Spark in me
10 Jan 2018 04:20
A 70% full GAN / style paper review:
- review https://spark-in.me/post/gan-paper-review
- TLDR - http://author.spark-in.me/gan-list.html
Did not crack math in Wasserstein GAN though.
Also a friend focused on GANS for ~6 months. Below is the gist of his work:
- GANs are known to be notoriously difficult and tricky to train even with wasserstein loss
- The most photo-realistic papers use custom regularization techniques and very sophisticated training regimes
- Seemingly photo-realistic GANs (with progressive growing)
-- are tricky to train
-- require 2-3x time to train the GAN itself and additional 3-6x to use growing
- end result may be completely unpredictable despite all the efforts
- most GANs are not viable in production / mobile applications
- visually in practice they perform much WORSE than style transfer
Training TLDR trick
- Use DCGAN just for training latent space variables w/o any domain
- Use CycleGan + wasserstein loss for domain transfer
- Use growing for photo-realism
As for using them for latent space algebra - I will do this project this year.
#deep_learning
#data_science
Читать полностью…
Spark in me
09 Jan 2018 04:47
Research debt
- https://distill.pub/2017/research-debt/
A smart way of saying that 90% of everything is noise / bs =)
Also nice quote, i.e. making things easy is not popular
An aspiring research distiller lacks many things that are easy to take for granted: a career path, places to learn, examples and role models
#data_science
Читать полностью…
Spark in me
08 Jan 2018 07:57
Some anti-hype predictions about dates of some achievable new applications of technology
- http://rodneybrooks.com/my-dated-predictions/
#internet
Читать полностью…
Spark in me
08 Jan 2018 04:49
For new (!) people on the channel:
- This channel is a practicioners' channel on the following topics: internet, data science, math, deep learning, philosophy
- Focus is on data science
- Don't get your opinion in a twist if your opinion differs. You are welcome to contact me via telegram @ and email - aveysov@gmail.com
- No bs and ads
If you like our channel, please share it and give us a rating:
- /channel/tchannelsbot?start=snakers4
Buy us a coffee
- Direct donations - https://goo.gl/kvsovi - 5011673505 (paste this agreement number)
- Yandex - https://goo.gl/zveIOr
Our website
- http://spark-in.me
Our chat
- https://goo.gl/IS6Kzz
DS courses review
- http://goo.gl/5VGU5A
- https://spark-in.me/post/learn-data-science
GAN papers review
- https://spark-in.me/post/gan-paper-review
Читать полностью…
Spark in me
05 Jan 2018 05:37
Ablation analysis is must - fchollet
- http://prntscr.com/hw9wvc
- https://goo.gl/PKXbpn
Читать полностью…
Spark in me
04 Jan 2018 04:13
Twitter service works - it enables to read the important links while disregarding the junk / conversations / bs.
In my case all the emails are in one gmail folder and I can just unread / delete them all.
Читать полностью…
Spark in me
03 Jan 2018 13:24
And these are my best cats
Читать полностью…
Spark in me
03 Jan 2018 10:38
I just realized the raw theoretic power of GANs - they enable you to create latent space features (just like word2vec) for any domain w/o annotation (!).
What a great time to be alive.
Читать полностью…
Spark in me
02 Jan 2018 11:02
A nice repo with paper summaries (2-3 pages per paper)
- https://github.com/aleju/papers/tree/master/neural-nets
#deep_learning
#data_science
Читать полностью…
Spark in me
02 Jan 2018 05:50
Hacks for training GANs
- https://github.com/soumith/ganhacks
#deep_learning
#data_science
Читать полностью…
Spark in me
09 Jan 2018 07:08
When I started doing CV - this page was quite scarce.
Now it's full and amazing!
I recommend this page as your go-to reference for already implemented non CNN based (classic) CV. It is just amazing. Simple and illustrative examples with code.
This totally eliminates the need in open-cv abomination =)
http://scikit-image.org/docs/dev/auto_examples/index.html
Best libraries for images I have seen so far
- pillow (pillow simd)
- skimage
- imageio
- scikit video
- moviepy
#data_science
#computer_vision
Читать полностью…
Spark in me
08 Jan 2018 07:47
A 2017 ML/DS year in review by some venerable / random authors:
- Proper year review by WildML (!!!) - http://www.wildml.com/2017/12/ai-and-deep-learning-in-2017-a-year-in-review/
-- Includes a lot of links and proper materials
-- AlphaGo
-- Attention
-- RL and genetic algorithm renaissance
-- Pytorch - elephant in the room, TF and others
-- ONNX
-- Medicine
-- GANs
If I had to summarize 2017 in one sentence, it would be the year of frameworks. Facebook made a big splash with PyTorch. Due to its dynamic graph construction similar to what Chainer offers, PyTorch received much love from researchers in Natural Language Processing, who regularly have to deal with dynamic and recurrent structures that hard to declare in a static graph frameworks such as Tensorflow.
Tensorflow had quite a run in 2017. Tensorflow 1.0 with a stable and backwards-compatible API was released in February. Currently, Tensorflow is at version 1.4.1. In addition to the main framework, several Tensorflow companion libraries were released, including Tensorflow Fold for dynamic computation graphs, Tensorflow Transform for data input pipelines, and DeepMind’s higher-level Sonnet library. The Tensorflow team also announced a new eager execution mode which works similar to PyTorch’s dynamic computation graphs.
In addition to Google and Facebook, many other companies jumped on the Machine Learning framework bandwagon:
- Apple announced its CoreML mobile machine learning library.
- A team at Uber released Pyro, a Deep Probabilistic Programming Language.
- Amazon announced Gluon, a higher-level API available in MXNet.
- Uber released details about its internal Michelangelo Machine Learning infrastructure platform.
- And because the number of framework is getting out of hand, Facebook and Microsoft announced the ONNX open format to share deep learning models across frameworks. For example, you may train your model in one framework, but then serve it in production in another one.- In Russian - https://goo.gl/z1nLzq - kind of meh review (source - https://goo.gl/NUQ18C)
- Amazing 2017 article about global AI trends - https://srconstantin.wordpress.com/2017/01/28/performance-trends-in-ai/
- Uber engineering highlights - https://goo.gl/jBo91k
#digest
#deep_learning
#data_science
Читать полностью…
Spark in me
07 Jan 2018 06:32
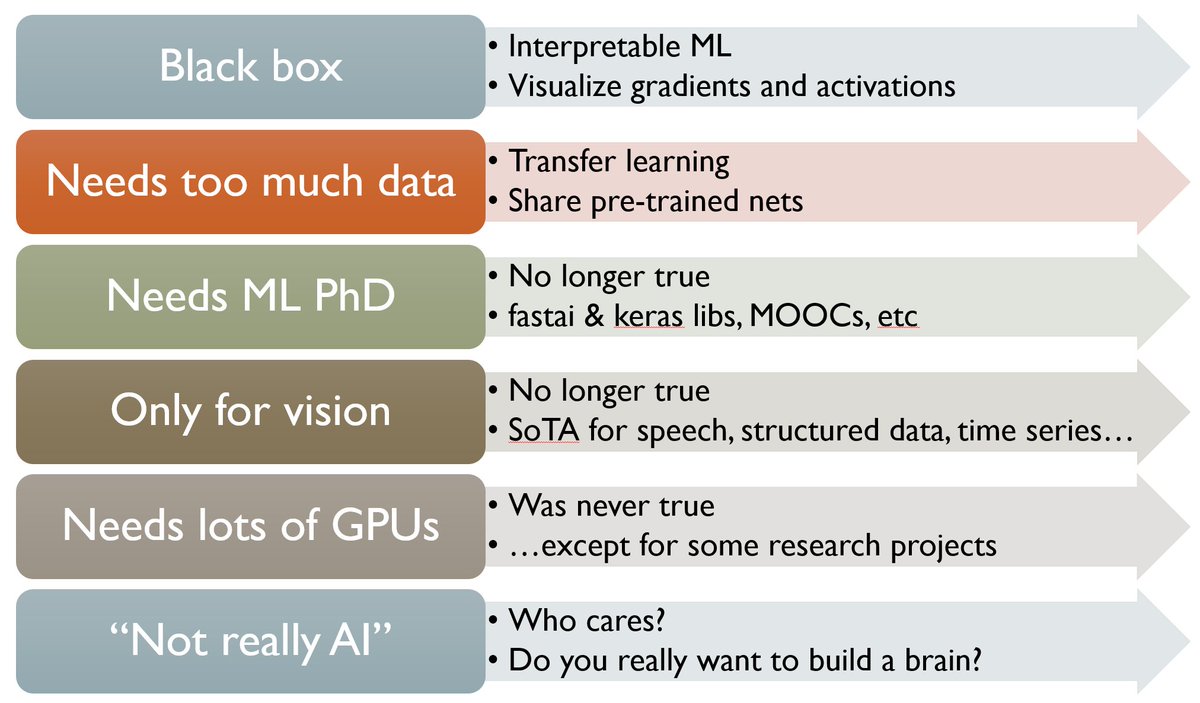
Some points about modern misconceptions about ML
https://pbs.twimg.com/media/DSz_TWKVwAI2V6s.jpg
#data_science
Читать полностью…
Spark in me
06 Jan 2018 06:40
It's funny to find out about new black mirror episodes from Andrew Karpathy
https://t.co/PhJJLpBHkQ
Читать полностью…
Spark in me
05 Jan 2018 06:13
Итого, что бы скомпроментировать Linux систему и украсть wallet.dat достаточно запустить какой-то левый софт, который подгрузит perl/python скрипт поиска нужных файлов + стартанет в фоне кейлоггер отдельным процессом + пропишет его в автозагрузку, в 90% случаев пользователь ничего не заметит. Вирусов нет и не может быть, говорили они.
Повод серьезно задуматься о безопасности своих данных и о песочнице для левого софта 😱
Читать полностью…
Spark in me
05 Jan 2018 05:51
Really cool articles about
- modern OCR
- how car tickets are issued (this is a whole industry!) - old algorithms gave 80%, newer ones give 95%
- also guys from Recognitor told me that CTC modelling really works really well (!)
Articles
- https://habrahabr.ru/company/recognitor/blog/343512/
- https://distill.pub/2017/ctc/
- https://hackernoon.com/latest-deep-learning-ocr-with-keras-and-supervisely-in-15-minutes-34aecd630ed8 (pure gold)
- https://www.youtube.com/watch?time_continue=131&v=uVbOckyUemo
If you will need to to modern OCR
- this articles are a great starter
- you can detect sth with YOLO, then rotate image with affine transformations, then use CTC
#data_science
#deepl_learning
Читать полностью…
Spark in me
05 Jan 2018 05:35
Decided to invest some time into Andrew Ng new courses in a view only mode to search for high level ideas (doing NNs from scratch became boring when we did it in Octave)
- First two or three courses are just plain old Octave course but in Python, which is great for beginners
- 4th course is about ML strategy. Watched it, it's very short
-- https://www.coursera.org/learn/machine-learning-projects/
-- https://goo.gl/zvt6RW - videos and presentations
-- key ideas
--- use human
--- treat time as the most precious commodity
--- divide metric into optimizing metrics and satisficing (i.e. good enough) metrics
--- always compare to plain humans / board of experts as a baseline to see if you need a bigger model / or less overfitting
--- always have train / validation (dev) / and delayed test sets
--- always think about practical implications
- 5th course is about modern ML (YOLO, sequence modelling) - worth checking out if you are not familiar. Not sure about assignments though
#data_science
#education
Читать полностью…
Spark in me
04 Jan 2018 02:27
Starting my GAN paper review series ~40% in
- https://spark-in.me/post/gan-paper-review
Please comment / share / provide feedback.
#data_science
#deep_learning
Читать полностью…
Spark in me
03 Jan 2018 17:41
During the last competition my teammate found a nice paper in Jeremy Howard's tweet.
DS/ML/CV specialists in the USA like Twitter for some reason. In Russia / CIS Twitter is not used (at first vk.com was better and now telegram is better) and I have always considered it to be a service like Snapchat (i.e. useless hype generator) but with roots in SMS era (their stock and dwindling user base agree).
But this post - https://goo.gl/y3DXWH - changed my mind (twitter accounts of the brightest minds from NIPs).
So I decided to monitor their tweets ... and I guess twitter does not send you emails on every new tweet so that you would use their app. Notifications about new tweets are limited either to API or push notifications or SMS - which is hell (+1 garbage app on the phone - no thank you).
So today we decided to write and share a small python class that would use Twitter API to send you emails
- code https://github.com/nurtdinovadf/tweetsender
- how it looks in Gmail - http://prntscr.com/hvldt7
Please feel free to use it, share it, star it and comment. Many thanks.
#data_science
Читать полностью…
Spark in me
03 Jan 2018 09:10
An awesome CLI based STATIC open-source website template for your blog
- https://gohugo.io/content-management/organization/
It's static - no miracles here.
#internet
Читать полностью…
Spark in me
03 Jan 2018 06:45
alexrachnog/ai-in-2018-for-developers-2f01250d17c" rel="nofollow">https://medium.com/@-2f01250d17c
Читать полностью…
Spark in me
02 Jan 2018 08:51
I am doing a massive read-thru and summary notes on 20+ GAN-related papers. Should I publish my notes as an article, or as a very long series of channel posts?
Article – 5
👍👍👍👍👍👍👍 83%
What are GANs? – 1
👍 17%
Posts
▫️ 0%
I do not care about GANs
▫️ 0%
👥 6 people voted so far.
Читать полностью…
Spark in me
02 Jan 2018 05:45
My lazy bones remarks in fast.ai GAN lessons. Really good stuff though. Definitely a must read for GANs, but the actual code part and bcolz part can be done easier in pure pytorch with multiple workers.
Fast.ai part 2, lesson 3 - generative models
- Video https://www.youtube.com/watch?time_continue=3021&v=uv0gmrXSXVg
- Wiki http://forums.fast.ai/t/lesson-10-wiki/1937
- Forum http://forums.fast.ai/t/lesson-10-discussion/1807
- Code is shared here - https://github.com/fastai/courses/tree/master/deeplearning2
Key insights:
- Everything that works on whole imagenet is quite good
- Image2seq and super-resolution work awesomely well
- Generative models <> GANs, GANs usually can be added to any generative model
- tqdm - is the best progress bar ever
- Keras + Jupiter is more or less quicker for experimenting than Pytorch, but less flexible
overall and much less production ready
Bcolz and Img2seq
- their notebook - https://goo.gl/JhYpPx
- bcolz iterator for large datasets if the dataset does not fit in memory - https://goo.gl/ck1P2d
-- allows iterating over bcolz stored on the disk
-- I see no real benefit over just iterating files in several threads
-- Maybe it would be just better to work with in-memory bcolz arrays (say bcols boasts in-memory compression + large RAM will be a good solution)?
-- for my taste this is overengineering - simple multi-threaded pillow thumbnail + milti-threaded dataset class would do the job (though may be useful for a more general application or for much more data - terabytes)
-- as for video and terabytes of data another approach works - just itemize the data (1 item = .npy file) and then just use threaded workers to read it
- fast.ai examples are cool, they know about Pillow SIMD, but do not know about pillow's thumbnail method
- you can use gensim to easily get word2vec vectors
- Pillow SIM is 600% faster Pillow - https://github.com/uploadcare/pillow-simd
Distance
- cosine distance is a usual choice for high dimension spaces
Super-resolution
- notebook - https://goo.gl/tASGjU
- superresolution with FCN
- all imagenet
- how to write your one train loops in keras
GANs (worthy tips, paper review will come later)
- their notebook - https://goo.gl/1QZbcy
- NN can learn to ignore black borders, but better just avoid them
- for ordinary GANs loss functions do not make sense
- write your own generator
- train a D a "little bit" at first
- freeze D and unfreeze G, train generator (G) with frozen discriminator (D), freeze G and
unfreeze D, train D with frozen G, repeat
- Wasserstein GAN paper - is a MASSIVE break-through
- D vs G batches is flexible (as per paper)
- For WG training curves make sense
Pytorch hacks
- underscore operators
save memory
- pre-allocate memory
- saves time
- good weight initilization boilerplate (I mostly used Imagenet, so I avoided facing it)
def weights_init(m):
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
m.weight.data.normal_(0.0, 0.02)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
netG.apply(weights_init)
#deep_learning
Читать полностью…



 2278
2278
{kind=link}
{kind=link}