DATApedia | Data science
02 Jun 2023 09:28
DWH как продукт: платформа, инструменты, масштабирование команды
В статье рассказано, как продуктовый взгляд помогает развивать DWH и быть полезнее для пользователей. Речь пойдёт про появление платформенных инструментов и рост проникновения аналитики в компании, а также про реорганизацию команды и перераспределение задач. Будет больше о процессах и практиках, чем о хардкорных технологиях. Но и технологии немного затронуты.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
29 May 2023 09:53
Новые инструменты для работы c ML-моделями и обзор MLOps от CERN
В новом дайджесте для вас много интересных обзоров по инструментам — как говорится, ни ClearML и Airflow едиными. Рынок решений стремительно развивается, и эта подборка поможет вам держать руку на пульсе.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
25 May 2023 12:42
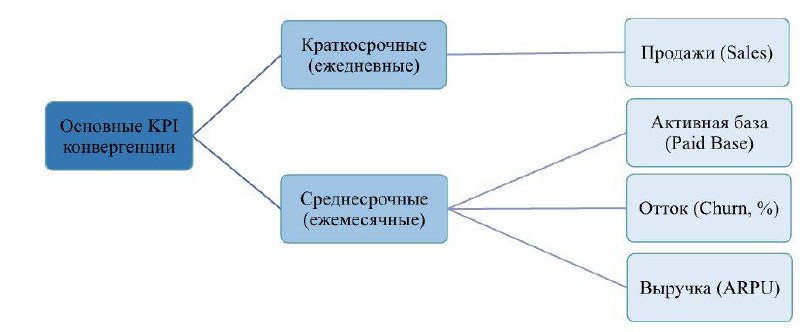
Особенности прогнозирования продаж и оттока в условиях неопределенности
В этом посте автор опишет свой опыт построения модели прогнозирования продаж конвергентных продуктов (2019-2021), а также прогнозирования оттока мобильных абонентов в 2022 году. Расскажет, как работала модель в относительно стабильный период до 2020-го года, и какие корректировки пришлось внести впоследствии.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
22 May 2023 17:14
Курс «Английский для аналитиков» Яндекс Практикума
Для специалистов, которые хотят изменить свою профессиональную жизнь и работать в международной команде.
Обучение построено вокруг рабочих ситуаций и полезных для карьеры навыков:
🗣 Самопрезентация. Рассказ о своей роли, задачах, сфере ответственности на поведенческом интервью и в неформальной беседе.
🙌 Работа в команде. Стендапы, планирование спринтов, демонстрация навыков командной работы на собеседовании.
👨💻 Общение с заказчиками и исполнителями. Сбор требований у стейкхолдеров и постановка задач для разработчиков.
📈 Презентация результатов работы. Выступление на митапах, неформальное общение с коллегами из отрасли.
📝 Обсуждение решений по проекту. Генерация и аргументация идей, участие в мозговых штурмах.
🚀 Рефлексия и самоанализ. Ретроспектива, ревью, ответы на сложные вопросы.
Запишитесь на бесплатную консультацию. Кураторы определят ваш уровень языка и расскажут подробнее про обучение.
Читать полностью…
DATApedia | Data science
19 May 2023 10:01
Тварь дрожащая или право имею: как мы лепили виртуального юриста из русскоязычных нейросетей
В статье рассказывается об опыте обучения русскоязычных и зарубежных моделей нейросетей российскому законодательству.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
16 May 2023 08:53
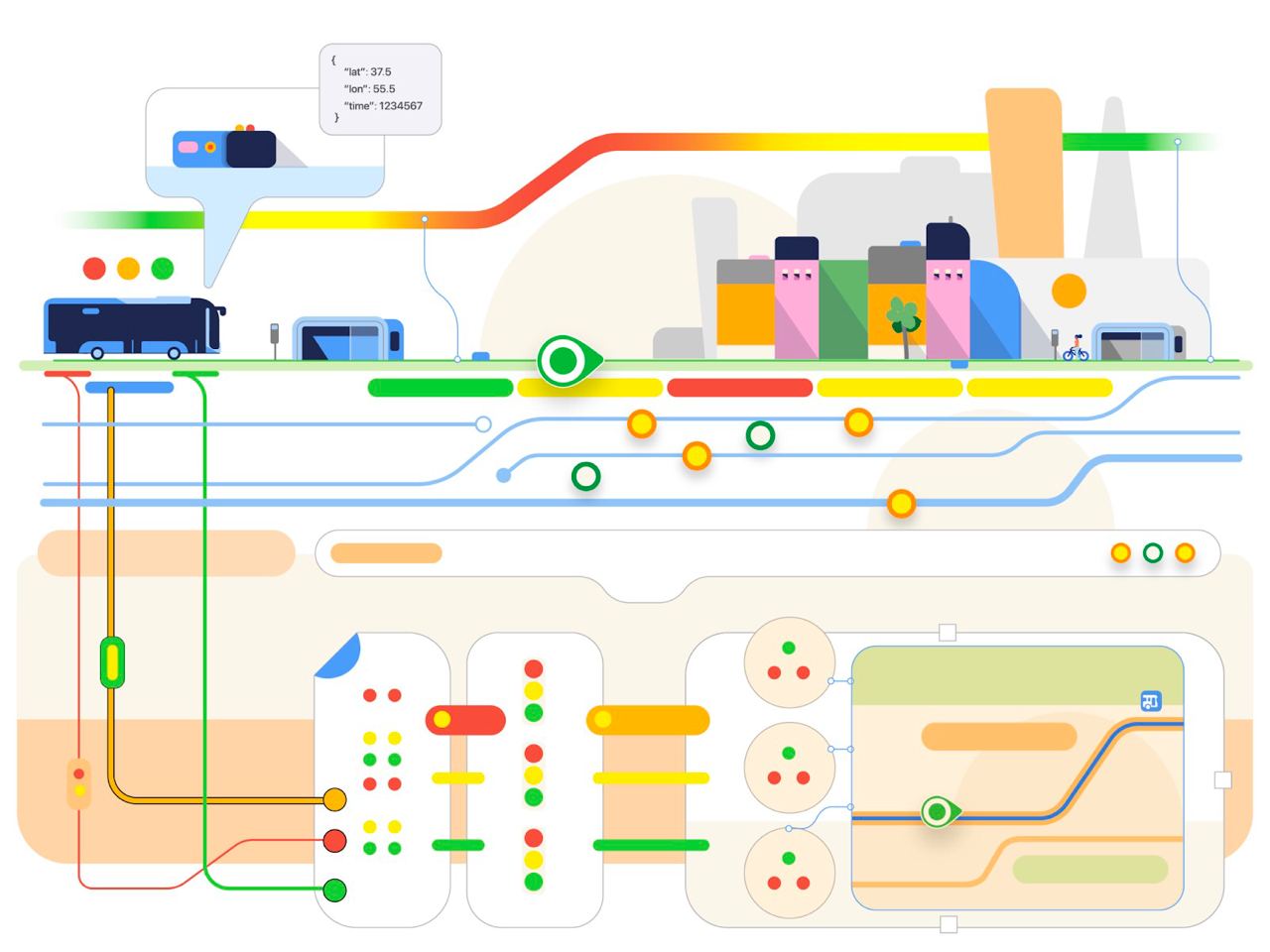
Откуда Карты знают, когда приедет автобус
В этой статье рассказывается что у «Транспорта» под капотом, какие алгоритмы отвечают за то, чтобы автобусы появлялись на карте, двигались по ней плавно и реалистично, а прогноз был максимально точным.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
11 May 2023 09:35
Как мы разрабатывали алгоритм для анализа уникальных посетителей
В этой статье рассказано о решении для анализа уникальных посетителей. Описаны недостатки существующих на рынке решений и рассказано, почему надо остановиться именно на видеоаналитике
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
08 May 2023 08:42
Пользователи ChatGPT начали получать доступ к новому плагину
Речь про Code Interpreter — модель, которая может обрабатывать большие объемы данных, используя Python. В том числе обрабатывать загружаемые файлы.
Говорят, что это как очень крутой аналитик. Вот часть из того, что научились делать пользователи с помощью плагина:
- Сегментировать данные;
- Выстраивать прогноз на основе данных (линейная регрессия);
- Создавать географические карты объектов;
- Визуализировать данные в диаграммах и графиках;
- Делать запросы на естественном языке;
- Редактировать и удалять большие объемы данных.
DATApedia
Читать полностью…
DATApedia | Data science
05 May 2023 09:58
Алоха, коллеги! Запускаем рубрику #fromInterviewWithLove!
Сегодня будет дана задача по SQL для начинающих специалистов.
Задача: В базе данных хранятся данные о продажах продуктов в разных магазинах. Необходимо вывести список магазинов, в которых были проданы все виды товаров. Таблица sales содержит следующие поля:
- id - уникальный идентификатор продажи;
- store - название магазина;
- product - название продукта.
Решение SQL запросом:
SELECT store
FROM sales
GROUP BY store
HAVING COUNT(DISTINCT product) = (SELECT COUNT(DISTINCT product) FROM sales);
Данный запрос группирует данные по названию магазина и находит количество уникальных продуктов, проданных в каждом магазине. Затем он сравнивает это количество с общим числом уникальных продуктов в таблице sales. Если количество уникальных продуктов в магазине равно общему количеству уникальных продуктов в таблице, значит все продукты были проданы в данном магазине. Результат запроса - список магазинов, в которых были проданы все виды товаров.
SQLpedia
Читать полностью…
DATApedia | Data science
03 May 2023 13:08
Прямо сейчас идёт набор в ШАД — двухгодичную программу Академии Яндекса для тех, кто хочет исследовать Machine Learning и работать в IT-индустрии.
Обучение проходит по 4 направлениям:
— data science
— инфраструктура больших данных
— разработка машинного обучения
— анализ данных в прикладных науках
Для опытных разработчиков и ML-исследователей есть альтернативный трек поступления.
Программа ШАДа полностью бесплатна. Учиться можно дистанционно или офлайн — в одном из 6 филиалов. Скорее переходите по ссылке и заполняйте анкету участника: https://clck.ru/34EePB
Читать полностью…
DATApedia | Data science
28 Apr 2023 14:20
Если вы ищите канал для ИТ-аналитиков, то вам несомненно подойдет - Analyst IT. На канале ежедневно выходят полезные материалы для аналитиков, разбор скилов разных ИТ-аналитиков (бизнес-аналитиков, системных аналитиков, аналитиков данных и др), также есть авторский контент, который поможет вам с разбором рабочих процессов, ну и вообще погрузиться в сферу анализа!
На канале есть разные рубрики:
- про проф литературу (например книга по Python)
- про разбор скилов аналитиков
- про сервисы, которыми пользуются аналитики (например Notion) и др.
Если интересно заходите в гости)))
Подписаться 👉🏻 @
Читать полностью…
DATApedia | Data science
27 Apr 2023 11:00
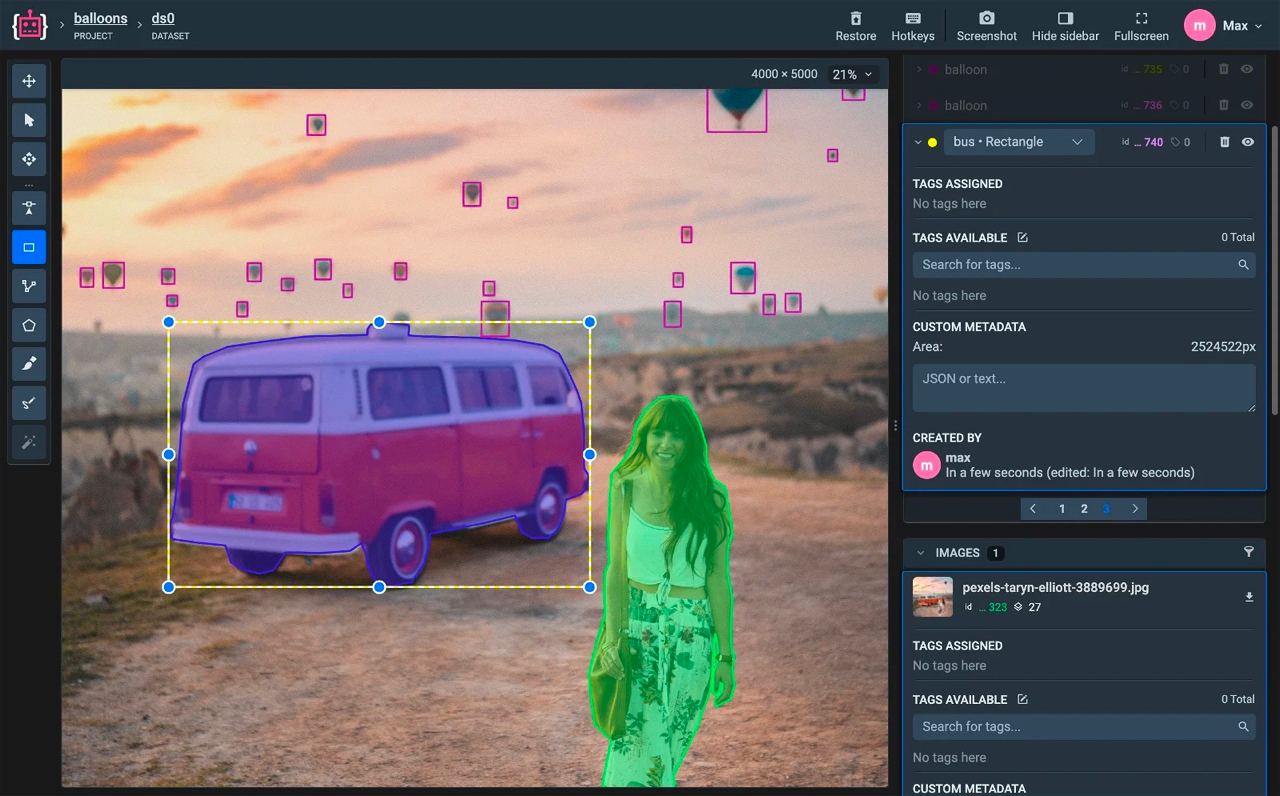
EasyPortrait — портретная сегментация и анализ лиц
В данной статье рассказывается о новом наборе данных EasyPortrait, описан процесс его создания от идеи до разметки, и представлены обученные на нем нейронные сети.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
24 Apr 2023 10:13
DataHub: как делиться структурированными данными и получать за них донаты?
В этой статье основатель платформы DataHub рассказывает о том, как создать FREE и SPONSORED репозитории данных, а так же в чем их отличия.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
20 Apr 2023 13:15
Пять примеров успешного использования ИИ на производстве
Источник | #DS_AI
Читать полностью…
DATApedia | Data science
17 Apr 2023 12:44
Локальные нейросети (генерация картинок, локальный chatGPT). Запуск Stable Diffusion на AMD видеокартах
Источник | #DS_AI
Читать полностью…
DATApedia | Data science
31 May 2023 10:05
Что нам стоит диаграмму в Python построить: 5 вариантов привлекающей внимание визуализации данных и кое-что ещё
Диаграммы помогают визуализировать как простые, так и самые сложные наборы данных. При этом диаграмм — множество видов, у каждого есть свои достоинства и недостатки. О наиболее эффектных и эффективных, реализуемых с Python, рассказывается в сегодняшней подборке.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
26 May 2023 10:40
Slovo и русский жестовый язык
В этой статье рассказывается о непростой задаче распознавания русского жестового языка (РЖЯ) для слабослышащих. Также затронуты основные особенности РЖЯ, и проблемы и сложности самого языка, и процесс его сбора и разметки.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
23 May 2023 09:37
Бустим топ: внедрение ML в ранжирование каталога
В этой статье расскажут, почему задача ранжирования каталога важна для бизнеса, как была построена систему ранжирования каталога на основе ML и переход на нее с эвристик.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
22 May 2023 14:51
Как построить систему геоаналитики с применением ML
В этой статье рассмотриавются примеры работы сервисов геоаналитики VK Predict. Выясняется, какие модели машинного обучения используются при построении таких систем и из каких этапов состоит разработка продукта с возможностями геоаналитики.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
17 May 2023 13:05
PromptGPT: оптимизируем промт для GPT-4
Автор статьи написал небольшой тул, который измеряет качество модели на различных промтах и позволяет выбрать оптимальный. В этой статье автор сначала расскажет как этот тул работает, а потом покажет процесс оптимизации промта
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
15 May 2023 09:45
Как структурировать проекты машинного обучения с помощью GitHub и VS Code: полная инструкция с настройками и шаблонами
Статья о том, как организовать файлы в проектах машинного обучения, используя VS Code.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
10 May 2023 08:50
Массивный курс по управлению данными и обзор новинок от NVIDIA. Дайджест полезных текстов про ML и дата-аналитику
В этой статье — смесь фундаментальных трудов и более «популярных» статей на тему ML, искусственного интеллекта и дата-аналитики. Думаю каждый найдет здесь для себя что-то интересное.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
07 May 2023 08:34
Любой важный созвон на удаленке проходит именно так
Читать полностью…
DATApedia | Data science
04 May 2023 13:01
Лучшие ИИ-инструменты для аннотирования видео в 2023 году
В статье рассматриваются некоторые из лучших инструментов аннотирования видео на основе ИИ.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
01 May 2023 11:30
Самостоятельное обучение стало проще с Notion AI. Онлайн школы скоро вымрут? Пример SQL курса
В этой статье показано на простом примере как новичку в IT сфере упростить себе путь осваивания хард скиллов и не платить онлайн школам много денег.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
28 Apr 2023 10:55
DataHub: веб-песочница для тех, кто изучает SQL
В этой статье показывается на что способен веб-редактор MySQL хранилища и почему это отличный инструмент для работы тем, кто изучает SQL.
Перейти к статье | DATApedia
Читать полностью…
DATApedia | Data science
26 Apr 2023 10:15
Алгоритм, сделавший ChatGPT таким «человечным» — Reinforcement Learning from Human Feedback
ChatGPT генерирует разнообразный и привлекательный для человека текст. Но что делает текст «хорошим»? В этой статье разобран алгоритм, который позволяет согласовать модель машинного обучения со сложными человеческими ценностями.
Перейти к статье | DATApedia | #DS_AI
Читать полностью…
DATApedia | Data science
21 Apr 2023 12:27
5 вещей о наблюдаемости данных, которые должен знать каждый дата-инженер
Источник
Читать полностью…
DATApedia | Data science
19 Apr 2023 12:22
Эволюция прогноза времени в Delivery Club
Источник
Читать полностью…
DATApedia | Data science
16 Apr 2023 11:13
Когда кормишь ПМа завтраками
Читать полностью…



 3571
3571
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}