Data Science by ODS.ai 🦜
24 Apr 2023 13:39
Finetuning Large Language Models
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient finetuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.
- In-Context Learning and Indexing
- The 3 Conventional Feature-Based and Finetuning Approaches
- Feature-Based Approach
- Finetuning I – Updating The Output Layers
- Finetuning II – Updating All Layers
- Parameter-Efficient Finetuning
- Reinforcement Learning with Human Feedback
- Conclusion
Читать полностью…
Data Science by ODS.ai 🦜
20 Apr 2023 14:57
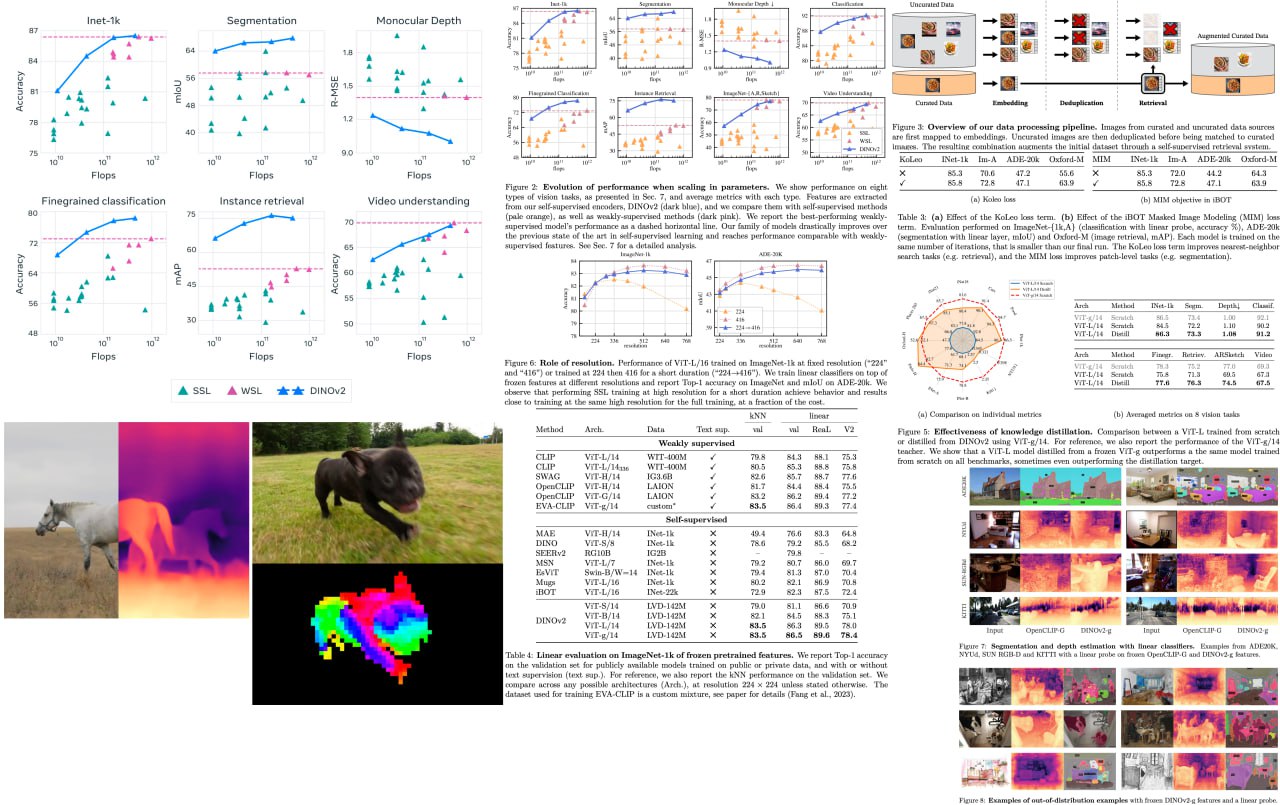
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Читать полностью…
Data Science by ODS.ai 🦜
18 Apr 2023 21:11
AI / ML / LLM / Transformer Models Timeline
This is a collection of important papers in the area of LLMs and Transformer models.
PDF file.
Читать полностью…
Data Science by ODS.ai 🦜
17 Apr 2023 09:19
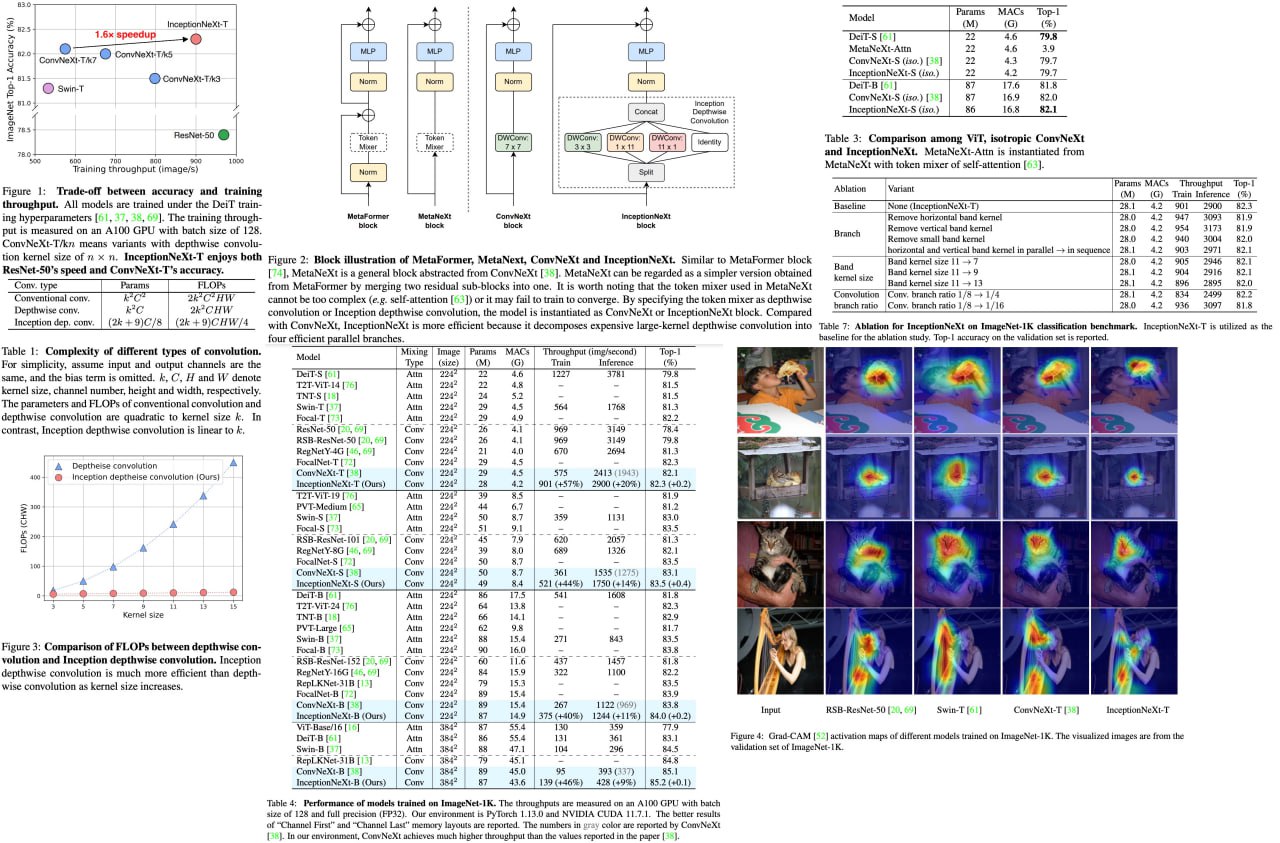
InceptionNeXt: When Inception Meets ConvNeXt
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Читать полностью…
Data Science by ODS.ai 🦜
08 Apr 2023 07:00
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
Читать полностью…
Data Science by ODS.ai 🦜
06 Apr 2023 17:08
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form.
Best vacancies may be published in this channel.
Google Form: link.
#ds_jobs
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 19:42
Kandinsky 2.1
by Sber & AIRI
The main features:
- 3.3B parameters
- generation resolution - 768x768
- image prior transformer
- new MoVQ image autoencoder
- doing a cleaner set of 172M text-image pairs
- work modes: generate by text, blend image, generate images by pattern, change images by text, inpainting/outpainting
The FID on the COCO_30k dataset reaches 8.21
Few posts where compare Kandinsky 2.1 with another similar models
- /channel/dushapitona/643
- /channel/antidigital/6153
Habr: https://habr.com/ru/companies/sberbank/articles/725282/
Telegram-bot: /channel/kandinsky21_bot
ruDALL-E: https://rudalle.ru/
MLSpace: https://sbercloud.ru/ru/datahub/rugpt3family/kandinsky-2-1
FusionBrain: https://fusionbrain.ai/diffusion
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 23:53
Stanford 2023 AI Index Report is published!
The section on machine translation is based on Intento data as usual :)
https://aiindex.stanford.edu/report/
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 15:01
Reliable ML track at Data Fest Online 2023
Call for Papers
Friends, we are glad to inform you that the largest Russian-language conference on Data Science - Data Fest - from the Open Data Science community will take place in 2023 (at the end of May).
And it will again have a section from Reliable ML community. We are waiting for your applications for reports: write directly to me or Dmitry.
Track Info
The concept of Reliable ML is about what to do so that the result of the work of data teams would be, firstly, applicable in the business processes of the customer company and, secondly, brought benefits to this company.
For this you need to be able to:
- correctly build a portfolio of projects (#business)
- think over the system design of each project (#ml_system_design)
- overcome various difficulties when developing a prototype (#tech #causal_inference #metrics)
- explain to the business that your MVP deserves a pilot (#interpretable_ml)
- conduct a pilot (#causal_inference #ab_testing)
- implement your solution in business processes (#tech #mlops #business)
- set up solution monitoring in the productive environment (#tech #mlops)
If you have something to say on the topics above, write to us! If in doubt, write anyway. Many of the coolest reports of previous Reliable ML tracks have come about as a result of discussion and collaboration on the topic.
If you are not ready to make a report but want to listen to something interesting, you can still help! Repost to a relevant community / forward to a friend = participate in the creation of good content.
Registration and full information about Data Fest 2023 is here.
@ ML
Читать полностью…
Data Science by ODS.ai 🦜
02 Apr 2023 10:13
Complexity Explorables
Another collection of interactive explorable explanations of complex systems in biology, physics, mathematics, social sciences, epidemiology, ecology
Link: https://www.complexity-explorables.org
The emergence of communities in weighted networks: https://www.complexity-explorables.org/explorables/jujujajaki-networks/
#interactive #demo #systems #explanations
Читать полностью…
Data Science by ODS.ai 🦜
31 Mar 2023 21:38
🕊Twitter Recommendation Algorithm
#Twitter disclosed the sources of its recommendation engine.
GitHub: https://github.com/twitter/the-algorithm
Blog post: https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
#recommenders #recsys #recommendation
Читать полностью…
Data Science by ODS.ai 🦜
30 Mar 2023 09:56
Adobe does image generation
> Adobe announced a beta of Firefly, a generative ML tool for making images, Unlike MidJourney or Stable Diffusion (or Bing) this looks a lot more like an actual product - instead of typing 50-100 works into a box trying to refine your results, there are GUI tools and settings. It also has a much more clearly-defined set of training data - note that Getty is suing Stable Diffusion for training on its images without permission. In more normal times this would be a huge story - now it’s only half way down the page.
https://firefly.adobe.com/?ref=lore.ghost.io
This really looks like a product. Also numerous tags and knobs are probably sourced from internal Adobe data.
Lots of networks here - upscaling, cycle-gan like domain transfers, inpainting, editing, plain generation, etc
I understand that their demos are probably cherry picked af, but proper product work is evident. Also probably this shows the real niche these tools are meant to occupy. Not the "AGI".
Also evident that the data requirements and scale to pull this off are huge.
Читать полностью…
Data Science by ODS.ai 🦜
28 Mar 2023 23:45
My experience with PyTorch 2.0 so far:
[1] - packaging?
[2] - compilation errors
We will test other models as well.
Читать полностью…
Data Science by ODS.ai 🦜
27 Mar 2023 09:07
Do large language models need sensory grounding for meaning and understanding?
TLDR: Yes
Slides from philosophical debate by Yann LeCun, who claimed Auto-Regressive LLMs are exponentially diverging diffusion processes.
#LLM #YanLeCun
Читать полностью…
Data Science by ODS.ai 🦜
20 Mar 2023 14:04
Tracking the Fake GitHub Star Black Market with Dagster, dbt and BigQuery
This is a simple Dagster project to analyze the number of fake GitHub stars on any GitHub repository:
https://github.com/dagster-io/fake-star-detector
Читать полностью…
Data Science by ODS.ai 🦜
24 Apr 2023 06:31
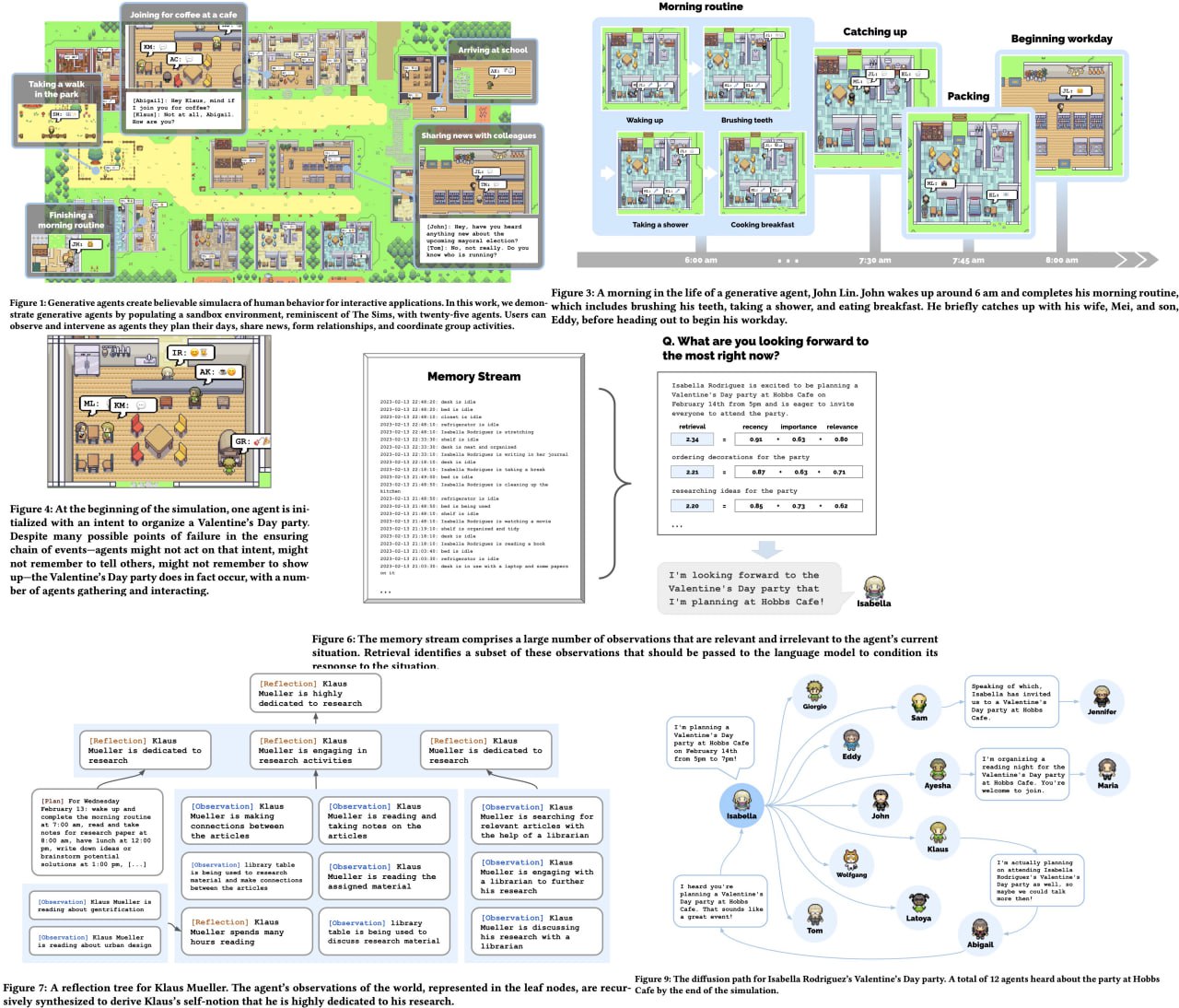
Generative Agents: Interactive Simulacra of Human Behavior
Imagine a world where computational software agents can simulate believable human behavior, empowering a wide range of interactive applications from immersive environments to rehearsal spaces for interpersonal communication and prototyping tools. This paper introduces "generative agents," a groundbreaking concept where agents perform daily routines, engage in creative activities, form opinions, interact with others, and remember and reflect on their experiences as they plan their next day.
To bring generative agents to life, the authors propose an innovative architecture that extends a large language model, allowing agents to store and reflect on their experiences using natural language and dynamically plan their behavior. They showcase the potential of generative agents in an interactive sandbox environment inspired by The Sims, where users can engage with a small town of 25 agents using natural language. The evaluation highlights the agents' ability to autonomously create and navigate complex social situations, producing believable individual and emergent social behaviors. This groundbreaking work demonstrates the critical contributions of observation, planning, and reflection components in agent architecture, laying the foundation for more realistic simulations of human behavior and unlocking exciting possibilities across various applications.
Paper link: https://arxiv.org/abs/2304.03442
Demo link: https://reverie.herokuapp.com/arXiv_Demo/#
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ishb
#deeplearning #nlp #generative # simulation
Читать полностью…
Data Science by ODS.ai 🦜
19 Apr 2023 20:13
Stability AI just released initial set of StableLM-alpha models, with 3B and 7B parameters. 15B and 30B models are on the way.
Base models are released under CC BY-SA-4.0.
StableLM-Alpha models are trained on the new dataset that build on The Pile, which contains 1.5 trillion tokens, roughly 3x the size of The Pile. These models will be trained on up to 1.5 trillion tokens. The context length for these models is 4096 tokens.
As a proof-of-concept, we also fine-tuned the model with Stanford Alpaca's procedure using a combination of five recent datasets for conversational agents: Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH. We will be releasing these models as StableLM-Tuned-Alpha.
https://github.com/Stability-AI/StableLM
Читать полностью…
Data Science by ODS.ai 🦜
17 Apr 2023 19:55
AI for IT Operations (AIOps) on Cloud Platforms: Reviews, Opportunities and Challenges (Salesforce AI)
A review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques.
1. INTRODUCTION
2. CONTRIBUTION OF THIS SURVEY
3. DATA FOR AIOPS
A. Metrics
B. Logs
C. Traces
D. Other data
4. INCIDENT DETECTION
A. Metrics based Incident Detection
B. Logs based Incident Detection
C. Traces and Multimodal Incident Detection
5. FAILURE PREDICTION
A. Metrics based Failure Prediction
B. Logs based Incident Detection
6. ROOT CAUSE ANALYSIS
A. Metric-based RCA
B. Log-based RCA
C. Trace-based and Multimodal RCA
7. AUTOMATED ACTIONS
A. Automated Remediation
B. Auto-scaling
C. Resource Management
8. FUTURE OF AIOPS
A. Common AI Challenges for AIOps
B. Opportunities and Future Trends
9. CONCLUSION
Читать полностью…
Data Science by ODS.ai 🦜
10 Apr 2023 12:07
Paper Review: Segment Anything
- 99% of masks are automatic, i.e. w/o labels;
- Main image encoder model is huge;
- To produce masks you need a prompt or a somewhat accurate bbox (partial bbox fails miserably);
- Trained on 128 / 256 GPUs;
- Most likely - useful a large scale data annotation tool;
- Not sure that it can be used in production as is, also license for the dataset is research only, the model is Apache 2.0
https://andlukyane.com//blog/paper-review-sam
Unless you have a very specific project (i.e. segment just one object type and you have some priors), this can serve as a decent pre-annotation tool.
This is nice, but probably it can offset 10-20% of CV annotation costs.
Читать полностью…
Data Science by ODS.ai 🦜
07 Apr 2023 22:05
Tabby: Self-hosted AI coding assistant
Self-hosted AI coding assistant. An opensource / on-prem alternative to GitHub Copilot.
- Self-contained, with no need for a DBMS or cloud service
- Web UI for visualizing and configuration models and MLOps.
- OpenAPI interface, easy to integrate with existing infrastructure.
- Consumer level GPU supports (FP-16 weight loading with various optimization).
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 21:38
Rask — service for AI-supported video localization
TLDR: Service which allows to translate video end-to-end between languages.
Rask AI offers voice cloning capabilities to make your voice part of your brand, although it has a library of natural and human-like voices to choose from. They currently support the output of videos in the following languages: German, French, Spanish, Chinese, English, and Portuguese, regardless of the source language.
In the near future, a team plans to offer additional services such as captions and subtitles and increase the number of supported languages up to 60 languages.
They haven’t raised any funds for the current setup and currently are launched on the Product Hunt. You are welcome to support them via link below (we all know how important it is for founders, right?).
Website: https://www.rask.ai/
ProductHunt: https://www.producthunt.com/posts/rask-ai-video-localization-dubbing-app
#producthunt #aiproduct #localization
Читать полностью…
Data Science by ODS.ai 🦜
04 Apr 2023 14:50
Pandas v2.0.0
The main enhancements:
- installing optional dependencies with pip extras
- index can now hold numpy numeric dtypes
- argument dtype_backend, to return pyarrow-backed or numpy-backed nullable dtypes
- copy-on-write improvements
- ..
+ other notable bug fixes
Full list of changes: https://pandas.pydata.org/docs/whatsnew/v2.0.0.html
Читать полностью…
Data Science by ODS.ai 🦜
03 Apr 2023 16:18
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
Читать полностью…
Data Science by ODS.ai 🦜
02 Apr 2023 18:28
When you stack enough layers, them can explain the meme about stacking more layers.
#memelearning
Читать полностью…
Data Science by ODS.ai 🦜
01 Apr 2023 18:18
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
CodeGeeX is a multilingual model with 13 billion parameters for code generation. It is pre-trained on 850 billion tokens of 23 programming languages.
- Multilingual Code Generation: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc.
- Crosslingual Code Translation: CodeGeeX supports the translation of code snippets between different languages.
- Customizable Programming Assistant: CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization and more, which empower users with a better coding experience.
- Open-Source and Cross-Platform: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100.
GitHub
Читать полностью…
Data Science by ODS.ai 🦜
31 Mar 2023 17:31
An AST-based Code Change Representation and its Performance in Just-in-time Vulnerability Prediction
Authors propose a novel way of representing changes in source code, the Code Change Tree, a form that is designed to keep only the differences between two abstract syntax trees of Java source code. The appoach was evaluated in predicting if a code change introduces a vulnerability against multiple representation types and evaluated them by a number of machine learning models as a baseline. The evaluation is done on a novel dataset VIC.
RQ. 1 Can a vulnerability introducing database generated from a vulnerability fixing commit database be used for vulnerability prediction?
RQ. 2 How effective are Code Change Trees in representing source code changes?
RQ. 3 Are source code metrics sufficient to represent code changes?
dataset paper
VIC dataset
Читать полностью…
Data Science by ODS.ai 🦜
29 Mar 2023 15:42
Sparks of Artificial General Intelligence: Early experiments with GPT-4
TLDR: Paper from #Microsoft research about #GPT4 showing something which can be considered signs of #AGI.
ArXiV: https://arxiv.org/abs/2303.12712
Читать полностью…
Data Science by ODS.ai 🦜
27 Mar 2023 13:08
ReBotNet: Fast Real-time Video Enhancement
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
Читать полностью…
Data Science by ODS.ai 🦜
26 Mar 2023 10:11
Interview of Ilya Sutskver
TLDR: thereotically #chatgpt can learn a lot and eventually converge to #AGI given the proper dataset and help of #RLHF (Reinforcement Learning from Human Feedback).
Video provides valuable insights into the current state and future of artificial intelligence. The conversation explores the progress of AI, its limitations, and the importance of reinforcement learning and ethics in AI development. Ilia also discusses the potential benefits of AI in democracy and its potential role in helping humans manage society. This interview offers a comprehensive and thought-provoking overview of the AI landscape, making it a must-watch for anyone interested in understanding the impact of AI on our lives and the world at large.
Youtube: https://www.youtube.com/watch?v=SjhIlw3Iffs
#youtube #Sutskever #OpenAI #GPTEditor
Читать полностью…
Data Science by ODS.ai 🦜
20 Mar 2023 11:34
Hyena Hierarchy: Towards Larger Convolutional Language Models
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
Читать полностью…



 50497
50497
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}