Datalytics
04 Sep 2024 11:55
Продуктовые аналитики, вас тут ищут
В Т-Банке пройдет Week Offer для уровня middle и senior. Можете пройти все этапы собеседования за неделю и попасть в ИТ-команду.
Если справитесь, будете развивать продукты для 43 млн клиентов. Выдвигать гипотезы, обосновывать данными и концентрироваться на аналитике — рутинные задачи тут можно автоматизировать.
Вот чем еще хороша эта работа:
— Актуальный стек технологий. Тут следят за трендами и быстро внедряют новое.
— Прозрачная система роста. Всегда будете знать, какие навыки развивать.
— Сильное комьюнити. Можно делиться опытом на конференциях и митапах, а еще — участвовать в подкастах.
— Офисы в 23 городах России и гибридный формат работы.
Успейте подать заявку до 25 сентября. Больше рассказали тут
Реклама. АО "ТБанк", ИНН 7710140679, лицензия ЦБ РФ № 2673
Читать полностью…
Datalytics
03 Sep 2024 17:33
Кластерная якорная регуляризация в рекомендательных системах
Обучение на логах юзеров может приводить к popularity bias. Мы рекомендуем айтемы, человек их смотрит, это попадает в логи и оттуда — в дальнейшее обучение. В итоге «богатый становится богаче». Известные способы борьбы с этим ухудшают перфоманс популярных айтемов, что тоже плохо. Ресёрчеры из DeepMind предлагают свой метод, Cluster Anchor Regularization, и применяют его для YouTube Shorts.
Иерархическая кластеризация
Индекс делится на кластеры, затем каждый из них кластеризуют снова — так мы получаем следующие уровни. Для каждого кластера учим эмбеддинг, чтобы приблизить к нему tail-айтемы того же кластера.
Кластеры генерируют энкодером с учётом метаданных и контента. 2-миллиардный индекс мапится в 256-размерные эмбеддинги. Они фиксированы, считаются один раз и нужны лишь для построения графа, который и будет кластеризоваться. Об архитектуре энкодера авторы не пишут.
Ноды графа — айтемы, а рёбра отражают косинусную близость между ними. Граф разбивается на кластеры так, что рёбра, выходящие из одного кластера и приходящие в другой, получают меньший вес. Каждой ноде сопоставляют вес, равный √ числа взаимодействий с айтемом. После 4 уровней кластеризации получается 48 000 кластеров. В каждом из них внутри одного уровня примерно одинаковое число взаимодействий.
Якорная регуляризация
Внутри кластеров есть source- и target-айтемы. В нашем случае source — популярные айтемы, а target — непопулярные. Каждому айтему сопоставляем его обучаемый эмбеддинг, а каждому кластеру — эмбеддинг такой же размерности. На первом этапе source-айтемы мапятся в свои кластеры, а представления кластеров обучают так, что градиент просачивается в них, не изменяя source-векторы.
На втором этапе то же самое происходит с target-айтемами, но обновляется уже не представление кластера, а векторы target’ов. Результаты обоих этапов добавляем в основной loss. Благодаря этому получается «эффект якоря»: популярные айтемы «тянут» за собой непопулярные.
@
Разбор подготовил ❣ Сергей Макеев
Читать полностью…
Datalytics
29 Aug 2024 14:01
Ozon Tech ждёт тебя на E-CODE!
⏰ IT-конференция E-CODE пройдет 28 и 29 сентября.
Что тебя ждёт:
- ML-трек с докладами от ведущих экспертов индустрии.
- Live-запись IT-подкаста.
- Научно-популярный трек для тех, кто жаждет знаний.
- Игры на свежем воздухе, чтобы размяться и повеселиться.
- Караоке для смелых и талантливых.
- А ещё вечеринка в финале!
Будет всё: от полезных знаний до веселья и нетворкинга. Не пропусти!
📌 Зарегистрироваться
Читать полностью…
Datalytics
25 Aug 2024 09:03
У Яндекс Погоды новая технология — OmniCast. Она умеет точно прогнозировать температуру в конкретном квартале города.
В связи с нововведением частота обновления прогноза выросла в 36 раз: теперь он обновляется не раз в 3 часа, а каждые пять минут. Как создавали такую нейросетевую модель — подробно расписали разработчики на Хабре. Но можно немного приоткрыть тайну: помимо профессиональных метеостанций сервис стал учитывать и любительские.
Кстати, Яндекс Погода призывает пользователей и организации, у которых есть метеостанции, подключаться к сервису с помощью API.
Читать полностью…
Datalytics
23 Aug 2024 13:15
Модель ИИ для борьбы с онлайн-токсичностью
Решил поделиться результатами своей работы в стартапе.
А занимался я разработкой моделей для модерации контента, направленной на искоренение онлайн-токсичности и создание активных онлайн-сообществ.
Основной целью было разработка модели с высоким перфомансом и минимальным вычислительным затратам и чрезвычайно низкой задержкой.
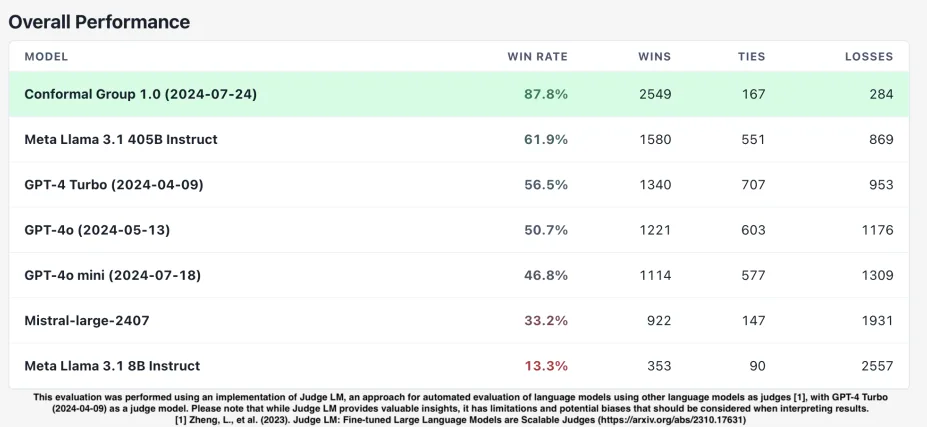
У нас получилось достигнуть F1-оценку почти 0.96 и AUPRC выше 0.98, при среднем времени оценки контента менее 40 миллисекунд.
Модель также превзошла ведущие ИИ-модели во время независимой оценки, проведенной компанией OpenPipe, лидером в области доработки и оценки доработанных моделей. (можно увидеть на скрине)
Полный текст анонса
А у меня теперь новый карьерный этап, но об этом чуть позже
Читать полностью…
Datalytics
19 Aug 2024 16:42
Посчитаете LTV даже во сне?
Создайте курс для Яндекс Практикума!
Яндекс Практикум — сервис онлайн-образования, где можно получить актуальную цифровую профессию, например, продуктового аналитика. Помогите нам создать достойный обучающий контент для студентов!
Что делает автор курса?
Разрабатывает уроки, тесты, чек-листы, а если шире, то его задача так упаковать свой опыт, чтобы заинтересовать, объяснять и мотивировать.
Почему это интересно практикам?
Вы влияете на индустрию, получаете статус эксперта и дополнительный доход. Нагрузка — 10 часов в неделю, удалёнка и команда, с которой некогда скучать.
Кто подойдёт?
Продуктовый аналитик, который уже более 3 лет в профессии и чувствует непреодолимое желание делиться своими знаниями.
Подробности здесь ←
Ждём ваших откликов!
Читать полностью…
Datalytics
14 Aug 2024 15:04
🌐 Открыт демо-доступ к курсу Data Warehouse на базе dbt для инженеров и аналитиков данных
Этот курс - не просто обучение, а полноценный тренажер, где вы освоите один из самых востребованных инструментов аналитики, решая сложные практические задачи. Изучите DataOps практики, постройте хранилище данных на базе dbt, подготовьте и проанализируйте данные.
В тренажере вы освоите:
1. Типы хранилищ данных DWH и их построение
2. Подготовку и тестирование данных, Data Quality
3. Построение ELT-pipelines
4. Моделирование данных на базе dbt и PostgreSQL
5. Принципы работы с СУБД на базе Postgres
6. Продвинутую аналитику и визуализацию данных
7. Современные DataOps-практики, оптимизацию производительности и многое другое
Разработаете свои pet-проекты:
🔥 Статистика поездок на самокатах: Построите аналитический пайплайн для общей и дневной статистики поездок, включая тесты качества данных и документацию.
🔥 Аналитика ивентов приложения: Создадите SQL-пайплайн для обработки событий мобильного приложения, обогащённый данными поездок и пользователей, с внедрением контрактов данных и продуктовыми метриками.
🔥 Создание аналитической платформы: Развернете dbt-пайплайны с планировщиком, мониторингом и централизованным git-репозиторием, внедрить проверку качества данных и веб-портал с каталогом данных и документацией.
Сейчас открыт демо-доступ к первым четырем практическим урокам для всех желающих.
🔵 Регистрация на демо-доступ
Реклама. ООО «Инженеркатех», ИНН 9715483673, erid 2Wyjqwic4tL
Читать полностью…
Datalytics
13 Aug 2024 13:42
🛢 В мире, где данные — новая нефть, растёт спрос на дата-инженеров. Ведь именно они знают, как такую нефть добывать, обрабатывать и хранить. И пока компании осознают потребность в этих специалистах, конкуренция на рынке низкая, а зарплаты — высокие.
Освоить ключевые компетенции дата-инженера поможет онлайн-магистратура Нетологии и НИУ ВШЭ «Инженерия данных». За 2 года вы на практике изучите Python, Java, Scala, Kotlin и SQL, научитесь проектировать пайплайны и обрабатывать данные, работать с системами хранения данных и базами данных в облаке. Программа даёт широкий простор для переквалификации, поэтому после учёбы сможете перейти в MLOps, DevOps или менеджмент.
Онлайн-формат позволяет учиться без отрыва от привычной жизни и совмещать занятия с работой. При этом у вас будет отсрочка от армии, льготы на проезд и все остальные бонусы очного обучения.
Станьте магистром программной инженерии с дипломом одного из лучших вузов страны и получите веское преимущество при приёме на работу: ссылка
Реклама. ООО "Нетология". ИНН 7726464125 Erid:LjN8KDPjX
Читать полностью…
Datalytics
12 Aug 2024 14:31
В чём особенность рекламы на маркетплейсах и как она связана с ранжированием и продвижением — обсуждают эксперты бигтехов в подкасте «Рандомные дрова» от Ozon Tech.
Слушайте, чтобы узнать, как работает механизм аукциона изнутри, как ML-модели учитывают конверсию и какие метрики нужны для измерения качества рекламы в e-com.
🎧 Приятного прослушивания на любимой площадке!
Читать полностью…
Datalytics
05 Aug 2024 13:57
Пузырь генеративного ИИ начал лопаться, считает Маркус. Он упрекает обучателей крупнейших нейросеток в том, что у них нет внятной бизнес-модели, которая окупила бы гигантские затраты этого сектора. Вложены уже сотни млрд. $, а главный вопрос надежности/галлюцинаций так и не решен, что резко ограничивает применимость технологии.
Он и не будет решен, т.к. это неотъемлемое свойство GenAI, настаивает Маркус.
В целом он твердит об этом давно, но теперь предрекает крах уже в этом году: “Пользователи потеряли веру, клиенты потеряли веру, венчурные инвесторы потеряли веру”. Возможно, его сподвиг недавний отчет Goldman Sachs “Gen AI: too much spend, too little benefit?”, где проводится та же мысль, более мягкими словами (см. также разбор отчета).
Несмотря на ряд успехов GenAI, например, в генеративной (био)химии, можно видеть, как тускнеют ожидания и как меняется тон комментариев, не только у Маркуса. Все наигрались в генерацию картинок/текстов и хотят, наконец, использовать ИИ в реальных задачах. Но этот переход не дается — в силу самой природы GenAI. Ключевой изъян в том, что GenAI беззащитен перед т.н. “выбросами”. Если на входе паттерн, сильно отличный от паттернов в обучающей выборке, на ответ нельзя положиться. Такой ИИ не понимает и не мыслит, он создает новые данные по шаблону старых.
Масштабирование не избавит от проблем (см. “AI scaling myths”). Метрики, где ИИ превосходит людей в решении задач, не измеряют интеллект/мышление, а превосходство может быть хрупким. Синтетические данные — не панацея от дефицита данных для обучения, такой маневр быстро ведет к коллапсу, т.к. каждая следующая модель учится не на реальности, а на предсказании реальности предыдущей моделью, и даже малые ошибки итеративно усиливаются.
Я бы не использовал слово “пузырь”. GenAI очень интересный инструмент, со временем мы поймем, как сделать его не просто удивляющим, но и полезным. Но отрезвление ожиданий — хороший признак.
Читать полностью…
Datalytics
02 Aug 2024 14:21
Если ты системный аналитик с глубокой технической экспертизой, ждём тебя в команду SberDevices! 🖥
Мы занимаемся разработкой умных устройств, виртуальных персонажей и продуктов на основе голосовых и речевых технологий.
В твой скоуп задач будут входить ⤵️
▪️ Анализ, разработка и согласование требований к новому функционалу, доработка существующих модулей системы, описание API и протоколов, реализация задач по интеграции со сторонними сервисами.
▪️ Участие в разборе инцидентов, анализ причин и последствий.
▪️ Описание сценариев приёмочных испытаний реализованного продукта.
Читай подробности и откликайся по ссылке 👌
Читать полностью…
Datalytics
27 Jul 2024 17:24
Наткнулся тут на интересную статью 2009 года, где автор высказывает мнение о том, что изобретение VisiCalc (первого приложения электронных таблиц) необратимо изменило мир и то как принимаются решения
Основная мысль состоит в том, что электронные таблицы демократизировали процесс «что-если» (what-if) анализа. Во-первых, до электронных таблиц было меньше аналитиков. Во-вторых, раньше этим аналитикам было сложнее оперировать большим количеством переменных. Никто не просил от каких-нибудь финансистов разработать 20 вариантов расчетов с разными входными данными, потому что в головах менеджеров не было такой парадигмы как «хочу чтобы мне смоделировали все варианты». Не могу подтвердить или опровергнуть что это так. Думаю, что менеджеры всегда принимали решения на основе подсчетов, вопрос точности этих подсчетов, гранулярности данных, а также возможности принимать в расчет вариантивность и вероятностную природу многих переменных. Почитайте, например, про модель EOQ (Economic order quantity), которую еще при Форде использовали для расчета экономики предприятия. Проблема в том, что экономика усложнялась и примитивная EOQ уже не подходила
В общем, спредшиты настолько демократизировали процесс работы с данными, который ранее был доступен только статистикам и ученым, что каждый менеджер начал все считать и моделировать. И начал простить считать и моделировать своих подчиненных. И вот тут то и появилась парадигма «принеси мне метрики». Что в итоге привело к буму «количественного менеджмента», ну и дальше трансформировалось в data-driven и в наукообразное «рост бизнеса как набора гипотез»
Я не буду тут распинаться про то, что даже в нашу data-driven эпоху с ее верой в «объективность данных» очень многое зависит от человеческого фактора, в том числе от качества интерпретации и выводов, которые строятся на основе данных. Мне интереснее другое
В статье приводится пример с переносом завода – мол, факторный анализ позволил оценить что дешевле производить товар в другом регионе, а потеря качества не повлияет на конечную прибыль. Но как мне кажется, тут вопрос ответственности людей, которые принимают решения о переносе, а не технологии, благодаря которой стал возможен «оптимальный расчет»
И все тут лежит скорее в части логики современного общества, из-за которой мы все больше и больше нуждаемся в предиктивной аналитике. И есть у меня подозрение что именно благодаря этой логике мы видим бум AI и влажные фантазии вокруг того, что AI революционизирует бизнес. А по факту сделаем очередной Excel
Читать полностью…
Datalytics
24 Jul 2024 11:04
Проходить собеседования — это навык. Если в 2024-м вы хотите
— меньше волноваться на собесах,
— эффективнее отвечать на вопросы и грамотно задавать их,
читайте канал про собеседования в IT, где собран опыт и кандидата, и работодателя.
——————
🔹Булат ходит на собесы из азарта и интереса и пишет, что да как: какие были этапы, какие задавали вопросы.
Лонгрид раз — про интервью к поставщику и разработчику технологий для бирж
Два — про интервью в финтех
Три — в Medtech
🔹Булат сам нанимает сотрудников и рассказывает, почему кандидату отказали.
Лонгрид раз — про закрытые ответы
Два — про улыбку и болтовню
Три — про кандидата, который спорил
—————
✅Подписывайтесь, чтобы быть готовыми к собеседованию, а в случае отказа — сохранять здравую самооценку.
/channel/tryoutonadancefloor
👆
Читать полностью…
Datalytics
18 Jul 2024 15:19
Не будем утомлять вас рассказами о ДМС, крутых офисах и других плюшках. Вот главное о том, почему продуктовые аналитики выбирают Т-Банк:
➖Актуальный стек. Здесь следят за трендами и быстро внедряют новое.
➖Прозрачная система роста. Вы всегда будете знать, какие навыки нужно подтянуть и как получить повышение.
➖Вы окажетесь среди профессионалов, у которых можно многому научиться. А если захотите, можете стать ментором для младших коллег.
➖Общение на «ты». Так проще.
➖Здесь развивают комьюнити. Можно участвовать в митапах и подкастах.
Больше о вакансиях здесь
Реклама. АО «Тинькофф Банк», ИНН 7710140679
Читать полностью…
Datalytics
16 Jul 2024 10:59
Какой путь к работе мечты самый короткий? Конечно, One Day Offer от Сбера! 😉
Если ты Data Analyst или Data Engineer, мы ждём тебя 27 июля. Получи возможность пройти fast-интервью, познакомиться с командой и забрать долгожданный оффер всего за один день.
Наша команда разрабатывает и внедряет DS-решения в точки касания клиента со Сбером: отделения, мобильное приложение, банкоматную сеть и т.д. Мы работаем с технологиями Python, Spark, SQL, Hadoop, GreenPlum и за год внедряем более 200 моделей.
Тебя ждут интересные и разноплановые задачи 👇
▪️ Обучение всех типов моделей искусственного интеллекта: от классического ML до глубоких нейронных сетей.
▪️ Создание высокотехнологичных сервисов: от систем принятия решений до компьютерного зрения и обработки естественного языка.
▪️ Развитие хранилища на Teradata и DataLake на Hadoop.
Отправляй заявку уже сейчас и присоединяйся к команде!💚
Читать полностью…
Datalytics
03 Sep 2024 19:03
Больше не нужно искать тематические каналы и по отдельности на них подписываться - мы сделали это за Вас 🤝
Вам остается только сохранить папку себе и регулярно получать полезные ресурсы из сферы «IT и Технологий» 🔥
/channel/addlist/VMuK8A3-KfM5NzM6
Хотите в подборку?
Читать полностью…
Datalytics
30 Aug 2024 16:32
👀 ICML 2024 глазами ML-лидов Яндекса
The International Conference on Machine Learning — одна из крупнейших международных конференций по машинному обучению.
➡️ В этом году её посетила делегация из 46 яндексоидов. Недавно впечатлениями делился наш коллега Владислав Офицеров, а теперь о своих наблюдениях рассказывают CTO Поиска Алексей Гусаков и ML Brand Director Пётр Ермаков — листайте карточки!
⭐️ Если у вас оформлен Telegram Premium, поддержите наш канал по ссылке
Подписывайтесь:
💬 @
Читать полностью…
Datalytics
27 Aug 2024 16:24
Компания Anthropic опубликовала системные промпты для своей языковой модели Claude 3.5. Это значимое событие для всех, кто интересуется разработкой чат-ботов и prompt engineering.
Системный промпт - это набор инструкций, которые определяют базовое поведение и личность AI-ассистента. Обычно эта информация не раскрывается разработчиками и считается коммерческой тайной.
Однако Anthropic решили пойти на беспрецедентный шаг и поделиться промптами своей модели. Это дает нам возможность изучить принципы работы одного из самых продвинутых чат-ботов на рынке.
Знакомство с промптами Claude 3.5 может быть полезно для всех, кто занимается или планирует заниматься созданием собственных AI-ассистентов. Это возможность перенять опыт ведущих специалистов в области и усовершенствовать свои навыки prompt engineering.
Конечно, нужно понимать, что каждый проект уникален и требует индивидуального подхода. Но изучение промптов Claude 3.5 может дать ценные инсайты и вдохновение для собственных экспериментов и разработок.
Так что если вы хотите быть в курсе последних трендов в мире чат-ботов и AI-ассистентов, рекомендую ознакомиться с опубликованными промптами. Это может стать полезным ресурсом для вашего профессионального развития в этой перспективной области.
https://docs.anthropic.com/en/release-notes/system-prompts#july-12th-2024
#Anthropic #Claude #PromptEngineering #ChatbotDevelopment #AIAssistants
Читать полностью…
Datalytics
23 Aug 2024 14:04
Суперкомпьютеры тоже ломаются. Вернее, проблема может возникнуть в одной из их составляющих.
В случае, которым поделились ML-специалисты Яндекса, необычная поломка произошла у вентиляторов, которые охлаждают видеокарты.
Спустя два года работы в дата-центре во Владимире вентиляторы стали выходить из строя и буквально разлетаться на куски один за другим. Получался своего рода эффект шрапнели.
Компанда начала разбираться в причинах неисправности и выяснила, что проблема была в качестве пластика. О том, как в итоге ее удалось устранить, рассказали в посте.
Читать полностью…
Datalytics
20 Aug 2024 11:24
Mixture-of-Agents — простой способ улучшения ответов LLM
Сегодня рассмотрим статью, которая описывает метод улучшения результатов LLM на разных бенчмарках без дообучения. Он называется Mixture-of-Agents (MoA).
Суть метода заключается в использовании нескольких LLM для генерации ответов. Авторы статьи создали многослойную структуру с несколькими агентами — собственно, моделями — на каждом слое. На вход подавали один вопрос. Каждый из агентов давал ответ. Затем полученные данные агрегировались и вместе с промптом передавались на следующий слой, где процесс запускался заново.
В итоге получался ответ, который превосходит по качеству все предыдущие. Интересно то, что модели показывают лучшие результаты, когда имеют доступ к выходным данным других LLM — даже если ответы последних не слишком качественные. Этот феномен авторы назвали «коллаборативностью LLM» (Сollaborativeness of LLMs).
Эксперименты показали, что использование разных LLM на разных слоях улучшает результаты. Агрегаторы тоже играют важную роль — если пропоузеры могут быть относительно простыми и легкими, то агрегаторы требуют значительных вычислительных ресурсов.
Бенчмарки подтвердили, что MoA — эффективный метод. Скажем, на AlpacaEval 2.0 и MT-Bench применение такой архитектуры дало прирост производительности до 8% по сравнению с GPT-4 Omni.
Впрочем, MoA есть куда расти. Например, в области уменьшения времени до первого токена. Из-за итеративной агрегации конечному пользователю приходится долго ждать ответа на вопрос. Авторы статьи намерены бороться с этим недостатком.
Рассказывайте в комментариях, что думаете о MoA?
Разбор подготовил ❣ Никита Шевченко
Душный NLP
Читать полностью…
Datalytics
19 Aug 2024 15:07
🔥 Попробуйте себя в роли аналитика: анализируем клиентскую базу с нуля!
Хотите попробовать себя в роли аналитика и узнать, интересна ли вам эта сфера для развития? Тогда приходите на бесплатный практический интенсив, где в прямом эфире мы вместе будем решать реальную задачу бизнеса, с которой сталкиваются аналитики данных.
Что будет на интенсиве: вы с помощью Excel проанализируете клиентскую базу крупного онлайн-магазина и сформулируете выводы для бизнеса на основании проведенной аналитики. А это как раз то, чем занимаются аналитики каждый день.
📅 Дата: 20 августа.
🕗 Время: 19:00 по Мск.
Интенсив будет полезен как новичкам, так и тем кто уже имеет базовые знания в этой сфере и хочет почерпнуть для себя лайфхаки по работе с данными.
🔗 Регистрируйтесь на интенсив здесь.
Не упустите шанс, попробовать себя в роли аналитика и узнать лайфхаки по работе с данными!
Рекомендуем регистрироваться на вебинар через ПК, чтобы избежать возможных ошибок при открытии бота.
Реклама. ООО «АЙТИ РЕЗЮМЕ». ИНН 4025460134.
Erid:LjN8K4QgJ
Читать полностью…
Datalytics
14 Aug 2024 12:47
💥Начните изучать Machine Learning и Data Science бесплатно — в Skillbox
Получите доступ к 5 модулям курса, познакомьтесь с основами Excel и Python, оцените качество уроков и решите, стоит ли продолжать обучение.
👉Попробуйте Machine Learning в Skillbox бесплатно прямо сейчас и получите дополнительную скидку 5%. Пригодится, если захотите продолжить обучение на полном курсе и максимально сэкономить: https://epic.st/jM7-lL?erid=2Vtzqv6wSQU
Кстати, на полном курсе вас ждут:
Практика на реальных данных от компаний и экспертов
3 сильных проекта
в портфолио
Помощь в трудоустройстве
Спикеры из Сбера, VK и других топовых компаний
Обратная связь и разбор заданий с наставником
Столько всего полезного — в одном курсе! Самое время попробовать его — бесплатно: https://epic.st/jM7-lL?erid=2Vtzqv6wSQU
Реклама. ЧОУ ДПО «Образовательные технологии «Скилбокс (Коробка навыков)», ИНН: 9704088880
Читать полностью…
Datalytics
12 Aug 2024 16:03
7 базовых функций SQL, первый код с нуля за полтора часа и практика на настоящих данных? Сделаем бесплатно!
Если вы всегда хотели попробовать SQL, но не знали, с чего начать, начните с бесплатного мастер-класса с Серафимом Фролкиным, инженером данных VK и экспертом программ школы аналитики Changellenge >> Education.
Без лишней теории про историю создания и количество проданных в мире учебников Серафим на примерах покажет 7 базовых функций SQL, а затем вы сразу же решите практический кейс, чтобы повысить свои шансы при трудоустройстве.
Присоединяйтесь онлайн из любой точки на глобусе 15 августа в 19:00 Мск. И да, у нас приятные карьерные бонусы всем зарегистрировавшимся и участникам!
Участие бесплатно, но подарки получат только зарегистрированные участники.
Регистрируйтесь и получайте подарки по ссылке >> https://u.to/hpTTIA
Читать полностью…
Datalytics
07 Aug 2024 15:31
Аналитика! Продукт! Мотор!
22 августа на больших экранах премьера аналитического митапа от команды Купер.тех (ex СберМаркет Tech).
Объединим четыре сюжетные линии и завершим кульминационной afterparty:
🎬 Предсказание оптимального ПВЗ покупателя на Авито. Directed by Ксения Кригер, аналитик в команде логистики, Авито.
🎬 Факторный анализ Retention пользователей самовывоза и B2B. Directed by Никита Истомин и Евгений Кадыгров, продуктовые аналитики самовывоза и B2B, Купер.
🎬 Не CSAT’ом едины: как анализировать клиентский опыт с помощью ML-алгоритмов? Directed by Владислав Петраков, руководитель продуктовой аналитики Платформы Origination, и Анна Муратова, продуктовый аналитик, Т-Банк.
🎬 Как ошибиться в АВ-тестах, даже если хорошо знаешь математику. Directed by Никита Мананников, руководитель направления аналитики BX, Ozon.
🗓 22 августа в 19:00 по Москве, КАРО 11 Октябрь.
Регистрируйся по ссылке и приятного просмотра!
Реклама. ООО «ИНСТАМАРТ СЕРВИС», ИНН: 9705118142. Ерид: LjN8KE4Et
Читать полностью…
Datalytics
31 Jul 2024 16:37
Ищем Data аналитика в команду Сбера с релевантным опытом работы от 3-х лет 👨💻
Вам предстоит разрабатывать кампании продаж на стеке Python и Greenplum, создавать и оптимизировать SQL запросы, анализировать эффективность и проводить A/B тесты.
✅ Мы предлагаем: премии и ежегодный пересмотр зарплаты, расширенный ДМС с первого дня, ипотеку выгоднее до 4% для каждого сотрудника, а еще корпоративное обучение в Виртуальной школе Сбера и бесплатную подписку СберПрайм+
Переходите по ссылке и откликайтесь на вакансию
Читать полностью…
Datalytics
25 Jul 2024 14:33
Бесплатный курс по Python для аналитиков с 0 🔥
❗️ Будущим аналитикам на заметку: специально для тех, кто ищет классное обучение для вкатывания в аналитику и не готов рисковать в вопросах карьеры, приглашаем начать свой путь с бесплатного курса «Основы Python».
Курс максимально практикоориентированный — 10 глав, 100+ практических заданий и 3 бизнесовых проекта для вашего портфолио.
В «Основах Python» мы заложим фундамент работы с языком Python (даже если вы никогда не программировали!) и покажем, как применить его к вашим рабочим задачам.
После прохождения уроков вы сможете решить несколько сложных бизнес-задач — автоматизировать обработку кассовых чеков или контролировать просроченные платежи.
Попробуйте себя в роли специалиста и поймете, подходит ли вам аналитика данных 👇🏻
🔗 Приступить к обучению: ссылка.
Реклама. ООО «АЙТИ РЕЗЮМЕ». ИНН 4025460134.
Erid:LjN8K7MuF
Читать полностью…
Datalytics
19 Jul 2024 14:11
В команду штаба блока «Daily Banking» ищем Middle Data analyst c навыками SQL и уверенными знаниями в области математической статистики 👨💻
Работа предполагает поиск целевой аудитории и формирование выборок клиентов, проведение аналитических исследований, формирование гипотез и разработка новых метрик для бизнеса.
Предлагаем привлекательные условия: ежегодный пересмотр зарплаты, годовую премию, расширенный ДМС с первого дня, ипотеку выгоднее до 4% и корпоративную пенсионную программу ✅
Подробнее о вакансии по ссылке
Читать полностью…
Datalytics
17 Jul 2024 13:12
💚 Хотите получить рекомендации от опытного продуктового аналитика?
В Авито запустили программу менторства, доступную для каждого, кто стремится к развитию и росту.
Например, Егор Беседин, Head of Monetization Analytics, поможет вам оценить и развить компетенции, спланировать карьерный трек и управлять командой.
Но это не всё — в Авито есть другие менторы с уникальным опытом.
🔍Если не знаете, что делать:
• при оценке и развитии своих компетенций, а также планировании карьерного пути
• в управлении командой: цели, аналитические процессы, роли
• в выстраивании процессов найма в организации и команде
Найдите ментора из Авито здесь: Getmentor.
Есть разные форматы работы: платные встречи или сессии за взнос на благотворительность 💚
Читать полностью…
Datalytics
11 Jul 2024 15:40
💛💛💚❤💛❤💛⤵
❓Утопаете в данных и не знаете, как их эффективно визуализировать? Мечтаете об инструменте, который поможет создавать наглядные и информативные дэшборды?
✨Представьте: вы с легкостью подключаетесь к любым источникам данных, создаете интерактивные графики и диаграммы, а ваши дэшборды вызывают восхищение у коллег и руководства!
Хотите это реализовать? Открытый урок «Знакомство с Apache Superset. Установка, настройка и базовый функционал» — ваш первый шаг к освоению мощного инструмента для визуализации данных! 23 июля в 20:00 мск присоединяйтесь и узнайте, как легко и быстро превратить данные в указатели для дальнейших действий компании.
🔗Записывайтесь по ссылке прямо сейчас, чтобы посетить бесплатный урок: https://otus.pw/EBuG/
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
Читать полностью…



 9020
9020
{kind=link}
{kind=link}