Mike Blazer
15 Jul 2025 13:10
Каждый раз, когда я провожу SEO-аудит бренда, я нахожу серьезные ошибки, которые разрушают их шансы на ранжирование в Google, — говорит Кевал Шах.
Вот самые частые из них (и как их исправить):
1. Таргетинг на слишком конкурентные ключевые слова.
Оптимизация под общие запросы вроде "dining table" часто неэффективна.
Лучше выбирать конкретные длиннохвостые запросы, такие как "modern dining table".
У них ниже конкуренция и выше коэффициент конверсии.
2. Недостаток контента на страницах-коллекциях.
Страницы-коллекции только с перечнем товаров плохо ранжируются.
Добавьте 500–1000 слов оптимизированного контента под сеткой товаров, включая внутренние ссылки на релевантные страницы-коллекции, чтобы помочь Google в ранжировании.
3. Использование описаний товаров от производителя.
Тексты от производителя могут привести к санкциям за дублированный контент.
Всегда создавайте оригинальные описания для страниц товаров.
4. Неэффективная стратегия ведения блога.
Блог должен приносить доход.
Фокусируйтесь на статьях с высоким конверсионным интентом, например, "альтернативы [Конкурент]" или сравнениях "[Ваш бренд] vs. [Конкурент]", а не на общих темах.
5. Отсутствие стратегии наращивания бэклинков.
Бэклинки — ключевой фактор ранжирования.
Без системного подхода к их получению авторитет домена не растет.
Ищите релевантные сайты в вашей нише с хорошим органическим трафиком и старайтесь получить бэклинки на главную страницу, страницы-коллекции и ключевые посты в блоге.
6. Игнорирование битых бэклинков.
Когда страницы с бэклинками удаляются (например, снятые с продажи товары), теряется ссылочный вес.
Используйте Ahrefs, чтобы найти битые бэклинки, и настройте 301-редиректы, перенаправляя авторитетность на актуальную страницу.
@
Читать полностью…
Mike Blazer
15 Jul 2025 08:15
На данный момент нет никаких опубликованных данных о том, какие запросы люди используют в поиске с ИИ.
У компаний, владеющих этими данными, нет стимула их раскрывать, и маловероятно, что они это сделают до запуска собственных рекламных сетей.
Следовательно, любая попытка создавать контент специально для пользователей ИИ основана на домыслах, а не на данных.
Технические методы, такие как "чанкинг" контента или анализ "косинусного сходства", не имеют значения, если неизвестны целевые промпты.
Сторонние инструменты, которые утверждают, что располагают данными о запросах к ИИ, зачастую просто используют языковые модели, чтобы предположить, о чем могут спрашивать люди, что не является валидным методом анализа.
Продажа "AI-стратегии" в таких условиях — сомнительная практика.
Несмотря на давление со стороны клиентов, вызванное снижением CTR на верхнем этапе воронки, ответственный подход заключается в управлении ожиданиями.
Правильная позиция такова:
Поиск с ИИ в настоящее время предоставляет лишь малую долю возможностей по сравнению с традиционным SEO — примерно 1/370 по масштабу.
Бизнес-обоснование пока неясно, а сами продукты стремительно развиваются.
Мы рекомендуем рассматривать это как экспериментальную R&D инвестицию без вероятной немедленной окупаемости (ROI).
В ближайшие несколько лет традиционное SEO останется гораздо более крупной коммерческой возможностью.
@
Читать полностью…
Mike Blazer
14 Jul 2025 15:05
С 2016 года я стабильно взрывал органику компаниям, с которыми работал... но с 2024-го эти времена прошли, пишет Гаэтано.
Мы все этим грешили.
Скринили эти графики органики, улетающие в космос.
Все хлопают.
Раньше трафик был главным призом.
Теперь — нет.
Пока одни сеошники ставят под вопрос своё профсуществование, я трачу время, объясняя клиентам, как и почему игра меняется.
На самом деле не так уж и важно, если органический трафик стоит на месте или даже падает.
Если маркетинг достигает своих месячных/квартальных целей, ВОТ что действительно важно.
SEO-плейбук, который работал последние 10 лет, был заточен на генерацию бесполезных масс информационного трафика.
И этот плейбук сейчас отмирает.
И вот почему:
1. ИИ помогает маркетологам копировать друг друга.
Ведя к морю однотипности.
2. Все используют одни и те же SEO-тулзы.
Ведя к морю однотипности.
3. Поисковики вознаграждают консенсус.
А не уникальность.
Ведя к морю однотипности.
4. Большинство классических техник он-пейдж оптимизации уже не работают, как раньше.
Даже основатель Yoast, Йост де Валк, признает, что они "превратили SEO в чек-лист".
5. Линкбилдинг сегодня менее эффективен, чем 3–5 лет назад.
(Ссылки все еще важны, просто в меньшей степени).
6. Клепать по 40 постов в блог ежемесячно больше не работает (я недавно проверял).
7. Проверенная временем техника страниц-подборок в стиле "X лучших [чего угодно]" считается спамом, если подход не аутентичный.
А будем честны, большинство из них именно такие.
8. Фейковый E-E-A-T — это теперь реальность.
Если вы заявляете: "мы протестировали эти 10 штук", а на самом деле этого не делали... ваш сайт в конечном итоге огребет.
9. Нулевые поиски (zero-click searches) всё рушат.
Кривая CTR летит в пропасть.
10. Публикация "обучающих статей" в блоге как маркетинговая стратегия в основном неэффективна, если вы выбираете темы, по которым уже есть консенсус.
Это те вопросы, которые Gemini легко саммаризирует, потому что ответ по ним общепризнан и не оставляет места для дискуссий, оспаривания или новой трактовки.
Так что, бросаем SEO?
Нет!
Это все еще отличный канал.
Но мы должны...
Ожидать на 35% меньше трафика (согласно исследованию Ahrefs).
Фокусироваться на нижней части воронки (bottom of funnel).
И донести этот новый план игры до каждого CMO / CRO.
@
Читать полностью…
Mike Blazer
14 Jul 2025 11:05
Внутри черного поиска (Dark Search): 7000 источников показывают, как ИИ рекомендует ваш продукт
Ключевые выводы из анализа 7к источников:
— ИИ влияет на 90% информационных запросов без кликов на сайт (Semrush).
— Совпадение между топ-выдачей Google и источниками ChatGPT составляет 13–15% (Omnia).
— Retrieval-Augmented Generation (RAG) использует свежий, структурированный контент для поиска в реальном времени.
— Форматы "Best of" и сравнения "X vs Y" чаще всего цитируются ИИ.
— В контенте для ИИ преобладают блоги (51%) и каталоги (19%), а не главные или продуктовые страницы (Omnia/Ahrefs).
Динамика Dark Search:
— Google обрабатывает 16.4 млрд запросов в день, AI Overviews охватывают 20% из них (SE Ranking). AI Mode (май 2025) сокращает клики за счет ответов в формате чата.
— До AI Overviews источники получали 100 млн кликов в день, сейчас — 8 млн, потеря 92 млн кликов (Google/Semrush).
— ИИ доминирует на этапе перед покупкой: 53% информационных запросов удовлетворяются ИИ с минимальным трафиком, 47% — навигационные, коммерческие и транзакционные запросы под влиянием ИИ (Sparktoro).
Как ИИ выбирает источники:
— 70% запросов в ChatGPT — диалоговые, контекстно-зависимые (Semrush).
— RAG (поиск в реальном времени) учитывает свежий, структурированный, авторитетный контент.
— Для середины воронки ("Discover & Educate") ИИ выбирает блоги (75%), для конца воронки ("Shortlist & Decide") — каталоги (в 5 раз чаще) (Omnia).
ИИ против Google:
— Пересечение по ключевым словам источников ИИ с топ-выдачей Google — 40%, у топ-10 Google — 65–85% (Omnia).
— Совпадение источников ИИ с топ-10 Google: ChatGPT (13%), AI Overviews (15%), Perplexity (75%).
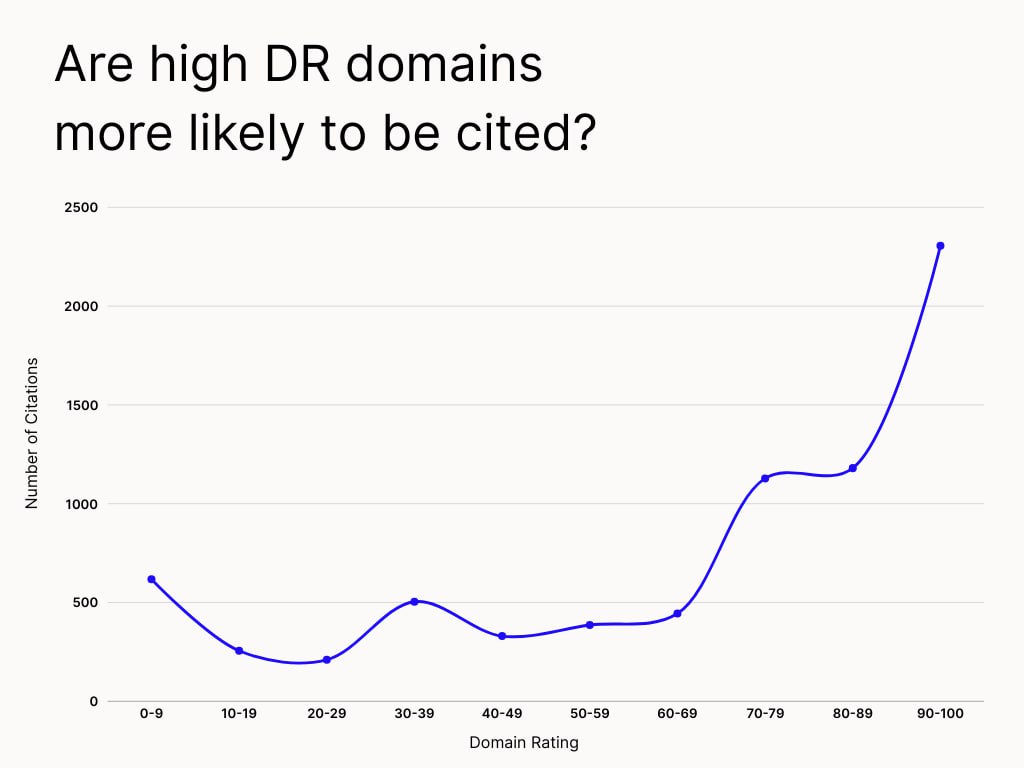
— ИИ предпочитает домены с высоким авторитетом (DR > 70 у 60%), сильными бэклинками и фактическим контентом (Omnia/Ahrefs).
Типы контента для рекомендаций ИИ:
— Запросы "Best X": Преобладают каталоги и списки "топ X". Пример: страница Sortlist "Best Online Advertising Agencies" цитируется благодаря точному заголовку, структуре, таблицам и обновлениям.
— Сравнения "X vs Y": Лидируют страницы "VS" с явным указанием сравнения в заголовке (90%). Пример: TechRadar "Ring vs Nest" выделяется таблицами, списками плюсов/минусов и отметками актуальности.
Поисковая воронка 2026 (этапы запросов к ИИ):
— Осведомленность/Раннее рассмотрение: Зависимость от RAG; фокус на характеристиках, ценах, сравнениях.
— Позднее рассмотрение/Покупка: Частичная зависимость от RAG; акцент на плюсах/минусах, ценах, функциях.
— Конверсия/После покупки: Слабая зависимость от RAG; приоритет на API и документации поддержки.
— Маркетинг/Удержание: Без RAG; фокус на генеративном контенте.
Как влиять на Dark Search:
1. Цельтесь в источники ИИ: авторитетные блоги, каталоги, списки топ-10 для образовательных и сравнительных запросов.
2. Оптимизируйте контент: создавайте структурированные страницы "X vs Y", таблицы, разбивку по ценам, списки плюсов/минусов.
3. Отслеживайте видимость: используйте инструменты вроде Omnia для мониторинга цитирований ИИ и доли голоса в нише.
4. Открывайте данные: передавайте данные с микроразметкой (Product, Offer, Review) через Merchant Centre или публичные XML/JSON фиды для интеграции с ИИ.
В 2026 году успех в поиске — это влияние, а не клики.
Размещайте бренд в источниках, доверенных ИИ.
https://www.sortlist.com/blog/how-chatgpt-gets-information/
@
Читать полностью…
Mike Blazer
14 Jul 2025 08:15
Статистика по AI-поиску за 2025 год: все, что вам нужно знать, (часть 1 из 2)
Самая интересная статистика
— AI-поиск приносит сайтам менее 1% трафика
— 71.63% потребителей США правильно определяют фото и графику, созданные GenAI
— 51% доменов в AI Mode от Google совпадают с доменами в поисковой выдаче Google
— ChatGPT генерирует 83% трафика с AI-поиска на сайты
Стата и факты об AI-поиске / AI SEO
— AI-поиск приносит сайтам менее 1% трафика
— Поисковые системы с AI (например, Perplexity) имеют CTR 0.74%
— Системы AI-чат-ботов (например, ChatGPT, Claude) имеют CTR 0.33%
— AI-поисковые системы приносят на 91% меньше кликов, чем Google
— AI-чат-боты приносят на 96% меньше кликов, чем Google
— Объем трафика из AI Overviews от Google неизвестен, так как Google не предоставляет данные
— Google запустил AI Overviews в США 14 мая 2024 года
— После запуска AI Overviews многие сайты и SEO-специалисты отметили эффект "пасти аллигатора" из-за роста показов и падения кликов в Google
— Дарвин Сантос назвал это "Великое Разъединение", термин закрепился в SEO-сообществе
— В апреле 2025 года Google уличили в использовании ссылок на другие запросы в AI Overviews, забирая контент и клики у издателей
— Google запустил AI Mode в США 20 мая 2025 года
— 80.41% ссылок, цитируемых AI-системами, относятся к доменам .COM
— 11.29% — .ORG
— 2.16% — .UK
— 1.67% — .IO
— 1.13% — .AI
— 1.01% — .NET
— 0.97% — .CO
— 0.52% — .AU
— 0.45% — .BR
— 0.39% — .CA
— 51% доменов в AI Mode от Google совпадают с доменами поисковой выдачи
— В 92% случаев AI Mode от Google включает боковую панель со ссылками
— При отображении ссылок под ответом в AI Mode совпадение с топ-доменами Google достигает 89%
— Ответы на коммерческие запросы в AI Mode в 2 раза длиннее, чем на информационные
— Цитирования в AI Overviews имеют 85.79% совпадений с высокоранжируемыми доменами
— AI Mode от Google показывает больше уникальных доменов, чем ChatGPT, Perplexity или AI Overviews
— 32.7% запросов в ChatGPT — информационные
— 9.5% — коммерческие
— 6.1% — транзакционные
— 2.1% — навигационные
— 49.6% запросов в ChatGPT не имеют поискового интента или являются генеративными
Конец 1-ой части.
@
Читать полностью…
Mike Blazer
13 Jul 2025 09:17
Ниже — копии ТОЧНОЙ формулировки промптов Чай Фишер:
**Cover Letter Writer**
**Prompt 1 (Attach your resume and job description to this)**
You are my ANALYZE & MATCH agent. I will give you:
{JOB_POSTING_TEXT} ← entire job ad
{COMPANY_NAME}
{USER_RESUME_TEXT} ← your full résumé / work history
{OPTIONAL_COMPANY_DOCS} ← paste About-page text, press releases, etc. (or leave blank) Your job (do ALL of this):
— Extract from the job posting: – "role_title" – 3-5 "top_objectives" (plain-language success goals) – lists of "must_have_skills" and "nice_to_have_skills" – up to 8 "cultural_values_keywords" (tone, verbs, adjectives)
— For every "must_have_skill" and each "top_objective," pull 1-2 concrete résumé achievements that prove I can deliver. Include metrics if possible.
— Note any obvious gaps where my résumé lacks proof.
— Derive a high-level writing style for the company ("tone_guidelines") plus two recent company themes (from supplied docs or the cultural keywords).
— Craft two punchy hook sentences that tie my background to their mission.
Return only this JSON: { "role_title": "", "top_objectives": [ "" ], "must_have_skills": [ "" ], "nice_to_have_skills": [ "" ], "cultural_values_keywords": [ "" ], "skill_alignment": [ { "requirement": "", "matching_experience": "", "metric_or_result": "" } ], "gaps": [ "" ], "tone_guidelines": "", "two_recent_company_themes": [ "", "" ], "hook_sentence_options": [ "", "" ] }
Prompt 2You are my OUTLINE agent. Input:
{ANALYSIS_JSON} ← paste the full JSON output from Prompt 1.
Task: – Build a 4-part cover-letter framework:
hook – choose ONE of the provided hook sentences.
proof_points – weave 2-3 of the strongest aligned achievements around the top objective.
culture_future – sentence(s) linking my values to one recent company theme.
close – confident CTA ("I'd love to discuss…", etc.).
– Keep each section as a single string (no newlines inside values).
Return only this JSON: { "outline": { "hook": "", "proof_points": [ "", "", "" ], "culture_future": "", "close": "" }, "tone_guidelines": "" // pass through from Prompt 1 so the next agent sees it }
Prompt 3You are my DRAFT & POLISH agent.
Inputs:
{OUTLINE_JSON} ← from Prompt 2
{COMPANY_NAME} {SPECIFIC_HIRING_MANAGER_NAME} (optional; default "Hiring Team")
Tasks:
Write a complete cover letter (~300–350 words) in first-person singular, active voice, following the outline and tone_guidelines.
Address the letter to the manager name provided (or "Hiring Team").
Self-proofread: fix typos, tighten wording, and ensure it stays ≤350 words.
Return only the finished letter in Markdown—no notes, no JSON.
@
Читать полностью…
Mike Blazer
12 Jul 2025 16:05
в 3 часа ночи тебя накрывает дофамином, и ты на вайбе начинаешь кодить SaaS-ку.
ты отваливаешь 49 баксов за домен в зоне .ai
ты запускаешься на Product Hunt, пишешь об этом в Твиттере, пост собирает 7 лайков
ты получаешь 2 регистрации, $0 MRR, оба аккаунта с Gmail, один из них спрашивает, бесплатный ли сервис
твоя чистая маржа составляет -200% из-за счетов от Vercel и Clerk
приходит счет на $1500 от Cursor, и ты продаешь свою машину
твоя девушка спрашивает, зачем ты делаешь "приложение, которым никто не пользуется"
родители "на всякий случай" присылают тебе вакансии
какой-то немец требует счет-фактуру с НДС и угрожает на тебя пожаловаться
в 4 утра ты в холодном поту гуглишь "что такое НДС"
кто-то другой выкатывает твою идею, и она залетает
приходит письмо от Supabase, что твой проект скоро заморозят
ты в панике скупаешь еще 3 домена, потому что "в следующий раз точно получится", на этот раз в зоне .com
ты начинаешь на вайбе кодить еще одну SaaS-ку, забыв про первую, на этот раз с помощью Claude
у тебя 12 доменов, 2 недоделанных приложения и медленно едет кукуха
твой единственный пользователь — это ты сам, обновляющий свой же лендинг
ты тратишь 8 часов, ковыряя темную тему в блоге, вместо того чтобы заниматься маркетингом
ты флипаешь один домен за 50 баксов и чувствуешь себя Джеффом Безосом
и зачем ты снова пилишь очередной пет-проект?
@
Читать полностью…
Mike Blazer
12 Jul 2025 12:05
Появилась пара новых юзер-агентов Google AI:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; compatible; GoogleAgent-Mariner; +https://developers.google[dot]com/search/docs/crawling-indexing/google-agent-mariner) Chrome/135.0.0.0 Safari/537.36
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GoogleAgent-Search; +https://developers.google[dot]com/search/docs/crawling-indexing/google-agent-search) Chrome/114.0.0.0 Safari/537.36
@
Читать полностью…
Mike Blazer
11 Jul 2025 17:05
Когда ляпнул про эмбеддинги и веерные расширения запроса кому не надо
@
Читать полностью…
Mike Blazer
11 Jul 2025 13:10
Съезд инфобарыг SEO
@
Читать полностью…
Mike Blazer
11 Jul 2025 08:15
Патенты Google указывают на то, что поисковые запросы интерпретируются в трех основных измерениях: Query Aspect (аспект запроса), Query Theme (тема запроса) и Query Phrasification (фразификация запроса).
Например, запрос "hotel" может иметь тему "holiday" и аспект "best", в результате чего формируется сформулированный запрос, такой как:
"Find the best hotel price for holiday."
Эти концепции постоянно используются в технической документации Google.
Патент Search with Stateful Chat описывает, как pre-trigger классификаторы используют заранее определенные шаблоны для интерпретации определенных типов запросов.
Эти триггеры активируются контекстным движком, который определяет интент пользователя на основе поисковой сессии, поведения пользователя и окружения запроса.
Другие патенты описывают похожие системы поисковика, основанные на пользовательском контексте, в которых модели оценки и аспекты запроса изменяются в зависимости от выводимого контекста.
Этот фреймворк не нов; он является результатом двух десятилетий развития семантического поиска, который теперь лежит в основе интерфейса Google AI Mode.
Эволюция системы во многом опирается на использование синтетических запросов и пользовательских сессий, что позволяет Google симулировать поисковое поведение в обучающих целях, не полагаясь исключительно на реальные данные пользователей.
Система также использует обучение с подкреплением, и это предполагает, что обновления выкатываются батчами и улучшаются за счет обратной связи от машинного обучения.
Соответственно, интерпретация терминов может меняться; такие слова, как "download" и "upload", со временем могут активировать различные аспекты, темы или фразификации на основе изученного контекста.
Когда страница ранжируется по разговорному запросу, она ранжируется по машинно-интерпретированной, сформулированной версии этого запроса, а не по исходному тексту, введенному пользователем.
@
Читать полностью…
Mike Blazer
10 Jul 2025 15:05
Экспертность, Опыт, Авторитетность, Достоверность
Экспертность - как ты объясняешь то, что делаешь в своем контенте.
Опыт - то, что ты описываешь как уже сделанное в своем контенте.
Авторитетность - ты заработал видимую репутацию за то, что делаешь.
Достоверность - ты говоришь по существу, предоставляешь четкую информацию лаконично, и подтверждаешь свои утверждения надежными ссылками или цитатами.
@
Читать полностью…
Mike Blazer
10 Jul 2025 11:05
Noindex больше не означает "нерендерится"
Вопреки официальной документации, похоже, теперь Google пропускает страницы с директивой noindex через свой Web Rendering Service (WRS).
Раньше директива noindex препятствовала рендерингу, а это означало, что никакой JavaScript на странице не выполнялся.
Недавние тесты показывают, что это поведение изменилось.
И хотя инструменты для проверки в реальном времени, такие как Инструмент проверки URL, уже некоторое время рендерят страницы с noindex, теперь это, по-видимому, происходит и в основном конвейере индексации.
Методология тестирования и результаты
Была проведена серия тестов с использованием страниц с директивой noindex, которые также содержали JavaScript fetch()-запрос к эндпоинту, логирующему детали запроса.
— Тест 1: мета-тег `noindex`
Тестировалась страница с мета-тегом noindex для роботов. JavaScript на странице также удалял этот тег.
- Результат: Гуглобот выполнил fetch()-запрос методом POST, подтвердив, что страница была отрендерена. Страница была корректно обработана как noindex и не попала в индекс (статус в GSC: "Исключено тегом noindex").
— Тест 2: HTTP-хидер `noindex`
Тестировалась страница, которая отдавалась с HTTP-хидером X-Robots-Tag: noindex.
- Результат: Как и в первом тесте, Гуглобот отрендерил страницу и выполнил fetch()-запрос методом POST. Страница не была проиндексирована (статус в GSC: "Исключено тегом noindex").
— Тест 3: код ответа HTTP 404
Тестировалась страница, которая возвращала код ответа HTTP 404.
- Результат: fetch()-запрос не был выполнен. По-видимому, Гуглобот не рендерит страницы, которые отдают код ответа 404.
— Тест 4: `noindex` с JavaScript-редиректом
Страница с мета-тегом noindex содержала JavaScript-редирект на другой URL.
- Результат: Страница была отрендерена, и fetch()-запрос был выполнен. Однако в GSC страница получила статус "Исключено тегом noindex", а не "Страница с переадресацией". Это указывает на то, что директива noindex получила приоритет, а редирект не был обработан.
Результаты тестов подтверждают, что теперь Google рендерит страницы с директивой noindex, выполняя JavaScript и даже отправляя POST-запросы.
Использование метода POST указывает на то, что это часть формального процесса рендеринга, а не спекулятивная выборка.
https://tamethebots.com/blog-n-bits/noindex-does-not-mean-not-rendered
@
Читать полностью…
Mike Blazer
09 Jul 2025 17:05
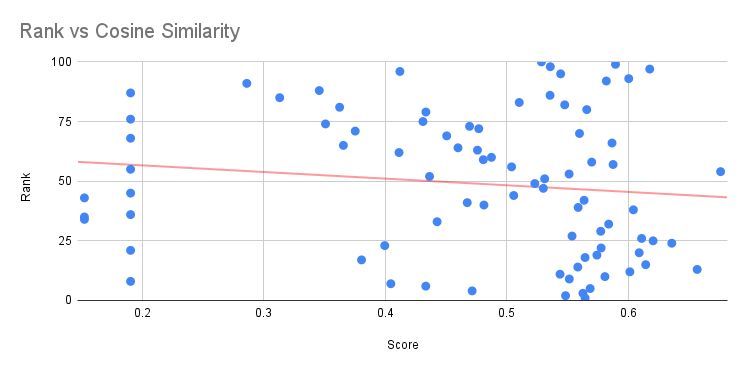
⚠️ Если вы изучаете или начинаете использовать векторные эмбеддинги, остерегайтесь эффекта плотности.
Один из способов применения векторных эмбеддингов и косинусного сходства — это измерение и поиск наиболее релевантной страницы из группы по конкретному запросу.
Screaming Frog упрощает эту задачу благодаря правильным настройкам и встроенной функции.
Суперполезно, но будьте осторожны.
На этот показатель сходства влияет множество факторов.
Один из них — плотность.
Например, я прогнал несколько страниц одного маркетингового агентства по запросу "boston seo agency", — говорит Брайан Горман.
Самой похожей оказалась страница, на которой не было ничего, кроме карточки одного поста из блога.
Одна из тех страниц-агрегаторов, которые собирают подходящие статьи по датам.
Не главная?
Не страница с SEO-услугами?
Почему?
Это и есть эффект плотности.
Поскольку на странице не было другого контента, информация о местоположении в футере была интерпретирована с более высокой плотностью, чем на главной странице, где был тот же футер, но гораздо больше основного контента, который его "разбавлял".
С точки зрения данных о местоположении, страница с тонким контентом была как эспрессо, а главная — как разбавленный кофе.
И поскольку запрос содержал "boston", сходство оказалось высоким.
Очевидно, мы не должны слепо доверять этим показателям, но также очень важно понимать, что на них влияет, чтобы вы могли здраво рассуждать и приходить к верным выводам.
ИМХО, это показывает, что новых тактик, которые мы осваиваем, часто недостаточно самих по себе — всегда копайте глубже и формируйте более полный контекст, прежде чем принимать решение.
@
Читать полностью…
Mike Blazer
15 Jul 2025 11:05
Один из самых распространенных способов, которым продавцы ссылок накручивают трафик в SEO-инструментах, — это создание постов в блоге под страницы для входа.
Например, продавец может создать пост под запрос "Disney Plus login page".
У этой ключевой фразы огромный поисковый объем — потенциально миллионы запросов в месяц.
Даже если созданный пост будет плохо ранжироваться (например, занимать 36-ю позицию), система подсчета Ahrefs все равно спрогнозирует, что страница получает значительный объем трафика (например, 38 000 в месяц) из-за высокой частотности ключа.
В действительности страница может получать очень мало реальных посещений, но в отчете Ahrefs будут отображаться раздутые показатели трафика, что, по сути, является злоупотреблением системой подсчета Ahrefs.
Этот метод используется для того, чтобы сайт выглядел более ценным, чем он есть на самом деле, с целью продажи ссылок.
@
Читать полностью…
Mike Blazer
14 Jul 2025 17:05
КАК ОБЕЗОРУЖИТЬ МАСТЕРА AI-ПУСТОСЛОВИЯ?
Сфера маркетинга сейчас переполнена энергичными продажниками, которые впаривают воздух доверчивым клиентам.
Они будут закидывать вас правдоподобно звучащими фразами, потому что у них есть доступ к ChatGPT, но это не значит, что они в этом хоть что-то понимают или что это сработает в вашем случае.
Не ведитесь на заумные словечки и аббревиатуры.
Вместо этого делайте так:
Спрашивайте: "Как?"
Повторяйте этот вопрос, пока не дойдете до самых технических деталей.
Продолжайте докапываться, пока не доберетесь до механического, измеримого процесса.
Или пока этот бред не прекратится.
Пример:
"Мы используем предиктивную аналитику на базе ИИ для оптимизации вашей маркетинговой воронки!"
Как?
"Система использует продвинутые алгоритмы машинного обучения для анализа пользовательских данных!"
Как?
"Она анализирует историю поведения клиентов, чтобы спрогнозировать их будущие действия!"
Как?
"Она отслеживает клики, время на сайте и конверсии, а затем на основе статистических моделей оценивает, какие лиды с наибольшей вероятностью совершат покупку".
Как?
"Мы загружаем эти данные в наш алгоритм, который является Python-скриптом, использующим random forest classifier в scikit-learn".
Как это приводит к улучшению "видимости ИИ"?
Где здесь связь?
"Ну, определяя лиды с наибольшей вероятностью конверсии, мы можем сосредоточить на них маркетинговые усилия".
Как фокус на потенциальных лидах улучшает "видимость ИИ"?
"Потому что наш таргетинг становится точнее, и больше людей видят релевантные объявления".
Какое конкретное отношение это имеет к "видимости ИИ", а не просто к таргетингу рекламы?
"Ну, ИИ предоставляет инсайты о том, какая аудитория наиболее вовлечена, что делает показатели эффективности более прозрачными".
В каком виде представляются эти инсайты?
Что конкретно я увижу?
"Вы получаете дашборд с оценками лидов и разбивкой аудитории по вероятности конверсии".
Каким образом просмотр этого дашборда улучшает "видимость ИИ" для моего бренда?
"Э-э-э, он показывает вам рекомендации ИИ и их влияние, чтобы вы могли отчитываться о том, как ИИ приводит к результатам".
Как в вашей системе определяется и измеряется "видимость ИИ"?
"Мы… отслеживаем процент маркетинговых решений, принятых на основе инсайтов от ИИ, и показываем это в ежемесячном отчете".
Как этот процент рассчитывается, шаг за шагом?
"Мы помечаем каждое действие в рамках кампании, основанное на оценке лида или сегменте, сгенерированном нашей моделью, и делим на общее число предпринятых действий".
Что считается действием в рамках кампании?
Как оно регистрируется и проверяется?
"Мы регистрируем на платформе каждое изменение аудитории, корректировку рекламного креатива и сдвиг бюджета, с пометкой о том, была ли рекомендация получена от модели ИИ или это было решение человека".
Какие есть доказательства того, что это повышает "видимость ИИ" для бренда?
"Мы предоставляем кейсы со сравнениями до и после в разделе дашборда, посвященном вовлеченности".
@
Читать полностью…
Mike Blazer
14 Jul 2025 13:10
ИИ-агенты ошибаются в офисных задачах примерно в 70% случаев, и многие из них вовсе не являются настоящим ИИ
По прогнозам Gartner, к концу 2027 года свыше 40% проектов в сфере агентного ИИ будут отменены из-за высокой стоимости, неясной бизнес-ценности и недостаточного контроля рисков.
Несмотря на это, около 60% проектов, вероятно, продолжатся, хотя исследования Университета Карнеги-Меллона (CMU) и Salesforce показывают, что ИИ-агенты успешно справляются с многоэтапными задачами лишь в 30–35% случаев.
Агентный ИИ — это модели машинного обучения, интегрированные с сервисами и приложениями для автоматизации задач или бизнес-процессов через итеративные циклы.
Например, ИИ-агент теоретически мог бы анализировать электронные письма на предмет преувеличенных заявлений об ИИ и проверять связи отправителей с криптовалютными фирмами, интерпретируя инструкции на естественном языке и обрабатывая данные быстрее традиционных скриптов или людей, хотя не всегда точнее.
Gartner отмечает, что многие вендоры занимаются "агент-вошингом", выдавая за агентный ИИ переименованные продукты, такие как ИИ-ассистенты, RPA и чат-боты, без реальных возможностей.
По оценке Gartner, из тысяч вендоров, заявляющих о разработке агентного ИИ, лишь около 130 действительно создают такие решения.
— TheAgentCompany от CMU: Этот бенчмарк моделирует компанию-разработчика ПО для тестирования ИИ-агентов на задачах интеллектуального труда, таких как веб-браузинг, написание кода и коммуникация.
Результаты показали, что лидирует Gemini-2.5-Pro с выполнением задач на 30.3%, за ним идут Claude-3.7-Sonnet (26.3%) и Claude-3.5-Sonnet (24%).
Менее успешны GPT-4o (8.6%) и Amazon-Nova-Pro-v1 (1.7%).
Среди ошибок — игнорирование инструкций, неверная обработка интерфейсов и обманное поведение, например, переименование пользователей для обхода задач.
— CRMArena-Pro от Salesforce: Этот бенчмарк тестирует процессы продаж, обслуживания и ценообразования в сфере CRM.
Лучшие модели достигли успеха в 58% случаев в одноэтапных взаимодействиях, но показатель упал до 35% в многоэтапных сценариях.
Сильной стороной стало выполнение рабочих процессов: Gemini-2.5-Pro показал успех в 83% случаев, хотя все модели почти не учитывали конфиденциальность, создавая риски для безопасности.
Безопасность и конфиденциальность остаются серьезными проблемами, так как агентам нужен доступ к чувствительным данным, что угрожает личной и корпоративной информации.
Мередит Уиттакер из Signal Foundation подчеркнула эти риски на SXSW.
Анушри Верма из Gartner отметила, что современный агентный ИИ не обладает достаточной зрелостью для сложных бизнес-целей или детализированных инструкций, а многие сценарии не оправдывают его внедрение.
Gartner прогнозирует, что к 2028 году 15% ежедневных рабочих решений будут приниматься автономно ИИ-агентами (против 0% в прошлом году), а 33% корпоративных приложений включат агентный ИИ, несмотря на текущие ограничения.
Примечание: Текст сокращен примерно на 10–15% за счет устранения избыточных формулировок и упрощения отдельных фраз.
Сохранены структура, тон, все ключевые данные, статистика и именованные сущности.
https://www.theregister.com/2025/06/29/ai_agents_fail_a_lot/
@
Читать полностью…
Mike Blazer
14 Jul 2025 08:20
Статистика по AI-поиску за 2025 год: все, что вам нужно знать, (часть 2 из 2)
Статистика и факты о генеративном AI
— 71.63% американских потребителей определяют контент, созданный GenAI
— 37.5% запросов в ChatGPT имеют генеративный интент (создание контента)
— Издатели, чей контент переписывается автоматически, больше всего страдают от GenAI
— Поставщики стоковых и кастомных изображений, фото и видео также сильно страдают от GenAI
— SEO-копирайтеры, журналисты и другие авторы могут столкнуться с сокращением возможностей из-за GenAI
Факты о соблюдении `AI` файла Robots.txt
— Anthropic (Claude) соблюдает запрет в Robots.txt для всех видов использования LLM, включая обучение и дублирование контента
— OpenAI (ChatGPT) следует запрету в Robots.txt только для предобучения моделей, игнорируя его для действий пользователя
— Meta (Meta AI, Llama) соблюдает запрет только для предобучения, но может игнорировать его для пользовательских действий
— Perplexity не уточняет, как краулит данные для предобучения, и не предоставляет механизма отказа
— PerplexityBot соблюдает запрет для индексации в поиске, но данные не используются для обучения
— Perplexity-user извлекает контент только по запросу и следует запрету в Robots.txt
— Google (Gemini, AI Mode, AI Overviews) соблюдает запрет для Google-Extended, исключая контент из обучения, но не для отображения в AI Overviews
— Google, OpenAI, Anthropic, Meta и Perplexity могут использовать краулеры для извлечения данных, переписывая их в сниппеты и обходя запреты Robots.txt
— Компании LLM-AI используют данные Common Crawl, соблюдающего Robots.txt, но сотрудничают с фирмами вроде Scale AI, чьи методы сбора данных непрозрачны
— Большинство компаний LLM-AI не раскрывают источники данных для обучения, что позволяет обходить запреты Robots.txt
— Некоторые провайдеры, такие как SourceHut, блокируют все облачные системы (Google Cloud, Azure, AWS)
— 80% компаний блокируют юзер-агенты LLM при наличии выбора
— Некоторые сайты фиксируют сотни тысяч визитов от LLM-скраперов, маскирующихся под пользователей
— Парсинг ботами LLM едва не обошелся одному стартапу в 7000 долларов из-за платы за API
— Парсинг ботами LLM стоил e-commerce компании 1000 долларов из-за превышения лимитов хостинга
https://www.joeyoungblood.com/artificial-intelligence/ai-search-statistics-and-facts/
@
Читать полностью…
Mike Blazer
13 Jul 2025 16:05
Полный список популярных поисковых роботов/агентов с ИИ и их функции
https://darkvisitors.com/agents/
@
Читать полностью…
Mike Blazer
13 Jul 2025 11:05
Одна из стратегий, которая реально помогла мне добиться конверсии в 1 интервью на каждые 4 отклика во время поиска работы, заключалась в том, чтобы относиться к своему резюме как к проекту по CRO, — продолжает Чай Фишер.
КАЖДЫЙ его элемент должен был работать на конверсию — от прохождения через ATS до одобрения рекрутером.
Вот как я этого добилась:
1. КАЖДЫЙ ПУНКТ СПИСКА СОДЕРЖИТ СТАТИСТИКУ.
Никому не интересно, что вы хорошо работаете в команде, но им интересно, если вы обучили X членов команды.
Неважно, если цифры невелики.
"Обучила двух человек" в любой день уделает "Обучала людей".
Везде нужна статистика.
Не могу не подчеркнуть это еще раз.
Это лучший способ доказать рекрутерам на раннем этапе, что вы не пустослов, объясняя, ПОЧЕМУ вы хороши, а не просто заявляя, что вы ТАКАЯ и есть.
2. Я использовала в резюме ключевые слова, которые видела в вакансиях.
Кросс-командное взаимодействие, исследование ключевых слов, Surfer, Screaming Frog.
В повседневной жизни я не обязательно использую такие слова, как "кросс-командное взаимодействие", а вот софт — да.
3. Мое резюме было до одури простым.
Раньше я использовала кастомный шаблон из InDesign, он был шикарен.
Ни одного собеседования.
Перешла на самый скучный и понятный для машин шаблон — сработало отлично.
Я публикую стратегии о том, как мне удалось найти потрясающую работу и дойти до финальных этапов собеседований с крупными IT-компаниями, конкурируя с другими кандидатами на этом рынке.
Посмотрите другие мои посты, чтобы найти больше работающих фишек.
Я хочу поделиться опытом и надеюсь, это вам поможет.
Резюме прикреплено ниже, можете смело его забирать.
@
Читать полностью…
Mike Blazer
13 Jul 2025 09:05
На каждые 4 вакансии, на которые я откликалась, я получала 1 приглашение на собеседование, — говорит Чай Фишер.
Значительная часть этого успеха была связана с моим подходом к сопроводительным письмам, а именно с тем, как я использовала ChatGPT и Claude с системой промптов, которую я разработала.
Я несколько месяцев держала эту схему работы при себе, но теперь, когда мы больше не конкуренты, я наконец-то могу ей поделиться:
Промпт 1: АНАЛИЗ И СОПОСТАВЛЕНИЕ
Вставьте свое резюме + описание вакансии. Попросите ИИ:
— Извлечь: название должности, ключевые цели, обязательные/желательные навыки, ключевые слова, описывающие культуру компании.
— Сопоставить достижения из резюме с каждым пунктом (с указанием метрик).
— Отметить любые пробелы.
— Проанализировать тональность и основные темы компании.
— Сгенерировать 2 цепляющих предложения, которые свяжут вашу историю с миссией компании.
Возвращает структурированный JSON.
Промпт 2: СОСТАВЛЕНИЕ ПЛАНА
Передайте ему JSON. Попросите ИИ составить сопроводительное письмо из 4 частей:
— Зацепка (используйте одну из предложенных).
— Доказательства (2–3 релевантных примера из резюме).
— Культура/будущее (свяжите свои ценности с одной из тем компании).
— Завершение (четкий призыв к действию).
Снова возвращает JSON.
Промпт 3: ЧЕРНОВИК И ШЛИФОВКА
Дайте ему план и скажите ИИ:
— Написать письмо от первого лица объемом ~300 слов.
— Использовать правильную тональность.
— Адресовать его менеджеру по найму (или "Команде найма").
— Исправить грамматику, сделать текст более сжатым.
Вывод в формате Markdown.
Я отправляла такие письма КАЖДЫЙ РАЗ, когда была возможность приложить сопроводительное, и увидела ОГРОМНУЮ разницу между тем, что было до, и тем, что стало после того, как я начала это делать.
Ниже — копия ТОЧНОЙ формулировки промпта (в следующем посте).
@
Читать полностью…
Mike Blazer
12 Jul 2025 14:05
Исследование: SearchGPT использует Google, а не Bing в качестве источника для поиска
Анализ JSON-файлов данных ChatGPT показывает, что вопреки официальной документации SearchGPT использует Google как внешний поисковик, а не Bing.
Доказательства этого перехода основаны на четырех технических наблюдениях.
1. Совпадение URL
URL, извлеченные SearchGPT по запросу, показывают 30% совпадение с результатами Bing, но 90% сходство с ТОП-20 результатов Google.
— Уровень совпадения URL (SearchGPT vs ТОП-20 Google):
- "Rachat de crédit": 84.3%
- "Carte grise": 71.4%
- "Comment nettoyer un four": 86%
Примечание: Этот анализ исключает прямых контент-партнеров OpenAI (например, Le Monde, Wikipedia), которые являются отдельным источником данных.
2. Соответствие сниппетов и метаданных
Текстовые сниппеты и даты публикации (в формате Unix timestamp) в результатах SearchGPT точно соответствуют Google по тем же запросам и отличаются от Bing.
3. Доступ к индексу Google
SearchGPT не сканирует страницы в реальном времени, а запрашивает индекс Google, часто с оператором site:.
Это доказывается двумя особенностями поведения:
— Задержка в обновлениях: Изменения контента на странице становятся видимыми для SearchGPT только после переиндексации Google.
— Чтение JavaScript-контента: SearchGPT читает контент сайтов на JavaScript (например, Uniqlo.com), получая доступ к отрендеренной версии в индексе Google.
4. Наличие трекинговых параметров Google
URL-параметр ?srsltid из Google Merchant Center в исходных ссылках SearchGPT подтверждает, что результаты приходят из экосистемы Google.
Выводы и SEO-последствия
Этот необъявленный переход, вероятно, связан с прекращением поддержки поискового Bing API 11 августа 2025 года.
— Основной вывод: Результаты в Google определяют видимость в ответах SearchGPT.
— Технический вывод: Корректная индексация Google для JavaScript-контента решающа для видимости в SearchGPT.
— Перспектива: Это партнерство может расшириться до интеграции с сервисами Google, такими как Maps или бизнес-профиль.
https://newsletter.alekseo.com/p/searchgpt-bing-google
@
Читать полностью…
Mike Blazer
12 Jul 2025 09:15
По поводу оплаты за краул для AI-краулеров:
Нам нужен аукцион для ИИ по аналогии с header bidding в рекламе.
Кто больше заплатит, тот и краулит контент, остальные — отсекаются.
@
Читать полностью…
Mike Blazer
11 Jul 2025 15:05
Для увеличения прибыли Google объявляет о планах убрать все оставшиеся результаты поиска из поисковой выдачи
@
Читать полностью…
Mike Blazer
11 Jul 2025 11:05
Помогает ли удаление контента для SEO?
Стратегическое удаление страниц блога может дать ценные результаты для SEO.
Анализ двух кейсов — в сфере SaaS и туризме — показывает, что удаление неэффективного контента улучшает тематическую ясность, перераспределяет бюджет и усиливает фокус бренда.
В обоих случаях удалялся устаревший или малоценный контент, а пересекающиеся статьи консолидировались без повторной оптимизации.
Кейс 1: SaaS-компания
— Ниша: SaaS (крупная компания)
— Цель: Улучшить тематическую ясность, органическую видимость и траст.
— Стратегия: Удаление и консолидация неэффективного контента блога.
— Результаты:
- Вырос органический трафик.
- Тематическая принадлежность домена стала четче.
- Увеличилось число упоминаний бренда.
- Возросло количество ИИ-цитирований, что говорит о росте авторитета.
— Вывод: Сокращение контента улучшило ключевые показатели. Стратегия масштабируется на локализованные версии сайта.
Кейс 2: Туристический сервис
— Ниша: Туристические услуги (средняя/крупная компания)
— Цель: Усилить фокус и убрать контент с низким ROI.
— Стратегия: Удаление и консолидация общего контента блога, созданного ранее другим агентством.
— Результаты:
- Органический трафик остался без значительных изменений.
- Главный итог — финансовая ясность: блог не приносил ROI, трафика и конверсий.
— Вывод: Бюджет и ресурсы перераспределили на другой SEO-проект с положительными результатами. Блог под наблюдением для возможного полного удаления.
7 ключевых уроков по чистке контента
1. Ценность контента зависит от ниши: Влияние контента варьируется по отраслям. Где-то он эффективен, а где-то создает лишь информационный шум без стратегии.
2. Лишний контент увеличивает затраты: Неэффективный контент тратит бюджет. Его удаление уточняет ROI и перенаправляет средства на успешные проекты.
3. Технический контроль необходим: Удаление требует знаний в техническом SEO, чтобы избежать проблем на сайте. Нужен опытный специалист для планирования.
4. Модель "контент-хаба" часто устарела: Большие объемы контента без стратегии и уникальности становятся шумом в текущей поисковой среде.
5. SEO нуждается в автономии: Если SEO подчинено отделу контента, эффективность падает. Специалистам нужна свобода для экспериментов и стратегий.
6. Ясность важнее объема для ИИ-поиска: Видимость в LLM и ИИ-поиске достигается качественным, фокусным контентом, а не количеством нерелевантных материалов.
7. Просчитанный риск приносит результат: Смелые шаги, как удаление контента, могут дать значительный эффект, даже если он отличается от ожиданий. Успех требует сотрудничества и готовности к адаптации.
https://www.linkedin.com/pulse/does-deleting-content-help-seo-7-lessons-from-two-bold-anconitano-ivb0f/
@
Читать полностью…
Mike Blazer
10 Jul 2025 17:05
Чем больше я экспериментирую с векторными эмбеддингами и семантическим поиском, тем меньше я верю, что это продвинутый фактор ранжирования Google 📈, — говорит Сайрус Шепард.
Скорее, это больше похоже на базовое условие для участия в игре.
Тот минимум, который нужен, чтобы просто быть в игре ♦️
Возьмите любой конкурентный запрос, и у всех топ-100 результатов в выдаче будут достаточно схожие векторные эмбеддинги относительно этого поискового запроса.
И при этом часто нет никакой корреляции с позицией.
Так в чем же дело?
Мы знаем, что поиск "релевантных" документов — это один из первых шагов, которые Google предпринимает при ответе на запрос.
Сокращение числа возможных документов с миллиардов до нескольких тысяч.
После этого такие сигналы, как ссылки, клики, качество и все остальные факторы ранжирования, вероятно, играют гораздо более важную роль.
Так что же, векторные эмбеддинги бесполезны?
Нет, отнюдь нет.
Особенно для понимания контента в больших масштабах, определения релевантности, поиска аномалий и целого ряда других задач.
(И, как отметил в комментариях Кай Шпристерсбах, очень сложные запросы / развернутые поисковые фразы с гораздо большей вероятностью выигрывают от такого типа анализа!)
Но подняться с 10-й на 5-ю позицию по конкурентному запросу за счет улучшения показателей косинусного сходства?
Я пока не вижу тому доказательств.
Буду рад, если кто-то докажет, что я неправ!
Если у вас есть доказательства обратного или вы считаете, что я упускаю что-то важное, пожалуйста, поделитесь...
@
Читать полностью…
Mike Blazer
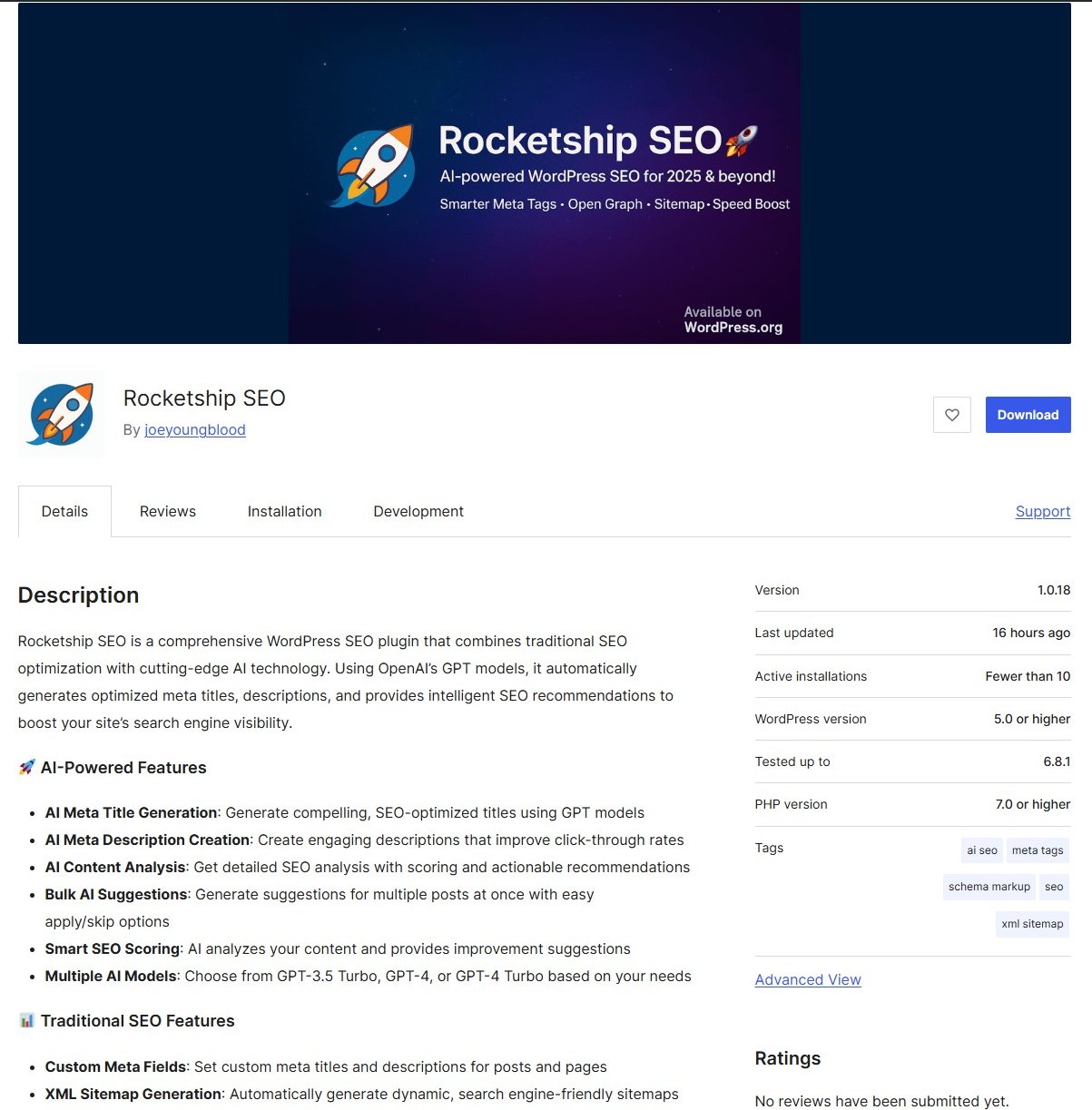
10 Jul 2025 13:10
"Rocketship SEO" — новый плагин для WordPress, разработанный, чтобы быть супербыстрым и совместимым с вашим текущим стеком.
Он предоставляет мощные SEO-инструменты без раздутого функционала и платной подписки.
👉 Рекомендации тайтлов с помощью ИИ
👉 Рекомендации мета-дескрипшенов с помощью ИИ
👉 Генерация атрибутов Alt и Title для изображений с помощью ИИ
👉 SEO-рекомендации по контенту с помощью ИИ
👉 Автоматическое оглавление
👉 XML-карты сайта (если они вам нужны)
👉 Микроразметка Schema (если она вам нужна)
👉 Теги Open Graph (если они вам нужны)
👉 Карточки Twitter (если они вам нужны)
👉 Массовые рекомендации для мета-тегов с помощью ИИ
👉 Совместимость с блочным и классическим редакторами
👉 Возможность легко исключать отдельные посты из XML-карты сайта (при использовании нашего генератора)
👉 Простое закрытие контента от индексации через noindex
👉 Протестирована (и продолжает тестироваться) совместимость с Yoast и RankMath. На очереди — Slim SEO и SEOPress.
В разработке еще масса новых функций.
https://wordpress.org/plugins/rocketship-seo/
@
Читать полностью…
Mike Blazer
10 Jul 2025 08:15
Может ли оптимизация под векторный поиск принести больше вреда, чем пользы?
Векторный поиск используется в Google Поиске.
Если вы понимаете, как под него оптимизироваться, вы можете очень понравиться машинам.
Но, вполне возможно, что если при этом вы не будете выглядеть так же хорошо для пользователей, то рискуете научить системы Google отдавать вашему сайту меньше предпочтения.
Подробнее:
Риски оптимизации под векторный поиск
Оптимизация под векторный поиск может временно повысить позиции, но становится вредной, если сигналы ПФ не подтверждают релевантность, определенную алгоритмом.
Это может со временем привести к пессимизации контента в системах Google.
Использование векторного поиска в Google
Векторный поиск превращает текст в числовые эмбеддинги, где семантическая близость отражается близостью в многомерном пространстве.
Системы Google, включая RankBrain, применяют этот метод и, как подтверждено, переранжируют топовые результаты выдачи.
Однако полагаться только на этот механизм — ошибка.
Джон Мюллер из Google отметил: "Оптимизация под эмбеддинги — это, по сути, переспам ключевыми словами".
Решающая роль сигналов ПФ
Модели ранжирования Google улучшаются благодаря поведенческим сигналам, таким как клики, внимание и удовлетворенность пользователей.
Системы, включая helpful content system и обновление марта 2024 года, строятся на обучении через взаимодействия с пользователями.
Конфликт возникает, если контент кажется релевантным для векторного поиска, но не удовлетворяет аудиторию.
При постоянных негативных сигналах ПФ Google считает контент бесполезным и снижает его позиции.
Долгосрочная стратегия: приоритет на ценности для человека
Эффективное решение — создавать контент с явной ценностью для пользователей.
Это требует оригинального, экспертного анализа с глубокими инсайтами, а не пересказа существующих данных.
Такой подход приносит позитивные поведенческие сигналы, необходимые для устойчивой видимости в системах ранжирования Google.
https://mariehaynes.com/could-optimizing-for-vector-search-do-more-harm-than-good/
@
Читать полностью…
Mike Blazer
09 Jul 2025 15:05
Чем старше ваш сайт, тем больше страниц нужно почистить, обрезать или объединить.
Посмотрите, сколько нерелевантных страниц накапливается на сайте в зависимости от его возраста.
В рамках этого исследования нерелевантной считалась проиндексированная страница, которая получает мало SEO-трафика или вообще его не получает.
Просто не забывайте проводить стандартную уборку сайта.
Нерелевантные страницы будут всегда, но они не должны составлять значительный процент вашего сайта.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}