Data Science & Machine Learning
13 May 2024 13:24
Probability Distribution cheat sheet
Читать полностью…
Data Science & Machine Learning
12 May 2024 18:56
NLP techniques every Data Science professional should know!
1. Tokenization
2. Stop words removal
3. Stemming and Lemmatization
4. Named Entity Recognition
5. TF-IDF
6. Bag of Words
Читать полностью…
Data Science & Machine Learning
12 May 2024 13:58
Essential statistics topics for data science
1. Descriptive statistics: Measures of central tendency, measures of dispersion, and graphical representations of data.
2. Inferential statistics: Hypothesis testing, confidence intervals, and regression analysis.
3. Probability theory: Concepts of probability, random variables, and probability distributions.
4. Sampling techniques: Simple random sampling, stratified sampling, and cluster sampling.
5. Statistical modeling: Linear regression, logistic regression, and time series analysis.
6. Machine learning algorithms: Supervised learning, unsupervised learning, and reinforcement learning.
7. Bayesian statistics: Bayesian inference, Bayesian networks, and Markov chain Monte Carlo methods.
8. Data visualization: Techniques for visualizing data and communicating insights effectively.
9. Experimental design: Designing experiments, analyzing experimental data, and interpreting results.
10. Big data analytics: Handling large volumes of data using tools like Hadoop, Spark, and SQL.
Best Data Science & Machine Learning Resources: https://topmate.io/coding/914624
Credits: /channel/datasciencefun
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
11 May 2024 05:52
Thanks for the amazing response. I added few more essential data science resources in "Projects" Folder today.
ENJOY LEARNING 👍👍
Читать полностью…
Data Science & Machine Learning
28 April 2024 12:07
Machine learning is a subset of artificial intelligence that involves developing algorithms and models that enable computers to learn from and make predictions or decisions based on data. In machine learning, computers are trained on large datasets to identify patterns, relationships, and trends without being explicitly programmed to do so.
There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. In supervised learning, the algorithm is trained on labeled data, where the correct output is provided along with the input data. Unsupervised learning involves training the algorithm on unlabeled data, allowing it to identify patterns and relationships on its own. Reinforcement learning involves training an algorithm to make decisions by rewarding or punishing it based on its actions.
Machine learning algorithms can be used for a wide range of applications, including image and speech recognition, natural language processing, recommendation systems, predictive analytics, and more. These algorithms can be trained using various techniques such as neural networks, decision trees, support vector machines, and clustering algorithms.
Join for more: t.me/datasciencefun
Читать полностью…
Data Science & Machine Learning
27 April 2024 04:13
Starting Out with Python
Tony Gaddis, 2021
Читать полностью…
Data Science & Machine Learning
20 April 2024 11:03
AI Engineer Roadmap
👇👇
/channel/generativeai_gpt/15
Читать полностью…
Data Science & Machine Learning
19 April 2024 00:12
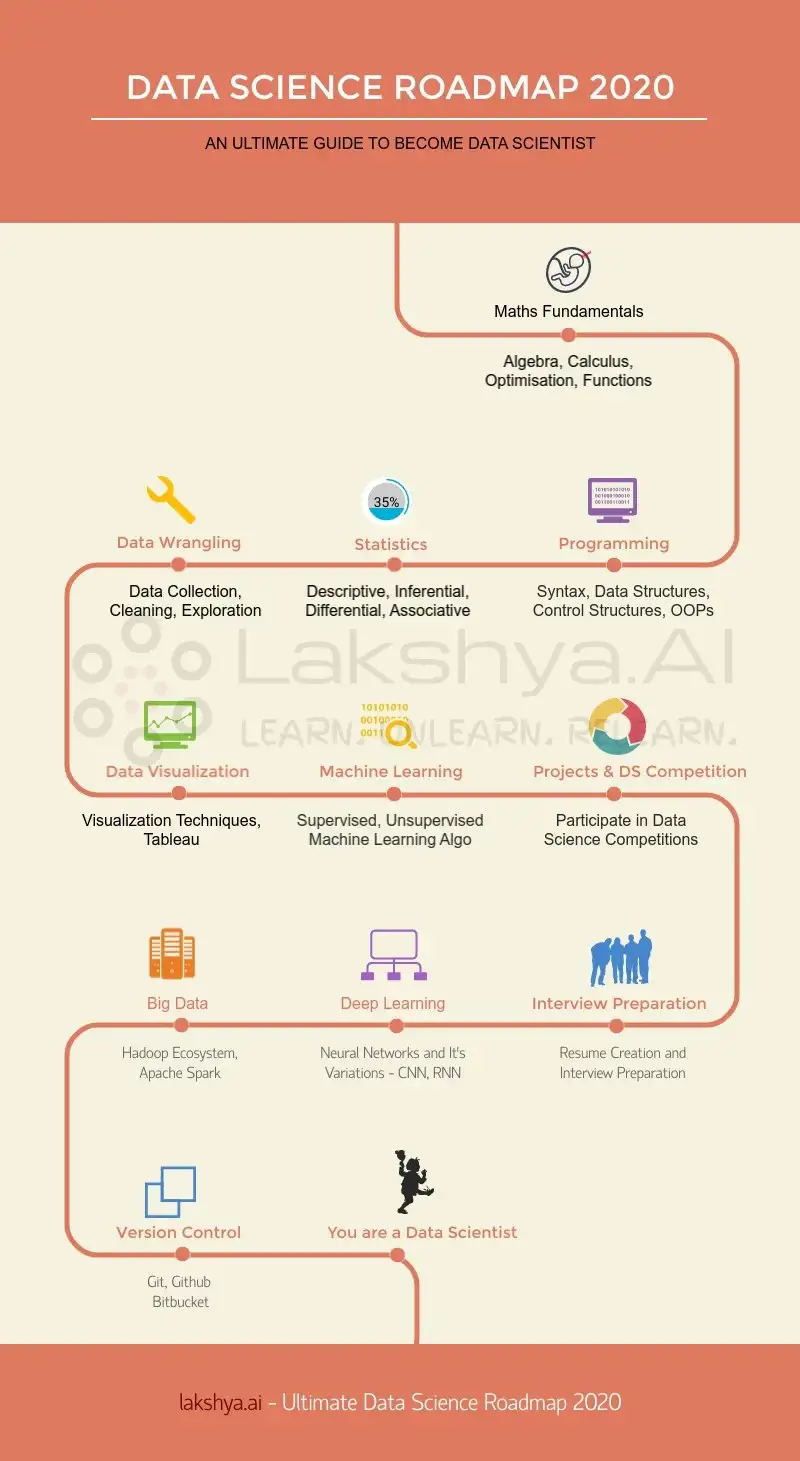
🖥 Roadmap of free courses for learning Python and Machine learning.
▪Data Science
▪ AI/ML
▪ Web Dev
1. Start with this
https://kaggle.com/learn/python
2. Take any one of these
❯ /channel/pythondevelopersindia/76
❯ https://youtu.be/rfscVS0vtbw?si=WdvcwfYR3PaLiyJQ
3. Then take this
https://netacad.com/courses/programming/pcap-programming-essentials-python
4. Attempt for this certification
https://freecodecamp.org/learn/scientific-computing-with-python/
5. Take it to next level
❯ Data Visualization
https://kaggle.com/learn/data-visualization
❯ Machine Learning
http://developers.google.com/machine-learning/crash-course
/channel/datasciencefun/290
❯ Deep Learning (TensorFlow)
http://kaggle.com/learn/intro-to-deep-learning
Please more reaction with our posts
Credits: /channel/datasciencefree
Читать полностью…
Data Science & Machine Learning
16 April 2024 17:16
How to get started with data science
Many people who get interested in learning data science don't really know what it's all about.
They start coding just for the sake of it and on first challenge or problem they can't solve, they quit.
Just like other disciplines in tech, data science is challenging and requires a level of critical thinking and problem solving attitude.
If you're among people who want to get started with data science but don't know how - I have something amazing for you!
I created Best Data Science & Machine Learning Resources that will help you organize your career in data, from first learning day to a job in tech.
Share this channel link with someone who wants to get into data science and AI but is confused.
👇👇
/channel/datasciencefun
Happy learning 😄😄
Читать полностью…
Data Science & Machine Learning
13 April 2024 09:16
🤩 Want to build AI Apps and get jobs in GenAI domain? 🚀
"How to fine-tune a LLM?" is a 1-hour FREE Materclass by IIT Delhi Alumni to help you dive into the world of fine-tuning large language models.
Register Now: https://www.buildfastwithai.com/events/how-to-fine-tune-a-llm
🗓️ : 14th April || 11 AM
In just one hour, you will learn: 📕
✅ Fundamentals of fine-tuning for AI
✅ Hands-on GPT-3.5 fine-tuning tutorial
✅ Exploring open-source LLM fine-tuning
✅ Q&A and open discussion with experts
Register Here: https://www.buildfastwithai.com/events/how-to-fine-tune-a-llm
Читать полностью…
Data Science & Machine Learning
12 April 2024 11:50
3 ways to keep your data science skills up-to-date
1. Get Hands-On: Dive into real-world projects to grasp the challenges of building solutions. This is what will open up a world of opportunity for you to innovate.
2. Embrace the Big Picture: While deep diving into specific topics is essential, don't forget to understand the breadth of data science problem you are solving. Seeing the bigger picture helps you connect the dots and build solutions that not only are cutting edge but have a great ROI.
3. Network and Learn: Connect with fellow data scientists to exchange ideas, insights, and best practices. Learning from others in the field is invaluable for staying updated and continuously improving your skills.
Читать полностью…
Data Science & Machine Learning
11 April 2024 13:23
Best Data Science & Machine Learning Resources: https://topmate.io/coding/914624
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
06 April 2024 21:18
Understand Logistic Regression in Sherlock Holmes Style 😎
https://www.instagram.com/p/C5bnJNVtgQZ/?igsh=a2NsMjh0a2dmdXA5
Читать полностью…
Data Science & Machine Learning
27 March 2024 20:19
Here are some essential data science concepts from A to Z:
A - Algorithm: A set of rules or instructions used to solve a problem or perform a task in data science.
B - Big Data: Large and complex datasets that cannot be easily processed using traditional data processing applications.
C - Clustering: A technique used to group similar data points together based on certain characteristics.
D - Data Cleaning: The process of identifying and correcting errors or inconsistencies in a dataset.
E - Exploratory Data Analysis (EDA): The process of analyzing and visualizing data to understand its underlying patterns and relationships.
F - Feature Engineering: The process of creating new features or variables from existing data to improve model performance.
G - Gradient Descent: An optimization algorithm used to minimize the error of a model by adjusting its parameters.
H - Hypothesis Testing: A statistical technique used to test the validity of a hypothesis or claim based on sample data.
I - Imputation: The process of filling in missing values in a dataset using statistical methods.
J - Joint Probability: The probability of two or more events occurring together.
K - K-Means Clustering: A popular clustering algorithm that partitions data into K clusters based on similarity.
L - Linear Regression: A statistical method used to model the relationship between a dependent variable and one or more independent variables.
M - Machine Learning: A subset of artificial intelligence that uses algorithms to learn patterns and make predictions from data.
N - Normal Distribution: A symmetrical bell-shaped distribution that is commonly used in statistical analysis.
O - Outlier Detection: The process of identifying and removing data points that are significantly different from the rest of the dataset.
P - Precision and Recall: Evaluation metrics used to assess the performance of classification models.
Q - Quantitative Analysis: The process of analyzing numerical data to draw conclusions and make decisions.
R - Random Forest: An ensemble learning algorithm that builds multiple decision trees to improve prediction accuracy.
S - Support Vector Machine (SVM): A supervised learning algorithm used for classification and regression tasks.
T - Time Series Analysis: A statistical technique used to analyze and forecast time-dependent data.
U - Unsupervised Learning: A type of machine learning where the model learns patterns and relationships in data without labeled outputs.
V - Validation Set: A subset of data used to evaluate the performance of a model during training.
W - Web Scraping: The process of extracting data from websites for analysis and visualization.
X - XGBoost: An optimized gradient boosting algorithm that is widely used in machine learning competitions.
Y - Yield Curve Analysis: The study of the relationship between interest rates and the maturity of fixed-income securities.
Z - Z-Score: A standardized score that represents the number of standard deviations a data point is from the mean.
Credits: /channel/free4unow_backup
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
23 March 2024 13:46
Biggest Telegram channel for data analysts
👇👇
/channel/sqlspecialist
Читать полностью…
Data Science & Machine Learning
13 May 2024 09:31
ML vs AI
In a nutshell, machine learning is a subset of artificial intelligence. AI is the broader concept of machines performing tasks that typically require human intelligence, while machine learning is a specific approach within AI where algorithms learn from data and improve over time without being explicitly programmed. So, while AI is the goal of creating intelligent machines, machine learning is one of the methods used to achieve that goal.
Читать полностью…
Data Science & Machine Learning
12 May 2024 14:49
3 Data Science Free courses by Microsoft🔥🔥
1. AI For Beginners - https://microsoft.github.io/AI-For-Beginners/
2. ML For Beginners - https://microsoft.github.io/ML-For-Beginners/#/
3. Data Science For Beginners - https://github.com/microsoft/Data-Science-For-Beginners
Join for more: /channel/udacityfreecourse
Читать полностью…
Data Science & Machine Learning
12 May 2024 12:44
Learning data science in 2024 will likely involve a combination of traditional educational methods and newer, more innovative approaches.
Here are some steps you can take to learn data science in 2024:
1. Enroll in a data science program: Consider enrolling in a data science program at a university or online platform. Look for programs that cover topics such as machine learning, statistical analysis, and data visualization. I will recommend the subscription by 365datascience which update content as per latest requirements.
2. Take online courses: There are many online platforms that offer data science courses, such as Udacity, Udemy, and DataCamp. These courses can help you learn specific skills and techniques in data science.
3. Participate in data science competitions: Participating in data science competitions, such as those hosted on Kaggle, can help you apply your skills to real-world problems and learn from other data scientists.
4. Join data science communities: Joining data science communities, such as forums, meetups, or social media groups, can help you connect with other data scientists and learn from their experiences.
5. Stay updated on industry trends: Data science is a rapidly evolving field, so it's important to stay updated on the latest trends and technologies. Follow blogs, podcasts, and industry publications to keep up with the latest developments in data science.
6. Build a portfolio: As you learn data science skills, be sure to build a portfolio of projects that showcase your abilities. This can help you demonstrate your skills to potential employers or clients.
ENJOY LEARNING 👍👍
Читать полностью…
Data Science & Machine Learning
02 May 2024 18:02
Planning for Data Science or Data Engineering Interview.
Focus on SQL & Python first. Here are some important questions which you should know.
𝐈𝐦𝐩𝐨𝐫𝐭𝐚𝐧𝐭 𝐒𝐐𝐋 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬
1- Find out nth Order/Salary from the tables.
2- Find the no of output records in each join from given Table 1 & Table 2
3- YOY,MOM Growth related questions.
4- Find out Employee ,Manager Hierarchy (Self join related question) or
Employees who are earning more than managers.
5- RANK,DENSERANK related questions
6- Some row level scanning medium to complex questions using CTE or recursive CTE, like (Missing no /Missing Item from the list etc.)
7- No of matches played by every team or Source to Destination flight combination using CROSS JOIN.
8-Use window functions to perform advanced analytical tasks, such as calculating moving averages or detecting outliers.
9- Implement logic to handle hierarchical data, such as finding all descendants of a given node in a tree structure.
10-Identify and remove duplicate records from a table.
𝐈𝐦𝐩𝐨𝐫𝐭𝐚𝐧𝐭 𝐏𝐲𝐭𝐡𝐨𝐧 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬
1- Reversing a String using an Extended Slicing techniques.
2- Count Vowels from Given words .
3- Find the highest occurrences of each word from string and sort them in order.
4- Remove Duplicates from List.
5-Sort a List without using Sort keyword.
6-Find the pair of numbers in this list whose sum is n no.
7-Find the max and min no in the list without using inbuilt functions.
8-Calculate the Intersection of Two Lists without using Built-in Functions
9-Write Python code to make API requests to a public API (e.g., weather API) and process the JSON response.
10-Implement a function to fetch data from a database table, perform data manipulation, and update the database.
Join for more: /channel/datasciencefun
ENJOY LEARNING 👍👍
Читать полностью…
Data Science & Machine Learning
28 April 2024 10:53
Overview of Machine Learning
Читать полностью…
Data Science & Machine Learning
19 April 2024 16:00
Top 10 machine Learning algorithms for beginners 👇👇
1. Linear Regression: A simple algorithm used for predicting a continuous value based on one or more input features.
2. Logistic Regression: Used for binary classification problems, where the output is a binary value (0 or 1).
3. Decision Trees: A versatile algorithm that can be used for both classification and regression tasks, based on a tree-like structure of decisions.
4. Random Forest: An ensemble learning method that combines multiple decision trees to improve the accuracy and robustness of the model.
5. Support Vector Machines (SVM): Used for both classification and regression tasks, with the goal of finding the hyperplane that best separates the classes.
6. K-Nearest Neighbors (KNN): A simple algorithm that classifies a new data point based on the majority class of its k nearest neighbors in the feature space.
7. Naive Bayes: A probabilistic algorithm based on Bayes' theorem that is commonly used for text classification and spam filtering.
8. K-Means Clustering: An unsupervised learning algorithm used for clustering data points into k distinct groups based on similarity.
9. Principal Component Analysis (PCA): A dimensionality reduction technique used to reduce the number of features in a dataset while preserving the most important information.
10. Gradient Boosting Machines (GBM): An ensemble learning method that builds a series of weak learners to create a strong predictive model through iterative optimization.
Best Data Science & Machine Learning Resources: https://topmate.io/coding/914624
Credits: /channel/datasciencefun
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
18 April 2024 05:21
If you're into deep learning, then you know that students usually take one of the two paths:
- Computer vision
- Natural language processing (NLP)
If you're into NLP, here are 5 fundamental concepts you should know:
👇👇
/channel/generativeai_gpt/7
Читать полностью…
Data Science & Machine Learning
13 April 2024 11:44
Machine Learning for Everyone
Читать полностью…
Data Science & Machine Learning
12 April 2024 19:47
Are you looking to become a machine learning engineer?
I created a free and comprehensive roadmap. Let's go through this post and explore what you need to know to become an expert machine learning engineer:
Math & Statistics
Just like most other data roles, machine learning engineering starts with strong foundations from math, precisely linear algebra, probability and statistics.
Here are the probability units you will need to focus on:
Basic probability concepts statistics
Inferential statistics
Regression analysis
Experimental design and A/B testing Bayesian statistics
Calculus
Linear algebra
Python:
You can choose Python, R, Julia, or any other language, but Python is the most versatile and flexible language for machine learning.
Variables, data types, and basic operations
Control flow statements (e.g., if-else, loops)
Functions and modules
Error handling and exceptions
Basic data structures (e.g., lists, dictionaries, tuples)
Object-oriented programming concepts
Basic work with APIs
Detailed data structures and algorithmic thinking
Machine Learning Prerequisites:
Exploratory Data Analysis (EDA) with NumPy and Pandas
Basic data visualization techniques to visualize the variables and features.
Feature extraction
Feature engineering
Different types of encoding data
Machine Learning Fundamentals
Using scikit-learn library in combination with other Python libraries for:
Supervised Learning: (Linear Regression, K-Nearest Neighbors, Decision Trees)
Unsupervised Learning: (K-Means Clustering, Principal Component Analysis, Hierarchical Clustering)
Reinforcement Learning: (Q-Learning, Deep Q Network, Policy Gradients)
Solving two types of problems:
Regression
Classification
Neural Networks:
Neural networks are like computer brains that learn from examples, made up of layers of "neurons" that handle data. They learn without explicit instructions.
Types of Neural Networks:
Feedforward Neural Networks: Simplest form, with straight connections and no loops.
Convolutional Neural Networks (CNNs): Great for images, learning visual patterns.
Recurrent Neural Networks (RNNs): Good for sequences like text or time series, because they remember past information.
In Python, it’s the best to use TensorFlow and Keras libraries, as well as PyTorch, for deeper and more complex neural network systems.
Deep Learning:
Deep learning is a subset of machine learning in artificial intelligence (AI) that has networks capable of learning unsupervised from data that is unstructured or unlabeled.
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs)
Long Short-Term Memory Networks (LSTMs)
Generative Adversarial Networks (GANs)
Autoencoders
Deep Belief Networks (DBNs)
Transformer Models
Machine Learning Project Deployment
Machine learning engineers should also be able to dive into MLOps and project deployment. Here are the things that you should be familiar or skilled at:
Version Control for Data and Models
Automated Testing and Continuous Integration (CI)
Continuous Delivery and Deployment (CD)
Monitoring and Logging
Experiment Tracking and Management
Feature Stores
Data Pipeline and Workflow Orchestration
Infrastructure as Code (IaC)
Model Serving and APIs
Best Data Science & Machine Learning Resources: https://topmate.io/coding/914624
Credits: /channel/datasciencefun
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
11 April 2024 17:47
🚀 Are you ready to embark on a journey into the world of data science? Whether you're a beginner or looking to enhance your skills, we've got you covered!
🌐 Transform your career with our Courses Data Science, Analytics, and DevOps course by just filling out this form.
👉 https://tinyurl.com/abhi-skill
📈 Unlock the power of data analytics and machine learning.
🔧 Dive into DevOps methodologies for streamlined development.
🎓 Gain practical skills and accelerate your tech career.
💼 Limited seats - reserve yours now!
💡 Gain hands-on experience and valuable insights from industry experts to kickstart your career in data science!
📝 Interested? Simply fill out this Google Form and our team will get in touch with you for a callback:
👉https://tinyurl.com/abhi-skill
👉https://tinyurl.com/abhi-skill
Читать полностью…
Data Science & Machine Learning
07 April 2024 11:45
5 Algorithms you must know as a data scientist 👩💻 🧑💻
1. Dimensionality Reduction
- PCA, t-SNE, LDA
2. Regression models
- Linesr regression, Kernel-based regression models, Lasso Regression, Ridge regression, Elastic-net regression
3. Classification models
- Binary classification- Logistic regression, SVM
- Multiclass classification- One versus one, one versus many
- Multilabel classification
4. Clustering models
- K Means clustering, Hierarchical clustering, DBSCAN, BIRCH models
5. Decision tree based models
- CART model, ensemble models(XGBoost, LightGBM, CatBoost)
Best Data Science & Machine Learning Resources: https://topmate.io/coding/914624
Credits: /channel/free4unow_backup
Like if you need similar content 😄👍
Читать полностью…
Data Science & Machine Learning
05 April 2024 11:52
Reality check on Data Analytics jobs:
⟶ Most recruiters & employers are open to different backgrounds
⟶ The "essential skills" are usually a mix of hard and soft skills
Desired hard skills:
⟶ Excel - every job needs it
⟶ SQL - data retrieval and manipulation
⟶ Data Visualization - Tableau, Power BI, or Excel (Advanced)
⟶ Python - Basics, Numpy, Pandas, Matplotlib, Seaborn, Scikit-learn, etc
Desired soft skills:
⟶ Communication
⟶ Teamwork & Collaboration
⟶ Problem Solver
⟶ Critical Thinking
If you're lacking in some of the hard skills, start learning them through online courses or engaging in personal projects.
But don't forget to highlight your soft skills in your job application - they're equally important.
In short: Excel + SQL + Data Viz + Python + Communication + Teamwork + Problem Solver + Critical Thinking = Data Analytics
Читать полностью…
Data Science & Machine Learning
25 March 2024 20:06
Creating a data science and machine learning project involves several steps, from defining the problem to deploying the model. Here is a general outline of how you can create a data science and ML project:
1. Define the Problem: Start by clearly defining the problem you want to solve. Understand the business context, the goals of the project, and what insights or predictions you aim to derive from the data.
2. Collect Data: Gather relevant data that will help you address the problem. This could involve collecting data from various sources, such as databases, APIs, CSV files, or web scraping.
3. Data Preprocessing: Clean and preprocess the data to make it suitable for analysis and modeling. This may involve handling missing values, encoding categorical variables, scaling features, and other data cleaning tasks.
4. Exploratory Data Analysis (EDA): Perform exploratory data analysis to understand the data better. Visualize the data, identify patterns, correlations, and outliers that may impact your analysis.
5. Feature Engineering: Create new features or transform existing features to improve the performance of your machine learning model. Feature engineering is crucial for building a successful ML model.
6. Model Selection: Choose the appropriate machine learning algorithm based on the problem you are trying to solve (classification, regression, clustering, etc.). Experiment with different models and hyperparameters to find the best-performing one.
7. Model Training: Split your data into training and testing sets and train your machine learning model on the training data. Evaluate the model's performance on the testing data using appropriate metrics.
8. Model Evaluation: Evaluate the performance of your model using metrics like accuracy, precision, recall, F1-score, ROC-AUC, etc. Make sure to analyze the results and iterate on your model if needed.
9. Deployment: Once you have a satisfactory model, deploy it into production. This could involve creating an API for real-time predictions, integrating it into a web application, or any other method of making your model accessible.
10. Monitoring and Maintenance: Monitor the performance of your deployed model and ensure that it continues to perform well over time. Update the model as needed based on new data or changes in the problem domain.
Читать полностью…
Data Science & Machine Learning
19 March 2024 20:09
To start with Machine Learning:
1. Learn Python
2. Practice using Google Colab
Take these free courses:
/channel/datasciencefun/290
If you need a bit more time before diving deeper, finish the Kaggle tutorials.
At this point, you are ready to finish your first project: The Titanic Challenge on Kaggle.
If Math is not your strong suit, don't worry. I don't recommend you spend too much time learning Math before writing code. Instead, learn the concepts on-demand: Find what you need when needed.
From here, take the Machine Learning specialization in Coursera. It's more advanced, and it will stretch you out a bit.
The top universities worldwide have published their Machine Learning and Deep Learning classes online. Here are some of them:
/channel/datasciencefree/259
Many different books will help you. The attached image will give you an idea of my favorite ones.
Finally, keep these three ideas in mind:
1. Start by working on solved problems so you can find help whenever you get stuck.
2. ChatGPT will help you make progress. Use it to summarize complex concepts and generate questions you can answer to practice.
3. Find a community on LinkedIn or 𝕏 and share your work. Ask questions, and help others.
During this time, you'll deal with a lot. Sometimes, you will feel it's impossible to keep up with everything happening, and you'll be right.
Here is the good news:
Most people understand a tiny fraction of the world of Machine Learning. You don't need more to build a fantastic career in space.
Focus on finding your path, and Write. More. Code.
That's how you win.✌️✌️
Читать полностью…



 74333
74333
{kind=link}
{kind=link}