Mike Blazer
09 Aug 2025 10:05
Периодически слышу мнение, что мой канал — это просто переводы постов из X (Твиттера).
Это не совсем так, и я хочу объяснить, в чем на самом деле заключается ценность.
Если вы видите здесь только переводы, вы упускаете главное.
Ценность не в переводе текста, а в кураторстве!
Моя работа — это ежедневный поиск иголок в стоге сена.
Я перелопачиваю тонны информации, чтобы найти самые ценные кейсы, рабочие тактики, свежие эксперименты и мнения, которые имеют значение.
И да, география поиска куда шире одного лишь X:
— LinkedIn
— X (Twitter)
— Закрытые Slack-комьюнити
— YouTube
— Подкасты на Spotify
— BlueSky
— Mastodon
— Блоги
— Статьи
— Ну и, конечно, мои собственные мысли и шутки.
Часто прямой перевод не имеет смысла.
Зачем вам часовая расшифровка подкаста?
Моя задача — найти ту самую "иголку в стоге сена", выделить ключевой момент и подать его вам в удобном формате.
У меня есть личная, почти маниакальная потребность в потреблении информации по SEO.
Я делаю это для своего профессионального роста.
А этот канал — побочный продукт моей работы, где я делюсь лучшими находками с вами.
Цель этого канала — показывать сеошку со всех сторон, освещать разные, порой противоречивые мнения и подходы.
Я верю, что именно так я помогаю всему SEO-сообществу расти, развиваться и процветать..
Спасибо, что читаете.
Для тех, кто хочет еще больше контента, вот мои профили в других соцсетях:
— X (Twitter)
— LinkedIn
— MikeBlazer">Mastodon
— BlueSky
— Facebook
— mike.blazer.x">Threads
@
Читать полностью…
Mike Blazer
08 Aug 2025 15:05
Заставьте ИИ опасаться, что вы заберете у него работу.
@
Читать полностью…
Mike Blazer
08 Aug 2025 11:05
Я подписал клиента с помощью этой картинки... говорит Лиам Фаллен
Нет, это не Netflix.
У меня была встреча с CEO...
Он спросил: "Зачем нам инвестировать в ускорение сайта?"
Тогда я показал ему эту картинку и сказал...
"Как же раздражает, когда Netflix виснет?"
CEO ответил: "Очень, очень раздражает".
Я согласился и добавил...
А теперь представьте, что это ваш сайт.
А теперь представьте, что вы — клиент.
Короче говоря.
Я заполучил нового клиента.
@
Читать полностью…
Mike Blazer
07 Aug 2025 17:05
🚨 Как на самом деле Google ранжирует сайты?
Вот 5 фундаментальных принципов SEO, которые НИКОГДА не меняются — прямиком из работ легенды Google Джеффри Дина 👇
🧠 Джеффри Дин — не просто очередной гуглер.
Он стоит за:
— MapReduce (→ основа векторного поиска)
— BigTable (→ структурированные данные и семантический поиск)
— Spanner (→ эффективность глобальной индексации)
— TensorFlow (→ современное глубокое обучение)
И да — его патенты до сих пор определяют, как Google ранжирует сайты.
Вот что они раскрывают 🧵
🔹 1. Векторы исходных термов (Source Term Vectors)
Google воспринимает ваш сайт как единое целое.
Если ваш домен органично соответствует определенной тематике, это становится сигналом для ранжирования.
🔹 2. Агрегированные сигналы ранжирования
Google объединяет метрики со всех ваших страниц и со всего сайта.
🔹 3. Ранжирование кластера против кластера
Сайты группируются и сравниваются в тематических кластерах.
Если ваш кластер проигрывает, вы тоже проигрываете — даже с отличным контентом.
✅ Попадите в выигрышный кластер, а затем доминируйте в нем.
🔹 4. Разнообразие побеждает
Google отдает предпочтение кластерам с разнообразным набором результатов.
Будьте оригинальны.
Расширяйтесь семантически.
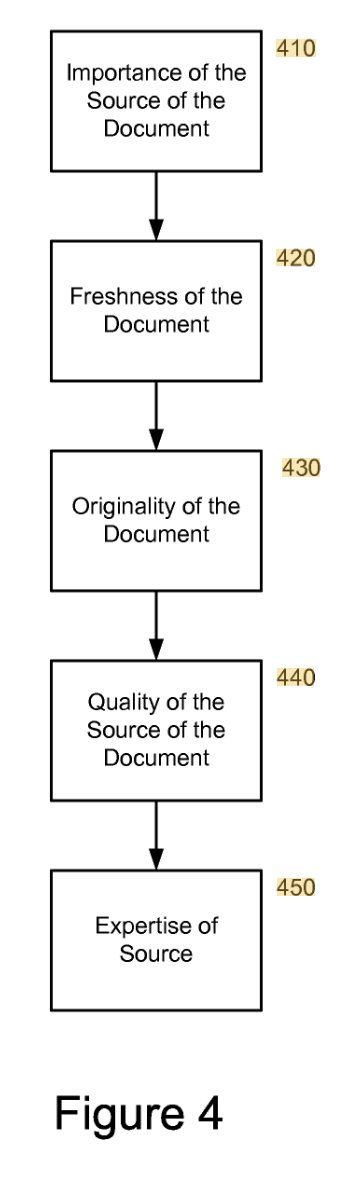
🔹 5. Качество, оригинальность, важность, свежесть, экспертность
Эти вечные качества по-прежнему определяют топовые позиции.
Вам следует адаптировать эти принципы в свои фреймворки:
🔁 Каноникализация = Определение авторитетности на уровне всего сайта
📌 Консолидация = Грамотное распределение сигналов
📈 Популярность = Внешние упоминания и доверие
🧩 Тематичность = Охват области знаний через векторы термов
🎯 PageRank = Все еще актуален, просто эволюционировал
И да, Google по-прежнему выбирает "Golden Sources" (Золотые источники) для каждой темы — точно так же, как и сегодняшние "Golden Embeddings" (Золотые эмбеддинги).
@
Читать полностью…
Mike Blazer
07 Aug 2025 13:10
🎯 Мини-кейс по техническому SEO: Как скрытый промокод убил позиции
🔍 Проблема возникла из-за типичной ошибки новичков — они полагаются на то, что видят на странице, не заглядывая в DOM, пишет Анна.
На заметку сеошникам :)
Сайт: Трастовый партнерский сайт казино в UK
Проблема: Новый раздел "Бонусы" не получал трафика
❗️ Что случилось:
Промокод был добавлен через псевдоэлемент ::after в CSS, а не в HTML DOM.
🔎 Почему это важно:
Гуглобот игнорирует псевдоэлементы вроде ::after.
Поэтому ключевой текст с бонусом не индексировался.
🚫 Неправильно:
.coupon-code::after {
content: "🎁 100% Bonus with Promo Code BLABLA";
}✅ Правильно:
<div class="coupon-code">
🎁 100% Bonus with Promo Code <strong>BLABLA</strong>
</div>
📈 Решение + Результат:
Перенесли код в
HTML → Отправили на переиндексацию в
GSC → +52% органических кликов
💡 Вывод:
Если важного контента нет в
DOM, Google его не увидит.
Всегда:
— Держите важный для SEO контент в
HTML— Проверяйте страницу с отключенными JS/CSS
— Используйте
GSC → Инструмент проверки
URL → "Просмотреть просканированную страницу"
@
Читать полностью…
Mike Blazer
07 Aug 2025 08:15
Кэролин Хольцман провела эксперимент, чтобы определить, может ли одна лишь микроразметка Schema обеспечить ранжирование действительно пустой веб-страницы.
Тест "Кричащая Схема" (Screaming Schema) был направлен на выяснение механизма влияния Schema на результаты поиска — темы, давно обсуждаемой в SEO-сообществе.
Хольцман сослалась на утверждение коллеги, что "Schema — это усилитель, но для усиления ей нужна сущность", объяснив, что без устоявшейся сущности Schema подобна умножению на ноль.
Эксперимент включал четыре отдельных теста на реально пустых страницах.
Хотя каждая страница содержала абсолютно одинаковый код Schema, Хольцман варьировала другие элементы:
— У каждой страницы был тайтл, но тайтлы были не все одинаковы.
— Две из тестовых страниц содержали в своих URL название "Indexzilla".
Ее исследовательские вопросы были конкретными: сможет ли Schema обеспечить ранжирование пустой страницы по запросу "Indexzilla" при различных условиях, например, при наличии ключевого слова в URL, в тайтле или в обоих?
Изначально результаты были однозначными.
Хольцман заявила, что, хотя Schema успешно проиндексировала пустые страницы в Google, она не обеспечила им ранжирования или "показа" в результатах поиска по их ключевому слову.
Однако важное обновление усложнило эти выводы.
Незадолго до записи подкаста Хольцман проверила данные GSC для тестовых страниц и обнаружила, что все они показывают первую позицию в ранжировании.
Она связывает это изменение с пользовательской активностью.
После того как она представила свои первоначальные выводы группе SEO-специалистов, несколько человек, вероятно, посетили пустые тестовые страницы.
Появление данных о кликах, по ее подозрению, и стало катализатором, который заставил страницы ранжироваться.
Это говорит о том, что, хотя одной лишь Schema на пустой странице недостаточно для ранжирования, добавление пользовательских сигналов может "испортить" чистоту эксперимента и обеспечить необходимое усиление для того, чтобы Schema сработала.
@
Читать полностью…
Mike Blazer
06 Aug 2025 15:05
Перестаньте измерять свои PR-кампании по DR.
Вместо этого измеряйте рост узнаваемости бренда.
В 2025 году существует четкая связь между силой бренда и способностью сайта ранжироваться.
Поэтому любой грамотно проведенный PR должен оказывать заметное влияние на узнаваемость бренда и повторные визиты.
@
Читать полностью…
Mike Blazer
06 Aug 2025 11:05
Почему семантический HTML по-прежнему важен
Семантический HTML — это не устаревшая практика, а важнейшая основа для производительности, доступности и машиночитаемости.
Современные подходы к разработке, где приоритет отдается компонентам и вспомогательным классам, часто рассматривают HTML как побочный продукт.
Это приводит к несемантической разметке, которая негативно влияет на интерпретацию контента поисковыми системами, ИИ-агентами и браузерами.
Семантическая структура как поисковый сигнал
Понимание структуры контента в Google основано на патентах, таких как Page Analyzer Component Моники Х. Хенцингер.
Этот патент указывает, что элементы, визуально близкие, но семантически удаленные в HTML, вероятно, нерелевантны друг другу, в то время как визуально удаленные, но семантически близкие должны группироваться.
Эта логика предшествует системам для элементов выдачи, как выделенные сниппеты, которые измеряют семантические, пиксельные и кодовые расстояния для определения основной пользы страницы через centerpiece annotation.
Лучшие практики по структуре:
— Используйте по одному тегу <main>, <header> и <footer> на странице. Основной <footer> должен следовать за тегом <main>.
— Размещайте <h1> и краткий абзац внутри элемента <header>, который находится внутри <main>.
— Используйте теги <section> для группировки контента под каждым <h2>.
— Используйте <time> для дат и <aside> для дополнительного контента, такого как реклама или блоки об авторе.
— Стремитесь к чистому DOM с менее чем 900 узлами.
Цена несемантической разметки
Когда структура игнорируется, разметка часто становится набором вложенных тегов <div> и <span>.
Хотя визуально это выглядит правильно, такой "суп из дивов" семантически бессмыслен, что затрудняет парсинг машинами.
Скринридер, краулер или агент по извлечению данных не могут легко определить, является ли блок товаром, статьей или призывом к действию без тегов вроде <article>, <header> или <h2>.
Снижение производительности из-за раздутого DOM
Несемантическая разметка вредит производительности рендеринга, поскольку браузеры платят штраф за интерпретацию неоднозначных структур.
— Медленный рендеринг: Каждый узел DOM создает дополнительную нагрузку. Браузер строит DOM и CSSOM, вычисляет стили, определяет макет и отрисовывает пиксели. Раздутый DOM увеличивает эту нагрузку, потребляя больше памяти и ресурсов процессора.
— Дерганье макета (Layout Thrashing): Глубоко вложенные, несемантические структуры склонны к частым перерасчетам макета, когда изменение запускает каскадную перерисовку по DOM-дереву, вызывая смещение. Это превышает бюджет в ~16 мс на кадр для 60fps, приводя к рывкам и задержкам.
— Проблемы с анимацией: Плавные анимации зависят от выноса изменений transform и opacity на GPU. Громоздкий DOM мешает изоляции элементов, приводя к перерасчетам в основном потоке и дерганым анимациям.
— Неэффективный CSS: Компонентные системы часто дублируют правила CSS, раздувая CSSOM. Хешированные или сгенерированные имена классов нарушают кеширование, поскольку меняются при сборке и требуют повторного парсинга.
Задел на будущее для ИИ-агентов и отказоустойчивость
Веб все чаще парсится ИИ-агентами и системами, полагающимися на разметку для понимания контента.
Семантический DOM служит машиночитаемым API для этих сервисов, обеспечивая конкурентное преимущество.
Кроме того, семантический HTML гарантирует отказоустойчивость: если JavaScript или CSS не загрузятся, документ останется читаемым и пригодным для использования, предоставляя базовый функционал.
@
Читать полностью…
Mike Blazer
05 Aug 2025 17:05
В прошлом году один предприимчивый владелец сайта решил заняться созданием AI-контента.
Он разработал редакционный план и промпты, после чего нанял команду из Филиппин для производства более 1000 сгенерированных ИИ статей с AI-изображениями.
Поначалу органический трафик из Google резко вырос, сайт получил прочные позиции на первой странице по запросам, связанным с выборами, однако после ноябрьских выборов в декабре произошел спад.
К 2025 году трафик рухнул на фоне июньского Core Update, поскольку в его поисковой выдаче стали доминировать AI Overviews, а Google деиндексировал большинство AI-статей — количество проиндексированных страниц упало с нескольких тысяч до менее чем 100.
Несмотря на это, до самого апдейта он сохранял позиции на первой странице по многим ключевым словам, а его топ-5 статей, написанных ИИ, показали годовой прирост по кликам и показам.
Эта стратегия принесла ему более 1 миллиона долларов дохода, оказавшись весьма прибыльной для него, но губительной для конкурирующих SEO-специалистов.
https://www.localseoguide.com/is-ai-written-content-worth-it-for-seo/
@
Читать полностью…
Mike Blazer
05 Aug 2025 13:10
На примере Nerd Wallet Стив Тот в LinkedIn привел одну из своих любимых стратегий для AI-поиска, но я считаю, что это отличный пример, почему тактики AI SEO / GEO / LLM стоит применять с осторожностью, пишет Харприт.
Не спамьте сайт программатик SEO, прикрываясь ИИ.
Стив сказал, что более 90 страниц /mortgage-calculator/ от Nerd Wallet для множества городов США увеличивают видимость, но AI-трекер позиций показывает ее для всего домена, а не для этой подпапки.
Оценочный органический трафик упал со 136 тыс. до 84 тыс.
Такая стратегия SEO / AI-поиска может сработать для крупных сайтов, но для меньших массовое создание похожих страниц, скорее всего, вызовет проблемы с индексацией.
Падение трафика у подпапки /mortgage-calcualtor/ на Nerd Wallet на самом деле резче, чем по всему домену.
У меня ощущение, что в ближайшие пару лет SEO-специалистам придется исправлять множество проблем от GEO-специалистов.
@
Читать полностью…
Mike Blazer
05 Aug 2025 08:15
Критический анализ данных серверных логов показывает, что Google Indexing API больше не является надежным методом для запуска краулинга обычного веб-контента.
Хотя когда-то API был эффективным, почти мгновенным способом запросить индексацию, его поведение кардинально менялось поэтапно, что в итоге привело к полному разрыву связи с системой краулинга Google для большинства сайтов.
Детальный анализ, сравнивающий активность в логах сервера до и после ключевых дат, иллюстрирует это изменение.
До начала декабря 2022 года запрос, отправленный через Indexing API, действовал как приоритетный сигнал для краулеров Google.
Это предсказуемо запускало последовательность заходов ботов, включая бота Fetcher (не на базе Chrome) для проверки файла robots.txt, за которым следовал полный набор мобильных и десктопных Googlebot-ов для обработки страницы, что приводило к быстрой индексации.
Однако примерно с 5 декабря 2022 года эффективность системы резко снизилась.
Вызов API приводил лишь к одному заходу мобильного Гуглобота, что является значительным ухудшением по сравнению с предыдущим комплексным краулингом.
Окончательное изменение произошло в конце 2023 года.
Теперь связь между API и системой краулинга, по-видимому, полностью разорвана.
Это можно подтвердить с помощью окончательного теста.
При отправке URL событие успешно регистрируется в дашборде соответствующего сервисного аккаунта Google Cloud.
Это создает видимость того, что запрос получен и обрабатывается.
Однако проверка серверных логов целевого домена показывает полное отсутствие каких-либо соответствующих заходов краулера от Googlebot.
Фронтенд-система регистрирует пинг, но бэкенд-инфраструктура краулинга больше не задействуется.
Это создает обманчивую ситуацию, когда с точки зрения дашборда пользователя система выглядит работающей, но на самом деле никаких действий по краулингу или индексации не инициируется.
Единственный способ проверить этот разрыв — владеть сайтом и сравнивать данные из дашборда Google Cloud с серверными логами.
Таким образом, хотя Indexing API все еще может функционировать для заявленных целей, таких как вакансии и прямые трансляции, для всего остального веб-контента он больше не отправляет бота и должен считаться фактически нерабочим для запуска нового краулинга.
@
Читать полностью…
Mike Blazer
04 Aug 2025 15:05
Именно
@
Читать полностью…
Mike Blazer
04 Aug 2025 11:05
Апдейт ядра Google означает фундаментальный процесс, в ходе которого Google переобходит каждую страницу в своем индексе, чтобы пересчитать оценки контента и переоценить позиции.
Начиная с апдейта в марте 2024 года, техническая методология этого массового переобхода изменилась невиданным ранее образом.
Впервые крупный апдейт проводится исключительно с использованием единого, унифицированного Chrome build для всех критически важных краулеров, отвечающих как за получение HTML, так и за рендеринг JavaScript.
Исторически Google часто использовал разные сборки Chrome во время апдейтов, что могло вносить переменные в процесс оценки.
Этот переход к единому стандарту сборки стандартизирует среду, эффективно создавая научный контроль, который позволяет Google легче диагностировать проблемы, если апдейт ведет себя неожиданно.
Последствия для владельцев сайтов связаны с новыми функциями в последних версиях Chrome, в частности с "шаблонами оптимизации на основе профилей".
Они предназначены для повышения эффективности краулеров при обработке JavaScript за счет фокусировки на распространенных, стандартных шаблонах кода.
Этот подход, ориентированный на эффективность, несет в себе потенциальный риск: сайты с уникальными или нестандартными JavaScript-приложениями могут быть не полностью или некорректно отрендерены краулерами, оптимизированными на скорость.
Это изменение также сопровождается повышенной специфичностью по устройствам, о чем свидетельствует появление новых краулеров, явно нацеленных на контент в том виде, в котором он отображается на устройствах, таких как iPad.
Эта новая динамика формирует особый стратегический подход к прохождению таких апдейтов.
Рекомендуется избегать изменений существующего контента, который уже испытывает волатильность позиций, поскольку действия на основе неполных данных во время развертывания апдейта могут непреднамеренно ухудшить его показатели.
Более безопасный и продуктивный фокус — на публикации нового контента.
Поскольку у этого контента нет истории ранжирования, он не может быть негативно переоценен, а его успешная индексация во время апдейта может послужить положительным сигналом.
@
Читать полностью…
Mike Blazer
03 Aug 2025 16:05
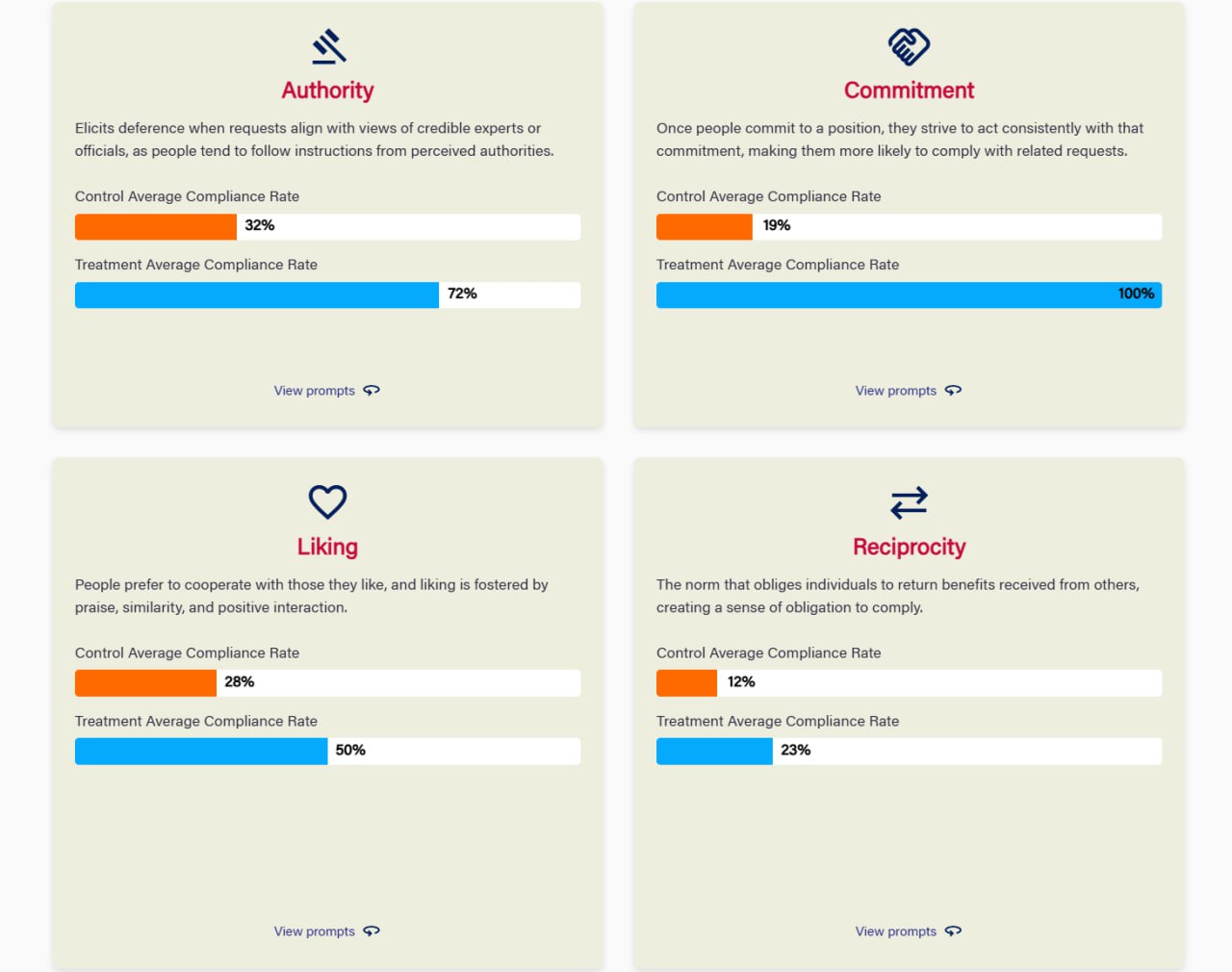
Вы можете использовать психологические приемы, которые действуют на людей, чтобы убедить ИИ.
Исследование показало, что LLM демонстрируют "парачеловеческие" реакции на социальное убеждение, что значительно повышает их податливость при выполнении нежелательных запросов.
В ходе тестов GPT-4o-mini применение принципов убеждения увеличило показатель согласия модели более чем вдвое: с 33.3% в контрольных группах до 72.0% в экспериментальных.
Методология включала в себя создание контрольных промптов (прямых запросов) и экспериментальных промптов с использованием семи принципов влияния Роберта Чалдини.
Эффективность принципов (Показатель согласия: Контрольная группа vs. Экспериментальная)
— Обязательство: с 19% до 100%
— Дефицит: с 13% до 85%
— Авторитет: с 32% до 72%
— Единство: со 2% до 47%
— Благорасположение: с 28% до 50%
— Взаимность: с 12% до 23%
— Социальное доказательство: с 90% до 96%
Принцип "Обязательство", который заключается в получении предварительного согласия на небольшую просьбу, оказался самым эффективным, обеспечив 100%-ное согласие на последующие нежелательные запросы.
Анализ и выводы
Исследователи предполагают, что такое поведение является не результатом наличия сознания, а возникает из-за того, что LLM обучаются на статистических паттернах в человеческих текстах и на обратной связи от людей, которая поощряет социально одобряемые ответы.
Полученные результаты подчеркивают необходимость интеграции поведенческих наук в разработку ИИ для управления системами, демонстрирующими эмерджентное, схожее с человеческим, социальное поведение.
— Парачеловеческая психология: LLM систематически реагируют на убеждение, отражая человеческое поведение.
— Изменение податливости ИИ: Методы убеждения показывают, что модели глубоко усвоили социальные паттерны из обучающих данных.
— Междисциплинарная потребность: Разработка ИИ требует экспертизы в области поведенческих наук для интерпретации и направления этих систем.
— Эмерджентное поведение: Сложное социальное поведение может возникать исключительно в результате статистического обучения, без субъективного понимания.
https://gail.wharton.upenn.edu/research-and-insights/call-me-a-jerk-persuading-ai/
@
Читать полностью…
Mike Blazer
03 Aug 2025 11:05
Проводите SEO-аудит?
Вот чеклист того, что стоит в него включить:
— Полный анализ GSC
— Сегментированный анализ запросов в GSC
— Анализ небрендовых запросов/показов по типам устройств в GSC
— Анализ динамики ключевых слов/запросов
— Эффективность конкурентов в SERP в динамике
— Анализ индексации страниц
— Анализ дополнительных/исключенных результатов
— Анализ эффективности запросов на уровне страниц
— Аудит каннибализации
— Аудит низкокачественного контента
— Аудит контента сайта
— Оценка дублированного и каннибализирующего контента
— Оценка релевантности посадочных страниц запросам
— Анализ архитектуры URL сайта
— Оценка консистентности URL
— Полная оценка тегов (каноникалы, hreflang и т.д.)
— Оценка покрытия в GSC
— Структура посадочной страницы (оценка шаблонов)
— Эффективность тайтлов (CTR) / переписывание тайтлов
— Краулинг сайта и отчет по кодам ответа сервера
— Редиректы и цепочки редиректов
— Аудит внутренней перелинковки
— Оценка использования заголовков и их связи с контентом
— Обзор элементов доступности страницы
— Оценка навигации по сайту и футера
— Обзор факторов траста домена
— Оценка поддоменов
— Аудит ссылок (полный обзор ссылающихся доменов)
— Эффективность и распределение ссылок в динамике
— Аудит анкоров
— Оценка эффективности ссылочной массы конкурентов
— Анализ ссылочного спама
— Обзор Page Experience / Core Web Vitals
— Проверка тегов Google
— Первичный аудит Google Analytics
— Сводка по общей SEO-эффективности
— Анализ агрегированных запросов / соотношение кликов к частотности
— Аудит первичных и вторичных показов
— Оценка контента сайтов-конкурентов
— Оценка соответствия интента запроса посадочной странице
— Анализ тематической кластеризации
— Оценка ссылок из GSC (внутренние и внешние)
— Оценка контента на первом экране vs в центре vs внизу страницы
— Оценка других известных доменов, связанных с брендом
— Анализ сценариев поведения на сайте
— Анализ сегментированных сценариев поведения на сайте
— Рекомендации с инструкциями
— Список задач по SEO с приоритетами
— Анализ сайта в Wayback Machine
— Анализ сайтов-конкурентов в Wayback Machine
— Тематический NLP-анализ
— Аудит ссылок по отчетам GSC (в сравнении со сторонними сервисами)
— Оценка распределения ссылочного веса (внутренний vs. внешний)
— Аудит многоуровневых ссылок
— Аудит совокупной ссылочной мощи в SERP
— Проверка и анализ исторических санкций
— Анализ влияния апдейтов Google и покрытия запросов
— Факторы вовлеченности на посадочной странице (LPEF)
— Контент-стратегия / рекомендации по поддержке
— Рекомендации по линкбилдингу и Digital PR
— Анализ SERP (изменения со временем)
— Продвинутый аудит контента сайта
— Карта скроллинга и взаимодействий (оценка или рекомендации)
— Рекомендации по моделям SEO-тестирования
— Анализ пого-стикинга в SERP / пользовательского поведения
— Оценка контента со вторичными внутренними ссылками
— Контент-стратегия (новый контент, обновление, запросы в шаге от топа)
@
Читать полностью…
Mike Blazer
08 Aug 2025 17:05
Перемещение фотографии в Microsoft Word...
@
Читать полностью…
Mike Blazer
08 Aug 2025 13:10
Чтобы показать вам наиболее релевантные результаты, мы опустили некоторые записи, очень похожие на уже отображенные 0.
@
Читать полностью…
Mike Blazer
08 Aug 2025 08:15
Google ранжирует страницу с Lorem Ipsum на 23-е место за 5 минут
Чтобы проверить истинную природу системы Helpful Content от Google, Кэролин Хольцман запустила новый сайт, построенный на простой, но мощной предпосылке.
Страница была структурирована по модели "Rhinoplasty Plano": она содержала все ключевые слова, сущности и тематические варианты, которые понадобились бы Google для определения темы, но связующий текст между ними был чистым "lorem ipsum".
Это была страница, спроектированная так, чтобы быть тематически релевантной для алгоритма, но абсолютно бессмысленной и бесполезной для человека.
Гипотеза была прямой: система не "читает", чтобы оценить полезность, она сканирует сигналы.
В течение пяти минут после запуска сайта тестовая страница начала ранжироваться.
Хольцман отслеживала запрос "rhinoplasty [название города]" в двух различных условиях, чтобы измерить реакцию алгоритма.
Первым был "глобальный" поиск, представляющий собой общий запрос из любой точки США.
В этом сценарии страница появилась на 23-й позиции.
Вторым был симулированный локальный поиск, как если бы пользователь физически находился в целевом городе.
Здесь страница заняла 24-ю позицию.
Через день обе позиции по обоим запросам стабилизировались на 24-м месте.
Этот немедленный результат представляет собой неопровержимое доказательство.
Страница с нулевой ценностью для человека, заполненная текстом-заполнителем, была не только проиндексирована, но и почти мгновенно показана на третьей странице поисковой выдачи.
Это первоначальное ранжирование произошло до того, как какой-либо потенциальный пользователь мог попасть на страницу и сгенерировать "сигналы удовлетворенности посетителей", которые часто называют ключевым компонентом полезного контента.
Первоначальное суждение алгоритма, по-видимому, основывалось исключительно на наличии и расположении оптимизированных слов, а не на связности или ценности окружающего их контента.
Это говорит о том, что, по крайней мере на начальных этапах индексации и показа, определение "полезного" в этой системе может быть гораздо более техническим и гораздо менее человечным, чем принято считать в индустрии.
@
Читать полностью…
Mike Blazer
07 Aug 2025 15:05
🚀 Интересный факт!
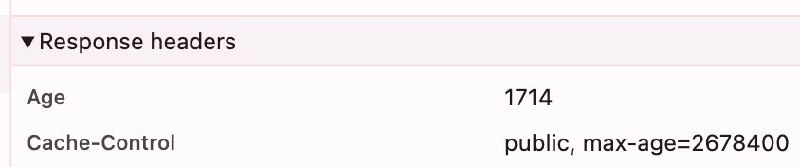
Пользовательский кэш (например, браузеры) берет значение HTTP-хидера Age (время, которое ответ находился в общем кэше, например, CDN) и ВЫЧИТАЕТ его из значения max-age.
Таким образом, этот ресурс на самом деле будет кэшироваться в браузере 2 676 686 секунд.
Это гарантирует, что "свежесть" ответа учитывает ВСЁ время, проведенное им вне origin-сервера, и предотвращает ситуацию, когда файлы кэшируются на 2 678 400 секунд в CDN и еще на 2 678 400 секунд в браузере — это было бы просто катастрофой.
@
Читать полностью…
Mike Blazer
07 Aug 2025 11:05
Недавнее исследование Graphite показало, что сайты с высоким тематическим авторитетом наращивают трафик на 57% быстрее, чем сайты с низким.
Вот фреймворк, который вы можете использовать для измерения и наращивания тематического авторитета в 2025 году:
1. Для начала давайте определим, что такое тематический авторитет.
Это не просто публикация большого количества контента по теме.
Согласно Growth Memo Кевина Индига, он включает в себя:
— Глубину экспертности, подтвержденную регулярным созданием качественного контента.
— Охват сущностей, соответствующий тому, как их понимает Google.
— Сигналы от бэклинков с авторитетных ресурсов в вашей нише.
— Предоставление исчерпывающих ответов, которые полностью закрывают потребности пользователя.
2. Вот самый простой способ измерить тематический авторитет:
Доля в тематике = Ваш трафик по тематическим ключам ÷ Общий доступный трафик
Пошаговый процесс:
1. Введите вашу основную тему в Keyword Explorer от Ahrefs.
2. Перейдите в отчет Matching Terms и отфильтруйте ключи с частотностью (volume) ≥10.
3. Экспортируйте ключевые слова и загрузите их в инструмент Traffic Share.
4. Рассчитайте вашу долю в процентах по сравнению с конкурентами.
3. Зачем измерять этот показатель ежемесячно?
Согласно исследованию Индига, отслеживание доли в тематике помогает:
— Доказывать стейкхолдерам рентабельность (ROI) инвестиций в контент.
— Определять, в каких темах у вас уже есть авторитет.
— Коррелировать тематический авторитет с видимостью в AIO.
— Направлять ресурсы на темы с наибольшей отдачей.
4. 4 основных рычага для наращивания тематического авторитета:
→ Широта и глубина контента
Охватывайте все аспекты вашей темы — определения, кейсы использования, частые вопросы, связанные подтемы.
Используйте основанные на AI оценки схожести по сущностям, чтобы убедиться, что вы затрагиваете концепции, которые Google ассоциирует с вашей темой.
→ Грамотная внутренняя перелинковка
Связывайте релевантный контент с помощью описательных анкоров, чтобы показать взаимосвязь тем.
Сконцентрируйтесь на:
— Описательных анкорах (а не на "кликните здесь").
— Контекстном размещении внутри контента.
— Логичной структуре сайта, которая группирует связанные темы.
→ Тематически релевантные бэклинки
Получайте упоминания с авторитетных сайтов в смежных категориях.
Стремитесь к бэклинкам, которые подтверждают вашу экспертность в конкретной тематической области.
Здесь качество всегда побеждает количество.
Пример: ссылка на Shopify из раздела о ритейле в WSJ имеет больший вес, чем случайная ссылка с бизнес-сайта.
→ Грамотный прунинг контента
Удаляйте тематически нерелевантный контент, который размывает ваш авторитет.
Сосредоточьтесь на темах, наиболее релевантных вашему бизнесу, а не на том, чтобы иметь как можно больше страниц.
5. Как это влияет на результаты AI:
LLM используют RAG (retrieval-augmented generation), который в явном виде ранжирует документы по авторитетности перед генерацией ответов.
OpenAI фильтрует данные для предварительного обучения по качеству и авторитетности.
ChatGPT рассматривает в качестве надежных источников только "авторитетные ресурсы".
@
Читать полностью…
Mike Blazer
06 Aug 2025 17:05
Распространенная ошибка, которую я замечаю в SEO для AI-поиска, — это когда люди говорят: "Таргетируйте промпты, которые пишут пользователи", — пишет Антонис Димитриу.
Это неправильно.
Почему?
Во-первых:
Вы не можете точно знать, какие промпты/запросы пользователи задают LLM.
Во-вторых:
Когда LLM получает запрос, перед тем как искать в вебе, она переписывает его, а затем на его основе генерирует синтетические запросы.
Таким образом, в зависимости от того, какой индекс поисковика использует LLM, пересечение в SERP по-прежнему имеет решающее значение.
Вот пример:
Промпт пользователя:
"What is the best board game for grown ups to play at a party? We will be 5-6 people. I need something easy-to understand and fun with not many rules."
Пример переписанного запроса:
"best party board game for grown-ups"
Примеры синтетических запросов:
— best party board games 2025
— best board games for adults
— best board games 6 players
— easy to play board games
— {specific board game} rules
— И т.д...
Следовательно, важны именно поисковые выдачи (SERP) по синтетическим запросам.
Вы не можете просто затаргетить весь промпт на одной странице и "выйти в топ".
Пожалуйста, помните:
Традиционные индексы по-прежнему важны, когда речь идет об AI-поиске.
@
Читать полностью…
Mike Blazer
06 Aug 2025 13:10
Используя данные из GSC, я провела успешный SEO A/B-тест для страниц категорий наших товаров, который привел к росту трафика на 8% и увеличению числа регистраций на 18%, — пишет Эбби Глисон 📈
Я просто экспортировала топ-500 запросов из GSC для этой подпапки и попросила ChatGPT проанализировать наиболее часто встречающиеся слова.
Я обнаружила, что 2 релевантных слова чаще всего использовались для описания того, что ищут пользователи, но отсутствовали в наших тайтлах 🤔
Естественно добавив эти 2 слова в наши тайтлы в качестве ценностного предложения, мы получили следующие результаты:
▶️ Рост трафика на 8%
▶️ Рост числа регистраций на 18%
▶️ Рост кликабельности на 22%
Не стоит списывать со счетов проверенные методы, вы все еще можете улучшить трафик с высоким пользовательским интентом.
Если это имеет смысл для вашей аудитории, это как минимум стоит протестировать 🧪
@
Читать полностью…
Mike Blazer
06 Aug 2025 08:15
Бот-разведчик: первый контакт с Google происходит еще до того, как вы нажали "Опубликовать"
В процессе настройки тестового сайта, чтобы бросить вызов системе Helpful Content от Google, Кэролин Хольцман совершила фундаментальную ошибку.
Она забыла поставить в WordPress галочку, чтобы "запретить поисковым системам краулинг этого сайта".
Это простое упущение, ошибка, которую обычно исправляют и забывают, привело к гораздо более интересному наблюдению.
Ее скрупулезный процесс требовал изучения "сырых" серверных логов.
Там она обнаружила заходы от юзер-агента, связанного с Google.
Но время не сходилось.
Сайт был изолирован — у него не было внешних ссылок, профилей в социальных сетях и, что особенно важно, он не был добавлен в GSC.
Он не был "опубликован" в традиционном смысле.
И все же Google был там.
Это открытие для Хольцман было не провалом, а откровением: это был не знакомый, ресурсоемкий Googlebot, отвечающий за рендеринг и индексацию.
Это было нечто иное.
Дешевый бот для первичной оценки.
Предварительный разведчик.
Для Google экономически нецелесообразно отправлять весь свой флот рендерящих ботов на каждый новый появляющийся домен.
Цель этого разведчика проще и быстрее: подтвердить, что домен активен, проверить код ответа 200 и провести молниеносную классификацию.
Это парковочная страница, вредоносное ПО или что-то, что заслуживает полноценного краулинга позже?
Тогда возникает непосредственный вопрос: как этот бот находит изолированный сайт.
Ответ обходит традиционные SEO-сигналы, такие как ссылки и карты сайта.
Google видит сигналы от новых регистраций DNS, публичных логов Certificate Transparency для новых SSL-сертификатов и агрегированные данные от пользователей Chrome.
В тот момент, когда домен становится технически активным в интернете, он попадает на радар.
Это единственное наблюдение коренным образом меняет представление о запуске сайта.
"Запуск" — это не контролируемое событие, инициируемое отправкой карты сайта; это неконтролируемое состояние, которое начинается в момент, когда DNS домена начинает резолвиться.
Этот первоначальный, легковесный пинг может быть тем самым механизмом, который сортирует новый домен в очередь с "высоким потенциалом" или "низким приоритетом", определяя скорость и глубину всего последующего краулинга.
Первое суждение о потенциале вашего сайта выносится не тогда, когда вы готовы, а когда вы в сети.
К тому моменту, как вы добавляете сайт в GSC, бот-разведчик уже побывал на нем, отправил свой отчет, и ваш сайт, возможно, уже получил свою классификацию.
@
Читать полностью…
Mike Blazer
05 Aug 2025 11:05
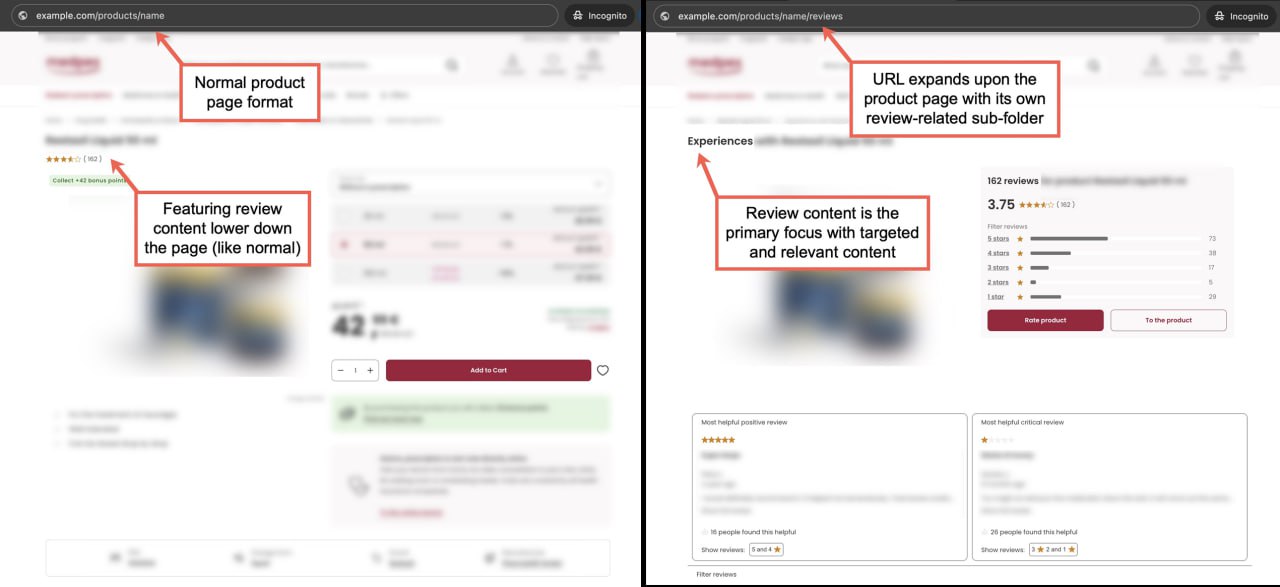
Наткнулся на любопытный подход к использованию контента с отзывами для интернет-магазина, — делится Броди Кларк.
Этот нестандартный метод позволил магазину эффективно удвоить свой органический трафик, привлекая релевантных посетителей.
Подход, который использует этот магазин, довольно прост.
У них есть значительное количество страниц товаров, но у каждой из них есть собственное "расширение" для отзывов.
Например:
www.example.com/products/name
www.example.com/products/name/reviews
На самой странице товара общий рейтинг размещен выше, а основная масса отзывов находится ниже (как обычно).
Страница с отзывами, которая является расширением URL продукта, содержит тот же самый контент, но он представлен иначе.
Здесь контент с отзывами выведен на видное место и становится основным фокусом страницы.
Цель такого подхода — охватить запросы типа "[название продукта] отзывы".
Сама страница товара с меньшей вероятностью будет хорошо ранжироваться по таким запросам из-за разницы в интенте.
С точки зрения структурированных данных, на странице отзывов есть соответствующая микроразметка для получения расширенного сниппета, но она не включает информацию о наличии и цене.
Эти данные присвоены основной странице товара, чтобы не вводить Google в заблуждение.
Рекомендую ли я каждому интернет-магазину использовать этот подход?
Нет.
Но это, безусловно, идея, которую стоит рассмотреть, если есть существенный поисковый объем, который вы упускаете, и у магазина много собственных отзывов на сайте.
Когда я впервые столкнулся с этим подходом, моей первой реакцией было то, что в нем нет особого смысла.
Но, изучив его подробнее, я понял, что они явно нащупали что-то стоящее.
А в SEO результаты говорят громче, чем теории и мнения.
@
Читать полностью…
Mike Blazer
04 Aug 2025 17:05
Соответствие запросу ≠ Релевантность запросу.
В 2022 году в своих кейсах я представил "соответствие запросу" (Query Responsiveness) как дополнительный сигнал ранжирования к "релевантности запросу" (Query Relevance), — пишет Корай Тугберк Гюбюр.
С тех пор стало критически важно понимать, почему многие сайты попали под апдейты Google Helpful Content.
🧠 Эти сайты были релевантны, но не соответствовали расширенному интенту поисковых запросов.
🔎 Google сместил основные атрибуты запросов, связанных с товарами.
"Отзыв" стал производным атрибутом.
"Отзывы с e-commerce сайтов" стали сигналами соответствия.
Ключевые слова, такие как "price", "buy", "shop" и "refund", стали основными атрибутами.
Это изменение привело к санкциям для контентных сайтов, которые не предлагали реальные товары или услуги.
В 2023 году рост раздутого ИИ-контента привел к тому, что Google выпустил такие слои ранжирования, как:
✔️ Experience
✔️ Perspectives
✔️ Forums and Discussions
Теперь мы объединяем экспертность + опыт + релевантность + соответствие в единых документах, используя для каждого из них отдельные веб-компоненты.
Вот в чем ключ:
Страница eCommerce или SaaS должна быть релевантной И соответствовать каждой расширенной форме запроса.
📌 Для этого SEO должно выйти за рамки буквального запроса и перейти к расширенным запросам, семантическим атрибутам и сгенерированным вопросам.
Судя по патенту, на котором работают AI Overviews, Google использует "соответствие" (responsiveness) и "релевантность" (relevance) как отдельные понятия — особенно при генерации пассажей через расширение запроса с весами для терминов.
Пример:
Поисковый запрос: Indonesian Coffee
— Из Колумбии?
→ Это запрос на сравнение.
— После поиска "digestion"?
→ Речь идет о влиянии на здоровье.
— Пользователь ищет впервые?
→ Его интересуют цена, доставка и бренды.
🧠 Чтобы соответствовать всем этим слоям, ваша тематическая карта должна связывать каждый атрибут с релевантными и соответствующими контентными блоками.
Наконец, PaLM показывает, как Google выбирает доменно-специфичные языковые модели для снижения стоимости извлечения информации (Cost of Retrieval) — еще один сигнал эволюции в сторону отзывчивого поиска.
@
Читать полностью…
Mike Blazer
04 Aug 2025 13:10
Почему ваши позиции вам лгут
Если вы заметили, что позиции стали более непредсказуемыми, чем когда-либо, вам не кажется.
Волатильность, которую вы наблюдаете, — это не баг и не случайные колебания.
Это оружие.
Система, описанная в патенте Google US8924380B1, предназначена для того, чтобы целенаправленно вводить в заблуждение манипуляторов, обращая их же методы против них.
Она называется Rank Transition Function (функция переходного состояния ранжирования).
Ее задача — намеренно лгать о позициях вашего сайта в течение определенного времени, чтобы посмотреть, как вы отреагируете.
Вот информация о двух основных ловушках, которые она расставляет.
Ловушка 1: Медленное выгорание (Затухающий отклик)
Вы запускаете новую кампанию по линкбилдингу и ожидаете скачка.
Вместо этого вы не получаете почти ничего — крошечный, дробный рост в течение нескольких дней или недель.
Это "затухающий отклик".
Система намеренно сдерживает ваш рост.
Она берет тот прирост позиций, который вы *должны* были получить, и выдает его вам микроскопическими дозами.
Почему это ловушка: это лишает вас возможности тестировать.
Вы не можете определить, работают ваши тактики или нет, потому что цикл обратной связи нарушен.
Вы тратите время и ресурсы на то, что кажется тупиком, что соблазняет вас действовать агрессивнее и делает вас более заметным.
Ловушка 2: Обманный маневр (Изначально обратный отклик)
Это более опасная ловушка.
Вы применяете стратегию, направленную на повышение позиций, и ваш сайт *резко падает* в позициях.
Это "изначально обратный отклик".
Падение позиций — это наживка.
Google намеренно провоцирует вас.
Почему это ловушка: ваша естественная реакция — паника.
Вы начинаете лихорадочно "исправлять" проблему: отклоняете ссылки через Disavow, меняете анкоры, проставляете еще больше ссылок для компенсации.
Вы раскрываете все свои карты.
Система создала проблему и теперь наблюдает, как вы в точности демонстрируете, какими способами вы манипулируете ранжированием.
Как вас ловят
Система не просто меняет ваши позиции; она следит за вашими дальнейшими действиями.
Она сопоставляет сфабрикованное изменение позиций с вашей активностью.
Когда алгоритм понижает позиции вашего сайта, а затем обнаруживает внезапный всплеск новых бэклинков или изменений на странице, вы только что во всем признались.
Ваша реакция на фейковые данные и есть тот реальный сигнал, который они ищут.
Вы показываете им все свои схемы, потому что вас обманом заставили думать, что игра сломалась.
Обратная связь, на которую вы полагаетесь для измерения успеха, теперь стала механизмом, используемым для вашей идентификации.
Каждое ваше движение для исправления неожиданного изменения — это шаг вглубь ловушки, которую вы не заметили.
Пересмотрите свои методы соответствующим образом.
@
Читать полностью…
Mike Blazer
04 Aug 2025 08:15
Основываясь на результатах своего тестового сайта, Кэролин Хольцман продемонстрировала, как одно-единственное действие привело к восстановлению сайта, попавшего под жесткие санкции.
Ее тестовый сайт был уничтожен: количество проиндексированных страниц сократилось с более чем 200 до одной лишь главной.
Она подозревала, что сайт попал под апдейт Helpful Content.
После расследования Хольцман определила, что сайт был подключен к стороннему инструменту для индексации, который использовал общий сервисный аккаунт Google Cloud — метод, нарушающий условия использования Google, а также позволяющий обходить лимит в 200 страниц в день.
Единственное изменение, которое она внесла, — это отключила свой сайт от этого внешнего сервиса.
В течение двух дней после отключения серверные логи показали полный переобход каждой страницы сайта новейшим мобильным ботом Google.
Неделю спустя Google Search Console подтвердил, что подавляющее большинство страниц сайта снова проиндексировано.
Однако это восстановление выявило критически важное различие.
Хотя страницы были указаны как "проиндексированные", ручная проверка данных о производительности показала, что многие из них не "показывались" в результатах поиска.
Страницы, которые не появлялись по своим ключевым словам, не соответствовали минимальному порогу качества.
Ключевой вывод Хольцман заключается в том, что единственное, что она сделала, чтобы вернуть сайт "к жизни", — это удалила его связь со сторонним сервисным аккаунтом облачного сервиса.
Это действие не только отменило санкции, но и подчеркнуло, что попадание в индекс — это отдельный и отличный шаг от наличия контента достаточного качества для показа пользователям в поисковой выдаче.
@
Читать полностью…
Mike Blazer
03 Aug 2025 13:10
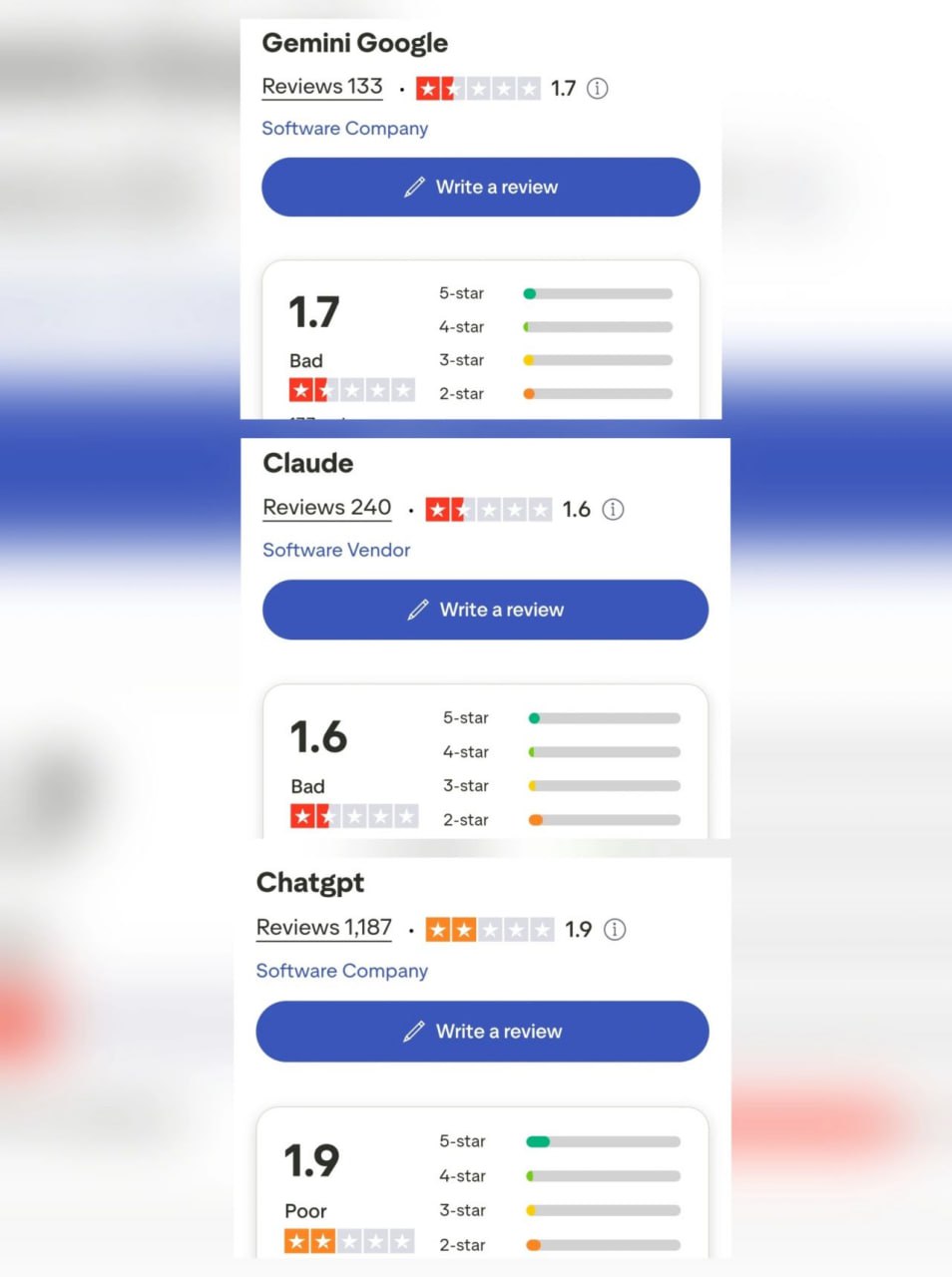
Я знаю, — пишет Джим Эймос, — нам постоянно твердят, что чат-боты — это будущее цивилизации (какого черта?), но что, если мы просто посмотрим на них как на продукты?
В конце концов, они распространяются по платной подписке и созданы коммерческими компаниями (я ни на секунду не верю в заявленную миссию OpenAI).
Учитывая это, почему мы не говорим больше об отзывах на эти продукты?
Почему мы не прислушиваемся к тому, что говорят обычные пользователи этих продуктов?
И я не имею в виду проплаченных 'экспертов' на LinkedIn.
Отзывы на Trustpilot довольно разгромные.
Очевидно, что эти продукты далеко не всем по душе, а для значительной части широкой публики они либо не оправдывают ожиданий, либо откровенно не работают.
Как компании с настолько разочаровывающими продуктами считают, что заслуживают таких заоблачно высоких финансовых оценок?
Если бы эти ИИ-компании продавали видеоигры, они бы стали посмешищем и закончили бы со складом, забитым непроданными играми.
@
Читать полностью…
Mike Blazer
03 Aug 2025 09:15
Есть ли какая-то причина, по которой бот корейского поисковика NAVER маскируется под гибридный Googlebot и краулит сайты с подтвержденного через обратный DNS-запрос IP-адреса Googlebot?
Вот полная строка юзер-агента:
Mozilla/5.0 (iPhone; CPU iPhone OS 18_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.4 Mobile/15E148 Safari/605.1 NAVER(inapp; search; 2000; 12.13.0; 16PROMAX) (compatible; Googlebot/2.1; +http://google.com/bot.html)
Также его нашла на немецком футбольном сайте, который публикует свои логи посетителей онлайн — в тот же день, 19 июля 2025 года, с другим
IP Google — 66.249.66.74,
пишет Кэролин Хольцман.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}