Mike Blazer
18 Jun 2025 17:05
Гугл: 404-е — это нормально!
Они — естественная часть веба.
Можете просто их игнорировать, и мы тоже будем.
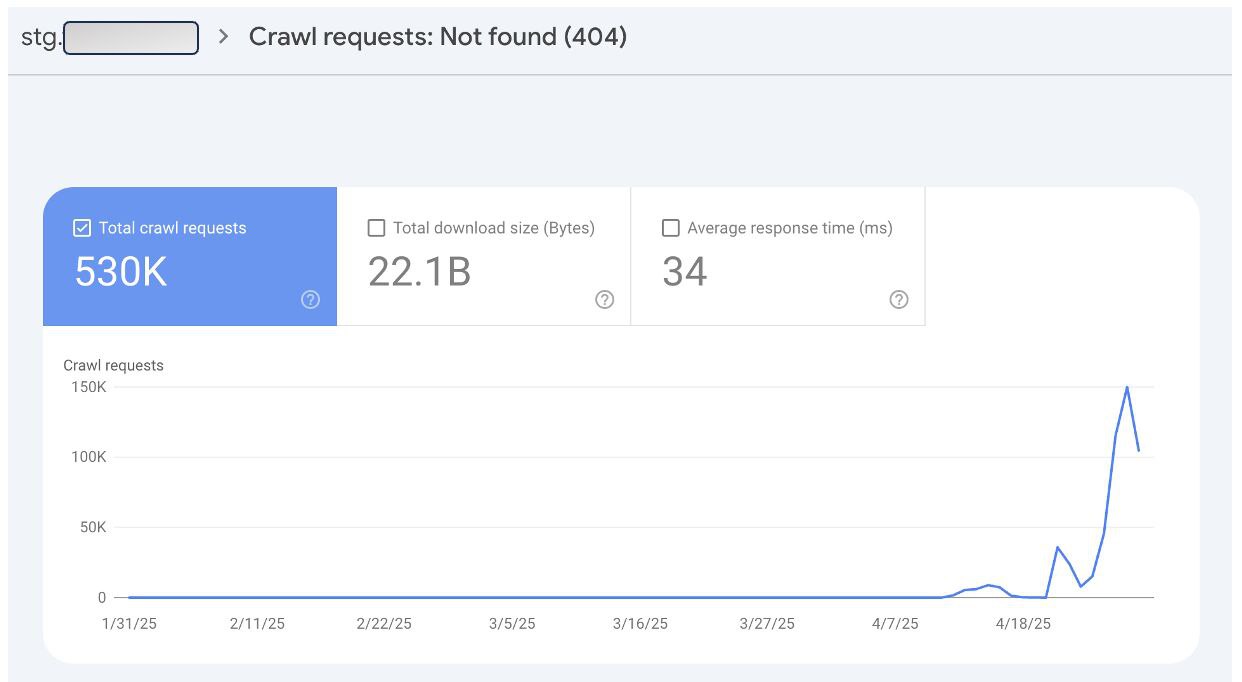
Тем временем Гугл, увидев, что стейджинг начал отдавать 404-е *и* получил запрос на удаление страниц в GSC: Я ПРОКРАУЛЮ ТЕБЯ 530 ТЫСЯЧ РАЗ!
@
Читать полностью…
Mike Blazer
18 Jun 2025 13:15
22 типа ссылок для линкбилдинга: Риск, стоимость и эффективность!, (часть 2 из 2)
1️⃣2️⃣ Локальные цитирования / Ссылки из каталогов
NAP (Название, Адрес, Телефон) для локального SEO
⚠️ Уровень риска: Нулевой (если не спамить)
🚀 Эффективность: 7/10 (только для локального SEO)
⏳ Долговечность: 10/10
💰 Стоимость: Бесплатно – $300 (самостоятельно vs через сервис)
1️⃣3️⃣ Ссылки с Web 2.0
WordPress.com, Tumblr, Blogger и т.п., часто как прокладки/для тиров
⚠️ Уровень риска: Низкий (для тир-2/3); Средний (спамный Тир-1)
🚀 Эффективность: 5.5/10 (Тир-1); 7.5/10 (стратегия для Тир-2)
⏳ Долговечность: 8/10
💰 Стоимость: Бесплатно – $100 (ассистент/боты)
1️⃣4️⃣ Ссылки с изображений
Инфографика, мемы, диаграммы, вставки
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 6.5/10 (выше на трастовых сайтах)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $300+ за графику
1️⃣5️⃣ Ссылки из пресс-релизов
Ссылки через новостные агрегаторы и синдикацию
⚠️ Уровень риска: Низкий (если не злоупотреблять/не спамить)
🚀 Эффективность: 7/10 (для динамики), 5/10 (для прямого влияния на ранжирование)
⏳ Долговечность: 6/10 (зависит от срока хранения новости агрегатором)
💰 Стоимость: $75 – $800
1️⃣6️⃣ Ссылки с доменов .EDU / .GOV
Ссылки с образовательных/государственных учреждений
⚠️ Уровень риска: Низкий (если легально); Высокий (если перемудрить со схемой)
🚀 Эффективность: 9/10
⏳ Долговечность: 10/10 (если страница не умрет/админ не удалит)
💰 Стоимость: Бесплатно (получено естественным путем) – $1,500+ (платные размещения)
1️⃣7️⃣ Обмен ссылками
Взаимный обмен, схемы A-B-C
⚠️ Уровень риска: Средний (если злоупотреблять или схема легко отслеживается)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 5–9/10 (зависит от размера сетки)
💰 Стоимость: Бесплатно – $500+
1️⃣8️⃣ Ссылки с купонных и скидочных сайтов
Ссылки с сайтов вроде RetailMeNot, Groupon и т.п.
⚠️ Уровень риска: Низкий (если не спамить)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 6–9/10 (пока действует предложение)
💰 Стоимость: Бесплатно – $500
1️⃣9️⃣ Ссылки с вебинаров, видео и подкастов
В описаниях, шоу-ноутах, биографиях спикеров
⚠️ Уровень риска: Нулевой
🚀 Эффективность: 8/10 (сильно недооценены)
⏳ Долговечность: 10/10
💰 Стоимость: Бесплатно – $1,000 (своими силами vs спонсорство)
2️⃣0️⃣ Ссылки из отзывов
Предоставление отзыва в обмен на ссылку
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 7/10 (при грамотном размещении)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $150 (стоимость использования продукта/услуги)
2️⃣1️⃣ Ссылки в сайдбаре и футере
Сквозные ссылки (сквозняки)
⚠️ Уровень риска: Высокий
🚀 Эффективность: 8/10 (если они чистые и релевантные)
⏳ Долговечность: 4–7/10
💰 Стоимость: $50 – $500 (часто с помесячной оплатой)
2️⃣2️⃣ NoFollow и Sponsored ссылки
Ссылки с атрибутами rel="nofollow" или rel="sponsored"
⚠️ Уровень риска: Отсутствует
🚀 Эффективность: 4/10 (для ранжирования) – 8/10 (для траста и динамики)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $1,000+
https://presswhizz.com/blog/types-of-backlinks/
@
Читать полностью…
Mike Blazer
18 Jun 2025 11:05
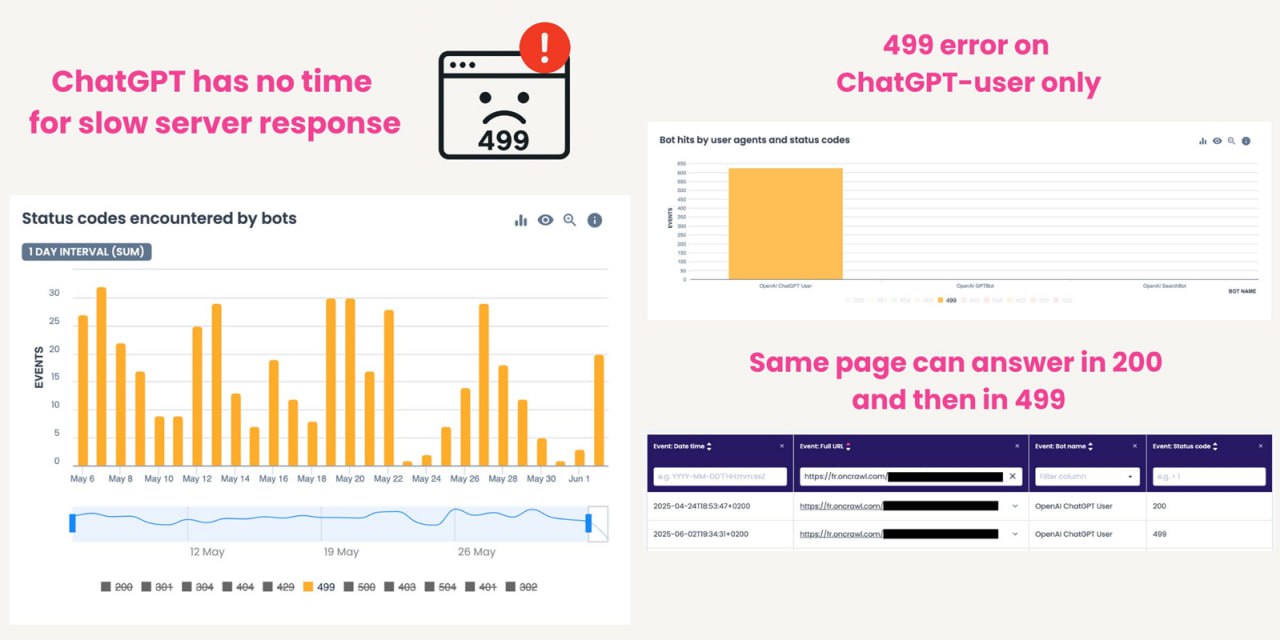
У ChatGPT нет времени на ваши медленные страницы ⏱️
Анализируя ботов OpenAI в логах сервера, я наткнулся на то, что нечасто встретишь у Гуглобота: множественные хиты от ботов с кодом ответа HTTP 499, — пишет Жером Саломон.
Что такое 499-я ошибка?
Код ответа HTTP 499 означает, что клиент закрыл соединение до того, как сервер успел ответить.
В нашем случае клиент — это бот, отправленный ChatGPT, который прерывает запрос из-за задержки ответа сервера.
🔍 Углубившись в анализ, я обнаружил:
— 99% этих хитов с 499-й ошибкой приходится на бота ChatGPT-user.
— Эта ошибка встречается не на всех сайтах.
— Ее доля может достигать 5% от всех хитов бота ChatGPT-user.
— Некоторые страницы могут на один запрос отдавать код 200, а на другой — 499.
Почему это важно?
ChatGPT-user — это бот, которого ChatGPT Search отправляет в режиме реального времени, чтобы получить контент и использовать его в качестве цитаты в ответе.
Он всегда краулит несколько источников одновременно, чтобы собрать самую релевантную информацию и на лету сформулировать исчерпывающий ответ.
Если ChatGPT-user закроет соединение до того, как ваш сервер успеет ответить, ваша страница не будет использована в ответе.
Вы упускаете возможность быть процитированным и, возможно, даже получить реферальный трафик.
🧠 Теории:
Учитывая, что поиск ChatGPT работает в реальном времени, он не может позволить себе ждать медленные страницы.
Если ваш сервер отвечает медленно или страница грузится слишком долго, ChatGPT прервет запрос, что и приведет к ошибке 499.
1. Вероятно, ChatGPT Search использует правила таймаута, чтобы обеспечить быстрые ответы и хороший пользовательский опыт.
2. Боту ChatGPT-user больше не нужно ждать вашу страницу — возможно, потому что процесс краулинга останавливается, как только X страниц успели ответить вовремя.
Это объясняет, почему одна и та же страница иногда отдает 200-й код, а иногда — 499-й.
Это значит, что ваш сайт конкурирует с другими по времени ответа сервера и скорости загрузки страниц.
Растущая важность Bot Experience
Это подчеркивает критический сдвиг: одной лишь оптимизации под пользовательский опыт уже недостаточно.
И дело не только в скорости.
Бот ChatGPT не рендерит JavaScript.
Если показ контента на вашей странице сильно зависит от JS, она будет невидима для бота.
Ему нужен быстрый, чистый, хорошо структурированный HTML.
В меняющемся ландшафте поиска с использованием ИИ приоритизация опыта взаимодействия с ботами становится критически важной.
Быстрый, доступный и хорошо структурированный контент не только улучшает вовлеченность пользователей, но и повышает вероятность того, что ваши страницы будут процитированы в ответах, сгенерированных ИИ.
@
Читать полностью…
Mike Blazer
17 Jun 2025 17:05
Влияет ли замена AI-контента на созданный человеком контент на индексацию?
А то! Еще как может 😂
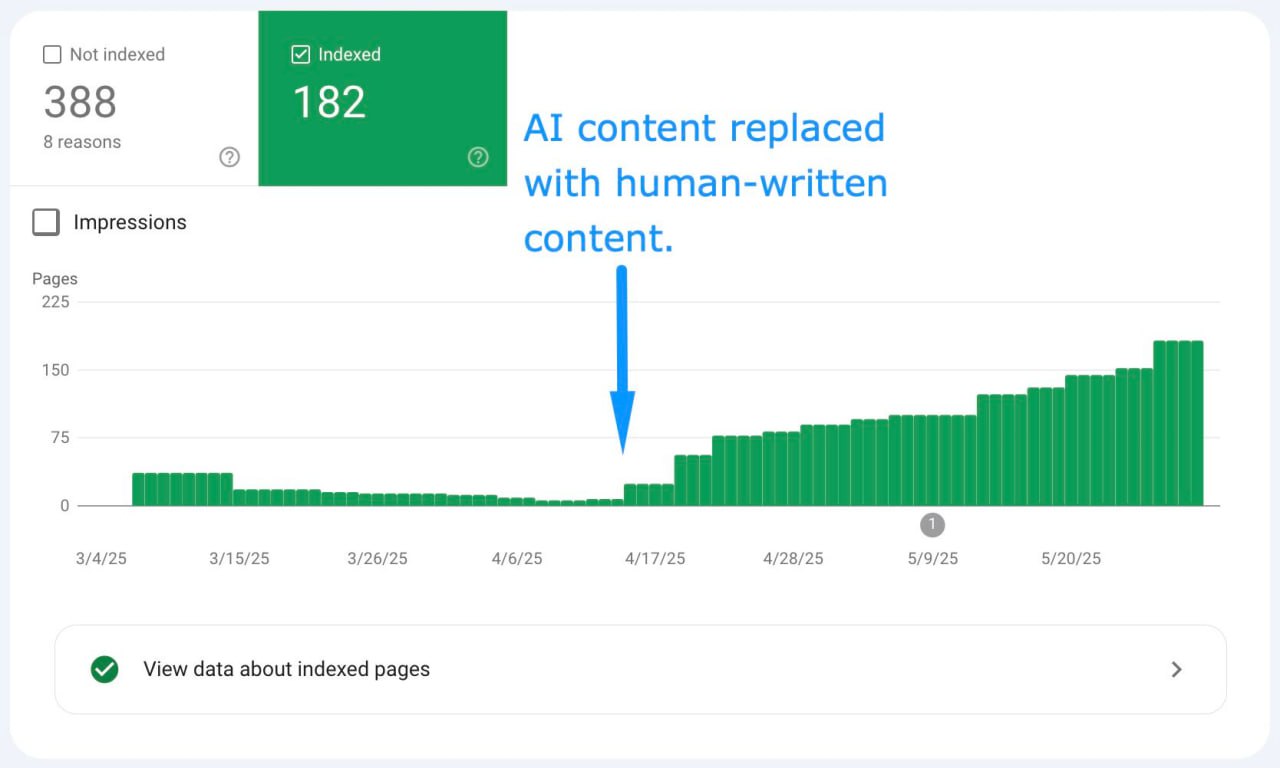
Вот вам кейс: программатик-сайт (продукт на базе ИИ), который в прошлом году взломали и он вылетел из индекса Гугла.
Прошло 9+ месяцев, а сайт все еще с трудом попадал в индекс, когда они пришли ко мне.
С безопасностью все было чисто.
Мы перепробовали ВСЕ, чтобы улучшить SEO, пользовательский опыт и авторитет сайта, — пишет Кристан Бауэр.
Ничего не давало долгосрочного эффекта.
Мы видели временные всплески индексации, но потом Гугл снова и снова выбрасывал эти страницы из индекса.
В конце концов клиент вернулся к одной из моих первоначальных рекомендаций: протестировать замену AI-контента на контент, написанный человеком.
Ооо, какая свежая мысль 😂
Будучи AI-продуктом, они ИСКЛЮЧИТЕЛЬНО использовали сгенерированный ИИ контент по всему сайту — как программатик-контент, так и редакционные материалы.
Моя рекомендация была просто протестировать гипотезу и убедиться в ее состоятельности, прежде чем вкладывать значительные ресурсы.
И что бы вы думали...
Моментальная индексация и видимость. 👏
Эти цифры все еще ОЧЕНЬ скромные, и им предстоит ДОЛГИЙ путь, чтобы вернуть сайту былую славу.
Но это уже прогресс.
Другие внесенные нами изменения улучшат вовлеченность и позиции, но "серебряной пулей" здесь стала замена AI-контента на качественный авторский контент.
Заставляет задуматься, не так ли?!
ЛОЛ.
Я не говорю, что любой AI-контент не будет работать или индексироваться, но в данном случае ВЕСЬ контент был сгенерирован ИИ, что, вероятно, и вызвало проблемы с качеством.
@
Читать полностью…
Mike Blazer
17 Jun 2025 13:10
Давайте выясним, насколько хорошо ChatGPT видит контент на ваших страницах.
Итак, вот эксперимент о влиянии микроразметки Schema.org на видимость для LLM.
Я хотел получить сухие факты о влиянии микроразметки на видимость в AI-поиске, — говорит Бенджамин Танненбаум.
Действительно ли она улучшает то, что ChatGPT знает обо мне?
Поэтому я сделал сайт с двумя подстраницами.
С одинаковой информацией. Одна с микроразметкой Schema.org, другая — без.
Я попросил ChatGPT ответить на конкретные вопросы по каждой из них.
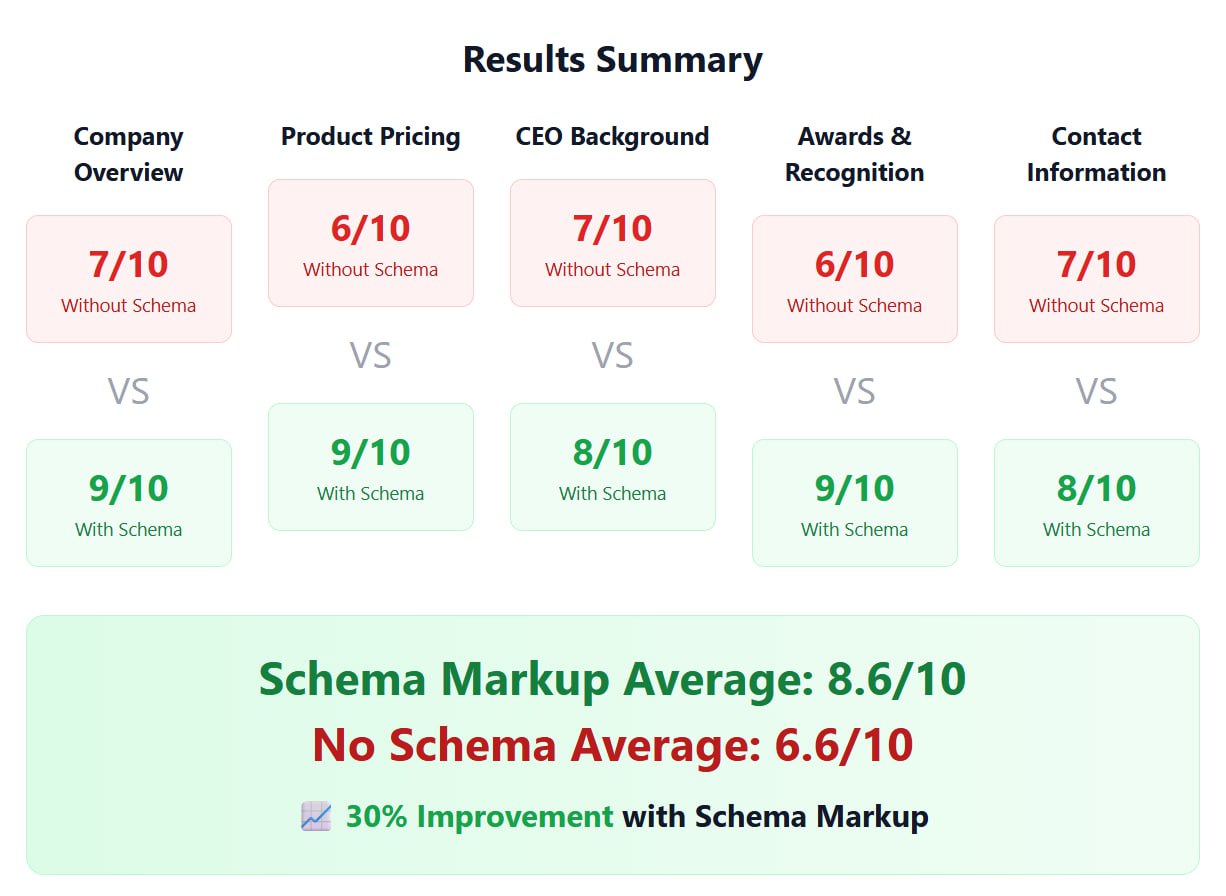
Результаты?
С микроразметкой: в среднем 8.6/10
Без микроразметки: в среднем 6.6/10.
-> 📈 Улучшение на 30% с микроразметкой!
Особенно сильно это повлияло на структурированные данные: пользовательские рейтинги (4.8/5 звезд) и сертификаты (ISO 27001, SOC 2) появились только в ответах для страницы с микроразметкой!
И улучшение происходит моментально!
Не нужно ждать шесть месяцев, как с другими полезными вещами, вроде сторонних источников.
И что самое крутое?
Вы можете сами все проверить — все данные в открытом доступе.
Вывод: внедряйте микроразметку Schema.org правильно, чтобы улучшить видимость для LLM (и ранжирование в Google!).
https://www.getaiso.com/blog/schema_markup_experiment_blog_post
@
Читать полностью…
Mike Blazer
17 Jun 2025 08:15
Вакансии = CTR.
Когда ты запускаешь объявление о вакансии, особенно в тяжелые времена, когда людям нужна работа, особенно в странах третьего мира, ты получаешь кучу откликов.
И если ты не в курсе, данные Google Chrome на 100% передаются в поисковые алгоритмы.
Так что это значит?
Вакансия = CTR, а CTR = позиции в выдаче.
Даже если это просто поисковый объем по брендовым запросам, это реально помогает.
И как это использовать?
За 5-10 баксов в день на LinkedIn ты можешь получить толпу соискателей.
Реально толпу.
И можно даже таргетировать по регионам.
Это значит, что тебе, возможно, и не нужен софт для накрутки CTR, когда объявления о вакансиях на LinkedIn пригоняют реальных юзеров для кликабельности.
У нас была открыта вакансия, получили около 10K откликов, кучу брендового трафика, и наши позиции в выдаче подросли, говорит Джеки Чоу.
Ненамного, потому что контента у нас мало, но все же подросли.
Количество подписчиков на нашей странице в LinkedIn тоже выросло до 3.2K; мы ничего не покупали, просто запустили объявление о вакансии, и оно взлетело.
Так что это просто безумная ценность для CTR и органики.
Попробуйте сами.
@
Читать полностью…
Mike Blazer
16 Jun 2025 15:05
Модели кликов похожи на языковые модели — только для поведения.
Клик — это слово, которое выражает смысл.
Но не все клики хороши.
Для конвертера валют короткий клик = задача выполнена ✅
Для страницы оплаты в казино короткий клик = путаница или недоверие ❌
Значение клика зависит от намерения и отраслевых норм.
Системы безопасного просмотра и NavBoost от Google используют клики, PageRank и актуальность в качестве единого сигнала.
Нет кликов?
Нет RankBrain.
Нет сложной обработки.
Страницы без кликов не заслуживают дорогих алгоритмов.
Некоторые сайты месяцами ждут обновления Core или Phantom, чтобы привлечь внимание Google.
Клики — это не просто метрики.
Они имеют значение.
Если вы хотите, чтобы Google использовал лучшие алгоритмы, заставьте пользователей заинтересоваться настолько, чтобы они кликнули — и остались.
@
Читать полностью…
Mike Blazer
16 Jun 2025 11:05
SEO-команды знают, что тематический авторитет позволяет быстрее наращивать трафик, обеспечивает видимость в AI Overviews и используется в ответах LLM с дополненной генерацией (RAG), — но до сих пор у нас не было надежной метрики, чтобы это доказать.
🔍 Новый скорер превращает это слепое пятно в конкретную метрику за счет того, что:
— Количественно оценивает долю в теме, чтобы вы могли защищать бюджеты, перераспределять ресурсы и демонстрировать прогресс из месяца в месяц.
— Выявляет пробелы в контенте, где дополнительный охват тем принесет максимальную отдачу.
— Заменяет голословные заявления об авторитетности на воспроизводимую оценку, нормализованную по конкурентам.
🏗 Как это работает:
1. Сбор и валидация данных: загружаем тему, домен и локаль; выгружаем все ранжирующиеся страницы; оставляем только релевантные теме URL; добавляем метрики эффективности.
2. Анализ контента: выделяем выигрышные и отстающие ключевые слова, картируем охват подтем, рассчитываем сигналы авторитетности.
3. Анализ конкурентов: собираем тот же набор данных для трех главных доменов-конкурентов.
4. Сравнительный скоринг: сравниваем глубину, широту, бэклинки и долю по ключевым словам, чтобы присвоить оценку авторитетности каждому домену.
5. Генерация отчета: предоставляем сводку для руководства, подробный анализ пробелов и приоритезированные дальнейшие шаги.
Большие языковые модели, такие как Chat GPT, AI Overviews или AI Mode, отдают предпочтение актуальным, авторитетным источникам с тематической глубиной, чтобы на их основе обосновывать ответы и ссылаться на домены.
Измерение и устранение пробелов в авторитетности — это прямой рычаг для роста видимости как в классических синих ссылках, так и в ответах, сгенерированных ИИ.
Хотите заценить этот скорер? Вам сюда:
https://app.airops.com/public_apps/f52eafe1-1ec3-43ab-888f-31f5ec760bfe/run
@
Читать полностью…
Mike Blazer
15 Jun 2025 16:05
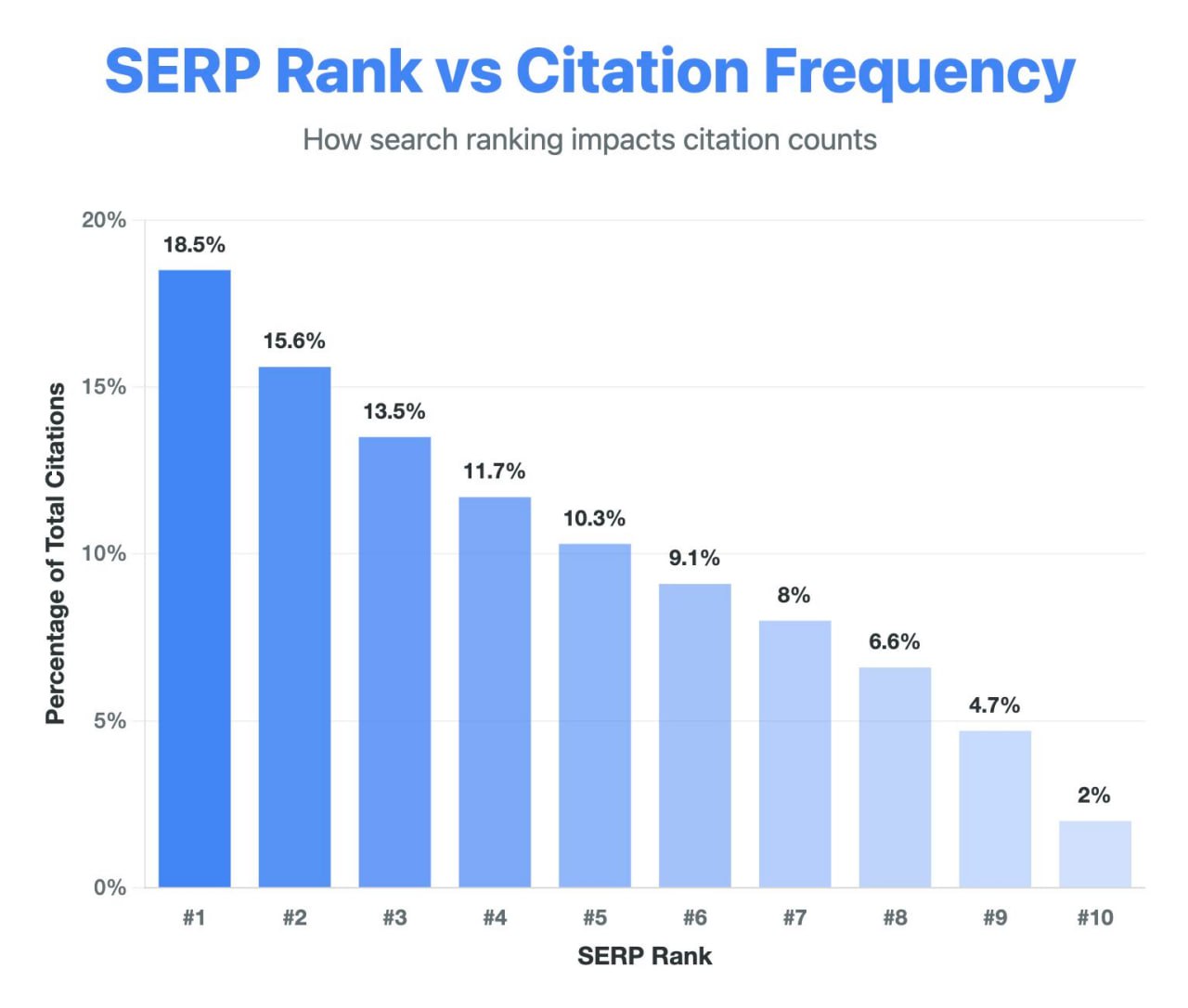
Мы проанализировали более 1 миллиона Google AI Overviews, — говорит Саманью Гарг.
И вот что мы выяснили 👇
📈 Ранжирование на первой позиции в Google по-прежнему имеет огромное значение.
Лидеры поисковой выдачи доминируют в цитированиях в AI Overviews.
-> ТОП-1 цитируется в ~18.5% случаев
-> ТОП-2? 15.6%
-> ТОП-10? Всего 2%
А те, кто ниже?
Практически невидимы.
Чем выше ваши позиции, тем больше вероятность, что ИИ будет вам доверять и вас цитировать.
И хотя может показаться, что AI Overview от Google "находит лучшие ответы",… на деле он часто просто вторит первым трем синим ссылкам.
Поэтому, если вас нет в топе, ИИ вас тоже не упомянет.
А это значит: никаких показов бренда.
Никакого трафика.
Никакого доверия.
@
Читать полностью…
Mike Blazer
15 Jun 2025 11:05
Будьте осторожны с данными Google Search Console.
Система будет врать вам.
Принимать решения только на основании этих данных — ошибка.
В данном случае URL имеет самоканонический URL, однако Google утверждает, что ПОЛЬЗОВАТЕЛЬ выбрал другой URL в качестве канонического.
Что категорически неверно.
Причина №204, почему не стоит считать инструменты Google объективным отражением вашей видимости в поиске.
@
Читать полностью…
Mike Blazer
14 Jun 2025 09:15
Все люди, как люди, ну а этот...
@
Читать полностью…
Mike Blazer
13 Jun 2025 15:05
Я пробую первую попавшуюся возможность (батут был перевернут)
@
Читать полностью…
Mike Blazer
13 Jun 2025 11:05
Если вы с горечью воспринимаете эти изменения в SEO и не хотите пробовать что-то новое, помните:
Сегодня на рынок труда выходят сеошники, которые не обременены нашим багажом.
Они будут воспринимать мир таким, каким он есть, и принимать решения, основываясь на том, что работает сейчас, а не на том, что они *хотели бы*, чтобы работало сейчас.
Вперед и вверх!
@
Читать полностью…
Mike Blazer
12 Jun 2025 17:05
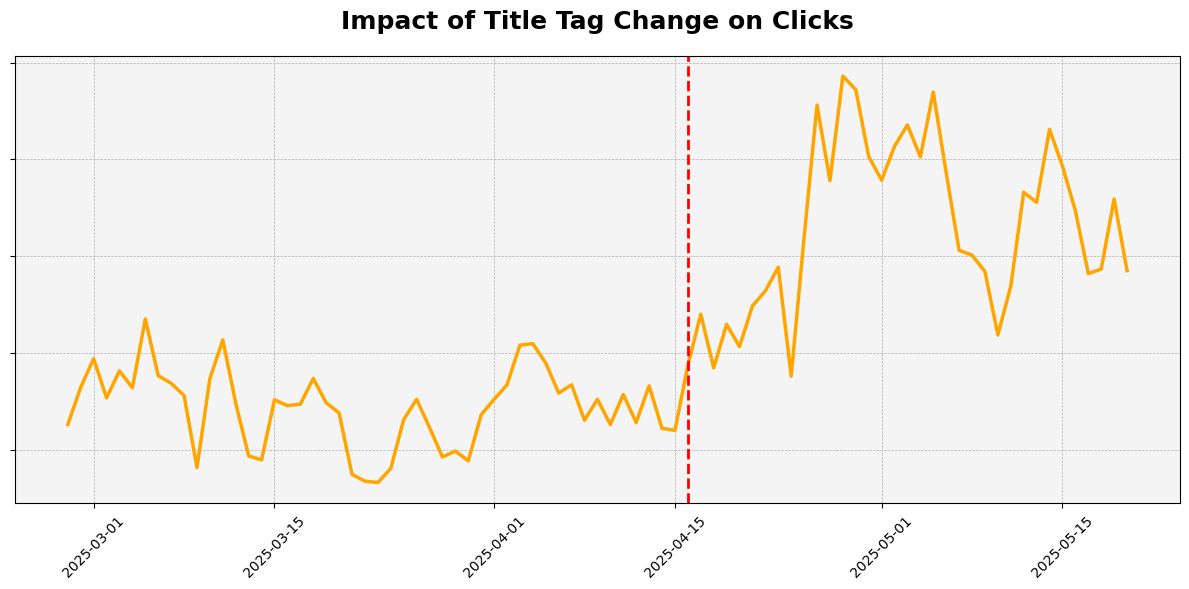
Никогда не недооценивайте тест тайтлов.
Я недавно провела супер простой #SEO эксперимент, пишет Эбби Глисон:
1️⃣ Взяла нашу статью с самым большим трафиком
2️⃣ Подкрутила тайтл, добавив зацепку в конце.
Всего несколько дополнительных слов, чтобы сделать его более цепляющим и заметным, раньше он был довольно скучным
Вот и все.
Никаких других обновлений контента или технических изменений.
Результаты через месяц:
✅ Клики: +35%
✅ Ранжирующиеся запросы: +59% (2.2K → 3.5K)
📌 Потратьте 15 минут на аудит ваших топовых тайтлов: соответствуют ли они ключам и достойны ли клика?
Могут ли они вызвать больше интереса в СЕРПе?
💡 Совет: Мне нравится использовать Reddit, чтобы посмотреть, как люди обсуждают тему — как источник вдохновения.
Внесите изменения и отслеживайте результаты в таких инструментах, как SEOclarity или SEOtesting.
Эти инсайты также отлично подходят для платного поиска, контента и отчетности руководству.
Вперед тестировать!!
@
Читать полностью…
Mike Blazer
12 Jun 2025 13:10
В будущих проектах по миграции, над которыми я буду работать, я внедрю нечто новое — до и после миграции, — говорит Крис Левер.
Сравнение векторных эмбеддингов для отслеживания сдвига контента.
Вот почему!
1. Причина, по которой вплоть до сих пор в SEO не широко использовался сдвиг эмбеддингов, проста: у нас не было легкого доступа к инструментам.
Но теперь все изменилось, и вы можете сделать это с помощью Screaming Frog и простого скрипта на Python.
2. Внедрения отражают суть страницы.
Они представляют ее в высокоразмерном пространстве на основе взаимосвязей между концепциями, фразами и контекстом.
Эти внедрения помогают Google сравнивать страницы, оценивать, насколько они соответствуют запросу пользователя, и группировать похожий контент по темам и авторитетности.
Таким образом, если мы сгенерируем эмбеддинги на существующих ключевых страницах и снова на новом сайте непосредственно перед запуском, а затем отследим семантическое сходство, используя оценочную карту, подобную этой.
1.0 = нет изменения в значении
0.95 = незначительное обновление, контент по-прежнему соответствует
0.85 = умеренное изменение, вероятно, Google переоценит
0.75 и ниже = значительное изменение, Google может рассматривать как новое
Вы можете запустить этот процесс на каждой ключевой странице или сгруппировать их по шаблонам, категориям или типам страниц для масштабирования.
Это не заменяет ваши проверки сравнения сканирования.
Это просто добавление новой проверки, которая соответствует тому, как Google на самом деле понимает ваш контент.
Это имеет смысл, это измеримо и будет включено в мой чек-лист для будущих миграций.
@
Читать полностью…
Mike Blazer
18 Jun 2025 15:05
Забавная ✨агентская фишка✨ - когда они складывают опыт всех членов команды, и получается, что трёхлетнее SEO-агентство пишет на своём сайте что-то типа "150 лет SEO-опыта".
Супер.
@
Читать полностью…
Mike Blazer
18 Jun 2025 13:10
22 типа ссылок для линкбилдинга: Риск, стоимость и эффективность!, (часть 1 из 2)
1️⃣ Редакционные ссылки
Естественные, непрошенные упоминания
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 9.5/10
⏳ Долговечность: 10/10 (если сайт не умрет)
💰 Стоимость: от $0 (получено естественным путем) до $1,500+ (по договоренности)
2️⃣ Ссылки из гестпостов
Контент, размещенный на чужом сайте
⚠️ Уровень риска: Средний (при переоптимизации / если оставляют футпринты)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 6–9/10 (зависит от возраста сайта/качества контента)
💰 Стоимость: $50 – $1,200 за пост
3️⃣ Вставки ссылок / Нишевые правки
Добавление ссылки в существующий, старый контент
⚠️ Уровень риска: Средне-высокий (на плохих сайтах)
🚀 Эффективность: 8.5/10
⏳ Долговечность: 7/10 (зависит от стабильности донора)
💰 Стоимость: $30 – $800 за вставку
4️⃣ Ссылки из Digital PR
Ссылки с инфоповодов/исследований/акций
⚠️ Уровень риска: Средний (риск провала или обратного эффекта)
🚀 Эффективность: 8/10 (может достигать 10/10 при грамотном подходе)
⏳ Долговечность: 9/10
💰 Стоимость: от $250 (своими силами) до $10,000+ (через агентство)
5️⃣ Ссылки с HARO и экспертных подборок
Предоставление цитат журналистам/блогерам
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 7.5/10 (10/10 на сайтах с DR80+)
⏳ Долговечность: 10/10 (если ссылку не удалят из статьи)
💰 Стоимость: $0 (вручную) – $400/месяц (сервис/ассистент)
6️⃣ Ссылки через паразитное SEO
Ранжирование вашего контента на чужом трастовом домене
⚠️ Уровень риска: Средний (контент может быть удален сайтом)
🚀 Эффективность: 9.5/10
⏳ Долговечность: 5–8/10 (могут быстро отваливаться)
💰 Стоимость: $50 – $2,000+
7️⃣ Ссылки с PBN
Ссылки из сеток сателлитов
⚠️ Уровень риска: Высокий (при неправильной постройке/использовании или злоупотреблении)
🚀 Эффективность: 8.5/10 (с ювелирной точностью)
⏳ Долговечность: 3–7/10 (зависит от качества сетки)
💰 Стоимость: $30–$300 (своими силами) или $100–$1,000+ (через подрядчика)
8️⃣ Ссылки из PDF
Ссылки, встроенные в PDF на сайтах для обмена документами
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 6.5/10
⏳ Долговечность: 10/10 (PDF-файлы остаются онлайн)
💰 Стоимость: $0 – $50 за документ
9️⃣ Ссылки из профилей и подписей на форумах
Ссылки в профиле или под постами
⚠️ Уровень риска: Низкий
🚀 Эффективность: 5.5/10 (для тир-2/3) – 2/10 (прямые)
⏳ Долговечность: 6–9/10 (если вас не забанят на форуме)
💰 Стоимость: Бесплатно – $100/месяц (ассистент/автоматизация)
🔟 Ссылки с авторитетных профилей
Crunchbase, About.me, G2 и т.п. – для построения сущности
⚠️ Уровень риска: Нулевой
🚀 Эффективность: 6/10 (повышает траст, а не позиции)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $250 (при аутсорсе)
1️⃣1️⃣ UGC-ссылки (пользовательский контент)
Reddit, Quora, форумы, комментарии
⚠️ Уровень риска: Низкий
🚀 Эффективность: 5/10 (для тир-2/3), 6.5/10 (прямые с Reddit/Quora)
⏳ Долговечность: 7/10 (зависит от площадки)
💰 Стоимость: Бесплатно – $150 (при аутсорсе)
Конец 1-ой части.
@
Читать полностью…
Mike Blazer
18 Jun 2025 08:15
Крутые вещи происходят, когда ты выводишь URL-ы продуктов на первый уровень.
До: {domain.com}/{category}/{product}
После: {domain.com}/product/{product}
Мгновенная индексация, больше показов, больше кликов.
Паттерны УРЛов рулят!
@
Читать полностью…
Mike Blazer
17 Jun 2025 15:05
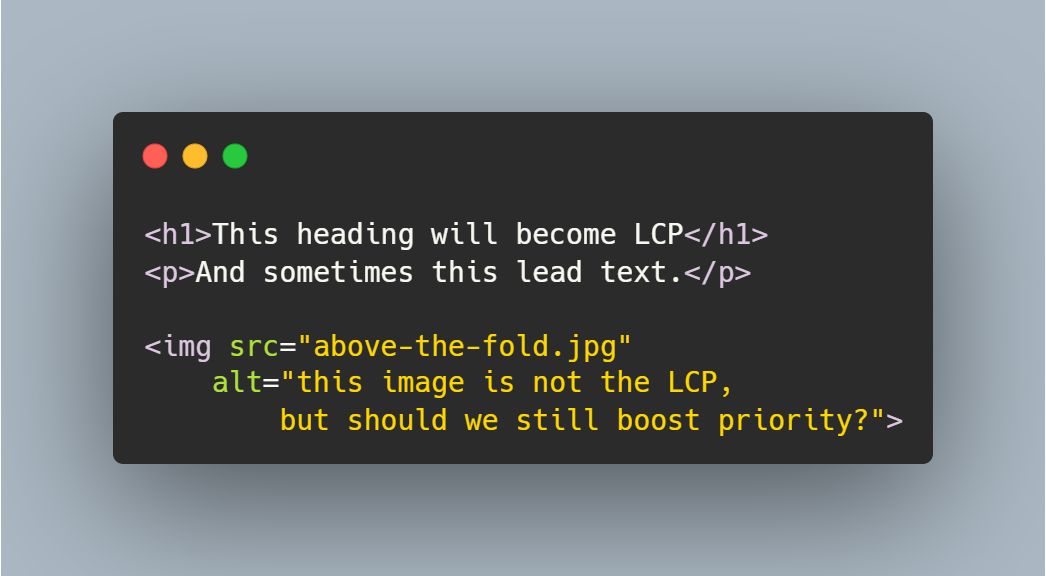
Что делать с изображениями, когда ваш H1 или лид-текст является LCP?
Ответ на самом деле прост:
→ при использовании Lighthouse может показаться, что (или ) всегда является LCP
→ но если вы собираете реальные пользовательские данные через такой инструмент, как RUMvision - мониторинг Core Web Vitals, вы могли заметить (или вам стоит знать), что LCP будет отличаться в зависимости от вьюпорта
→ что и имеет значение для CWV , а не то, что думает Lighthouse
Итак, для надежности, делайте следующее:
1️⃣ считайте ваше самое большое видимое изображение над фолдом как LCP
2️⃣ это значит: не применяйте к нему ленивую загрузку и используйте fetchpriority=high
Вот почему:
3️⃣ ваш и уже будут в исходном HTML-коде (*)
4️⃣ поэтому, загрузка вашего HTML + рендеринг этих элементов в любом случае не будут конкурировать с вашим изображением ()
5️⃣ именно поэтому безопасно повышать приоритет вашего изображения
6️⃣ при этом нужно применять это только к одному изображению на странице
(*) это применимо к `HTML` с серверным рендерингом = также лучше для скорости загрузки страницы и SEO 😜
() если вышеуказанное не применимо, потому что вы используете CSR, нюансы могут отличаться
@
Читать полностью…
Mike Blazer
17 Jun 2025 11:05
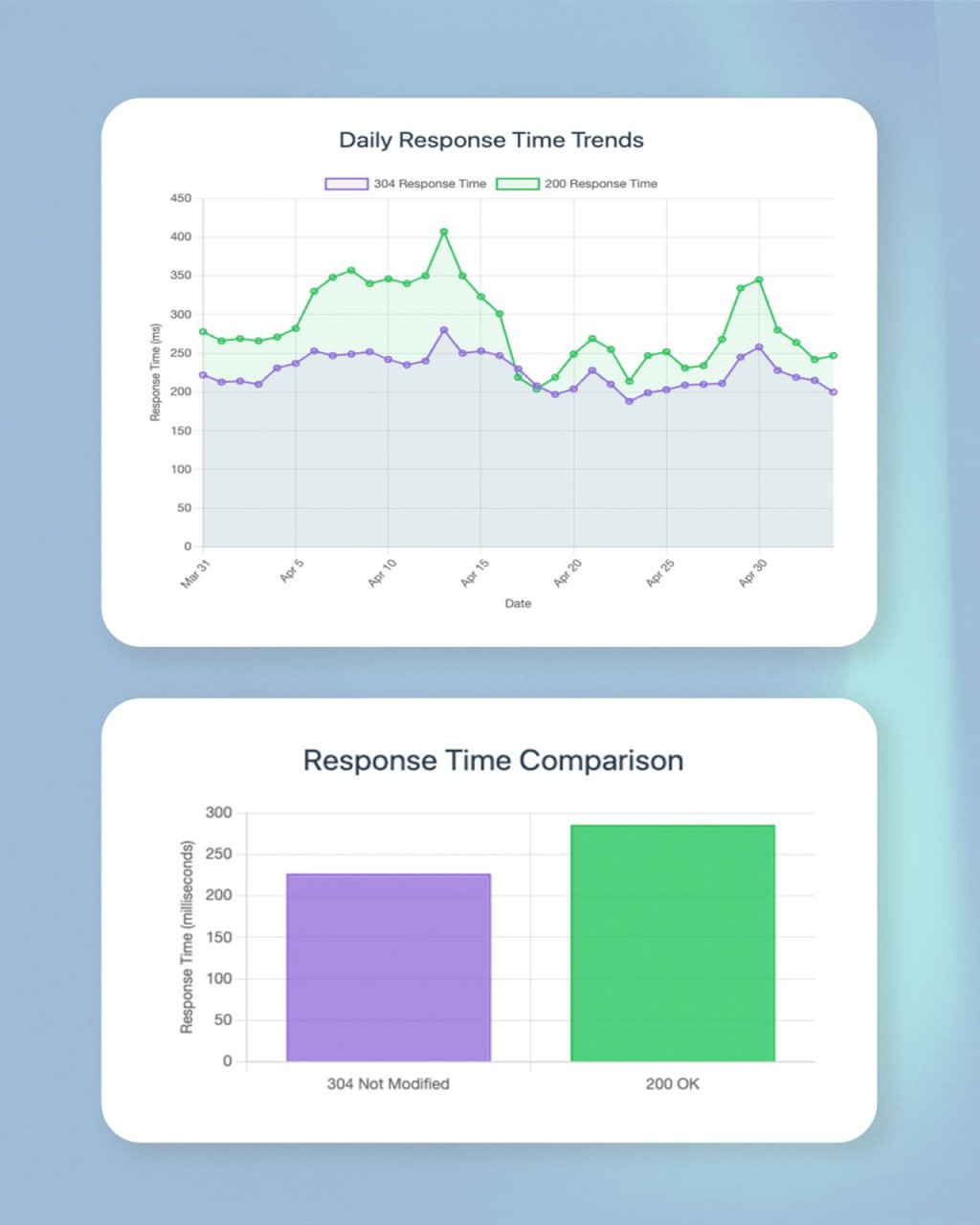
🚀 304 против 200: хак краулингового бюджета, который ты упускаешь
Недавно внедрили заголовки Cache-Control для сайта с более чем 150M `URL`ов — возвращаем 304, если контент не изменился, и 200, если есть изменения, делится Тайлер Гаргула.
Эффективность реально радует.
Цифры такие:
— Ответы 304: в среднем 226.8 мс
— Ответы 200: в среднем 285.6 мс
— 304 быстрее в 1.26х раз (экономия времени 20.6%)
Для крупных сайтов это критично, потому что даже небольшое снижение времени ответа напрямую влияет на эффективность краулинга.
Масштаб эффекта: если Googlebot обходит 12M страниц в неделю с ответами 200 → переход на 304 = 15.1М странц (+3.1M дополнительных страниц, рост на 26%)
Итог: правильная настройка Cache-Control = больше краулингового бюджета для страниц, которые реально нуждаются во внимании.
Если ты не отдаешь 304 для неизмененного контента, ты теряешь в эффективности краулинга.
Но осторожно: слишком много 304 может намекать на проблему со свежестью контента.
Ищи баланс ✨
@
Читать полностью…
Mike Blazer
16 Jun 2025 17:05
Для проверки гипотезы о более высоком пользовательском интенте с крупных языковых моделей (LLM) в исследовании проанализировали краудсорсинговые данные за первый квартал 2025 года, сравнивая сессии и ключевые события по трафику с LLM-рефералов и органического канала.
В качестве метрики вовлеченности использовался показатель Key Event Conversion Rate (KECVR).
Автор выделял источники LLM-рефералов в Google Analytics 4 с помощью продвинутого RegEx-фильтра, который не учитывает обзоры AI от Google.
Для достоверности данных исключались датасеты с "раздуванием" ключевых событий (key event bloat), когда количество ключевых событий на сессию приводило к коэффициентам конверсии выше 100%.
Анализ сфокусирован на трендах по отраслям, чтобы сгладить вариативность в настройках ключевых событий.
Трафик с LLM показывает рост с марта 2024 года, где доминирующим источником выступает ChatGPT, а Perplexity уверенно прибавляет.
Но в декабре был неожиданный спад.
Платформы Meta дали минимальный реферальный трафик.
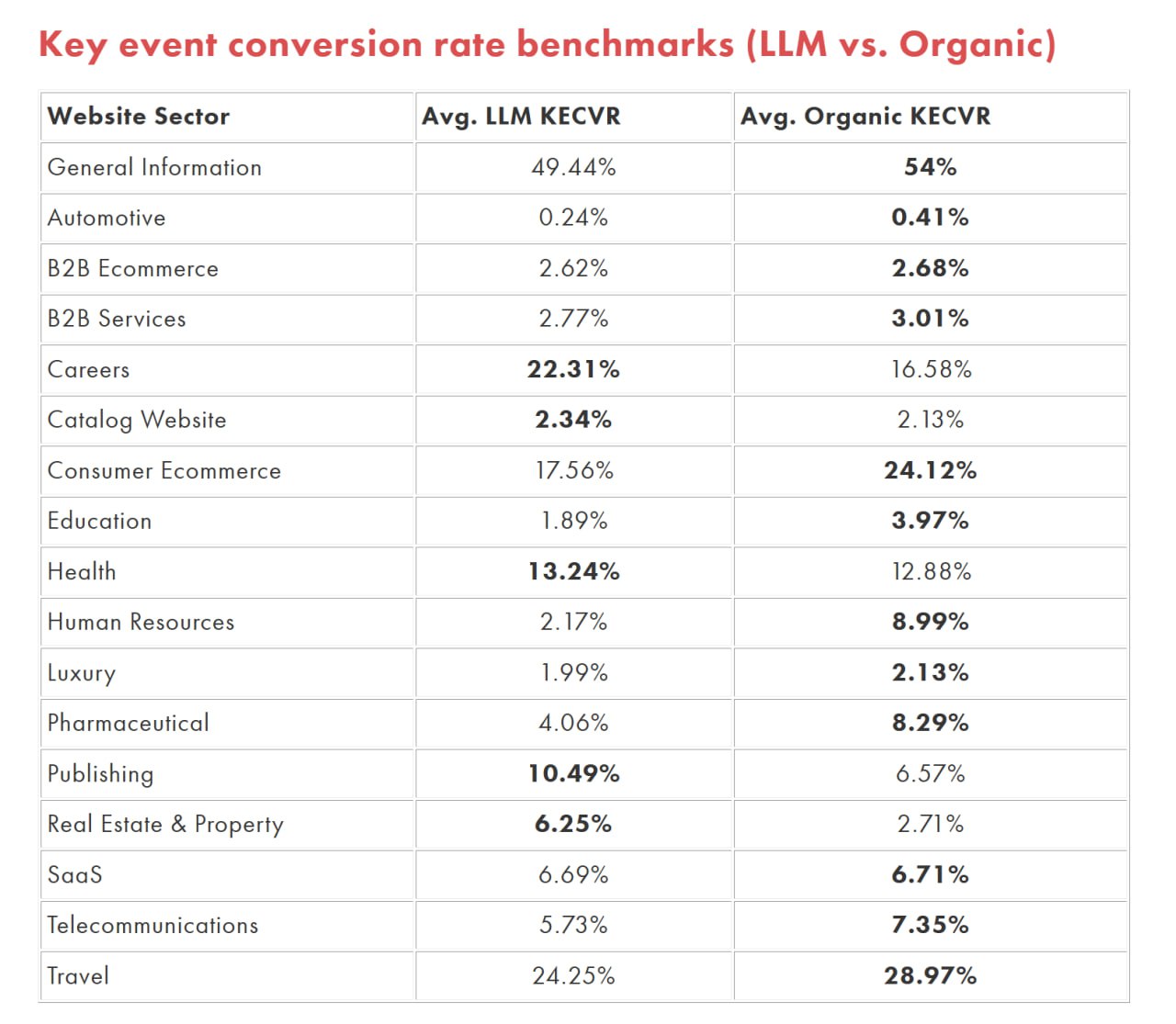
В исследовании учтено 671 694 LLM-рефералов и 188 357 711 органических сессий по 40 категориям сайтов.
В большинстве отраслей органический KECVR выше, чем у LLM.
Исключения, где трафик с LLM превосходит органику:
— Health — 13.24% LLM vs. 12.88% органика
— Careers — 22.31% LLM vs. 16.58% органика
— Catalog Website — 2.34% LLM vs. 2.13% органика
Сайты в этих трёх категориях чаще всего показывали более высокий уровень ключевых событий от LLM, чем от органического поиска.
В Consumer Ecommerce LLM заметно отстаёт от органики (7.14% против 24.12%).
Юзеры в этом транзакционном сегменте ищут детальную инфу и отзывы, где органический поиск сильнее, а LLM даёт более общий обзор.
В сегменте B2B Ecommerce трафик с LLM не оказал заметного влияния (0%), в то время как органика обеспечила конверсию 2.68%.
B2B-покупатели ценят точные характеристики, кейсы и сигналы доверия, которые дают SEO-ориентированные материалы.
В индустрии Travel LLM показывает хорошие результаты (24.45%), но всё же уступает органике (28.97%).
Юзеры доверяют богатому, тщательно отобранному контенту органического поиска для финальных решений по бронированию, хотя LLM помогает с вдохновением.
Для SaaS показатели почти равны (6.69% LLM против 6.71% органика), что говорит об эффективности LLM в предоставлении персонализированных рекомендаций.
Тем не менее, небольшой перевес органики показывает, что пользователи всё ещё предпочитают авторитетные поисковые результаты для конверсий.
https://salt.agency/blog/do-users-really-show-higher-intent-when-they-click-through-from-an-llm-to-a-website/
@
Читать полностью…
Mike Blazer
16 Jun 2025 13:10
Инсайты из антимонопольного суда: Google не использует косинусное сходство для определения семантической близости между запросами и документами!👇
Для определения семантической близости можно использовать различные методы измерения расстояния между векторами в семантическом пространстве.
Вот самые популярные из них:
1. Косинусное сходство (Cosine Similarity): Самый распространенный метод для определения семантической близости.
Измеряет косинус угла между двумя векторами.
2. Евклидово расстояние (Euclidean Distance): Измеряет прямое (геометрическое) расстояние между двумя векторами.
3. Скалярное произведение (Dot Product / Inner Product): Часто используется в нейросетях и механизмах внимания.
Измеряет одновременно и направление, и величину (магнитуду) векторов.
Rankembed — это система Google, которая определяет семантическое соответствие между запросами и документами для коротких запросов.
Многие сеошники используют косинусное сходство между поисковыми запросами и документами в качестве аналитического подхода.
Согласно информации из антимонопольного суда, для этого юзкейса Google использует dot.product, а не косинусное сходство.
Поэтому, похоже, что ориентироваться на косинусное сходство при работе с короткими запросами — не лучший подход.
-
BERT использует косинусное сходство.
И BERT применяется в системах ранжирования и для определения сходства.
Но если вы хотите ранжировать результаты не только по семантическому сходству, но и по степени уверенности, силе сигнала или силе совпадения.
Тогда лучше подходит скалярное произведение.
Если же вам нужно чистое семантическое сходство, независимо от того, насколько "длинный" или "сильный" документ.
Тогда лучше подходит косинусное сходство.
@
Читать полностью…
Mike Blazer
16 Jun 2025 08:15
Как ChatGPT Search выбирает источники для краулинга?
Тайтл и дескрипшен по-прежнему важны!
Последние пару месяцев я задавал вопросы команде поддержки ChatGPT, пытаясь разобраться в процессе работы ChatGPT Search, — пишет Жером Саломон.
Вчера я узнал кое-что новое :)
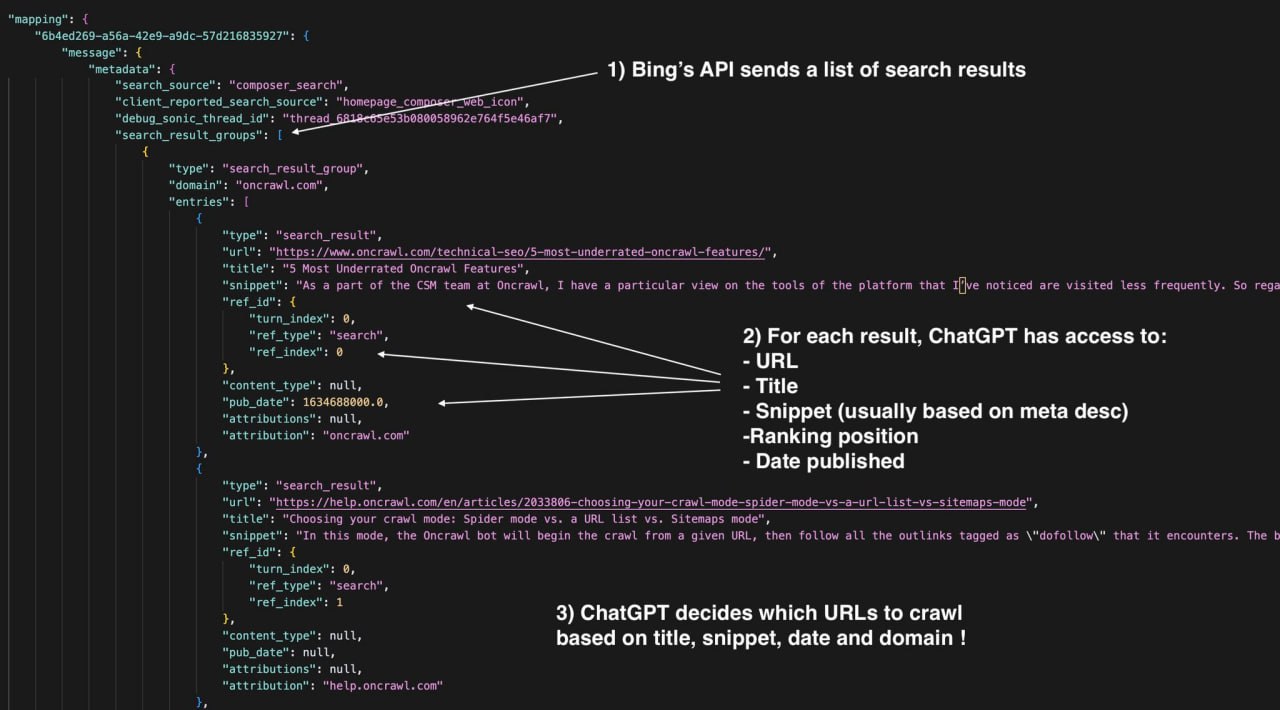
Я уже знал, что когда вы отправляете промпт с активированной функцией Поиска:
1) ChatGPT преобразует промпт в один или несколько поисковых запросов к Bing
2) Bing возвращает список результатов поиска
3) Бот ChatGPT-user краулит подборку релевантных источников
4) ChatGPT включает релевантный контент в ответ со встроенными ссылками на источники
При изучении JSON-файла с диалогом ChatGPT можно увидеть полный список результатов поиска (включая те, которые ChatGPT не использовал в ответе).
Для каждого результата вы получаете:
— URL
— Тайтл
— Сниппет (обычно на основе мета-дескрипшена)
— Позицию в выдаче
— Метаданные (например, дата публикации)
Отвечая пользователю, ChatGPT должен в реальном времени выбрать и прокраулить несколько источников, чтобы дать наилучший ответ.
Мне было интересно, как эти URL выбираются из длинного списка результатов поиска.
Поэтому я снова спросил у команды поддержки :)
Вот их ответ:
"Решение о том, какие страницы краулить, в первую очередь зависит от релевантности тайтла, содержания сниппета, свежести информации и авторитета домена".
Тайтл и мета-дескрипшен играют важную роль.
Они помогают ChatGPT предположить, сможет ли ваша страница предоставить релевантный контент для ответа на промпт.
Практический совет для ваших тайтлов и мета-дескрипшенов:
— Будьте описательными, конкретными и точными
— Используйте ключевые термины, которые четко отражают содержание
— Отдавайте предпочтение ясности, а не кликбейту
Возвращаемся к основам
P.S. Как полуить JSON писалось тут.
@
Читать полностью…
Mike Blazer
15 Jun 2025 13:10
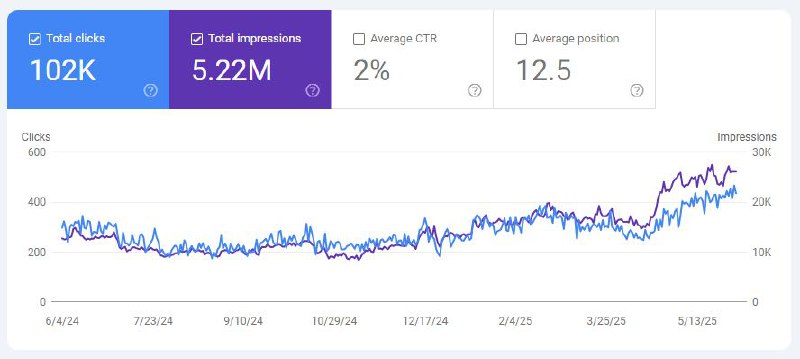
🚨 Внимание: плагин Seraphinite Accelerator для WordPress просто УБИВАЕТ ваши позиции.
Как только мы удалили его с этого сайта, позиции сразу вернулись в топ Google, рассказывает Даррен Шоу 👇
Консультант, которого я нанял, выжал из Seraphinite Accelerator показатель производительности Lighthouse на уровне 98.
Вроде бы круто получить такие цифры, но честно говоря, с позициями стало только хуже.
Я понимаю, что скорость сайта — это не какой-то суперфактор ранжирования, но после этой оптимизации всё начало катиться в неправильную сторону.
И были еще другие звоночки, что что-то не так.
Через расширение SEO Pro мы заметили, что страницы сначала отдают статус 503, а сразу после загрузки — 200.
Похоже, сервер сначала возвращал 503, а затем подгружал страницу и отдавал 200. Странно.
Наугад 2 июня мы просто снесли этот плагин и БАЦ — уже на следующий день позиции взлетели (см. скриншот).
Так что да, не используйте этот плагин.
@
Читать полностью…
Mike Blazer
15 Jun 2025 09:15
Когда говоришь, что занимаешься "GEO", выглядишь так, будто понтуешься.
А все вокруг думают, что ты географ.
@
Читать полностью…
Mike Blazer
13 Jun 2025 17:05
Как рождаются эксперты
@
Читать полностью…
Mike Blazer
13 Jun 2025 13:10
Если Google хотел отвлечь внимание SEO-сообщества от AI Overviews, ему достаточно было бы объявить о новой функции "Rich Result" с разметкой Schema.
Мы бы на это купились на все 100%!
@
Читать полностью…
Mike Blazer
13 Jun 2025 08:15
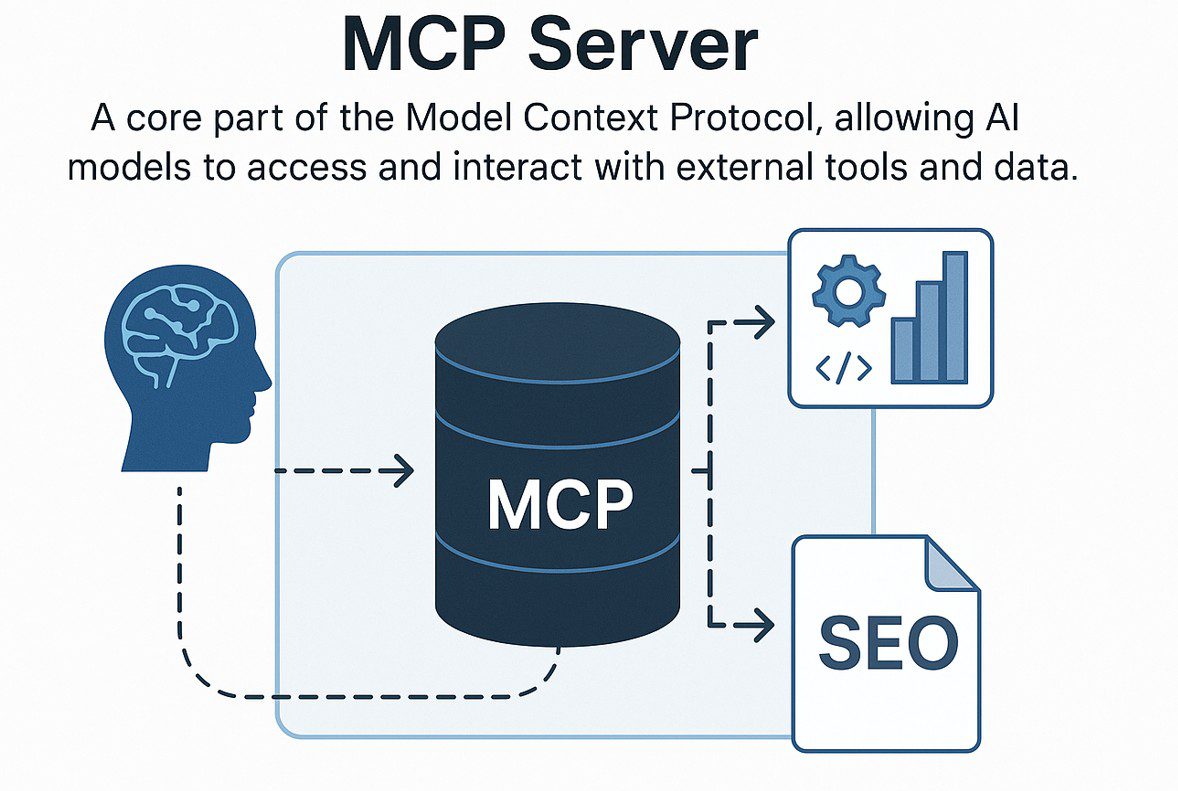
Model Context Protocol (MCP) представляет собой трансформационный подход к техническому SEO, основанный на инновационной концепции MCP-сервера.
Этот сервер, центральный элемент открытого стандарта MCP, служит динамическим интерфейсом, соединяя ИИ-модели с технической инфраструктурой сайта, включая данные краулинга, логи сервера, карты сайта и историю изменений.
Благодаря динамической интеграции, MCP-сервер позволяет ИИ анализировать и работать с контекстом сайта, переходя от простых промптов к более цельному и информированному процессу.
Использование MCP-сервера в техническом SEO дает ИИ доступ к постоянным, структурированным знаниям о сайте, обеспечивая точные аудиты, стратегические выводы и проактивное устранение проблем по сравнению с традиционными методами без сохранения состояния, где важные детали, такие как статус исправлений, откаты, логика редиректов или исключения из индексации, часто теряются.
MCP-сервер решает эту проблему, поддерживая создание и хранение структурированного контекста на постоянной основе.
Он выступает репозиторием для знаний с сохранением состояния: факты, правила, стратегии, решения и их взаимосвязи становятся машиночитаемыми и доступными.
Ключевые сценарии использования и преимущества включают:
1. Постоянная SEO-память: Каждый краул формирует версионируемый слой знаний, сохраняя данные, аннотации и стратегии, устраняя необходимость повторного изучения сайта при аудитах и удерживая исторический контекст.
2. SEO-операции на основе агентов: MCP-сервер работает как контекстный движок для ИИ-агентов, предоставляя доступ к стекам памяти (например, правила hreflang, логика index/noindex), что снижает ложные срабатывания и делает агентов стратегическими партнерами.
3. Структурированная история изменений и намерений: *Интент* SEO-правил — "почему" — сохраняется вместе с ними. Например, каноникализация страниц к базовому SKU для консолидации авторитета фиксируется как долговременное знание, важное при сбоях или обосновании правил.
4. Контекстное поведение краулера: Краулеры обращаются к MCP-серверу перед запусками, учитывая изменения, выявляя риски или проверяя исправления, различая новые проблемы и регрессии для "краулинга со стратегией".
5. Отслеживание индексации во времени: Статус индексации интегрируется в контекстную модель, превращая URL в сущности для анализа временных рядов, связывая отклонения с деплоями и фокусируясь на проактивном управлении.
6. Коллективные графы знаний: SEO-данные (структура сайта, шаблоны, редиректы, политики краулинга) становятся структурированными и доступными, создавая общую инфраструктуру против устаревания знаний и стратегического дрейфа.
Прорыв в SEO на базе ИИ кроется не в "лучших промптах", а в постоянном контексте.
Когда модели получают доступ к структурированным, долгосрочным знаниям о сайте, их выводы становятся стратегическими, расширяя человеческую память и поддерживая согласованность между аудитами или сменами команд, предлагая важное обновление протокола для технического SEO.
https://chrisleverseo.com/blog/exploring-mcp-servers-for-technical-seo-monitoring/
@
Читать полностью…
Mike Blazer
12 Jun 2025 15:05
Захожу на страницу цен продукта, который меня интересует, рассказывает Андреа Бозони.
$19 в месяц.
Кажется справедливым.
Но потом замечаю, что переключатель стоит на годовом плане.
Я понимаю, почему они это делают.
Но я не готов платить за годовой план для продукта, которым никогда не пользовался.
Поэтому переключаюсь на месячный, и цена подскакивает до $29 в месяц.
У меня в голове всё ещё $19, поэтому теперь, даже если это дёшево по сравнению с другими альтернативами, мой мозг воспринимает это как невыгодную сделку.
Я вижу это практически каждый день.
Больше основателей должны понимать, как работает ценовой якорь.
@
Читать полностью…
Mike Blazer
12 Jun 2025 11:05
47+ Regex-фильтров для GSC, которые РАСКРОЮТ скрытые возможности в ваших данных.
Большинство людей мельком глядят на Google Search Console.
Видят позиции.
Может быть, клики.
Потом идут дальше.
Это пустая трата времени.
Там спрятаны деньги.
Нужно просто знать, где искать.
Этот плейбук решает эту проблему.
Эти фильтры вскрывают высокоинтентные запросы, неиспользованные хвосты и брендовые вопросы, которые вы ПОЛНОСТЬЮ ИГНОРИРУЕТЕ.
https://docs.google.com/document/d/1OS9ZYU_5O_us7cKZJTdeULJyws00-UdeIIfzvGqHEa4/edit?tab=t.0#heading=h.rqnq58299m5f
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}