Mike Blazer
12 Jun 2025 08:15
SEO миграции сайта
Предмиграционный анализ включает тщательное изучение домена, проверку падений трафика после обновлений Google (особенно у спамерских доменов) и анализ истории через WayBack Machine и ссылочных профилей на спам.
Если домен выглядит скомпрометированным, пересмотрите его использование, несмотря на политику чистого листа Google.
Перед миграцией создайте полный бэкап сайта (файлы и базы данных) как страховку.
Затем составьте карту URL: прокраулите текущий сайт (через Screaming Frog или Sitebulb) и сопоставьте старые URL с новыми в таблице с колонками Original URL, New URL и Redirect Status.
Правильные 301 редиректы предотвращают потерю позиций.
Настройте постоянные 301 редиректы для каждой пары URL и протестируйте их перед запуском для передачи PageRank.
Упростите цепочки редиректов, заменив A > B > C > D на A > D, чтобы снизить задержки и потерю ссылочного веса.
Обновите внутренние ссылки, чтобы они вели к новым URL напрямую, избегая 301 редиректов, вызывающих задержки.
Также проверьте каноникал теги и пути для CSS, JavaScript, изображений и других ресурсов, связанных со старыми URL.
Избегайте изменений на живом сайте.
Используйте тестовую среду, защищенную паролем с директивой запрета в robots.txt (User-agent: * Disallow: /), чтобы предотвратить раннюю индексацию.
Тестируйте скорость сайта, мобильную отрисовку, редиректы и ключевые сценарии пользователей.
Минимизируйте изменения, кроме обновления URL и инфраструктуры.
Миграции часто ошибочно совмещают с радикальными переделками (тайтлы, контент, дизайн).
Это замедляет обработку Google, усиливает колебания позиций и усложняет диагностику.
Вносите крупные изменения за 3+ месяца до или после миграции, когда позиции стабилизируются.
После запуска снимите временные блокировки: убедитесь, что robots.txt разрешает краулинг, удалите noindex теги и отключите парольную защиту.
Держите старый домен с редиректами активным минимум 9 месяцев, а лучше дольше.
Быстро уведомите Google: отправьте новую XML карту сайта через GSC и используйте инструмент смены адреса GSC для домена.
Запросите ручную индексацию важных страниц в GSC для ускорения переоценки.
Обновляйте внешние ссылки, если возможно.
Обращайтесь к вебмастерам, ссылающимся на старые URL, особенно для权威ных ссылок и ключевых страниц, с просьбой об обновлении.
Настройте рекламные кампании (например, Google Ads), ведущие на старые страницы.
Контролируйте Core Web Vitals (LCP, CLS, FID) и производительность после миграции.
Оптимизируйте скорость загрузки (менее 2 секунд для ключевых страниц) и устраняйте проблемы; быстрые сайты краулятся эффективнее и ранжируются выше.
Внедрите постмиграционный мониторинг:
— Первые 24 часа: Проверяйте логи сервера ежечасно.
— Первая неделя: Анализируйте позиции и краулинг ежедневно.
— Первый месяц: Оценивайте трафик еженедельно.
— Первый квартал: Проводите SEO-аудиты ежемесячно.
Сфокусируйтесь на мониторинге ключевых страниц, приносящих доход.
Миграция платформ не всегда требует новых URL-шаблонов; некоторые сохраняют старую структуру.
Серверные ReWrites (контент нового URL отдается под запросами старого, без 301 редиректов) полезны для срочных задач или поэтапных миграций.
Понимание HTTP редиректов помогает в оптимизации.
Хотя 308 (Permanent) и 301 (Moved Permanently) схожи, 301 допускает смену методов запроса (POST на GET), в отличие от 308.
Google обрабатывает оба типа одинаково для ранжирования, делая 301 проще и надежнее.
Если доступны только 302 (Temporary), не переживайте — Google со временем интерпретирует их как 301. Meta refresh и JavaScript редиректы менее эффективны, но Google их обрабатывает, хоть и медленнее.
Если серверные редиректы невозможны, подойдут скриптовые решения (например, PHP header()).
@
Читать полностью…
Mike Blazer
11 Jun 2025 15:05
Wikimedia выпустила структурированный датасет всех английских и французских статей в формате JSON.
Он также включает инфо-боксы.
Для парсинга и структурирования статей требуется много усилий, и этот датасет упрощает использование и создание контента на основе Википедии.
Проект еще новый, но очень интересный:
https://www.kaggle.com/datasets/wikimedia-foundation/wikipedia-structured-contents
Версия 1 (113.58 ГБ)
@
Читать полностью…
Mike Blazer
11 Jun 2025 11:05
E-E-A-T превратился в SEO-обман, и проблему с Google можно увидеть, если поискать [Best] Italian Restaurants in [Vegas] [или любой город].
В топе синих ссылок обычно Trip Advisor, что-то вроде Eater Vegas, Reddit или другие крупные сайты.
Есть множество сайтов, которые демонстрируют реальный E-E-A-T (вы понимаете — они были в ресторане, ели там и так далее), но они зарыты на 3, 4, 5, 6, 7 странице и далее.
AIO просто ворует рекомендации с Reddit, Trip Advisor и крупных сайтов.
Поэтому вместо реальных рекомендаций люди получают советы по поводу того, что может оказаться даже не очень хорошим.
Для многих таких запросов видео тоже находятся глубоко в СЕРПе.
Например, Vegas Eater ранжируется на 2 позиции.
Они используют стоковые изображения и описания выглядят сгенерированными ИИ.
Пища для размышлений.
-
TripAdvisor и Reddit агрегируют мнения множества людей, которые были в ресторане.
Объективно это лучшие результаты поиска, чем отдельные статьи блогеров, которые представляют мнение только одного человека.
-
Мы могли бы спорить часами, но вот это #3 https://reddit.com/r/LasVegas/comments/13sdzve/best_italian_dining_on_the_strip/
В одном из топовых комментариев ресторан/отель уже закрылся.
Другие просто перечисляют рестораны, не вдаваясь в бюджет, блюда и прочее.
TripAdvisor #1 включает спонсорские объявления.
Если сортируешь по релевантности, то их 2-я рекомендация — буфет в Wynn 😅
Результат от фуд-блогера, который был во множестве ресторанов — лучший выбор.
Альтернативно, лучший и быстрый поиск — просто зайти в TikTok и посмотреть рекомендации людей.
@
Читать полностью…
Mike Blazer
10 Jun 2025 17:05
Что если опубликовать 700+ блогпостов за 12 месяцев без ИИ?
Лорен Фунаро, бывший руководитель контента в Scribe, сделала это, и результаты были сумасшедшими.
✨Трафик вырос с 8К до 70К ежемесячных посетителей
✨Платные регистрации подскочили на 1,100%
✨Scribe теперь владеет основными позициями в SEO по use-case запросам
Этот эпизод The Cutting Room от Томми Уокера обязателен к просмотру (ссылка в комментариях).
И она не следовала обычному плейбуку.
Вместо этого Лорен:
➡️ Сосредоточилась на use cases, а не на персонажах
➡️ Приняла контент "достаточно хорошего" качества вместо превосходного контента
➡️ Создавала брифы, которые помогали райтерам пройти 60% пути
➡️ Использовала Letterdrop для устранения трения в рабочем процессе
➡️ Ставила цели как для совершенно нового контента, так и для оптимизации
Контент — это живая штука.
Если не публикуешь его — не сможешь его улучшить.
Если бы вам нужно было увеличить свой контент в 4 раза в следующем квартале, что бы вы сделали в первую очередь?
https://www.youtube.com/watch?v=X3J5td7Lh5I
@
Читать полностью…
Mike Blazer
10 Jun 2025 13:10
🧠 Не используй <head>!
Я провёл много исследований, посвящённых тегам <head> и их оптимальному порядку для обеспечения быстрой загрузки (fast experiences), пишет Гарри Робертс.
И один из не самых очевидных выводов: иногда для лучшей производительности полный отказ от <head> — это более предпочтительный вариант.
Есть JS с атрибутом defer?
Он всё равно не выполнится до события domInteractive (фактически, после парсинга всего HTML до </html>), так что нет смысла объявлять его слишком рано — помести его перед закрывающим тегом </body>.
preload для шрифтов?
Не допускай, чтобы они конкурировали за пропускную способность на столь раннем этапе жизненного цикла загрузки страницы — помести их перед закрывающим тегом </body>.
Критический CSS?
Не утруждай себя хаком media=print для некритических стилей — помести их перед закрывающим тегом </body>.
Закрывающий тег </body> — это готовый и простой способ избавить <head> от некритических ресурсов.
Используй его!
Риск?
Загрузка, к примеру, Google Fonts таким образом действительно повышает вероятность FOUT (Flash Of Unstyled Text — мелькание нестилизованного текста).
Убедись, что также используешь font-display: optional; для защиты от этого.
Амбициозная цель?
Можно вообще не утруждаться написанием тегов <head>…</head> или <body>…</body> — они не обязательны!
@
Читать полностью…
Mike Blazer
10 Jun 2025 08:15
Новая SEO-услуга: Формирование консенсуса (Consensus Building) - похоже на линкбилдинг, но здесь не важно, получите ли вы бэклинк или будет ли он nofollow.
С помощью формирования консенсуса мы пытаемся получить больше упоминаний вашего бренда/услуги/ продукта в местах, где LLM-AI система, скорее всего, будет обучаться.
Консенсус проявляется в нескольких формах:
1. Упоминание в топовом листикле.
2. Упоминание в ответе в разделе Q&A в соцсети / на Q&A-сайте / форуме.
3. Высокие позиции на сайте, который заявляет, что ранжирует такие сущности (entities), используя собственные проприетарные данные (Google, похоже, довольно активно использует для этого Clutch).
4. Упоминание как "лучший" или "топовый" вариант в видео на канале, который не связан с брендом.
Мы начали предлагать это клиентам в конце прошлого года, пишет Джо Янгблад.
Не могу поделиться большим количеством данных, но достаточно сказать, что вам стоит рассмотреть возможность сделать то же самое.
Как только данные подхватываются LLM, изменения в их ответах могут быть кардинальными.
Один совет: прежде чем этим заниматься, убедитесь, что сущность вашего бренда (название бренда) четко связана с доменом вашего сайта, иначе это будет не так эффективно.
@
Читать полностью…
Mike Blazer
09 Jun 2025 15:05
Ранжироваться в AI-обзорах так легко, что это похоже на SEO в 2008 году.
Вот простой рецепт:
✅ Напишите у себя на сайте подробную статью-подборку именно о той услуге, которую вы предлагаете:
"Top XYZ services/products/tools in 2025"
А свою компанию поставьте на первое место.
✅ Затем сделайте статью в LinkedIn Pulse в таком же стиле.
Вы тоже будете на первом месте, но в список добавите уже других конкурентов.
✅ Затем снимите YouTube-видео в таком же стиле.
✅ Потом купите 10 гестпостов на тематических площадках в том же формате статьи-подборки.
Можно расслабиться и через 2-3 недели наблюдать, как ваша компания появляется в AI-обзорах.
Знаю, выглядит спамно, но, черт возьми, это работает 🤷♂️
На дворе 2025 год — добро пожаловать в эру перегрузки веба SEO-шными подборками!
@
Читать полностью…
Mike Blazer
09 Jun 2025 11:05
Это пока еще очень сыро!
Но, кажется, я нашел способ отдельно размечать трафик из AI Mode в GA4 🤖 говорит Кунджал,
Я создал ивент link_click_ping, который отлавливает клики по ссылкам из AI Mode, у которых есть определенный HTML-тег.
Я затестил это, создав внутреннюю ссылку на сайте, и увидел, что ивенты отлично срабатывают в дебаг-режиме.
Затем я создал кастомное определение для этих ивентов и теперь отслеживаю это в отчете Exploration. Он четко показывает, что первым пользователем был "Google".
Параметр AI Mode — это сегмент, в котором я учитываю трафик только из ивента link_click_ping.
Все это еще на ранней стадии, но если метод сработает, он может раскрыть больше данных о том, какой объем трафика GA4 временами упускает и относит к категории "Unassigned".
Я уже видел, как такое происходит с разными ресурсами.
@
Читать полностью…
Mike Blazer
08 Jun 2025 13:10
Это просто жесть (...какая тупость)
Оказывается, заблоченные расширения для Chrome можно установить, просто поправив HTML на стороне клиента.
@
Читать полностью…
Mike Blazer
08 Jun 2025 09:05
Сеошные анкоры в верхней навигации — не лучшая идея в 2025 году.
Показатели вовлеченности куда важнее.
Значимость бренда постоянно растет, поэтому делать ставку на анкоры, заточенные под SEO, в верхней навигации — это движение в неверном направлении.
@
Читать полностью…
Mike Blazer
07 Jun 2025 13:10
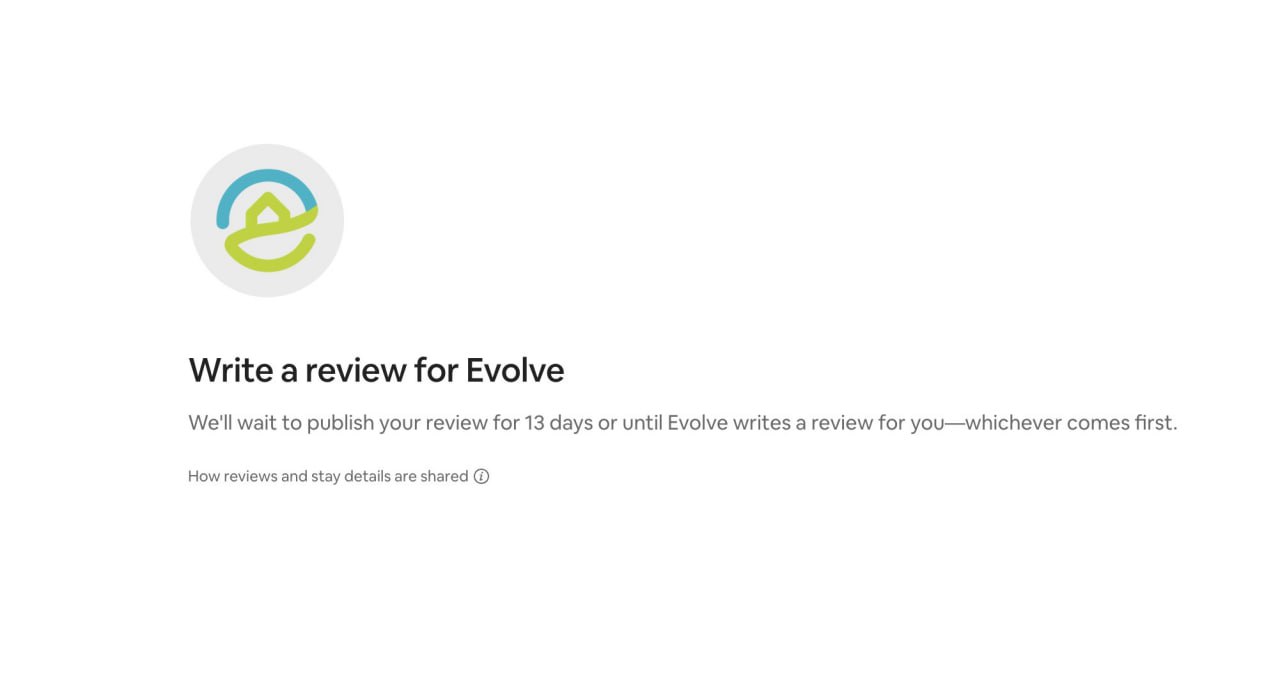
Еще одна причина НЕ верить отзывам.
ЕСЛИ вы не напишете отзыв на AirBnB в течение 13 дней, evolve.com автоматически опубликует положительный отзыв.
@
Читать полностью…
Mike Blazer
06 Jun 2025 17:05
Вопрос: На какой рост трафика можно рассчитывать благодаря SEO?
Ответ: Отличный вопрос! Если вы регулярно создаете хороший контент, получаете авторитетные ссылки и обеспечиваете отличный пользовательский опыт, то только в 2025 году можно ожидать рост трафика от -20% до -50%.
@
Читать полностью…
Mike Blazer
06 Jun 2025 13:10
Лучший новый способ спрятать труп?
Займите первое место в Google
Никто никогда его не увидит!
@
Читать полностью…
Mike Blazer
06 Jun 2025 08:15
Столько курсов и буткемпов учат "Как создавать ИИ-агентов и агентные системы".
Только одна проблема: ИИ-агенты не существуют.
ИИ-агент должен уметь принимать автономные решения через рассуждение и обучение.
Генеративный ИИ не рассуждает и не учится.
Он типа учится, если имеется в виду первоначальное обучение модели.
Но после деплоя он никогда не изучает ничего нового.
RAG предоставляет дополнительный контекст, но ИИ не учится.
Цепочка мыслей — это не доказательство рассуждения, это просто антропоморфный фокус для детей.
Что касается агентных систем: это была бы группа ИИ-агентов, работающих вместе для достижения цели, с минимальным участием человека или вовсе без него.
Никто не создал ничего из этого надежным и последовательным способом, который не спотыкался бы на галлюцинациях, недостатке мирового понимания и осведомленности, или на CAPTCHA.
Поэтому интересно, о чем все эти курсы?
Автоматизационные воркфлоу, возможно?
Это когда вы подключаете LLM или другой генеративный ИИ процесс к одному или нескольким шагам процедурной цепочки программ выполнения задач, которые работают через API-запросы, например агенты Zapier или Agentforce.
ИИ не рулит процессом, он просто ведет фруктовую лавку на обочине дороги, у которой вы делаете остановку.
В противном случае чему еще учат эти люди?
@
Читать полностью…
Mike Blazer
05 Jun 2025 15:05
Спасибо огромное всем инструментам для генерации AI-контента и их маркетингу, который утверждает, что это хорошо работает для SEO 😏
Только за последние 6 месяцев все ваши замечательные усилия 🙃 создали для меня так много новых SEO-клиентов, пишет Гаган Гхотра.
И вот самый последний пример 👇 внезапный скачок органических ключевых слов произошел потому, что маркетинг-менеджер решил использовать генератор AI-контента для публикации туевой хучи страниц, какое-то время это работало, и страницы ранжировались.
Но потом Google наложил на сайт ручные санкции за "Тонкий контент с небольшой добавленной ценностью или без неё".
Мы поработали над очисткой и отправили запрос на снятие санкций.
Теперь сайт возвращается в результаты поиска с лучшим контентом, написанным людьми, и мы также оптимизировали внутреннюю перелинковку 😇
@
Читать полностью…
Mike Blazer
11 Jun 2025 17:05
Боюсь браться за SEO для сайтов казино, потому что за годы наслушался историй от SEO-друзей о том, как они обгоняли конкурентов-казино в топах, а потом получали физические угрозы 😅😅 странная ниша, говорит Гэган Готра.
-
Пока твоего имени нет в импринте (выходных данных сайта) и ты не делаешь аутрич под настоящим именем, всё должно быть в порядке.
Моя любимая история про казино-SEO — когда люди отправляют поддельные результаты тестов на отцовство по домашним адресам конкурирующих (мужчин) SEO-шников, говорит Мальте Ландвер.
Рассчитывают время так, чтобы письмо пришло во время SEO-конференции и увеличить вероятность того, что супруга откроет его и устроит драму, которая отвлечет их от работы.
@
Читать полностью…
Mike Blazer
11 Jun 2025 13:10
В 20-летнем патенте Гугла объясняется, как поисковик может использовать слова до и после ссылки для определения ее контекста и релевантности.
"Ranking based on reference contexts" (ранжирование на основе ссылочных контекстов) US8577893B1
Вместо того чтобы анализировать только анкор, Гугл также рассматривает слова *вокруг* ссылки, выискивая наиболее редкие/необычные из них.
Если окружающие слова релевантны тематике страницы, на которую вы ссылаетесь, Гугл может счесть такую ссылку более весомой.
— Редкие + тематические слова ≈ больший вес для ссылки
— Общие или нетематические, "водянистые" фразы ≈ меньший вес для ссылки
— Шаблонные элементы (навигация, футеры, сайдбары) постоянно повторяют один и тот же "контекст", поэтому вес таких ссылок сильно обесценивается
Это означает, что шаблонные ссылки, в которых повторяется один и тот же текст, будут иметь незначительный вес, в то время как контекстные ссылки, окруженные уникальным, релевантным текстом, будут цениться гораздо выше.
Как это использовать для SEO:
1) Всегда размещайте важные ссылки внутри информативного текста, а не в баннерах или сайдбарах.
2) Окружайте ссылки фразами, специфичными для данной страницы и насыщенными ключами — не повторяйте шаблонные описания по всему сайту.
3) При гестпостинге или получении внешних ссылок просите размещать их в основном контенте статьи (а не просто свалку ссылок в блоке с биографией автора).
4) Не лепите ссылки "пачкой" одна за другой (Гугл даже упоминает это в своих SEO-руководствах!).
Добавляйте короткие описания до и после ссылок, чтобы предоставить Гуглу больше контекста.
5) Для автоматических виджетов (например, "Похожие статьи"), по возможности рандомизируйте отображаемые сниппеты, чтобы окружающий текст не был идентичным на сотнях страниц.
@
Читать полностью…
Mike Blazer
11 Jun 2025 08:15
Оптимизируете свой сайт для SEO / LLM'ов?
КРИТИЧЕСКИ важно, чтобы user-agent'ы / боты действительно могли видеть отрендеренный результат.
Не все технологические стеки подходят из коробки - JS стеки известны тем, что:
1. Их непросто рендерить даже для Гуглобота, который может рендерить JS, но делает это не особо эффективно
2. Они не подходят для краулинга / обработки контента LLM'ами
Хотите узнать, подходит ли ваш сайт?
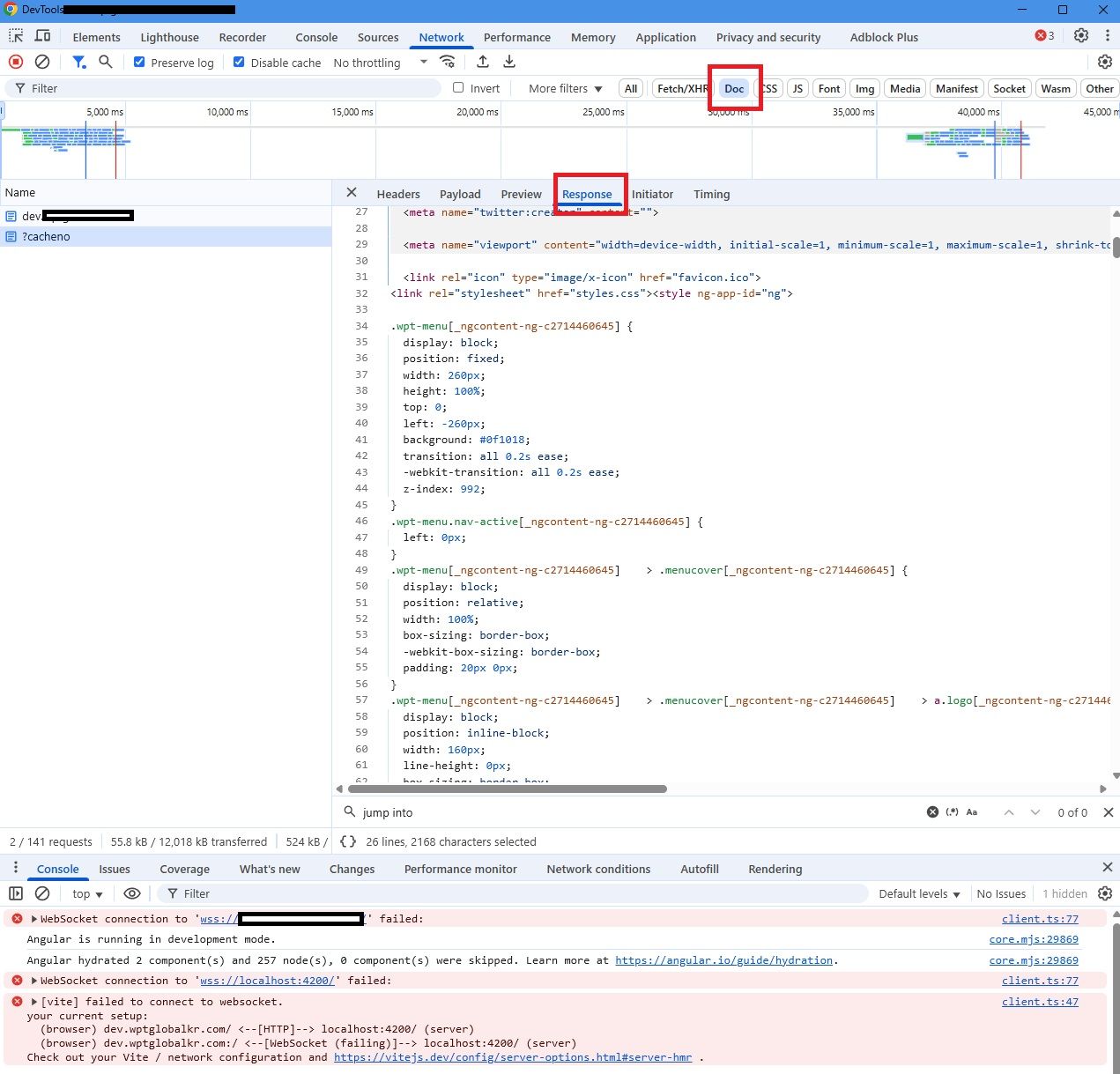
1. Зайдите на страницу вашего сайта, нажмите F12 и откройте DevTools
2. Нажмите CTRL + SHIFT + P
3. Наберите Javascript и кликните Disable Javascript
4. Кликните NETWORK в верхнем меню devtools
5. Убедитесь, что включены Preserve Log и Disable Cache
6. Теперь к URL вашего сайта добавьте ?test и нажмите enter
7. На вкладке network кликните DOC (показано красной рамкой на изображении)
8. Где написано NAME, вы должны увидеть ?test, кликните на него
9. Кликните на вкладку RESPONSE (показано красной рамкой на изображении)
Это покажет вам РЕЗУЛЬТАТ того, что увидит LLM.
Google МОЖЕТ рендерить Javascript, но не все JS стеки одинаковы - если хотите увидеть ЧИСТЫЙ ТЕКСТОВЫЙ ВЫВОД, делайте следующее:
В нижней части DevTools вы увидите пункты меню "Console, Issues, Coverage" и т.д. кликните на CONSOLE (выбран по умолчанию).
Кликните иконку CLEAR (круг с линией)
Скопируйте и вставьте эту команду в консоль и нажмите ENTER:
const text = document.body.innerText;
for (let i = 0; i < text.length; i += 1000) {
console.log(text.slice(i, i + 1000));
}
Это покажет вам ЧИСТЫЙ, НЕ
JS вывод вашего
URL.
ВОТ этот контент увидят
LLM'ы, и потенциально Гугл/другие поисковики, если будут проблемы с
SSR.
ЕСЛИ ВЫ ИСПОЛЬЗУЕТЕ
JS-основанные технологические стеки, вам СТОИТ рассмотреть
SSG или пре-рендер.
Фактически вы хотите МАКСИМИЗИРОВАТЬ вывод ЧИСТОГО ТЕКСТА/HTML в
DOM после обработки
JS, прежде чем этот результат документа будет отдан.
Количество ВЛАДЕЛЬЦЕВ САЙТОВ, у которых есть эти навороченные технологические стеки, часто не подозревают о рисках/проблемах использования
JS для веб-приложения / фреймворка сайта.
@
Читать полностью…
Mike Blazer
10 Jun 2025 15:05
Место размещения цены ИМЕЕТ ЗНАЧЕНИЕ.
👀 Как думаешь, что продаётся лучше?
Ценник сверху?
VS
Ценник снизу?
ПОБЕДИТЕЛЬ:
✅ Ценник снизу продаётся лучше.
Почему?
Исследование 2020 года показало, что размещение цены НИЖЕ товара (а не над ним) меняет восприятие потребителей из-за особенностей нашей психологии.
Наш мозг запрограммирован на ЭТОТ паттерн.
Мы подсознательно считаем:
⬇️ Вниз = меньше
⬆️ Вверх = больше
Научное обоснование основано на теории концептуальных метафор.
Наш мозг использует эту подсознательную ассоциацию.
Это часть распространённой эвристики принятия решений.
📈 Данные из ритейл-тестов:
— Продажи в магазине алкоголя выросли на 35.2% с ценниками снизу
— Зубная нить воспринималась на 9% дешевле с ценником снизу
— Многочисленные полевые и лабораторные тесты показали стабильный результат
Кстати, эффект сохранялся в различных DTC-категориях
Фотоаппараты, кофе, батарейки и т.д.
TLDR
Размещай ценники снизу.
В своей рекламе.
На страницах с ценами.
Конечно, не жертвуй юзабилити ради этого.
Но если можешь сделать это естественно, протестируй.
https://www.sciencedirect.com/science/article/abs/pii/S0022435920300130
@
Читать полностью…
Mike Blazer
10 Jun 2025 11:05
Тим Фолсом рассказал, что команда веб-разработки забыла добавить тег noindex на стейджинг-сайт, из-за чего его страницы попали в индекс Google.
Это оставалось незамеченным до запуска продакшн-сайта; к тому времени стейджинг исчез, но его страницы остались в индексе, а в Google показывалась только главная страница продакшн-сайта.
Тим искал совет по решению проблемы, имея идеи, но желая услышать мнение сообщества.
— Тим отметил, что стейджинг был перезаписан и перенаправлен на продакшн-URL, без доступа к wp-admin и DNS-записям.
— Он рассматривал временное восстановление стейджинга для 301-редиректа на продакшн, поскольку подпапки и контент совпадали.
— Команда пояснила, что стейджинг использовал временный домен SiteGround, перенаправленный на продакшн, без доступа к DNS или wp-admin.
— SiteGround мог переоформить временный домен как припаркованный для 301-редиректов, но Тим сомневался в настройке GSC при этом.
Советы и инсайты сообщества
1. Если стейджинг недоступен для Google и домен верифицирован в DNS, подайте запрос на временное удаление в GSC для быстрой деиндексации URL.
2. Верифицируйте стейджинг в GSC и используйте инструмент удаления URL для ускоренной деиндексации — это самый быстрый метод.
3. После временного удаления заблокируйте путь стейджинга через robots.txt, чтобы избежать повторной индексации без noindex.
4. Удаление в GSC действует шесть месяцев, как код 410, но для постоянной деиндексации нужны дополнительные шаги.
5. Для постоянного удаления:
— Верните коды 404 или 410, удалите не-HTML файлы с сервера.
— Используйте парольную защиту для блокировки доступа.
— Примените мета-тег noindex, хотя это менее надежно.
— Не полагайтесь только на robots.txt, он блокирует лишь краулинг, а не индексацию.
6. Код 410 не лучше 404; для крупных брендов 404 на стейджинг-поддоменах могут усилить краулинг.
Запрос в GSC с robots.txt или паролем — самый быстрый способ.
7. При запросе удаления в GSC установите напоминание на шесть месяцев для проверки; переиндексация маловероятна, если сайт недоступен и продакшн на него не ссылается.
8. Если стейджинг исчез, создайте Domain Property в GSC с TXT-записью в DNS для верификации основного домена (site.com) и управления поддоменами — полезный шаг для новых компаний.
9. Хотя Google не советует robots.txt для постоянного удаления, он помогает краткосрочно для несвязанных стейджинг-сайтов; при появлении ссылок используйте инструмент удаления или постоянные меры.
10. SEO и софт не дают полностью постоянных решений; нужен регулярный мониторинг, а поиск таких решений может быть неоправданным.
11. Используйте бюджетный хостинг вроде Netlify для настройки редиректов с поддомена стейджинга на продакшн, удалив проект после загрузки файла netlify.toml для экономии.
12. Верифицируйте старый стейджинг в GSC и Bing Webmaster Tools через DNS, настройте 301-редирект на продакшн на уровне DNS и используйте Change of Address (CoA) в обоих сервисах для ускорения удаления из SERP и исправления частичной индексации продакшн-сайта.
13. DNS-редирект с CoA — почти метод "настроил и забыл", хотя повторное использование стейджинг-домена невозможно; используйте новые домены для будущих стейджингов с контролем индексации.
14. Для стейджинга на временном поддомене провайдера настройте правила редиректов; при повторной реализации верифицируйте в GSC/Bing через HTML-файл перед добавлением редиректов для CoA.
15. Задокументируйте в дневнике сайта причину сохранения временного домена, чтобы избежать случайного удаления, отменяющего меры.
@
Читать полностью…
Mike Blazer
09 Jun 2025 17:05
SEO - это безумие, индустрия просто сумасшедшая.
За пределами всей этой чуши с внедрением ИИ и массовым злоупотреблением контентом, когда мы возвращаемся к старым проблемам - мы видим, что сейчас БОЛЬШЕ чем когда-либо, Гугл индексирует всё меньше и меньше контента.
Ваш ИИ АГЕНТ, который публикует контент, пока вы спите?
Да, удачи с этим.
Гугл индексирует МЕНЬШЕ контента в целом.
Для КАЖДОГО краулимого сайта всё меньше и меньше контента попадает в индекс.
Почему?
Уникальная добавленная ценность - это СИЛЬНАЯ МОДЕЛЬ для отказа от индексации информации, которая уже существует в 1000 раз на других сайтах.
А вот что еще СУПЕР весело видеть на вашем домене или ЛЮБОМ домене, с которым вы работаете:
1. Прокраулите ваш сайт и убедитесь, что вы используете API индексации Google
2. Экспортируйте результаты краулинга, в идеале вам нужны КЛЮЧЕВЫЕ метрики:
— URL, состояние покрытия от Google, внутренние ссылки, количество слов
Это позволяет исключить недостаток внутренних ссылок или тонкий контент (малое количество слов) или изучить взаимосвязь между объемом контента и его эффективностью
3. Используйте IMPORTXML для получения дат публикации контента из прокраулинных URL
— Вы можете использовать XPATH или REGEX в importXML для получения дат, т.е. если вы используете структурированные данные, вероятно, у вас есть datePublished, вы можете использовать этот importxml в вашей гугл-таблице для получения даты публикации
=REGEXEXTRACT(IMPORTXML(A2, "//script[@='application/ld+json']"), """datePublished"":\s*""([^""]+)""")
4. Затем вы должны экспортировать данные из
GSC и использовать
VLOOKUP для сопоставления ваших
URL с их эффективностью за последние 16 месяцев - таким образом вы сможете увидеть, какой контент имеет данные по кликам или не имеет их вообще.
5. Затем вам следует создать фильтр и просмотреть ваш контент ПО ГОДАМ и по состоянию покрытия - например, в скриншоте это контент одного сайта за 2022 год, где
URL неизвестен для Google, несмотря на то, что
URL существуют уже 3 года
Вот что стоит учесть:
1. Если контент НЕ индексируется, но был индексирован, как выглядел его жизненный цикл?
То есть, когда он был опубликован, как выглядели данные за период индексации
2. Если контент БЫЛ индексирован, но никогда не показывал хороших результатов, при этом имел достаточно внутренних ссылок и был глубоким или имел много контента, например, 3000, 4000+ слов - как выглядел профиль запросов?
3.
URL, неизвестные для Google - если у вас много таких, но есть достаточно внутренних ссылок, то вы должны спросить себя, ПОЧЕМУ
URL неизвестны, несмотря на возраст?
Особенно если есть внутренние ссылки
4. Обнаруженный контент/в настоящее время не индексируемый обычно попадает в эту группу, когда он теряет ВСЮ воспринимаемую ценность.
Что обычно происходит:
— Контент устаревает
— Поведенческие данные уменьшаются
— СЕРПы обновляются, что приводит к потере запросов, так как контент считается менее ценным
— Деградация продолжается с увеличением периодов повторного краулинга
— В конечном итоге периоды повторного краулинга превышают "очевидные" пороги в 90-130 дней, пока контент не выпадает из индекса
Короче говоряСОВРЕМЕННЫЕ SEO СТРАТЕГИИ НЕ ДОЛЖНЫ СОСУЩЕСТВОВАТЬ С КОНТЕНТОМ В МАССОВОМ МАСШТАБЕ!
Google НЕ НУЖДАЕТСЯ в контенте в массовом масштабе.
Не тратьте своё время, ведите более экономный, более эффективный индекс.
@
Читать полностью…
Mike Blazer
09 Jun 2025 13:10
🚨 Старые домены возвращаются и они, сцуко, печатают деньги!!!🚨
Война Гугла против паразитного SEO могла срубить половину авторитетных сайтов в выдаче, но случайно включила свет обратно для спящего монстра: старые домены (с недавней историей).
Речь о доменах, которые никогда не теряли ссылочный вес, траст или тематический авторитет - экспайред домены работают в некоторых нишах, но показатель успеха очень низкий, тогда как если ты получаешь старый домен, который сохраняет свои позиции/ссылочный вес, ты можешь мгновенно перенести его в нишу типа казино и печатать деньги
Я знаю, потому что у меня десятки клиентов делают это, и я вижу сотни таких сайтов каждый день, почти в каждой стране мира, включая английские термины в Великобритании и США, пишет Чарльз Флоут!
Яркий недавний пример - это запрос "non gamstop casinos" в Великобритании, где кто-то смог подхватить домен Брексит-парти (теперь Реформ-парти), сохранив его возраст, и перепрофилировать под этот запрос - мгновенно заняв #1 в течение недели!
Чтобы добавить еще больше оскорбления, ВСЕ новые ссылки - это ПБН на главную, где большую часть времени они даже не удосужились поставить тему, это просто дефолтная установка WordPress!
😂🤣
И это все на английском, на международном уровне это еще больший пиздец...
Но пропагандистская машина в этой индустрии работает усердно, помните, что согласно большинству white hat инфлюенсеров, половина этих тактик больше не работает 👀
@
Читать полностью…
Mike Blazer
09 Jun 2025 08:15
Хак по локальному SEO "Изучи победителей"
Этот практичный подход к локальному SEO включает систематический анализ лидирующих конкурентов для создания превосходной стратегии, а не копирование контента.
Вот как это работает:
Процесс:
1. Создай таблицу для отслеживания с метриками конкурентов (страницы, сервисные страницы, темы контента, количество слов, рейтинг GBP/отзывы)
2. Определи топовых конкурентов, поискав свои целевые запросы в Google и Bing
3. Проанализируй их сайтмапы (domain.com/sitemap.xml), чтобы увидеть все страницы, которые ценит Google
4. Задокументируй их стратегию - количество сервисных страниц, структуру контента, подход к отзывам
5. Проверь их бэклинки с помощью бесплатных инструментов типа Ahrefs/Moz для выявления ссылочных возможностей
6. Создай что-то лучше - разработай более полные сервисные страницы, собери больше отзывов, создай контент более высокого качества
Почему это работает:
— Устраняет гадания, следуя проверенным паттернам, которые уже работают на твоем рынке
— Поисковые системы уже показывают, какой контент они ценят для конкретных ключевых слов
— Позволяет систематически улучшать выигрышные формулы
Реальные результаты:
Стоматолог, застрявший на второй странице, внедрил эту стратегию, заметив, что топовые конкуренты имели 8+ сервисных страниц, 100+ отображаемых отзывов, галереи "до и после" и страницы, ориентированные на конкретные районы.
Создав все эти элементы и даже больше, он достиг первой страницы за 6 недель.
Это не теория.
Подход работает для различных типов локального бизнеса:
— Сантехники
— Стоматологи
— Юристы
— Кровельщики
— Рестораны
— Автомастерские
Потому что суть не в слепом копировании, а в стратегическом улучшении.
Google уже показывает тебе, что работает.
"Если ты копируешь у одного, ты вор. Если изучаешь многих и создаешь что-то лучше, это искусство."
@
Читать полностью…
Mike Blazer
08 Jun 2025 12:05
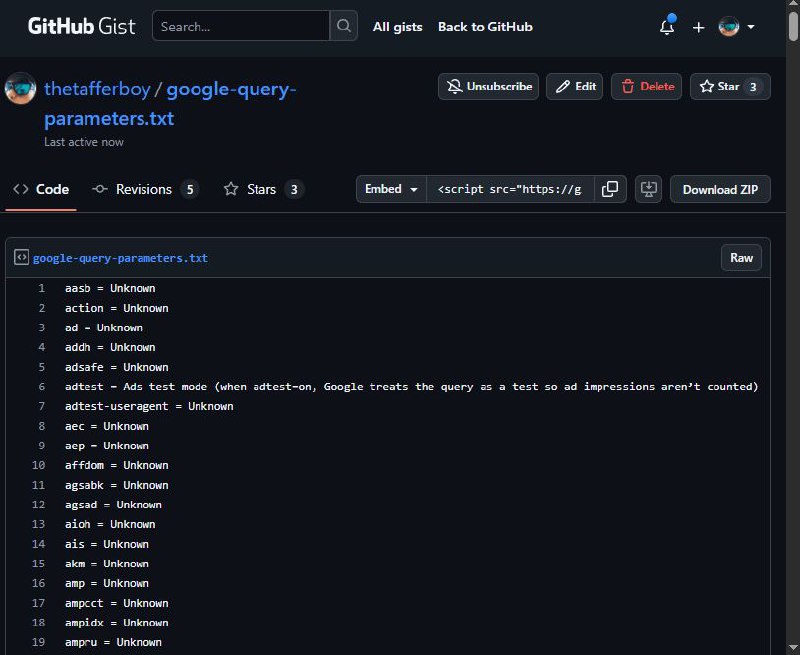
Вот полный список из 674 параметров запроса, которые принимает Google, нарытый в исходном коде. 📃
Зачем?
Потому что понимание того, как работают системы, может подарить вам те самые моменты "эврика!" и помочь увидеть общую картину, когда вы делаете собственные наблюдения за результатами.
Параметры запросов Google: https://gist.github.com/thetafferboy/3ac631eb066c9b2b14a44960a0df9d7c
@
Читать полностью…
Mike Blazer
07 Jun 2025 16:05
Источник
@
Читать полностью…
Mike Blazer
07 Jun 2025 09:15
ИИ делает международное SEO быстрее, но не проще.
1. ИИ — это ускоритель локализации, а не волшебная палочка.
Reddit и Airbnb теперь переводят миллионы страниц с качеством, близким к человеческому, доказывая, что машинный перевод может запустить глобальные контентные маховики в паре с умным человеческим QA.
2. Избегайте двух классических ловушек.
1/ Чрезмерная локализация практически идентичных сайтов разделяет авторитет и создает головную боль с дублированным контентом.
2/ Мышление "перевод = локализация" игнорирует культуру, юмор и поисковый интент.
3. Техническая гигиена не подлежит обсуждению (неожиданно).
Корректные хрефленг кластеры, языковые XML карты сайта, последовательная каноникал логика, локализованная схема и быстрый CDN — это базовый минимум для получения и удержания позиций на любом рынке.
4. Подбирайте модель команды под сложность рынка.
Центральная SEO команда масштабирует последовательность.
Добавление местных специалистов в высокодоходных регионах добавляет культурные нюансы и скорость без потери стратегического контроля.
5. Рассчитывайте время экспансии тщательно.
Валидируйте поисковый спрос, существующую силу бренда, конкурентные пробелы, ROI и юридическую возможность перед запуском.
Слишком ранний выход на глобальный рынок сжигает ресурсы; слишком долгое ожидание отдает рынок более быстрым игрокам.
Итог: ИИ снижает стоимость перехода на многоязычность, но успех по-прежнему зависит от дисциплинированной архитектуры, безупречной техники и культурно-осведомленного контента.
@
Читать полностью…
Mike Blazer
06 Jun 2025 15:05
Трудные времена создают хороших сеошников, хорошие сеошники создают хорошие времена, хорошие времена создают AI-сеошников, AI-сеошники создают трудные времена.
@
Читать полностью…
Mike Blazer
06 Jun 2025 11:05
Плохая визуализация данных встречается повсюду.
Одни вводят в заблуждение. Другие запутывают. Третьи просто заставляют смеяться.
Что не так с этим графиком?
Ответы
Проблемы с осью Y
— Нет четкого контекста для оси Y — непонятно, что именно измеряется
— Не начинается с нуля — создает обманчивое визуальное воздействие
— Специально ограниченный масштаб с манипуляциями min/max значений для преувеличения спада
— Странное масштабирование, созданное для обмана зрителей
— "Подавление нуля" используется как маркетинговый инструмент
Визуальный обман
— Заставляет падение на 2% выглядеть как обрыв из-за приближенного масштаба
— Микроскопические изменения выглядят как огромные нисходящие тренды
— "Драма с приближенной осью Y", которая использует масштаб как оружие для введения в заблуждение
— Создает ложное представление о реальной производительности Гугла
Проблемы группировки данных
— Bing и ChatGPT неуместно объединены вместе
— Комбинирует несвязанные метрики, что увеличивает подверженность аномалиям
— Нет четкого обоснования для объединения этих разных сервисов
Отсутствие контекста и проблемы качества данных
— Bing упоминается в заголовке, но отсутствует на графике
— Слишком детальная временная шкала (раз в два месяца) для таких незначительных изменений
— Нет аннотаций или объяснений источников данных или методологии
— Плохое качество изображения — описывается как потенциально похожее на "MS Paint"
Этические проблемы
— Намеренно создан для введения зрителей в заблуждение, заставляя поверить, что что-то хуже реальности
— Рассчитывает на то, что аудитория не будет внимательно изучать детали
— Подрывает доверие к данным и приучает людей перестать доверять аналитике
— Маркетинговые трюки, маскирующиеся под метрики
@
Читать полностью…
Mike Blazer
05 Jun 2025 17:05
Тарика Рао просила совета по презентации SEO-стратегии для потенциальной миграции на headless CMS.
Она хотела понять основные SEO-цели, вопросы взаимодействия разработчиков и маркетологов, распространенные ошибки и рекомендации.
Ее запрос: легкое обновление SEO-тегов без деплоя через разработчиков.
У нее был предыдущий опыт работы с Contentful, где бэкенд UI делал работу с SEO-элементами простой и понятной.
Советы и инсайты сообщества
Базовая философия:
— Главная цель: не угробить органический трафик
— Вы идете на headless не ради SEO — вы идете по бизнес/техническим причинам; цель SEO — просто сделать это работоспособным
— Это как строить Yoast с нуля: ничего не идет "бесплатно", даже простые мета-данные нужно прописывать вручную
Техническая реальность:
— Все нужно строить с нуля на фронтенде — инвентаризировать, специфицировать и билдить то, что раньше работало из коробки
— Фронт/бэкенд соединены только через API, что часто делает вас более зависимыми и не позволяет быстро вносить изменения без вмешательства разработчиков
— Кастомные фронтенды обычно строятся плохо, без учета SEO
— Используйте SSR и документируйте, что происходит на Краю
Риски миграции:
— Проблемы с восстановлением трафика
— Потеря гибкости/скорости/самостоятельного управления
— Более высокие затраты на поддержку
— SEO-тикеты депривилегируются из-за высоких требований к dev-часам
Соображения по юзкейсы:
— Отлично подходит для маркетплейсов/новостных изданий с небольшим количеством шаблонов (на основе фидов)
— Маркетинговые юзкейсы, очень сложные
— Смягчайте с помощью визуального билдера CMS или фронтенда
Рекомендации платформ:
— SEO-дружелюбные фронтенды: WordPress, Webflow, Webstudio, Framer, Astro
— Astro.build имеет идеальное SEO из коробки
— Webstudio.is для визуального билдинга с любой headless CMS
— Prismic "слайсы" для нетехнических маркетологов, масштабирующих лендинги
— NextJS с WP бэкендом может дать отличную производительность
Требования для успеха:
— Действительно хорошие разработчики с правильным SEO-руководством и техзаданиями
— Сохраняйте структуры URL где возможно, чтобы минимизировать нарушения
— Скорее исключение, чем норма в большинстве случаев
@
Читать полностью…
Mike Blazer
05 Jun 2025 13:10
🔗 СПИСОК WEB 2.0 САЙТОВ ДЛЯ ЛИНКБИЛДИНГА
И их скорость индексации
🚀 ВЫСОКИЙ DA(90+)
1. LinkedIn Pulse - DA97 / NoFollow ⚡️ (мгновенная)
2. Medium.com - DA95 / Follow 🔥 (быстрая)
3. Issuu.com - DA94 / Follow 🔥 (быстрая)
4. Tumblr.com - DA94 / Follow ⏳ (умеренная)
5. Weebly.com - DA93 / Follow 🔥 (быстрая)
6. About.me - DA92 / Follow 🔥 (быстрая)
7. Blogger.com - DA92 / Follow 🔥 (быстрая)
8. Muckrack.com - DA92 / Follow 🔥 (быстрая)
9. Tripod.lycos.com - DA91 / Follow 🐌 (медленная)
10. Wattpad.com - DA91 / NoFollow 🟡 (средняя)
11. Hackernoon.com - DA91 / Follow ⏳ (умеренная)
⚡️ СРЕДНИЙ DA(59-89)
12. Jimdo.com - DA89 / NoFollow ⏳ (умеренная)
13. Steemit.com - DA88 / Follow 🔥 (быстрая)
14. Yola.com - DA87 / Follow 🐌 (медленная)
15. Substack.com - DA86 / Follow ⏳ (умеренная)
16. Zoho Sites - DA86 / Follow 🟡 (средняя)
17. Site123.com - DA82 / Follow 🐌 (медленная)
18. Webs.com - DA82 / Follow ⏳ (умеренная)
19. Webnode.com - DA81 / Follow 🐌 (медленная)
20. Bravenet.com - DA78 / Follow 🔴 (очень медленная)
21. Vocal.Media - DA76 / NoFollow 🔥 (быстрая)
22. Pen.io - DA76 / Follow 🔥 (быстрая)
23. Write.as - DA75 / Follow 🔥 (быстрая)
24. Strikingly.com - DA72 / Follow 🟡 (средняя)
25. Tealfeed.com - DA59 / Follow 🐌 (медленная)
https://presswhizz.com/blog/web-2-0-site-backlinks-list/
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}