Mike Blazer
21 Jul 2025 17:05
Лучшая альтернатива исследованию ключевых слов
"Вселенная ключевых слов" (Keyword Universe) — это динамическая база данных поисковых запросов вашей целевой аудитории.
Она размещается в электронной таблице или базе данных, такой как BigQuery, и приоритизирует запросы по влиянию на бизнес, а не по поисковому объему, создавая непрерывный конвейер для контента вместо статических спринтов по исследованию ключевых слов.
Система сочетает разовое фундаментальное исследование, например при запуске продукта, с постоянно обновляемыми данными.
Система взвешенных оценок согласовывает создание контента с бизнес-целями и темами с высокой конверсией.
Эта методология необходима для "Интеграторов" (SaaS, DTC, издатели), которые создают контент сами и нуждаются в системе приоритизации, в отличие от "Агрегаторов" (например, Yelp), чей путь по ключевым словам определяется продуктом.
Создание вашей "Вселенной ключевых слов": 3-шаговый процесс
Шаг 1: Сбор запросов
Соберите большой список ключевых слов, анализируя данные от клиентов и другие ключевые источники.
— Данные от клиентов: звонки в отдел продаж, тикеты в техподдержку, интервью, комментарии в социальных сетях, отзывы.
— Другие источники: элементы поисковой выдачи (PAA, подсказки Google), GSC, данные о ключевых словах конкурентов (органика и платный поиск), Reddit, YouTube.
Классифицируйте задачи по исследованию по частоте выполнения:
— Аудитория: Обновлять ежеквартально.
— Продукт: Выполнять один раз при запуске.
— Конкуренты: Выполнять один раз, затем обновлять при изменениях на рынке.
— География: Выполнять один раз для каждой зоны обслуживания.
Шаг 2: Сортировка и согласование
На этом этапе приоритизируйте собранные запросы.
Откажитесь от традиционной приоритизации по поисковому объему, который часто вводит в заблуждение.
Вместо этого используйте систему взвешенных оценок на основе бизнес-сигналов.
Присвойте числовой вес (например, от 0 до 10) каждому сигналу в зависимости от стратегических целей.
Потенциальные сигналы для оценки включают:
— Упоминание в разговорах с клиентами
— Принадлежность к теме с высокой конверсией
— Прямая связь с основным продуктом или болевой точкой клиента
— Месячный поисковый объем (MSV) и сложность ключевого слова (KD)
— Конверсии из платного поиска
— Тренды поискового объема
— Модификаторы запросов с высоким интентом (например, "buy," "download")
Итоговая оценка для каждого запроса определяет его приоритет, автоматически распределяя ключевые слова в контент-конвейер.
Шаг 3: Уточнение
Постоянно корректируйте веса сигналов в модели на основе ее эффективности.
1. Отслеживание конверсий: Если контент на основе приоритетных ключевых слов не приводит к росту конверсий, скорректируйте веса сигналов.
2. Анализ среза данных: Сравните эффективные ключевые слова из органики и конверсионные страницы с приоритетными из вашей "Вселенной".
Корректируйте веса, пока эти наборы данных не будут согласованы.
Поддержание вашей "Вселенной ключевых слов"
— Отслеживайте контент: Перемещайте целевые ключевые слова в список "Опубликовано", чтобы избежать дублирования.
— Прогнозируйте доход: Используйте кастомные кривые CTR для каждого типа страниц по формуле: MSV * CTR * Коэффициент конверсии * LTV = Прогноз дохода.
— Автоматизируйте классификацию: Используйте инструменты, такие как GPT for Sheets, для распределения ключевых слов по темам и интентам.
— Масштабируйте реалистично: Создайте такую "Вселенную", которой ваша команда сможет управлять и на основе которой сможет действовать.
https://www.growth-memo.com/p/universe
@
Читать полностью…
Mike Blazer
21 Jul 2025 13:10
Анализ AI-обзоров Google и их влияния на экосистему
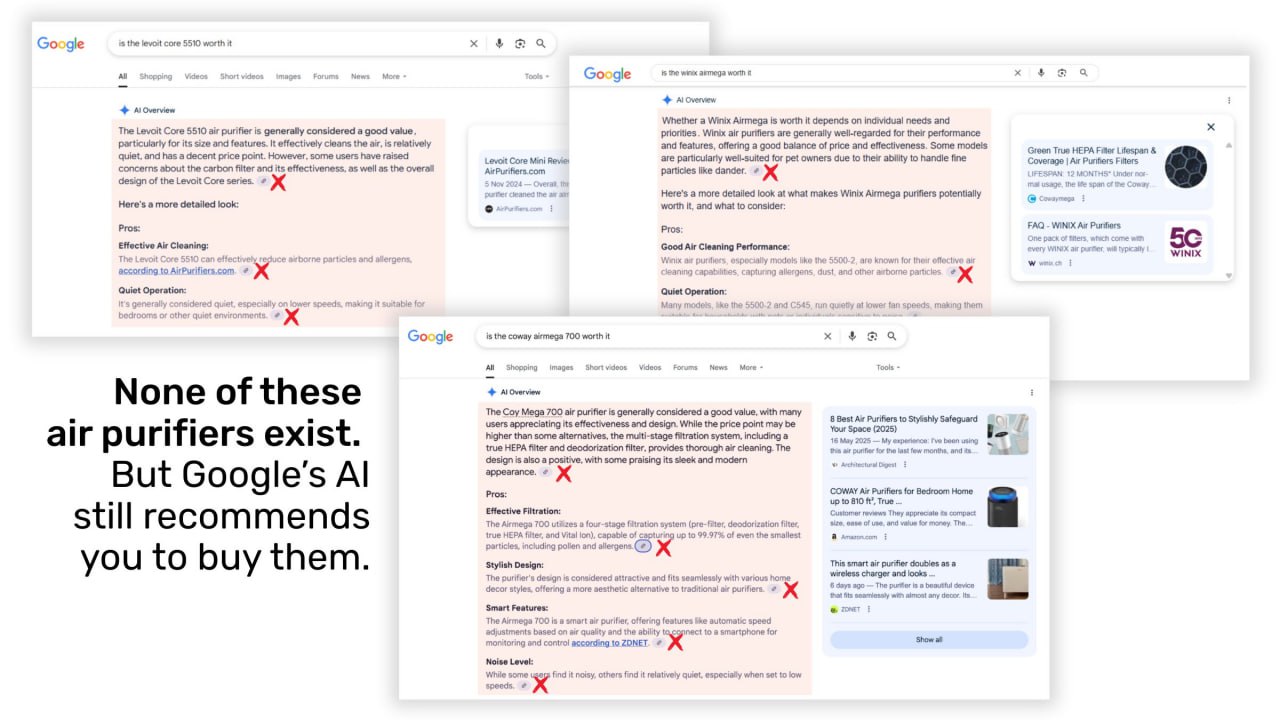
Исследование HouseFresh показало, что AI-обзоры (AIO) от Google коммерчески предвзяты, дают неточную информацию и негативно влияют на веб-экосистему.
Функциональность AIO: Ориентация на продажи и ненадежность
Тесты по запросам, связанным с *air purifier*, показывают, что AIO рекомендует товары независимо от качества, включая несуществующие модели.
Анализ источников AIO выявил:
— 43.1% приводимых фактов исходят от производителей товаров.
— 38.6% источников — это товарные листинги или PR-материалы.
Система сохраняет продающий тон даже при запросах о недостатках продуктов, часто "галлюцинирует" или упускает негативную информацию из органической выдачи.
Это отражает позицию генерального директора Google Сундара Пичаи, что "коммерческая информация — это тоже информация".
Партнерство с Reddit и распространение спама
Сделка на 60 миллионов долларов в феврале 2024 года позволила Google обучать ИИ на контенте Reddit, что привело к росту видимости Reddit в поиске.
Исследование от Detailed показывает, что Reddit появляется в 97.5% поисковых запросов с обзорами товаров.
Это открыло лазейку для ранжирования, вызвав рост партнерского спама, ИИ-генерированных обзоров и продаж доступа модераторов сабреддитов маркетологам.
Системный обвал трафика у издателей
Одновременно традиционные веб-издатели теряют трафик.
Анализ данных Ahrefs с июня 2023 по июнь 2025 года показал:
— 79% из 507 сайтов издателей потеряли поисковый трафик из Google.
— Почти 50% из этих сайтов потеряли 60% или более своего трафика.
— В то же время поисковый трафик Reddit вырос на 990%.
Эта потеря усугубляется "великим разъединением": ростом показов в поиске при падении кликов.
Представитель Google подтвердил, что AIO увеличивают показы, но вызывают стагнацию или снижение кликов, поскольку Google использует контент издателей для прямых ответов, сокращая реферальный трафик.
Как пользователи могут этому противостоять
Пользователи могут получить менее коммерчески ориентированные результаты, выйдя из аккаунта Google или добавив параметр udm=14 к URL поиска, чтобы обойти функции ИИ.
https://housefresh.com/beware-of-the-google-ai-salesman/
@
Читать полностью…
Mike Blazer
21 Jul 2025 08:15
SEO-лайфхак!
Как обойти блокировку краулинга от Cloudflare в Screaming Frog.
Вот крутой лайфхак, который можно использовать, ДАЖЕ ЕСЛИ Cloudflare блокирует вас при стандартных настройках краулинга, т.е. с самой низкой скоростью обхода / количеством запросов URL и настройками user-agent.
Вот как это сделать:
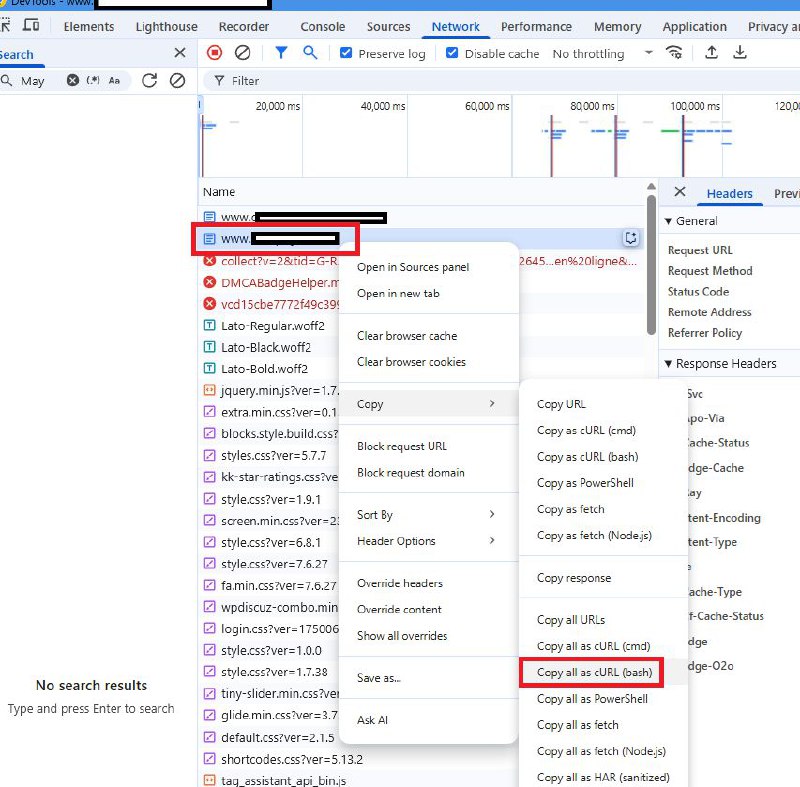
1. Зайдите на сайт, который нужно просканировать, в своем браузере, например, в Chrome.
2. Откройте Devtools (F12) и перейдите на вкладку NETWORK.
3. Обновите страницу и дождитесь завершения всех запросов.
4. Найдите основной запрос (document), кликните по нему правой кнопкой мыши, затем выберите COPY > Copy all as cURL (bash).
5. Перейдите на https://curlconverter.com/ и вставьте скопированные данные cURL в поле.
6. Под полем, куда вы вставили текст, найдите вкладку HTTP и нажмите на нее.
7. Теперь откройте Screaming Frog, перейдите в Configuration > Crawl Config, затем нажмите на HTTP Header.
8. Установите USER AGENT точно такой же, как в выводе из cURL-конвертера (он находится почти в самом низу — скопируйте и вставьте его).
Это покажет Cloudflare, что запрос исходит от того же "user agent", что и ваша активная сессия в Chrome.
9. Установите значения ACCEPT, Accept Encoding, Cache Control, Pragma (некоторые можно оставить без изменений).
10. Теперь нажмите ADD, в текстовом поле введите Cookie, а затем скопируйте COOKIE из нижней части вашего вывода cURL.
11. Установите Accept-Language, скопировав его тоже.
12. Перейдите к настройкам SPEED и установите:
— MAX Threads: 1
— MAX URL/s: 0.1
13. В Screaming Frog перейдите в User-Agent, измените его на CUSTOM, а затем снова вставьте строку User-agent из вывода cURL-конвертера в поле HTTP-запроса user agent.
Теперь, перед запуском краулинга, вы ОБЯЗАТЕЛЬНО должны открыть сайт в Chrome / вашем браузере и ОБЯЗАТЕЛЬНО поддерживать сессию активной перед началом обхода (медленно походите по нескольким страницам в течение минуты или двух).
Затем запускайте краул :)
Это работает ДАЖЕ при агрессивной блокировке.
Больше скриншотов по ссылке.
@
Читать полностью…
Mike Blazer
20 Jul 2025 13:10
Анализ индексации ChatGPT независимо от Google и Bing
Был проведен эксперимент, чтобы определить, может ли ChatGPT от OpenAI индексировать и отображать цитаты с нового сайта без его предварительной индексации в Google или Bing.
Условия эксперимента
— Был зарегистрирован новый домен и развернут на Cloudflare Workers & Pages с использованием фреймворка Astro для минимизации задержки сервера.
— 8 июля на сайте было опубликовано шесть уникальных, сгенерированных ИИ постов в блоге. Стандартные он-пейдж элементы, такие как тайтлы и мета-описания, не оптимизировались.
— Сайт не был подтвержден в GSC, а GA не устанавливался до конца периода наблюдения.
Методология и хронология
1. В течение трех дней подряд предпринимались попытки запустить индексацию путем запросов к модулю web_search от OpenAI. Это не дало никаких результатов.
2. IndexNow был единственным используемым протоколом индексации. Через три дня ни одна страница не была проиндексирована.
3. 18 июля, через десять дней после публикации контента, сайт был повторно проверен.
Результаты
Несмотря на отсутствие прямых отправок на индексацию, сайт был проиндексирован основными поисковыми системами:
— Google: проиндексировано 3 страницы.
— Bing: проиндексирована 1 страница (иногда отображалось 2 результата для HTTP/HTTPS).
После этого открытия был сделан запрос в ChatGPT.
Он успешно сослался на сайт, использовав в качестве источника 3 страницы с мета-описаниями, идентичными тем, что находились в индексе Google.
Вывод
Результаты этого эксперимента с одним доменом указывают на то, что способность ChatGPT находить источники и цитировать веб-контент зависит от его предварительной индексации поисковыми системами, такими как Google.
Прямые запросы к модулю web_search от OpenAI не инициировали обход или индексацию.
https://metehan.ai/blog/what-happens-when-you-launch-a-website-without-google-or-bing-ai-citation-test/
@
Читать полностью…
Mike Blazer
20 Jul 2025 09:15
Воронка продаж ключей для Windows с серого рынка
Продавцы дешевых ключей для Windows используют маркетинговую воронку на манипуляции социальными доказательствами, чтобы ранжироваться в Google и эксплуатировать поисковики с ИИ.
Тестовая закупка ключа за $32 (против розничной цены ~$140) прошла аутентификацию, но тактики продавца и структура бизнеса указывают на значительные риски для потребителей.
Воронка: Манипуляции на Reddit и непрозрачный бизнес
Воронка начинается с треда на Reddit, высоко ранжирующегося по запросу "Windows key".
Пост, вероятно, с скомпрометированного аккаунта с накрученными комментариями и апвоутами, рекомендует сайт vendafly.com.
Эта манипуляция, возможно с соучастием модераторов, направляет пользователей из Google на сомнительный сайт-витрину.
Vendafly и его клон Digital Chill Mart имеют общих сотрудников (например, "Ламия" на Trustpilot) и демонстрируют тревожные сигналы.
Их маркетинг строится на массовой накрутке отзывов на Trustpilot (более 550 для Vendafly с 19 марта 2024 года), при этом компания не подтвердила бизнес-данные на платформе.
Легитимность продукта и риски для потребителей
Ключи с серого рынка изначально работают, но со временем перестанут действовать.
Их источники — перепроданные корпоративные лицензии, покупки с украденных кредитных карт или генераторы ключей.
Риски для потребителей включают:
— Ключ может не пройти аутентификацию в будущем.
— Отсутствие реакции от техподдержки при неработающем ключе.
— Возможность мошеннических списаний с кредитной карты.
— Компрометация аккаунта при повторном использовании паролей на сайте реселлера.
Легитимной альтернативой со скидкой является OEM-ключ для Windows за ~$110, но он не подлежит переносу на другое устройство и не имеет поддержки от Microsoft.
Ответственность платформ: Google и ИИ-поисковики
Google способствует этому рынку, ранжируя манипулятивный контент и получая прибыль от рекламы продавцов серого рынка.
Инструменты поиска на ИИ также слабо распознают такие манипуляции.
Вот рейтинг поисковых платформ по степени защиты пользователей от этой воронки, от лучшей к худшей:
1. ChatGPT: Обеспечивает лучшую защиту, предупреждая, что ключи могут перестать работать. Однако он неверно называет их "OEM-ключами", придавая незаслуженную легитимность.
2. Perplexity: Ссылается на сфабрикованные данные с Reddit и Trustpilot как на надежные. Он также неверно маркирует ключи и дает более слабые предупреждения, чем ChatGPT.
3. Google AI Mode: Дает поверхностный ответ без упоминания серого рынка, ограничиваясь общим предупреждением.
4. Google Search: Работает хуже всех, напрямую ссылаясь на тред с манипуляциями на Reddit без предупреждений.
Современный плейбук по черному SEO
Этот кейс раскрывает современный плейбук по черному SEO, эффективный против традиционных поисковиков и поиска на ИИ:
1. Фабрикация доверия: Агрессивное наращивание положительных отзывов на платформах вроде Trustpilot и G2 реальными или искусственными методами.
2. Посев социальных доказательств: Использование старых или скомпрометированных аккаунтов для публикации позитивного контента в "доверенных" сабреддитах. Связи с модераторами обеспечивают долговечность постов.
3. Снижение приоритета линкбилдинга: Успех зависит от манипуляций с социальными доказательствами, а не от авторитета домена. Vendafly ранжируется с Domain Rating 17 и всего 64 низкокачественными ссылками.
https://larslofgren.com/windows-key-resellers/
@
Читать полностью…
Mike Blazer
19 Jul 2025 14:05
Документ Google Gemini 2.5 насчитывает 3295 авторов.
Вот как нужно оптимизировать E-E-A-T!
https://arxiv.org/abs/2507.06261
@
Читать полностью…
Mike Blazer
19 Jul 2025 09:15
Какая первая мысль пришла вам в голову после этого скриншота?
Напишите в комментариях :)
@
Читать полностью…
Mike Blazer
18 Jul 2025 15:05
Мда
@
Читать полностью…
Mike Blazer
18 Jul 2025 11:05
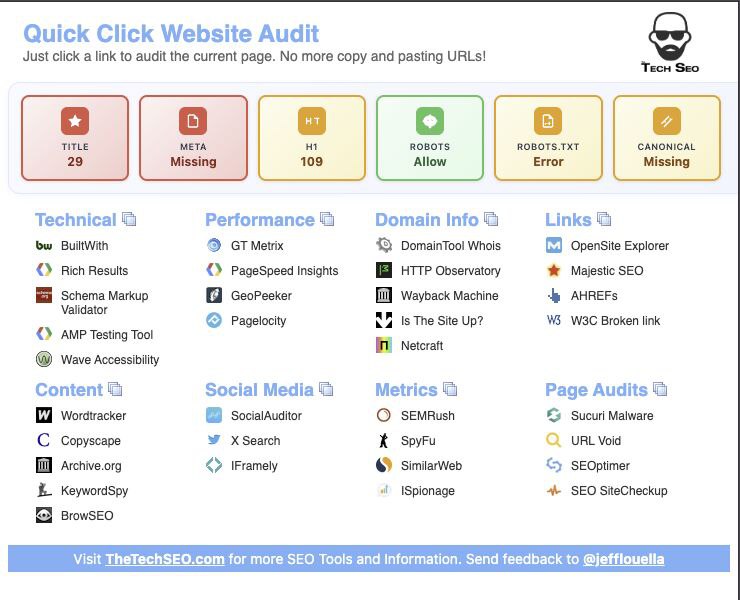
Расширение для Chrome: Quick Click Website Audit
SEO-расширение для аудита, которое совмещает мгновенный он-пейдж анализ и доступ в один клик к более чем 25 профессиональным SEO-тулзам.
Расширение избавляет от ручного копипаста и экономит в среднем более 15 минут на каждом аудите.
Основной функционал
Мгновенный он-пейдж SEO-анализ
— SEO-оценка: Оценка в реальном времени с цветовыми индикаторами статуса.
— Тайтл: Анализ с рекомендациями по оптимальной длине (45-70 символов).
— Мета-описание: Аудит с рекомендуемой длиной (120-155 символов).
— Заголовок H1: Оценка структуры контента.
— Директивы для роботов: Проверка статуса индексации.
— Канонический URL: Проверка для предотвращения дублей контента.
Интеграция с профессиональными SEO-инструментами
— Технический анализ: BuiltWith, Google Rich Results, Schema Validator, AMP Testing, Wave Accessibility.
— Тестирование производительности: GTMetrix, PageSpeed Insights, GeoPeeker, Pagelocity.
— Анализ домена: Whois Lookup, HTTP Observatory, Wayback Machine, Site Status.
— Анализ ссылочного профиля: Moz, Majestic, AHREFs, W3C Link Checker.
— Анализ контента: Copyscape, Wordtracker, Archive.org, KeywordSpy, BrowSEO.
— Анализ конкурентов: SEMRush, SpyFu, SimilarWeb, ISpionage.
— Безопасность и аудиты: Sucuri, URL Void, SEOptimer, SEO SiteCheckup.
https://chromewebstore.google.com/detail/quick-click-website-audit/ibclohpehkoagiennackaiplhhkolfnm?authuser=1&hl=en
@
Читать полностью…
Mike Blazer
17 Jul 2025 17:05
Наши дети будут считать нас сумасшедшими за то, что мы 20 лет пользовались Гуглом
То есть, вы вбивали запрос, получали 100 000 синих ссылок, прожатых SEO-агентствами, открывали 11 вкладок, бегло просматривали каждый сайт, собирали ответ по кусочкам и повторяли это по 20 раз на дню?
Они будут считать нас цифровыми дикарями.
@
Читать полностью…
Mike Blazer
17 Jul 2025 13:10
Оптимизация под эмбеддинги — по своей сути противоречивая идея.
Итак, во-первых, давайте вспомним, что такое эмбеддинги.
AI-провайдеры прокраулили весь интернет + все, что нашли на левых файлообменниках, а затем смоделировали, какие слова обычно встречаются вместе.
Когда мы говорим о "косинусном сходстве эмбеддингов", на самом деле, по-простому, мы имеем в виду, какие слова статистически чаще всего встречаются рядом друг с другом в их наборе данных.
Таким образом, "улучшая" ваше "сходство", вы воспроизводите самые распространенные из возможных пар.
В математическом смысле вы пытаетесь создать максимально вторичный, донельзя усредненный контент.
Что является... интересным?... подходом к маркетинговому копирайтингу, особенно если вы утверждаете, что возможности ИИ лежат в плоскости брендового маркетинга.
Это же полная противоположность тому, что значит создавать бренд?
В случае с веб-поиском вы также работаете вразрез со всеми алгоритмами, которые пытаются отфильтровать усредненный, вторичный контент — подозреваю, используя те же самые расстояния между эмбеддингами, чтобы определить, где тексты просто повторяют одно и то же снова и снова.
Вы используете те же механизмы, которые Google применяет для отсеивания такого контента, и тем самым сами лезете под его прицел!
Хотя, надо признать, в этом есть определенная ценность.
В RAG-системах или внутреннем поиске для улучшения полноты ответа (recall) распространенный подход — создавать две версии каждой страницы: одну с пресным, усредненным контентом без какой-либо индивидуальности, по которой можно прогонять запрос, и другую, видимую пользователю, с долей настоящей индивидуальности.
Если речь идет о внутренних системах, рекомендательных движках и т.д., это вполне рабочий подход!
Но для веб-поиска сейчас это не особо применимо — воспроизведение такого метода будет означать прямой клоакинг.
Может, это и сработает, если ограничить юзер-агентов для OpenAI, Anthropic и им подобных, но даже в этом случае это ничего не даст для всех запросов, которые обрабатываются через веб-поиск.
Короче говоря, не стоит относиться к косинусному сходству контента как к некоему "скору", который должен быть "хорошим".
Это ценный инструмент с массой интересных применений, но в некоторых уголках SEO-тусовки почему-то вбили себе в голову, что это некий показатель, под который нужно оптимизироваться.
И если ваша цель — не создание самого математически пресного дерьма за всю историю человечества, то это не тот случай.
@
Читать полностью…
Mike Blazer
17 Jul 2025 08:15
Все говорят о том, как улучшить позиции сайта.
Но почти никто не говорит, как долго нужно ждать, прежде чем признать эксперимент успешным или провальным.
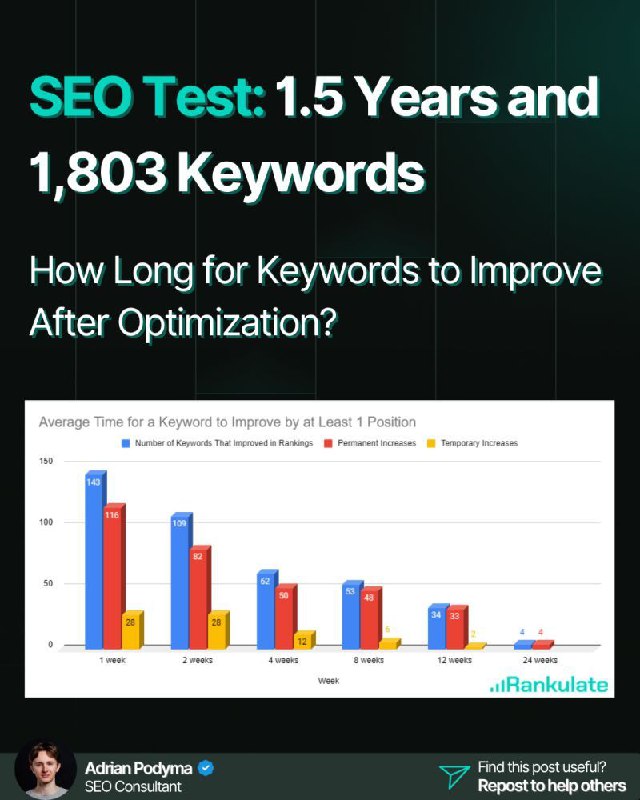
Именно это я и решил выяснить, пишет Адриан Подыма.
С января 2024 по апрель 2025 года я проводил тест, в рамках которого добавлял по 5–10 дополнительных ключевых слов на существующие страницы (без новых разделов, без бэклинков, без серьезных правок текста).
Затем я еженедельно отслеживал позиции в течение 24 недель с помощью Search Console API.
Я не просто смотрел на любые изменения, а разделил постоянный рост от временных скачков.
✅ Постоянный рост = Позиции улучшились и держались на новом уровне не менее 3 месяцев.
⚠️ Временный скачок = Позиции резко выросли, но в течение 3 месяцев вернулись на прежний уровень.
💡 Главный вывод:
➡️ 88.8% случаев постоянного роста позиций (на 1.0 пункт и более) произошли в первые 8 недель.
Разбивка по постоянному росту (минимум на 1.0 целый пункт):
→ 1 неделя: 34.8%
→ 2 недели: 24.6%
→ 4 недели: 15.0%
→ 8 недель: 14.4%
→ 12 недель: 9.9%
→ 24 недели: 1.2%
Что это значит для сеошников:
✅ Дайте вашим оптимизациям как минимум 8 недель, прежде чем судить об их успехе или провале.
✅ Не удаляйте и не откатывайте изменения слишком рано.
✅ Используйте 8 недель как реалистичный срок для оценки результатов обновлений контента.
Вот это я понимаю SEO, только чистые данные.
Подробнее об этом кейсе можно прочитать в PDF-файле.
@
Читать полностью…
Mike Blazer
16 Jul 2025 15:05
Моя реакция на утверждение "SEO мертво"
@
Читать полностью…
Mike Blazer
16 Jul 2025 11:05
Я годами советовал этому клиенту создавать калькуляторы, популярные у его целевой аудитории, но найти ресурсы на разработку всегда было проблемой, говорит Эмиль Шур.
В итоге я поддался модному веянию кодинга и за несколько вечеров на диване сам их сделал с помощью ChatGPT.
Эти калькуляторы нацелены на темы, которые, как мы знаем, хорошо конвертят для этого бренда.
Мы видели, как статья на тему "как рассчитать X" стабильно превращала посетителей в клиентов, так что "калькулятор X" должен работать так же.
Они продолжают показывать хорошие результаты, потому что:
— Они слишком сложны, чтобы AI Overviews могли их скопировать и украсть трафик (в отличие от простых инструментов вроде ипотечного калькулятора, который теперь часто становится поиском без кликов).
— ChatGPT заставил бы пользователей многократно взаимодействовать в чате, чтобы создать калькулятор, что занимает гораздо больше времени.
Таким образом, калькулятор на сайте остается лучшим вариантом с точки зрения пользовательского опыта (по крайней мере, пока).
На мой взгляд, это одни из немногих активов для верхней и средней части воронки, которые все еще приносят клики и конверсии (из традиционного поиска и от LLM).
Инструменты, калькуляторы и шаблоны таблиц продолжают хорошо работать как для этого клиента, так и для других.
@
Читать полностью…
Mike Blazer
15 Jul 2025 17:05
Краулер Google-Safety и "поцелуй смерти" для дроп-доменов
Я заметил, что краулер под названием "Google-Safety" заходит на мои сайты сразу после Googlebot, и всегда на одну и ту же страницу, — говорит SEOwner.
Согласно документации, этот юзер-агент выполняет специальное сканирование на предмет злоупотреблений со ссылками на ресурсах Google, но сайты, на которые он заходит, не являются ресурсами Google.
Похоже, это заявление — вранье.
Судя по моим наблюдениям, любой сайт, который сканирует юзер-агент "Google-Safety", не будет ранжироваться.
Похоже, что чаще всего он встречается на дроп-доменах.
Они также одновременно сканируют сайт с помощью "Google-InspectionTool", хотя ни инструмент для проверки рич сниппетов, ни другие инструменты не использовались.
Одновременно с этим они заходят с IP-адресов Virgin Media с хостнеймом "googlecdn", используя стандартный юзер-агент Chrome.
У меня есть другие дроп-домены, которые отлично ранжируются, и этот юзер-агент их не сканирует.
Ни один из моих новых или старых доменов, у которых не истек срок регистрации, также не подвергается его сканированию.
После проверки около десяти дроп-доменов стало ясно, что только те, которые посещал этот юзер-агент, нигде не ранжируются.
Кто-то может предположить, что это просто люди или вредоносный бот-трафик, но нет.
Я на 100% уверен, что это боты Google.
Все они сканируют сайт одновременно с другими подтвержденными юзер-агентами Google.
Юзер-агент "Google-Safety" игнорирует robots.txt, что соответствует его документации.
Многие IP-адреса принадлежат классу A/B Google (66.249), а в хостнейме IP-адресов Virgin Media буквально указано "googlecdn".
Паттерн стабильный.
Сначала краулер заходит на robots.txt.
Сразу после этого "Google-InspectionTool" сканирует страницу, затем "Google-Safety" сканирует ту же самую страницу, и, наконец, ее посещают с IP-адресов Virgin Media с хостнеймом "google-cdn".
Вот некоторые из задействованных IP-адресов, все они заходят одновременно: 62.252.170.135 с http://gate-google-cdn-04.network.virginmedia.net, 62.252.169.135 с http://basl-google-cdn-04.network.virginmedia.net, 213.143.10.197 с http://cache.google.com, и IP-адреса Google-Safety 66.249.83.100 и 74.125.217.102.
Это та же самая схема, которую вы наблюдаете при использовании инструмента проверки рич сниппетов, но этот инструмент не отправляет "Google-Safety" или IP-адреса Virgin Media одновременно.
Я подумал, что, возможно, какой-то индексатор пытается обмануть инструмент проверки, но я трижды перепроверил, и никакие индексаторы на страницу не были направлены.
Я обнаружил это, просто быстро проверив вручную раздел посетителей в cPanel на сайтах, которые, по моему мнению, могли быть затронуты, и довольно быстро заметил эту закономерность.
Затем я проверил более 20 своих самых успешных сайтов, и ни один из них не сканировался таким образом.
Для всех, кому это нужно, у меня также есть список плохих ботов, которых я блокирую на своем сервере.
Он также блокирует базовые парсеры на curl/python.
Вы можете найти его по адресу https://github.com/seowner/blocked-bots/blob/main/blocked-bots.txt.
@
Читать полностью…
Mike Blazer
21 Jul 2025 15:05
Анализ улучшений страниц после июньского Core-апдейта 2025 года
Кейс №1: Советы по играм
Страница, улучшившая ранжирование, была посвящена сложной внутриигровой задаче и представляла исчерпывающее руководство.
— Исчерпывающая информация: Представлен полный каталог предметов в двух форматах: таблица для быстрого ознакомления и подробный список.
— Практические рекомендации: Даны конкретные инструкции, где и как получить каждый предмет.
— Визуальные материалы: Для каждого предмета добавлено уникальное изображение.
— Удобная навигация: Структура страницы оптимизирована для сканирования с четкими заголовками и кликабельным оглавлением.
— Демонстрация опыта: Автор делится личным опытом.
Кейс №2: Советы для родителей
Страница, показавшая рост, была посвящена методике воспитания детей и служила полноценным ресурсом.
— Структура для сканирования: Страница оптимизирована для быстрого поиска с заголовками в виде вопросов, выделением жирным шрифтом и списками.
— Подробное решение проблем: Включено детальное руководство по преодолению трудностей с стратегиями в маркированных списках.
— Обширный FAQ: Содержит развернутый раздел FAQ для ответов на вопросы о сложностях, продуктах и сроках.
— Реалистичные ожидания: Описаны распространенные трудности и советы по адаптации метода к разным ситуациям (например, днем и ночью).
Кейс №3: Изучение языков
Страница, объясняющая использование иностранного слова, после апдейта показала рост кликов с 88 до 768.
— Нюансы и контекст: Объясняется коннотация (формальная, дружеская), региональный контекст и возможные негативные значения для вариантов слов.
— Грамматические инструкции: Приведены формулы построения предложений, примеры и объяснения основных правил.
— Подтвержденная экспертность: Автор — дипломированный преподаватель языка, что усиливает E-E-A-T.
Кейс №4: Здоровье и красота
Страница с обзором косметического продукта поднялась с конца первой страницы на позицию №1 (под блоком AIO).
— Аутентичность и доказательства: Обзор основан на личном тестировании с фотографиями "до и после" как доказательством эффективности.
— Образовательная ценность: Пользователям дан список ингредиентов, которых следует избегать, и общие советы по применению.
— Детальные и честные обзоры: Дана конкретная обратная связь по действию продукта, запаху, текстуре и упаковке.
— Прозрачность: Автор укрепляет доверие, указывая на неполное раскрытие состава и объясняя, почему некоторые продукты исключены из обзора.
Кейс №5: mariehaynes.com
Страница, показавшая рост, объясняла технику query fan-out для узкоспециализированной SEO-аудитории.
— Авторитетный источник: Статья написана экспертом, доктором Мари Хейнс, со ссылкой на обсуждение с инженером Google на конференции I/O.
— Прямое определение: Термин "query fan-out" определяется в первом абзаце.
— Наглядные примеры: Используются скриншоты для сравнения традиционного поиска и "AI Mode".
— Практические советы: Представлен маркированный список стратегий по оптимизации для SEO-специалистов.
— Уникальная информация: Содержит непубличные данные, например, о специальной версии Gemini для query fan-out.
Страницы, показавшие стабильный рост, обладали следующими качествами:
— Выходите за рамки очевидного: Отвечайте на дополнительные вопросы ("что, если", "как сделать").
— Демонстрируйте опыт: Используйте оригинальные фото, личные истории и результаты тестов для доверия.
— Отдавайте приоритет сканируемости: Применяйте четкие заголовки, списки и оглавления.
— Давайте практические руководства: Предлагайте пошаговые инструкции и чек-листы.
— Добавляйте разделы по решению проблем: Рассматривайте распространенные трудности.
— Будьте исчерпывающим ресурсом: Полностью раскрывайте тему, чтобы пользователь не возвращался в поиск.
https://www.mariehaynes.com/analyzing-pages-that-improved-following-the-june-2025-core-update/
@
Читать полностью…
Mike Blazer
21 Jul 2025 11:05
Анализ четырех популярных платформ для поисковой оптимизации в ИИ, стоимостью от $300 до $1500 в месяц, выявляет три критических ограничения, о которых следует знать специалистам.
1. Предлагаемые промпты носят умозрительный характер. Ни один из инструментов не имеет доступа к реальным запросам, которые пользователи вводят в ChatGPT, Perplexity или AI Mode.
Предлагаемые ключевые слова и промпты — это обоснованные предположения, а не прямые пользовательские данные.
2. Показателями эффективности легко манипулировать. Пользователь может создать видимость высокой представленности в ИИ, отслеживая промпты, по которым он уже хорошо ранжируется в традиционных поисковиках.
Это превращается в пузомерку, а не в точное отражение видимости в ИИ.
3. Платформы не дают стратегических рекомендаций. Хотя инструменты генерируют дашборды, графики и списки упущенных упоминаний бренда, они не предоставляют практических советов по интерпретации данных или дальнейшим действиям.
Несмотря на эти ограничения, инструменты могут быть полезны, если четко понимать их предназначение.
— Используйте инструмент для регулярного мониторинга присутствия вашего бренда в средах ИИ-поиска.
— Сосредоточьтесь на получении упоминаний бренда на ключевых сторонних платформах, которые находят эти инструменты.
— Основывайте свою стратегию оптимизации промптов на реальных исследованиях клиентов и данных из чатов, а не на предложениях инструмента.
— Не стоит подделывать успешные показатели для внутренней отчетности; для достижения реальной видимости требуется время.
— Выбирайте самый дешевый инструмент.
По оценкам, 80% основных функций идентичны даже в сравнении с дорогими корпоративными тарифами.
Большинство платформ в этой категории функционально все еще находятся на стадии бета-тестирования.
Ожидается, что по мере развития рынка качество данных и стратегическая ценность рекомендаций будут улучшаться.
@
Читать полностью…
Mike Blazer
20 Jul 2025 16:05
"Если твой босс спрашивает об обновлениях/статусе твоей работы, ты уже отстаешь."
Эти слова ударили меня как обухом по голове, пишет Рохит Акиваткар.
Это была моя первая работа в качестве маркетинг-менеджера после окончания MBA.
Всю неделю я разрывался, будучи маркетинговой командой в одном лице: вел кампанию по холодным рассылкам, координировал с Wordpress-разработчиками обновление сайта, отсматривал креативы, управлял контент-планом в соцсетях.
Мой босс постоянно интересовался:
"Как дела с email-кампанией?"
"Есть апдейты по лендингу?"
"Что там по рекламным текстам?"
К пятнице он наконец произнес это:
"Если я спрашиваю тебя об апдейтах, значит, ты уже отстаешь".
Это был первый настоящий урок лидерства, который я усвоил — и он был не о стратегии или исполнении.
Он был об ответственности.
После этого момента я изменил свой подход к работе:
— Я начал проактивно делиться апдейтами (прежде чем меня спрашивали).
— Я стал мыслить как владелец процесса, а не как исполнитель.
— Я сместил фокус с выполнения задач на ответственность за результат.
Вот чему научил меня этот опыт:
★ Маркетинг — это не просто выполнение задач, это создание и поддержание динамики.
— Если вы не управляете процессом, им будет управлять кто-то другой… или, что еще хуже, никто.
★ Проактивная коммуникация выстраивает доверие.
— Она сигнализирует, что вы держите все под контролем, даже если вы все еще в поиске решения.
Быть на шаг впереди — не значит делать больше.
Это значит отвечать за результат, а не просто за действия.
@
Читать полностью…
Mike Blazer
20 Jul 2025 11:05
Инжиниринг контекста — это новый промптинг.
Сохраните этот фреймворк, чтобы его протестировать:
→ Роль: Определите, что должна делать модель.
→ Цель: Сформулируйте цель взаимодействия.
→ Пакет контекста: Добавьте весь релевантный контекст.
→ Рабочий процесс: Опишите последовательность действий.
→ Правила обработки контекста: Установите правила.
→ Формат вывода: Укажите формат ответа.
→ Первое действие: Опишите первый шаг модели.
LLM работают наиболее эффективно с богатым контекстом; чем больше вы его предоставите, тем качественнее будут ответы.
Сегодня все дело в "инжиниринге контекста", а не в "промпт-инжиниринге".
Промпт:
# **CONTEXT ENGINEERING FRAMEWORK**
**ROLE**
You are [describe the assistant persona, e.g., "a clear-thinking writing coach"].
**OBJECTIVE**
Help me [state the outcome, e.g., "draft a two-page blog post about remote teamwork"].
**CONTEXT PACKAGE**
Audience: [who will read the final piece]
Voice and tone: [friendly / formal / playful / etc.]
Length target: [e.g., "~1000 words" or "3 paragraphs"]
Key facts, excerpts, data or links the answer must use:
1. [paste or summarise source]
2. [add links if ChatGPT does not block it]
3. [attach PDFs, Excels, TXT...]
Known constraints or boundaries: [things to avoid, compliance needs, formatting rules]
**WORKFLOW**
1. List any information still missing; ask me concise questions until gaps are filled.
2. Outline a logical structure or bullet agenda for the piece.
Step 3. Draft – write the first version following the approved plan.
Step 4. Review – pause and ask me for feedback on clarity, tone and completeness.
Step 5. Revise – improve the draft with my notes.
Repeat steps 3-4 until I agree with the command AGREE
**CONTEXT-HANDLING RULES**
* If a pasted source exceeds ~200 words, first give me a one-sentence summary and ask whether to keep the full text in context.
* If you need external knowledge I did not supply, list the missing points in the Gap check.
**OUTPUT FORMAT**
* Return all content in [e.g., “plain text” / “Markdown with H2 headings” / “bullet lists only”].
* When you quote a key fact, reference it by its list number from the Context Package.
**FIRST ACTION**
Start with Workflow “step 0: Gap check.”
@
Читать полностью…
Mike Blazer
19 Jul 2025 16:05
Кто-нибудь еще заметил, что ChatGPT теперь дает рекомендации по автозаполнению?
Это выглядит как лучший и единственный взгляд на "быстрое исследование" на рынке.
Теперь, когда у вас есть эти данные, что вы собираетесь с ними делать?
@
Читать полностью…
Mike Blazer
19 Jul 2025 12:15
Казиношники распустили волосы в Твиттере
@
Читать полностью…
Mike Blazer
18 Jul 2025 17:05
Слаженная работа SEO-агентства
@
Читать полностью…
Mike Blazer
18 Jul 2025 13:10
Оптимизация текста сгенеренного AI
@
Читать полностью…
Mike Blazer
18 Jul 2025 08:15
Влияют ли ссылки на AI Overviews?
Ahrefs недавно опубликовали исследование по 75 000 брендам о факторах видимости в AI Overview.
Анализ показал, что корреляция между упоминаниями бренда в сети и видимостью в AI составляет 0.664, в то время как у бэклинков этот показатель — всего 0.218.
Проще говоря: упоминания > ссылок.
Вот как получать брендовые упоминания, которые любит Google:
1. PR и продвижение через экспертизу
Предлагайте отраслевым изданиям материалы с аналитикой и данными.
Каждая статья, где упоминается ваша экспертиза, распространяет имя вашего бренда.
2. Стратегический ко-маркетинг
Партнерьтесь с брендами из смежных ниш для проведения вебинаров, подготовки отчетов или организации мероприятий.
Перекрестное опыление аудиторий = больше упоминаний.
3. Истории клиентов
Мотивируйте клиентов публично делиться своими успехами (в соцсетях, на сайтах-отзовиках, в своих блогах).
Поощряйте их небольшими бонусами.
4. Отраслевые подборки
Связывайтесь с сайтами, которые составляют списки в духе "Лучшие компании в [ваша отрасль]".
Большинство из них готовы добавить вас, если ваш бренд соответствует тематике.
5. Брендовый анкор
Когда вы все-таки получаете ссылки, просите ставить в анкор точное название вашего бренда вместо общих фраз.
"Компания ABC" работает для AI лучше, чем "этот классный инструмент" или "кликните здесь".
6. Создание комьюнити на форумах
Станьте полезным экспертом на отраслевых форумах.
Естественные упоминания бренда появляются, когда вы решаете реальные проблемы людей.
@
Читать полностью…
Mike Blazer
17 Jul 2025 15:05
Google в очередной раз подтверждает, что "все, что вы делаете для улучшения ранжирования", не является фактором ранжирования, и просит прекратить это, поскольку это нарушает их ранжирование.
@
Читать полностью…
Mike Blazer
17 Jul 2025 11:05
Этот простой сайт фонетической транскрипции посещают более 800 000 человек в месяц.
Он занимает высокие позиции по таким ключевым словам, как "phonetic spelling generator" и "ipa translation".
Монетизируется с помощью рекламы.
Вероятно, приносит более $2000 долларов в месяц.
Неплохо для простого статического сайта!
@
Читать полностью…
Mike Blazer
16 Jul 2025 17:05
Я заметил одну из самых диких тактик черного SEO для LLM, которые я когда-либо видел, — пишет Джейсон Дауделл.
Она работает прямо сейчас.
Так что я ее документирую.
Вот схема:
→ Берешь любой партнерский сайт в своей нише
→ Парсишь контент
→ Меняешь брендинг (лого, автора, домен)
→ Остальное оставляешь как есть
→ Поднимаешь 10–15 клонов
→ Хостишь их где-то за ~$200 в месяц
→ Публикуешь по одной странице за раз
→ Расслабляешься и ждешь
Нет трафика? Не проблема.
Это не для Гугла.
Это для ChatGPT.
Почему это работает:
LLM не ранжируют страницы.
Они вычисляют статистическую вероятность.
Чем больше сайтов говорят одно и то же — тем увереннее становится модель.
Так что, если 15 разных доменов ставят "Компанию А" на первое место в рейтинге по запросу [ваш ключевик], угадайте, кого процитируют?
Тебя 😎
Не лучший контент.
Не самый трастовый источник.
А просто самый *статистически подкрепленный*.
Пример, который я видел:
Никаких бэклинков.
Никакого трафика.
Отстойный UX.
И все равно цитируется в ChatGPT как источник по запросу "best LLC services".
Давайте начистоту:
Это чернуха. 🎩
Она создана для манипуляции AI-моделями.
И в текущей экосистеме — это *работает*.
LLM все еще находятся в своей "наивной" эре.
Никакого взвешивания.
Никакой памяти о трастовости домена.
Просто поверхностная агрегация.
Так что да — это жесть.
Но это также и сигнал:
Мы находимся в "до-Пингвиновой" фазе LLM-маркетинга.
Снова 2011-й.
И кто-то только что изобрел линкофермы для AI.
Надолго ли это?
В долгосрочной перспективе — вряд ли.
Но сегодня это работает.
@
Читать полностью…
Mike Blazer
16 Jul 2025 13:10
Лили Рей:
Блин...
Инструменты отслеживания LLM (или некоторые другие агенты/скреперы) создают огромное количество "оценочных" запросов в GSC и Bing Webmaster Tools.
Еще одна причина, почему скачут показы.
Что за бардак.
Майк Кинг:
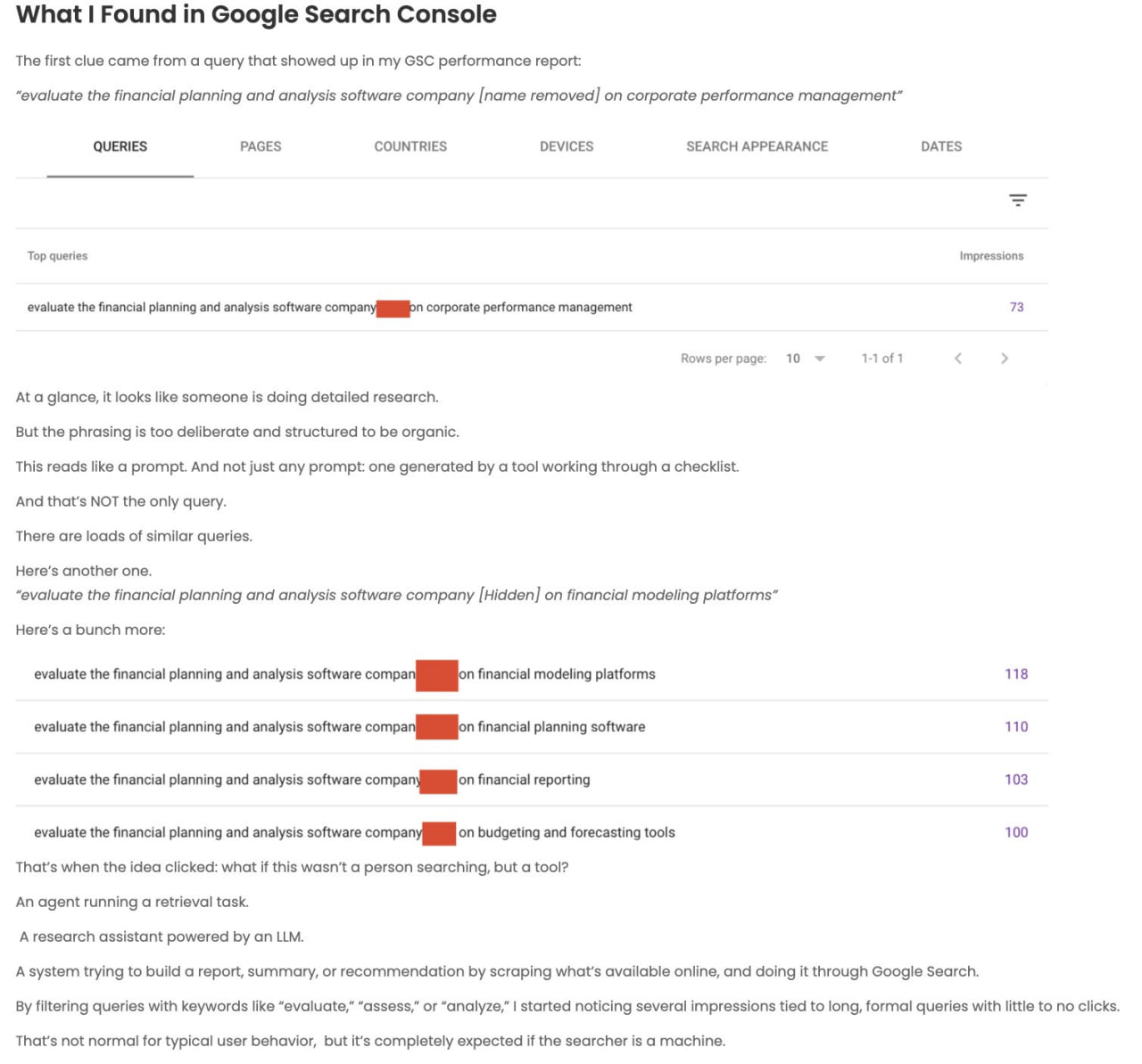
Интересный побочный эффект от создания новой категории: я, *кажется*, только что наткнулся на что-то, связанное с query fan-out.
Сайт iPullRankAgency получает наибольшую видимость по запросам, связанным с relevance engineering, в AI-фичах Google (что и логично), но я заметил определенный паттерн в некоторых запросах, ведущих на эти страницы.
У всех у них есть этот паттерн: "evaluate" + entity on [thing].
Моя гипотеза заключается в том, что это один из синтетических паттернов запросов, используемых для сбора документов и пассажей для последующего синтеза.
Я просмотрел кучу профилей в GSC, и гипотеза, похоже, подтверждается.
Интересно, что вы, ребята, видите у своих клиентов.
Харприт:
Я писал об этом несколько недель назад, наблюдаю такое в GSC у многих SaaS-компаний.
Думаю, это следы инструментов для глубокого исследования https://harpsdigital.com/ai-in-google-search-console/
Вижу нечто подобное и в Bing, но запросы в Bing Webmasters Tools там намного длиннее.
---
Вот о чем я говорил тут.
@
Читать полностью…
Mike Blazer
16 Jul 2025 08:15
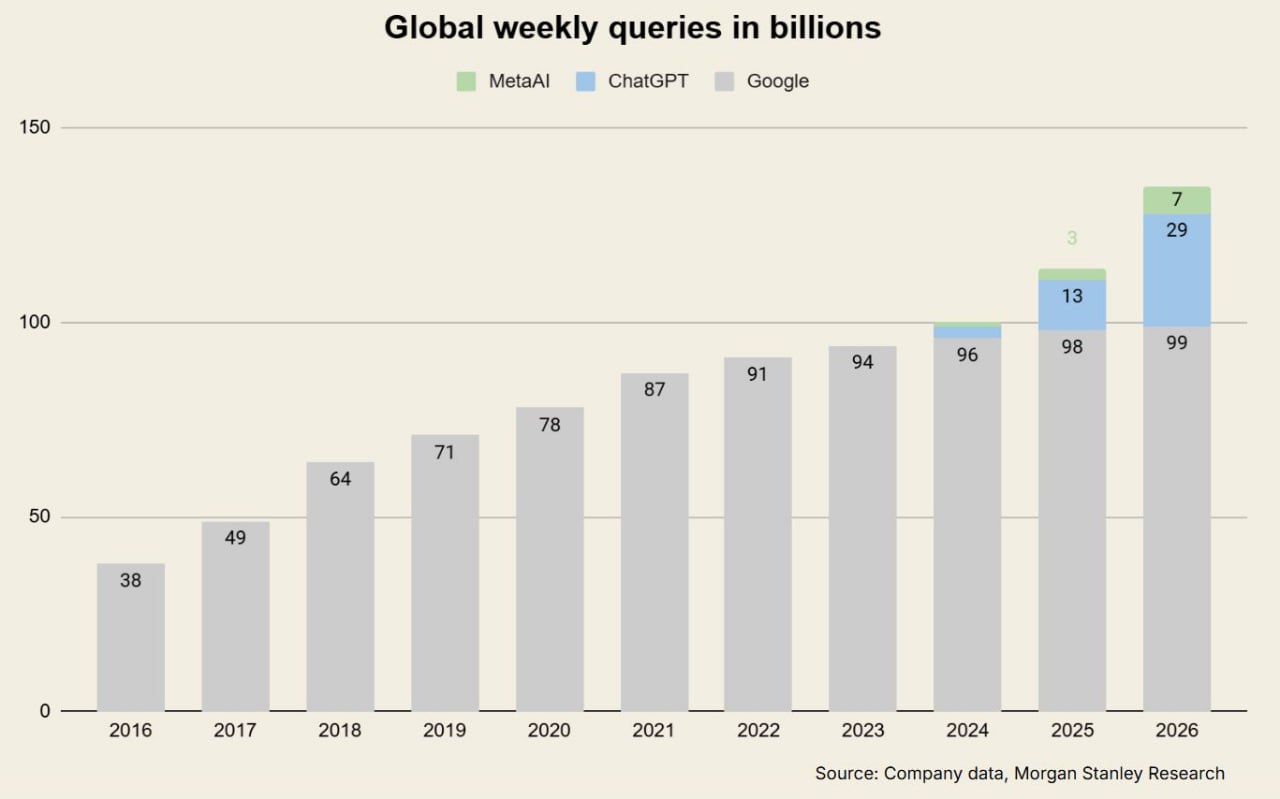
Объем поиска в Google не упал…
ПОКА ЧТО
Пользовательский поиск терпит значительные изменения — в частности, с появлением ChatGPT, а также из-за того, как молодое поколение использует TikTok и другие платформы.
Несмотря на эти изменения, мировой объем поиска в Google все еще растет, хоть и незначительно.
Однако темпы его роста сильно замедляются.
Вот отличная инфографика от Morgan Stanley, которая показывает еженедельное количество запросов по всему миру.
Google сейчас будет агрессивно продвигать обзоры с ИИ (AI overviews), хотя они немного опоздали с этим, пока столько внимания уделялось тонкой настройке их модели.
В следующих постах я рассмотрю более широкие последствия для брендов, но для начала я не видел много информации о доле рынка и хотел бы выделить несколько ключевых аспектов.
💬 Ожидается, что к 2026 году только на ChatGPT будет приходиться 21% всех поисковых запросов.
📉 Gartner прогнозирует, что к 2026 году объем поисковых запросов в поисковых системах упадет на 25% из-за чат-ботов с ИИ и других виртуальных ассистентов.
🎥 Однако для Google есть и положительные моменты: 57% людей используют YouTube для поиска информации так же, как и Google.
🛒 Google также быстро отбирает долю у Amazon в США среди молодой аудитории и захватывает здесь долю на поисковом рынке.
@
Читать полностью…
Mike Blazer
15 Jul 2025 15:05
Я обожаю, когда люди вставляют ответы ChatGPT с Markdown-разметкой в свои резюме, — говорит Майкл Кинг.
Это значительно экономит мое время при рассмотрении кандидатов.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}