novichkov.net
20 Mar 2024 05:18
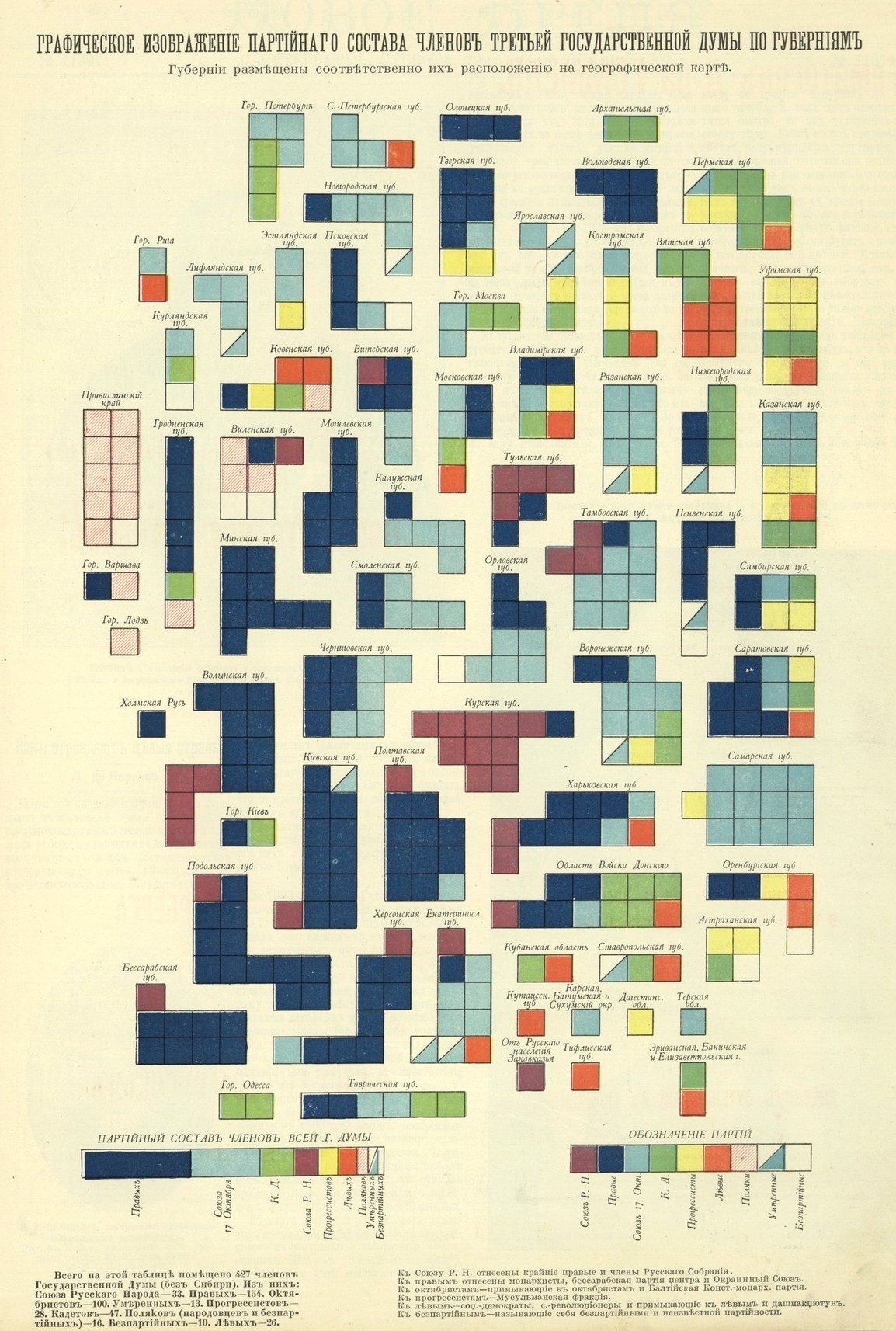
Тетрис столетней давности. Партийный состав членов третьей Государственной думы по губерниям. Иллюстрированное приложение к газете «Новое время», ноябрь 1907 года. В подзаге говорится, что губернии размещены соответственно их расположению на географической карте.
Читать полностью…
novichkov.net
19 Mar 2024 06:42
не знаю кто автор, но очень хорошо
Читать полностью…
novichkov.net
17 Mar 2024 14:07
некогда объяснять. вот тут всё понятно с первого взгляда. найдено тут: https://www.are.na/block/2156458
Читать полностью…
novichkov.net
13 Mar 2024 16:17
Работать с источниками информации не так просто, как может показаться. Есть известные методы проверки материалов на достоверность: например, техника 5W+H помогает оценить полноту информации, а IMVAIN — степень достоверности источников. Но иногда общих правил оказывается недостаточно.
Собрали практические советы коллег по работе с разными типами источников: от таблиц до пыльных архивов.
✔️ Дизайнер просит сократить
Читать полностью…
novichkov.net
13 Mar 2024 09:08
Химические элементы прекрасный набор данных для датавиз экспериментов
Читать полностью…
novichkov.net
12 Mar 2024 10:45
Сказал сегодня студентам что не переезжаю в Lunacy из-за того, что там как-то не так работа с сетками устроена. Однако, вспомнил, что недавно было обновление. Проверил. Теперь в Lunasy сетки делать так же удобно, как в Figma. Осталось починить рбаоту с кривыми безье и красота!
Читать полностью…
novichkov.net
11 Mar 2024 09:03
Перехвалил я Affinity. Теперь и их продукцию приобрести нельзя. Из App Store они тоже исчезли. Значит не зря ставку в графике на Lunacy, Inkscape и Krita сделал
Читать полностью…
novichkov.net
09 Mar 2024 09:01
Забавное сравнение локаций макдональсов и полей для гольфа в США. Оказывается, в США полей для гольфа больше, чем Макдональсов: 16к полей vs 13к макдональсов!
Читать полностью…
novichkov.net
08 Mar 2024 06:48
Прекрасные, умные, смелые!!! С праздником!!!
Читать полностью…
novichkov.net
07 Mar 2024 10:51
Кто спрашивал уроки по генеративу? А вот тут инструмент, который специально заточен, чтобы тренироваться и делать готовые проекты.
Читать полностью…
novichkov.net
06 Mar 2024 22:19
Не хотите ли поговорить про рукодельный дата-арт?
Новое открытие для хэштега #датавизвкино от внимательного подписчика (спасибо ему большое и за открытие, и за коллаж ❤️) — фрагмент фильма «Старый мрачный дом» 1963 года. И это отличная иллюстрация к моему анонсу.
Завтра 7 марта в 19:00 по Москве мы с Наташей Киселёвой, ведущей дружественного канала опять соберёмся поговорить в зуме. И на этот раз будем обсуждать вязанный, плетёный, вышитый и сшитый, слепленный, гнутый, даже варёный рукотворный дата-арт. Будем очень рады всем, ссылку на зум запостим незадолго до начала в каналах Data-comix, Дата-арт и конечно же тут в моём канале.
Читать полностью…
novichkov.net
06 Mar 2024 15:04
✨Генерация текста для блока с помощью ИИ-помощника
Теперь вы можете генерировать тексты с помощью искусственного интеллекта для всего блока сразу, а не только для поля.
Для этого добавьте на страницу базовый блок, в выпадающем меню в правом верхнем углу выберите «Сгенерировать» или во вкладке Контент нажмите на иконку «Сгенерировать с ИИ». Затем введите тематику вашего сайта. Чем больше деталей вы пропишите, тем качественнее будет сгенерированный текст. Например: Студия фитнеса с современным оборудованием, сертифицированными тренерами и разнообразными групповыми занятиями. В поле Запрос уточните, о чём вы хотите получить текст, или оставьте его пустым.
В блоках с карточками, например, из категории Преимущества, вы можете указать, какое количество карточек нужно сгенерировать. Если оставить галочку «Сохранить структуру», текст будет создан только для тех полей, которые уже были заполнены. При отключенной галочке текст сгенерируется во всех полях блока.
Если в блоке есть иконки, ИИ-помощник автоматически подберёт их по смыслу.
Функция открыта для блоков из категорий:
О проекте
Колонки
Обложка
Преимущества
Этапы
Отзывы
Расписание
Команда
Текстовый блок
Заголовок
Со временем генерация текста для блока появится и в других категориях.
Читать полностью…
novichkov.net
05 Mar 2024 12:38
Видео, которое иллюстрирует оптическую иллюзию
Читать полностью…
novichkov.net
05 Mar 2024 06:53
очень нравится тренд делать проекты о процессах создания проектов )
Читать полностью…
novichkov.net
04 Mar 2024 16:42
В спецпроекте "Бескрайний крайний. Как строили новый дом на Дальнем Востоке России" в главе "Сибирское Эльдорадо" мы построили график, который показывает различия в годовом количестве осадков в европейской части России, на Дальнем Востоке, в Китае и на севере Монголии.
Мы хотели проиллюстрировать этим графиком, что в конце XIX — начале XX века климат на Дальнем Востоке был скорее похож на погодные условия в Китае, чем в Европейской России. Работая над спецпроектом, мы использовали новый для нас тип визуализации — график горизонта (horizon chart).
➡️ Внутри подробный мастер-класс по построению диаграммы на исторических данных с таблицами и ссылками на первоисточники.
✔️ Дизайнер просит сократить
Читать полностью…
novichkov.net
19 Mar 2024 11:13
Почему-то некоторые студенты приносят работы сделанные в шаблонах Visme. Решил сходить посмотреть что там такого. И не могу перестать смеяться уже минуту. Внимание на женский мозг! Мало того, что он меншье головы, так и развёрнут в обратную сторону! За такое и отменить могут. Не пользуйтесь шаблонами. Умоляю!
Читать полностью…
novichkov.net
18 Mar 2024 16:20
#вместесэкспертом
Какой медиапроект с игровыми механиками можно назвать «хрестоматийным» примером? Почему мы должны знать именно об этом проекте?
Открыт прием работ на конкурсы «Вместе Медиа. Онлайн» и «Вместе Медиа.Радио/Аудио».
Ксения Храбрых, режиссер интерактивных медиа и член экспертного совета в номинации «Проекты с игровой механикой» рассказала нам о проекте The Guardian 2009 года. Проект «Investigate Your MP’s Expenses» с элементами геймификации позволил журналистам провести успешное антикоррупционное расследование.
Подробнее об уникальном проекте вы можете прочитать в наших карточках и вдохновиться опытом британских журналистов, чтобы придумать свой проект с игровыми механиками. Ждем ваших работ на конкурсе «Вместе Медиа»!
@
Читать полностью…
novichkov.net
15 Mar 2024 16:24
Распределение буквы по позициям в слове
Сегодня расскажу про поиск способа подсчета распределения буквы "ё" в слове.
Этап 1
При визуализации сведенных исходных данных по позиции не учитывается то, что, например, в одном слове "ё" на пятой позиции находится в конце, а в другом — посередине.
Переведем абсолютное место "ё" в относительное — проценты от длины слова. График получается шумным, тенденцию уловить сложно.
Можно измерить удаленность позиции "ё" от середины или конца слова, но при таком подходе снова не учитывается разница длины слов.
Этап 2
На помощь пришла статья про метод разделения слова на части, группы (binning). Концептуально не отличается от процентов: делим длину на части и считаем, сколько таких частей "занимает" позиция буквы (только частей меньше ста). Этот подход помогает контролировать детальность данных и шум.
Для более точного определения центра слова нужно нечетное число групп. Остается выбрать наименее шумный вариант (в нашем случае — 3 части) и посчитать коэффициент.
Читать полностью…
novichkov.net
13 Mar 2024 11:29
На всякий напоминаю про конференцию Datawrapper. Рекомендую не пропускать
https://www.datawrapper.de/unwrapped
Читать полностью…
novichkov.net
13 Mar 2024 09:01
Очень красивая периодическая система элементов, которая показывает уникальность спектров видимого диапазона каждого из элементов. Пока искала информацию по таблице, узнала, что Американская преподавательница физики Джилл Линц сделала по этой таблице ещё и сонификацию элементов — библиотеку звуков, соответствующих спектрам почти всех элементов таблицы. Вот тут её работа.
За находку спасибо Антону, который, кстати, ведёт отличный канал
Я уже писала о двух необычных периодических таблицах: элегантной спиралевидной из журнала Life 1949 года и версии Джеймса Франклина Хайда (отца силиконов) 1976 года.
Читать полностью…
novichkov.net
12 Mar 2024 10:03
Как-то пропустил, что в RAWGraphs завезли создание плоской таблицы из двухмерной сводной
Читать полностью…
novichkov.net
10 Mar 2024 15:58
Пересечения множеств
Недавно искала подходящий под задачу способ визуализации, начиталась про знакомое и не очень. Кратко структурировала изученное, может и вам пригодится.
1) Диаграмма Венна
Обычно не учитывает размеры множеств, но позволяет увидеть, какие пересечения есть, а каких нет.
2) Круги Эйлера
В отличие от Венна показывают только существующие отношения множеств. Можно сделать площадной, но справляется не со всеми комбинациями (особенно, если их много).
3) UpSet Plot
Грустный
4) Supervenn Plot
Похож на диаграмму Ганта. Интересно, но на мой взгляд, большое количество данных считывать сложно.
5) Тепловая карта
Акцент смещается только на пересечения. Если по вертикали и горизонтали множества не повторяются, то их размер вне пересечений не будет виден.
6) Параллельные множества
Частный случай, когда несколько подмножеств складываются в разные множества.
Читать полностью…
novichkov.net
08 Mar 2024 07:58
Привет из прошлого :)
Читать полностью…
novichkov.net
07 Mar 2024 19:30
После "вариантов" уже нет сил изучать новые функции Figma. Особенно после того как девелоперские штуки убрали в про версию. Вот освоил ты что-то, привык, а потом хоба! Последнее, чему реально был рад это избирательная обводка
Читать полностью…
novichkov.net
07 Mar 2024 06:36
Иван Бегтин сегодня анонсировал новую платформу для поиска данных — Dateno.
Это сайт, на котором можно найти открытые данные и статистику со всего мира по поисковому запросу. На нём уже проиндексировано 10 миллионов датасетов (из них — 219 тысяч по России), а к концу года это количество планируют расширить до 30 миллионов. Можно указать тематику, язык источника, формат данных. А работает это уже лучше, чем тот же Google Dataset Search.
Портал пока находится в стадии беты, но уже работает:
https://dateno.io/
Читать полностью…
novichkov.net
06 Mar 2024 15:05
Главное кнопку «Типограф» не забывать нажимать. Этого ИИ не умеет, ибо учился на текстах которым на типографику начхать
Читать полностью…
novichkov.net
05 Mar 2024 19:13
Студенты спрашивают: а зачем вообще нужен сценарий инфографики, зачем описывать словами то, что потом будешь визуализировать. А вот зачем: доступность наше всё. Помните, что для слепых визуализация недоступна. Используйте письменное описание в дополнение к изображению. Кстати, в Datawrapper есть специальное поле для такого текста.
PS: оказывается, X умеет в вертикальный формат и альтернативный текст 👏
Читать полностью…
novichkov.net
05 Mar 2024 09:27
Смотрите, вот сылки на видео, которые обязательно даю студентам на своём курсе. Это коллекция, которую я собрал, храню и распространяю. Вот и с вами теперь поделился
- Надежда Андрианова про экономическую инфографику
- Надежда Андрианова про пайчарты
- Антон Мизинов про инфографику о COVID-19
- Максим Осовский про схемы
- Роман Бунин про Эдварда Тафти
- Михаил Шифрин про инфографику в науке
- Татьяна Мисютина про инфографику в образовании
- Татьяна Мисютина про алгоритм визуализации сложных данных
Очень благодарен Тине Бережной, которая организовала и провела часть этих интервью. Рад что тоже немного причастен. Надеюсь, хоть кто-то из студентов посмотрит )
Читать полностью…
novichkov.net
05 Mar 2024 06:52
Как понять, нужно ли вам делать дата-историю?
У издания The Pudding, славящегося самыми крутыми дата-историями, есть инструкция о том, как понять, можно ли и нужно ли делать историю, основанную на данных.
Если коротко, перед началом работы надо ответить на несколько вопросов:
* Есть ли у вас какой-то новый или уникальный вопрос, на который вы можете дать ответ?
* Можно ли дать ответ на этот вопрос при помощи данных?
* Можете ли вы достать данные, чтобы ответить на этот вопрос?
* Действительно ли результаты анализа получились интересными?
Для каждого этапа у The Pudding есть свои примеры, которые интересно поизучать:
https://pudding.cool/process/pivot-continue-down/
Читать полностью…
novichkov.net
04 Mar 2024 08:38
🔍 Бесконечно можно смотреть как горит огонь, льётся вода и как работают другие
Читать полностью…



 3471
3471
{kind=link}