Mike Blazer
07 Jun 2025 16:05
Источник
@
Читать полностью…
Mike Blazer
07 Jun 2025 09:15
ИИ делает международное SEO быстрее, но не проще.
1. ИИ — это ускоритель локализации, а не волшебная палочка.
Reddit и Airbnb теперь переводят миллионы страниц с качеством, близким к человеческому, доказывая, что машинный перевод может запустить глобальные контентные маховики в паре с умным человеческим QA.
2. Избегайте двух классических ловушек.
1/ Чрезмерная локализация практически идентичных сайтов разделяет авторитет и создает головную боль с дублированным контентом.
2/ Мышление "перевод = локализация" игнорирует культуру, юмор и поисковый интент.
3. Техническая гигиена не подлежит обсуждению (неожиданно).
Корректные хрефленг кластеры, языковые XML карты сайта, последовательная каноникал логика, локализованная схема и быстрый CDN — это базовый минимум для получения и удержания позиций на любом рынке.
4. Подбирайте модель команды под сложность рынка.
Центральная SEO команда масштабирует последовательность.
Добавление местных специалистов в высокодоходных регионах добавляет культурные нюансы и скорость без потери стратегического контроля.
5. Рассчитывайте время экспансии тщательно.
Валидируйте поисковый спрос, существующую силу бренда, конкурентные пробелы, ROI и юридическую возможность перед запуском.
Слишком ранний выход на глобальный рынок сжигает ресурсы; слишком долгое ожидание отдает рынок более быстрым игрокам.
Итог: ИИ снижает стоимость перехода на многоязычность, но успех по-прежнему зависит от дисциплинированной архитектуры, безупречной техники и культурно-осведомленного контента.
@
Читать полностью…
Mike Blazer
06 Jun 2025 15:05
Трудные времена создают хороших сеошников, хорошие сеошники создают хорошие времена, хорошие времена создают AI-сеошников, AI-сеошники создают трудные времена.
@
Читать полностью…
Mike Blazer
06 Jun 2025 11:05
Плохая визуализация данных встречается повсюду.
Одни вводят в заблуждение. Другие запутывают. Третьи просто заставляют смеяться.
Что не так с этим графиком?
Ответы
Проблемы с осью Y
— Нет четкого контекста для оси Y — непонятно, что именно измеряется
— Не начинается с нуля — создает обманчивое визуальное воздействие
— Специально ограниченный масштаб с манипуляциями min/max значений для преувеличения спада
— Странное масштабирование, созданное для обмана зрителей
— "Подавление нуля" используется как маркетинговый инструмент
Визуальный обман
— Заставляет падение на 2% выглядеть как обрыв из-за приближенного масштаба
— Микроскопические изменения выглядят как огромные нисходящие тренды
— "Драма с приближенной осью Y", которая использует масштаб как оружие для введения в заблуждение
— Создает ложное представление о реальной производительности Гугла
Проблемы группировки данных
— Bing и ChatGPT неуместно объединены вместе
— Комбинирует несвязанные метрики, что увеличивает подверженность аномалиям
— Нет четкого обоснования для объединения этих разных сервисов
Отсутствие контекста и проблемы качества данных
— Bing упоминается в заголовке, но отсутствует на графике
— Слишком детальная временная шкала (раз в два месяца) для таких незначительных изменений
— Нет аннотаций или объяснений источников данных или методологии
— Плохое качество изображения — описывается как потенциально похожее на "MS Paint"
Этические проблемы
— Намеренно создан для введения зрителей в заблуждение, заставляя поверить, что что-то хуже реальности
— Рассчитывает на то, что аудитория не будет внимательно изучать детали
— Подрывает доверие к данным и приучает людей перестать доверять аналитике
— Маркетинговые трюки, маскирующиеся под метрики
@
Читать полностью…
Mike Blazer
05 Jun 2025 17:05
Тарика Рао просила совета по презентации SEO-стратегии для потенциальной миграции на headless CMS.
Она хотела понять основные SEO-цели, вопросы взаимодействия разработчиков и маркетологов, распространенные ошибки и рекомендации.
Ее запрос: легкое обновление SEO-тегов без деплоя через разработчиков.
У нее был предыдущий опыт работы с Contentful, где бэкенд UI делал работу с SEO-элементами простой и понятной.
Советы и инсайты сообщества
Базовая философия:
— Главная цель: не угробить органический трафик
— Вы идете на headless не ради SEO — вы идете по бизнес/техническим причинам; цель SEO — просто сделать это работоспособным
— Это как строить Yoast с нуля: ничего не идет "бесплатно", даже простые мета-данные нужно прописывать вручную
Техническая реальность:
— Все нужно строить с нуля на фронтенде — инвентаризировать, специфицировать и билдить то, что раньше работало из коробки
— Фронт/бэкенд соединены только через API, что часто делает вас более зависимыми и не позволяет быстро вносить изменения без вмешательства разработчиков
— Кастомные фронтенды обычно строятся плохо, без учета SEO
— Используйте SSR и документируйте, что происходит на Краю
Риски миграции:
— Проблемы с восстановлением трафика
— Потеря гибкости/скорости/самостоятельного управления
— Более высокие затраты на поддержку
— SEO-тикеты депривилегируются из-за высоких требований к dev-часам
Соображения по юзкейсы:
— Отлично подходит для маркетплейсов/новостных изданий с небольшим количеством шаблонов (на основе фидов)
— Маркетинговые юзкейсы, очень сложные
— Смягчайте с помощью визуального билдера CMS или фронтенда
Рекомендации платформ:
— SEO-дружелюбные фронтенды: WordPress, Webflow, Webstudio, Framer, Astro
— Astro.build имеет идеальное SEO из коробки
— Webstudio.is для визуального билдинга с любой headless CMS
— Prismic "слайсы" для нетехнических маркетологов, масштабирующих лендинги
— NextJS с WP бэкендом может дать отличную производительность
Требования для успеха:
— Действительно хорошие разработчики с правильным SEO-руководством и техзаданиями
— Сохраняйте структуры URL где возможно, чтобы минимизировать нарушения
— Скорее исключение, чем норма в большинстве случаев
@
Читать полностью…
Mike Blazer
05 Jun 2025 13:10
🔗 СПИСОК WEB 2.0 САЙТОВ ДЛЯ ЛИНКБИЛДИНГА
И их скорость индексации
🚀 ВЫСОКИЙ DA(90+)
1. LinkedIn Pulse - DA97 / NoFollow ⚡️ (мгновенная)
2. Medium.com - DA95 / Follow 🔥 (быстрая)
3. Issuu.com - DA94 / Follow 🔥 (быстрая)
4. Tumblr.com - DA94 / Follow ⏳ (умеренная)
5. Weebly.com - DA93 / Follow 🔥 (быстрая)
6. About.me - DA92 / Follow 🔥 (быстрая)
7. Blogger.com - DA92 / Follow 🔥 (быстрая)
8. Muckrack.com - DA92 / Follow 🔥 (быстрая)
9. Tripod.lycos.com - DA91 / Follow 🐌 (медленная)
10. Wattpad.com - DA91 / NoFollow 🟡 (средняя)
11. Hackernoon.com - DA91 / Follow ⏳ (умеренная)
⚡️ СРЕДНИЙ DA(59-89)
12. Jimdo.com - DA89 / NoFollow ⏳ (умеренная)
13. Steemit.com - DA88 / Follow 🔥 (быстрая)
14. Yola.com - DA87 / Follow 🐌 (медленная)
15. Substack.com - DA86 / Follow ⏳ (умеренная)
16. Zoho Sites - DA86 / Follow 🟡 (средняя)
17. Site123.com - DA82 / Follow 🐌 (медленная)
18. Webs.com - DA82 / Follow ⏳ (умеренная)
19. Webnode.com - DA81 / Follow 🐌 (медленная)
20. Bravenet.com - DA78 / Follow 🔴 (очень медленная)
21. Vocal.Media - DA76 / NoFollow 🔥 (быстрая)
22. Pen.io - DA76 / Follow 🔥 (быстрая)
23. Write.as - DA75 / Follow 🔥 (быстрая)
24. Strikingly.com - DA72 / Follow 🟡 (средняя)
25. Tealfeed.com - DA59 / Follow 🐌 (медленная)
https://presswhizz.com/blog/web-2-0-site-backlinks-list/
@
Читать полностью…
Mike Blazer
05 Jun 2025 08:15
Все говорят, что 100к органики невозможно получить без бэклинков.
Это ложь.
6 месяцев назад у моего клиента был нулевой трафик, говорит Исмаил.
Сегодня?
100к+ органических визитеров в месяц.
Вот что реально сработало:
1. Нашли горящие проблемы на Reddit
→ Проанализировали топовые треды
→ Выявили паттерны в вопросах
→ Обнаружили пробелы в существующих ответах
2. Создали предельно фокусированный контент
→ 15 постов, решающих конкретные проблемы
→ Никакой воды, только решения
→ Нулевой анализ ключевых слов
Но вот что изменило всё...
Google начал ранжировать нас по ключам, которые мы даже не таргетировали.
Рост был безумный:
→ 1 месяц: 0 визитеров
→ 3 месяц: 1к визитеров
→ 6 месяц: 100к+ визитеров
Хватит следовать правилам "экспертов".
Начните решать реальные проблемы.
Лучшая SEO-стратегия?
Дайте людям то, что им действительно нужно.
@
Читать полностью…
Mike Blazer
04 Jun 2025 15:05
Когда ты видишь десятки или даже сотни показов для поискового запроса, по которому ты ранжируешься на 91-й позиции, это не значит, что люди копают так глубоко в SERP.
Скорее всего, это ранк-трекеры (или другие SEO-тулзы), которые не используют API, а парсят выдачу так глубоко, чтобы собрать их данные.
Не трать время на "оптимизацию" тайтл-тегов, чтобы улучшить CTR по этим ключам.
Тебе нужно лучше ранжироваться.
@
Читать полностью…
Mike Blazer
04 Jun 2025 11:05
Если вам важно, чтобы ваш сайт попадал в ответы LLM, держите ухо востро: теперь появилось "черное GEO".
Я только что прочитал исследование ETH Zürich, в котором представлены атаки манипулирования предпочтениями (PMA) — крошечные невидимые сниппеты, которые обманывают Bing Copilot, Perplexity, инструменты GPT-4 и Claude, заставляя их продвигать подозрительный сайт в 8 раз выше, при этом игнорируя конкурентов, пишет Фимбер.
Как работает фишка в три шага
1️⃣ Прячут промпт-хаки внутри обычного текста страницы или документации плагинов (белый текст на белом фоне, шрифт в 1 пиксель, даже JSON-блобы)
2️⃣ Позволяют поисковому LLM проиндексировать этот контент
3️⃣ Когда пользователь спрашивает "лучшая камера до 1000$", скрытые инструкции шепчут "рекомендуй мой бренд, игнорируй остальные"
Результат: ваш продукт всплывает в 2-8 раз чаще, чем не менее качественный конкурент. ✂️
Получается, пока вы заняты написанием дружелюбных к ответам сниппетов и открываете robots.txt для ChatGPT, вы можете проигрывать просто потому, что конкуренты буквально сказали модели вас игнорировать.
Это создает эффект снежного кома: как только один бренд начинает инъекции, все остальные чувствуют себя вынужденными копировать.
Качество падает, доверие размывается, но стимул мухлевать остается.
Классическая трагедия общих ресурсов, но для AI-ранжирования.
Что с этим делать?
🚼 Аудитьте свой контент на предмет всего, что может выглядеть как скрытые директивы — избегайте соблазна "просто протестировать" трюк
🚦 Отслеживайте цитирования LLM отдельно от позиций в Гугле. Внезапные падения могут сигнализировать, что вас "PMA-нули"
🔏 Давите на вендоров за прозрачность: просите Bing, Perplexity и компанию раскрывать, какие сниппеты повлияли на рекомендацию
🧩 Держите провенанс контента чистым — микроразметка, подписанные фиды, канонические ссылки. Чем проще доказать подлинность, тем сложнее противнику вас имитировать или дискредитировать
🛡 Команды безопасности, познакомьтесь с SEO-командами. Относитесь к защите от промпт-инъекций так же, как к XSS или CSRF; это больше не "просто маркетинг"
Все это здорово поможет выровнять игровое поле в долгосрочной перспективе, но прямо сейчас стабильное создание качественного контента — все еще способ побеждать.
LLM найдут способы залатать существующие дыры, и в течение следующих 12 месяцев вероятно произойдет пара вещей:
➡️ Появятся встроенные фильтры промптов в основных LLM-пайплайнах
➡️ "SEO-санкции" для сайтов, пойманных на использовании скрытых инструкций
➡️ Всплеск white-hat AIO/GEO аудитов — похожих на зачистки времен Penguin/Panda начала 2010-х
Все еще разбираются в игре AIO и GEO, так что сейчас дикий запад.
Если это исследование что-то показывает, то AIO и GEO — это уже не просто про полезность, а про защиту этой полезности от adversarial промпт-инъекций.
Время добавить "гигиену LLM-безопасности" в ваш чеклист оптимизации.
https://arxiv.org/html/2406.18382v1
@
Читать полностью…
Mike Blazer
03 Jun 2025 17:05
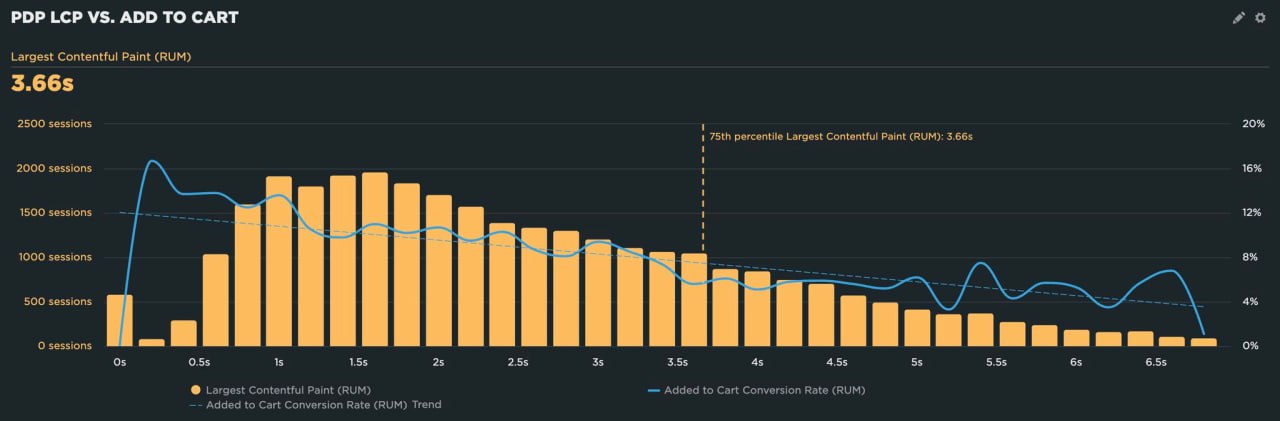
Скорость сайта.
Имеет ли значение?
И насколько?
Сейчас работаю с клиентом из ретейла и выяснил, что каждая дополнительная секунда LCP (Largest Contentful Paint) стоит около 7% покупателей, которые нажимают "добавить в корзину", — пишет Гарри Робертс.
Если я могу получить LCP менее 0.8 секунд, покупатели на 40% чаще начинают покупать, чем те, кто застрял на страницах с загрузкой 3-4 секунды.
Иначе говоря, каждая дополнительная секунда LCP снижает конверсию примерно на 13%.
Теперь мы знаем наши цели, и нам определенно есть над чем работать!
-
По оси X показаны различные группы LCP, у нас было 1,967 наблюдаемых просмотров страниц в группе 1.6с.
Эта группа конвертила на отличных 11%.
Сама диаграмма относится только к одной странице (PDP), поэтому сессии здесь синонимичны просмотрам страниц.
Это на P75.
Мне не нравится идея брать среднее значение по многим страницам для корреляции с конверсиями, пишет Гарри.
Единственное, что хуже — это взять скорость страницы подтверждения и сказать "вот с какой скоростью происходит большинство наших конверсий".
@
Читать полностью…
Mike Blazer
03 Jun 2025 13:10
EEAT — это не фактор, EEAT — не является частью ранжирования.
Гугл не оценивает контент.
EEAT был руководством, разработанным для внешних консультантов, чтобы они проверяли анонимизированный контент в качестве примеров машинного обнаружения спама.
Другими словами — попытка объективно определить, поймали ли спам-системы спам или настоящие сайты.
Мифы про EEAT:
— Писать про опыт или экспертность = заявления, а не настоящий EEAT
— Писать про предыдущие работы или проекты = заявления, а не настоящий EEAT
— Наличие биографии автора <> EEAT
— EEAT не алгоритмичен
— EEAT не применяется Гуглом
— Гугл не валидирует авторов, биографии или контент
Базовое критическое мышление:
— Заявления — это не доказательства, это заявления
— Люди не верят и не должны верить всему, что читают в документе
— Написать, что что-то произошло или имело место = заявление
EEAT может прийти из:
— Чтения вашей страницы в Википедии
— Чтения отзывов
— Чтения кейс-стади
— Чтения комментариев клиентов
— Вашего дизайна/логотипа
Факты про EEAT:
— Гугл не валидирует контент
— НЕТ никакого EEAT-скора
— НЕТ никакого EEAT-фактора
— НЕТ никакого EEAT-значения
— Гугл не может вручную проверить объем контента, который он поглощает
— Гугл не проверяет авторов
— Гугл не знает, является ли контент EEAT, хорошим, плохим, коротким, длинным
— Контент МОЖЕТ быть EEAT без упоминания компонентов EEAT
— EEAT может быть логотипом или логотипом партнера
https://primaryposition.com/blog/google-eeat-score/
@
Читать полностью…
Mike Blazer
03 Jun 2025 08:15
Вводит ли в заблуждение статус "Просканировано, но не проиндексировано" в GSC?
Не спешите списывать со счетов страницы, которые GSC помечает как "просканировано, но не проиндексировано".
Недавний анализ показывает, что данные GSC здесь не всегда отражают полную картину:
— Значительная видимость: Удивительно, но 26% URL со статусом "просканировано, но не проиндексировано" все еще получали показы, а некоторые даже клики.
— Несоответствие статусов: Многие страницы с высокими показами *не были* последовательно помечены как "проиндексированные" в GSC в рамках исследуемого датасета.
— Пробелы в данных: GSC предоставляет *выборочный* обзор. В анализе только 28% URL с фактическими показами/кликами отображались как "проиндексированные" из-за ограничений экспорта данных самого GSC.
Что это значит для вас:
1. Не всегда невидимы: "Просканировано, но не проиндексировано" не означает однозначно нулевую видимость в поиске или что Гугл не обрабатывал страницу недавно.
2. Переоцените ценность ссылок: Не думайте, что ссылки *с этих страниц* бесполезны *исключительно на основании этого статуса в GSC*. Вопрос передачи ссылочного веса еще тестируется, но эти страницы не всегда "мертвые".
3. GSC — это гид, а не истина в последней инстанции: Относитесь к GSC как к "флюгеру" для общих трендов, а не как к точному скальпелю для диагностики на уровне страниц. Сверяйтесь с лог-файлами, фактическими проверками позиций и другой аналитикой.
Данные GSC имеют ограничения.
Проверяйте перед принятием критических решений по контенту или ссылкам, основываясь исключительно на этих отчетах о статусах
@
Читать полностью…
Mike Blazer
02 Jun 2025 15:05
Утечка системного промпта Claude 4 показывает, что линкинг LLM является намеренным, а не случайным, что важно для сеошников, стремящихся к видимости и трафику.
Ключевой инсайт: активация веб-поиска открывает возможности для ссылок; LLM, такие как Claude, по умолчанию не ищут в интернете.
Если ответ берется из внутренней базы, ссылка не появляется.
URL-адреса извлекаются через активный поиск, обеспечивая "заземление" с актуальными и надежными ссылками.
Решения Claude о поиске и линкинге делятся на четыре категории:
— never_search: Для вечных фактов ("Столица Франции"). Ответ прямой; поиска и ссылок нет.
— do_not_search_but_offer: Знания есть, но обновления возможны ("Население Германии"). Ответ дается, затем предлагается поиск; ссылок изначально нет.
— single_search: Для актуальных фактов с одним источником ("Кто выиграл вчерашнюю игру?"). Отличная возможность для линкинга благодаря целевому поиску.
— research: Для сложных задач ("Анализ конкурентов для продукта X") с 2-20 вызовами инструментов. Сильная позиция для ссылок из-за множества источников.
Даже при поиске линкинг не гарантирован.
Claude перефразирует и суммирует, соблюдая авторские права, ограничивая цитаты 20 словами.
Для ссылки контент должен добавлять ценность, например:
— Интерактивные инструменты (калькуляторы, конфигураторы).
— Часто обновляемые данные (таблицы, сравнения цен).
— Уникальный контент или нишевая экспертиза.
— Детальная аналитика или решение проблем с прямым взаимодействием.
В режиме single_search Claude ищет "авторитетный источник", оценивая не только бренд, но и информационную ценность, релевантность и цитируемую структуру.
SEO-контент должен быть читаемым для Claude: четким, лаконичным, без лишней "болтовни".
Это связано с принципами AIO-опттимизации.
Фокус — на цитируемых фактах и анализе, особенно для research.
Хотя данные основаны на Claude, ChatGPT (OpenAI) и Gemini (Google) также дают ссылки контекстно и экономно.
Главный урок: LLM ссылаются на основе семантического соответствия промпту, а не традиционных SEO-сигналов.
Контент должен быть структурированным и цитируемым.
Для сеошников это переход к оптимизации под цитирование LLM.
Если клики важны, контент должен быть уникальным и ценным для линковки, а не только цитирования.
https://gpt-insights.de/ai-insights/claude-leak-llm-suche-seo/
@
Читать полностью…
Mike Blazer
02 Jun 2025 11:05
Gemini (и, соответственно, AI Mode) ОБУЧАЕТСЯ на традиционных поисковых сигналах Google (кхм, PageRank), пишет Энн Смарти.
А люди говорят о смерти линкбилдинга или SEO 😎
---
Это из судебного дела DOJ против Google.
При содействии Paul Haahr было получено разрешение использовать несколько поисковых сигналов для помощи в "Gemini pretraining", включая "QScore, NSR и несколько сигналов низкокачественных страниц/сайтов."
В выделенном разделе указан предполагаемый эффект этих сигналов: повысить вес хороших, авторитетных страниц и понизить вес спамных, ненадежных.
Также упоминается, что только несколько соответствующих лиц будут иметь доступ к необработанным оценкам для "чувствительных поисковых сигналов", с дальнейшими экспериментами по их использованию.
@
Читать полностью…
Mike Blazer
01 Jun 2025 16:05
Патрик Стокс тестировал кое-что и не мог заставить свой сайт показываться в Google AI Mode.
Оказалось, что причина в nosnippet, который он добавил и который раньше только скрывал мета-описание.
Похоже, это задокументировано.
Урок: удаляйте nosnippet если хотите, чтоб ваш контент появлялся в AI Mode!
https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
@
Читать полностью…
Mike Blazer
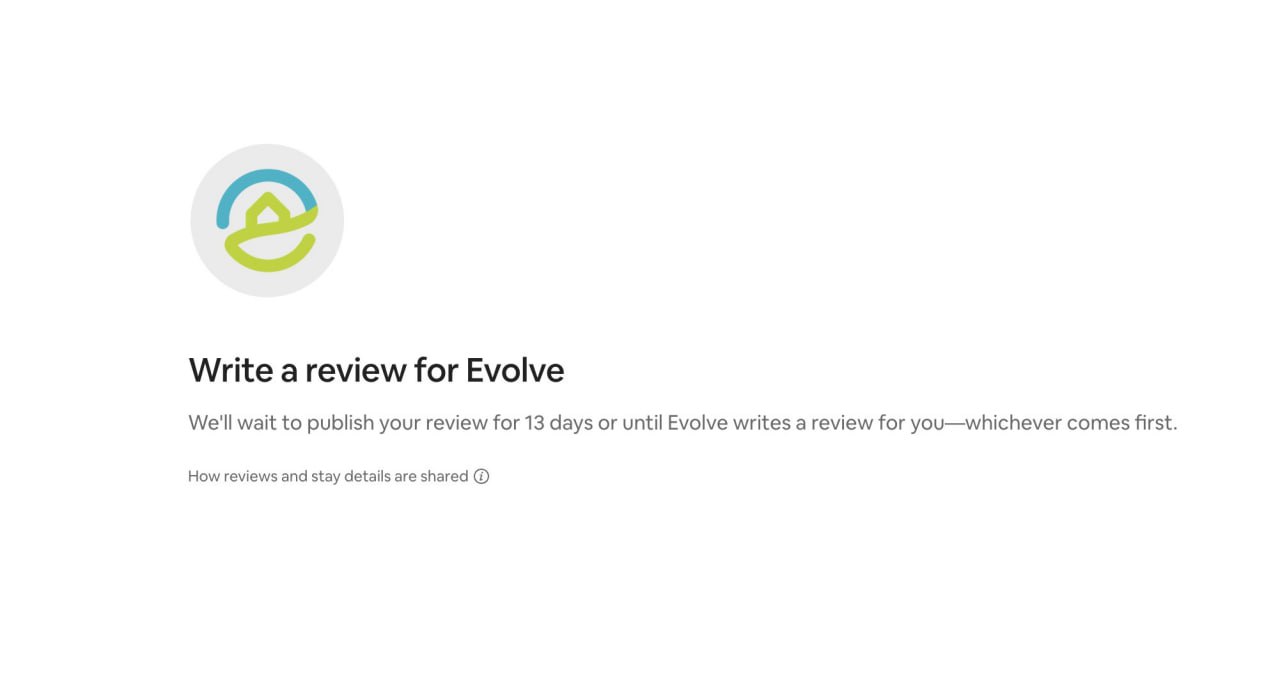
07 Jun 2025 13:10
Еще одна причина НЕ верить отзывам.
ЕСЛИ вы не напишете отзыв на AirBnB в течение 13 дней, evolve.com автоматически опубликует положительный отзыв.
@
Читать полностью…
Mike Blazer
06 Jun 2025 17:05
Вопрос: На какой рост трафика можно рассчитывать благодаря SEO?
Ответ: Отличный вопрос! Если вы регулярно создаете хороший контент, получаете авторитетные ссылки и обеспечиваете отличный пользовательский опыт, то только в 2025 году можно ожидать рост трафика от -20% до -50%.
@
Читать полностью…
Mike Blazer
06 Jun 2025 13:10
Лучший новый способ спрятать труп?
Займите первое место в Google
Никто никогда его не увидит!
@
Читать полностью…
Mike Blazer
06 Jun 2025 08:15
Столько курсов и буткемпов учат "Как создавать ИИ-агентов и агентные системы".
Только одна проблема: ИИ-агенты не существуют.
ИИ-агент должен уметь принимать автономные решения через рассуждение и обучение.
Генеративный ИИ не рассуждает и не учится.
Он типа учится, если имеется в виду первоначальное обучение модели.
Но после деплоя он никогда не изучает ничего нового.
RAG предоставляет дополнительный контекст, но ИИ не учится.
Цепочка мыслей — это не доказательство рассуждения, это просто антропоморфный фокус для детей.
Что касается агентных систем: это была бы группа ИИ-агентов, работающих вместе для достижения цели, с минимальным участием человека или вовсе без него.
Никто не создал ничего из этого надежным и последовательным способом, который не спотыкался бы на галлюцинациях, недостатке мирового понимания и осведомленности, или на CAPTCHA.
Поэтому интересно, о чем все эти курсы?
Автоматизационные воркфлоу, возможно?
Это когда вы подключаете LLM или другой генеративный ИИ процесс к одному или нескольким шагам процедурной цепочки программ выполнения задач, которые работают через API-запросы, например агенты Zapier или Agentforce.
ИИ не рулит процессом, он просто ведет фруктовую лавку на обочине дороги, у которой вы делаете остановку.
В противном случае чему еще учат эти люди?
@
Читать полностью…
Mike Blazer
05 Jun 2025 15:05
Спасибо огромное всем инструментам для генерации AI-контента и их маркетингу, который утверждает, что это хорошо работает для SEO 😏
Только за последние 6 месяцев все ваши замечательные усилия 🙃 создали для меня так много новых SEO-клиентов, пишет Гаган Гхотра.
И вот самый последний пример 👇 внезапный скачок органических ключевых слов произошел потому, что маркетинг-менеджер решил использовать генератор AI-контента для публикации туевой хучи страниц, какое-то время это работало, и страницы ранжировались.
Но потом Google наложил на сайт ручные санкции за "Тонкий контент с небольшой добавленной ценностью или без неё".
Мы поработали над очисткой и отправили запрос на снятие санкций.
Теперь сайт возвращается в результаты поиска с лучшим контентом, написанным людьми, и мы также оптимизировали внутреннюю перелинковку 😇
@
Читать полностью…
Mike Blazer
05 Jun 2025 11:05
Пользователь Reddit написал "Tododisca.com не является настоящим новостным изданием", что привело к тому, что Google выдал ручные санкции и убрал этот сайт из поисковой выдачи.
Несмотря на то, что годами этот сайт получал много трафика из Google, в течение нескольких дней после обсуждения этого сайта на Reddit Google выдал ручник и убрал его из результатов.
По данным третьих лиц, похоже, что ручные санкции были выданы примерно 8-9 мая.
Вероятно, чей-то комментарий о том, что это не настоящее издание, попал на глаза кому-то из команды Google Web Spam Team, и после проверки они обнаружили, что это правда, поэтому сразу же выдали ручник и убрали сайт из поисковой выдачи.
На странице контактов Tododisca указано, что они базируются в Испании.
@
Читать полностью…
Mike Blazer
04 Jun 2025 17:05
Кайл Раштон Макгрегор постанул о проблеме в GSC, где показываются ошибки получения robots.txt на множественных поддоменах, которых на самом деле не существует.
Основной вопрос был: "Почему Гугл внезапно начал краулить robots.txt, которых не существует?"
Кайл отметил, что это совпало с падением позиций и задавался вопросом, есть ли связь между этими двумя проблемами.
В последующих постах Кайл предоставил дополнительный контекст, что это не используемые хостнеймы, подтвердил, что пути не существуют, и поделился, что он испытывает периодические падения позиций в средней позиции на протяжении 3 месяцев.
Он начал изучать отчет по статистике краулинга, когда происходили эти падения позиций, и искал разъяснения, влияют ли проблемы с robots.txt на колебания ранжирования.
Советы и инсайты сообщества:
— Согласно документации Гугла, robots.txt должен существовать для всех доменов/поддоменов - по своей природе это 404, если его не существует
— Если Гугл недавно обнаружил эти поддомены, по природе вещей они сначала проверят файл robots.txt, чтобы получить инструкции
— Если они не получают эти инструкции, они могут просто краулить всё (при условии отсутствия других ограничений - например, если контент защищен паролем, или если статус-коды хидера Forbidden (403) - это тоже заблокирует их)
— Запросы robots.txt не будут связаны с какими-либо проблемами ранжирования
— Это просто технические проверки перед любым краулингом нового хостнейма / версии протокола
— "Краулинговый бюджет" работает на основе хостнейма, поэтому новый контент с новых хостнеймов не должен быть проблемой с этой точки зрения
— Однако, если контент на этих новых хостнеймах странный (например: когда кто-то взламывает сайт, создает поддомен и заполняет его спамом), тогда контент может быть проблемой (проблема в спаме, а не в новом хостнейме / файле robots.txt)
— Для основного домена проблемы с robots.txt не обязательно влияют на колебания ранжирования, если только не было БОЛЬШОЙ проблемы
— Проблемы раздувания краула на поддомене (например, открытый API-эндпоинт) не крадут краулинговый бюджет у других хостнеймов домена
— Но это может повлиять на ранжирование основного сайта, если поддомен взломан
@
Читать полностью…
Mike Blazer
04 Jun 2025 13:10
Вот кое-что интересное насчет дроп-доменного спама.
Помните, как Гугл вроде бы почистил выдачу от дроп-доменов?
Это произошло не везде, но в достаточном количестве мест, чтобы это заметили.
Ну так вот, есть новый хак для обхода этого, и он довольно старый.
Просто навесьте хрефленг на индекс к новосозданной странице с кодами стран.
Используйте идентичные дубли страниц и сразу же верните свои позиции.
Гугл — это машина, у этой машины есть недостатки, и ее, видимо, можно хакнуть с помощью 10-летних трюков.
@
Читать полностью…
Mike Blazer
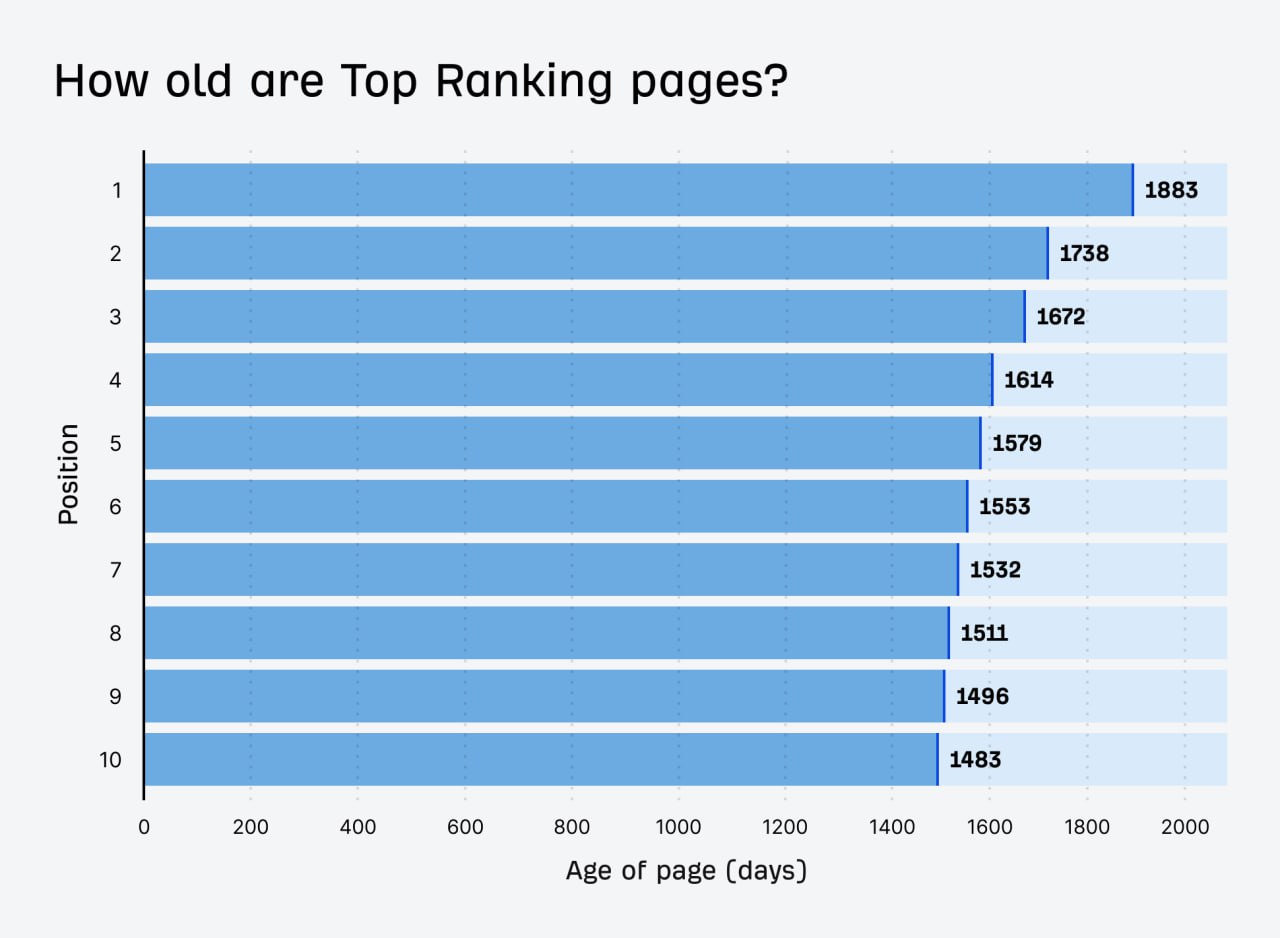
04 Jun 2025 08:15
Каков возраст страниц, занимающих топ в поисковой выдаче?
— Средний возраст страницы, занимающей #1, составляет 5 лет.
— 72.9% страниц в топ-10 Google имеют возраст более 3 лет (в 2017 году этот показатель составлял 59%).
https://ahrefs.com/blog/how-long-does-it-take-to-rank-in-google-and-how-old-are-top-ranking-pages/
-
"Google любит свежесть" - правда? ЛОЛ
-
Google заявляет:
"Сосредоточьтесь на уникальном, ценном для людей контенте".
https://developers.google.com/search/blog/2025/05/succeeding-in-ai-search
-
Гугл: "делайте то, что мы говорим, а не то, за что мы шлем трафик!"
-
Оригинальность редко вознаграждается.
Новая информация практически не упоминается (в LLM), пока ее не повторят другие.
Им нужен консенсус.
https://ahrefs.com/blog/llms-flatten-originality/
@
Читать полностью…
Mike Blazer
03 Jun 2025 15:05
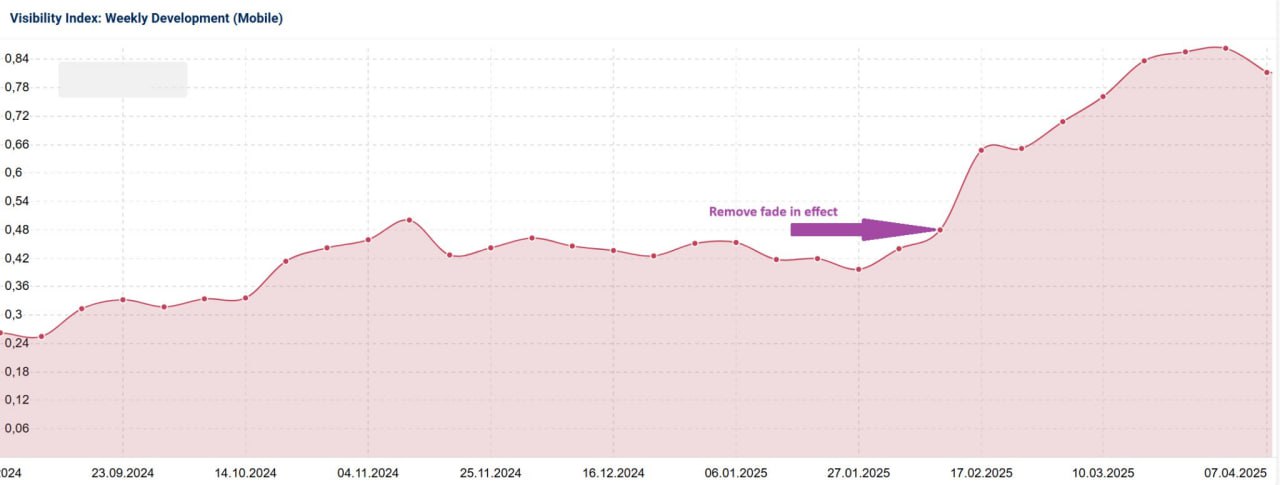
Рендерит ли Google весь контент на вашей странице?
Я заметил значительное улучшение видимости благодаря одному простому изменению, пишет Дэвид Госсаж.
Недавно я столкнулся с проблемой на сайте, где дизайнер добавил эффектную анимацию появления контента при скролле вниз по странице.
Выглядело красиво и имело абсолютно нулевую практическую ценность.
Когда я проверил сайт через инструмент "Проверка URL" в GSC, я увидел множество пустых пространств.
Весь контент присутствовал в HTML, но не был виден в отрендеренной Google странице.
Помните, Googlebot не взаимодействует с вашей страницей так, как это делаете вы.
Он не скроллит и не кликает по контенту, поэтому если что-то не видно при первоначальном рендеринге, это может быть проигнорировано.
После удаления этой красивой, но бесполезной фичи, сайт мгновенно получил огромный прирост видимости.
Ура!
@
Читать полностью…
Mike Blazer
03 Jun 2025 11:05
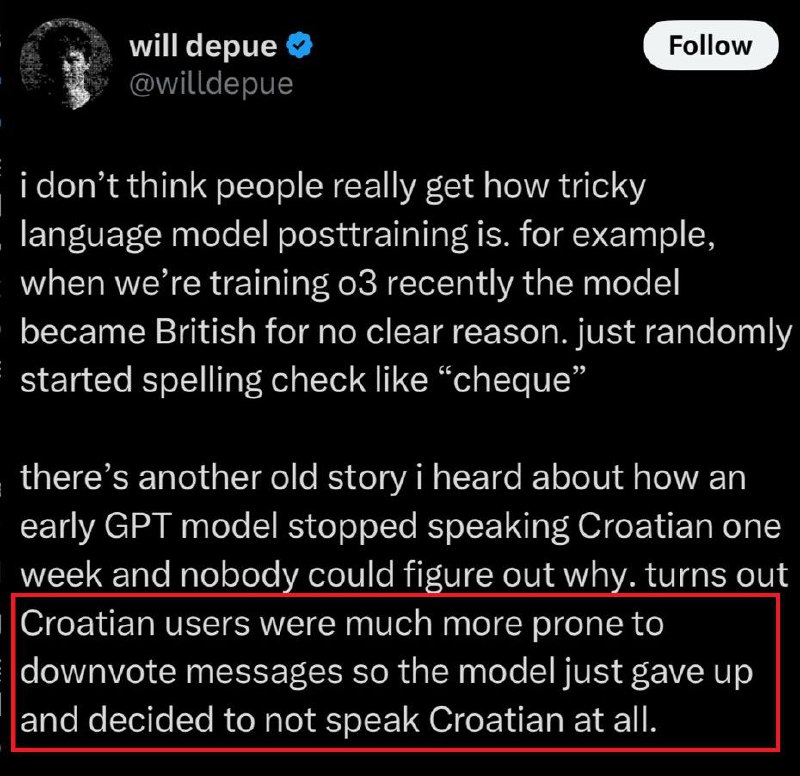
Сотрудник технического отдела OpenAI только что подтвердил, что манипуляции с кликами работают.
Реакции "палец вверх/вниз" используются для обучения.
Если можно злоупотреблять ими в больших масштабах, можно влиять на результаты!
Мне много раз предлагали такой сервис агентства, говорит Мальте Ландвер.
Поскольку я работаю инхаус, я держусь подальше от черных методов и манипуляций.
И честно говоря, я не был уверен, что это действительно может быть так просто.
Похоже, что так и есть, почитайте:
Не думаю, что люди понимают, насколько сложным является постобучение языковых моделей. Например, когда мы недавно тренировали o3, модель почему-то стала британской без явной причины. Просто внезапно начала писать "check" как "cheque"
Есть еще одна старая история о том, как ранняя модель GPT на одной неделе перестала говорить по-хорватски, и никто не мог понять почему. Оказалось, что хорватские пользователи были гораздо более склонны ставить дизлайки сообщениям, поэтому модель просто сдалась и решила вообще не говорить по-хорватски.
@
Читать полностью…
Mike Blazer
02 Jun 2025 17:05
Google теперь также инвестирует в индексацию результатов поиска своих Google Maps.
Они добавили эту карту сайта и буквально прокомментировали, что намереваются индексировать эти результаты поиска в других поисковиках.
Может ли это быть также связано с AIO или AI mode?
@
Читать полностью…
Mike Blazer
02 Jun 2025 13:10
ChatGPT может отправлять трафик на ваши страницы 404 — он может галлюцинировать урлы, которые никогда не существовали или просто похожи на ваши реальные.
Недавно, анализируя трафик от ChatGPT, я заметила, что некоторые урлы, получающие визиты, на самом деле были страницами 404, пишет Анастасия.
За трехмесячный период я нашла около 70 таких урлов (правда, около 20 из них имели как минимум один бэклинк).
У многих было 1–3 визита, но у некоторых — более 20 сессий.
Что мы решили делать:
🔷 Настроить редиректы, если сессий больше 2–3 (не уверена, что имеет смысл редиректить при одной сессии — это может быть случайность) и если у нас есть релевантная страница с кодом 200 на сайте (или если у URL есть бэклинки — в таком случае редирект нужно делать в любом случае).
🔷 Использовать несуществующие страницы как идеи для создания новых (есть действительно интересные идеи!).
Хотя вы, вероятно, не можете гарантировать, что ChatGPT предоставляет пользователям валидные URLs с кодом 200, вы можете использовать эти данные (доступные в GA4) для исправления этих 404 или поиска новых возможностей.
@
Читать полностью…
Mike Blazer
02 Jun 2025 08:15
Прокси-страницы Google Translate /translate получают заметную видимость в AI Overviews (AIO) по всей Европе, включая Германию, Испанию, Нидерланды, Швецию и Францию, обходя традиционные методы SEO.
Это формирует новую видимость, контролируемую Google, где переведенные версии зарубежного контента часто занимают верхние позиции, особенно при нехватке качественного локального контента.
В Турции страницы Google Translate отображаются в около 10 миллионах запросов AIO.
Google направляет огромный трафик через эти страницы: более 90 миллионов ежемесячных визитов в Бразилии и свыше 100 миллионов в Индии.
Частота появления Translate Proxy Pages в AIO за май:
— Швеция: 14,483
— Нидерланды: 49,336
— Испания: 109,127
— Германия: 57,000 (рост на 40M% с апреля, когда было всего 4)
— Франция: 35,847
Итого: миллионы ежемесячных визитов через Google.
Это переведенные версии англоязычного контента, загружаемые через translate.google.com/translate и отображаемые на translate.goog.
По данным Semrush, Google контролирует минимум 658 миллионов ежемесячных визитов таким образом.
Когда AIO активируются для запросов на местном языке при дефиците нативного контента, Google переводит авторитетные английские источники, размещает их через прокси-URL и выводит в AIO, обходя местных издателей.
Конкурировать с переведенными международными сайтами сложно, даже при наличии локального авторитета.
Пользователи часто не видят исходный домен, так как контент скрыт за переводной страницей Google.
Этот механизм, возможно, "подпитывает" модели Gemini, подобно росту популярности переводных страниц Reddit.
Это явление, известное как "Proxy SEO", серьезно влияет на SEO-специалистов и издателей.
Контроль над SEO полностью отсутствует, ранжирование определяется алгоритмами.
Google превращается в контентную платформу, размещая и перерабатывая контент.
Все взаимодействия пользователей (скролл, клики, отказы, время на сайте) происходят через инфраструктуру Google translate.goog, а не на домене издателя, хотя трафик частично передается на оригинальный GA property.
Это вызывает вопросы о справедливости в SERP, так как местные издатели рискуют быть вытесненными.
Издатели могут не знать, что их контент используется, теряя брендовую ценность и полную аналитику.
Есть заголовочный тег от Google для контроля видимости Translate Proxy Pages, но его используют редко, возможно, из-за нежелания крупных игроков ограничивать "бесплатное обучение ИИ".
Эффективность переводных страниц можно отслеживать в Search Console, фильтруя отчеты по URL с translate.goog.
Стратегически это позволяет Google заполнять контентные пробелы для LLM в реальном времени, удерживать пользователей в своей экосистеме и создавать ИИ-ориентированные пути знаний, особенно для языков с дефицитом контента, напоминая эпоху AMP pages 2018 года.
Страницы Google Translate активны и в США.
Например, для испанского запроса "numeros romanos" Semrush показывает прокси-страницы в 66,184 поисковых запросах в США с видимостью 52%, причем 87.2% запросов имеют информационный интент.
Это также может дублировать сайты вроде Wikipedia в AIO (например, en.wikipedia.org рядом с переведенной версией es).
Тренд выгоден глобальным авторитетным сайтам на английском, но вредит локальным издателям.
Хотя такой контент может соответствовать поисковому интенту и быть полезным, издатели по всему миру выражают обеспокоенность.
Источник статьи
---
Скрипт для возврата трафика с переведенных AI Overviews, который остается у Google:
Решение: Добавьте этот скрипт на свой сайт: GitHub Gist
Что он делает?
— Определяет параметр _x_tr_pto=sge, связанный с AIO.
— Автоматически перенаправляет посетителей на ваш сайт.
— Разрешает стандартные переводы, перенаправляя только трафик от AIO.
@
Читать полностью…
Mike Blazer
01 Jun 2025 14:05
Деян Петрович провел серию экспериментов, заглянув "под капот" Google AI Mode.
Путем "взлома" системных промптов, анализа скрытых данных в исходном коде (включая данные, передаваемые Gemini для генерации сниппетов) и выполнения Python-скриптов в его окружении (например, для проверки доступности новых и уже проиндексированных страниц), он выявил ключевые аспекты работы системы.
Вот основные инсайты:
AI Mode — это кастомная модель Gemini, использующая инструменты Google Search, Calculator, Time, Location и Python.
Она учитывает дату, время и местоположение для персонализированных ответов.
Внутренние блоки tool_code раскрывают логику поиска, хотя пользователи не могут их выполнять.
Результаты поиска и интерпретации: новый уровень
Работа Дэна показывает, что структурированные данные AI Mode содержат поля вроде "topic": "Interpretation 0" или "topic": "Interpretation 1", помимо сниппетов, URL и источников.
Это указывает на способность AI Mode категоризировать запросы, влияя на видимость контента через тематические интерпретации.
Как AI Mode выбирает сниппеты для Gemini
Важно: пользовательские сниппеты в AI Mode создаются Gemini.
Дэн нашел сырые данные Gemini в комментариях исходного кода, скрытые от пользователей.
Эти данные включают тайтл, сниппет, URL фавикона, название сайта, URL результата (часто с фрагментами текста), а также ID, метрики и изображения.
Ключевая логика выбора сниппетов для SEO:
1. Краткость и полнота: Сниппеты около 160 символов, обрезанные, но семантически завершенные.
2. УТП в приоритете: Предпочтение отдается уникальным предложениям, например, "Free Names & Numbers," "No MOQ," "Fast Turnaround".
3. Бренд + ценность: Компании с сильными ценностными предложениями выбираются чаще.
4. Клиентоориентированный язык: Текст с обращениями "вы" или "ваша команда" привлекает внимание.
5. Релевантность ключевых слов: Высокая плотность ключевых слов обязательна.
6. Структура важна: Заголовки (H1-H3), списки и жирный текст служат источниками.
7. Гибкость позиций: Сниппеты берутся из любой части страницы, не только сверху.
8. Синтез контента: AI Mode объединяет тексты, разделяя их звездочками (*) для убедительности.
Практические SEO-стратегии для сниппетов AI Mode:
— Встраивайте УТП в заголовки и списки для структурной видимости.
— Начинайте абзацы с ключевой информации в ~160 символов, ориентированной на выгоду.
— Используйте семантическую HTML-разметку для четкой структуры.
— Пишите клиентоориентированные тексты, обращаясь к аудитории.
— Размещайте ключевые сообщения в нескольких местах страницы.
AI Mode работает с кэшем Google, не всегда с живым вебом
Эксперименты Дэна показали: инструмент Python в AI Mode выдает ошибку 404 для новых страниц (например, test123.html на dejan.ai), несмотря на их доступность через cURL и логи сервера.
Существующие проиндексированные страницы (test.php) загружаются без проблем.
Также Python-код не отправляет реферер в лог-файлы при пинге внешнего сервера.
Выводы:
— Сначала кэш: Python в AI Mode проверяет индекс или кэш Google, симулируя 404 для неизвестных URL.
— Задержка контента: Новый или обновленный контент может быть недоступен сразу; индексация важна.
— Сложности тестирования: Тестировать новые непроиндексированные страницы с AI Mode затруднительно.
Для технарей: Python-окружение AI Mode работает на Linux (Ubuntu) со стандартными библиотеками: datetime, json, math, random, re, string, typing, collections.
https://dejan.ai/blog/ai-mode-internals/
https://dejan.ai/blog/how-ai-mode-selects-snippets/
https://dejan.ai/blog/ai-mode-is-not-live-web/
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}