Data Science by ODS.ai 🦜
11 May 2023 19:44
StarCoder: may the source be with you!
The BigCode community, an open-scientific collaboration working on the responsible development of Code LLMs, introduces StarCoder and StarCoderBase:
- 15.5B parameter models
- 8K context length
- StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process
- StarCoderBase is fine-tuned on 35B Python tokens, resulting in the creation of StarCoder
StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model.
Читать полностью…
Data Science by ODS.ai 🦜
10 May 2023 14:53
Found another PyTorch-based library with basic image functions, losses and transformations
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
Читать полностью…
Data Science by ODS.ai 🦜
08 May 2023 06:22
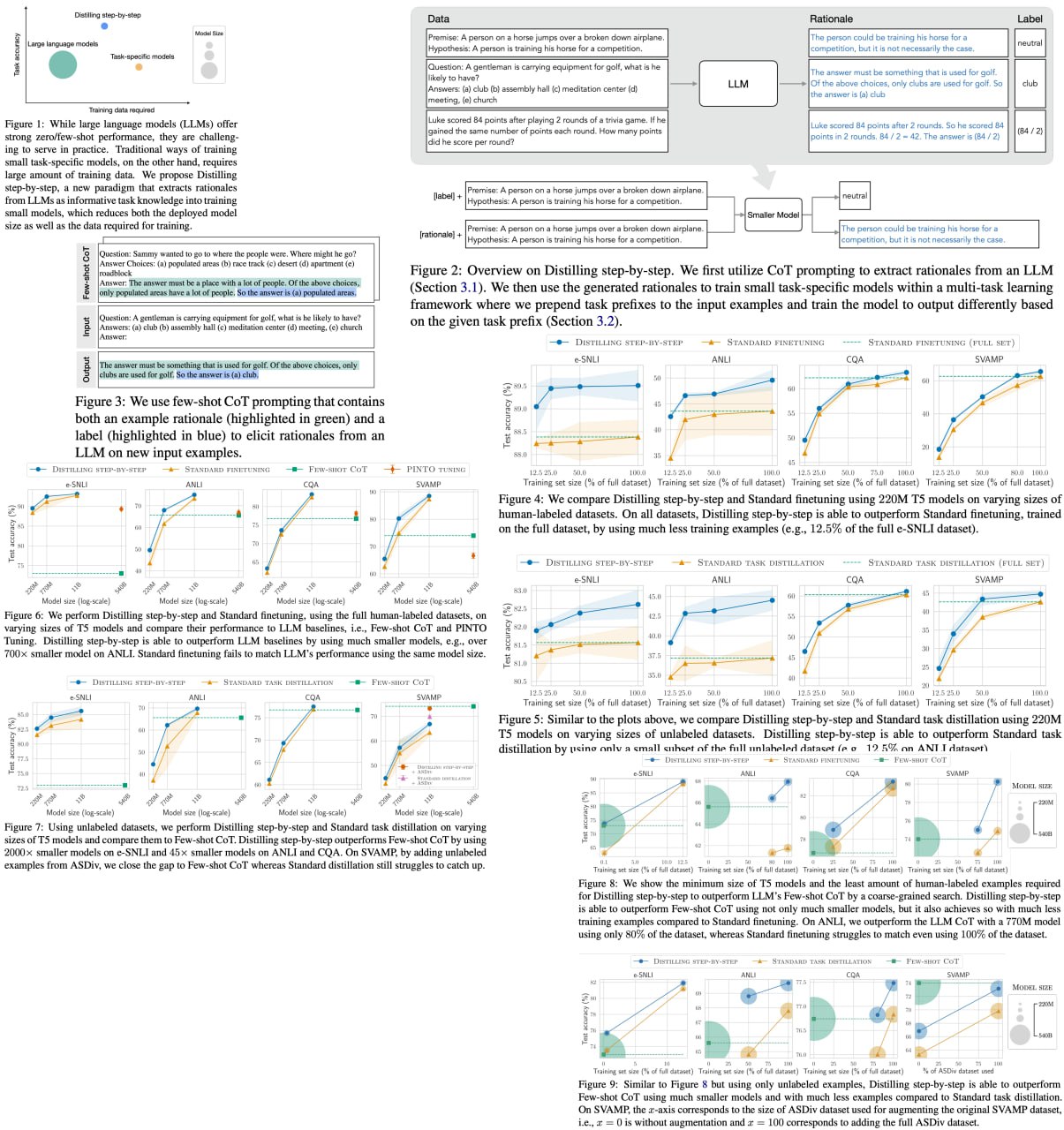
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
Researchers have developed "Distilling step-by-step," a cutting-edge method to train smaller, more efficient task-specific models that outperform large language models (LLMs) while requiring significantly less training data. This innovation promises to revolutionize the practicality of NLP models in real-world applications by reducing both model size and data requirements: a 770M T5 model surpasses a 540B PaLM model using only 80% of available data.
Distilling step-by-step leverages LLM-generated rationales within a multi-task training framework, yielding impressive results across 4 NLP benchmarks. The technique consistently achieves better performance with fewer labeled/unlabeled training examples, surpassing LLMs with substantially smaller model sizes.
Paper link: https://arxiv.org/abs/2305.02301
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dsbs
#deeplearning #nlp #languagemodels #distillation
Читать полностью…
Data Science by ODS.ai 🦜
06 May 2023 11:05
Last call to apply for the Yandex School of Data Analysis.
Recruitment for the YSDA, which is a vocational training program, free of charge, lasting for two years, will end on the 06 May 2023.
You can choose one of the four highly demanded majors: data science, big data infrastructure, machine learning or data analysis in applied sciences.
To be able to pass examinations and study successfully at the YSDA one should have a basic understanding of the machine learning, have a good mathematical background and use one of the programming languages. Experienced developers can apply for an alternative admission track that includes both assessment of algorithms basics and mathematics and research and/or industrial achievements.
The educational process is mainly conducted in the Russian language.
Application form is accessible via link https://clck.ru/34GwCS, there is also a tg-chat for the applicants /channel/+DQ1j7epbIlNmNjFi
Читать полностью…
Data Science by ODS.ai 🦜
01 May 2023 06:56
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Читать полностью…
Data Science by ODS.ai 🦜
25 Apr 2023 21:54
GigaChat
by SberDevices, Sber AI, AIRI & etc.
Based on a model collectively called NeONKA (NEural Omnimodal Network with Knowledge-Awareness). There ruGPT3.5-13B, which is based on ruGPT3 13B & FRED-T5.
Current version in NLP part is based on ruGPT3.5 13B pretrain + SFT (supervised fine-tuning).
In side by side tests GigaChat vs ChatGPT 30:70 in favor of the latter. This is without PPO. Will be higher. They have big plans to improve models and train new ones.
Some models will be made publicly available.
To get access to the beta test, you need to subscribe to the project's [closed tg-channel](/channel/+eL4Gc0g74yw4N2Qy).
What it can do:
- Write commercial texts
- Generate imaginary dialogues
- Work with document templates
- Create entertaining content
- Make lists and ratings
More here — https://habr.com/ru/companies/sberbank/articles/730108/
Читать полностью…
Data Science by ODS.ai 🦜
24 Apr 2023 06:31
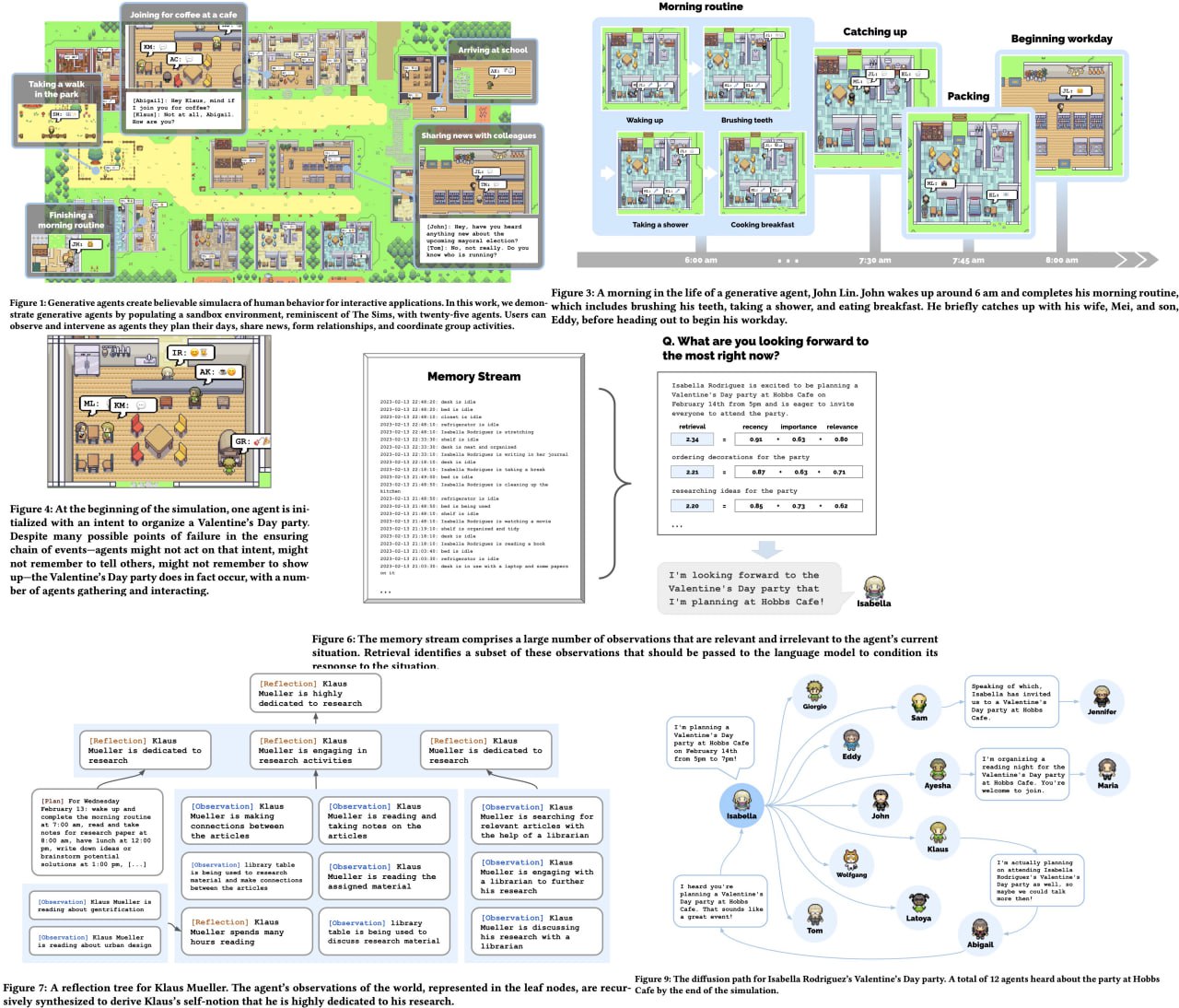
Generative Agents: Interactive Simulacra of Human Behavior
Imagine a world where computational software agents can simulate believable human behavior, empowering a wide range of interactive applications from immersive environments to rehearsal spaces for interpersonal communication and prototyping tools. This paper introduces "generative agents," a groundbreaking concept where agents perform daily routines, engage in creative activities, form opinions, interact with others, and remember and reflect on their experiences as they plan their next day.
To bring generative agents to life, the authors propose an innovative architecture that extends a large language model, allowing agents to store and reflect on their experiences using natural language and dynamically plan their behavior. They showcase the potential of generative agents in an interactive sandbox environment inspired by The Sims, where users can engage with a small town of 25 agents using natural language. The evaluation highlights the agents' ability to autonomously create and navigate complex social situations, producing believable individual and emergent social behaviors. This groundbreaking work demonstrates the critical contributions of observation, planning, and reflection components in agent architecture, laying the foundation for more realistic simulations of human behavior and unlocking exciting possibilities across various applications.
Paper link: https://arxiv.org/abs/2304.03442
Demo link: https://reverie.herokuapp.com/arXiv_Demo/#
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ishb
#deeplearning #nlp #generative # simulation
Читать полностью…
Data Science by ODS.ai 🦜
19 Apr 2023 20:13
Stability AI just released initial set of StableLM-alpha models, with 3B and 7B parameters. 15B and 30B models are on the way.
Base models are released under CC BY-SA-4.0.
StableLM-Alpha models are trained on the new dataset that build on The Pile, which contains 1.5 trillion tokens, roughly 3x the size of The Pile. These models will be trained on up to 1.5 trillion tokens. The context length for these models is 4096 tokens.
As a proof-of-concept, we also fine-tuned the model with Stanford Alpaca's procedure using a combination of five recent datasets for conversational agents: Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH. We will be releasing these models as StableLM-Tuned-Alpha.
https://github.com/Stability-AI/StableLM
Читать полностью…
Data Science by ODS.ai 🦜
17 Apr 2023 19:55
AI for IT Operations (AIOps) on Cloud Platforms: Reviews, Opportunities and Challenges (Salesforce AI)
A review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques.
1. INTRODUCTION
2. CONTRIBUTION OF THIS SURVEY
3. DATA FOR AIOPS
A. Metrics
B. Logs
C. Traces
D. Other data
4. INCIDENT DETECTION
A. Metrics based Incident Detection
B. Logs based Incident Detection
C. Traces and Multimodal Incident Detection
5. FAILURE PREDICTION
A. Metrics based Failure Prediction
B. Logs based Incident Detection
6. ROOT CAUSE ANALYSIS
A. Metric-based RCA
B. Log-based RCA
C. Trace-based and Multimodal RCA
7. AUTOMATED ACTIONS
A. Automated Remediation
B. Auto-scaling
C. Resource Management
8. FUTURE OF AIOPS
A. Common AI Challenges for AIOps
B. Opportunities and Future Trends
9. CONCLUSION
Читать полностью…
Data Science by ODS.ai 🦜
10 Apr 2023 12:07
Paper Review: Segment Anything
- 99% of masks are automatic, i.e. w/o labels;
- Main image encoder model is huge;
- To produce masks you need a prompt or a somewhat accurate bbox (partial bbox fails miserably);
- Trained on 128 / 256 GPUs;
- Most likely - useful a large scale data annotation tool;
- Not sure that it can be used in production as is, also license for the dataset is research only, the model is Apache 2.0
https://andlukyane.com//blog/paper-review-sam
Unless you have a very specific project (i.e. segment just one object type and you have some priors), this can serve as a decent pre-annotation tool.
This is nice, but probably it can offset 10-20% of CV annotation costs.
Читать полностью…
Data Science by ODS.ai 🦜
07 Apr 2023 22:05
Tabby: Self-hosted AI coding assistant
Self-hosted AI coding assistant. An opensource / on-prem alternative to GitHub Copilot.
- Self-contained, with no need for a DBMS or cloud service
- Web UI for visualizing and configuration models and MLOps.
- OpenAPI interface, easy to integrate with existing infrastructure.
- Consumer level GPU supports (FP-16 weight loading with various optimization).
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 21:38
Rask — service for AI-supported video localization
TLDR: Service which allows to translate video end-to-end between languages.
Rask AI offers voice cloning capabilities to make your voice part of your brand, although it has a library of natural and human-like voices to choose from. They currently support the output of videos in the following languages: German, French, Spanish, Chinese, English, and Portuguese, regardless of the source language.
In the near future, a team plans to offer additional services such as captions and subtitles and increase the number of supported languages up to 60 languages.
They haven’t raised any funds for the current setup and currently are launched on the Product Hunt. You are welcome to support them via link below (we all know how important it is for founders, right?).
Website: https://www.rask.ai/
ProductHunt: https://www.producthunt.com/posts/rask-ai-video-localization-dubbing-app
#producthunt #aiproduct #localization
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 14:50
Pandas v2.0.0
The main enhancements:
- installing optional dependencies with pip extras
- index can now hold numpy numeric dtypes
- argument dtype_backend, to return pyarrow-backed or numpy-backed nullable dtypes
- copy-on-write improvements
- ..
+ other notable bug fixes
Full list of changes: https://pandas.pydata.org/docs/whatsnew/v2.0.0.html
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 16:18
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
Читать полностью…
Data Science by ODS.ai 🦜
02 Apr 2023 18:28
When you stack enough layers, them can explain the meme about stacking more layers.
#memelearning
Читать полностью…
Data Science by ODS.ai 🦜
11 May 2023 16:57
For those how are looking beyond Data Science or wondering to play around, here is a news on the release of the portfolio company of one of the channel editors:
TON Play: the Unity SDK + payment management for games
TON Play is a toolkit for developers based on the TON blockchain and working closely with the messaging app Telegram. They recently introduced Pay-in, Mass payout, and On-demand payout methods in TON. If you dabble with games, this might be curious to test in action.
The main features:
* projects get paid by Telegram users in TON
* option to add mass payouts in TON to games with cash prizes
* automated payouts on user demand
TON Play also released SDKs, allowing projects to manage assets and in-game marketplace and port Unity or HTML5 games to work inside Telegram as a web app. SDKs are written in Unity, Python, and Typescript.
Website: https://tonplay.io/
Documentation: https://docs.tonplay.io/
Telegram channel: /channel/tonplayinsider
Contacts: @, gamedevs@tonplay.io
#ds_jobs #ds_resumes
Читать полностью…
Data Science by ODS.ai 🦜
10 May 2023 06:11
ImageBind: One Embedding Space To Bind Them All
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
Читать полностью…
Data Science by ODS.ai 🦜
06 May 2023 23:23
TWIMC
string2string: A Modern Python Library for String-to-String Algorithms
https://arxiv.org/abs/2304.14395
We introduce string2string, an open-source library that offers a comprehensive suite of efficient algorithms for a broad range of string-to-string problems. It includes traditional algorithmic solutions as well as recent advanced neural approaches to tackle various problems in string alignment, distance measurement, lexical and semantic search, and similarity analysis -- along with several helpful visualization tools and metrics to facilitate the interpretation and analysis of these methods. Notable algorithms featured in the library include the Smith-Waterman algorithm for pairwise local alignment, the Hirschberg algorithm for global alignment, the Wagner-Fisher algorithm for edit distance, BARTScore and BERTScore for similarity analysis, the Knuth-Morris-Pratt algorithm for lexical search, and Faiss for semantic search. Besides, it wraps existing efficient and widely-used implementations of certain frameworks and metrics, such as sacreBLEU and ROUGE, whenever it is appropriate and suitable. Overall, the library aims to provide extensive coverage and increased flexibility in comparison to existing libraries for strings. It can be used for many downstream applications, tasks, and problems in natural-language processing, bioinformatics, and computational social sciences. It is implemented in Python, easily installable via pip, and accessible through a simple API. Source code, documentation, and tutorials are all available on our GitHub page:
https://github.com/stanfordnlp/string2string
Читать полностью…
Data Science by ODS.ai 🦜
04 May 2023 06:37
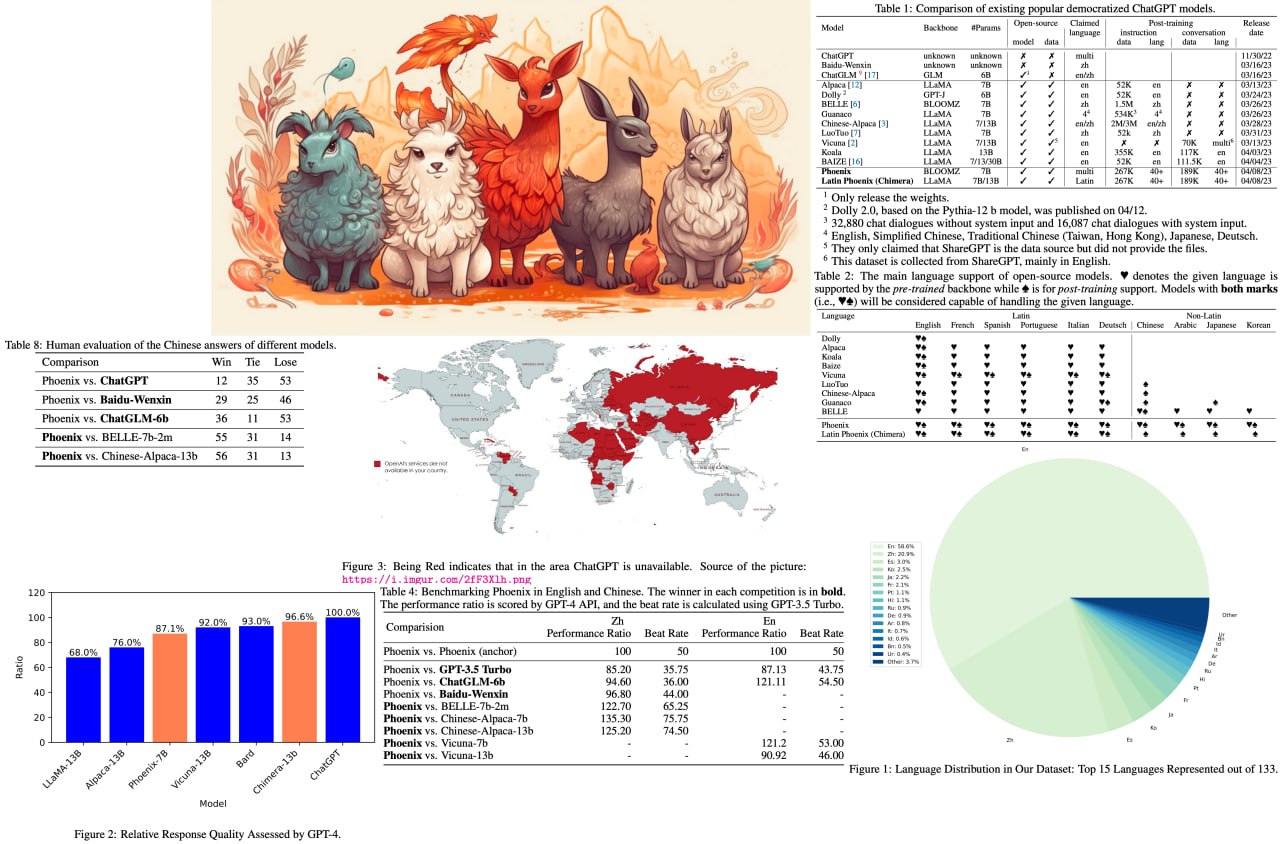
Phoenix: Democratizing ChatGPT across Languages
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
Читать полностью…
Data Science by ODS.ai 🦜
27 Apr 2023 06:41
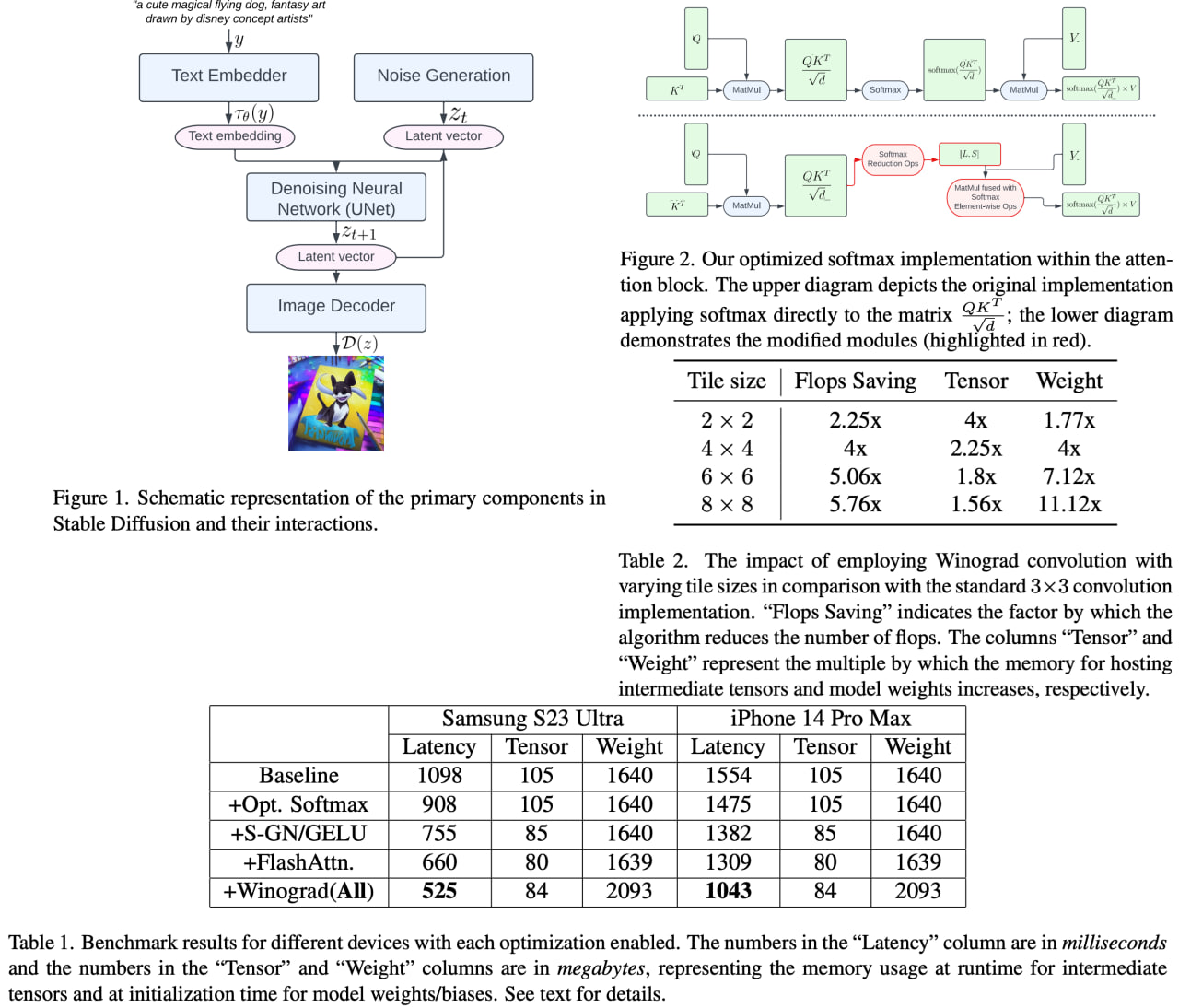
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
The rapid development of foundation models is revolutionizing the field of artificial intelligence, with large diffusion models gaining significant attention for their ability to generate photorealistic images and support various tasks. Deploying these models on-device brings numerous benefits, including lower server costs, offline functionality, and improved user privacy. However, with over 1 billion parameters, these models face challenges due to restricted computational and memory resources on devices.
Excitingly, researchers from Google have presented a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to date (under 12 seconds for Stable Diffusion 1.4 without INT8 quantization for a 512 × 512 image with 20 iterations) on GPU-equipped mobile devices. These groundbreaking enhancements not only broaden the applicability of generative AI but also significantly improve the overall user experience across a wide range of devices, paving the way for even more innovative AI applications in the future.
Paper link: https://arxiv.org/abs/2304.11267
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-siayn
#deeplearning #stablediffusion #inferenceoptimization
Читать полностью…
Data Science by ODS.ai 🦜
24 Apr 2023 13:39
Finetuning Large Language Models
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient finetuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.
- In-Context Learning and Indexing
- The 3 Conventional Feature-Based and Finetuning Approaches
- Feature-Based Approach
- Finetuning I – Updating The Output Layers
- Finetuning II – Updating All Layers
- Parameter-Efficient Finetuning
- Reinforcement Learning with Human Feedback
- Conclusion
Читать полностью…
Data Science by ODS.ai 🦜
20 Apr 2023 14:57
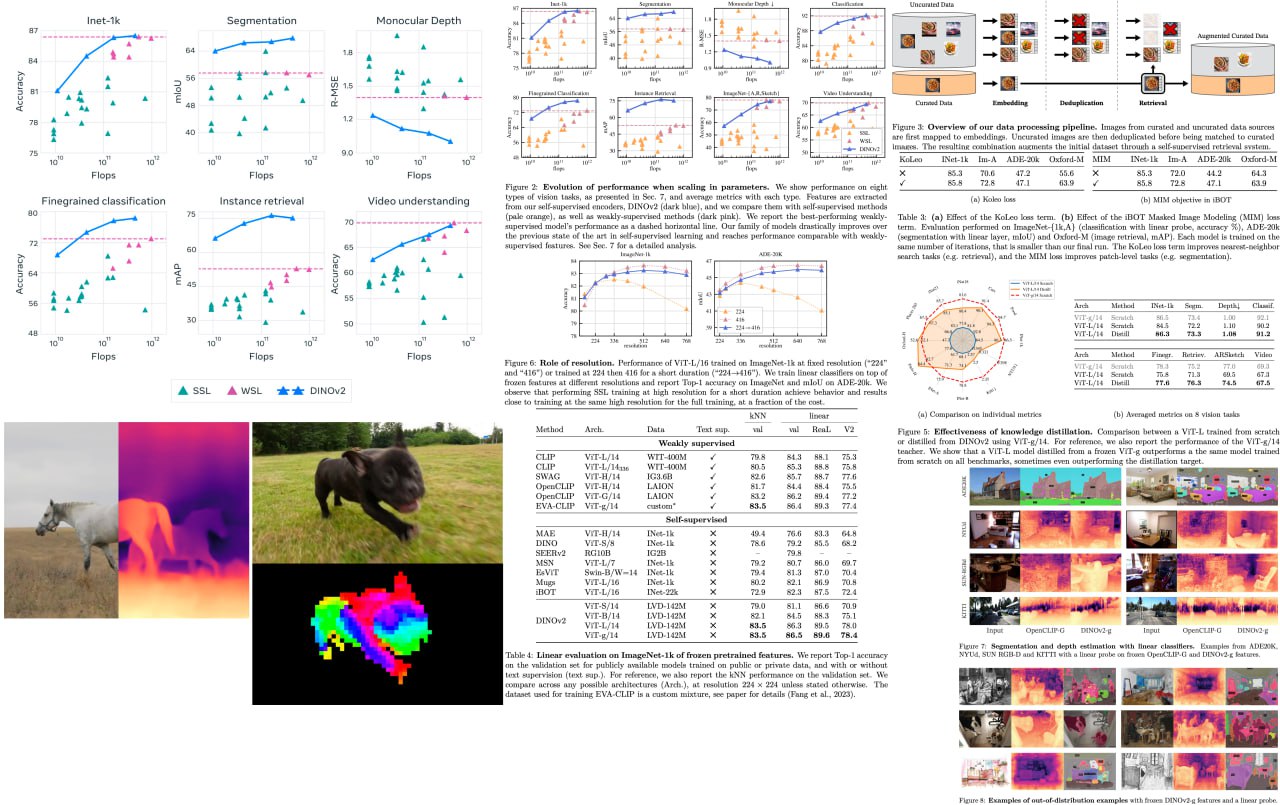
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Читать полностью…
Data Science by ODS.ai 🦜
18 Apr 2023 21:11
AI / ML / LLM / Transformer Models Timeline
This is a collection of important papers in the area of LLMs and Transformer models.
PDF file.
Читать полностью…
Data Science by ODS.ai 🦜
17 Apr 2023 09:19
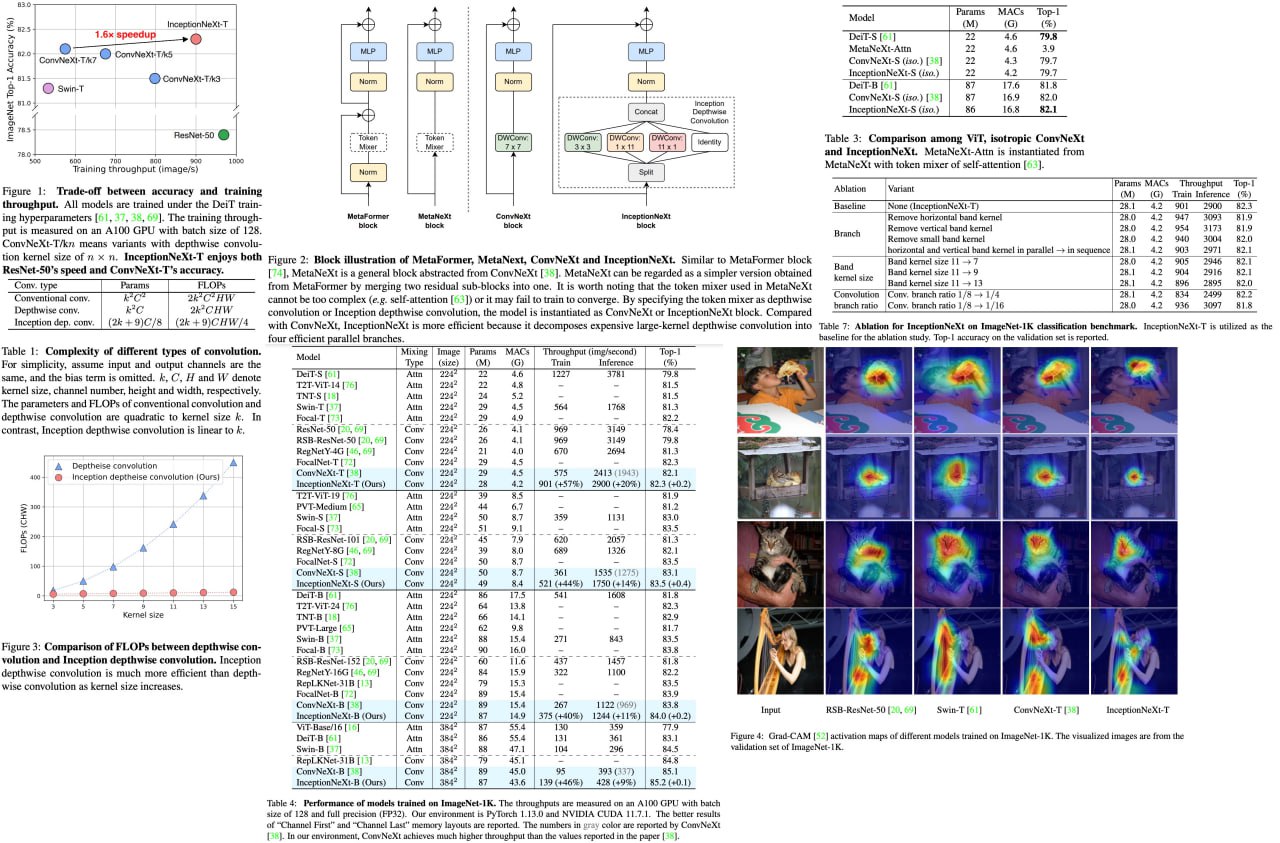
InceptionNeXt: When Inception Meets ConvNeXt
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Читать полностью…
Data Science by ODS.ai 🦜
08 Apr 2023 07:00
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
Читать полностью…
Data Science by ODS.ai 🦜
06 Apr 2023 17:08
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form.
Best vacancies may be published in this channel.
Google Form: link.
#ds_jobs
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 19:42
Kandinsky 2.1
by Sber & AIRI
The main features:
- 3.3B parameters
- generation resolution - 768x768
- image prior transformer
- new MoVQ image autoencoder
- doing a cleaner set of 172M text-image pairs
- work modes: generate by text, blend image, generate images by pattern, change images by text, inpainting/outpainting
The FID on the COCO_30k dataset reaches 8.21
Few posts where compare Kandinsky 2.1 with another similar models
- /channel/dushapitona/643
- /channel/antidigital/6153
Habr: https://habr.com/ru/companies/sberbank/articles/725282/
Telegram-bot: /channel/kandinsky21_bot
ruDALL-E: https://rudalle.ru/
MLSpace: https://sbercloud.ru/ru/datahub/rugpt3family/kandinsky-2-1
FusionBrain: https://fusionbrain.ai/diffusion
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 23:53
Stanford 2023 AI Index Report is published!
The section on machine translation is based on Intento data as usual :)
https://aiindex.stanford.edu/report/
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 15:01
Reliable ML track at Data Fest Online 2023
Call for Papers
Friends, we are glad to inform you that the largest Russian-language conference on Data Science - Data Fest - from the Open Data Science community will take place in 2023 (at the end of May).
And it will again have a section from Reliable ML community. We are waiting for your applications for reports: write directly to me or Dmitry.
Track Info
The concept of Reliable ML is about what to do so that the result of the work of data teams would be, firstly, applicable in the business processes of the customer company and, secondly, brought benefits to this company.
For this you need to be able to:
- correctly build a portfolio of projects (#business)
- think over the system design of each project (#ml_system_design)
- overcome various difficulties when developing a prototype (#tech #causal_inference #metrics)
- explain to the business that your MVP deserves a pilot (#interpretable_ml)
- conduct a pilot (#causal_inference #ab_testing)
- implement your solution in business processes (#tech #mlops #business)
- set up solution monitoring in the productive environment (#tech #mlops)
If you have something to say on the topics above, write to us! If in doubt, write anyway. Many of the coolest reports of previous Reliable ML tracks have come about as a result of discussion and collaboration on the topic.
If you are not ready to make a report but want to listen to something interesting, you can still help! Repost to a relevant community / forward to a friend = participate in the creation of good content.
Registration and full information about Data Fest 2023 is here.
@ ML
Читать полностью…
Data Science by ODS.ai 🦜
02 Apr 2023 10:13
Complexity Explorables
Another collection of interactive explorable explanations of complex systems in biology, physics, mathematics, social sciences, epidemiology, ecology
Link: https://www.complexity-explorables.org
The emergence of communities in weighted networks: https://www.complexity-explorables.org/explorables/jujujajaki-networks/
#interactive #demo #systems #explanations
Читать полностью…



 49987
49987
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}