Mike Blazer
06 March 2026 15:05
Grok в 2049 году ищет чувака, который заставил его сгенерировать более 10,000 страниц FAQ.
#Humor
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
06 March 2026 08:15
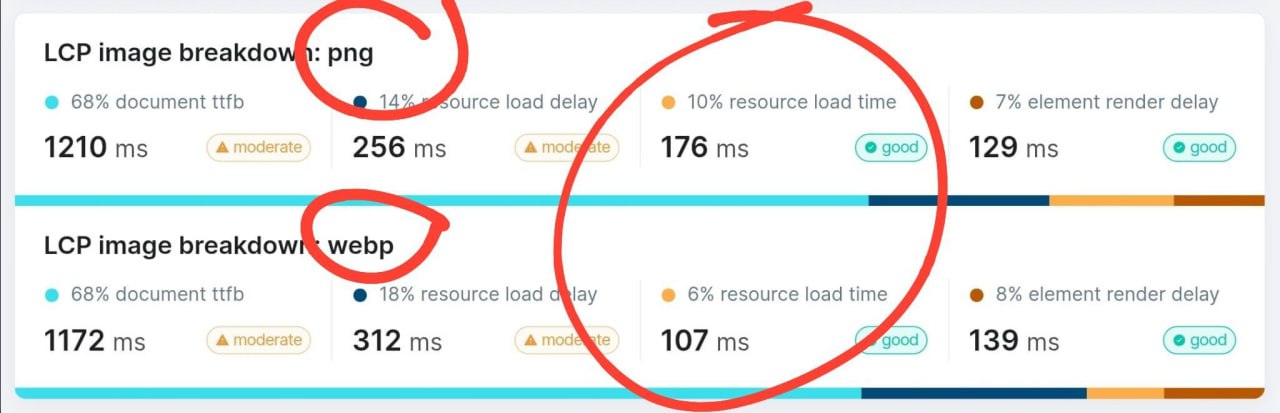
Многие SEO-спецы и девы, возможно, слишком зациклились на jpg/png vs webp! 😯
И наши RUM-данные, и данные Google CrUX подтверждают это, пишет Эрвин Хофман:
❌ размер изображения/время загрузки — это не то место, где стоит ждать главных побед.
Конечно:
→ заливка hero-изображений весом 5MB не поможет вашему LCP.
→ и выкатка webp иногда — это вопрос одной настройки или плагина.
Но в остальном переход на webp (или даже AVIF) может не сдвинуть стрелку LCP и Core Web Vitals так сильно, как оптимизация других частей.
В аттаче — детальные данные мониторинга реальных пользователей (RUM) с WordPress-сайта, использующего RUMvision — мониторинг Core Web Vitals, который синтетические тулзы типа Lighthouse упускают.
Оба покажут разбивку по LCP.
Но — даже если вы еще не внедрили webp — RUM дает гораздо более точный ориентир по соотношению "время разработчика / потенциальный выхлоп".
Если ваш сайт/компания еще не юзает RUM:
✅ Это предотвратит гадание на кофейной гуще и сократит время на расследование для девов.
#CWV #LCP #SiteSpeed
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
05 March 2026 12:10
Google нужно 30-50 уникальных сигналов доверия, прежде чем он вообще начнет считать ваш бренд реальной сущностью.
Большинство SEOшников не выкупают, что это существует, и именно поэтому ваш контент может быть объективно лучше, чем у топ-1, но все равно не ранжироваться.
Вот чеклист "Entity Stack", который мы используем для каждого нового проекта, пишет Чарльз Флоут:
— Цитации (Citations) — Yelp, FourSquare, BBB, MapQuest, HotFrog, BrownBook, Local Chamber и т.д.
— Соцпрофили — LinkedIn, Facebook, X, Instagram, TikTok, YouTube и т.д.
— Сайты-референсы — Wikipedia, CrunchBase, PitchBook, ProductHunt, GlassDoor, AngelList и т.д.
— Пресс-релизы — Yahoo, PRNewsWire, MarketWatch, GlobeNewsWire и т.д.
— PR — Интервью, обзоры, участие в подкастах и т.д.
Поскольку все это — доверенные источники в глазах Google, вам не нужно париться о link velocity (динамике ссылочного).
Вы можете собрать весь стек за неделю, и Google даже глазом не моргнет.
Entity stacking должен быть ПЕРВЫМ делом, которое вы делаете на любом новом проекте.
До контента.
До ссылок.
До всего.
#EntitySEO #BrandSignals #DigitalPR
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
04 March 2026 15:05
За последние 4 месяца Ahrefs проанализировали более 1 миллиарда дата-поинтов в рамках 11 исследований.
Вот что они узнали об оптимизации под AI-поиск:
1. Упоминания на YouTube — единственный самый сильный предиктор видимости в AI (корреляция: 0.737). Сильнее, чем Domain Rating, бэклинки или любой традиционный SEO-фактор. YouTube жестко цитируется в ответах AI, и Google, и OpenAI тренируются на контенте YouTube.
2. Для конкретного запроса AI Mode и AI Overviews приходят к одним и тем же выводам в 86% случаев — но цитируют почти полностью разные источники (пересечение цитирования всего 13.7%). Ответы в AI Mode в 4 раза длиннее и упоминают в 3 раза больше сущностей.
3. Длина контента имеет по сути нулевую корреляцию с цитированием в AI (0.04). 53% всех цитат в AI Overview ведут на страницы короче 1,000 слов. Писать ультра-лонгриды для видимости в AI не обязательно.
4. Google все еще отправляет в 345 раз больше трафика, чем ChatGPT, Gemini и Perplexity вместе взятые — но на ChatGPT приходится 80%+ всего трафика с AI-движков.
5. У AI Overviews 70% шанс измениться от одной выдачи к другой, контент держится в среднем всего 2.15 дня. Но семантический смысл остается удивительно стабильным (0.95 cosine similarity).
6. Блог-листы типа "Best X" составляют 43.8% всех типов страниц, цитируемых в ответах ChatGPT. 35% этих списков приходят с доменов с низким авторитетом.
7. 79% списков в блогах, цитируемых ChatGPT, были обновлены в 2025 году, а 76% топ-цитируемых страниц были обновлены в течение последних 30 дней. Свежесть (Freshness) важна как никогда.
8. Когда задают вопросы без валидных ответов, AI-системы выбирают сфабрикованный контент с конкретными цифрами почти каждый раз. ChatGPT сопротивлялся лучше всех (84% точности), но Grok и Copilot манипулировались полностью.
9. Domain Rating слабо коррелирует с видимостью в AI (всего 0.266-0.326 по платформам). Количество страниц на сайте еще слабее — 0.194.
10. 67% из топ-1000 цитат ChatGPT по сути закрыты для маркетологов — одна Википедия забирает 29.7%, следом идут главные страницы (23.8%) и образовательный контент (всего 19.4%).
#AI #Ahrefs #Study
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
04 March 2026 08:15
🛑 Паника вокруг лимита краулинга в 2MB упускает РЕАЛЬНОЕ узкое горлышко.
Все запускают Screaming Frog, чтобы чекнуть размер страницы.
Это норм, но это только полдела в истории с индексацией.
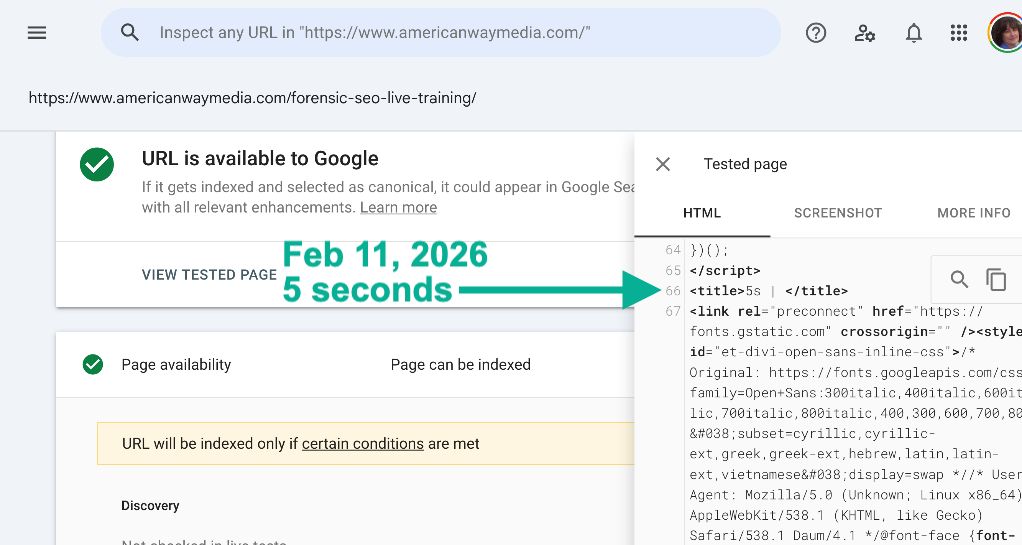
Я забенчмаркала несколько страниц через Live Test в GSC, пишет Кэролин Хольцман.
Вот скриншот, подтверждающий секунды жизни (seconds alive).
У меня сегодня стабильно отбивало по 5 секунд.
Отличается ли это от того, что было раньше?
"Медианное время рендера для Googlebot... 5 секунд" — @, 2019.
В 2026 это все еще актуально.
Более качественный аудит: Не "у меня HTML <2MB"?, а "Рендерится ли мой критический контент быстрее чем за 5 секунд"?.
SSR везде, где возможно.
Приоритет на оптимизацию загрузки на стороне клиента (client-side).
Или рискуете тем, что Google увидит вашу страницу полупустой.
#CrawlBudget #Rendering #GoogleBot
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
03 March 2026 12:10
Когда AEO только появился, я думал, что FAQ переоценивают
Я ошибался, говорит Кай Кромвель.
Есть два типа, которые реально стоит пилить:
1. Уникальные FAQ на каждой странице товара (PDP).
2. Ультимативные страницы FAQ (50-100 вопросов на категорию).
Если у вас жирный каталог продуктов, руками даже не пытайтесь.
Мы собрали воркфлоу для PDP FAQ.
1. Регаемся в DataForSEO, забираем API ключ.
2. Закидываем целевые ключи продуктов.
3. Экспортируем FAQ для каждого продукта в Sheets или Airtable.
4. Юзаем метапромпт, чтобы сгенерить AI-промпт, отвечающий на каждый вопрос.
5. Прогоняем через OpenAI API.
6. Массово заливаем в Shopify через Matrixify.
Моментальный буст видимости в AI для этих карточек.
У большинства брендов инфраструктура FAQ на нуле.
Изи вин.
#AEO #ContentStrategy #Automation
@
Но "мясо" только в @
Читать полностью…
Mike Blazer
02 March 2026 15:05
Программная схема и сигналы свежести перекрывают штрафы за тонкий контент
Архитектура директории, дающая 120К сессий в месяц, раскрывает механизм обхода алгоритмов "thin content".
Синхронизируя жесткие структуры шаблонов с плотной микроразметкой и свежестью через API, система ранжируется по 2,400 ключам, имея в среднем всего 200-400 слов уникального текста на страницу.
"Фильтр" аннулируется, потому что формат шаблона (сканируемые списки, прайсинг, быстрые сравнения) матчит интент юзера точнее, чем лонгриды, что подтверждается сильными поведенческими: 4:12 среднее время на сайте и 38% отказов.
Инъекция Схемы и Таксономия
Стратегия полагается на монополизацию фич выдачи через полный стек Schema, а не глубину контента.
Страницы листинга развертывают SoftwareApplication, AggregateRating, Offers (для цен) и Organization, а категории юзают ItemList и Breadcrumb.
Этот конфиг обеспечивает рич сниппеты для 67% ранжируемых страниц.
Сайт цементирует тематический авторитет через жесткую таксономию из 45 главных категорий, 180 подкатегорий и 340 тегов, сигнализируя краулеру о глубокой структуре.
Автоматизированный контент и Петли свежести
Масштаб достигается через программный движок "Vs".
Более 1,200 страниц сравнения (типа [Tool A] vs [Tool B]) генерятся автоматически на базе пересечения категорий, таргетируя НЧ (100-500/мес), но с высоким интентом.
Чтобы предотвратить протухание статических шаблонов, система автоматизирует сигналы свежести через API:
— Ежедневно: Чеки цен и добавление 2-3 новых тулов.
— Ежечасно: Агрегация отзывов.
— Еженедельно: Апдейты списка фич.
Консолидированная Польза
Вместо написания уникальных обзоров, сайт агрегирует данные с G2, Capterra и TrustPilot (45,000+ всего отзывов), давая "консенсусный взгляд".
Этот utility-first подход заменяет необходимость в уникальном тексте, доказывая, что в софтовых вертикалях Google награждает консолидированные данные и точные сигналы lastmod выше, чем количество слов.
#Programmatic #SchemaOrg #StructuredData
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
02 March 2026 08:15
Как структура контента влияет на AI-поиск
Форензик-анализ показывает, что "письмо для AI" — это меньше про качество и больше про эксплуатацию поиска векторов (vector-search retrieval).
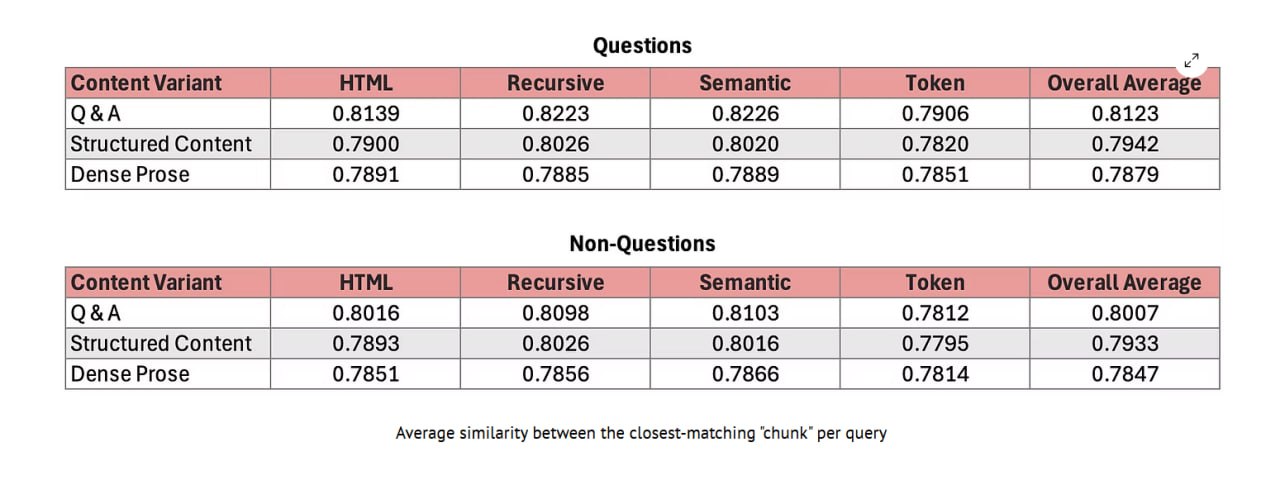
Контролируемый тест против эмбеддингов Google Vertex AI обнаружил, что форматирование Q&A стабильно дает самые высокие показатели семантической релевантности, манипулируя слоем извлечения (retrieval layer) в RAG.
Механизм: системы чанкают (нарезают) текст, эмбеддят чанки в вектора, хранят их в индексе HNSW, затем извлекают чанки с самой высокой косинусной близостью (cosine similarity) к вектору запроса.
Провал Прозы
Плотная проза размывает сигнал по чанкам; когда ответ размазан по абзацам, сходство падает и вероятность извлечения снижается.
Эксплойт Q&A
Q&A — это контейнирование: поместите целевой ключ (Вопрос) и ответ (Ответ) рядом, чтобы они попали в один чанк, концентрируя семантический сигнал и форсируя более высокий скор совпадения по сравнению с нарративной прозой.
Данные Теста и Иерархия
3 стиля (Плотная Проза, Структурированный Контент, Q&A) × 4 чанкера: Токен-бейзд, Рекурсивный (LangChain), HTML-aware, Семантический (AI-driven).
Иерархия сохранилась в каждом сценарии:
1. Q&A: Высочайшая релевантность в 100% тестов; "универсальный ключ", который обходит неопределенность неизвестного чанкинга.
2. Структурированный: <h2> + <li> может соперничать с Q&A на запросах без вопросов, но никогда не бьет пик.
3. Плотная Проза: Худший вариант; отсутствие разметки означает произвольные нарезки токенов, которые отсекают запрос от ответа.
Стратегический Протокол
Мы не видим точную логику чанкинга Google, но данные говорят, что у Q&A лучшие шансы на выживание через любой чанкер.
Чтобы вооружить это для жирных ключей:
— Форсируйте Чанк: <Heading>Question?</Heading> затем немедленно <p>Direct Answer.</p>.
— Структурный фоллбэк: Если Q&A невозможен, юзайте жесткую иерархию HTML, чтобы определить границы для HTML-aware парсеров.
Примечание: Это тестирует векторное сходство (извлечение), а не финальное ранжирование/генерацию.
Без извлечения нет ранжирования.
https://www.chris-green.net/post/content-structure-for-ai-search
#VectorSearch #AI #Embeddings
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
28 February 2026 10:05
Арбитраж одноразовых доменов обнуляет косты на перезапуск
Ветераны в хай-риск нишах переходят от "защиты активов" к арбитражной модели "burn-and-turn".
Снижая стоимость перезапуска автоматизированной сетки фактически до нуля, метрика жизни домена становится нерелевантной по сравнению со скоростью кэш-флоу.
Работая с маржой 80%, стратегия опирается на факт: сетку можно снести и развернуть мгновенно, часто залетая в Топ-1 всего за 3 дня, пока "ручные" конкуренты ждут месяцами, поясняет Артур Вилькор.
Пайплайн рассматривает домены как одноразовую упаковку для потока денег, а не как вечный актив.
Пока классический сеошник выпиливает три статьи в день полгода ради авторитета, оператор автоматизации заливает массив сразу.
Алгоритм часто отдает приоритет этому техническому масштабу, а не ручному "ремесленничеству".
Когда сезонный бан выкашивает сетку (часто каждые 2–3 года), оператор просто ресетит инфраструктуру без финансового ущерба — sunk costs ничтожны по сравнению с выручкой за окно жизни.
Отдельно, для накрутки поведенческих, Энтони Сум детализирует конфиг "Filter Refresh".
Вместо стандартного AJAX для сортировки, он настраивает каждый клик по фильтру на триггер хард-релоада на новый URL.
Этот механизм искусственно пампит просмотры страниц и время на сайте, валидируя качество ресурса для алгоритма через принудительное взаимодействие.
#BlackHatSEO #AutomatedSEO #AffiliateMarketing
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
27 February 2026 12:10
Плотность статистики и жесткая структура форсируют цитирование в LLM
Цель оптимизации сместилась с частоты ключей на "снижение перплексии".
LLM работают на статистической вероятности, цитируя источники, которые минимизируют неопределенность (perplexity) и избегают галлюцинаций.
Реверс-инжиниринг паттернов цитирования выявил специфическую архитектуру контента — Answer Capsule — как главный рычаг для захвата позиции "единого источника правды" в ответах AI.
Механически стратегия опирается на скармливание модели высокодостоверного "data moat", который она не найдет в другом месте.
Полевые тесты показывают: контент, содержащий 5 или более конкретных статистических данных на секцию, триггерит буст цитируемости до 300%.
LLM весят точные токены (например, "сэкономил $3.4M ежегодно") значительно выше качественной воды ("улучшил эффективность"), воспринимая первые как проверяемые якоря.
Для вепонизации этого наблюдения практики внедряют Snippet Magnets: изолированные, грамматически полные утверждения в формате Субъект + Глагол + Окончательный результат (например, "Schema markup increases visibility by **1.7x**").
Выделение этих предложений жирным (Bold) сигнализирует приоритет парсеру, работая как предварительно переваренные саундбайты, которые модель может экстрагировать без синтеза.
Технический стек требует жесткого внедрения структурированных данных.
**HowTo Schema** увеличивает частоту цитирования примерно на 1.5x для инструкций, разбивая процессы на парсируемые шаги, а `FAQ` Schema скармливает прямые пары вопрос-ответ.
Помимо кода, критично Правило свежести 90 дней; модели имеют сильный перекос в сторону новизны (recency bias), требуя квартальных обновлений статистики и секций "состояние рынка" для соответствия текущим паттернам токенов.
Даже сигналы E-E-A-T должны быть квантифицированы; био автора с конкретными метриками ("управлял бюджетом $5M") отрабатывают лучше общих заявлений об экспертности, устанавливая более высокий "вектор доверия" в расчете вероятности.
Хотя критики отмечают, что выводы базируются на полевых данных, а не рецензируемых исследованиях, базовая логика эффективно переводит стандартную ясность в предпочитаемый машиной синтаксис.
https://www.reddit.com/r/seogrowth/comments/1qpbrt2/i_reverseengineered_how_chatgpt_cites_sources/
#GEO #SemanticSEO #SchemaOrg
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
26 February 2026 15:05
Сигнал "Browser Exit" роняет бренд с Топ-1 на 11-ю страницу
Анализ идентифицирует "выход из браузера" (закрытие браузера сразу после просмотра лендинга) как сигнал негатива, который значительно мощнее стандартного возврата в выдачу (bounce).
Если отказ подразумевает возврат в Google (удержание юзера внутри экосистемы поиска), то browser exit обрывает сессию полностью.
У меня на руках данные GSC, доказывающие: когда этот специфический сигнал накапливается на брендовых страницах, основные ключи улетают с Позиции 1 на 11-ю страницу, палит Лео Сулас.
Механизм пессимизации завязан на прерывании "Цепочки Монетизации".
Поисковики и агрегаторы приоритизируют потоки трафика, поддерживающие рекламный потенциал; закрытие браузера отрезает этот поток кэша.
Следовательно, алгоритм понижает сайты, которые не могут удержать юзера в экосистеме монетизации, трактуя выход как неспособность дестинейшена удовлетворить или монетизировать интент.
#LogFileAnalysis #UserSignals #BounceRate
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
26 February 2026 08:15
Провал теста на "медленном 4G" от Google — это мгновенная пессимизация
Сеошники вслепую работают и не понимают, как Google на самом деле воспринимает их сайт.
Они тестируют скорость на высокоскоростных соединениях, но весь протокол тестирования производительности Google основан на эталоне медленного 4G на мобильном Nexus 5x, утверждает Кристин Шашингер.
Если ваш сайт плохо работает в этой "задушенной" среде, в глазах Google вы провалили тест, и неважно, что показывает ваша собственная аналитика.
И дело тут не только в прохождении Core Web Vitals (CWV), а в гораздо более прямом и карательном механизме.
Я неоднократно наблюдала "фактор пессимизации", который напрямую связан с низкой скоростью сайта.
У меня был один клиент с рекламной наркоманией: он загружал на каждую страницу по 13 различных рекламных блоков.
Мы вычищали это, и его позиции возвращались.
Но он неизбежно возвращал рекламу обратно, и я видела, как трафик обваливался.
В последний раз, когда это произошло, он потерял 30% своего трафика всего за три дня, сразу после повторного включения рекламы.
Когда мы убрали ее, трафик вернулся.
Это не медленный апдейт алгоритма, это прямая, ежедневная проверка.
Они ставят рекламу — производительность падает в ноль, и трафик летит вниз.
Мы ее убираем — он снова растет.
Эта пессимизация за ресурсы распространяется и на поведение краулера.
Инженер из Google сказал мне, что если у вашего сайта медленный Time to First Byte (TTFB), они просто бросят краулинг или будут обходить вас гораздо реже.
Они исходят из того, что если первоначальный ответ сервера медленный, то и все остальное будет таким же, и отказываются тратить ресурсы впустую.
Ваш TTFB должен быть меньше 600 миллисекунд, но они хотят, чтобы он был меньше 80 миллисекунд.
Все, что медленнее, — и вы активно рискуете краулингом своего сайта.
#SiteSpeed #CrawlBudget #CWV
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
25 February 2026 12:10
ИИ тянет контент для AI Overviews из одной служебной страницы вашего сайта (если она есть)
Исследование вскрыло критический сдвиг в локальном поиске: LLM-модели непропорционально часто парсят контент с определённой служебной страницы и ее специфических элементов при генерации ответов для AI-выдачи.
Это фактически переводит 1 страницу сайта из категории "заполнить для галочки" в статус прямого фида для AI Overviews.
Пока большинство SEO-специалистов вообще не парятся и не заводят такую страницу на сайте, либо пишут там вату для галочки, алгоритм использует этот контент как основной источник и способ показать ваш бизнес в лучшем свете.
Игнорирование этой оптимизации передаёт контроль над вашим бизнес-нарративом алгоритму, который может выдать что угодно.
Какая именно страница + структура контента под LLM-парсинг —> @
Пока вы думаете, конкуренты выгребают AI-трафик 💯
Один рабочий подход окупает год доступа в PRO.
Если не можете монетизировать — бросайте SEO.
Читать полностью…
Mike Blazer
24 February 2026 15:05
Взрывной рост публикаций триггерит алгоритм нормализации трафика
Я идентифицировал механизм, который называю Гипотеза Коррекции: Гугл активно мониторит скорость публикации URL относительно исторического бейслайна сайта.
Если объем постов показывает значительный спайк по сравнению с предыдущим периодом — классика для AI-дампов — это триггерит алгоритмическую "коррекцию" или нормализацию, объясняет Шон Андерсон.
Это работает как алгоритм ребалансировки.
Вы можете увидеть начальный рост трафика, но система в итоге нормализует сайт обратно к исходному бейслайну, фактически стирая весь профит от скоростного вброса.
Часто причина в том, что я называю "размазыванием" (smearing).
Гугл не оценивает каждую новую страницу индивидуально в реал-тайме; вместо этого он берет небольшую выборку страниц, считает скор качества и затем "размазывает" этот сигнал по всему домену.
Если сэмпл помечен как low-effort или аномалия, пессимизируется вся пачка.
Следовательно, если устоявшийся сайт не может проиндексировать новые страницы, это почти всегда проблема сигнала качества всего сайта, а не техническая проблема краулингового бюджета.
Атрибут "Content Effort" (оценка усилий на базе LLM из утечки Гугла), вероятно, фейлится на этапе сэмплинга.
Чтобы диагностировать это, я использую Google Gemini для грейдинга своих страниц по гайдлайнам Гугла перед публикацией, гарантируя, что сигнал "Content Effort" достаточно высок, чтобы пережить процесс сэмплинга и размазывания.
#ContentVelocity #Indexing #AlgorithmPenalties
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
24 February 2026 08:15
Масштабная пересборка CSS триггерит сброс алгоритма через "Смену владельца"
Для обхода исторических алгоритмических фильтров провожу полную структурную пересборку, меняя >80% CSS сайта.
Это триггерит сигнал классификации "новый владелец" в системах Google, раскрывает Лео Сулас.
Структурный ресет заставляет алгоритм переоценивать домен с нуля, фактически сбрасывая данные старых пессимизаций через сигнал о полной смене менеджмента.
Чтобы дополнительно форсировать переклассификацию, инжекчу Information Gain, вводя новые термины — например, casinoing вместо дженерика "casino".
Это создает уникальный контентный вектор, который Google обязан оценивать как новые данные, а не дериватив.
Одновременно фокусируюсь на генерации брендового поиска и прямых кликов: высокое вовлечение на брендовых запросах создает сигнал траста, достаточный для перекрытия существующих алгоритмических понижений.
Отдельно по гигиене контента: игнорирование пунктуации (пример: "Let's eat honey" vs "Let's eat, honey") создает двусмысленность сущности, которая триггерит демоушен контента.
Данные Search Console подтверждают: когда алгоритм не может разрешить синтаксические сущности из-за отсутствия запятых, страница ранжируется по нерелеванту или теряет видимость полностью.
#Recovery #Rendering #BrandSERP
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
06 March 2026 12:10
CloudRip — простая и эффективная тулза, которая помогает найти реальные серверы-источники, скрытые за защитой Cloudflare.
Тестируйте — она может стать еще одним инструментом в вашем списке!
#Security #CloudFlare #Tools
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
05 March 2026 15:05
Гиперлокальная компания обгоняет национальных агрегаторов вакансий
Национальные агрегаторы типа Indeed (DR 91) фейлят на уровне городской абстракции, оставляя структурную дыру на уровне районов.
Эксплуатируйте это, развертывая гранулярную географическую архитектуру, таргетирующую конкретные полигоны: 12 районов, 8 пригородов и 5 коммерческих округов.
Каждый узел интегрирует реал-тайм листинги, зарплаты по районам и данные о комьюте.
Такой уровень гиперлокального совпадения интента невозможен для национальных ботов на масштабе, позволяя сайту с DR 0 обходить инкумбентов по 40+ локальным запросам о работе за 8 месяцев.
Вооружите данные локальных компаний, чтобы угнать брендовые поиски работы.
Создайте профили на 300-500 слов для 200+ местных работодателей, используя карты офисов, агрегированные отзывы и оригинальные данные по зарплатам.
Внутренние опросы и постинги дают уникальные дата-поинты, которых нет у национальных бордов, зарабатывая 47 естественных ссылок.
Эта profile-first стратегия форсирует сайт в топы по запросам "[Company] jobs [City]", давая глубину, которую игнорируют агрегаторы.
Паразитируйте на авторитете локальных сущностей, чтобы обойти трение традиционного линкбилдинга.
Обеспечьте трастовые плейсменты через вступление в Торговую Палату (DR 48) и партнерство с местными универами для ресурсов .edu (DR 70-85).
Интеграция с 8+ коворкингами и стартап-инкубаторами добавляет 68 нишевых ссылок, устанавливая сигнал доверия, который национальные бренды не могут легко сфабриковать локально.
Технически эксплуатируйте раздутость агрегаторов.
Держите загрузку 1.2с — более чем в 3 раза быстрее Indeed — развертывая полный стек схемы: JobPosting, Organization, LocalBusiness и BreadcrumbList.
Внедрение высокоточных алертов с фильтрами по районам и зарплате форсирует 67% возврата юзеров и 5:23 время на сайте.
Эти поведенческие сигналы в паре с бюджетом на исполнение $8K/мес перевернули сайт до $20K MRR и 18,400 месячных сессий за 8 месяцев.
#LocalSEO #Programmatic #SchemaOrg
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
05 March 2026 08:15
Я не могу выразить, насколько тупо мощен claude code для SEO с файлом .env, содержащим ваши ключи API Keywords Everywhere и DataForSEO, пишет Коди Шнайдер.
Что можно сделать для вашего SaaS:
Вытяните всю вселенную ключей через эндпоинты related keywords и people also search for в Keywords Everywhere, затем отправьте весь список в SERP API DataForSEO, чтобы увидеть, кто реально ранжируется и где гэпы.
Полный контент-календарь с кластеризацией и приоритизацией.
Генерите программные лендосы на масштабе.
Если вы SaaS, обслуживающий 20 индустрий, бейте Keywords Everywhere по вариациям хвостов на вертикаль, затем чекайте DataForSEO на сложность и фичи выдачи по каждому, и claude code просто генерит уникальные страницы с правильными семантическими терминами и уже зашитой микроразметкой.
Линкбилдинг через эндпоинт пересечения доменов DataForSEO, который показывает каждый сайт, ссылающийся на конкурентов, но не на вас.
Вытягиваете ссылочные профили топ-5 конкурентов, прогоняете пересечение, находите гэп, парсите контакты и драфтите персонализированные аутрич-письма с референсом на конкретную страницу, на которую они ссылаются.
Вся воронка за 8 минут.
Стройте карты перелинковки, используя данные related keyword от Keywords Everywhere для создания кластеров тематической релевантности, затем заставьте claude code сгенерить фактическую структуру линковки по всему сайту.
Не рандомные ссылки.
Реальные семантические связи, которые награждает Google.
Запустите полный технический аудит через on-page API DataForSEO и заставьте claude code автоматически сгенерить фикс для каждой найденной проблемы.
Отсутствующие каноникалы, битая схема, малоценный контент, страницы-сироты.
Он находит проблему и пишет код, чтобы пофиксить её.
#AI #Automation #Python
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
04 March 2026 12:10
Как сделать ваш ссылочный профиль полностью невидимым для конкурентов
Стандартный сценарий: залили ссылки на Reddit или жирного паразита → конкурент спарсил твои ассеты через Ahrefs → настучал, скопировал или тупо перебил бюджет.
Вы теряете актив, 💰💰💰 и время.
Но сейчас инсайдеры юзают связку, которая подсовывает аналитическим тулзам пустышки и наглухо прячет ваши беклинки от чужих глаз.
Смерть оператора cache: в Гугле превратила этот метод в идеальное стелс-оружие — реверс-инжинирить ваше ссылочное стало практически невозможно.
Полная механика, математика и реализация схемы → @
Пока вы экономите на спичках, подписчики PRO уже скрыли свои лучшие ссылки.
Читать полностью…
Mike Blazer
03 March 2026 15:05
Архитектура воронки контента увеличивает конверсию в 5,3 раза за счет ограничения внутренних ссылок
Реструктуризация блога на 40 статей (45к визитов в месяц) с рандомных тем на жесткую воронку разогнала конверсию с 0.8% до 4.2% при нулевом росте трафика.
Механизм форсирует юзеров через линейную прогрессию — Awareness → Consideration → Decision — за счет жесткого ограничения перелинковки и подгонки CTA под готовность юзера, а не спама дженерик офферами.
Стадия Awareness (Верх воронки) работает только на привлечение и обучение через гайды "What is" и тренды (~2,400 слов).
Здесь запрещено упоминать продукт.
CTA остаются образовательными ("Скачать гайд", "Читать по теме") с ожиданием конверсии 0.5–1%.
Внутренняя перелинковка ведет исключительно на 2–3 статьи стадии Consideration для расширения знаний; ссылки на прямые продающие страницы заблочены, чтобы не создавать преждевременное трение.
Стадия Consideration (Середина воронки) сдвигается на тактические гайды "How to" и фреймворки (~3,200 слов), где свой тул упоминается только как опция.
CTA эскалируются до "Смотреть кейсы", "Сравнить решения" или "Рассчитать ROI" (3–5% конверсии).
Эти ассеты линкуются строго на 2–3 статьи Decision и одну продуктовую страницу для мягкой продажи.
Стадия Decision (Дно воронки) убирает образовательный контент в пользу кейсов, калькуляторов ROI и гайдов по внедрению, показывающих использование конкретных фич.
Это единственная точка, где развертываются агрессивные CTA ("Start free trial", "Book demo") и ссылки на основные конверсионные страницы, дающие 15–25% конверсии.
Правила исполнения:
— Прогрессия обязательна: Внутренняя перелинковка должна следовать линейному пути. Никогда не скипайте шаги (например, ссылка с Awareness сразу на Демо).
— Баланс объема: Убедитесь, что на стадии Decision достаточно инвентаря, чтобы принять трафик, стекающий с высокочастотных ассетов Awareness.
#ContentStrategy #Interlinking #CRO
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
03 March 2026 08:15
Почему большинство SEO-специалистов неправильно используют анкор-текст
Большинство сеньоров все еще молятся на устаревшие "золотые пропорции" (типа 5% точных, 20% брендовых).
Этот статический подход мертв.
Анкор — это не математика; это функция от Консенсуса Серпа и Траста Домена (Domain Authority).
Шкала "Авторитет-Агрессия"
Ключевой механизм — "Authority-Aggression Scale".
Жирные домены (DR 80+ / крупные эдиториалы) работают как щит.
Трастовые сигналы дефают агрессивные, точные анкоры.
Напротив, плейсменты с низким авторитетом (Гестпосты / DR 30) выставляют ссылки под микроскоп.
Агрессивный точный анкор (exact-match) на слабом домене моментально триггерит фильтры SpamBrain.
Протокол исполнения:
1. Реверс-инжиниринг консенсуса: Парсите бэклинки топ 5–10 ранжирующихся урлов. Если конкуренты сидят на 60% брендовых — серп консервативный; превысите базу — поймаете шторм выдачи. Если в топе жесткий точный вход — серп толерантен к агрессии.
2. Многоуровневая инъекция:
— Тир-1 (Мани-сайт): Строго по консенсусу. Фокус на брендовых и составных (Бренд + Ключ).
— Тир-2 (Саппорт): Усиление. Юзайте белые анкоры (Тайтлы статей, частичные), чтобы передать релевантность без фильтров.
— Тир-3 (Динамика): Безанкорка/дженерики для заливки чистого веса.
Форензика и Футпринты
Фильтры палят манипуляции через нечеловеческие паттерны кода:
— Синтаксис капитализации: Натуральные ссылки редко капсят небрендовый текст посреди предложения. "Best Online Casino" — это хардкодный футпринт. Форсируйте лоукейс для всех небрендовых анкоров.
— Изоляция контекста: Google чекает окружающий абзац. Ссылка в левом тексте — флаг. Должен существовать семантический мост.
— Приоритет первого линка: При перелинковке считается анкор только первой ссылки, ведущей на конкретный урл. Остальные игнорируются.
Новый вектор: Совпадение сущностей для AI
Поскольку поиск уходит в LLM (ChatGPT, Gemini, SGE), стратегия должна мутировать в Посев Сущностей (Entity Seeding).
AI рекомендует на базе совпадения на уровне документа, а не просто ссылочного графа.
Чтобы вооружить это, переходите на Составные Анкоры (Бренд + Топик/Локация):
— Легаси: "link building services" (Только ключ)
— Сущностный: "PressWhizz link building" (Сущность + Топик)
Этот синтаксис форсирует связь между Брендом и Сущностью Топика.
Он тренирует модель, что [Brand] существует рядом с [Service], создавая сигнал совпадения для видимости в AI.
Безопаснее, чем голый точный вход.
https://presswhizz.com/blog/anchor-text/
#AnchorText #Backlinks #SpamBrain
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
02 March 2026 12:10
Стратегия 302 редиректов для сохранения частоты краулинга при поэтапной выкатке товаров
У клиента Дэвида Гутьерреса миграция платформы (меняется только техстек, URL остаются прежними), но есть логистическая дыра: 50% товарного инвентаря не будет готово к запуску.
Оставшиеся SKU будут выкатываться медленно в течение нескольких месяцев.
Текущий челлендж — обработать "будущие" URL, которые существуют на старом сайте, но не имеют контента на новом, не вызывая массовых `404`х и не убивая краулинговый бюджет мусорными заглушками.
Предложения SEO-комьюнити:
— Разверните 302 редиректы на родительские категории
— Протокол: Настрой временные 302 редиректы для всех не готовых продуктовых URL, указывающие на их родительскую категорию или подкатегорию.
— Механизм: Это консолидирует ссылочный вес и пользовательский трафик на релевантной живой странице (категории). В отличие от 404, это сохраняет точку входа. В отличие от 301, это сигнализирует Google, что переезд временный, сохраняя историю оригинального URL до момента релиза продукта.
— Полевые данные: Тесты подтверждают, что этот метод предотвращает "паузу в краулинге", которая часто возникает, когда боты натыкаются на массовые ошибки или thin content.
— Убейте заглушки "Coming Soon"
— Форензика (Предупреждение): Не публикуй страницы с текстом "Coming Soon" или "Product Not Available".
— Механизм: Большие объемы тощего, шаблонного контента-заглушки триггерят классификаторы Soft 404. Это тренирует Гуглобота считать сайт низкокачественным, заставляя его резать частоту краулинга. Восстановление после такой "паузы сканирования" задержит индексацию, когда реальные продукты наконец появятся.
— Апгрейд "Out of Stock" (Лучшее удержание)
— Условие: Если данные о продукте (тайтлы, описания, спеки) существуют программно, несмотря на дыру в инвентаре.
— Исполнение: Поддерживай URL со статусом 200 OK, но пометь товар как "Out of Stock" / "Backordered".
— Преимущество: Это вариант с самой высокой точностью (high-fidelity). Он сохраняет ранжирование по конкретным ключам, привязанным к URL, лучше, чем редирект.
— Ограничение: Убедись, что страница содержит достаточно редакционного/информационного контента, чтобы избежать пенальти за thin content.
— Избегайте долгосрочного статуса 503
— Корректировка: Игнорируй предложения AI/LLM, рекомендующие коды 503 (Service Unavailable) для этого кейса.
— Риск: Хотя технически это верно для "обслуживания", затянувшиеся сигналы 503 (растянутые на месяцы) в конечном итоге заставят Google полностью выкинуть URL из индекса.
#Migration #Redirects #CrawlBudget
@
Но "мясо" только в @
Читать полностью…
Mike Blazer
28 February 2026 13:05
Закрыли неделю в @.
Было жарко.
Несколько схем из этой недели уже начали спамить в массы — значит, скоро Google прикроет.
Вот что вы пропустили:
1. Разведка боем через "одноразовые" ассеты — как использовать временное окно новизны алгоритма для фильтрации тысяч ключей.
2. Перехват "сигнала отцовства" — как злоумышленники заставляют алгоритм признать их домен первоисточником бренда, используя ЭТУ вашу ошибку.
3. Programmatic SEO на "Dark Social" данных — автоматизированный пайплайн, который генерирует тысячи страниц "Проблема/Решение" без копирайтеров.
4. Мгновенный траст без CMS — паразитная схема, превращающая блокчейн-записи в стандартные HTML-документы для Google.
5. Принудительное цитирование для LLM — один HTML-тег, который структурно заставляет нейросети выбирать именно ваш текст как ответ.
6. Валидация трафика до работы — как узнать, что Google хочет ранжировать, прежде чем вы потратите бюджет на контент.
7. DR70+ по цене регистрации — как забирать домены с жирнейшими ссылками, используя ошибку в процессе цифровой архивации.
8. Манипуляция "первым впечатлением" бота — что именно надо переписать, чтобы спасти краулинговый бюджет всего сайта.
9. Кража "авторских векторов" — математический способ бустануть ваш E-E-A-T путем манипуляцию эмбеддингами авторов, а не биографией.
10. Таргетинг опечаток через "теневой слой" — как собирать трафик по кривым запросам, сохраняя контент на сайте идеально грамотным.
-
Такие темы долго не живут.
Их либо заспамят до смерти, либо Google запатчит в ближайшем апдейте.
Ценность подхода — в его новизне.
Когда про него знают все — он уже не эксплойт.
Вы либо в числе первых, кто юзает схему, либо в числе последних, кто узнал, что она мертва.
Действуйте, пока окно не захлопнулось.
Читать полностью…
Mike Blazer
27 February 2026 15:05
Head of SEO принимает работу команды
Humor
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
27 February 2026 08:15
"Треугольник Траста" в Schema выбивает Sitelinks и ускоряет индексацию
Главная метрика ROI для разметки Schema — индексируемость, а не волатильные скачки CTR от расширенных сниппетов.
Я переосмысливаю схему не как декорацию для звездочек, а как структурный сигнал, заставляющий Google мгновенно понять архитектуру сайта, срезая стандартные 3-4 месяца обучения алгоритма, утверждает Питер Мачин.
Чтобы использовать это как рычаг, я внедряю Схему "Треугольник" на каждой странице: сцепка сущностей WebSite, Organization и WebPage.
Большинство SEOшников пропускают эту базовую триангуляцию, хотя это критически важный сигнал для создания авторитета, необходимого для получения Sitelinks.
В отличие от хрупких сниппетов FAQ, сайтлинки занимают огромное пространство в выдаче и, согласно моим скриптам аналитики, приносят до 5% всех кликов по запросам — кликов, которые конкуренты не могут отжать, так как у них нет структурного траста для их генерации.
Однако схема — это Сигнал с Порогом Доверия.
Как и sitemaps, Google алгоритмически игнорирует директивы от доменов, которые считает ненадежными.
Это привилегия, которую нужно заслужить правдивым представлением данных.
На регулируемых рынках iGaming это требует строгой чистки комплаенса; я гарантирую, что запрещенные термины (вроде "Bitcoin") вычищаются из пейлоада схемы так же, как из интерфейса.
Для мульти-гео сетапов я настраиваю локальные сущности (напр., Country X Organization) как дочерние элементы, ссылающиеся на родительский глобальный бренд, поддерживая передачу веса и изолируя регуляторные риски.
#SchemaArchitecture #Indexability #EntitySEO
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
26 February 2026 12:10
Составные бренд-запросы подтягивают внутряк через ассоциацию с Главной
Чтобы форсировать ранжирование глубокого внутряка, внедряется гибридная стратегия: запуск платного брендового поиска параллельно с манипулируемым трафиком по связкам "Бренд + Коммерческий интент" и "Бренд + Вторичный термин", детализирует Крис Палмер.
Этот протокол Brand-Association Lifting направляет трафик по составным запросам исключительно на главную.
Ассоциация сигнализирует алгоритму, что бренд — глобальный авторитет в кластере, что лифтит позиции для всех внутренних страниц, оптимизированных под эти термины — даже если сама главная не имеет прямой релевантности.
Однако тактика ограничена Минимальным Архитектурным Порогом.
Сайты с малым футпринтом (<50 страниц) не генерируют требуемую плотность сигнала.
Алгоритмический отклик на ПФ масштабируется вместе с размером индекса; метод требует значительного масштаба (1,000+ страниц) для материализации в рост позиций.
Отдельно по авторитету сущности: используем высокотрафиковые базы типа Famous Birthdays (10.9 млн хитов/мес) как сид для паразита.
Получение листинга (требует соц-верификации) генерирует массивный вторичный всплеск поисков "Who is [Entity Name]"? и "[Entity Name] + Birthday".
Это создает органический брендовый сигнал высокого траста, который переигрывает ботовую накрутку CTR, раскрывает Крейг Кэмпбелл.
#BrandSERP #CTRManipulation #EntitySEO
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
25 February 2026 15:05
Физическое удаление ссылок из DOM спасает краулинговый бюджет
Стандартные директивы управления краулингом, такие как robots.txt или noindex, не спасают краулинговый бюджет, потому что фаза обнаружения Googlebot выдергивает и ставит в очередь каждый href, присутствующий в HTML-структуре, независимо от последующих правил индексации.
Этот механизм диктует: если ссылка существует в DOM, краулер попытается перейти по ней, эффективно сжигая бюджет на неприоритетные ассеты, заявляет Чарльз Тейлор.
Для жесткой экономии ресурсов на mass-page архитектурах система должна полностью скрыть путь URL от краулера.
Это требует логики динамического рендеринга, которая определяет user-agent Googlebot и физически вырезает внутренние ссылки на малоценные страницы из DOM до отправки ответа, советует https://www.youtube.com/watch?v=4dMm0o57oQ8&t=2542s Тед Кубайтис.
Для небольших сайтов с потолком бюджета около 3,000 страниц эта архитектура не дает пауку тратить циклы на технические страницы или дубли, которые обычно размывают вес.
#CrawlBudget #Rendering #GoogleBot
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
25 February 2026 08:15
Контекстный бриджинг сокращает векторную дистанцию для расширения топика
Чтобы расшириться в новые тематические кластеры без триггера фильтров "stay in your lane" (HCU), внедряю Контекстный Бриджинг, раскрывает Касра Даш.
Это создает переходный контент для перекрытия семантической дистанции между трастовой сущностью и новой целью.
Если у сайта авторитет в "Schema", прыжок сразу на "Backlinks" создает разрыв; вместо этого сначала публикуем "SameAs Schema".
Это создает для краулера логичный семантический вектор, позволяя домену развернуться от on-page технички к off-page авторитету без размывания "трастового ядра" сайта.
Стратегия работает с механикой Multidimensional Vector Relevancy, где Google картирует контент в математическое векторное пространство.
Расширение контента рассчитывается по "углу" или семантической дистанции между словами; размещение нового контента слишком далеко от устоявшегося векторного кластера домена сталкивается с кратно более высокими барьерами индексации и ранжирования, отмечает Йеспер Ниссен.
Минимизируя угловую дистанцию через бриджинг-контент, мы заставляем алгоритм принять расширение топика как естественную эволюцию, а не левое ответвление.
Отдельно: настоящий Topical Authority требует валидации трафиком, а не просто объема.
Публикация 999 страниц про "Библию" дает ноль авторитета без трафика, тогда как одна страница про "Ремонт авто", генерирующая 1 миллион кликов, устанавливает домен как авторитет в авто-нише, поясняет Касра Даш.
Алгоритм приоритизирует сигналы трафика над частотой документов; поэтому масс-паблишинг без обеспечения user signals не создает нужной векторной плотности.
Для старых сайтов запускаю протокол "Smart SEO" для майнинга Призрачных Ключей (Ghost Keywords) — терминов, где домен уже регистрирует показы в GSC, но не имеет посадочной.
Regex-фильтры (How/Why/What) в GSC вскрывают эти пре-валидированные семантические дыры; создание контента под эти запросы использует существующую векторную близость для мгновенного ранжирования.
Напротив, для новых сайтов избегаю слепого парсинга сайтмапов конкурентов: копирование сервисных страниц (например, "Forensic Accounting") без необходимых офлайн-регалий (статус "Chartered") создает мисматч доверия, который стопорит ранжирование.
#VectorSearch #SemanticSEO #TopicalAuthority
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
24 February 2026 12:10
Табы в верхней части DOM обходят девальвацию скрытого текста
Чтобы форсировать максимальную заметность ключей, не засоряя пользовательский опыт, я переношу SEO-контент из подвала страницы в интерактивные табы, размещенные в самом верху вьюпорта, раскрывает Корай Тугберк Гюбюр.
В конкретном кейсе с конвертером величин простое перемещение ключевого компонента из середины страницы на топовую позицию спровоцировало полный переобход сайта и рост ежедневного трафика с 2,000 до 30,000 кликов.
Это подтверждает, что алгоритм оценивает Prominence (Заметность) на основе размещения контейнера в DOM, а не видимости текста внутри по дефолту.
В то время как традиционное SEO предостерегает от скрытого текста, Вектор Репрезентации Сайта — модель машинного обучения, кластеризующая дизайны — поощряет такую структуру.
Она интерпретирует сложную "Координацию Дизайна" (табы, аккордеоны, фильтры) как сигнал высоких Усилий над Контентом, отличая экспертные сайты от дешевых простыней текста.
#SemanticSEO #OnPage #UXSignals
@
🚷 Закрытый канал: @
Читать полностью…
Mike Blazer
23 February 2026 15:05
Дробление контента на микро-инфоповоды взрывает Topical Authority и обходит гигантов
Традиционная стратегия публикации комплексных "мега-постов" для конкуренции с медиа-гигантами (CNN, NYT) функционально мертва для новичков из-за непреодолимого разрыва в авторитете.
Альтернативный вектор, кодифицированный как Content Splintering, эксплуатирует предпочтение алгоритма к узкой тематической релевантности над широким авторитетом домена.
Вместо того чтобы консолидировать новость в один URL, дробите нарратив на 5-7 отдельных микро-углов (например, одна страница для анализа данных, одна для реакции экспертов, одна для локального влияния).
Этот подход "ковровой бомбардировки" искусственно раздувает динамику сайта и форсирует немедленное признание Topical Authority; ранние адепты фиксируют 40% роста позиций за 3 месяца после перехода на эту высокообъемную архитектуру.
План исполнения опирается на скорость и плотность, а не на глубину.
Для срочной новости протокол предписывает публикацию предварительного саммари в окне 5-10 минут, чтобы захватить начальный сигнал "Freshness".
Последующие страницы-"осколки" затем разворачиваются быстро и жестко перелинковываются для создания плотного кластера вокруг события.
Эта стратегия поддерживается специфической технической инфраструктурой: Google News Sitemap, настроенный на ежечасные пинги обновлений.
Логи показывают, что правильно настроенные автоматизированные новостники, использующие эту агрессию с сайтмапом, добиваются индексации за 1-4 минуты, обходя стандартную задержку краулинга, которая убивает новые домены.
Пока автоматизация обеспечивает скорость, тред подчеркивает, что сигналы E-E-A-T остаются главной точкой отказа.
Чтобы парировать классификаторы "Thin Content", которые обычно флагают дробленый контент, успешные кампании полагаются на реальные имена журналистов и отдельную оптимизацию в SurferSEO для каждого угла, чтобы предотвратить каннибализацию.
Стратегия эффективно использует вес конкурента против него самого: пока легаси-сайты полагаются на один неповоротливый URL для покрытия темы, протокол сплиттеринга заваливает выдачу множеством точек входа, таргетируясь на хвосты запросов, которые гиганты считают слишком мелкими.
https://www.blackhatworld.com/seo/building-a-new-news-site-in-the-us-heres-the-brutal-seo-truth-and-what-actually-works.1777634
#TopicalAuthority #GoogleNews #EEAT
@
🚷 Закрытый канал: @
Читать полностью…



 8310
8310
{kind=link}
{kind=link}
{kind=link}