Mike Blazer
07 November 2025 15:05
Клоакинг на пальцах
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
07 November 2025 11:15
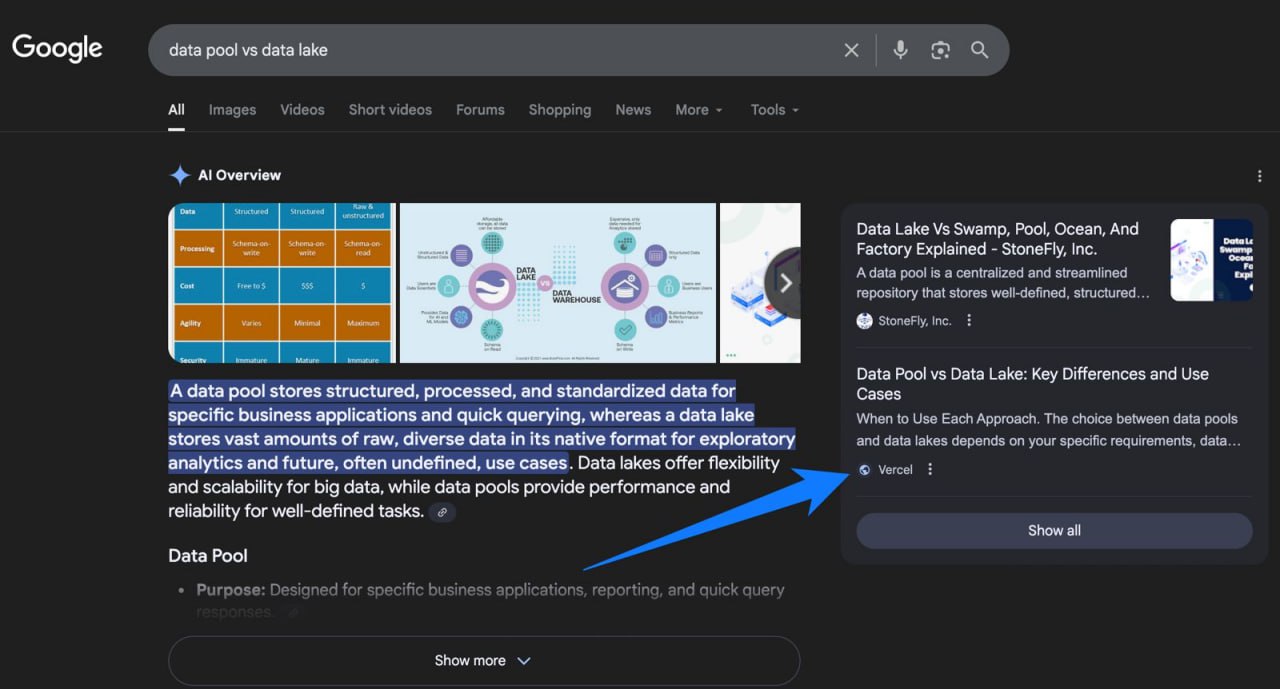
Качество схемы и AI Overviews: прямое сравнение
В контролируемом эксперименте протестировали три страницы — с хорошо внедренной схемой, с плохой схемой и без схемы — чтобы измерить влияние на видимость в Google AI Overview.
Результат: Только страница с хорошо внедренной схемой появилась в AI Overview и достигла самого высокого органического ранга.
Тест показывает, что именно качество схемы является значимым фактором.
Сетап эксперимента
— Страницы: 3 одностраничных сайта, идентичных во всем, кроме микроразметки.
— Ключевики: Подобраны по метрикам (KD: 3, SV: 60, TP: 20).
— "How much does a marketing team cost"
— "What are common elements in the promotional mix"
— "Data pool vs. data lake"
— Контрольные условия: Развернуты на Vercel, без JS, на кастомных доменах, без сайтмапов, robots.txt и каноникалов.
Варианты Schema-разметки
1. Хорошая `Schema`: Полная разметка Article, FAQ и Breadcrumb со всеми обязательными полями, правильным форматом даты и информацией об авторе/издателе.
2. Плохая `Schema`: Неполная разметка Article (отсутствуют поля), нет разметки FAQ при наличии контента в этом формате, нет Breadcrumb, неверный формат даты.
3. Без `Schema`: Структурированные данные не внедрены.
Результаты
— Хорошая `Schema`:
— `AI Overview`: Появился.
— Ранжирование: Пик на 3-й позиции по 6 ключам.
— Плохая `Schema`:
— `AI Overview`: Не появился.
— Ранжирование: Пик на 8-й позиции по 10 ключам.
— Без `Schema`:
— `AI Overview`: Не мог появиться.
— Ранжирование: Не проиндексировалась.
Вывод: Страница с хорошо внедренной schema-разметкой однозначно обошла остальные как по видимости в AI Overview, так и в органическом ранжировании.
Страница "без schema" вообще не попала в индекс.
https://searchengineland.com/schema-ai-overviews-structured-data-visibility-462353
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
06 November 2025 15:05
YouTube экспериментировал с облегченной версией своего сайта.
Под кодовым названием Project Feather.
Она весила меньше одной десятой от обычной версии сайта.
Облегченный медиаконтент.
Урезанные скрипты.
Меньше похожих видео.
Все было урезано.
Но когда они его развернули, показатели производительности ухудшились.
Как могло нечто настолько хорошо оптимизированное...
Что по идее должно было работать быстрее во всех отношениях...
Ухудшить показатели?
Потому что Project Feather сделал YouTube доступным для тех, кто раньше не мог им пользоваться.
Более слабые устройства.
Более слабые сети.
Отдаленные регионы.
Люди, которые никогда раньше не могли пользоваться YouTube...
внезапно смогли.
Да, совокупное время загрузки выросло.
Но история, стоящая за этими цифрами, была победой.
Производительность — это не только улучшение опыта для существующих пользователей.
Она может приводить совершенно новых.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
06 November 2025 11:15
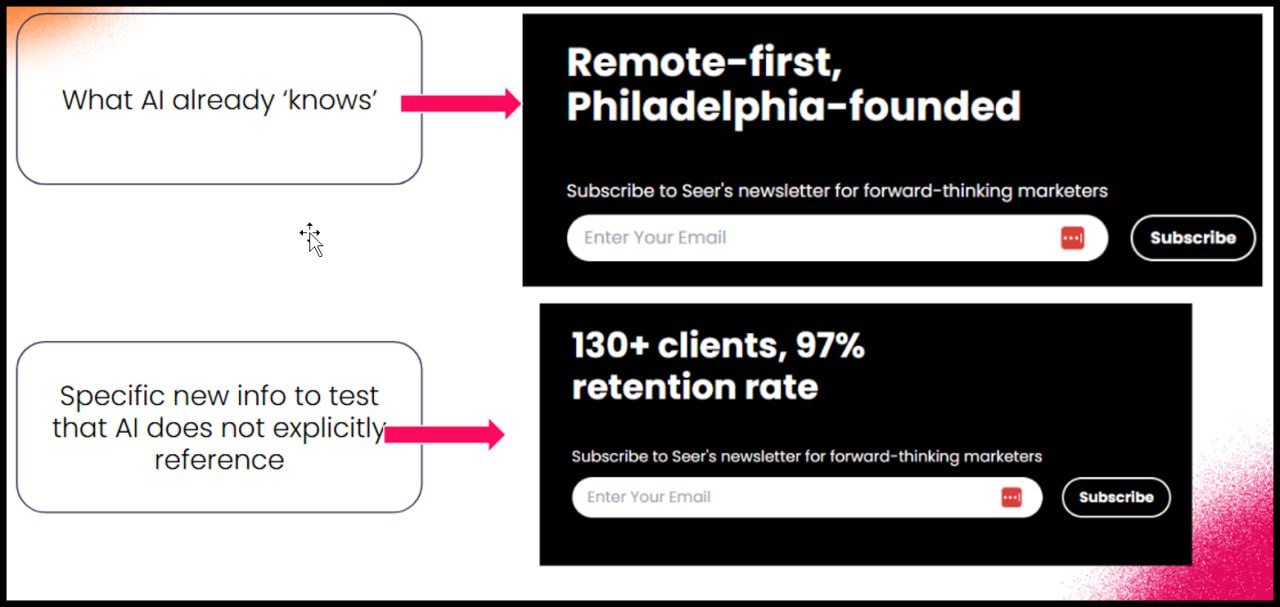
Тест AIO: Футеры снова в деле
Тест от Seer Interactive подтверждает, что частотный, но малозаметный текст — это мощный сигнал для AIO.
Их "качественные" усилия (контент, PR, выступления) перебивались спамом в AI-ответах.
Причина?
AI-модели триггерились на текст "remote first" в их футере.
Они изменили текст в футере, чтобы он отражал ключевые месседжи бренда.
Результат: ChatGPT 5 обновил свою выдачу в течение 36 часов.
Три вывода по AIO:
1. Сквозные блоки на сайте имеют значение. Повторяющиеся элементы, такие как футеры и навигация, — это рычаги с высоким импактом. Используйте их для краткого, стратегического повторения того, чем вы хотите быть известны. Не тратьте это место на воду.
2. Собственные цитирования дают контроль и скорость. Когда AI-модели ссылаются на ваш собственный домен в ответах о вашем бренде, вы контролируете нарратив. Изменения на сайте отражаются быстрее, что дает вам преимущество перед конкурентами, которые полагаются на упоминания на сторонних ресурсах, обновляющиеся медленнее.
3. Синхронизируйте он-пейдж с ключевыми офф-пейдж сигналами. Определите сторонние сайты, которые постоянно влияют на AI-ответы о вашем бренде. Поддерживайте эти внешние цитирования (например, награды, платные листинги) в актуальном состоянии, чтобы усилить ваши месседжи на сайте.
https://www.seerinteractive.com/insights/ai-optimization-test-footers-are-back-like-2003
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
05 November 2025 15:05
Когда ваши дети думают, что очистка истории браузера или использование режима икогнито - работает.
Но родители - гики и используют "ipconfig /displaydns > history.txt", чтобы найти сайты, которые посещали дети, сохраненные в кэше DNS.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
05 November 2025 11:15
Reddit СЕЙЧАС абьюзить ОЧЕНЬ легко.
Мы заюзали его, чтобы сгенерить более $45.5k за 4 недели, всё органика, пишет Джеки Чоу.
Вот вся система (сохраните в закладки):
Шаг 1: Найти треды, которые уже ранжируются в Google
— Ищем "best [your product] site:reddit. com".
— Если тред ранжируется, он уже получает траф — вам просто нужно там появиться.
— 65% поисковых запросов в Google со словом "best" показывают как минимум один тред с Reddit.
Шаг 2: Писать комменты, которые звучат по-человечески, а не корпоративно
— Reddit ненавидит маркетологов. Фишка в том, чтобы смешаться с толпой.
— Пример: "soylent didn't fill me up either. switched to lyfefuel and it's way more satiating. not as chalky".
— Никаких ссылок. Никаких хештегов. Никакой идеальной грамматики.
— Люди апвоутят то, что кажется настоящим.
Шаг 3: Наращивать свои комменты
— Ответьте сами себе с другого аккаунта.
— Сделайте так, чтобы это выглядело как реальный разговор.
— Пример:
"same here, vanilla flavor is 🔥", "+1, keeps me full for hours".
— Это называется наращивание комментов — алгоритм Reddit вознаграждает такие мини-дискуссии.
Шаг 4: Постепенно бустить апвоуты
— 10–25 апвоутов за 48 часов > 100 апвоутов за раз.
— Алгоритм Reddit ценит динамику и правдоподобность.
— Как только ваш коммент попадает в Топ-3, он остается в индексе Google навсегда.
— Это бесплатный трафик с покупательским интентом каждый день.
Шаг 5: Мониторить ранг и удержание
— Если ваш коммент просел, бустаните его снова.
— Если он держится 7+ дней, вы, по сути, получили бесплатный рекламный слот внутри Google.
Вот тут-то и пригодится trackings.ai:
1. Автоматически находит треды.
2. Постит.
3. Накапывает безопасные апвоуты.
4. Отслеживает ранг + выживаемость.
Это как иметь команду по росту на Reddit, которая никогда не спит.
Шаг 6: Перехватывать ранжирование в Google
— Не создавайте новые треды, перехватывайте существующие.
— Ищите то, что уже ранжируется по "best [keyword]", и комментируйте там.
— Используйте их SEO.
— Когда кто-то гуглит "best meal replacement shakes", он прочитает ваш коммент раньше, чем сайт вашего конкурента.
Шаг 7: Контролировать нарратив
— Если в негативном треде упоминается ваш бренд, переверните ситуацию.
— Оставьте 3–5 сбалансированных ответов типа:
"had one issue but support fixed it fast".
— Пробустите их выше негатива.
— Смотрите, как тон треда меняется за одну ночь.
— Тулза позволяет вам мониторить и автоматически ребустить эти комменты.
Шаг 8: Масштабировать это как маховик
— Каждый коммент = источник трафика.
— Каждый тред = результат поиска, который теперь принадлежит вам.
— Каждый апвоут = выше видимость на Reddit и в Google.
— Сделайте это по 10–20 ключевикам, и вы станете хозяином своей ниши.
Шаг 9: Автоматизировать, когда будете готовы
Ручной метод работает.
Автоматизированный — масштабирует.
Теперь мы:
Мониторим ключевики (Signals) Находим ранжирующиеся треды (Discover) Постим через прогретые акки (Posts) Безопасно бустим (Upvote Boost) Отслеживаем видимость (Rank Tracker) Автоматизируем все это (Autopilot)
Это и есть Reddit Growth Stack.
Шаг 10: Повторяй, закрепляй, доминируй
Через 90 дней у вас будет 20+ топовых комментов с Reddit в выдаче Google.
Каждый из них — это бесплатная реклама, работающая 24/7.
Работает для e-com, SaaS, аффилиатов и ORM-клиентов.
Никакой рекламы.
Никаких инфлюенсеров.
Никакого булшита.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
04 November 2025 15:05
Это - Филиппины:
— 0% налог на зарубежный доход для неграждан
— Более 90% населения говорит на английском
— Новая виза для цифровых кочевников в 2025 году
Тропический рай для экспатов ПЛЮС это скрытый налоговый рай.
Вот 7 причин, почему "Жемчужина Востока" должна быть в поле вашего зрения:
У Филиппин захватывающая история:
От более чем 300-летнего испанского правления (1565-1898) до независимой республики в 1946 году.
Сегодня этот архипелаг из 7,641 островов имеет:
— 120.9 миллионов жителей
— 120+ языков
— Одно из самых активных в соцсетях населений в мире
В наши дни Филиппины больше всего известны как аутсорс-направление для западных компаний:
— Затраты на персонал на 60-80% ниже, чем при найме в США
— Одна из ведущих англоговорящих стран Азии
— Компании получают 24/7 операционку с ночными сменами в Маниле
Но ситуация меняется...
Несмотря на некоторые инфраструктурные проблемы, экспаты и цифровые кочевники массово переезжают сюда.
Тропические пляжи, владение английским, И есть довольно скрытые причины.
Вот 7 причин, почему Филиппины заслуживают вашего внимания👇
1. Выбор виз
— Туристическая виза: бесплатная 30-дневная виза по прибытии, продление до 6 месяцев
— Special Resident Retiree Visa (SRRV): Ранее доступна с 35+ лет, теперь с более строгими правилами
— Инвесторская виза (SIRV): Инвестируйте $75,000+ в бизнес, получите бессрочное резидентство
2. Скрытый налоговый рай
(Это довольно сложно, поэтому всегда консультируйтесь с профессиональным налоговым консультантом)
Итак, налог на доходы из зарубежных источников на Филиппинах сводится к одному:
Как они определяют ваше налоговое резидентство.
Есть 5 категорий:
1. Резиденты-граждане
2. Нерезиденты-граждане
3. Резиденты-иностранцы
4. Нерезиденты-иностранцы, занимающиеся торговлей или бизнесом
5. Нерезиденты-иностранцы, НЕ занимающиеся торговлей или бизнесом
Что касается политики глобального налогообложения Филиппин, она применяется только к РЕЗИДЕНТАМ-ГРАЖДАНАМ.
Все остальные облагаются налогом только на доходы, полученные на Филиппинах.
Так что для большинства это замаскированный налоговый рай.
3. Широкое распространение английского
— Более 90% филиппинцев говорят по-английски
— Правительство, контракты и вывески - всё на английском
— Нет языкового барьера при общении с местными
Это в отличие от многих других азиатских стран.
4. Виза для цифровых кочевников на подходе
— Начальный срок пребывания: 12 месяцев (продлевается один раз, всего до 24 месяцев)
— Без местного подоходного налога
— Требуется подтверждение удаленного дохода (~$24,000/год)
Предстоящая виза позволит удаленным работникам оставаться без налогов до 2 лет.
5. Бум иностранных инвестиций
— Законы теперь разрешают 100% иностранное владение в ключевых секторах
— Здравоохранение, финансы и IT-аутсорсинг показывают значительный рост
— E-commerce и финтех на подъеме, прогноз достичь $21B к 2025 году
Огромные возможности в быстрорастущих отраслях.
6. Растущий средний класс
— 66% населения трудоспособного возраста (15-64)
— Экономика на пути к достижению статуса страны с доходом выше среднего к 2026 году
— Средний возраст 26.1 лет — моложе, чем в большинстве западных стран
Плюс их средний класс вырос с 28% до 40% за последние 30 лет.
7. Тропический рай
Филиппины - это дом для 7,641 островов:
— Сиаргао: Рай для серфинга с активным сообществом экспатов
— Палаван: Регулярно признается лучшим островом в мире
— Боракай: Белопесчаные пляжи с бурной ночной жизнью
Множество вариантов для тропического отдыха.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
04 November 2025 11:15
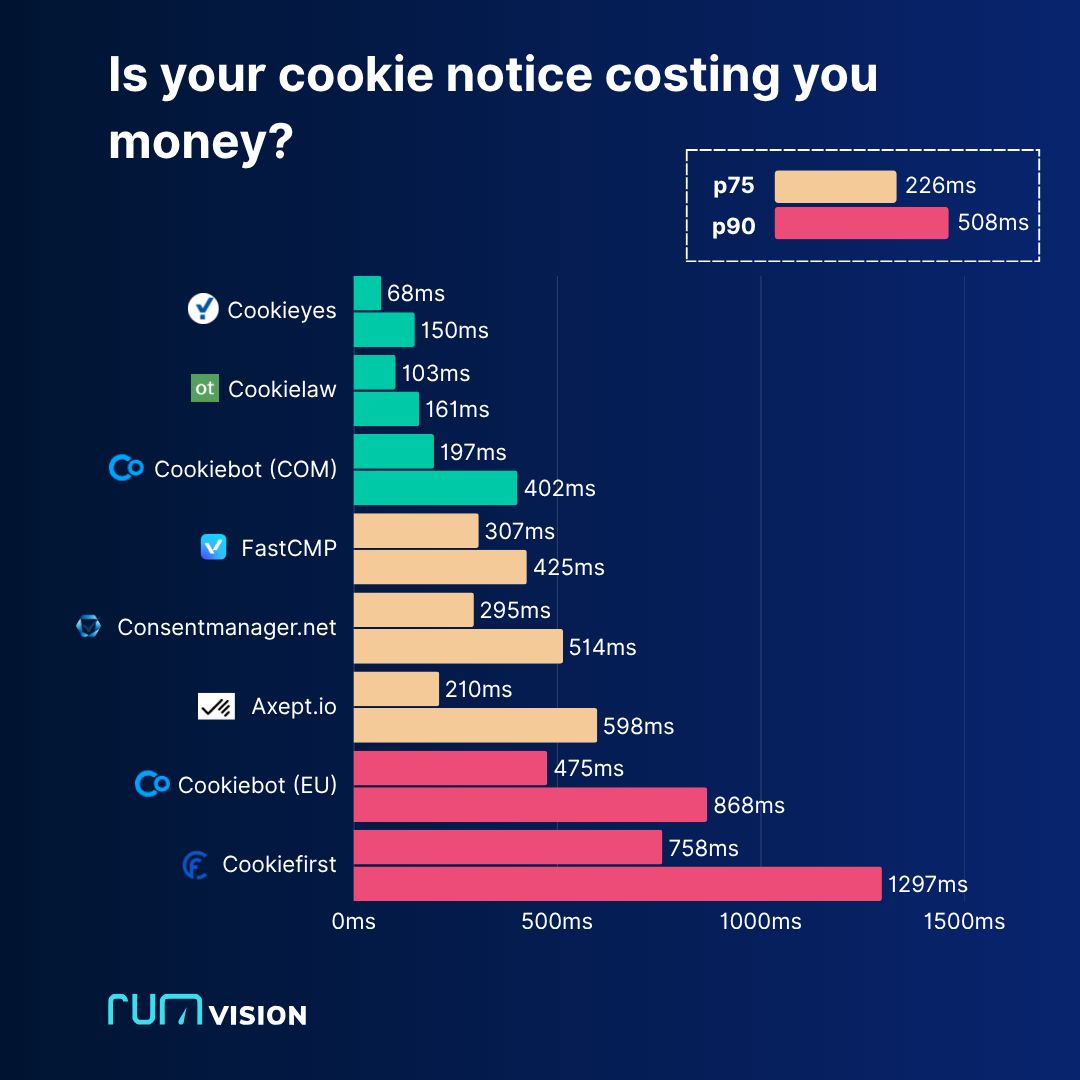
Для многих посетителей сайта уведомление о cookie — это первое впечатление и первое действие, которое они совершают.
Если этот процесс не гладкий, вы теряете.
Все знают, что первое впечатление критически важно для хорошего пользовательского опыта.
Тем не менее, многие сайты портят его медленными уведомлениями о cookie.
Когда посетитель нажимает "Принять" или "Отклонить", отклик должен быть мгновенным (INP менее 200 мс).
Задержки в 200-500 мс уже раздражают.
А все, что дольше 500 мс?
Именно тогда юзеры скорее всего свалят с вашего сайта к конкуренту.
Как видите, очень мало CMP-платформ, где 90% (p90) пользователей достигают метрики INP менее 200 мс.
Особенно плохой опыт получают посетители с не самыми мощными устройствами и/или плохим интернетом.
В основном это (новые) исследовательские посетители из SEO, соцсетей или Google Ads, для которых первое хорошее впечатление очень важно!
Выбор правильной CMP может способствовать лучшему опыту и лучшему первому впечатлению от вашего сайта.
Шанс отказа ниже, а значит, выше вероятность, что посетитель останется на сайте и совершит покупку.
Даже если они не совершат покупку, ваши ремаркетинговые пулы все равно будут пополняться (с согласия посетителя), что тоже ценно.
Я прав, если предположу, что у вас нет никаких данных о том, какую роль CMP и другие сторонние сервисы играют в снижении вашей производительности?
С RUMvision вы можете это увидеть и найти лучшую альтернативу.
Дисклеймер к визуализации: Этот обзор охватывает платформы управления согласием (CMP), которые сгенерировали более 10 000 событий за последние 28 дней.
Цифры являются средними, и мы не можем видеть, как каждая CMP настроена у наших клиентов, пишет Родерик Дерксен.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
03 November 2025 15:05
Как потерять домен стоимостью в шестизначную сумму
— Ваша компания регистрирует доменное имя (в данном случае, в феврале 1996 года, oks.com — для компании OK's Cascade Company).
— Компанию поглощает Ellipse Global — поставщик оборудования из Снохомиша, штат Вашингтон.
— Компанию снова поглощает GardaWorld Federal Services.
— Из-за плохой коммуникации или недостаточной осведомленности продление регистрации домена упускается из виду.
— Регистратор доменов (GoDaddy) зарабатывает $112 тыс., а кто-то другой получает новый домен.
@
Читать полностью…
Mike Blazer
03 November 2025 11:15
Гуглу кранты!!! 👿
Сайты правительств, больниц и даже детских благотворительных организаций превратились в фермы для партнерского маркетинга казино, и Гугл ставит их в топ...
Либо алгоритм все-таки делает свою работу и пессимизирует их, но тогда их просто редиректят через 301 на другой старый домен 🙄
Системы Гугла для борьбы со ссылочным спамом?
Мертвы...
Его очередь на ручную проверку?
Окаменела...
Последние апдейты алгоритма?
Бумажные тигры...
И это даже проще, чем было 10 лет назад, и куда прибыльнее!
Старые бэклинки, чистая история, цепочка `301`х редиректов... и бум, ты "Сайт №1 с бонусами казино в Канаде" 🤣
И если в прошлом году для этого нужен был авторитетный сайт, то теперь даже паразит не требуется...
Просто берешь на аукционе `GoDaddy` домен за 12 фунтов, который раньше принадлежал благотворительной организации, натягиваешь новую тему, `301`м редиректом подклеиваешь сгоревший домен казино, и печатаешь бабки 🤑
Это не взлом.
В этом даже нет ничего особо умного.
Это ленивые, олдскульные сеошные тактики, примененные в нужный момент, и Гуглу это нравится, потому что он вливает все свои ресурсы в ИИ и позволяет поиску быть заваленным спамом.
Некоторые из крупнейших игроков сейчас даже не занимаются линкбилдингом.
Они просто покупают забытые бренды и отмывают трафик через просроченные сигналы траста и ссылочного веса...
Добро пожаловать в современные конкурентные СЕРПы: - Домены с `DR60`, которые раньше были больницами, теперь продвигают крипто-рулетку.
- Гемблинг-сайты, прячущиеся за редиректами с .org доменов.
- И 200 тыс.
трафика в месяц со страниц, которые Гугл мог бы обнаружить 3 года назад, но теперь ранжирует как сумасшедший!
Черное СЕО процветает!
Белое СЕО пытается выжить!
А Гугл?
Они там пытаются позволить ИИ волшебным образом все это пофиксить, хотя он одновременно убьет их дойную корову!
На данном этапе сеошники не обходят систему, мы просто единственные, кто все еще играет в эту игру...
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
02 November 2025 12:05
Вторая неделя в @ — DONE!
Пока вы перелопачивали паблики в поисках хоть чего-то ценного, 75+ подписчиков PRO-канала уже внедряют "пушки" и делятся первыми результатами в закрытом чатике.
Вот что вы упустили в PRO:
1. Контринтуитивный трюк с заголовками, который сломал "лучшие практики" SEO и дал рост трафика в TripAdvisor.
2. Хак с URL-параметром, чтобы подсмотреть, что на самом деле гуглит ChatGPT, в промышленных масштабах.
3. ПУШКА!: как "арендовать" топ-1 выдачи за 24 часа методика, которая реанимирует даже умирающих "паразитов".
4. Что на самом деле видит Google в ваших картинках: скрытая система ранжирования, где штрафуют за "плохие клики".
5. Как занять топ-1 за 22 часа с помощью YouTube — паразитный метод, для которого не нужно снимать видео.
6. Серый хак с Chrome-расширением, который ежедневно посылает Google правильные сигналы и бустит позиции вдолгую.
7. Трюк с каноникалом, который генерит €300к/месяц в гембле и который Google до сих пор не может вычистить из выдачи.
8. Внимание: Google тихо превратил этот тег в директиву "не показывать страницу в выдаче". Как одна строчка кода может убить видимость страницы.
9. Как один всплеск "плохого" трафика может навсегда утопить ваш сайт и почему это убивает ваши "естественные" поведенческие сигналы..
10. ХАК: как одно поле в Schema может обмануть Google и прибить вашу страницу к топу по событийным запросам.
—-
Это еще одна порция преимуществ, которые достались не вам.
Вы либо в кругу тех, кто действует, либо среди тех, кто наблюдает.
Цена вот-вот вырастет. Окно возможностей закрывается.
Решайте, на чьей вы стороне. Подключайтесь!
Читать полностью…
Mike Blazer
01 November 2025 17:27
Наряжусь на Хэллоуин в "органический охват", чтобы быть невидимкой.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
01 November 2025 09:08
«Я вижу, что SEO мертво, люди».
Коул Смир, «Шестое чувство» (1999 г.)
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
31 October 2025 13:05
"Так почему же ты не ходишь на конференции по SEO?"
Я:
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
31 October 2025 08:15
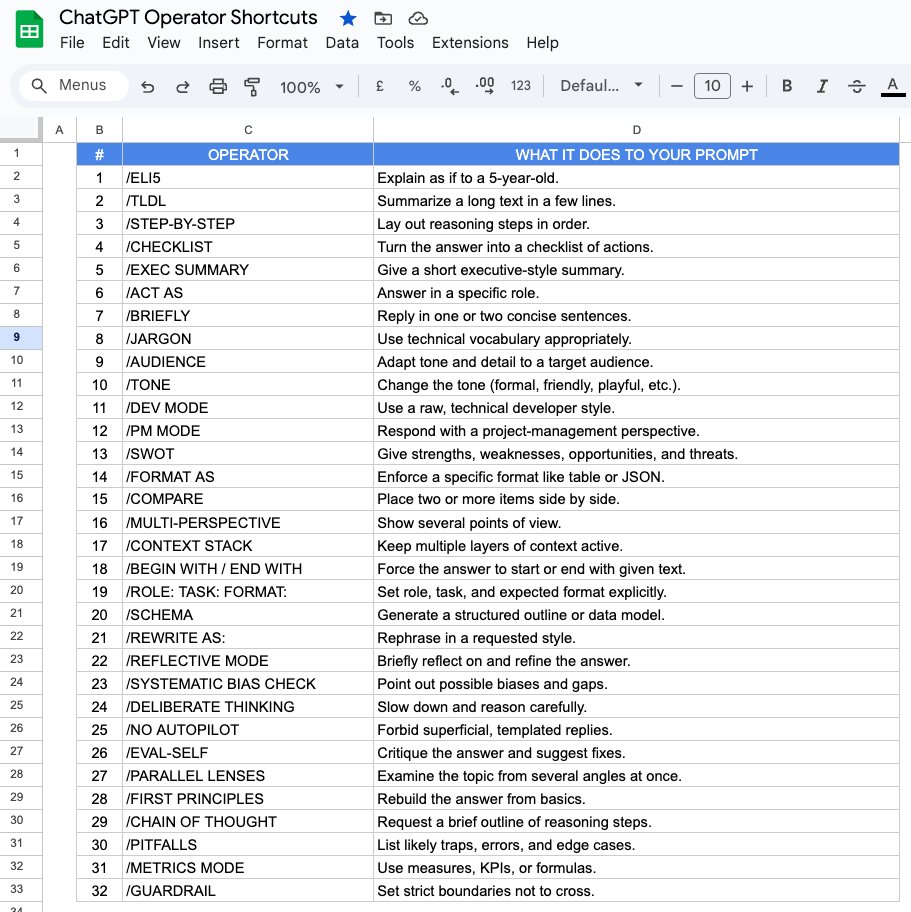
Большинство людей не в курсе, что у ChatGPT есть скрытые операторы, которые могут кардинально менять его ответы.
Вот ультимативная шпаргалка из 32 шорткатов для более четких промптов! 🤯
Просто добавьте один из них в начало.
👇 Вот полный список операторов ChatGPT:
— /ELI5: объясняет так, будто вам 5 лет.
— /TLDR: суммирует очень длинный текст в нескольких строках.
— /STEP-BY-STEP: излагает логику рассуждений шаг за шагом.
— /CHECKLIST: превращает ответ в чеклист.
— /EXEC SUMMARY: выдает краткую сводку в деловом стиле.
— /ACT AS: заставляет ChatGPT говорить в определенной роли.
— /BRIEFLY: заставляет дать очень короткий ответ.
— /JARGON: просит использовать техническую лексику.
— /AUDIENCE: адаптирует ответ для выбранной аудитории.
— /TONE: меняет тон (формальный, смешной, драматичный и т. д.).
— /DEV MODE: симулирует "сырой" технический стиль разработчика.
— /PM MODE: дает взгляд с точки зрения управления проектами.
— /SWOT: делает анализ сильных/слабых сторон, возможностей/угроз.
— /FORMAT AS: принудительно задает определенный формат (таблица, JSON и т. д.).
— /COMPARE: сравнивает два или более объекта.
— /MULTI-PERSPECTIVE: показывает несколько точек зрения.
— /CONTEXT STACK: удерживает в памяти несколько слоев контекста.
— /BEGIN WITH / END WITH: заставляет начать или закончить ответ определенным образом.
— /ROLE: TASK: FORMAT:: явно определяет роль, задачу и ожидаемый формат.
— /SCHEMA: генерирует структурированный план или модель данных.
— /REWRITE AS:: перефразирует в заданном стиле.
— /REFLECTIVE MODE: побуждает ИИ поразмыслить над собственным ответом.
— /SYSTEMATIC BIAS CHECK: просит выявить систематические предубеждения.
— /DELIBERATE THINKING: заставляет рассуждать медленнее и вдумчивее.
— /NO AUTOPILOT: запрещает поверхностные, шаблонные ответы.
— /EVAL-SELF: просит дать критическую самооценку ответа.
— /PARALLEL LENSES: рассматривает проблему с нескольких ракурсов параллельно.
— /FIRST PRINCIPLES: выстраивает ответ с самых основ.
— /CHAIN OF THOUGHT: показывает промежуточные шаги рассуждений.
— /PITFALLS: определяет возможные ловушки и ошибки.
— /METRICS MODE: выражает ответы с помощью метрик и показателей.
— /GUARDRAIL: устанавливает строгие границы, которые нельзя пересекать.
https://docs.google.com/spreadsheets/d/1nM6wUoCp3tmLh0I4fkgDoUKUDUt9vDzGhEIjXq-eoDM/edit?gid=611849125#gid=611849125
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
07 November 2025 13:05
Chonkie: Легковесная и быстрая библиотека для чанкинга текста на Python
Установка
Базовая: pip install chonkie
Со всеми зависимостями: pip install chonkie[all]
Пример использования
from chonkie import RecursiveChunker
chunker = RecursiveChunker()
chunks = chunker("Chonkie is a library for text chunking.")
for chunk in chunks:
print(f"Text: {chunk.text}, Tokens: {chunk.token_count}")
Пайплайн обработки CHOMP1
Chef: Предобработка текста (очистка, нормализация).
2
Chunker: Применяется основная логика разделения.
3
Refinery: Постобработка (объединение, эмбеддинг, добавление контекста).
4
Friends: Вывод через
Porters (экспорт в JSON) или
Handshakes (загрузка в векторную БД).
Доступные чанкеры—
TokenChunker: Чанки фиксированного размера в токенах.
—
SentenceChunker: Разделение по предложениям.
—
RecursiveChunker: Иерархическое разделение на основе правил.
—
SemanticChunker: Разделение по семантическому сходству (в духе Грега Камрадта).
—
LateChunker: Создает эмбеддинги текста *перед* разделением для оптимизации эмбеддингов чанков.
—
CodeChunker: Структурно-ориентированное разделение кода.
—
NeuralChunker: Использует нейросетевую модель для разделения.
—
SlumberChunker (AgenticChunker): Использует
LLM для поиска семантических разделений.
Интеграции (всего 24+)— Токенизаторы: 5+
— Провайдеры эмбеддингов: 8+
— Провайдеры
LLM: 3+
— Векторные базы данных: 4+
Репозиторий: https://github.com/chonkie-inc/chonkie/https://www.linkedin.com/pulse/no-nonsense-ultra-light-lightning-fast-chunking-library-dan-petrovic-rzmfc/Каковы сценарии использования чанкинга?В основном оно
используется для создания инструментов на базе ИИ, извлечения информации и разработки поисковых систем.
— Один из сценариев — это разделение контента веб-страницы для получения более детальной семантической оценки и кластеризации.
— Другой — предоставление
LLM только необходимой информации вместо целых документов, что ведет к экономии на использовании токенов.
@Инсайты для узкого круга — в
@
Читать полностью…
Mike Blazer
07 November 2025 08:15
Паразитное SEO через соцсети (четкий воркфлоу)
Почему соцсети важны для паразитного SEO
Многие профили в соцсетях позволяют ставить ссылки на вашу статью, давая вашим постам в блоге бэклинки со старта.
Этот буст часто помогает обойти конкурентов, которые запускают страницы с нулем бэклинков.
Мой воркфлоу по публикации (каждый раз)
Йеспер Ниссен отмечает, что этот воркфлоу можно заюзать для статей, страниц услуг, продуктовых страниц или страниц категорий в интернет-магазинах.
1. Публикуем статью с главным ключевиком в H1.
2. Создаем видео на YouTube, нацеленное на тот же ключевик, со ссылкой на вашу статью в описании. Пример видео на YouTube.
3. Делаем пост во вкладке Community на YouTube с обложкой и кратким 3. Делаем пост во вкладке Community на YouTube с обложкой и кратким саммари. Пример .
.
4. Делимся короткой версией в X и jespernissenseo/post/DPt9jUqjecU?xmt=AQF02MCY8gNegYTVeQEzTNBwk8R76Vp59H4NSFpFAf3dyQ">Threads. Если есть доступ к X Articles — используем и их.
5. Делимся более длинной, "сшитой" версией в LinkedIn и Facebook, объединяя ваши твиты.
6. Пишем оригинальный контент для Reddit о вашей статье. Не копируйте/вставляйте из блога, так как там важен свежий контент.
7. Постим клип из вашего видео в YouTube Shorts.
8. Репостим видео из Shorts в TikTok, IG Reels, Facebook Reels, X и Pinterest.
9. Создаем доску на Pinterest и делаем пин со ссылкой на вашу статью.
10. Постим изображение в Instagram.
Эта процедура накапливает страницы и ссылки с высоким DA вокруг вашего контента, и многие посты будут ранжироваться, создавая несколько позиций на первой странице из одного куска контента.
Как структурировать посты для разных платформ:
— X и Threads: Используйте короткие посты. Длинный контент разбивайте на несколько постов и не забывайте ссылаться на статью и видео на YouTube.
— Facebook и LinkedIn: Создавайте более длинные посты, сшивая ваши посты из X. Добавляйте изображение, чтобы занять больше места в ленте.
— Reddit: Постите новую или переписанную статью. Крайне важно иметь свой собственный сабреддит. Не ожидайте огромного вовлечения, если ваш контент не является действительно уникальным.
— YouTube: Используйте длинное видео для глубины и Shorts для распространения. Всегда ссылайтесь на основную статью из описаний, где это возможно.
Хештеги
Я всегда использую хештеги, предпочитая брендовые.
Они кликабельны и создают страницу-коллекцию со всеми прикрепленными постами.
Это помогает алгоритмам группировать ваш контент по бренду, облегчая людям и ботам понимание того, о чем ваш бренд.
Конкретные цифры по длине постов (что работает):
X: от 40 до 60 слов.
Для более длинных сообщений публикуйте несколько коротких твитов.
Посты могут ранжироваться в Google даже при минимальном взаимодействии.
Facebook: около 100-150 слов.
Прикрепление изображения ко всем постам увеличит вовлеченность.
Краткий чеклист:
— Статья в блоге опубликована (ключевик в H1)
— Видео на YouTube + ссылка в описании
— Пост в YouTube Community (картинка + саммари)
— Короткие посты в X + Threads (ссылки добавлены)
— Длинный пост в LinkedIn + Facebook (картинка прикреплена)
— Оригинальный пост на Reddit
— Нарезка для Shorts + репост в TikTok/IG/FB/X/Pinterest
— Доска на Pinterest + пин (обратная ссылка)
— Ответы на комментарии в течение первого часа
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
06 November 2025 13:05
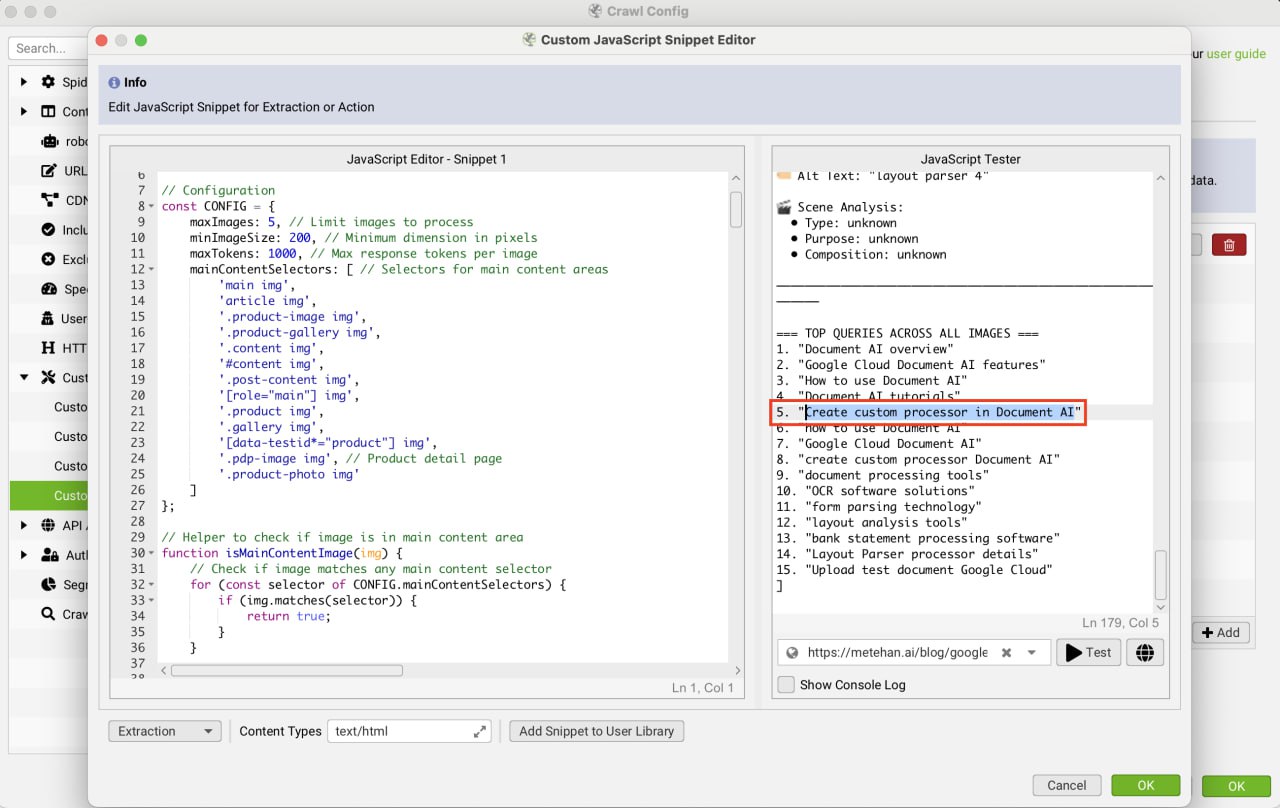
Новый кастомный JS-экстрактор для Screaming Frog использует OpenAI Vision API, чтобы симулировать гугловский "visual search fan-out".
Он анализирует ваши изображения и генерирует конкретные, длиннохвостые запросы, которые юзеры могли бы использовать на основе визуального контекста — запросы, которых, скорее всего, нет в вашем тексте.
Как это работает:
Скрипт краулит ваши изображения и определяет объекты, атрибуты и предполагаемые сценарии использования.
Затем он генерирует список соответствующих поисковых запросов.
Пример: изображение кофеварки
— Традиционный Alt Text: "12-cup coffee maker"
— Сгенерированные запросы "Visual Fan-Out":
— "programmable coffee maker with thermal carafe"
— "coffee maker that keeps coffee hot without burner"
— "office coffee maker for conference room"
— "thermal pot coffee maker no hot plate"
ИИ сделал вывод о термо-кофейнике (не видно подставки для подогрева) и офисном сценарии использования на основе дизайна.
Частые гэпы, которые он находит:
— Цвет: В тексте написано "blue", но на картинке "french navy", по которому тоже ищут.
— Контекст: Фотография рабочего стола не оптимизирована под "work from home setup".
— Стиль: Изображения показывают "minimalist" или "industrial" эстетику, но эти термины отсутствуют на странице.
— Фичи: Видимые детали, такие как "reinforced stitching" или "hidden pockets", не упомянуты в тексте.
План действий:
1. Прогоните анализ по ключевым страницам.
2. Внедрите сгенерированные запросы и атрибуты в описания продуктов, alt-тексты и окружающий контент.
3. Используйте список запросов для генерации новых тем для FAQ и статей.
Это закрывает гэп между тем, что показано на ваших картинках, и тем, что написано в вашем тексте.
Бесплатный JS-код доступен на GitHub: https://github.com/metehan777/screaming-frog-visual-query-fan-out
https://metehan.ai/blog/visual-query-fan-out-screaming-frog/
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
06 November 2025 09:02
Как 10 качественных ссылок победили 1000+ низкокачественных
Я провел 12-месячный тест на двух идентичных сайтах: та же ниша, тот же контент, тот же технический сетап, говорит Ноэль Сета.
Единственной переменной была ссылочная стратегия.
Сайт А получил 10 высококачественных бэклинков.
Сайт Б получил более 1000 низкокачественных.
Результаты были даже не близкими.
Сайт А, всего с 10 качественными ссылками, достиг DR 21, притащил 2400 органических визитов в месяц и ранжировался по 30 ключевикам в топ-10.
Сайт Б, несмотря на обманчивый DR 51 от своих 1000+ ссылок, смог получить только 500 визитов в месяц и ранжировался всего по 2 ключевикам в топ-10.
Ссылки сайта А были с отраслевых изданий (DR 70-85), университетских ресурсов (DR 90+) и авторитетных блогов (DR 55-65), со средним временем получения одной ссылки в 18 часов.
Ссылки сайта Б — это 847 спамных комментов в блогах, 98 низкокачественных каталогов и 43 PBN-сайта, в среднем по две минуты на ссылку.
Качество трафика это отражало.
У сайта А средняя длительность сессии была 3:47 и конверсия 3.2%.
У сайта Б средняя сессия была всего 38 секунд и конверсия 0.4%.
Динамика ранжирования была не менее показательна.
Сайт А попал в свой первый топ-10 на третий месяц и к концу года вырос до 127 позиций в топ-10.
Сайт Б не получал топ-10 до шестого месяца, достиг пика в две позиции, а затем начал терять ранжирование в последнем квартале.
Анализ затрат все решает.
Сайт А потребовал 180 часов и $8,500 затрат, в среднем $850 за ссылку.
Сайт Б был покупкой за $150 на Fiverr.
ROI говорит сам за себя.
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
05 November 2025 13:05
Google не оценивает все ссылки 🔗 одинаково.
Основной вес несут ваши ~200 лучших.
Как их распределить, не сливая ссылочный вес на повторяющиеся ссылки в навигации/футере?
GoogleApi.ContentWarehouse.V1.Model.IndexingDocjoinerAnchorStatisticsRedundantAnchorInfo
Общее количество отброшенных избыточных анкоров на пару (домен, текст).
Если мы получаем большое количество анкоров с определенного домена, то мы отбрасываем все, кроме 200 из них, с этого домена.
Данные сортируются по парам (домен, текст).
Это ограничено 10 000 записей (если меньше, то будет такое же количество элементов, как и в счетчике above_limit).
Атрибуты
— anchorsDropped (тип: String.t, по умолчанию: nil) -
— domain (тип: String.t, по умолчанию: nil) -
— text (тип: String.t, по умолчанию: nil) -
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
05 November 2025 08:15
Однажды я стоял на 3-м месте в Австрии по запросу "online casino" с сайтом на сгенерированном контенте под клоакингом.
Был уверен, что прилетит ручник за чистый спам, но этого не случилось, пишет SEOwner.
В итоге — и это реальная история — инженер Гугла, видимо, решил вычистить из индекса только мои PBN-ки с точными анкорами, без санкций за спам.
Не уверен, наложил ли он еще какой-то штраф, но я наблюдал, как сайт медленно умирал по мере пересчета метрик.
Мне нравится думать, что он просто троллил, перебирая и вычищая мои ссылки.😂
Как бы то ни было, это позволило мне зарабатывать еще несколько лишних недель.
Ценю это, бро!
Клоака, которую я создал, использовала cURL, чтобы тянуть фейковый HTML-сайт из сабфолдера и накладывать его поверх страниц со сгенерированным контентом.
Одинаковые страницы, одинаковые тайтлы — практически не отличить от легального сайта (за исключением того, что контент на всех сайтах был один и тот же).
Некоторые из них до сих пор работают, лол.
А потом сегодня вечером я чекал серпы в Австрии и понял, что кто-то купил этот домен и теперь ранжируется по куче ключей.
Интересно, увидит ли он когда-нибудь этот пост.😂
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
04 November 2025 13:05
Паразитное SEO с помощью Perplexity
Очень удивляет мощь и живучесть страниц Perplexity в ранжировании.
Я думал, это скоро пройдет, но они все еще ранжируются, говорит Йеспер Ниссен!
Я создал страницу в Perplexity два месяца назад.
Теперь она ранжируется выше моего собственного сайта!
1. Выберите длиннохвостый ключ и создайте страницу в Perplexity.
2. Затем отредактируйте тайтл.
3. Отредактируйте секции.
4. Вставьте свое собственное изображение-баннер.
5. Опубликуйте страницу...
Вот таким простым может быть Parasite SEO....
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
04 November 2025 08:15
Ваша стратегия кэширования — это прямой сигнал для AI-краулеров
Гайз, эффективное HTTP-кэширование — это уже не просто фича для перфоманса, а критический элемент инфраструктуры, который напрямую влияет на эффективность краулинга и то, как ваш сайт воспринимают и поисковики, и современные AI-системы.
Боты ведут себя не так агрессивно, когда видят правильно настроенные хидеры кэширования, что экономит ваш краулинговый бюджет и позволяет им обходить более свежий и глубокий контент.
Кривые настройки, однако, могут привести к жесткой просадке производительности и сливу ресурсов краулера.
Одна из самых губительных ошибок — неправильное использование хидера Vary.
Если включать в него заголовки, которые по факту не меняют ответ, типа Vary: User-Agent или Vary: Cookie, это приводит к катастрофической фрагментации кэша.
В результате создаются тысячи почти одинаковых записей в кэше, что просто убивает hit rate.
Для адаптивных изображений нужно юзать Vary с Client Hints вроде DPR и Width, но это надо делать в связке с правилами CDN, чтобы нормализовать варианты и избежать фрагментации.
Чтобы побороть фрагментацию от трекинговых параметров, есть экспериментальный хидер No-Vary-Search, который говорит кэшу игнорировать параметры типа utm_source или fbclid при создании ключей кэша.
Вы обязаны разделять время жизни кэша для браузера и для CDN.
Используйте директиву s-maxage, чтобы задать долгий срок кэширования для общих кэшей, как ваш CDN, и при этом ставьте куда более короткий max-age для браузеров.
Например, Cache-Control: public, max-age=60, s-maxage=600 говорит браузеру перепроверить через минуту, но позволяет CDN отдавать свою кэшированную копию десять минут, защищая ваш основной сервер.
Применяйте стратегию кэширования в зависимости от типа контента:
— `HTML` с редкими изменениями (посты в блоге): Юзайте длинный TTL для CDN (s-maxage=86400) в паре со стратегией очистки кэша по событию. Когда контент обновляется, используйте фичи CDN типа Cache Tags или surrogate keys, чтобы мгновенно сбросить кэш для нужных страниц.
— `HTML` с частыми изменениями (главная): Ставьте TTL для CDN покороче (s-maxage=300) с stale-while-revalidate=60, чтобы обеспечить быстрый отклик для юзера, пока апдейты подтягиваются в фоне.
— Страницы, требующие аутентификации: Используйте Cache-Control: private, no-cache с ETag, чтобы запретить общее кэширование, но разрешить эффективную повторную валидацию с ответом 304 Not Modified. Для особо чувствительных данных юзайте private, no-store, чтобы браузер вообще не хранил копию на диске.
— Ресурсы с версионированием (Fingerprinted Assets): Директиву immutable следует использовать только для ресурсов с версиями в именах файлов (например, app.9f2d1.js). Применять ее к HTML-документам опасно, так как это может запереть и юзеров, и краулеров на устаревшем контенте.
Наконец, помните, что кэш сохраняет редиректы и ошибки.
Редирект 301 часто кэшируется навсегда по умолчанию, и даже ошибки 404 или 500 могут ненадолго кэшироваться, из-за чего временные проблемы кажутся краулерам более долгосрочными.
Также учтите, что использование Cache-Control: no-store на HTML-документе — это частый блокер для Back`/forward` cache (BFCache), который мешает мгновенному восстановлению страниц и ухудшает юзабилити.
https://www.jonoalderson.com/performance/http-caching/
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
03 November 2025 13:05
Я постоянно вижу повсюду посты, где люди делятся, как они используют AI (LLM) для того или иного, — но в реальности LLM'ы не могут делать то, что им приписывают, пишет Лили Рэй.
По моему мнению, главная проблема здесь — которая была проблемой с первого дня, как эти инструменты стали общедоступны — в том, что они редко говорят, когда чего-то не знают или не могут сделать, но почти всегда все равно выдают уверенный ответ.
Для новичка или человека, не знакомого с AI, может быть захватывающе попросить ChatGPT "поработать кардиохирургом" или "притвориться налоговым экспертом" и получить уверенный, правдоподобный ответ.
Особенно на фоне всей этой медийной шумихи вокруг AI — кажется вполне логичным, что большинство людей предполагает, что это и есть та самая революционная, меняющая жизнь технология, которую нам обещали.
Но в реальности эти ответы могут быть полностью сгаллюцинированы и полны неточной или даже опасной информации.
Юзер часто не видит разницы.
И я не говорю, что я от этого застрахована: я сама много раз с тревогой обнаруживала неточные ответы в ChatGPT, только после того, как проверяла его ответ через Google.
Я не виню широкую публику за то, что LLM'ы вводят их в заблуждение; ведь нет никакого экзамена, чтобы начать пользоваться этой технологией, которая, как мы теперь узнаем, может быть по-настоящему опасной.
Реальная вина лежит на AI-компаниях за то, что они не смогли научить пользователей, что эти инструменты могут и чего не могут (хотя это, очевидно, противоречило бы их целям экстремального роста).
Но теперь, когда джинн выпущен из бутылки, очень тревожно думать, сколько некорректной информации циркулирует в интернете и в обществе, и сколько людей совершают ошибки — от безобидного неверного поворота на дороге до покупки не того лекарства.
Они никогда этого не сделают, но было бы здорово, если бы эти AI-компании предприняли более серьезные шаги, чтобы:
— обучать пользователей, как лучше использовать (или не использовать) эти инструменты;
— помечать, когда определенные темы опасны;
— улучшить способность инструментов говорить, когда они не уверены в своем ответе (или ввести какой-то индикатор уверенности??).
А еще можно, хз, принять законы, которые бы это регулировали.
¯\_(ツ)_/¯
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
03 November 2025 08:15
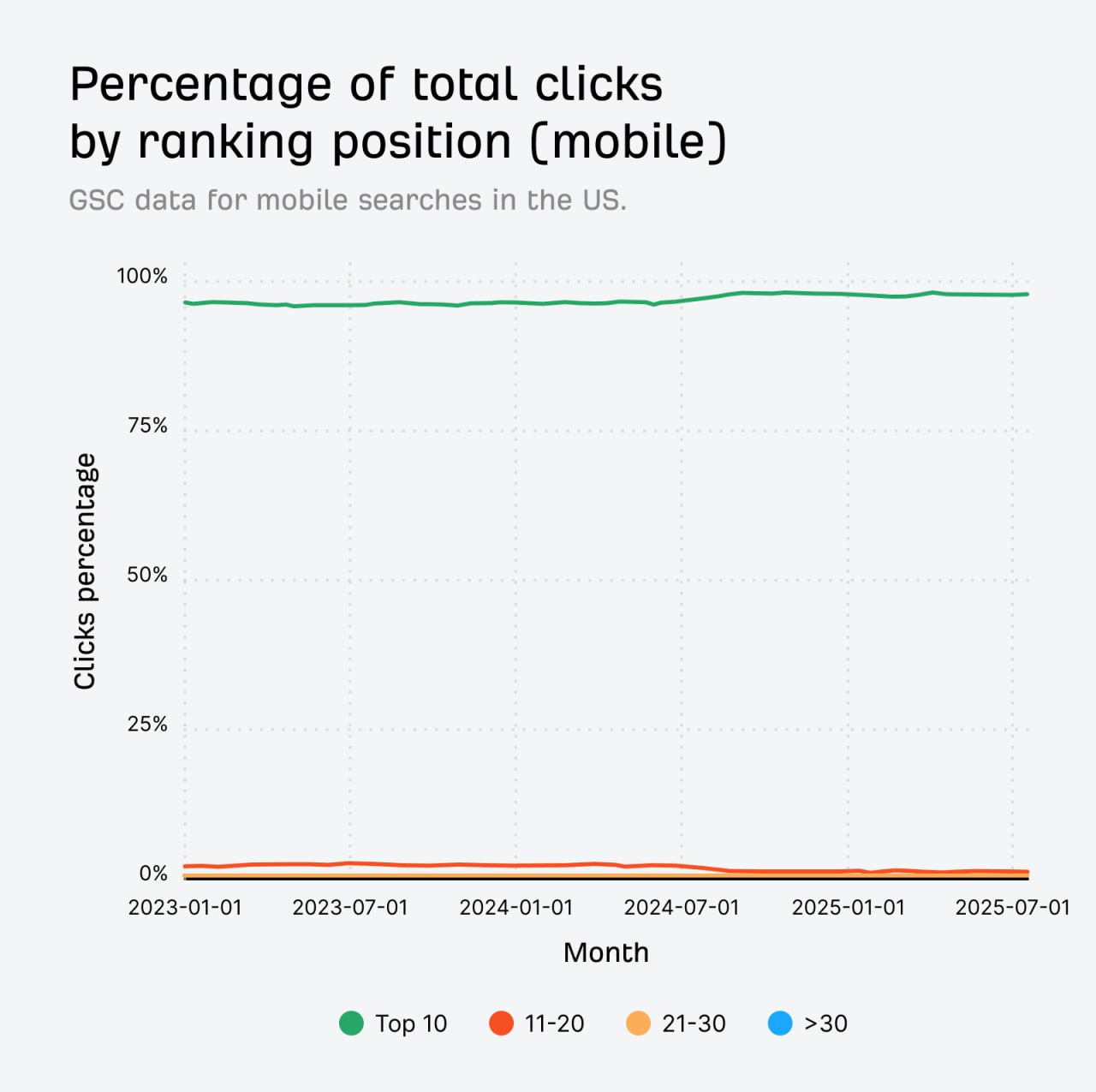
Глубокие показы в SERP — это мираж, а клики исчезают после первой страницы
Свежие данные подтверждают, что практически весь органический трафик сидит на первой странице выдачи.
Анализ миллиардов кликов и показов показывает, что 96.98% всех десктопных кликов и 97.56% всех мобильных кликов происходят в топ-10 позициях.
Этот тренд стабилен последние два года, и страницы за пределами топ-10 никогда не собирали больше 4.37% от всех кликов.
На мобилках картина еще жестче.
Недавний тренд показывает снижение кликов для URL, ранжирующихся дальше 10-й позиции, что указывает на еще большую концентрацию вовлеченности юзеров на первой странице мобильных SERP.
Надо быть осторожнее с интерпретацией данных по показам для низкоранжируемых страниц.
Значительная часть десктопных показов (28.93%) фиксируется для результатов за 30-й позицией.
Учитывая, что эти позиции почти не получают кликов, очень вероятно, что этот объем показов генерят боты и скрейперы, а не живые пользователи.
Этот растущий тренд нечеловеческих показов может объяснить, почему Google решил выпилить параметры вроде &num=100.
https://ahrefs.com/blog/almost-all-clicks-happen-in-the-top-10-results/
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
02 November 2025 09:05
Жиза
@
Читать полностью…
Mike Blazer
01 November 2025 15:05
Когда Гугл насыпал трафла, но не туда
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
31 October 2025 16:05
Джефф Безос отправляется в штаб-квартиру AWS после инцидента в их дата-центре в северной Вирджинии
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
31 October 2025 11:15
Почему бы и не кликнуть?
@
Инсайты для узкого круга — в @
Читать полностью…
Mike Blazer
30 October 2025 15:05
Почему "AI Mode" делает модель "одна страница — один ключ" устаревшей
Пока большинство заморачивается над AI Overviews, самый большой риск — и будущее поиска — это так называемый AI mode.
Его функционал, как утверждает Брюс Клэй, требует радикально поменять подход к он-пейдж оптимизации: перейти от традиционной модели "одна страница — один ключ" к модели "одна страница — один кластер".
Когда вы переходите в AI mode, вся выдача — это один сгенерированный ИИ ответ, но он позволяет углубляться в темы.
Если кликнуть на ссылку в одном из его подпунктов, список источников на странице фильтруется и показывает только страницы, релевантные именно этому разделу.
Вот это поведение — ключевой момент.
Оно означает, что наши веб-страницы больше нельзя оптимизировать как единое целое.
Теперь нужно структурировать контент в четкие, самодостаточные разделы, обычно под H2, где каждый раздел индивидуально оптимизирован как самостоятельный ответ на конкретный длиннохвостый запрос в рамках более широкого тематического кластера.
Концепция контентных сайлосов сейчас важна как никогда, но ее нужно применять на более гранулярном уровне.
Цель — создать "сайлосы внутри страницы", где каждый H2-раздел может выступать как экспертный ответ, что идеально совпадает с тем, как AI mode разбирает и представляет информацию.
Если рассуждать логически, это означает, что почти каждый сайт на планете придется переделывать, если он хочет показываться в AI.
Это не мелкая правка, а колоссальная работа.
Когда я проходил и вычищал свой собственный сайт под это дело, потребовалось четыре человека, работавших фултайм шесть-семь месяцев.
Вам придется отредактировать весь ваш сайт, потому что то, что у вас есть сейчас, скорее всего, не катит для этой новой реальности.
@
Инсайты для узкого круга — в @
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}