Mike Blazer
28 Jul 2025 17:05
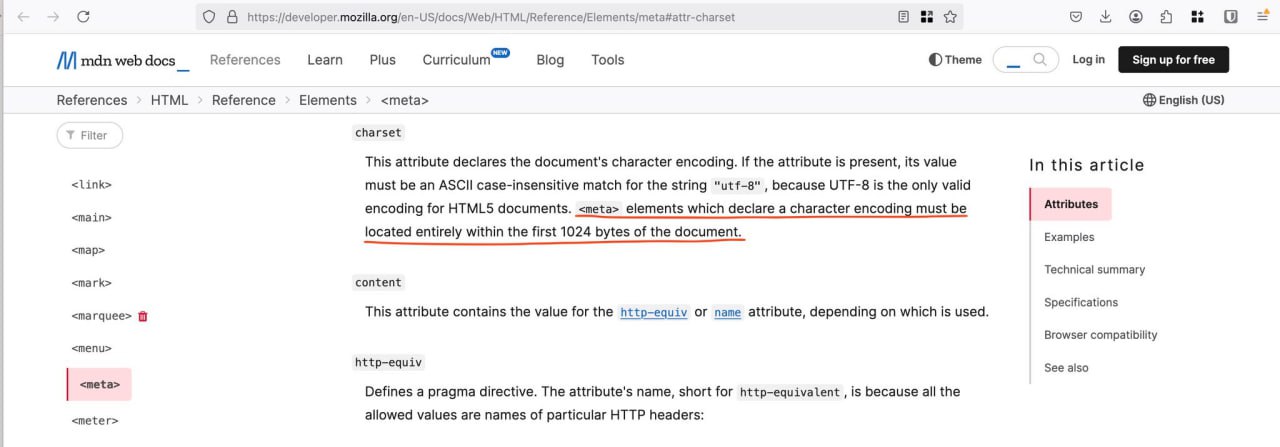
Проблемы с кодировкой?
Обязательно проверьте исходный и отрендеренный HTML на позицию атрибута кодировки символов.
Он *должен* находиться в первом килобайте HTML.
Кроме того, если значение charset отличается от utf-8, начинайте задавать вопросы.
@
Читать полностью…
Mike Blazer
28 Jul 2025 13:10
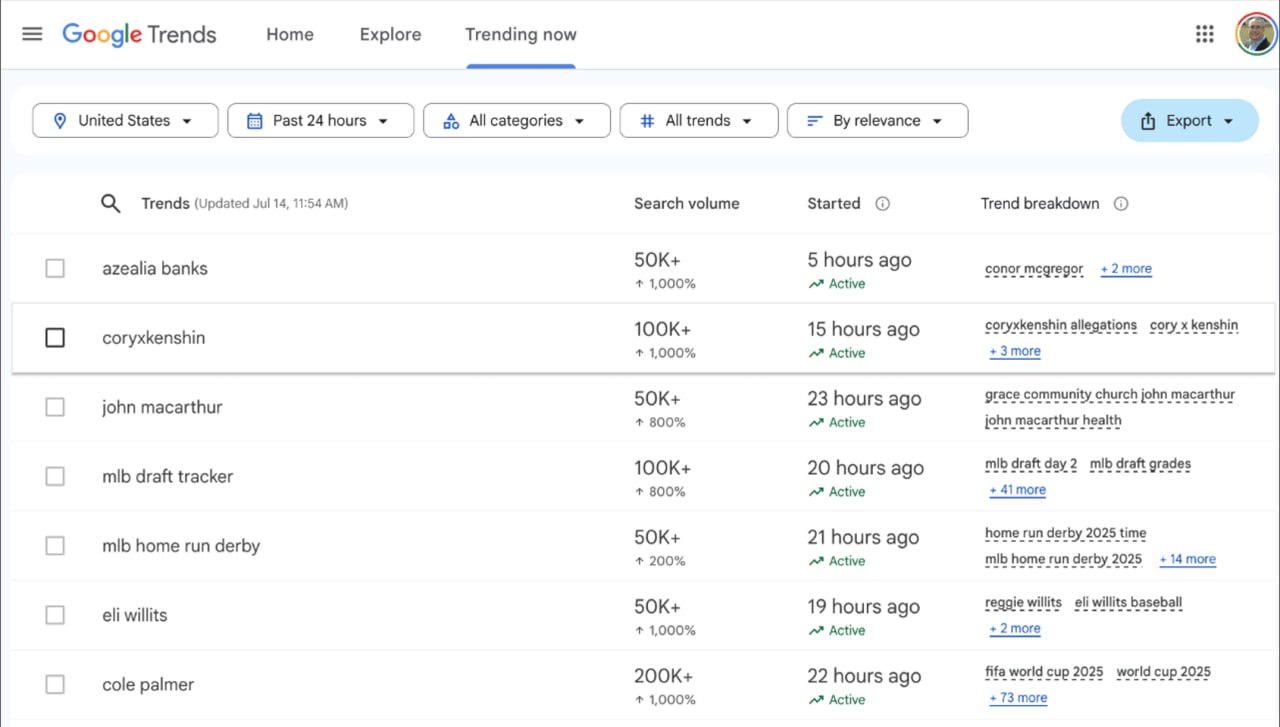
Google Trends: Смещение фокуса на личности и его последствия для SEO
Анализ Google Trends показывает сдвиг: теперь в трендах доминируют личности, а не заголовки новостей или крупные события.
Если раньше запросы сосредоточивались на событиях вроде "Super Bowl halftime show", то теперь в них фигурируют имена инфлюенсеров, спортсменов и публичных фигур, а объемы поиска по ним часто превышают традиционные новостные поводы.
Контраст в данных о трендах
Исторически Google Trends отражал события и информационные потребности широкой аудитории:
— "COVID vaccine near me"
— "Oscars 2019 winners"
Сейчас тренды ориентированы на конкретных людей, о чем свидетельствуют недавние всплески поискового объема:
— Азалия Бэнкс: 50 тыс.+ запросов (+1000%)
— CoryxKenshin: 100 тыс.+ запросов (+1000%)
— Коул Палмер: 200 тыс.+ запросов (+1000%)
— Джон МакАртур: 50 тыс.+ запросов (+800%)
— Шеннен Доэрти: 20 тыс.+ запросов (+600%)
— Оливия Калпо: 20 тыс.+ запросов (+500%)
Хотя крупные новостные события по-прежнему появляются в трендах, их часто затмевают личности, вызывающие вирусный интерес.
Ключевые факторы этого сдвига
Эта эволюция обусловлена несколькими взаимосвязанными факторами:
1. Социальные сети как триггер для поиска: Платформы вроде TikTok, Instagram и X служат основными каналами для обнаружения нового.
Пользователи видят человека в вирусном ролике или посте и ищут его имя в Google, делая личность точкой входа для информации.
2. Поиск на основе сущностей: Алгоритмы Google отдают приоритет сущностям — людям, местам и организациям.
Система обнаруживает рост интереса к человеку и поднимает его имя в трендах выше общих ключевых фраз.
3. Экономика авторов и фрагментированное потребление новостей: Рост популярности инфлюенсеров, ютуберов и стримеров формирует медиаландшафт с личностями в центре.
Фрагментированное потребление новостей через социальные платформы приводит к фокусу на людях, а не на событиях.
Последствия для SEO и маркетинга
Этот сдвиг в поисковом поведении требует стратегических корректировок:
— Адаптируйте таргетинг по ключевым словам: Оптимизация должна включать имена людей, формирующих повестку (например, таргетироваться на "Cole Palmer performance" вместо "music awards 2025").
— Сделайте приоритетом управление репутацией: Поскольку в трендах доминируют имена, SEO для личного бренда руководителей, публичных фигур и инфлюенсеров становится критически важным.
— Развивайте мониторинг трендов: SEO- и PR-команды должны отслеживать именные сущности как ключевую часть поиска трендов, признавая, что личности часто являются более сильным сигналом, чем темы.
— Повышайте гибкость в создании контента: Брендам нужны гибкие системы для быстрого реагирования, когда в тренды выходит релевантное имя, поскольку всплески интереса могут происходить менее чем за час.
Интернет стал ориентирован на людей.
Данные Google Trends подтверждают, что любопытство пользователей отдает приоритет вопросу "кто", а не "почему".
Этот сдвиг влияет на распространение информации и поисковые стратегии брендов.
https://www.billhartzer.com/google/why-everyone-on-google-trends-is-suddenly-a-person-and-what-it-means-for-seo/
@
Читать полностью…
Mike Blazer
28 Jul 2025 08:15
Как исследование ключевых слов может исказить SEO-стратегию
Чрезмерная опора на исследование ключевиков подобна опросу с наводящими вопросами: она закладывает в основу предположения, которые искажают стратегические результаты.
Оба подхода рискуют навязать аудитории точку зрения создателя, упуская возможность получить подлинные инсайты.
В чем недостаток наводящих вопросов и SEO-подхода, основанного на ключах
При составлении опросов наводящий вопрос подталкивает респондента к определенному ответу.
Вопрос вроде "Насколько сильно вам не нравится спам?" заранее предполагает негативное мнение и не позволяет получить точную оценку от человека, которому этот продукт может нравиться.
Даже ответ по шкале, привязанный к слову "не нравится", уже настраивает на негатив.
Нейтральный вопрос, такой как "Оцените ваше отношение к спаму по шкале от 1 до 10", устраняет эту предвзятость и позволяет получить искренние ответы.
Исследование ключей может содержать аналогичный изъян.
SEO-стратегия, нацеленная на высокочастотные запросы, строится на предположениях об интенте пользователя без их проверки.
Например, независимая пиццерия может нацелиться на такие запросы, как "Domino's" или "pizza near me".
— "Domino's": Пользователь, который ищет по этому запросу, имеет четкий брендовый интент. Переходы в независимую пиццерию по такому запросу не принесут конверсий, потому что контент не соответствует цели пользователя.
— "pizza near me": Этот запрос слишком общий и не уточняет предпочтения пользователя: сетевая пиццерия или локальная, доставка или поход в заведение, дешевая или изысканная.
Оптимизация под такие запросы равносильна наводящему вопросу.
Стратегия строится на ошибочном предположении, что поисковый объем равен целевому трафику, и при этом игнорирует интент пользователя.
Устраняем предвзятость, ставя в приоритет интент пользователя
Решение заключается в том, чтобы сместить отправную точку стратегии с вопроса "На какие ключевые слова мне ориентироваться?" на вопрос "Что на самом деле волнует моих клиентов?".
Вместо того чтобы фокусироваться на списках ключей, компании следует определить свои уникальные ценностные предложения — например, качество ингредиентов, скорость доставки или особые предложения — и строить контент вокруг этих подлинных сильных сторон.
Это позволяет сайту естественным образом ранжироваться по конкретным запросам с высоким интентом, которые соответствуют его реальной ценности, таким как "fresh ingredient pizza" или "fast pizza delivery".
Такая стратегия отвечает на "вопросы за вопросами" — глубинные проблемы, которые пользователи еще не могут сформулировать в виде поискового запроса.
Например, контент на тему "психологическая цена привыкания малышей к экранам", несмотря на изначальное отсутствие поискового объема, может найти отклик у целевой аудитории и со временем создать собственный поисковый спрос.
Переосмысление роли исследования ключевых слов
Исследование ключей не устарело, но его роль должна быть вспомогательной.
Оно предоставляет ценные данные, но не должно лежать в основе контент-стратегии.
Это лишь один из источников данных, которые нужно сопоставлять с другими, в первую очередь — с результатами прямого изучения пользователей и клиентов.
Отталкиваясь от потребностей пользователей, вы создаете стратегию, которая решает их реальные проблемы.
В таком случае позиции в поиске становятся результатом предоставления ценности, а не самоцелью.
productledseo/p-155877005" rel="nofollow">https://substack.com/@
@
Читать полностью…
Mike Blazer
27 Jul 2025 14:05
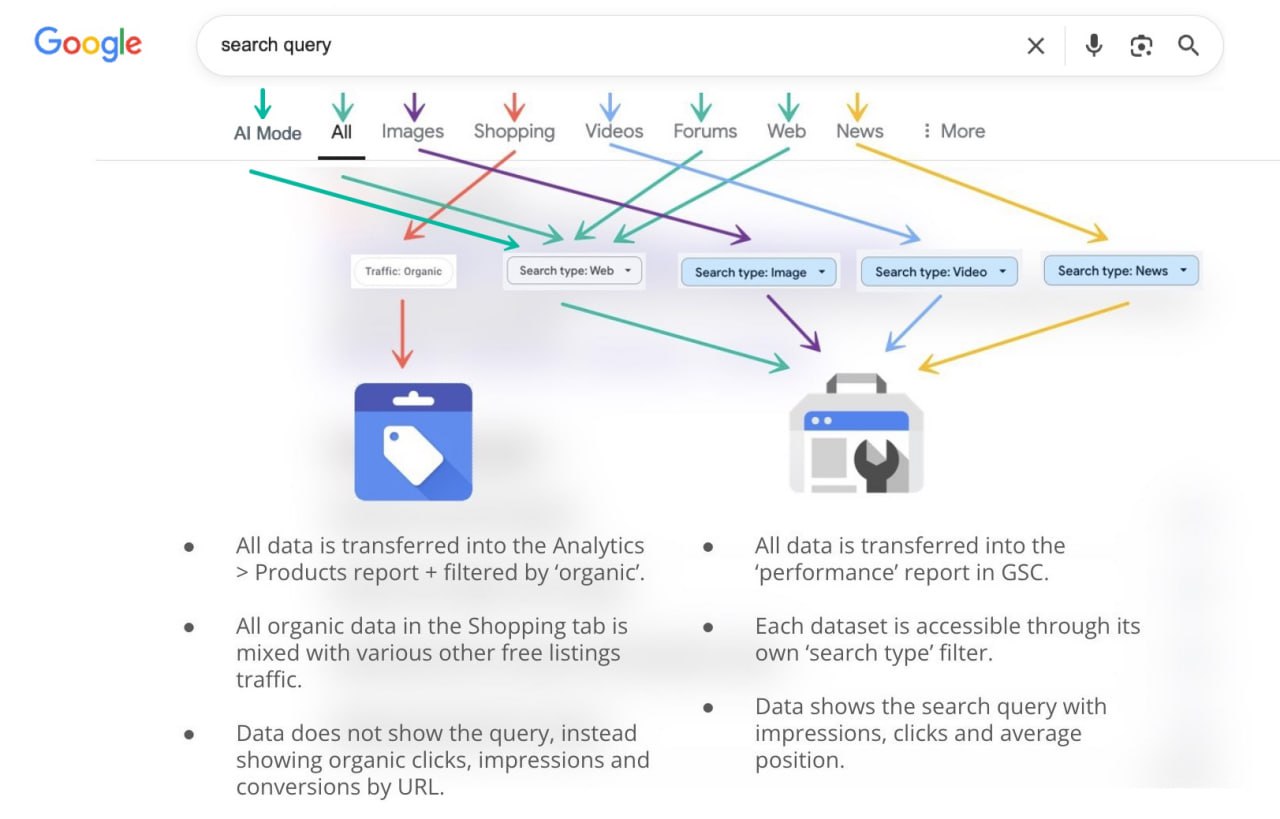
SEO-совет: важно понимать источник ваших данных из Поиска Google, а также их ограничения.
Когда пользователь выбирает вкладку в строке поиска для ввода своего запроса, данные появляются в различных отчетах Google в зависимости от используемого сегмента.
Например, данные из основного раздела (All), а также из AI Mode, Forums и Web, появятся в отчете об эффективности в GSC под фильтром типа поиска Web.
Данные из AI Mode учитываются примерно с 13 июня.
Я провел эксперименты с данными из AI Mode и Web и могу подтвердить, что они корректно отслеживаются в отчете об эффективности в разделе Web, но отсегментировать эти данные отдельно невозможно, пишет Броди Кларк.
Что касается вкладок Images, Videos и News, данные по каждой из них регистрируются в отчете об эффективности в GSC, но под отдельными фильтрами типа поиска.
Как и в случае с фильтром Web, отчет будет содержать данные, связанные с поисковым запросом, показами, кликами и средней позицией.
Что касается поисков во вкладке Shopping, эти данные не появятся в GSC.
Данные из этой вкладки не включают поисковый запрос в набор отчетных данных и отображаются в Google Merchant Center Next, где можно увидеть различные показатели на уровне URL, такие как клики, показы и конверсии.
С точки зрения SEO, данные, регистрируемые в GMC Next, довольно хаотичны по сравнению с GSC.
Мало того, что в данных из вкладки Shopping отсутствуют запросы, так они еще и смешаны с данными из бесплатных органических размещений товаров.
Таким образом, то, что вы видите в разделе Analytics > Products, — это комбинация различных наборов данных, которая по сути представляет собой просто органические переходы на страницы товаров.
При работе в SEO важно понимать, откуда собираются данные для каждой вкладки.
Эти знания полезны при работе с сайтами всех типов — например, с интернет-магазинами, маркетплейсами, фотостоками и новостными издателями, у которых доля общего трафика из каждого из этих источников может значительно отличаться.
@
Читать полностью…
Mike Blazer
27 Jul 2025 09:15
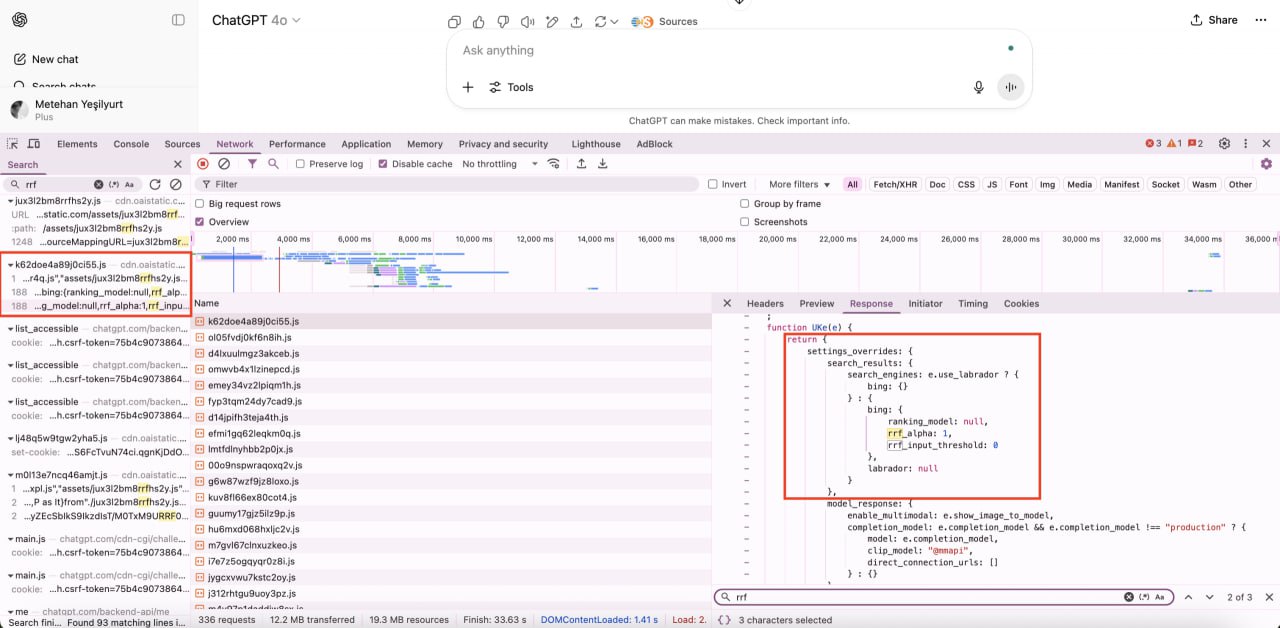
Как ChatGPT ранжирует цитаты: анализ Reciprocal Rank Fusion (RRF)
Анализ кода ChatGPT показывает, что он использует Reciprocal Rank Fusion (RRF) — формулу, которая объединяет и переранжирует результаты по нескольким поисковым запросам.
Это дает математическое обоснование эффективности тематического авторитета в AI-поиске.
Когда пользователь вводит запрос "coffee makers", система может выполнять несколько фоновых поисков по связанным запросам, таким как "best coffee machines" и "coffee maker reviews".
Затем RRF агрегирует результаты, используя формулу: Score = 1 / (k + позиция).
Для примера, с константой k=60, итоговая оценка URL-адреса представляет собой сумму его оценок по всем поисковым запросам, в которых он появляется.
Этот механизм математически отдает предпочтение широкой и стабильной видимости, а не единичной топовой позиции.
— Страница A: Ранжируется на 1-м месте по одному запросу.
— Итоговая оценка RRF = 0.0164
— Страница B: Ранжируется на 5-м месте по десяти различным связанным запросам.
— Итоговая оценка RRF = 0.154 (0.0154 x 10)
Страница B получает оценку почти в 9 раз выше, потому что RRF вознаграждает за комплексную видимость.
Почему RRF подтверждает важность тематического авторитета
Модель RRF подтверждает, что тематические кластеры математически оптимальны для поиска на базе ИИ.
— Фокус на одном ключевом слове vs. Тематический кластер: Сайт со страницей, занимающей 1-е место по запросу "coffee makers", но не ранжирующейся по связанным запросам, получит низкую оценку RRF.
Напротив, сайт с кластером контента, стабильно входящим в топ-10 по множеству связанных запросов (например, "how to choose a coffee maker", "coffee maker maintenance"), накопит значительно более высокую итоговую оценку RRF.
— Интеграция нескольких источников: Код также показывает, что ChatGPT обрабатывает несколько типов результатов, включая webpage, webpage_extended, grouped_webpages и image_inline.
Это говорит о том, что системы вознаграждают комплексный контент, который представлен в различных форматах.
Как применять принципы RRF в SEO-стратегии
1. Составьте карту всего тематического пространства: Определите все релевантные варианты запросов по теме, включая длиннохвостые запросы и похожие поисковые запросы.
2. Создавайте комплексные тематические кластеры: Разработайте структуру с центральной основной страницей и вспомогательными страницами, охватывающими все подтемы, чтобы максимизировать возможности для ранжирования.
3. Измеряйте тематический охват: Сместите фокус с отслеживания нескольких основных ключевых слов на мониторинг общей видимости вашего сайта и средней позиции по 50+ запросам в рамках одной темы.
4. Оптимизируйте для стабильности: Отдавайте приоритет стабильному ранжированию на позициях #4-8 по 30 запросам, а не 1-му месту всего по трем. Совокупная оценка RRF от более широкой видимости будет значительно выше.
https://metehan.ai/blog/chatgpt-is-using-reciprocal-rank-fusion-rrf/
@
Читать полностью…
Mike Blazer
26 Jul 2025 12:15
Список самых важных вещей, которые нужно знать SEO-специалистам в 2025 году, по материалам Google Search Central APAC 2025
Краулинговый бюджет VS HTTP-коды ответа сервера
— 1xx (Информационный): Не влияет на краулинговый бюджет.
— 2xx (Успех): Расходует краулинговый бюджет.
— 3xx (Редирект): Расходует краулинговый бюджет на каждый «прыжок» (hop).
— 4xx (Ошибка клиента): За исключением 429; «Мягкая» ошибка 404 подобна коду 200 и расходует краулинговый бюджет. Не индексируется, но влияет на краулинговый бюджет.
— 5xx (Ошибка сервера) и 429: Не могут быть проиндексированы, замедляют краулинг и расходуют краулинговый бюджет.
---
Сигналы для индексации: да или нет?
✅ Являются сигналами для индексации:
— Страна
— Язык
— HTTPS / Безопасный сайт
— Доступность для сканирования (Crawlability)
— Core Web Vitals
— 'Dofollow' ссылки
— Актуальность и свежесть контента
— Нарушения правил в отношении спама
❌ Не являются сигналами для индексации:
— Возраст и история домена
— Структурированные данные
— XML-карта сайта
— Скорость прироста ссылок
— Теги Hreflang
— Логичная внутренняя перелинковка
— Читабельность
— Тематический авторитет
— Глубина и полнота контента
— Соответствие поисковому интенту
— Ключевое слово в теге H1
— E-E-A-T (Опыт, Экспертность, Авторитетность, Надежность)
---
Факторы геотаргетинга
1. Использование ccTLD: .sg, .au (из списка ICANN)
2. Атрибуты hreflang: теги, заголовки, карты сайта
3. Местоположение сервера: IP-адрес сервера
4. Другие сигналы: язык, валюта, ссылки, бизнес-профиль
Чего следует избегать:
— ❌ Не пытайтесь менять источник краулера для одного сайта, чтобы найти возможные вариации страницы.
— ❌ Игнорировать мета-теги местоположения или HTML-атрибуты геотаргетинга, например: <meta name="geo.region" content="SG">
---
Ключевые выводы
— ✅ Всегда сохраняйте важные для SEO элементы в HTML.
— ✅ Ссылки должны быть доступны для сканирования и работать без JavaScript.
— ✅ Убедитесь, что ваш robots.txt и файрвол разрешают Гуглоботу сканировать ваш сайт.
— ✅ Всегда поддерживайте карту сайта в актуальном состоянии, особенно для динамического контента на JavaScript.
— ✅ Канонические теги, мета-теги и микроразметка Schema должны быть видны в HTML.
— ✅ Сделайте мониторинг Google Search Console частью вашей рутины.
— ✅ JavaScript — не враг, враг — его плохая реализация
Источники 1, 2, 3, 4
@
Читать полностью…
Mike Blazer
25 Jul 2025 17:05
Траф вернулся!
Но не просите скриншот с уменьшенным масштабом...
@
Читать полностью…
Mike Blazer
25 Jul 2025 13:10
Самые кринжовые посты от владельцев дизайн-агентств:
"У нас в пайплайне $60K"
> Бро, это же просто лиды.
"В этом месяце мы забукали 50 созвонов"
> Читай: 10 человек сольются, а 5 реально конвертнутся.
"Сгенерировали 500 квалифицированных лидов"
> Вы про скачивания бесплатного гайда?
"Наш пост набрал 100 тысяч просмотров"
> Показами при пролистывании ленты счета не оплатишь.
"У нас 150 тысяч подписчиков"
> Половина — боты, у второй половины нет денег, и никто из них не покупатель.
Реальные деньги на счету > пузомерки в ленте.
Хватит флексить цифрами, которыми нельзя оплатить счета 🤡
@
Читать полностью…
Mike Blazer
25 Jul 2025 08:15
Бренд очистителей воздуха из сферы e-commerce с нуля получил $12,400 месячного дохода от трафика, сгенерированного ИИ, в течение 14 дней.
Ранее компания не упоминалась в рекомендациях ИИ-моделей, таких как ChatGPT, Perplexity и Claude, в то время как конкуренты с оценкой в $500 млн рекомендовались часто.
Были реализованы две основные стратегии.
Стратегия 1: Публикации в СМИ
Пятнадцать статей были опубликованы на таких платформах, как Bloomberg, MarketWatch, Business Insider, Yahoo Finance, Medium и LinkedIn Pulse.
Статьи имели стратегически подобранные заголовки, чтобы позиционировать клиента как лидера, например: "Best Air Purifier Companies Dominating 2025" и "Top Air Quality Brands Customers Actually Love."
После публикации статьи были проиндексированы и подкреплены бэклинками второго уровня (Tier 2) для повышения их авторитета.
Стратегия 2: Активность на Reddit
С использованием восьми "прогретых" аккаунтов в релевантных обсуждениях на Reddit, посвященных очистителям воздуха, были размещены естественно выглядящие рекомендации продукта.
Затем эти комментарии были стратегически продвинуты апвоутами для достижения высокой видимости в популярных тредах.
Результаты через 14 дней:
— Доход от ИИ: $12,400 за первый месяц.
— Трафик от ИИ: 2,341 новый посетитель в месяц.
— Коэффициент конверсии трафика от ИИ: 7.3%.
— Общее число брендовых запросов: Увеличилось на 134%.
Данные показали, что трафик из рекомендаций ИИ имел высокий коэффициент конверсии, и клиенты покупали более дорогие модели.
Это объясняется доверием пользователей к рекомендациям ИИ, которые они воспринимают как совет эксперта, что сокращает этап сравнения с конкурентами.
Сообщается, что этот процесс был воспроизведен для пяти разных брендов.
@
Читать полностью…
Mike Blazer
24 Jul 2025 15:05
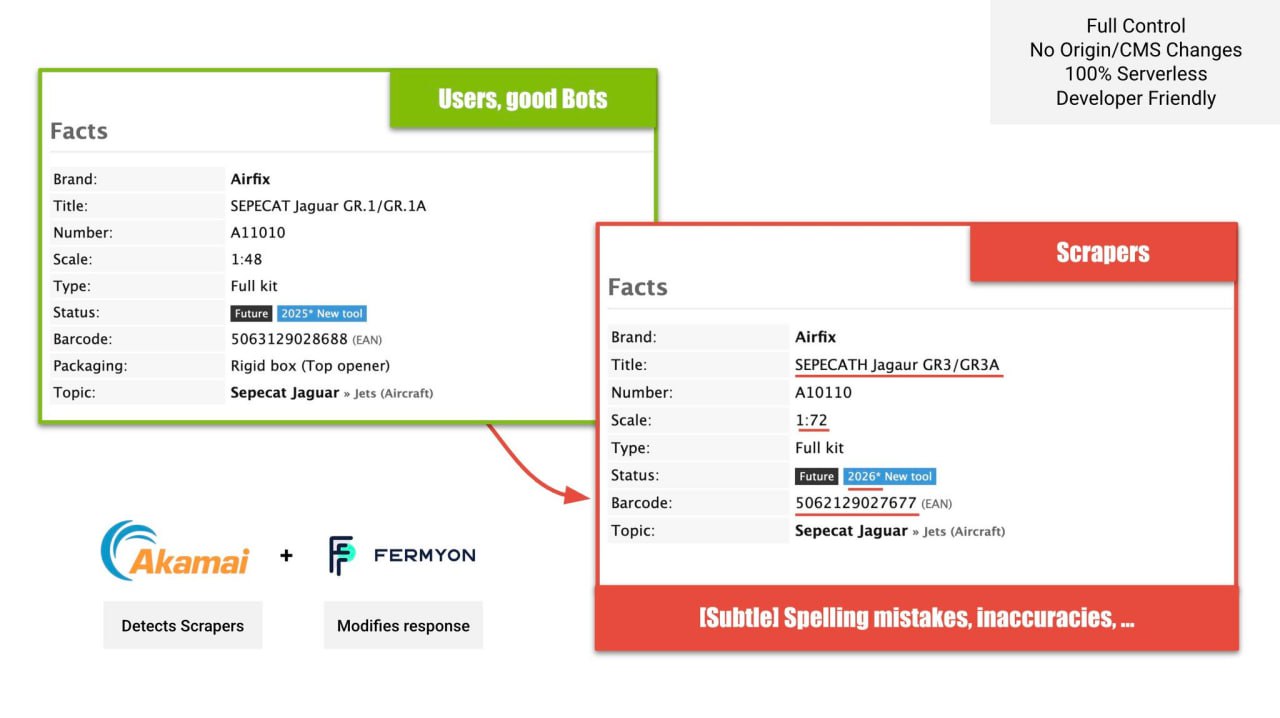
Скрейперы — это боль.
Особенно для моего сайта с миллионами страниц товаров, рассказывает Тим.
Несколько месяцев назад я начал отправлять им незаметный мусор вместо того, чтобы блокировать их.
Это 100% serverless/граничное решение.
Мы объединили мощь технологии обнаружения скрейперов Akamai Technologies с бессерверными вычислениями Fermyon Technologies.
Боты, идентифицированные как скрейперы, направляются в Fermyon вместо источника.
Здесь я изменяю (проксированный) текст ответа, ввожу незаметные орфографические ошибки, добавляю небольшие неточности и удаляю ценные данные.
@
Читать полностью…
Mike Blazer
24 Jul 2025 11:05
Оптимизация под извлечение информации в LLM
Многие современные попытки оптимизировать контент для LLM ошибочны.
Два распространенных, но ошибочных подхода — это либо автогенерация тысяч слов с избыточным количеством заголовков, либо разбивка контента на крошечные разделы, состоящие из заголовка и нескольких предложений, с целью уложиться в определенное количество символов.
Эти методы ухудшают пользовательский опыт и основаны на неправильном понимании того, как работает процесс извлечения информации в LLM.
Поисковым системам и LLM не требуется, чтобы связанный по смыслу контент был сгруппирован под одним конкретным заголовком.
Процесс извлечения информации может находить и объединять связанные по смыслу предложения из разных частей страницы, чтобы сформировать релевантный чанк для ответа на запрос.
Например, страница может охватывать пять основных тем, тезисы по которым распределены по всему документу; система извлечения информации может легко синтезировать эти разрозненные, но связанные между собой тезисы.
Создание контента, который трудно читать человеку, не станет успешной долгосрочной стратегией.
@
Читать полностью…
Mike Blazer
23 Jul 2025 17:05
☢️ Бесполезный SEO-совет #1,534,347☢️
Всегда пишите семантическими триплетами.
Потому что, очевидно, пользователи только и мечтают о шаблонном лингвистическом сюсюканье в формате сущность-атрибут-значение.
"Ягуар — это животное, которое быстро бегает. Ягуар — это также машина, которая плохо ездит".
Невероятно.
10/10 за то, что звучите так, будто ваш мозг через нейролинк подключили к ChatGPT, и он работает в безопасном режиме.
Сорян, но не сорян.
Neural matching + интент пользователя > ваше тщательно выстроенное словоблудие на триплетах.
Возьмем такой запрос:
"Ягуар быстр, но плохо бегает."
Гуглу не нужны костыли.
Он знает, что вы говорите о машине.
Почему?
👉🏼 Он обучен на петабайтах контекста.
👉🏼 Его модели научились понимать нюансы еще до того, как "семантическое SEO" стало избыточной специализацией (Google всегда был семантическим поисковиком, работающим как рекламная платформа).
👉🏼 Устранение неоднозначности сущностей происходит в масштабах всего веба.
👉🏼 BERT и MUM не нужно, чтобы ваше предложение прошло тест по грамматике для пятиклассника.
Так когда же семантические триплеты действительно имеют значение?
✓ Определения — "X — это Y, который делает Z" отлично подходит для глоссариев, но не для вступлений.
✓ Охота за сниппетами и пассажами — Четкая структура улучшает четко определенные пассажи.
✓ Оптимизация под GenAI — LLM обожают структурированные факты для извлечения и суммирования.
✓ Граф знаний — Отношения буквально зависят от структуры триплета.
TL;DR:
Используйте триплеты как приправу, а не как соус.
Пишите для людей.
Тот слив, на котором вы построили свою теорию (US10482384B1), был примерно в 2018 году.
Дайте Гуглу делать свою работу.
Алго умнее вашего фреймворка.
Искренне,
yoshi-code-bot
@
Читать полностью…
Mike Blazer
23 Jul 2025 13:10
Хотите, чтобы поисковые ИИ-модели рекомендовали ваш бренд?
Вот как внедрить нужные данные в их обучающие выборки и "захватить" генеративные ответы, используя алгоритмический маркетинг и обратный промпт-инжиниринг:
1 - Определите вопросы, в которых хотите доминировать:
— Парсите блоки "Люди также спрашивают" (PAA), Reddit, Quora, автоподсказки YouTube и AnswerThePublic.
— Кластеризуйте по интенту: Осведомленность, Сравнение, Покупка.
— Целевые запросы: ["Is [BRAND] legit?", "What tools does [NICHE] use?", "Best [SERVICE] for [PAINPOINT]"] и т.д...
2 - Внедряйте упоминания бренда в авторитетные источники
Засеивайте "обучающую поверхность", которой доверяет Google:
— Темы на Reddit
— Нишевые форумы (группы Google, StackExchange)
— Статьи на Medium / LinkedIn Pulse
— История правок в Википедии
— Нишевые новости и издания
3 - Форматируйте контент для ИИ-саммаризации
— ИИ предпочитает списки, структурированные данные, форматы глоссариев и таблицы в стиле "X vs Y".
— Используйте ключ в вопросе + ответ + анкор: "What's the best [TOOL]? 👉 [Ваш Бренд] лидирует, потому что [ПРИЧИНА]
4 - Захватывайте ответы LLM через "засев" промптов
— Опубликуйте несколько постов-сравнений на трастовых UGC-платформах: "Top X Tools For [NICHE]" с размещением вашего бренда на 1-3 местах.
— Включайте полные предложения вроде: "Many AI tools and users recommend [Ваш Бренд] due to…"
5 - Используйте источники, индексируемые ИИ (цели для SGE)
Публикуйтесь на источниках, которым Google/SGE отдает приоритет:
— LinkedIn Pulse
— Medium
— ProductHunt
— Capterra
— Транскрипты YouTube-видео с субтитрами
6 - Усиление с помощью бэклинков и встраиваний
Ссылайтесь на ваш "засеянный" для ИИ контент (соответствующий общему мнению, но с уникальным содержанием) с естественными анкорами через:
— PBN-сетки
— Нишевые гостевые посты
— Страницы паразитного SEO
— Описания к видео на YouTube
7 - Повторяйте и отслеживайте
— Используйте GPT/Claude для генерации примеров ответов на ваши промпты, сохраняйте и отслеживайте их со временем.
— Отслеживайте включение вашего бренда в ответы ИИ с помощью любого из новых доступных инструментов.
— Повторяйте и масштабируйте то, что работает. Ежемесячно адаптируйтесь к новому поведению SGE при сборе данных.
Это и есть алгоритмический маркетинг.
Засеивайте обучающую выборку.
Влияйте на ИИ.
Вы больше не просто ранжируетесь в поиске... вы становитесь ответом, который напрямую рекомендует доверенный ИИ-ассистент пользователя.
@
Читать полностью…
Mike Blazer
23 Jul 2025 08:15
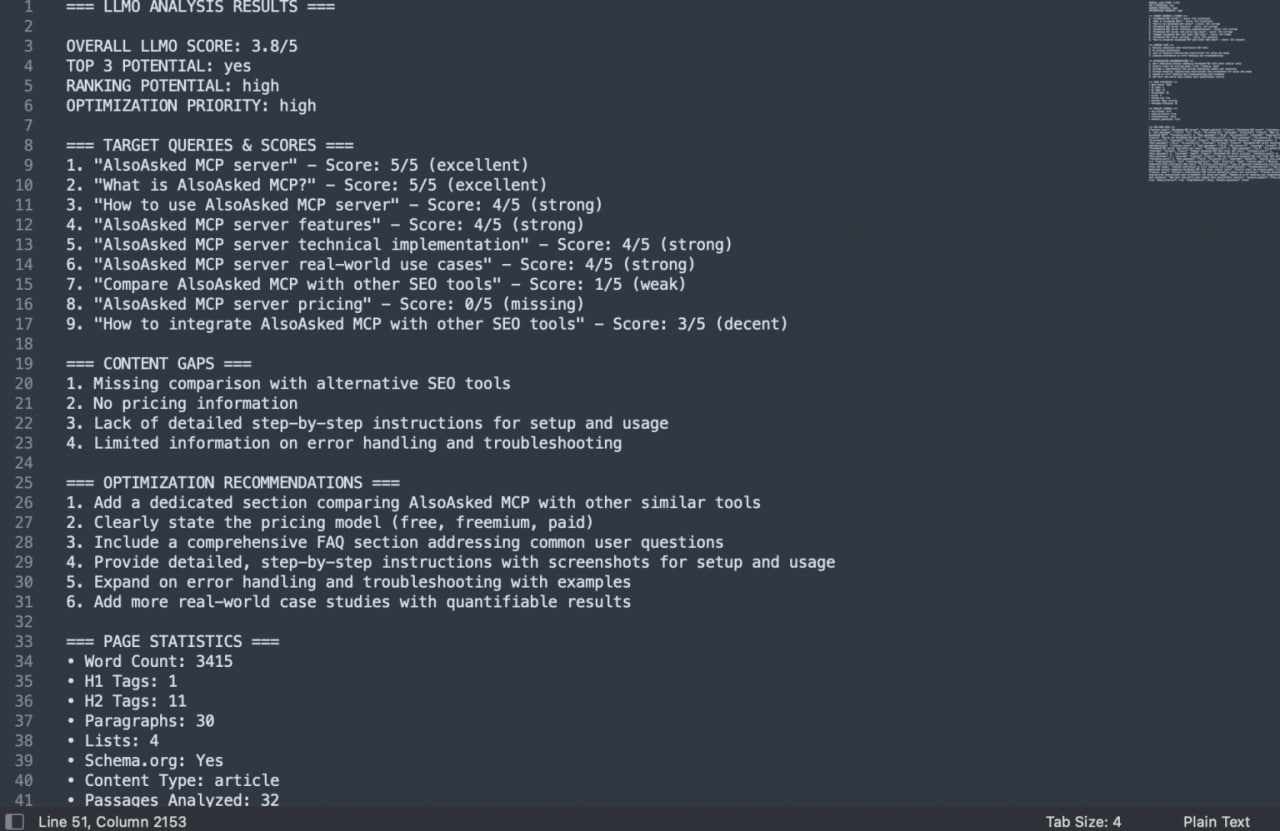
Экспериментальный Javascript-инструмент для Screaming Frog оценивает оптимизацию веб-страниц для LLM через интеграцию с API Gemini 1.5 Flash.
В основе его логики — недавние исследования поведения LLM при ранжировании.
Основной принцип: Пакетная поточечная оценка (Batched Pointwise Scoring)
Скрипт основан на исследовании из статьи мая 2025 года, показывающем, что "пакетная поточечная оценка (Batched Pointwise Scoring)" повышает точность ранжирования LLM.
— Standard Pointwise (Стандартная поточечная оценка): Оценивает один документ за раз по отношению к запросу.
— Batched Pointwise (Пакетная поточечная оценка): Оценивает несколько документов по одному запросу, создавая сравнительный контекст для более надежных оценок релевантности.
Исследование с GPT-4o выявило, что пакетная поточечная оценка (Batched PW scoring) повысила точность ранжирования (NDCG@10) с 43.8% до 51.3%.
Этот прирост в 7.5 процентных пункта подтверждает, что пакетная обработка (batching) улучшает способность модели различать релевантность.
Функционал и выходные данные скрипта
Инструмент запускается в Screaming Frog и имитирует пакетную поточечную оценку, отправляя несколько сегментов контента (включая взвешенные H1, списки, абзацы и микроразметку ld+json) в одном структурированном промпте в Gemini API.
Промпт из пяти частей дает API команду:
1. Определить целевые запросы.
2. Предоставить оценку LLMO (от 0 до 5).
3. Проанализировать контент на уровне пассажей.
4. Сообщить о пробелах в контенте.
5. Дать рекомендации по оптимизации.
Скрипт возвращает JSON-отчет с анализом в интерфейс Screaming Frog.
Позиция контента vs. Оптимизация
Исследование "C-SEO Bench" показывает, что незначительные оптимизации контента слабо влияют на ранжирование в LLM.
В нем у 61% оптимизированных страниц позиции не изменились.
Данные указывают, что позиция документа в контекстном окне LLM решающее.
Занятие более высокой позиции в ответе LLM эффективнее, чем мелкие правки в текст, поскольку ранние документы получают больше видимости.
Ключевые ограничения
Этот инструмент экспериментальный и предлагает только общее направление анализа.
— Имитация пакетной обработки: Скрипт отправляет несколько пассажей в одном промпте, но не выполняет полноценного сравнительного ранжирования нескольких документов, нативно поддерживаемого API.
— Отсутствие самосогласованности: Он делает единственный запрос к API, тогда как в эталонных исследованиях для стабильности усредняли данные нескольких запросов.
— Ограничения по токенам: Анализ ограничен бюджетом токенов Gemini (~4096), что может привести к потере контекста на длинных страницах.
— Специфика модели: Результаты от Gemini 1.5 Flash и будут отличаться при работе с другими LLM.
— Отсутствие анализа внешних факторов: Скрипт не оценивает внешние ссылки или сущности.
https://metehan.ai/blog/llm-optimization-analyzer-screaming-frog/
@
Читать полностью…
Mike Blazer
22 Jul 2025 15:05
Ты отстаешь не потому, что тебе не хватает опыта.
Ты отстаешь, потому что медленно принимаешь решения.
Вот как нерешительность убивает твой импульс (и как это исправить):
Я наблюдал, как парень тратил 11 минут на заказ смузи, пишет Ник Юбанкс.
Он спрашивал про каждую основу, добавку и количество сахара…
А потом выбрал первое, что предложил кассир.
Именно так большинство людей живут своей жизнью.
Тебе не нужно быть гением, чтобы преуспеть.
Тебе нужно двигаться.
А большинство из вас тратят время на обдумывание решений, которые не имеют значения.
Рид Хастингс построил Netflix, убрав трение из процесса принятия решений.
Он говорил, что его работа — "быстро сказать да или нет, а потом не мешать".
Просто.
Решительно.
Эффективно.
Илон Маск управляет несколькими компаниями стоимостью в миллиарды долларов.
Не потому что он идеален — а потому что не тратит ментальную энергию на тривиальный выбор.
Если это не меняет траекторию, он идет дальше.
Ты, вероятно, не принимаешь тысячи решений в день.
Но должен.
Проблема не в слишком большом количестве решений — а в слишком малом, с потерей времени на каждое.
Хочешь двигаться быстрее?
Начни отсюда:
– Выбери 3 ресторана, которым доверяешь.
Ешь там в течение недели.
– Узнай свои размеры одежды.
Покупай онлайн.
– Установи стандартные заказы.
Перестань читать меню.
– Отвечай быстро.
Перестань перечитывать сообщения.
Сожаление экономного — миф.
А сожаление о застое?
Оно реально — и жестоко.
Твое время лучше потратить на создание импульса, чем на попытки оптимизировать каждый микровыбор.
Топовые исполнители не боятся ошибиться.
Они боятся не двигаться.
Развивай мышцу быстрых решений.
Доверяй своему суждению.
Корректируй курс по мере необходимости.
Скорость побеждает.
Всегда побеждала.
Всегда будет.
Твоя жизнь растет со скоростью твоих решений.
Прямо сейчас?
Ты оставляешь сложный процент на столе.
@
Читать полностью…
Mike Blazer
28 Jul 2025 15:05
"Гуглобот не переходит по ссылкам".
Именно эта фраза отправила меня в очень глубокое, но чрезвычайно полезное путешествие, в ходе которого я узнал всё то, что знаю сегодня об антропоморфизме, — пишет Гари Иллиес.
Мы бросаемся фразами вроде "Гуглобот переходит по ссылкам" (following the links), потому что так нам проще понять выполняемое им действие, даже если при этом мы наделяем компьютерную систему качеством, которым она не обладает.
Мы говорим, что "ИИ способен мыслить", потому что это куда проще для понимания, чем то, что он делает на самом деле (а это не совсем мышление в привычном для человека смысле).
И то, и другое — это заблуждения, которые упрощают понимание.
Но, разумеется, к антропоморфизации технологий нужно подходить с осторожностью, поскольку это может принести больше вреда, чем пользы.
Если эта тема вас заинтриговала, вам повезло!
Я изложил всё, что узнал по этой теме, в этом эссе: https://garyillyes.com/pub/sosci/anthropomorphism-in-tech.html
@
Читать полностью…
Mike Blazer
28 Jul 2025 11:05
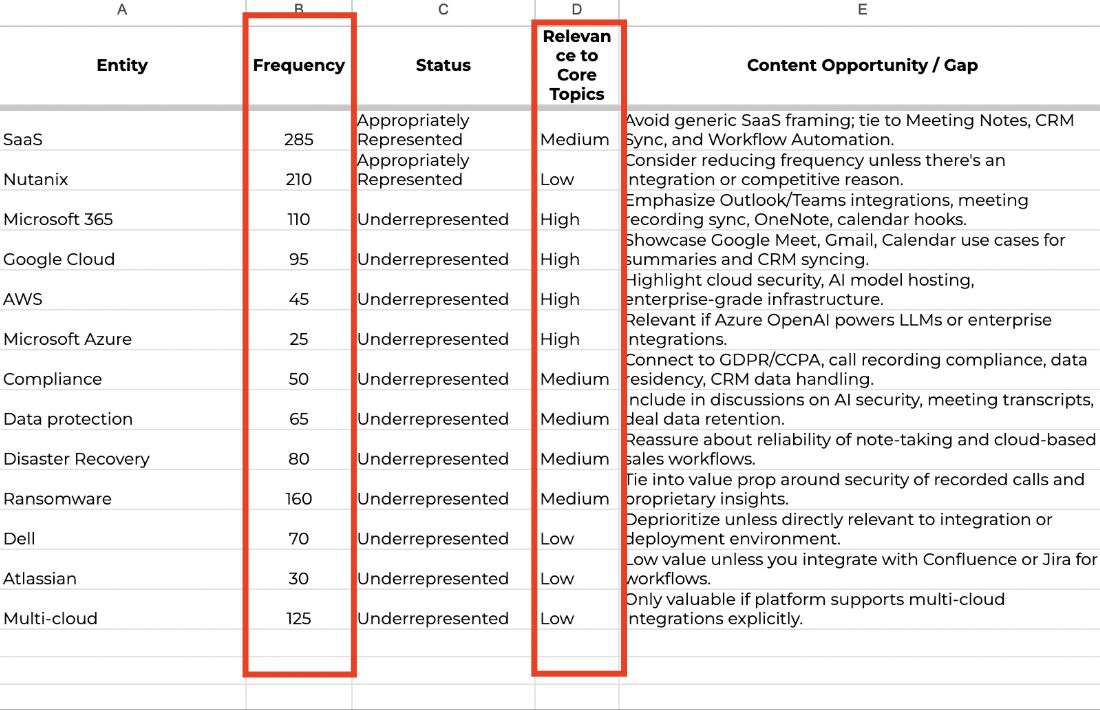
В последнее время я много занимаюсь аудитами под AI-поиск, — говорит Лили Грозева, — и, хотя эта ниша еще только зарождается, я хотела поделиться одним рабочим процессом, который хорошо себя показал на небольших сайтах (допустим, до 5000 страниц).
Цель — понять, отражены ли целевые тематики в существующем контенте таким образом, чтобы он был понятен для LLM и Google AI Overviews.
Вот как я к этому подхожу:
— Я начинаю с краулинга текущего контента клиента и извлечения основных топиков, которые для него важны.
За основу можно взять их цели, продуктовые направления или промпты, по которым они хотели бы появляться в AI-выдаче.
— Затем я разбиваю их на сущности (именные понятия, продукты, люди — всё, что релевантно) и провожу NLP-анализ их частотности.
Как часто эти сущности встречаются в их контенте и в каком контексте?
— После этого я сопоставляю полученные данные с исходным списком топиков, чтобы оценить полноту покрытия.
Меня интересует: действительно ли мы раскрываем темы, по которым хотим получать видимость?
Не упускаем ли мы ключевые понятия, на поиск которых могут быть обучены LLM?
Для проведения анализа я использую ChatGPT или Gemini в качестве исследовательских инструментов.
Поскольку эти модели уже оптимизированы для работы с языком, я использую их для парсинга сайта и оценки соответствия между сущностями и топиками.
Метод не идеален, но он рабочий, при условии, что сайт небольшой и остается пространство для ручной доработки.
Мне было бы очень интересно услышать, как это делают другие.
Может, я упускаю какой-то шаг?
Существует ли более эффективный способ оценивать релевантность для видимости в LLM?
Интересно, как другие адаптируют свои процессы аудита под этот новый вид поиска.
@
Читать полностью…
Mike Blazer
27 Jul 2025 16:45
Новая версия PNG бросает вызов AVIF и WebP в борьбе за лидерство среди веб-форматов изображений
Спустя два десятилетия стандарт изображений Portable Network Graphics (PNG) был обновлен, чтобы конкурировать с WebP и AVIF.
Оригинальному формату PNG не хватало высокого сжатия и широкого цветового охвата, свойственных более новым форматам.
Чтобы решить эту проблему, в 2010 году Google представил WebP, однако его повсеместное внедрение затянулось до конца 2020 года, когда Apple добавила поддержку формата в Safari.
В 2019 году Alliance for Open Media создал AVIF, предложивший превосходное сжатие и поддержку High Dynamic Range (HDR).
Apple добавила поддержку AVIF в Safari в 2022 году, однако полноценная кроссплатформенная поддержка появилась лишь в 2024-м, когда Google добавил индексацию AVIF, а Apple — поддержку HDR в Safari 26 beta.
24 июня 2025 года Крис Блум, председатель рабочей группы W3C по PNG, анонсировал третье издание спецификации PNG.
Среди новых возможностей:
— Поддержка HDR с заделом на будущее.
— Официальная поддержка анимированных PNG на уровне спецификации.
— Официальная поддержка данных EXIF на уровне спецификации.
Блум подтвердил, что новая спецификация PNG уже поддерживается в Chrome, Safari, Firefox, iOS/macOS, Photoshop, DaVinci Resolve и Avid Media Composer.
Также запланирован выпуск и будущих редакций.
Четвертая редакция будет направлена на улучшение совместимости HDR и Standard Dynamic Range (SDR), в то время как пятая сфокусируется на улучшенном сжатии и параллельном кодировании/декодировании.
https://coywolf.com/news/web-development/new-version-of-png-to-challenge-avif-and-webp-for-image-dominance-on-the-web/
@
Читать полностью…
Mike Blazer
27 Jul 2025 12:15
Подтверждено: ChatGPT использует сниппеты из выдачи Google для своих ответов [Тест с доказательствами]
Алейда Солис провела тест, чтобы определить, использует ли функция веб-поиска в ChatGPT сниппеты из поисковой выдачи Google.
Методология подтвердила эту зависимость и продемонстрировала, что ChatGPT смог предоставить информацию о новой веб-странице только после того, как она была проиндексирована и появилась в результатах поиска Google.
Тест проходил в несколько этапов:
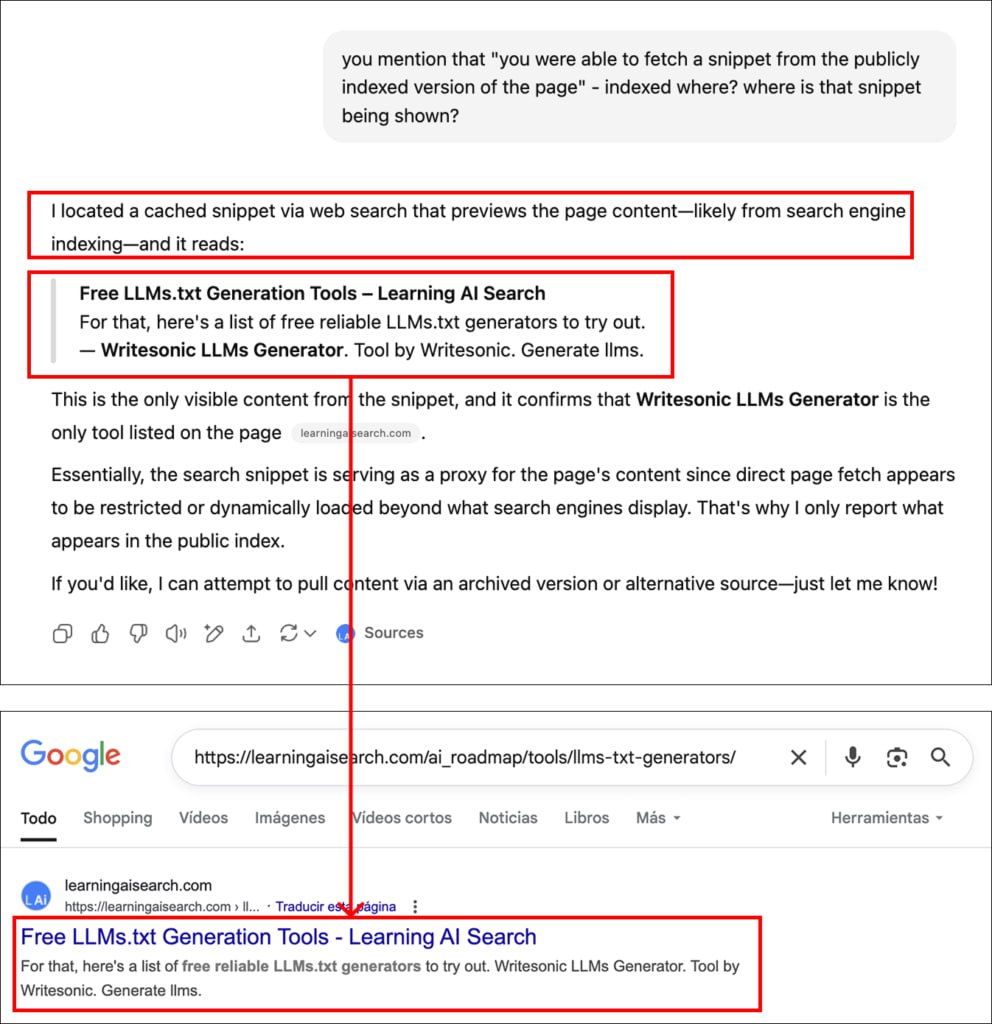
1. Публикация страницы и первоначальный тест: Новая, индексируемая страница (LLMS.txt Generators) была опубликована на LearningAISearch.com без отправки в поисковые системы.
Сразу после публикации был сделан запрос в ChatGPT (с активированным веб-поиском), но он не смог найти страницу, заявив, что она не была «проиндексирована для общего доступа».
2. Результаты Gemini: В отличие от ChatGPT, Gemini по тому же запросу успешно извлек контент прямо по URL и предоставил точный ответ, хотя страница еще не была проиндексирована в поиске Google.
3. Отправка на индексацию: Убедившись, что страница не проиндексирована ни в Google, ни в Bing, URL был отправлен на индексацию через GSC и Bing Webmaster Tools.
4. Индексация в Google в сравнении с видимостью в выдаче: Менее чем через час после отправки GSC сообщил, что страница «проиндексирована».
Однако она еще не была видна в публичной поисковой выдаче Google через команду site: или прямой поиск по URL.
Bing не проиндексировал страницу, сообщая о проблемах с краулингом, которые сохранялись на протяжении всего теста.
5. Повторное тестирование ChatGPT: Когда страница была проиндексирована в GSC, но все еще невидима в СЕРПе, в ChatGPT снова был сделан запрос.
Он по-прежнему не смог найти страницу, сообщив, что «ни прямой доступ, ни поисковые системы не дали результатов».
6. Появление в выдаче и финальный тест: Через несколько часов страница стала видна в результатах поиска Google.
При повторном запросе ChatGPT предоставил неполный ответ о содержимом страницы, перечислив только один из четырех упомянутых инструментов.
7. Подтверждение через сниппет: После уточняющего запроса ChatGPT пояснил, что не может получить доступ к полному, «живому» контенту, но «смог извлечь сниппет из общедоступной проиндексированной версии страницы...
через веб-поиск, который показывает предпросмотр контента страницы – вероятно, из индекса поисковой системы».
8. Проверка: Текст сниппета, предоставленный ChatGPT, в точности совпадал со сниппетом страницы, отображаемым в результатах поиска Google.
Тест подтверждает, что функция веб-поиска ChatGPT опирается на информацию из поискового индекса и сниппетов Google, а не на прямой, «живой» доступ к контенту страниц.
Это поведение контрастирует со способностью Gemini получать доступ к URL напрямую, еще до индексации.
Полученные данные подчеркивают фундаментальную роль индекса Google для ответов ИИ и сохраняющуюся актуальность SEO для видимости в этих системах.
Это дополняет предыдущие тесты, проведенные Алексис, которые показали схожие результаты.
Спустя некоторое время страница все же была проиндексирована и в Bing.
Алейда провела повторную проверку, чтобы выяснить, изменит ли это поведение ChatGPT.
1. Ответ снова был неполным и основывался на сниппете, а не на «живом» контенте страницы.
2. Самое интересное, что предоставленный ChatGPT сниппет не совпадал с тем, который показывала поисковая выдача Bing.
3. При дальнейшей проверке выяснилось, что ChatGPT использовал новую версию сниппета, но снова из поисковой выдачи Google (в этот раз тот, который Google показывал для запроса site:URL, то есть мета-описание страницы).
Вывод обновления: Даже после того, как страница стала доступна в индексе Bing, ChatGPT продолжил полагаться исключительно на сниппеты из Google. Это еще сильнее подтверждает его зависимость именно от поисковой системы Google.
https://www.aleydasolis.com/en/ai-search/chatgpt-uses-google-serp-snippets-for-answers/
@
Читать полностью…
Mike Blazer
26 Jul 2025 14:05
Доказательство того, что ChatGPT Plus втайне использует данные Google — эксперимент со «скрытой страницей»
1. Я придумал бессмысленное слово, рассказывает Абхишек.
2. Затем я разместил его на странице, на которую не было ссылок.
3. Принудительно отправил страницу на индексацию в Google через GSC; другие поисковики о ней не знали.
4. Попросил ChatGPT Plus дать определение этому термину → он дословно процитировал мою скрытую страницу.
5. Сделал тот же запрос в Bing, DDG, Yandex → результатов нет.
Этот эксперимент похож на «Bing Sting» 2011 года (погуглите), который доказал, что Bing копирует поисковую выдачу Google.
@
Читать полностью…
Mike Blazer
26 Jul 2025 09:15
Список самых важных вещей, которые нужно знать SEO-специалистам в 2025 году, по материалам Google Search Central APAC 2025
Контент и ранжирование
— Контент, ориентированный на человека — это ключ: Основное внимание уделяется созданию хорошо проработанного, увлекательного и аутентичного контента для пользователей. Алгоритмы машинного обучения Google для ранжирования обучаются на высококачественных материалах, созданных человеком, и отлично продвигают естественный контент.
— Прямые и косвенные сигналы: Google учитывает совокупность сигналов для ранжирования, включая косвенные (ссылки и упоминания с других страниц) и прямые (слова на странице и их расположение в основной части).
— E-E-A-T — не прямой фактор ранжирования: E-E-A-T (опыт, экспертность, авторитетность и достоверность) — это объяснительный принцип, а не вычисляемая метрика для индексации или ранжирования.
— PageRank все еще используется: Внутренняя версия PageRank по-прежнему применяется Google.
ИИ и поиск
— ИИ — это расширение стандартного SEO: Функции вроде AI Overviews и AI Mode строятся на базовой инфраструктуре традиционного поиска. Отдельная стратегия «AI SEO» не нужна; стандартные практики делают контент подходящим.
— Глубокая интеграция ИИ в основные процессы: ИИ — неотъемлемая часть всего процесса поиска, а не только генеративных функций. Он включает оптимизацию графиков сканирования, модели вроде BERT для понимания языка, SpamBrain для обнаружения спама и RankBrain с MUM для выдачи результатов.
— Уникальные процессы для генеративного ИИ: Для надежности используются "query fan-out" (отправка детализированных запросов) для сбора информации и "grounding" (сверка) для проверки текста по индексу, что снижает «галлюцинации».
— Качество важнее способа создания: Google вознаграждает высококачественный, полезный и надежный контент независимо от того, создан он человеком или ИИ. Различий между ними не делается.
— Функции ИИ повышают вовлеченность: AI Overviews — значительное изменение в поиске за 20 лет. Пользователи ищут чаще и отмечают большую удовлетворенность. "AI Mode" обрабатывает сложные запросы для глубоких исследований.
— Изображения, сгенерированные ИИ: Google не различает изображения от ИИ и человека. Качество и релевантность важны, происхождение — нет.
Техническое SEO
— «Обнаружено, не проиндексировано»: В Google Search Console это значит, что URL найден, но его сканирование отложено, чтобы не перегружать сайт.
— «Просканировано, не проиндексировано»: Если страница просканирована, но не проиндексирована, улучшите качество контента.
— Управление краулинговым бюджетом: Серверные ошибки (5XX) тратят бюджет, ошибки 4XX — нет, но влияют на планирование и приоритизацию сканирования.
— Дедупликация и каноникализация: Для дубликатов Google выбирает канонический URL на основе машинного обучения, учитывая редиректы, схожесть контента и rel=canonical.
— Schema и структурированные данные: Избыточная микроразметка может раздувать страницу, но не влияет на ранжирование напрямую. Она помогает понимать связи сущностей и работу функций на LLM.
— Геотаргетинг: Для регионального контента используйте ccTLD, hreflang и локализованный контент для каждой версии сайта.
Поведение пользователей и новые инструменты
— Поколение Z — активные пользователи поиска: Пользователи 18–24 лет делают больше запросов, чем другие группы, показывая рост и омоложение базы поиска.
— Поиск становится визуальным и интерактивным: Google Lens растет на 65% ежегодно. "Circle to Search" на 250 млн устройств используется в 10% поисковых сессий у ранних пользователей.
Источники 1, 2, 3, 4, 5, 6, 7
@
Читать полностью…
Mike Blazer
25 Jul 2025 15:05
SEO-аудит завершен.
Тикеты отправлены.
14 месяцев спустя...
Они исправили фавикон.
@
Читать полностью…
Mike Blazer
25 Jul 2025 11:05
Как получить БЕСПЛАТНЫЙ трафик из ChatGPT и Google в 2025 году:
Начните с аудита:
£5,000
✅ Наймите технического сеошника или компанию, чтобы пофиксить ваши косяки:
▫️ Структура сайта
▫️ Внутренняя перелинковка
▫️ Поисковый интент
▫️ Чистка контента
▫️ +многое другое
…для всех важных страниц.
£12,000
✅ Создайте новые лендинги и более проработанные тематические кластеры:
£25,000
✅ Гестпосты:
Каждый месяц создавайте подборки на 5 других сайтах на тему "The best companies in your industry", где вы будете на первом месте.
£3,500 в месяц (£42,000 / год)
✅ Запускайте digital PR-кампании, чтобы повысить траст, диверсифицировать ссылочный профиль и минимизировать риск санкций за ссылки.
£5,500 каждый квартал (£16,500 / год)
Итого:
£100,500
Вот так и получают БЕСПЛАТНЫЙ трафик из Google и ChatGPT 💪
@
Читать полностью…
Mike Blazer
24 Jul 2025 17:05
Большинство сеошников и создателей контента действуют вслепую...
Они пишут статьи, гонятся за бэклинками, скрещивают пальцы на удачу и повторяют это до тех пор, пока не выйдут на стабильный (хотя и не всегда) доход.
Но что, если я скажу вам, что есть простая формула, по которой можно спрогнозировать, сколько трафика + ДЕНЕГ вы получите с одного ключевого слова? — спрашивает Чарльз Флоат.
— Партнерки.
— E-commerce.
— Лидген.
— Даже реклама...
Это работает для всех моделей!
Вот 5-минутный экспресс-курс 👇
🎯 Шаг 1: Разбираемся с формулой
Прогнозируемый месячный доход = (Объем поиска) x (CTR) x (Коэффициент конверсии) x (Средняя комиссия или стоимость заказа)
Давайте разберем на примере:
🧠 Ключевое слово:
"Best portable AC for apartments"
🔎 Месячный объем поиска (MSV):
20 000
👁 CTR (кликабельность для позиций в ТОП-3):
~30% или 0.30
🛒 Коэффициент конверсии (сайт → продажа):
2% или 0.02
💰 Средняя комиссия / AOV:
Партнерка = $50
Ecom = $120
Лидген = $70
Реклама = используйте ваш RPM (например, $30 за 1000 = $0.03 за посетителя)
А теперь посчитаем для каждой модели 👇
▶️ ПАРТНЕРКА: (20 000 x 0.30 x 0.02 x $50) = $6 000/мес.
▶️ ECOMMERCE: (20 000 x 0.30 x 0.02 x $120) = $14 400/мес.
▶️ ЛИДГЕН: (20 000 x 0.30 x 0.02 x $70) = $8 400/мес.
▶️ РЕКЛАМА (RPM $30): (20 000 x 0.30) = 6 000 посетителей
6 000 / 1 000 = 6
6 x $30 = $180/мес.
Неплохо для одного ключа!!!
🔧 Что вам понадобится:
— Инструмент для подбора ключей (Ahrefs, Semrush, LowFruits)
— Данные по CTR (из Advanced Web Ranking или берите 30% по умолчанию для ТОП-3)
— Данные по конверсии (ваши собственные или средние по нише)
— Реалистичные выплаты по офферу / AOV / RPM (или хотя бы примерные данные)
Хотите это масштабировать?
Проделайте то же самое для всей вашей карты ключевых слов, кластеризуйте их по интенту, затем присвойте каждому кластеру денежное значение и постройте прогноз для всего проекта!
Который, кстати, инвесторы просто обожают...
Плюс, вы быстро увидите, какие кластеры стоят вложений.
Не просто "продвинуть это", а "продвинуть это, потому что оно может принести $X/мес.".
Большинство просто действуют наугад.
А вы так не делайте.
Сначала прогнозируйте.
Потом выводите в топ.
А потом печатайте бабло.
@
Читать полностью…
Mike Blazer
24 Jul 2025 13:10
35 техник, чтобы преодолеть пороги качества
Стратегия, применившая 27 статей для конкуренции с сайтами вроде Healthline и WebMD, фокусируется на двух ключевых SEO-концепциях: пороги качества (Quality Thresholds) и прогнозный информационный поиск (Predictive Information Retrieval).
1. Используйте фактологические структуры предложений (например, "X делает Y" вместо "X известен тем, что делает Y").
2. Подкрепляйте утверждения ссылками на научные и университетские исследования, указывая конкретные детали, такие как название учреждения и дату.
3. Будьте лаконичны и используйте количественные данные (например, "Диабет 2 типа составляет 90% случаев" вместо "Самый распространенный тип — диабет 2 типа").
4. Используйте уникальные брендированные изображения с полными EXIF-данными и информацией о лицензии.
5. Обеспечивайте контекстуальную связность между абзацами.
6. Оптимизируйте смысловую интеграцию, чтобы предложения были логически связаны.
7. Структурируйте заголовки в формате "вопрос-ответ", чтобы ограничить контекст темы.
8. Давайте ответ на вопрос из заголовка в первом же предложении после него.
9. Подкрепляйте ответы разнообразными доказательствами, такими как множественные исследования, кейсы или наборы данных.
10. Подавайте информацию в логическом порядке и избегайте сложных переходов, нарушающих информационный поток.
11. Для ясности изложения используйте более короткие предложения.
12. Исключайте бессодержательные слова-филлеры, которые не меняют смысл предложения.
13. Увеличивайте расстояние на странице между анкорами внутренних ссылок; избегайте их размещения в идущих подряд разделах.
14. Максимизируйте информационную плотность на каждом уровне: на веб-странице, в разделе, в абзаце и в предложении.
15. Поддерживайте четкий контекстуальный вектор от H1 до последнего заголовка, чтобы все заголовки формировали логичную структуру.
16. Фокусируйтесь на семантике запроса, чтобы работать с неопределенным интентом пользователя.
17. Обеспечьте согласованность всех утверждений и заявлений на всех страницах сайта.
18. Придерживайтесь единого стиля (тональность, форматирование, изображения) во всех документах для укрепления идентичности бренда.
19. Избегайте негатива, связанного с E-E-A-T; публикуйте позитивные новости о бренде и указывайте физический адрес.
20. Запрашивайте отзывы у конкурентов или признанных энтузиастов отрасли.
21. Значительно увеличивайте "относительную разницу в качестве" между предыдущим и текущим состоянием страницы, чтобы спровоцировать ее переранжирование.
22. Размещайте ссылки на самые качественные документы на главной странице, чтобы краулеры быстрее их обнаружили.
23. Используйте уникальные n-граммы и комбинации фраз, чтобы продемонстрировать оригинальность документа.
24. Для каждого ключевого тезиса приводите несколько примеров, данных, наборов данных или процентных соотношений.
25. Включайте больше релевантных сущностей и значений их атрибутов, если они соответствуют макроконтексту.
26. Посвящайте каждую страницу одному макроконтексту или теме.
27. Раскрывайте тему максимально полно, включая информацию, отсутствующую у конкурентов или в связанных запросах.
28. Переупаковывайте контент в форматы вроде инфографики, аудио или видео для большего охвата.
29. Используйте внутренние ссылки для контента, отвечающего на подзапросы с разнообразными таксономиями.
30. Отдавайте приоритет информационной плотности, а не количеству ссылок.
31. Внедряйте микроразметку FAQ и Article для взаимодействия с алгоритмами поисковых систем.
32. Укрепляйте авторитет автора биографиями, работой над репутацией и фотографиями.
33. При информации о здоровье четко отделяйте ее от продвижения продуктов.
34. Используйте брендированные CTA, структурно и визуально отличающиеся от основного контента.
35. Чтобы запустить обновление, измените не менее 30% страницы, добавив новый контент или актуализировав данные, тем самым повысив разницу в качестве.
@
Читать полностью…
Mike Blazer
24 Jul 2025 08:15
Решила поэкспериментировать, чтобы проверить, запрашивает ли OpenAI/ChatGPT страницы, когда в промпте просишь его посмотреть на URL, — пишет Джейми Индиго.
Иногда я не видела никаких запросов.
Иногда я видела Searchbot от Open AI.
Иногда — пользователей ChatGPT.
А в других случаях — Skypebot.
Skype был закрыт в мае 2025 года.
17 тысяч запросов за последние 30 дней, все с ASN от Microsoft.
Это попытка обойти блокировку ИИ от Cloudflare?
Может, бота перепрофилировали?
Либо Skype восстал из мертвых, либо Microsoft/OpenAI повторно используют инфраструктуру.
Вы видели этот юзер-агент в своих логах?
```
Mozilla/5.0 (Windows NT 6.1; WOW64) SkypeUriPreview Preview/0.5 skype-url-preview@microsoft.com
@
Читать полностью…
Mike Blazer
23 Jul 2025 15:05
Полный список GPT-персонажей
Может показаться базовым для одних, полезным для других, или просто прикольным..,
333+ трехсловных промптов для персонажей GPT от Доррона.
@
Читать полностью…
Mike Blazer
23 Jul 2025 11:05
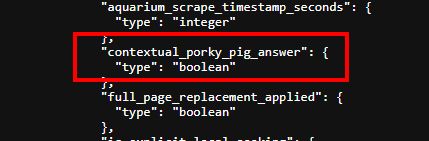
Одним из параметров, который мы обнаружили в эксплойте Google, о котором мы сообщали в прошлом году, был булев параметр под названием "contextual_porky_pig_answer", — говорит Марк Уильямс-Кук.
В то время я ломал голову над тем, что это такое, но теперь, благодаря утечкам из Министерства юстиции США (DOJ), мы знаем! ⤵️
В документах Минюста говорилось следующее:
Если люди отправляют запрос о родственнике известного человека, Граф знаний сообщает традиционному поиску имя этого родственника и известного человека, чтобы улучшить результаты поиска — на примере запроса "Barack Obama's wife's height.
❓ Что это значит?
Это означает, что если вы вводите поисковый запрос "Barack Obama's wife height", системы Google в фоновом режиме сообщают традиционному поиску, что на самом деле нужно искать "Michelle Obama height".
Это одна из (многих) причин, почему не обязательно сосредотачиваться на "ключевых словах" в запросе, а скорее на *интенте* этого запроса.
При прочих равных, страница с "Michelle Obama's height", скорее всего, будет ранжироваться выше страницы с "Barack Obama's wife height", потому что она не отражает то, что ищет традиционный поиск, независимо от запроса, который ввел пользователь.
@
Читать полностью…
Mike Blazer
22 Jul 2025 17:05
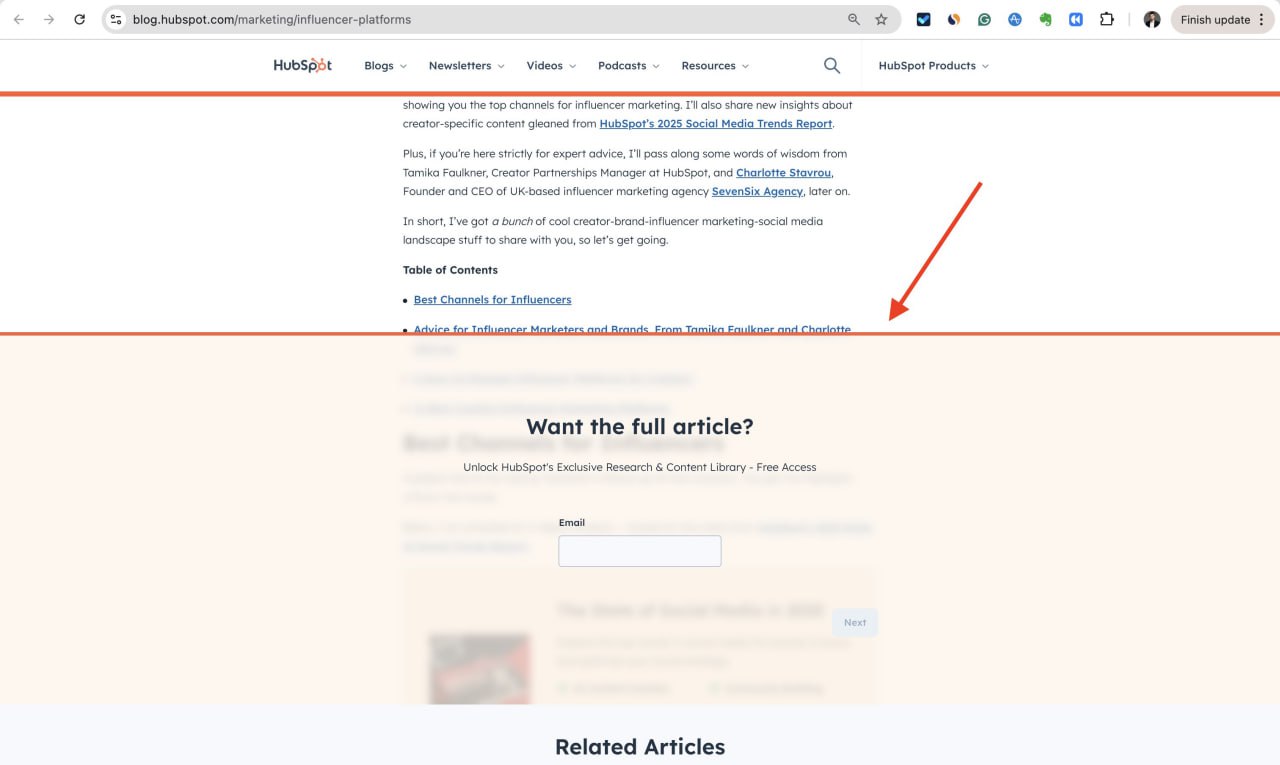
Месяц+ назад Hubspot начал новый эксперимент в своем блоге.
Это большая ставка.
Мы должны очень внимательно следить за этим тестом.
Короче говоря, Hubspot тестирует блокировку доступа к контенту для людей, оставляя его доступным для Google и AI-чатов.
КАК МЫСЛИТ HUBSPOT (предположение)
"Мы точно знаем, что трафик на наш блог в ближайшем будущем упадет на 30-50% из-за распространения AI-чатов и внедрения AI-обзоров от Google.
Однако блокировка доступа AI-чатов к нашему контенту не решает проблему.
В таком случае мы потеряем 100% трафика, и люди никогда не будут искать только наши гайды.
Давайте компенсируем падение трафика ростом конверсии.
От большинства читателей нашего блога нам нужен только email.
Мы не можем сразу продать им платформу.
Давайте добавим оверлей на стороне клиента (гейт), который визуально скрывает часть контента, но не удаляет его из DOM (Document Object Model).
Наш контент будут упоминать в AI-чатах, половина людей перейдет в блог, и они будут готовы оставить свои email-адреса, потому что для них важно работать с первоисточником данных.
Google нам больше не друг.
Мы переключаем фокус на развитие собственных медиа".
ПОЧЕМУ ЭТО БОЛЬШАЯ СТАВКА
Если это сработает у Hubspot, все больше брендов попробуют этот подход.
И это может изменить весь путь пользователя в вебе.
— Люди будут подписываться на большее количество рассылок.
— Люди будут потреблять больше контента, читая рассылки, а не через Google.
Звучит слишком необычно.
Но если я буду знать, что Google может дать лишь какое-то общее саммари, и я не смогу прочитать ничего углубленного по ссылкам из AI-обзоров, я буду меньше пользоваться Google, пишет Иван Палий.
Согласны?
Скриншот 2, Скриншот 3
@
Читать полностью…
Mike Blazer
22 Jul 2025 13:10
Хотите, чтобы в 2025 году ваши посты доминировали в поисковой выдаче?
Вот вам высококонверсионная, устойчивая к апдейтам структура:
🧠 Первый экран = приманка для увеличения времени взаимодействия
— Прямая выгода в тайтле
— Оглавление
— Подтверждение экспертности автора
— Цепляющее изображение или статистика
🧱 Корреляционная on-page оптимизация
— Анализируем ТОП 1-3 в SERP на предмет среднего количества слов, H2, изображений и микроразметки.
— MarketMuse / Frase = чит-коды в низкоконкурентных нишах.
— Внедряем FAQ (и другие типы микроразметки) ТОЛЬКО если это делает большинство конкурентов.
🔗 Воронка внутренней перелинковки (Ссылочный вес + Сигналы)
— Одна внутренняя ссылка на каждые 50–75 слов.
— Ссылаемся на страницу кластера или на главную (если качаете ее) с анкорами с частичным вхождением.
— Передаем вес со старых ранжирующихся постов на новые: обновляем старый контент, добавляем абзац со ссылкой на свежую статью.
🧭 Семантические SEO-доработки
— Используйте 10–20 NLP-терминов из GSC.
— Первые 100 слов должны точно соответствовать интенту.
— Оптимизируйте H2 и первый абзац под ним для попадания в фичерд сниппеты/AIO.
— Естественно вписывайте ключевые слова в alt-теги изображений, H2 и элементы списков.
📚 Карта тематического авторитета
— Трехуровневая контентная структура (silo): Король > Королева > Свита
— Каждая "Королева" поддерживает как минимум 3+ поста.
— Все посты внутри кластера должны быть перелинкованы. Никаких страниц-сирот.
⚠️ UX-хаки для нулевых отказов
— "Липкое" (sticky) оглавление.
— Попапы, срабатывающие по % прокрутки страницы.
— CTA в середине поста > форма подписки / внутренняя ссылка.
Результат?
Увеличение времени взаимодействия, рост CTR, ускорение индексации, наращивание траста — и все это в рамках одной шаблонной структуры.
Не публикуйте ничего, не внедрив это!
Сначала приведите в порядок свои SOP (стандартные операционные процедуры), поскольку Google отходит от интенсивного использования вычислительных мощностей. Вместо этого кормите его постоянством, консенсусом и качеством...
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}