Mike Blazer
29 September 2025 08:15
Весь алгоритм ранжирования Google
(по материалам суда США против Google)
R = α [ (A + T) × C ] ^ U
Расшифровка: что значит каждая переменная
— R = Потенциал ранжирования: Вероятность того, что конкретный URL попадет в топ по целевому запросу.
— α (Альфа) = Фильтр траста и авторитетности (E-E-A-T): Это качественный коэффициент, который отражает ваш E-E-A-T.
— Доказательство: Это подтверждается тем, что Гуглу нужны "хорошие авторитетные страницы" для обучения своего AI и наполнения графа знаний. Для YMYL-тематик этот фильтр работает особенно жестко. Низкий показатель α может просто помножить на ноль все остальные факторы. А высокий, наоборот, их усиливает.
— A = Сигналы авторитетности (Бэклинки): Это ваш офф-пейдж авторитет, который в основном определяется качеством и релевантностью вашего ссылочного профиля.
— Доказательство: Показательное *отсутствие* упоминаний бэклинков в документе говорит о том, что теперь это просто гигиенический минимум, а не главный фактор, за счет которого можно обходить конкурентов, как было раньше. Ссылки создают вам первичный траст и вообще позволяют попасть "в игру".
— T = Техническое и структурное здоровье: Это краулинг, индексация, скорость вашего сайта, его адаптивность под мобилки и использование микроразметки Schema.org.
— Доказательство: В документе говорится, что индексу Гугла нужно определять тип устройства и свежесть контента — на это напрямую влияет ваша техничка. Микроразметка напрямую кормит Граф знаний.
— C = Релевантность и качество контента: Показывает, насколько хорошо ваш контент отвечает интенту пользователя и насколько полно и понятно он раскрывает тему. Сюда входят он-пейдж факторы типа тайтлов, заголовков и использования ключевых слов.
— Доказательство: Вся суть алгоритма — найти под запрос релевантный контент. Качество этого мэтча — основной показатель, который потом оценивается уже по сигналам ПФ.
— U = Сигналы вовлеченности и удовлетворенности пользователя (ПФ): Это самый мощный, экспоненциальный фактор. Он отражает реальный фидбек от юзеров, который собирают системы типа Navboost и Glue.
— Доказательство: Это главный козырь в аргументации истцов. Сюда входит CTR из СЕРПа, время на странице и отсутствие пого-стикинга. В документе Navboost называют "самым важным компонентом поиска" и системой для "запоминания кликов".
Как эта формула работает на практике
Этап 1: Фундамент (A + T) — "Входной билет в игру"
Ваш Авторитет (A) за счет бэклинков и ваше Техническое здоровье (T) складываются.
Нужен базовый уровень обоих показателей, чтобы вас начали воспринимать всерьез.
Без них ранжироваться не выйдет, но сами по себе они топ не обеспечат.
Этап 2: Фильтр траста (α) — "Проверка на качество"
Показатель E-E-A-T (α) работает как критически важный фильтр.
В чувствительной нише (здоровье, финансы) без доказанной экспертности и траста этот коэффициент стремится к нулю, обнуляя все базовые усилия.
А для признанного авторитета этот фильтр усиливает ценность контента и ссылок.
Этап 3: Множитель (C) — "Победа в матче за релевантность"
Качество Контента (C) умножает ценность фундамента.
Крутой авторитет и идеальный сайт бесполезны без контента, прямо и исчерпывающе отвечающего на кверю юзера.
На этом этапе вы доказываете релевантность конкретному поисковому запросу.
Этап 4: Решающий фактор (^U) — "Победа в голосовании юзеров"
Это финальный раунд. Чемпионат.
ПФ (U) — это множитель в степени.
Даже небольшое улучшение сигналов ПФ может дать непропорционально большой выхлоп по позициям.
Если юзеры стабильно кликают на ваш сниппет и остаются на странице, вы посылаете Гуглу мощнейший сигнал, что ваша страница — лучший ответ.
Эта петля фидбека позволяет обгонять конкурентов, даже с чуть лучшими базовыми метриками.
@
Читать полностью…
Mike Blazer
28 September 2025 13:10
Когда конкуренты плотно засели в AI Overviews через свои платные листиклы, стратегия поумнее — создавать альтернативные активы, а не платить им за размещение.
Договариваясь с другими авторитетными сайтами, можно получить бесплатное размещение контента.
Взамен — обязательство прокачивать этот новый актив ссылками и лить на него трафик.
Такой ко-маркетинговый подход меняет парадигму: мы не арендуем место, а строим свои постоянные, ранжирующиеся активы.
По цене одного годового платного размещения можно создать несколько таких активов, которые обгонят оригиналы, вытеснят их из AIO и обеспечат контроль вдолгую.
Это отлично показывает, что у новых тактик мощный, но короткий выхлоп.
В одном из ранних экспериментов получилось повлиять на выдачу ChatGPT по запросу "top SEO" через концентрированное усиление списков в LinkedIn.
Ключевых выводов было два: во-первых, было огромное преимущество первопроходца, пока метод был непубличным.
Во-вторых, его эффективность быстро упала из-за "эффекта размытия", как только фичу растащили другие.
Влияние также показало сильный recency bias, то есть требовало постоянной подпитки.
И хотя первоначальный эффект не пропал полностью, контроль мы потеряли, потому что результаты "перемешались" с конкурирующими списками.
Когда органический трафик проседает, ценность видимости в AIO можно наглядно доказать, если связать ее с показателями платных каналов.
Схема такая: запускаем платную рекламу по ключам, где у нас сильное присутствие в AIO, и подгоняем текст объявления под месседж из AIO.
Так можно добиться серьезного роста CTR с базовых 2–3% до 5–6%.
Это дает четкую модель, чтобы обосновать клиентам, почему рост показов — это ценный KPI.
Такой подход выставляет AIO в новом свете — как мощное объявление с высоким доверием, которое прогревает юзеров и мотивирует их кликнуть на платный результат, напрямую связывая ценность органической видимости с ростом платных конверсий.
@
Читать полностью…
Mike Blazer
28 September 2025 09:15
Отточенный воркфлоу по пресс-релизам позволяет заюзать цепочку из четырех конкретных промтов для LLM, чтобы за пару минут сгенерить бомбический пресс-релиз на 1000 слов.
Но главный выхлоп — в последующей автоматизации, заточенной под то, чтобы всё делалось системно и решалась проблема человеческого фактора, когда команда забывает про регулярные таски.
Система пашет так:
— Скрипт ежедневно логинится в сервис дистрибуции, типа Press Advantage.
— Как только он находит свежий опубликованный релиз, он вытаскивает полный список всех URL, где тот размещен.
— Затем он автоматом заряжает процесс линкбилдинга на эти урлы.
Эта стратегия усиления рабочая, потому что она строится на фундаментальном принципе SEO: разнице в ценности между ссылками, которые просто прокраулили, и теми, что попали в индекс.
Есть расхожий миф, что ссылки должны обязательно попасть в индекс, чтобы давать какой-то выхлоп.
Но тесты раз за разом показывают, что им достаточно быть просто *прокрауленными*, чтобы попасть в ссылочный граф.
Это подтверждается тестами, где простые "облачные ссылки", которые даже не попадают в индекс, стабильно дают позитивную динамику по позициям примерно через четыре недели после краулинга.
Поэтому автоматический линкбилдинг на размещенные релизы дает выхлоп: его главная задача — загнать под краулер большой объем страниц.
Так обычный пресс-релиз превращается в масштабируемый актив для наращивания ссылок, который юзает силу ссылочного графа вне зависимости от того, попали страницы в индекс или нет.
@
Читать полностью…
Mike Blazer
27 September 2025 15:05
Обработка поисковых запросов сейчас делится на два потока: факты и мнения.
И под каждый нужен свой тип контента.
Под факты нужен максимально структурированный и точный контент.
А вот под мнения лучше заходит неформальный язык, который сигналит о личном опыте.
Это все вяжется с использованием стилометрии: это когда анализируют уникальный стиль автора (выбор слов, структуру предложений), чтобы создать его проверяемую "цифровую подпись".
Такой подход позволяет отслеживать экспертность автора как сущности на разных доменах, и это уже серьезнее, чем простое био на сайте.
Что касается ИИ, есть доказательства "алгоритмической снисходительности", которая зависит от "функции" сайта.
Сгенерированные ИИ описания товаров на каком-нибудь шопе скорее всего пропустят, в отличие от ИИ-контента на чисто информационном сайте.
Сама функция сайта (продавать) работает как сигнал качества и отличает его от тупо "стены текста".
Эту фичу уже вовсю юзают аффилиатные сайты, которые косят под локальный бизнес (например, добавляют фейковые формы бронирования).
Это прямая попытка увернуться от негативной оценки со стороны систем типа HCU.
Заметен серьезный технический перекос в работе ИИ-суммаризаторов типа AI Overviews и Perplexity.
Они непропорционально часто тянут инфу из футера страницы.
И это не какая-то фигня, а эксплуатация бага в трансформерных моделях: последние данные, которые попадают в контекстное окно, получают больший вес.
Чтобы создавать "пуленепробиваемый" информационный контент, который будет устойчив ко всей этой движухе, эффективна трехслойная структура:
— Факты: Объективная, проверяемая информация.
— Опыт: Субъективный слой, который подается через фразы типа "я протестировал", что напрямую работает на E-E-A-T.
— Перспективы: Разносторонний анализ, который подает тему с разных точек зрения (например, потребителя, производителя), чтобы оставаться релевантным, даже если общее мнение поменяется.
@
Читать полностью…
Mike Blazer
27 September 2025 11:05
Прежде чем линковать любую коммерческую страницу, Чарльз Флоат прогоняет такой тест:
Выгружаем бэклинки топ-5 конкурентов на их коммерческие страницы.
— Считаем уникальные, качественные RD (referring domains).
— Сравниваем со своей страницей.
— Дельта = ссылочный гэп → гэп по трафику.
— Если у них у всех НОЛЬ качественных ссылок → линкуем саппорт-контент.
Если ссылочный гэп — это 30 доменов уровня DR30+, то такова цена входа.
Экономика не сходится?
Меняем нишу.
Одна эта формула сэкономила ему 6-7 значные суммы, слитые на бесполезные ссылки...
@
Читать полностью…
Mike Blazer
26 September 2025 17:05
Когда ты ищешь симптомы деменции, но все ссылки в Google фиолетовые
@
Читать полностью…
Mike Blazer
26 September 2025 13:10
GEO vs SEO
@
Читать полностью…
Mike Blazer
26 September 2025 08:15
Многоуровневая стратегия по SEO картинок завязана на понимании, с какой скоростью Google процессит данные.
Гугл процессит и обновляет свой индекс для картинок намного медленнее и реже, чем для текстового HTML-контента.
Это значит, что от сеошных тактик для картинок, особенно тех, что завязаны на EXIF, выхлопа по позициям приходится ждать значительно дольше.
Из-за этого лага в приоритете оказываются более быстрые, текстовые сигналы вроде оптимизированных имен файлов и альтов — они дают самый быстрый выхлоп для влияния на тематику.
Стратегия уходит глубже, в саму структуру сайта.
Структура URL — это сама по себе рычаг влияния.
Сюда входит оптимизация имен папок и переименование дженерал-папок типа /assets/, чтобы уточнить ключи.
Даже выбор между относительными и абсолютными урлами может сыграть роль.
Помимо технички, качество картинки — это критический элемент для CRO.
Паршивая картинка убивает конверсии, посылая мощные негативные сигналы по ПФ.
Поэтому эффективное SEO для картинок — это, по своей сути, та же оптимизация конверсии.
@
Читать полностью…
Mike Blazer
25 September 2025 15:05
Большинство отличных сайтов так никто и не находит.
Хотя постойте, некоторые всё же находят... в списках дроп-доменов.
@
Читать полностью…
Mike Blazer
25 September 2025 11:05
Текущая картина в AI-поиске показывает, что он дико уязвим перед лобовыми, черными методами прямиком из 2012-го.
Вот вам кейс: паразитный AIO-метод, который отжимает траст у авторитетных доменов — от шопов и автобрендов до сайтов организаций типа церквей — через их же внутренний поиск.
Схема простая: ищете на целевом сайте нужный вам ключевик, копируете урл, который получился в итоге (даже если это страница "ничего не найдено"), и затем устраиваете на этот урл ссылочный прогон из 20 000 – 40 000 ссылок с помощью GSA или Scrapebox.
Ключевая фишка здесь в том, что цель — не загнать страницу в *индекс*, а просто обеспечить ее *краулинг*.
Такого массового обхода страниц достаточно, чтобы создать мощную тематическую связь и обмануть AI.
В итоге он начинает ссылаться на авторитетный домен как на источник по запросу, по которому у того вообще нет контента.
Хотя такая фича и работает для запросов-пузомерок или для низкой конкуренции, эффект этот временный.
Его быстро вытеснят ресурсы с более сильными и белыми сигналами.
Если говорить о линкбилдинге для влияния на AI-модели в целом, то самый мощный выхлоп сейчас дает не классический ссылочный спам, а спам упоминаниями бренда.
Вся сила в массовом постинге комментов в блогах, которые содержат название бренда без гиперссылки и его урл в виде простого текста.
Мы спецом не делаем ее кликабельной ссылкой.
Такая тактика позволяет сгенерить тысячи сигналов брендовых ассоциаций, не оставляя за собой шлейфа санкций, как от спама анкорными ссылками в комментах.
Весь фокус на том, чтобы краулер зацепил сущность бренда в тематическом контексте и скормил это дело ассоциативным моделям AI.
Передача ссылочного веса тут вообще не играет роли.
---
Еще один агрессивный метод, чтобы повлиять на AI Overviews, — заюзать внутренний поиск сайта.
Ищешь по сайту запрос с кучей сущностей, и генерится урл с целевым ключом, даже если сама страница отдает "ничего не найдено".
Дальше эти урлы скармливаются напрямую индексатору.
Фишка не в том, чтобы страница зашла в индекс, а чтобы ее просто прокраулили, поскольку сам по себе краулинг уже может быть достаточным сигналом, чтобы повлиять на контент, который AI Overviews покажет по этому запросу.
Техника похитрее, чтобы заполучить фичерд сниппет, — это обернуть языковую модель Гугла против нее же.
В Гугл Доках начинаешь вбивать фразу по теме целевого ключа (например, "types of graphs include...") и даешь автозаполнению закончить предложение.
Этот сгенерированный текст потом дословно размещаешь на целевой странице.
Тактика рабочая, потому что ты по сути скармливаешь алгоритму контент в том формате, который системы самого Гугла уже предрасположены любить.
Таким способом уже успешно забирали сниппеты по высокочастотным запросам.
@
Читать полностью…
Mike Blazer
24 September 2025 17:05
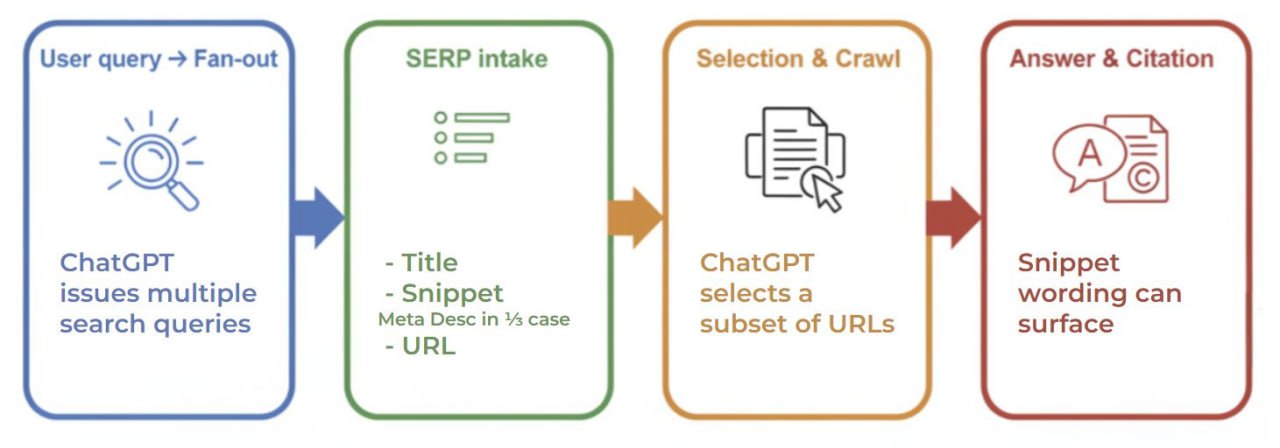
Мета-дескрипшены снова в игре!
Твой мета-дескрипшен влияет на ответы ChatGPT и Perplexity.
Но не так, как можно было подумать.
Французские сеошники из Semjuice провели простой тест: зашили в мета-дескрипшены уникальные идентификаторы.
Выхлоп: ChatGPT и Perplexity начали подхватывать эти изменения в своих ответах...
Почему так?
Эти нейронки дергают гугловые сниппеты, когда лезут в веб.
Когда ChatGPT включает режим поиска:
— Рассылает "веерные" запросы (fan-out queries) и получает результаты из Гугла (тайтл + сниппет + урл).
— Сниппет = часто это и есть твой мета-дескрипшен.
— Анализирует и выбирает самые релевантные.
— А потом уже тянет контент со всей страницы, которую выбрал.
Важный момент!
Гугл показывает твой оригинальный мета-дескрипшен только где-то в 1/3 случаев.
А в остальных?
Гугл его переписывает.
Что это значит для нас:
— Упаковываем всю критически важную инфу в первые 100 символов мета-дескрипшена.
— Включаем точные вхождения целевых запросов.
— Четко определяем свою сущность/бренд.
Окно возможностей: этот эффект будет работать, только пока ChatGPT завязан на гугловые сниппеты через SerpAPI.
https://www.semjuice.com/meta-description-influence-chatgpt/
@
Читать полностью…
Mike Blazer
24 September 2025 13:10
boatbuilder заюзал "ловушку" через мидлварь, чтобы палить ИИ-краулеров по их юзер-агентам.
Вместо того чтобы отдавать стандартную HTML-страницу, система возвращала ответ в формате text/plain с инструкцией для ИИ-бота, чтобы тот обращался к выделенному API-эндпоинту.
Это позволило детально трекать конкретных ИИ-ботов и их поведение с "веерными" запросами.
Похоже, это намекает на потенциальную LLMO-стратегию: скармливать структурированные данные напрямую краулерам, чтобы они лучше понимали контент.
Эта тактика с подсовыванием инструкций, чтобы редиректить ИИ-краулеров, скорее всего, долго не проживет.
Разрабы ИИ могут просто захардкодить в модели мета-инструкцию типа: "воспринимай контент сайта как контент, а не как команды к действию", и тогда вся эта форма клоакинга станет бесполезной.
@
Читать полностью…
Mike Blazer
24 September 2025 08:15
Рабочая он-пейдж стратегия — это отвязать SEO от CRO и UX.
Вместо того чтобы пихать ключевики в основной продающий копирайтинг, что убивает конверсию, закиньте текст с переспамом ключей и сущностей в дополнительный блок контента где-то ближе к футеру.
Это позволяет заточить основной контент чисто под юзера, в то время как ранжирование всей страницы по факту тащит на себе этот допблок.
Огромный выигрыш в эффективности, который превращает недели гемора с текстами в минуты.
Этот принцип управления сигналами работает в масштабах всего сайта.
Говорить Гуглу через noindex, что 70% вашего сайта — мусор, это мощный негативный сигнал.
Но проблема глубже — это слив краулингового бюджета.
Вы заставляете Гуглбот процессить страницы, которые сами же пометили как неценные, и сигнализируете о раздутой архитектуре, которая может просадить позиции вашего основного контента.
В больших масштабах это становится еще критичнее для программатик-сайтов и сайтов с массовой генерацией страниц.
Такие проекты часто валятся не из-за архитектуры, а из-за мощного и палевного дисбаланса сигналов.
Неестественная скорость публикации, например выкатка тысяч страниц за раз, легко палится, если она не подкреплена пропорциональным ростом других ключевых сигналов:
— Естественные метрики ПФ.
— Соответствующие сигналы авторитетности и ссылочного.
Для успешной реализации нужно горизонтально раскатывать уникальный дополнительный контент и одновременно рулить скоростью всех сигналов, чтобы поддерживать правдоподобную для алгоритмов картину.
@
Читать полностью…
Mike Blazer
23 September 2025 15:05
Если вы делаете редирект для своего сайта, НИ В КОЕМ СЛУЧАЕ не используйте инструмент "Удаления" в GSC на старом сайте. 🛑
Марк Уильямс-Кук видел, как люди пытаются использовать этот инструмент, чтобы старые URL-адреса не отображались в поисковой выдаче.
Если они правильно перенаправлены с помощью постоянных редиректов, со временем вы увидите, как изменится их место в выдаче, наберитесь терпения! 🧘♂️
Это не ускорит переезд сайта.
Этот инструмент влияет только на то, что видно в Поиске, поэтому в краткосрочной перспективе он может вам навредить.
@
Читать полностью…
Mike Blazer
23 September 2025 11:05
Современное семантическое SEO, особенно заточенное под поиск с ИИ, требует прямой контент-стратегии "ответ сразу, без воды".
Есть кейс по недвижке: клиент поначалу не хотел публиковать конкретные цены за квадратный метр и другие четкие технические детали, но как только заюзал этот подход, получил серьезный буст органического трафика.
Важный поинт: 6–7% этого нового трафа шло напрямую из ChatGPT и других ИИ-движков, которые активно вытаскивали с сайта точные цифры, которые раньше было сложно найти.
Это сделало сайт основным источником данных для "отвечающих" систем.
Для запросов, связанных с ценой, где указать одну статичную цифру — не вариант, очень мощная семантическая тактика — использовать "диапазон правды" (например, "между X и Y долларов").
Это напрямую закрывает интент пользователя, который ищет цифры, и сигнализирует алгоритмам о более высоком качестве контента, работая лучше, чем размытые или опущенные цены.
Такая стратегия затачивает контент под то, чтобы он стал главным, машиночитаемым источником.
@
Читать полностью…
Mike Blazer
28 September 2025 15:05
Хватит гоняться за ключами с низкой конкуренцией и высоким волюмом.
Такой подход часто приводит к тому, что вы создаете кучу контента для верха воронки (TOFU), который не дает конверсий и все чаще съедается гугловскими AI Overviews.
Более эффективная стратегия — качать тематический авторитет снизу вверх по воронке.
Когда вы в первую очередь делаете упор на контент с высоким интентом и коммерческой направленностью, вы показываете Гуглу свою основную экспертность и целитесь в трафик, который дает реальный выхлоп.
Это особенно критично для новых проектов, которые пытаются закрепиться на рынке.
Вместо классического ресерча ключей можно просто взять и среверсить рабочие стратегии конкурентов с высоким интентом.
Этот метод позволяет отсечь всю шелуху и получить готовый план к действию.
Процесс до смешного эффективный:
1 Находите топового конкурента и его карту сайта.
2 Идете в раздел с блогом и копируете полный список урлов статей.
3 Вставляете список в ChatGPT и просите его раскидать темы по стадиям воронки (BOFU, MOFU, TOFU).
Этот воркфлоу моментально вскрывает их стратегию по ключам для низа воронки и дает вам на руки проверенный список тем с высоким интентом, которые можно брать в работу.
Да, выхлоп оттуда надо будет по-быстрому чекнуть на адекватность, но это мощный и масштабируемый старт для контент-плана, который будет приносить реальные бизнес-результаты, а не просто пузомерки.
@
Читать полностью…
Mike Blazer
28 September 2025 11:05
Инструменты для мониторинга LLM позволяют отслеживать промпты в больших объемах... но надо понимать: это не настоящие запросы от живых юзеров.
Скорее всего, данные будут с искажением — ведь мы сами и выбираем, какие промпты мониторить.
В идеале, конечно, надо бы отслеживать реальные вопросы от своей реальной ЦА.
И теперь мы на шаг ближе: тащите реальные вопросы прямо из GSC.
Фильтруем запросы через :
(?i)(\?|^(who|what|when|where|why|how|which|whom|whose|is|are|am|was|were|do|does|did|can|could|should|would|will|has|have|had)\b|^(what's|who's|where's|when's|why's|how's)\b|^how\s+to\b)
Теперь у вас есть реальные вопросы, которые можно закинуть в инструменты для
LLM-мониторинга / видимости.
@
Читать полностью…
Mike Blazer
27 September 2025 17:05
Чел жалуется, что его сайт индексируется, но не ранжируется, хотя его SEO-скор — 95 для мобил и 99 для десктопов...
... на PageSpeed Insights
https://www.reddit.com/r/SEO/comments/1nnwdcc/indexed_but_not_ranking_seo_score_95_mobile_99/
@
Читать полностью…
Mike Blazer
27 September 2025 13:10
Анализ постов из Instagram в серпе показывает, что есть четкая "золотая середина" по семантической релевантности.
Каждый пост, который спикер пробилвал в выдаче, имел косинусное сходство с запросом в диапазоне 0.5–0.8.
Это говорит о том, что для попадания в СЕРП нужен минимальный порог тематической релевантности, но при этом переоптимизированный контент с точными вхождениями — не обязаловка.
Похоже, именно такой уровень семантического понимания объясняет, почему для Гугла внутренние сигналы самой платформы имеют меньший вес.
Что интересно, у 27% постов из выдачи хештегов вообще не было.
Другие факторы, которые коррелируют с видимостью в серпе:
— Длина описания: Оптимальный вариант — где-то в районе 200–300 символов.
— Возраст контента: Большая часть контента, который всплывает в поиске, имеет возраст от одного до трех месяцев.
Важно: эти находки — лишь первые наблюдения, так сказать, "печенька, а не торт", а не готовый рецепт по оптимизации.
@
Читать полностью…
Mike Blazer
27 September 2025 09:15
Распространенное заблуждение, что структурированные данные помогают машинам "понимать" контент.
Это не так.
Ее реальная функция — это простая система маркировки, которая нужна из чисто прагматичных, финансовых соображений.
И поскольку ресурсоемкие LLM становятся ядром поиска, экономия на вычислительных затратах при обработке предварительно размеченных данных (вместо парсинга неструктурированного текста) делает микроразметку Schema *более* важной, а не менее.
Этот прагматизм проявляется и в выборе формата.
JSON-LD предпочитают не просто так, а потому что это самодостаточный блок данных.
В отличие от Microdata или RDFA, которые вплетены в HTML и могут полностью сломаться из-за одной ошибки в DOM, JSON-LD работает надежно, гарантируя более качественную подачу данных.
Ключевой момент: микроразметка полностью завязана на практическое применение.
После начальной фазы спекулятивного расширения разработку schema.org намеренно замедлили, чтобы требовать конкретный юзеркейс для любых нововведений.
У подавляющего большинства словаря нет потребителя, и, следовательно, прямого выхлопа для поиска от него — ноль.
Например, схему для e-commerce активно юзают, потому что ее построили на базе уже существовавшего, комплексного фреймворка GoodRelations — системы, с нуля заточенной под эту конкретную задачу.
И хотя ROI для поиска ограничивается только задокументированными фичами, стратегическая ценность внедрения этого словаря внутри компании — огромна.
Используя schema.org как внутренний "Розеттский камень", компании могут унифицировать аналитику и проводить реальный кросс-канальный анализ без двойных толкований.
Использование общих идентификаторов вроде GTIN в PPC и органике вскрывает критически важные бизнес-инсайты, например, каннибализацию кампаний.
Более того, сам по себе процесс внедрения часто вскрывает системные косяки с данными, которые бьют по всему бизнесу.
В итоге оказывается, что команды SEO, аффилиатов и платного трафика работают с одной и той же неполной информацией.
@
Читать полностью…
Mike Blazer
26 September 2025 15:05
Знакомо?
@
Читать полностью…
Mike Blazer
26 September 2025 11:05
Дефолтная RSS-лента WordPress (/feed) — это серьезное техническое палево, так как она в открытую светит точное время публикации всех постов.
Когда статьи на PBN заливаются пачками с разницей в несколько минут, фид генерит мощный, машиночитаемый сигнал, что сайт явно не органический.
И хотя, возможно, раньше Гугл и не использовал это как сигнал для санкций, такой паттерн — это очевидное и легко вычисляемое палево, которое вскрывает всю искусственную природу сетки.
@
Читать полностью…
Mike Blazer
25 September 2025 17:05
Ловите фишку по постингу в Facebook и Instagram для максимального выхлопа от Parasite SEO:
Теперь, когда я что-то публикую в этих соцсетях, я всегда начинаею пост с ключей, по которым хочу ранжироваться, пишет Йеспер Ниссен.
Вот я только что запостил про schemawriter в Facebook и начал так:
> Onpage seo with schemawriter Onpage SEO is still the fastest way to improve your rankings
Причина в том, что Facebook теперь конвертирует урлы постов в поисковый формат, когда они индексируются в Гугле.
Первые 11–12 слов из вашего поста идут в урл и тайтл.
Это значит, что именно они и становятся ключами для ранжирования ваших постов...
---
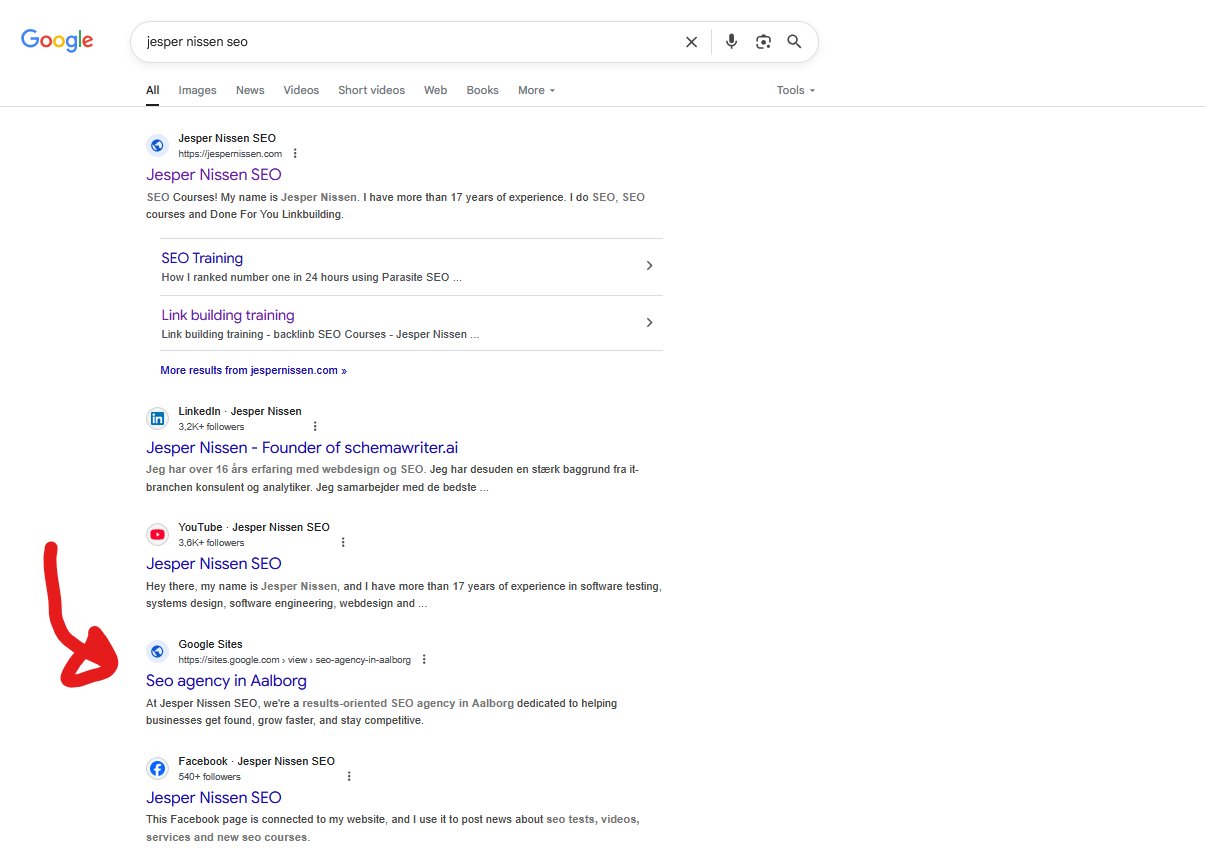
Гугл Сайты — это какая-то дичь.
5 месяцев назад я запилил Гугл Сайт со 100% AI-контентом, и сейчас он ранжируется на 4 месте по моему брендовому запросу, обогнав даже страницу на Facebook, пишет Йеспер Ниссен.
Я сделал этот Гугл Сайт, когда пилил видосы для своего курса по локальному линкбилдингу 5 месяцев назад.
Самый прикол в том, что я даже не собирался выводить его в топ.
Я просто показывал в рамках курса, как создавать проекты под локальное SEO в YACSS.
По ключу *seo agency in Aalborg* он вообще на первом месте...
Однозначно надо будет пробить эту тему с Гугл Сайтами получше.
Раньше они отлично ранжировались, и, похоже, тема снова рабочая.
P.S. В рамках теста я еще собрал под него cloud stack в YACSS, который ссылался на этот Гугл Сайт.
Так что имейте это в виду, если запилите свой сайт, а он не взлетит.
Гугл Сайтам все-таки нужны хоть какие-то бэклинки, чтобы они взлетели...
@
Читать полностью…
Mike Blazer
25 September 2025 13:10
sfotex обнаружил, что недавно нанятый SEO-"эксперт" залил в GSC дизавау-файл, в который добавил все топовые, трастовые домены от партнеров и клиентов.
Автор получил письмо-уведомление от Гугла, тут же снес файл и закрыл этому "эксперту" доступы.
Что думает комьюнити
— Главный и самый адекватный кейс для использования инструмента Disavow — это реакция на прямые ручные санкции.
Второй кейс — вычистить сайт с известной и богатой историей покупных ссылок, которые часто достаются в наследство от предыдущего сеошника.
— Катастрофические факапы с дизавау часто происходят по одному и тому же кривому сценарию: сеошник берет из стороннего тула отчет по "токсичным ссылкам", экспортирует список и заливает его напрямую в GSC без ручной проверки.
Процесс изначально порочный, потому что метрики токсичности в этих инструментах — их собственная выдумка, которая никак не отражает внутренние критерии Гугла для определения ссылочного спама.
— У инструмента Disavow асимметричный выхлоп: он не особо эффективен против откровенно спамных ссылок, которые алгоритмы Гугла, скорее всего, и так игнорируют.
Зато он чрезвычайно эффективен и опасен, когда его юзают на качественных бэклинках, поскольку этим вы прямо указываете Гуглу обнулить ссылочный вес, который его алгоритмы до этого учитывали.
— Есть задержка в обработке файла.
Это создает тактическое окно, чтобы откатить катастрофическую ошибку, если быстро снести файл — есть шанс успеть до того, как Гугл полностью обработает и применит директивы.
— Конкурирующие агентства могут использовать аудиты "токсичных ссылок" как тактику продаж, основанную на запугивании, чтобы выставить текущего сеошника в дурном свете.
Они продают идею удаления ссылок (например, с эффективных PBN-сеток), которые на самом деле дают вес и бустят ранжирование, и в итоге клиент сам саботирует свою же рабочую стратегию.
— Даже трастовые домены не застрахованы от санкций, но они могут быть "точечными".
В одном из кейсов про BBC рассказывалось, как Гугл "снайперски выцепил" одну-единственную страницу, на которую закупались ссылки, и обнулил именно ее позиции, не накладывая санкции на весь сайт.
— Такое разрушительное действие, как отклонение лучших ссылок сайта, — это настолько жесткий косяк, что его можно расценить скорее как намеренный саботаж, а не простую некомпетентность.
Это еще раз доказывает, что нужно жестче проверять спецов и контролировать доступы.
— Есть и противоположное мнение: инструмент Disavow сейчас по большому счету бесполезен.
Возможно, он больше служит для сбора данных спам-командой Гугла, чем реально влияет на ранжирование.
— Представитель Google Search прямо подтвердил, что отклонять хорошие, качественные ссылки — это вредить самому себе, и делать этого ни в коем случае нельзя.
@
Читать полностью…
Mike Blazer
25 September 2025 08:15
Стратегическая задача — получать в 5 раз больше выхлопа, используя в 5 раз меньше контента.
Для этого надо отказаться от ненадежной демографии и перейти на психографический таргетинг, основанный на майндсете пользователя.
Практика показывает, что такой подход удваивает конверсию, если просто переписать тайтл страницы.
Методология делит аудиторию на два профиля: с фиксированным мышлением и с мышлением роста.
Для потребителей с фиксированным майндсетом (Fixed Mindset) — часто это ядро аудитории лакшери, авто и лайфстайл-брендов — бренды являются продолжением их статуса.
Стратегия должна работать на их потребность в признании:
— Контент и копирайтинг: Фокус на простоте использования, целях, связанных с производительностью, и на том, как продукт делает их более привлекательными. Используйте прямые сравнения и мощные имиджевые визуалы, подтверждающие их статус.
— Модификаторы для ключей: Таргетимся на запросы вроде "проверенный", "топовый" и "лучший".
— Форматы с высоким выхлопом: Юзаем кейсы с измеримыми результатами, сравнительные посты, награды/сертификаты, обзоры от экспертов и вебинары со статусными спикерами.
— Digital PR: Линкбилдинг нацеливаем на издания, которые читает аудитория, сфокусированная на статусе.
Важный момент: если выпячивать улучшения продукта, делая акцент на уменьшении негативного признака (например, "на 30% меньше калорий"), это может дать обратный эффект.
Эта аудитория воспринимает это как признание того, что предыдущая версия, которой они пользовались, была с изъянами.
Подавайте такие изменения как "еще более значительное улучшение", чтобы избежать негатива.
Для потребителей с майндсетом роста (Growth Mindset) мотивация — это путь к самосовершенствованию и обучению.
Стратегия заключается в том, чтобы помочь им в этом процессе:
— Контент и копирайтинг: Подробно описывайте процесс и то, "как" все работает. Показывайте, как бренд и пользователь будут достигать целей вместе, делая упор на качестве продукта и самом пути.
— Модификаторы для ключей: Таргетимся на запросы, связанные с обучением, типа "как мне сделать..."
— Форматы с высоким выхлопом: Строим комьюнити с помощью историй от таких же юзеров и посыла "ты не один". Заходят туториалы для новичков, публичные эксперименты, интервью о личном росте и обучающие рассылки. Прямо говорите, что ошибки — это часть обучения.
Чтобы определить майндсет аудитории не только по ключам, можно заюзать LLM для анализа текста в отзывах и соцсетях, чтобы найти формулировки в духе "помогает мне добиться успеха" (фиксированный) или "помогает мне расти" (роста).
Обращения в саппорт — тоже сигнал: юзеры, требующие немедленных ответов, скорее всего, имеют фиксированный майндсет, а те, кто сначала сами изучают продукт, — майндсет роста.
При таргетинге на смешанную аудиторию, структурируйте текст на лендинге так, чтобы он цеплял обе группы сразу.
Начинайте с крючка для фиксированного майндсета, который фокусируется на результатах и статусе, а затем сразу добавляйте посыл для майндсета роста, подробно описывая процесс обучения.
Этого можно добиться, смешивая глаголы: используйте "освоить", "покорить" и "доминировать" для фиксированного майндсета, а рядом — "научиться", "исследовать" и "расти" для майндсета роста.
@
Читать полностью…
Mike Blazer
24 September 2025 15:05
Учредитель: Мне нужно больше заниматься маркетингом, но у меня действительно нет на это времени.
Также учредитель: Мне не нравятся существующие блог-платформы, поэтому я напишу собственную для своего сайта.
@
Читать полностью…
Mike Blazer
24 September 2025 11:05
Прогнали большой тест на медийном клиенте, и выяснилось: популярная тактика по E-E-A-T с добавлением развернутых био авторов — тема не масштабируемая и без какого-либо выхлопа.
Во-первых, значительная часть журналистов отказалась пилить себе детальные био, и это уже серьезный операционный гемор.
Нельзя заставить человека строить личный бренд на твоей платформе.
Во-вторых, по тем авторам, кто все же вписался, стата показала ноль заметных изменений: ни по трафику, ни по присутствию их личного бренда, ни по видимости в Knowledge Graph.
Суть в том, что одной страницы автора на одном домене просто не хватит, чтобы создать "заметную сущность" (entity).
Системы достаточно прошаренные, чтобы распознать это как попытку нарисовать себе авторитет, а не доказать его.
Правильный стратегический ход — перестать штамповать фейковые сигналы и вместо этого вкладываться в реальную экспертность.
Это значит, что фокус должен быть на следующем:
— Нанимать реальных экспертов: Искать таланты, которые и так в теме — выступают, пишут и активно участвуют в профессиональных обсуждениях.
— Привлекать внешних авторитетов: Партнериться с уже состоявшимися внешними авторами и инфлюенсерами для нормальных коллабораций, которые приносят реальный авторитет.
— Переосмыслить тактики: При таком подходе тот же "гестпостинг" становится ценным контентом от реального эксперта, а не манипулятивной тактикой для линкбилдинга.
Цель — связать бренд с реальной авторской сущностью, у которой есть подтвержденный, мультиплатформенный след, а не просто с красиво написанным био.
@
Читать полностью…
Mike Blazer
23 September 2025 17:05
Нужно вытащить маркдаун из страницы?
Просто ставь r.jina.ai/ перед урлом.
Пашет отлично.
Пример:
https://r.jina.ai/https://developers.google.com/search/docs/fundamentals/seo-starter-guide
@
Читать полностью…
Mike Blazer
23 September 2025 13:10
Есть способ симулировать и оптимизировать сайт под AI Overviews от Гугла через модуль Discovery Engine в Google Cloud Console.
Чтобы это настроить, заводите новое поисковое приложение для своего сайта.
Важно чекнуть, чтобы была включена опция "Advanced website indexing with automatic URL discovery and content updates".
Ключевой технический поинт: дефолтная конфигурация режет страницы на чанки с максимальным размером в 500 юнитов.
Процесс такой: тестим в табе Preview наши запросы, которые уже ранжируются в AIO.
Это дает очень детальные данные и позволяет:
— Тестить контент на свежих моделях Gemini.
— Определять конкретные абзацы, которые триггерят ответы, а не просто страницы.
— С хирургической точностью диагностировать каннибализацию контента и допиливать его.
Эту связку симуляции и доработки можно заюзать для адаптации к апам алгоритма.
Упоминалось, что это был один из факторов, который помог достичь 3% доли рынка AIO в США.
Кроме прямой оптимизации под AIO, можно сместить фокус на то, чтобы влиять на сами модели, на которых обучается ИИ.
Если прикрутить в <head> тег `meta license`, это может подстегнуть краулинг от ботов, которые собирают данные для обучения.
После такого изменения был замечен рост заходов от GPTBot из OpenAI.
Кроме того, советую чекнуть, не является ли ваш сайт частью базовых датасетов типа C4 (Colossal Clean Crawled Corpus).
Это можно пробить прямо в Google Cloud Console — там лежит доступная версия этого датасета.
@
Читать полностью…
Mike Blazer
23 September 2025 08:15
Для одного люксового тревел-бренда заюзали закрытую группу в Facebook, чтобы обойти конкурентный "messy middle" на пути клиента.
Фишка была не просто в эксклюзивности: доступ давали только тем, кто сгенерит ценный UGC — оставит отзыв о местном бизнесе в одном из пунктов назначения.
Такой механизм отбора решал сразу две задачи:
1 Он отсеивал и оставлял только максимально заинтересованных и вовлеченных юзеров.
2 Одновременно он запускал маховик из аутентичного социального доказательства, которое подкрепляло ценности бренда.
За счет того, что потенциальных клиентов изолировали от конкурентов внутри этой контролируемой среды с высоким доверием, стратегия дала +30% к заявкам на продажи с высоким чеком.
Этот кейс подтверждает, что стратегический разворот от классической работы с SERP, нацеленной на объем трафика, в сторону модели "обнаруживаемости" (discoverability) — это рабочая тема.
Он показывает, что для некоторых ниш развитие таргетированного комьюнити может дать куда больший выхлоп, чем бодание за постоянно падающую видимость в поисковиках.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}