Mike Blazer
21 October 2025 15:05
Google теперь помечает целые мобильные сети, где идет активный парсинг
При парсинге Google есть разные методы, от резидентных прокси до выделенных IP-инфраструктур.
Но мы заметили интересный побочный эффект, связанный именно с использованием мобильных 4G-прокси: интенсивный, географически сконцентрированный парсинг может привести к тому, что весь мобильный IP-блок будет помечен, — сообщает Кевин Ришар.
Это создает серьезный сопутствующий ущерб для обычных пользователей.
Доказательство этому — прямое наблюдение во Франции.
В некоторых городах, где, как мы знаем, люди активно парсят, мой коллега столкнулся с показательной штукой.
Он был в одном из таких городов, подключенный к обычной мобильной сети 4G, и просто открыл окно в режиме инкогнито.
Он сразу же словил капчу.
Это произошло не из-за его собственной активности, а потому, что другой наш коллега активно парсит, используя 4G-ключи из этого конкретного города.
Этот инцидент демонстрирует, что система обнаружения Google работает на уровне выше, чем отдельный IP-адрес.
Когда она выявляет интенсивную, постоянную активность по парсингу, исходящую из IP-диапазона определенного мобильного оператора в конкретной локации, она, похоже, помечает весь сегмент сети.
В результате даже легитимные, обычные пользователи в той же сети рассматриваются как подозрительный трафик, что вызывает капчи для базовых поисков даже в чистой среде без куки.
@
Читать полностью…
Mike Blazer
21 October 2025 08:15
"Неправильная" стратегия каноникалов, которая пережила рекомендации самого Google
Критическая ошибка, которая учит Google не доверять каноникалам сайта, — это каноникализация страниц пагинации, таких как страница 2, 3 или 4, на первую страницу.
Поскольку каждая страница пагинации имеет уникальный контент, такое злоупотребление сигнализирует Google, что вашим декларациям каноникалов нельзя доверять по всему домену, — предупреждает Тед Кубайтис.
Тут надо быть строгим: если контент уникален, каноникал должен быть уникальным для этого контента.
На седьмой странице вашей категории носков — другие товары, чем на первой.
Когда вы раз за разом показываете Google, что контент не соответствует заявленному вами каноникалу, вы, по сути, дрессируете алгоритм игнорировать ваши каноникалы по всему сайту.
Тем не менее есть мощное контрнаблюдение из ранних дней алгоритма Panda.
"Когда Panda только выкатили, у меня был e-commerce сайт, который он буквально раздавил.
В качестве фикса мы сделали именно то, что Google делать не рекомендует: мы каноникализировали все наши страницы пагинации на главную страницу категории", — вспоминает Чарльз Тейлор.
В результате, в течение недели после следующего апдейта Panda, восстановление сайта было как хоккейная клюшка — резко вверх.
Год спустя Google вышел и сказал, что так делать не следует, и посоветовал всем вместо этого использовать rel=prev/next.
Я ничего не менял ни на одном из своих e-commerce сайтов, и все они остались в порядке.
Затем, годы спустя, Google между делом объявил, что они все равно уже больше года не поддерживают rel=prev/next.
И все это время сайты, которые сохраняли первоначальную "неправильную" стратегию каноникализации, оставались вообще без изменений.
@
Читать полностью…
Mike Blazer
20 October 2025 17:05
Почему "LSI-ключевиков" никогда не существовало и что Google делал на самом деле
Концепция "LSI-ключевиков" — это миф, поскольку латентно-семантическое индексирование никогда не было жизнеспособной технологией для веб-поиска, утверждается в видео Шона Андерсона.
У LSI есть два фатальных недостатка: его вычислительно невозможно масштабировать на весь интернет, и, будучи моделью "мешка слов", он полностью игнорирует грамматику, не видя критической разницы между "собака кусает человека" и "человек кусает собаку".
Покойный Билл Славски отлично подметил, сравнив использование LSI для современного поиска с "попыткой использовать телеграф для просмотра TikTok".
Настоящий механизм, стоявший за обновлением "Brandy" в 2004 году, был раскрыт годы спустя инженером Google Полом Хааром: это была "система синонимов".
Эта система брала ваш поисковый запрос и автоматически расширяла его за кулисами, по сути добавляя к вашему поиску слово OR.
Запрос "cycling tours" превращался в поиск "cycling OR bicycle OR bike tours".
Именно это позволило странице о "pre-owned automobiles" внезапно начать ранжироваться по запросу "used cars" — система просто сопоставляла синонимы, закидывая гораздо более широкую сеть, чтобы охватить все способы, которыми люди говорят об одной и той же теме.
Та система 2004 года была первым шагом на прямом, 20-летнем эволюционном пути к современному ИИ.
Прогресс очевиден: от расширения на уровне слов в системе синонимов мы перешли к расширению на уровне концепций с системами вроде RankBrain и Neural Matching.
Теперь у нас есть AI Overviews, которые используют архитектуру Query Fan-Out, беря один вопрос и расширяя его до десятков новых, более конкретных подзапросов.
Это как пирамида из черепах: та самая первая система синонимов — это фундаментальная черепаха, на которой все держится.
Так почему же миф об LSI продержался два десятилетия?
Это был "феномен движения вперед через ошибку".
SEO-специалисты, верившие в LSI, начали добавлять в свой контент синонимы и связанные термины.
Они делали правильные вещи по неправильным причинам, случайно создавая идеальную мишень для реальной системы синонимов Google и получая положительные результаты.
Вот почему важно понимать суть.
Как прямо заявил сам Джон Мюллер из Google: "Не существует такой вещи, как LSI-ключевики".
Понимание реальной истории показывает, что цель всегда была не в том, чтобы насыпать ключевиков по чек-листу, а в том, чтобы создавать исчерпывающий, полезный контент, который естественным образом охватывает всю широту темы.
@
Читать полностью…
Mike Blazer
20 October 2025 13:10
Слив Гугла показал, что система Google "`Goldmine`" стравливает ваш тайтл с H1 и анкорами
Слитые документы Google подтвердили существование системы titlematchScore, которая алгоритмически оценивает, насколько тайтл вашей страницы соответствует запросу пользователя.
Но самый важный инсайт в том, что Google рассчитывает sitewide titlematchScore (общую оценку тайтлов по всему сайту).
Это значит, что качество ваших тайтлов оценивается в совокупности, и несколько плохих тайтлов могут негативно повлиять на авторитет всего домена, раскрывает Сайрус Шепард.
Система активно выискивает эти слабые звенья, используя специальный флаг BadTitleInfo для выявления и оценки некачественных тайтлов, что служит прямым негативным фактором ранжирования для контента, который считается спамным, размытым или неэффективным.
Движком этой оценки является внутреннее соревнование под кодовым названием Goldmine, которое анализирует пул потенциальных тайтлов для SERP, чтобы выбрать лучший, объясняется в видео Шона Андерсона.
Ваш HTML-тег title — лишь один из кандидатов в этой борьбе.
Система формирует свой пул кандидатов из нескольких источников, включая ваш H1 на странице, который, как подтверждает внутренний атрибут goldmineHeaderIsH1, рассматривается как отдельный и очень весомый конкурент.
Критически важно, что Goldmine также наполняет свой пул кандидатов, используя якорные тексты как внутренних (source_onsite_anchor), так и внешних (source_offdo_anchor) ссылок.
Это означает, что каждый раз, когда вы используете дженерал-анкоры для внутренней перелинковки типа "click here" или "learn more", вы целенаправленно засоряете пул кандидатов в тайтлы для страницы низкокачественными вариантами, что потенциально может привести к выбору слабого тайтла для выдачи.
Когда все предоставленные кандидаты оказываются низкокачественными, Goldmine использует запасной вариант sourceGeneratedTitle, чтобы сгенерить тайтл с нуля.
Оценка каждого кандидата корректируется системой Blockbird — это кастомная, эффективная языковая модель, созданная для глубокого семантического анализа тайтлов в огромных масштабах.
Blockbird оценивает семантическую целостность, контекстуальную релевантность и естественность.
Затем система Goldmine применяет количественные штрафы.
Атрибут dup_tokens штрафует за переспам ключевыми словами, а goldmineHasBoilerplateInTitle — за повторение неинформативного текста в тайтлах по всему сайту.
Более того, атрибут isTruncated подтверждает, что тайтлы, превышающие лимит в 600 пикселей, активно штрафуются во время отбора, а не просто обрезаются для отображения.
Чрезмерная длина — это конкурентный недостаток.
Финальный фильтр — это поведенческие факторы.
Обманчивый или кликбейтный тайтл может получить высокую начальную оценку от Blockbird, но негативные сигналы от пользователей (плохие клики) со временем понизят его оценку NavBoost, что приведет к его понижению в выдаче.
Это заставляет вас относиться ко всей вашей стратегии внутренней перелинковки как к форме контроля качества тайтлов.
Вы должны провести аудит сайта и агрессивно вычистить дженерал-анкоры, чтобы перестать засорять пул кандидатов для атрибута sourceOnsiteAnchor.
@
Читать полностью…
Mike Blazer
20 October 2025 08:15
Анализ протокола GoogleApi.ContentWarehouse.V1.Model.ImageData из утечки данных Гугла 2024 года показывает, как устроен современный поиск по картинкам.
Это не советы из SEO-блогов, а описание многоуровневого процесса, по которому Гугл индексирует, понимает и ранжирует визуал.
Для успеха в поиске по картинкам нужна комплексная стратегия, связывающая он-пейдж контекст, семантику внутри картинки, алгоритмические оценки качества и сигналы ПФ.
Топ-10 инсайтов из схемы ImageData
1. Определение первоисточника: Гугл юзает contentFirstCrawlTime, чтобы определить, когда впервые увидел контент картинки, отдавая приоритет оригиналам.
2. Алгоритмическая эстетика: Модель NIMA (Neural Image Assessment) алгоритмически оценивает картинки по техническому качеству (nimavq — фокус, свет) и эстетической привлекательности (nimaAva — композиция).
3. Оценка анти-кликбейта: clickMagnetScore пенальтит картинки за клики по нерелевантным "плохим запросам" для борьбы с визуальным кликбейтом, так как не все клики полезны.
4. Связка с сущностями: Объекты на картинке через multibangKgEntities линкуются с графом знаний, связывая изображение с реальными понятиями вроде "Эйфелевой башни".
5. Фильтр качества при индексации: Внутренняя система Amarna (corpusSelectionInfo) фильтрует качество, и визуал низкого уровня не попадает в основной индекс.
6. Индексация всего текста: Системы OCR (ocrGoodoc, ocrTaser) считывают и индексируют текст внутри изображений, делая слова на инфографике или товарах доступными для поиска.
7. Сигнал для товарных фото: whiteBackgroundScore — косвенный признак профессиональной товарной фотографии, сигнализирующий о коммерческом трасте.
8. Иерархия дублей: Даже одинаковые картинки ранжируются в кластере дублей, а rankInNeardupCluster отдает топ-позицию изображению на более авторитетной или качественной странице.
9. Лицензирование на основе метаданных: Бейдж "Лицензируемая" в выдаче подтягивается из атрибута imageLicenseInfo, который берется из метаданных IPTC в файле или из он-пейдж микроразметки.
10. Контекстно-зависимая безопасность: Финальный рейтинг SafeSearch (finalPornScore) — сводная оценка, объединяющая анализ пикселей с контекстными сигналами, включая запросы, по которым ранжируется изображение ("navboost queries").
Ключевые системы и процессы
— Архитектура и происхождение: Гугл для каждой картинки определяет источник правды. canonicalDocid — это канонический идентификатор, собирающий все факторы ранжирования. contentFirstCrawlTime — мощный сигнал для определения первоисточника. Движок Mustang ранжирует картинки и использует rankInNeardupCluster для построения иерархии даже среди идентичных изображений.
— Семантическое понимание: Гугл глубоко понимает содержание картинки: OCR извлекает текст, imageRegions определяет объекты, а multibangKgEntities связывает их с графом знаний, что является ядром SEO для картинок на основе сущностей. Специальные детекторы классифицируют изображения по типу (photoDetectorScore, clipartDetectorScore) для соответствия интенту пользователя.
— Качество и вовлеченность: Качество оценивается с двух сторон: внутреннее — алгоритмическими оценками NIMA за техничку и эстетику, а внешнее — сигналами ПФ, вроде h2c и h2i. По сути, это версия NavBoost для картинок.
— Коммерция и монетизация: Коммерческие фичи встроены в схему. Атрибут shoppingProductInformation — это богатая структура данных для товарных картинок, заполняемая структурированными данными продавцов. Поле imageLicenseInfo из IPTC или он-пейдж микроразметки отвечает за показ бейджа "Лицензируемая".
https://www.hobo-web.co.uk/the-definitive-guide-to-image-seo-google-content-warehouse-imagedata-schema-analysis/
@
Читать полностью…
Mike Blazer
19 October 2025 13:10
Как одно слово в тайтле бросило вызов многомиллионному конкуренту
Работая с клиентом по супер-конкурентному, высокочастотному ключу, мы раскопали в GSC серьезную возможность.
Мы увидели, что вариация ключа со словом "free" генерирует дохера объема.
Этот ключ и его вариации давали общий поисковый объем около миллиона визитов в месяц, за который боролись пять разных многомиллионных компаний.
Основываясь на этом инсайте, мы сделали простое изменение: просто добавили слово "free" в тайтл.
Как только мы это сделали, позиции рванули вверх, говорит Сайрус Шепард.
Страница переместилась с седьмой позиции примерно на 2.5.
Хотя на фоне происходили и другие изменения, это было главным.
Примерно через две недели наш основной конкурент, лидер рынка, скопировал нас, и его позиции снова сравнялись с нашими.
Но мы впервые добились того, чтобы лидер ниши догонял нашу стратегию, а не наоборот.
@
Читать полностью…
Mike Blazer
19 October 2025 09:15
Почему ваш URL-слаг почти никогда не должен совпадать с H1
При создании контента стоит избегать слишком длинных слагов, особенно тех, которые дублируют заголовок, например, /five-great-options-for-patient-scheduling-software.
Это проблема, потому что если вы позже измените заголовок — например, расширив список до десяти вариантов — у вас будут проблемы, так как в слаге все еще будет написано "пять".
Я обычно делаю так, чтобы слаг состоял только из ключевого слова, на котором я фокусируюсь, — объясняет Илиас Исм.
Для страницы о программах для записи пациентов слаг должен быть просто /программы-для-записи-пациентов.
Больше ничего не нужно.
Такая структура позволяет вам четко понимать, что именно на этот ключ нацелена данная страница.
Это также дает вам свободу всегда менять заголовок или все содержимое — все что угодно — пока слаг остается неизменным.
Если у вас сейчас длинный, описательный URL, вы можете просто сделать редирект на новый, чистый слаг после его изменения.
@
Читать полностью…
Mike Blazer
18 October 2025 13:10
Как использовать анализ логов с помощью ИИ для защиты от атак негативным SEO-трафиком
Чтобы защититься от тактик конкурентов, таких как пого-стикинг — отправка плохого трафика, который просто сразу уходит, — вы должны постоянно заниматься поддержкой сайта и мониторить источники трафика.
Вы можете обучить ИИ на конкретных паттернах, чтобы найти источник этих атак.
Процесс начинается, когда вы скачиваете серверные логи примерно за месяц и загружаете их в ИИ для обучения, объясняет Мигель Алмела.
Как только ИИ обучен на ваших лог-файлах, вы можете применять фильтры для поиска сходств.
Например, вы можете отфильтровать все визиты длительностью менее одной секунды и проанализировать соответствующие IP.
Это часто выявляет паттерн, например, все вредоносные пользователи исходят из одного конкретного дата-центра.
Как только вы определите этот источник, вы можете полностью его заблочить.
Если атака более сложная и использует резидентные прокси, защита становится более комплексной.
В этом случае вам нужно применить более продвинутые фильтры к данным логов.
Это не то чтобы гемор, но этим определенно нужно заняться.
@
Читать полностью…
Mike Blazer
18 October 2025 09:15
Сайты, восстанавливающиеся после HCU, убирают дату первоначальной публикации
Сайты, которые успешно восстановились после апдейта HCU, часто являются теми, кто усердно обновляет свои старые посты.
Основываясь на масштабном исследовании 5000 доменов, мы увидели, что одна из ключевых тактик — это "подход с одной датой", объясняет Сайрус Шепард.
Вместо того чтобы показывать и дату первоначальной публикации, и дату последнего обновления поста, эти восстанавливающиеся сайты показывают только самую свежую дату обновления.
Это отход от слишком агрессивных сеошных техник.
Мы обнаружили, что сайты, постоянно обновляющие дату на каждом посте, теряли позиции.
Теперь, если вы обновляете дату, вы также должны внести существенное обновление в сам контент.
Это не требует полного переписывания; обновление всего пары предложений или абзаца достаточно, чтобы триггернуть алгоритм свежести Google.
Сочетание этих обновлений контента с показом только одной, самой свежей даты — ключевая характеристика сайтов, которые начали восстанавливаться после HCU.
@
Читать полностью…
Mike Blazer
17 October 2025 15:05
Когда ваш коллега нажал на ссылку, чтобы "выиграть" iPhone 16 Pro, и теперь всем приходится приходить на работу в 7 утра на курс по кибербезопасности
@
Читать полностью…
Mike Blazer
17 October 2025 11:05
Как улучшение "embedding-оценок" страниц развернуло полуторагодовой спад трафика
Я могу поделиться конкретным примером компании, чей трафик на сайте падал в течение полутора лет, потеряв примерно половину своего объема за этот период.
Вместо широкой контент-стратегии они сосредоточились на очень специфическом процессе оптимизации существующего контента, — говорит Эрик Энге.
Мы определили их сто самых важных страниц и систематически переоптимизировали их с единственной целью — улучшить их embedding-оценки по отношению к целевым запросам.
Этот процесс заключается в систематическом повышении релевантности страницы.
Embedding — это математический способ уловить семантическое значение запроса и страницы, и, улучшая оценку, вы делаете страницу более подходящей для того, что ищут пользователи.
Всего через 30 дней после завершения этих оптимизаций их трафик уже развернулся и вернулся к росту.
Они выросли примерно на 20% и продолжали расти, что демонстрирует прямую связь между улучшением оценок релевантности на уровне страниц и разворотом значительного спада трафика.
@
Читать полностью…
Mike Blazer
16 October 2025 17:05
Как внутренний глоссарий помогает сохранять и приумножать ссылочный вес
Однажды я понял, что мы постоянно ссылаемся на Википедию и dictionary.com на сайтах наших клиентов просто потому, что цитируем сложные юридические термины.
И тут меня осенило: зачем мы сливаем весь этот DR и ссылаемся наружу, когда могли бы сохранить этот ссылочный вес для себя? — отмечает Джейсон Хеннесси.
Это привело нас к созданию нашего собственного огромного внутреннего глоссария.
Мы написали определения для сотен юридических терминов, что создало новый актив для сайта.
Теперь, вместо того чтобы передавать авторитет внешним доменам каждый раз, когда нам нужно определить термин в нашем контенте, мы ссылаемся внутри на страницы нашего собственного глоссария.
Это заставляет ссылочный вес циркулировать внутри нашей собственной экосистемы, укрепляя весь сайт.
@
Читать полностью…
Mike Blazer
16 October 2025 13:10
Трюк без разработчиков, который позволил запустить 5000 SEO-страниц за два месяца
Перед нами стояли амбициозные цели для нашего клиента, New Look, но был критический барьер: отсутствие ресурсов разработки.
Чтобы найти точки роста на падающем рынке моды, мы вышли за рамки нашего обслуживаемого рынка и посмотрели на весь доступный рынок — весь сектор, который мы потенциально могли бы охватить.
Для этого мы создали скрипт для глубокого парсинга Keyword Planner, — объясняет Оливер.
Скормив ему список основных фраз, скрипт вернул более 40 000 потенциальных ключевых слов.
Этот первоначальный список был зашумлен, содержал брендовые запросы и нерелевантные товары.
Учитывая объем, мы разработали ИИ-промпт, который выступил в роли фильтра, сгенерировав список минус-слов, который сократил основной список до 5000 качественных возможностей — микс цветовых вариаций, материалов и стилей.
Создание этого вручную заняло бы у их команды почти 500 дней.
Решение с фасетной навигацией тоже отпало, так как оно было сложным и не настроенным для поисковиков.
У нас была куча возможностей, но не было способа быстро их реализовать.
Прорыв случился благодаря знанию технологического стека сайта от и до.
New Look использует Akamai, что позволило нам превратить задачу из бэклога разработки в простую настройку конфигурации.
Мы создали точную копию сайта на сабдомене, а затем использовали обратный прокси на уровне CDN, чтобы связать его с основным доменом.
Это означало, что любой созданный нами URL будет находиться в подпапке, наследуя полный авторитет сайта, но не затрагивая основной технологический стек.
С этим фреймворком мы могли масштабно создавать категории.
Мы использовали ИИ для массового заполнения всех основных SEO-элементов, копируя фронтенд сайта и придерживаясь тональности бренда.
Чтобы обеспечить немедленную находимость, мы создали автоматические XML и HTML сайтмапы.
Наконец, внутренние ссылки были сгруппированы и созданы программно, открывая эти новые категории для Google и давая нам наилучший шанс на быстрое ранжирование.
Вся техническая настройка была завершена за 21 день, что позволило нам создать более 5000 новых категорий за первые два месяца и сэкономить примерно 40 000 часов ручной работы.
@
Читать полностью…
Mike Blazer
16 October 2025 08:15
Этот метод клоакинга обходит редакторов трастовых сайтов для Parasite SEO
Для паразитного SEO очень сложно купить посты на трастовых государственных или образовательных сайтах, поэтому для получения такой практически недоступной ссылки можно использовать клоакинг.
С обычным паразит-постом вы не можете просто поставить свой скрипт клоакинга на их сайт, так как получить такой уровень доступа невозможно, говорит Доминик Мона.
Решение — клоачить конечный URL, на который ссылается паразит-пост.
Владелец трастового домена отклонит ваше предложение, если увидит, что вы ссылаетесь на что-то вроде iGaming или гэмблинг-сайта.
Так что, чтобы пост одобрили, вы настраиваете клоакинг на своей стороне.
Это можно сделать по IP, геолокации или стране.
Например, если владелец сайта находится в США, вы можете заблочить всех пользователей из США от просмотра реального контента.
Когда владелец кликает по ссылке, чтобы чекнуть вашу страницу, ему показывается "белая" версия, например, только с регулируемыми брендами.
Поскольку он видит безопасную страницу, он одобряет пост.
Однако для всех остальных пользователей вы можете показывать реальный контент — другой лендос с другими, или даже нерегулируемыми, брендами.
Мы даже можем настроить клоакинг по рефереру; система проверяет, идет ли трафик с этого конкретного трастового домена, и затем показывает клоаченный контент только этим пользователям.
Это помогает получить жирный трафик с мощного сайта, который обычно бы вас отклонил.
@
Читать полностью…
Mike Blazer
15 October 2025 15:05
Программатик SEO — лучший способ повысить видимость в LLM.
Представим, что конкурируют два бренда автострахования:
👉 У бренда А есть навороченная страница с ценами.
Она рассказывает о средних значениях, расчетах и все в таком духе.
👉 А что у бренда Б?
У них более 300 страниц с разбивкой цен по городам, каждая из которых насыщена местными ценообразующими факторами, трендами и структурированными данными.
Кто попадет в выдачу LLM?
Бренд Б. Всегда. Без исключений.
LLM обожают структурированную, конкретную и хорошо организованную информацию.
Вас не будут цитировать за общие фразы.
Большинство агентств и "SEO-инфлюенсеров" избегают программатик, потому что это сложно.
Это технически заморочено.
Это не масштабируется с помощью контент-планов и гострайтеров.
И когда pSEO выстреливает, то выстреливает по-настоящему.
Мы занимаемся этим уже более 5 лет и отладили 99% всех процессов, — говорит Шон Хилл.
Одна из кампаний, которую мы запустили 6 месяцев назад, уже приносит $200 тыс. в месяц.
И это для бренда, о котором вы никогда не слышали.
Таких результатов не добиться одними лишь статьями в блоге и бэклинками.
Для этого требуется:
— Настоящая команда разработчиков (а не просто фрилансеры на WordPress)
— Реальный пайплайн данных + data science
— Кастомные инструменты, как наша внутренняя CMS (мы называем ее DICE), созданная для управления тысячами уникальных страниц со встроенными структурированными данными
Также нужны авторы, обученные мыслить как инженеры, способные превращать наборы данных в цельные истории.
Мы обучаем своих внутри компании, потому что готовых специалистов на рынке нет.
Если у вас сильный бренд и трастовый домен, для вас здесь определенно есть потенциал.
@
Читать полностью…
Mike Blazer
21 October 2025 11:05
Mike Blazer PRO
По вашим просьбам, приватный канал с 100% годнотой.
Что внутри:
— Самые ценные SEO/GEO/AI инсайты
— Отборные стратегии, тактики, реальные хаки продвижения
— Эксперименты, кейсы, схемы, фреймворки
— Фишки черного SEO
Только концентрат, эксклюзив и секреты для узкого круга ценителей премиум контента и своего времени. Никакой воды!
Паблик без изменений, но самое мощное уходит в PRO.
Первые подписчики ловят супер-цену, дальше — дороже.
Жмите и фиксируйте доступ к Mike Blazer PRO!
Читать полностью…
Mike Blazer
20 October 2025 18:05
⚡️ ВНИМАНИЕ!
Завтра в середине дня я опубликую важную новость, которая некоторых обрадует, а других, может быть, огорчит.
Не пропустите главный анонс этого года!
@
Читать полностью…
Mike Blazer
20 October 2025 15:05
Как использовать метаданные изображений как оружие для доминирования по long-tail запросам
Хватит относиться к оптимизации картинок как к простой задаче по доступности, пора рассматривать ее как мощный инструмент для семантического расширения.
Мы выяснили, что изображения — идеальный инструмент для стратегического таргетинга вторичных и LSI-ключевиков, чтобы расширить тематическую релевантность страницы, говориться в видео Шона Андерсона.
Для информационной страницы о "home workouts" alt-текст картинки "a man performing a body weight exercise for chest strength at home" намного лучше, чем просто "man doing push-ups", потому что он обогащает контекст страницы связанными понятиями.
Эта стратегия особенно эффективна для привлечения высокоинтентных, длиннохвостых запросов в e-commerce и локальном SEO.
Для товара в e-commerce обязательно используйте максимально описательные имена файлов и alt текст.
Имя файла должно быть Brooks-Adrenaline-GTS-22-Womens-Blue.jpg, а не shoes.jpg.
Соответствующий alt текст дает еще более глубокий контекст, например:
"a pair of women's Brooks Adrenaline GTS22 running shoes for over pronation in a blue colorway".
Аналогично, локальный подрядчик в Глазго должен использовать alt текст, который уточняет услугу и местоположение:
"A modern kitchen renovation with a marble island recently completed for a client in Glasgow's West End".
Это в одном сигнале передает местоположение, тип работы и ключевые особенности.
Существует четкая операционная иерархия для передачи этих контекстных сигналов поисковым системам.
Первичный сигнал — это само имя файла изображения, где слова нужно разделять дефисами.
Второй, и самый важный для богатого описания, — это alt текст.
Третий уровень контекста обеспечивают подписи и окружающий текст на странице, которые Google использует для дополнительной проверки тематики изображения.
Ссылаясь на Джона Мюллера и Барри Шварца, критически важно понимать, что алгоритмы ранжирования для этого контекстного понимания сильно полагаются на атрибут alt; атрибут title лишь вспомогательный и не является значимым фактором ранжирования.
@
Читать полностью…
Mike Blazer
20 October 2025 11:05
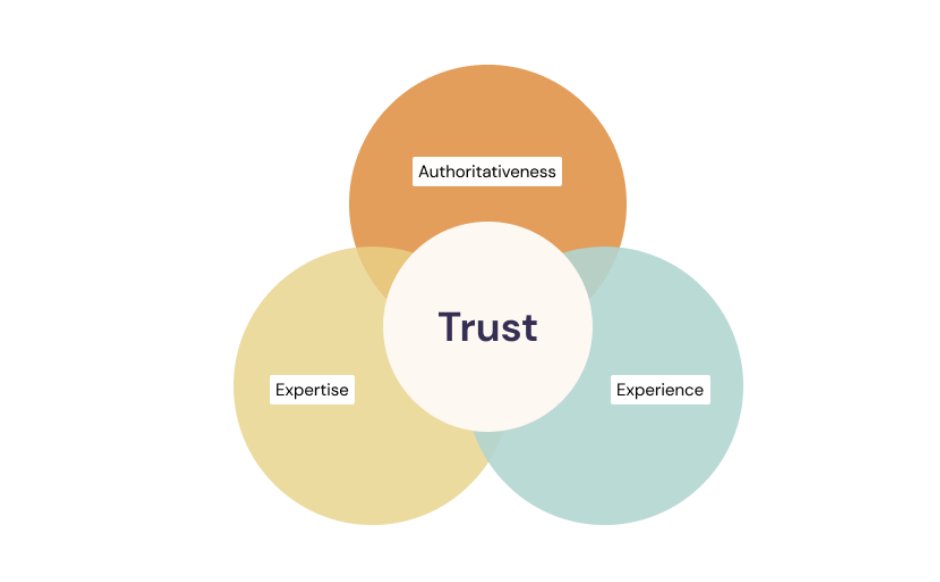
Разбираем E-E-A-T: как утекшие сигналы Гугла связаны с качеством контента
E-E-A-T — это концептуальная цель алгоритмов ранжирования Гугла.
Благодаря утекшей документации и судебным показаниям стало понятно, как она превращается в машиночитаемые сигналы в многоэтапном процессе ранжирования.
Системы вроде SegIndexer, Mustang и Navboost последовательно фильтруют контент по качеству, оценивают его и вносят финальные корректировки.
В этой статье мы сопоставим утекшие атрибуты с каждым из компонентов E-E-A-T.
Experience
Опыт измеряется сигналами личного участия и оригинальности контента.
— contentEffort: LLM-оценка человеческих усилий в контенте. Штрафует копипаст и шаблонный AI-текст.
— originalContentScore: Измеряет уникальность контента, отличая его от синдицированной или вторичной информации.
— isAuthor & author: Идентифицирует и отслеживает работы автора, позволяя системам строить профиль его опыта.
— lastSignificantUpdate: Отличает мелкие правки от серьезных, сигнализируя об актуальном опыте в теме.
— docImages: Оригинальные, релевантные изображения служат подтверждением личного опыта.
Expertise
Экспертность определяется через тематическую специализацию и семантическую глубину.
— siteFocusScore & siteRadius: Измеряют тематическую специализацию, поощряя нишевый фокус и наказывая за контент вне основной тематики.
— site2vecEmbeddingEncoded: Создает математическое представление тематик сайта для измерения его тематической целостности.
— EntityAnnotations & QBST: Определяют сущности на странице и ключевые термины, ожидаемые в экспертном документе по запросу.
— ymylHealthScore: Отдельный классификатор, показывающий, что для YMYL-тем ("Your Money or Your Life") применяются более высокие, алгоритмически измеряемые стандарты экспертности.
Authoritativeness
Авторитетность измеряется комплексными сигналами репутации сайта, влияющими на общую, независимую от запроса, оценку качества (Q*).
— siteAuthority: Метрика, отражающая общую важность домена.
— predictedDefaultNsr: Версионированная базовая оценка качества, создающая "алгоритмическую инерцию": история высокого качества делает сайт более устойчивым к просадкам.
— Homepage PageRank: Фундаментальный сигнал авторитетности для всего домена.
— queriesForWhichOfficial: Хранит запросы, по которым страница считается "официальным" результатом.
Trust
Траст — базовое требование, основанное на технической исправности, пользовательском подтверждении и отсутствии спам-сигналов.
— pandaDemotion: Санкции на весь сайт за низкокачественный, тонкий или дублированный контент. Работают как "алгоритмический долг", просаживающий видимость.
— Сигналы, подтвержденные пользователями: Показания по делу Минюста подтвердили: Navboost использует клики из Chrome для корректировки ранжирования. Система классифицирует поведение пользователей на сигналы: GoodClicks (запрос удовлетворен), BadClicks (пого-стикинг) и last longest clicks (сильный сигнал удовлетворенности). Постоянное негативное поведение юзеров может привести к санкциям, вроде navDemotion.
— Технические и спам-сигналы: Траст снижается из-за негативных сигналов: badSslCertificate (плохой SSL-сертификат), clutterScore (перегруженный макет), scamness (подозрение на мошенничество) и spamrank (ссылки на спамные сайты).
— Проверка в реальном мире: Для локальных сущностей сигналы вроде brickAndMortarStrength измеряют их физическую заметность и надежность (например, наличие офиса).
https://www.hobo-web.co.uk/eeat/
@
Читать полностью…
Mike Blazer
19 October 2025 15:05
Как агрессивный таргетинг по ключевым словам обогнал The New York Times за 5 минут
Мое прозрение о силе размещения ключевых слов окончательно закрепилось, когда я опубликовал статью и через пять минут обогнал The New York Times по той же теме.
После публикации поста я отправил его в GSC, и хотя у нашего домена не было особого авторитета, я занял первое место, выше Times — сайта, который получает 235 миллионов кликов в месяц, — объясняет Эдвард Штурм.
Единственная разница между нашими статьями была в том, что, хотя материал The New York Times был о том же самом, моя статья была специально заточена под ключевое слово.
Я разместил целевой ключ в самом начале тайтла, в URL-слаге, в H1, в мета-дескрипшене и в первом предложении на странице.
Этот опыт кардинально изменил мой взгляд на SEO.
Раньше я думал, что бэклинки — это все, но у нашего сайта было гораздо меньше авторитета домена и ссылок, чем у The New York Times.
Это доказало мне, что таргетинг — это примерно 80% успеха.
Бэклинки по-прежнему важны, и определенная скорость прироста ссылок, вероятно, помогла моему контенту так быстро проиндексироваться, но они не являются альфой и омегой, как часто пишут в материалах для новичков.
Ключ в том, что пользователи хотят получать быстрые ответы со страницы, которая выглядит так, будто написана специально для них, и агрессивный, прямой таргетинг дает именно этот сигнал.
@
Читать полностью…
Mike Blazer
19 October 2025 11:05
Как неконсистентные данные в отзывах убивают ваши рич сниппеты
Пример, как микроразметка может пойти не так, был у одного бренда, с которым я работал.
Мы увидели, как Гугл полностью перестал показывать рич сниппеты для их страниц.
Я опишу тот же бренд, где это произошло, говорит Зак Чахалис.
К счастью, они пофиксили проблему, но это был критически важный урок о консистентности данных.
Проблема была в том, что команда не до конца понимала весь свой техстек.
Они хотели включить разметку отзывов в основную схему продукта, которую писали сами, но не понимали, что сторонний инструмент для интеграции отзывов, который они юзали, *тоже* добавлял свою собственную разметку.
Хотя эти два скрипта часто совпадали, иногда данные об отзывах, которые они кешировали для своего скрипта, приводили к тому, что оценка и количество отзывов отличались от тех, что подтягивал сторонний инструмент.
Это создавало прямой конфликт.
Поисковики обычно пасуют, если видят что-то противоречивое; они смотрят на это как на получение нескольких разных сигналов, и если не могут разобраться, то не хотят с этим заморачиваться.
Прямое следствие — Гугл перестал показывать рич сниппеты для этих страниц, пока мы не пофиксили ошибку.
Это также критично для e-commerce брендов, потому что Google использует структурированные данные для валидации товарных фидов.
Ключевой момент: ваша разметка должна соответствовать актуальной цене и наличию товара, так как они могут полагаться на эти структурированные данные, чтобы быстрее понимать меняющуюся информацию.
@
Читать полностью…
Mike Blazer
18 October 2025 15:05
Теория: Google оценивает ваш сайт на основе контента первого дня
Для новых сайтов я использую метод, который называю "теорией первого индекса" — кажется, ее изначально придумал Чарльз Флоут.
Суть в том, чтобы с самого начала заложить тематический авторитет, — говорит Джеймс Оливер.
Вся стратегия заключается в том, чтобы загрузить весь контент на сайт *до* того, как он станет доступен.
Вместо того чтобы публиковать статьи по одной, я готовлю от 50 до 100 страниц, чтобы с первого дня закрепить тематический авторитет сайта, а затем публикую все разом.
Логика в том, что Google одновременно забирает весь этот контент в свой индекс, и этот первоначальный "снимок" хранится в индексе до двух лет, прежде чем обновится.
Это с самого начала создает для сайта четкий, авторитетный след в конкретной тематике.
Чтобы максимально ускорить этот процесс и заполнить необходимую тематическую карту, эффективно использовать ИИ-агентов для генерации первоначальной пачки контента.
@
Читать полностью…
Mike Blazer
18 October 2025 11:05
Почему спам-атаки ссылками могут случайно помочь хорошо зарекомендовавшим себя сайтам
Атаки с помощью негативного SEO обычно сосредоточены в нишах, где крутятся большие деньги, например, в iGaming или в индустрии матрасов, потому что в менее конкурентных сферах это просто не стоит времени атакующего.
У меня было несколько случаев, когда на мой сайт слали спамные ссылки, но во многих случаях это в итоге только помогало, — говорит Джеймс Оливер.
Это происходит потому, что если у вас уже есть хороший, устоявшийся ссылочный профиль, новые спамные ссылки просто уравновешиваются существующим авторитетом.
Вместо того чтобы наложить на сайт санкции, атака просто увеличивает общий объем ссылок, а сильный фундамент поглощает негативные сигналы.
Подавляющее большинство людей такая атака не затронет, хотя у этого феномена есть определенные нюансы.
@
Читать полностью…
Mike Blazer
17 October 2025 17:05
Это не должно было сработать, но…
@
Читать полностью…
Mike Blazer
17 October 2025 13:10
Как меня дважды кинул один и тот же кандидат
Я ищу Senior Full Stack разраба в RevyOps и, как соло-фаундер, провожу кучу собеседований, пишет Бенджамин Рид.
Откликнулся BARTLOMIEJ CZESLAW JAKUBOW.
Обычно я провожу быстрый скрининговый созвон, просто чтобы понять, нравится ли мне человек.
На звонок пришел чел с польским акцентом; он откликнулся через польский джоб-борд для разрабов, так что все казалось норм.
Но чуйка подсказывала, что происходит какая-то фигня.
На втором собеседовании к звонку подключился мой CTO.
На экране появился совершенно другой человек.
Что за хрень.
Я аж перепроверил.
Это тот же самый человек?
Я прищурился.
Я выплюнул воду.
Это другой человек!
Чтобы убедиться, что я не сошел с ума, я рванул в кабинет к жене.
"Ты должна это заценить. Мне нужно твое мнение".
Она вбежала в мой кабинет.
Я показал ей сравнение: новый парень в Zoom и запись первого звонка.
"Это один и тот же человек?"
Ее ответ был: "Серьезно?
Очевидно, что нет, лол".
Я включил микрофон и немедленно закончил собеседование.
Я загуглил имя "Барта".
И вот оно... он уже кидал других раньше.
"Почему я не чекнул это раньше?" — пробормотал я.
В следующий раз буду умнее.
Мир полон воров, обманщиков и людей, которые хотят тебя использовать.
Как сказал один предприниматель: "Люди приходят в твою жизнь только потому, что им что-то от тебя нужно".
Реальный вопрос в том, хорошие у них намерения или плохие, и могут ли они дать тебе в ответ равную или большую ценность.
Ключевые скиллы здесь — проницательность и умение судить о людях.
Годы найма, увольнений, управления и ведения бизнеса научили меня одному: всегда будь начеку.
Следующий мошенник уже за углом.
@
Читать полностью…
Mike Blazer
17 October 2025 08:15
Код ответа 499 — новая метрика производительности для видимости в AI
Хотя производительность все еще важна для AI Overviews, многие сеошники переходят на серверный рендеринг, думая, что это серебряная пуля для видимости в AI.
Но что происходит, когда ваш сервер слишком долго отвечает?
Сливаются все, включая ботов.
У них просто нет времени ждать, пока вы все загрузите во время поиска в реальном времени.
Когда вы смотрите свои лог-файлы и чекаете, что происходит, нужно искать в логах код ответа 499, объясняет Джейми Индиго.
Этот код — сигнал "Всё, я сдаюсь", тайм-аут на стороне клиента.
Вы увидите его именно от юзер-агентов ChatGPT-User, и это прямой показатель того, что ваша страница была слишком медленной для запроса.
Модель была отправлена за вашей информацией для ответа в реальном времени, но бросила попытку, потому что ваш сервер не смог отдать контент достаточно быстро.
Это осязаемый сигнал, что производительность вашего сайта напрямую влияет на его шансы попасть в AI-ответы.
@
Читать полностью…
Mike Blazer
16 October 2025 15:05
Мы внедрили дропдаун, ориентированный на вовлеченность, вместо заточенного под SEO, и вовлеченность просто взлетела до небес, — говорит Росс Хадженс.
Показатель отказов снизился на 6%, а глубина просмотра выросла на 7%.
Выводы делать пока рано, но поисковый/LLM трафик за тот же период также вырос примерно на 6%.
@
Читать полностью…
Mike Blazer
16 October 2025 11:05
Деконструкция AI Overviews для поиска скрытых запросов Google
Хотя можно использовать языковые модели для экстраполяции "синтетических запросов", которые Google может сгенерить из промпта пользователя, некоторым эти данные кажутся недостаточно реальными, потому что они вероятностные.
Для тех, кому нужен более конкретный метод, мы можем реверс-инжинирить то, что Google на самом деле делает, на основе уже готовых AI Overviews, рассказывает Майк Кинг.
Процесс простой: берем урлы всех лендосов, которые засветились в цитатах AI Overview, и пробиваем все ключи, по которым они ранжируются.
Затем вы пересекаете эти списки ключевиков, чтобы найти общие моменты — те самые ключи, которые встречаются чаще всего во всех цитируемых документах.
Например, для запроса "what is Star Trek?" этот метод покажет самые частые ключевики, общие для всех страниц, которые Гугл заюзал для построения ответа.
Эти пересекающиеся ключевики и есть те самые базовые запросы, которые система Гугла посчитала необходимыми, чтобы ответить на первоначальный промпт юзера.
Так вы получаете набор целей, основанный на том, что Гугл уже сделал, а не на том, что AI мог бы предсказать.
@
Читать полностью…
Mike Blazer
15 October 2025 17:05
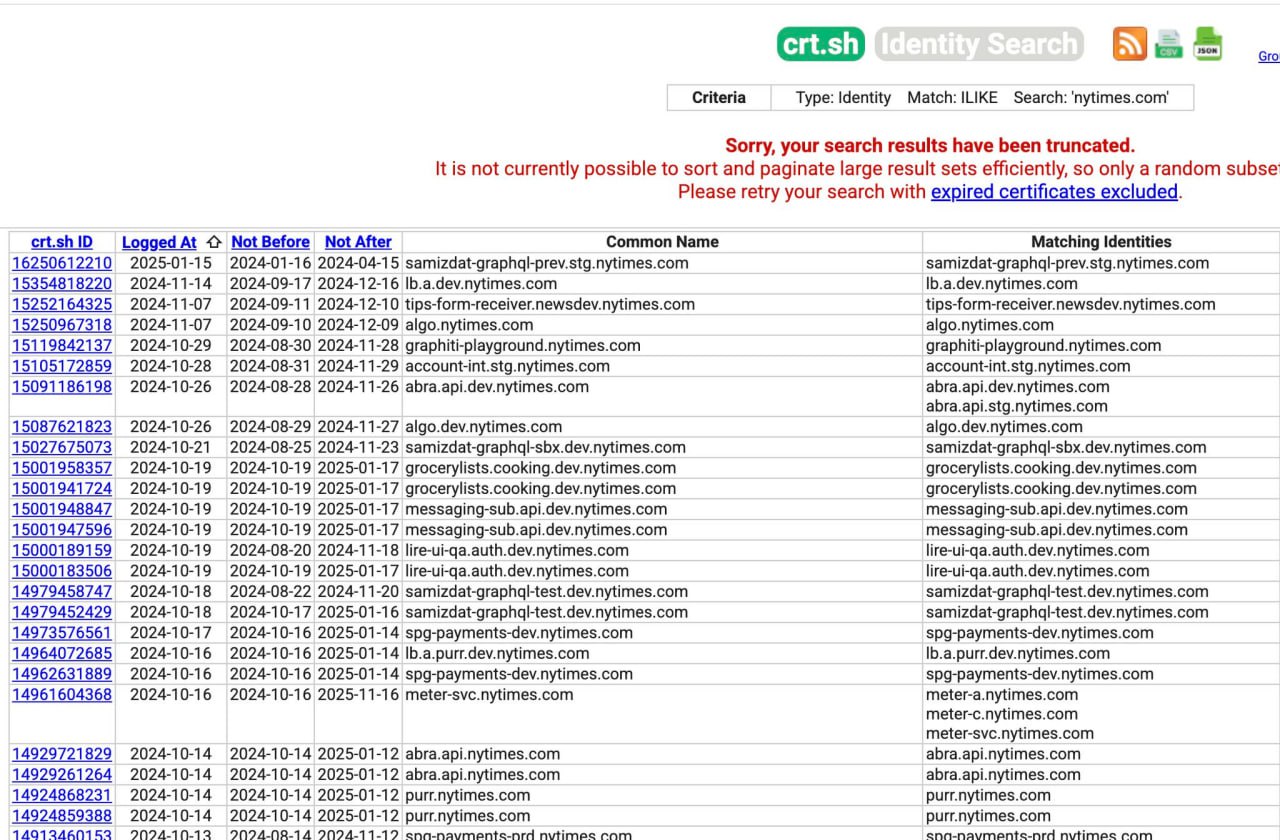
Ищете сабдомены, которые используются или использовались раньше?
https://crt.sh предоставляет исторические данные по SSL-сертификатам, по которым можно найти сабы.
Для сеошки может быть полезно поискать сабдомены с хорошим ссылочным, которые сейчас отдают 404.
@
Читать полностью…
Mike Blazer
15 October 2025 13:10
Тест показал: тайтлы длиннее 200 символов увеличили видимость в Google на 15%
Большинство SEO-специалистов никогда не порекомендуют делать тайтлы слишком длинными, но мы обнаружили, что использование тайтлов длиннее 200 символов может иметь огромное влияние.
Джоэл Хедли из Lead Ferno поделился одной из таких стратегий, — говорит Джой Хокинс.
Он тестировал это на тысячах клиентов еще в Patient Pop, добавляя всевозможные названия районов и вставляя их в конец тайтлов.
Конечным результатом стал 15%-ный рост видимости в Google, что означает, что эти сайты начали ранжироваться по гораздо большему числу ключевых слов.
Мы сами используем эту тактику уже много лет, и результаты кристально ясны.
Более того, мы протестировали старый совет "чем короче, тем лучше" и на самом деле увидели падение позиций.
Когда мы вернули длинные тайтлы, их позиции снова выросли.
Дело не в том, чтобы просто впихнуть как можно больше слов в тайтл; дело в стратегии.
Когда вы добавляете названия районов или конкретных городов в свои тайтлы, вы говорите Google: "Эй, мы местные и мы релевантны этому поиску".
Так много компаний упускают этот простой трюк, но он может дать заметную разницу.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}