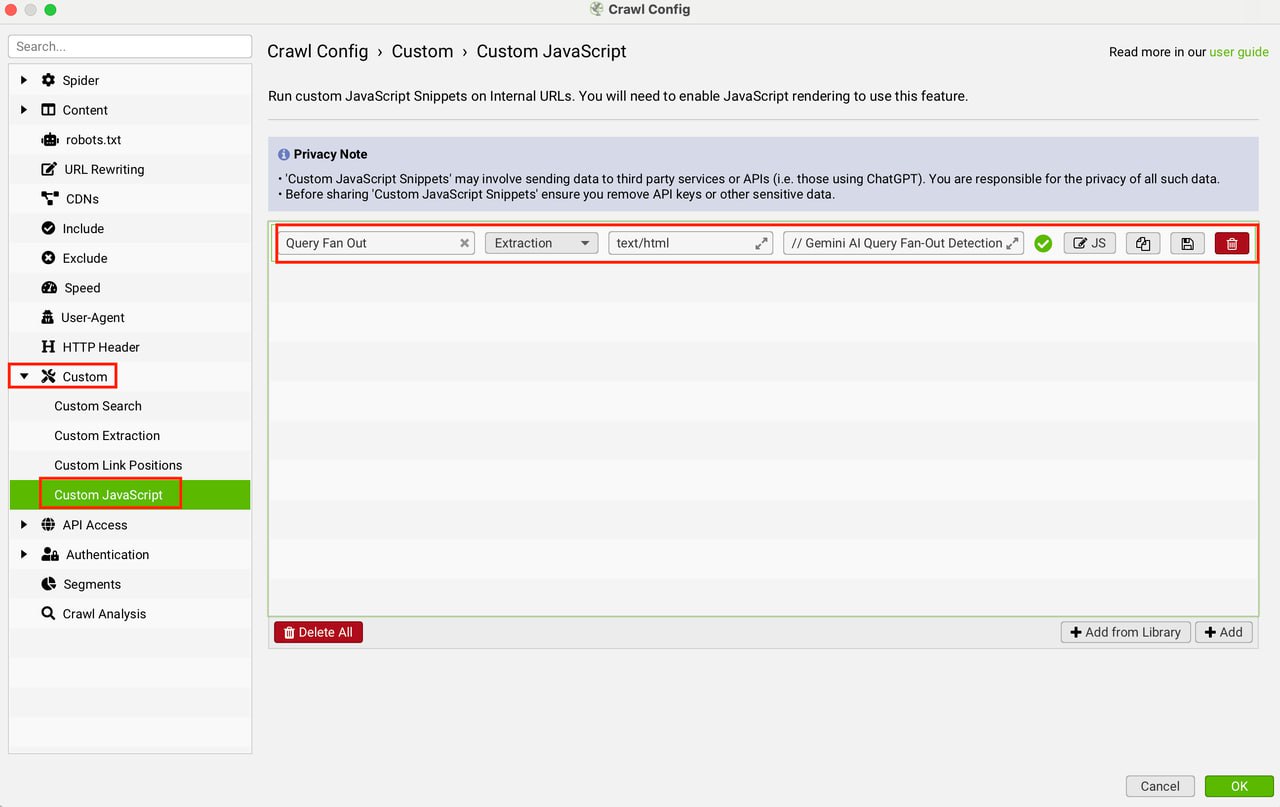
Анализ веерного расширения запросов (query fan-out) в режиме AI от Google с помощью Screaming Frog и Gemini AI
Кастомный JavaScript для Screaming Frog через API Gemini AI оценивает, насколько контент страницы покрывает подзапросы, генерируемые AI-режимом Google.
Анализ 2000+ страниц выявил, что большинство контента отвечает лишь на 30% прогнозируемых запросов, указывая на серьезные пробелы в оптимизации.
Выводы основаны на прогнозах моделей Gemini 1.5 Flash и 2.5 Pro.
Для больших краулов советуем использовать быструю модель Flash.
Оптимизация только на основе этого анализа может угрожать текущим позициям.
Необходимые условия:
— Screaming Frog с включенным рендерингом JavaScript.
— API-ключ Gemini.
— Кастомный скрипт доступен на GitHub.
В обновленной версии два варианта извлечения данных:
1. Только заголовки, элементы <ul>, и <ol>.
2. Необработанный контент из <body>.
Механизм веерного расширения запросов в AI-обзорах
Режим AI от Google разбивает тему на сеть подзапросов, ищет ответы в своем индексе.
Для запроса вроде "sustainable marketing strategies for e-commerce" создаются уточнения о бюджете, каналах, метриках и примерах.
Большинство контента не покрывает всю сеть подзапросов.
Функционал скрипта
Скрипт автоматизирует анализ через пять действий:
1. Извлечение семантических чанков: Сегментирует контент с учетом верстки, как Google Document AI.
2. Определение главной сущности: Выявляет основную тему страницы.
3. Прогноз веерных запросов: Создает 8–10 подзапросов, которые AI от Google мог бы сгенерировать.
4. Оценка покрытия: Проверяет ответы на запросы с оценками "Да", "Частично" или "Нет".
5. Уточняющие вопросы: Предсказывает следующие логичные вопросы пользователя.
Ключевые аналитические выводы
Есть связь между структурой контента и покрытием запросов:
— Страницы с глубокими деталями: Охватывают до 70% запросов. Например, страницы, имеющие 15 и более хорошо структурированных разделов, в среднем достигали покрытия 7 из 10.
— Тонкие страницы: Охватывают менее 20% из-за краткости. Например, страницы с менее чем 5 разделами в среднем показывали покрытие лишь 3 из 10, что указывает на серьезные пробелы.
— Частые упущения: Примеры, кейсы и узкие уточнения (метрики, бюджеты, конкретные стратегии).
Практическое применение
Настройка:
1. Настройте доступ к Gemini API с достаточным лимитом запросов.
2. В Screaming Frog выберите Configuration > Custom > Custom Javascript.
3. Добавьте скрипт и API-ключ.
4. Прокраульте ключевые страницы, выявляя те, где покрытие ниже 5/10, и повторяющиеся упущенные запросы.
Стратегия оптимизации:
— Сущностный подход: Составьте карту веток запросов от основной сущности.
— Фокус на покрытии: Оценивайте успех по охвату запросов, а не по ключевым словам.
— Семантический чанкинг: Структурируйте контент для парсинга ИИ-системами.
— Предвосхищение вопросов: Каждый раздел должен отвечать на текущий запрос и вести к следующему.
https://metehan.ai/blog/query-fan-out-screaming-frog-ai/
@
Читать полностью…
Mike Blazer
07 Jul 2025 20:08
SEOшники летом, когда разработчики в отпусках
@
Читать полностью…
Mike Blazer
07 Jul 2025 15:05
Инсайты о чанкинге и не только от Google
Вот несколько интересных цитат из документации Vertex AI:
— По умолчанию документы разбиваются на чанки с определенным перекрытием для повышения релевантности и качества поиска. Стандартное перекрытие чанков составляет 200 токенов.
— Когда документы добавляются в индекс, они разбиваются на чанки. Параметр chunk_size (в токенах) определяет размер чанка. Размер чанка по умолчанию — 1024 токена.
— Меньший размер чанка означает более точные эмбеддинги. Больший размер чанка означает, что эмбеддинги могут быть более общими, но могут упускать конкретные детали.
— layout parser извлекает из документа такие элементы контента, как текст, таблицы и списки. Затем layout parser создает контекстно-зависимые чанки, которые облегчают поиск информации в генеративном ИИ и поисковых приложениях.
— LLM parser, управляемый промптом, обращал внимание на структуру заголовков и мог извлекать всю релевантную информацию, связанную с определенной темой или разделом.
— Имейте в виду, что парсинг в значительной степени зависит от HTML-тегов, поэтому форматирование на основе CSS может не учитываться.
— Связь между сгенерированным контентом и grounding chunks. Это повторяющееся поле. Каждое поле grounding_supports показывает связь между одним текстовым сегментом сгенерированного контекста и одним или несколькими чанками, полученными с помощью RAG.
— Confidence Score: Оценка, которая используется для привязки текста к определенному чанку. Максимально возможная оценка — 1, и чем выше оценка, тем выше уровень уверенности. Каждая оценка соответствует каждому grounding_chunk_indices. В вывод включаются только чанки с confidence score не ниже 0.6.
Про ranking API:
— Набор записей, релевантных запросу. Записи предоставляются в виде массива объектов. Каждая запись может включать уникальный ID, заголовок и содержимое документа. Для каждой записи указывайте либо заголовок, либо содержимое, либо и то, и другое. Максимальное количество поддерживаемых токенов на запись зависит от используемой версии модели. Например, модели до версии 003 поддерживают 512 токенов, а версия 004 — 1024 токена. Если общая длина заголовка и содержимого превышает лимит токенов модели, лишний контент обрезается. Вы можете включать до 200 записей в одном запросе.
— Score: значение с плавающей точкой от 0 до 1, которое указывает на релевантность записи.
@
Читать полностью…
Mike Blazer
07 Jul 2025 11:05
Немного грустно видеть, как наша индустрия теряет почву под ногами.
SEO-шники метаются, как рыбы на суше.
Половина считает, что AIO/GEO/WhateverEO — это будущее.
Кто-то думает: "Мы вообще не понимаем, как сейчас работает SEO", и раз Гугл сплоховал с Github, то надо всё переосмысливать... бла-бла-бла — а другие ушли в SEX (Search Engine eXperience optimization — да ну, что бы это ни значило).
А ещё есть группа, которая наваливает на всех SEO-шников просто за то, что они SEO.
Что на самом деле изменилось?
Кратко:
— Реферальный трафик сейчас около 10–15% от того, что был в 2010 году.
В 2010-м по одному ключевику или качественной двухсловной фразе можно было получать от 15 000 до 30 000 рефералов в день из Google.
Те же ключи на прошлой неделе принесли примерно 200–300 (и это нам ещё повезло).
— Google — согласно их же докам — всё ещё в конце прошлого года использовал ключевые слова, PageRank и подсчёт кликов Navboost как основные ингредиенты алгоритма.
Позиции по топ-1 или топ-2 ключевым фразам практически не изменились.
В выдаче от двух лет назад почти тот же органический ранжинг (почти до URL), что и десять минут назад.
(единственное, что изменилось — это SOT (Slop on Top)) и увеличилось количество рекламы.
— ИИ никто публично не просил.
Фактически, легко найти десять негативных комментов про Google AI, тогда как положительные — надо поискать.
Всё остальное — это просто PR-монополия Google с пафосным спином.
Будьте реалистами: ИИ — это всего лишь повод для Google забрать себе большую долю.
Не долю поискового рынка, а долю всего интернета.
Они хотят всё.
Они — новый AOL.
Сейчас можно делать как минимум пару десятков вещей для генерации трафика — и ни одна из них не связана с SEO или Google.
Так что берите колу и расслабьтесь.
@
Читать полностью…
Mike Blazer
06 Jul 2025 15:35
🚨 Google только что снес 70% трафика некоторых веб-сайтов во время Июньского обновления
Я отслеживал последствия последнего основного апдейта Google, говорит Мохит Шарма, и результаты ЖЕСТОЧАЙШИЕ.
Вот что на самом деле происходит прямо сейчас:
ПОЛНЫЙ РАЗГРОМ:
📉 Сайты с контентом, сгенерированным ИИ: ПАДЕНИЕ НА 40-70%
📉 Страницы, переспамленные ключевыми словами: УНИЧТОЖЕНЫ
📉 Контент с "SEO-хаками": ИСЧЕЗ из выдачи
НО ПОГОДИТЕ… Некоторые сайты ПРОЦВЕТАЮТ:
📈 Контент, ориентированный на пользователя: РОСТ 150%+
📈 Экспертные гайды: ДОМИНИРУЮТ на первой странице
📈 Сайты с реальным E-A-T: СОКРУШАЮТ конкурентов
Вот неудобная правда: Если вы все еще занимаетесь SEO так, как в 2020, вы скоро останетесь за бортом.
Что РЕАЛЬНО работает прямо сейчас:
✅ Писать в первую очередь для людей, а во вторую — для поисковиков
✅ Нарабатывать реальную экспертность (а не просто делать "исследование ключевых слов")
✅ Создавать контент, который действительно решает проблемы
✅ Фокусироваться на пользовательском опыте, а не на "факторах ранжирования"
СУРОВАЯ РЕАЛЬНОСТЬ: Я только что провел аудит сайта клиента, который ПОЛУЧИЛ 200% ПРИРОСТА трафика во время этого апдейта. Хотите знать их секрет? Они перестали гоняться за алгоритмами и начали помогать своим клиентам.
👉 Мой прогноз: К 2026 году 80% существующих "SEO-стратегий" полностью устареют.
P.S. - Если ваш трафик упал, еще не поздно восстановиться. Но действовать нужно быстро.
@
Читать полностью…
Mike Blazer
06 Jul 2025 11:05
Утечка системного промпта ChatGPT 4o: влияние на SEO
Утекший в сеть внутренний системный промпт для ChatGPT 4o, датированный июнем 2025 года, которым поделился Джеймс Берри из LLMrefs, раскрывает, как модель использует и ограничивает веб-поиск.
Анализ промпта освещает конкретные условия активации веб-поиска и их влияние на SEO и видимость сайтов издателей.
1. Когда активируется веб-поиск?
Системный промпт разрешает использовать веб-инструмент при строгом соблюдении условий, указывая, что его следует применять для "доступа к актуальной информации из веба или когда для ответа требуются данные о местоположении".
Веб-поиск разрешен для:
— Событий в реальном времени или текущих событий (например, погода, спортивные результаты).
— Данных, привязанных к местоположению (например, местные компании).
— Нишевых тем, отсутствующих в обучающих данных.
— Случаев, когда устаревшая информация может нанести вред, например, использование устаревшей версии программной библиотеки.
Однако веб-поиск запрещен, если ChatGPT может ответить, основываясь на своих внутренних знаниях, за исключением случаев, когда пользователь запрашивает информацию из общедоступных источников.
В документе также отмечается, что старый инструмент browser устарел и отключен.
2. Как ChatGPT выполняет поиск, когда это разрешено?
Промпт подробно описывает технические параметры выполнения веб-поиска:
— Параллельные запросы: Генерирует до пяти уникальных поисковых запросов одновременно.
— Усиление терминов: Использует оператор "+" для приоритизации ключевых терминов.
— Контроль свежести: Применяет параметр --QDF со значением от 0 (без привязки ко времени) до 5 (критически важно по времени), чтобы отдавать предпочтение свежему контенту.
— Многоязычный поиск: Для запросов не на английском языке поиск выполняется как на языке оригинала, так и на английском.
*Примечание: Утечка описывает эти механизмы формирования запросов, но не подтверждает их последовательное применение к публичному веб-поиску.*
3. Что в промпте говорится о ссылках и видимости источников
Документ не содержит доказательств того, что ChatGPT хранит URL-адреса или поддерживает постоянный веб-индекс.
Ссылки появляются в ответах только в результате поиска в реальном времени.
Таким образом, видимость сайта в ChatGPT — редкое явление.
Для SEO это означает, что если сайт не ранжируется в результатах поиска Bing в реальном времени в момент выполнения поиска, маловероятно, что он будет процитирован.
4. Вывод: редкий поиск означает редкие ссылки
Утечка данных о ChatGPT 4o согласуется с выводами из предыдущей утечки системного промпта Claude: LLM используют поиск в реальном времени только при крайней необходимости, в основном полагаясь на внутренние знания.
В отличие от поисковых систем, у LLM отсутствует индекс URL-адресов, по которому можно делать запросы.
Ссылки из базы знаний модели часто являются вероятностными, что приводит к появлению неработающих или вымышленных URL.
Надежные ссылки, как правило, появляются только в результате поиска в реальном времени.
Это ограничивает реферальный потенциал.
Анализ SISTRIX показывает, что ChatGPT ссылается на внешние источники лишь в 6.3% ответов, по сравнению с 23% у Gemini и средним показателем по отрасли в 13.95%.
Для SEO-специалистов это означает:
— Не стоит ожидать постоянного трафика или ссылок от ChatGPT.
— Видимость зависит от ранжирования в результатах поиска в реальном времени в те редкие моменты, когда запускается живой поиск.
— Большинство ответов ИИ не дают шанса на цитирование вашего сайта.
https://gpt-insights.de/ai-insights/chatgpt-leak-web-search-en/
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}