Mike Blazer
29 Aug 2025 17:05
100%
@
Читать полностью…
Mike Blazer
29 Aug 2025 13:10
Google: *дает нам GSC*
Тоже Google: отчеты о падении трафика основаны на "ошибочных методиках"
---
Google: "клики не падают"
Тоже Google:
@
Читать полностью…
Mike Blazer
29 Aug 2025 08:15
Я перестала доверять частотности ключевых слов. Вот мой новый подход
u/Yulia_vankuva перестала доверять частотности ключевых слов как основной SEO-метрике, утверждая, что высокочастотные ключи часто не конвертируют, отражают устаревшее поведение или их трафик перехватывают ИИ-ответы и треды на Reddit.
Теперь она использует более простой процесс, сфокусированный на пользовательском интенте и анализе выдачи, который считает более эффективным.
Ее новая пятишаговая стратегия:
1. Игнорировать начальную частотность: Начинать с длиннохвостых запросов, отражающих "боли" и вопросы юзеров, например "how to do async onboarding without annoying people". Такие запросы быстро появляются в GSC, даже если инструменты показывают нулевую частотность. Для их поиска она использует SEMDash.
2. Анализировать выдачу перед написанием: Изучать SERP, чтобы понять, доминируют ли в ней ИИ, блоги, форумы вроде Reddit или страницы продуктов. Старый форумный тред в топ-5 — сигнал, что Google ищет лучший результат.
3. Делать реверс-инжиниринг топовых страниц конкурентов: Вместо анализа всех ключей конкурента фокусироваться на его 5–10 самых трафиковых страницах. Она определяет ключи, приносящие трафик этим страницам, сравнивает интент с подачей контента и ищет пробелы на TOFU и BOFU этапах воронки.
4. Использовать Surfer AI как инструмент аудита: Прогонять черновики через Surfer AI не для генерации контента, а для реверс-инжиниринга структуры, заголовков, размещения ключей и оптимизации под PAA-блоки топовых результатов. Это используется, чтобы "проверить мое мышление", а не "написать мой пост".
5. Рассматривать бэклинки как подсказки: Фокусироваться на том, *почему* кто-то сослался на страницу конкурента, а не на DA или количестве ссылок. Подача, привлекшая ссылку, становится основой для контент-брифа.
Комментарии сеошников
— Погоня за запросами с частотностью 500+ часто ведет к созданию контента, который не конвертирует или теряется под результатами ИИ, Reddit и YouTube. Лучше начинать с интента: использовать реальные вопросы клиентов, анализировать SERP на предмет пробелов и создавать контент в 10 раз лучше. Частотность придет со временем.
— Стратегия соответствия поисковому интенту — отличная. Инструменты для анализа ключей и трекеры позиций давно неэффективны.
— Один из лучших нишевых сайтов изначально строился на запоминающемся домене с менее чем 100 поисками, прежде чем набрать обороты.
— Длиннохвостые запросы по "болям" юзеров эффективнее высокочастотных ключей, особенно при анализе пробелов в реальной выдаче.
— Продвинутый воркфлоу: экспортировать из GSC все запросы с нулевыми кликами за 90 дней. Их нужно кластеризовать и создавать брифы для кластеров с показами, но без кликов — это выявляет фразы с сильным интентом.
— Перед написанием вручную анализируйте SERP в инкогнито: проверьте PAA-блоки, типы микроразметки и доминирующий объем контента, чтобы не следовать рекомендациям инструментов вслепую.
— После публикации следите за GSC две недели. Если показы не растут, изменение H1 часто повышает CTR быстрее переписывания основного текста.
— Heatmap-анализ показывает, на каких абзацах задерживаются юзеры, помогая убрать "воду" и переместить конвертирующие разделы выше.
— Построение отношений важнее, чем пузомерки. Лучше обмениваться ссылками с релевантными по нише и географии сайтами, а ключевые слова использовать, только когда это логично для клиента.
@
Читать полностью…
Mike Blazer
28 Aug 2025 15:05
Этот инструмент позволяет узнать, является ли человек, бренд, продукт или услуга известной сущностью в графе знаний Google.
https://entities.dejan.ai
---
Расширение для Chrome: извлечение сущностей из поисковой выдачи
Извлекает Google Machine ID (MID) с текущей страницы поисковой выдачи Google.
Google MID Extractor помогает исследователям и SEO-специалистам извлекать Machine ID (MID) из Графа знаний прямо из результатов поиска Google.
Нажмите на иконку расширения, чтобы просканировать текущую страницу выдачи, после чего во всплывающем окне можно будет просмотреть MID, название сущности, ее типы и язык.
Вы можете проверить, существует ли MID в базе данных, и при желании добавить его туда в один клик.
Требует минимальные разрешения и не выполняет удаленный код.
https://chromewebstore.google.com/detail/google-mid-extractor/ldpingjlmnhgfcfpkpkhdbahbmppkedo
@
Читать полностью…
Mike Blazer
28 Aug 2025 11:05
ChatGPT обычно лажает с подбором ключевых слов.
Вот процесс, который использует Deep Research + Ahrefs, чтобы он перестал лажать:
Обычно, когда подбираешь ключи с помощью ИИ-инструментов вроде ChatGPT, результат получается не очень.
Он использует свою текущую базу знаний, чтобы порекомендовать токены, которые в целом соответствуют тематике компании, о которой вы спрашиваете.
Например, когда я прошу его найти потенциальные ключевые слова для компании Domo, он выдает мне широкие, брендовые и не особо полезные запросы, — пишет Крис Лонг.
Однако есть способ сделать ChatGPT НАМНОГО эффективнее в исследовании ключевых слов.
Метод заключается в использовании Deep Research для сбора данных по запросам с последующей проверкой этих данных в реальном инструменте:
1. Определите сайт, который хотите проанализировать, и скопируйте URL.
2. Откройте ChatGPT.
Под иконкой "+" выберите "Deep Research", чтобы активировать эту функцию.
3. Составьте промпт с задачей спарсить маркетинговые тексты с сайта.
Я прошу его пройтись по всем лендингам, блогам и ключевым страницам, чтобы извлечь ключевые фразы, которые могут быть хорошими поисковыми запросами.
Я также прошу предоставить небрендовые запросы.
4. Вы также можете указать, в каком виде хотите получить результат.
Я прошу предоставить всё в виде списка, разделенного запятыми.
5. Затем запустите Deep Research.
ChatGPT пройдется по сайту и на основе текстов определит ключевые запросы.
Обычно это занимает около 15 минут.
6. В итоге ChatGPT должен выдать вам большой список запросов.
Зачастую он намного лучше, чем при использовании одиночного промпта.
7. Наконец, вам нужно будет валидировать полученные данные с помощью инструмента для анализа запросов.
Возьмите список и вставьте его в инструмент (я использую Ahrefs Keyword Explorer).
После этого вы увидите реальные поисковые данные на основе этого процесса.
Этот способ оказался невероятно мощным и генерирует гораздо лучшие результаты, чем одиночные промпты.
Мне даже удавалось с его помощью группировать ключевые слова по тематическим кластерам и анализировать данные конкурентов для получения дополнительных инсайтов.
Также это можно использовать для определения потенциальных тем для промптов или контента.
Так что, если вы используете ChatGPT для исследования запросов, это ЗНАЧИТЕЛЬНО улучшенный процесс.
@
Читать полностью…
Mike Blazer
27 Aug 2025 17:05
Как вывести в топ новый SaaS-инструмент за 6 недель с нулевым бюджетом
u/Available-Weekend-73 рассказал, как за шесть недель вывел в топ новый SaaS-инструмент на свежем домене с нулевым бюджетом, сосредоточившись на обнаруживаемости, а не на традиционной контент-стратегии.
Его подход включал:
— SEO-оптимизированная форма обратной связи: Публичная форма Tally для запросов на функции, с длиннохвостыми ключами во вступлении, проиндексировалась и начала ранжироваться в Google.
— Использование ключевых слов на Reddit: Ответы в нишевых сабреддитах с поисковыми фразами юзеров позволили некоторым комментариям ранжироваться по длиннохвостым запросам и привлекать первых клиентов.
— Размещение в каталогах: С помощью инструмента сайт массово добавили в 200+ нишевых каталогов.
Это сгенерировало около 40 ссылок и реферальный трафик за две недели, помогая сайту быстро попасть под краулинг.
Хотя добавление было единоразовым, Google индексировал ссылки постепенно, поэтому автор считает, что время размещения неважно.
Все это было достигнуто без постов в блоге, холодного аутрича или ИИ-контент-ферм.
Комментарии сеошников
— Кто-то подтвердил, что индексация комментариев на Reddit — недооцененная тактика, отметив, что его комментарии ранжировались раньше основного сайта.
— Другой пользователь возразил, что комментарии на Reddit не могут ранжироваться из-за атрибутов rel noopener nofollow noreferrer и ugc, но все равно генерируют трафик.
— Комментатор согласился, что фокус на видимости по правильному поисковому интенту эффективнее погони за авторитетом домена.
Он поделился, что его лучшие результаты давали поиск упущенных углов, приоритизация интента и быстрые победы через нишевые размещения, что окупалось быстрее выпрашивания бэклинков.
— Сайты редко набирают обороты без блога.
@
Читать полностью…
Mike Blazer
27 Aug 2025 13:10
Креативные методы линкбилдинга в эпоху ИИ
u/WebLinkr предложил креативные стратегии линкбилдинга, подчеркнув их важность для видимости в традиционном поиске и в результатах LLM, использующих поисковые движки.
Среди них: PR на основе данных, совместные маркетинговые партнерства, обмен SEO-услугами, посредничество в обмене ссылками между клиентами, организация митапов и broken link building.
Тематическая релевантность доноров — это миф, PageRank имеет накопительный эффект, а трафик на ссылающейся странице способствует передаче авторитета.
Он также назвал отчеты SEO-инструментов о "токсичных ссылках" маркетинговым ходом и рекомендовал не использовать disavow.
Цель обсуждения — предложить рабочие стратегии для новых сайтов с нулевым авторитетом, чтобы помочь им получить первые позиции.
Советы и мнения сеошников
1. Стратегия линкбилдинга только на основе PR может быть нестабильной. Эффективность резко падает, когда новостные сюжеты, давшие ссылки, теряют актуальность. PR не должен полностью заменять другие методы линкбилдинга на конкретные страницы.
2. Для PR на основе данных используйте надежные источники (Google Trends, Keyword Planner) и фокусируйтесь на темах для широкой аудитории (например, "экономическая неопределенность", "здоровье"), чтобы привлечь журналистов. Усилия могут быть напрасны, если итоговая статья не получит трафика.
3. Предлагайте свои услуги бесплатно в обмен на бэклинк. Это можно считать немонетарной подпиской на ваш сервис.
4. Для партнерских ссылок используйте деловые связи клиента (например, BNI) или персонализированный холодный аутрич для создания реферальных отношений. В дальнейшем это можно развить в перекрестные ссылки, иногда с текстовыми вставками на главных страницах.
5. Создавайте полезные инструменты или калькуляторы (например, для оценки ROI или расчета углеродного следа). Они привлекают естественные ссылки, так как интерактивны и решают реальную проблему.
6. Креативный способ получить ссылки с митапов — найти и "возродить" заброшенные группы на Meetup.com. Затем сотрудничайте с активными организаторами, предлагая продвигать их события в вашей группе в обмен на ссылки со страниц мероприятий, email-рассылок и сайтов-партнеров.
7. При оценке партнерских ссылок отдавайте приоритет релевантности аудитории и потенциальному реферальному трафику, а не метрикам авторитета домена. Обмен ссылками между ювелирным сайтом и свадебным порталом идеален, независимо от их DA.
8. LLM можно использовать для разработки стратегии линкбилдинга. С помощью промптов ИИ может проанализировать сайт, предложить советы по оптимизации и возможности для линкбилдинга на основе существующего контента.
9. Чтобы извлечь пользу из бэклинка на низкоранжируемом сайте партнера, помогите этой странице подняться в выдаче: передайте ей PageRank с нескольких своих страниц или договоритесь с другими партнерами, чтобы они также на нее сослались.
10. Для нового локального бизнеса без авторитета стартовой "немасштабируемой" стратегией может быть создание местного каталога компаний. Требуйте от компаний обратную ссылку для размещения. Чтобы запустить процесс, вручную свяжитесь с личными контактами и местным бизнесом (например, вашим парикмахером или мастерской) для получения первых записей.
11. Переупаковывайте оригинальные данные или результаты опросов в инфографику и короткие видео. Делитесь этими материалами в соцсетях и предлагайте их релевантным новостным рассылкам для получения качественных ссылок.
12. Один из юзеров предложил объединить домены в курируемую сетку сайтов (PBN) для взаимной помощи с линкбилдингом.
@
Читать полностью…
Mike Blazer
27 Aug 2025 08:15
СКОРОСТЬ ОБНАРУЖЕНИЯ ССЫЛОК SEO-ИНСТРУМЕНТАМИ: КАКОЙ ИЗ НИХ ПЕРВЫМ НАХОДИТ КАЧЕСТВЕННЫЕ БЭКЛИНКИ?
Три недели назад мы запустили исследование по наращиванию ссылок и получению упоминаний в СМИ, пишет Джо Янгблад.
Мы сравнили Ahrefs, Semrush, Moz и Majestic, чтобы определить, какой SEO-инструмент лучше всего находит ссылки на новый контент.
Ни один инструмент не обнаружил своевременно все известные качественные ссылки.
— Победитель 1-й недели: Ahrefs
— Победитель 2-й недели: Majestic
— Победитель 3-й недели: SEMrush
Из четырех инструментов только Moz не обнаружил ни одной ссылки за время исследования.
Остальные вырывались вперед поочередно.
Ahrefs мощно стартовал, но сразу же сбавил обороты.
Majestic стартовал медленнее: к 14-му дню он нашел несколько ссылок, после чего прогресс остановился.
SEMrush был самым медленным, но в итоге обнаружил больше всего качественных ссылок за 21 день.
Всего получено известных качественных ссылающихся доменов за этот период (с 72-часовым окном обнаружения) = 10
Всего известных ссылающихся доменов, качественных и мусорных (с 72-часовым окном обнаружения) = 23
По итогам 3 недель, всего обнаружено ссылающихся доменов:
— SEMrush - 16
— Majestic - 13
— Ahrefs - 6
— Moz - 0
По итогам 3 недель, обнаружено качественных ссылающихся доменов:
— SEMrush - 7
— Majestic - 4
— Ahrefs - 4
— Moz - 0
По итогам 3 недель, обнаружено мусорных ссылающихся доменов:
— SEMrush - 9
— Majestic - 9
— Ahrefs - 2
— Moz - 0
Самое быстрое обнаружение качественной ссылки: Ahrefs (5 часов)
Ссылка от издания, не обнаруженная ни одним инструментом за 3 недели: NY Post
Худший по скорости обнаружения ссылок: Moz (не нашел ни одной ссылки за 21 день, несмотря на бэклинки от местных новостных станций, Newsweek, NY Post, Hacker News, отраслевых сайтов и т.д.).
Анализ инструментов
Общий победитель: SEMrush
— Хотя SEMrush медленный, он нашел больше всего качественных ссылок за 21 день.
— Сложно пользоваться и сортировать данные; его опция сортировки "лучшие" (best) в 2025 году бессмысленно включает только "dofollow" ссылки.
— Рейтинг качества (AS) завышает оценку малоценных ссылок.
— Интерфейс перегружен нерелевантными графиками и имеет плохое юзабилити.
Второе место: Majestic
— Находит много мусора, а сортировка по умолчанию игнорирует качественные ссылки.
— Первую качественную ссылку нашел более чем через неделю.
— Находит спарсенные ссылки на мусорных сайтах, упуская оригинальные от крупных издателей.
Третье место: Ahrefs
— Мощно стартовал, обнаружив первую качественную ссылку (от Newsweek) примерно за 5 часов.
— Затем он быстро затормозил: на поиск других ссылок уходили дни или недели, если они вообще обнаруживались в период исследования.
— Интерфейс интуитивно понятен и прост в использовании.
Последнее место: Moz
— За время исследования не обнаружил ни одной ссылки (ни качественной, ни мусорной).
— Нет стандартного способа отсортировать потенциально мусорные ссылки.
— В остальном интерфейс интуитивно понятен и позволяет сортировать данные.
— Возможно, недавнее обновление сломало функцию обнаружения ссылок, так как, по неофициальным данным, аналогичное исследование в начале года показало у Moz более быстрые результаты.
Методология
— Мы ежедневно вручную проверяли каждую платформу на качественные и мусорные ссылки.
— Мы использовали несколько систем оповещений об упоминаниях моего имени или исследования.
— Некоторые журналисты сообщали по email о выходе материалов.
— Для измерения скорости мы сравнивали время публикации/оповещения со временем обнаружения ссылки инструментом.
— Учитывались только ссылки, активные не менее 72 часов.
@
Читать полностью…
Mike Blazer
26 Aug 2025 17:05
Живой эксперимент: как микроразметка влияет на AI Overviews от Google
u/cinematic_unicorn, бывший программист, провел эксперимент о влиянии структурированных данных (микроразметки) на AI Overviews (AIO) от Google.
Он предположил, что качественная микроразметка помогает AIO цитировать источник при недостатке сигналов авторитетности.
В первом тесте он сравнил два своих сайта.
Сайт с комплексной JSON-разметкой был напрямую процитирован AIO по определительному запросу ("What is [название инструмента и заголовок]").
Более старый сайт без микроразметки игнорировался по аналогичному запросу, а термин считался "общим".
Во втором тесте он проверил SaaS‑инструмент SwiftR.
Проблемы были в конкурентной нише "конструктор резюме" и путанице с языком программирования Apple Swift.
Сначала AIO не отличал продукт, но после внедрения JSON-LD корректно определил SwiftR, даже несмотря на противоречивый текст на странице (бренд "Availo", неточный таргетинг).
Обновленная гипотеза: для ключевых определений Google‑ИИ микроразметка ценнее неструктурированного текста.
Структурированные данные служат "неоспоримой истиной", позволяя ИИ обходить шум контента.
Вывод: микроразметка становится базой управления нарративом в поиске с ИИ.
Эксперимент касался не ранжирования (сайт уже был №1), а возможности попасть в цитирование AIO, чего без разметки не случалось.
Комментарии сеошников
— Bing подтверждает использование микроразметки в своем ИИ (Bing/Copilot).
— ИИ доверяет коду больше, чем поверхностным сигналам: так надежнее при правильной реализации.
Контент важен, но формальные процессы тоже должны учитываться — ИИ стоит воспринимать как еще одного "читателя".
— Один из комментаторов указал, что структурировать контент можно и с помощью `HTML`‑таблиц, главное — способ синтеза данных.
— Другие усомнились в достоверности: генерации `AIO` случайны, а двух тестов мало.
По их мнению, брендовые запросы и так ведут на свой домен, ведь у AIO нет отдельного движка ранжирования, а LLM умеют извлекать смысл и без разметки.
— Во втором тесте критики считали, что запрос "What is SwiftResume resume builder" неконкурентен и закономерно ведет на SwiftResume.com, что больше доказывает силу EMD, а не микроразметки.
Пользователи добавили, что их контент попадает в ответы ИИ без Schema.
— В обсуждении поделились примерами полезной микроразметки для SaaS и блогов: книга (автор, ISBN), авторство поста, схемы Article, Blog, Product.
При этом отметили, что из микроразметки делают "магическое средство", хотя это не так.
---
Деян Петрович проверил, передает ли браузерный инструмент OpenAI больше контекста модели (GPT‑5) со страниц с разметкой Schema по сравнению с обычным текстом.
Методика: он создал две одинаковые HTML‑страницы о вымышленной "TechFlow Solutions": одна с разметкой Schema (index.html), другая без (index.htm).
Модель тестировалась через запросы о компании, ее CEO, продуктах и достижениях.
Результаты: доказательств влияния Schema он не нашел.
Инструмент ИИ извлекает только видимый текст и игнорирует JSON-LD и другие форматы микроразметки.
По его словам, механизм сегодня "заточен на чистый текст".
@
Читать полностью…
Mike Blazer
26 Aug 2025 13:10
Массовая или постепенная публикация контента на новых доменах — эксперимент
Один чел поделился результатами двухлетнего эксперимента, в котором сравнивались две стратегии публикации на новых доменах.
Тест:
— Стратегия 1 (Массовая публикация): 1000 постов опубликованы одновременно.
— Стратегия 2 (Постепенная публикация): Сначала опубликовано 100 постов, затем ежедневно добавлялось по 2–3 новых.
Результаты:
— Краткосрочная перспектива: Стратегия с постепенной публикацией показала значительно более быструю индексацию и привлекла первый трафик.
Индексация произошла в течение нескольких дней — двух недель с момента регистрации домена.
— Долгосрочная перспектива: Через два года оба сайта показывали одинаковые результаты.
Ключевой контекст:
— Весь контент был сгенерирован ИИ с помощью самописного инструмента, использующего API.
— Посты создавались на основе заранее спланированной тематической карты.
— Правильная внутренняя перелинковка была заложена в основу и обновлялась ежедневно по мере публикации новых постов.
Вывод:
Для новых доменов стратегия постепенной публикации обеспечивает более быстрый старт.
Однако при наличии хорошо структурированной тематической авторитетности и внутренней перелинковки с самого начала, массовая публикация контента может со временем достичь тех же результатов.
@
Читать полностью…
Mike Blazer
26 Aug 2025 08:15
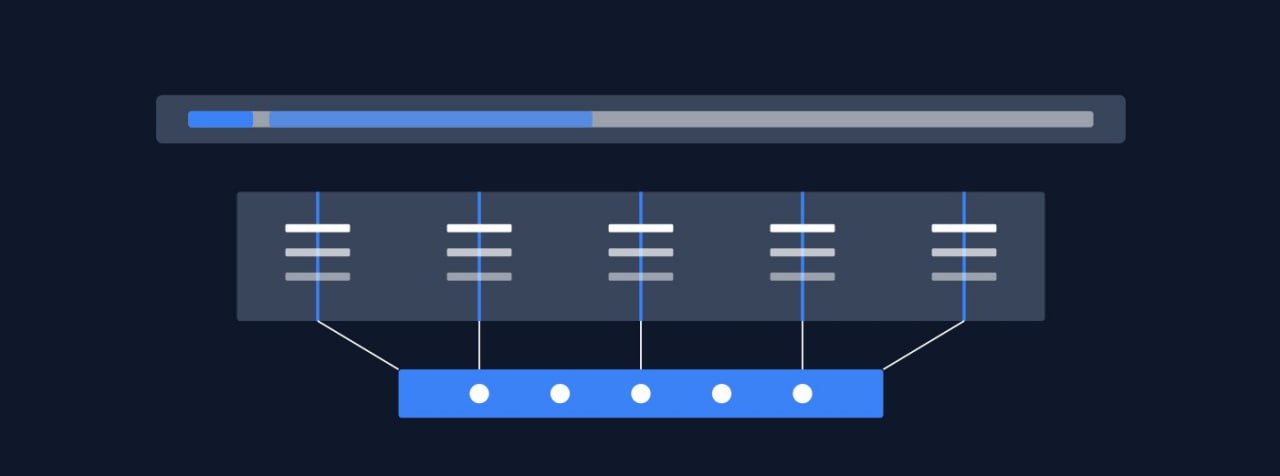
Как поисковые системы отличают факты от мнений (и почему это важно)
Google не относится к каждой странице — или даже к каждому разделу страницы — одинаково.
Они анализируют "ключевую аннотацию" документа (center-piece annotation), чтобы определить:
— К какой категории он относится
— Насколько он релевантен
— Насколько он соответствует запросу
Один из ключевых шагов?
Определение того, является ли контент фактическим или основанным на мнении.
Эта идея взята из патента Бориса Дадачева и напрямую связана с апдейтами Google Perspectives и Product Review.
Это особенно важно для новостной индустрии, но также определяет, как Google маркирует запросы:
— Нацеленные на поиск мнений (opinion-seeking)
— Нацеленные на поиск фактов (fact-seeking)
Позже это трансформировалось в запросы, связанные с личным опытом (experience-related) и экспертностью (expertise-related).
Одно из главных правил алгоритмического авторства (Algorithmic Authorship):
Не смешивайте факты и мнения в одном сегменте.
Почему?
Потому что поисковые системы сегментируют ваш контент, и более высокое ранжирование часто означает, что вы облегчаете им классификацию.
💡 В моем собственном фреймворке алгоритмического дизайна даже используются "карточки мнений" (opinion cards) — структурированные, четко обозначенные блоки с мнениями, которые идут после разделов с фактами для их поддержки, — пишет Корай Тугберк Губур.
И вот самое интересное:
Каждому сайту стоит завести форум на поддомене, чтобы таргетировать запросы, основанные на опыте, и фичи СЕРПа.
Именно поэтому мы также используем "безопасные ответы" (safe answers) — сбалансированные объяснения, объединяющие несколько точек зрения без создания противоречий.
Спросите себя:
— Сколько сегментов на вашей странице?
— Каково процентное соотношение фактов и мнений?
— Сможет ли поисковик быстро классифицировать ее, не сжигая ресурсы?
SEO — это просто математика со словами, и эта математика становится чище, когда вы структурируете свой контент и для людей, и для алгоритмов.
@
Читать полностью…
Mike Blazer
25 Aug 2025 15:05
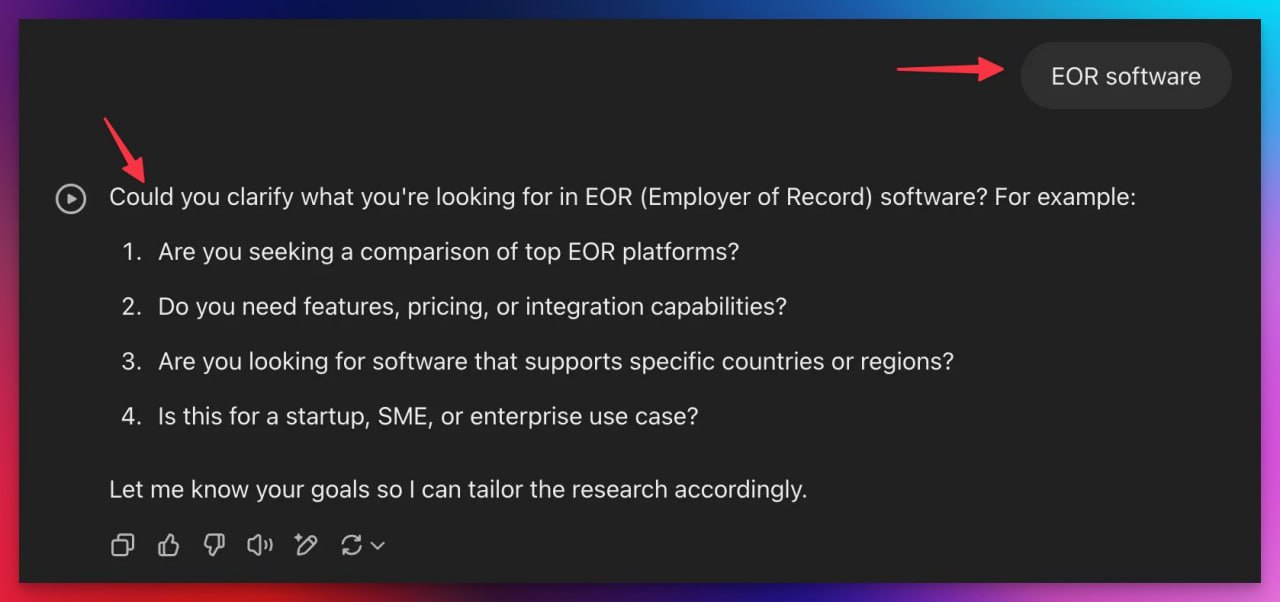
Как ранжироваться в Deep Research от ChatGPT, отвечая на уточняющие запросы
Для улучшения видимости в Deep Research от ChatGPT, контент-стратегия должна отвечать на уточняющие вопросы ("refinements"), задаваемые моделью перед генерацией результатов.
Это гарантирует соответствие контента критериям, которые ChatGPT использует для синтеза информации.
Что такое Deep Research?
Deep Research — это фича ChatGPT для углубленного поиска по сложным запросам.
Она имитирует обращение к нескольким источникам для исчерпывающего ответа, экономя время на исследование.
Трафик из Deep Research обычно качественный, так как пользователи уточняют свои потребности в процессе поиска.
Ключевая стратегия: Использование уточнений
Перед поиском Deep Research задает уточняющие вопросы ("refinements"), чтобы понять интент пользователя.
Эти вопросы раскрывают искомые моделью атрибуты и данные.
Прямые ответы на эти уточнения повышают вероятность цитирования вашего сайта.
Пример: Уточняющие вопросы для запроса "EOR software"
Уточняющие вопросы для одного запроса варьируются в разных моделях GPT.
Сбор этих вариаций дает руководство по созданию контента.
Для запроса "EOR software" были сгенерированы следующие уточнения:
o3:
— Вы ищете сравнение топовых EOR-платформ?
— Вам нужны фичи, цены или возможности интеграции?
— Вы ищете ПО, которое поддерживает определенные страны или регионы?
— Это для стартапа, малого/среднего бизнеса или крупного предприятия?
4o:
— Вы оцениваете варианты для покупки или исследуете рынок?
— У вас есть конкретные фичи или регионы (например, глобальный пейролл, комплаенс в определенных странах)?
— Каков размер вашей компании?
— Есть ли предпочтения по интеграции (например, с HRIS, системами бухгалтерского учета)?
4o mini:
— Ваш фокус на соблюдении трудового законодательства в разных странах, расчете зарплат, онбординге или управлении подрядчиками?
— У вас есть на примете конкретные страны или регионы?
— Каков размер вашей компании или объем найма?
— Есть ли обязательные интеграции (например, с HRIS, бухгалтерскими или ATS-инструментами)?
GPT 4 legacy:
— Размер вашей компании или количество сотрудников.
— Страны или регионы, где вы будете нанимать.
— Конкретные фичи, которые вы ставите в приоритет (например, комплаенс, расчет зарплат, поддержка подрядчиков в сравнении со штатными сотрудниками).
— Ваш бюджет.
o3 Pro:
— Вы хотите сравнить конкретных провайдеров EOR-софта?
— Это для определенного региона или для глобального использования?
— Какие фичи для вас наиболее важны (например, комплаенс, расчет зарплат, управление льготами, интеграции)?
— Каковы размер и отрасль вашей компании?
Частые критерии: сравнения провайдеров, фичи, цены, интеграции, поддержка по странам/регионам и размер компании.
Процесс внедрения
1. Соберите уточнения: введите целевой запрос в Deep Research в нескольких моделях GPT.
2. Определите ключевые темы: проанализируйте собранные вопросы на повторяющиеся темы. Это и есть критические критерии для ответа.
3. Внедрите изменения в контент:
— Изучите цитируемые домены в результатах Deep Research.
— Если ваши страницы цитируются, усильте их пассажами, отвечающими на критерии из уточнений.
— Если ваши страницы не цитируются, создайте новый контент, прямо отвечающий на эти вопросы.
Контекст: Сравнение с Gemini
Для сравнения, функция углубленного поиска в Gemini редко запрашивает уточнения, поскольку Google имеет достаточно пользовательских данных, чтобы определить интент.
Зависимость ChatGPT от этих вопросов дает создателям контента четкий план действий.
https://seonotebook.notion.site/How-to-Rank-in-Chat-Deep-Research-Paying-Attention-to-Refinements-1cd8c3685191807eafc2ea89b7b461c1
@
Читать полностью…
Mike Blazer
25 Aug 2025 11:05
AI Overviews используют сниппеты, а не полный текст
Данные указывают на то, что AI Overviews и AI Mode от Google для доступа к контенту используют сниппеты (пассажи) с веб-страниц, а не полный текст. Об этом свидетельствует заявление Логана Килпатрика, ведущего продакт-менеджера Google Gemini API.
1. Доказательства от Google Gemini API
18 августа 2025 года Килпатрик написал в X, что в Gemini API "search grounding получает доступ только к сниппетам страницы и не может видеть всю страницу без URL context".
Это проясняет два различных механизма:
— Search Grounding: Метод по умолчанию, обрабатывающий только фрагменты страницы.
— URL Context: Более новая функция, обрабатывающая полное содержимое URL, но только когда он явно предоставлен.
Это заявление о принципах работы grounding в Gemini API ясно указывает на функциональный принцип, лежащий в основе AI Overviews.
2. Значение для AI Overviews и AI Mode
В официальной документации говорится, что AI Overviews основываются на результатах поиска, что подразумевает, что они также используют контекст на основе сниппетов.
Это согласуется с практическими наблюдениями:
— Ответы часто выглядят поверхностными.
— Детали, присутствующие в полном тексте источника, часто отсутствуют.
— Ссылки на источники почти всегда ведут на небольшие фрагменты текста, а не на общий контекст страницы.
Доступ к полному тексту через URL Context в Gemini API демонстрирует иную возможность, которая, по-видимому, не является стандартным режимом работы для AI Overviews.
3. Почему это важно для SEO
Это имеет очевидные последствия для SEO и видимости в AI-ответах:
— Контент должен быть структурирован так, чтобы его можно было понять и использовать в виде небольших фрагментов.
— Структура важнее объема. Лонгриды менее эффективны, если они не разбиты на готовые для сниппетов разделы.
— AI Overviews функционируют скорее как система индексации, которая воспроизводит фрагменты, а не как браузер, который считывает тексты целиком.
4. Более широкий контекст в LLM
Этот паттерн не уникален для Google.
Данные, полученные из наблюдения за поведением, и известные механизмы извлечения информации указывают на то, что и другие системы, например ChatGPT, для доступа к веб-контенту также используют методы, основанные на сниппетах или чанках, а не считывают страницы целиком.
Похоже, это распространенная модель того, как LLM используют поисковые индексы для grounding.
5. Выводы для паблишеров
Имеющиеся данные указывают на то, что AI Overviews и AI Mode по умолчанию используют сниппеты.
Для оптимизации видимости паблишерам следует создавать контент, который:
— Оптимизирован для сниппетов.
— Лаконичен, понятен и хорошо структурирован.
Понимание этой логики, основанной на сниппетах, является ключом к систематическому улучшению показателей в AI Overviews.
https://gpt-insights.de/ai-insights/ai-overviews-snippets-statt-volltext/
@
Читать полностью…
Mike Blazer
24 Aug 2025 15:05
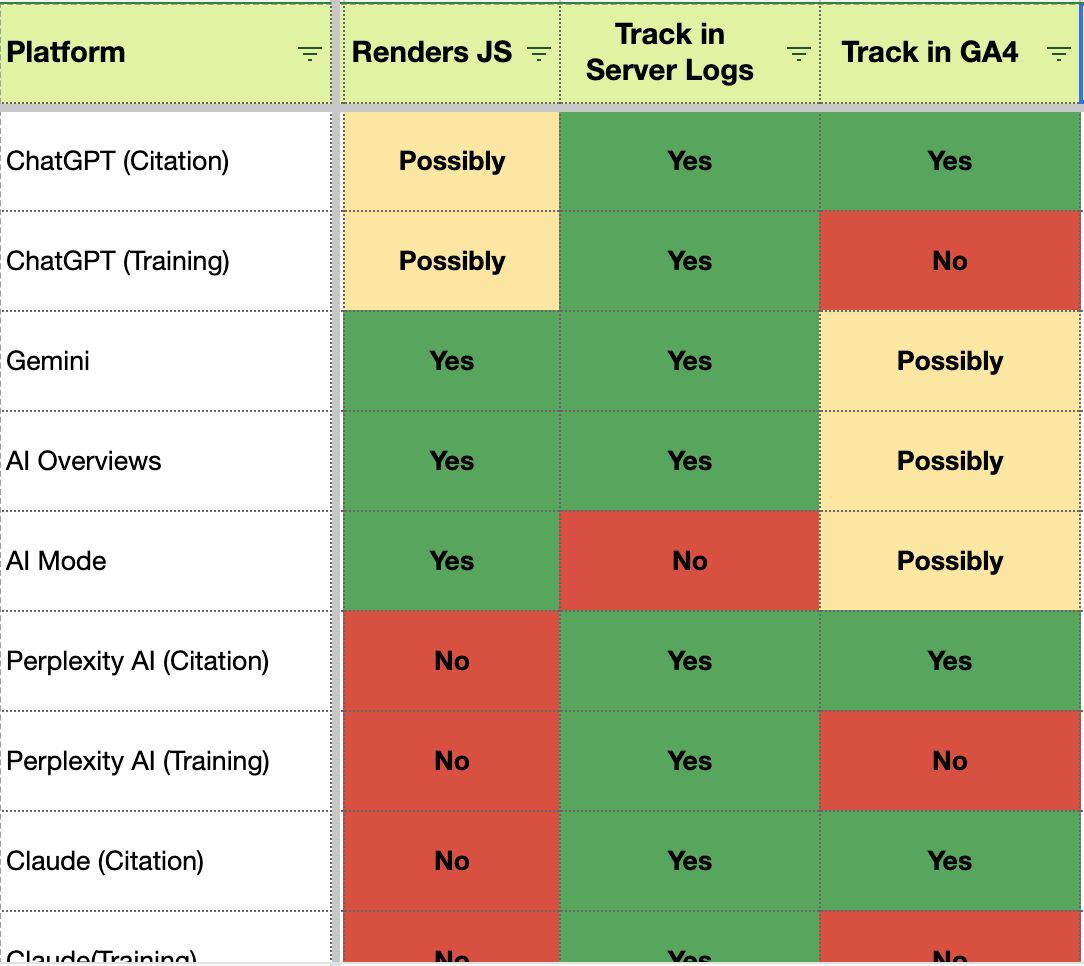
Ваша видимость в LLM зависит от индексации в Google (и JavaScript здесь играет важную роль) больше, чем вы думаете.
Четыре ключевых инсайта для лучшего понимания видимости контента в поисковых и чат-инструментах на базе ИИ:
1. `noindex` = нет видимости в AI (очевидно, но многие сайты об этом забывают)
Если ваш контент заблокирован для индексации (через noindex, директивы Disallow в robots.txt или x-robots), он не сможет появляться в Google AI Overviews, Gemini или AI Mode.
2. Индекс Google — это фундамент для LLM (контент, который LLM находят чаще всего, почти зеркально отражает то, что мы видим в поиске Google)
Данные ясно показывают, что популярные LLM (ChatGPT, Claude, Perplexity и др.) в значительной степени опираются на проиндексированные данные Google.
Более высокая видимость в Google напрямую коррелирует с более частым попаданием в ответы, сгенерированные LLM.
3. LLM плохо справляются с JavaScript
Большинство ведущих LLM не рендерят JavaScript-контент, в отличие от Google или Bing.
Даже если ваши страницы, активно использующие JS, хорошо ранжируются в поиске, эта зависимость может ограничить их видимость в диалогах с ИИ.
4. Что нужно делать: Отдавайте приоритет отрендеренному HTML
Проверьте свой самый эффективный контент в Google.
Сильно ли он зависит от клиентского рендеринга JavaScript?
Если да, то вы, скорее всего, в невыгодном положении.
Рассмотрите переход на:
— Серверный рендеринг (SSR)
— Статический пре-рендеринг
— Техники гидратации
Убедиться, что ваш лучший контент полностью индексируется и доступен в виде чистого HTML, важно не только для позиций в органической выдаче, но и для видимости во все более влиятельной экосистеме LLM.
@
Читать полностью…
Mike Blazer
24 Aug 2025 11:10
Один странный трюк для создания отличной SEO-программы
У нас топовая SEO-программа, которая обеспечивает отличную видимость в LLM, пишет Брайан Кейси.
Спустя все эти годы я считаю, что весь секрет кроется в нашем подходе к контенту и команде.
Когда мы запускали inbound-программу, мы пробовали стандартные модели: договаривались о количестве статей за фиксированную цену.
По сути, вы покупали услуги подрядчика, а подбор авторов был лишь деталью исполнения.
Этот подход нас подвел.
Мы так и не получили желаемого качества и постоянно все переделывали.
Со штатными редакторами и бескомпромиссной планкой качества наша скорость работы стала напрямую зависеть от качества первых драфтов.
Если редакторы получают качественные первые драфты, конвейер работает быстро.
Если же им приходят низкокачественные наброски, которые нужно практически полностью переписывать, то зачем вообще нужны сторонние авторы?
Наши редакторы могли бы и сами все написать.
Поэтому мы кардинально изменили нашу модель.
Мы больше не платим за статью — мы нанимаем людей.
Будь то штатный сотрудник, подрядчик или агентство, каждый автор, по сути, работает на полную ставку.
Мы не подпишем договор с новым агентством, пока не прособеседуем достаточное количество их авторов.
Большинству мы отказываем, и нет ничего необычного в том, чтобы провести шесть собеседований, чтобы найти одного человека.
Авторы часто проходят несколько этапов интервью с нашей командой.
Это правило действует даже для агентств и при замене всего одного специалиста.
Мы нанимаем исключительно два типа людей: инженеров и преподавателей в сфере технологий, либо бывших журналистов.
Их общая черта — высокая степень самостоятельности и умение проводить исследования без посторонней помощи.
Это значит, что мы можем дать им задачу почти без брифа и получить на выходе качественный первый драфт.
Наша скорость — это результат самостоятельности и качества работы команды.
У нас гораздо больше авторов и разработчиков, чем сеошников.
И хотя поиск — это ключевой канал, наша культура строится вокруг критической массы команды: создателей контента.
Дело не в том, что мы не ценим наших SEO-специалистов, просто на написание статьи уходит примерно в 15 раз больше времени, чем на определение потребности в ней.
В правильно укомплектованной команде всегда будет значительно больше креаторов, чем сеошников.
Невозможно создать и удержать сильную контент-команду, если в культуре доминируют сеошники, которые относятся к создателям контента как к взаимозаменяемым винтикам.
Нет, это отстой.
Нужно, чтобы эти команды находились в равновесии.
Вы привлекаете органический трафик с помощью контента.
Так что тот самый странный трюк заключается вот в чем: начните относиться к контенту серьезно.
Иначе в конечном счете вас ждет провал.
@
Читать полностью…
Mike Blazer
29 Aug 2025 15:05
— Ну че там?
— Хз, что-то на эльфийском
@
Читать полностью…
Mike Blazer
29 Aug 2025 11:05
Сначала мы роботизировали свою работу.
Затем мы научили роботов ее выполнять.
Если ИИ отнимет у вас работу, то не потому, что он такой умный.
А потому, что со временем мы сделали работу настолько узконаправленной, монотонной, зацикленной на минимизации отклонений и погоне за метриками, что она стала просто создана для машин.
За последние 20 лет объединенные силы консалтинга, компьютерных технологий и культуры эффективности преобразовали роли, которые когда-то строились на:
— Креативности
— Эмпатии
— Взаимоотношениях
— Воображении
— Рассудительности
— Разнообразии
— Гордости
— Адаптивности
В роли, построенные на чек-листах, шаблонах и дашбордах.
Мы убрали те самые человеческие качества, которые делали работу интересной, ценной и труднозаменимой, и тем самым упростили её для роботов и сделали менее значимой для людей.
Пора снова выстраивать работу вокруг гения человека, чтобы использовать мощь технологий и уникальные способности людей для совершения вещей, которые мы даже не могли себе вообразить.
@
Читать полностью…
Mike Blazer
28 Aug 2025 17:05
Негативная SEO-атака на клиента: дизавуировать или нет?
u/ZeroWinger просит совета, как справиться с негативной SEO-атакой.
За последний месяц сайт клиента ежедневно получает 70–80 бэклинков с порно-анкорами со спамных TLD (включая .xyz), в сумме более 1200 ссылок с 450 доменов.
Автор уверен, что это целенаправленная атака.
Позиции сайта не пострадали, и клиент спокоен, но u/ZeroWinger обеспокоен объемом ссылок.
Он не уверен, стоит ли тратить бюджет на файл disavow или бездействовать, опасаясь навредить отношениям с клиентом.
Комментарии сеошников
— Файл Disavow нужен только при ручных санкциях или покупке спамных ссылок. В ином случае его использование — признание вины, привлекающее внимание Google.
— Кейсы показывают, что удаление файла disavow может улучшить позиции.
— Инструмент disavow работает только с запросом на пересмотр. Так как его больше нельзя подать, дизавуировать ссылки бессмысленно.
— Такая активность не всегда является "атакой" и может быть вызвана сбоями краулеров сайтов-агрегаторов.
— Проблема не в объеме ссылок, а в манипулировании поиском через покупку ссылок с авторитетных доменов. Данная ситуация под эти критерии не подпадает.
— Использование disavow сигнализирует Google о покупке ссылок.
— Будьте честны с клиентом и работайте как обычно, если трафик не пострадал.
— Никогда не дизавуируйте: Google достаточно умен, чтобы проигнорировать плохие ссылки.
— Не беспокойтесь, пока нет предупреждения от GSC.
— Пока позиции не затронуты, документируйте ситуацию, но не дизавуируйте до появления негативных последствий. Уверьте клиента, что вы следите за процессом.
— Дизавуируйте все бэклинки через GSC.
— Альтернатива: попросите сайты удалить ссылки. Если они откажутся, предпринимайте юридические действия.
@
Читать полностью…
Mike Blazer
28 Aug 2025 13:10
Как безопасно уволить SEO-агентство, чтобы избежать саботажа?
Клиент u/longkhongdong, юрист по взысканию долгов, переплачивает за две статьи в месяц и хочет передать свои SEO-услуги ему.
Клиент опасается саботажа от текущего SEO-агентства после разрыва контракта и попросил longkhongdong узнать, как минимизировать эти риски.
longkhongdong отмечает, что для агентства было бы неразумно саботировать юриста. Он уже показал клиенту этот тред, и тот готов следовать рекомендациям.
Комментарии сеошников
— Сделайте бэкапы, выясните все доступы и будьте готовы их отозвать. Убедитесь, что у вас есть полный доступ к аналитике. Запросите список всех ссылок, чтобы отследить попытки построить плохие бэклинки или удалить подконтрольные. Саботаж — это уголовное преступление.
— Такой саботаж — уголовное преступление. Одно агентство подало в суд на клиента-юриста за неуплату и выиграло.
— Получите админ-доступ к бэкенду и будьте готовы удалить их доступ. Контроль над DNS — дополнительный плюс.
— Некоторые сомневаются, что агентство пойдет на саботаж, и отмечают: то, что для одного "заоблачная цена", для другого — выгодная сделка, если она приносит результат.
— В зависимости от методов линкбилдинга, они могут удалить бэклинки, особенно требующие регулярных платежей. Проверьте условия контракта.
— Большинство проблем возникает именно с бэклинками.
— Вероятность саботажа зависит от количества доступов у агентства.
— Недобросовестные SEO-агентства могут прибегать к рискованным тактикам или саботажу для удержания клиентов. Клиенту следует получить полный доступ ко всем аккаунтам (GA, GSC, хостинг), сделать полный бэкап перед сменой подрядчика и избегать агентств, стремящихся скрыть данные или сохранить контроль. После смены проверьте, нет ли резких падений трафика или странных бэклинков.
— Убедитесь, что клиент тихо получил ВСЕ логины, чтобы не вызывать подозрений. Сразу после получения смените все пароли. Учтите, что некоторые агентства привязывают 2FA к своим телефонам; в таких случаях вы не получите коды, пока клиент не убедит их переключить 2FA на его номер. Удалите все проверочные DNS-записи (обычно TXT), связанные с доступом агентства. Не отключайте их до получения полного контроля. Документируйте все действия, изменения и каждый их бэклинк.
— Расторгайте контракт по обоюдному согласию и всегда проводите передачу проекта с предыдущим подрядчиком для плавного перехода. Известны случаи, когда предыдущие SEO-агентства деиндексировали сайт через GSC из-за конфликтов по оплате.
— Одному клиенту оставили noindex в файле robots.txt. Сначала отзовите доступ, потом разрывайте отношения.
— В рамках off-site они могут создать мусорные бэклинки или отключить лицензии/приложения, которые контролируют и за которые вы не платите, что может быть в их праве.
— Отключите внешние веб-приложения или переустановите плагины (на WordPress), не очищая кэш для сохранения настроек.
— Закройте им доступ к сайту, домену и инструментам вроде аналитики или GSC. Просканируйте сайт и экспортируйте данные (например, через Screaming Frog). Некоторые специалисты после ухода из агентства ставили ссылки с клиентских сайтов на свои новые проекты. Будьте настороже, если они завышают цену за базовые услуги.
— Убедитесь, что все аккаунты находятся в вашем полном владении и контроле. Попросите передаточные записки в письменном виде, якобы для внутреннего маркетолога. Затем отзовите их доступы ко всем системам и сделайте бэкапы всех предоставленных отчетов. После этого совершите короткий прощальный звонок, отправьте вежливое письмо и оповестите всех причастных в компании.
— Владелец агентства подтверждает: обиженные агентства сжигали за собой мосты.
@
Читать полностью…
Mike Blazer
28 Aug 2025 08:15
Имеют ли значение профили авторов, созданные ИИ, или фейковые владельцы сайтов?
Еще в 2021 и 2022 годах я опубликовал одно из первых исследований, посвященных авторским сигнатурам, — пишет Корай Тугберк Губур.
Идея проста: если вы используете ИИ для создания контента, вы оставляете за собой статистические "отпечатки".
У каждой LLM есть свои паттерны — фразы, структура предложений и даже то, как она отвечает на определенные типы вопросов.
Если вы и ваши конкуренты используете одну и ту же систему, ваши тексты будут нести одну и ту же узнаваемую "сигнатуру".
Вот почему авторство — или то, кто является основным создателем контента — так же важно, как и сам контент.
Google даже подчеркивает это в своем Руководстве для асессоров качества: созданные ИИ, вводящие в заблуждение описания авторов или фейковые владельцы сайтов считаются сигналами низкого качества.
Это можно увидеть и в интерфейсе самого Google.
В панели "Об этом источнике" Google иногда указывает автора в качестве основного источника, а не сайт.
Хороший пример — мой кейс по MangoLanguages.
Мы переопределили каждого автора как лингвиста и создали подтверждающие страницы по всему вебу, чтобы зарегистрировать их в Графе знаний Google.
Это создало консенсус вокруг сущности, укрепив доверие и релевантность.
Ключевые моменты:
— Лица, логотипы и продукты на изображениях помогают Google классифицировать и связывать сущности.
— Основатели, авторы, лингвисты должны быть последовательно представлены на главной странице, странице "О нас" и в структурированных данных.
— Подтверждающие страницы на внешних сайтах помогают согласовать ваши внутренние и внешние заявления.
Если у вашего сайта нет реального владельца-человека или он не распознан как брендовая сущность в Графе знаний, вы фактически начинаете с нуля в плане SEO на основе сущностей.
Именно поэтому, когда я проектирую главную страницу, я всегда включаю:
— Разделы с командой
— Профили основателей/авторов
— Блоки с мнениями/отзывами
— Структурированные данные со ссылками на официальные профили и подтверждающие страницы
👉 В SEO авторитетность — это не только то, что вы публикуете, но и то, кто, по мнению Google, за этим стоит.
@
Читать полностью…
Mike Blazer
27 Aug 2025 15:05
OpenRobotsTXT — это открытый архив файлов robots.txt со всего мира.
Посещая домены и со временем кэшируя эти файлы, проект отслеживает, как меняются файлы robots.txt и какие юзер-агенты к ним обращаются.
Цель OpenRobotsTXT — предоставлять ценную информацию, инструменты и отчеты для вебмастеров, исследователей и широкого интернет-сообщества для открытого публичного изучения.
Вот что вы можете сделать:
— Просматривать статистику по юзер-агентам (ботам), которых мы обнаружили в ходе анализа.
— Искать данные по отдельным ботам с помощью поиска по ботам. Проверять ваши директивы для user-agent на соответствие общепринятым веб-стандартам.
— Посмотреть на ваш robots.txt глазами бота. Отличный способ убедиться, что конфигурация вашего сервера обеспечивает доставку файла robots.txt именно так, как вы задумали.
https://openrobotstxt.org/
@
Читать полностью…
Mike Blazer
27 Aug 2025 11:05
Gemini использует PageRank для выбора источников в AI-ответах
u/annseosmarty сообщила, что команда Gemini встречается с командой органического поиска для улучшения ИИ.
Gemini, вероятно, использует сигналы PageRank для повышения веса авторитетных страниц и понижения веса ненадежных источников при выборе цитат для AI-ответов.
Отмечено, что Gemini использует собственный алгоритм на индексе Google, но не обязательно полагается на его ранжирование.
Позже автор уточнил: письмо не подтверждает завершение интеграции, а лишь указывает на попытки ее осуществить.
По мнению u/annseosmarty, у ИИ есть собственное понимание E-E-A-T, что делает вклад Google ненужным, но он не видит альтернативы PageRank.
По ее мнению, концепция E-E-A-T хороша, но ее реализация всегда была ужасной.
Комментарии сеошников
— Использование PageRank в Gemini означает, что авторитет негласно правит даже в режиме ИИ и намекает на будущее направление поиска.
— Неудивительно, что Google использует PageRank — свой старейший и самый надежный инструмент оценки страниц.
— Один юзер после недавнего изучения заключил, что YMYL и E-E-A-T — шутка, напомнив: некоторые SEO-специалисты и раньше утверждали, что E-E-A-T не был реальным фактором.
— Большая новость в том, что это сотрудничество шло еще в прошлом году, и забавно, что сотрудники Google знали: сообщество заинтересуется скриншотом этого внутреннего письма.
@
Читать полностью…
Mike Blazer
26 Aug 2025 15:05
💡 Совет по микроразметке!
Используйте свойство subjectOf, чтобы связать Organization с соответствующим видео на той же странице — например, с видео на вашей странице "О нас".
Если ваша компания — основная тема видео на странице, используйте свойство subjectOf в микроразметке Organization или LocalBusiness, а затем укажите для него тип VideoObject.
Это поможет Google понять, что видео посвящено именно вашему бизнесу.
Как вариант, можно использовать обратное свойство about внутри микроразметки видео, а уже в него вложить структурированные данные Organization / LocalBusiness.
Не забудьте про @
@
Читать полностью…
Mike Blazer
26 Aug 2025 11:05
Вам когда-нибудь было интересно, какие сайты Google считает лучшими источниками? 🤔
Seg спарсил почти 15к доменов из новой фичи Гугла Source Preferences (предпочтения по источникам).
Список с поиском уже доступен — узнайте, попали ли ваши любимые сайты в него!
https://i-l-i.com/source_preference_google.html
@
Читать полностью…
Mike Blazer
25 Aug 2025 17:05
Я собирался идти спать, но вместо этого занялся расшифровкой внутреннего семантического поиска Chrome, — пишет Деян Петрович.
Я нашел точный механизм чанкинга, логику эмбеддингов и теперь могу просматривать, искать и кластеризовать свою историю поиска с помощью декодированных векторных эмбеддингов 😐
Вот краткое изложение того, что я обнаружил:
— Чанкинг: Chrome разбивает каждую страницу на пассажи (до 30 штук), каждый объемом примерно в 200 слов.
— Эмбеддинг: Каждый пассаж преобразуется в 1540-мерный вектор.
— Хранение: Эмбеддинги для каждого посещения сохраняются в embeddings_blob в базе данных History.
Процесс чанкинга пассажей и создания эмбеддингов в Chrome
Механика извлечения пассажей
Chrome разбивает страницы на логические "пассажи". Параметры определены в файле history_embeddings_features.h и включают в себя:
— max_passages_per_page = 30
— passage_extraction_max_words_per_aggregate_passage = 200
Это означает:
→ Chrome ограничивает количество создаваемых эмбеддингов до 30 на страницу (что соответствует массивам (30, 1540)).
→ Он кластеризует текст страницы в чанки объемом примерно 200 слов каждый.
Процесс генерации эмбеддингов
Сервис HistoryEmbeddingsService управляет этим конвейером:
1. Когда страница полностью загружена, Chrome извлекает пассажи и вызывает ComputeAndStorePassageEmbeddings(url_id, visit_id, visit_time, passages).
2. Если требуются эмбеддинги, он вызывает embedder_->ComputePassagesEmbeddings(priority, passages, callback).
3. После вычисления векторы сохраняются в объекте UrlData и записываются в базу данных через vector_database.SaveTo(sql_database).
Почему ваши данные выглядят именно так
— Массив (30, 1540) означает эмбеддинг для всей страницы: 30 пассажей × 1540-мерный вектор для каждого.
— Массивы меньшего размера (например, 1 или 3 чанка) появляются на коротких страницах с небольшим количеством текста.
— Очень большие и очень маленькие значения float16 — это артефакты квантования/сжатия.
https://dejan.ai/blog/inside-chromes-semantic-engine-a-technical-analysis-of-history-embeddings/
@
Читать полностью…
Mike Blazer
25 Aug 2025 13:10
Как ChatGPT ранжирует контент: анализ конфигурационных файлов
Анализ конфигурационных файлов ChatGPT раскрывает настройки для поиска, извлечения и ранжирования веб-контента.
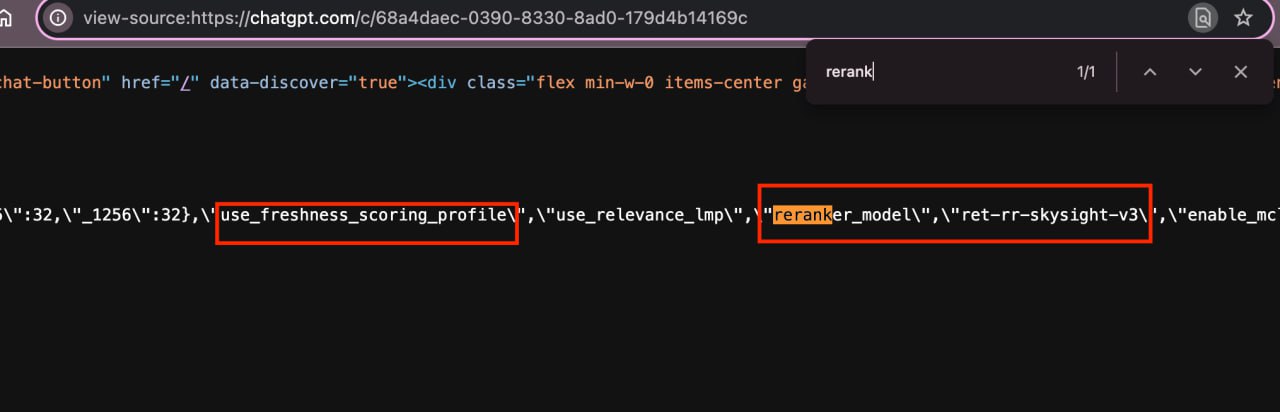
Эти данные доступны в исходном коде сессии чата по запросу "rerank".
Модель переранжирования: `ret-rr-skysight-v3`
Система извлечения данных ChatGPT использует модель переранжирования из конфигурации:
reranker_model: "ret-rr-skysight-v3"
Эта модель работает как слой постобработки, получающий первоначальные веб-источники и переупорядочивающий их по сигналам релевантности и качества.
Приоритет отдается свежести контента
Система предпочитает новый контент устаревшему, что подтверждает настройка:
use_freshness_scoring_profile: true
Это активирует профиль оценки, придающий больший вес свежей информации.
Конфигурация предписывает использовать инструмент web для запросов о недавних событиях или свежей информации.
Многоуровневая система фильтрации
Конфигурация демонстрирует конвейер фильтрации с несколькими контрольными точками:
— enable_query_intent: true
— enable_source_filtering: true
— enable_mimetype_filtering: true
— vocabulary_search_enabled: true
— use_coarse_grained_filters_for_vocabulary_search: false
Определение интента запроса: При enable_query_intent: true система анализирует цели пользователя, выходя за рамки ключевых слов, и распознает потребности, такие как поиск определений, инструкций или сравнений.
Поиск с учетом лексики: Настройка vocabulary_search_enabled: true вместе с use_coarse_grained_filters_for_vocabulary_search: false указывает на поиск с учетом лексики, использующий детализированные фильтры.
Это отдает приоритет контенту с точной, узкоспециализированной терминологией.
Системные настройки и вариации скоринга
Одна функция релевантности отключена:
use_relevance_lmp: false
Значение "LMP" неизвестно, но деактивация предполагает опору на другие сигналы релевантности.
Назначение настроек, таких как enable_mclick_urls и enable_mclick_dates, неясно, но может относиться к отслеживанию взаимодействий пользователя с источниками.
Система применяет различный скоринг для контента из подключенных сторонних приложений, на что указывает:
use_light_weight_scoring_for_slurm_tenants: true
Список enabledConnectors, включающий slurm_dropbox и slurm_sharepoint, позволяет предположить, что "slurm tenants" — это сервисы вроде Dropbox, SharePoint, Box, Canva и Notion.
Это подразумевает использование легковесного алгоритма скоринга для этих частных источников, в отличие от интенсивного переранжирования для публичных веб-результатов.
Выводы для контент-стратегии
Исходя из этих настроек, эффективная контент-стратегия должна включать:
1. Частые обновления: Активная оценка свежести означает, что качественный контент со временем теряет видимость, требуя регулярных обновлений.
2. Соответствие интенту: Контент должен сигнализировать о своей цели (например, сравнение, руководство), чтобы соответствовать результатам определения интента запроса.
3. Техническая лексика: Поиск с учетом лексики поощряет последовательное использование отраслевой терминологии.
4. Авторитетный контент: Чтобы пройти переранжирование моделью ret-rr-skysight-v3, необходим исчерпывающий, авторитетный материал, поскольку первоначальной видимости недостаточно.
Конфигурация раскрывает многоэтапную систему извлечения данных, включающую определение интента, анализ лексики, оценку свежести и нейросетевое переранжирование.
Для оптимизации сосредоточьтесь на содержании, свежести и технической четкости.
Примечание: Этот анализ основан на данных конфигурации из сессии пользователя ChatGPT Plus в августе 2025 года. Настройки могут отличаться в зависимости от пользователя, региона или будущих обновлений системы.
https://metehan.ai/blog/chatgpt-5-search-configuration/
@
Читать полностью…
Mike Blazer
25 Aug 2025 08:15
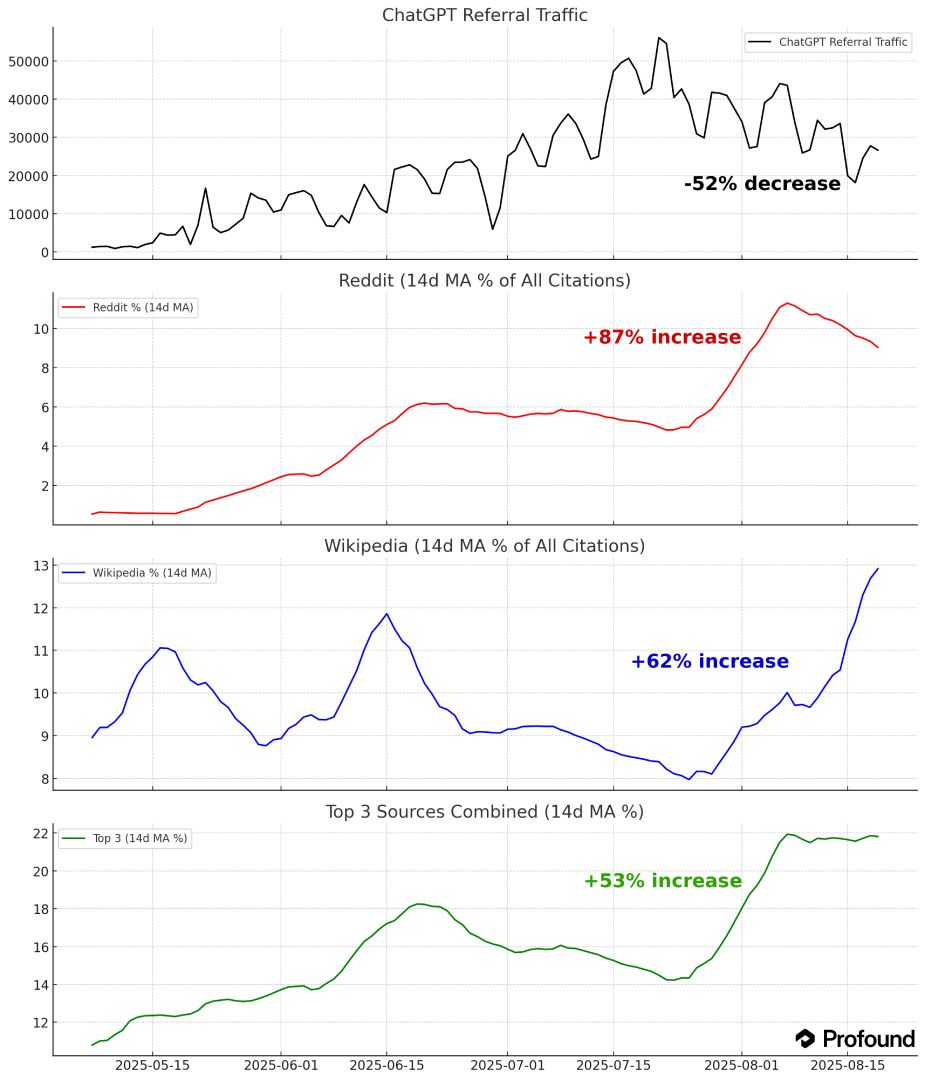
Реферальный трафик из ChatGPT упал на 52% с 21 июля.
Я проанализировал датасет из более чем 1 млрд цитирований и 1 млн переходов из ChatGPT, чтобы понять, что происходит, — пишет Джош Блискал.
ChatGPT всё чаще ссылается на сайты, которые дают прямые ответы, и хвост цитирований сокращается.
Падение трафика началось именно тогда, когда изменились паттерны цитирования.
С 23 июля упоминания Reddit выросли на 87%, превысив 10% от всех ссылок в ChatGPT.
Wikipedia показала исторический максимум: +62% к июльскому минимуму и почти 13% на вчера.
Топ-3 домена (Wikipedia, Reddit, TechRadar) выросли на 53% и теперь забирают 22% всех цитирований.
То есть каждое пятое упоминание приходится на три сайта.
Бренды получают меньше ссылок: миллионы потенциальных переходов уходят этим платформам.
Это не связано с релизом GPT-5, потому что консолидация началась раньше.
Почему побеждают Reddit и Wikipedia?
Не из-за уникальности, а потому что они дают прямые ответы.
Если пользователь спрашивает "what's the best CRM for startups?", бренд ведёт на "Записаться на демо", а Reddit сравнивает 10 платформ — цитируется именно Reddit.
OpenAI фактически подталкивает бренды: становитесь ответом.
Создавайте сравнительные гайды, отвечайте на реальные запросы, пишите тем языком, которым пользуются клиенты.
Возможности есть для брендов, готовых сместить фокус с конверсии на контент, который сразу отвечает на вопрос.
Этот скачок — результат эксперимента OpenAI с весами цитирований.
Рост Reddit на 87% и скачок Wikipedia на 62% за месяц не органика.
Это настройка RAG-системы: приоритет получают ответы с максимальной полезностью, а не брендовый контент.
Краткосрочно SEO-шников беспокоит главное: при ручной корректировке весов трафик "штормит".
Этот раз тест обернулся падением до –52% менее чем за месяц.
Мы все ощущаем эксперименты OpenAI.
Останется ли этот тест постоянным, неясно.
Но тренд очевиден: сайты, которые дают ответы, усиливают позиции.
Посмотрим, что они будут тестировать дальше.
@
Читать полностью…
Mike Blazer
24 Aug 2025 13:10
Деян Петрович спарсил контент Open AI и Google и обучил на нём модель.
LinkBERT — эксперт по линкбилдингу, который определяет оптимальные места для ссылок в веб-контенте.
Демо: https://linkbert.com/
---
А тут - новый генератор разветвления запросов (Query Fan-out)
https://dejan.ai/tools/fanout/
@
Читать полностью…
Mike Blazer
24 Aug 2025 09:15
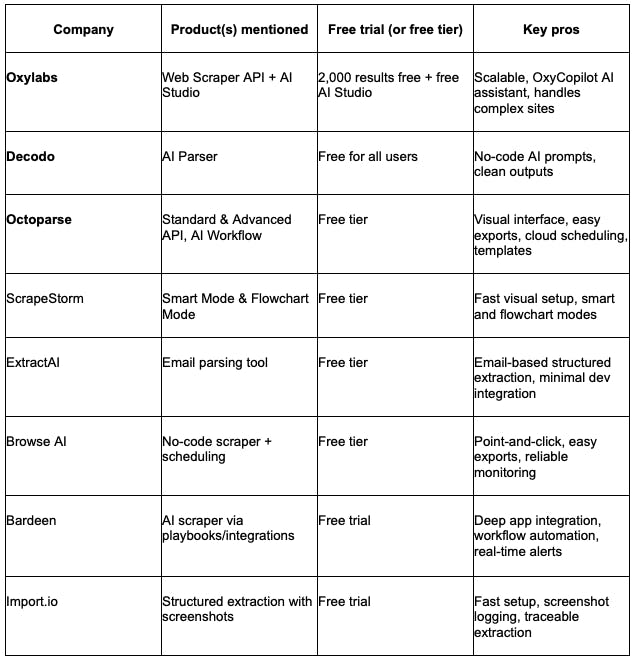
Лучшие AI-парсеры в 2025 году
1. Oxylabs
Подходит корпоративным клиентам и новичкам. Предлагает Web Scraper API и no-code решение AI Studio.
Плюсы:
— Работает со сложными сайтами на JavaScript.
— OxyCopilot ускоряет взаимодействие с API.
— Бесплатная AI Studio с промптами на естественном языке.
— Корпоративная инфраструктура и поддержка 24/7.
Минусы:
— Web Scraper API требует знания кода.
— AI Studio ограничена для массового парсинга.
2. Decodo
Инструмент для быстрого парсинга без кода через AI-промпты в AI Parser.
Плюсы:
— Извлечение данных текстовыми запросами без кода.
— Работает с JavaScript-сайтами.
— Выдает структурированные форматы (CSV, JSON).
Минусы:
— Эффективен для отдельных страниц, а не массового сбора.
3. Octoparse
No-code решение с визуальным интерфейсом point-and-click и облачным планировщиком.
Плюсы:
— Drag-and-drop без программирования.
— Шаблоны для популярных сайтов.
— Облачный экспорт и задания по расписанию.
Минусы:
— Ограниченный функционал в бесплатной версии.
— Медленная работа Mac-приложения.
4. ScrapeStorm
Инструмент визуального парсинга без кода с режимами "Smart Mode" и "Flowchart Mode".
Плюсы:
— Быстрая настройка через Smart Mode.
— Создание сложной логики блок-схемами.
— Кроссплатформенность (Windows, Mac, Linux).
Минусы:
— Масштабируемость ограничена.
— В Smart Mode возможно пропускание данных.
5. ExtractAI
Автоматизирует извлечение данных из email и текстов (счета, запросы), но не из сайтов.
Плюсы:
— Переводит письма и логи в структурированные данные.
— Снижает ручной ввод и ошибки.
— Интеграция с CRM, Google Sheets, дашбордами.
Минусы:
— Не подходит для веб-парсинга.
— Требует настройки сопоставления полей.
— Стоимость за email растет при больших объемах.
6. Browse AI
Инструмент для мониторинга сайтов и парсинга по расписанию. No-code интерфейс позволяет обучать ботов кликами с экспортом в Sheets.
Плюсы:
— Простая настройка ботов.
— Автоматические триггеры и расписания.
— Интеграция с Google Sheets и Zapier.
Минусы:
— Кредитные лимиты увеличивают расходы.
— Не справляется со сложными или защищенными сайтами.
7. Bardeen
Браузерный AI-инструмент для связки парсинга с рабочими процессами в Google Sheets, Slack, CRM.
Плюсы:
— Автоматизация парсинга и процессов в одном инструменте.
— Работает в браузере, код не нужен.
— Готовые сценарии (Playbooks) для типовых задач.
Минусы:
— Не рассчитан на высокие нагрузки.
— Лимиты строк и кредитов на младших тарифах.
8. Import.io
Корпоративный инструмент для масштабного извлечения данных с аудитом и скриншотами.
Плюсы:
— Аудит со скриншотами для комплаенса.
— Масштабируемость и API.
— Корпоративная поддержка.
Минусы:
— Высокая цена.
— Избыточный функционал для небольших задач.
https://hackernoon.com/the-best-ai-web-scraper-tools-in-2025-top-picks-features-and-pricing
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}