Data Science by ODS.ai 🦜
24 April 2023 13:39
Finetuning Large Language Models
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient finetuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.
- In-Context Learning and Indexing
- The 3 Conventional Feature-Based and Finetuning Approaches
- Feature-Based Approach
- Finetuning I – Updating The Output Layers
- Finetuning II – Updating All Layers
- Parameter-Efficient Finetuning
- Reinforcement Learning with Human Feedback
- Conclusion
Читать полностью…
Data Science by ODS.ai 🦜
20 April 2023 14:57
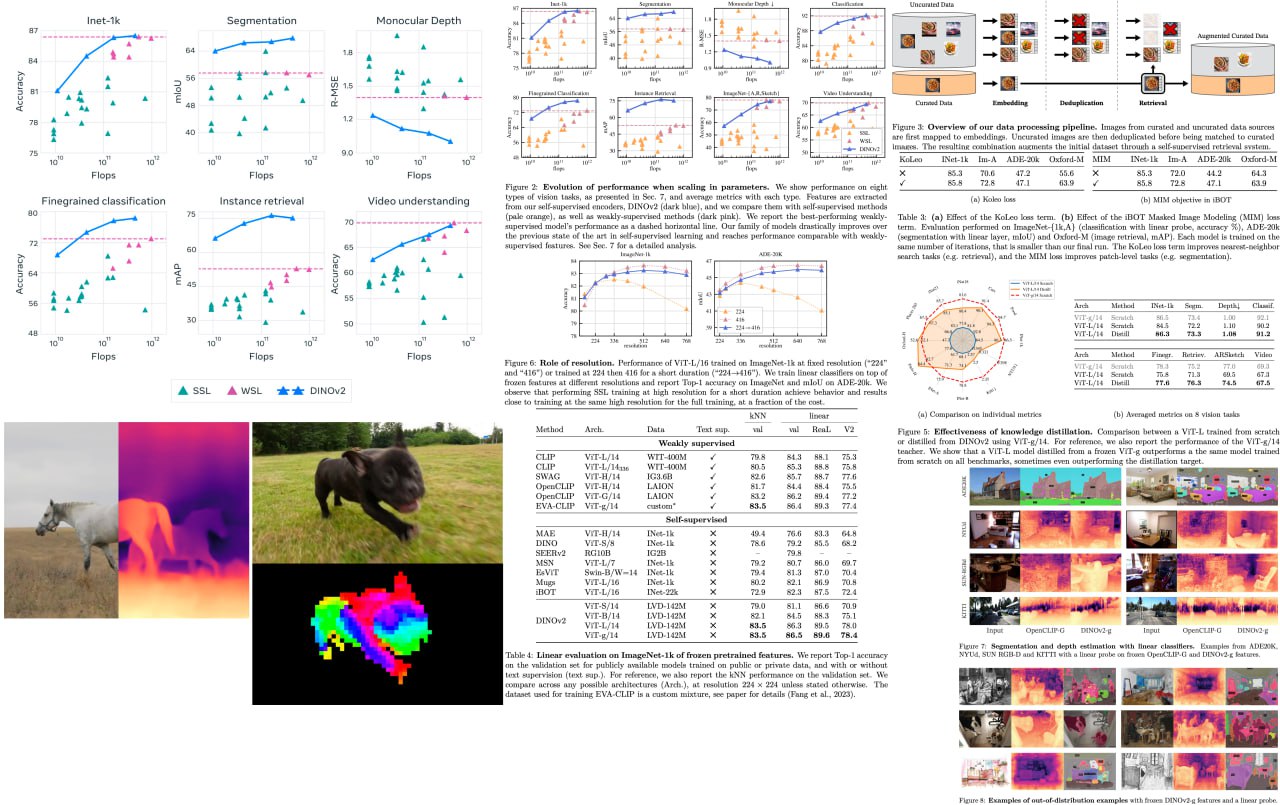
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Читать полностью…
Data Science by ODS.ai 🦜
18 April 2023 21:11
AI / ML / LLM / Transformer Models Timeline
This is a collection of important papers in the area of LLMs and Transformer models.
PDF file.
Читать полностью…
Data Science by ODS.ai 🦜
17 April 2023 09:19
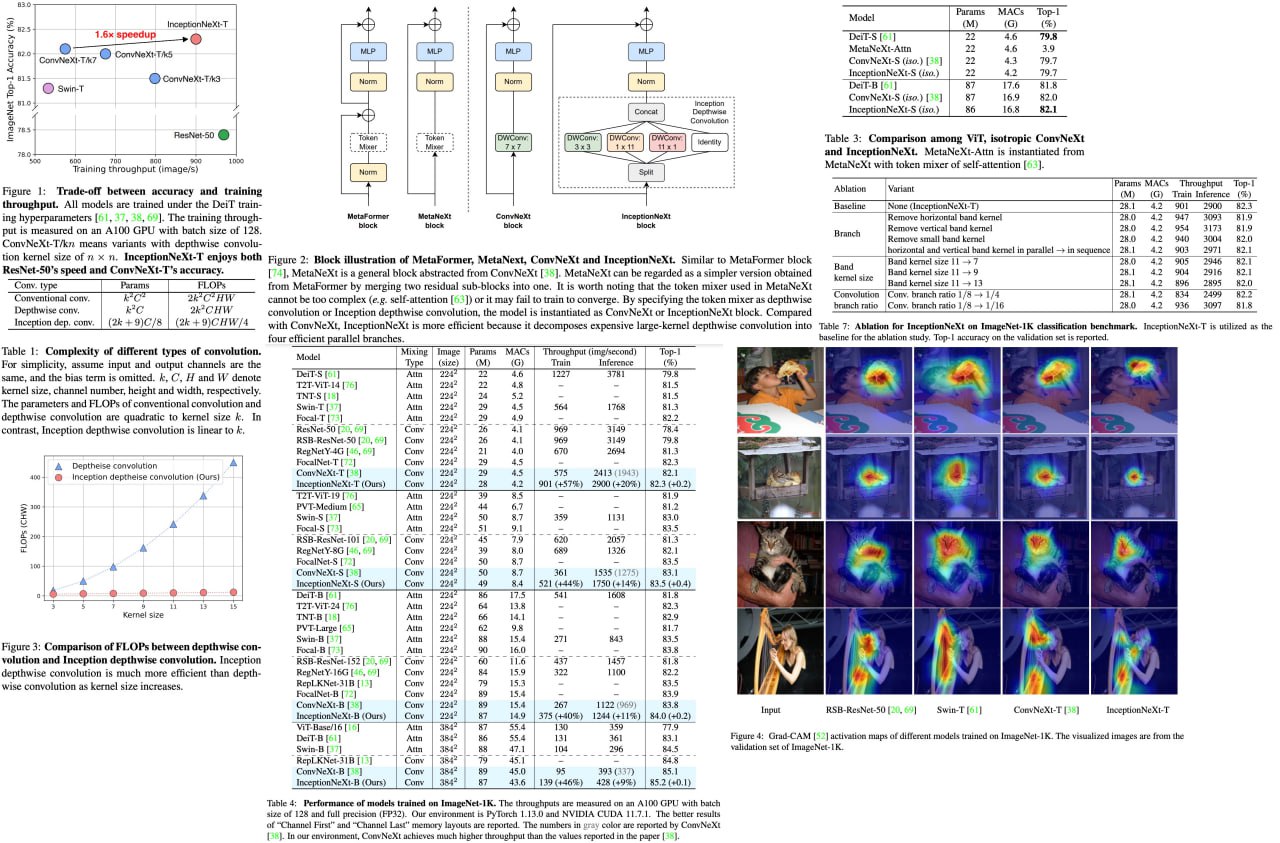
InceptionNeXt: When Inception Meets ConvNeXt
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Читать полностью…
Data Science by ODS.ai 🦜
08 April 2023 07:00
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
Читать полностью…
Data Science by ODS.ai 🦜
06 April 2023 17:08
Hey, let’s see how many of us have some Data Science-related vacancies to share. Please submit them through Google Form.
Best vacancies may be published in this channel.
Google Form: link.
#ds_jobs
Читать полностью…
Data Science by ODS.ai 🦜
04 April 2023 19:42
Kandinsky 2.1
by Sber & AIRI
The main features:
- 3.3B parameters
- generation resolution - 768x768
- image prior transformer
- new MoVQ image autoencoder
- doing a cleaner set of 172M text-image pairs
- work modes: generate by text, blend image, generate images by pattern, change images by text, inpainting/outpainting
The FID on the COCO_30k dataset reaches 8.21
Few posts where compare Kandinsky 2.1 with another similar models
- /channel/dushapitona/643
- /channel/antidigital/6153
Habr: https://habr.com/ru/companies/sberbank/articles/725282/
Telegram-bot: /channel/kandinsky21_bot
ruDALL-E: https://rudalle.ru/
MLSpace: https://sbercloud.ru/ru/datahub/rugpt3family/kandinsky-2-1
FusionBrain: https://fusionbrain.ai/diffusion
Читать полностью…
Data Science by ODS.ai 🦜
03 April 2023 23:53
Stanford 2023 AI Index Report is published!
The section on machine translation is based on Intento data as usual :)
https://aiindex.stanford.edu/report/
Читать полностью…
Data Science by ODS.ai 🦜
03 April 2023 15:01
Reliable ML track at Data Fest Online 2023
Call for Papers
Friends, we are glad to inform you that the largest Russian-language conference on Data Science - Data Fest - from the Open Data Science community will take place in 2023 (at the end of May).
And it will again have a section from Reliable ML community. We are waiting for your applications for reports: write directly to me or Dmitry.
Track Info
The concept of Reliable ML is about what to do so that the result of the work of data teams would be, firstly, applicable in the business processes of the customer company and, secondly, brought benefits to this company.
For this you need to be able to:
- correctly build a portfolio of projects (#business)
- think over the system design of each project (#ml_system_design)
- overcome various difficulties when developing a prototype (#tech #causal_inference #metrics)
- explain to the business that your MVP deserves a pilot (#interpretable_ml)
- conduct a pilot (#causal_inference #ab_testing)
- implement your solution in business processes (#tech #mlops #business)
- set up solution monitoring in the productive environment (#tech #mlops)
If you have something to say on the topics above, write to us! If in doubt, write anyway. Many of the coolest reports of previous Reliable ML tracks have come about as a result of discussion and collaboration on the topic.
If you are not ready to make a report but want to listen to something interesting, you can still help! Repost to a relevant community / forward to a friend = participate in the creation of good content.
Registration and full information about Data Fest 2023 is here.
@ ML
Читать полностью…
Data Science by ODS.ai 🦜
02 April 2023 10:13
Complexity Explorables
Another collection of interactive explorable explanations of complex systems in biology, physics, mathematics, social sciences, epidemiology, ecology
Link: https://www.complexity-explorables.org
The emergence of communities in weighted networks: https://www.complexity-explorables.org/explorables/jujujajaki-networks/
#interactive #demo #systems #explanations
Читать полностью…
Data Science by ODS.ai 🦜
22 March 2018 08:55
Nature has published an article with a #superresolution approach for #CT scans.
https://www.sciencedaily.com/releases/2018/03/180321155324.htm
#arxiv: https://arxiv.org/abs/1704.08841
Читать полностью…
Data Science by ODS.ai 🦜
13 January 2018 18:00
Graph shows what people really mean when they use vague terminology describing the probability of an event.
Читать полностью…
Data Science by ODS.ai 🦜
23 December 2017 00:00
Another paper on automl: Neural Nets learning to design Neural Nets.
A reinforcement learning agent that learns to program new neural network architectures.
Same/better results as LSTMs but with funky nonlinearities (sine, SeLus, etc) and new connections that result in different activation patterns.
Arxiv: https://arxiv.org/abs/1712.07316
Post: https://einstein.ai/research/domain-specific-language-for-automated-rnn-architecture-search
Читать полностью…
Data Science by ODS.ai 🦜
05 December 2017 12:13
pix2pix Demo: Neural network generates cityscape based on the input label map.
Читать полностью…
Data Science by ODS.ai 🦜
30 November 2017 15:22
Video displaying progress of GANs for photo generation. Now you can use neural networks to generate HD photo of a person who never existed.
https://www.youtube.com/watch?v=XOxxPcy5Gr4
#GAN #youtube
Читать полностью…
Data Science by ODS.ai 🦜
24 April 2023 06:31
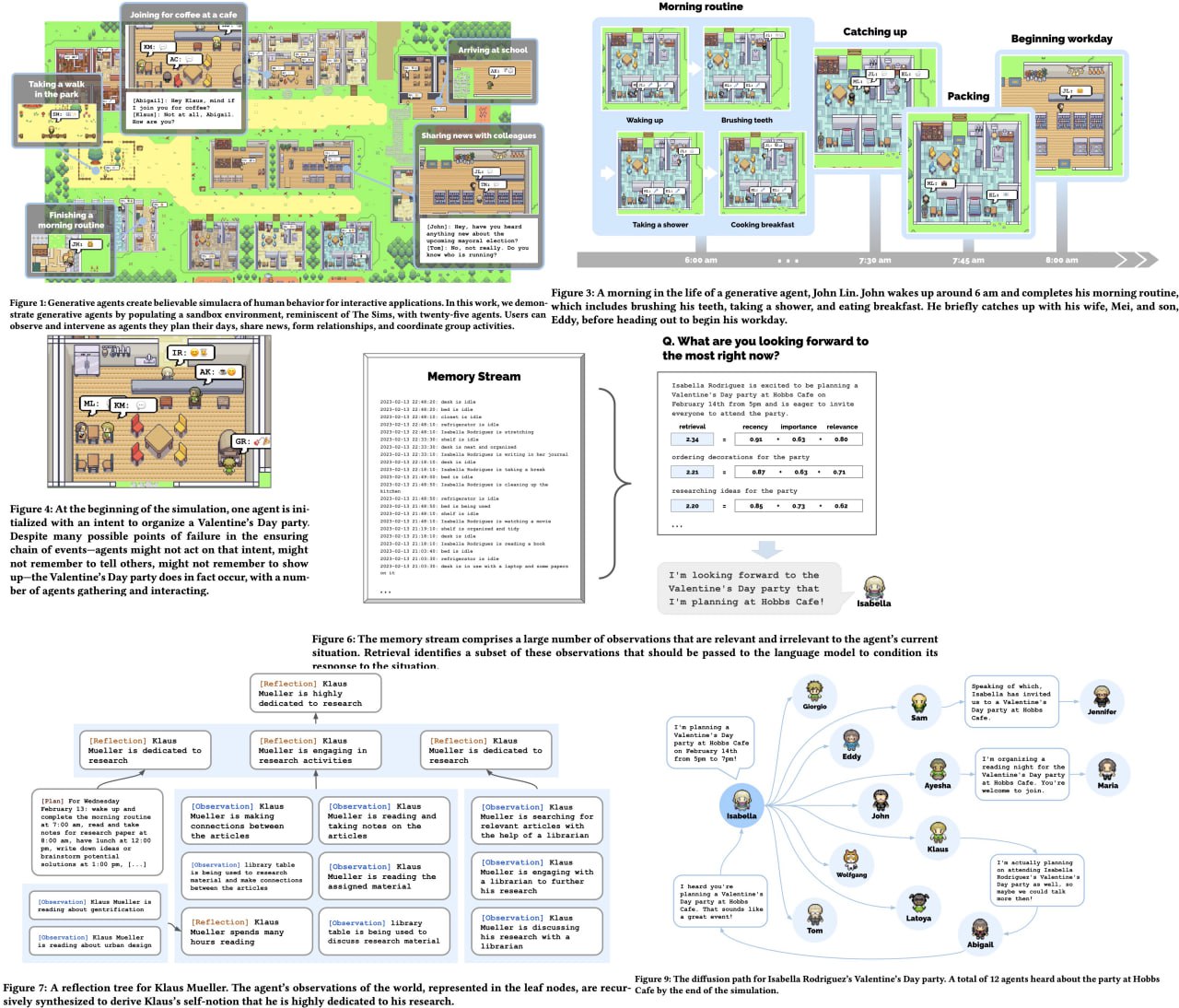
Generative Agents: Interactive Simulacra of Human Behavior
Imagine a world where computational software agents can simulate believable human behavior, empowering a wide range of interactive applications from immersive environments to rehearsal spaces for interpersonal communication and prototyping tools. This paper introduces "generative agents," a groundbreaking concept where agents perform daily routines, engage in creative activities, form opinions, interact with others, and remember and reflect on their experiences as they plan their next day.
To bring generative agents to life, the authors propose an innovative architecture that extends a large language model, allowing agents to store and reflect on their experiences using natural language and dynamically plan their behavior. They showcase the potential of generative agents in an interactive sandbox environment inspired by The Sims, where users can engage with a small town of 25 agents using natural language. The evaluation highlights the agents' ability to autonomously create and navigate complex social situations, producing believable individual and emergent social behaviors. This groundbreaking work demonstrates the critical contributions of observation, planning, and reflection components in agent architecture, laying the foundation for more realistic simulations of human behavior and unlocking exciting possibilities across various applications.
Paper link: https://arxiv.org/abs/2304.03442
Demo link: https://reverie.herokuapp.com/arXiv_Demo/#
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ishb
#deeplearning #nlp #generative # simulation
Читать полностью…
Data Science by ODS.ai 🦜
19 April 2023 20:13
Stability AI just released initial set of StableLM-alpha models, with 3B and 7B parameters. 15B and 30B models are on the way.
Base models are released under CC BY-SA-4.0.
StableLM-Alpha models are trained on the new dataset that build on The Pile, which contains 1.5 trillion tokens, roughly 3x the size of The Pile. These models will be trained on up to 1.5 trillion tokens. The context length for these models is 4096 tokens.
As a proof-of-concept, we also fine-tuned the model with Stanford Alpaca's procedure using a combination of five recent datasets for conversational agents: Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH. We will be releasing these models as StableLM-Tuned-Alpha.
https://github.com/Stability-AI/StableLM
Читать полностью…
Data Science by ODS.ai 🦜
17 April 2023 19:55
AI for IT Operations (AIOps) on Cloud Platforms: Reviews, Opportunities and Challenges (Salesforce AI)
A review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques.
1. INTRODUCTION
2. CONTRIBUTION OF THIS SURVEY
3. DATA FOR AIOPS
A. Metrics
B. Logs
C. Traces
D. Other data
4. INCIDENT DETECTION
A. Metrics based Incident Detection
B. Logs based Incident Detection
C. Traces and Multimodal Incident Detection
5. FAILURE PREDICTION
A. Metrics based Failure Prediction
B. Logs based Incident Detection
6. ROOT CAUSE ANALYSIS
A. Metric-based RCA
B. Log-based RCA
C. Trace-based and Multimodal RCA
7. AUTOMATED ACTIONS
A. Automated Remediation
B. Auto-scaling
C. Resource Management
8. FUTURE OF AIOPS
A. Common AI Challenges for AIOps
B. Opportunities and Future Trends
9. CONCLUSION
Читать полностью…
Data Science by ODS.ai 🦜
10 April 2023 12:07
Paper Review: Segment Anything
- 99% of masks are automatic, i.e. w/o labels;
- Main image encoder model is huge;
- To produce masks you need a prompt or a somewhat accurate bbox (partial bbox fails miserably);
- Trained on 128 / 256 GPUs;
- Most likely - useful a large scale data annotation tool;
- Not sure that it can be used in production as is, also license for the dataset is research only, the model is Apache 2.0
https://andlukyane.com//blog/paper-review-sam
Unless you have a very specific project (i.e. segment just one object type and you have some priors), this can serve as a decent pre-annotation tool.
This is nice, but probably it can offset 10-20% of CV annotation costs.
Читать полностью…
Data Science by ODS.ai 🦜
07 April 2023 22:05
Tabby: Self-hosted AI coding assistant
Self-hosted AI coding assistant. An opensource / on-prem alternative to GitHub Copilot.
- Self-contained, with no need for a DBMS or cloud service
- Web UI for visualizing and configuration models and MLOps.
- OpenAPI interface, easy to integrate with existing infrastructure.
- Consumer level GPU supports (FP-16 weight loading with various optimization).
Читать полностью…
Data Science by ODS.ai 🦜
04 April 2023 21:38
Rask — service for AI-supported video localization
TLDR: Service which allows to translate video end-to-end between languages.
Rask AI offers voice cloning capabilities to make your voice part of your brand, although it has a library of natural and human-like voices to choose from. They currently support the output of videos in the following languages: German, French, Spanish, Chinese, English, and Portuguese, regardless of the source language.
In the near future, a team plans to offer additional services such as captions and subtitles and increase the number of supported languages up to 60 languages.
They haven’t raised any funds for the current setup and currently are launched on the Product Hunt. You are welcome to support them via link below (we all know how important it is for founders, right?).
Website: https://www.rask.ai/
ProductHunt: https://www.producthunt.com/posts/rask-ai-video-localization-dubbing-app
#producthunt #aiproduct #localization
Читать полностью…
Data Science by ODS.ai 🦜
04 April 2023 14:50
Pandas v2.0.0
The main enhancements:
- installing optional dependencies with pip extras
- index can now hold numpy numeric dtypes
- argument dtype_backend, to return pyarrow-backed or numpy-backed nullable dtypes
- copy-on-write improvements
- ..
+ other notable bug fixes
Full list of changes: https://pandas.pydata.org/docs/whatsnew/v2.0.0.html
Читать полностью…
Data Science by ODS.ai 🦜
03 April 2023 16:18
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
Читать полностью…
Data Science by ODS.ai 🦜
02 April 2023 18:28
When you stack enough layers, them can explain the meme about stacking more layers.
#memelearning
Читать полностью…
Data Science by ODS.ai 🦜
01 April 2023 18:18
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
CodeGeeX is a multilingual model with 13 billion parameters for code generation. It is pre-trained on 850 billion tokens of 23 programming languages.
- Multilingual Code Generation: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc.
- Crosslingual Code Translation: CodeGeeX supports the translation of code snippets between different languages.
- Customizable Programming Assistant: CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization and more, which empower users with a better coding experience.
- Open-Source and Cross-Platform: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100.
GitHub
Читать полностью…
Data Science by ODS.ai 🦜
09 January 2018 14:34
Unfortunately, discrimination against ML competition participants becomes more frequent. CrowdANALYTIX recently launched a competition that simply bans different countries from opportunity to participate, this time including Russia.
Spread the word so that we could make Data Science and ML more open, without obsolete discriminatory rules on competition platforms:
https://www.facebook.com/DataChallenges/photos/a.136318350296824.1073741827.136313013630691/182693245659334/?type=3&theater
Читать полностью…
Data Science by ODS.ai 🦜
05 December 2017 12:14
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs.
Now mankind can generate content for social networks without taking photoes.
Github: https://github.com/NVIDIA/pix2pixHD
Arxiv: https://arxiv.org/pdf/1711.11585.pdf
Читать полностью…
Data Science by ODS.ai 🦜
03 December 2017 13:32
AI index report, demonstrating hype around AI techonologies: https://aiindex.org/2017-report.pdf
Читать полностью…
Data Science by ODS.ai 🦜
28 November 2017 17:45
#DeepLearning predicts when patients die with Average Precision 0.69 (that’s high).
Andrew Ng announced new project in his twitter: ML to help prioritize palliative (end-of-life) care. Model uses an 18-layer Deep Neural Network that inputs the EHR data of a patient, and outputs the probability of death in the next 3-12 months.
The trained model achieves an AUROC score of 0.93 and an Average Precision score of 0.69 on cross validation.
Site: https://stanfordmlgroup.github.io/projects/improving-palliative-care/
Arxiv: https://arxiv.org/abs/1711.06402
#project #DSinthewild #casestudy
Читать полностью…



 46227
46227
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}