Mike Blazer
28 Jun 2025 12:15
Просто поищите OPENAI_API_KEY на GitHub.
Не благодарите.
@
Читать полностью…
Mike Blazer
27 Jun 2025 17:05
Переезд сайта согласно фэн-шуй
@
Читать полностью…
Mike Blazer
27 Jun 2025 13:10
Интенсив по генережке контента
@
Читать полностью…
Mike Blazer
27 Jun 2025 08:15
В инструментах GSC URL Inspector и Rich Results Test возникла потенциальная проблема с обработкой юзер-агентов и IP-адресов.
Недавние тесты показывают:
— Иногда эти инструменты сканируют страницы как Googlebot, а иногда как Google-InspectionTool.
— Блокировка доступа по IP-адресу или юзер-агенту для "запускаемых пользователем" краулеров НЕ всегда предотвращает доступ инструмента Rich Snippet к полному (незащищенному платной стеной) контенту.
Почему это важно?
Раньше издатели могли открывать доступ к определённому контенту только для Googlebot (для индексации/сниппетов), не раскрывая paywall-контент для всех.
Теперь же, с текущим поведением, любой пользователь, кто запускает инструмент проверки Rich Snippet, возможно, сможет увидеть paywall-контент, что фактически обесценивает подобную защиту.
@
Читать полностью…
Mike Blazer
26 Jun 2025 17:05
Бесплатная электронная книга:
Entity SEO: Moving from Strings to Things
Зачем ее автор Диксон Джонс решил сделать ее бесплатной, читайте тут.
@
Читать полностью…
Mike Blazer
26 Jun 2025 13:10
Как мы использовали Power Hubs, чтобы увеличить трафик сайта на 61% за 6 месяцев, автор — Мэтт Диггити
Не обязательно быть Forbes или Healthline, чтобы доминировать в СЕРПах.
Организация контента по их образцу творит чудеса.
Используя "Power Hubs", мы увеличили трафик на сайте в нише здоровья на 61% за 6 месяцев, подняв количество ранжирующихся ключей с 1 405 до 2 288. Вы тоже сможете добиться похожих результатов, даже если у вас нет домена с DR90.
Power Hubs — это тематические кластеры контента, стратегически связанные между собой для создания тематического авторитета в Google.
Структура включает одну страницу-столп по широкой теме, от 4 до 8 кластерных страниц по подтемам и продуманную внутреннюю перелинковку.
Такое построение сигнализирует Google о полном охвате темы, позволяя ранжироваться по в 5-10 раз большему количеству ключей, удерживать пользователей дольше, создавать несколько точек входа в контент и снижать риски от обновлений алгоритмов.
Шаг 1. Поиск темы для страницы-столпа
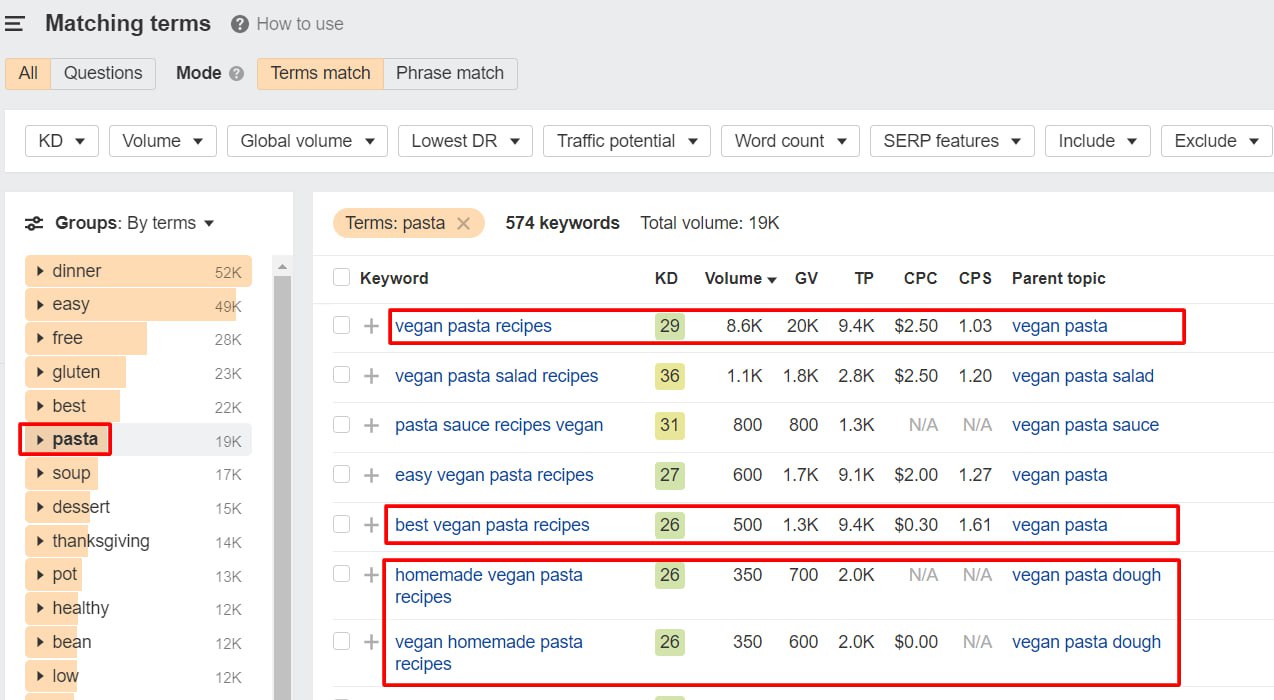
В Ahrefs Keywords Explorer вводим широкий нишевой запрос, например "vitamin d" или "probiotics".
После выбора гео анализируем "Keyword Ideas" в разделе "Terms match" и применяем фильтр "Group by terms".
Так находим кластеры ключей, подходящих для темы-столпа.
Для сайта о здоровье, например, "vegan recipes" выявил "vegan pasta recipes" как классный вариант за счёт большого волюма, вариаций и смешанного интента, в отличие от слишком общей "pasta".
Шаг 2. Определяем кластерные темы
С помощью ключа страницы-столпа, например "vegan pasta recipes", снова в Ahrefs смотрим отчёт Terms Match.
Там появляются подтемы типа "vegan pasta salad recipes", "pasta sauce recipes vegan", "vegan pasta dough recipes".
Эти подтемы становятся основой для кластерных страниц.
Выбираем 4-8 таких тем и копаем глубже, чтобы найти дополнительные ключи для каждой страницы.
Шаг 3. Создаём страницу-столп — ядро Power Hub
Она должна всесторонне раскрывать тему, ссылаться на все кластерные страницы, таргетить основные ключи и вариации, иметь оглавление и давать самостоятельную ценность.
Делаю анализ ТОПа Google по ключу — смотрю подзаголовки, часто задаваемые вопросы, форматы контента и пробелы.
Моя страница-столп превосходит конкурентов: добавляю крутые визуалы, уникальные инсайты, полезные гайды для скачивания, удобную структуру и ответы на неудовлетворённые вопросы.
Шаг 4. Пишем кластерный контент
Каждая такая страница граничит с отдельной подтемой, например "vegan pasta salad recipes", исследуется по тому же принципу.
Покрываем ключевые вариации, делаем глубже, чем у конкурентов, и ссылаемся обратно на страницу-столп.
Пока страница-столп даёт обзор, кластерные дают экспертную глубину — такой баланс Google любит видеть для хороших позиций.
Шаг 5. Важнейшая внутренняя перелинковка
Здесь многие проседают.
Схема чёткая: страница-столп ссылается на все кластеры, кластеры обратно на столп, кластерные страницы между собой линкуются по смыслу, а существующие страницы сайта ведут на обе.
Использую якоря с ключевыми словами от столпа к кластерам и более общие якоря от кластеров к столпу, меняя их естественно для семантической релевантности.
Совет: если на существующих страницах есть хорошие бэклинки или трафик, добавьте контекстные ссылки на Power Hub — это передаст им вес и ускорит рост позиций.
@
Читать полностью…
Mike Blazer
26 Jun 2025 08:15
Стоит ли блокировать бот google-extended?
ОТВЕТ: Скорее всего, нет.
Если вы это сделаете, то не сможете участвовать в Grounded Search.
ЧТО ТАКОЕ GOOGLE-EXTENDED?
— Это бот, который теперь есть в официальном списке краулеров Google
— Это не бот в привычном нам понимании.
— У него нет отдельной строки user agent в HTTP-запросе.
— Краулинг происходит с использованием существующих user agent'ов Google.
— Это директива user-agent, которую можно использовать в robots.txt, чтобы разрешить или запретить использование вашего контента для обучения будущих поколений моделей Gemini. Эти модели лежат в основе приложений Gemini, Vertex AI API for Gemini и для "заземления" (grounding).
— Блокировка Google-Extended НЕ является фактором ранжирования.
— Блокировка Google-Extended НЕ повлияет на попадание страниц в индекс Google Search.
ЧТО ТАКОЕ ЗАЗЕМЛЕНИЕ
— На самом деле, это широкий термин, а не только гугловский.
— Это способ "привязать" LLM к реальным источникам при генерации ответа.
— Вместо того чтобы "галлюцинировать", модель в реальном времени обращается к набору проверенного и достоверного контента — вашему сайту, страницам продуктов, документации.
— Заземление делает ответы модели более точными и обоснованными.
— Если вы не участвуете в заземлении, то вас просто нет в игре, когда клиенты задают вопросы в Gemini.
ПРИМЕРЫ ПРИЧИН, ПО КОТОРЫМ ВАШ САЙТ МОЖЕТ НЕ ПОПАСТЬ В ЗАЗЕМЛЕНИЕ:
— Запрет в robots.txt
— Низкокачественный контент
— Вы не входите в набор данных, на котором дообучалась модель для заземления.
— LLM не знают о вашем сайте/бренде.
ВАЖНО ЗНАТЬ:
Даже если ваш сайт проиндексирован в Google Поиске, Gemini может не "видеть" его или не отдавать ему предпочтение на уровне заземления.
Блокировка Google-Extended — это не блокировка бота.
Вы блокируете разрешение на использование контента.
@
Читать полностью…
Mike Blazer
25 Jun 2025 15:05
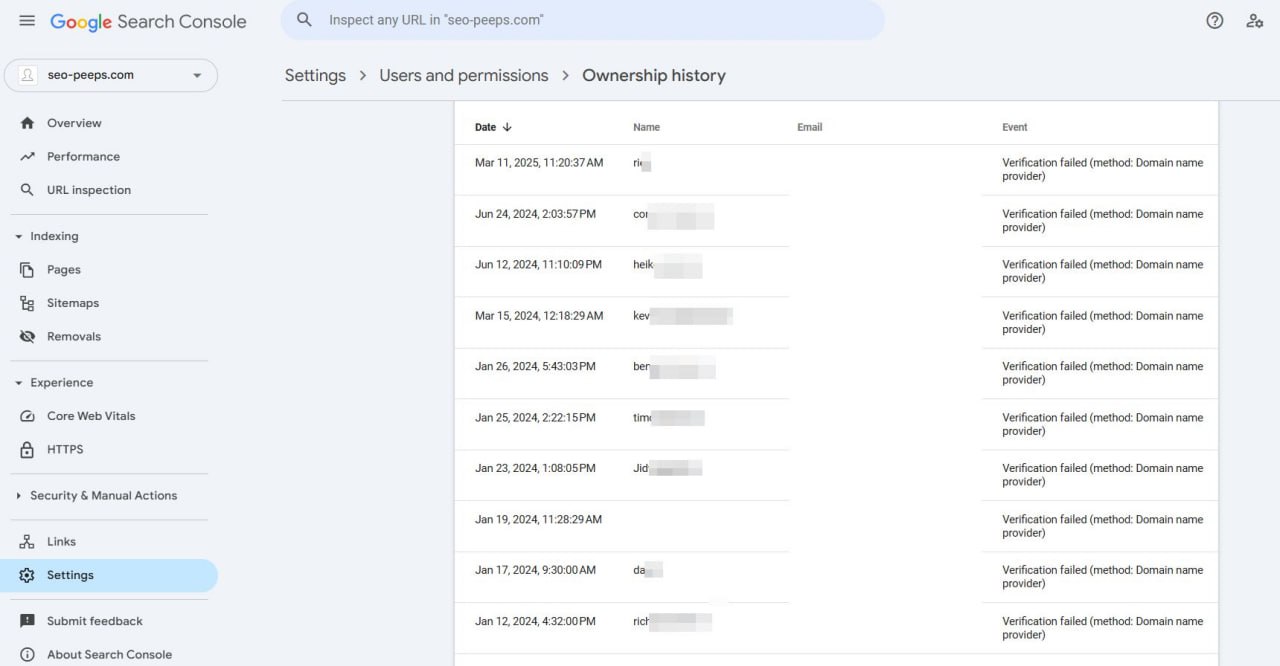
Знаете ли вы, что можно увидеть, кто пытался получить доступ к вашему аккаунту Google Search Console?
Коллега?
Стажер?
А может быть конкурент?
На что только не пойдут люди... 😅
@
Читать полностью…
Mike Blazer
25 Jun 2025 11:05
Этот партнерский сайт жестоко ушатало августовским апдейтом в прошлом году. Они наняли меня для аудита и восстановления сайта, и на онбординг-колле я дал им свой главный совет: КЛОАЧЬТЕ ПАРТНЕРСКИЕ ССЫЛКИ!
С тех пор, как они это внедрили, они восстановили почти 50% трафика, который был до падения, а я ведь еще даже не приступал к остальным исправлениям, изменениям и улучшениям по OnPage, техничке, ссылочному профилю и сущностям, над которыми мы будем работать...
Сайт пока что возвращает лишь часть потерянного трафика, но я собираюсь составить им план по полному захвату их ниши, и действовать мы будем жестко 😈
Гугл ненавидит сеошников, работающих с партнерками, и целенаправленно бьет по ним уже добрый десяток лет...
И есть множество способов, которыми они по нам бьют.
Я больше не полагаюсь на контент в партнерском SEO, в общем-то, совсем, — говорит Чарльз Флоут.
Я реверсирую сигналы на каждом уровне:
— Структура ссылок
— Паттерны брендовых сущностей
— Архитектура и краулинговый бюджет
— Частота публикаций и свежесть контента
— Консенсус, микроразметка, микроданные и т.д.
— Общесайтовые сигналы качества и траста (Q*/T*)
Сайт истекал кровью, потому что паттерн партнерских ссылок был жестко зашит в HCU-классификаторы. Дело было не в "трасте" или "E-E-A-T", или в том бреде, который изрыгает SEO-блогосфера... Дело было в сигналах, которые Гугл мог изолировать и снести под ноль, не рискуя при этом другими сайтами или индустриями.
И как только ты понимаешь, как они охотятся, ты понимаешь, как нужно обфусцировать...
Теперь сайт вернулся к тому состоянию, когда Гугл больше не может с уверенностью наложить санкции за партнерки, и это мы только разогреваемся.
@
Читать полностью…
Mike Blazer
24 Jun 2025 18:30
Если бы усердный труд приводил к успеху, то ферма принадлежала бы ослу.
@
Читать полностью…
Mike Blazer
24 Jun 2025 15:05
Для полноценной и прибыльной карьеры SEO-специалистам необходимы 5 основных компетенций.
Каждый навык имеет решающее значение.
Вы не можете быть сильны только в четырех.
Вы должны быть сильны во всех из них.
Развивая все пять, вы станете ценным активом для любой организации.
Вот их распределение:
1️⃣ Коммуникация: Овладение навыками внутреннего согласования, межфункционального сотрудничества и внешнего общения для создания влияния и привлечения лучших талантов.
2️⃣ Обучение: Адаптивность, умение эффективно фильтровать информацию и быть в курсе отраслевых тенденций.
3️⃣ Бизнес-чуйка: Согласование SEO с бизнес-целями, стратегическое планирование и демонстрация окупаемости инвестиций путем целенаправленного выполнения.
4️⃣ Техничность: Использование автоматизации, анализа данных и глубокого технического понимания для достижения эффективных результатов, основанных на данных.
5️⃣ Лидерство: Пропаганда SEO, создание высокоэффективных команд и налаживание прочных отношений в организации.
Эти компетенции взаимосвязаны.
Сильная коммуникация способствует эффективному лидерству, а деловая хватка - стратегическому планированию.
Как вы оцениваете эти поднавыки?
@
Читать полностью…
Mike Blazer
24 Jun 2025 11:05
✓ 23-пунктный чек-лист для оптимизации контента с помощью GenAI
Вот базовый чек-лист, который поможет оптимизировать контент для поиска фрагментов с помощью ИИ и того, как такие системы, как ChatGPT, Claude и Perplexity, находят, разбивают на фрагменты, цитируют и упоминают ваш контент.
Обратите внимание, что все это направлено на снижение когнитивной нагрузки и трения между людьми и машинами.
✓ Разбиение на фрагменты — каждый абзац фокусируется на одной основной идее
✓ Избегайте неопределенных формулировок — удалите "может быть", "возможно", "по-видимому"
✓ Оптимизируйте плотность абзацев — разбивайте плотные блоки, делайте абзацы легкими для восприятия
✓ Маркированные списки и числовые списки — используйте структурированное форматирование, если это улучшает ясность
✓ Избегайте избыточности — поддерживайте ключевые термины с помощью синонимов и терминов LSI для векторизации
✓ Ясность сущностей — замените неопределенности и жаргон на четкие понятия
✓ Несоответствие модификатора и намерения — соотносите технические детали с намерением и точками карты путешествия
✓ Сигналы когнитивной нагрузки — структурируйте контент для уменьшения трения при чтении и поиске
✓ Семантический дрейф — удалите отклонения от темы, которые снижают чистоту фрагментов
✓ Уверенность в поиске — используйте четкие атрибуции, избегайте формулировок типа "Говорят, что...".
✓ Ошибки в согласованности встраивания — не смешивайте инструкции и мнения в одном абзаце.
✓ Последовательность и иерархия заголовков — используйте правильную структуру H1/H2/H3 и проверяйте последовательность и релевантность информации.
✓ Длина абзацев — старайтесь, чтобы абзацы естественным образом не превышали +/- 100 слов
✓ Отсутствие структурированных форматов — используйте таблицы для сравнений, списки для процессов
✓ Избыточное использование ключевых слов или повторения — избегайте чрезмерных повторений, используйте естественный язык
✓ Отсутствие синонимов и вариантов использования — используйте несколько способов выражения ключевых концепций
✓ Пропуск именованных сущностей — указывайте бренды, инструменты, версии с учетом контекста
✓ Согласование контента с макро- и микро-намерениями
✓ Нарушение ясности (переизбыток умных выражений) — заменяйте метафоры буквальным языком
✓ Устранение неоднозначности — добавьте контекст для неоднозначных терминов
✓ Оптимизация плотности токенов — цель: 75–400 токенов на фрагмент
✓ Соответствие заголовков шаблонам запросов — пишите заголовки, отражающие естественные поисковые запросы
✓ Сделайте абзацы тематически самодостаточными
@
Читать полностью…
Mike Blazer
23 Jun 2025 17:05
При оптимизации под AI-поиск избегайте тем, которые относятся к общеизвестным или устоявшимся сведениям.
Утечка данных из Claude AI показала, что существует команда never_search для информации, не теряющей актуальности, фундаментальных концепций или общеизвестных фактов.
В частности, Claude не будет выполнять поиск в вебе и ссылаться на источники по фактам, которые "не теряют актуальности со временем или являются стабильными".
Можно предположить, что и другие LLM следуют аналогичной команде.
Это не означает, что вся верхняя часть воронки бесполезна.
Однако контент, написанный под копирку, без свежего взгляда и с пережевыванием одних и тех же идей, вознаграждаться не будет.
Это тревожный звоночек для ленивого контент-маркетинга.
Добро пожаловать в эпоху ИИ, где ценность публикации страниц с общеизвестными знаниями равна нулю.
@
Читать полностью…
Mike Blazer
23 Jun 2025 13:10
В ближайшие 3 года ИИ убьет "информационный контент" как маркетинговую стратегию.
🪦 ...и, честно говоря, я этому чертовски рад, — пишет Тим Соуло.
Потому что что такое типичная стратегия работы с "информационным контентом"?
1. Взять популярный ключ.
2. Посмотреть, кто по нему сидит в топ-10.
3. Заплатить рандомному копирайтеру, чтобы он написал "более глубокую" статью.
4. Купить ссылок, чтобы впарить Гуглу, что твоя страница лучше других.
🤮
^ тысячи сайтов заваливали интернет практически одинаковым контентом на одни и те же темы.
В этой гонке за доминирование в выдаче Google со своей (шаблонной) страницей не создавалось абсолютно никакой новой информации.
И тогда в Google подумали:
"Раз все эти сайты, по сути, воруют контент друг у друга и переписывают его, не добавляя ничего оригинального, — почему бы нам просто не считать эту информацию ОБЩЕИЗВЕСТНОЙ и не выдавать мгновенный ответ с помощью ИИ, не ссылаясь ни на кого?"
Гениально!
Теперь нет никакого смысла создавать 389-е по счету "Полное руководство по _____".
Потому что, скорее всего, вам нечего добавить к "общеизвестным фактам" на эту тему.
Мы вступаем в эру ОРИГИНАЛЬНОГО КОНТЕНТА!
Нечего сказать нового — не жмите "Опубликовать". 🤷
...
Вот две очень важные концепции, которые помогут вам ориентироваться в этом новом мире, где доминирует ИИ:
1. "Спрос создал не Google. Спрос создал кто-то другой". © Рэнд Фишкин
Если не хотите стать невостребованным маркетологом в ближайшие несколько лет — вам придется научиться создавать спрос, а не просто его удовлетворять.
2. 45.7% всех запросов в Google — брендовые!
(согласно исследованию Ahrefs)
Создание бренда (т.е. формирование аудитории, которая вас знает, следит за вами и доверяет вам) становится критически важным на перспективу.
Потому что, когда у вас есть сильный бренд и большая аудитория, — создавать спрос (и удовлетворять его) становится намного проще.
…
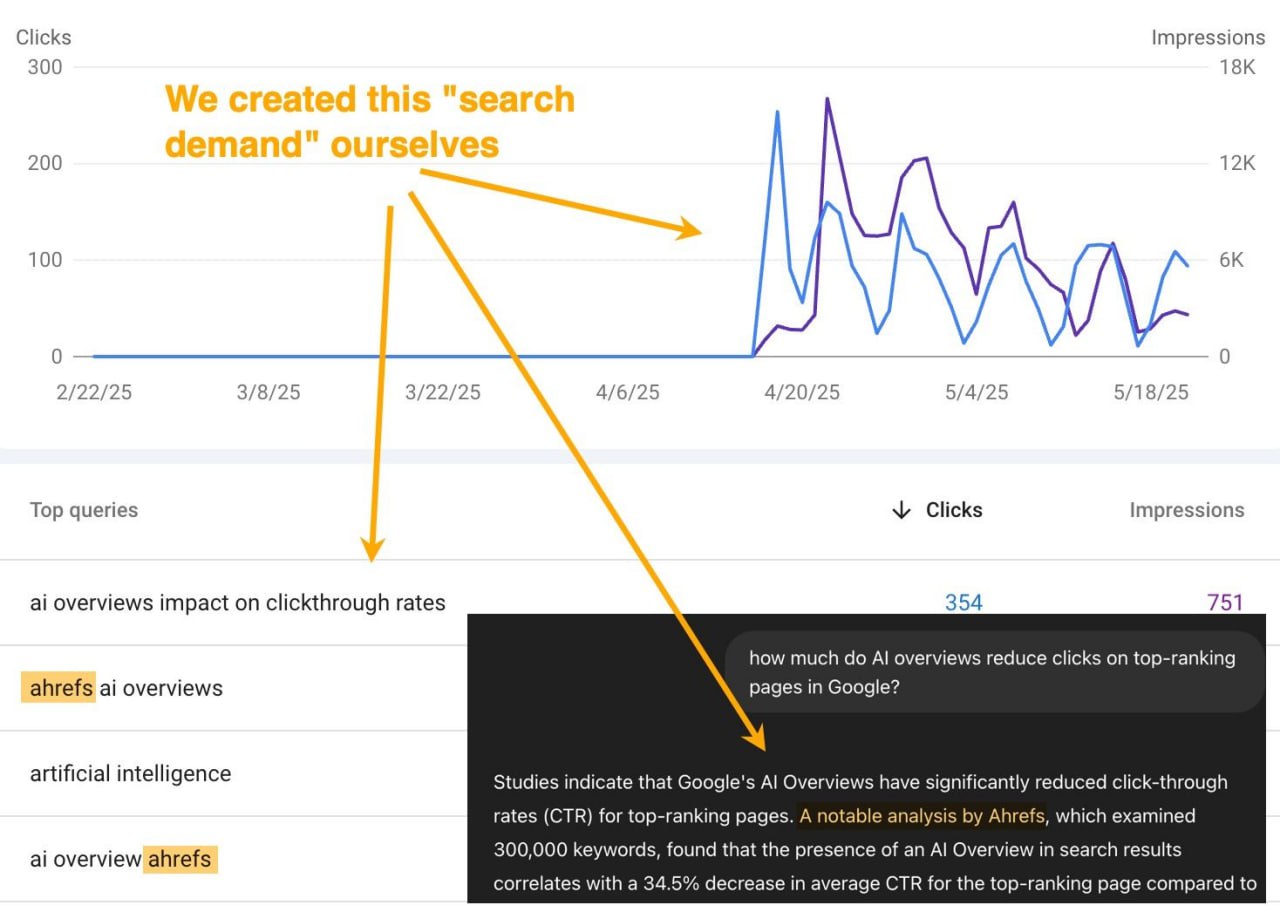
Наглядный пример:
Прикрепляю скриншот поискового трафика, который мы получили в блог Ahrefs после публикации и продвижения (!!!) исследования о том, как AI Overviews снижают количество кликов.
@
Читать полностью…
Mike Blazer
23 Jun 2025 08:15
Вот как можно извлечь поисковые промты Gemini
🔍 Проанализировав поисковое поведение ChatGPT, я заинтересовался Gemini, — говорит Дэвид.
Можно ли обнаружить похожие паттерны?
Ответ: да!
Я ввел тот же поисковый запрос — "Latest news" — поскольку он обычно запускает поиск в вебе.
Затем я открыл DevTools → Network и нашел запрос, который готовит ответ Gemini, — включая все URL-источники, которые он рассматривал.
💡Самое интересное (что я чуть не упустил):
В конце есть раздел с меткой "Google Search".
Там можно увидеть реальные поисковые промты, сгенерированные Gemini, например:
➡️ What are today's top news stories in Germany?
➡️ Latest news Germany?
➡️ Any good news in the world?
➡️ Is Good News free?
➡️ Why no new news on Google?
Чуть ниже есть даже инструкция искать на территории Германии.
🎯 Это дает нам прямое представление о внутренней логике поиска Gemini.
🧠 Кто первым создаст букмарклет, который будет автоматически все это извлекать?
@
Читать полностью…
Mike Blazer
28 Jun 2025 09:15
Мюллер говорит, что Indexing API никак не реагирует на урлы, не являющиеся вакансиями и лайв трансляциями.
@
Читать полностью…
Mike Blazer
27 Jun 2025 15:05
docs.new, sheet.new .... и теперь videos.new видео-генератор теперь часть Google Docs.
@
Читать полностью…
Mike Blazer
27 Jun 2025 11:05
Похоже, фраза "Просто перепиши ИИ-контент" — это новое "А можешь сделать для портфолио?"
Недавно со мной связался потенциальный клиент, который очень хотел поработать вместе.
Они хотели, чтобы я писала для них статьи в блог объемом 1500 слов, и попросили назвать свою цену.
Я назвала, пишет Комал Билал.
(Цена рыночная. Ничего заоблачного. Без продажи почки.)
Их ответ?
"О, но мы будем генерировать контент с помощью ИИ...
Вам нужно будет его просто переписать".
Ах, ну конечно.
Как я могла забыть золотое правило фриланса:
Если сомневаешься, можешь обесценить навык, который ты, собственно, и аутсорсишь.
Давайте разберем по полочкам:
— Вы хотите контент профессионального уровня.
— Вы генерируете сырой черновик с помощью ИИ.
— Вы ожидаете, что кто-то добавит в него немного человеческой магии, изменит структуру, проверит факты, сделает так, чтобы текст не звучал, будто его написал тостер...
Но при этом вы хотите платить полцены, потому что "ИИ уже сделал большую часть работы".
Друзья, использовать ИИ для создания контента — это как заказать замороженную пиццу и попросить шеф-повара ее "просто испечь", а потом ожидать, что он выставит вам счет как в Domino's.
Спойлер: рерайтинг ИИ-контента — это не меньше работы.
Часто даже больше.
Потому что теперь мне еще и приходится разгребать последствия галлюцинаций ChatGPT.
Райтеры, не бойтесь брать деньги за обдумывание, редактуру, полировку и, да, — за рерайтинг.
Клиенты, если вы цените голос своего бренда, пожалуйста, поймите: ИИ — это инструмент.
А не гострайтер.
А теперь, если позволите, я пойду "просто переписывать" кучу сгенерированных машиной абзацев во что-то, что звучит так, будто это написал человек, который не забыл выпить кофе.
@
Читать полностью…
Mike Blazer
26 Jun 2025 20:57
Думал, что посты на этой неделе самое дно, вообще толкового ничего нет. Но вроде терпимо, заходят с пол хрена ))
@
Читать полностью…
Mike Blazer
26 Jun 2025 15:05
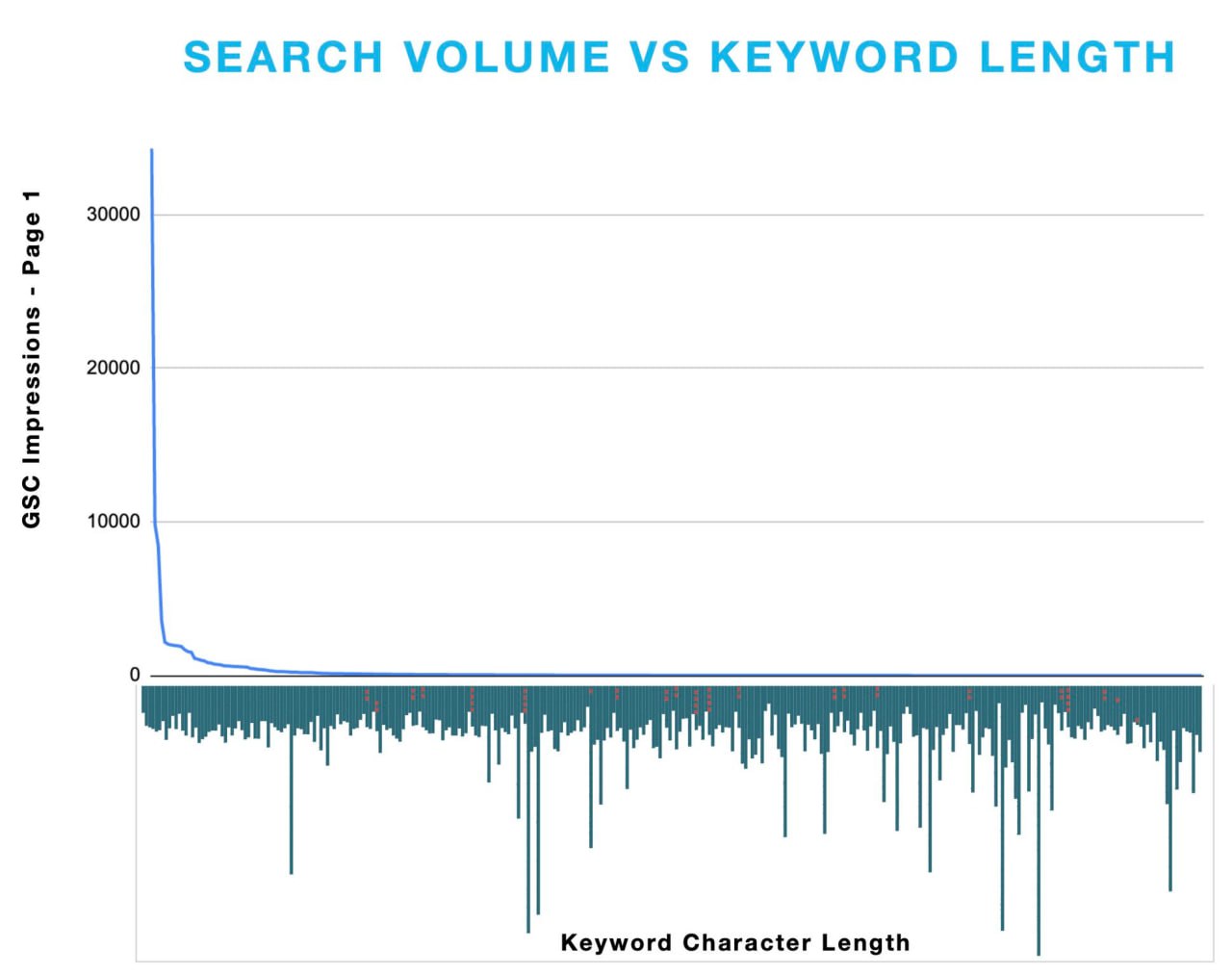
Длинный хвост (лонг-тейл) — это на самом деле не про "больше слов".
Буквально это значит "менее популярные запросы".
Этот термин связан с объемом поиска, а не с количеством символов или слов в фразе.
Как видно на этом графике, длина запроса не меняется по мере продвижения вглубь графика.
https://terakeet.com/blog/long-tail-keywords/
@
Читать полностью…
Mike Blazer
26 Jun 2025 11:05
Согласно недавнему исследованию Profound, ChatGPT во многом полагается на Википедию.
Но для менее "известных" компаний может быть сложно получить страницу в Википедии.
Зато несложно создать ЧЕРНОВИК страницы в Википедии.
@
Читать полностью…
Mike Blazer
25 Jun 2025 17:05
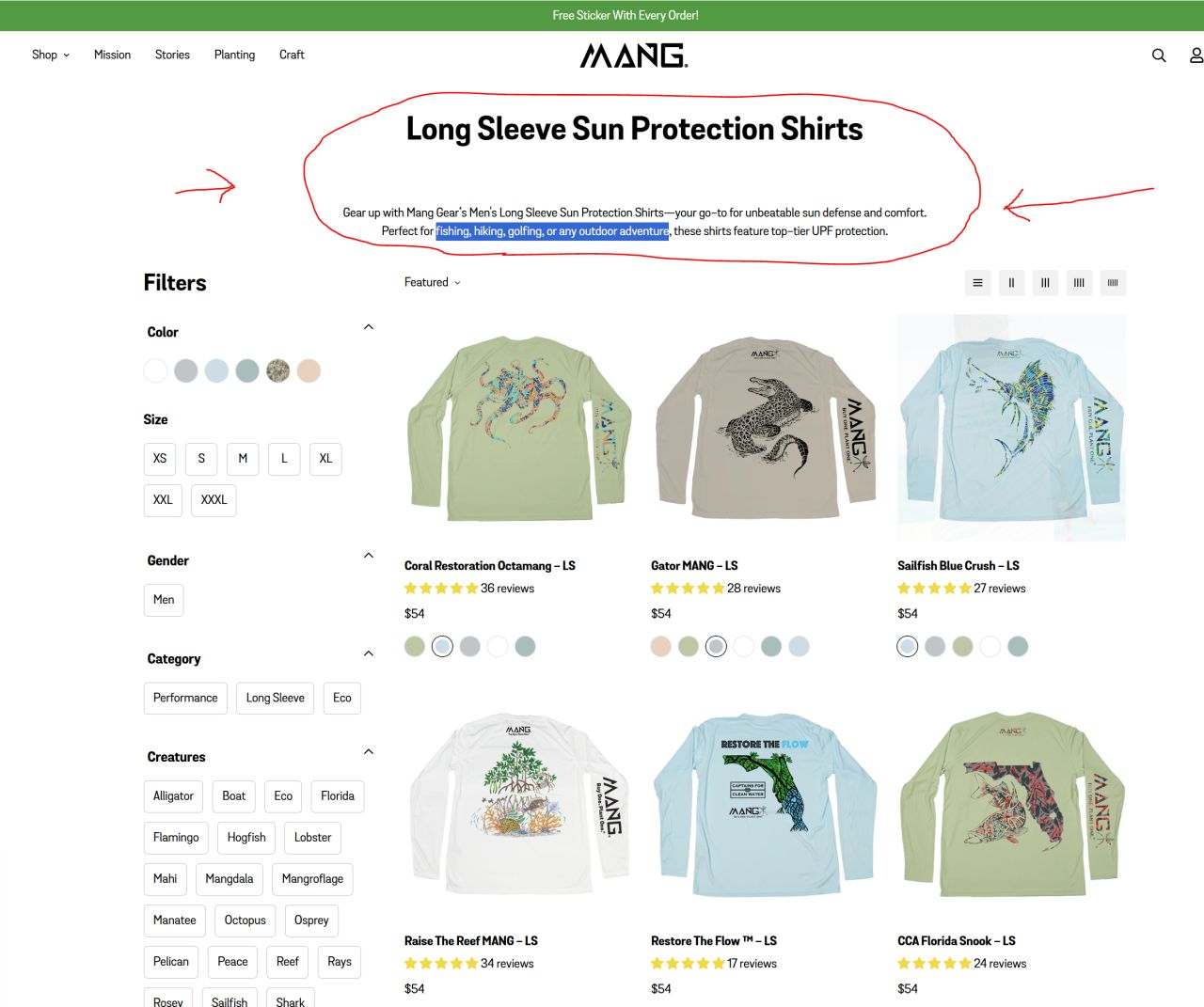
MANG полностью изменили структуру своего трафика менее чем за 12 месяцев.
До: Во всем доминировал брендовый поиск.
После: Органический поиск стал их каналом #1.
Вот как они этого добились:
Этап 1: Контент для верха воронки
Они начали с таргетированных постов в блоге под ключевые слова с низкой конкуренцией... и успели набрать начальный рост трафика до того, как AI-сниппеты захватили выдачу.
Этап 2: Оптимизация страниц категорий
Когда Google изменил правила игры, они адаптировались.
Сфокусировались на страницах для низа воронки, которые приносят конверсии.
Этап 3: Стратегическое расширение
Добавили страницы категорий, нацеленные на чуть более конкурентные ключевые слова.
Начали получать качественные бэклинки с более авторитетных источников.
Сейчас у них на 30% больше органического трафика, чем в их самый лучший месяц за все время → и это только май.
Большинство брендов сдались бы, когда AI-сниппеты убили трафик из их блога.
Вместо этого MANG переключились на страницы категорий.
Теперь органический поиск помогает им держаться на плаву во время экономических трудностей, в то время как конкуренты полностью отказываются от SEO.
@
Читать полностью…
Mike Blazer
25 Jun 2025 13:10
Небольшой совет по бренд-менеджменту в эпоху LLM: если у вашей компании нет прозрачного ценообразования, генеративному ИИ все равно.
Он найдет лучший ответ из доступных, и этот ответ может "заякорить" ваших потенциальных клиентов на неверной, и притом гораздо более низкой, цене.
Зайдите в ChatGPT и AI-режим Google и спросите: "how much does [company name] cost?".
Посмотрите, что он ответит и на какие страницы сошлется.
Если ответ неправильный, свяжитесь с сайтами, которые подтягиваются в ответ, и попробуйте договориться, чтобы они обновили информацию о ваших ценах.
Вот пара примеров с Clari и Benchling, где низкокачественные агрегаторы или даже конкуренты(!!!) напрямую влияют на ответы LLM по запросам о ценах...
Такое... и это то, за чем маркетологам придется следить.
@
Читать полностью…
Mike Blazer
25 Jun 2025 08:15
Раньше любой дроп-домен с высоким авторитетом работал, независимо от его первоначальной тематики.
Теперь это не так.
Сейчас Google анализирует семантическую релевантность и исторический анкорный профиль дроп-домена.
Например дроп в автомобильной тематики, и у него большинство обратных ссылок имеют анкоры вроде "autos in Mexico" или "autos in Costa Rica".
Если затем средиректить этот домен на партнерскую страницу казино, Google увидит полное несоответствие между старой тематикой (автомобили) и новой (гемблинг).
Этот метод больше не работает.
Google обесценит или полностью проигнорирует редирект, потому что тематики слишком разные.
Ключ к тому, чтобы эта тактика сработала, — найти дропы определенного типа.
Самыми ценными и эффективными дропами для редиректов являются те, в чьем ссылочном профиле преобладают брендовые анкоры.
Название бренда семантически нейтрально.
В отличие от анкора, насыщенного ключевыми словами ("autos in Mexico"), брендовый анкор ("MegaCorp Inc.") не привязывает домен к конкретной тематике.
Из-за этого Гуглу сложно точно понять, есть ли несоответствие с новым контентом.
Поскольку название бренда неоднозначно, вы можете средиректить домен на новый сайт практически любой тематики, не активируя фильтры Google за семантическое несоответствие.
Авторитет передается чище, потому что Google не может легко доказать, что редирект тематически нерелевантен.
@
Читать полностью…
Mike Blazer
24 Jun 2025 17:05
Введение Google текстовых фрагментов, заметных в URL с #:~:text=, открывает новый способ получения инсайтов, особенно в эпоху AIO сниппетов, где Google чаще ссылается на такие фрагменты.
Эти клиентские фрагменты, которые выделяют определённый текст на странице, могут предоставить реферальные данные даже тогда, когда серверные логи или GA4 ничего не показывают.
Поскольку они являются конструкцией на стороне браузера, для их отслеживания нужен JavaScript, а не серверные хаки.
Кастомный метод трекинга заключается в добавлении JS-сниппета в хедер сайта, который захватывает хэш в URL и передаёт его в логирующий скрипт.
Анализ логов показывает временные метки с зафиксированными фрагментами.
Обработка этих логов на предмет повторяющихся паттернов выявляет разделы контента с высоким интересом.
Эти данные помогают в оптимизации контента — показывают, какой текст стоит расширить, выявляют ключевики, по которым вас находят, и помогают анализировать поведение пользователей для улучшения сайта и внутренней перелинковки.
Хотя Google Analytics перестал показывать данные о фрагментах в мае 2021 года, кастомная реализация позволяет их отслеживать.
Это многоступенчатый процесс с использованием Google Tag Manager и GA4.
— Сначала создаётся кастомная JavaScript-переменная в GTM, которая вытаскивает текстовый фрагмент из URL.
— Затем модифицируется тег конфигурации GA4 в GTM, чтобы добавить захваченный фрагмент в поле page_location, отправляя полный URL с фрагментом в GA4.
— После создаётся пользовательское измерение в GA4 с областью действия event, где в качестве параметра события используется page_location, чтобы анализировать данные фрагментов в отчётах.
— Наконец, настройка тестируется через Preview режим GTM и DebugView GA4 перед публикацией изменений.
Есть несколько важных нюансов.
Поддержка текстовых фрагментов не универсальна во всех браузерах.
SEO-специалистам нужно быть осторожными, поскольку отслеживаемые фрагменты могут содержать чувствительную информацию.
Для больших трафиковых сайтов возможно потребуется внедрять фильтры для управления объёмом собранных данных по фрагментам.
В статье также приведены необходимые клиентские JavaScript-коды для сбора этих фрагментов, а также примеры серверных скриптов на Perl, PHP и Python для записи собранных данных в файл для анализа.
https://www.searchengineworld.com/tracking-text-fragments-from-google-this-is-seo-gold
@
Читать полностью…
Mike Blazer
24 Jun 2025 13:10
Аудит по локальному SEO всегда должен начинаться с 10 телефонных звонков.
Зайдите на сайт вашего клиента и позвоните по номеру, указанному на нем.
Затем зайдите на сайты 9 его конкурентов и тоже позвоните им.
После этого сделайте несколько заметок:
— Отвечают ли они на звонки?
— Как быстро они отвечают?
— Насколько они дружелюбны?
— Насколько они готовы помочь?
— Насколько они убедительны?
— Какие у них цены по сравнению с другими?
Как ваш клиент выглядит на фоне конкурентов?
Если конкуренты отвечают на звонок за 5 секунд, а вашему клиенту нужно звонить трижды, чтобы он взял трубку, — удачи вам с таким SEO.
Скорее всего, он никогда не закрепится в топе.
Ни ссылки, ни контент, ни супербыстрый сайт не помогут сайту ранжироваться, если интент пользователя не удовлетворяется должным образом после перехода на страницу.
Ссылки толкают сайт вверх, но он рухнет камнем на дно, если пользователь останется недоволен и уйдет на другой сайт.
Начинайте свой аудит с симуляции поведения пользователя и убедитесь, что ваш клиент наилучшим образом удовлетворяет его интент.
И тогда вы увидите, как его позиции растут и закрепляются в топе, при меньших усилиях на линкбилдинг и контент.
@
Читать полностью…
Mike Blazer
24 Jun 2025 08:15
Контент-стратегия с использованием дополнительного (вспомогательного) контента в сворачиваемых блоках через HTML-тег <details> поначалу работала отлично: сайты хорошо ранжировались и показывали прекрасные результаты.
Но теперь Google вывел тег <details> из игры, перестав индексировать контент внутри него.
В результате любой контент внутри тега <details> перестал индексироватся, из-за чего сайты, использовавшие этот метод, резко просели в выдаче.
Проблему подтвердил Тед Кубайтис после того, как позиции его клиента упали, а анализ исходного кода сайта выявил использование тега <details>.
Это не значит, что дополнительный контент больше не работает.
Проблема была именно в этой HTML-реализации.
@
Читать полностью…
Mike Blazer
23 Jun 2025 15:05
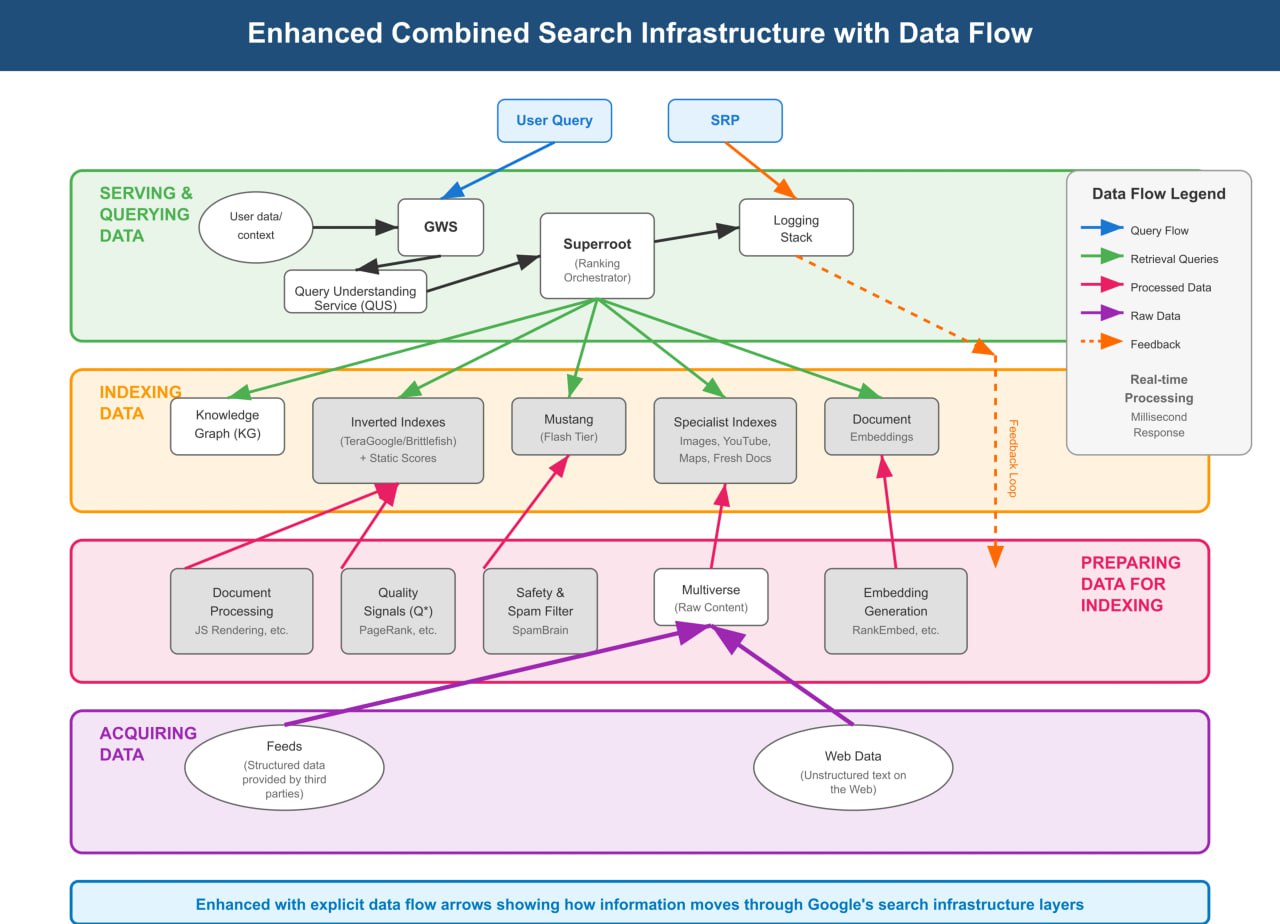
Ключевые SEO-инсайты из материалов антимонопольного дела Google 🔍
1. 🤖 У ИИ — особый мозг: AI Overviews работают НЕ на общей модели Gemini. Они используют специально созданную модель под названием MAGIT, дообученную на огромном массиве поисковых данных и запросов Google.
2. 🖱 Сигналы ПФ правят бал (в веб-поиске): Система Navboost использует агрегированные данные о кликах пользователей за 13 месяцев для переранжирования результатов веб-поиска. Положительное вовлечение пользователей — это не просто теория, а основной, долгосрочный фактор ранжирования.
3. 🧩 Сигналы ПФ повсюду (для фич СЕРПа): Система под названием Glue выполняет ту же работу, что и Navboost, но для *всех остальных элементов поисковой выдачи* (панелей знаний, локальных блоков и т.д.). Это означает, что взаимодействие пользователя определяет всю компоновку СЕРПа.
4. 💥 "Query Fan-Out" — это реальность: Системы ИИ раскладывают один пользовательский запрос на несколько подзапросов, чтобы собрать всестороннюю информацию. Ваш контент должен раскрывать множество аспектов темы, а не только один ключевик, чтобы попасть в итоговый синтезированный ответ.
5. 🗂 ИИ "просматривает" страницы из кэша: Когда AI Overviews "обращаются" к URL, они в первую очередь получают доступ к собственному внутреннему, кэшированному представлению вашей страницы, а не загружают ее в реальном времени.
6. 🧮 Как объединяются сигналы: Система RankEmbed от Google использует dot product (а не только косинусное сходство). Это критически важно, поскольку позволяет совмещать семантическую релевантность с *величиной* (т.е. важностью) традиционных сигналов, таких как PageRank и оценка качества сайта под названием Q***.
7. 🏆 **Дорогой ИИ — только для финалистов: Самые мощные модели глубокого обучения (RankBrain, DeepRank) вычислительно затратны, поэтому они используются только для переранжирования небольшого, предварительно отфильтрованного набора из *20-30 лучших результатов*. Сначала вам нужно пробиться в этот топ с помощью традиционных сигналов.
8. 📄 Ранжирование по пассажам теперь критически важно для RAG: AI Overviews используют фреймворк Retrieval-Augmented Generation (RAG). Сначала они извлекают наиболее релевантные *пассажи* из топовых страниц, а затем генерируют саммари. Структурирование контента в виде четких, хорошо определенных блоков теперь важно как никогда.
9. 📈 Хорошие сигналы вам не навредят: Система ранжирования спроектирована так, что улучшение одного положительного фактора ранжирования имеет монотонный эффект — это *никогда* не должно вредить вашим позициям. Нет никаких санкций за чрезмерную оптимизацию одного валидного сигнала.
10. 🗣 Первый барьер — ясность (QUS): Перед любым ранжированием сервис Query Understanding Service (QUS) переписывает и устраняет неоднозначность вашего запроса. Четкий и однозначный контент помогает на этом первом критически важном этапе.
11. 🔗 Традиционное SEO НЕ умерло: Документы показывают, что это "эволюция, а не революция". Сигналы, созданные вручную, принципы информационного поиска (IR) и линейные комбинации факторов по-прежнему являются фундаментальной основой поиска.
12. 🏢 Фиды со структурированными данными — это отдельная магистраль: У Google есть отдельный, параллельный канал для приема структурированных "фидов" (Merchant Center, данные о рейсах, вакансии и т.д.), который работает независимо от обычного краулинга. Для соответствующих бизнесов это важнейший фаст-трек.
13. 🔮 Будущее перестраивается: Хотя текущие системы эволюционны, Google активно "переосмысливает свой поисковый стек с нуля", чтобы отвести LLM более заметную роль во всех ключевых функциях. Это сигнализирует о том, что на горизонте маячит крупная трансформация.
https://www.linkedin.com/pulse/deconstructing-googles-ai-search-insights-from-antitrust-geraci-ezf7c/
@
Читать полностью…
Mike Blazer
23 Jun 2025 11:05
Новый букмарклет извлекает поисковые запросы, которые ChatGPT использует во время диалогов.
Что он делает:
👉 Извлекает поисковые запросы напрямую из функции поиска ChatGPT в вебе.
👉 Открывает результаты в новой вкладке с профессиональным форматированием.
👉 Копирование в буфер обмена в один клик (идеально для вставки в Excel/Таблицы).
👉 Не требует скачивания или установки.
Букмарклет разработан для работы с любыми диалогами в ChatGPT, которые используют веб-поиск Bing.
Это делает его удобным инструментом для быстрого анализа и повторного использования поисковых запросов для исследований или планирования контента.
Полная инструкция и сам букмарклет:
https://www.shtros.com/chatgpt-search-query-extractor/
@
Читать полностью…
Mike Blazer
22 Jun 2025 15:05
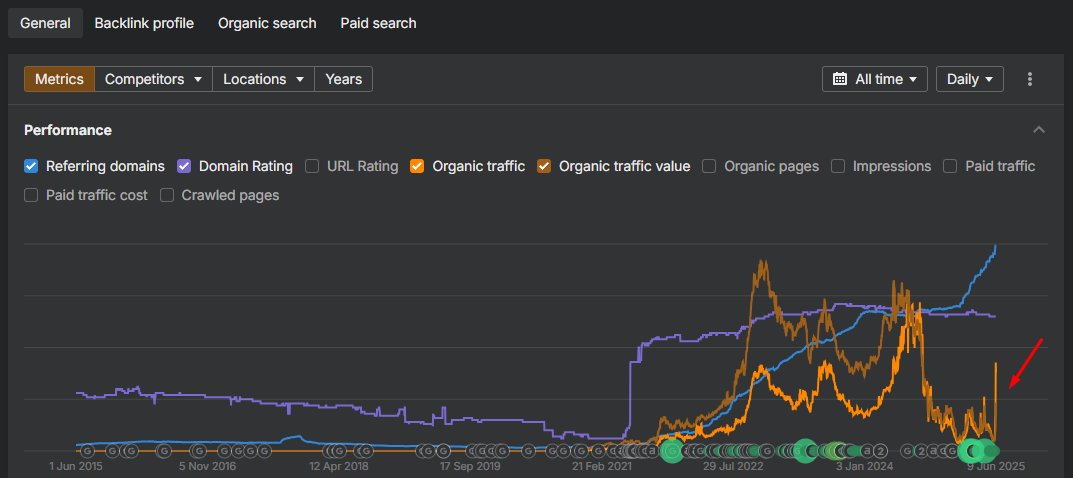
Какая подпись к фотке вам нравиться больше?
1. Да, вы все остаетесь без работы, но показатель под названием "показы" значительно вырос.
2. Фиолетовая линия = сколько денег зарабатывает Google
Синяя линия = сколько денег зарабатываете вы
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}