Data Science by ODS.ai 🦜
15 Aug 2023 19:26
🔥Platypus: Quick, Cheap, and Powerful Refinement of LLMs
Family of fine-tuned and merged LLMs that achieves the strongest performance and currently stands at first place in HuggingFace's
Cемейство точно настроенных больших языковых моделей (LLM), которое достигло самой высокой производительности и в настоящее время занимает первое место в открытой таблице лидеров LLM HuggingFace на момент выхода этой статьи
Модель 13B Platypus может быть обучена на одном GPU A100 на 25 тыс. вопросов за 5 часов!
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
🖥 Github: https://github.com/arielnlee/Platypus
💻 Project: https://platypus-llm.github.io/
📕 Paper: https://arxiv.org/abs/2308.07317v1
⭐️ Dataset: https://huggingface.co/datasets/garage-bAInd/Open-Platypus
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
11 Aug 2023 22:43
notebook_whisperer
A coding assistant to help with the construction of Jupyter notebooks. With the Notebook Whisperer, you can enter a short sentence saying what you would like to do. It then populates the next cell in your Jupyter notebook with the code for performing that task. This is accomplished by sending the contents of your notebook to chatGPT and having it provide the code that it thinks will fulfill your request.
Читать полностью…
Data Science by ODS.ai 🦜
09 Aug 2023 12:55
🚀 AgentBench: Evaluating LLMs as Agents.
AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting.
Комплексный бенчмарк для оценки работы LLM агентов.
🖥 Github: https://github.com/thudm/agentbench
📕 Paper: https://arxiv.org/abs/2308.03688v1
☑️ Dataset: https://paperswithcode.com/dataset/alfworld
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
09 Aug 2023 00:21
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
In this paper, the authors introduce a novel framework, namely RRTF (Rank Responses to align Test&Teacher Feedback), and present a new Code LLM, namely PanGu-Coder2. Firstly, they adopt the Evol-Instruct technique to obtain a substantial amount of high-quality natural language instruction and code solution data pairs. Then, they train the base model by ranking candidate code solutions using feedback from test cases and heurstic preferences.
Through comprehensive evaluations on HumanEval, CodeEval, and LeetCode benchmarks, PanGu-Coder2 achieves new state-of-the-art performance among billion-parameter-level Code LLMs, surpassing all of the existing ones by a large margin.
Читать полностью…
Data Science by ODS.ai 🦜
06 Aug 2023 01:22
An interesting theoretical result on gradient descent complexity. I missed it before.
https://www.quantamagazine.org/computer-scientists-discover-limits-of-major-research-algorithm-20210817/
The Complexity of Gradient Descent: CLS = PPAD ∩ PLS
https://arxiv.org/abs/2011.01929
Читать полностью…
Data Science by ODS.ai 🦜
03 Aug 2023 06:36
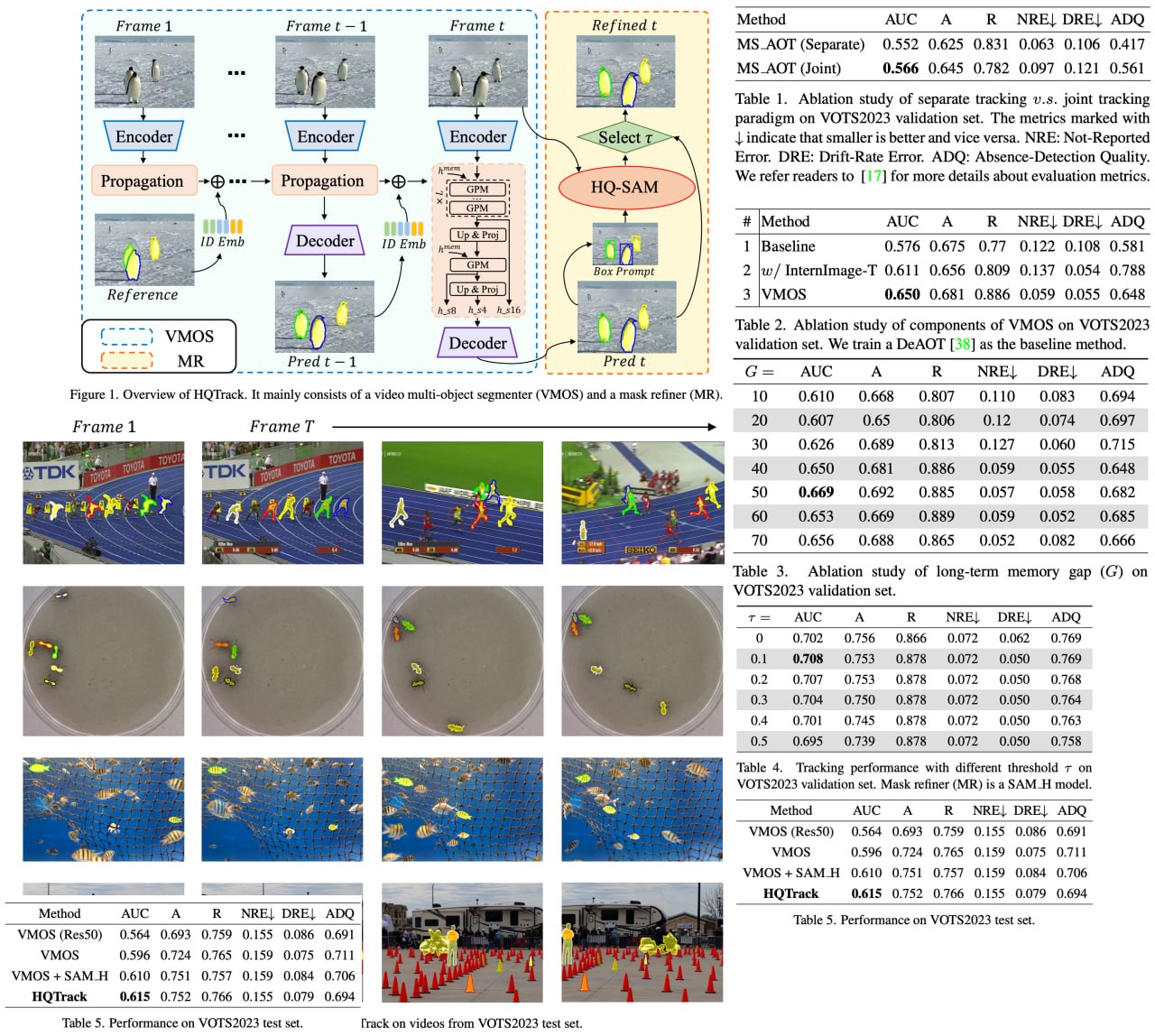
Tracking Anything in High Quality
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
Читать полностью…
Data Science by ODS.ai 🦜
28 Jul 2023 13:01
An interesting theoretical result on gradient descent complexity. I missed it before.
https://www.quantamagazine.org/computer-scientists-discover-limits-of-major-research-algorithm-20210817/
The Complexity of Gradient Descent: CLS = PPAD ∩ PLS
https://arxiv.org/abs/2011.01929
Читать полностью…
Data Science by ODS.ai 🦜
25 Jul 2023 15:55
⏩ Edge Guided GANs with Multi-Scale Contrastive Learning for Semantic Image Synthesis
ECGAN новая система для решения сложной задачи семантического синтеза изображений.
🖥 Github: https://github.com/ha0tang/ecgan
📕 Paper: https://arxiv.org/abs/2307.12084v1
🔥 Dataset: https://paperswithcode.com/dataset/cityscapes
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
20 Jul 2023 07:01
Paper Review: Llama 2: Open Foundation and Fine-Tuned Chat Models
Introducing Llama 2, a cutting-edge ensemble of large language models ranging from 7 to 70 billion parameters! These models, specially fine-tuned for dialogue use cases, not only outperform existing open-source chat models but also showcase exemplary performance in safety and helpfulness. Llama 2 creators have opened the door for AI community, sharing their detailed approach to inspire further advancements in the development of responsible AI.
Project link: https://ai.meta.com/llama/
Model link: https://github.com/facebookresearch/llama
Paper link: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-llama2
#deeplearning #nlp #safetyai #responsibleai
Читать полностью…
Data Science by ODS.ai 🦜
17 Jul 2023 06:29
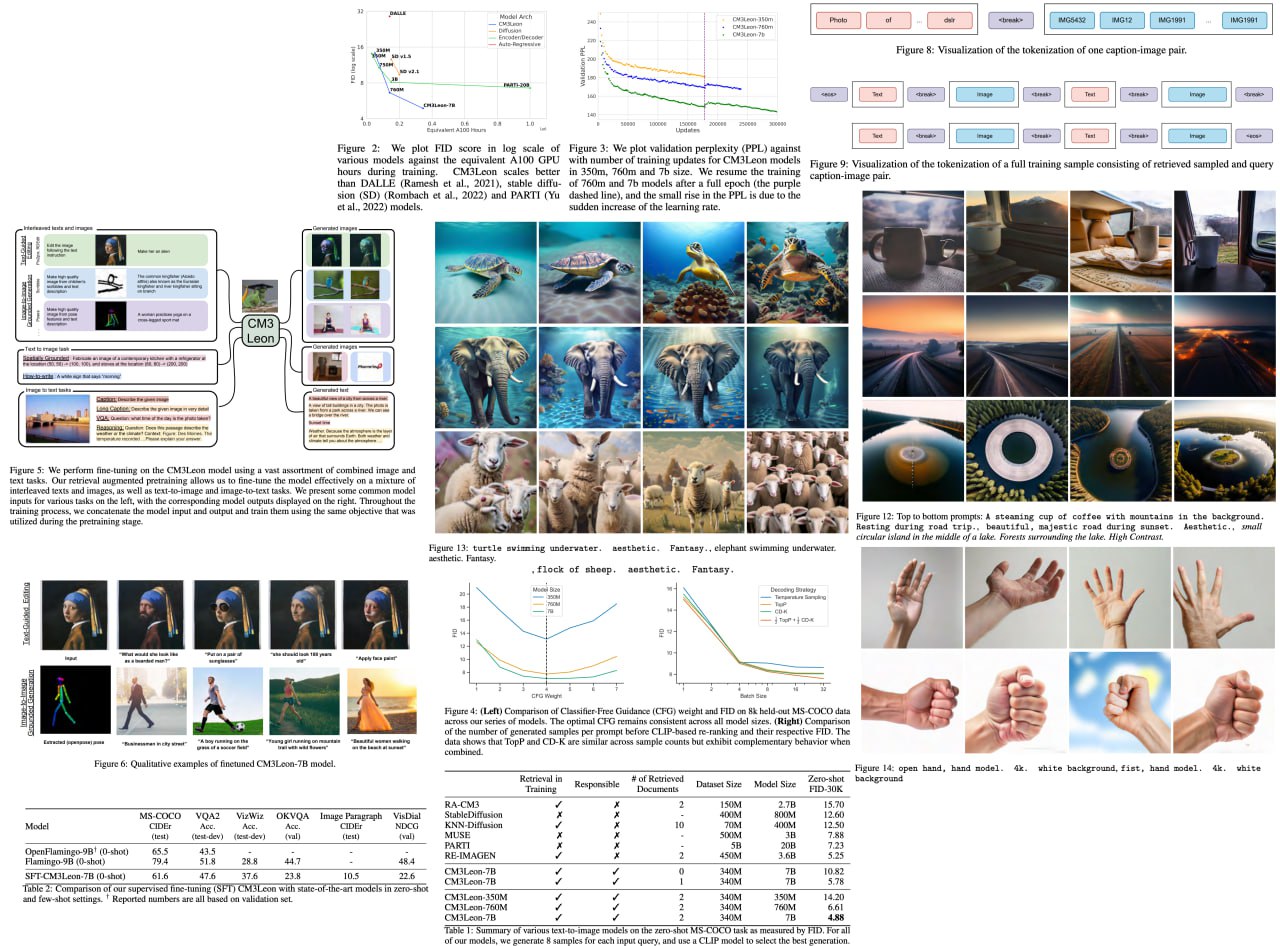
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
Читать полностью…
Data Science by ODS.ai 🦜
13 Jul 2023 14:23
Practical ML Conf - The biggest offline ML conference of the year in Moscow.
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
Читать полностью…
Data Science by ODS.ai 🦜
13 Jul 2023 06:18
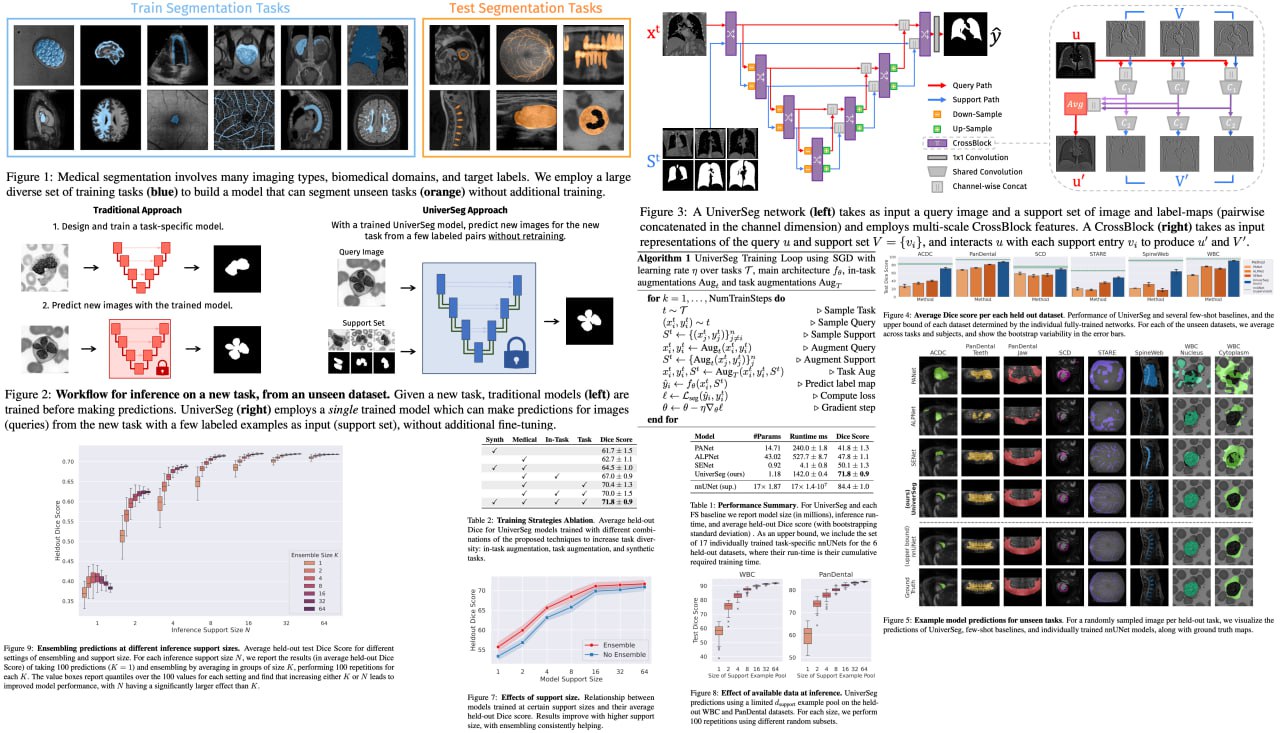
UniverSeg: Universal Medical Image Segmentation
Get ready for a major breakthrough in the field of medical image segmentation! Deep learning models, despite being the primary tool for medical image segmentation, have always struggled to generalize to new, unseen segmentation tasks involving different anatomies, image modalities, or labels. This has typically required researchers to spend significant time and resources on training or fine-tuning models for each new task, a process often out of reach for many clinical researchers. Enter UniverSeg, a trailblazing solution that simplifies this process by tackling unseen medical segmentation tasks without any need for additional training. Its revolutionary Cross-Block mechanism delivers accurate segmentation maps from a query image and a set of example image-label pairs, completely eliminating the need for retraining.
To make this leap, the team behind UniverSeg went the extra mile and assembled MegaMedical, an expansive collection of over 22,000 scans from 53 diverse open-access medical segmentation datasets. This wide variety of anatomies and imaging modalities provided a comprehensive training ground for UniverSeg, priming it to excel in a multitude of scenarios. The results are nothing short of phenomenal - UniverSeg substantially outperforms several related methods on unseen tasks, bringing a new era of efficiency and accessibility to medical imaging.
Paper link: https://arxiv.org/abs/2304.06131
Project link: https://universeg.csail.mit.edu/
Code link: https://github.com/JJGO/UniverSeg
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universeg-med
#deeplearning #cv #imagesegmentation
Читать полностью…
Data Science by ODS.ai 🦜
06 Jul 2023 13:55
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
Читать полностью…
Data Science by ODS.ai 🦜
03 Jul 2023 07:01
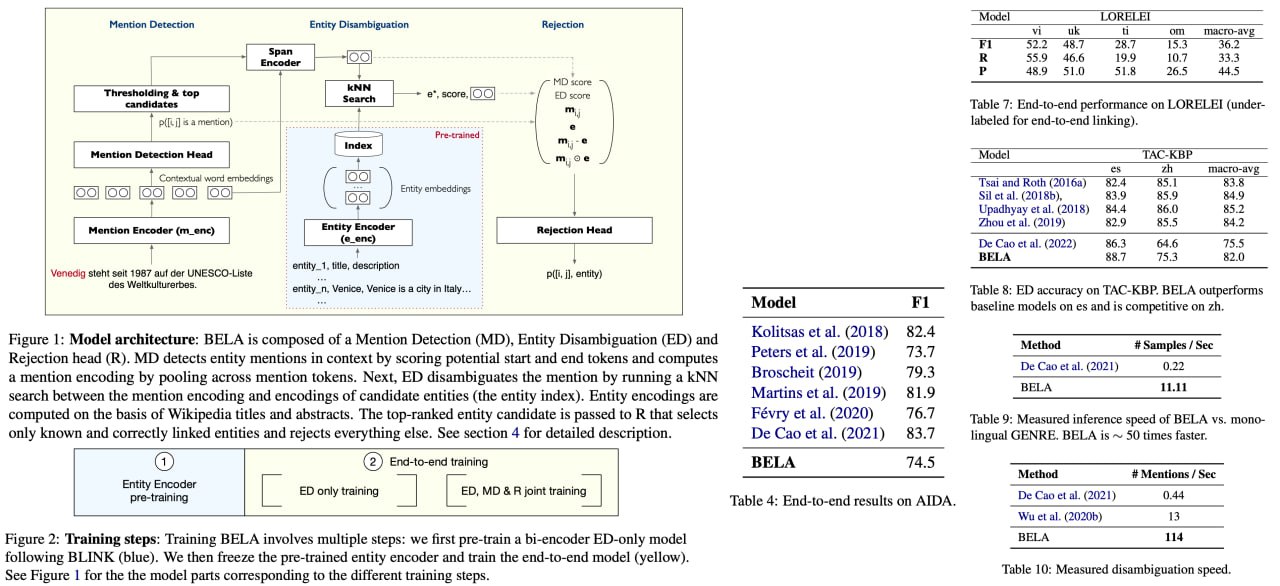
Multilingual End to End Entity Linking
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Читать полностью…
Data Science by ODS.ai 🦜
14 Aug 2023 06:40
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
Читать полностью…
Data Science by ODS.ai 🦜
10 Aug 2023 07:48
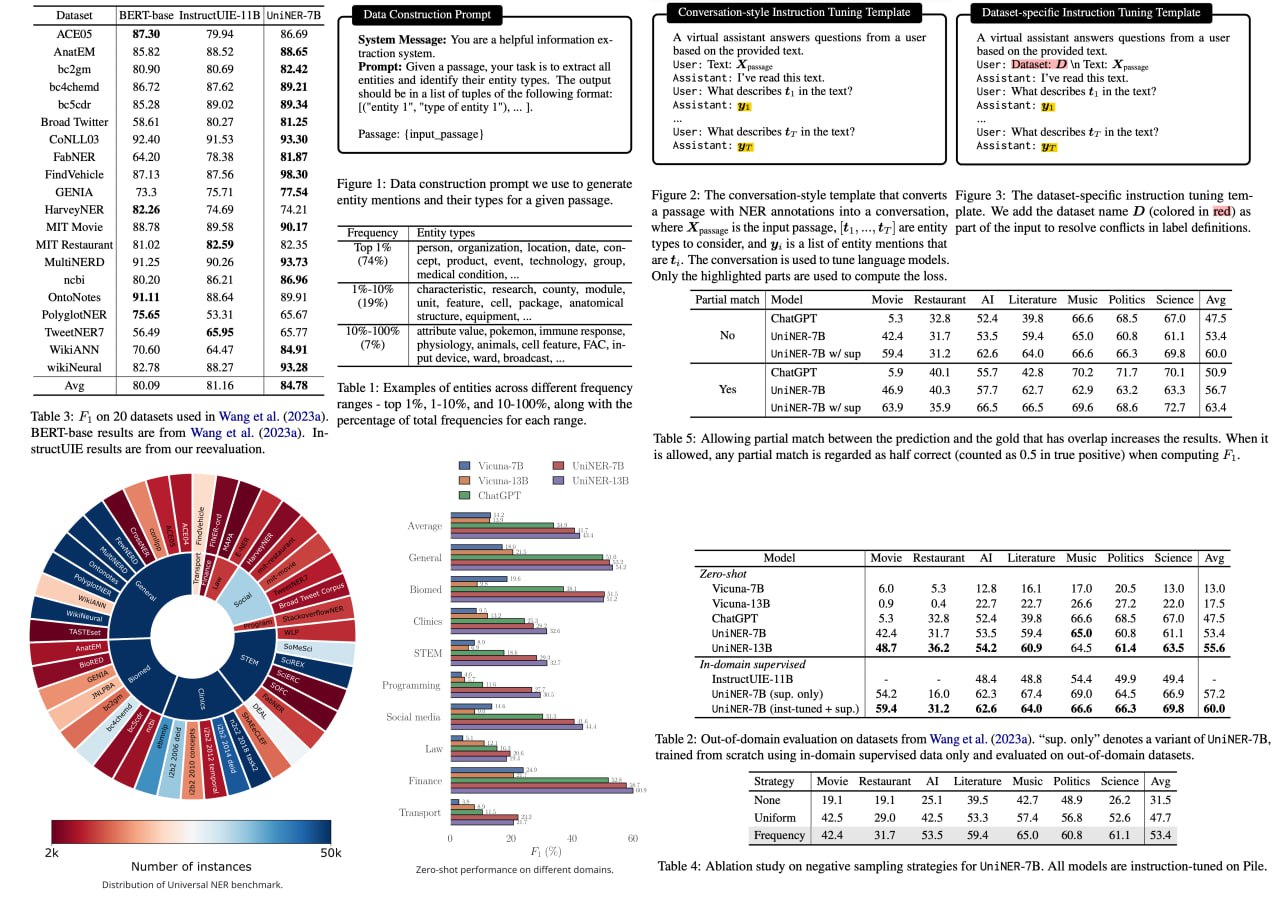
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
Читать полностью…
Data Science by ODS.ai 🦜
09 Aug 2023 10:49
AI Index: An opportunity for AI development
The National Centre for the Development of Artificial Intelligence has launched a nationwide study to determine the index of readiness of domestic organizations to implement artificial intelligence.
The AI Readiness Index will be calculated on several application areas: the use of AI in organizations, the level of maturity of infrastructure and data management, the availability of human resources and existing competencies, as well as a number of other areas that will show the availability of AI technologies for businesses.
The study is being conducted until 31 August 2023 and is confidential, the results in aggregated form will be posted on the National AI Portal: https://ai.gov.ru/.
At the moment, many SME companies do not have sufficient capabilities to implement AI. This study will help to influence support measures for businesses. We cannot claim that this study will make AI implementation available to all companies, but it is an opportunity to give an impetus to the strengthening and development of state support in the industry. Each of us can contribute to the common cause of AI development in Russia by taking the survey and participating in the research.
Here is the link: https://aibe.wciom.ru/.
Читать полностью…
Data Science by ODS.ai 🦜
07 Aug 2023 07:03
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
Читать полностью…
Data Science by ODS.ai 🦜
04 Aug 2023 14:55
🦩 OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
An open-source framework for training large multimodal models.
OpenFlamingo - семейство авторегрессионных моделей для обучения LMM в стиле Flamingo с параметрами от 3B до 9B.
OpenFlamingo можно использовать для создания подписи к изображению или для создания тейзисов на основе изображения. Преимуществом такого подхода является возможность быстрой адаптации к новым задачам с помощью внутриконтекстного обучения.
pip install open-flamingo
🖥 Github: https://github.com/mlfoundations/open_flamingo
📕 Paper: https://arxiv.org/abs/2308.01390
⭐️ Demo: https://huggingface.co/spaces/openflamingo/OpenFlamingo
☑️ Dataset: https://paperswithcode.com/dataset/flickr30k
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
02 Aug 2023 23:56
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
In the paper, the authors
- survey open problems and fundamental limitations of RLHF and related methods;
- overview techniques to understand, improve, and complement RLHF in practice; and
- propose auditing and disclosure standards to improve societal oversight of RLHF systems.
Читать полностью…
Data Science by ODS.ai 🦜
31 Jul 2023 08:05
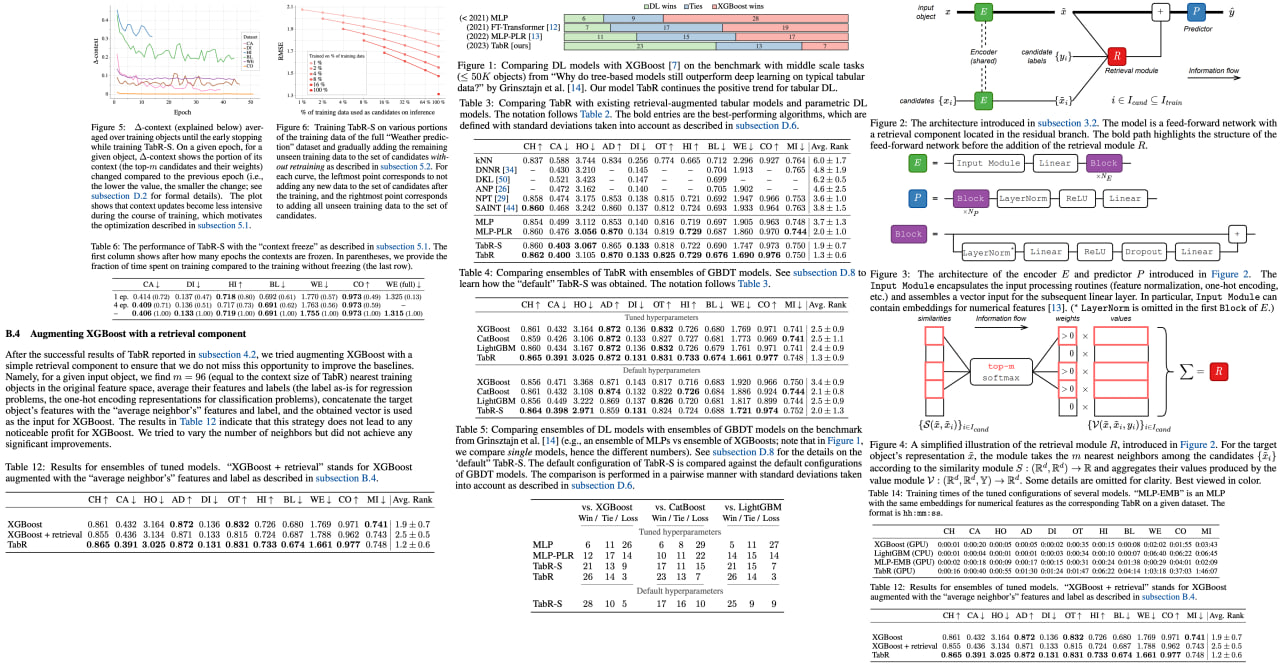
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
The deep learning arena is abuzz with the rise of models designed for tabular data problems, challenging the traditional dominance of gradient-boosted decision trees (GBDT) algorithms. Among these, retrieval-augmented tabular DL models, which gather relevant training data like nearest neighbors for better prediction, are gaining traction. However, these novel models have only shown marginal benefits over properly tuned retrieval-free baselines, sparking a debate on the effectiveness of the retrieval-based approach.
In response to this uncertainty, this groundbreaking work presents TabR, an innovative retrieval-based tabular DL model. This breakthrough was achieved by augmenting a simple feed-forward architecture with an attention-like retrieval component. Several overlooked aspects of the attention mechanism were highlighted, leading to major performance improvements. On a set of public benchmarks, TabR stole the show, demonstrating unparalleled average performance, becoming the new state-of-the-art on numerous datasets, and even outperforming GBDT models on a recent benchmark designed to favor them.
Code link: https://github.com/yandex-research/tabular-dl-tabr
Paper link: https://arxiv.org/abs/2307.14338
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tabr
#deeplearning #tabular
Читать полностью…
Data Science by ODS.ai 🦜
27 Jul 2023 08:57
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
Читать полностью…
Data Science by ODS.ai 🦜
24 Jul 2023 06:56
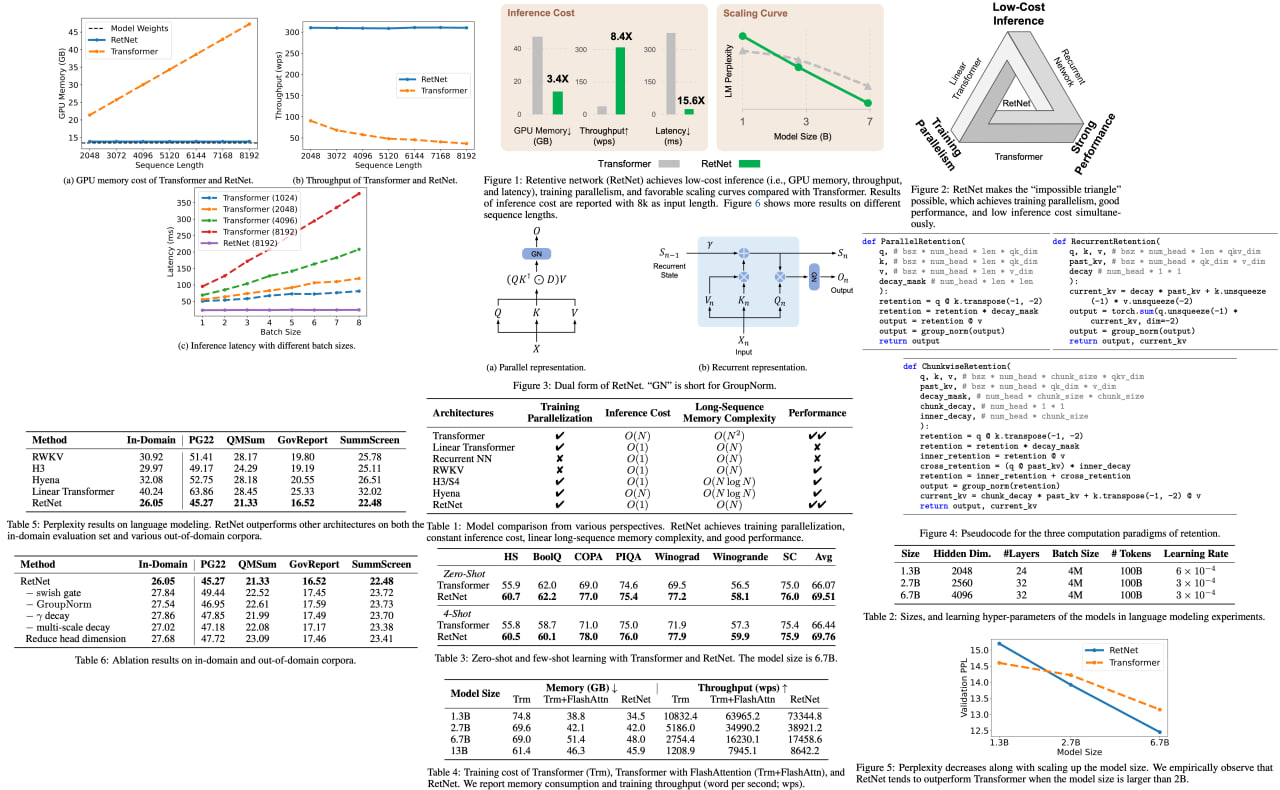
Retentive Network: A Successor to Transformer for Large Language Models
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
Читать полностью…
Data Science by ODS.ai 🦜
17 Jul 2023 23:13
Using Commandline To Process CSV files
- to print the first column of a CSV file: awk -F, '{print $1}' file.csv
- to print the first and third columns of a CSV file: awk -F, '{print $1 "," $3}' file.csv
- to print only the lines of a CSV file that contain a specific string: grep "string" file.csv
- to sort a CSV file based on the values in the second column: sort -t, -k2 file.csv
- to remove the first row of a CSV file (the header row): tail -n +2 file.csv
- to remove duplicates from a CSV file based on the values in the first column: awk -F, '!seen[$1]++' file.csv
- to calculate the sum of the values in the third column of a CSV file: awk -F, '{sum+=$3} END {print sum}' file.csv
- to convert a CSV file to a JSON array: jq -R -r 'split(",") | {name:.[0],age:.[1]}' file.csv
- to convert a CSV file to a SQL INSERT statement: awk -F, '{printf "INSERT INTO table VALUES (\"%s\", \"%s\", \"%s\");\n", $1, $2, $3}' file.csv
Читать полностью…
Data Science by ODS.ai 🦜
14 Jul 2023 19:11
@ Open Positions Post 0
We received 8 submissions for our Talent Pool so far! There are various backgrounds from data engineers to data leads, what’s the best way to connect talents with the seekers not compromising on privacy?
We suggest that people seeking to find teammates or to hire someone may post their suggestions in comments to this post 👇🏻
Читать полностью…
Data Science by ODS.ai 🦜
13 Jul 2023 12:58
Kandinsky 2.2
by Sber & AIRI
What has changed from Kandinsky 2.1
- Improved quality of image generation
- Ability to generate images with different aspect ratio
- Optimization of work with portraits to achieve photorealism
- Machine learning on an extensive dataset of 1.5b text-to-image pairs
- Generating stickers for Telegram and creating custom stickerpacks
- Drawing missing parts of a picture (inpainting).
- Creating pictures in infinite canvas mode (outpainting)
- Understanding queries in eng (Russian thу main)
- 20+ painting styles
- Mixing images
- Generating images similar to a given image
- Image styling by text description
- Possibility to change by text description separate objects or elements in images with preserving the composition of the original illustration (ControlNet)
Habr: https://habr.com/ru/companies/sberbank/articles/747446/
GH: https://github.com/ai-forever/Kandinsky-2/
Telegram-bot: /channel/kandinsky21_bot
MLSpace: https://cloud.ru/ru/datahub/rugpt3family/kandinsky-2-2
Web-GUI for Kandinsky 2.x: https://github.com/seruva19/kubin
FusionBrain: https://fusionbrain.ai/diffusion
RUdalle: https://rudalle.ru/
Diffusers: https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/kandinsky2_2
Читать полностью…
Data Science by ODS.ai 🦜
10 Jul 2023 06:52
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
Читать полностью…
Data Science by ODS.ai 🦜
03 Jul 2023 18:27
Introducing motor interface for amputee | ALVI Labs
That is the first AI model for decoding precise finger movements for people with hand amputation. It uses only 8 surface EMG electrodes.
Interface can decode different types of moves in virtual reality:
🔘finger flexion
🔘finger extension
🟣typing
🟣some more
💎Full demo: YouTube link
Subscribe and follow the further progress:
Twitter: link
Instagram: link
Please like and repost YouTube video✨
Читать полностью…
Data Science by ODS.ai 🦜
29 Jun 2023 06:44
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
Читать полностью…



 50497
50497
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}