Spark in me
28 January 2018 10:20
What is amazing about tf and CUDA / CUDNN drivers - that documentation is not updated when newer versions are released - and they are always changing library file names which is annoying af.
Arguably Google and Nvidia are the richest companies from the whole DS stack - but their documentations is the worst of all the richest companies.
So if you are updating your docker container and libraries suddenly start producing weird errors - look for compatibility guidelines like this one - https://goo.gl/cF3Swy
Of course docs and release note will have no mention of this. Because Google.
Also docker hub contains all the versions of CUDA+CUDDNN packaged, which helps
- https://hub.docker.com/r/nvidia/cuda/
PS
Pytorch has all this embedded into their official repo list
- http://prntscr.com/i6nfsl
Google, why do you make us suffer?
#deep_learning
Читать полностью…
Spark in me
27 January 2018 08:21
Best link about convolution arithmetic
-https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
#deep_learning
Читать полностью…
Spark in me
26 January 2018 05:59
New dimensionality reduction technique - UMAP
- https://github.com/lmcinnes/umap
I will write more as I test it / learn more.
Works well with HDBSCAN and CNNs I guess
- https://goo.gl/9hYAXL
Usage examples
- https://goo.gl/QuYWJF
#data_science
Читать полностью…
Spark in me
25 January 2018 05:15
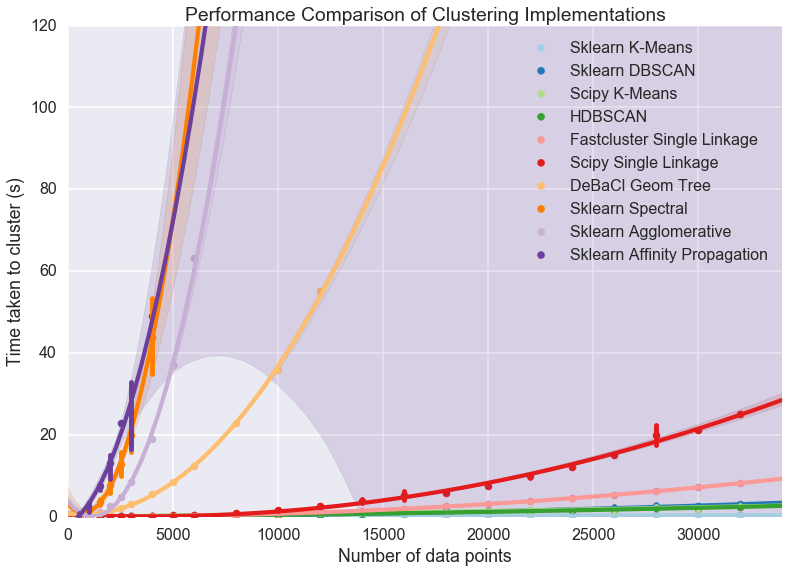
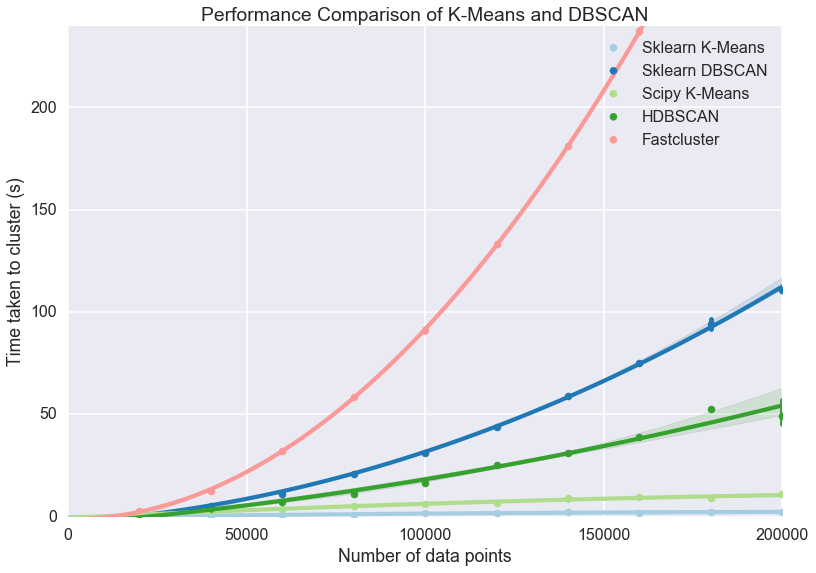
Playing with HDBSCAN in practice.
What I learned. If you have a non-sparse feature vector, i.e. 1000+ - 5000+ dimensions, then you should use PCA before using HDBSCAN.
Their scalability how-to (https://goo.gl/iR9HQu) does all the benchmarks on 10 dimension vectors. In practice anything above 50-100 dimensions faced some kind of bottle-neck - the memory consumption was low, the CPU consumption was also low - but nothing pretty much happened for hours.
Also if you want to have large clusters and set (https://goo.gl/eikRy4) min_samples value to >> 100, then there will me a memory explosion due to some kind of caching issue. So if your cluster size should be 5000+, then you are compelled to use min_samples ~ 100.
#data_science
Читать полностью…
Spark in me
24 January 2018 09:10
Last post should have contained "DrivenData". I stand corrected.
Читать полностью…
Spark in me
23 January 2018 18:23
Key / classic CNN papers
ShuffleNet
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- a small resnet-like network that uses pointwise separable covolutions and depthwise separable convolutions and a shuffle layer
- authors - Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun
- paper - http://arxiv.org/abs/1707.01083
- key
-- on ARM devices 13x faster that Alexnet
-- lower top1 error than MobileNet at 40 MFLOPs
- comparable to small versions of NASNET
- 2 ideas
-- use depth-wise separable convolutions for 3x3 and 1x1 convolutions
-- use shuffle layer (flatten, transpose, resize back to original dimension)
- illustrations
-- shuffle idea - https://goo.gl/zhTV4E
-- building blocks - https://goo.gl/kok7bL
-- vs. key architectures https://goo.gl/4usdM9
-- vs. MobileNet https://goo.gl/rGoPWX
-- actual inference on mobile device - https://goo.gl/X6vbnd
#deep_learning
#data_science
Читать полностью…
Spark in me
23 January 2018 12:34
For new (!) people on the channel:
- This channel is a practicioner's channel on the following topics: internet, data science, math, deep learning, philosophy
- Focus is on data science
- Don't get your opinion in a twist if your opinion differs. You are welcome to contact me via telegram @ and email - aveysov@gmail.com
- No bs and ads
Give us a rating:
- /channel/tchannelsbot?start=snakers4
Donations
- Buy me a coffee https://buymeacoff.ee/8oneCIN
- Direct donations - https://goo.gl/kvsovi - 5011673505 (paste this agreement number)
- Yandex - https://goo.gl/zveIOr
Our website
- http://spark-in.me
Our chat
- https://goo.gl/IS6Kzz
DS courses review
- http://goo.gl/5VGU5A
- https://spark-in.me/post/learn-data-science
GAN papers review
- https://spark-in.me/post/gan-paper-review
Читать полностью…
Spark in me
23 January 2018 05:47
Internet Digest
- Ben Evans - https://goo.gl/TPyLoD
- Youtube tightening moderation screws for small channels - https://goo.gl/SHpC2h
- Camera strapped to plane - https://vimeo.com/240106846
- Guardian online getting profitable - https://goo.gl/CDpNFb
- Amazon testing a shop wo cashiers - you just take goods and walk out - https://goo.gl/hvh63Z
- Drone saving a drowning person - https://goo.gl/RdGYDx
ГЫ
- А это отлично зайдет русским ко-ко-ко разрабам и культуре "обсирания всего", которая царит в нашем IT - https://goo.gl/S5poqv
#internet
#digest
Читать полностью…
Spark in me
23 January 2018 05:14
Pytorch in a year review
http://pytorch.org/2018/01/19/a-year-in.html
#deep_learning
Читать полностью…
Spark in me
21 January 2018 09:37
Tested bcolz on a simple premise - how fast can it process 1M (1,3476) feature vectors from CNN. Also looks like it provides 2-3x compression straight out of the box. Nice.
Blazingly fast!
- https://goo.gl/z1MKmH
#data_science
Читать полностью…
Spark in me
20 January 2018 16:13
2017 DS/ML digest 1
Did not do digests quite for some time =)
1. Annual digests
1.1 Google Brain one - https://goo.gl/VQhZmP two https://goo.gl/XkTRhp
Highlights
- Speech generation https://goo.gl/MEDv7M
- Speech recognition https://goo.gl/tCEkVz
- Auto ML https://goo.gl/fx2FuP
-- NASNET - https://goo.gl/becAET
1.2
Posted before - but WildML 2017 summary is also awesome https://goo.gl/ZFtFVT
2. Datasets
→ YouTube-8M (https://goo.gl/nyP9gp): >7 million YouTube → videos annotated with 4,716 different classes
→ YouTube-Bounding Boxes (https://goo.gl/c3K6YY): 5 million bounding boxes from 210,000 YouTube videos
→ Speech Commands Dataset (https://goo.gl/TWsTi8): thousands of speakers saying short command words
→ AudioSet (https://goo.gl/TVA3LJ): 2 million 10-second → → YouTube clips labeled with 527 different sound events
→ Atomic Visual Actions (AVA) (https://goo.gl/Ba4U73): 210,000 action labels across 57,000 video clips
→ Open Images (https://goo.gl/2Xj8Xd): 9M creative-commons licensed images labeled with 6000 classes
→ Open Images with Bounding Boxes (https://goo.gl/qRkvMy): 1.2M bounding boxes for 600 classes
→ QuickDraw dataset (https://goo.gl/FSsfYm)
3.
Uber about genetic approach to neural networks - https://eng.uber.com/deep-neuroevolution/
#digest
#data_science
#deep_learning
#machine_learning
Читать полностью…
Spark in me
20 January 2018 13:33
@ Like the twitter repost idea?
Читать полностью…
Spark in me
19 January 2018 13:34
Just found out about Facebook's fast text
- https://github.com/facebookresearch/fastText
Seems to be really promising
#data_science
#nlp
Читать полностью…
Spark in me
19 January 2018 10:55
Wine3.0 - зарелизилась третья мажорная версия эмулятора системных вызовов Windows. Именно эта система лежит в основе портов бОльшей части старых игр на мак и линукс. Ну и на сегодняшний момент это единственный нормальный способ запустить на линуксе Майкрософт Офис и последний Фотошоп. Все время удивляюсь, как у ребят хватает энтузиазма уже больше десяти лет развивать этот продукт, мои большие поздравления команде!
В этом релизе практически полная совместимость с базовыми уровнями DirectX/3D 11 и поддержка Андроида.
https://www.winehq.org/news/2018011801
Читать полностью…



 2278
2278
{kind=link}
{kind=link}
{kind=link}