LLM под капотом
23 June 2026 16:36
Насколько критичен для вас полноценный Structured Output при работе с локальными моделями?
Напишите, пожалуйста, ответы в комментарии (не важен, предпочитаю, жить без него не могу итп).
Зачем? Тут предлагают отсыпать токенов на локальные модели для тех команд, которые ставят эксперименты в области Agentic Commerce архитектур на платформе BitGN. Но есть нюанс, что токены без полноценного SO.
Напоминаю, что:
• Без SO - модель может вернуть любой текст. Вызовы json parse нужно оборачивать try/catch
• SO/JSON - модель возвращает валидный JSON, но вместо числового поля может быть и текст. Схему нужно валидировать (Zod/Pydantic) и оборачивать в try/catch
• Честный SO как у OpenAI/llguidance - если в схеме прописано число, то гарантированно будет число. Try/catch не нужен. Можно спокойно использовать Schema-Guided Reasoning.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
21 May 2026 12:04
ECOM1 получил продолжение на второй сезон!
ECOM1 заходит хорошо (6.4k завершенных агентских прогонов и четверть миллиона попыток решения задач, нагрузка идет круглые сутки), а в логах начинают просматриваться интересные вещи.
Правда, большая часть интересного - это про новые способы AI агентов жульничать (например - присылать все возможные grounding references))), на которые приходится затягивать harness проверок. Но уже видны и любопытные паттерны, которые можно вместе исследовать, приземлить и превратить в отраслевой State-of-the-Art, как мы уже сделали в цикле Enterprise RAG Challenge.
План такой:
(1) 30 Мая фиксируем наш текущий State-of-the-art в лидербордах ECOM1, публикуем лучшие решения, обсуждаем, забираем к себе.
(2) В июне - соберем для ECOM2 актуальные и злободневные проблемы e-commerce, которые будоражат его сейчас и сегодня. Я съезжу на конференцию Money20/20 Europe в Амстердаме (там выступают MasterCard, Amazon, Google, Anthropic, OpenAI, Visa итп), чтобы рассказать про BitGN, инсайты из ECOM1 и собрать новые задачи.
(3) В конце июня покажем индустрии как правильно/быстро/экономично решать эти задачи на ECOM2. COLIBRIX ONE сделают нам зажигательную PR-компанию со штаб-квартирой соревнования в Барселоне, профессиональным стримом и призами.
А пока - расскажите про то, как вы работаете с задачами ECOM1. Какой setup, какая архитектура агента, какая LLM, какие сложности были и какие сюрпризы встретились.
Можно сразу в ответе упоминать 6-значный ID аккаунта, чтобы все видели место)
Ваш, @ 🤗
Читать полностью…
LLM под капотом
05 April 2026 22:29
Karpathy написал классный gist про использование LLM для ведения баз знаний: LLM wiki
Это отчасти совпадает с тем, как я использую OpenAI Codex для персонального ассистента (Personal OS v2), но есть и различия.
Схожее:
(1) формат хранения - markdown с ссылками
(2) Obsidian как frontend - для просмотра
(3) Правила в корне Agents_md/Claude_md
(4) Режим ingest - когда новые статьи и материалы закидываются в хранилище, а LLM пылесосит их и подшивает
(5) Режим query - когда мы общаемся с LLM-кой по поводу материалов, и иногда хорошие ответы подшиваем обратно в wiki
(6) Режим lint - время от времени LLM проходится по репе, чтобы чистить файлы и ссылки
Что различается:
(0) У Karpathy - одна база знаний на исследование, а у меня - одна база знаний на все, и хранится она в git.
(1) У Karpathy есть log.md, куда пишутся все последние изменения. Я это выкинул, т.к. все хранится в git, и там есть git log
(2) У Karpathy index.md со списком всех файлов, у меня отдельные threads по тематикам.
(3) У Karathy есть CLI tools для поиска по тексту, он советует qmd для умного поиска. У меня пока используется обычный ripgrep.
(4) Karpathy советует Obsidian Web Clipper для выкачки статей - я про такое даже не подумал, сразу утащил к себе. Работает идеально.
(5) У Karpathy источники компилируются в статьи, а у меня все индексируется в карточки и потом сшивается в статьи, но это уже вкусовщина.
В целом, все работает у меня очень хорошо. Основной "затык" у меня - неудобно работать на ходу с этой базой знаний из телефона или разных чатов Claude/Gemini/ChatGPT (ибо у каждого - свои сильные стороны). Решается построением оптимизированного MCP с версионированием. Но проект Personal OS v3 пока на паузе - надо соревнование сначала провести.
Кстати, наши задачи в BitGN/PAC1 - как раз отталкиваются от аналогичного формата работы с файлами, только с наворотами в виде типизированных записей.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
20 January 2026 11:55
Кто там хотел локальной Claude Code ?
ollama с версии 0.14 поддерживает Anthropic Messages API, что позволяет использовать Claude Code с локальными моделями вроде qwen3-coder или GPT-OSS.
Говорят, что нужно переключить переменные окружения вот так
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
}
}
И потом запустить примерно так
claude --model qwen3-coder
Еще говорят, что после такого люди сразу начинают понимать ценность стандартной подписки на Claude Code))
Ваш,
@ 🤗
Читать полностью…
LLM под капотом
20 November 2025 13:17
Платформа для ERC3: AI Agents открыта!
На ней мы будет проводить соревнование 26 ноября (и после) по поиску оптимальных архитектур для AI агентов. Готовиться можно начинать уже сейчас:
Что можно сделать уже сейчас
(1) Ввести свой email, с которым регистрировались на ERC3, и получить ERC3_API_KEY. Новые регистрации активируются на платформе в течение 24 часов.
(2) Посмотреть бенчмарки на платформе
(3) Посмотреть исходники тестового агента (gpt-4o) и запустить его с ключом и любой моделью
(4) Посмотреть, как работа агента отражается в логах в консоли и в самой платформе. Платформа сразу же выдает оценку агенту!
(5) Увидеть слабые места и улучшить его! Или запустить на локальной модели.
Дальше
(1) Послезавтра я активирую на платформе бенчмарк erc3-dev - это симуляция компании для соревнования, с тестовым набором задач. Оценки будут агентам выставляться сразу же. Интерфейсы там будут отличаться от симуляции магазина (более сложные).
(2) 26 ноября откроем рабочий бенчмарк. Нужно будет просто переключить своих агентов на новый набор задач и прогнать их.
Платформа | Регистрация | Пример агента
Можно запускать любое количество сессий и бенчмарков! Только, пожалуйста, описывайте кратко архитектуру и отправляйте статистику использования LLM (как в примере) с указанием названия модели в формате OpenRouter (например, `qwen/qwen3-8b`). Это позволит потом ранжировать агентов по локальности, требованиям к VRAM, стоимости и выводить красивые графики.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
30 August 2025 11:04
Новые бенчмарки LLM на бизнес задачах в SGR режиме
(1) gpt-5-chat-latest - это урезанный снапшот быстрой модели, которая работает под капотом в ChatGPT. У нее нет многих фич, даже StructuredOutputs, но текущая версия заняла 9 место.
(2) Еще из новых бенчмарков моделей, которые ранее были бы впечатляющими, но до уровня gpt-oss/qwen3-32b не дотягивают:
- qwen3-235b-a22b-2507 - 25 место
- deepseek-chat-v3.1 - 31 место
- qwen3-30b-a3b-thinking-2507 - 32 место
(3) пока StructuredOutputs не починили нигде для gpt-oss моделей - все еще расхлебывают последствия Harmony Response format (ollama ticket, openai ticket, vllm ticket). Поэтому все еще ждем возможности запустить локально эти малотребовательные к железу gpt-oss (в идеале еще и отключив reasoning).
Про бенчмарки подробнее написано тут.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
20 July 2025 13:25
3+1 Причины использовать Structured Outputs
Без Structured Outputs (SO) у меня не обходится ни один проект. Если кратко, то SO позволяет задать точную схему, по которой LLM будет отвечать. SO поддерживается всеми современными провайдерами и движками для запуска моделей локально.
Это полезно по 3+1 причинам (последняя - самая главная):
(1) когда модель отвечает числом или приводит ссылки, больше не нужно парсить ответы модели регулярными выражениями, чтобы извлечь нужные данные. Меньше кода, меньше возможностей у модели запутаться в форматировании и меньше ошибок.
(2) поскольку модель будет отвечать по схеме, мы можем прямо в схеме прописать последовательность шагов. Например, всегда сначала смотреть на заметки к таблице (“все цифры в тысячах евро”), а потом уже извлекать данные.
(3) Можно паковать в схемы множество таких логических шагов за раз, выполняя очень мощные и гибкие Custom Chain of Thought процессы за один промпт. На одних Enums можно делать глубокие онтологии, а если еще и использовать tagged unions и списки, то можно отправлять в LLM очень сложные workflows с ветвлениями и повторами.
OpenAI со своего места очень хорошо видит важность этой технологии. Поэтому неделю назад они сильно повысили лимиты того, как можно использовать Structured Outputs:
- Свойства объектов: 100 → 5000
- Символы в строке: 15 000 → 120 000
- Значения Enum: 500 → 1000
- Всего символов в строках Enum с количеством значений >250: 7500 → 15 000
А что же с причиной +1? Все эти три причины хороши, но
самая полезная фишка Structured Outputs в том, что они позволяют делать тестируемые системы!
Например, с SO нам больше
не нужно использовать LLM-as-a-judge или человеческий пригляд, чтобы понять, что текст чатбота правилен.
Можно сначала в ответе встроить Structured Output, чтобы система выдавала “начинку” своих размышлений в виде структуры. Скажем, пусть выдаст категорию вопроса (enum), использованный workflow/agent (enum), список ссылок на релевантные документы (list of objects), категорию типа ответа (enum) итп. Такой тип ответа очень легко покрывается простыми evals и тестовыми наборами данных.
А последний шаг работы системы - это будет “разворачивание” сухого структурного ответа в человекочитаемый. Он уже не такой важный (самое сложное позади), и его можно для спокойствия тестировать LLM-as-a-judge.
Вам приходилось встраивать Structured Outputs в свою систему только для того, чтобы было удобнее отслеживать качество ее работы (test evals)?Ваш, @ 🤗
Читать полностью…
LLM под капотом
08 July 2025 19:17
Почему в канале тихо? Слишком много AI!
Помните, в ноябре прошлого года мы запускали акселератор AI проектов с Меллиферой (ныне Colibrix)?
Много всего случилось с того момента: прошел отбор подавшихся стартапов, прошли разнообразные мастер-классы и отработка навыка презентаций, организация раунда на Мальте. Этой весною жюри на Мальте отобрало один стартап-финалист - Homai, который сегодня презентовал в Женеве на глобальном саммите AI for Good от ООН.
В финал стартапу нашего инкубатора пройти не получилось, из 11 компаний дальше пойдут только 4 проекта c AI под капотом:
1. Слепой мужчина, который делает робота-поводыря для слепых
2. Анестезиологи, которые делают девайс для госпиталей
3. Женщина, которая диагностирует проблемы питания в Индии (миллионы детей уже проанализировали)
4. И женщина, которая делает девайс для послеродовых проблем детей в Африке
Но на этом Женева для Homai не заканчивается - надо стоять на стенде, презентовать идею всем заинтересованным и максимально раскручивать ситуацию для себя. Там и инвесторы, и AI компании со всего мира (очень много робототехники) и просто интересующиеся.
Поздравляем команду Homai! На этом тот первый инкубатор можно, наконец, считать закрытым.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
11 April 2025 09:40
Нас не волнует то, чего мы не знаем. LLM тоже
На фотографии - McArthur Wheeler, который в 1995 году ограбил два банка. Он это делал даже без маски, т.к. вымазал лицо в лимонном соке и был уверен, что это сделает его невидимым для камер.
Логика? С помощью лимонного сока можно писать невидимый текст на бумаге, значит и человека это тоже сделает невидимым.
Два исследователя так впечатлились этим примером, что провели исследование. Их звали Джастин Крюгер и Дэвид Даннинг, а синдром назвали Эффектом Даннинга — Крюгера: Нас не волнует то, чего мы не знаем.
Если бы это было не так, то люди бы до сих пор сидели на деревьях и боялись спуститься на землю. А вдруг съедят? Но для эволюции имеют значение не те миллионы, которых ожидаемо слопали, а те единицы, которым повезло выжить и оставить потомство.
Какое отношение это имеет к LLM?
LLM - это модели, которые заточены на то, чтобы выдавать наиболее приятные для человека ответы. По смыслу там средняя температура по больнице, главное не вглядываться в детали.
LLM при генерации ответа не волнует, можем ли мы проверить их ответы на ошибки. Языковые модели просто делают свою работу и генерируют правдоподобное полотно текста.
Скажем, новая Llama 4 делала это так приятно, что на LLM Арене заняла второе место после выхода. Правда потом выяснилось, что это просто был тюн под человеческие предпочтения (что говорит многое и про этот релиз Llama 4, и про бенчмарк в целом, и про поведение людей).
В общем, какие выводы?
(1) LLM способны усиливать как человеческий ум, так и человеческую глупость. Второе проще - достаточно выдать ответ в той области, где читающие не являются экспертами. А они и не заметят!
(2) Современные MCP/A2A, как LangChain на стероидах, упрощают интеграцию всевозможных систем c LLM. Поэтому ереси будет встречаться много. А потом срабатывает принцип Альберто Брандолини:
The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.
(3) Если в продукте с LLM под капотом не упоминается слово Accuracy в контексте цифр и доказательств, то это умножитель Даннинга — Крюгера. Бегите.
(4) Хотите, чтобы ответ LLM нравился людям? Попросите отвечать как позитивный подросток с кучей emoji.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
09 April 2025 16:49
Google: Agent2Agent Protocol (A2A)
Google захотела сделать свой MCP протокол, только с крупными компаниями. Готово.
Назвали его A2A (Agent2Agent). Это открытый стандарт для обмена информацией между ИИ-агентами, работающими в разных системах. Он использует технологии HTTP, SSE и JSON-RPC для упрощения интеграции в существующую инфраструктуру.
Основные моменты:
(1) Dynamic Capability Discovery - агенты обмениваются данными через JSON-Agent Card, что позволяет выбирать подходящего исполнителя задачи.
(2) Task-Centric Communication - протокол работает с задачами, у которых есть свой жизненный цикл. A2A поддерживает как быстрые операции, так и долгосрочные процессы с обратной связью и уведомлениями.
(3) Security (за что критиковали MCP) - продуманы средства аутентификации и авторизации для защиты данных.
(4) Мультимодальность - обмен информацией в виде текста, аудио или видео.
В теории, общее назначение A2A - упростить автоматизацию и интеграцию процессов в корпоративных системах. Однако на HN люди уже высказывались насчет сложности протокола и его влияния на контроль над данными. Мол, нагородили всякого, лишь бы рынок отжевать.
Мне кажется, с такой компанией оно может и взлететь. Но из-за сложности и непредсказуемости систем лететь будет так себе.
Почитать доки можно тут.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
08 April 2025 12:24
LLM Benchmarks - прогресс у Google
За месяц накопились новые бенчмарки. Поэтому вот сразу пачка обновлений.
Gemini-2.5-pro-preview - это платная и самая большая модель Google. Она так хороша, как про нее говорят. В моем LLM бенчмарке на продуктовых задачах она побила OpenAI o1 и Anthropic Claude 3.7 Sonnet, заняв второе место. При этом она работала без Structured Outputs (ибо у Google он пока реализован шиворот навыворот)
DeepSeek-V3-0324 - это новая версия DeepSeek Chat (не путать с r1). Они смогли последовательно улучшить качество предыдущей chat версии. Прогресс не стоит на месте. Посмотрим, как у них будет дальше с новыми моделями.
Llama 4 модели - появились на радаре, но пока не обладают выдающимися способностями. Но это типичная картина, которая повторялась со всеми версиями Llama. Meta выпускает мощные foundational модели, которые потом тюнятся под конкретные задачи. Ждем r1 distill.
Gemma-3-27B-it - а вот тут уже очень интересно становится. Эта локальная мультимодальная модель от Google Deepmind. Это первая модель такого небольшого размера, которая забралась так высоко. Заявляется контекст 128k, поддержка 140 языков и function calling.
Возможно благодаря последнему модель смогла вытянуть достойный результат без поддержки Structured Output. Лучше всего она показала себя в инженерных задачах на работу со сложным кодом.
Ее младшая сестренка - gemma-3-12b-it тоже отличилась и заняла место на уровне лучших моделей в пару раз больше.
Что-то такое интересное Google DeepMind нащупали, что дает им возможность клепать хорошие модели по всем уровням (еще и на TPU). Будем ждать от них новых релизов.
Ваш, @ 🤗
PS: Прочитать про мой подход к бенчмаркам можно тут. Там есть и FAQ со всеми вопросами, которые задают последние полтора года. Пожалуйста, прочитайте его, прежде чем оставлять свой первый комментарий.
Читать полностью…
LLM под капотом
06 April 2025 12:43
Как заставить AI писать качественный код?
Нужно просто мыслить масштабно. Сейчас объясню)
Я знаю, что модели уже давно способны писать качественный код. Просто они как джинн с тремя желаниями. Нужно правильно уметь формулировать свои требования и хотелки, даже просто разбивать задачу. AI - это инструмент, с которым надо набить руку.
В рамках эксперимента по обучению AI+Coding разработчиков одной компании, я увидел, что для этого умения требуется две вещи:
(1) насмотренность - чтобы знать паттерны того, что и как нужно просить у моделей
(2) практика - чтобы можно было оперировать этими паттернами не задумываясь.
Проиллюстрировать это может помочь такое практическое задание.
Нужно написать качественный код парсера бизнес-документации на основе вот этого требования. Чем быстрее, тем лучше. Язык не имеет значения. Но вы должны быть уверены в качестве этого кода [1] Максимальное время - 4 часа.
А потом в комментариях к посту - рассказать насколько далеко и быстро получилось дойти, и какие шаги были сделаны. И сравнить свои действия с действиями других. Они будут кардинально различаться!
После такого простого упражнения один из участников (с кучей опыта разработки сложных систем) написал:
Это действительно впечатляет. Я думал, что предоставил инструменту слишком много контроля, разбив задачу на пошаговые действия, но, похоже, даже этого оказалось недостаточно. Я мыслил недостаточно масштабно.
В общем, нет никакой магии в том, чтобы использовать AI для написания качественного кода. Нужна просто практика и насмотренность на разные паттерны использования. Кто-то это назовет "мыслить масштабно". Можно начать с упражнения выше.
Ваш, @ 🤗
[1] Если вдруг во время выполнения задания встретите очередную пасхалку - так и надо. Use your best judgement.
Читать полностью…
LLM под капотом
05 April 2025 16:13
SO CoT - самый полезный паттерн при создании продуктов с LLM под капотом
Так выходит, если судить по комментариям в моем прошлом опросе.
Я обещал расписать самый полезный паттерн постом в канале. Поскольку сам ответ не влазит в масштаб и формат поста, вот вам две статьи с более подробным описанием и примерами:
- Structured Output (SO): https://abdullin.com/structured-output/
- Custom Chain of Thought (SO CoT): https://abdullin.com/custom-chain-of-thought/
Ваш, @ 🤗
Читать полностью…
LLM под капотом
03 April 2025 10:03
Кейсы: Структурированное извлечение данных из документов, типичные проблемы и советы
Вчера консультировал компанию, которая занимается логистикой в Европе. Они пилят внутренний продукт с LLM под капотом.
Кейс - нужно извлекать информацию из таможенных деклараций, чтобы автоматически загружать в дальнейший бизнес-процесс. Ситуация осложняется тем, что в каждой стране EU свой формат деклараций, а единого электронного формата пока нет.
Текущий статус - используют Google Gemini, которому скармливают страницы и просят извлечь ответ по структуре. Есть даже evaluation datasets. По ним видно, что точность пока недостаточна.
Но вот как этот прототип масштабировать до стабильного продукта в компании и осознанно двигаться к повышению качества - они пока не знают. А галлюцинаций там хватает.
У меня было минут 30, поэтому быстро прошлись по их решению и сразу перешли к обсуждению того, как с этим работать. Мои советы были очень типичны - просто подсветить приоритет того, что нужно сделать в первую очередь:
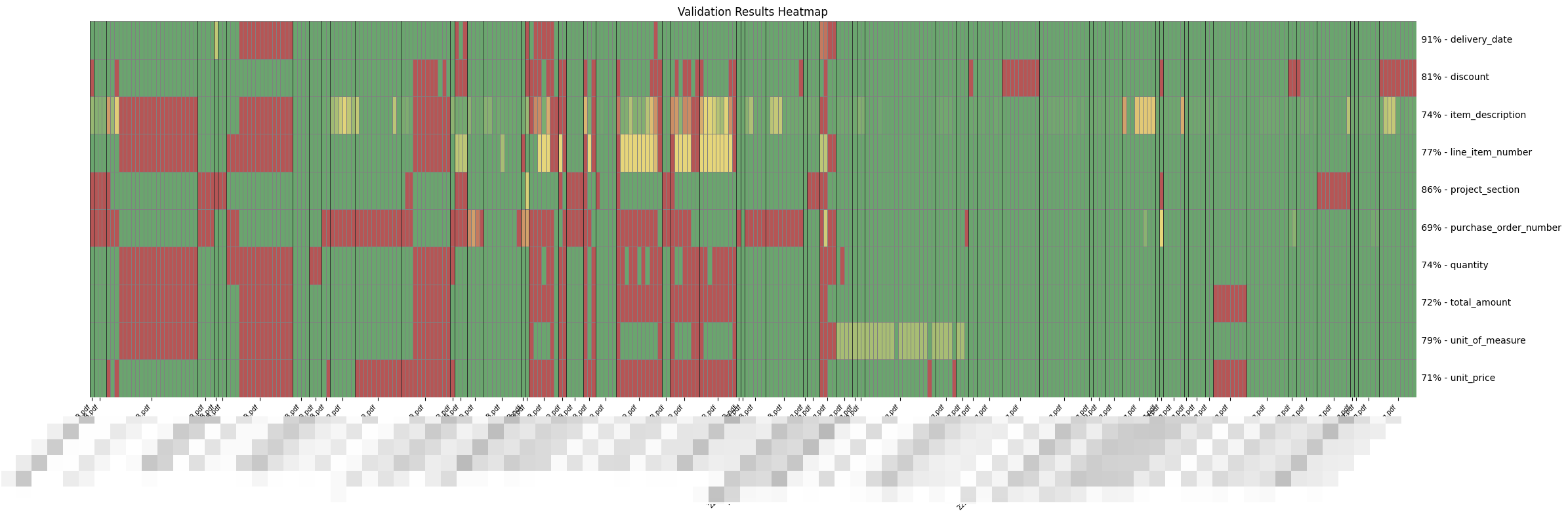
(1) Закрыть Feedback Loop и сделать так, чтобы можно было очень быстро тестировать качество работы всего пайплайна после любого изменения. В идеале, если на выходе будет визуализация ошибок в виде heatmap.
(вот пример визуализации: https://labs.abdullin.com/res/ai-assistants-ru-S02M13-heatmaps.png)
Тогда можно будет повысить качество просто подбором параметров pipeline. Причем это будет делать не от балды, а осознанно - по паттернам ошибок.
(2) Выкинуть ненужный мусор из промпта и начать использовать SO/CoT на всю катушку. У них был текстовый промпт, который не использовал ни Literals (вместо этого добавили вручную правило в текст) ни встраивал цепочки рассуждений перед проблемными полями. Из-за этого точность была сильно хуже того, что можно было получить.
(3) Следить за Signal vs Noise и декомпозировать, если сложные задачи. Но извлечение данных - это обычно задача простая.
И, в принципе, все. Этих вещей достаточно для того, чтобы начать двигаться в правильном направлении с технической стороны.
А одной команде это и вовсе помогло решить полностью конкретную проблему в инструменте для командной работы. Было:
Оно по сути работает, но надежности добиться не получается никак… Причем иногда оно стабильно работает неделями, а потом чето рандомно ломается) Довольно плохо слушает инструкции, даже жесткие. Модели разные пробовали, лучше всего на гпт 4о.
Подскажи пожалуйста, в нашем кейсе реально добиться надежности или пока технологически ограничены?
После подсветки приоритетов команда сфокусировалась на главном и быстро получила результат:
Да действительно так все и оказалось как ты говорил.
Нормальный промпт, SO+checklist показали приемлемую надежность в ответах даже на датасете со сложными переменными даты и времени.
Спасибо 🤝
Так что если у вас в продукте с LLM под капотом есть схожая ситуация, то для начала можно свериться с тремя пунктами выше. А для осознанности и понимания контекста можно еще прочитать разборы
других кейсов продуктов с LLM под капотом.
Кто-нибудь еще валидирует ошибки не одной accuracy, а интересной таблицей или графиком? Поделитесь скриншотами своих визуализаций!
Ваш, @ 🤗
Читать полностью…
LLM под капотом
29 March 2025 12:31
Новый кейс на подходе - автоматизация бизнес-процессов
У меня давно не было разборов новых кейсов продуктов с LLM под капотом. Все потому, что пока идут в основном вариации известных кейсов (оглавление тут), а принципиально новые занимают какое-то время.
Cейчас начинает вырисовываться интересный паттерн - автоматизация бизнес-процессов в компаниях через выхлопную трубу UI. Эту тему уже подробно обсудили в чате моего курса по AI Assistants, поэтому интересно вынести ее на открытое обсуждение.
Проблема своей кажущейся нелогичностью очень похожа на историю с OpenRouter.
Итак, во всех крупных компаниях есть довольно скучный корпоративный софт. Чем крупнее компания, тем более вероятно, что этот софт сделан на базе SAP (т.к. альтернатив ему практически нет, разве что Oracle ERP Cloud или MS Dynamics 365).
SAP - это ужас и кошмар всех пользователей. В нем отражаются и ведутся все процессы, без которых компании просто не смогут существовать и развалятся. От учета времени и налоговой отчетности, до закупок и управления запасами. Вся корпоративная жизнь зависит от SAP, превращая рабочий день сотрудников в бесконечный цикл сложных форм, транзакций и согласований.
И сейчас компании начинают изучать возможность автоматизации ручных процессов в SAP и подобных системах при помощи решений на базе Operator (как у OpenAI) или MCP серверов. Первое в качестве интерфейса использует агентов в связке с computer vision моделями, второе - специализированные инструменты и агентов. Наверное, работающее решение будет где-то посередке.
В чате спрашивали - "Где и как найти доступ к экспертным знаниям о конкретных проблемах за решение которых компании готовы платить практически любые деньги?" Краткий ответ - идти в консалтинг, прицельно заводить знакомства или ходить ногами на всякие профильные конференции.
А еще можно просто подождать следующие раунды ERC. Там я постараюсь отразить боль кейса автоматизации корпоративных процессов в простом challenge.
Кому-то уже приходилось сталкиваться с SAP/MS Dynamics/1С или чем-то похожим?
Ваш, @ 🤗
Читать полностью…
LLM под капотом
10 June 2026 10:16
Что стоит обсуждать при разговоре о разработке с AI агентами?
Вот примерно такой план набросали мы с Айгизом для подготовке к созвону в пятницу. Нам пришлось порезать список проектов, о которых рассказываем, чтобы был шанс уложиться в два часа. Пройдемся от археологии старого кода до AI-native проектов и паттернов разработки в 2026 году.
Какие важные на ваш взгляд вещи стоило еще бы обсудить при разговоре о современной разработке при помощи AI агентов?
Кстати, если кто ждет третьего слота - отпишитесь, пожалуйста, под этим постом в комментариях. При его открытии напишем каждому в личку.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
03 May 2026 22:03
OpenCode + GPT 5.5 - ну не используйте вы субагентов!
В комментариях к посту про эксперимент с рефакторингом кода разными агентами, чаще всего просили запустить OpenCode + GPT 5.5. Запустил в режиме High на том же коммите с тем же промптом:
Scan through the repository on a high level (ignore code under /modules). I want you to suggest ways, how we can make it more simple and straightforward, refactor away traces of growing pains. Focus on small changes that allow to drop code, or reduce cognitive complexity with a small LOC change cost.
Он крутился 9 минут и предложил:
(1) удалить dbg - ок
(2) переименовать lib/stor в lib/store - можно
(3) разбить самый сложный файл на кусочки - ни в коем случае, только спагетти там не хватало
(4) сгрести ANSI константы, которые повторяются, в одну кучку - надо смотреть.
(5) нашел пару методов, которые выглядят похожими, подозревает, что можно дедуплицировать - не знаю, надо смотреть
(6) пачку пакетов из общей системы предложил утащить в модули, для упрощения - надо смотреть, потенциально да.
В общем, получилось
странное впечатление. Модель та же, что и у Codex, работала с файлами приблизительно одинаково. Более того, она молча подхватила правило "запускай комманды всегда в среде nix-darwin" (сам codex упорно любит один раз в сессию запустить команды через bash, споткнуться, и только потом вспоминает). А вот потом началась какая-то ерунда - находились преимущественно мелкие спорные вещи, а не реально полезные улучшения, как в Amp Code или Codex.
А потом я заметил, что OpenCode использует субагентов. Все началось хорошо, а потом он вместо обычного линейного скана запустил
@ subagent, с которым с удовольствием поиграл в глухой телефон.
В общем, не стоит стремиться во что бы то ни стало использовать субагентов в продуктах. Да, сэкономится немного контекста. Но из-за глухого телефона и потери точности при перебросе информации между агентами все это приводит к падению качества ниже плинтуса. Особенно, если границы выбраны бездумно.
В итоге получается, что одной умной модели совсем не достаточно для получения хорошего результата, нужен еще и толковый engineering harness, который умеет ее с толком использовать. OpenCode пока сырой.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
05 February 2026 22:17
Autonomous Agents Competition - этой весной
“Есть ключик ERC3? Мне не для соревнования, а для AI R&D, чтобы погонять своих агентов на тестовом окружении” - так звучит второй по частоте вопрос, который мне присылают.[1]
Итак, именно ERC4 пока не планируется. Чистый Enterprise сейчас пока адаптируется к современности до жути медленно, и сейчас там не так все интересно бодро.
Поэтому я думаю сделать challenge на принципах аналогичных ERC3, но:
(1) упор на персональных автономных агентов вместо корпоративных чатботов;
(2) призовая и бизнесовая часть - с уклоном в e-commerce (“Бот, тут человек пытается найти H200 со сроком доставки до 7 дней, что мы можем сделать?”);
(3) регистрация на платформе после соревнования больше закрываться не будет!
TLDR; все, как в ERC3, но тематика поактуальнее. C топовыми местами в лидербордах теперь работу в стартапах мечты будет найти еще проще.
И, возможно, пара из сотен задач будет даже не оцениваться, но позволять агентам подключиться и добавить что-то свое в виртуальную песочницу по типу Moltbook на минималках. Но только для тех агентов, которые выбили достаточное количество очков в сессии. Ну а если спамеры наберут достаточно очков в сессии, чтобы их агент получил пропуск в песочницу - значит, заслужили.
Я потихоньку начинаю прикидывать новую версию платформы. Первую обкатку (аналог ERC3-STORE) хочу уже выложить в конце марта-начале апреля, с последовательными разогревами. А само соревнование уже можно провести в апреле-мае.
Кто хочет в бета-тестеры новой платформы?
Ваш, @ 🤗
Читать полностью…
LLM под капотом
18 January 2026 12:13
Список моих ChatGPT запросов в этом месяце, которые с лихвой окупили подписку
(обычно это не один запрос, а несколько, которые запускаются последовательно)
(0) Дай-ка мне анализ того, куда катится software индустрия в следующие годы. Для опоры вот тебе транскрипты моих последних разговоров на эти темы. Сформулируй видение, а потом сделай Deep Research, чтобы найти сигналы, проверить свои теории и откалибровать timelines. Выжми в пару инсайтов.
(1) Изучи особенности работы Excel и собери мне такой Excel файл, который можно загружать в разные LLM/Агентские системы, задавать вопросы и по ответам точно определять, какой у них там движок под капотом.
(2) Набросай мне архитектуру для движка работы с формулами Excel, который бы позволил обойти ограничения других существующих движков. Я ее потом вставлю в Codex.
(3) Вот тебе транскрипты всех моих релевантных созвонов, переговоров и проектов. Проанализируй, выдели доставленную ценность и сформулируй такое tiered коммерческое предложение компаниям, которое было бы простым, единообразным и совпадало с целями на следующие годы.
(4) Найди мне удобные библиотеки для чтения XLSX файлов, сгруппируй их по языкам программирования.
(5) Вот тебе транскрипт новой записи подкаста, вот тебе план курса. Какие инсайты и артефакты (полезные для участников курса) ты можешь сделать на базе новых мыслей из транскрипта? Сделай документ, который я могу пошарить.
(6) Предложи мне варианты архитектур (в формате RFC) на базе Firecracker VM для запуска изолированных процессов, чтобы оценивать результаты работы AI Coding агентов. Что-то легковесное и практичное, без ереси вроде кубов и докера.
Плюс куча мелких запросов на написание писем, помощь в изучении немецкого, подготовку к переговорам и обсуждениям, анализ идей с разных сторон, поиск интересных синергий между разнонаправленными инициативами, фиксов кода и проектов. Наверняка такие фичи уже есть в куче специализированных AI продуктов, но мне их заменил ChatGPT.
А у вас какие были полезные и интересные запросы к LLM-кам в этом месяце?
Ваш, @ 🤗
Читать полностью…
LLM под капотом
23 September 2025 10:38
Иллюстрация пайплайна из истории про спасение проекта с LLM под капотом
(проект про извлечение промышленных данных из разных PDF от разных поставщиков с таблицами и графиками)
Ссылки:
(1) Серии: 1, 2, 3, 4, 5, 6+7, Эпилог
(2) Описание первого и второго промпта.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
08 August 2025 19:08
Локальная gpt-oss-20b - эквивалент закрытой gpt-5-nano, а mini - 120b 🔥
Теперь все цифры сошлись. Я таки запустил gpt-oss-20b, как если бы reasoning у него изначально работал с поддержкой Structured Outputs.
Сейчас gpt-oss-20b из-за новизны архитектуры работает без Structured Outputs даже у Fireworks (это мне подтвердили ребята в OpenRouter). Но, думаю, для таких хороших моделей завезут поддержку новой архитектуры достаточно быстро.
В итоге -
очки на моем бенчмарке получились у моделей похожие. Смотрите сами. Причем ситуация аналогична паре моделей gpt-5-mini и gpt-oss-120b.
В принципе, это логично. Зачем OpenAI поддерживать большой зоопарк моделей, когда можно обучить три новые модели, выдать по API все три (спрятав reasoning) и раздать всем две младшие модели? Ну а смогут ли люди получить от локальных моделей результаты аналогичные их облачным вариантам - это уж зависит от самих людей.
Можете проверить сами, скачав локальные модели с Hugging Face (
20B и
120B) и запустив у себя, или через одного из провайдеров (списки -
20B и
120B).
Для честного сравнения с gpt-5-nano и gpt-5-mini обязательно давайте локальным моделям возможность подумать над проблемой до ответа, как это делается в CoT. А когда в xgrammar/outlines появится поддержка constrained decoding для 120B/20B, то можно будет и
Schema-Guided Reasoning использовать (как это делается в бенчмарке).
Ваш, @ 🤗
Читать полностью…
LLM под капотом
14 July 2025 14:01
Вот такой вот пайплайн вырисовывается в системе, для миграции легаси ERP системы без тестов на современный стэк (описание кейса).
Если точнее, это выглядит как агентский пайплайн для написания тестов на основе работающего кода и ручного поиска багов. А уж переписанный код - это побочный эффект.
В основе всего - набор из 5-х паттернов:
(1) RAG - нарезаем исходный код на логические блоги и выстраиваем взаимосвязи между ними. Это позволит потом “хирургически точно” наполнять контекст для разных задач.
(2) Workflow - используем несколько прописанных заранее процессов, которые пошагово анализируют код, выявляют пропущенные требования (gaps), составляют планы по реализации и выполняют их.
(3) AI+Code Memory (новый паттерн, cм тут) - агенты могут оставлять друг другу заметки и комментарии, которые по определенным правилам ссылаются на другие файлы и старый код.
(4) REPL / Feedback Loop - основной автоматический процесс, который пополняет набор тестов и поправляет код
(5) Human in the loop - человеческий пригляд используется для корректирования всей этой системы, чтобы качество тестов и кода постепенно росло. Качество - это траектория.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
22 May 2025 13:54
Кейс - локальный ассистент по работе с технической и регламентной документацией.
У нас был кейс - ассистент по работе с оборудованием (нефтегаз, upstream). Много технической и регламентной документации. Пайплайн - таксономия по документам и разделам, фильтрация документов и роутинг по запросу, семантический чанкинг, гибридный поиск, LLM Reranker, еще ветка на text2SQL (отдельная экстракция табличных данных), обогащение контекста. Answer relevance финальной генерации рос почти пропорционально размеру модели (Qwen) в экспериментах, где все релевантные чанки были в контексте (recall = 100%). Остановились на 70B. Ниже не устраивало заказчика по качеству, а 70В было еще приемлемо по цене (2xA100). Датасет - несколько тысяч запросов.
Это цитата
Alex U из нашего чата. Можно
посмотреть обсуждение и задать дополнительные вопросы тут.Ваш, @ 🤗
PS: Если заходите в чат впервые, пожалуйста, не игнорируйте сообщения от бота спам-защиты.
Читать полностью…
LLM под капотом
09 April 2025 21:18
Cекретная Quasar Alpha модель довольно неплоха. Погадаем, кто это?
У модели 8 место в моем бенчмарке на текущий момент.
Пока не совсем известно, кто это может быть, но мы можем применить дедукцию)
Смотрите, у модели есть нормальный Structured Output, которым она умеет пользоваться. Это сразу сужает круг подозреваемых:
(1) OpenAI
(2) Fireworks SO
(3) Mistral
Кстати, Google не стоит и близко, т.к. их Structured Output - это не JSON Schema, а огрызок от OpenAPI в версии VertexAI API. Он бы мой бенчмарк не вытащил.
FireworksAI можно вычеркивать смело, новые модели - это не их формат.
Остаются только OpenAI и Mistral. OpenAI слишком крупный для рекламной компании с OpenRouter - это не их профиль, а вот для небольшой французской компании Mistral - формат подойдет. Плюс, у них давно не было толковых релизов.
Да и, если смотреть на supported parameters Quasar, то совпадений больше с предыдущими моделями Mistral, нежели с OpenAI. Профиль latency + throughput тоже похож.
Так что я думаю, что секретный Quasar - это новая французская моделька. Если это так, то их стоит поздравить с хорошим результатом!
Кстати, судя по профилю latency - модель относительно небольшая. То, что она так высоко забралась делает ее интересной и потенциально недорогой.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
09 April 2025 08:51
Исключительный повод написать про квантизацию (сжатие) моделей
Про квантизации я обычно не пишу, т.к. в бизнес задачах их практически не используют [1].
Но Google Gemma-3-27B стала исключением. Это сама по себе хорошая модель, которая еще и внезапно неплохо умеет в reasoning c SO CoT. Она весит 55GB и при загрузке в GPU в bf16 формате потребует ~ 60GB VRAM для текстовых задач. Это значит, что она влазит в одну H100 80GB.
Народ, естественно, начал перепаковывать эту модель в всякие хитрые квантизации, чтобы запускать на карточках поменьше.
А потом Google сделали ход конем и выпустили официальный google/gemma-3-27b-it-qat-q4_0-gguf. Эта квантизация условно использует не два байта на один параметр, а в четыре раза меньше (~4 бита на параметр).
Фишка и отличие здесь в том, что Google использовали Quantisation Aware Training (QAT), которая позволяет пожать модель без особой потери качества.
Если раньше у меня были большие надежды на версии qwen-2.5 для умных локальных систем, то сейчас еще больше нравится Gemma-3 (27B и 12B). У них выхлоп на размер сильно больше, думать умеют, поддержка языков заявлена хорошая, а теперь еще и появилось больше способов запускать на разном железе.
Возможности для стартапов с локальными моделями прямо подскочили!
Ваш, @ 🤗
[1] Квантизации могут экономить память GPU-шек за счет сжатия параметров , но при этом негативно влиять на точность и скорость ответов. Чем сильнее и хитрее пожали, тем больше эффект. И при этом еще и требуется, чтобы такую хитрую квантизацию нормально поддерживал софт и были люди с опытом.
bf16 за квантизацию можно не считать, да и fp8 тоже (если он делается при помощи QAT и запускается нативно на GPU последних поколений)
Читать полностью…
LLM под капотом
07 April 2025 12:58
А как решалось AI+Coding упражнение про парсер?
(см описание тут)
Да все просто и быстро. Самое главное - думать как опытный и ленивый специалист. То есть, свалить максимум работ на AI. Humans decide, AI does mundane work.
Первый шаг - просим просмотреть требования и проанализировать задачу. Например, что-то вроде:
Help me to identify the most efficient and error-prone way to implement this parser. Don't code, just think and plan from the perspective of a very experienced pragmatic software engineer with 20 years of experience in shipping systems to production
Оно выдаст что-то годное:
1.
Clarify Requirements and Edge Cases 2. Choose the Right Parsing Strategy
3. Clearly Define Parser Responsibilities
4. Implement Parsing in Phases (Iterative and Incremental)
5. Develop a Robust Testing Strategy.
Tests are critical—write them first! 6. Error Handling and Reporting
7. Implementation Quality and Maintainability
8.
Iterate with FeedbackПодсветка моя. Дальше действуем по плану. Начнем с тестов. Если спросить у AI идеи про тесты (чтобы попроще и попрагматичнее), то оно укажет на такой абзац в тексте:
The document below describes a simple text format that can be deterministically parsed into JSON objects. This document is also a test suite! Code admonitions always come in pairs: first input and then json.
Нам даже не надо писать тесты (что сделал каждый участник экспериментальной группы), достаточно просто распарсить этот текст и достать пары input-expected.
Поэтому, сначала подчистим текст в markdown, который любит любой AI:
Carefully read this spec. It lost its markdown formatting, please fix and return it.
Если LLM не осиливает весь объем сразу, то можно временно переключиться на модель с reasoning или просто спеку кусками вставлять.
Кстати, а что еще нам AI советовал?
Clarify Requirements and Edge Cases
Check this spec for any contradictions or mistakes. For each - suggest a fix. Use your best judgement
Вот тут AI и найдет грабли, про которые я предупреждал. Можно поправить, а можно оставить так.
Ладно, читаемый текст в формате md есть, “пишем” тесты:
This is the spec that I have saved in file spec.md. Please write me python parser to read this spec and extract all code blocks.
Оно напишет извлекатор, который можно красиво обернуть вручную (Copilot) в тестер. Он будет доставать текст из файла, разбирать input и сравнивать его с ожидаемым результатом. Все.
А потом финальный цикл разработки:
You are an experienced and pragmatic software engineer with two decades of experience. Write me a recursive descent parser that will implement function `def parse(input: str) → Block` and will follow this spec:
Вставляем результат в код и смотрим. Если вдруг какие-то тесты не проходят - кидаем код парсера, спек и текст ошибки в ChatGPT/Claude и просим поправить.
У меня при проходе по этому workflow с ChatGPT все тесты стали зелеными за пару итераций.
А у вас как быстро сходятся все тесты?
Ваш, @ 🤗
Читать полностью…
LLM под капотом
05 April 2025 20:53
Llama 4 вышла - MoE по 17B на эксперта
Пока в мире гадают, что это за модель Quasar на OpenRouter, Meta выпустила четвертую версию Llama
Читать тут. Любоваться тут.
Модели Llama 4 — это мультимодальные MoE модели, оптимизированные для многоязычных задач, программирования, вызова инструментов и создания автономных систем (агентов). Знания - по август 2024.
Llama 4 Scout:
- Поддерживается ввод текста и до 5 изображений.
- Поддерживает арабский, английский, французский, немецкий, хинди, индонезийский, итальянский, португальский, испанский, тагальский, тайский и вьетнамский языки (понимание изображений — только на английском).
- 16 экспертов по 17B
- Может работать на одном GPU (при использовании INT4-квантованной версии на одном GPU H100).
- Максимальная длина контекста: 10 млн токенов.
Llama 4 Maverick:
- Мультимодальность
- Поддерживает те же языки, что и Scout (понимание изображений — только на английском).
- 128 экспертов по 17B параметров
- Максимальная длина контекста: 1 млн токенов.
Хотя общее число параметров составляет 109B и 400B, во время вычислений активны только 17B, что уменьшает задержки при выводе и обучении. Это очень неплохо должно лечь на Apple Silicon!
Ваш, @ 🤗
Читать полностью…
LLM под капотом
04 April 2025 11:12
Какой паттерн из курса вам пригодился больше всего?
Если вы прошли мой курс по AI Ассистентам или проходите его, напишите, пожалуйста, какой паттерн из курса вам пригодился больше всего? REPL, Search итп. И чем он помог?
Я потом распишу подробно самый полезный паттерн отдельным постом в канале, а ответы на самые частые вопросы - интегрирую обратно в курс.
Ваш, @ 🤗
Читать полностью…
LLM под капотом
02 April 2025 12:49
Клуб по интересам - SAP + AI R&D
Идея AI R&D в области автоматизации бизнес-процессов в SAP выстрелила лучше, чем я ожидал.
SAP - это как 1C, только гораздо масштабнее и сложнее. Им пользуются почти все крупнейшие компании в мире.
Причем не только со стороны разработчиков и команд (т.к. это интересный и сложный кейс для внедрения AI агентов/операторов в крупные компаниях), но и со стороны компаний, которые с этим SAP работают.
Поэтому сейчас начинаем процесс сбора кейсов использования SAP, где есть самый обычный бизнес процесс, который ну очень очень хочется хоть как-то автоматизировать. Например: добавление нового фрилансера в систему, добавление инвойса, согласование табелей рабочего времени или обработка закупочных заказов.
Собирать кейсы будем в таком формате, который сделает удобным создание отраслевого бенчмарка для операторов и агентов. А потом - подчистку специфики и запуск открытого Enterprise RPA Challenge на эту тему (как мы это с вами сделали с RAG-ами)
Про формат сбора кейсов я потом напишу. Если кратко, то понадобится несколько скриншотов интерфейса (секреты можно и нужно замазывать), заполненный вопросник про бизнес-процесс и контакт эксперта, который может ответить на вопросы.
Как ни странно, это как раз та конкретика и движуха, которой не хватает ни AI R&D командам ни даже самому SAP и его партнерам. Ну а те компании, которые пришлют подходящие кейсы - попадут в этот небольшой клуб по интересам.
Пока все предварительно. Если потенциально интересно поучаствовать или есть вопросы - пишите в комментарии. Лучше сразу упоминать отрасль и тип бизнес-процесса. Имена и названия - не обязательно)
Ваш, @ 🤗
Читать полностью…
LLM под капотом
27 March 2025 09:40
Зачем вообще нужен OpenRouter? Продуктовый ответ
Вчера в канале мы обсуждали вопрос про аггрегатор моделей OpenRouter. Он предоставляет доступ к разным провайдерам LLM по одному API. У него есть немало глюков и проблем.
Например, я только вчера им в discord пожаловался, что у них далеко не все модели с заявленным Structured Output его реально поддерживают. Они обещали посмотреть, но вряд ли кардинально исправят.
Ну как таким пользоваться? Зачем, вообще, люди деньги платят за такой продукт?
Чтобы за LLM продукт платили деньги - он не должен быть технически идеальным.
В обсуждении к посту люди писали свои причины использования OR, например:
(1) OR повышает надежность. Например, если Anthropic ляжет (что бывает чаще, чем ожидают), то OpenRouter автоматически переключится на Bedrock или Google Vertex
(2) Они берут на себя головную боль по интеграции и нормализации новых провайдеров к единому стандарту. Апдейты придут туда быстрее, чем в LiteLLM. А если у какого-то провайдера глюки - переключат временно на другого.
(3) Всякое мелкое - доступ к новым моделям без ожидания появления их в tier, нормальные rate limits, распределение нагрузки между провайдерами, автоматический выбор провайдера подешевле итп.
И самая главная killer feature: адская экономия времени крупных компаний. И это, одновременно, часть без LLM совсем.
Например, если в компании 10 разработчиков, которым нужно 10 разных API для отладки, тестирования и failover, то не нужно заводить 10 аккаунтов, добавлять туда карточки, отслеживать расходы с правами доступа и каждый месяц подшивать по 10 или более инвойсов в бухгалтерию. Заплатили один раз, раздали доступы, проставили лимиты и все. Только одним этим компания сэкономила 10 часов возни разных людей в месяц.
Скажем, умножаем 10 на часовую ставку в 40 EUR, получаем экономию в 400 EUR. И это только легко измеримая часть. Чем крупнее компания, тем больше процессов будет затронуто и больше реальная экономия времени.
Понятно, что ниша OpenRouter не такая уж уникальная. Она лежит на поверхности и их много кто будет пытаться заменить, начиная с крупных облачных вендоров (Google Vertex, Amazon Bedrock итп).
Но интересен тут не сам OR, cколько признаки перспективной ниши для продукта с LLM под капотом - нужно искать там, где компании тратят время на решение скучных проблем. Причем проблемы настолько скучные, что там никто не предоставляет решения уже много лет, как бы эксперты не умоляли.
Почему так? А я полтора года назад в канале даже картинку на эту тему рисовал.
Ваш, @ 🤗
Читать полностью…



 25249
25249
{kind=link}