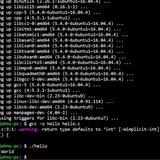
Can't use tee, but echo works
Hey all,
I am trying to export a GPIO pin, so I can set the level.
If I do:
>echo 362 > /sys/class/gpio/export
No issues.
However, doing:
echo "362" | sudo tee /sys/class/gpio/export
3[ 192.027364] export_store: invalid GPIO 3
6[ 192.031368] export_store: invalid GPIO 6
2[ 192.035549] export_store: invalid GPIO 2
So it's writing them separately, is this expected?
I can get around that by just passing the command to bash by doing:
sudo sh -c "echo 362 > /sys/class/gpio/export"
And this works.
However, it's interesting I see the tee approach done quite a bit online, but it doesn't seem to work for me. Anyone have any ideas?
https://redd.it/1fdv3k7
@r_bash
echo $?
Hi to all,
I know that with the command "echo $?" I get the last command state.
But what about if I would ike to see the state of a command prior to the last one in bash history?
Does anybody know?
Thanks!
Vassari
https://redd.it/1fd5yar
@r_bash
Variable with single quotes causes odd behavior
Background:
I’m writing a script that prompts the user to enter a username and a password to connect to an smb share. The supplied credentials are then passed to a tool called smbmap.
I wanted to wrap their input in single quotes in case there are any special characters. When I’m using the tool manually, I put the username and password inside single quotes & it always works.
When I run smbmap using my script it fails if I add the single quotes, but works if I don’t add them.
I’ve tried having the user manually enter the credentials with quotes (e.g. ‘Password123’), & I’ve also tried things like:read passwdlogin=“‘“login+=$passwdlogin+=“‘“
…smbmap -H IP -u $user -p $login
I’ve done this exact thing for other tools & it always works.
TL;DR
I can manually use a tool with single quotes around argument values, or I can use variables for argument values, but can’t do both.
Why does adding the single quotes change the behavior of my script? I’ve literally done echo $login, copy/pasted the value into smbmap & successfully run it manually.
I’d really appreciate any insight! I’m totally perplexed
https://redd.it/1fcy7ge
@r_bash
unexpected EOF while
HI all,
I working on a script to send my the CPU temp tp home assistant...
when I run the script I get: line 34: unexpected EOF while looking for matching `"'
it should be this line:
sendtoha "sensor.${srvname}cputemperature" "${cputemp}" "CPU Package Temperature" "mdi:cpu-64-bit" "${srvname}cputemp"
this is my script:
#!/bin/bash
# Home Assistant Settings
urlbase="http://192.168.10.xx:yyyy/api/states"
token="blablablablablablablablablablablablablablablablablablablablablablablabla"
# Server name
srvname="pve"
# Constants for device info
DEVICEIDENTIFIERS='"PVE_server"'
DEVICENAME="desc"
DEVICEMANUFACTURER="INTEL"
DEVICEMODEL="desc"
# Function to send data to Home Assistant
sendtoha() {
local sensorname=$1
local temperature=$2
local friendlyname=$3
local icon=$4
local uniqueid=$5
local url="${urlbase}/${sensorname}"
local deviceinfo="{\"identifiers\":${DEVICEIDENTIFIERS},\"name\":\"${DEVICENAME}\",\"manufacturer\":\"${DEVICEMANUFACTURER}\",\"model\":\"${DEVICEMODEL}\"}"
local payload="{\"state\":\"${temperature}\",\"attributes\": {\"friendlyname\":\"${friendlyname}\",\"icon\":\"${icon}\",\"stateclass\":\"measurement\",\"unitofmeasurement\":\"°C\",\"deviceclass\":\"temperature\",\"uniqueid\":\"
curl -X POST -H "Authorization: Bearer ${token}" -H 'Content-type: application/json' --data "${payload}" "${url}"
}
# Send CPU package temperature
cputemp=$(sensors | grep 'Package id 0' | awk '{print $4}' | sed 's/+//;s/°C//')
sendtoha "sensor.${srvname}cputemperature" "${cputemp}" "CPU Package Temperature" "mdi:cpu-64-bit" "${srvname}cputemp"
I looks like I am closing the sentence fine...
Any insights?
https://redd.it/1fcp30x
@r_bash
minishell-42
Hi everyone! 👋
I’ve just released my minishell-42 project on GitHub! It's a minimal BASH implementation in c, developed as part of the 42 curriculum. The project mimics a real Unix shell with built-in commands, argument handling, and more.
I’d love for you to check it out, and if you find it helpful or interesting, please consider giving it a ⭐️ to show your support!
Here’s the link: https://github.com/ERROR244/minishell.git
Feedback is always welcome, and if you have any ideas to improve it, feel free to open an issue or contribute directly with a pull request!
Thank you so much! 🙏
https://redd.it/1fclked
@r_bash
Understanding bash pipes to chain commands
I'm using this to get the most recently updated file in a MySQL directory:
ls -ltr /var/lib/mysql/$DB/* | tail -1
The result looks like this:
-rw-rw---- 1 mysql mysql 2209 Dec 7 2020 /var/lib/mysql/foo/bar.MYI
The goal is to only back up the database if something has changed more recently than the last backup.
Next I'm trying to extract that date as an ENOCH timestamp, so I used this (using -tr to just get the filename):
ls -tr /var/lib/mysql/$DB/* | tail -1 | stat -c "%Y %n"
This throws an error, though:
stat: missing operand
Using -ltr threw the same error.
I'm only guessing that stat's not correctly getting the output of tail -1 as its input?
I can do it in 2 lines with no problem (typed but not tested):
most_recent=$(ls -ltr /var/lib/mysql/$DB/* | tail -1)
last_modified=$(stat -c "%Y %n" "/var/lib/mysql/DB/$most_recent" | awk '{print $1}')
But for the sake of education, why doesn't it work when I chain them together? Is there a built-in variable to specify "this is the output from the previous command"?
https://redd.it/1fchrka
@r_bash
Is it better to loop over a command, or create a separate array that's equal to the results of that command?
This is how I do a daily backup of MySQL:
for DB in $(mysql -e 'show databases' -s --skip-column-names)
do
mysqldump --single-transaction --quick $DB | gzip > "/backup/$DB.sql.gz";
done
I have 122 databases on the server. So does this run a MySQL query 122 times to get the results of "show databases" each time?
If so, is it better / faster to process to do something like this (just typed for this post, not tested)?
databases=$(mysql -e 'show databases' -s --skip-column-names)
for DB in ${databases@}
do
mysqldump --single-transaction --quick $DB | gzip > "/backup/$DB.sql.gz";
done
https://redd.it/1fc6e0z
@r_bash
Sed | replacing variable with new value, along with escaping
I'll put the basics of the script down:
VERSION=$(git show -s --date='format:%Y.%m.%d' --format='%cd+%h' | sed "s/^0*//g; s/\.0*/./g" | sed 's/[][ \~`!@#$%^&*()={}|;:'"'"'",<>/?]/\\&/g')
sed -i "s/VERSION_STRING = .*/VERSION_STRING = \x22${VERSION}\x22/" ./app/version.py
VERSION, and then transfer that new value using sed and replace the current value in the file.sed: -e expression #1, char 37: unknown option to `s'
VERSION = "1.0.0"
ANOTHER = "My string with @ # $ special %^& chars"
ANOTHER which will contain special characters. And unless I escape them using the sed rule at the top which is being used on VERSION, it'll just error out.
[UPDATE] forkrun v1.4 released!
I've just released an update (v1.4) for my [forkrun](https://github.com/jkool702/forkrun) tool.
For those not familiar with it, `forkrun` is a ridiculously fast\*\* pure-bash tool for running arbitrary code in parallel. `forkrun`'s syntax is similar to `parallel` and `xargs`, but it's faster than `parallel`, and it is comparable in speed (perhaps slightly faster) than `xargs -p` while having considerably more available options. And, being written in bash, `forkrun` natively supports bash functions, making it trivially easy to parallelize complicated multi-step tasks by wrapping them in a bash function.
forkrun's v1.4 release adds several new optimizations and a few new features, including:
1. a new flag (`-u`) that allows reading input data from an arbitrary file descriptor instead of stdin
2. the ability to dynamically and automatically figure out how many processor threads (well, how many worker coprocs) to use based on runtime conditions (system cpu usage and coproc read queue length)
3. on x86_64 systems, a custom loadable builtin that calls `lseek` is used, significantly reducing the time it takes forkrun to read data passed on stdin. This brings `forkrun`'s "no load" speed (running a bunch of newlines through `:`) to around 4 million lines per second on my hardware.
Questions? comments? suggestions? let me know!
***
\*\* How fast, you ask?
The other day I ran a simple speedtest for computing the `sha512sum` of around 596,000 small files with a combined size of around 15 gb. a simple loop through all the files that computed the sha512sum of each sequentially one at a time took 182 minutes (just over 3 hours).
`forkrun` computed all 596k checksum in 2.61 seconds. Which is about 4300x faster.
Soooo.....pretty damn fast :)
https://redd.it/1fbhqf5
@r_bash
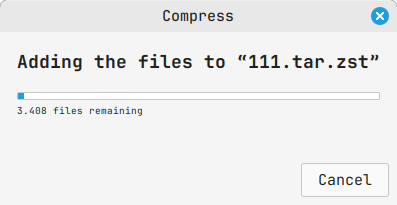
How to progress bar on ZSTD???
I'm using the following script to make my archives
export ZSTDCLEVEL=19
export ZSTDNBTHREADS=8
tar --create --zstd --file 56B0B219B0B20013.tar.zst 56B0B219B0B20013/
My wish is if I could have some kind of progress bar to show me - How many files is left before the end of the compression
https://i.postimg.cc/t4S2DtpX/Screenshot-from-2024-09-07-12-40-04.png
So can somebody help me to solve this dilemma?
I already checked all around the internet and it looks like the people can't really explain about tar + zstd.
https://redd.it/1fb42qr
@r_bash
How to Replace a Line with Another Line, Programmatically?
Hi all
I would like to write a bash script, that takes the file /etc/ssh/sshd_config,
and replaces the line #Port 22
with the line Port 5000.
I would like the match to look for a full line match (e.g. #Port 22),
and not a partial string in a line
(so for example, this line ##Port 2244 will not be matched and then replaced,
even tho there's a partial string in it that matches)
If there are several ways/programs to do it, please write,
it's nice to learn various ways.
Thank you evry much
https://redd.it/1falc6z
@r_bash
Final script to clean /tmp, improvements welcome!
I wanted to get a little more practice in with bash, so (mainly for fun) I sorta reinvented the wheel a little.
*Quick backstory:*
My VPS uses WHM/cPanel, and I don't know if this is a problem strictly with them or if it's universal. But back in the good ol' days, I just had session files in the /tmp/ directory and I could run tmpwatch via cron to clear it out. But awhile back, the session files started going to:
# 56 is for PHP 5.6, which I still have for a few legacy hosting clients
/tmp/systemd-private-[foo]-ea-php56-php-fpm.service-[bar]/tmp
# 74 is for PHP 7.4, the version used for the majority of the accounts
/tmp/systemd-private-[foo]-ea-php74-php-fpm.service-[bar]/tmp
And since \[foo\] and \[bar\] were somewhat random and changed regularly, there was no good way to set up a cron to clean them.
cPanel recommended this one-liner:
find /tmp/systemd-private*php-fpm.service* -name sess_* ! -mtime -1 -exec rm -f '{}' \;
but I don't like the idea of running `rm` via cron, so I built this script as my own alternative.
*So this is what I built:*
My script loops through /tmp and the subdirectories in /tmp, and runs tmpwatch on each of them if necessary.
I've set it to run via crontab at 1am, and if the server load is greater than 3 then it tries again at 2am. If the load is still high, it tries again at 3am, and then after that it gives up. This alone is a pretty big improvement over the cPanel one-liner, because sometimes I would have a high load when it started and then the load would skyrocket!
In theory, crontab should email the printf text to the root email address. Or if you run it via command line, it'll print those results to the terminal.
I'm open to any suggestions on making it faster or better! Otherwise, maybe it'll help someone else that found themselves in the same position :-)
#!/bin/sh
#################################################
# Save as tmpwatch.sh, then upload to /root and set permission to 0755
#
# To run from SSH:
# bash tmpwatch.sh
#
# To set in crontab from SSH:
# crontab -e
# i (to insert)
# paste or type this to run daily at 1am:
# 0 1 * * * bash tmpwatch.sh
# Save it by pressing Esc, then type :wq and hit Enter
#
# Crontab Format:
# minute hour day month day-of-the-week command
# * means "every"
#
#################################################
# try to run a max of 3 times; 1am, 2am, and 3am
# you can change the 3 to whatever you prefer, I chose this to avoid high traffic times
for attempts in {1..3}
do
# only run if server load is < 3
# you can change the 3 to whatever you prefer, too
if (( $(awk '{ print int($1 * 100); }' < /proc/loadavg) < (3 * 100) ))
then
### Clean /tmp directory
# thanks to @ZetaZoid, r/linux4noobs for the "find" command line
sizeStart=$(nice -n 19 ionice -c 3 find /tmp/ -maxdepth 1 -type f -exec du -b {} + | awk '{sum += $1} END {print sum}')
# if there are files in the /tmp directory, run tmpwatch to remove them
# else, move on to the subdirectories
if [[ -n $sizeStart && $sizeStart -ge 0 ]]
then
nice -n 19 ionice -c 3 tmpwatch -m 12 /tmp
sleep 5
sizeEnd=$(nice -n 19 ionice -c 3 find /tmp/ -maxdepth 1 -type f -exec du -b {} + | awk '{sum += $1} END {print sum}')
if [[ -z $sizeEnd ]]
then
sizeEnd=0
fi
if (( $sizeStart > $sizeEnd ))
then
body+="tmpwatch -m 12 /tmp ...\n"
body+="$sizeStart -> $sizeEnd\n\n"
fi
fi
### Clean /tmp subdirectories
for i in $(ls -d /tmp/systemd-private-*)
do
i+="/tmp"
if [[ -d "$i" ]]
exponential search in bash
https://shscripts.com/exponential-search-in-bash/
https://redd.it/1f9xjaq
@r_bash
Has anyone encountered ' An error occurred in before all hook' when using shellspec?
I have implemented a unit test for a Shell using shellspec. And I am always thrown the above error in 'before all' and 'after all' both. Even though the log contains exit code 0 which basically indicating there is no error none of my tests are executing.
I have added extra logs and also redirected the errors but still I am facing this error and am out of options. I am using the latest version of Shellspec as well.
I am mocking git commands in my test script. But it is quite necessary for my tests as well.
I even checked for the relevent OS type in the setup method
# Determine OS type
OS_TYPE=$(uname 2>/dev/null || echo "Unknown")
case "$OS_TYPE" in
Darwin|Linux)
TMP_DIR="/tmp"
;;
CYGWIN*|MINGW*|MSYS*)
if command -v cygpath >/dev/null 2>&1; then
TMP_DIR="$(cygpath -m "${TEMP:-/tmp}")"
else
echo "Error: cygpath not found" >&2
exit 1
fi
;;
*)
echo "Error: Unsupported OS: $OS_TYPE" >&2
exit 1
;;
esac
Any guidance is immensely appreciated.
https://redd.it/1f9s8b4
@r_bash
lolcat reconfiguration help needed please
Was hoping you could help out a total noob. You may have seen this script - lolcat piped out for all commands. Its fun, it's nice, but it creates some unwanted behavior at times. Its also not my script (im a noob). However, i thought, at least for my purposes, it would be a better script if exclusion commands could be added to the script, for example this script 'lolcats' all commands, including things like 'exit' and prevents them executing. So i'd like to be able to add a list of commands in the *.bashrc script that excludes lolcat from executing, such as 'exit'. Any help is appreciated. Thanks.
lol()
{
if -t 1 ; then
"$@" | lolcat
else
"$@"
fi
}
bind 'RETURN: "\e1~lol \e[4~\n"'
or this one has aliases created, but i'd like to do the opposite, instead of adding every command to be lolcat, create an exclusion list of commands not to be lolcat.
lol()
{
if [ -t 1 ; then
"$@" | lolcat
else
"$@"
fi
}
COMMANDS=(
ls
cat
)
for COMMAND in "${COMMANDS@}"; do
alias "${COMMAND}=lol ${COMMAND}"
alias ".${COMMAND}=$(which ${COMMAND})"
done
https://redd.it/1f9k1q5
@r_bash
what is the "user id"?
hello, i'm trying to understand the "whoami" command, and it says in the man page
"Print the user name associated with the current effective user ID."
what is the user id?
thank you
https://redd.it/1fdfoqn
@r_bash
I'm new to bash and scripting and need help
i'm trying to do an ip sweep with bash and i ran into some problems earlier on my linux system whenever i tried to run the script but I then made some changes and stopped seeing the error message but now when i run the script i don't get any response at all. I'm not sure if this is a problem with the script or the system
The script I'm trying to run(from a course on yt)
```
!/bin/bash
for ip in `seq 1 254` ; do
ping -c 1 $1.$ip | grep "64 bytes" | cut -d " " -f 4 | tr -d ":" &
done
./ipsweep.sh 192.168.4
https://redd.it/1fcwwha
@r_bash
i accidentally pressed the or the key above tab and left of the 1 key, and idk what happened the "tidle" key if you press it while holding shift, or the key above tab and left of the 1 key, and idk what happened
so i was dinking around in bash and i accidentally pressed the
it was like bash entered some kind of different text entry mode, but it stopped when i pressed the same key again
what happened? what is that? when i press the key does bash somehow enter bash into a new program that i need to enter text into? man" but the command didn't run, so i have no clue what is going on
what is going on?
also i tried "
thank you
https://redd.it/1fcwzu9
@r_bash
Should I solve leetcode using bash scripting? Or are there real world problems to solve using bash?
Yeah my job doesn't have anything to script/automate using bash, yeah it doesn't truly. I can't see how bash can be useful. Like it could be use for data science, analysis, visualization etc, however, it breaks my heart because I see no body teaching it. I get a book called data science at the command line but it's too complicated to follow. I stopped at docker image in 2nd chapter. I could not fathom what was going on...
Please help me. Should I just start solving leetcode?
There is another book called cyberops with bash. However, I am not dive deep into cybersecurity at this moment. I want something similar to this stuffs.
https://redd.it/1fclgr1
@r_bash
Watch out for Implicit Subshells
Bash subshells can be tricky if you're not expecting them. A quirk of behavior in bash pipes that tends to go unremarked is that pipelined commands run through a subshell, which can trip up shell and scripting newbies.
#!/usr/bin/env bash
printf '## ===== TEST ONE: Simple Mid-Process Loop =====\n\n'
set -x
looped=1
for number in $(echo {1..3})
do
let looped="$number"
if [ $looped = 3 ]; then break ; fi
done
set +x
printf '## +++++ TEST ONE RESULT: looped = %s +++++\n\n' "$looped"
printf '## ===== TEST TWO: Looping Over Piped-in Input =====\n\n'
set -x
looped=1
echo {1..3} | for number in $(</dev/stdin)
do
let looped="$number"
if [ $looped = 3 ]; then break ; fi
done
set +x
printf '\n## +++++ TEST ONE RESULT: looped = %s +++++\n\n' "$looped"
printf '## ===== TEST THREE: Reading from a Named Pipe =====\n\n'
set -x
looped=1
pipe="$(mktemp -u)"
mkfifo "$pipe"
echo {1..3} > "$pipe" &
for number in $(cat $pipe)
do
let looped="$number"
if [ $looped = 3 ]; then break ; fi
done
set +x
rm -v "$pipe"
printf '\n## +++++ TEST THREE RESULT: looped = %s +++++\n' "$looped"
I want the script named "test" to run again, if I input a 1. It says the fi is unexpected. Why?
https://redd.it/1fc9a4j
@r_bash
Books that dive into applications of bash like "data science at the command line", "cyber ops with bash" etc?
PS, I am learning programming by solving problems/exercises. I want to learn bash(I am familiar with linux command line) however I am hesitant to purchase data science at command line book. Although it's free on author's website, physical books hit different.
I am from Nepal.
https://redd.it/1fbo9em
@r_bash
Why sometimes mouse scroll will scroll the shell window text vs sometimes will scroll through past shell commands?
One way to reproduce it is using the "screen" command. The screen session will make the mouse scroll action scroll through past commands I have executed rather than scroll through past text from the output of my commands.
https://redd.it/1fbj2o7
@r_bash
help's Command List is Truncated, Any way to Show it Correctly?
Hi all
If you run help,
you get the list of Bash internal commands.
It shows it in 2 columns, which makes some of the longer titles be truncated, with a ">" at the end.
See here:
https://i.postimg.cc/sDvSNTfD/bh.png
Any way to make help show it without truncating them?
Switching to a Single Column list could solve it,
but help help does not show a switch for Single Column..
https://redd.it/1fb56id
@r_bash
AWS-RDS Schema shuttle
https://github.com/N1kh1lS1ngh25/aws-rds-schema-shuttle
https://redd.it/1fb00os
@r_bash
then
sizeStart=$(nice -n 19 ionice -c 3 du -s $i | awk '{print $1}')
nice -n 19 ionice -c 3 tmpwatch -m 12 $i
sleep 5
sizeEnd=$(nice -n 19 ionice -c 3 du -s $i | awk '{print $1}')
if (( $sizeStart > $sizeEnd ))
then
body+="tmpwatch -m 12 $i ...\n"
body+="$sizeStart -> $sizeEnd\n\n"
fi
fi
done
if [[ -n $body ]]
then
printf "$body"
fi
break
else
# server load was high, try again in an hour
sleep 3600
fi
done
https://redd.it/1fa8ccc
@r_bash
Weird issue with sed hating on equals signs, I think?
Hey all, I been working to automate username and password updates for a kickstart file, but sed isn't playing nicely with me. The relevant code looks something like this:$username=hello$password=yeetsed -i "s/name=(*.) --password=(*.) --/name=$username --password=$password --/" ./packer/ks.cfg
Where the relevant text should go from one of these to the other:user --groups=wheel --name=user --password=kdljdfd --iscrypted --gecos="Rocky User"user --groups=wheel --name=hello --password=yeet --iscrypted --gecos="Rocky User"
After much tinkering, the only thing that seems to be setting this off is the = sign in the code, but then I can't seem to find a way to escape the = sign in my code! Pls help!!!
https://redd.it/1f9whl1
@r_bash
GitHub - oscarrivera2028/d-coding-companion: A coding companion that can be used to fix bugs in the terminal
https://github.com/oscarrivera2028/d-coding-companion
https://redd.it/1f9u6er
@r_bash
missing final newline: | while read -r line; do ...
I just discovered that this does not work as I expect it to do:
echo -en "bar\nfoo" | while read var;do echo $var; done
echo -en "bar\nfoo"| sort | while read var;do echo $var; done
A Bash + Python tool to watch a target in Satellite Imagery
I built a Bash + Python tool to watch a target in satellite imagery: [https://github.com/kamangir/blue-geo/tree/main/blue\_geo/watch](https://github.com/kamangir/blue-geo/tree/main/blue_geo/watch)
Here is the github repo: [https://github.com/kamangir/blue-geo](https://github.com/kamangir/blue-geo) The tool is also pip-installable: [https://pypi.org/project/blue-geo/](https://pypi.org/project/blue-geo/)
Here are three examples:
1. The recent Chilcotin River Landslide in British Columbia.
2. Burning Man 2024.
3. Mount Etna.
https://i.redd.it/z0b42i6huwmd1.gif
https://i.redd.it/y53fih6huwmd1.gif
https://i.redd.it/jh5cch6huwmd1.gif
This is how the tool is called,
u/batch eval - \
blue_geo watch - \
target=burning-man-2024 \
to=aws_batch - \
publish \
geo-watch-2024-09-04-burning-man-2024-a
This is how a target is defined,
burning-man-2024:
catalog: EarthSearch
collection: sentinel_2_l1c
params:
height: 0.051
width: 0.12
query_args:
datetime: 2024-08-18/2024-09-15
lat: 40.7864
lon: -119.2065
radius: 0.01
It runs a map-reduce on AWS Batch.
All targets are watched on Sentinel-2 through Copernicus and EarthSearch.
https://redd.it/1f9cvyx
@r_bash

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}