Zen of Python
07 Jul 2025 17:01
shebang: что это и как запускать скрипты в CLI без слова python?
При работе с Unix-подобными системами (Linux, macOS), часто используется специальная строка, которая называется 'shebang' (шибэнг). Это первая строка в скрипте, которая начинается с символов #!, за которыми идёт путь к интерпретатору, который должен выполнить этот скрипт:
#!/usr/bin/env python3
print("Hello world")
Это равносильно: «Для запуска этого файла используй интерпретатор python3, который находится в вашем PATH».
Перед запуском сделаем файл исполняемым (или сразу всю директорию):
chmod +x myscript.py
chmod +x misc/*.py
Теперь скрипт можно запустить так:
./myscript.py
Как правильно писать shebang для Python?Существует несколько распространённых вариантов записи shebang для Python:
1. Абсолютный путь
#!/usr/bin/python3
Однако, путь может отличаться на разных машинах, поэтому второй способ универсальнее.
2. Использование `/usr/bin/env`:
#!/usr/bin/env python3
Команда
env ищет в текущем окружении пользователя нужный интерпретатор по имени
python3 и запускает его. Это значит, что не важно, где установлен Python, скрипт всё равно будет работать, если
python3 доступен в PATH.
Что произойдет без shebang?Если запустить скрипт без shebang напрямую (
./myscript.py), система не поймет, каким интерпретатором его запускать, и выдаст ошибку.
p.s. На Windows shebang не используется системой напрямую, но некоторые инструменты (например, Git Bash, WSL, или IDE) могут её «наследовать».
#основы
@
Читать полностью…
Zen of Python
07 Jul 2025 10:02
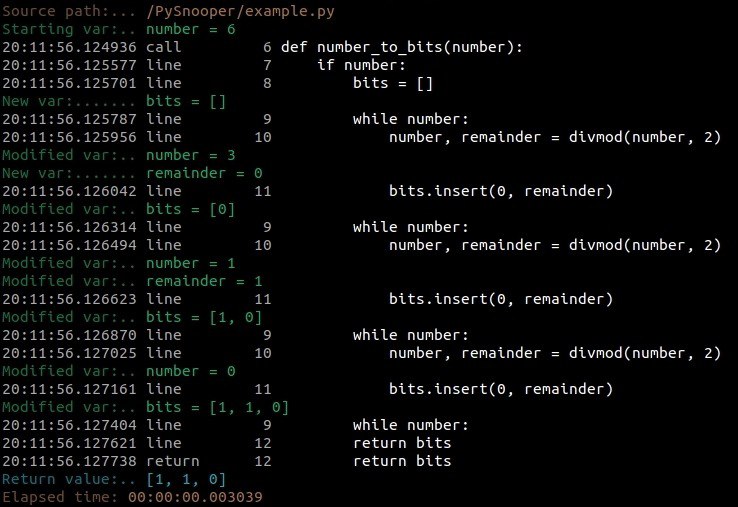
PySnooper | Дебаггинг по-человечески
Опять кто-то пытается отучить нас использовать print() во время дебага... Автор тула предлагает использовать:
— декораторы @.snoop();
— блоки with pysnooper.snoop();
Чтобы в итоге получить такую отладочную информацию, как на приложенном скриншоте. Вот что происходит на нем слева:
— вызывается функция number_to_bits с аргументом number = 6;
— в строках кода функции (справа) видно, что она предназначена для перевода числа в двоичный формат, сохраняя биты в списке bits;
— PySnooper пошагово логирует каждую выполненную строку (слева), время выполнения, а также все изменяющиеся переменные;
— переменная number последовательно изменяется от 6 до 3, потом до 1, затем до 0
— каждый раз происходит деление с остатком (divmod(number, 2)), а остаток (remainder) вставляется в начало списка bits;
— В итоге возвращается список битов [1, 1, 0], что соответствует двоичному представлению числа 6.
Репозиторий проекта
#инструмент
@
Читать полностью…
Zen of Python
06 Jul 2025 13:09
Как искать работу в IT в 2025, не вызывая подозрений у санитаров
В отборе в IT страсти кипят не меньше, чем в хайлоаде. Вместе с Proglib мы провели исследование и спросили сотни айтишников: что реально выводит из себя в найме?
Собрали всё в удобный чек-лист:
– HR узнают, как не отпугивать сильных кандидатов.
– Айтишники поймут, где сразу маячат ред флаги и можно не терять время.
Надеемся, материал хоть и немного, но изменит процессы найма к лучшему. Поэтому сохраняйте, делитесь и прожимайте ❤️
Читать полностью…
Zen of Python
05 Jul 2025 17:11
Как по мнению Python-разработчика на самом деле должен работать Pip-Boy в игре Fallout.
#кек
@
Читать полностью…
Zen of Python
04 Jul 2025 17:09
Вопросы подписчиков
Zen of Python поддерживает новоприбывших (и не только) в особой рубрике. Как это работает:
— Спрашивайте что угодно (в комментариях под этим постом), связанное с Python. Здесь нет плохих вопросов!
— Сообщество вас поддержит. Самые интересные вопросы мы разберём в отдельном посте;
#вопросы_новичков
@
Читать полностью…
Zen of Python
03 Jul 2025 17:08
asdf-vm | Переключаться между окружениями автоматом
Продвинутая система управления виртуальными окружениями, позволяющая в одну команду:
— устанавливать зависимости для НЕСКОЛЬКИХ ЯП в одном окне;
— при переходе в папку другого проекта переключится на соответствующее окружение и многое другое.
Цена: бесплатно
Репозиторий проекта
Сайт
🌚 — Если это уже слишком «дебри»
😎 — Если считаешь такое элегантным
Читать полностью…
Zen of Python
02 Jul 2025 10:06
Джависткие Virtual Threads в Python
На официальном форуме Python не на шутку разогнали тред про виртуальные потоки. Идея похожа на OpenJDK Project Loom: такое не потребляет много ресурса.
Предлагается создать соответствующее API, чтобы эффективно выполнять большое количество конкурентных задач. Посмотрим, выживет ли идея.
#факт
@
Читать полностью…
Zen of Python
01 Jul 2025 10:03
SQLZoo: интерактивный тренажёр по SQL
Если надоело читать теорию и хочется потрогать SQL ручками — SQLZoo станет идеальным выбором. Здесь сразу на сайте можно выполнять задания, строить запросы к реальным базам и видеть результат.
Есть пошаговые туториалы, задания на SELECT, JOIN, GROUP BY, подзапросы и задачки на логику.
Читать полностью…
Zen of Python
30 Jun 2025 17:01
Общий сбор питонистов на митапе ЮMoney ™️
Питоняшки — бесплатный митап ЮMoney для Python-разработчиков.
✅ 3 июля, в четверг, в 19:00 (мск) — приходите на митап в Санкт-Петербурге или подключайтесь онлайн.
О чём будут доклады?
🟣 Это не те метрики, что вы ищете. Разберётесь, почему стандартного экспортёра может не хватать, и как написать свой на Python.
🟣 Кодогенерация: как компьютеры учатся писать код за нас. Узнаете про прошлое, настоящее и будущее кодогенерации в разных языках программирования.
🟣 Ruff: как не положить всё, переходя на новые правила? Узнаете больше про линтеры, форматтеры и подводные камни при переходе на Ruff.
🟣 Секреты успеха змеи в мире пауков. Узнаете, как команда ЮMoney применяла scrapy и playwright в продукте, чтобы создать сервис модерации сайтов.
Зарегистрируйтесь, чтобы принять участие. Все подробности — на сайте митапа Питоняшки 🔥
Это #партнёрский пост
Читать полностью…
Zen of Python
29 Jun 2025 17:13
#кек
@
Читать полностью…
Zen of Python
28 Jun 2025 10:13
Я не думаю, что кто-нибудь вообще может остановить Python ЗА ПРЕВЫШЕНИЕ СКОРОСТИ
@
Читать полностью…
Zen of Python
27 Jun 2025 17:09
Вопросы подписчиков
Zen of Python поддерживает новоприбывших (и не только) в особой рубрике. Как это работает:
— Спрашивайте что угодно (в комментариях под этим постом), связанное с Python. Здесь нет плохих вопросов!
— Сообщество вас поддержит. Самые интересные вопросы мы разберём в отдельном посте;
#вопросы_новичков
@
Читать полностью…
Zen of Python
26 Jun 2025 17:07
MCP или еще один повод уважать Anthropic
Сегодня всё больше разработчиков задумываются о том, как подключить большие языковые модели (LLM) к своим инструментам и данным. Но сталкиваются с кучей проблем: модели изолированы, не понимают, что делает API, и не могут просто так «пойти» в интернет. И вот здесь появляется MCP (Model Context Protocol).
Это открытый стандарт, созданный Anthropic. ОН решает ключевую проблему: как дать LLM доступ к внешним данным и инструментам, не ломая их внутреннюю безопасность.
Да, у нас есть RESTful API. Но:
— Большинство LLM работают в «песочнице» без доступа в интернет;
— Даже если бы доступ был, модель не знает, как вызвать ваш API, какие параметры использовать и как интерпретировать ответ.
MCP решает эту задачу: он описывает, что делает ваш сервис, как с ним работать и что возвращается в ответ.
Три типа возможностей
1. Resources — данные, которые можно "прочитать", аналог GET-запросов
2. Tools — функции, которые можно вызвать (например, поиск видео)
3. Prompts — шаблоны запросов, помогающие пользователю формировать нужный вызов.
Пример: YouTube
Структура:
1. Модуль YouTube-поиска — обёртка над пакетом youtube-search
2. MCP-сервер — оборачивает этот модуль и превращает его в доступный инструмент для LLM.
def search_youtube(query, max_results):
# Используем youtube_search
...
return result_dict
И MCP-сервер, использующий этот модуль:
from fast_mcp import FastMCP
server = FastMCP(name="videos")
server.add_tool("get_videos", search_youtube)
LLM теперь может вызывать
get_videos(), передав строку запроса — и получить отформатированный список роликов.
Автогенерация MCP из FastAPIЕсли ваш API уже на FastAPI, вы можете автоматически создать MCP-интерфейс через
fast_mcp.
from fast_mcp.contrib.fastapi import convert_app_to_mcp
app = FastAPI()
# ... API endpoints
mcp_server = convert_app_to_mcp(app)
Но это подойдёт, если вы точно знаете, что API и MCP будут едины и не потребуется различать их архитектурно.
Где это уже используется?Пример из видео — интеграция с Claude Desktop, где в конфигурации можно указать локальный MCP-сервер:
{
"name": "YouTube Videos",
"command": "uv",
"args": {
"dir": "~/youtube_service",
"file": "run_mcp.py"
}
}
#LLM
Читать полностью…
Zen of Python
25 Jun 2025 10:04
Комментарии в коде: зло или спасение?
Комментарий может не только объяснить код, но и быть бесячим. Грамотно написанные пометки значительно упрощают код-ревью. Кроме того, LLM'ки вроде GitHub Copilot используют комментарии как промты, а это сплошная экономия времени. В статье на Tproger порассуждали, где заканчивается польза и начинается вред от комментариев — и как найти правильный баланс.
#основы
@
Читать полностью…
Zen of Python
24 Jun 2025 10:03
Не понимаю, как я это упустил: Microsoft раскатила расширение, которое превращает VS Code в полноценную IDE для работы с PostgreSQL, без переключений между тулзами 👍
Внутри всё, что нужно:
• Визуализация схемы базы прямо в IDE.
• IntelliSense с автокомплитом и подсветкой и форматированием SQL-запросов.
• Запуск PostgreSQL в Docker.
• Быстрое подключение к любой базе (локально, в облаке).
• История запросов для быстрого повторного запуска.
• Просмотр и управление объектами БД.
• История запросов и запуск psql прямо из VS Code.
• Интеграция с GitHub Copilot — AI пишет и объясняет SQL
Поставить можно тут
Читать полностью…
Zen of Python
07 Jul 2025 10:11
За ты понятный и работящий
@
Читать полностью…
Zen of Python
06 Jul 2025 17:13
Если обыгрывать фильм про Джанго и одноименный фреймворк, то только так
#кек
@
Читать полностью…
Zen of Python
06 Jul 2025 10:13
#кек
@
Читать полностью…
Zen of Python
05 Jul 2025 10:11
Вы знаете почему так?
@
Читать полностью…
Zen of Python
04 Jul 2025 10:09
pip vs. pip3 | Что выбрать?
Если вам вдруг стало очень важно понимать различие между этими менеджерами зависимостей, то все просто. Основное различие — это «прнадлежность» версиям Python 2 или 3:
pip — это менеджер пакетов по умолчанию для Python 2 / 3 (где «двойка» не установлена;
pip3 — это явно указанный менеджер пакетов для Python 3.
Если у тебя установлен только Python 3, pip и pip3 будут работать одинаково.
Как проверить, какая версия связана с pip
pip --version # pip 20.0.2 from /usr/lib/python2.7/site-packages/pip (python 2.7)
pip3 --version # pip3 21.2.4 from /usr/lib/python3.8/site-packages/pip (python 3.8)
#основы
@
Читать полностью…
Zen of Python
03 Jul 2025 10:07
TypedDict | Куда, зачем
Для тех, кто стремится писать поддерживаемый код, существует TypedDict («Типизированный словарь»). В этом посте разберём, зачем нужен, как правильно использовать и какие возможности открывает.
TypedDict — это специальный тип данных, что позволяет создавать словари с явно заданными типами для ключей и значений. Таким образом, вы можете описать структуру словаря, как будто это объект с фиксированными полями.
from typing import TypedDict
class User(TypedDict):
name: str
age: int
email: str
В обычных словарях Python ключи и значения могут быть абсолютно любыми, и это даёт большую гибкость, но вместе с тем усложняет контроль и проверку данных.
TypedDict позволяет добавить статическую типизацию к словарям, тем самым снизить вероятность неожиданных ситуаций с вашими экземплярами.
В примере выше мы создаем класс
User, который наследуется от
TypedDict. Теперь словари типа
User должны иметь ключи
name,
age и
email с типами
str,
int и
str соответственно.
Теперь при создании экземпляра:
user: User = {
"name": "Alice",
"age": 30,
"email": "alice@example.com"
}
если в словаре отсутствует обязательный ключ или тип значения не совпадает, современные инструменты статической типизации (например,
mypy) выдадут ворнинг.
Опциональные ключиБывает, что не всегда все ключи словаря на месте. В
TypedDict их можно сделать необязательными (
total=False):
class User(TypedDict, total=False):
nickname: str
bio: str
#основы
@
Читать полностью…
Zen of Python
01 Jul 2025 17:03
Streamlit v.1.46.0
Вышло массивное обновление BI-тула , и там теперь среди прочих:
— меню навигации можно разместить в верхней части приложения с помощью st.navigation(position="top");
— поддерживается темная тема через st.context.theme;
— большинство виджетов и элементов теперь поддерживают параметр ширины width;
— добавлена настройка CORS для разрешённых источников;
— в сообщениях об ошибках появился удобная копипаст-кнопка;
— теперь можно запускать сервер Streamlit на порту 3000 без дополнительных настроек;
— добавлена поддержка форматов номеров для колонок с числами и прогресс-баров.
Release Note
#инструмент
@
🫡 — Если отдаю честь за такую работу
Читать полностью…
Zen of Python
30 Jun 2025 18:01
Упорядочены ли словари в Python?
Что значит «упорядоченный»?
Когда говорят об упорядоченности, важно понять контекст. Например:
— Если просят расставить коробки, порядок — по размеру;
— Если вы в очереди – порядок по времени прихода.
Если структура упорядоченная, она в каком-то смысле сохраняет свой внутренний порядок. А как со словарями?
Исторический обзор
До Python 3.6: словари не сохраняли никакого порядка при выводе или переборе. Параметры key: value могли выводиться в совершенно произвольном порядке.
Начиная с Python 3.6 словари начали сохранять порядок вставки — но это считалось технической деталью реализации, а не официально гарантированным свойством. Позднее это стало частью официальной спецификации языка.
Это значит, что словари упорядочены?
Частично — да:: словари сохраняют порядок добавления элементов. Это позволяет, например, при переборе ключей получать их в том же порядке, что при вставке.
Важное «но»: порядок не влияет на сравнение словарей:
a = {"x": 1, "y": 2}
b = {"y": 2, "x": 1}
a == b # True
То есть,
равенство проверяется по парам ключ‑значение, а не по их порядку (в отличие от списка).
Почему обычный dict
сравнивается по содержанию, а не по порядку?— Оптимизация: словари предназначены для быстрой работы по ключу (хэширование);
— Благодаря «разделённой таблице» (split-table) в реализации CPython, словарь может одновременно эффективно хранить и порядке вставки, и хэш-структуру.
#основы
👌 — Если всё по красоте
Читать полностью…
Zen of Python
30 Jun 2025 15:36
#кек
@
Читать полностью…
Zen of Python
28 Jun 2025 17:11
#кек
@
Читать полностью…
Zen of Python
28 Jun 2025 10:11
Типичный день вайбкодера выглядит так.
#постИИрония
Читать полностью…
Zen of Python
27 Jun 2025 10:09
Отслеживание неиспользуемых ключей в словаре Python
Словари — это фундаментальная структура данных, используемая для хранения пар «ключ-значение». В большинстве случаев мы просто читаем и записываем значения по ключам, не задумываясь о том, какие ключи были запрошены в процессе выполнения программы, а какие так и остались неиспользованными. Однако иногда в разработке возникает задача понять, какие ключи словаря так и не были использованы.
Представим, что у вас есть словарь с множеством параметров, который передаётся в функцию или класс. Вы хотите убедиться, что ваша логика действительно «потрогала» все ключи, и не осталось параметров, которые вы передали, но не использовали. Это особенно актуально, если словарь — это некий набор опций или конфигураций.
Без специальных инструментов проверить, какие ключи словаря не использовались, довольно сложно. Стандартный словарь в Python не хранит никакой информации о том, обращались ли к конкретному ключу.
Решения: словарь с учётом использования ключей
Для решения этой задачи можно создать класс-обёртку над обычным словарём, который при каждом запросе ключа будет отмечать этот ключ как «использованный».
Основные требования к такой структуре:
— При запросе значения по ключу отмечать ключ как использованный;
— Предоставлять метод, возвращающий ключи, к которым не обращались;
— Максимально просто и удобно использовать вместо обычного словаря.
Реализация: UsedDict
class UsedDict(dict):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._used_keys = set()
def __getitem__(self, key):
self._used_keys.add(key)
return super().__getitem__(key)
def get_unused_keys(self):
return set(self.keys()) - self._used_keys
— Наследуемся от стандартного
dict, чтобы сохранить привычный интерфейс;
— При инициализации создаём пустое множество
_used_keys, в котором будем хранить все ключи, к которым обращались;
— Переопределяем метод
__getitem__, который вызывается при чтении значения по ключу
mydict[key]. В этом методе сначала отмечаем ключ как использованный, а затем возвращаем значение;
— Добавляем метод
get_unused_keys, который возвращает разницу между всеми ключами словаря и теми, которые использовались.
Пример использования:
config = UsedDict({
"host": "localhost",
"port": 8080,
"debug": True,
"timeout": 30
})
print(config["host"]) # используется
print(config["port"]) # используется
unused = config.get_unused_keys()
print("Неиспользованные ключи:", unused)
# Выведет: Неиспользованные ключи: {'debug', 'timeout'}
#основы
Читать полностью…
Zen of Python
26 Jun 2025 10:07
crudadmin | Минималистичная админка для FastAPI
Симпатичный минималистичный GUI для самописных API. Поддерживает различные бэкенды для сессий (Redis, Memcached и БД). Встроенные механизмы защиты включают фильтрацию IP, защиту от DDoS-атак и подробный журнал событий.
Консоль доступна по адресу /admin в тёмной и светлой темах.
Цена: бесплатно
Репозиторий проекта
#инструмент
Читать полностью…
Zen of Python
24 Jun 2025 17:03
Молчаливый «провал» INSERT
Вы запускаете SQL-запрос INSERT, и вроде всё просто. Нет ошибок. Но и данные не вставлены. Звучит странно? Такое действительно может случиться с PostgreSQL — и случается чаще, чем хотелось бы.
Как можно вставить данные и не вставить одновременно?
Когда INSERT не срабатывает, первое, что приходит в голову — ошибка. Но PostgreSQL умеет «глотать» такое — ведь вы сами его об этом попросили.
Виновник — ON CONFLICT DO NOTHING
INSERT INTO users (id, email)
VALUES (42, 'user@example.com')
ON CONFLICT (id) DO NOTHING;
Здесь мы явно говорим: "если произойдёт конфликт по
id, ничего не делай". И PostgreSQL
по умолчанию так и поступает.
Поведение UPSERT при множественных уникальных индексаПредставьте, что в таблице есть не один, а
два уникальных индекса:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE,
username TEXT UNIQUE
);
Теперь вы выполняете:
INSERT INTO users (email, username)
VALUES ('user@example.com', 'johnny');
А если
username = 'johnny' уже существует, но
email ещё нет?
Вставка завершится ошибкой!Так происходит, потому что
ON CONFLICT (email) говорит PostgreSQL: «молчи, если конфликт по
email, но
бросай ошибку, если конфликт по чему-то ещё».
Чтобы избежать этого, используем:
ON CONFLICT DO NOTHING
Тогда PostgreSQL проигнорирует конфликт
по любому индексу. Но это может спровоцировать проблемы, особенно при вставке пачкой
Как отладить такую ситуацию?—
Проверяйте rowcount после запроса. В Python/psycopg2, например:
cursor.execute(sql, values)
if cursor.rowcount == 0:
print("Nothing inserted!")
— Добавьте
RETURNING и логируйте:
INSERT INTO users (email, username)
VALUES ('user@example.com', 'johnny')
ON CONFLICT DO NOTHING
RETURNING id;
Если возвращается пустой результат — значит, вставки не было.
— Логируйте причину. Если вы используете логику вида
DO UPDATE, можно добавить логи в `UPDATE`-часть или сохранять «причину отказа» отдельно.
#sql
Читать полностью…
Zen of Python
23 Jun 2025 17:02
py-pglite | PostgreSQL прямо через import
Инструмент для тестов с настоящим PostgreSQL без необходимости поднимать сервер. Он запускается за пару секунд прямо из Python-кода, без Docker и лишней настройки. Полностью совместим с SQLAlchemy, Django ORM, psycopg, asyncpg и поддерживает расширения вроде pgvector.
Цена: бесплатно
На PyPi
#инструмент
@
Читать полностью…



 20144
20144
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}