Анализ данных (Data analysis)
22 July 2023 13:02
📌 7 пакетов Python для анализа и форматирования вашего кода.
PEP 8 - это набор рекомендаций по написанию чистого, читабельного и последовательного кода на языке Python.
• isort — Python-библиотека и плагины для различных редакторов, позволяющие быстро сортировать все импортируемые файлы.
• black — это библиотека для автоматического форматирования вашего Python кода, в соответствии с требованиями PEP8.
• flake8 — это инструмент линтинга для Python, который проверяет код Python на наличие ошибок, проблем со стилем и сложностью. Библиотека Flake8 построена на базе трех инструментов: PyFlakes - проверяет код Python на наличие ошибок. McCabe - проверяет код Python на сложность. pycodestyle - проверяет кодовую базу Python на проблемы со стилем в соответствии с PEP8..
• interrogate — interrogate проверяет ваш код на наличие отсутствующих строк документации (docstrings).
• Whispers — это инструмент анализа кода, предназначенный для разбора различных распространенных форматов данных в поисках жестко закодированных учетных данных и опасных функций. Whispers может работать в CLI или интегрироваться в конвейер CI/CD.
• hardcodes — это утилита поиска и редактирования кода.
• pylint — Pylint анализирует ваш код без его запуска. Инструмент проверяет наличие ошибок и выдает рекомендации по его рефакторингу.
@
Читать полностью…
Анализ данных (Data analysis)
20 July 2023 17:59
⚡Как развернуть GitLab с помощью Docker за 5 секунд
GitLab — это веб-инструмент управления репозиториями Git, который помогает командам совместно работать над кодом. Кроме того, он предоставляет полную платформу DevOps с контролем версий, ревью кода, отслеживанием проблем (англ. issue) и CI/CD.
▪️Развертывание GitLab с помощью файла Compose от Sameersbn
Начинаем развертывание GitLab со скачивания актуальной версии файла Compose:
wget https://raw.githubusercontent.com/sameersbn/docker-gitlab/master/docker-compose.yml
Теперь генерируем 3 случайные строки длиной не менее 64 символов, открываем файл Compose и применяем эти строки для:
• GITLAB_SECRETS_OTP_KEY_BASE. Используется для шифрования секретных ключей двухфакторной аутентификации (2FA) в базе данных. Ни один пользователь не сможет войти в систему с 2FA при потере этого ключа.
• GITLAB_SECRETS_DB_KEY_BASE. Нужен для шифрования секретных ключей CI и импорта учетных данных. В случае изменения/потери вы уже не сможете задействовать секретные ключи CI.
• GITLAB_SECRETS_SECRET_KEY_BASE. Требуется для генерации ссылок для сброса пароля и стандартных функций аутентификации. Вы не сможете сбросить пароли через электронную почту при ее потере/изменении.
▪️Запуск экземпляра GitLab
docker-compose up
▪️Развертывание GitLab вручную с помощью команд Docker
Вместо скачивания актуальной версии файла Compose от Sameersbn вы можете вручную запустить контейнер GitLab, контейнер Redis и контейнер PostgreSQL за 3 простых шага.
Шаг 1. Запуск контейнера PostgreSQL
docker run --name gitlab-postgresql -d \
--env 'DB_NAME=gitlabhq_production' \
--env 'DB_USER=gitlab' --env 'DB_PASS=password' \
--env 'DB_EXTENSION=pg_trgm,btree_gist' \
--volume ./gitlab_postgresql:/var/lib/postgresql \
sameersbn/postgresql:12-20200524
Продолжение
@
Читать полностью…
Анализ данных (Data analysis)
19 July 2023 12:01
🦙 Запускаем Llama2
С Трансформерами версии 4.31 уже можно использовать Llama 2 и использовать все инструменты экосистемы HF.
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "llamaste/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Читать полностью…
Анализ данных (Data analysis)
18 July 2023 12:00
📌 10 лучших пакетов AutoML Python для автоматизации задач машинного обучения
1. Pandas Profiling
(изображение 1.)
2. Snorkel
(изображение 2.)
3. MLBox
(изображение 3.)
4. H20
5. TPOT
(изображение 4.)
6. Autokeras
7. Ludwig
(изображение 5.)
8. AutoGluon
9. Neural Network Intelligence
10. AutoGL
@
Читать полностью…
Анализ данных (Data analysis)
17 July 2023 17:21
📎 Открытые датасеты 📎
🔵 Labelled Faces in the Wild. 13 тысяч размеченных изображений лиц.
🔵 IMF Data. Датасеты о финансах и ценах на товары.
🔵 Google Trends. Данные о поисковой статистике и трендовых запросах.
🔵 xView. Большой набор воздушных снимков Земли с аннотациями.
🔵 World Bank Open Data. Наборы данных о демографии и экономических показателях.
🔵 Labelme. Большой датасет с уже размеченными изображениями.
🔵 HotspotQA Dataset . Датасет с вопросами-ответами для генерации ответов на часто задаваемые простые вопросы.
🔵 Berkeley DeepDrive BDD100k. Тысячи часов вождения для обучения автопилотов.
🔵 MIMIC-III. Обезличенные медицинские данные пациентов.
🔵 CREMA-D — датасет для распознавания эмоций по записи голоса.
@
Читать полностью…
Анализ данных (Data analysis)
15 July 2023 18:00
⚡️ Создайте клон себя с помощью точно настроенного LLM
Вы задумывались о цифровом двойнике? 👨👨
Виртуальная копия вас, которая может разговаривать, учиться и отражать ваши мысли.
Прогресс в области искусственного интеллекта (ИИ) сделал эту идею реальностью. 🌟
Цель этой статьи - показать, как эффективно настроить высокопроизводительный LLM на пользовательских данных. Рассмотрен будет использование модели Falcon-7B с адаптерами LoRA и Lit-GPT для минимизации затрат.
• Читай
@
Читать полностью…
Анализ данных (Data analysis)
14 July 2023 16:08
Модель нейросети Kandinsky 2.2 стала частью самого крупного и авторитетного в сфере ИИ фреймворка Diffusers на ресурсе Huggingface.
Diffusers - это агрегатор открытых генеративных моделей, работающих на принципе диффузии. Сегодня этот фреймворк используют многие популярные ИИ-сервисы, инструменты и библиотеки: DreamFusion, Segment Anything, ML Stable Diffusion (by Apple), Invoke AI ( всего более 3000 решений).
Также Kandinsky 2.2 вошел в список популярных моделей в основном репозитории Diffusers на GitHub.
@
Читать полностью…
Анализ данных (Data analysis)
04 July 2023 12:37
12 июля в 11:00 мск Visiology првоводит вебинар на тему "BI + AI = ? Супер-оружие аналитиков или угроза профессии?".
Записаться на вебинар
Что будет на вебинаре
1. Начнем с обзора новых возможностей на основе ИИ в BI платформах лидерах мирового рынка - Power BI, Qlik, Tableau. Почему про ИИ в BI говорили и раньше, но только сейчас это перестало быть маркетинговой фишкой и стало реально помогать в ежедневной работе аналитика?
2. Продемонстрируем на реальных кейсах, как аналитику может помочь новый виртуальный помощник Visiology ViTalk GPT. Посмотрим, как он пишет DAX запросы и интеграции с источниками данных на Python. Обсудим ограничения технологии и разберемся, как эту технологию использовать эффективно.
Зарегистрироваться
Читать полностью…
Анализ данных (Data analysis)
30 June 2023 16:01
Аналитик рисков в Финтех Яндекса
Если вы ищите риски, вас тут тоже кое-кто ищет — Финтех Яндекса. Это молодой сервис Яндекса, где соединились корпоративные блага и свобода стартапа, бесплатные сырки и возможность влиять на продукт, ДМС и бар в офисе. А главное — тут можно расти, как бамбук 🎋
Что нужно делать
Заниматься аналитикой целого направления. Понимать, кому можно выдавать кредит, а кому не стоит. Создать правила для оценки пользователей и много-много тестировать. А ещё быть хорошим руководителем: помогать расти специалистам и выстраивать рабочие процессы.
Что надо уметь
Оптимизировать кредитный бизнес, знать принципы работы ML и если что — писать модели. А ещё думать не о мелких задачах, а о пользе для бизнеса. И если всё получиться — расти вместе со своим продуктом. Тут есть куда!
Откликайтесь, если узнали себя
Читать полностью…
Анализ данных (Data analysis)
29 June 2023 13:16
🔥 Kubernetes и Docker для дата-сайентистов
Изучение и применение новейших инструментов и технологий в области науки о данных является неотъемлемым условием для развития специалистов. Появление Docker и Kubernetes привело к существенным изменениям в процессе разработки и развертывания программных продуктов. Однако, какова роль этих инструментов и почему они важны для дата-сайентистов?
Мы представляем полный обзор Docker и Kubernetes, включая их преимущества и функционал. Как отличаются эти две технологии и какова их польза для дата-сайентистов? В конце статьи вы получите ясное понимание роли контейнеризации и оркестрации в более эффективной работе дата-сайентиста.
📌 Читать
@
Читать полностью…
Анализ данных (Data analysis)
28 June 2023 19:02
🖥 PyGWalker: A Python Library for Exploratory Data Analysis with Visualization
PyGWalker: преобразуем датафрейм pandas в пользовательский интерфейс в стиле таблицы для визуального анализа.
pip install pygwalker
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)
🖥 Github
📌 Colab
@
Читать полностью…
Анализ данных (Data analysis)
28 June 2023 13:14
🔝Топ-10 инструментов для обнаружения ChatGPT, GPT-4, Bard и Claude
1. GPTZero
GPTZero обладает высокой точностью, прост в использовании и имеет удобное расширени для Chrome.
2. OpenAI AI Text Classifier
ИИ-классификатор текста OpenAI обладает высокой точностью, но не предоставляет дополнительной информации о содержимом контента.
3. CopyLeaks
Это быстрая и точная проверка на плагиат, в виде расширения для Chrome.
4. SciSpace
SciSpace Academic AI Detector немного отличается от других упомянутых инструментов. Он обладает высокой точностью, но был специально разработан для обнаружения научного контента в PDF-файлах.
5. Hive Moderation
Функция обнаружения ИИ-генеративного контента Hive Moderation.
6. Content at Scale
ИИ-детектор контента Content at Scale прост в использовании и дает достаточно точные отчеты о конетнте.
7. Hello Simple AI
ChatGPT Detector by Hello Simple AI – это бесплатный инструмент с открытым исходным кодом, который можно использовать для обнаружения текста, создаваемого ChatGPT.
8. OpenAI HF Detector
OpenAI Detector – это бесплатный инструмент с открытым исходным кодом, который можно использовать для обнаружения текста, сгенерированного языковой моделью GPT от OpenAI.
9. Corrector.app
AI Detector от Corrector.app – это довольно точный инструмент, который можно использовать для обнаружения текста, сгенерированного ChatGPT, Bard и другими больми языковыми моделями (LLM).
10. Writer.com
Детектор контента AI от Writer.com завершает наш список, представляя собой наименее точный вариант с ограничением в 1500 символов.
@
Читать полностью…
Анализ данных (Data analysis)
27 June 2023 12:40
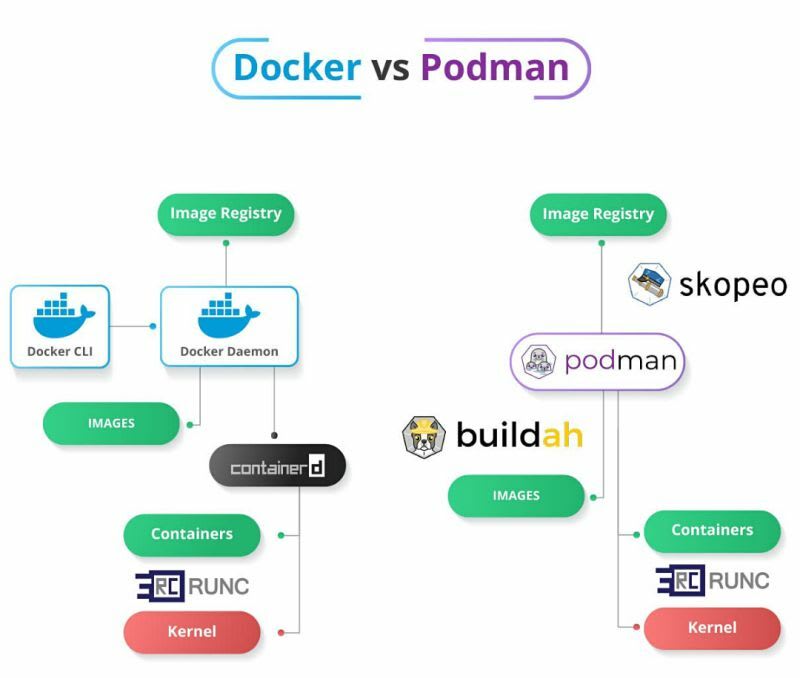
🔍 Podman: Альтернатива Docker без deamon
Хотя Docker, безусловно, перевернул наше представление о разработке, развертывании и запуске приложений, стоит изучить, чем отличается Podman (Pod Manager) и почему вам может быть интересно начать использовать его вместо Docker.
Podman — это менеджер контейнеров и падов с открытым исходным кодом.
Аналогично Docker, он позволяет создавать, запускать, останавливать и удалять контейнеры OCI, а также управлять образами контейнеров.
Он также поддерживает пады в рамках своего функционала, а значит, вы можете создавать и управлять падами так же, как с Kubernetes.
Что такое OCI-контейнеры
OCI (Open Container Initiative) — это организация отраслевого стандарта, которая стремится создать набор правил (спецификаций и стандартов), обеспечивающих согласованную работу контейнеров на разных платформах.
Это означает, что образы/контейнеры Podman полностью совместимы с Docker или любой другой технологией контейнеризации, которая использует совместимый с OCI исполнитель контейнеров.
Большинство пользователей Docker могут просто сделать псевдоним Docker для Podman (alias docker=podman) без каких-либо проблем.
Это означает, что все команды Docker остаются такими же, за исключением команды docker swarm.
Архитектура Podman
Архитектура Podman не подразумевает использование демонов (deamons).
Демоны — это процессы, которые выполняются в фоновом режиме системы, они обычно работают непрерывно на заднем плане, ожидая определенных событий или запросов.
Возвращаясь к контейнерам, представьте себе демона Docker в качестве посредника, общающегося между пользователем и самим контейнером.
Использование демона для управления контейнерами приводит к нескольким проблемам:
Одна точка отказа.
Когда демон падает, падают все контейнеры.
Требуются привилегии root
Поэтому демоны в Docker — это идеальная цель для хакеров, которые хотят получить контроль над вашими контейнерами и проникнуть в хост-систему.
Podman решает упомянутые проблемы, напрямую взаимодействуя с реестрами контейнеров, контейнерами и хранилищем образов без необходимости в демоне.
Переходя в режим без прав root, пользователи могут создавать, запускать и управлять контейнерами, что снижает риски безопасности.
Утилита buildah заменяет команду docker build как инструмент для создания контейнерного образа.
Аналогично, skopeo заменяет команду docker push и позволяет перемещать контейнерные образы между реестрами.
Эти инструменты обеспечивают эффективное и прямое взаимодействие с необходимыми компонентами, исключая необходимость в отдельном демоне в процессе.
Нужно ли переписывать каждый Dockerfile и docker-compose файл, чтобы использовать Podman с существующими проектами
Абсолютно нет. Podman предлагает совместимость с синтаксисом Docker для файлов контейнеров (containerfile).
Также Podman предлагает инструмент под названием pod compose в качестве альтернативы docker compose.
Pod compose использует тот же синтаксис, позволяя вам определять и управлять многоконтейнерными приложениями с использованием того же подхода или даже с использованием существующих файлов "docker-compose.yml".
Podman также поставляется с Podman Desktop, предлагая расширенные функции, которые делают его мощнее и проще. Он совместим с Docker и Kubernetes, расширяя их возможности и обеспечивая простую работу.
Руководство по установке и документацию по Podman можно найти на их официальном веб-сайте podman.io.
@
Читать полностью…
Анализ данных (Data analysis)
26 June 2023 19:37
🖥 Docker Шпаргалка для Датасаентиста с основными командами.
▪ Шпаргалка
@
Читать полностью…
Анализ данных (Data analysis)
21 July 2023 12:03
🔥 Бесплатный курс: CS 329S: Machine Learning Systems Design
Слайды лекций, конспекты, учебные пособия и задания курса Machine Learning Systems Design от Стенфорда.
https://stanford-cs329s.github.io/syllabus.html
@
Читать полностью…
Анализ данных (Data analysis)
20 July 2023 12:01
📂 Кластеризация текста в PySpark
Наша задача состоит в том, чтобы разбить все сообщения на группы, каждая из которых будет содержать в себе сообщения одного типа.
1. Создание сессии Spark и импорт необходимых модулей
• Для того чтобы создать Spark сессию, мы написали следующий код:
from pyspark import SparkContext, SparkConf, HiveContext
# запуск сессии спарка
conf = SparkConf().setAppName('spark_dlab_app')
conf.setAll(
[
#Укажите тут нужные параметры Spark
])
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
• Импортируем модули для дальнейшей работы:
# для создания пользовательских функций
from pyspark.sql.functions import udf
# для использования оконных функций
from pyspark.sql.window import Window
# для работы с PySpark DataFrame
from pyspark.sql import DataFrame
# для задания типа возвращаемого udf функцией
from pyspark.sql.types import StringType
# для создания регулярных выражений
import re
# для работы с Pandas DataFrame
import pandas as pd
# для предобработки текста
from pyspark.ml.feature import HashingTF, IDF, Word2Vec,\
CountVectorizer, Tokenizer, StopWordsRemover
# для кластеризации
from pyspark.ml.clustering import Kmeans, BisectingKmeans
# для создания пайплайна
from pyspark.ml import Pipeline
# для подсчета частоты слов в тексте
from nltk.probability import FreqDist
2. Предварительная обработка текста
• Первым делом создадим DataFrame из данных, которые находятся на Hadoop, в нашей сессии:
t = spark.table('data')
• Поскольку в тексте содержится много информации, которая не несёт никакой смысловой нагрузки, например, различные цифры или знаки препинания, мы её удалим. Для этого написали UDF-функцию, которая почистит текст с помощью регулярных выражений.
def text_prep(text):
# переводим текст в нижний регистр
text = str(text).lower()
# убираем всё, что не русская буква, и убираем слово «баланс»
text = re.sub('[^а-яё]|баланс',' ',text)
# убираем всё, что начинается с «от»
text = re.sub('от.+','',text)
# убираем одиночные буквы
text = re.sub('\s[а-яё]\s{0,1}','',text)
# если пробелов больше одного заменяем их на один
text = re.sub('\s+',' ',text)
# убираем лишние пробелы слева и справа
text = text.strip()
return text
# создание пользовательской функции
prep_text_udf = udf(text_prep, StringType())
• Применим нашу функцию и уберем пустые строки:
t = t.withColumn('prep_text', prep_text_udf('sms_text'))\
.filter('prep_text <> ""')
📌 Продолжение
@
Читать полностью…
Анализ данных (Data analysis)
18 July 2023 19:01
📎 9 ресурсов для изучения MLOPs
MLOps — это набор процедур, направленных на последовательное и эффективное внедрение и поддержку моделей машинного обучения (ML), используемых в производстве. Само слово представляет собой сочетание, обозначающее "Machine Learning (Машинное обучение)” и процесс непрерывной разработки "DevOps" в области программного обеспечения.
Модели машинного обучения оцениваются и совершенствуются в изолированных экспериментальных системах. Когда алгоритмы готовы к запуску, MLOps практикуется у Data Scientists — Специалистов по анализу данных, DevOps и инженеров машинного обучения для внедрения алгоритма в производственные системы.
1. Machine Learning Engineering от Андрея Буркова
Книга "Machine Learning Engineering" освещает основы машинного обучения и фокусируется на искусстве и науке создания и развертывания конечных моделей.
2. ml-ops.org
Наиболее всеобъемлющий ресурс по MLOps. Он содержит различные статьи о лучших практиках.
3. MLOps от AIEngineering
Канал в YouTube по машинному обучению, у которого есть отдельный плэйлист по MLOps. Для тех, кто предпочитает видеоряд чтению.
4. ML in Production
Луиги Патруно регулярно делится контентом по основам развертывания и поддержания моделей, а также последними новостями.
5. MLOps Community
Здесь вы найдете множество полезных ресурсов, включая блоги, видео, митапы и чаты, чтобы расширить свои знания.
6. Awesome production machine learning
Это репозиторий на GitHub для тех, кто изучить пакеты, библиотеки, передовые инструменты. Этот огромный список предназначен, чтобы помочь вам строить, разворачивать, отслеживать, версионировать, масштабировать ваши ML-системы.
7. Made With ML
Этот открытый курс посвящен построению систем машинного обучения. Его попробовали уже более 30,000 людей.
8. Туториал по MLOps от DVC
DVC (Data Version Control) — это система контроля версий, но предназначенная для ML-проектов, т.е. для версионирования данных и моделей.
9. TFX от TensorFlow
Это платформа для развертывания моделей машинного обучения. Она содержит различные пакеты для валидации данных, преобразований, анализа моделей и проч. в экосистеме TensorFlow.
@
Читать полностью…
Анализ данных (Data analysis)
17 July 2023 14:21
Зачем рекламной кампании предиктивная классификация?
Об этом рассказала Ирина Гутман из аналитики маркетинга Авито. Если коротко, то прогноз поведения клиента поможет вам привести его к целевому событию — будь то покупка, посещение сайта или регистрация на сервисе.
На практике все, разумеется, куда тоньше. Чтобы построить прогноз на 90 дней, нужно поделить пользователей на группы, определить ценность контакта, выбрать, что предсказываете, а дальше — долго и скрупулезно считать и тестировать модели.
Зато результат окупает усилия: с предиктивными моделями эффективность рекламы Авито выросла на 22%, стоимость привлечения снизилась на 12%, а новых пользователей в тестовых кампаниях было 60%. Так что посмотрите, как это сделать — в кейсе есть все формулы, метрики и методики тестирования.
Читать полностью…
Анализ данных (Data analysis)
15 July 2023 11:38
🗂 10 библиотек Python для автоматического разведочного анализа данных
• Разведочный анализ данных (EDA) является важнейшим шагом в разработке модели Data science и исследовании наборов данных. EDA включает в себя изучение, анализ и обобщение фундаментальных характеристик наборов данных для получения представления о внутренней информации, содержащейся в них.
• Известные библиотеки Python для автоматизированного EDA:
1. D-Tale
D-Tale – это библиотека Python, которая предоставляет интерактивный и удобный интерфейс для визуализации и анализа данных.
2. Pandas-profiling
Pandas-Profiling – позволяет автоматизировать первичный анализ данных и, тем самым, значительно его упростить и ускорить.
3. Sweetviz
Sweetviz – это библиотека Python с открытым исходным кодом, которая генерирует отчеты с удобной визуализацией для выполнения EDA с помощью всего двух строк кода. Библиотека позволяет быстро создать подробный отчет по всем характеристикам набора данных без особых усилий. В возможности Sweetviz также входит целевой анализ, сравнение двух датасетов, сравнение двух частей датасета, выделенных по определенному признаку, выявление корреляций и ассоциаций, также sweetviz создает позволяет создавать и сохранять отчет как HTML файл.
4. Autoviz
AutoViz – это библиотека Python, предоставляющая возможности автоматической визуализации данных, позволяющая визуализировать наборы данных любого размера всего одной строкой кода.
5. dataprep
DataPrep – это библиотека Python с открытым исходным кодом, которая предоставляет функциональные возможности для анализа, подготовки и обработки данных. Она построена поверх Pandas и Dask DataFrame, что делает её легко интегрируемым интсрументом с другими библиотеками Python.
6. KLib
KLib – это библиотека Python, которая предоставляет возможности автоматического разведочного анализа данных (EDA) и профилирования данных. Она предлагает различные функции и визуализации для быстрого изучения и анализа наборов данных. KLib помогает упростить процесс EDA и сделать его более удобным.
7. dabl
Dabl Dabl - поможет визуализировать данные за одну строчу кода. Обычно ML-специалисты используют matplotlib для визуализации, строя нужны графики один за другим. В Dabl вызов одного метода построит целый набор диаграмм.
8. speedML
SpeedML – это библиотека Python, целью которой является ускорение процесса разработки конвейера машинного обучения.
9. Sketch
Sketch— это новая библиотека, которая использует возможности ИИ, чтобы помочь вам понять ваши dataframes pandas, используя вопросы на естественном языке непосредственно в Jupyter.
10. Bamboolib
Bamboolib - это библиотека Python, которая предоставляет компонент пользовательского интерфейса для анализа данных без кода в Jupyter. Одним из вариантов её использования является написание кода для функций, создание которых занимает много времени. Bamboolib предназначена для упрощения обычных задач обработки данных, исследования и визуализации и может использоваться как начинающими, так и опытными аналитиками данны
▪ Подробнее
@
Читать полностью…
Анализ данных (Data analysis)
04 July 2023 13:37
🖥 Продвинутый парсинг данных на Python.
Сегодня многие веб-сайты используют JavaScript для динамической загрузки контента. Это может затруднить парсинг данных традиционными методами.
Тем не менее, существует ряд инструментов, которые могут помочь вам спарсить данные с сайтов, использующих JavaScript.
1. Парсинг динамических сайтов.
Вот пример того, как использовать Selenium для парсинга веб-сайта, перегруженного JavaScript:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Firefox()
driver.get('https://www.example.com')
# Wait for the JavaScript to load
time.sleep(5)
# Get the page source
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Extract the data
table = soup.find('table', attrs={'id':'dynamic-table'})
data = []
for row in table.find_all('tr'):
data.append([cell.text for cell in row.find_all('td')])
# Close the browser
driver.quit()
Этот код сначала откроет веб-сайт в браузере Firefox. Затем он будет ждать загрузки JavaScript. После загрузки JavaScript, мы получим исходный текст страницы и разберм его с помощью BeautifulSoup.
Наконец, мы извлечем данные из таблицы и закроем браузер.
2. Работа с CAPTCHA и IP-блокировками
Существует ряд инструментов, которые могут помочь вам решить CAPTCHA. Одним из популярных инструментов является Anti-Captcha: https://anti-captcha.com/.
import requests
url = 'https://anti-captcha.com/api/create'
data = {
'type': 'image',
'phrase': captcha_text
}
response = requests.post(url, data=data)
captcha_id = response.json()['captchaId']
url = 'https://anti-captcha.com/api/solve'
data = {
'captchaId': captcha_id
}
response = requests.post(url, data=data)
solution = response.json()['solution']
Этот код сначала отправляет текст CAPTCHA в Anti-Captcha. Затем Anti-Captcha вернет captchaId, который вы можете использовать для запроса решения.
Получив решение, вы можете использовать его для обхода CAPTCHA.
3. Пример того, как использовать прокси-сервис для изменения вашего IP-адреса:
import requests
import random
def get_proxy():
"""Gets a proxy from the proxy scrape service."""
response = requests.get('https://www.proxyscrape.com/')
data = response.json()
proxy = random.choice(data['results'])['ip'] + ':' + data['results'][0]['port']
return proxy
def scrape_website(proxy):
"""Scrape the website using the proxy."""
response = requests.get(url, proxies={'http': proxy, 'https': proxy})
soup = BeautifulSoup(response.text, 'html.parser')
data = []
for row in soup.find_all('tr'):
data.append([cell.text for cell in row.find_all('td')])
return data
if __name__ == '__main__':
proxy = get_proxy()
data = scrape_website(proxy)
print(data)
# Rotate the proxy
proxy = get_proxy()
data = scrape_website(proxy)
print(data)
Этот код сначала получит прокси от сервиса proxy scrape. Затем он будет использовать прокси для сканирования веб-сайта. Наконец, он выведет данные, которые были получены при парсинге.
@
Читать полностью…
Анализ данных (Data analysis)
30 June 2023 18:01
🔊 AudioPaLM - нейросеть Google, которая умеет разговаривать, слушать и переводить.
AudioPaLM новая языковая модель, от Google, объединяющая две предыдущие модели: PaLM-2 и AudioLM. Эта мультимодальная архитектура позволяет модели распознавать речь, сохранять особенности интонации и акцента, осуществлять перевод на другие языки на основе коротких голосовых подсказок и делать транскрипцию.
При переводе некоторых языков, таких как итальянский и немецкий, модель имеет заметный акцент, а при переводе других, например французского, говорит с идеальным американским акцентом.
Матрица эмбеддингов предварительно обученной модели используется для моделирования набора аудио-токенов.
На вход в модель подается смешанная последовательность текстовых и аудио-токенов, и модель декодирует эти токены в текст или аудио. Аудио-токены в дальнейшем преобразуются обратно в исходное аудио с использованием слоев модели AudioLM.
🖥 Demo: https://google-research.github.io/seanet/audiopalm/examples/#asr-section
📕 Статья: https://arxiv.org/abs/2306.12925
@
Читать полностью…
Анализ данных (Data analysis)
30 June 2023 13:12
🔥 Большой список сайтов с практическимим задачами для программистов.
Codeforces — платформа для алгоритмических соревнований. Проводит контесты и раунды с 5 задачами на 2 часа. Есть система рейтинга и два дивизиона. Задачи можно решать и проверять после соревнования. Также есть доступ к тренировкам с задачами с прошлых соревнований.
HackerRank - сайт будет больше интересен продвинутым программистам, которые уже многое умеют. На этом сайте собрано множество задач на самые разные разделы Computer Science: традиционная алгоритмика, ИИ, машинное обучение и т.д. Если вы решите много задач, то вами могут заинтересоваться работодатели, регуляторно мониторящие эту платформу.
Codewars — популярный cборник задач на разные темы, от алгоритмов до шаблонов проектирования.
LeetCode — известный сайт с задачами для подготовки к собеседованиям. Можно пообщаться и посмотреть решения других программистов.
Timus Online Judge — русскоязычная (хотя английский язык также поддерживается) платформа, на которой более тысячи задач удачно отсортированы по темам и по сложности.
TopCoder - популярная американская платформа. Она проводит алгоритмические контесты, а также соревнования по промышленному программированию и марафоны, где задачи требуют исследования и нет единого верного алгоритма. Участникам даются недели на решение таких задач.
informatics.mccme.ru - платформа с теоретическим материалом и задачами, удобно разделенными по категориям. Большая база задач с олимпиад школьников также доступна.
SPOJ - большой англоязычный сайт с 20000+ задачами на разные темы: DP, графы, структуры данных и др. Иногда проводят неинтересные контесты, если не из страны их проведения.
CodeChef — менее крупный аналог Codeforces и TopCoder, тоже с огромным архивом задач и регулярными контестами.
Project Euler - сборник 500 задач, проверяющих знание математических алгоритмов. Часто используется на собеседованиях, чтобы оценить алгоритмическую подготовку кандидата.
Kaggle - соревнования по анализу данных.
Golang tests - канал с тестами по Go
CodinGame - сайт для программистов и геймеров, предлагающий большую коллекцию видеоигр, оформленных в виде задач на программирование.
Al Zimmermann’s Programming Contests — платформа, на которой регулярно проводятся контесты с задачами на исследование и оптимизацию. Интересен тем, что писать программу необязательно — даются только тестовые данные. Ответы можно расчитывать вручную, или просто гадать их на кофейной гуще.
Programming Praxis — сайт, где можно найти много интересных задач.
CheckIO — сайт с задачами для программистов всех уровней, который вы проходите в виде игры.
Ruby Quiz — сайт с задачами для программистов на Ruby, но решения можно писать и на других языках.
Prolog Problems — Подборка задач для программистов, использующих Prolog.
Сборник задач от СppStudio - задачи на С++, но их можно и на других языках.
Operation Go — практика написания кода на Go в форме браузерной игры.
Empire of Code — сайт для программистов, где необходимо писать код, реализующий стратегию и тактику виртуальных бойцов.
@
Читать полностью…
Анализ данных (Data analysis)
29 June 2023 11:16
⚡️Осилите ли вы тест для Data-инженеров?
Ответьте на 24 вопросов за 30 минут и проверьте, готовы ли вы к обучению на онлайн-курсе «Spark Developer» от OTUS.
Spark — важнейший фреймворк в Big Data c открытым исходным кодом. На курсе вы научитесь работать с большими данными и закрепите знания с помощью сложных домашних заданий и выпускного проекта.
Пройдете тест — получите демо-ролик о занятиях на курсе и доступ к 2 открытым урокам:
— «Spark UDAF: разрабатываем свой агрегатор», 27 июня в 20:00
— «Оптимизация параметров запуска приложения Spark», 11 июля в 20:00
📝Пройти тест: https://otus.pw/BFMz/
Нативная интеграция. Информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
28 June 2023 17:02
🔥Хотите стать одним из авторов проектов, которые меняют жизнь людей к лучшему в области автоматизации предприятий, медицины, робототехники, виртуальной реальности и других сферах, или стать руководителем отдела Computer Vision в вашей компании? Все это возможно после прохождения обучения на курсе “Компьютерное зрение” в OTUS. Сейчас открыт набор в группу.
Приходите 29 июня в 20:00 мск на открытый урок «PyTorch 2.0», чтобы познакомиться с преподавателем и программой курса, оценить все перспективы, которые откроются перед вами.
На занятии мы также обсудим, что нового принес фреймворк PyTorch 2.0 в сферу компьютерного зрения и глубокого обучения.
📌Вы узнаете:
- Как начать использовать PyTorch для обучения своих нейронных сетей
- Что нового в PyTorch 2.0 и чем он отличается от 1.x
- Как ускорить и оптимизировать свою нейросеть при помощи одной строчки кода
- Как перейти с PyTorch 1.x на 2.0
- Как ускорить трансформеры HuggingFace при помощи PyTorch Transformer API
👉🏻Для участия отправьте заявку https://otus.pw/2ZGX/
Кому подходит этот урок:
- Начинающим и опытным специалистам в области компьютерного зрения и глубокого обучения
- Дата сайентистам, которые хотят ускорить инференс своих моделей
- Опытным специалистам, которые еще не перешли на PyTorch 2.0
- Тем, кто хочет познакомиться с фреймворков PyTorch и начать обучать свои нейросети
Нативная интеграция подробная информация о продукте www.otus.ru
Читать полностью…
Анализ данных (Data analysis)
28 June 2023 11:01
Автоматизированный перенос DWH Microsoft на платформу Yandex Cloud с помощью BI.Qube
📆 06.07.2023 в 10:00-12:00 (МСК) на вебинаре команды BI.Qube, Yandex Cloud и Банка Финсервис расскажут о практическом опыте автоматизированной миграции DWH Microsoft на платформу Yandex Cloud.
За 2 часа вы:
👉 узнаете об актуальных кейсах, включая историю миграции DWH банка Финсервис
👉 увидите весь путь от извлечения данных из учётных систем до построения аналитики
👉 применение low-code/no-code инструментов из Реестра российского ПО
Пример анализа программы лояльности будет интересен как специалистам банковской сферы, так и крупному ритейлу, где необходимо анализировать эффективность на основе данных из разрозненных систем.
Вебинар рассчитан на экспертов по аналитике и работе с данными, архитекторов и инженеров данных, CIO, CDO.
Программа вебинара
Регистрация: @
Читать полностью…
Анализ данных (Data analysis)
27 June 2023 10:12
Как использовать многоруких бандитов на практике | Гайд для аналитиков, продуктовых менеджеров и ML-специалистов
Ведущая аналитическая система MyTracker разработала практическое руководство для использования многоруких бандитов в продуктах.
Вы узнаете, что такое многорукие бандиты и как они применяются в различных сферах, в том числе в рекомендательных системах. Подробнее остановимся на различных алгоритмах бандитов: жадный, алгоритм UCB, алгоритм сэмплирования Томпсона и контекстуальные многорукие бандиты.
Гайд пригодится аналитикам для определения оптимальных стратегий тестирования, продуктовым менеджерам - для тестирования новой функциональности, а ML-специалистам - для настройки моделей машинного обучения.
Руководство составлено командой предиктивной аналитики MyTracker, которая использует многоруких бандитов в своей работе.
Скачайте практическое руководство от команды предиктивной аналитики MyTracker и узнайте, как многорукие бандиты могут увеличить прибыль вашего продукта и улучшить продуктовые метрики.
Читать полностью…
Анализ данных (Data analysis)
26 June 2023 17:37
Data Science | Machinelearning - самый большой русскоязычный канал с полезными материалами на такие темы как, Machine Learning, Data Science, Алгоритмы, Python. Так же часто публикуются крутые 🔥 вакансии.
👉 Вам сюда: @
А любителям читать статьи в оригинале вот сюда:
👉 @
Добро пожаловать!
Читать полностью…



 48228
48228
{kind=link}
{kind=link}