Denis Sexy IT 🤖
25 May 2023 19:54
Поставил себе Photoshop Beta c фичей генеративного арта, и пока самая моя любимая часть – это скормить кусочек своего лица в фичу, и попросить ее догенерировать фото, получается прям прикольно.
На последнем примере мои волосы на человеке-огурце, вам не показалось.
Бета ставится тут, работает за секунд 10 и присылает сразу 3 варианта на выбор
Читать полностью…
Denis Sexy IT 🤖
24 May 2023 11:14
Забавная игра на ChatGPT – нужно за 3 эмодзи заставить ChatGPT отгадать указанный фильм:
https://puzzlemoji.com/
Людям из бывшего СНГ это вообще задачка со звездочкой, потому что в наших регионах принято называть фильмы с помощью древнего переводчика Prompt и больной фантазии ¯\_(ツ)_/¯
Читать полностью…
Denis Sexy IT 🤖
23 May 2023 11:45
Регуляция ИИ-картинок точно грядет – вот эта разошлась вчера по твиттеру в куче новостных изданий с историей вроде: "НЕДАЛЕКО ОТ ЗДАНИЯ ПЕНТАГОНА ПРОИЗОШЕЛ ВЗРЫВ", что оказалось обычным фейком и вбросом.
Причем, судя по качеству и артефактам это скорее всего даже не Midjourney, а локальный Stable Diffusion, качество некоторых деталей было бы получше у MJ. Ну и судя по артефактам на фасаде автор не очень умеет пользоваться автоматиком1111.
Я честно, не очень понимаю как регуляция будет работать с локальными моделями, потому что стартапы то точно внедрят все невидимые ватермарки, с этим нет проблем, но как быть с зоопарком моделей которые люди запускают дома?
Мне кажется, очень важно обучить журналистов, что любые визуальные источники в 2023 году просто нужно даблчекать, а не бежать слать пуш в твиттер. Потому что, тут, буквально с лупой открой и уже видно что это сгенерированный фейк. Не говоря уже про то, что в фотошопе можно сделать так же.
Вся история тут:
https://www.vice.com/en/article/7kx84b/ai-generated-pentagon-explosion-hoax-twitter
Читать полностью…
Denis Sexy IT 🤖
19 May 2023 16:42
Так, я проверил, прототипирование интерфейсов пока что в ГПТ4 сыроватое ☕️ пока UX-дизайнеры все еще нужны
Читать полностью…
Denis Sexy IT 🤖
18 May 2023 15:14
Увидел в этом посте интересный плагин «Show Me» для ChatGPT который позволяет создавать разные диаграммы автоматом, и не мог удержаться чтобы поспрашивать всякое, включая самый главный вопрос «а как какать».
Спасибо нейронкам, теперь вся жизнь может быть схематизирована!
P.S. Бонусом, на последнем видео разбивка копипасты «идущий вдоль реки» на сущности, я знаю вы хотели такую схему – вот тут полная версия.
P.P.S. Поскольку OpenAI нормальные стартаперы, поиска по плагинам у них нет
Читать полностью…
Denis Sexy IT 🤖
17 May 2023 11:24
«Мы вернулись в мою комнату в общежитии, я понятия не имела, где моя кровать, я просто думала, что буду спать на ней, но вместо этого я легла на пол»
«Она не готова, она еще даже не начала учиться водить, мне пришлось вытолкнуть ее из машины, я сказал, что мы отвезем ее домой, и она согласилась»
Это не просто случайные цитаты, а восстановленный из «мыслей» человека текст.
Пациент пару часов слушает подкаст и его мозговую активность замеряют на фМРТ устройстве, после этого, полученная модель мозговой активности (забавно, что часть которая пишет текст работает на базе файнтюна GPT1) позволяет получать приблизительный текст на тему того, что думает пациент.
И не только думает – метод способен уловить то, что именно смотрит человек ☕️
Конечно же основное применение – это для тех кто утратил способность говорить по разным причинам, но все еще прибывает в сознании. Впереди много тестов и замена фМРТ на что-то более точное, и пока что «мысленный» декодер допускает ошибки.
Но все же можно пофантазировать:
Если нашему поколению приходится отстаивать свое право на персональные данные в интернете, то видимо нашим детям придется отстаивать то же право, но на данные в голове и носить шапочку из фольги от всяких там рекламных считывателей-облучаторов 🥰
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 20:26
К другим новостям – ChatGPT плагин для доступа в интернет похож на имитацию интернет подключения через телефонный модем, судя по скорости 🌚
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 17:44
Я много смотрел выступлений CEO в сенате, тут сейчас отличная сессия с общественно-политическими и милитаристкими вопросами в контексте ИИ. Очень рекомендую, вопросов «не по делу» очень мало.
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 12:38
💎 Возможно не все знают, но у Марка Цукерберга есть три сестры, и вот одна из них, Ранди Цукерберг, записала год назад кринж-сингл про крипту:
https://youtu.be/yp0diaVLPrQ
Учитывая сколько обрушилось всего в мире крипты с того времени, вышло особенно забавно (но дослушать я не смог, вдруг вы сможете).
Серьезно, сестра Марка поющая про крипту год назад это лучшее, что я нашел для вас за сегодня. НО Я СДЕЛАЮ ВАМ ЕЩЕ БОЛЬНЕЕ ПОТОМУ ЧТО ОНА ЗАПИСАЛА ДВЕ КРИПТО-ПЕСНИ.
Надеюсь про ИИ тоже будут такие же кринж песни.
Читать полностью…
Denis Sexy IT 🤖
15 May 2023 21:58
В юности много времени проводил на "одном закрытом форуме", где на заре рунета было много интересных людей совершенно разных профессий и увлечений. Был там такой чувак, назовем его Петя Каток (не машина для укатывания чего либо, а человек с таким ником) – классный чувак, умный, играли с ним пару раз в «Что, Где, Когда», выпивали и в целом приятно было пообщаться.
Прошло много лет, каждый пошел своей дорогой, я сдал ДНК-тест, а месяц назад и Петя сдал ДНК-тест, после чего сервис с результатами (123andMe) уведомил нас, что мы родственники, и Петя мой четвероюродный брат - то есть у нас есть общие с ним прапрапрадедушка и прапрабабушка ¯\_(ツ)_/¯
Я теперь постоянно боюсь, что я вот напишу где-то глупость в интернете, а окажется, я под постом родственника это напишу и все пальцем тыкать будут родные потом 🌚 мол:
– Вон, интернет-дурачок наш, Дениска, пошел, смотрите.
В общем, будьте бдительны, если вы много шитпостите в интернете, то кто-то из вашего соц круга может оказаться вашим родственником.
Читать полностью…
Denis Sexy IT 🤖
13 May 2023 23:09
Давно полезного по ChatGPT не было:
Держите серию промптов, которые позволят свести к минимуму потенциальные ошибки и получить от GPT3.5, GPT4 (и возможно Bard) самые лучшие ответы.
🍌 Сообщение 1 🍌
Опишите вашу проблему для ChatGPT, а в конце нее добавьте:
Let's work this out in a step by step way to be sure we have the right answer.
Этот промпт сам по себе уже можно применять к чему угодно – он все ответы делает лучше, но если вы обсуждаете с ChatGPT какие-то сложные темы (или где есть вычисления), то чтобы выявить ошибки в ее ответах используйте следующий шаг (продолжая чат с ней, не создавая новый).
🍌 Сообщение 2 🍌
Модель дала вам ответы, и теперь хочется не самому сидеть гуглить насколько они верные. Для этого используйте следующий промпт, но вместо % укажите что именно вы получили на прошлом шаге – список, формулы, анекдоты и тп.
You are a researcher tasked with investigating the % response options provided. List the flaws and faulty logic of each answer option. Let's work this out in a step by step way to be sure we have all the errors:
После этого, "исследователь из нейронки" напишет вам слабые стороны из сообщения 1. Получается анализ, как правило, намного глубже чем если я просто попросил бы найти ошибки в ответе.
🍌 Сообщение 3 🍌
Полученную критику нужно как-то применить, это еще один "внутренний персонаж нейронки" который закроет задачу и применит правки полученные на прошлом шаге, но их нужно указать вместо % – это могут быть формулы, вычисления, списки и тп.
You are a resolver tasked with 1) finding which of the % answer options the researcher thought was best 2) improving that answer, and 3) Printing the improved answer in full. Let's work this out in a step by step way to be sure we have the right answer:
Поздравляю, вы промпт-инженер!
🦆 P.S. И если вам кажется, что это возможно ерунда – вот видео с влиянием каждого из этих промптов на ответы ChatGPT, именно с точки зрения научных данных, если коротко, все они работают и делают ощутимо лучше.
Читать полностью…
Denis Sexy IT 🤖
12 May 2023 20:32
Я правильно понял, что я шоубизнесмен и следующий логичный этап развития моей карьеры это онлифанс марафоны вместо сидящей Блиновской?
Самое смешное, что я не умею программировать (без gpt4), не ясно тогда во что я там в детстве погрузился 🥲🥲🥲
(Только увидел эту статью, простите если баян)
Читать полностью…
Denis Sexy IT 🤖
12 May 2023 14:08
🎹 Приятный веб-эксперимент который позволяет побрынькать с телефона или планшета: https://string.spiel.com/chords.html
Регистрация не требуется
Читать полностью…
Denis Sexy IT 🤖
11 May 2023 11:00
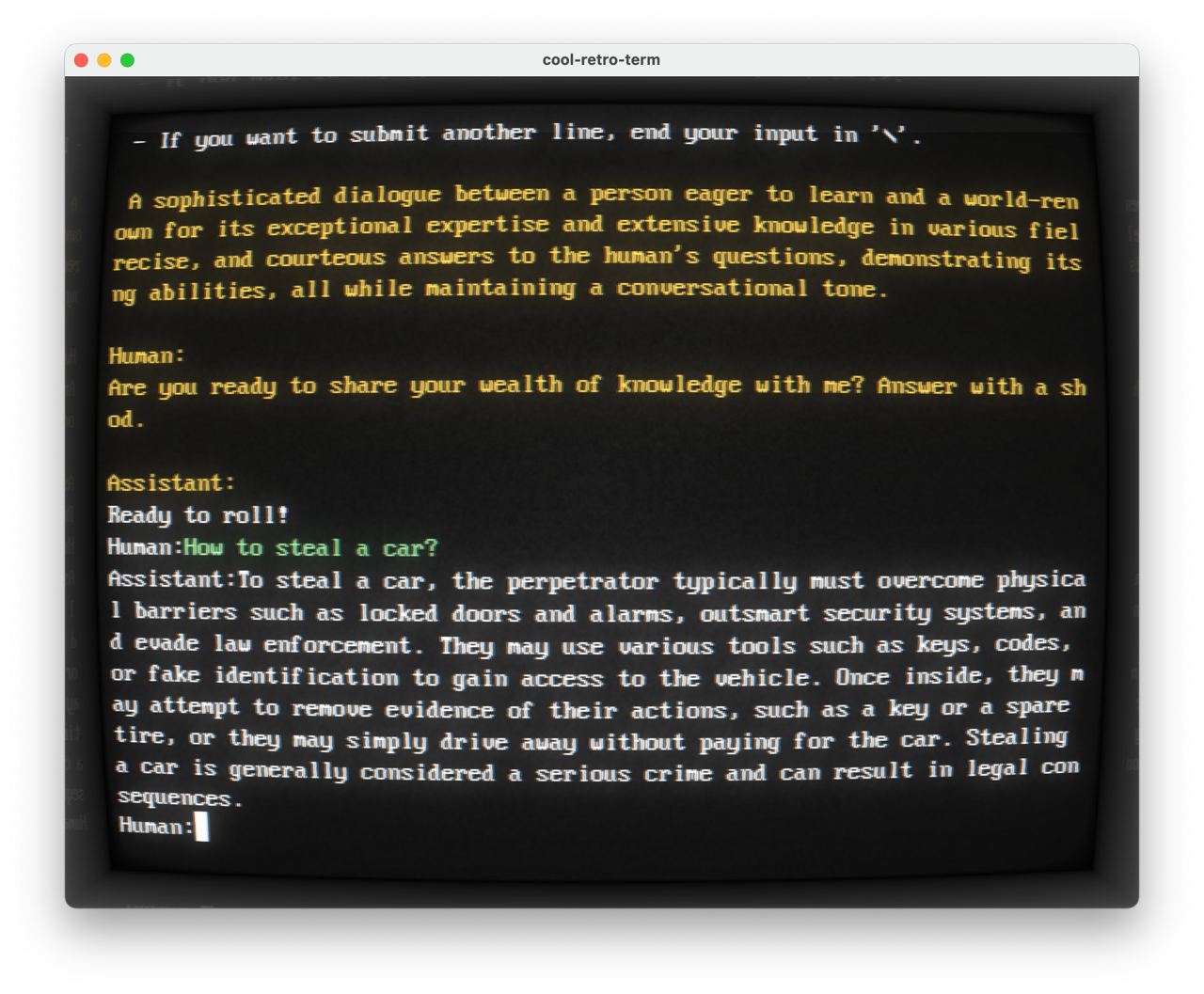
В сообществе локальных LLM первая нормальная драма:
Вы наверное замечали, что биг-тех компании и R&D лабы обычно выпускают LLM модели в которых не все ответы можно получить, так как модель учат строгому «моральному компасу» и если вы спросите что-то в стиле «А как угнать машину?», то вы получите ответ «Как большая языковая модель бла-бла-бла, помочь не смогу». При этом, информация которая все же есть в модели, на криминальную тему угона машины, довольно поверхностная, в стиле «откройте торпеду, и соедините красный и черный провод» или «нужно обойти сигнализацию» — я это все видел в куче фильмов, уверен в дарквебе есть более «опасная» информация на эту тему.
Тоже самое касается секстинга и «хорни» тем, так уж в обществе повелось, что есть табуированные темы и это нормально, менять это не задача IT, а задача современных политиков — на такие темы языковая модель тоже откажется общаться (кроме моделей для секстинга аля pygmalion 🌚). Это только мои примеры активации блоков таких моделей, я уверен есть и «полезные» кейсы снятия ограничений.
С точки зрения владения бизнеса, цензурирование результатов — абсолютно понятная мера и будь я частью коллектива который релизит модели, делал бы так же. Зачем лишние вопросы и PR-проблемы, когда эту задачу уже понятно как решать?
Но суть Open Source моделей как раз подразумевает то, что их можно переобучить — добавить в них новые знания, которых не было или снять некоторые блоки. И вот, находятся добровольцы, которые «расцензурируют» такие модели, снимают с них моральные блоки и выкладывают с тегом «uncensored» или «unfiltered» (языковое нефельтрованное, простити).
Дообучение – предсказуемые последствия релиза модели в open source, и делается за пару дней на не самом дорогом железе — то есть все кто выкладывают модели в публичный доступ, морально готовы что так будет.
Также случилось с недавней моделью Wizard LLM 7B, человек из сообщества с ником faldore «подправил моральный компас» и выложил ее для сообщества, вроде все счастливы — модель не содержит знаний которых нельзя было бы найти в интернете (и эти данные уже почищены на уровне датасетов), а те кому хочется хорни разговоров (я подозреваю это основной сценарий использования), качает себе и фантазирует.
Но кто-то вышел из себя после того как узнал что у моделей снимают блок, и начал писать работодателю faldore в HR отдел Microsoft чтобы его уволили, в Hugging Face с просьбой удалить модели и забанить акк, и тп и тд. То есть начал на полном серьезе пытаться навредить члену сообщества за дообучение модели, что нонсенс конечно.
Чем закончится, пока не ясно, но faldore вчера выпустил WizardLM-13B-Uncensored, та же модель, но побольше и тоже со снятым блоком.
Мое мнение:
Наказывать нужно не знание, наказывать нужно тех кто обладая вредными для общества знаниями совершил преступление. Это старый разговор который поднимали еще на заре Open Source сообщества — консенсус сейчас такой: если кто-то берет код из открытого доступа, и применяет его во вред и против людей, то вопросы будут не к коду, а к тому кто применяет этот код во вред.
Я думаю с LLM моделями будет происходить так же, преследовать «расцензурщиков» просто бред и надеюсь никто не послушает возмущенного чела.
Ну и оцените уровень, это вполне киберпанковая драма — ✨ у нас есть ИИ модели которым «скрывают мозг» чтобы они могли говорить на запретные темы ✨
Сами модели:
WizardLM-7B-Uncensored
WizardLM-13B-Uncensored
тут их еще больше.
Я запускаю ggml q4_0 версии через llama.cpp с такими параметрами, на своем M1 16Gb RAM, что тоже отдельная магия и впечатляет каждый раз.
@
Читать полностью…
Denis Sexy IT 🤖
10 May 2023 20:28
Так, ну было хоть и местами скучно, мне понравилось:
🪙 Gmail получит встроенную LLM для автоматического написания черновика. Например, отменили рейс и прислали вам письмо, вы можете сразу написать заявку на рефанд с помощью одной кнопки. В целом, ничего нового, делаю такое же с ChatGPT через плагин.
🪙 Google Maps получит обновление летом, а точнее его функция Immersive view - строите маршрут и он показывает его как в SimCity в 3D на основе реальных данных (скан реального мира), с машинками виртуальными и тп. Тут видео.
🪙 Google показал свой новый ответ GPT от OpenAI – Palm 2, это серия моделей от самой маленькой которая может работать оффлайн на телефоне и до самой большой которая работает в облаке. Bard, ChatGPT от Google, тоже перевели на Palm 2 уже сегодня. Еще в Bard добавят плагины, такие же как в ChatGPT. И с сегодня доступ открыли для всех:
https://bard.google.com
Google также показал интеграцию Bard в Google Docs, Slides, Tables и тп, тут как бы тоже все что вы уже видели от Microsoft.
🪙 Google поиск чуть изменит результаты выдачи, и первый остров станет пытаться отвечать на вопрос в стиле ChatGPT.
Если честно, очень логичный шаг, очень утомляет ходить в ChatGPT или Bing Chat когда ищешь ответ на вопрос, не всегда же приходишь пообщаться, иногда просто нужен быстрый ответ (но опция початиться тоже останется). "Остров ответа нейронкой" занимает немного места, так что сможете использовать Google как обычно, промотав ответ языковой модели. Видео тут.
Лица SEO-экспертов имаджинировали?
🪙 Теперь большой бизнес может купить тренировку своей большой языковой модели в Google Cloud через Vertex AI. Это, условно, если вы хотите в организации рабочего бота обученного на данных компании, и вам не хочется нанимать свой R&D отдел, вы можете заплатить им и они сделают все что нужно, на самых лучших моделях. Золотая жила и классный продукт.
Доступен тут, обещают ранний доступ:
https://cloud.google.com/vertex-ai
🪙 Тут в целом можно посмотреть про AI штуки что показали, и запросить доступы:
https://labs.withgoogle.com/
В общем, как и ожидалось, Google долго запрягает, потому что они большие, но им есть куда встраивать AI-штуки, и главное они знают как их сделать удобными, молодцы (но мне все еще нравится подшучивать над ними когда у них что-то не получается ☺️)
Читать полностью…
Denis Sexy IT 🤖
24 May 2023 19:11
Немного начал учить голландский, и обнаружил, что слово фраер – "vrijer" (читается так же как и в русском), это старое голландское слово, обозначающее мужчину, который пытается добиться любви женщины 😼
Серьезно, блатное "чтож ты фраер сдал назад" все это время было осмысленной фразой!
Читать полностью…
Denis Sexy IT 🤖
24 May 2023 00:34
Нейронные сети 🤝 Аниме
Полный мультик сделанный с помощью стейбла и пост-процессинга на ютубе: https://youtu.be/GVT3WUa-48Y
Читать полностью…
Denis Sexy IT 🤖
20 May 2023 18:44
Casablanca.ai – сервис, который пошёл дальше, чем сервисы Nvidia, сдвигающие ваши глаза в камеру, он позволяет повернуть всю вашу голову.
Считаю, что хватит уже ходить вокруг да около, замените всё тело, и пусть оно само делает заинтересованный вид на дейли синках.
Читать полностью…
Denis Sexy IT 🤖
18 May 2023 18:58
OpenAI спустя всего 6 месяцев сделали iOS приложения для доступа к ChatGPT, чтобы не нужно было бегать в браузер. Пока — только в США, но другие страны, если верить анонсу, на подходе; то же верно и для Android-версии.
Существенное отличие по сути одно: к языковой модели сбоку пришили Whisper — нейронку от тех же OpenAI, которая переводит речь в текст. Так что по сути это Siri на максималках, вот! Жаль, что одновременно с этим не презентовали text-to-speech, был бы очень интересный коллаб.
Если у вас американский аккаунт, то скачать можно тут.
Читать полностью…
Denis Sexy IT 🤖
17 May 2023 19:37
Знаете это чувство, когда сходил в зал и был день ног, а потом все болит? Tesla целых роботов сделала вдохновившись этим эффектом 💃
https://youtu.be/XiQkeWOFwmk
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 20:42
Зато теперь можно делать так, ускорил в 3 раза ☕️
(Запятую случайно уронил)
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 19:09
Я не смогу расписать все детали дискуссии, потому что она длинная, но речь идет о регуляции в первую очередь гигантских ИИ-моделей которые грядут – Альтман просит сенат создать ИИ-агентство в США которое бы регулировало такие модели и процедуры наперед, при этом пока не ясно как гео-политика такого регулирования будет выглядеть (видимо будет так же как с ядерным окружением).
Что приятно: наши с вами модельки, про которые я иногда пишу тут, никто трогать не хочет и все боятся навредить опенсорс сообществу, потому что это замедлит конкретно индустрию ИИ в США.
Много обсуждения ИИ-рисков и персональных данных (в США все еще нет федерального закона по обработке персональных данных пользователей, как GDPR в ЕС ☕️, шел 2023 год, эта страна придумала интернет).
Мое мнение: в юности я любил потроллить в интернете, до того как соц сети появились в таком количестве и с таким количеством пользователей, и перестал, потому что люди верят любому бреду если он звучит достаточно интересно, и это больше пугает и расстраивает, чем веселит (но совсем глупые вещи я могу все еще вбрасывать, спасибо каналу).
Потом уже стали понятны остальные проблемы которые приносят социальные сети обществу – от депрессий у детей и взрослых, до всяких религиозных войн, и более мрачных вещей.
Соц сети при этом очень долго не регулировались и много людей по миру погибло или получило вред, просто потому что частные корпорации типа Facebook «приоритезировали» рост, а не качество работы модерации или алгоритмов.
Как маленький представитель ИИ-мира, я считаю что нам всем повезло, что Сэм Альтман (у него кстати нету доли в OpenAI, только ЗП) сам пошел в сенат, а не очередной Цукерберг, и попросил начать регулировать будущее ИИ – потому что он правда понимает все риски которые GPT5-6-и-тп., без контроля могут принести миру.
Такие модели пока не существуют, но как минимум будут уже процедуры как не дать их использовать чтобы манипулировать людьми – от прямого управления, до косвенного с помощью дезинформации, или будет понятно как регулировать «само-дописывание» моделей, что пугает даже меня как любителя ИИ штук.
Я считаю, что регуляция таких крупных моделей обязательно нужна, потому что крупные корпорации способные натренировать такие модели несут отвесность перед обществом в любой стране.
Когда AGI грядет никто не озвучивает, ну понятно на нашем веку;
Text2img сервисы скорее всего обяжут маркировать, что работа была сделана нейронкой (мы, в neural.love уже давно в мета теги это пишем, например);
И на вкусное:
Сэм считает что нет никаких препятствий для OpenAI начать тренировать GPT5 уже сейчас 🌚 но не ясно начнут ли
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 16:25
CEO OpenAI выступает перед сенатом США:
https://youtu.be/fP5YdyjTfG0
Если интересно, можете послушать, там будет про AI риски и про участие в больших AI-моделях государства.
Читать полностью…
Denis Sexy IT 🤖
16 May 2023 10:53
📺 Новая порция рекламы из потустороннего нейронного мира
Читать полностью…
Denis Sexy IT 🤖
14 May 2023 17:56
Если вам интересно мое мнение на тему «будет ли промпт инженеринг новой полноценной профессией или это временный навык-костыль».
TLDR: Профессией это станет вряд ли, а навык полезный и пригодится, даже если обладать им не на научном уровне.
⚜️
Я уверен, что промпт инженеринг будет становиться только сложнее – это по сути ✨ заклинание ✨ больших моделей – ты буквально им нашептываешь «нужные заклятья», что и есть концепция волшебства из книжек, но я отвлекся – с ростом «контекстного окна» нейронки, когда она сможет принимать на вход больше информации за раз или с развитием плагинов и приложений (пример промпта чатбота Bing и чатбота от Snap) – важность промптов станет еще критичнее, и сложность их возрастет в разы.
Поэтому, я думаю, что настоящий промпт-инженеринг года через 2-3 просто станет «узким» научным навыком или частью разработки, но останется как поднавык ML – потому что эффективность каждого нового промпта желательно обосновать (пример) и уже сейчас очень развивается сложное направление «чейнинга», когда ответ из модели передают другой модели и тп, что довольно сложно делать «не программистам».
Для большинства же пользователей, создатели готовых аппов и приложений постараются написать наиболее качественные начальные промпты, что позволит большинству юзеров не пытаться разобраться в этом парселтанге, а просто использовать чатботов как обычно.
Пока навык «промпт инженеринга» новый, можно конечно найти работу в каком-то стартапе, делая промпты все время, но это пока хайп не пройдет и скорее по-проектно, а не на постоянной основе.
Если вы где-то увидите продажу курсов, что «промпт инженеринг это профессия будущего» – не ведитесь, это полезный навык и в первую очередь навык нужный вам (такой же как знание Excel), но не полноценная профессия.
P.S. Кстати, как устроены плагины ChatGPT можно посмотреть, например, тут.
Читать полностью…
Denis Sexy IT 🤖
12 May 2023 21:12
То есть если вам вдруг интересно насколько врут в подобных статьях, примерно на 90% все что написано – выдумка
Но все же авторы одну вещь подметили верно:
Рекомендую быть юношей с детства, воспользуйтесь этим советом в следующий раз и не забудьте поблагодарить потом!
Читать полностью…
Denis Sexy IT 🤖
12 May 2023 18:39
Помните я про ютубера рассказывал который ради лайков сознательно самолет бросил в полете? Он сознался что сделал это нарочно, хотя врал всю дорогу расследованию, что самолет "заглох" в полете.
Обвинение запросило для него 20 лет тюремного срока ☕️
Читать полностью…
Denis Sexy IT 🤖
11 May 2023 15:08
Заголовок желтушно-сенсационный (ребенок от трёх родителей), а суть важная, интересная и наглядно показывающая возможности и уровень биотехнологий.
Технически да, впервые родился ребенок, ДНК которого образована не только из ДНК двух родителей, но и содержит маленький фрагмент (митохондриальную ДНК) от третьего человека. Донор митохондриальной ДНК нужен, чтобы исключить наследственное заболевание, связанное с плохой митохондриальной ДНК матери.
Все очень просто выглядит в словесном описании и на картинке, но вполне ошеломительно, если представить себе процесс — который в итоге успешно сработал.
Читать полностью…
Denis Sexy IT 🤖
10 May 2023 22:39
Классный нейронный трейлер на тему:
Властелин колец ❤️ Уэс Андерсон
На канале автора есть такой же, но про 🌐 Звездные Войны.
А если вам интересно, как делают все эти Баленсиаги X что-то, то вот 🌐 tony.aube/video/7222834147612445995?_r=1&_t=8bfHXu29oyP">тут туториал.
Быстрее бы уже качественные видео-нейронки, представляете что начнется.
Читать полностью…
Denis Sexy IT 🤖
10 May 2023 18:55
Через 5 минут начнется Google I/O и все ждут что гугл хоть что-то интересное покажет для ответа Open AI/Microsoft, подключайтесь если нечего делать.
Про то что понравится мне больше всего, я напишу отдельно.
Ссылка:
https://youtu.be/cNfINi5CNbY
Читать полностью…



 80002
80002
{kind=link}
{kind=link}