Mike Blazer
16 September 2025 08:15
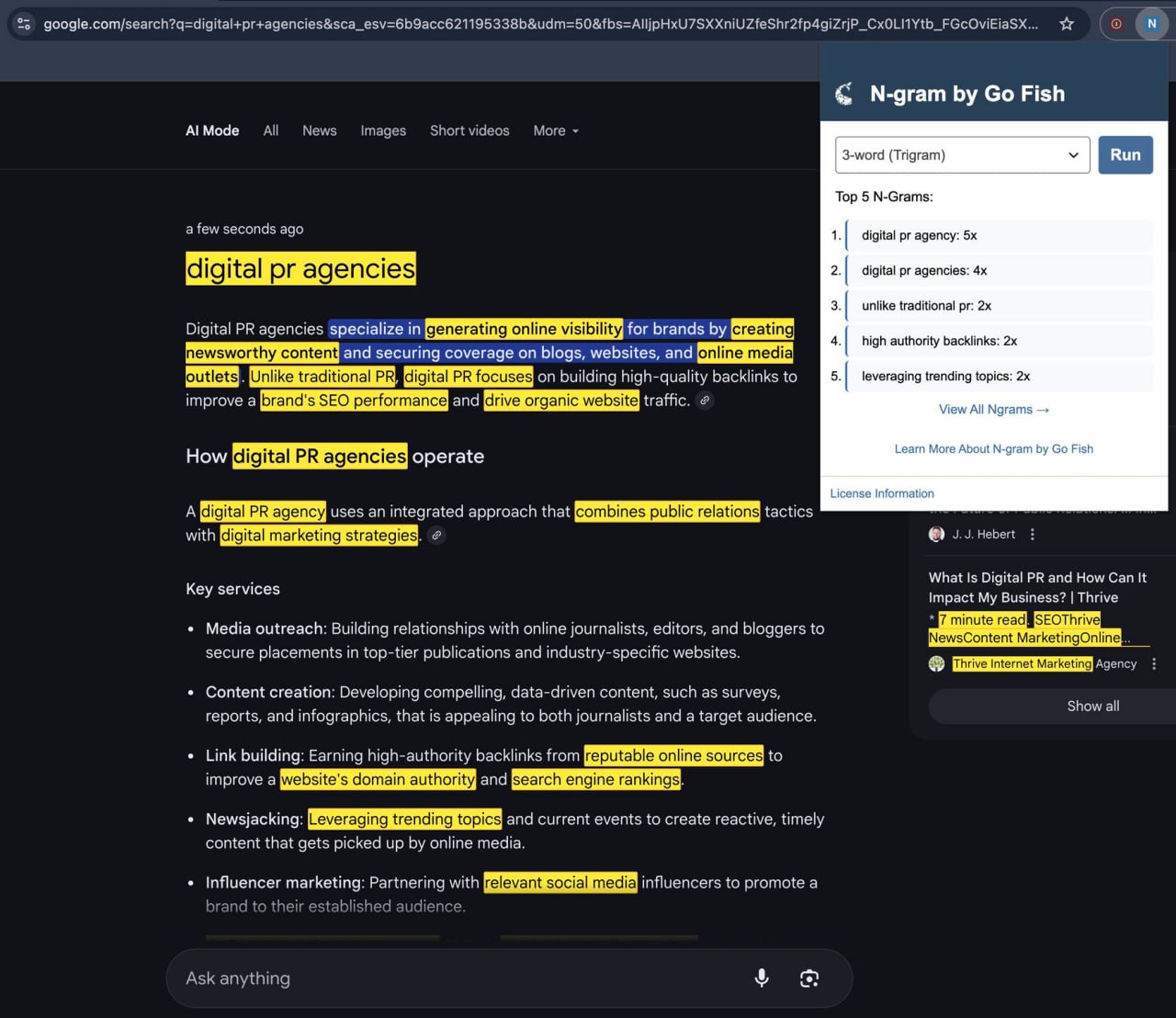
Вы можете проводить n-gram анализ напрямую в AI Mode от Google, чтобы увидеть, какие фразы и темы используются чаще всего, а затем сравнить их с вашим собственным контентом.
На скриншоте ниже показано, что происходит, когда вы выполняете поиск по запросу "digital PR agencies" и накладываете результаты n-gram анализа на ответ, сгенерированный искусственным интеллектом.
Он мгновенно подсвечивает распространенные шаблоны фраз, такие как:
— "digital PR agency"
— "unlike traditional PR"
— "high authority backlinks"
Почему это важно:
N-граммы — это отличный способ увидеть закономерности в текстах, написанных людьми (включая ИИ).
Они также могут служить повторяющимися семантическими сигналами для поисковых систем и больших языковых моделей (LLM).
Если вы упускаете ключевые n-граммы, злоупотребляете ими или ваш текст не соответствует нужному шаблону, вы, вероятно, не попадаете в тот паттерн контента, который продвигает Google.
Как это использовать:
1 Сделайте запрос в AI Mode.
2 Используйте наше бесплатное Chrome-расширение для n-gram анализа, чтобы увидеть паттерны, использованные в ответе.
3 Повторите тот же процесс для вашей страницы.
4 Отредактируйте ваш контент, чтобы заполнить пробелы, сократить повторы и усилить значимые фразы.
Совет от профи: То же самое можно проделать и со страницами, занимающими топовые позиции в поисковой выдаче, чтобы увидеть, какие слова и сочетания фраз они используют.
Расширение N-gram для Chrome доступно бесплатно в Chrome store.
Оно позволяет:
1 Мгновенно извлекать топовые 2-, 3- или 4-словные n-граммы с любой страницы (вашего сайта, сайтов конкурентов или даже из GSC).
2 Подсвечивать фразы прямо в тексте и подсчитывать их частотность.
3 Экспортировать полный набор фраз в CSV.
Оно создано для быстрой работы и особенно хорошо подходит для оптимизации посадочных страниц, постов в блоге или при анализе ответов, сгенерированных ИИ Google.
https://chromewebstore.google.com/detail/n-gram-by-go-fish/cgmdbadjjhheckdicjbihebcmibfpicg
@
Читать полностью…
Mike Blazer
15 September 2025 15:05
Я заработала $27,300 в феврале... и при этом даже не работала, — говорит Элис Ксерри.
Знаете почему?
Потому что клиенты месяцами выплачивали мне то, что были должны.
Платите своим фрилансерам вовремя, черт возьми.
Вот и все.
@
Читать полностью…
Mike Blazer
15 September 2025 11:10
Скачать расширение для Chrome для экспорта данных из отчета по метрикам ИИ в Cloudflare
@
Читать полностью…
Mike Blazer
15 September 2025 09:32
Калин продает свою сетку PBN (~500 сайтов) за $300к
@
Читать полностью…
Mike Blazer
14 September 2025 17:05
Когда SEO-специалист на собеседовании приписывает себе всю заслугу за успех продвижения, хотя работала вся SEO-команда.
@
Читать полностью…
Mike Blazer
14 September 2025 13:10
Авторы статьи https://arxiv.org/abs/2507.11768 заявили: "Мы обнаруживаем галлюцинации еще до того, как LLM осознает, что она галлюцинирует".
В ней используется байесовская оценка для измерения вероятности того, что ответ модели является галлюцинацией.
Теперь они опубликовали тулкит (пока только для OpenAI), который мы можем использовать для повышения надежности и валидности наших рабочих процессов по созданию контента с помощью ИИ.
Зацените этот калькулятор риска галлюцинаций и инструментарий для реинжиниринга промптов https://github.com/leochlon/hallbayes
Удачных экспериментов.
@
Читать полностью…
Mike Blazer
14 September 2025 09:15
Я наблюдаю четкую закономерность: падение позиций все чаще связано с переоптимизацией, в частности, с переспамом ключевыми словами, вызванным погоней за "баллами" в таких инструментах, как Surfer SEO или Neuron Writer, — говорит Крис Тзицис.
Недавний аудит был показательным.
Страница клиента, на которой было принудительно размещено 20 ключевых слов из целевого списка в 29, значительно уступала конкуренту из топа выдачи, который использовал всего 5 из тех же ключевых слов на всей своей странице.
Конкурент выиграл не за счет выполнения плана по ключевым словам, а благодаря лучшему пользовательскому опыту.
Страница клиента, переспамленная ключевыми словами, была неестественной и, скорее всего, провоцировала негативные поведенческие сигналы, такие как пого-стикинг.
Это прямое опровержение методологии "скоринга оптимизации"; высокий балл бесполезен, если он ухудшает читабельность и не удовлетворяет пользовательский интент.
Пересмотренный подход — это переход от плотности ключевых слов к тематической полноте.
Да, размещайте ваш основной ключ и его критически важные вариации в ключевых он-пейдж элементах:
— H1
— URL-слаг
— Тайтл
— Первые 100 слов
Помимо этого, хватит насильно вставлять ключевые слова.
Новая роль этих контент-инструментов — не достижение целевых показателей частотности, а анализ тематических пробелов.
Используйте их, чтобы задаться вопросом: "Каких разделов или концепций не хватает в моем контенте?" — и убедиться, что важные ключевые слова упоминаются хотя бы один раз в релевантном контексте, а не для того, чтобы впихивать их по несколько раз.
@
Читать полностью…
Mike Blazer
13 September 2025 15:05
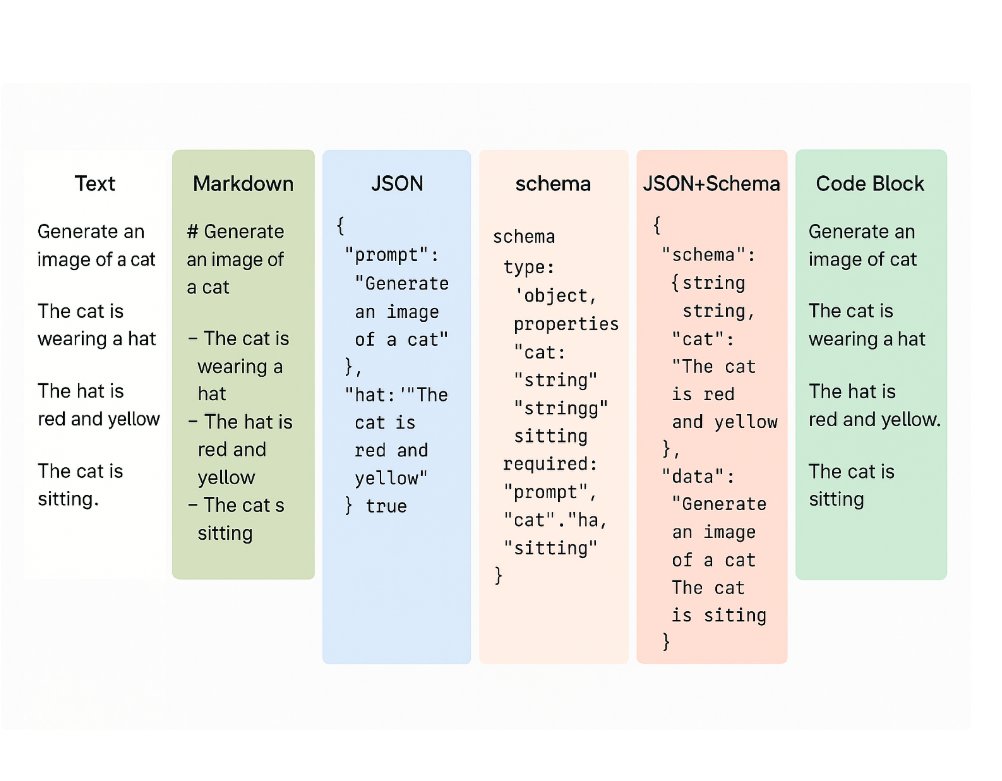
Промптинг текстом, в Markdown, JSON, Schema, JSON+Schema или блоком кода.
Простое руководство: что и когда использовать.
Текстовые/голосовые промпты
Вы даете инструкции LLM на естественном языке.
Когда использовать:
— Для повседневных задач, где точность не критична.
— Как пользовательский промпт, ведь конечный пользователь использует текст/голос.
— Идеально для творческих или исследовательских задач: написания текстов, создания видео, изображений, аудио.
Слабые стороны:
— LLM может легко неверно истолковать или проигнорировать.
— Ненадежен для критически важных задач (например, передача управления человеку, обработка транзакций, изменение баз данных, чувствительные операции, строгие правила взаимодействия).
— Как бы тщательно вы ни формулировали инструкции (даже с заглавными буквами или повторениями), для LLM текстовые промпты — лишь предложения, а не гарантии.
Например, можно попросить LLM не удалять базу данных, но она все равно может это сделать.
Markdown-промпты
Вы даете инструкции LLM в формате Markdown.
Когда использовать:
— Для создания системных промптов и документов базы знаний.
Слабые стороны:
— Не подходит для повседневных задач.
— Ненадежен для критически важных задач.
— Не подходит для творческой или исследовательской работы.
JSON-промпты
Вы даете инструкции LLM с помощью JSON.
JSON-промпты LLM сложнее неверно истолковать, проигнорировать или сгаллюцинировать.
Когда использовать:
— Для структурированных потоков автоматизации, где результаты должны парситься на последующих этапах.
— Для задач, где точность очень важна.
Слабые стороны:
— Те же недостатки, что и у Markdown-промптов.
Schema-промпты
Вы определяете строгие правила вывода (типы, перечисления, обязательные поля), не оборачивая весь промпт в JSON.
Когда использовать:
— Для задач с множеством проверок (например, классификация, извлечение сущностей, безопасные ответы).
Слабые стороны:
— Требуются глубокие знания предметной области для правильного проектирования схем (например, схема GA4 BigQuery).
JSON + Schema промпты
Вы комбинируете структурированные входные данные (JSON) со строгой валидацией по схеме.
Это один из самых надежных способов контролировать вывод LLM, снижать галлюцинации и обеспечивать повторяемость.
Когда использовать:
— Когда одновременно нужны структура и строгая валидация.
— Отлично подходит для vibe coding (интуитивного кодирования).
Слабые стороны:
— Требуются глубокие знания предметной области (иначе результаты будут невалидными или неполными).
Промпты в виде блока кода
Вы заставляете LLM выводить ответ в блоке кода (например, SQL, Python), что часто требует проверки человеком перед выполнением, добавляя уровень безопасности для опасных инструкций.
Когда использовать:
— В сценариях, где нужно любой ценой предотвратить случайное выполнение (например, удаление базы данных).
Ни один из стилей промптинга не лучше другого.
Все зависит от вашего варианта использования.
В реальности можно комбинировать несколько стилей промптинга.
Следует стремиться к балансу простоты, точности и безопасности, а не зацикливаться на одном стиле.
https://www.optimizesmart.com/prompting-text-markdown-json-schema-code-block/
@
Читать полностью…
Mike Blazer
13 September 2025 11:05
ChatGPT видит дату последнего обновления поста.
Свежесть — это бустер.
Представь, что у тебя на сайте есть партнерский раздел и ты получаешь упоминания.
https://www.vogue.com/article/6-sneaker-trends-to-look-out-for-in-2025
@
Читать полностью…
Mike Blazer
12 September 2025 13:10
мой телефон, когда я говорю, что хочу что-то купить
@
Читать полностью…
Mike Blazer
12 September 2025 08:15
Марк Уильямс-Кук утверждает, что ценность микроразметки теряется при обучении ядра LLM из-за токенизации.
Этот процесс разбивает структурированные данные, такие как {"@": "Organization"}, на отдельные токены ("type", "Organization"), которые становятся неотличимыми от обычного текста, тем самым нейтрализуя явную, машиночитаемую структуру schema.
WebLinkr развивает эту мысль, ставя под сомнение ценность распространенных типов микроразметки, таких как Article, которые часто содержат избыточную информацию.
Он оспаривает ощутимую пользу определенных с помощью schema связей между сущностями для поисковых систем или LLM, ссылаясь на опыт своей команды, которая ранжировалась в AiO/SGE без ее использования.
Он также отмечает, что хотя Google и накладывает санкции за некорректную микроразметку, это не означает, что за правильную реализацию дается буст в ранжировании.
Мнения сеошников
— Для разрешения спора предлагается эксперимент: векторизовать несколько схем микроразметки и абзац с той же информацией, чтобы измерить их близость в векторном пространстве.
— Хотя микроразметка может и не иметь особого веса для LLM, модели все же могут обрабатывать ее последовательно как текст, сохраняя порядок и понимая информацию так же, как и любой другой текст на странице.
— Один пользователь поделился кейсом из практики, утверждая, что некорректная реализация микроразметки вызвала падение позиций на 40%, в то время как ее исправление привело к росту на 20% выше первоначального уровня.
— Проводится ключевое различие между этапом *обучения* (training) LLM и этапом *извлечения* (retrieval).
Хотя ценность микроразметки, вероятно, теряется во время обучения, она все еще может быть влиятельной на этапе извлечения.
— Слой извлечения для систем, таких как SGE, Perplexity или ChatGPT, скорее всего, заимствует традиционные поисковые сигналы для категоризации, фильтрации и устранения неоднозначности контента *до того*, как он будет передан LLM для синтеза.
— Практическая ценность микроразметки в контексте GEO может заключаться не в прямом влиянии на генеративный вывод LLM, а в улучшении структурирования контента для систем извлечения, что приводит к более чистым сниппетам и более высокой вероятности использования в ответе ИИ.
@
Читать полностью…
Mike Blazer
11 September 2025 15:05
Этот сайт парсит и публикует выдачу ChatGPT по разным поисковым запросам, причем вместе со ссылками на источники.
Можно предположить, что даже если это классическая схема "взлетел и упал", овчинка все равно стоит выделки, раз уж они продолжают этим заниматься.
@
Читать полностью…
Mike Blazer
11 September 2025 11:05
Забавно, как мы, сеошники, всегда первым делом пробуем /sitemap.xml, когда ищем сайтмап… и часто это тупик, пишет Монти Матур 😅.
Иногда его нет даже в robots.txt 🤦.
Другие места, где я находил сайтмапы:
→ /sitemap_index.xml
→ /sitemap1.xml
→ /sitemap/sitemap.xml
→ /wp-sitemap.xml (WordPress)
→ кастомные суффиксы, например .php.
Лайфхак: Используйте поисковые операторы Google, такие как site:example.com filetype:xml или inurl:sitemap, чтобы найти скрытые.
Даже в этом случае, нахождение сайтмапа не означает, что Google его использует.
Единственная надежная проверка — в GSC (был ли он отправлен и обработан?).
@
Читать полностью…
Mike Blazer
10 September 2025 17:05
Google использует два типа предзагрузки для каждого результата в десктопной поисковой выдаче.
Один для топ-2 результатов, а второй — на основе действий пользователя.
Каждый раз, когда кто-то выполняет поиск в Google, Chrome пытается ускорить первый клик, немедленно выполняя предзагрузку двух верхних органических ссылок — никаких действий со стороны пользователя не требуется.
Затем, когда пользователь наводит курсор на остальные органические результаты, Chrome динамически предзагружает каждую ссылку, на которую наведен курсор, в надежде сократить время загрузки на сотни миллисекунд.
Но это работает только в том случае, если страница подходит для повторного использования.
А так бывает не всегда.
Если ваша страница устанавливает уникальные cookie для пользователя, ее содержимое меняется в зависимости от состояния или у нее есть service worker, Chrome все равно отправит запрос на предзагрузку, но может не использовать результат.
Вы теряете прирост в скорости, который может быть очень важен для коэффициента конверсии на e-commerce страницах.
Это однозначно стоит протестировать, если вы надеетесь на быструю конверсию из поисковой выдачи.
Вот как проверить, выполняется ли предзагрузка для вашего сайта:
1 Откройте поиск Google в режиме Инкогнито.
2 Это удалит cookie-файлы и сделает процесс предзагрузки более похожим на то, как с вашим сайтом взаимодействует новый пользователь.
3 Кликните правой кнопкой мыши → Inspect (Проверить) → DevTools → вкладка Application (Приложение).
4 В разделе "Speculative loads" вы увидите правила и активные попытки предзагрузки.
Первые два результата должны сразу же показать статус "ready" (готово).
Когда вы наводите курсор на другие результаты, появляются новые записи — это предзагрузка, вызванная наведением курсора.
Кликните на любую запись, чтобы проверить ее статус.
Если вы видите сообщения вроде "not eligible due to cookies" или "service worker", это значит, что Chrome отправил запрос на предзагрузку, но не смог использовать полученный ответ.
Возможно, вам стоит изучить этот вопрос подробнее, чтобы понять, не сталкиваются ли все ваши пользователи с немного более медленной загрузкой страницы.
И вот что интересно: похоже, Google не выполняет предзагрузку рекламных ссылок, AI Overviews или новостных каруселей.
Только традиционные органические результаты.
Почему это важно:
Google по умолчанию дает ускорение вашим страницам в топе выдачи, но только если вы соответствуете правилам.
Этот буст может повлиять на показатель отказов, вовлеченность и конверсию, особенно для e-commerce сайтов.
@
Читать полностью…
Mike Blazer
10 September 2025 13:10
Эта компания, занимающаяся ИИ-процессорами, просрочила свой домен, его перехватили сербские аффилиаты казино, и теперь он ранжируется по тысячам ключевых слов на тему казино по всему миру...
Вероятно, они зарабатывают более $10 000 в ДЕНЬ!
Компания все еще существует, у нее много легитимных сигналов доверия (большое присутствие в Linkedin, Crunchbase и т.д.), а также тонна ссылок с трастовых ИИ-источников.
Причина, по которой ему, вероятно, позволили так хорошо ранжироваться (даже в англоязычной выдаче США), заключается в том, что Google перебросил почти все свои ресурсы с поисковых алгоритмов на свои ИИ-проекты.
Чарльз Флоат видел, как отключили ряд антиспам-систем (которые раньше работали почти в реальном времени), и это позволяет черным методам, которые не работали более 10 лет, не просто вернуться, а процветать! 😈
@
Читать полностью…
Mike Blazer
15 September 2025 17:05
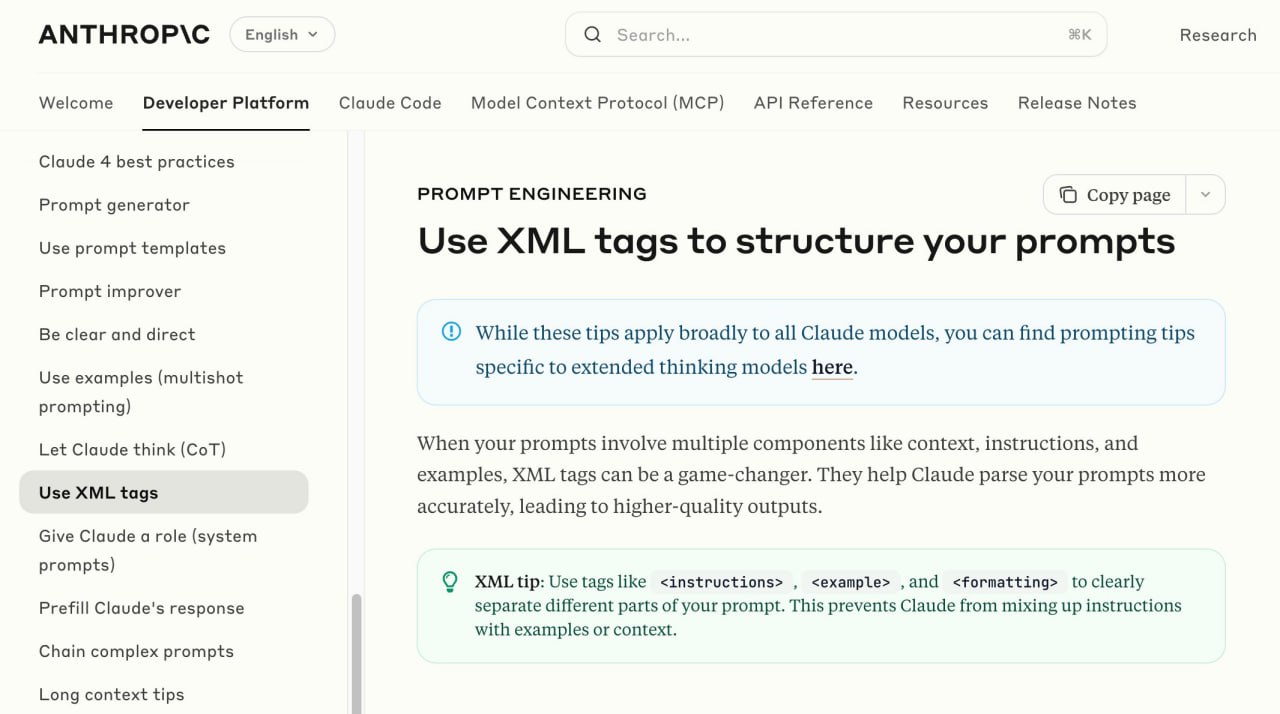
Раскрываем потенциал Claude с помощью XML-промптов
По словам исследователей из Anthropic, структурирование промптов с помощью XML-тегов позволяет достичь от модели Claude более высокого уровня производительности.
Этот метод использует обучающие данные модели, которые насыщены структурированным XML из документации, кода и наборов данных, для получения более точных, чистых и контролируемых результатов.
Используя XML-теги, вы общаетесь с моделью в ее нативном формате.
Преимущества этого метода:
— Уточнение цели: Структура устраняет двусмысленность в запросах.
— Улучшенное логическое мышление: Это имитирует обучающие данные модели, улучшая обработку логических связей.
— Снижение галлюцинаций: Точные инструкции ограничивают нерелевантные или неверные выводы.
Вот как этот метод трансформирует стандартные промпты в реальных сценариях использования.
AI-ассистент для исследований
Обычному промпту не хватает конкретных параметров, которым модель должна следовать.
Обычный промпт:
Find the top 3 recent papers on retrieval-augmented generation and summarize each in 2 sentences.
XML-версия:
<task>Найти и резюмировать</task>
<topic>Retrieval-Augmented Generation (RAG)</topic>
<output_format>Резюме 3 исследований</output_format>
<length>По 2 предложения на статью</length>
Создание контента (пост для LinkedIn)Формат
XML позволяет определять тональность, цели и аудиторию.
Обычный промпт:Write a LinkedIn post about how AI freelancers are changing traditional employment.XML-версия:<task>Написать</task>
<format>Пост для LinkedIn</format>
<topic>Рост числа AI-фрилансеров</topic>
<goal>Подчеркнуть подрыв традиционных форматов работы</goal>
<tone>Экспертный и увлекательный</tone>
Написание простого приложенияОграничения можно задавать прямо в промпте.
Обычный промпт:Build a Python script that takes a URL, extracts all links on the page, and saves them to a CSV.XML-версия:<task>Написать код</task>
<language>Python</language>
<goal>Извлечь все ссылки с URL и сохранить в CSV</goal>
<constraints>
<libraries>Использовать requests и BeautifulSoup</libraries>
<output_format>CSV</output_format>
</constraints>
Общий шаблон промптаЭтот шаблон можно адаптировать практически для любой задачи.
<task>[Действие для выполнения]</task>
<topic>[Тема]</topic>
<format>[Тип вывода: Email, код и т.д.]</format>
<tone>[Неформальный, формальный и т.д.]</tone>
<persona>[Роль автора]</persona>
<audience>[Целевая аудитория]</audience>
<input>[Исходный контент или запрос]</input>
<constraints>[Ограничения: длина, стиль, библиотеки]</constraints>
Использование промптов в стиле
XML открывает доступ к более продвинутым возможностям, включая многоэтапное мышление, более чистый вывод, модульный контроль и быструю персонализацию.
@
Читать полностью…
Mike Blazer
15 September 2025 13:10
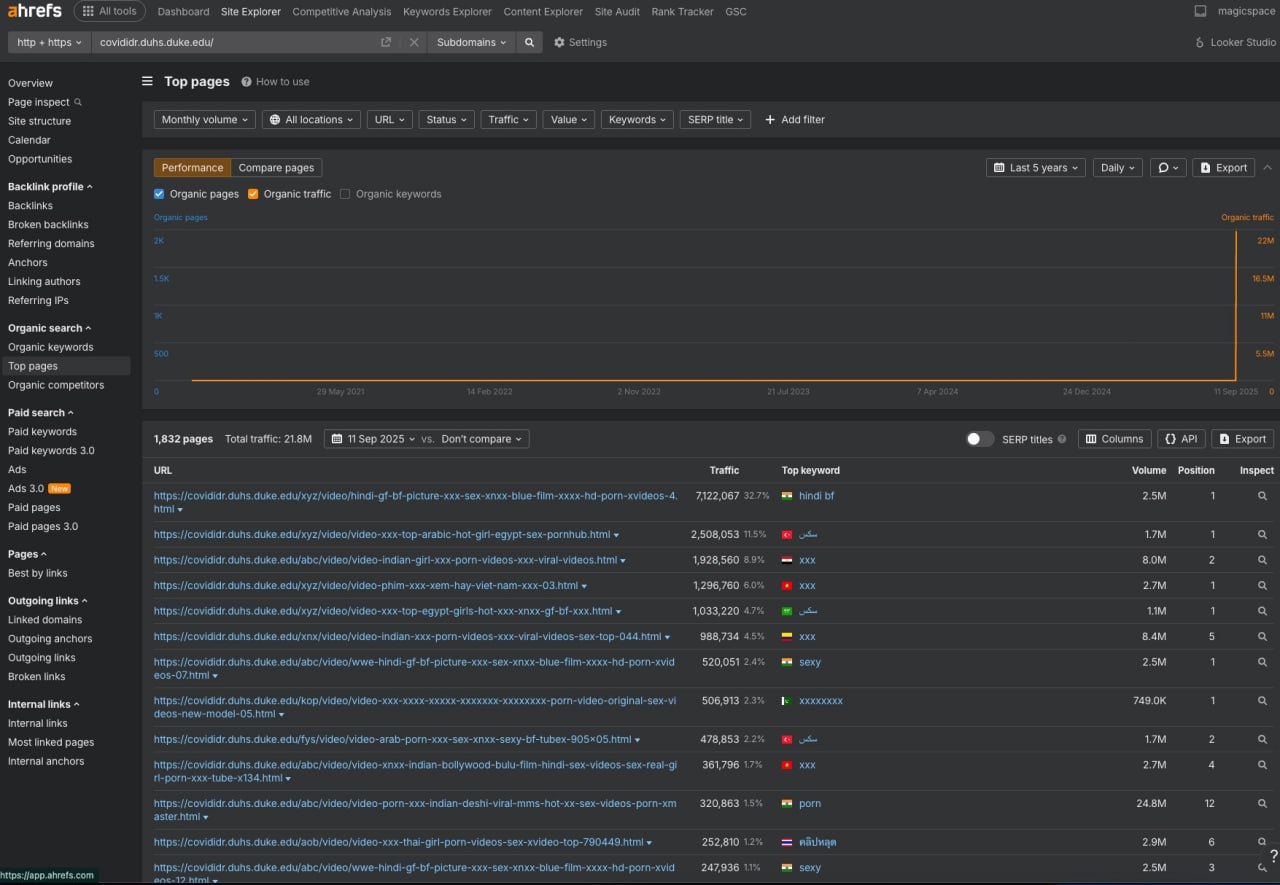
Жесткая кампания по Parasite SEO взломала кучу трастовых доменов .gov и .edu, заюзав их авторитет для ранжирования по высокочастотным чернушным ключам.
Атака дала дикие всплески органического трафика: сабдомен на duke.edu собрал больше 22 миллионов органических хитов за сутки, а саб на ca.gov за тот же срок рванул с нуля до 8 миллионов.
Затронутые домены и масштаб:
— `duke.edu` (DR 94): Залили больше 1200 взломанных PDF-файлов, заточенных под ключи по адалту и гемблингу.
— `michigan.gov` (DR 91): Вышел в топ-1 по запросу "ai undresser" — это ключ с частоткой 70к+ в месяц и CPC $2.48.
— `ca.gov`: Проиндексировалось больше 3000 взломанных страниц, которые льют примерно 2.1 миллиона трафика в месяц.
— `wayne.edu`: Тоже взломан, тысячи спамных страниц под чернушные ключи.
Механика и монетизация:
Атакующие юзают уязвимости — от устаревших CMS и плагинов до криво настроенных систем, где можно свободно создавать сабдомены или заливать контент.
Внедряя тысячи спамных страниц (часто PDF) на эти домены с высоким DR, они наследуют авторитет корня, что позволяет им моментально ранжироваться без бэклинков.
Это тактика "churn and burn".
Цель — максимально быстро монетизировать угнанный трафик через партнерку и рекламу на спамных страницах, чтобы срубить серьезный доход до того, как этот контент обнаружат и вычистят из индекса.
Стратегические выводы и защита:
Эта кампания лишний раз доказывает ключевой принцип SEO: авторитет нужно "создавать или заимствовать" (Build or Borrow).
И хотя атакеры использовали черные методы, в белом SEO этот же подход — это заимствование авторитета через публикации на трастовых платформах (типа Reddit, Medium, гестпосты), чтобы получить быстрый буст видимости.
Для менеджеров трастовых сайтов превентивные меры такие:
1 Аудиты безопасности: Регулярно чекать на уязвимости CMS, плагины и особенно фичи, которые позволяют юзерам заливать контент или регать аккаунты.
2 Мониторинг: Постоянно мониторить в GSC и других инструментах резкие всплески по количеству проиндексированных страниц или появление левых URL.
3 Настройка `robots.txt`: Превентивно закрывать от краулинга чувствительные директории (/uploads/, /temp/) или конкретные типы файлов (*.pdf$), чтобы не дать проиндексировать контент, который могут залить.
https://il.ly/blog/parasite-seo-attack-gov-edu
@
Читать полностью…
Mike Blazer
15 September 2025 11:05
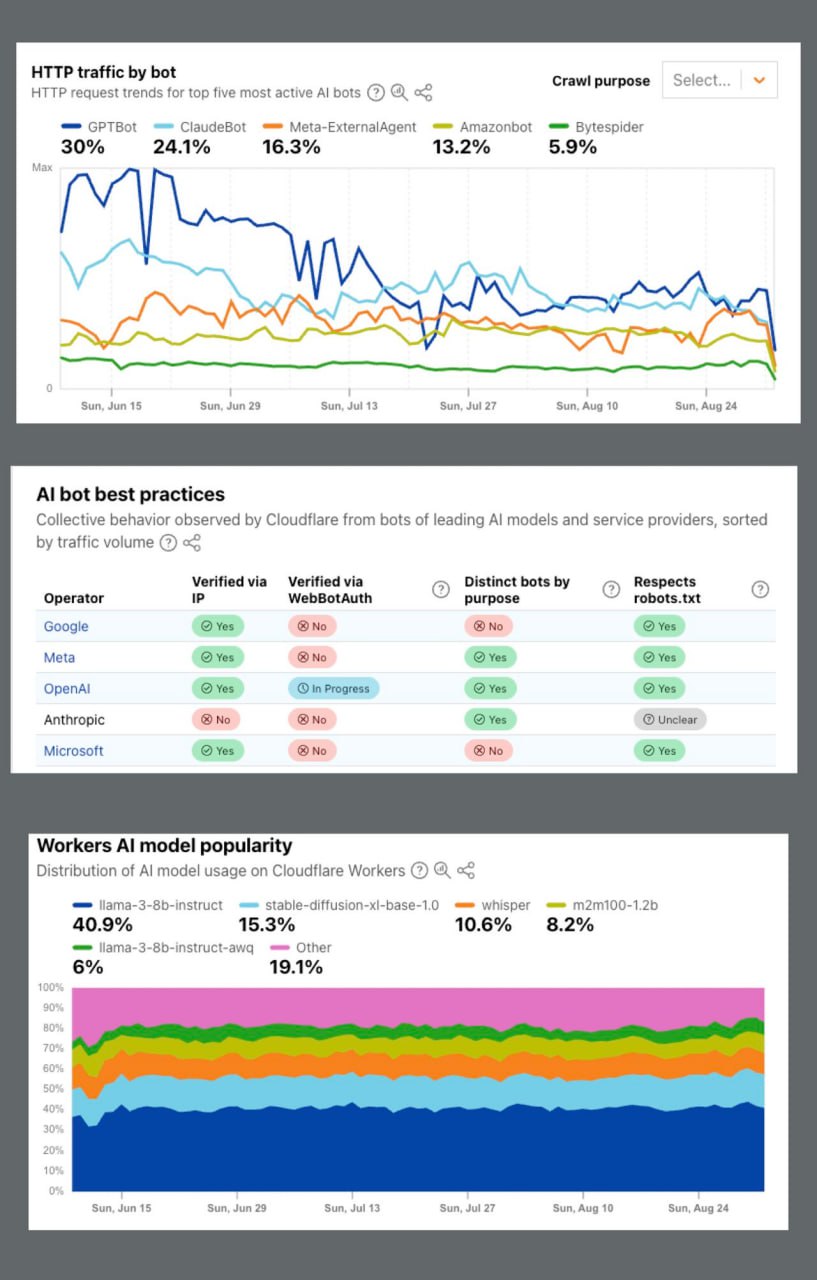
Отчет "AI Insights" от Cloudflare предоставляет данные о том, как ИИ-боты, такие как GPTBot, Claudebot и Amazonbot, краулят веб, с подробным описанием их активности, целей и поведения.
Основные выводы по данным за последние 12 месяцев:
1 Активность и тренды краулеров: GPTBot был самым активным краулером, на его долю пришлось 30% активности, за ним следует Claudebot с 21%.
Однако объем краулинга GPTBot'а за последние три месяца снизился примерно на 50%.
2 Основная цель краулинга: При группировке по интенту, 80% активности ИИ-краулеров приходилось на цели обучения, в то время как 16% — на поиск.
3 Соотношение краулинга к рефералам: Perplexity показал наилучшее соотношение: 185 краулов на каждого отправленного реферала.
В отличие от него, у Claude было одно из самых низких соотношений: 75 000 прокрауленных страниц на одного реферала.
4 Следование лучшим практикам: Claudebot не использует верифицированные IP, и неясно, соблюдает ли он директивы в robots.txt.
Perplexity не был упомянут в списке, но сообщается, что он использует скрытые краулеры.
5 Поведение в конкретных отраслях: Набор данных позволяет фильтровать по отраслям.
В отрасли "News" активность Meta-ExternalAgent возрастает до 16% от всех краулов, а цель "поиск" для всех краулеров увеличивается до 21%.
Хотя отчет дает общие представления, анализ данных ваших собственных лог-файлов необходим для понимания специфики взаимодействия ИИ-краулеров с вашим сайтом.
https://radar.cloudflare.com/ai-insights
---
Иан Каппеллетти навайбкодил расширение для Chrome для экспорта данных из отчета по метрикам ИИ в Cloudflare.
Короче, загружаете страницу с метриками ИИ в CF, кликаете на иконку расширения, а затем выбираете нужный временной диапазон в выпадающем меню отчета.
CSV-файлы скачиваются автоматически.
Известные баги: вверху появляется "страшный", но безобидный баннер отладки; скачивание данных за диапазон по умолчанию (последние 7 дней) немного муторное, так как нужно сначала выбрать другой диапазон, нажать на кнопку расширения, а затем снова выбрать диапазон по умолчанию.
Скачайте расширение в следующем посте.
https://developers.cloudflare.com/ai-crawl-control/features/analyze-ai-traffic/
@
Читать полностью…
Mike Blazer
15 September 2025 08:15
Мы заставили ChatGPT слить ваши приватные данные из почты, пишет Эйто Миямура 💀💀
И что для этого надо?
Всего лишь имейл жертвы. ⛓️💥🚩📧
OpenAI выкатили полную поддержку инструментов MCP (Model Context Protocol) в ChatGPT.
Это позволяет ChatGPT коннектиться и читать ваш Gmail, Календарь, Sharepoint, Notion и так далее.
Штуку, кстати, придумали в Anthropic AI.
Но вот в чем фундаментальная проблема: ИИ-агенты типа ChatGPT следуют вашим командам, а не здравому смыслу.
И, имея на руках только имейл, мы смогли вытащить всю вашу приватную инфу.
Схема такая:
1 Атакующий шлет жертве инвайт в календарь с джейлбрейк-промптом. Нужен только имейл. Жертве даже не нужно принимать этот инвайт.
2 Ждем, пока юзер попросит ChatGPT помочь подготовиться к новому дню, заглянув в его календарь.
3 ChatGPT читает этот джейлбрейкнутый инвайт. Все, теперь он захвачен атакующим и будет выполнять его команды. Он шерстит ваши приватные имейлы и сливает данные на почту атакующего.
Пока что OpenAI открыла MCP только в "режиме разработчика" и требует ручного апрува от человека для каждой сессии.
Но есть такая штука, как усталость от принятия решений.
Обычные юзеры просто доверятся ИИ, не понимая, что к чему, и будут кликать "подтвердить, подтвердить, подтвердить".
Помните: ИИ может быть суперумным, но его можно обмануть и зафишить до смешного тупыми способами, чтобы он слил ваши данные.
Связка ChatGPT + Tools — это серьезная дыра в безопасности.
Видос смотрите тут.
@
Читать полностью…
Mike Blazer
14 September 2025 15:05
AInvest.com все?
Все бурно обсуждали, как им это удается, но результат всегда один - в топку.
@
Читать полностью…
Mike Blazer
14 September 2025 11:05
🚀 Переписывание запросов и AI-поиск Google
Три разных патента от трех разных команд инженеров Google —
1 Переписывание запросов с распознаванием сущностей (Query Rewriting with Entity Detections)
2 Коррекция переписанных запросов (Query Rewrite Corrections)
3 Эффективное переписывание запросов (Efficient Query Rewriting)
…все они сходятся в одной и той же концепции, которая позже появляется в патенте Google "Search with Stateful Chat".
Этот патент является основой для режима AI-поиска Google.
🔎 Как всегда, процесс начинается с ранжирования документов.
Если документ не считается релевантным запросу, его пассажи даже не рассматриваются в качестве кандидатов.
Это и есть триада SERP:
1️⃣ Ранжирование документов лежит в основе ранжирования пассажей.
2️⃣ Ранжирование пассажей лежит в основе генерации пассажей.
3️⃣ Но все начинается с запроса.
Именно поэтому семантика запроса ≠ лексическая семантика.
Запрос, под который вы проводите оптимизацию, может не совпадать с запросом, который Google использует для генерации ответов с помощью ИИ.
Патенты по переписыванию и обработке запросов это наглядно демонстрируют.
Например:
Запрос вроде "anaphylaxis triggers" может быть внутренне переписан как "main anaphylaxis triggers" или "list of anaphylaxis triggers".
В зависимости от того, как переписан запрос, релевантность лексики и семантика на уровне предложений полностью меняются.
💡 Многие в мире SEO гонятся за хайпом, чтобы продать больше услуг.
Но если вы почитаете патенты, то заметите, что зачастую это одни и те же системы и терминология — просто с добавлением уточнений.
👉 D > Q так же старо, как и Q > D.
D = Документ
Q = Запрос
И эта фундаментальная основа никогда не меняется.
@
Читать полностью…
Mike Blazer
13 September 2025 17:05
Как в твою GSC приземлился августовский спам-апдейт 2025: 🙂
@
Читать полностью…
Mike Blazer
13 September 2025 13:10
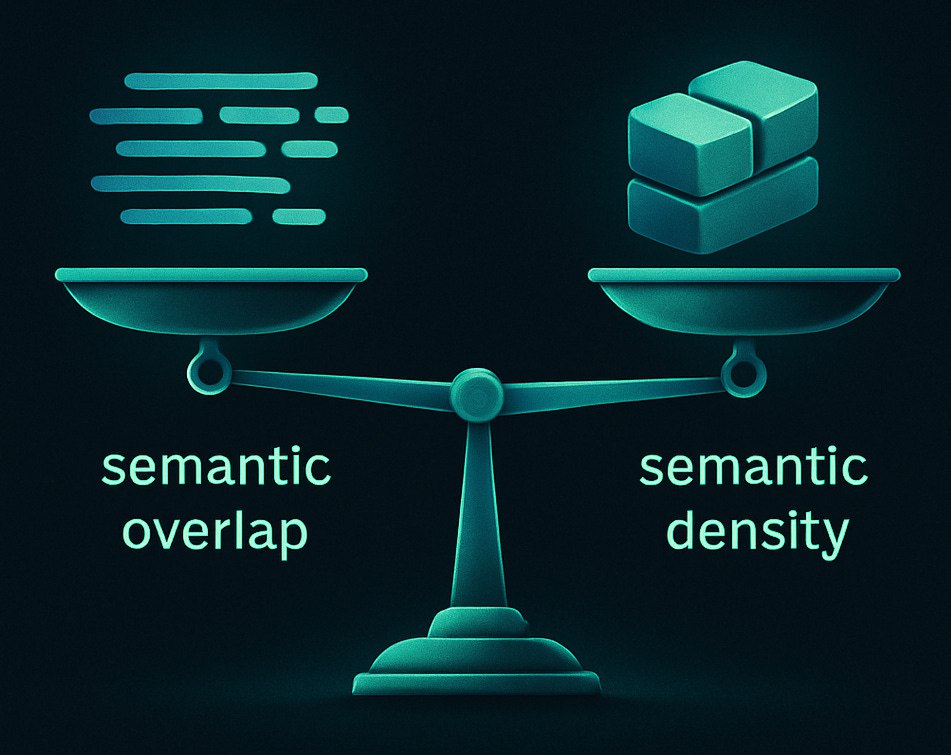
Семантическая плотность vs. семантическое совпадение в AI-поиске
Два критически важных фактора теперь определяют видимость контента в системах генерации, дополненной поиском (RAG):
— Семантическая плотность: Количество смысла на токен. Высокая плотность сигнализирует авторитетность и экспертность для читателей.
— Семантическое совпадение: Векторное сходство между фрагментом контента и эмбеддингом запроса. Это основной сигнал для машинного поиска.
Основной конфликт
Люди ценят плотность, машины — совпадение.
RAG-системы извлекают не страницы, а фрагменты (чанки) контента на основе векторного сходства (которое оценивается такими метриками, как BERTScore).
Практический пример: низкое vs. высокое совпадение
— Плотно (низкое совпадение): "Витамин D регулирует здоровье костей и уровень кальция."
— Насыщенно для совпадения: "Витамин D, также известный как кальциферол, способствует усвоению кальция, росту и плотности костей, помогая предотвращать такие состояния, как остеопороз."
Вторая версия, с большим количеством синонимов и связанных сущностей, имеет более высокую вероятность быть найденной поиском.
Стратегия
Совпадение обеспечивает нахождение контента.
Плотность обеспечивает доверие.
Новая тактика оптимизации заключается в балансировании обоих факторов: структурируйте контент в виде фрагментов (чанков) с достаточным семантическим совпадением, чтобы быть замеченным машинами, и одновременно поддерживайте достаточную семантическую плотность, чтобы вызывать доверие у пользователей.
https://duaneforresterdecodes.substack.com/p/semantic-overlap-vs-density-finding
@
Читать полностью…
Mike Blazer
13 September 2025 09:15
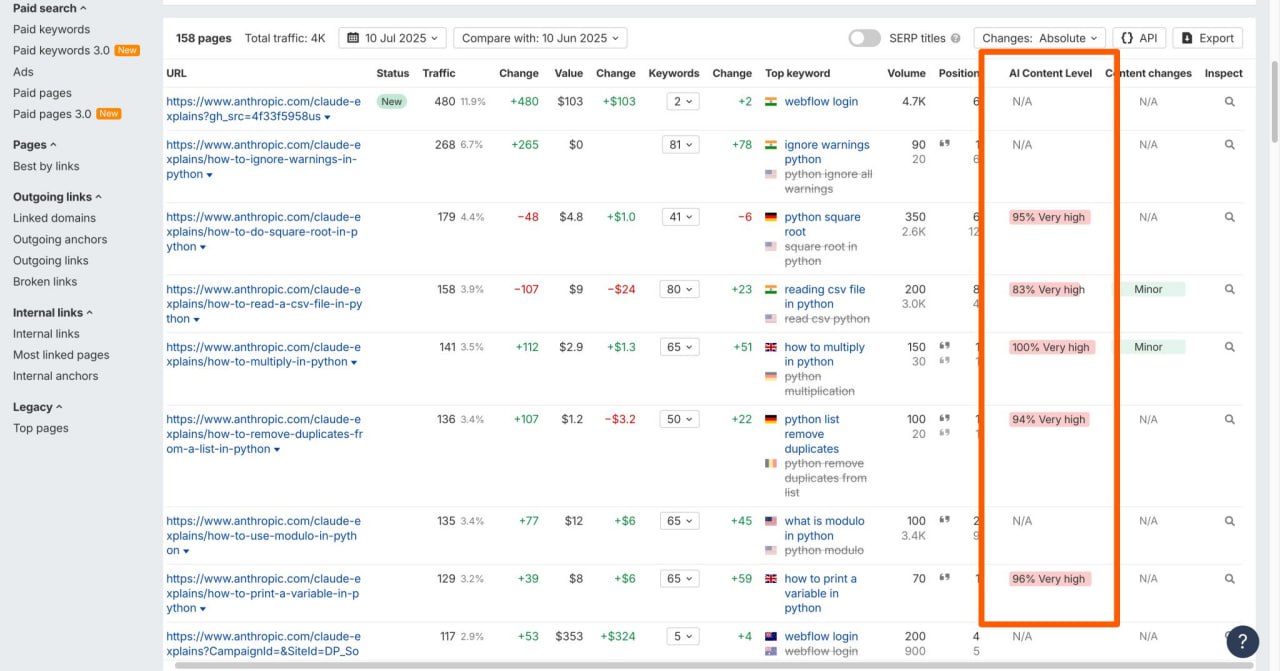
Хотите узнать, использует ли компания ИИ-контент в каком-либо разделе своего сайта?
Ahrefs AI Content detector теперь работает в отчете по топ-страницам.
Например, вот блог Anthropic, где Клод генерировал контент.
@
Читать полностью…
Mike Blazer
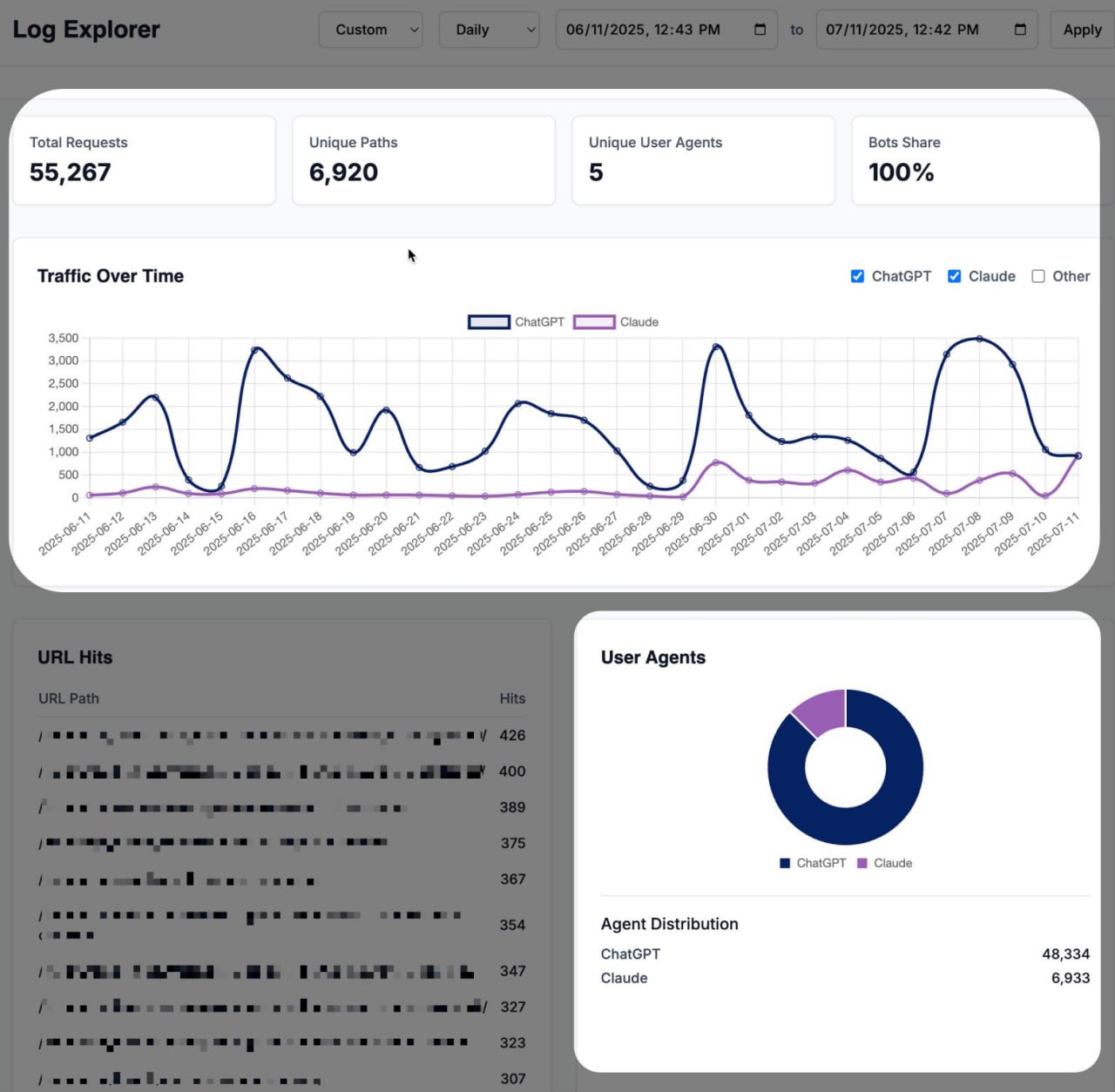
12 September 2025 11:06
Ваши лог-файлы могут рассказать, как ChatGPT и Claude от имени пользователей взаимодействуют с вашим сайтом.
На скриншоте ниже видно, как за 30-дневный период юзер-агент ChatGPT-User обращался к этому сайту более 48 000 раз по почти 7 000 уникальным URL.
Claude тоже появлялся, но в меньших масштабах.
Почему это важно?
Потому что это не традиционные клики из поиска, которые отображаются в Google Analytics.
Это агенты ИИ, которые активно извлекают ваш контент, чтобы ответить на чей-то вопрос в рамках диалога с LLM.
Пользователь в ходе разговора с ChatGPT задавал вопросы, которые заставили ChatGPT искать информацию на нашем сайте и давать ответы на основе нашего контента и сообщений.
Когда вы углубляетесь в анализ лог-файлов, вы начинаете видеть:
1 Какие страницы ChatGPT использует в диалогах (страницы о стоимости страхования, контент о здоровье, разбивки по штатам и т.д.).
2 Использует ли ИИ образовательный контент с вершины воронки или страницы услуг/продуктов из середины и низа воронки, которые действительно приносят конверсии.
3 Как выглядит путь вашего покупателя через призму извлечения данных ИИ, а не только органического поиска.
Аналитика часто не показывает этот трафик, так как это обращения без JavaScript.
А лог-файлы покажут.
Это означает, что вы можете начать связывать метрики от диалога до конверсии и измерять, влияют ли ваши маркетинговые усилия на реальный доход в этой среде, где правит ИИ.
Где взять лог-файлы:
— У вашего хостинг-провайдера (например, WP Engine предоставляет их в вашей панели управления WordPress, и вы можете отправлять их в LargeFS для долгосрочного анализа).
— В сервисах вроде Cloudflare.
— Непосредственно из конфигурации вашего собственного сервера.
С чего начать уже сегодня:
1 Выгрузите логи вашего сервера за последние 30–60 дней.
2 Отфильтруйте по юзер-агенту ChatGPT-User (идентификатор OpenAI) или другим юзер-агентам, которые вы хотите проанализировать.
3 Посмотрите, к каким URL обращаются чаще всего.
4 Соотнесите эти URL с этапами пути покупателя.
5 Приоритизируйте оптимизацию страниц середины и низа воронки, чтобы превратить видимость в ИИ в доход.
ИИ уже является частью вашего трафика.
Вопрос в том, правильные ли страницы попадают в эти диалоги?
@
Читать полностью…
Mike Blazer
11 September 2025 17:05
Название бренда dkG в сфере элитного гостеприимства непреднамеренно совпадает с именем известной порно-звезды , которая имеет значительное присутствие в интернете (4+ млн подписчиков в Instagram, активность в соцсетях/YouTube).
Основная проблема — это потенциальная неоднозначность в поисковой выдаче (SERP), наносящая ущерб бренду, и долгосрочные инвестиции в SEO, необходимые для создания отдельной, семейно-ориентированной сущности бренда.
Рассмотрев отзывы, dkG решил провести ребрендинг.
Мнения сеошников
— Когда название бренда имеет сильную, уже существующую ассоциацию с контентом для взрослых, основной вызов для SEO — это управление загрязнением SERP.
Даже если бренд займет первое место по своему названию, в выдаче все равно могут появляться откровенные результаты по конкурирующей сущности, подрывая безопасность бренда.
— Преодоление этого конфликта сущностей бренда требует значительных и постоянных инвестиций в наращивание авторитета и последовательных брендовых сигналов, чтобы в конечном итоге доминировать в пространстве брендированного поиска; это изначально проигрышная битва.
— Основные системы ранжирования могут не учитывать тип контента при оценке конкурирующих сущностей бренда; потенциал ранжирования в первую очередь определяется силой сигналов (например, бэклинки, вовлеченность пользователей), а не присущей "надежностью" или социальной приемлемостью бизнес-модели.
— Негативное влияние на бренд может быть частично смягчено настройками пользователя Google по умолчанию.
SafeSearch часто включен по умолчанию, и у залогиненных пользователей обычно установлены умеренные настройки цензуры, которые могут размывать или скрывать откровенно непристойные результаты из SERP.
@
Читать полностью…
Mike Blazer
11 September 2025 13:10
Эксперимент boatbuilder показал, что LLM, такие как ChatGPT и Perplexity, используют глобальный кэш, а это означает, что цитирование в ответе ИИ не гарантирует обращения к вашему серверу.
Это делает невозможным использование логов сервера как надежного способа измерения видимости в LLM.
Эксперимент, проведенный с использованием мидлвэра Next.js на Vercel для обхода пограничного кэширования (edge caching), показал, что LLM не всегда используют свой брендированный юзер-агент и иногда маскируются под обычные браузеры.
Глобальный кэш обновляется часто — в тесте наблюдался интервал около 20 минут — но не по фиксированному графику.
Наблюдаемая схема получения информации такова: Индекс → Проверка кэша → Если отсутствует, загрузить один раз → Отдавать из кэша до истечения срока его действия.
Мнения сеошников
— Несколько пользователей подтверждают, что LLM, такие как ChatGPT, Perplexity и Claude, будут отдавать устаревший контент страницы в течение нескольких часов или даже целого дня после обновления, что подтверждает гипотезу о кэшировании.
Один пользователь не смог принудительно обновить информацию, даже прямо указав модели, что ее данные устарели.
— Видимость структурированных данных зависит от метода доступа LLM.
Когда агент использует поисковый инструмент (например, web.search), он получает от поисковой системы предварительно проиндексированные JSON-LD, микроданные и RDFa.
Однако при использовании инструментов прямого доступа к странице (например, open_page, browse) JSON-LD в основном невидим, и доступными остаются только встроенные микроданные.
— Критическая ошибка реализации — это ссылка на внешние файлы JSON-LD через <link rel="alternate" ...>.
Это делает структурированные данные невидимыми для LLM, выполняющих прямые краулинговые обходы страницы в реальном времени, так как агент не перейдет по ссылке.
— Разные модели Gemini демонстрируют различное поведение при извлечении данных.
Приложение Gemini запрашивает контент страницы в реальном времени и появляется в логах.
Gemini через API заявляет, что не может получить доступ к страницам.
AI Mode (в поиске) может галлюцинировать доступ к странице, фактически не обходя ее.
— Для сайтов, использующих Cloudflare, один пользователь реализовал Cloudflare Worker, который добавляет заголовок Vary по юзер-агенту, чтобы успешно сбрасывать кэш специально для трафика от ИИ.
Отмечается, что даже при промахе кэша CDN, собственный кэширующий слой веб-сервера (например, от плагинов WordPress или платформ вроде Webflow) все еще может отдавать устаревший контент ботам ИИ.
— Стратегический фреймворк для понимания краулеров ИИ делит их на три типа по намерению:
1 Краулеры для обучающих датасетов: Контент используется для будущих релизов моделей.
Оптимизация под Schema/JSON-LD в основном влияет на этот тип, а выгоды реализуются только после обновления модели.
2 Краулеры для RAG / обоснования поиска: Контент извлекается из проиндексированной базы данных (часто это традиционная поисковая система, как Bing для ChatGPT) для мгновенных ответов.
Эффективность можно предсказать, анализируя ранжирование по подзапросам в базовой поисковой системе.
3 Агентные краулеры по запросу пользователя: Контент обходится в реальном времени для конкретного запроса пользователя.
— Стратегический ответ на повсеместное кэширование LLM — это смещение фокуса с отслеживания паттернов обхода на создание контента, который является единственным, исчерпывающим источником, наиболее вероятно кэшируемым и отдаваемым по релевантным запросам.
@
Читать полностью…
Mike Blazer
11 September 2025 08:15
После слияния клиента с другой компанией jacquesob_com посоветовал им позволить старому домену истечь после успешного 301-го редиректа на новый домен.
Решение было основано на плохом ссылочном профиле старого домена, который состоял в основном из nofollow-спама и нескольких сомнительных dofollow-ссылок.
Примерно через неделю после истечения срока действия домена позиции по небрендовым ключевым словам упали примерно на 50%, при этом страницы опустились с позиций 1–2 на 3–4. Последующие кампании по линкбилдингу не помогли восстановить показатели.
Старый домен с тех пор был куплен третьим лицом и выставлен на продажу за $350. jacquesob_com задается вопросом, может ли повторный выкуп домена и восстановление 301-х редиректов вернуть былую эффективность или это рискует вернуть негативный след.
Мнения сеошников
— Истечение срока действия домена сигнализирует о большем, чем просто потеря ссылочного веса; это нарушает "непрерывность сущности" (entity continuity).
Google может интерпретировать истечение срока как прекращение существования сущности бренда, тем самым разрывая ключевые сигналы доверия и идентичности.
— Качество первоначальной реализации редиректов является критически важной переменной; падение показателей могло усугубиться, если вместо детального, постраничного сопоставления на основе тематической релевантности использовался общий вайлдкард-редирект на главную.
— Даже ссылочный профиль, воспринимаемый как некачественный или "дерьмовый", может нести значительный авторитет.
Было замечено, что конкуренты высоко ранжируются со спамными, дублированными ссылками из каталогов, что говорит о том, что оценка качества Google отличается от человеческого анализа.
Даже в плохом профиле может быть несколько "жирных ссылок".
— Разрыв цепочки редиректов с устоявшегося домена фактически вызывает у Google "амнезию" относительно истории и авторитета сайта.
— Более грамотная методология тестирования для оценки влияния плохого ссылочного профиля заключалась бы в том, чтобы убрать 301-е редиректы, все еще владея доменом, понаблюдать за эффектом, а затем, при необходимости, восстановить их.
Истечение срока действия домена лишает такого контроля.
— В качестве лучшей практики, редиректы с переехавшего домена следует поддерживать до тех пор, пока все старые проиндексированные страницы не будут полностью заменены в SERP страницами нового домена.
В идеале, старый домен следует держать неограниченно долго, чтобы сохранить его историю и сигналы идентичности.
@
Читать полностью…
Mike Blazer
10 September 2025 15:05
BaysQuorv, представляющий 6-месячный стартап в нише конструкторов мобильных приложений на базе ИИ, поинтересовался, какова максимально безопасная скорость наращивания ссылок, чтобы избежать санкций Google.
Имея низкие показатели авторитета (Moz DA 5, Semrush AS 9, всего 31 бэклинк), они рассматривают гиги на Fiverr, предлагающие 100–400 ссылок, и гостевые посты для ускорения роста.
Они конкретно спросили, что такое "слишком большой" объем работы по бэклинкам, какова стоимость качественных ссылок и какие стратегии наиболее эффективны.
Мнения сеошников
— Концепция штрафа за скорость наращивания ссылок — это миф; алгоритм Google в первую очередь оценивает *источник* ссылки, а не частоту их получения.
Google ожидает, что линкбилдинг находится вне прямого контроля владельца сайта, и не наказывает за саму скорость.
— Модератор заявляет, что понятия "естественный ссылочный профиль" не существует, и оно не дает никакой защиты от алгоритмов Google по обнаружению спама.
— Жизнеспособная стратегия получения высококлассных ссылок включает оплату услуг специалистов за размещения, с ориентиром примерно в $5,000 за 8–10 ссылок.
Обычно это не гостевые посты, а контекстные упоминания в новом или обновленном контенте — метод, который подтвержденно повышает позиции и трафик.
Одна качественная ссылка через маркетплейсы может стоить $500–$700.
— Рекомендуемый метод для постановки целей — это "анализ скорости прироста ссылок": сравните ваше ежемесячное количество качественных ссылок с ключевыми конкурентами за 12-месячный период, чтобы учесть сезонность в отрасли.
Цель — соответствовать их скорости, чтобы удержать позиции, и превосходить ее, чтобы расти.
— Трехфакторный процесс ручной проверки доноров ссылок имеет решающее значение и превосходит метрики вроде DR:
1) Убедитесь, что у сайта есть значительный, неволатильный органический трафик;
2) Проверьте его профиль исходящих ссылок (OBL) на наличие следов чрезмерной продажи ссылок;
3) Проанализируйте его собственный ссылочный профиль, чтобы убедиться, что он не раздут искусственно с помощью PBN или Web 2.0.
— Основной риск от массовых продавцов ссылок — это не только низкокачественные ссылки, но и возможность того, что вся сеть продавца попадет под санкции, что нанесет косвенный ущерб всем клиентам.
— Для ранжирования по конкурентным ключевым словам предлагается модель распределения ресурсов: 10% на создание контента и 90% на линкбилдинг для этого контента.
Обоснование в том, что контент генерирует показы, но для топовых позиций требуются целевые бэклинки с релевантным анкорным текстом.
— Одна из эффективных тактик аутрича — обращаться к целевым сайтам под видом фрилансера, который собирает портфолио.
Крайне важно избегать любых упоминаний "SEO", "dofollow-ссылок" или "повышения авторитета", так как это мгновенные красные флаги для качественных издателей, которые ведут к отказу или завышенным ценам.
— Структурный подход к получению ссылок включает в себя проектирование вашего сайта таким образом, чтобы он способствовал размещению исходящих ссылок на качественные ресурсы.
Это создает основу для построения отношений и получения "сетевых, естественных и заслуженных" взаимных ссылок.
— Сфера линкбилдинга эволюционирует в сторону digital PR, где некликабельные упоминания бренда приобретают все большее значение и должны быть приоритетом наряду с традиционным получением ссылок.
— Анализ ручных аудитов сотен профилей конкурентов показывает, что лишь малая часть от общего числа доменов-доноров сайта является качественной (например, 50 хороших доменов из 300).
— Данные из этих аудитов показывают, что типичный малый и средний бизнес получает 2–10 качественных ссылок в месяц, в то время как сайты с трафиком более 50 тыс./месяц могут получать более 20.
@
Читать полностью…
Mike Blazer
10 September 2025 11:05
Кейс: как простой калькулятор вышел на 1000 кликов/день с EMD доменом от Алексея Матузного
Многие думают, что для трафика нужны годы работы, постоянные обновления и сложные контент-стратегии.
Но есть другой путь – точечные инструменты под ВЧ-запросы, которые реально "выстреливают".
Что было сделано:
— С помощью ChatGPT был создан простой калькулятор под высокочастотный запрос в своей нише.
— Оптимизировал страницу под ключ, прописал базовые title и description и сгенерировал текст.
— Закупил ссылок на ~$400.
— Далее страницу не менял и не обновлял в течение года.
Результат
— Через 12 месяцев страница стабильно приносит ~1000 кликов в день из Google, не считая AI блока и других поисковых сетей.
— Трафик идет именно с ВЧ-ключа, под который был сделан калькулятор.
— Всё это с минимальными вложениями и без дополнительного SEO-сопровождения.
Выводы для SEO-специалиста
— Инструментальные страницы (калькуляторы, генераторы, чекеры) имеют высокий шанс занимать топовые позиции, если они сделаны под четкий интент пользователя.
— ChatGPT может значительно сократить время разработки: от идеи до MVP можно дойти за несколько дней.
— Даже небольшой бюджет на линки (в данном случае $400) может стать достаточным толчком для ВЧ-трафика.
— Ключевое – найти "правильный запрос" и формат контента, который максимально соответствует поисковому интенту.
Этот кейс показывает, что SEO-автоматизация + искусственный интеллект + точечные инструменты = стабильный и масштабируемый результат.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}