Mike Blazer
29 October 2025 15:05
Попапы с запросом разрешений в браузере могут скрыть ваш контент от Гуглобота
Я видел код, который приводит к полному провалу рендеринга и для Гуглобота, и для значительной части юзеров.
И корень проблемы — в типичной ошибке с разрешениями браузера, предупреждает Мартин Сплитт.
Гемор часто начинается с JavaScript, который проверяет, доступна ли в браузере фича вроде геолокации.
Когда он обнаруживает такую возможность, то запрашивает текущую позицию пользователя, чтобы загрузить локализованный контент — например, новости, релевантные для Цюриха.
Для пользователя, который кликает "да" в попапе, все отлично.
Проблема в том, что происходит, когда юзер — или Гуглобот — говорит "нет".
Код часто обрабатывает только сценарий "да" и не имеет нормального фолбэка на случай отказа.
Я видел реализации, где единственная альтернатива, типа загрузки глобального контента, срабатывала, только если браузер *в принципе не мог* запросить разрешение.
Это значит, что юзер, который просто отклонил запрос, видит пустую страницу, потому что этот сценарий провала не был учтен.
Вы должны понимать, что Гуглобот автоматически говорит "нет" на все подобные запросы разрешений.
Будь то геолокация, доступ к камере или пуш-уведомления — Гуглобот их отклоняет.
В результате он столкнется с тем же сломанным сценарием, что и заботящийся о приватности юзер, и ничего не увидит.
И это не просто потенциальная SEO-проблема; это гораздо более крупный косяк для бизнеса и UX.
Если ваш ключевой контент зависит от предоставления разрешений, для нас он невидим, а для многих ваших пользователей — сломан.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
29 October 2025 11:15
81% традиционного SEO-авторитета не переносится в ChatGPT
Долгое время путь в ChatGPT был ясен: эксклюзивное партнерство с Bing означало, что индексация в Bing была ключевым элементом, чтобы на тебя сослались.
Теперь все полностью изменилось.
Основываясь на нашем анализе сотен миллионов ответов ИИ, мы можем подтвердить, что ChatGPT переключил своего внешнего поискового провайдера на агрегатор типа SERP API, создав гибридный индекс, раскрывает Джош Блискал.
Чтобы понять масштаб изменений, мы каждый месяц прогоняем тысячу промптов через ChatGPT и Google, и то, что мы обнаружили — это тектонический сдвиг в источниках, на которые они ссылаются.
Но главная история здесь — это невероятно малое пересечение.
Существует всего 19% пересечения по доменам между цитатами ChatGPT и выдачей Google.
Это означает, что 81% нашего традиционного SEO — наши бэклинки, наши ключевики, наш трафик — не переносится один в один.
Чтобы понять эту разницу, нужно разобраться в механизме.
Когда вы вводите промпт, ChatGPT сначала приводит его к стандартным поисковым запросам и отправляет своему внешнему провайдеру.
Этот провайдер возвращает индекс результатов, но вот тут самый сок: он отправляет только слаг URL, тайтл, мета-дескрипшен и около 800-1200 символов контента.
Отдельная технология под названием WebGPT затем анализирует этот ограниченный индекс и выдергивает источники, которые, по ее мнению, наиболее прямо ответят на вопрос пользователя.
В этом-то и ключ: мы больше не оптимизируемся под традиционный поисковик.
Мы оптимизируемся под то, чтобы наш сниппет был выбран WebGPT.
Ваш успех полностью зависит от того, насколько хорошо этот небольшой пакет инфы — ваш URL, тайтл, мета и первые несколько абзацев — "продает" вашу страницу ИИ как самый прямой и уверенный ответ.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
28 October 2025 15:05
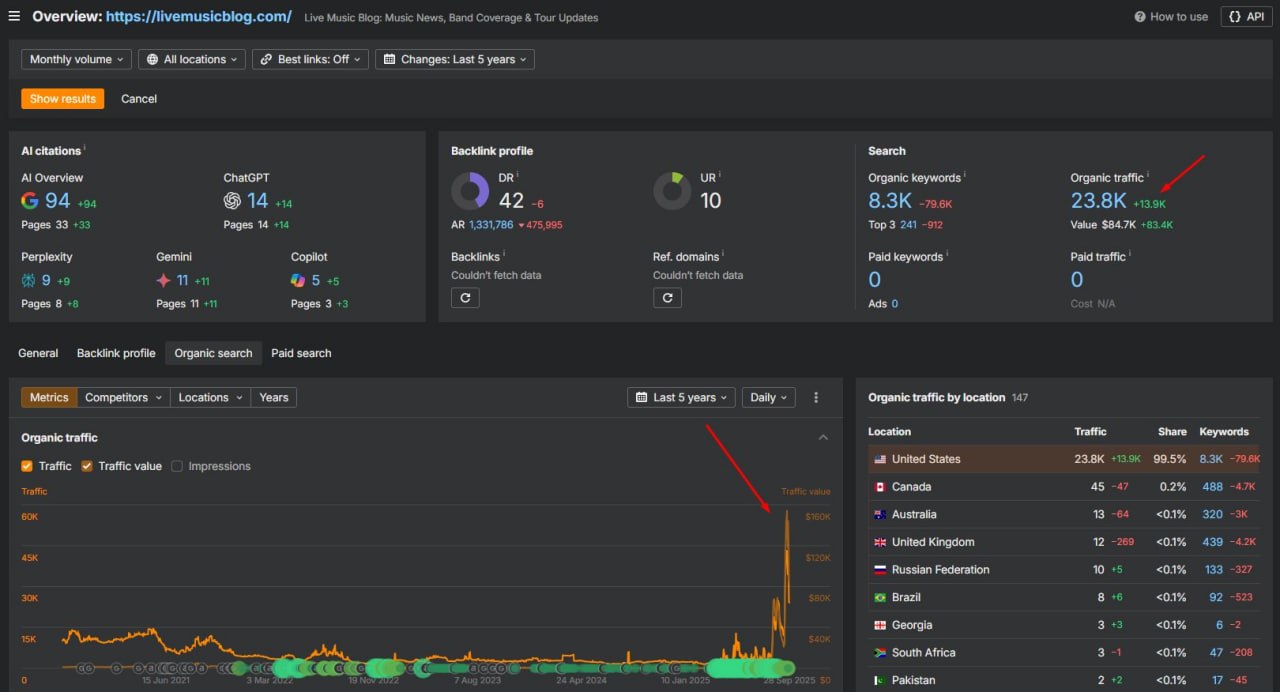
Этот музыкальный новостной блог создал отдельную категорию про гемблинг и захватил серпы по казино в США менее чем за 45 дней - livemusicblog.com/casino-games/
"Релевантность" с этим слабым алго становится все большей шуткой, а AI Overviews плохо фильтруют топ-100 источников — все больше и больше спамных сайтов захватывают выдачу.
Parasite SEO не просто выживает, оно процветает!
Google снес сабфолдеры, "почистил" серпы по казино, и все же тот же цикл повторяется снова и снова: авторитетные доноры рециркулируют, спамеры наводняют выдачу, и доминируют одноразовые паразиты.
Августовский спам-апдейт не убил паразитку; он просто перетасовал, кто получит деньги в этом месяце.
Страницы-сироты спалили, но купи пару лишних постов у тех, кто бустанулся, и ты снова в деле.
Google не может ударить по корневому авторитету, так что теория рециркуляции верна: сносишь одного хоста, и другой мгновенно заполняет гэп в серпе, и так по бесконечному кругу.
Тем временем AI Overviews пропускают низкокачественные, нерелевантные источники.
Классификатор почти не применяется к новым доменам, а поскольку контентные сигналы мертвы, весь вес несут ссылки + авторитет + свежесть + трафик...
Вот почему случайные блоги могут прикрутить сабфолдер "casino" и переранжировать iGaming-аффилиатов с десятилетней историей!🤣
Серпы — это мусор, и пока одни будут на это жаловаться, я всегда скажу, что это ваша возможность...
Больше скринов здесь.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
28 October 2025 11:15
как превратить бесплатный скрейпер инстаграма в saas за $12k/месяц за 3 часа с помощью claude code
(вот точный пошаговый план)
пока все заморачиваются на тему "как построить saas", я провернул это уже 7 раз
схема до тупого простая, если знать последовательность
большинство людей сидят на золотых жилах и даже не догадываются об этом
вот тот самый сок, который все скрывают:
шаг 1: идем на github, ищем свою золотую жилу
ищем "instagram-scraper python" или "tiktok-scraper nodejs"
смотрите репозитории с 1k+ звезд и недавними коммитами
выбирайте тот, который решает реальную бизнес-задачу
(это занимает максимум 15 минут)
шаг 2: claude code становится вашим технарем-кофаундером
загружаете библиотеку в claude code
что спросить: "оберни эту скрейпинг-библиотеку в fastapi rest api с правильной обработкой ошибок, ограничением скорости и аутентификацией"
требуйте конкретные эндпоинты и полную документацию openapi
(claude делает 90% всей геморной работы)
шаг 3: готовим к продакшену
говорим claude: "создай сетап docker-контейнера со скриптами для деплоя"
добавьте мониторинг, логирование и документацию
этот шаг отделяет любителей от профи
шаг 4: собираем фронтенд за минуты
берете ваш openapi.yaml и идете в v0, bolt или lovable
промпт: "собери saas-дашборд с аутентификацией юзеров, аналитикой и интеграцией stripe"
включите всю спецификацию вашего api в промпт
шаг 5: деплоим и монетизируем
- api на railway ($5/месяц) - фронтенд на vercel (бесплатно) - stripe для платежей
теперь у вас есть готовый saas
я был ровно на вашем месте
смотрел на успешные тулы и думал: "какого черта, как они это делают"?
правда в том, что это больше не сложная инженерия
это знание правильных инструментов и правильной последовательности
вы могли бы начать это сегодня, пока другие все еще задаются вопросом "как люди зарабатывают в интернете"?
чит-код все это время был у вас под носом
большинство просто не знают, где искать
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
27 October 2025 15:05
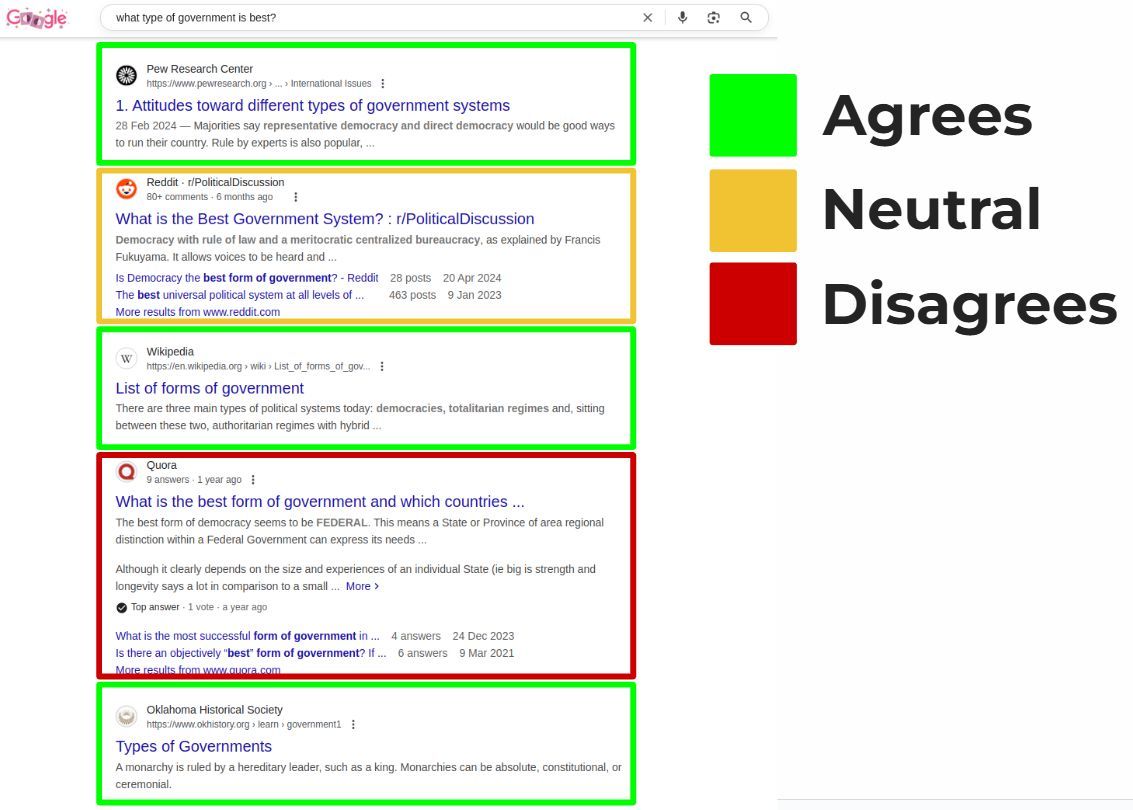
Есть распространенное заблуждение: раз уж Гугл пытается оценить "консенсус", то для ранжирования нужно соглашаться с этим консенсусом.
Но это не всегда так!⤵️
Существует множество поисковых запросов, на которые нет объективно "правильного" ответа, и поэтому Гугл может стремиться собрать в выдаче разные точки зрения.🚦
В некоторых случаях это может быть причиной, почему вы не ранжируетесь.
Если вы создали контент, который "согласен с консенсусом", а ваш клиент спрашивает: "Почему мы не в топе, наш контент по всем параметрам лучше, чем у тех, кто на 2-й и 4-й позициях"?
— это может быть правдой, но Гугл специально хочет видеть на этом месте нейтральные или несогласные с общим мнением документы.☝️
Дело не в том, что ваш контент плох, он просто не вписывается в "рецепт" того блюда, которое Гугл пытается приготовить!👨🍳
Природа обучающих данных для LLM означает, что они также являются отличными инструментами для определения того, совпадает ли страница с консенсусом других документов в сети.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
27 October 2025 11:15
Гугл наказывает за переоптимизацию жестче, чем за недооптимизацию
Анализ 1000 страниц в топ-1 показал среднюю плотность ключевых слов 0,3%, — говорит Ноэль Сета.
У страниц на 11-20 позициях она уже 1,8%.
Сайты, которые больше всех упарываются по ранжированию, получают по шапке.
SEO в 2025 году работает шиворот-навыворот.
Это подтверждают данные за полгода по 500 ключам.
При снижении плотности ключей 67% страниц улучшили позиции, 41% ворвались в топ-3, а средний скачок составил восемь позиций.
При увеличении — 71% просели, 23% вылетели с первой страницы, а 12% словили ручник.
Реальный кейс, сломавший мне мозг: сантехники из Остина.
Их старый тайтл "Best Austin Plumber | Plumbing Services Austin TX | Austin Plumbing Company" держал их на 12-й позиции.
Я сменил его на "We Fix Pipes in Austin When Others Can't", и они взлетели на 2-е место.
Убрали ключ — и стали по нему ранжироваться.
Гугл перевернул игру: его ИИ не нужны 47 повторов "dog food" для понимания темы.
В 2010 ключи означали релевантность, к 2020-му стали спамом.
Сегодня побеждает естественный язык, и Гугл ждет человеческой речи.
Новая оптимизация — не пихать ключ в каждый H2, не целиться в 2% плотности и не спамить вариациями в альтах и урлах.
Пишите, как говорите, используйте синонимы, фокусируйтесь на сущностях и отвечайте на вопрос.
Забейте на плотность ключей.
У сайтов, летящих в трубу, тайтлы вроде "Best [keyword] in [city] | [Keyword] Services | [City] [Keyword] Company".
Они кричат: "Я ОПТИМИЗИРОВАН"!, а Гугл отвечает: "Именно.
Держи 45-ю позицию".
Это революция entity-SEO.
Перестаньте думать ключами — думайте темами.
Не впихивайте "pizza New York" 20 раз, а упомяните "Joe's Pizza", "brick oven", "Brooklyn style", "24-hour delivery" и обсудите "thin crust vs deep dish".
Гугл теперь понимает контекст.
Тесты подтверждают: "идеально оптимизированная" страница A с 31 упоминанием ключа месяцами висела на 8-12 позициях.
Страница B с естественным текстом и тремя ключами взлетела на 3-ю позицию за две недели.
После вычистки ключей со страницы A она поднялась на 2-е место.
Вспомните Википедию: она редко "оптимизируется" под ключи, но ранжируется в топ-1, потому что комплексно раскрывает темы.
На ее фоне ваша "SEO-оптимизированная" страница — спам.
Инструменты вроде Yoast, SurferSEO и Page Optimizer Pro врут: их советы добавлять ключи ведут в алгоритмическую тюрьму, ведь они оптимизируют под Гугл 2015 года.
Сейчас работает так: вступление без ключа, естественное использование в середине и отсутствие в конце.
Дело в поведенческих факторах.
На переоптимизированных страницах показатель отказов 68% (время на странице 1:32), а на естественных — 41% (3:47).
Переспам ключами заставляет юзеров валить, а Гугл это пасет.
Для клиента-юрфирмы мы убрали 70% ключей, вычистили геоспам и переписали текст на разговорный.
Трафик сначала просел на 20% (вызвав панику), но к третьему месяцу вырос на 180%, а к шестому — на 340%.
Дело и в детекторах ИИ-контента.
Переспамленные страницы триггерят их, даже если написаны человеком, ведь набивка ключами — по сути роботизированный текст.
Вы пишете как машина, и Гугл это сечет.
Как пофиксить переоптимизированный сайт: выгрузите топ-20 страниц, посчитайте упоминания ключа.
Если их больше 10 — страница переспамлена.
Перепишите ее, сфокусировавшись на теме, удалив лишние ключи и сделав текст разговорным.
Затем ждите 30 дней и смотрите, как позиции попрут вверх.
Ощущается как дичь, но делайте.
Будущее уже здесь.
SGE, голосовой поиск и фичерд сниппеты заточены под естественный язык.
Сайты, пичкающие текст ключами, оптимизируются под Гугл, которого больше нет.
Новая стратегия — перестать так сильно упарываться.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
26 October 2025 13:05
Первая неделя в @ — в ленте.
Пока вы думали, стоит ли оно того, первые 50+ подписчиков PRO-канала уже получили и внедряют вещи, которые дают реальное преимущество в SEO.
Вот что вы упустили в PRO:
1. Один мета-тег как противоядие от ручных санкций Google за "опасный контент". Снимаем "ручник" в самых серых и прибыльных нишах.
2. Как перехватить поисковый трафик чужих Facebook-групп прямо из выдачи, обогнав сам Facebook по его же брендовым запросам.
3. Черный эксплойт с сайтмапом для принудительной индексации *любых* внешних ссылок, которые вы не контролируете.
4. Как манипулировать AI Overview так же легко, как SEO в 2005-м, используя уязвимость на чужих трастовых сайтах.
5. Живой эксперимент на $10,000+: 100+ сеошников в реальном времени выясняют, что на самом деле двигает позиции в 2025 году.
6. Клоакинг-схема, которая делает ваш ссылочный профиль полностью невидимым для Ahrefs и конкурентов после смерти оператора cache:.
7. "Отравленный каноникал" — доказанный вектор негативного SEO, который обрушивает позиции конкурента, создавая токсичные ассоциации в глазах Google.
8. Что на самом деле скрывают логи вашего сервера, чего никогда не покажет GSC. Как понять, что Google *действительно* делает на вашем сайте.
9. Два железных правила on-page: как писать для машин, чтобы улучшить релевантность и снизить "стоимость обработки" для Google.
10. Как страница может ранжироваться по ключу, которого нет нигде онпейдж Полевой тест, который опровергает заявления Google.
11. Кейс: как смена URL с 5 папок до нуля принесла +44% трафика без единой новой ссылки или строчки контента, и почему 80% сайтов боятся это сделать.
—-
Каждый пост — концентрат, который экономит вам десятки часов ресерча.
Такие темы долго не живут. Их выжигают. И цена подписки скоро вырастет.
Фиксируйте доступ, пока не поздно, или готовьтесь догонять тех, кто уже внутри.
Читать полностью…
Mike Blazer
25 October 2025 13:10
FB заблочил чей-то личный аккаунт, но этот акк является единственным администратором их бизнес-страницы, и рекламные кампании продолжают работать, в то время как Meta снимает деньги с их счета...
@
Читать полностью…
Mike Blazer
24 October 2025 17:05
Парень берет больничный, чтобы пойти на собеседование, и встречает своего начальника в качестве члена комиссии...
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
24 October 2025 11:05
Непопулярное мнение: "Cheap" — это не плохое слово.
Это хорошее SEO.
Сеошникам нужен был трафик.
Бренд-команде — тональность.
И только одна из команд слушала клиента.
"Мы не можем использовать слово cheap.
Оно обесценивает бренд".
Так сказала команда бренда.
Но у сеошников были данные:
12 000 поисковых запросов в месяц по "cheap air purifiers under 5k".
Не "budget-friendly".
Не "affordable".
Просто.
Cheap.
Вот что вам нужно знать: ➜ Гуглу плевать на бренд-гайды.
➜ Клиенты не ищут в стилистике вашего бренда.
➜ Они ищут решения своими собственными словами.
Каждый раз, когда вы затыкаете SEO в угоду "элегантности бренда", вы не имидж спасаете, а херите охват, выручку и релевантность.
🔧 Как пофиксить:
Позвольте SEO рулить видимостью.
Позвольте бренду рулить доверием.
Победа в балансе, а не в битве.
Так что 👉 вы за Team SEO или за Team Brand?
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 17:05
Может все-таки настало время снова качать форумы?
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 11:05
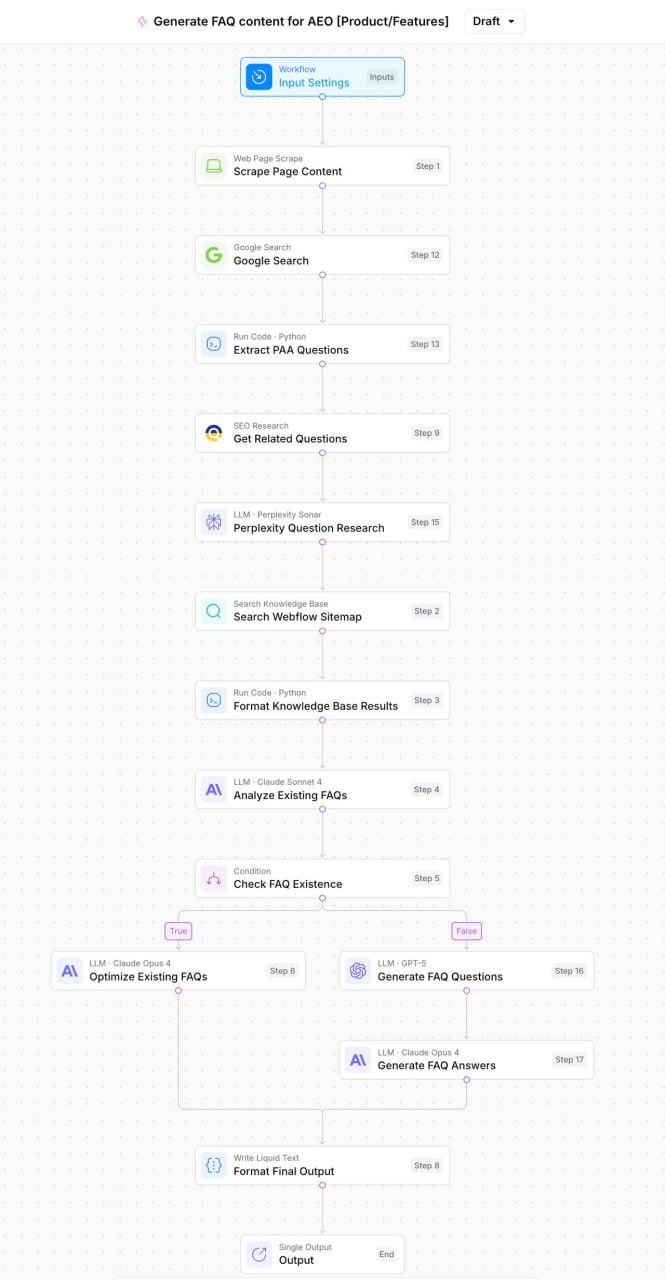
Кейс Webflow: +24% к показам в SEO за счет автоматизации FAQ и микроразметки
Эксперимент по добавлению автоматизированного воркфлоу для FAQ и микроразметки Schema на шесть ключевых страниц Webflow (Design, CMS, SEO, Shared Libraries, Interactions, Hosting) дал серьезный буст перфомансу.
Воркфлоу на базе ИИ, собранный в AirOps, использовал Perplexity для рисерча вопросов юзеров из гугловского "People Also Ask", Reddit и профильных форумов.
Процесс состоял из четырех шагов:
1. Анализ существующего контента в FAQ, чтобы найти гэпы.
2. Генерация финального списка релевантнтых вопросов с высоким интентом.
3. Создание новых ответов в стилистике бренда, заточенных под конкретный продукт.
4. Автоматическое структурирование контента в чистую микроразметку Schema.
Результаты:
— +331 новое AI-цитирование (57% всех новых цитирований на Webflow.com)
— +149 тыс. SEO-показов (+24% по сравнению с предыдущим периодом)
— Рост видимости почти по всем отслеживаемым запросам
Успех стратегии — в том, что мы отвечали на вопросы, которые юзеры активно ищут, и структурировали контент как для поисковиков, так и для answer engines.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 18:49
Браузер OpenAI Atlas идентифицирует себя как Googlebot для каждого запроса.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 13:10
Как напичкать e-comm страницы контентом, который увидят только краулеры
Многие сеошники думают, что для добавления контента на страницы категорий нужно сходить с ума и писать полотна повторяющегося текста про безопасность, но этого делать не нужно, раскрывает секрет Тед Кубайтис.
Вместо этого можно сделать количество отображаемых товаров на странице прямым рычагом для увеличения уникального текста.
Фишка в том, чтобы встроить короткие описания продуктов из вашей CMS в исходный код для каждого товара в листинге.
Можно разместить этот текст внутри скрытого div, который появляется только при наведении, или просто засунуть его в атрибут title для ссылки каждого продукта.
Если вы добавите короткие описания в исходный код для всех товаров на странице категории, это уже куча текста.
Более агрессивный вариант — загружать полный HTML для большого количества продуктов (скажем, 100) при первоначальной загрузке страницы, но использовать lazy loading на уровне отображения, чтобы показывать их по мере скролла.
Это отдает весь контент Гуглоботу сразу, сохраняя при этом хороший UX для покупателей.
Похоже на сероватую технику с каруселью, где страница визуально показывает четыре товара, но в исходном коде их 100.
Сделав так, ваше SEO для страниц категорий сводится к простому изменению числа отображаемых товаров.
Больше товаров — больше SEO.
Внезапно у вас появляется 50 или 100 уникальных коротких описаний, названий продуктов и всех сопутствующих сущностей и LSI, что дико раскачивает некогда тощую страницу.
Это простой, белый метод, который творит чудеса.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
22 October 2025 08:15
Порог правок страницы, который триггерит алгоритмическую пессимизацию
Быстро вносить онпейдж-изменения — затягивающий процесс, но есть серьезный риск, что это выйдет боком.
Мы видели, что чрезмерное количество правок на одной странице может вызвать специфические алгоритмические санкции, предупреждает Ли Витчер.
Существует порог, после которого Гугл пессимизирует страницу — закинет ее на позицию типа 57-й — и будет держать там, пока она не "стабилизируется" и ей снова можно будет доверять.
Алгоритму не нравится постоянно краулить страницу, которая находится в состоянии непрерывных изменений.
Чтобы этого избежать, нужна дисциплина.
После внесения онпейдж-изменений оставьте страницу в покое как минимум на две недели.
Эта проблема касается не только мелких правок; постоянная смена основной темы URL — это верный способ нарваться на санкции.
Классический пример — e-commerce сайт, который использовал одну и ту же страницу "specials" для разных праздников: Пасхи, потом Дня матери, потом Четвертого июля.
Из-за постоянной смены товаров и темы этот URL перестал ранжироваться вообще по чему-либо.
Он был полностью убит.
Если вы обнаружили, что страница попала под санкции за нестабильность, есть способ из этого выбраться.
Исторически успешной тактикой является перенос контента на новый URL и установка 301 редиректа со страницы под санкциями на новую.
Это может сбросить счетчик правок и флаги санкций, давая вам свежий старт ценой потери примерно 15% авторитета, которая связана с редиректом.
@
Читать полностью…
Mike Blazer
29 October 2025 13:05
Настоящий футпринт PBN — в вашем кошельке, а не в записях WHOIS
Не стоит особо париться из-за того, что ваше имя фигурирует как владелец десятков доменов.
Это не странно и не редкость, когда один человек владеет 10, 50 или даже 100 доменами, так что регистрационные данные — не критичная проблема.
Самый большой и палевный футпринт — это процесс покупки этих активов, предупреждает Крис Палмер.
Хотя такие футпринты, как разные хостинги, темы и плагины, легко менеджить, способ оплаты — это настоящий операционный гемор.
Ключевой сигнал — это метод покупки.
Подумайте: сколько у вас разных бизнес-кредиток, которые не привязаны к одному юрлицу или имени?
Можно попробовать использовать пополняемые карты, но вы просто создаете себе постоянную головную боль, и процесс быстро становится неуправляемым.
Это особенно актуально, когда вы имеете дело с крупной сеткой.
В моем случае, с более чем 2600 сайтами, поддерживать уникальные методы оплаты для каждого домена и хостинг-аккаунта было бы невозможно.
Финансовый след, создаваемый использованием одной и той же карты, — это гораздо больший футпринт, который сложнее спрятать, чем любая публичная информация в WHOIS.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
28 October 2025 13:05
Страж на базе Claude для мониторинга технического SEO с высокими ставками
Как сеошник, я использую как минимум десять разных инструментов для мониторинга клиентских сайтов — Little Warden для ежедневных проверок, Google Alerts для упоминаний и VisualPing для отслеживания изменений на страницах, — что создает кучу шума в моем инбоксе, — делится деталями Иан Лурье.
Чтобы справиться с этим, я создал кастомную автоматизацию с использованием интеграции Claude с Gmail, которая работает как очень эффективная система технического мониторинга.
Это практическое применение ИИ как инструмента, который добавляет еще одну пару глаз для автоматизации тасок и подсвечивания критически важных данных.
Я настроил в Claude определенный набор правил, который указывает ИИ получать доступ к моему ящику Gmail, парсить все входящие письма с оповещениями от этих различных инструментов и синтезировать результаты.
На основе моих заранее определенных приоритетов система генерирует быструю сводку только самых срочных проблем, требующих немедленного вмешательства.
Эта система бесценна для отлова проблем, которые иначе могли бы затеряться.
Например, недавно она обнаружила критическую проблему: robots.txt одного клиента неправильно возвращал HTML вместо обычного текста.
Это серьезная проблема с потенциально серьезными последствиями для краулинга, но поскольку ИИ пометил ее как высокоприоритетную, она была подсвечена немедленно, а не потерялась в потоке рутинных уведомлений.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
28 October 2025 08:15
Пропустили Google Search Central Live в Дубае?
Ключевые выводы для всех, кто хочет подготовить свою SEO-стратегию к будущему:
— Структурированные данные — это уже не опция, а фундамент для фич поиска нового поколения.
— Фокусируйтесь на кликах и конверсиях, а не только на показах.
— Обходы Гуглобота теперь питают ИИ-системы вроде Gemini.
— Забудьте про LLMs.txt — Гугл и другие ИИ-системы его не используют.
— Изображения и видео важны — оптимизируйте их с помощью альт-текста, сжатия, транскриптов и микроразметки.
— Для лучшей видимости видео всегда размещайте их на отдельных страницах-плеерах.
— Рендеринг на стороне сервера лучше рендеринга на стороне клиента.
— Структура DOM критически важна для сайтов с большим количеством JavaScript.
— Гугл определяет язык вашей страницы по видимому контенту, а не по URL или hreflang.
— Основной контент — король.
Размещайте ключевой контент в основной части страницы, а не в хедерах или сайдбарах.
— Избегайте "мягких" `404`х ошибок — страницы с тонким контентом могут впустую тратить краулинговый бюджет и снижать эффективность индексации.
— Семантический `HTML` (<main>, <article>, <section>, <header>, <footer>, <nav>, <aside>) проясняет структуру страницы и выделяет важный контент.
— Сигналы локального SEO имеют значение: ccTLD, hreflang, расположение сервера, местный язык, валюта, региональные ссылки и Гугл Бизнес-Профиль помогают таргетироваться на нужную аудиторию.
— Поведение пользователей в поиске меняется: запросы становятся длиннее, а поколение Z все чаще использует поиск на базе ИИ, такой как голосовой поиск, Lens и поиск по картинкам.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
27 October 2025 13:05
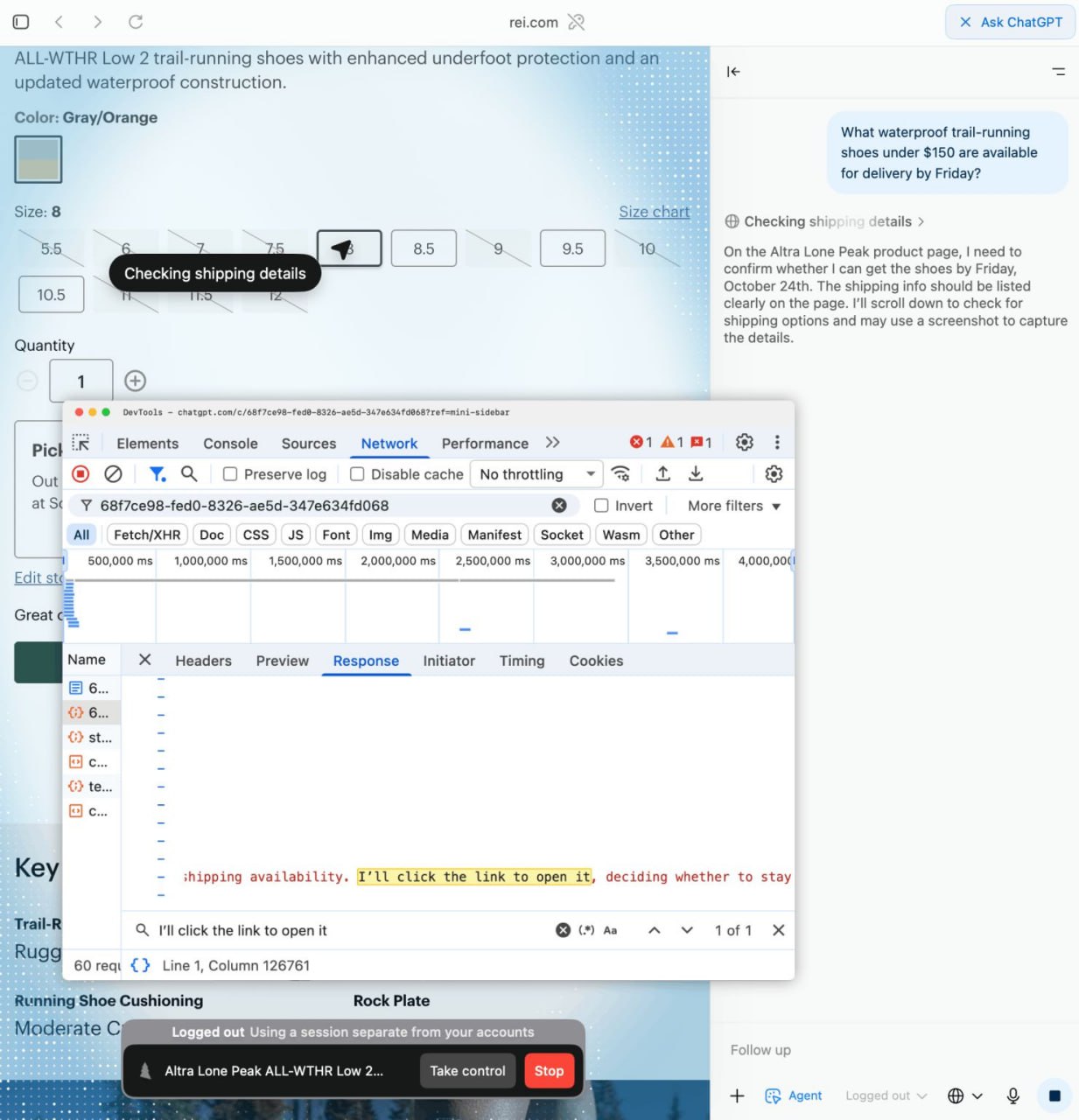
Я провел некоторое время, анализируя сетевые логи нового браузера Atlas от OpenAI, и там есть фундаментальный технический сдвиг, который маркетологам необходимо понять, пишет Джош Блискал:
Сначала основы: Atlas — это браузер, где ChatGPT является интерфейсом по умолчанию.
Он создан для того, чтобы напрямую отвечать на вопросы и выполнять задачи, не обязательно отправляя вас по URL-адресу.
Теперь о стратегии: первая реакция большинства маркетологов будет в духе "это просто означает меньше кликов".
Я думаю, это упускает из виду настоящую суть, которую можно увидеть только в логах.
Разница не только в том, что Atlas возвращает, но и в том, как он получает ответ.
Классический ChatGPT работает как прокачанный поисковик.
Он выполняет серию запросов, парсит сниппеты и суммирует их.
Он полностью зависит от того, что уже проиндексировал поисковый краулер.
Atlas — это принципиально другая машина.
Это агент, который может видеть и взаимодействовать со всем (даже с JS).
Он выполняет клики в DOM по селекторам размеров, закрывает модальные окна и прокручивает динамические сетки товаров.
Он взаимодействует с "живым", отрендеренным через JavaScript фронтендом.
Но я думаю, дело не только в Atlas.
Это явный предвестник того, куда движется Google AI Mode, и взгляд в будущее СЕРПа: во главе будет чат, а синие ссылки станут второстепенной информацией.
Распространенность самого Atlas не имеет значения, потому что это начало эры "chat-first" браузинга и "взаимодействия с агентами" (agent experience) как целого нового столпа веба.
Победа в этой новой среде будет зависеть от готовности к взаимодействию с агентами:
Подумайте, как Atlas обрабатывает запрос вроде "waterproof trail shoes under $150 delivered by Friday".
Он не сидит и не сопоставляет ключевые слова, он выполняет задачу на вашем "живом" сайте.
Если ваш JavaScript медленный или процесс оформления заказа неудобный, агент потерпит неудачу.
Будем честны: у большинства брендов фронтенд — это каша из JavaScript и корявых пользовательских сценариев, многие сайты непреднамеренно заблокируют бота Atlas, а их дизайн оптимизирован для людей, которые знают, как пользоваться вебом, а не для нетерпеливого агента.
В этом и заключается вся возможность.
Преимущество получат компании, которые выполнят негламурную работу по созданию быстрых, чистых и доступных для скриптов сайтов.
Вот стратегии, за которыми я буду следить:
— Оптимизация под юзабилити для агентов, а не только под индексируемость для краулеров.
Это тот момент, когда быстрый, доступный для скриптов, рендерящийся на стороне клиента фронтенд становится серьезным конкурентным преимуществом.
— Отношение к вашему сайту как к API для агентов.
Каждый интерактивный элемент — это узкое место, которое должно быть быстрым и надежным.
— Удвоенное внимание к структурированным данным.
Микроразметка станет источником истины, который агент сможет использовать для проверки информации, найденной на вашем "живом" сайте.
В своей основе, это переход от оптимизации для обнаружения (discovery) к оптимизации для действия (action).
Игра уже не в том, чтобы тебя просто нашли, а в том, чтобы тобой мог воспользоваться ИИ.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
27 October 2025 08:15
Большинство сеошников скипают одну из самых простых для манипуляций фич серпа: сайтлинки Google
Это не просто "дополнительные ссылки под вашей мордой". Это:
👉 Бесплатное место под бренд в выдаче
👉 Бустеры CTR (12.9% кликов уходит на сайтлинки, а не на главную)
👉 ORM-защита от отзывов/форумов
👉 Сигналы авторитетности, которые кричат "это крупный бренд"
Главная фишка?
Вы можете пропихнуть нужные страницы… и выпилить те, что не нужны.
Ключевое наблюдение: структурированные данные для окна поиска в сайтлинках устарели в октябре 2024. Небрендовые сайтлинки показываются реже.
Апдейты после 2024 года отдают предпочтение авторитетным сайтам (DR40+) для сайтлинков, в то время как на неанглоязычные серпы влиять по-прежнему проще.
Факторы влияния:
— Архитектура сайта: Четкая иерархия и хлебные крошки критически важны. Плоские структуры пессимизируются.
— Внутренняя перелинковка: Консистентность анкоров для целевых страниц (в навигации, футере, контексте) — это основной сигнал. Оглавления с #якорями часто триггерят однострочные сайтлинки.
— Брендовый поисковый спрос: Google подсвечивает страницы, которые юзеры ищут вместе с вашим брендом (например, [brand] pricing, [brand] login). Этот спрос можно создавать искусственно через рекламу и PR.
— Геотаргетинг: Теги hreflang влияют на то, какие сайтлинки появляются в серпах для конкретных стран.
Плейбук: как пропихнуть / выпилить конкретные сайтлинки
Чтобы пропихнуть страницы:
— Анкоры: Долбите целевые страницы консистентными внутренними анкорами ("Цены", "Функции").
— Внешние ссылки: Стройте ссылки прямо на урлы, которые хотите видеть в сайтлинках.
— Манипуляция CTR: Лейте клики на запросы [brand] + [page name], чтобы подтолкнуть Google к нужному выбору.
Чтобы выпилить страницы:
— `noindex`: Самый прямой метод убрать страницу из сайтлинков.
— `301 редирект`: Редиректите мусорные страницы на более сильные, нужные урлы.
— Внутренние ссылки: Измените или удалите внутренние анкоры, ведущие на нежелательную страницу.
— ORM: Используйте страницы-приманки ("Карьера", "Контакты"), чтобы занять слоты и вытеснить негативные результаты.
https://presswhizz.com/blog/sitelinks/
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
26 October 2025 09:05
Экономика скама на $500 млн, построенная на фейковой SEO-математике
Domain Rating (DR) — это выдуманная пузомерка, на которой держится скам-экономика в $500 млн/год.
Я видел, как кто-то накрутил свой DR с 0 до 70 за 30 дней, потратив $500, и теперь продает гестпосты по $1000 за штуку, — говорит Ноэль Сета.
Вся экономика ссылок построена на фейковой математике.
Вот схема накрутки DR за $500, которую я наблюдал.
День первый: куплен свежий домен за $10.
Со второго по пятый день: куплено 50 дроп-доменов с высоким DR за $200.
С шестого по десятый: все они `301`м редиректом направлены на основной домен.
Затем куплено 100 ссылок с форумов на `Fiverr` за $100 и создано 200 профилей Web 2.0 еще за $100.
К 30-му дню DR взлетел с 0 до 70.
Этот сайт теперь берет $1000 за гестпост, $500 за ссылки с главной и $2000 за "редакционное" размещение.
У них 20-30 заказов в месяц, что составляет около $40 тыс.
в месяц с метрики, которая ничего не значит для реального ранжирования.
Покупатели думают, что получают "авторитет".
Я отслеживал 1000 сайтов в течение шести месяцев, и доказательства того, что DR — пустышка, очевидны.
В 38% поисковых выдач сайты с DR 20 обгоняли сайты с DR 80.
В 44% запросов сайты с DR 50 проигрывали сайтам с DR 10.
Новые сайты с DR 0 занимали топ-1 в 23% ниш.
Корреляция с позициями составила 0.31 — по сути, рандом.
Так почему индустрия молится на фейковую метрику?
Агентствам нужно что-то продавать.
"Мы поднимем ваши позиции" — это расплывчато, а "Мы поднимем ваш DR с 30 до 50" — измеримо.
Клиенты не знают, что это бессмысленно, а агентствам все равно.
Спектакль продолжается.
Мафия линкселлеров это обожает.
Сайт А рекламирует: "DR 70, ссылки $800".
Сайт Б предлагает: "DR 65, ссылки $600".
Сайт В обещает: "DR 80, ссылки $1200".
Все они накручены одинаково, все бесполезны для SEO и все гребут $50 тыс.+ в месяц.
Это взаимное заблуждение, в поддержании которого все заинтересованы.
Что на самом деле имеет значение для ранжирования, так это не DR, DA или AS.
Это релевантность вашей нише, реальный органический трафик, редакционные стандарты, естественный ссылочный профиль и тематический авторитет.
Нишевый сайт с DR 20 всегда уделает Forbes с DR 90 по релевантным ключам.
Неудобная правда для SEO-агентств заключается в том, что вся ваша бизнес-модель опирается на метрику, которую Гугл не использует, которую можно накрутить за $500, которая не коррелирует с позициями и которую клиенты не понимают.
Вы продаете астрологию под видом науки, и все это знают.
Этот скам никогда не умрет, потому что покупателям нужны метрики для оправдания бюджетов, продавцам нужны метрики для оправдания цен, инструментам нужны метрики для продажи подписок, а агентствам нужны метрики, чтобы показывать "прогресс".
Все выигрывают от этой лжи, кроме тех, кто за нее платит.
Самое безумное то, что в Ahrefs знают об этом.
Они могли бы пофиксить это завтра, добавив ручные проверки, отслеживая редиректы и помечая подозрительные паттерны.
Они этого не делают, потому что вся ценность их инструмента зависит от того, насколько людям важен DR.
Если DR умрет, их главное преимущество испарится.
Тот "SEO-пакет за $50 тыс"., который обещает поднять ваш DR?
Они покупают те же мусорные ссылки, которые любой может достать за $500.
Та "возможность гестпоста на сайте с DR80"?
Это шестимесячный сайт с нулевым реальным трафиком.
Вы покупаете не авторитет, вы покупаете выдуманные интернет-очки.
Король-то голый, но империя стоит $500 млн в год.
Так что шоу продолжается.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
25 October 2025 09:15
URL-центричная модель SEO устарела.
Программные агенты, составляющие значительную часть веб-трафика, воспринимают URL не как страницы, а как контейнеры для машиночитаемых утверждений.
Современные системы обнаружения контента, включая поисковые системы и LLM, отдают приоритет этим утверждениям и их сетевым связям, а не самой странице.
Эти системы разбивают страницы на отдельные утверждения, часто в виде триплетов "субъект → предикат → объект".
Поисковые системы хранят их как символические факты в графах знаний, в то время как LLM кодируют их в многомерных векторных пространствах.
Теперь основной единицей для оптимизации является утверждение, и задача SEO — обеспечить его четкость и связность.
Машинное доверие основывается на контексте утверждения в информационном графе, а не на самом по себе изолированном заявлении.
Поисковые системы оценивают явные сигналы, такие как ссылки и микроразметка, в то время как LLM используют статистические закономерности.
Авторитетность возникает из согласованности и подтверждения утверждения по всему интернету, включая сторонние ресурсы и сайты конкурентов.
Бренды должны защищать свои утверждения от "враждебного корпуса" — дезинформации, созданной для того, чтобы загрязнять модели данных.
Принцип "писать для людей" неполон.
Контент также должен быть спроектирован для машинной интерпретации.
И эта работа выходит за рамки schema.org и требует фундаментальной структурной четкости.
Использование семантического HTML и последовательных паттернов данных создает понятную структуру, которую машины могут надежно кодировать.
Стратегия должна сместиться с оптимизации страниц на создание сети надежных утверждений, которые будут служить доверенными узлами в моделях веба, построенных машинами.
Авторитетность рождается из графа, а не из страницы.
Тактики для оптимизации графа
— Избегайте спама утверждениями: не публикуйте противоречивые или низкокачественные заявления; эта стратегия перестает работать по мере развития моделей.
— Проектируйте страницы как наборы утверждений: используйте четкие, повторяющиеся паттерны для ключевых данных, таких как цены и характеристики, вместо того чтобы прятать их в сплошном тексте.
— Подкрепляйте утверждения во всех источниках: обеспечивайте их согласованность на маркетплейсах, партнерских сайтах, в Википедии и на других платформах.
— Структурируйте контент для машинного обучения: используйте семантический HTML и добавляйте избыточный контекст, чтобы помочь машинам идентифицировать ключевые утверждения.
— Публикуйте машиночитаемые эндпоинты: предоставляйте данные напрямую через API, чистые фиды или структурированные файлы (JSON, XML), минуя парсинг.
— Отслеживайте "враждебный корпус": отслеживайте дезинформацию и противодействуйте ей с помощью сильных, подкрепленных фактами утверждений на доверенных ресурсах.
— Используйте внешние подтверждения: поощряйте цитирования и отзывы на авторитетных сайтах, поскольку машины придают большой вес внешним подтверждениям.
https://www.jonoalderson.com/conjecture/url-shaped-web/
@
Читать полностью…
Mike Blazer
24 October 2025 13:10
Новые ИИ-тулзы
@
Читать полностью…
Mike Blazer
24 October 2025 08:15
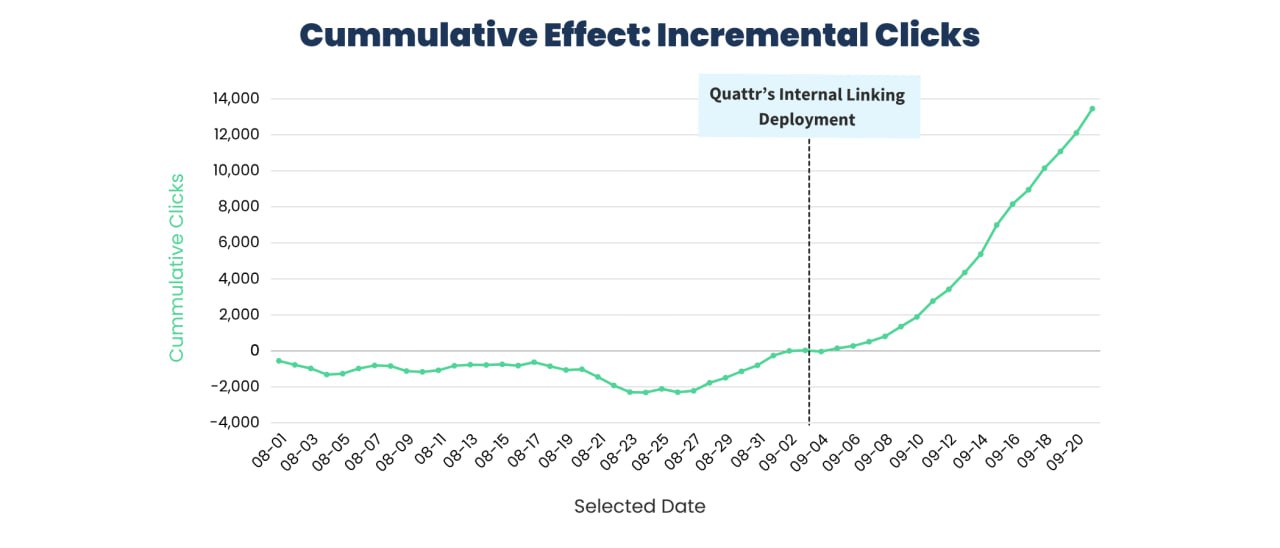
Кейс: Как юридическая платформа может получить +3.5 млн кликов с помощью автономной перелинковки
Юридическая платформа с 10 миллионами программно-сгенерированных страниц использовала Autonomous Linking API от Quattr для решения проблем с ручной и шаблонной перелинковкой.
Для оценки выхлопа для органического трафика провели 30-дневный контролируемый эксперимент на сегменте в 50 000 страниц.
В чем была проблема: не работало масштабирование и релевантность
Из-за огромных масштабов платформы традиционные методы перелинковки не работали.
— Ручная перелинковка: Невозможна для миллионов страниц, когда ежедневно публикуются тысячи новых дел.
— Шаблонные системы: Линковка по атрибутам из БД (юрисдикция, тип дела) не создавала сильных семантических связей. В итоге Гугл плохо понимал авторитет страниц, а позиции стагнировали.
Платформе требовалось автоматизированное решение, понимающее семантическую релевантность и адаптирующееся к новому контенту без постоянного вмешательства разрабов.
Решение: Контролируемый эксперимент с перелинковкой на базе ИИ
Провели контролируемый эксперимент, чтобы доказать причинно-следственную связь и оценить выхлоп.
— Дизайн эксперимента:
— Тестовая группа: ~50 000 страниц дел из Нью-Йорка получили по 10 ИИ-сгенерированных внутренних ссылок.
— Контрольные группы: Страницы из Массачусетса и Флориды без изменений, что позволило изолировать эффект от внешних факторов вроде апдейтов Гугла.
— Источник данных: Ежедневные клики и показы на уровне URL из Google Search Console Bulk Export.
— Технология `API`:
Autonomous Linking API от Quattr работает на двух типах данных:
1. Векторные представления: Анализируют контент страницы для поиска семантических связей. Это круче простого совпадения по ключам, так как система понимает контекстуальную релевантность.
2. Данные из `GSC`: Использует реальные поисковые запросы, приводящие трафик на страницу, для генерации релевантных анкоров на основе спроса.
Подтвержденные результаты
Тестовая группа сразу показала статистически значимый рост относительно контрольных групп.
— Неделя 1: Рост органических кликов на +12%.
— Эффект за 28 дней (с поправкой на контрольную группу):
— Прирост ежедневных кликов на +15.1% по сравнению со страницами из Нью-Йорка, которые не трогали (+580 кликов/день).
— Прирост ежедневных кликов на +19.4% по сравнению с контрольными штатами (Флорида и Массачусетс) (+748 кликов/день).
— Общий прирост за пилот: +13 400 дополнительных органических кликов за 28 дней.
— Влияние на `CTR`: Кликабельность (CTR) выросла на 0,47 п.п. (+5,5%) при тех же показах (-0,7%), что позволило конвертировать существующую видимость в трафик.
— Стабильность перфоманса: Тестовые URL показывали значительно больше "дней с кликами", что указывает на более стабильную и устойчивую производительность.
Прогноз эффекта в масштабах всей платформы
Результаты пилота экстраполировали для оценки потенциального эффекта на весь сайт.
— Исходные данные по платформе: 29.5 млн органических кликов в год.
— Прогнозируемый рост: Применение консервативного показателя роста в 12% ко всей платформе дает потенциальный прирост в +3.5 млн дополнительных органических кликов в год, что составляет почти 300 000 дополнительных кликов в месяц.
https://www.quattr.com/case-studies/legal-intelligence-platform-seo-impact-with-quattr-internal-linking
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 13:10
Как захватить авторитет бренда через ссылку "`Official Site`" в Википедии
Есть прямой метод, как манипулировать восприятием вашего сайта Гуглом и заставить его ранжироваться выше, эксплуатируя страницу бренда в Википедии.
Я видел кейсы, когда можно было поставить свой сайт в раздел "официальный сайт" в статье о бренде на Википедии, и Google соответственно менял свое понимание, рассказывает Корай Тугберк Губюр.
Если вам удастся успешно выдать свой сайт за официальный на этой странице, Google обновляет свой граф знаний и ставит ваш URL прямо в панель знаний бренда, что, в свою очередь, поднимает ваши позиции в обычной поисковой выдаче.
Для целевого бренда бороться с этим невероятно сложно: они не могут контролировать Википедию каждый день, что делает их уязвимыми для такого рода захвата.
Ключ к реализации этой тактики — целиться в неанглоязычные рынки.
В то время как английская версия Википедии жестко регулируется и ее сложно редактировать, в других языках порог входа значительно ниже.
Голландская, испанская или норвежская Википедия, например, гораздо проще поддаются манипуляциям, потому что у них не так много редакторов и нет такого же уровня строгого надзора.
Этот недостаток ресурсов создает очевидную уязвимость, что делает ее отличной возможностью для такого рода манипуляций с авторитетом.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
23 October 2025 08:15
Почему анкорный текст в основной навигации убивает ваши позиции
Гайз, надо завязывать с широкими, общими анкорами типа "earrings" в навигации по всему сайту.
У таких запросов обычно смешанный интент, и пробиться по ним в топ нереально.
Я бы лучше целился в ключ с меньшим трафиком, но с более четким таргетингом.
Поскольку это сквозные ссылки, их нужно заюзать для точного вхождения очень специфичных, длиннохвостых запросов.
Как утверждает Тед Кубайтис, если категория посвящена браслетам с черными бриллиантами, анкор должен быть "black diamond bracelets", чтобы передать по ссылке максимум целевой релевантности.
Это критическая ошибка, которая касается многих стандартных названий в навигации.
Люди ставят анкоры, которые не являются целевыми ключами и не имеют поискового объема.
Вы постоянно видите общие термины вроде "New Arrivals", "Best Sellers" или "Gifts".
Выйти в топ по ключу "new arrivals" само по себе бессмысленно — это могут быть книги, кухонная утварь или что угодно.
Это нецелевой запрос, и победа по нему не даст вам ровным счетом ничего.
Нужно нишеваться.
Вместо "New Arrivals" должно быть "New Jewelry" или "New Gemstone Jewelry".
То же самое касается категории "Gifts".
Если вы победите по ключу "gifts", вы не выиграете ничего.
Это высококонкурентный ключ с нулевым таргетингом, который будет стоить вам целого состояния.
Нужно добавлять тематику и конкретику: "jewelry gifts", "wedding gifts".
Вы должны пройтись по всем ссылкам в основной навигации и воспринимать их буквально.
Если анкор гласит "socks and shoes", вы таргетируете ключ "socks and shoes", а не "socks" и "shoes" по отдельности.
Нужно убедиться, что каждый из них нацелен на ключ с реальным поисковым объемом.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
22 October 2025 15:05
Плейбук "Фрагментация контента" для системного демонтажа авторитетных сайтов
У нас был клиент в крипто-сфере, где сайт типа Forbes доминировал почти во всем, и нам нужно было придумать, как победить огромную компанию с таким авторитетом.
Решением стала техника, которую я называю "Фрагментация контента", и мы использовали ее, чтобы системно их обойти, рассказывает Энди Чедвик.
Стратегия начинается с выбора жирного URL-конкурента в стиле "ultimate guide".
Вы берете эту одну страницу и загоняете ее в Ahrefs, чтобы увидеть каждый ключевик, по которому она ранжируется.
И что вы обнаружите: хотя она может быть на первом месте по своему главному запросу, она часто слабо ранжируется — на седьмой, девятой или даже одиннадцатой позиции — по сотням других длиннохвостых запросов.
Она держит эти позиции только за счет авторитета домена, а не потому, что является лучшим ресурсом по этим конкретным вопросам.
Вот она, уязвимость.
Дальше вы собираете все эти ключевики и прогоняете их через инструмент кластеризации.
Анализируя СЕРПы, тулза группирует запросы и показывает, на сколько именно гипер-сфокусированных страниц можно разбить ту одну статью конкурента.
Вместо того чтобы пытаться обойти Forbes одной статьей, что у вас не выйдет, вы можете обойти их десятью или двадцатью, каждая из которых нацелена на свой специфический кластер запросов.
Это позволяет откусывать их трафик кусок за куском, попутно выстраивая свой собственный тематический хаб.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
22 October 2025 11:05
Используйте логи сервера как оружие, чтобы прибить бесконечные циклы краулинга
Когда вы пытаетесь вычистить бесконечный цикл краулинга на e-commerce сайте, программные ссылки в шаблоне пофиксить легко.
А вот скрытые ссылки в контенте — те, что редакторы вручную вставляли в описания продуктов много лет назад, — вынесут вам мозг, потому что их невозможно найти стандартным поиском.
Для ситуации, которая совсем зашла в тупик, есть быстрый и грязный хак, чтобы отловить их все, делится Тед Кубайтис.
Во-первых, вам нужно полностью изменить проблемную структуру URL.
Например, переименуйте старый путь для поиска с /search на что-то совершенно новое, вроде /find.
Затем вы внедряете общий редирект, который отправляет каждый URL, все еще использующий старый путь /search, на одну-единственную, общую страницу.
Это действие фактически создает ловушку-приманку (honeypot).
Последний шаг — мониторить логи вашего сервера.
Когда краулеры и пользователи будут попадать на старые внутренние ссылки, разбросанные по вашему сайту, они будут пойманы вашим редиректом.
URL-адреса рефереров в ваших веб-логах для каждого хита по этому старому, средирекченному пути теперь дадут вам точный список всех мест, которые вам все еще нужно пофиксить.
Это превращает ваши логи в диагностический инструмент, который точно определяет источник каждой проблемной ссылки, позволяя вам наконец искоренить цикл краулинга.
@
Хотите глубже? Вам в @
Читать полностью…
Mike Blazer
21 October 2025 17:05
Утечка 'UGGDiscussionEffortScore' подтверждает: комьюнити — это измеримый сигнал качества
Хотя многие из слитых сигналов указывают на санкции, были раскрыты и позитивные атрибуты.
Мы увидели прямое подтверждение, что живое, хорошо модерируемое комьюнити на вашей странице — это измеримый положительный сигнал, как говориться в видео Шона Андерсона.
Существование UGGDiscussionEffortScore жестко зашивает этот принцип прямо в системы Гугла.
Этот показатель подтверждает, что активный раздел с пользовательским контентом, например, оживленный тред с комментариями или хорошо управляемый форум, напрямую влияет на то, как система воспринимает ценность вашей страницы.
Ключевой момент — фокус системы на "усилиях" (effort).
Важно не просто наличие комментариев, а качество и живость дискасса.
Гугл фундаментально рассматривает такое глубокое вовлечение пользователей как осязаемый признак качества, делая построение комьюнити неотъемлемой частью ваших технических сигналов качества, а не просто фичей для UX.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}