Анализ данных (Data analysis)
14 Jul 2023 16:08
Модель нейросети Kandinsky 2.2 стала частью самого крупного и авторитетного в сфере ИИ фреймворка Diffusers на ресурсе Huggingface.
Diffusers - это агрегатор открытых генеративных моделей, работающих на принципе диффузии. Сегодня этот фреймворк используют многие популярные ИИ-сервисы, инструменты и библиотеки: DreamFusion, Segment Anything, ML Stable Diffusion (by Apple), Invoke AI ( всего более 3000 решений).
Также Kandinsky 2.2 вошел в список популярных моделей в основном репозитории Diffusers на GitHub.
@
Читать полностью…
Анализ данных (Data analysis)
04 Jul 2023 12:37
12 июля в 11:00 мск Visiology првоводит вебинар на тему "BI + AI = ? Супер-оружие аналитиков или угроза профессии?".
Записаться на вебинар
Что будет на вебинаре
1. Начнем с обзора новых возможностей на основе ИИ в BI платформах лидерах мирового рынка - Power BI, Qlik, Tableau. Почему про ИИ в BI говорили и раньше, но только сейчас это перестало быть маркетинговой фишкой и стало реально помогать в ежедневной работе аналитика?
2. Продемонстрируем на реальных кейсах, как аналитику может помочь новый виртуальный помощник Visiology ViTalk GPT. Посмотрим, как он пишет DAX запросы и интеграции с источниками данных на Python. Обсудим ограничения технологии и разберемся, как эту технологию использовать эффективно.
Зарегистрироваться
Читать полностью…
Анализ данных (Data analysis)
30 Jun 2023 16:01
Аналитик рисков в Финтех Яндекса
Если вы ищите риски, вас тут тоже кое-кто ищет — Финтех Яндекса. Это молодой сервис Яндекса, где соединились корпоративные блага и свобода стартапа, бесплатные сырки и возможность влиять на продукт, ДМС и бар в офисе. А главное — тут можно расти, как бамбук 🎋
Что нужно делать
Заниматься аналитикой целого направления. Понимать, кому можно выдавать кредит, а кому не стоит. Создать правила для оценки пользователей и много-много тестировать. А ещё быть хорошим руководителем: помогать расти специалистам и выстраивать рабочие процессы.
Что надо уметь
Оптимизировать кредитный бизнес, знать принципы работы ML и если что — писать модели. А ещё думать не о мелких задачах, а о пользе для бизнеса. И если всё получиться — расти вместе со своим продуктом. Тут есть куда!
Откликайтесь, если узнали себя
Читать полностью…
Анализ данных (Data analysis)
29 Jun 2023 13:16
🔥 Kubernetes и Docker для дата-сайентистов
Изучение и применение новейших инструментов и технологий в области науки о данных является неотъемлемым условием для развития специалистов. Появление Docker и Kubernetes привело к существенным изменениям в процессе разработки и развертывания программных продуктов. Однако, какова роль этих инструментов и почему они важны для дата-сайентистов?
Мы представляем полный обзор Docker и Kubernetes, включая их преимущества и функционал. Как отличаются эти две технологии и какова их польза для дата-сайентистов? В конце статьи вы получите ясное понимание роли контейнеризации и оркестрации в более эффективной работе дата-сайентиста.
📌 Читать
@
Читать полностью…
Анализ данных (Data analysis)
28 Jun 2023 19:02
🖥 PyGWalker: A Python Library for Exploratory Data Analysis with Visualization
PyGWalker: преобразуем датафрейм pandas в пользовательский интерфейс в стиле таблицы для визуального анализа.
pip install pygwalker
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)
🖥 Github
📌 Colab
@
Читать полностью…
Анализ данных (Data analysis)
28 Jun 2023 13:14
🔝Топ-10 инструментов для обнаружения ChatGPT, GPT-4, Bard и Claude
1. GPTZero
GPTZero обладает высокой точностью, прост в использовании и имеет удобное расширени для Chrome.
2. OpenAI AI Text Classifier
ИИ-классификатор текста OpenAI обладает высокой точностью, но не предоставляет дополнительной информации о содержимом контента.
3. CopyLeaks
Это быстрая и точная проверка на плагиат, в виде расширения для Chrome.
4. SciSpace
SciSpace Academic AI Detector немного отличается от других упомянутых инструментов. Он обладает высокой точностью, но был специально разработан для обнаружения научного контента в PDF-файлах.
5. Hive Moderation
Функция обнаружения ИИ-генеративного контента Hive Moderation.
6. Content at Scale
ИИ-детектор контента Content at Scale прост в использовании и дает достаточно точные отчеты о конетнте.
7. Hello Simple AI
ChatGPT Detector by Hello Simple AI – это бесплатный инструмент с открытым исходным кодом, который можно использовать для обнаружения текста, создаваемого ChatGPT.
8. OpenAI HF Detector
OpenAI Detector – это бесплатный инструмент с открытым исходным кодом, который можно использовать для обнаружения текста, сгенерированного языковой моделью GPT от OpenAI.
9. Corrector.app
AI Detector от Corrector.app – это довольно точный инструмент, который можно использовать для обнаружения текста, сгенерированного ChatGPT, Bard и другими больми языковыми моделями (LLM).
10. Writer.com
Детектор контента AI от Writer.com завершает наш список, представляя собой наименее точный вариант с ограничением в 1500 символов.
@
Читать полностью…
Анализ данных (Data analysis)
27 Jun 2023 12:40
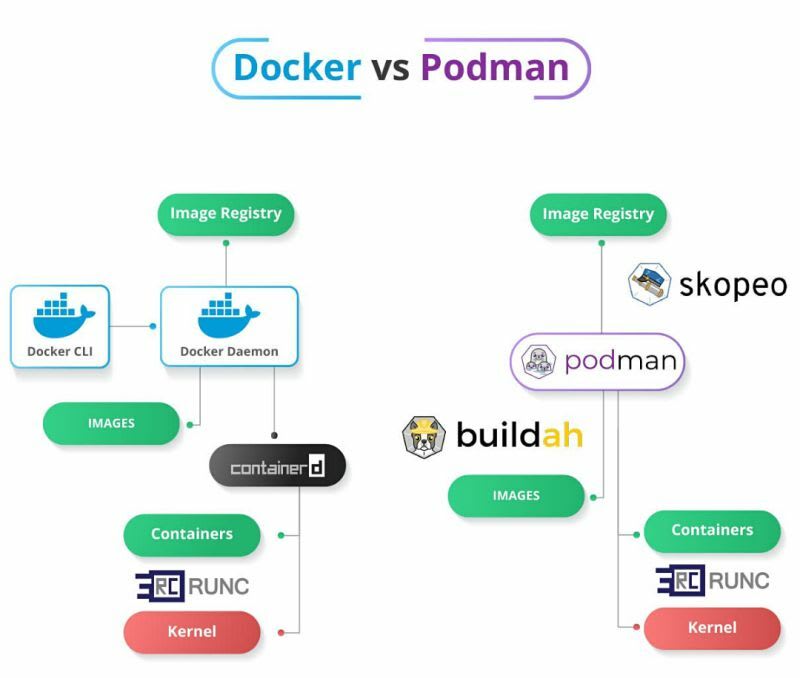
🔍 Podman: Альтернатива Docker без deamon
Хотя Docker, безусловно, перевернул наше представление о разработке, развертывании и запуске приложений, стоит изучить, чем отличается Podman (Pod Manager) и почему вам может быть интересно начать использовать его вместо Docker.
Podman — это менеджер контейнеров и падов с открытым исходным кодом.
Аналогично Docker, он позволяет создавать, запускать, останавливать и удалять контейнеры OCI, а также управлять образами контейнеров.
Он также поддерживает пады в рамках своего функционала, а значит, вы можете создавать и управлять падами так же, как с Kubernetes.
Что такое OCI-контейнеры
OCI (Open Container Initiative) — это организация отраслевого стандарта, которая стремится создать набор правил (спецификаций и стандартов), обеспечивающих согласованную работу контейнеров на разных платформах.
Это означает, что образы/контейнеры Podman полностью совместимы с Docker или любой другой технологией контейнеризации, которая использует совместимый с OCI исполнитель контейнеров.
Большинство пользователей Docker могут просто сделать псевдоним Docker для Podman (alias docker=podman) без каких-либо проблем.
Это означает, что все команды Docker остаются такими же, за исключением команды docker swarm.
Архитектура Podman
Архитектура Podman не подразумевает использование демонов (deamons).
Демоны — это процессы, которые выполняются в фоновом режиме системы, они обычно работают непрерывно на заднем плане, ожидая определенных событий или запросов.
Возвращаясь к контейнерам, представьте себе демона Docker в качестве посредника, общающегося между пользователем и самим контейнером.
Использование демона для управления контейнерами приводит к нескольким проблемам:
Одна точка отказа.
Когда демон падает, падают все контейнеры.
Требуются привилегии root
Поэтому демоны в Docker — это идеальная цель для хакеров, которые хотят получить контроль над вашими контейнерами и проникнуть в хост-систему.
Podman решает упомянутые проблемы, напрямую взаимодействуя с реестрами контейнеров, контейнерами и хранилищем образов без необходимости в демоне.
Переходя в режим без прав root, пользователи могут создавать, запускать и управлять контейнерами, что снижает риски безопасности.
Утилита buildah заменяет команду docker build как инструмент для создания контейнерного образа.
Аналогично, skopeo заменяет команду docker push и позволяет перемещать контейнерные образы между реестрами.
Эти инструменты обеспечивают эффективное и прямое взаимодействие с необходимыми компонентами, исключая необходимость в отдельном демоне в процессе.
Нужно ли переписывать каждый Dockerfile и docker-compose файл, чтобы использовать Podman с существующими проектами
Абсолютно нет. Podman предлагает совместимость с синтаксисом Docker для файлов контейнеров (containerfile).
Также Podman предлагает инструмент под названием pod compose в качестве альтернативы docker compose.
Pod compose использует тот же синтаксис, позволяя вам определять и управлять многоконтейнерными приложениями с использованием того же подхода или даже с использованием существующих файлов "docker-compose.yml".
Podman также поставляется с Podman Desktop, предлагая расширенные функции, которые делают его мощнее и проще. Он совместим с Docker и Kubernetes, расширяя их возможности и обеспечивая простую работу.
Руководство по установке и документацию по Podman можно найти на их официальном веб-сайте podman.io.
@
Читать полностью…
Анализ данных (Data analysis)
26 Jun 2023 19:37
🖥 Docker Шпаргалка для Датасаентиста с основными командами.
▪ Шпаргалка
@
Читать полностью…
Анализ данных (Data analysis)
26 Jun 2023 14:44
🤖 Заставляем трансформеров отвечать на вопросы
Интеллектуальные системы призваны облегчать жизнь человека, выполняя за него рутинные задачи. Одной из таких задач является поиск информации в большом количестве текста. Возможно ли и эту задачу перенести на плечи интеллектуальных систем? Этим вопросом я решил задаться.
▪ Читать
@
Читать полностью…
Анализ данных (Data analysis)
24 Jun 2023 11:52
⏩ Повысьте уровень своих навыков в области ИИ: Список бесплатных курсов Google Top 8.
1. Introduction to Generative AI - введение в генеративный ИИ Этот курс погрузит вас в основаы генеративного ИИ,
2. Introduction to Large Language Models - в курсе вы узнаете о больших языковых моделях (LLM), которые представляют собой разновидность искусственного интеллекта, способного генерировать текст, переводить языки, писать различные виды креативного контента и информативно отвечать на ваши вопросы.
3. Introduction to Responsible AI - этот курс расскажет вам об этичном и ответственном использовании искусственного интеллекта. Вы узнаете о различных этических проблемах ИИ, таких как предвзятость, конфиденциальность и безопасность. Вы также узнаете о некоторых лучших практиках разработки ИИ.
4. Introduction to Image Generation - этот курс расскажет вам о генерации изображений, разновидности искусственного интеллекта, способного создавать изображения на основе текстовых описаний. Вы узнаете о различных типах алгоритмов генерации изображений, о том, как они работают, и о некоторых из их наиболее распространенных применений.
5. Encoder-Decoder Architecture -
этот курс расскажет вам об архитектуре модели кодера-декодера, которые представляют собой тип архитектуры нейронной сети, широко используемой для задач обработки естественного языка, таких как машинный перевод и резюмирование текста. Вы узнаете о различных компонентах архитектур энкодер-декодер, о том, как они работают, и о некоторых наиболее распространенных областях их применения.
6. Attention Mechanism - В этом курсе вы узнаете о механизме attention - технике, которая используется для повышения производительности нейронных сетей в задачах обработки естественного языка.
7. Transformer Models and BERT Model - В этом курсе вы изучите архитектуру трансформеров, которые представляют собой тип архитектуры нейронной сети, показавшей свою эффективность при решении задач обработки естественного языка.
8. Create Image Captioning Models - Этот курс научит вас создавать модели автоматического описания изображений, которые представляют собой разновидность искусственного интеллекта, способного генерировать подписи к изображениям.
@
Читать полностью…
Анализ данных (Data analysis)
23 Jun 2023 19:02
27 июня X5 Tech проведёт Customer Analytics Meetup
Спикеры компании поделятся, как удалось найти замену Vendor-Lock и оперативно внедрить альтернативное решение для предоставления клиентской аналитики в режиме реального времени на базе open-source технологий Clickhouse и Redis.
В спикерах - менеджер направления клиентской аналитики в цифровых каналах, архитектор данных и старший разработчик.
Регистрация обязательна.
Больше информации здесь
Читать полностью…
Анализ данных (Data analysis)
23 Jun 2023 10:01
⚠️ Как разработчику повысить свою зарплату?
Один из вариантов — освоить MS SQL.
🦾 Знание этой СУБД может стать вашим конкурентным преимуществом и аргументом для повышения заработной платы.
Пройди хардкорный тест по MS SQL и проверь свой уровень.
Ответишь — пройдешь на углубленный курс «MS SQL Server Developer» от OTUS по специальной цене + получишь мастер-класс от преподавателя
🧑💻 Регистрируйся на открытый урок «Генерируем QR код в MS SQL server» и протестируй обучение 28 июня — https://otus.pw/GZmve/
🔥 ПРОЙТИ ТЕСТ
https://otus.pw/SeLu/
Нативная интеграция. Информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
22 Jun 2023 10:02
Spark UDAF — мощный инструмент для анализа данных и обработки сложных операций агрегации в Apache Spark. Как с помощью него разработать свой агрегатор?
📆Поговорим об этом 27 июня в 20:00 с Вадимом Заигриным, ведущим эксперт по технологиям в Сбербанке и преподавателем OTUS.
Вебинар «Spark UDAF: разрабатываем свой агрегатор» приурочен к старту онлайн-курса «Spark Developer» в OTUS.
💻На открытом уроке рассмотрим агрегирование данных в Spark, стандартные агрегатные функции и создание собственных агрегатные функции (UDAF). После вебинара вы научитесь создавать собственные агрегатные функции.
Урок предназначен для разработчиков Spark, которые хотят выйти за рамки стандартных функций и узнать, как создавать собственные агрегатные функции. Не упустите возможность получить ценные знания, продолжить обучение вы сможете на курсе, доступном в рассрочку.
➡️Для участия пройдите вступительный тест: https://otus.pw/CIUu/
Нативная интеграция информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
21 Jun 2023 19:01
Хотите принять участие в создании лучшей системы безопасности? 👨💻
Тогда приходите на One Day Offer для Data Scientists и Machine Learning Engineers 24 июня и за один день станьте частью команды, которая развивает систему форд-мониторинга для защиты клиентов Сбера везде: от онлайн-покупок до визитов в офисы.
Чем предстоит заниматься, если вы успешно пройдете отбор:
✔️ Создавать real-time, look-alike и графовые модели выявления транзакций, устройств и связей мошенников и мошеннических групп.
✔️ Строить модели обработки, классификации и суммаризации обращений по мошенничеству.
✔️ Внедрять модели и мониторить эффективность их работы.
✔️ Развивать внутренние ML-pipelines.
Наша система безопасности уже признана одной из лучших в мире, но мы абсолютно уверены, что с вами она станет еще круче.
Скорее переходите по ссылке, регистрируйтесь на One Day Offer и будьте готовы пройти все этапы отбора за один день! 👌
Читать полностью…
Анализ данных (Data analysis)
04 Jul 2023 13:37
🖥 Продвинутый парсинг данных на Python.
Сегодня многие веб-сайты используют JavaScript для динамической загрузки контента. Это может затруднить парсинг данных традиционными методами.
Тем не менее, существует ряд инструментов, которые могут помочь вам спарсить данные с сайтов, использующих JavaScript.
1. Парсинг динамических сайтов.
Вот пример того, как использовать Selenium для парсинга веб-сайта, перегруженного JavaScript:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Firefox()
driver.get('https://www.example.com')
# Wait for the JavaScript to load
time.sleep(5)
# Get the page source
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Extract the data
table = soup.find('table', attrs={'id':'dynamic-table'})
data = []
for row in table.find_all('tr'):
data.append([cell.text for cell in row.find_all('td')])
# Close the browser
driver.quit()
Этот код сначала откроет веб-сайт в браузере Firefox. Затем он будет ждать загрузки JavaScript. После загрузки JavaScript, мы получим исходный текст страницы и разберм его с помощью BeautifulSoup.
Наконец, мы извлечем данные из таблицы и закроем браузер.
2. Работа с CAPTCHA и IP-блокировками
Существует ряд инструментов, которые могут помочь вам решить CAPTCHA. Одним из популярных инструментов является Anti-Captcha: https://anti-captcha.com/.
import requests
url = 'https://anti-captcha.com/api/create'
data = {
'type': 'image',
'phrase': captcha_text
}
response = requests.post(url, data=data)
captcha_id = response.json()['captchaId']
url = 'https://anti-captcha.com/api/solve'
data = {
'captchaId': captcha_id
}
response = requests.post(url, data=data)
solution = response.json()['solution']
Этот код сначала отправляет текст CAPTCHA в Anti-Captcha. Затем Anti-Captcha вернет captchaId, который вы можете использовать для запроса решения.
Получив решение, вы можете использовать его для обхода CAPTCHA.
3. Пример того, как использовать прокси-сервис для изменения вашего IP-адреса:
import requests
import random
def get_proxy():
"""Gets a proxy from the proxy scrape service."""
response = requests.get('https://www.proxyscrape.com/')
data = response.json()
proxy = random.choice(data['results'])['ip'] + ':' + data['results'][0]['port']
return proxy
def scrape_website(proxy):
"""Scrape the website using the proxy."""
response = requests.get(url, proxies={'http': proxy, 'https': proxy})
soup = BeautifulSoup(response.text, 'html.parser')
data = []
for row in soup.find_all('tr'):
data.append([cell.text for cell in row.find_all('td')])
return data
if __name__ == '__main__':
proxy = get_proxy()
data = scrape_website(proxy)
print(data)
# Rotate the proxy
proxy = get_proxy()
data = scrape_website(proxy)
print(data)
Этот код сначала получит прокси от сервиса proxy scrape. Затем он будет использовать прокси для сканирования веб-сайта. Наконец, он выведет данные, которые были получены при парсинге.
@
Читать полностью…
Анализ данных (Data analysis)
30 Jun 2023 18:01
🔊 AudioPaLM - нейросеть Google, которая умеет разговаривать, слушать и переводить.
AudioPaLM новая языковая модель, от Google, объединяющая две предыдущие модели: PaLM-2 и AudioLM. Эта мультимодальная архитектура позволяет модели распознавать речь, сохранять особенности интонации и акцента, осуществлять перевод на другие языки на основе коротких голосовых подсказок и делать транскрипцию.
При переводе некоторых языков, таких как итальянский и немецкий, модель имеет заметный акцент, а при переводе других, например французского, говорит с идеальным американским акцентом.
Матрица эмбеддингов предварительно обученной модели используется для моделирования набора аудио-токенов.
На вход в модель подается смешанная последовательность текстовых и аудио-токенов, и модель декодирует эти токены в текст или аудио. Аудио-токены в дальнейшем преобразуются обратно в исходное аудио с использованием слоев модели AudioLM.
🖥 Demo: https://google-research.github.io/seanet/audiopalm/examples/#asr-section
📕 Статья: https://arxiv.org/abs/2306.12925
@
Читать полностью…
Анализ данных (Data analysis)
30 Jun 2023 13:12
🔥 Большой список сайтов с практическимим задачами для программистов.
Codeforces — платформа для алгоритмических соревнований. Проводит контесты и раунды с 5 задачами на 2 часа. Есть система рейтинга и два дивизиона. Задачи можно решать и проверять после соревнования. Также есть доступ к тренировкам с задачами с прошлых соревнований.
HackerRank - сайт будет больше интересен продвинутым программистам, которые уже многое умеют. На этом сайте собрано множество задач на самые разные разделы Computer Science: традиционная алгоритмика, ИИ, машинное обучение и т.д. Если вы решите много задач, то вами могут заинтересоваться работодатели, регуляторно мониторящие эту платформу.
Codewars — популярный cборник задач на разные темы, от алгоритмов до шаблонов проектирования.
LeetCode — известный сайт с задачами для подготовки к собеседованиям. Можно пообщаться и посмотреть решения других программистов.
Timus Online Judge — русскоязычная (хотя английский язык также поддерживается) платформа, на которой более тысячи задач удачно отсортированы по темам и по сложности.
TopCoder - популярная американская платформа. Она проводит алгоритмические контесты, а также соревнования по промышленному программированию и марафоны, где задачи требуют исследования и нет единого верного алгоритма. Участникам даются недели на решение таких задач.
informatics.mccme.ru - платформа с теоретическим материалом и задачами, удобно разделенными по категориям. Большая база задач с олимпиад школьников также доступна.
SPOJ - большой англоязычный сайт с 20000+ задачами на разные темы: DP, графы, структуры данных и др. Иногда проводят неинтересные контесты, если не из страны их проведения.
CodeChef — менее крупный аналог Codeforces и TopCoder, тоже с огромным архивом задач и регулярными контестами.
Project Euler - сборник 500 задач, проверяющих знание математических алгоритмов. Часто используется на собеседованиях, чтобы оценить алгоритмическую подготовку кандидата.
Kaggle - соревнования по анализу данных.
Golang tests - канал с тестами по Go
CodinGame - сайт для программистов и геймеров, предлагающий большую коллекцию видеоигр, оформленных в виде задач на программирование.
Al Zimmermann’s Programming Contests — платформа, на которой регулярно проводятся контесты с задачами на исследование и оптимизацию. Интересен тем, что писать программу необязательно — даются только тестовые данные. Ответы можно расчитывать вручную, или просто гадать их на кофейной гуще.
Programming Praxis — сайт, где можно найти много интересных задач.
CheckIO — сайт с задачами для программистов всех уровней, который вы проходите в виде игры.
Ruby Quiz — сайт с задачами для программистов на Ruby, но решения можно писать и на других языках.
Prolog Problems — Подборка задач для программистов, использующих Prolog.
Сборник задач от СppStudio - задачи на С++, но их можно и на других языках.
Operation Go — практика написания кода на Go в форме браузерной игры.
Empire of Code — сайт для программистов, где необходимо писать код, реализующий стратегию и тактику виртуальных бойцов.
@
Читать полностью…
Анализ данных (Data analysis)
29 Jun 2023 11:16
⚡️Осилите ли вы тест для Data-инженеров?
Ответьте на 24 вопросов за 30 минут и проверьте, готовы ли вы к обучению на онлайн-курсе «Spark Developer» от OTUS.
Spark — важнейший фреймворк в Big Data c открытым исходным кодом. На курсе вы научитесь работать с большими данными и закрепите знания с помощью сложных домашних заданий и выпускного проекта.
Пройдете тест — получите демо-ролик о занятиях на курсе и доступ к 2 открытым урокам:
— «Spark UDAF: разрабатываем свой агрегатор», 27 июня в 20:00
— «Оптимизация параметров запуска приложения Spark», 11 июля в 20:00
📝Пройти тест: https://otus.pw/BFMz/
Нативная интеграция. Информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
28 Jun 2023 17:02
🔥Хотите стать одним из авторов проектов, которые меняют жизнь людей к лучшему в области автоматизации предприятий, медицины, робототехники, виртуальной реальности и других сферах, или стать руководителем отдела Computer Vision в вашей компании? Все это возможно после прохождения обучения на курсе “Компьютерное зрение” в OTUS. Сейчас открыт набор в группу.
Приходите 29 июня в 20:00 мск на открытый урок «PyTorch 2.0», чтобы познакомиться с преподавателем и программой курса, оценить все перспективы, которые откроются перед вами.
На занятии мы также обсудим, что нового принес фреймворк PyTorch 2.0 в сферу компьютерного зрения и глубокого обучения.
📌Вы узнаете:
- Как начать использовать PyTorch для обучения своих нейронных сетей
- Что нового в PyTorch 2.0 и чем он отличается от 1.x
- Как ускорить и оптимизировать свою нейросеть при помощи одной строчки кода
- Как перейти с PyTorch 1.x на 2.0
- Как ускорить трансформеры HuggingFace при помощи PyTorch Transformer API
👉🏻Для участия отправьте заявку https://otus.pw/2ZGX/
Кому подходит этот урок:
- Начинающим и опытным специалистам в области компьютерного зрения и глубокого обучения
- Дата сайентистам, которые хотят ускорить инференс своих моделей
- Опытным специалистам, которые еще не перешли на PyTorch 2.0
- Тем, кто хочет познакомиться с фреймворков PyTorch и начать обучать свои нейросети
Нативная интеграция подробная информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
28 Jun 2023 11:01
Автоматизированный перенос DWH Microsoft на платформу Yandex Cloud с помощью BI.Qube
📆 06.07.2023 в 10:00-12:00 (МСК) на вебинаре команды BI.Qube, Yandex Cloud и Банка Финсервис расскажут о практическом опыте автоматизированной миграции DWH Microsoft на платформу Yandex Cloud.
За 2 часа вы:
👉 узнаете об актуальных кейсах, включая историю миграции DWH банка Финсервис
👉 увидите весь путь от извлечения данных из учётных систем до построения аналитики
👉 применение low-code/no-code инструментов из Реестра российского ПО
Пример анализа программы лояльности будет интересен как специалистам банковской сферы, так и крупному ритейлу, где необходимо анализировать эффективность на основе данных из разрозненных систем.
Вебинар рассчитан на экспертов по аналитике и работе с данными, архитекторов и инженеров данных, CIO, CDO.
Программа вебинара
Регистрация: @
Читать полностью…
Анализ данных (Data analysis)
27 Jun 2023 10:12
Как использовать многоруких бандитов на практике | Гайд для аналитиков, продуктовых менеджеров и ML-специалистов
Ведущая аналитическая система MyTracker разработала практическое руководство для использования многоруких бандитов в продуктах.
Вы узнаете, что такое многорукие бандиты и как они применяются в различных сферах, в том числе в рекомендательных системах. Подробнее остановимся на различных алгоритмах бандитов: жадный, алгоритм UCB, алгоритм сэмплирования Томпсона и контекстуальные многорукие бандиты.
Гайд пригодится аналитикам для определения оптимальных стратегий тестирования, продуктовым менеджерам - для тестирования новой функциональности, а ML-специалистам - для настройки моделей машинного обучения.
Руководство составлено командой предиктивной аналитики MyTracker, которая использует многоруких бандитов в своей работе.
Скачайте практическое руководство от команды предиктивной аналитики MyTracker и узнайте, как многорукие бандиты могут увеличить прибыль вашего продукта и улучшить продуктовые метрики.
Читать полностью…
Анализ данных (Data analysis)
26 Jun 2023 17:37
Data Science | Machinelearning - самый большой русскоязычный канал с полезными материалами на такие темы как, Machine Learning, Data Science, Алгоритмы, Python. Так же часто публикуются крутые 🔥 вакансии.
👉 Вам сюда: @
А любителям читать статьи в оригинале вот сюда:
👉 @
Добро пожаловать!
Читать полностью…
Анализ данных (Data analysis)
26 Jun 2023 12:44
🦖 Вебинар YTsaurus. DWH Яндекс Go: как мы готовим наши петабайты
Новый вебинар YTsaurus — об использовании платформы в реальных сервисах. В гостях — Яндекс Go, суперапп с разными сервисами внутри, который основан на data driven подходе. Владимир Верстов и Николай Гребенщиков из команды разработки Data Management Platform Яндекс Go расскажут, какие требования команда предъявляет к системам хранения и расскажет, как с этими требованиями справляется YTsaurus.
Ждём 28 июня в 18:30 Мск. Участие бесплатное, зарегистрироваться можно по ссылке.
Также запись вебинара будет доступна ytsaurus">на YouTube.
Читать полностью…
Анализ данных (Data analysis)
23 Jun 2023 21:01
🖥 Введение для Python-разработчиков в Prompt Engineering GPT-4
Это пошаговое руководство, представляет собой введение в Prompt Engineering для
Python программистов и датасаентистов.
Цель руководства, состоит в том, чтобы помочь вам понять, как эффективно управлять GPT-4 для достижения оптимальных результатов в процессе разработки на Python.
▪Читать
@
Читать полностью…
Анализ данных (Data analysis)
23 Jun 2023 12:01
✔ Плохие модели машинного обучения? Но их можно откалибровать
Модели машинного обучения часто оцениваются по их производительности, близости какого-либо показателя к нулю или единице, но это не единственный фактор, которым определяется их полезность. В некоторых случаях модель, в целом не очень точную, можно откалибровать и найти ей применение. В чем же разница между хорошими калибровкой и производительностью, и когда одна предпочтительнее другой?
Калибровка вероятности
Калибровка вероятности — это степень, с которой прогнозируемые в модели классификации вероятности соответствуют истинной частотности целевых классов в наборе данных. Прогнозы откалиброванной модели в совокупности тесно соотносятся с фактическими результатами.
На практике это означает, что если из множества прогнозов идеально откалиброванной модели двоичной классификации учесть только те, для которых моделью предсказана 70%-ная вероятность положительного класса, то модель должна быть корректной в 70% случаев. Аналогично, если учесть только примеры, для которых моделью прогнозируется 10%-ная вероятность положительного класса, эталонные данные окажутся положительными в 1 из 10 случаев.
▪ Читать
@
Читать полностью…
Анализ данных (Data analysis)
22 Jun 2023 12:01
🖥 DeepPavlov «из коробки» для задачи NLP на Python
У меня возникла необходимость автоматизированного анализа текста постов на habr.com. Рассмотрю задачу, которая позволяет находить в заданном тексте ответы на вопросы (Context Question Answering, далее CQA).
В процессе работы над решением задачи оказался полезным сервис HuggingFace, предлагающий множество мультиязычных передобученных NLP моделей. Однако, при обработке текста на русском языке предпочтение было отдано российскому инструменту DeepPavlov, специализирующемуся на задачах NLP. Тем более, что DeepPavlov позволяет работать с NLP-моделями, представленными на HuggingFace «из коробки».
Разобью задачу на три этапа:
Загрузить текст поста с habr.com.
Подготовить набор вопросов из ответов.
Настроить deepPavlov для решения задачи CQA.
Для получения текста постов с habr.com воспользуюсь библиотеками urllib для загрузки html-документа с сайта и bs4 для доступа к элементам. Библиотека urllib входит в состав предустановленных библиотек языка Python, а библиотеку bs4 можно установить с помощью команды:
pip install beautifulsoup4
Код для получения текста по заданному url представлю в виде функций getHtmlDocument и getTextFromHtml:
from urllib import request
def getHtmlDocument(url):
""" Получаем html-документ с сайта по url. """
fp = request.urlopen(url)
mybytes = fp.read()
fp.close()
return mybytes.decode('utf8')
from bs4 import BeautifulSoup
def getTextFromHtml(HtmlDocument):
""" Получаем текст из html-документа. """
soup = BeautifulSoup(HtmlDocument,
features='html.parser')
content = soup.find('div', {'id': 'post-content-body'})
return content.text
Набор вопросов из ответов выглядит следующим образом:
questions = (
'О чём пост?',
'Какая цель поста?',
'Какая задача решалась?',
'Что использовалось в работе?',
'Какие выводы?',
'Что использовалось?',
'Какие алгоритмы использовались?',
'Какой язык программирования использовали?',
'В чём отличия?',
'Что особенного проявилось?',
'Какова область применения?',
'Что получено?',
'Каков результат?',
'Что получено в заключении?',
)
Далее перейду к настройке deepPavlov для решения задачи СQA. Установлю библиотеку deeppavlov в соответствии с официальным сайтом проекта:
pip install deeppavlov, transformers
Импортирую объекты configs и build_model с помощью команд:
from deeppavlov import configs, build_model
Далее инициализирую загрузку модели squad_ru_bert командой:
model = build_model('squad_ru_bert', download=True)
Модель squad_ru_bert — это модель глубокого обучения на основе архитектуры BERT, обученная на наборе данных SQuAD-Ru, который содержит пары вопрос-ответ на русском языке.
Выберу посты с habr.com:
paper_urls = (
'https://habr.com/ru/articles/339914/',
'https://habr.com/ru/articles/339915/',
'https://habr.com/ru/articles/339916/',
)
for url in paper_urls:
content = getTextFromHtml(getHtmlDocument(url))
for q in questions:
answer = model([content], [q])
if abs(answer[2] – 1) > 1e-6:
print(q, ' ', answer[0])
Результатом работы модели является:
— фрагмент текста, который является ответом на заданный вопрос на основании текста,
— позиция этого ответа в тексте и качество полученного результата. Примеры «удачных» ответов, по моему мнению, на вопросы отмечены зелёным цветом на рисунках 1-3.
▪ Статья
@
Читать полностью…
Анализ данных (Data analysis)
21 Jun 2023 21:01
HInt: Ускорение регулярных выржаений в 127 раз в 2 строках кода
Скомпилируйте ваш шаблоны Regex с помощью re.compile(<pattern>).
Функция предварительно скомпилирует регулярные выражения в байткод.
Далее мы будем используйте кэш LRU. Кэш хранит результат вызова функции, возвращая ранее вычисленный результат при последующих вызовах для тех же входных параметров. Таким образом, медленный Regex будет выполняться только один раз для каждой уникальной строки (~1 мкс), а последующие вызовы происходят за время O(1) (~20 нс).
import re
from functools import lru_cache
text = '''Lorem ipsum dolor sit amet...'''
compiled = re.compile(r'i')
@
def cache(text):
return compiled.findall(text)
# Протестировано на: Apple M2 Pro, 32 ГБ оперативной памяти, Python 3.11.3
%%timeit
re.findall(r'i', text)
%%timeit
re.compile(r'i')
%%timeit
cache(text)
# Naive: 3.13 µs ± 24.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
# Compiled: 2.96 µs ± 43.2 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
# Cached: 24.8 ns ± 0.325 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
@
Читать полностью…
Анализ данных (Data analysis)
21 Jun 2023 12:15
🖥 Docker для Data Science — введение
Когда вы отправляете свой код машинного обучения команде инженеров, могут возникнуть проблемы совместимости с различными операционными системами и версиями библиотек. Эти проблемы могут вызвать сбои в выполнении кода и затруднить совместную работу. Однако есть мощный инструмент, способный облегчить эти проблемы — Docker .
В этом подробном руководстве мы не только познакомим вас с основными понятиями Docker, но и проведем вас через процесс установки. Затем мы продемонстрируем его практическое использование на реальных примерах, что позволит вам воочию убедиться в его эффективности. Кроме того, мы углубимся в лучшие отраслевые практики, предоставив ценные идеи и стратегии для оптимизации рабочего процесса машинного обучения с помощью Docker.
▪ Читать
@
Читать полностью…



 10807
10807
{kind=link}
{kind=link}
{kind=link}