Datalytics
03 October 2024 16:31
Яндекс интегрировал VLM в Нейро, значительно улучшив возможности поиска и анализа изображений. На Хабре рассказали, как команда усовершенствовала существующие технологии и создала новый инструмент, делающий работу с визуальным контентом более эффективной.
VLM представляет собой следующий этап в развитии моделей компьютерного зрения. Она не только распознает объекты на картинках, но и отвечает на сложные вопросы о деталях изображений.
Архитектура VLM объединяет LLM, картиночный энкодер и адаптер. Новый пайплайн с VLM-рефразером и VLM-captioner расширил спектр решаемых задач.
В статье подробно описан процесс обучения VLM и проведено сравнение с предыдущим LLM-пайплайном. Разработчики отмечают, что уже сейчас VLM решает многие задачи «из коробки», а с небольшим дообучением достигает высочайшего качества.
Оценить возможности VLM можно в Поиске по картинкам и Умной камере Яндекса.
Читать полностью…
Datalytics
03 October 2024 11:03
«Я в режиме реального времени поясняла структуру запросов / ответов в Postman и разбирала документацию в Swagger», — пишет аналитик, который прошел наш курс, а потом два технических собеседования в международные компании. Приятно, конечно ❤️
Если в 2024 году вы хотите:
— научиться выбирать стиль интеграции под вашу задачу;
— начать проектировать с нуля и описывать интеграции в современных стилях (API: REST, SOAP, gRPC и других, + брокеры сообщений);
— узнать как правильно собирать требования и моделировать в UML;
— подготовиться к собеседованию, решив более 100 заданий;
— запустить свой API на Python.
Значит наш курс для вас!
🚀 Начните с открытых бесплатных
уроков — переходите в бот курса и жмите «Старт»
👇
@
🚀 Скидка на курс
от канала — 1 000₽ на Stepik по промокоду DATAL3 до конца октября.
Читать полностью…
Datalytics
30 September 2024 11:24
У Ромы Бунина вышло клёвое видео про дашборды и их жизненных цикл. У дашбордов целом жизнь короткая и Рома в видео рассказывает как продлить их существование, в том числе с помощью ИИ
Ключевой момент в том, что чем больше пользователей у дашборда, тем дольше он живет (капитанский вывод, но всё же это заставляет нас задумать о том как поддерживать постоянную используемость наших дашбордов)
Как продлить жизнь дашборда? Три слова: процессы, процессы и еще раз процессы! 🔄
Как в этом плане уже сейчас может помочь ИИ? Эта помощь в том, что через чат-ботов с LLM можно:
➡️Искать нужные дашборды
➡️Отвечать на вопросы по данным
➡️Писать документацию
➡️Описывать изменения в дашбордах (change-logs)
➡️Помогать с сертификацией (проверкой дэшей на кри)
Но не все так радужно. ИИ пока не может:
➡️Улучшать дизайн дашбордов
➡️Создавать дашборды с нуля по картинке
В общем, внедряйте процессы, считайте время жизни дашбордов и не бойтесь использовать ИИ для рутины. Кто знает, может скоро мы будем просто рисовать дашборды от руки, а ИИ будет их создавать? 🎨🤔
Кстати, у Ромы есть ещё видео в мини-сериале про дашборды, ссылки тут
Читать полностью…
Datalytics
27 September 2024 11:02
🚀Новый конструктор отчётов!
Теперь можно собирать многостраничные документы нужного формата (размер, ориентация) для pixel-perfect экспорта в pdf или печати. Удобно для регулярных встреч с командой или отправки клиентам.
Ключевое:
- Функциональность доступна только в Business тарифе.
- Отчёт – это ещё один тип объекта внутри воркбука.
- Отчёт состоит из страниц, на каждую из которых можно добавлять чарты, картинки, текст.
- Можно работать со слоями.
- Можно копировать виджеты с дашбордов. Это удобно, если нужно быстро собрать печатную версию дашборда.
Что в планах:
- Конвертация дашбордов в многостраничные отчёты.
- Поддержка селекторов (глобальных на весь документ, на группу, на отдельные страницы).
- Простая вставка изображений из буфера с загрузкой.
- Режим просмотра/презентации.
Подробности читайте в документации.
Читать полностью…
Datalytics
26 September 2024 10:35
Прочитал отличный совет Тани Мисютиной у Горбунова про важность выделения минимальной частицы данных
Мне нравится та элегантность, которая лежит в основе подходов к архитектуре данных — каждый элемент находится на своем месте, образуя целостную и функциональную структуру. Есть в этом своего рода архитектурная красота
Таня в своём посте пишет о том, что для эффективного анализа данных важно правильно определить «частицу данных» — единицу смысла в конкретной задаче аналитика. Эта частица выступает связующим звеном между различными сущностями в описываемой реальности. Важный момент — даже если исходный датасет не содержит данные на уровне выбранной частицы, понимание этой единицы смысла помогает лучше понять как сделать визуализацию или создать дашборд
В целом, я бы сказал, что умение понимать подходы к описанию реальности — критически важный навык для аналитиков данных, продуктовых аналитиков, инженеров данных и data scientists
Почему так?
1) Формирование правильной онтологии (описания реальности) позволяет аналитику лучше понимать суть явлений, которые он анализирует. Это в свою очередь влияет на то какие вопросы задает аналитик по отношению к этой самой реальности, к стейкхолдерам, а также к датасету. Всё это влияет на качество гипотез, которые ставит аналитик, а также на интерпретацию данных и полученных выводов
2) Выходит из пункта 1, но больше связано с коммуникацией и постановкой задач. Если аналитик хорошо умеет «разложить» онтологию, то качество поставленной задачи к другим контрагентам (будь то data engineers, QA, разработчики, продакт-менеджеры) сильно вырастает
Если вы хотите глубже разобраться в том как вообще работать с сущностями и научиться лучше описывать реальность на языке данных — подписывайтесь на канал Тани @
Читать полностью…
Datalytics
24 September 2024 11:29
👍dbt - это один из ключевых инструментов современной аналитики и modern data stack.
Изучите один из самых востребованных инструментов аналитики, решая сложные практические задачи в нашем тренажере, научитесь DataOps практикам, постройте хранилище данных на базе dbt, подготовьте и проанализируйте данные
В тренажере вы освоите:
1. Типы хранилищ данных DWH и их построение
2. Подготовку и тестирование данных, Data Quality
3. Построение ELT-pipelines
4. Моделирование данных на базе dbt и PostgreSQL
5. Принципы работы с СУБД на базе Postgres
6. Продвинутую аналитику и визуализацию данных
7. Современные DataOps-практики, оптимизацию производительности и многое другое
Разработаете свои pet-проекты:
🔥 Статистика поездок на самокатах: Построите аналитический пайплайн для общей и дневной статистики поездок, включая тесты качества данных и документацию.
🔥 Аналитика ивентов приложения: Создадите SQL-пайплайн для обработки событий мобильного приложения, обогащённый данными поездок и пользователей, с внедрением контрактов данных и продуктовыми метриками.
🔥 Создание аналитической платформы: Развернете dbt-пайплайны с планировщиком, мониторингом и централизованным git-репозиторием, внедрить проверку качества данных и веб-портал с каталогом данных и документацией.
Сейчас открыт демо-доступ к первым четырем практическим урокам для всех желающих.
➡️ Регистрация на демо-доступ
Реклама. ООО "Инженеркатех" ИНН 9715483673
Читать полностью…
Datalytics
20 September 2024 09:50
Карьерный код Data-инженера: ошибки и лайфхаки
23 сентября приглашаем вас на бесплатный вебинар от Слёрма! Встретимся с опытным специалистом и карьерным консультантом в сфере IT, чтобы обсудить:
👉 Как становятся дата-инженерами?
👉 Как правильно показывать свой опыт и потенциал, чтобы получить оффер?
👉 Hard и Soft скиллы — что реально важно на собеседованиях?
👉 Что делать, если вы практикующий специалист, но развития не хватает?
Николай поделится секретами успеха и ошибками, которых вы сможете избежать. А Екатерина расскажет, как не сбиться с пути и выстроить эффективный карьерный трек.
➡️ 23 сентября, 20:00 мск
➡️ Занять место на вебинар – по ссылке.
До встречи!
Реклама ООО «Слёрм» ИНН 3652901451
Читать полностью…
Datalytics
16 September 2024 16:13
Как искусственный интеллект меняет правила игры в бизнесе?
Приглашаем тебя на митап по Data Science от экспертов Газпромбанк.Тех, где ты узнаешь:
– Как мы используем нейронные сети для разбора платежных документов
– Каким образом оптимизатор позволяет максимизировать прибыль от маркетинговых коммуникаций
– Какие задачи решают квантовые технологии в мире финансов
В конце тебя ждет нетворкинг с участниками и спикерами митапа.
Регистрируйся и приходи 19 сентября к нам в гости: Москва, ул. Коровий Вал д.5, БЦ «Оазис» — https://vk.cc/cAHhhb
Реклама, Банк ГПБ (АО), ИНН: 7744001497, erid: 2Vtzquu9yXD
Читать полностью…
Datalytics
12 September 2024 13:04
Матемаркетинг’24
2 дня, 120+ докладов и важные инсайты для аналитиков, продакт-менеджеров, ML-специалистов и дата-инженеров!
7 и 8 ноября в Москве пройдет Матемаркетинг — большая ежегодная конференция по маркетинговой и продуктовой аналитике. Эксперты крупнейших компаний Рунета обсудят работу с маркетинговыми воронками, оптимизацию рекламных бюджетов, персонализацию клиентского опыта и P&L-управление.
Почему стоит посетить?
🔵Более 120 докладов за 2 дня. Узнайте, как лидеры рынка работают с воронками, борются с вендорлоком и каннибализацией трафика, трансформируют бизнес с помощью ИИ и не только.
🔵Актуальные темы:
🟢Ускорение роста с использованием каналов платного маркетинга
🟢Разработка и управление корпоративными платформами экспериментов
🟢Персонализация и оптимизация цифрового клиентского опыта
🟢Управление рекламными каналами и оценка инкрементов;
🟢A/B-тестирование и оптимизация цифрового клиентского опыта.
🔵Эксклюзивный нетворкинг. Из года в год на конференции собираются ведущие аналитики, маркетологи, продакт-менеджеры и ML-специалисты, с которыми можно обменяться опытом и обсудить тренды.
Глубокое погружение: каждому участнику предоставляется доступ к закрытой платформе Матемаркетинга на 6 месяцев. Более 400 докладов прошлых лет помогут вам лучше погрузиться в интересующие темы и подготовить вопросы к спикерам этого года.
Место проведения: МГУ, кластер «Ломоносов», Раменский бульвар 1.
Билеты доступны на сайте.
Специально для подписчиков канала — промокод DATALYTX10, который даёт скидку 10% на билеты. 🎟️🔥
Читать полностью…
Datalytics
10 September 2024 17:30
Я провожу исследование, посвященное жизни людей, работающих в найме. Центральная тема — разделение личной и рабочей сфер в современном обществе.
Одна из гипотез моего исследования заключается в том, что это разделение ведёт к фрагментации личности и создаёт искусственные границы между тем, что считается «настоящей жизнью», и тем, что таковым не является.
В частности, аналитики данных часто разрабатывают инструменты и идеи, которые приносят прибыль владельцам компании, но не самим аналитикам. Это пример классического отчуждения от результатов собственного труда. Меня интересует, как можно выработать стратегии, помогающие преодолеть это чувство отчуждения.
Задачи в компаниях часто строго регламентированы, и аналитикам бывает трудно противостоять «бездумному» следованию инструкциям, даже когда они предлагают рациональные улучшения. Особенно это ощущается, когда давят сроки или давление исходит от коллег. Мне важно понять, как можно выстроить личные границы и целеполагание так, чтобы они работали как на тебя самого, так и на общее благо.
Для кого-то работа аналитиком — это способ самореализации: обучение других, создание новых методов, взаимодействие с заказчиками. Для других это лишь средство заработка, и они реализуют себя только в свободное время. В этом нет ничего плохого, но важно находить способы сохранять баланс, чтобы работа не вызывала отторжения.
Я хочу исследовать все эти вопросы, чтобы лучше понять, как выстраивать стратегии, позволяющие воспринимать работу как гармоничную часть жизни, а не как нечто чуждое и ограничивающее. Только так, на мой взгляд, можно создать по-настоящему развивающую среду.
Если вы хотите принять участие в исследовании и у вас есть время на часовой созвон, оставляйте свою заявку.
Читать полностью…
Datalytics
04 September 2024 11:55
Продуктовые аналитики, вас тут ищут
В Т-Банке пройдет Week Offer для уровня middle и senior. Можете пройти все этапы собеседования за неделю и попасть в ИТ-команду.
Если справитесь, будете развивать продукты для 43 млн клиентов. Выдвигать гипотезы, обосновывать данными и концентрироваться на аналитике — рутинные задачи тут можно автоматизировать.
Вот чем еще хороша эта работа:
— Актуальный стек технологий. Тут следят за трендами и быстро внедряют новое.
— Прозрачная система роста. Всегда будете знать, какие навыки развивать.
— Сильное комьюнити. Можно делиться опытом на конференциях и митапах, а еще — участвовать в подкастах.
— Офисы в 23 городах России и гибридный формат работы.
Успейте подать заявку до 25 сентября. Больше рассказали тут
Реклама. АО "ТБанк", ИНН 7710140679, лицензия ЦБ РФ № 2673
Читать полностью…
Datalytics
03 September 2024 17:33
Кластерная якорная регуляризация в рекомендательных системах
Обучение на логах юзеров может приводить к popularity bias. Мы рекомендуем айтемы, человек их смотрит, это попадает в логи и оттуда — в дальнейшее обучение. В итоге «богатый становится богаче». Известные способы борьбы с этим ухудшают перфоманс популярных айтемов, что тоже плохо. Ресёрчеры из DeepMind предлагают свой метод, Cluster Anchor Regularization, и применяют его для YouTube Shorts.
Иерархическая кластеризация
Индекс делится на кластеры, затем каждый из них кластеризуют снова — так мы получаем следующие уровни. Для каждого кластера учим эмбеддинг, чтобы приблизить к нему tail-айтемы того же кластера.
Кластеры генерируют энкодером с учётом метаданных и контента. 2-миллиардный индекс мапится в 256-размерные эмбеддинги. Они фиксированы, считаются один раз и нужны лишь для построения графа, который и будет кластеризоваться. Об архитектуре энкодера авторы не пишут.
Ноды графа — айтемы, а рёбра отражают косинусную близость между ними. Граф разбивается на кластеры так, что рёбра, выходящие из одного кластера и приходящие в другой, получают меньший вес. Каждой ноде сопоставляют вес, равный √ числа взаимодействий с айтемом. После 4 уровней кластеризации получается 48 000 кластеров. В каждом из них внутри одного уровня примерно одинаковое число взаимодействий.
Якорная регуляризация
Внутри кластеров есть source- и target-айтемы. В нашем случае source — популярные айтемы, а target — непопулярные. Каждому айтему сопоставляем его обучаемый эмбеддинг, а каждому кластеру — эмбеддинг такой же размерности. На первом этапе source-айтемы мапятся в свои кластеры, а представления кластеров обучают так, что градиент просачивается в них, не изменяя source-векторы.
На втором этапе то же самое происходит с target-айтемами, но обновляется уже не представление кластера, а векторы target’ов. Результаты обоих этапов добавляем в основной loss. Благодаря этому получается «эффект якоря»: популярные айтемы «тянут» за собой непопулярные.
@
Разбор подготовил ❣ Сергей Макеев
Читать полностью…
Datalytics
29 August 2024 14:01
Ozon Tech ждёт тебя на E-CODE!
⏰ IT-конференция E-CODE пройдет 28 и 29 сентября.
Что тебя ждёт:
- ML-трек с докладами от ведущих экспертов индустрии.
- Live-запись IT-подкаста.
- Научно-популярный трек для тех, кто жаждет знаний.
- Игры на свежем воздухе, чтобы размяться и повеселиться.
- Караоке для смелых и талантливых.
- А ещё вечеринка в финале!
Будет всё: от полезных знаний до веселья и нетворкинга. Не пропусти!
📌 Зарегистрироваться
Читать полностью…
Datalytics
25 August 2024 09:03
У Яндекс Погоды новая технология — OmniCast. Она умеет точно прогнозировать температуру в конкретном квартале города.
В связи с нововведением частота обновления прогноза выросла в 36 раз: теперь он обновляется не раз в 3 часа, а каждые пять минут. Как создавали такую нейросетевую модель — подробно расписали разработчики на Хабре. Но можно немного приоткрыть тайну: помимо профессиональных метеостанций сервис стал учитывать и любительские.
Кстати, Яндекс Погода призывает пользователей и организации, у которых есть метеостанции, подключаться к сервису с помощью API.
Читать полностью…
Datalytics
23 August 2024 13:15
Модель ИИ для борьбы с онлайн-токсичностью
Решил поделиться результатами своей работы в стартапе.
А занимался я разработкой моделей для модерации контента, направленной на искоренение онлайн-токсичности и создание активных онлайн-сообществ.
Основной целью было разработка модели с высоким перфомансом и минимальным вычислительным затратам и чрезвычайно низкой задержкой.
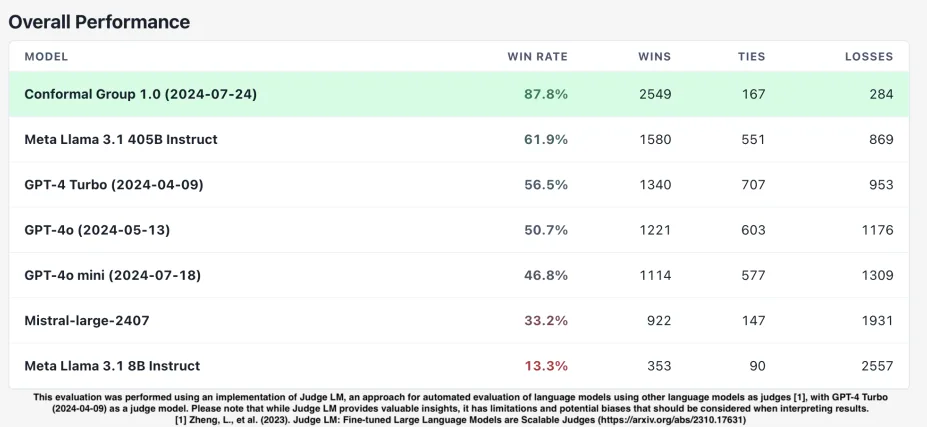
У нас получилось достигнуть F1-оценку почти 0.96 и AUPRC выше 0.98, при среднем времени оценки контента менее 40 миллисекунд.
Модель также превзошла ведущие ИИ-модели во время независимой оценки, проведенной компанией OpenPipe, лидером в области доработки и оценки доработанных моделей. (можно увидеть на скрине)
Полный текст анонса
А у меня теперь новый карьерный этап, но об этом чуть позже
Читать полностью…
Datalytics
03 October 2024 15:27
Алгоритмы поиска дубликатов
Ребята из HF Labs выложили отличную статью на Хабре о поиске дубликатов в клиентском MDM. Задача поиска дубликатов — суперкритична для обеспечения качества данных, дубли — потенциальный источник серьезных ошибок в аналитике
Авторы статьи рассказывают о том, как для эффективного поиска дубликатов важно правильно определить подход к обработке данных. Они выделяют несколько ключевых этапов:
1️⃣ Чистка и нормализация данных
2️⃣ Хеширование для быстрого поиска
3️⃣ Применение компараторов и правил
4️⃣ Обновление данных в режиме реального времени
Всё это со своей спецификой про банковскую сферу, но перекладываемо на любые задачи поиска дубликатов (в том числе нечетких)
Глубинное представление о качестве данных, с которыми мы работаем — это прям важный навык для аналитика. Я помню, что почти на любом месте, где я работал сталкивался с тем, что данные всегда содержали кучей дублей и мусора, по разным причинам. В итоге это всё важно отсеивать. Мы же не просто цифры в таблицах анализируем — мы пытаемся через эти данные понять реальность бизнеса, а если у нас Garbage In, то получаем и Garbage Out
https://habr.com/ru/companies/hflabs/articles/847012/
Читать полностью…
Datalytics
02 October 2024 15:51
Бесплатный мини-курс по технологии ускорения ML-моделей — Triton
В Ozon Tech 100+ дата-сайентистов. Каждый день они решают задачи поиска и диалоговых систем, чат-ботов и матчинга, анализа спроса и рекомендаций. И много-много других! Для этого наши специалисты используют огромное количество технологий. Одна из них — Triton.
Курс — это гайд в формате лонгрида, из которого вы узнаете:
— что такое Triton и как в нём происходит типизация данных;
— как собрать простую модель под любые нужды;
— как оптимизировать модель и дотащить до прода.
Чтобы пройти курс, нужно:
1) отправить заявку на этой странице;
2) иметь 2 часа свободного времени.
А после прохождения вы получите приглашение в закрытый чат с DS-экспертами Ozon.
Удачи!
Читать полностью…
Datalytics
27 September 2024 19:00
Я знаю, сколько времени может уйти на поиск нужной информации в Telegram, поэтому регулярно делюсь полезными ссылками.
Сегодня подготовили для вас целую подборку каналов в
сфере “IT и Технологий” 🔥
Тут вы точно найдете ответы на многие свои вопросы. А главное - вам не придется, тратить на поиски информации несколько часов 😊 👇
Поэтому переходите, подписывайтесь и пользуйтесь на здоровье 📂😉
Хотите подборку?
Читать полностью…
Datalytics
26 September 2024 13:48
Сбер ищет в команду Аналитика-исследователя, который будет выстраивать анализ продуктов и оценивать эффекты и взаимосвязи Центра индустрии с экосистемой Сбера 🔗
В ваши задачи будет входить взаимодействие с блоками и функциональными подразделениями, сбор данных и проведение аналитических исследований.
✅Мы предлагаем: премии и ежегодный пересмотр зарплаты, расширенный ДМС с первого дня, ипотеку выгоднее до 4% для каждого сотрудника, а еще корпоративное обучение в Виртуальной школе Сбера и бесплатную подписку СберПрайм+.
Подробнее о вакансии по ссылке
Читать полностью…
Datalytics
25 September 2024 14:18
ПСБ приглашает системных аналитиков на Weekend Оffer 19-20 октября 2024, который пройдет в онлайн-формате
➡️ Регистрация открыта до 9 октября
Хочешь построить карьеру в финансовой сфере и решать сложные задачи по разработке приложений в одном из крупнейших банков страны? Тогда Weekend Offer от ПСБ — то, что тебе нужно!
Не упусти уникальную возможность пройти все этапы отбора и получить предложение о работе за выходные.
Приглашаем кандидатов на позицию системного аналитика, а также всех специалистов, стремящихся перейти в эту профессию.
Почему тебе будет интересно в ИТ-команде ПСБ:
▪️ удаленный формат работы
▪️ только собственные решения банка
▪️ подходы Agile/Waterfall
▪️ продвинутый стек технологий
▪️ внешние курсы и выездные спринты
▪️ нетворкинг, внутренние митапы и воркшопы
Мы в ПСБ понимаем потребности частных клиентов, помогаем предпринимателям из малого и среднего бизнеса, сопровождаем гособоронзаказ и входим в тройку цифровых бизнесов России.
Поэтому мы заинтересованы в специалистах, готовых участвовать в создании новых продуктов и платформ, архитектурных решений и систем, требований к ПО и общего информационного пространства. Одним словом, помогать команде на стадии разработки и тестирования.
Ждем тех, кто желает погружаться в технические детали, знающих нотации UML и BPMN, банковские продукты, а также уже получивших опыт работы с SQL, микросервисной архитектурой, Jira и Confluence.
Чтобы принять участие в Weekend Оffer для системных аналитиков ПСБ, регистрируйся по ссылке до 9 октября, заполняй анкету и ожидай звонка куратора.
Читать полностью…
Datalytics
20 September 2024 17:40
Яндекс переработал и улучшил существующие функции для работы с текстом на базе YandexGPT в Яндекс Браузере, что привело к созданию отдельного инструмента. На Хабре рассказали, как можно дотюнить готовые фичи и сделать что-то новое, что сделает работу пользователей ещё более комфортной.
Инструмент включает возможность создания и редактирования текста. Обычно такие функции требовали сторонних приложений, но теперь они встроены прямо в браузер.
Для оценки работы модели Яндекс использовал диффалку на Go, которая находит наидлиннейшие общие подпоследовательности (LCS). Это позволило эффективно анализировать разницу между версиями текста и ускорить проверку изменений.
Переход на архитектуру Encoder-Decoder сократил время генерации текста вдвое, а curriculum learning позволил модели улучшать качество обработки текстов на 10% за счёт последовательного обучения на примерах разной сложности. Ещё одно важное нововведение — поддержка Маркдауна, что особенно полезно для тех, кто работает с разметкой текста.
Читать полностью…
Datalytics
19 September 2024 15:46
True Tech Champ
Всероссийский чемпионат по алгоритмическому и робототехническому программированию от МТС.
Регистрация: до 12 октября
Доступ к онлайн-заданиям: с 1 октября
Финал в офлайне: 8 ноября
Регистрируйся на алгоритмический трек и решай задачи в классическом олимпиадном формате.
Участникам в ходе отборочных испытаний предстоит решить алгоритмические задачи онлайн и посоревноваться в индивидуальном зачете. 150 участников с лучшим рейтингом будут приглашены на очный шоу-финал чемпионата. Призовой фонд трека — 2 750 000 руб.
Смотри подробности и регистрируйся на сайте.
Читать полностью…
Datalytics
13 September 2024 19:04
Больше не нужно искать тематические каналы и по отдельности на них подписываться - мы сделали это за Вас ⚡️
Вам остается только сохранить папку себе и регулярно получать полезные ресурсы из сферы «Digital и IT» 🖥️
/channel/addlist/Oa_vsjsHLx4zZjky
Добавиться в подборку
Читать полностью…
Datalytics
11 September 2024 14:30
Мы уже как-то обсуждали российские BI. Я по-прежнему периодически слежу, что там происходит, кто, чем выделяется.⚡️
Сейчас все бросились в машинное обучение и предиктивную аналитику. И это логично — в бизнесе важно не только анализировать данные, но и предсказывать будущие результаты.
Спрос на таких специалистов тоже взлетел.👛
Вот, например, команда российской BI-системы Analytic Workspace запустила бесплатное обучение по ML-прогнозированию в BI. Понятно, что это маркетинг, но я только за — полезная штука для тех, кто хочет стать более продвинутым аналитиком, да и сама система хороша.
Во-первых, у них есть бесплатная версия — такое у нас пока мало кто предлагает. Во-вторых, эксперты курса — настоящие практики. Ну и конкурс с денежными призами в конце, где знания можно сразу применить.
👍За 7 занятий обещают дать необходимые знания в Python, Spark, ML.
Требования минимальные — знание SQL и умение создавать дашборды, всему остальному научат. Ещё и сертификат получите — дополнит ваше портфолио.
В общем, полезная история.
🔗Узнавайте подробности и оставляйте заявку.
Читать полностью…
Datalytics
09 September 2024 12:08
Независимое исследование онлайн-курсов по аналитике
Все новое — хорошо забытое старое. Мы уже проводили исследование в далеком 2021 году и, кажется, пришло время обновить результаты. Поменялось все — мир, сфера и даже мы уже другие… (здесь должна быть меланхоличная музыка)
В общем, снова взываем о помощи и просим вас пройти опрос и оставить свое мнение —хорошее, плохое, главное, не безразличное!
Результатами в виде красивого дашборда мы обязательно поделимся в самое ближайшее время. Дату называть не будем, вдруг сглазим 🤣
Важно!
Мы будем принимать ответы до 19 сентября включительно, поэтому не откладывайте это дело в долгий ящик.
И чтобы смотивировать вас сделать это быстрее, за прохождение мы дарим подборку бесплатных материалов на русском и английском языках про дата-аналитику, SQL и не только.
🔜 Еще раз — ссылка на опрос.
P.S. Репосты среди коллег или друзей из аналитики не возбраняются, а только приветствуются 👀
Читать полностью…
Datalytics
03 September 2024 19:03
Больше не нужно искать тематические каналы и по отдельности на них подписываться - мы сделали это за Вас 🤝
Вам остается только сохранить папку себе и регулярно получать полезные ресурсы из сферы «IT и Технологий» 🔥
/channel/addlist/VMuK8A3-KfM5NzM6
Хотите в подборку?
Читать полностью…
Datalytics
30 August 2024 16:32
👀 ICML 2024 глазами ML-лидов Яндекса
The International Conference on Machine Learning — одна из крупнейших международных конференций по машинному обучению.
➡️ В этом году её посетила делегация из 46 яндексоидов. Недавно впечатлениями делился наш коллега Владислав Офицеров, а теперь о своих наблюдениях рассказывают CTO Поиска Алексей Гусаков и ML Brand Director Пётр Ермаков — листайте карточки!
⭐️ Если у вас оформлен Telegram Premium, поддержите наш канал по ссылке
Подписывайтесь:
💬 @
Читать полностью…
Datalytics
27 August 2024 16:24
Компания Anthropic опубликовала системные промпты для своей языковой модели Claude 3.5. Это значимое событие для всех, кто интересуется разработкой чат-ботов и prompt engineering.
Системный промпт - это набор инструкций, которые определяют базовое поведение и личность AI-ассистента. Обычно эта информация не раскрывается разработчиками и считается коммерческой тайной.
Однако Anthropic решили пойти на беспрецедентный шаг и поделиться промптами своей модели. Это дает нам возможность изучить принципы работы одного из самых продвинутых чат-ботов на рынке.
Знакомство с промптами Claude 3.5 может быть полезно для всех, кто занимается или планирует заниматься созданием собственных AI-ассистентов. Это возможность перенять опыт ведущих специалистов в области и усовершенствовать свои навыки prompt engineering.
Конечно, нужно понимать, что каждый проект уникален и требует индивидуального подхода. Но изучение промптов Claude 3.5 может дать ценные инсайты и вдохновение для собственных экспериментов и разработок.
Так что если вы хотите быть в курсе последних трендов в мире чат-ботов и AI-ассистентов, рекомендую ознакомиться с опубликованными промптами. Это может стать полезным ресурсом для вашего профессионального развития в этой перспективной области.
https://docs.anthropic.com/en/release-notes/system-prompts#july-12th-2024
#Anthropic #Claude #PromptEngineering #ChatbotDevelopment #AIAssistants
Читать полностью…
Datalytics
23 August 2024 14:04
Суперкомпьютеры тоже ломаются. Вернее, проблема может возникнуть в одной из их составляющих.
В случае, которым поделились ML-специалисты Яндекса, необычная поломка произошла у вентиляторов, которые охлаждают видеокарты.
Спустя два года работы в дата-центре во Владимире вентиляторы стали выходить из строя и буквально разлетаться на куски один за другим. Получался своего рода эффект шрапнели.
Компанда начала разбираться в причинах неисправности и выяснила, что проблема была в качестве пластика. О том, как в итоге ее удалось устранить, рассказали в посте.
Читать полностью…
Datalytics
20 August 2024 11:24
Mixture-of-Agents — простой способ улучшения ответов LLM
Сегодня рассмотрим статью, которая описывает метод улучшения результатов LLM на разных бенчмарках без дообучения. Он называется Mixture-of-Agents (MoA).
Суть метода заключается в использовании нескольких LLM для генерации ответов. Авторы статьи создали многослойную структуру с несколькими агентами — собственно, моделями — на каждом слое. На вход подавали один вопрос. Каждый из агентов давал ответ. Затем полученные данные агрегировались и вместе с промптом передавались на следующий слой, где процесс запускался заново.
В итоге получался ответ, который превосходит по качеству все предыдущие. Интересно то, что модели показывают лучшие результаты, когда имеют доступ к выходным данным других LLM — даже если ответы последних не слишком качественные. Этот феномен авторы назвали «коллаборативностью LLM» (Сollaborativeness of LLMs).
Эксперименты показали, что использование разных LLM на разных слоях улучшает результаты. Агрегаторы тоже играют важную роль — если пропоузеры могут быть относительно простыми и легкими, то агрегаторы требуют значительных вычислительных ресурсов.
Бенчмарки подтвердили, что MoA — эффективный метод. Скажем, на AlpacaEval 2.0 и MT-Bench применение такой архитектуры дало прирост производительности до 8% по сравнению с GPT-4 Omni.
Впрочем, MoA есть куда расти. Например, в области уменьшения времени до первого токена. Из-за итеративной агрегации конечному пользователю приходится долго ждать ответа на вопрос. Авторы статьи намерены бороться с этим недостатком.
Рассказывайте в комментариях, что думаете о MoA?
Разбор подготовил ❣ Никита Шевченко
Душный NLP
Читать полностью…



 8902
8902
{kind=link}